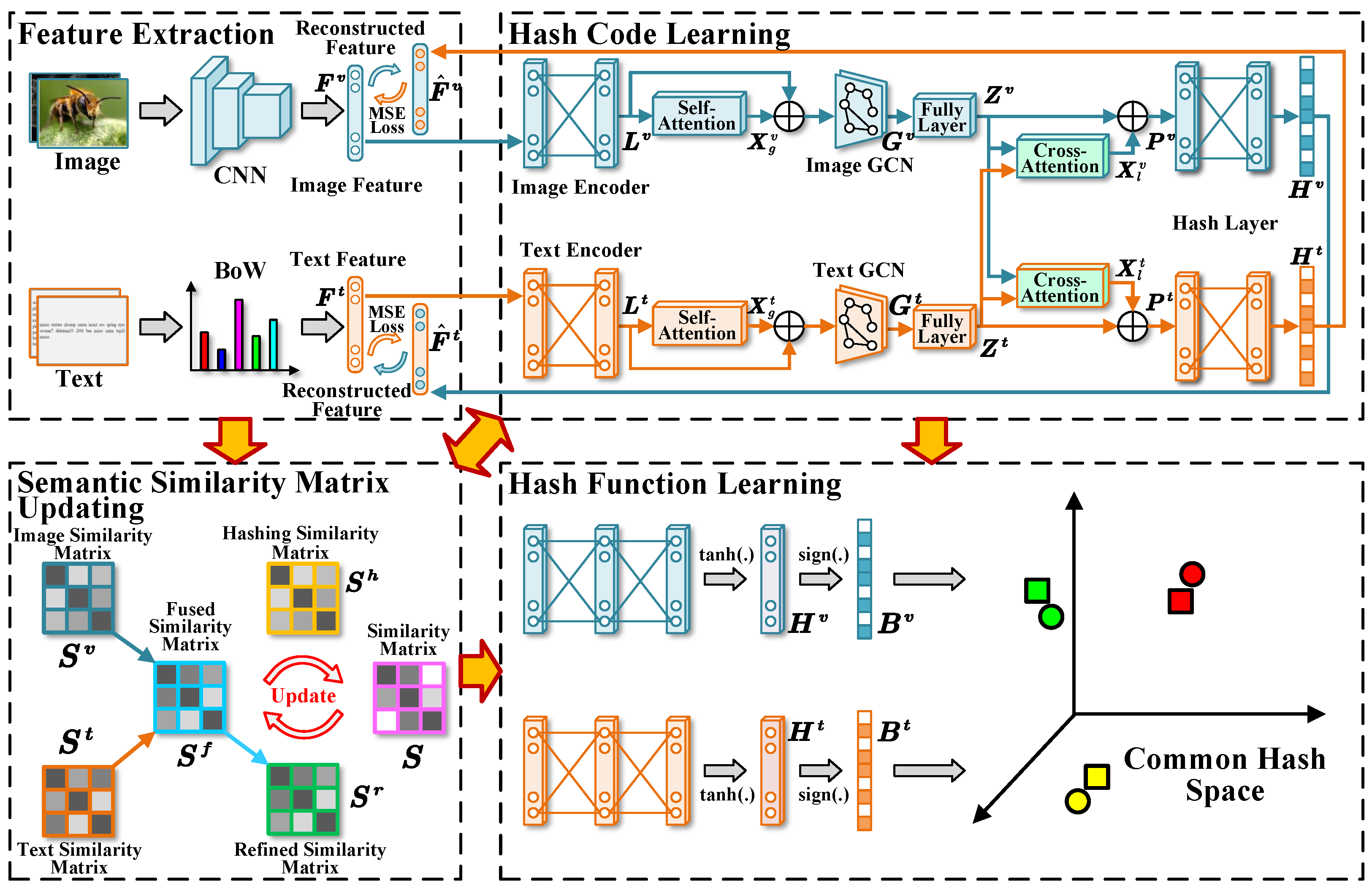
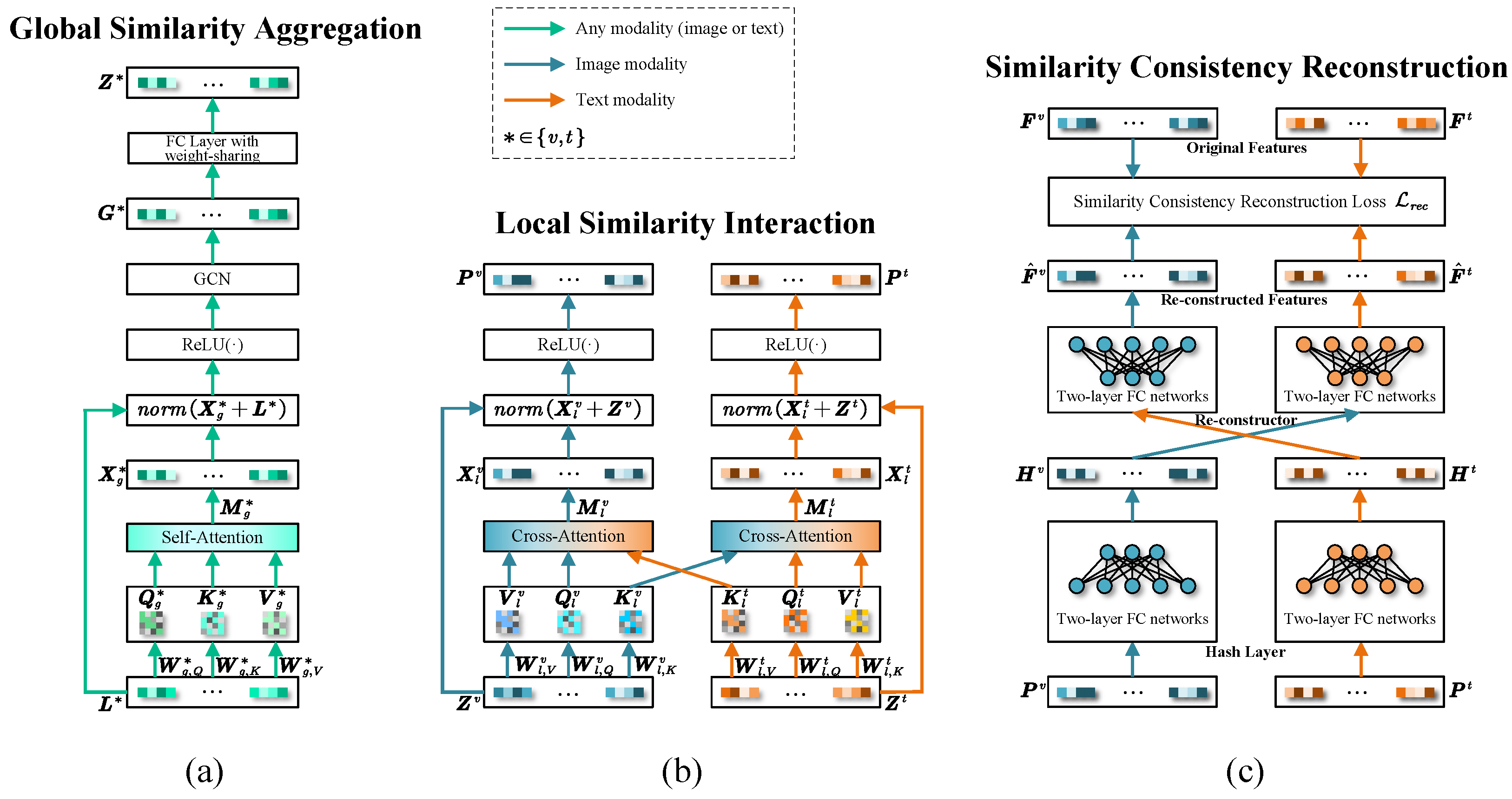
This section presents experiments and analysis to assess the retrieval performance of the proposed method. We begin by introducing the experimental settings, including datasets, evaluation metrics, baselines, and implementation details. Subsequently, we provide a performance comparison between our method and several baselines, along with an ablation analysis to validate the impact of each component.
