Abstract
The analysis of infrared video images is becoming one of the methods used to detect thermal hazards in many large-scale engineering sites. The fusion of infrared thermal imaging and visible image data in the target area can help people to identify and locate the fault points of thermal hazards. Among them, a very important step is the registration of thermally visible images. However, the direct registration of images with large-scale differences may lead to large registration errors or even failure. This paper presents a novel two-stage thermal–visible-image registration strategy specifically designed for exceptional scenes, such as a substation. Firstly, the original image pairs that occur after binarization are quickly and roughly registered. Secondly, the adaptive downsampling unit partial-intensity invariant feature descriptor (ADU-PIIFD) algorithm is proposed to correct the small-scale differences in details and achieve finer registration. Experiments are conducted on 30 data sets containing complex power station scenes and compared with several other methods. The results show that the proposed method exhibits an excellent and stable performance in thermal–visible-image registration, and the registration error on the entire data set is within five pixels. Especially for multimodal images with poor image quality and many detailed features, the robustness of the proposed method is far better than that of other methods, which provides a more reliable image registration scheme for the field of fire safety.
1. Introduction
With the rapid development and application of image processing technology, thermal hazard monitoring and fire detection and alarm technology based on thermal infrared video images have received extensive attention in the field of fire protection. Especially in cases involving large spaces, such as substations, the traditional temperature-sensitive and smoke-sensitive fire detectors [1,2] have a small effective detection scope, and cannot provide information such as fire location and fire size. This makes it difficult for them to meet the needs of large-space fire detection in substations. Video image fire detection [3,4] is gradually replacing the traditional fire detection method because of its advantages of a large detection space, its fast response, and its provision of more fire information. In the infrared-image fire detection of the substation, an infrared camera is usually used to measure the overall temperature field inside the transformer body and the distribution board, and the distribution of the temperature field is obtained at different positions in the substation under different working conditions. At the same time, the video images collected by the video monitoring system are analyzed and processed, and the characteristics of the images are compared to determine whether there are thermal hazards and whether an alarm is necessary to be triggered to form a reliable fire detection and alarm system. The registration and fusion of infrared images and visible images based on this scheme is indispensable.
Image registration is a critical procedure that establishes the most precise alignment between two images of the same scene; these images may have been acquired concurrently or at distinct time points, may have utilized identical or diverse sensors, and may have been captured from corresponding or disparate viewpoints [5]. Generally speaking, the registration process consists of four steps: feature detection, feature matching, transform model estimation, and image resampling and transformation. The core task of image registration is to ascertain the geometric transformation function that facilitates the mapping of one image onto another. The transformation function converts the image to a reference image to align the spatial coordinates of the two images.
Image registration methods are generally divided into three categories: area-based methods, feature-based methods, and deep-learning-based methods. Firstly, for the area-based method, there is no feature detection in essence, which means it does not detect the salient features in the image but directly uses the predefined window for feature matching. Common region-based methods include the following: (1) correlation-like methods [6,7,8,9,10] (2) Fourier methods [11,12,13,14,15] (3) mutual information methods [16,17,18,19]; (4) optimization methods [17,20,21,22,23]. For those images whose image features are not obvious and do not have rich details, region-based image registration methods are usually used. For example, images in the medical field can selectively adopt the external features of patients through expert experience, to reduce the impact of feature loss. However, this method has many limitations: firstly, for predefined windows, only rigid transformations between images can be registered. If more complex elastic transformations occur between images, registration cannot be completed, which is also this method’s inherent disadvantage; secondly, the region-based method matches the features of the entire window, and cannot detect and match the local features of different parts of the image, resulting in a poor accuracy and robustness. Finally, because the method is based on the image pixel intensity of image registration, in the process of thermal image and visible image registration, due to the lack of texture in the thermal image, the intensity mapping between the infrared image and visible-light image is very complex and difficult to predict. Therefore, the effectiveness of area-based registration methods is limited when it comes to registering thermal images with visible-light images.
Compared with the region-based method, the feature-based method does not directly process the image intensity value, but uses more advanced feature information, such as points, lines, edge contours and regional features. After the point feature is detected and matched, its coordinate position can be directly utilized for the computation of the transformation model parameters. This kind of detection and registration method using feature points is almost not affected by the change in the overall pixel strength of the image, which is conducive to adapting to the change in illumination or dealing with the analysis of multiple acquisition devices. Scholars’ research on feature-based methods is presented in the following paragraphs.
Lowe D G proposed a scale-invariant feature transform (SIFT) [24] for feature point matching. Firstly, the feature points in the scale space are found by calculating the extreme points in the Gaussian difference pyramid [25]. Then, the key point descriptor is generated by histogram statistics. Finally, the matching is completed by the feature vector of the key points. Because of its good scale and rotation invariance, SIFT has become one of the most effective local feature description algorithms, and many scholars have also proposed improved algorithms based on SIFT [26,27,28,29,30].
Bay et al. [31] proposed an improved algorithm, Speeded Up Robust Features (SURF), based on SIFT. Firstly, the image is transformed by the Hessian matrix, and the matrix determinant is calculated to detect the extreme point. Secondly, the box blur is used to find the Gaussian blur approximation. Finally, the feature points are described by haar wavelet transform. Compared with SIFT, this method significantly enhances operational efficiency without compromising the accuracy of the outcomes. Rublee E et al. [32] proposed the feature-matching algorithm Oriented FAST and Rotated BRIEF (ORB) for real-time alignment, which first performs key point extraction using improved FAST, and then conducts a feature description using BRIEF, which is two orders of magnitude faster than SIFT.
