1. Introduction
Evolutionary algorithms (EAs) constitute an essential component of non-deterministic optimization algorithms. These algorithms utilize a set of control parameters that govern the search process and dictate the convergence speed. A considerable focus has been dedicated to addressing the significance of optimizing the control parameters of EAs [
1]. Most evolutionary algorithms are population-based [
2], and as a control parameter, the population size critically affects the performance of EAs [
3,
4]. The selection of an appropriate population size plays an important role in striking a balance between the exploitation and exploration process and ultimately enhancing the performance of EAs [
2]. Properly selected population size not only enhances the quality of solutions, but also ensures wise usage of computational resources [
5,
6]. On the one hand, inadequate small population sizes may lead to premature convergence towards sub-optimal solutions [
7]. On the other hand, excessively large population sizes are not necessarily beneficial in EAs, and instead may waste valuable computational resources, thus adding to the computational complexity [
3].
As a prominent evolutionary algorithm, differential evolution (DE) stands as a versatile and powerful global search technique that has been successfully utilized to address a wide range of optimization problems in various domains [
8,
9]. Central to the operational efficacy of the DE algorithm are its control parameters, namely, the crossover rate (
), the scale factor (
F), and notably, the population size (
). While a substantial amount of research has been dedicated to the optimization of
and
F due to their pronounced impact on the performance of the DE algorithm [
10,
11,
12,
13], the pivotal role of (
) in determining DE success cannot be overlooked. The influence of the population size on the performance of the DE algorithm has been widely acknowledged in the existing body of research [
5,
14,
15].
Since the inception of the DE algorithm, conventional guidelines have been proposed to provide users with recommendations for determining the population size. These guidelines suggest the selection of the population size either as a function of the problem dimension or the adoption of a fixed value as clearly highlighted in previous review studies [
16]. Conventional guidelines suggesting population sizes based on problem dimensions often stem from limited experimental investigations, which may not be generalizable. Concrete evidence about a linear relationship between the population size and the problem dimensionality has never been found [
17,
18]. The study by Piotrowski in 2020 reveals a nonlinear relationship between the population size and the problem dimension in the context of the particle swarm optimization (PSO) algorithm [
18]. There appears to be a lack of comprehensive research in the literature related to the DE algorithm that investigates the link between population size and problem-specific characteristics across various dimensions and complexities. Nevertheless, the practice of the adoption of a fixed value for the population size, based on experimental analysis, seems primarily applicable to the specific problems investigated. Determining the appropriate population size within the DE algorithm remains a daunting task, critically influencing DE performance.
Acknowledging the significance of the population size on the performance of the DE algorithm, researchers have increasingly explored adaptive DE strategies that provide more flexible and dynamic approaches. Accordingly, a plethora of research has emerged to address the challenge of improving DE performance by incorporating adaptive mechanisms to adjust the population size throughout the search process [
19,
20,
21,
22,
23,
24,
25,
26,
27,
28,
29,
30,
31,
32,
33,
34,
35,
36,
37,
38,
39,
40,
41,
42,
43,
44,
45,
46,
47,
48,
49,
50].
Numerous adaptive strategies have focused on reducing the population size throughout generations to enhance the DE search abilities and to achieve better convergence while reducing the computational burden [
19,
20,
21,
22,
23,
24,
25,
26,
27]. Another perspective is the adoption of variable population size strategies, wherein the population size is dynamically varied based on certain information gathered during the optimization process, such as the achieved performance level, convergence speed, and problem-specific information [
28,
29,
30,
31,
32,
33,
34,
35,
36,
37,
38,
39,
40,
41]. In addition to the aforementioned strategies, self-adaptive population size strategies have also been proposed [
42,
43,
44,
45,
46,
47,
48,
49,
50].
It is, however, worth mentioning that a significant number of studies, including those focused on adaptive DE strategies, have adopted the practice of determining the initial population either as a function of the problem dimension [
27,
28,
34,
37,
38,
40,
41,
43,
44,
47,
48,
50,
51,
52,
53,
54,
55,
56,
57,
58,
59,
60,
61], or a fixed value [
19,
20,
21,
22,
23,
24,
25,
26,
29,
30,
32,
35,
36,
39,
42,
46,
49,
62,
63,
64,
65,
66,
67,
68,
69,
70,
71]. Moreover, while dynamic population size adjustment offers a certain level of flexibility, setting a fixed initial population size may impose limitations of a predetermined population and could potentially restrict the ability of the algorithm to effectively respond to the dynamic nature of the search process. This limitation also arises in adaptive strategies that impose lower and upper limits for the population size, thereby becoming constrained by these bounds [
16]. Piotrowski [
16] emphasizes that the performance of self-adaptive strategies with lower and upper limits for the population size depends largely on these bounds. In a study by Zhu et al. [
31], the population size increased beyond the upper bounds when the population stagnated.