4.1. Datasets
We conduct thorough experiments on two prominent multimedia benchmark datasets, namely MIRFLICKR-25K [
55] and NUS-WIDE [
56], widely employed for cross-modal retrieval evaluation. A concise introduction to these datasets is provided below.
MIRFLICKR-25K. The MIRFLICKR-25K dataset includes 25,000 image-text pairs from the popular photo-sharing platform Flickr. Each image is accompanied by multiple text labels. In our experiment, we specifically selected instances with at least 20 text tags. With AlexNet [
50], we converted each image into a depth feature of 4096 dimensions, while the text labels were converted into a BoW [
51] vector of 1386 dimensions. In addition, each instance is manually annotated with at least one of 24 unique tags. We experimented with 20,015 examples selected from the dataset.
NUS-WIDE. The NUS-WIDE dataset is a substantial real-world web image collection, featuring more than 269,000 images accompanied by over 5000 user-provided tags and 81 concepts across the entire dataset. Using AlexNet [
50], each image instance is represented as a 4096-dimensional deep feature, while the textual content is condensed into a 1000-dimensional BoW [
51] vector. For our experiment, we excluded instances lacking labels and focused on those associated with the 10 most frequent categories, resulting in a curated set of 186,577 image-text pairs.
Table 5 presents the statistics of the above two datasets, and some samples of these two datasets are shown in
Figure 4.
4.2. Evaluation Metrics
In our experiments, we conducted two types of cross-modal retrieval tasks: retrieving texts using image queries (denoted as “I2T”) and retrieving images using text queries (denoted as “T2I”). Next, we utilized two standard hashing performance protocols, Hamming ranking and hash lookup [
57], to assess the effectiveness of our method and its competitors. For the Hamming ranking protocol, we utilized mean average precision (mAP) to measure accuracy, while precision-recall curves (P-R curves) were employed for the Hash lookup protocol. For mAP and P-R curves, we considered images and texts to be similar if they shared at least one label; otherwise, they were considered dissimilar. Specifically, given a query
, the average precision (AP) of the top-
N results is defined as:
where
N is the number of relevant instances in the result set,
R represents the total amount of data.
denotes the precision of the top-
r results. If the
r-th retrieved result is relevant to the query instances,
; otherwise,
. The mAP value is defined as the average AP across all queries
:
where
M represents the number of queries.
4.3. Baselines and Implementation Details
Baselines. we compare the proposed MGSPU method with nine baselines, including CMFH [
31], DBRC [
58], UDCMH [
35], DJSRH [
12], JDSH [
36], DSAH [
37], AGCH [
26], DAEH [
27], DRNPH [
49], which are briefly described as follows:
CMFH: This method learns uniform binary feature vectors for different modalities through collective matrix factorization of latent factor models.
DBRC: This approach proposes a deep binary reconstruction model to preserve inter-modal correlation.
UDCMH: This method utilizes deep learning and matrix factorization with binary latent factor models for multi-modal data search.
DJSRH: This approach integrates original neighborhood information from different modalities into a joint-semantics affinity matrix to extract latent intrinsic semantic relations.
JDSH: This method introduces a distribution-based similarity decision and weighting scheme for generating a more discriminative hash code.
DSAH: This approach explores similarity information across modalities and incorporates a semantic-alignment loss function to align features’ similarities with those between hash codes.
AGCH: This method utilizes GCNs to uncover semantic structures, coupled with a fusion module for correlating different modalities.
DAEH: This approach attempts to train hash functions with discriminative similarity guidance and an adaptively-enhanced optimization strategy.
DRNPH: This method implements unsupervised deep relative neighbor relationship preserving cross-modal hashing for achieving cross-modal retrieval in a common Hamming space.