For the aerial image fusion alignment problem, Sun et al. [33] used a particle swarm optimization (PSO)-based algorithm as a search strategy, and an alignment metric (AM) for judgment, to achieve multi-source image alignment for infrared and visible light.
Jian C et al. [34] presented the Partial Intensity Invariant Feature Descriptor (PIIFD) algorithm, a multimodal image alignment approach. The Harris detector [35] is used to detect corner points and determine the principal direction for each corner point. PIIFD is then applied to describe the features, effectively addressing the issue of alignment for low-quality retinal images. Du et al. [36] proposed a scale-invariant multi-scale descriptor SI-PIIFD for feature description (scale-invariant PIIFD). This method uses a set of variable size windows (40 × 40,36 × 36, 32 × 32, 28 × 28, 24 × 24, and 20 × 20) for feature description. The best scale information is obtained through the majority voting strategy, and the window size of the image of the same information source is fixed to improve the matching accuracy. To a certain extent, scale invariance is realized, but this only considers the scale differences caused by image resolution, and the image blur caused by different sensors will also seriously affect the feature information of the image. Therefore, SI-PIIFD still cannot achieve continuous scale invariance. Gao et al. [37] used a Harris detector to detect feature points in Gaussian blurred images at different scales, which can achieve a better scale invariance.
With the continuous advancements in machine learning in the field of computer vision at the present stage, methods based on deep learning [38,39,40] have emerged. In the field of image registration, these also show good results. By training the neural network model, the similarity standard between moving image and fixed image is calculated, and the transformation model is continuously optimized to realize the registration between image pairs. Dosovitskiy et al. [41] proposed classifying the features in the image using a convolutional neural network. Compared with the traditional SIFT descriptor, the effect of feature point detection and matching has been significantly improved. Different from the traditional feature-based method, DeTone et al. [42] proposed using a deep convolutional neural network to estimate the relative homography between image pairs, and training the neural network to directly perform geometric transformation to achieve the registration of two images.
In summary, most of the current image registration methods are limited to medical images, remote sensing images, pedestrian detection, etc. In the field of fire monitoring for electrical equipment, the quality of the images to be registered is often low, and the scenes tend to be complex. Furthermore, there is a critical need for real-time registration in such cases. Unfortunately, existing image registration methods have proven inadequate in meeting these demands. Therefore, a two-stage registration strategy for substation thermal–visible images based on multi-modal PIIFD is proposed, which solves the registration task in special scenes of low image quality and complex images, and provides key preliminary work for subsequent image fusion analysis.
2. Proposed Methodology
The whole registration process of the thermal visible image in the fire alarm system is shown in Figure 1, which includes two stages: (i) initial registration and (ii) second registration. The initial registration process is carried out at the monitoring end, and the spatial coordinates are roughly aligned by preliminarily registering the initial frames of the image pairs collected in one cycle. The monitoring camera used to collect thermally visible image pairs includes infrared sensors and general visible-light cameras. Due to factors such as product design and cost control, the thermal images collected by the equipment are usually low-resolution and have a narrow line of sight, which leads to great differences in multiple dimensions among thermally visible image pairs. Because direct registration is usually suitable for image pairs of the same scale, it is not recommended in this case. Therefore, the rapid initial registration of the image at the monitoring end can not only reduce the impact of differences in image scale, but also reduce the dependence on camera parameter settings and expand the application range of the method.
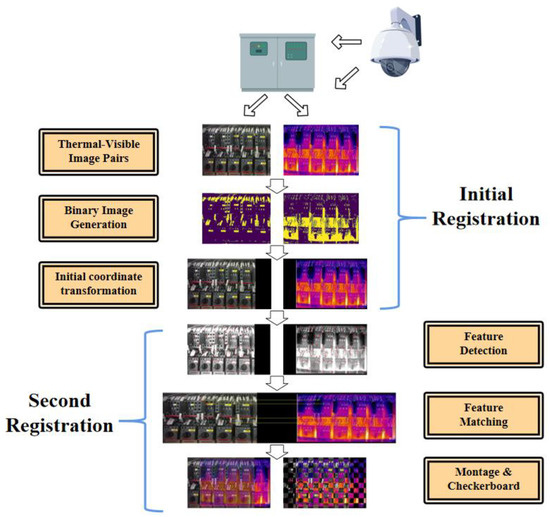
Figure 1.
Data flow of the thermal–visible substation image registration.
The second registration process is running in the background processing system of fire-monitoring. The image pairs first registered at the monitoring end are used as input, and the image pairs are registered more accurately by the improved PIIFD algorithm. The second registration process is the same as the common feature-based registration algorithm process, including feature detection, feature matching, Transform model estimation, and image resampling and transformation.
2.1. Initial Registration
In order to minimize the impact of the difference in scale between the thermally visible image pairs on image registration, this paper adopts an improved algorithm based on FAST to perform an initial coordinate transformation based on the image pairs of the input device. The process of this method is shown in Figure 2.