Notably, the emergence of adaptive population size strategies did not resolve the problem of initial population size selection since the user is not relieved from the hassle of the determination of the initial populations. Furthermore, the adaptive strategies for the population size in the DE algorithm often introduce additional control parameters, and thus are difficult to implement and tune [
72].
Despite the acknowledged significance of
, the guidelines for its determination exhibit a notable lack of clarity and precision, making it an ongoing research question that necessitates further investigation and refinement. The available guidelines for the determination of the population size in the DE algorithm have led to a one-size-fits-all setting that may not always align with the optimal parameters selection for specific problems. Such guidelines, although being widely applied, often fall short of accommodating the dynamic nature of different optimization scenarios, including the problem-specific characteristics and interrelationship between DE control parameters. A thorough examination of the presented papers reveals that the majority of studies focus on the adaptation of
F and
together while adapting the population size individually [
72]. The interaction between the population size and other DE control parameters is under-researched. Specifically, the side-effects introduced by individually changing the values of one control parameter on other DE control parameters have yet to be explored.
In light of the aforementioned challenges, the main objectives of this study are as follows:
Evaluate the credibility and effectiveness of existing guidelines for setting the population size in the DE algorithm: Critically assess the efficacy of proposed guidelines for determining population size within the DE algorithm, considering various problem modalities and dimensional complexities.
Investigate the correlations between population size and the fitness landscape characteristics of various problems: Analyze how varying population sizes affect DE performance across the distinct fitness landscapes of unimodal problems, multimodal problems, hybrid problems, and composition problems.
Analyze the significance of the population size in the DE algorithm: Utilize functional analysis of variance (fANOVA) to quantitatively assess the relative importance of the population size (), along with other DE control parameters, namely, the scale factor (F) and the crossover rate ().
Investigate the interrelationship between the population size and other DE control parameters: Examine the interplay and dependencies between the population size () and other DE control parameters (F and ) using fANOVA. More specifically, the objective is to capture any possible interaction between DE control parameters and to uncover how these parameters collectively affect the performance of the DE algorithm.
It is worth mentioning that this study employs the original differential evolution algorithm as proposed by Storn and Price [
9]. The selection of the original DE algorithm allows for a focused investigation without the confounding effects of advanced DE variants. Since the guidelines for determining the population size proposed in past studies are based on the original DE, this paper continues to investigate the credibility of these guidelines specifically within the context of the original DE algorithm. This investigation is necessary to facilitate a comprehensive understanding of the credibility of these guidelines, providing a performance reference for potential future studies involving advanced DE variants. Concerning DE, research that considers various problem modalities, the relative importance, and the interactions between DE control parameters has yet to be reported in the relevant literature.
To effectively address the research objectives, this paper is organized as follows:
Section 2 offers a detailed exploration of the necessary background information and delivers a review of the existing literature relevant to the topic.
Section 3 provides an overview of the basic DE algorithm considered in this study, along with the statistical approach employed, namely, the functional analysis of variance fANOVA. The methodology, experimental analysis, and the results and discussion are presented in
Section 4,
Section 5,
Section 6,
Section 7 and
Section 8. Finally,
Section 9 summarizes the key findings of the research and highlights areas for possible future directions.
5. Experimental Setup
To achieve the objectives, the DE/rand/1/bin strategy was applied to a set of well-known benchmark problems. Since population size determination guidelines have been derived from the original DE, this paper continues to focus on the original DE to analyze the credibility of these guidelines. Also, the CEC provides predefined benchmark suites that are commonly used to test algorithm performance [
108,
109,
110,
111]. The standard problems defined in CEC 2014 [
109] were chosen for the purpose of experimentation. The selection of the CEC 2014 benchmark suite is primarily attributed to its ability to provide a diverse set of problems that cover a wide range of characteristics, complexities, and dimensions. Despite being over ten years old, the CEC 2014 problems remain widely used due to their diversity and complexity, which continue to benchmark modern algorithms, including advanced variants of the DE algorithm. Moreover, these benchmark problems have been extensively used to provide a consistent testbed for analyzing the population size for DE [
16] and other well-known algorithms, like the PSO algorithms recently in 2020 [
18], which enables comparisons with previous studies and build upon the existing literature. (The following study demonstrates that there are no significant differences in the fitness landscape characteristics between the CEC 2014 benchmark functions and those in later benchmark sets. Therefore, CEC 2014 remains a sufficient and relevant benchmark suite [
112]).
The CEC 2014 benchmark suite comprises 30 problems and covers relatively simple unimodal problems (problems 1–3), multimodal problems (problems 4–16), hybrid problems (problems 17–22), and other composition problems (problems 23–30, which are considered extremely complex). All problems are scalable, which were tested using 10, 20, 30, 50, and 100 dimensions. Detailed descriptions of these problems are given in the work by Liang et al. [
110]. The CEC 2014 benchmark problems are sufficient to provide evidence supporting the main hypothesis and to draw sound conclusions on the aspects investigated in this study.