Except for CMFH, All other approaches use deep features to generate cross-modal hash codes.
Implementation Details. As discussed above, the learning process is divided into two stages. In hash code learning stage, three hyperparameters
are used to weight
, respectively. In hash function learning stage, three other hyperparameter
are used to adjust the ratio between
. On the MIRFLICKR-25K dataset, we set
. On NUS-WIDE dataset, we set
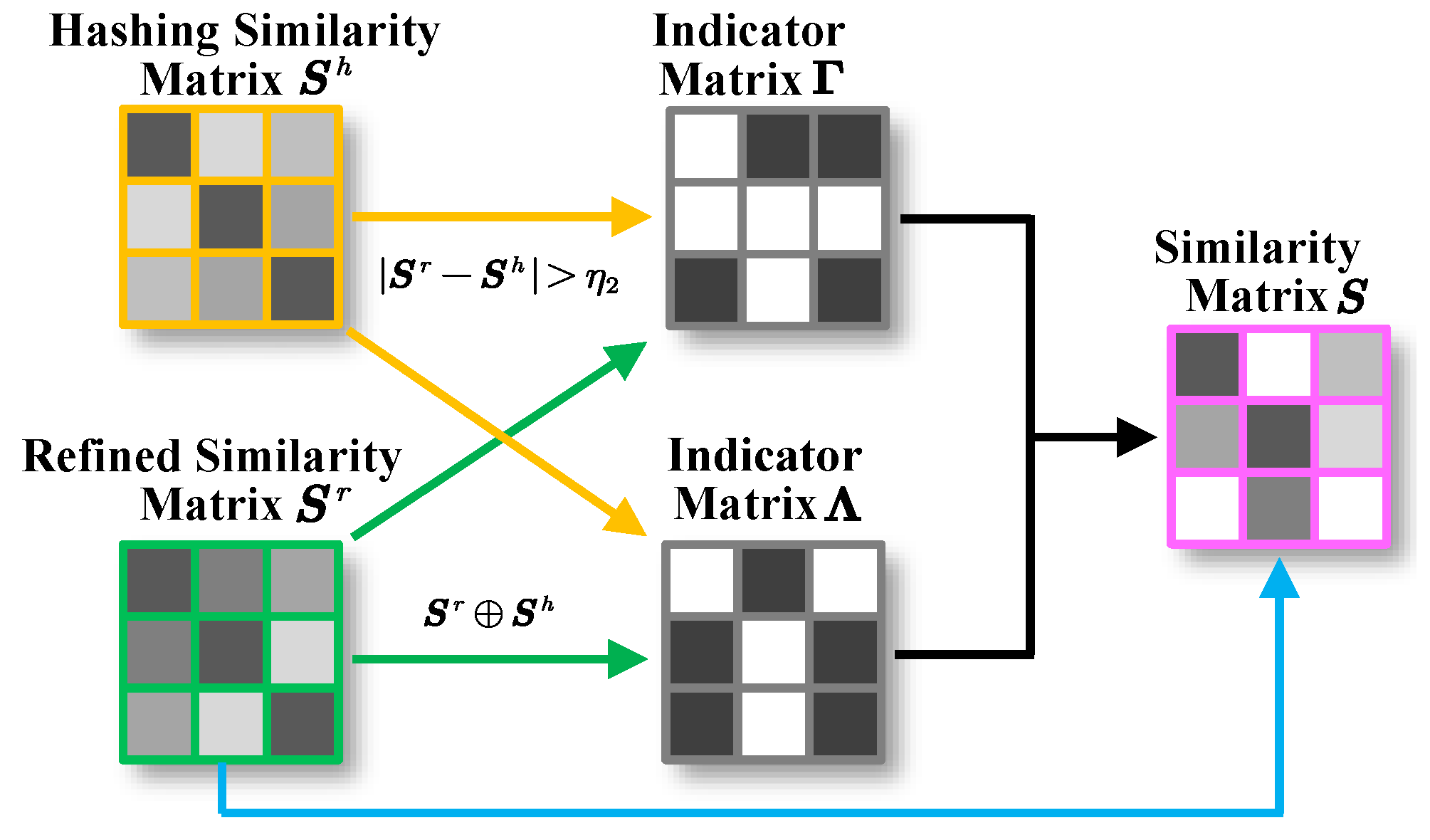
. In the process of semantic similarity matrix construction, we set
on the MIRFLICKR-25K, and set
on the NUS-WIDE. In GSA sub-module,
kNN algorithm is used to aggregate nodes in a certain neighborhood for each modality. We set
and
for MIRFLICKR-25K and NUS-WIDE, respectively. The optimization algorithm used is the Adam optimization algorithm [
54]. For MIRFLICKR-25K, we set the learning rates for hash code learning and hash function learning to 0.001 and 0.0001, respectively, and for NUS-WIDE, both are set to 0.0001. The batch size is consistently set at 512. The number of iterations is defined as 60 for MIRFLICKR-25K and 100 for NUS-WIDE. It’s worth noting that, under the same experimental setup, we directly utilize mAP@50 results provided in the original papers of the baseline methods.