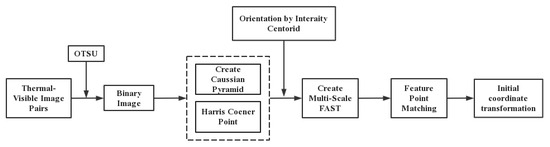
Figure 2.
Process of the initial registration.
Firstly, the OTSU threshold [43] is calculated for the original thermal visible image, and is converted into the corresponding binary image. Taking the visible image in Figure 1 as an example, its original size is (359 × 269) 96,571 pixels, and the binarized image contains about 5400 pixels of edge information, but fewer than 6% of the pixels contain most of the key corner features and significant edge line features in the image. This improves the calculation speed of the subsequent image processing at the expense of information density. Then, FAST is selected to detect the key points of the generated binary image. In order to further improve the operation speed, we chose FAST-9 (where the radius from the detection center point to the ring pixel is 9) as the feature point detector. Because FAST cannot detect angle feature information and is very sensitive to edge contour feature information, The Harris corner measure was chosen as the method to filter and rank the keypoints detected by the FAST algorithm. To pursue a good scale invariance, the FAST keypoints filtered by Harris corner measurements in each layer of the image pyramid are calculated according to the scale space theory to achieve multi-scale FAST. Finally, the intensity centroid [44] proposed by Rosin is used to locate the diagonal direction. Usually the intensity centroid of an image block deviates from its physical center, so this deviation can be used to calculate a direction. Rosin defines the moments as:
Here, denotes the intensity value of the image at this point; and denote the order of and , respectively.
Therefore, the centroid can be expressed as:
Taking the center O of the corner as the origin of the coordinate system, the vector from the point O to the centroid C represents the direction of the angle. The angle of this direction can be expressed as:
After using the multi-scale FAST descriptor to detect and match the feature points of the image pair, the affine matrix is calculated and the coordinate transformation parameters are transmitted back to the system side, together with the image pair.
2.2. Second Registration
After the initial registration is completed, the coordinates of the thermal visible image pairs are roughly aligned. In order to register the two images more accurately, this paper proposes adaptive-downsampling-unit PIIFD to perform a two-stage registration of the processed image pairs. The process of this method is shown in Figure 3. The thermally visible image pair, which has undergone an initial coordinate transformation, is utilized as the input for this process. After simple filtering and denoising, the Harris Corner Detector was chosen to extract the feature points from the single-band grayscale image. Then, the Gaussian pyramid of the image was constructed, and the PIIFD descriptor was created for the Harris corner point in each layer. The detected feature points are matched by bilateral best-bin-first (BBF) [45]. After screening out the mismatched key points, the calculation of the transformation model parameters is completed. After that, the model parameters need to be scored periodically to optimize the hyperparameters of the scale space of the constructed image.
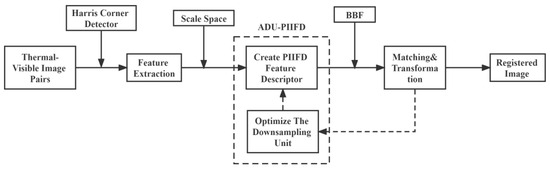
Figure 3.
Process of the second registration.
2.2.1. Feature Point Extraction
The stable and efficient extraction of feature points in the image is very important for the follow-up work of image registration. The images from the monitoring camera are often not clear enough, the details are lost, and the features are unstable, which will lead to an inability to extract enough effective feature points. In view of the above problems, SIFT [24], SURF [31] and Harris [35] are usually used as feature point detectors. Among these, SIFT can still provide effective detection results for images of poor quality. Compared with SIFT, SURF has better robustness to outliers and noise in the image, and its calculation speed is also significantly improved. However, the above two methods still have the problem of being sensitive to pixel intensity, and they are both designed for single-mode image registration. However, in multi-source image pairs, such as the thermal–visible image studied in this paper, many detailed features existing in the visible image do not appear in the thermal image, which will lead to the above methods being unable detect enough effective feature information in multi-source images. In contrast, the Harris detector is more sensitive to diagonal structure features, can effectively locate common features, even in multi-modal images, and has higher repeatability for the detected feature points. Therefore, the Harris detector was chosen to extract the features from the thermal visible image.
2.2.2. Adaptive-Downsampling-Unit PIIFD
PIIFD was originally designed to register blurred multi-modal retinal images. The thermal–visible-image registration with a monitoring video as the information source that was studied in this paper also has the problem of poor image quality, and registration occurs between images of different modes. Therefore, PIIFD was selected as the descriptor of feature points.
However, the scale difference between the medical images registered by the PIIFD algorithm is usually very small, and the local window, with a size of 40 × 40 pixels, in the feature point field is used for feature description, so the scale invariance cannot be realized at the beginning of the design. For the thermal image and visible-light image pair, due to the large difference in scale in the parameter setting of the sensor, the local feature information is quite different, which makes the traditional PIIFD unable to describe it effectively.
In order to solve the above problems, MS-PIIFD achieves multi-scale feature description by constructing a Gaussian pyramid of the image. It gradually downsamples the original image and blurs the images at different scales, and then obtains the neighborhood information of Harris corners in the whole scale space for feature description. This method is used to complete the registration task of multi-modal remote sensing images at different scales, and has good scale invariance.