For each problem, the maximum number of function evaluations was
(where
D is the problem dimension), as previously advised in Liang et al. [
109]. Consequently, simulations using 20 individuals were run for 5000 iterations, whereas simulations using 100 individuals were run for 1000 iterations. Moreover, as per the recommendations in [
109], a total of 51 independent runs were performed for each problem, per dimension, and parameter setting combination. The obtained results were subjected to rigorous statistical validation, as detailed in the subsequent sections.
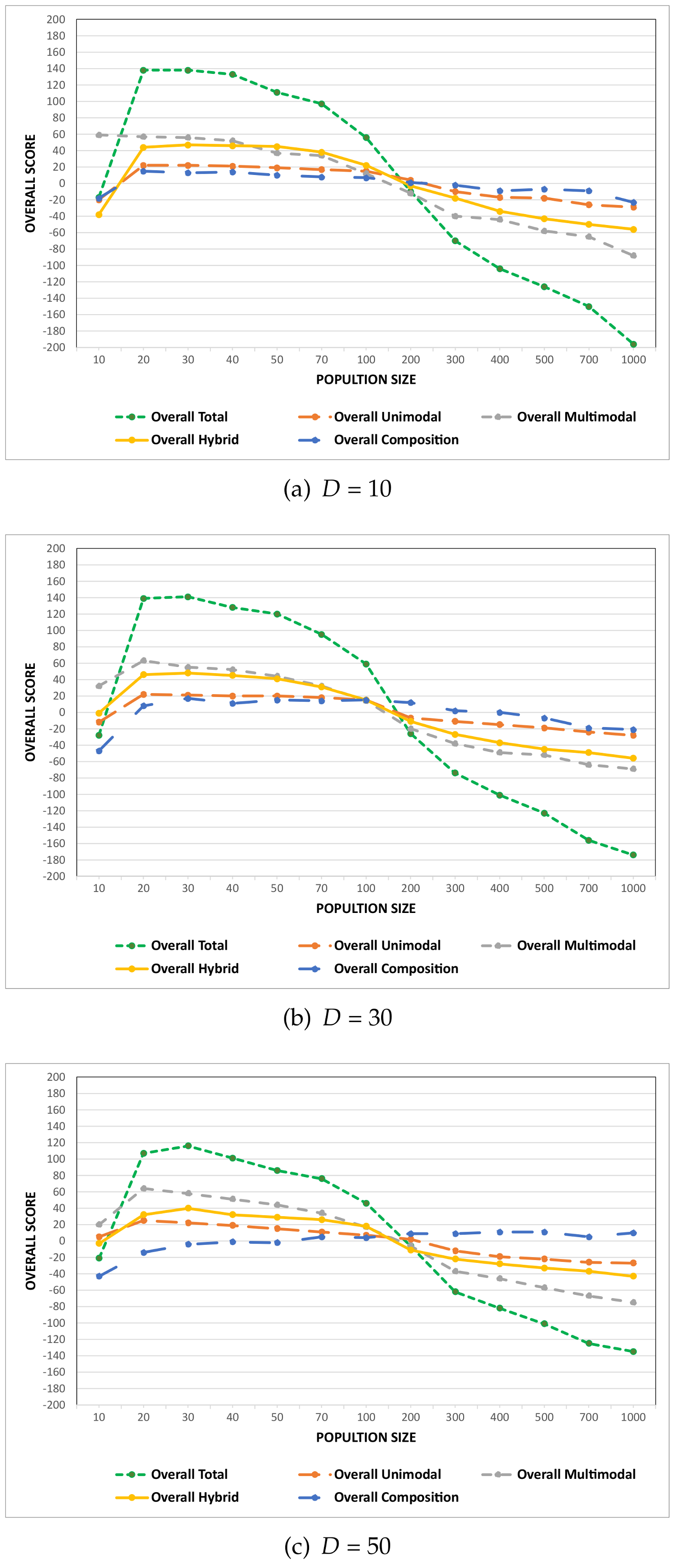
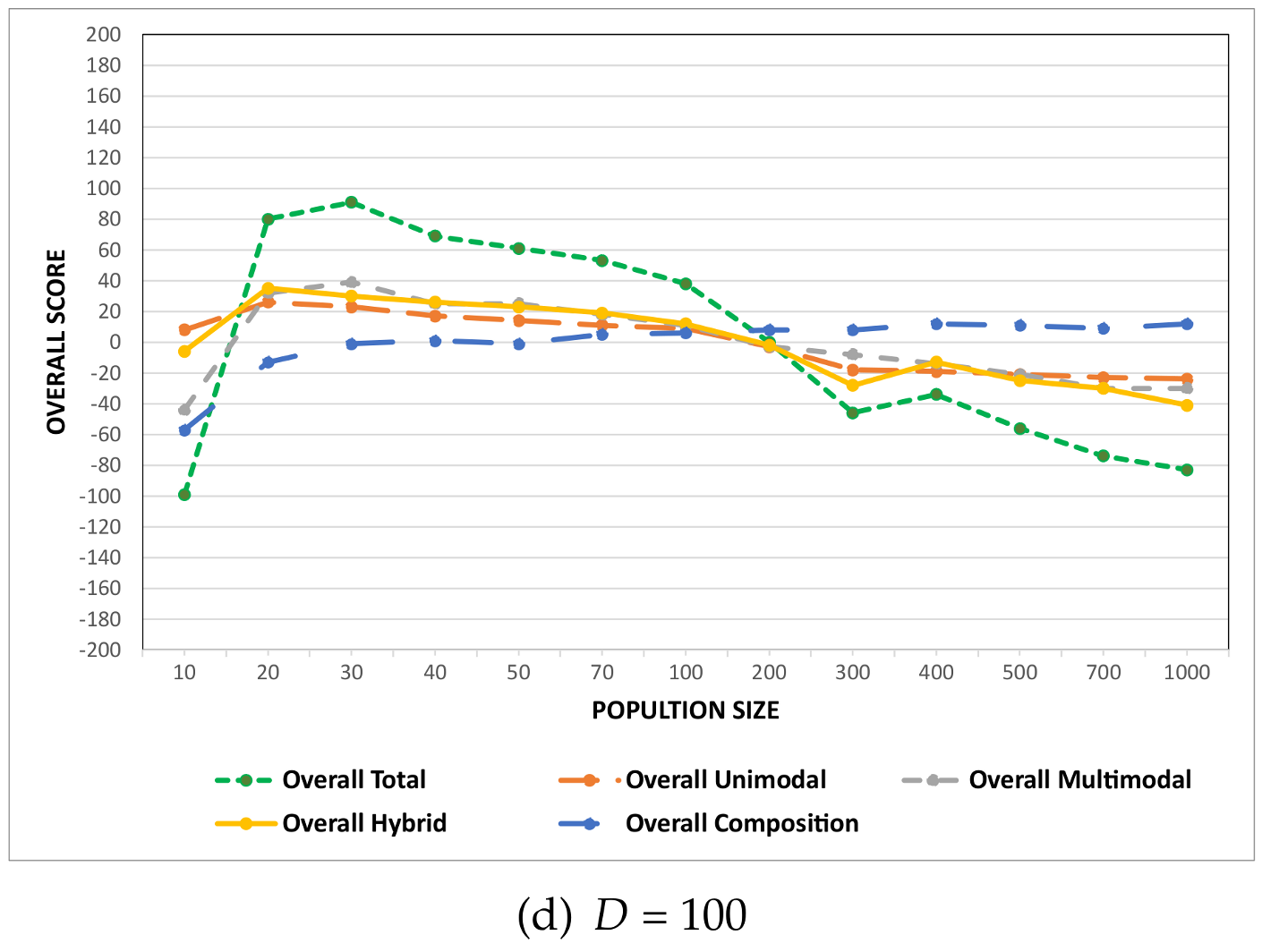
Two distinct experiments were conducted to achieve the objectives of this paper. The first experiment focuses on assessing the credibility of the proposed guideline used to determine the population size in the DE algorithm and empirically investigates how varying the population size affects DE performance across various fitness landscapes associated with different problem modalities. In this experiment, the population size was the sole control parameter that was varied using a range of values. The other control parameters of DE, i.e., the scale factor
F and the crossover rate
, were maintained at constant values in accordance with the recommendations by Storn and Price in [
9]. The analysis is conducted for each problem at various specified dimensions. Keeping all other control parameters fixed while changing the population size for diverse problem modalities and various problem dimensions allowed for a comprehensive assessment of the proposed population size guidelines on the performance of the DE algorithm and the effect of various population sizes on problem modalities.
In the second experiment, the values of all DE control parameters, including the population size, the crossover rate, and the scale factor, were systematically varied. This was done to achieve the objective of examining the relative importance of the population size and the mutual interactions between DE control parameters using the fANOVA technique. A comprehensive discussion of the experimental procedures and results obtained from both experiments is provided in the following sections, alongside detailed insights and analysis.