Experimental Environment. All the experiments are performed on a workstation with Intel(R) Core i9-12900K 3.9 GHz CPU, 128 GB RAM, 1 TB SSD storage, 2TB HDD storage, and 1 NVIDIA GeForce RTX 3090Ti GPU with ubuntu-22.04.1 operating system. All the techniques are implemented by Python 3.9 on PyTorch 2.0.1.
4.4. Performance Evaluation
We compare the proposed method with nine baselines on MIRFLICKR-25K and NUS-WIDE datasets. The performance of all these methods are evaluated by Hamming Ranking protocol and hash lookup protocol.
Table 6 and
Table 7 illustrates the mAP@50 results of our method and the competitors varying hash code lengths (16, 32, 64, 128 bits) on MIRFLICKR-25K and NUS-WIDE.
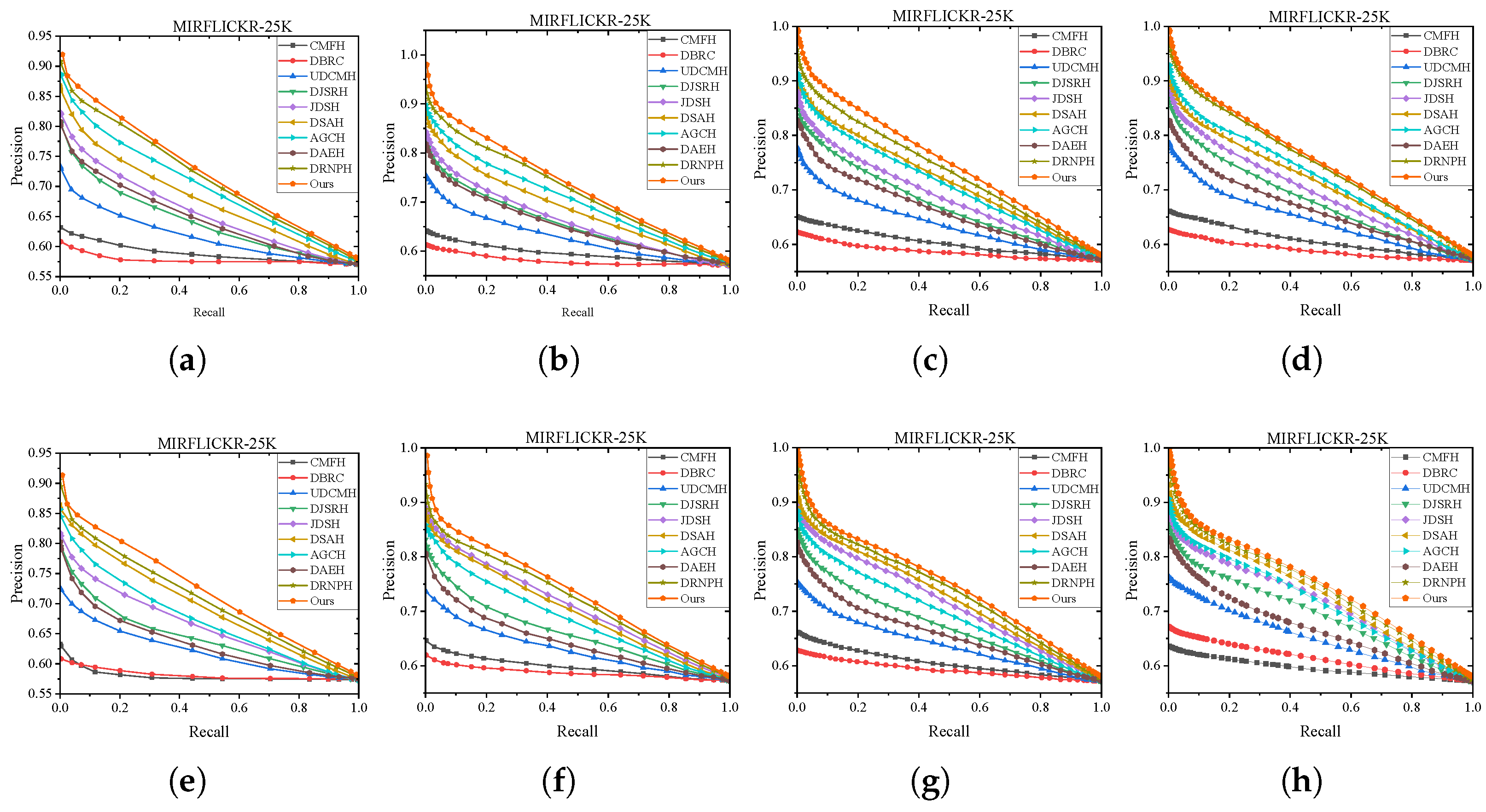
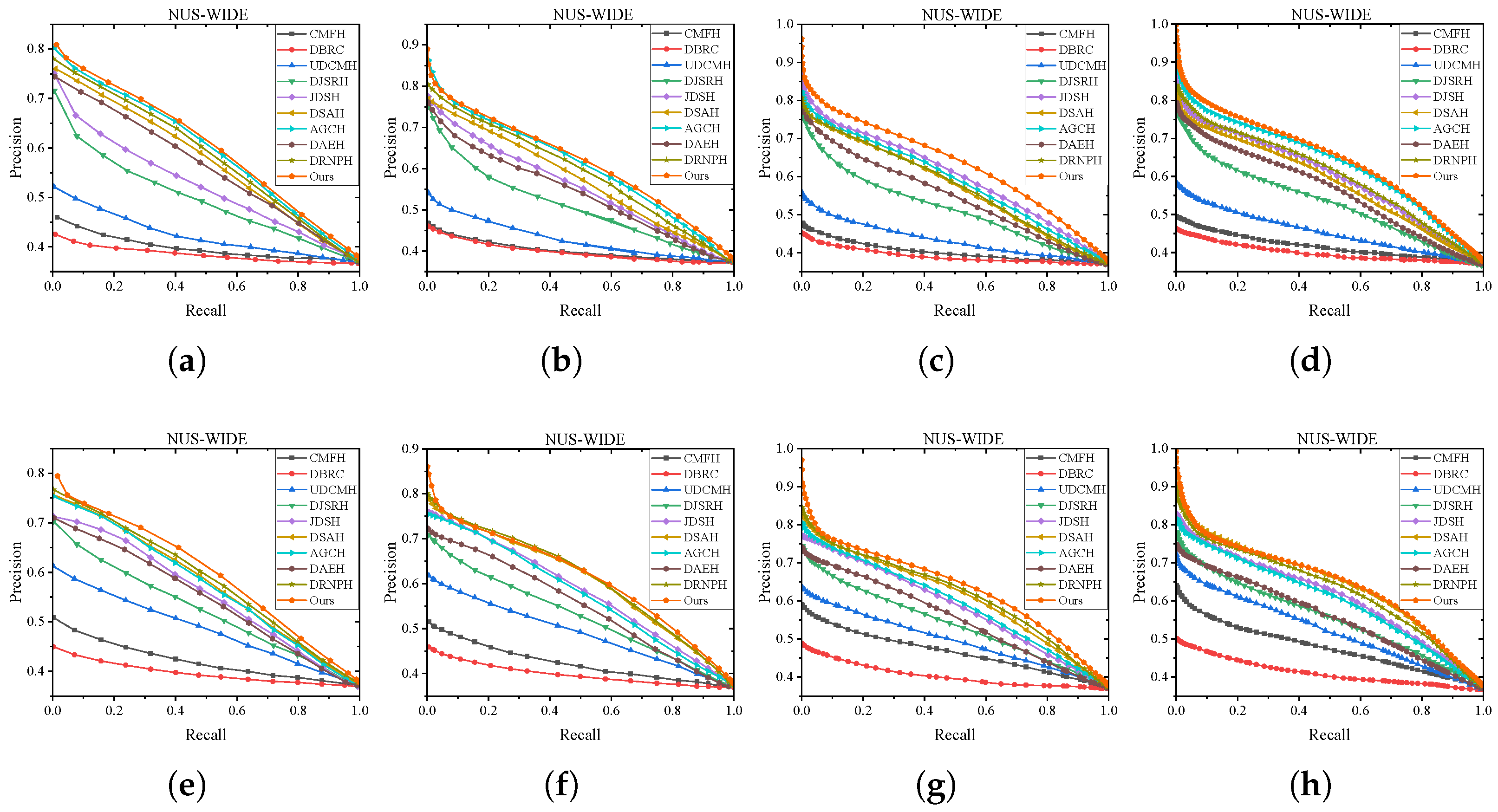
Figure 5 and
Figure 6 show the P-R curves on these two datasets in various code length. The detailed analysis and observation are presented as follows.