However, MS-PIIFD relies too much on experimental experience to set parameters when constructing the scale space of the image, which is feasible for highly fixed remote sensing images. However, the monitoring camera that is used for fire detection will produce displacement or adjust the internal parameters of the sensor under different conditions according to the actual needs. These changes will result in varying scales in the output image.
In order to cope with this situation, this paper proposes adaptive downsampling unit PIIFD to solve the problems caused by this special scenario. Figure 4 shows how ADU-PIIFD gradually reconstructs the scale space. Once the sensor parameter’s interval changes, the comprehensive registration index under different downsampling times is recalculated, and the index is defined as follows:
where is the number of downsampling images; is the matching accuracy, which is calculated using the ratio of the correct matching number of corresponding points to the total matching number. is the additional weight of the matching accuracy, and the default setting is 0.5. is the average running time of the extracted descriptor, is the additional weight of the average running time, and the default setting is 0.5. The best comprehensive registration index can be defined as:
where is the number of target downsamplings.
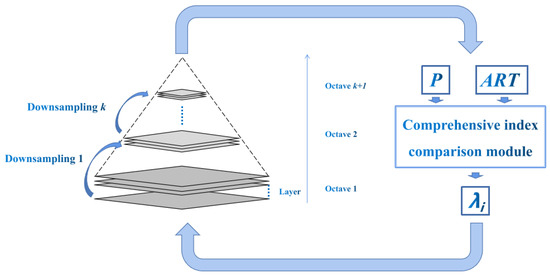
Figure 4.
The process of constructing the Gaussian pyramid via ADU-PIIFD.
After selecting the optimal downsampling unit, the scale pyramid of the image in this cycle is constructed, and the optimization process is activated at the beginning of each cycle. In addition, the different requirements of practical engineering can be met by adjusting the proportion of additional weights.
2.2.3. Feature Matching and Transformation
After obtaining a description of the feature points, it is necessary to establish the correct correspondence between these features.
BBF performs feature matching. The algorithm extracts the feature vector of the high-dimensional space, and provides a correct probability estimation to the approximate matching, arranges all approximate matching in a sorted manner, and selects the optimal matching as the initial matching result. Furthermore, the algorithm establishes an absolute time constraint for the search process. When all the matching results in the priority queue have been inspected, or the match time is over the time threshold, the algorithm designates the presently acquired optimal result as the approximate nearest neighbor. After completing the matching verification on one side, the image alignment is rechecked by the mechanism to review the matching results, and the same results of the two matchings are screened out. However, there will still be false matches in the optimal bilateral matching results selected by the above work, and the geometrical constraint [46] is used to filter the results again. The local domain structure around the control point is detected, and the nearest neighbor of the control point under the Euclidean distance is used as its neighborhood. A penalty mechanism based on the distance consistency of the matching pair is introduced to measure whether all the assumed matching pairs satisfy the geometric constraints used to maintain the local neighborhood structure to eliminate incorrect matchings. Finally, image pairs usually have almost the same viewing angle, but when the camera is close to the target object, there can still be significant differences in the viewing angles. This leads to projection distortion when mapping objects from three-dimensional space onto a two-dimensional image. Therefore, projective transformation is used to calculate the coordinate transformation model to address the issues caused by differences in viewing angles.
The above is the whole process of thermal–visible-image registration.
3. Experimental Results and Discussion
In this section, we demonstrate and verify the effectiveness and robustness of the proposed two-stage registration strategy for thermal–visible images, and compare it with several methods: PSO-SIFT, MS-PIIFD, SI-PIIFD, RANSAC. This method was implemented using MATLAB® 2019a and the testing was conducted on an Intel Core CPU i5 (2.30 GHz frequency) with 8 GB RAM, the device manufacturer is from Lenovo in the Wuhan region of China.
3.1. Experimental Setup and Dataset
In this paper, 30 pairs of substation images from Yujiatou Substation in Wuhan, China, were selected as experimental registration images. To validate the efficacy of the proposed method across diverse scenarios, the selected experimental data contain the vast majority of the problems with thermally visible image registration: scale differences, perspective differences, image distortion, a large number of detailed features, noise, and rotation.
The two-stage registration strategy proposed in this paper contains five parameters that affect the registration results, namely, the threshold value for the number of feature points in the Harris corner detector, the number of layers and octaves in the scale space, the additional weight of the matching accuracy and the additional weight of the average running time.
In general, it is necessary to obtain a large number of highly repetitive feature points to form sufficient matching candidate points. However, an abundance of feature points will adversely impact computational efficiency and result in an excessive number of outliers. Therefore, it is necessary to limit the number of detected feature points. Following the experiment using 30 sets of images, we set the initial value of the threshold to 500 and increased this incrementally by 100 each time until reaching 1200, and we found that, at a threshold of 800, all images were well registered. Below this value, some images showed obvious registration errors, and above this value, the overall calculation time was significantly improved. Therefore, the threshold value for the number of feature points in the Harris corner detector was set to 800 in this experiment.