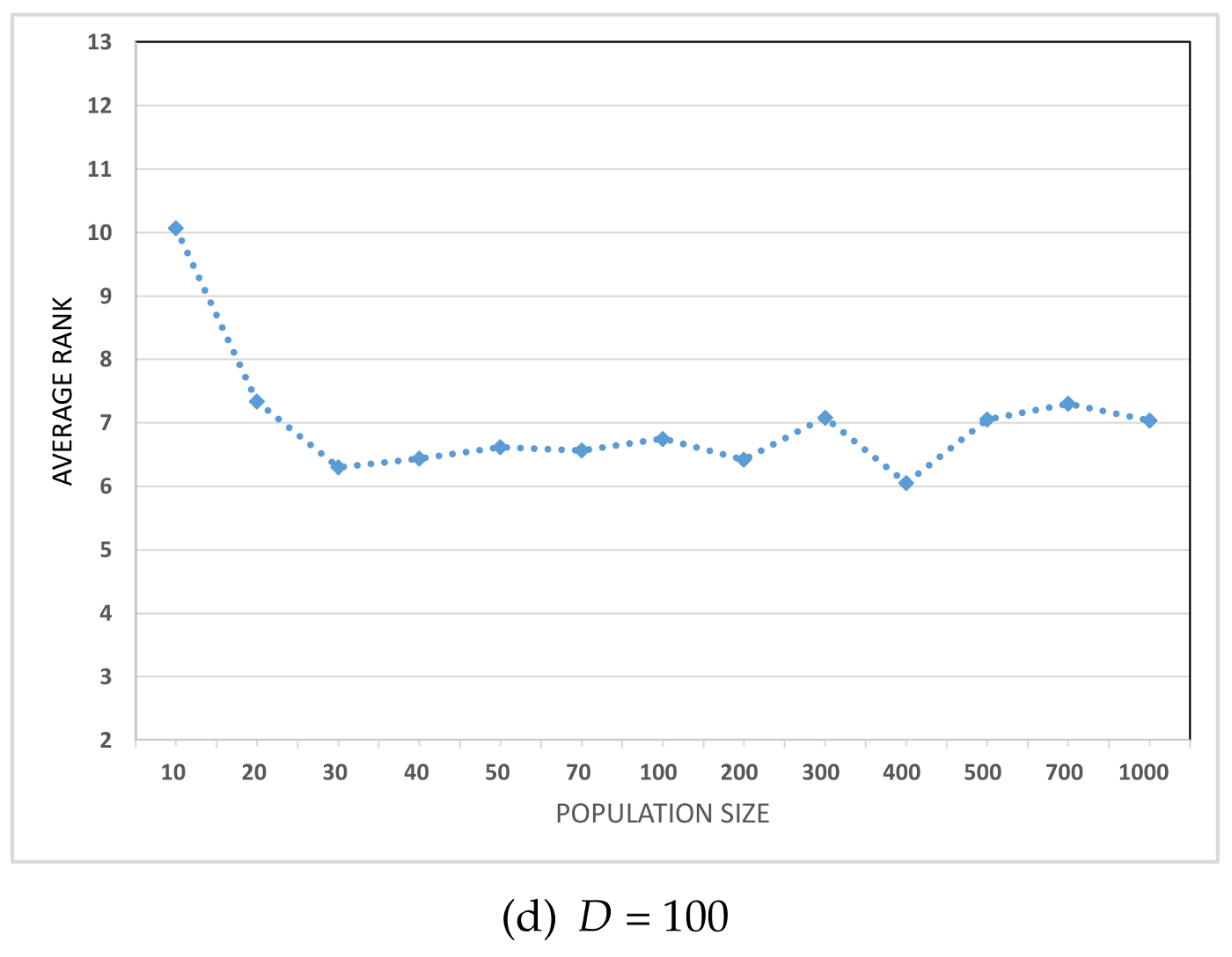
7. Experiment 2: The Importance of Population Size and Interrelation with Other DE Control Parameters
The primary objective of this experiment is to investigate the importance of the population size as a control parameter within the framework of the DE algorithm. Additionally, this experiment aims to examine the mutual interactions and interrelationships between the population size and other DE control parameters, namely, the scale factor, F, and the crossover rate, .
The experiment was performed on a 20-dimensional CEC 2014 benchmark suite. A total of 13 different population sizes were employed, specifically, 10, 20, 30, 40, 50, 70, 100, 200, 300, 400, 500, 700, and 1000 individuals. The scale factor F and the crossover rate were sampled in increments of 0.1 in the ranges [0.1, 1], producing a total of 1300 parameter configurations per problem and collectively producing 39,000 simulations for 30 problems, each of which comprised 51 independent runs.
The algorithm was terminated as per the specified number of fitness evaluations, specifically,
evaluations. The fANOVA approach was used to analyze the importance of the population size and highlight the mutual interactions between the population size and the other DE control parameters. As a powerful statistical approach, the fANOVA allowed for the assessment of the proportion of variance in fitness associated with each control parameter and, hence, to predict the individual importance of each control parameter. The results of the analysis indicating the individual importance of each control parameter are presented in
Table 1.