Hamming Ranking. It is clearly from the
Table 6 and
Table 7 that the proposed method performs better than the baselines. Specifically, on MIRFLICKR-25K, we found that our method achieved the highest mAP@50 score for both retrieval tasks (I2T: mAP@50 = 0.898 (16 bits), mAP@50 = 0.915 (32 bits), mAP@50 = 0.927 (64 bits), mAP@50 = 0.936 (128 bits); T2I: mAP@50 = 0.876 (16 bits), mAP@50 = 0.883 (32 bits), mAP@50 = 0.889 (64 bits), mAP@50 = 0.900 (128 bits)). For example, our method beats out the strongest competitor, DRNPH, by a significant margin on both two tasks, especially in shorter hash code length: 0.022 (16 bits), 0.013 (32 bits), 0.013 (64 bits) on I2T task, and 0.016 (16 bits), 0.011 (32 bits) on T2I task. The reason behind these results is obvious: with the engagement of the proposed similarity matrix updating strategy, our method can gradually eliminate the noise of the original features used in the similarity relationship construction so as to improve similarity consistency preserving, which is unfortunately ignored by DRNPH. In all but a few case (32 bits code length on I2T and I2T task, MGSPU was defeated by AGCH and DSAH marginally), our method won the competition again on NUS-WIDE by stand-out performance: mAP@50 = 0.811 (16 bits), 0.826 (32 bits), 0.844 (64 bits), 0.858 (128 bits) on I2T task, and mAP@50 = 0.780 (16 bits), 0.786 (32 bits), 0.806 (64 bits), 0.813 (128 bits) on T2I task. Compared with mainstream solutions, complex similarity correlations can be greatly mined through the semantic similarity matrix update strategy, and the MGSP module further retains the potential similarity structure between data.