Similarly, constructing a suitable scale space is also key to ensuring the registration effect and computational efficiency. In our experiments, we set the number of layers in the scale space to 4–8 and the octave of the scale space for initial registration was 2–4. After testing the above 15 combinations, we found that the optimal combination of layers and octave under this experiment was 6 and 3, and the octave of the two stages of registration was determined by the comprehensive registration index. The parameter settings described above are specifically tailored to this experiment. For other scenarios, adjustments to the parameters should be made according to the actual circumstances.
The additional weights of the matching accuracy and average running time were set to 0.5 in this experiment, which can be adjusted according to field requirements in practical applications.
3.2. Evaluation Matrices
To objectively ascertain the effectiveness of the method, this paper proposes two evaluation indicators: precision and target registration error (TRE). The precision represents the proportion of the correct number of matching (CNM) correspondences in the total number of matches (TNM). The precision can be defined as follows:
This metric indicates the accuracy of key point matching when obtaining the transformation matrix. TRE represents the Euclidean distance between the key points after coordinate transformation and the real corresponding points. The TRE is calculated as follows:
is the transformation map of the ground truth key points, and is the transformation map of the key points extracted after the second registration of the image.
However, it is impossible to find the real coordinate transformation matrix between image pairs. Therefore, this paper uses the control point selector in MATLAB to manually select 12 pairs of sub-pixel accuracy feature points in the image to generate an approximate ground truth transformation model. By employing the approximate transformation matrix, the keypoints of the matched visible image undergo a transformation process.
3.3. Visual Results
To validate the registration performance of the proposed method under various scenarios, Figure 5 shows the four most representative experimental results.

Figure 5.
Four sets of experimental results of the proposed method, including original thermal-visible image pair (left top&right top), fusion form (left bottom), and checkerboard form (right bottom).
The main results are as follows: (a) such images contain a large amount of detailed information, including small electronic components, intricate cables and other complex structures common to substations; (b) there is a huge difference in scale between these image pairs, and the thermal image usually has a narrow viewing distance and can only cover part of the information of the visible image; (c) these images include large differences in viewing angles, and some contain spatial distortion due to the different camera angles and positions used; (d) these images are of low quality and contain a lot of noise, especially in thermal images, due to the poor camera quality or long distance from the target object.
We can roughly compare the edge consistency of the foreground objects by observing the registration results of fusion and checkerboard images, and judge the degree of image alignment. Through an artificial observation of the above four groups of experimental results, there is no obvious deviation in the image, and the stable registration performance is maintained in various scenarios.
However, we can find obvious virtual shadows in scene c and scene d. This is attributed to the inferior quality of the infrared images and the presence of spatial distortion. Several basic image transformation methods cannot completely correct the two image. In order to make up for the lack of pixels and achieve better registration results, function interpolation and fitting methods are used to correct the registration results.
In order to fully evaluate the effectiveness and advantages of this method, the following section will provide a detailed comparative analysis of its performance with other mainstream and state-of-the-art methods in the current field, especially key indicators such as precision and robustness. Figure 6 compares the experimental results of five methods, including the proposed method. It can be seen that PSO-SIFT and SI-PIIFD failed to register successfully. MS-PIIFD has a small registration error. The experimental results of the proposed method and RANSAC are the best, and there is no obvious difference.
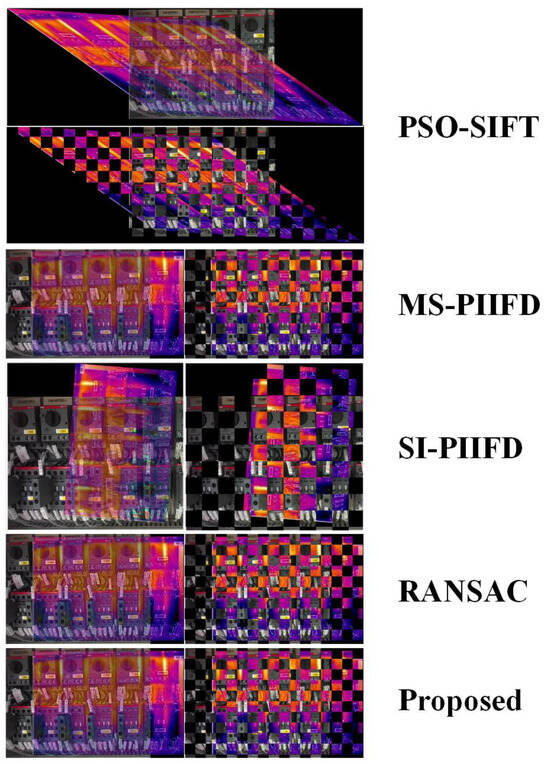
Figure 6.
Comparison of test results for different registration methods on image pair.
3.4. Quantitative Analyses
A comparative analysis of matching accuracy among various methods is presented in Figure 7. The experimental results show that the proposed method has the best matching accuracy, the average accuracy is 85.88%, and there are no obvious outliers. The experimental results are stable and robust. In several other methods, the matching accuracy of PSO-SIFT is the lowest, making the registration almost impossible, and the performance of RANSAC is relatively improved. However, there are obvious outliers in these four methods, indicating that some images have not been successfully matched.