Table 1 presents the individual influence of each control parameter on the overall fitness variation. The results in
Table 1 indicate that the crossover rate
exhibits the highest contribution to the overall average fitness variation across almost all problems. On average,
alone accounted for 43.6% (or 0.436) of the total variance, making it the most influential control parameter that requires careful tuning. Following the scale factor
F, the population size
emerged as the second most influential control parameter, contributing to 21.9% (or 0.219) of the overall average fitness variation. In contrast, the scale factor,
F, was found to be the least important influential control parameter, accounting for only 3% (or 0.030) of the overall average fitness variance.
In more specific terms, the results presented in
Table 1 indicate that
had the highest impact on the fitness variance for most problems, except for
(
defines the shifted rotated Weierstrass function) and
(
defines the composition problem 4, which includes
as a sub-function). Notably, the fitness variances associated with
for
and
were 0.2% and 15%, respectively, which is significantly below the overall average variance for
of 43.6%. Moreover, for both the
and
problems,
yielded the highest influence on the fitness variance and was thus identified as the most influential control parameter for these specific two problems. It is worth mentioning that both
and
are highly computationally complex problems, and the landscape of these two functions was found to be highly convoluted (the CEC 2014 problems are described in detail in Liang et al. [
109]). This further provides a clue that the choice of proper population size could be of critical importance in determining the performance of the DE algorithm for highly complex problems like
and
. Interestingly, the control parameters did not have similar influential impact on all problems.
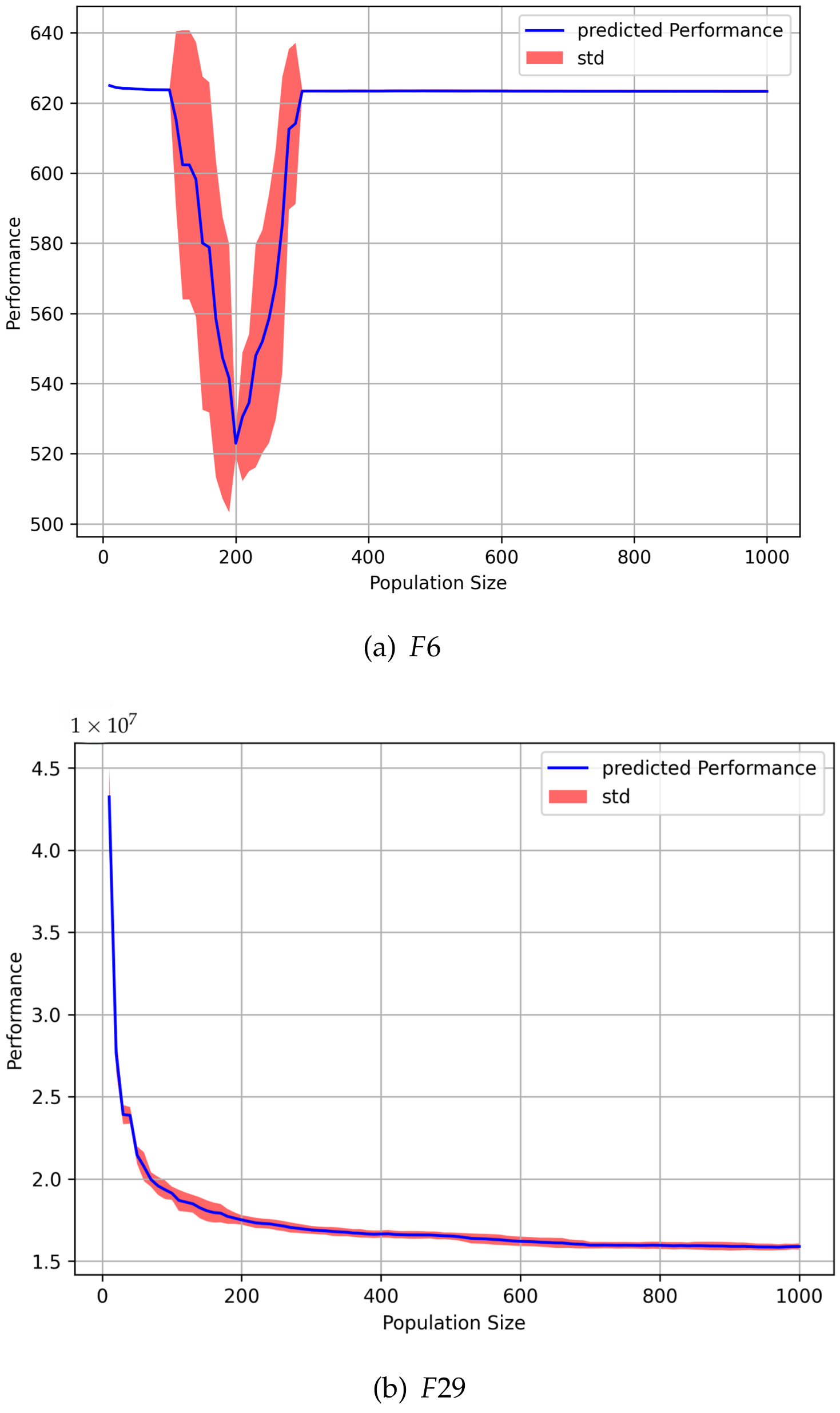
Figure 5 presents the average fitness, with respect to
, on selected problems.