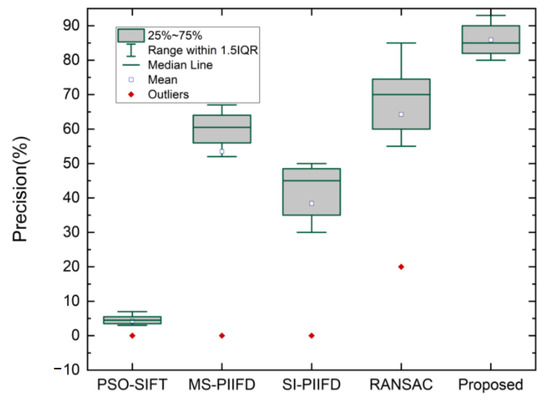
Figure 7.
Comparision of precsion performance according to different related methods.
Table 1 presents the average and standard deviation of the TRE for different methods. The results demonstrate that the proposed method exhibits a superior performance, with a registration error of less than 5 pixels. The average error and standard error of the target registration for different images are shown in Figure 8. PSO-SIFT and SI-PIIFD manifest significant registration errors. The average TRE value of RANSAC is 6.36 pixels, which is relatively good, but its standard error is 0.97, indicating that its stability is poor. The average TRE value of the proposed method is 4.53 pixels, the standard error is 0.39, and the overall performance is the best.

Table 1.
Average (Avg) and standard deviation (Std) of TRE across various registration methods.
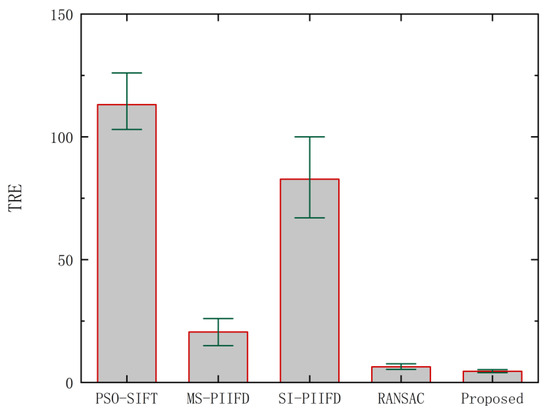
Figure 8.
Average TRE values of image pairs with various methods.
3.5. Discussion
In some special working scenarios, the main reason for the failure of existing registration methods is usually due to the large difference in scale between image pairs. The two-stage registration strategy proposed in this paper solves this problem well, and we adjusted the image pairs to similar scales during the first registration, which greatly improved the robustness of the proposed method in the different experimental scenarios. After that, through the second, more detailed, adjustment, the problem of complex pictures and blurred images is solved, so that the image pair can be perfectly registered. However, the method proposed in this paper only realizes the adaptive adjustment of some key parameters, and parameters such as feature point extraction threshold still need to be adjusted according to the actual scene. In the future, we will continue to research algorithm optimization and full-parameter adaptive adjustment so that they can be used in more application scenarios.
4. Conclusions
This paper proposes a two-stage substation thermal–visible-image registration method. Firstly, the original image pair is binarized, and a fast initial registration is performed using an improved FAST algorithm to reduce the difference in scale. Secondly, a registration framework is proposed, with ADU-PIIFD as the core. By comparing the comprehensive registration indexes in spaces with a different scale, the construction scheme of the image pyramid is determined to achieve a more precise transformation, enhance the accuracy of registration, and significantly improve the adaptability to different scenes. According to the analysis of experimental results, the method proposed in this paper shows an excellent registration performance in various complex scenes. Even in the case of extremely blurred images, the registration error can be controlled within five pixels, and the robustness is excellent. In the field of fire safety, this concept is supposed to have promising potential in the field of fire safety.
Author Contributions
Conceptualization, W.S. and H.G.; methodology, W.S.; software, W.S. and C.L.; validation, W.S. and H.G.; formal analysis, W.S.; investigation, W.S. and H.G.; resources, H.G.; data curation, W.S. and C.L.; writing—original draft preparation, W.S.; writing—review and editing, W.S. and H.G.; visualization, W.S. and C.L.; supervision, H.G.; project administration, W.S. and C.L. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Data are contained within the article.
Conflicts of Interest
The authors declare no conflict of interest.
References
- He, X.; Feng, Y.; Xu, F.; Chen, F.-F.; Yu, Y. Smart fire alarm systems for rapid early fire warning: Advances and challenges. Chem. Eng. J. 2022, 450, 137927. [Google Scholar] [CrossRef]
- Mtz-Enriquez, A.I.; Padmasree, K.; Oliva, A.; Gomez-Solis, C.; Coutino-Gonzalez, E.; Garcia, C.; Esparza, D.; Oliva, J. Tailoring the detection sensitivity of graphene based flexible smoke sensors by decorating with ceramic microparticles. Sens. Actuators B Chem. 2020, 305, 127466. [Google Scholar] [CrossRef]
- Horng, W.-B.; Peng, J.-W.; Chen, C.-Y. A new image-based real-time flame detection method using color analysis. In Proceedings of the Proceedings 2005 IEEE Networking, Sensing and Control, Tucson, AZ, USA, 19–22 March 2005. [Google Scholar]
- Chen, J.; He, Y.; Wang, J. Multi-feature fusion based fast video flame detection. Build. Environ. 2010, 45, 1113–1122. [Google Scholar] [CrossRef]
- Zitová, B.; Flusser, J. Image Registration Methods: A Survey. Image Vis. Comput. 2003, 21, 977–1000. [Google Scholar] [CrossRef]
- Sawhney, H.S.; Kumar, R. True Multi-Image Alignment and Its Application to Mosaicing and Lens Distortion Correction. IEEE Trans. Pattern Anal. Mach. Intell. 1999, 21, 235–243. [Google Scholar] [CrossRef]
- Sanjay-Gopal, S.; Chan, H.-P.; Wilson, T.; Helvie, M.; Petrick, N.; Sahiner, B. A Regional Registration Technique for Automated Interval Change Analysis of Breast Lesions on Mammograms. Med. Phys. 1999, 26, 2669–2679. [Google Scholar] [CrossRef]
- Xu, M.; Varshney, P.K. A Subspace Method for Fourier-Based Image Registration. IEEE Geosci. Remote Sens. Lett. 2009, 6, 491–494. [Google Scholar] [CrossRef]
- Bacharach, S.L.; Douglas, M.A.; Carson, R.E.; Kalkowski, P.J.; Freedman, N.M.; Perrone-Filardi, P.; Bonow, R.O. Three-Dimensional Registration of Cardiac Positron Emission Tomography Attenuation Scans. J. Nucl. Med. 1993, 34, 311–321. [Google Scholar]
- Samritjiarapon, O.; Chitsobhuk, O. An FFT-Based Technique and Best-First Search for Image Registration. In Proceedings of the International Symposium on Communications and Information Technologies, Vientiane, Laos, 1 October 2008. [Google Scholar] [CrossRef]
- Bracewell, R.N. The Fourier Transform and Its Applications; McGraw-Hill: New York, NY, USA, 1965. [Google Scholar]
- Chen, Q.; Defrise, M.; Deconinck, F. Symmetric Phase-Only Matched Filtering of Fourier-Mellin Transforms for Image Registration and Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 1994, 16, 1156–1168. [Google Scholar] [CrossRef]
- Lucchese, L.; Doretto, G.; Cortelazzo, G. A Frequency Domain Technique for Range Data Registration. IEEE Trans. Pattern Anal. Mach. Intell. 2002, 24, 1468–1484. [Google Scholar] [CrossRef]
- Reddy, B.S.; Chatterji, B.N. An FFT-Based Technique for Translation, Rotation, and Scale-Invariant Image Registration. IEEE Trans. Image Process. 1996, 5, 1266–1271. [Google Scholar] [CrossRef] [PubMed]
- Foroosh, H.; Zerubia, J.; Berthod, M. Extension of Phase Correlation to Subpixel Registration. IEEE Trans. Image Process. 2002, 11, 188–200. [Google Scholar] [CrossRef] [PubMed]
- Ritter, N.; Owens, R.; Cooper, J.; Eikelboom, R.; Van Saarloos, P. Registration of Stereo and Temporal Images of the Retina. IEEE Trans. Med. Imaging 1999, 18, 404–418. [Google Scholar] [CrossRef]
- Maes, F.; Collignon, A.; Vandermeulen, D.; Marchal, G.; Suetens, P. Multimodality Image Registration by Maximization of Mutual Information. IEEE Trans. Med. Imaging 1997, 16, 187–198. [Google Scholar] [CrossRef]
- Viola, P.; Wells, W.M. Alignment by Maximization of Mutual Information. In Proceedings of the International Conference on Computer Vision, Washington, DC, USA, 20 June 1995; pp. 137–154. [Google Scholar] [CrossRef]
- Thevenaz, P.; Unser, M. Spline Pyramids for Inter-Modal Image Registration Using Mutual Information. In Proceedings of the SPIE: Wavelet Applications in Signal and Image Processing, San Diego, CA, USA, 1 January 1997; pp. 236–247. [Google Scholar]
- Pascual Starink, J.P.; Backer, E. Finding Point Correspondences Using Simulated Annealing. Pattern Recognit. 1995, 28, 231–240. [Google Scholar] [CrossRef]
- Jenkinson, M.; Smith, S. A Global Optimisation Method for Robust Affine Registration of Brain Images. Med. Image Anal. 2001, 5, 143–156. [Google Scholar] [CrossRef]
- Sharma, R.K.; Pavel, M. Multisensor Image Registration; Society for Information Display: Silicon Valley, CA, USA, 1997; pp. 951–954. [Google Scholar] [CrossRef]
- Wolberg, G.; Zokai, S. Image Registration for Perspective Deformation Recovery. In Proceedings of the SPIE Conference on Automatic Target Recognition X, Orlando, FL, USA, 17 August 2000. [Google Scholar] [CrossRef]