Figure 5 provides additional insights into the relationship between the population size (
) and the average fitness. Examination of
Figure 5a shows that for
, improvement in performance was reported with a population size
= 200 individuals, while population sizes of smaller or larger than 200 demonstrated relatively worse performance. In contrast,
Figure 5b suggests that an increase in the population size had a positive impact on the performance of
.
Recall that
is a multimodal problem, while
is a composition problem. The different shapes of the plots in
Figure 5a,b, for different problems further support the findings of Experiment 1, indicating that the optimal population size is problem-dependent. Experimental evidence collected indicates that different behaviors were observed for population sizes across different problem modalities.
To further investigate the mutual interactions and interrelationships between the DE control parameters, pairwise marginals were obtained using the fANOVA technique. Considering all possible pairs of control parameters, the pairwise marginals provide insight into how the variations in one control parameter affect the impact of another control parameter on the algorithm’s performance.
The pairwise marginal results are presented in
Table 2.
It is evident that different pairwise marginals were obtained for different problems, which suggests that the interactions between DE control parameters are problem-specific and that parameter tuning approaches need to be problem-tailored. Moreover, the results reveal that, on average, the combined influence of the population size and the crossover rate was found to be marginally the most important across the CEC 2014 problems. Specifically, the combined effect of and on the DE performance exhibited the highest impact on DE performance for twenty problems, while the combined effect of F and had the highest impact on DE performance for ten problems. Notably, the combination of and F was not found to have a high impact for any of the problems.
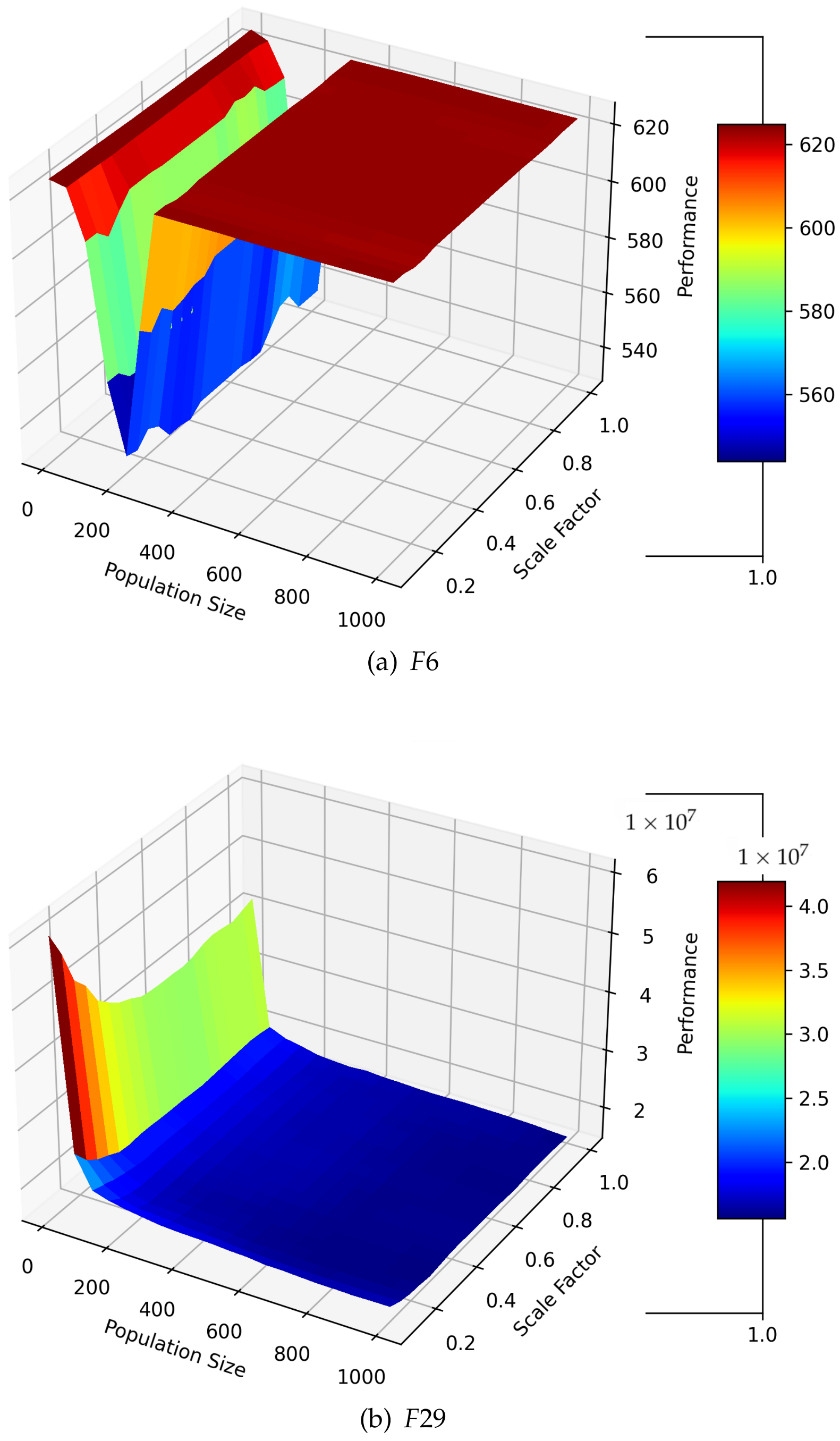
To further investigate the interaction effects of the population size with respect to other control parameters, the pairwise marginal plots between
and
F, and between
and
are depicted in
Figure 6 and
Figure 7, respectively.