- Lowe, D.G. Object Recognition from Local Scale-Invariant Features. In Proceedings of the IEEE Xplore, Kerkyra, Greece, 1 September 1999. [Google Scholar]
- Lindeberg, T. Scale-Space Theory: A Basic Tool for Analyzing Structures at Different Scales. J. Appl. Stat. 1994, 21, 225–270. [Google Scholar] [CrossRef]
- Ma, W.; Wen, Z.; Wu, Y.; Jiao, L.; Gong, M.; Zheng, Y.; Liu, L. Remote Sensing Image Registration with Modified SIFT and Enhanced Feature Matching. IEEE Geosci. Remote Sens. Lett. 2017, 14, 3–7. [Google Scholar] [CrossRef]
- Yan, K.; Sukthankar, R. PCA-SIFT: A More Distinctive Representation for Local Image Descriptors. In Proceedings of the 2004 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, CVPR 2004, Washington, DC, USA, 27 June 2004. [Google Scholar] [CrossRef]
- Mikolajczyk, K.; Schmid, C. A Performance Evaluation of Local Descriptors. IEEE Trans. Pattern Anal. Mach. Intell. 2005, 27, 1615–1630. [Google Scholar] [CrossRef]
- Dellinger, F.; Delon, J.; Gousseau, Y.; Michel, J.; Tupin, F. SAR-SIFT: A SIFT-like Algorithm for SAR Images. IEEE Trans. Geosci. Remote Sens. 2015, 53, 453–466. [Google Scholar] [CrossRef]
- Sedaghat, A.; Ebadi, H. Remote Sensing Image Matching Based on Adaptive Binning SIFT Descriptor. IEEE Trans. Geosci. Remote Sens. 2015, 53, 5283–5293. [Google Scholar] [CrossRef]
- Bay, H.; Tuytelaars, T.; Van Gool, L. SURF: Speeded up Robust Features. In Computer Vision–ECCV 2006; Bay, H.H., Tuytelaars, T., Eds.; Springer Nature: Berlin/Heidelberg, Germany, 2006; pp. 404–417. [Google Scholar]
- Rublee, E.; Rabaud, V.; Konolige, K.; Bradski, G. ORB: An Efficient Alternative to SIFT or SURF. In Proceedings of the IEEE International Conference on Computer Vision, Washington, DC, USA, 1 November 2011. [Google Scholar]
- Sun, M.; Zhang, B.; Liu, J.; Wang, Y.; Yang, Q. The Registration of Aerial Infrared and Visible Images. In Proceedings of the 2010 International Conference on Educational and Information Technology, Chongqing, China, 1 September 2010. [Google Scholar] [CrossRef]
- Chen, J.; Tian, J.; Lee, N.; Zheng, J.; Smith, R.T.; Laine, A.F. A Partial Intensity Invariant Feature Descriptor for Multimodal Retinal Image Registration. IEEE Trans. Biomed. Eng. 2010, 57, 1707–1718. [Google Scholar] [CrossRef] [PubMed]
- Harris, C.G.; Stephens, M.J. A combined corner and edge detector. In Proceedings of the Alvey Vision Conference, Manchester, UK, 1 January 1988. [Google Scholar] [CrossRef]
- Du, Q.; Fan, A.; Ma, Y.; Fan, F.; Huang, J.; Mei, X. Infrared and Visible Image Registration Based on Scale-Invariant PIIFD Feature and Locality Preserving Matching. IEEE Access 2018, 6, 64107–64121. [Google Scholar] [CrossRef]
- Gao, C.; Wei, L. Multi-Scale PIIFD for Registration of Multi-Source Remote Sensing Images. arXiv 2021, arXiv:2104.12572. [Google Scholar] [CrossRef]
- Kim, J.; Yang, Z.; Ko, H.; Cho, H.; Lu, Y. Deep learning-based data registration of melt-pool-monitoring images for laser powder bed fusion additive manufacturing. J. Manuf. Syst. 2023, 68, 117–129. [Google Scholar] [CrossRef]
- Zhao, L.; Pang, S.; Chen, Y.; Zhu, X.; Jiang, Z.; Su, Z.; Lu, H.; Zhou, Y.; Feng, Q. SpineRegNet: Spine Registration Network for Volumetric MR and CT Image by the Joint Estimation of an Affine-Elastic Deformation Field. Med. Image Anal. 2023, 86, 102786. [Google Scholar] [CrossRef]
- Haskins, G.; Kruger, U.; Yan, P. Deep Learning in Medical Image Registration: A Survey. Mach. Vis. Appl. 2020, 31, 1–18. [Google Scholar] [CrossRef]
- Fischer, P.; Dosovitskiy, A.; Brox, T. Descriptor Matching with Convolutional Neural Networks: A Comparison to SIFT. arXiv 2014, arXiv:1405.5769. [Google Scholar]
- DeTone, D.; Kruger, U.; Yan, P. Deep Image Homography Estimation. NASA ADS, 1 June 2016. Available online: https://ui.adsabs.harvard.edu/abs/2016arXiv160603798D/abstract (accessed on 21 July 2023).
- Otsu, N. A Threshold Selection Method from Gray-Level Histograms. IEEE Trans. Syst. Man Cybern. 1979, 9, 62–66. [Google Scholar] [CrossRef]
- Rosin, P.L. Measuring Corner Properties. Comput. Vis. Image Underst. 1999, 73, 291–307. [Google Scholar] [CrossRef]
- Beis, J.S.; Lowe, D. Shape Indexing Using Approximate Nearest-Neighbour Search in High-Dimensional Spaces. In Proceedings of the Conference on Computer Vision & Pattern Recognition, San Juan, Puerto Rico, 17 June 1997. [Google Scholar] [CrossRef]
- Ma, J.; Zhao, J.; Guo, H.; Jiang, J.; Zhou, H.; Gao, Y. Locality Preserving Matching. In Proceedings of the Twenty-Sixth International Joint Conference on Artificial Intelligence, Melbourne, Australia, 1 August 2017. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).