Figure 6 further supports the fANOVA results, demonstrating that the combined effect of
and
F was less influential on overall DE performance. Conversely, the plots in
Figure 7 indicate that the influence of the population size
was significantly higher for smaller values of the
compared to larger values. Such interaction effects could not be demonstrated by the single marginal plots and should be considered when control parameters are configured.
Two significant findings arise from the aforementioned analysis: Firstly, the evidence collected demonstrates that the behavior of the population size varies across different problem modalities, and there are notable interaction effects between , , and F. As a result, it can be reasonably claimed that tuning of control parameters individually without considering the inter-dependencies with other control parameters may not result in an optimal parameter configuration and hence may not lead to optimized performance. Secondly, the research findings from Experiment 2 further highlight the necessity of incorporating the characteristics of the search space when control parameters are tuned. Different problems may exhibit different complexities, requiring tailored parameter configurations to attain optimal performance.
In summary, based on the analysis conducted in the second experiment on the CEC 2014 problems, the population size as a control parameter has demonstrated critical significance, in alignment with the findings of the past studies on the DE algorithm. The results provide empirical evidence that the population size was the second most influential control parameter with respect to overall fitness. Moreover, the effect of the interaction between and was found to be the most influential on DE performance. The observed interaction results revealed that as a control parameter is of critical importance for small values of compared to large values.
9. Conclusions
The current approaches to set the population size in the differential evolution (DE) algorithm based on problem dimensionality or as a subjective fixed value lack the reliability and precision necessary for optimizing DE performance across diverse problems complexities. This study meticulously examined the efficacy of existing guidelines for setting the population size within the DE algorithm across various problem types and modalities utilizing the CEC 2014 benchmark suite. Moreover, the relative importance and interrelationships between DE control parameters were investigated using the functional analysis of variance (fANOVA) approach.
The analysis revealed that conventional guidelines may often lead to over-estimations of initial populations and hence highlights the need for a reevaluation of how population sizes are determined in the DE algorithms. Furthermore, a link between population size and fitness landscape characteristics was found, revealing that different problems favor various population sizes. Specifically complex composition problems were found to benefit from larger population sizes, a finding not previously emphasized in the DE literature. Additionally, the investigation highlighted the paramount importance of the population size as a critical control parameter in the DE algorithm, ranking its significance second only to the crossover rate and preceding the scale factor in terms of impact. Notably, the crossover rate contributed 43.6% to the total fitness variation, making it the most influential control parameter, followed by the population size at 21.9%. In contrast, the scale factor accounted for only 3% of the fitness variation. These results highlight the critical need to carefully tune DE control parameters for optimal DE performance. This study also explores the interrelationships between DE control parameters and identifies the crossover rate as the most influential factor affecting fitness variance in the DE algorithm. Moreover, the interaction between population size and the crossover rate shows a significant influence on the DE performance, with larger population sizes proving particularly advantageous at lower crossover rates to optimize DE performance.
An important and potential direction for future research involves conducting experiments on real-world problems. Currently, the focus of the study is on the CEC 2014 benchmark problems, which may not fully capture the diversity of real-world problem modalities. Moreover, a promising future work is the integration of machine learning techniques (such as regression trees and random forests) to predict optimal population size preemptively. Another direction for future work could also focus on developing adaptive DE strategies to dynamically adjust the population size based on fitness landscape characteristics of problems and convergence. This involves investigating the relationship between the population diversity and convergence speed across problems of various fitness landscape characteristics, particularly incorporating additional fitness landscape characteristics, such as ruggedness, deception, and searchability. Additionally, a potential avenue for future work is to further investigate the interaction between DE control parameters considering a broader spectrum of problems of various complexities including real-world problems. This investigation is not only needed to gain a better understanding of DE control parameters optimization but also to facilitate the development of more sophisticated, problem-specific guidelines for setting population sizes in the DE algorithms.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}