Hash Lookup. To comprehensively showcase the comprehensive performance comparison of MGSPU with baselines, we draw P-R curves in
Figure 5 and
Figure 6 with different code lengths on both two datasets. As expected, in addition to dramatically defeating hand-crafted feature based method CMFH, MGSPU outperforms state-of-the-art competitors DRNPH, DSAH and AGCH on various hash code length. This observation is mainly due to the search performance boosting from the interplay of similarity updating and multi-grained similarity preserving of hash codes.
Discussion. It is no secret that, the main reason of poor performance of early models (such as CMFH and DBRC) is their shallow feature extraction techniques that cannot obtain feature representations with rich semantic information. With the help of powerful deep learning techniques, deep neural networks based methods such as DJSRH, JDSH, AGCH and DAEH achieved good results. Among them, DJSRH is equiped with a reconstruction framework for training, which is more competitive than batch training. AGCH uses GCN to aggregate neighborhood information and enhance feature expression. DAEH leverages teacher networks to enhance weaker hashing networks. However, all of them build similarity matrices based on original features, which inevitably bring noises into semantic relationships so as to introduce biases. Furthermore, these methods either maintain local or global similarities to preserve the semantic relationships. For example, the similarity matrix in DJSRH contains redundant information from intra-modal fusion items, while DAEH ignores the semantic relationships of intra-modal details. Comparing with these solutions, therefore, we argue that stepwise denoising through a similarity matrix update strategy can greatly mine complex similarity correlations, thereby generating high-confidence supervision signals. In addition, the MGSP method can effectively improve the hash code quality due to further preserving the potential similar structures within and between modalities. Both the mAP@50 score on the hash ranking protocol and the area under the P-R curves on the hash lookup procotol strongly support our view.
4.5. Ablation Study
To verify the validity of each design in MGSPU, we conducted ablation experiments on the MIRFLICKR-25K and NUS-WIDE datasets, serveral variations were considered for this purpose:
MGSPU-1: it removes semantic similarity matrix updating from MGSPU.
MGSPU-2: it removes the similarity consistency reconstruction from MGSPU.
MGSPU-3: it modifies similarity consistency reconstruction by replacing inter-modal reconstruction with intra-modal reconstruction.
MGSPU-4: it removes the GCN module from MGSPU.
From
Table 8 and
Table 9, the following observations can be obtained: firstly, the comparison of MGSPU-1 with our the full MGSPU method verifies that the proposed dual instruction fusion updating strategy can improve the quality of instance similarity matrix to enhance the retrieval performance. Specifically, the retrieval accuracy of MGSPU-1 for both I2T and T2I task show decrease in some extent: on MIRFLICKR-25K, mAP@50 results of I2T task drop from 0.898 (16 bits), 0.915 (32 bits), 0.927 (64 bits), 0.936 (128 bits) to 0.894 (16 bits), 0.912 (32 bits), 0.924 (64 bits), 0.933 (128 bits), respectively; mAP@50 results of T2I task drop from 0.876 (16 bits), 0.883 (32 bits), 0.889 (64 bits), 0.900 (128 bits) to 0.872 (16 bits), 0.876 (32 bits), 0.883 (64 bits), 0.892 (128 bits), respectively. It indicates that without the semantic similarity matrix updating, complex similarity relationship learning suffers from disturbance by noise. Secondly, we can clearly observe that MGSPU-2 has a remarkably performance degradation compared with the full version of MGSPU. This phenomenon confirms that similarity consistency reconstruction is beneficial to preserve semantic information into hash code. Thirdly, with intra-modal reconstruction, MGSPU-3 performs better than MGSPU-2 especially on long hash codes (e.g., 64 or 128 bits). However, compared with the inter-modal reconstruction used in our method, the performance of MGSPU-3 is slightly weaker, which indicates that the inter-modal reconstruction is more helpful to reduce the heterogeneity between the original feature and the hash code. Lastly, after removing GCN module, MGSPU-4 achieves lower retrieval accuracy than ours. these results show that the structural similarity aggregated from neighborhoods by the GCN module is essential to enrich the similarity relationship information of each instance.
4.6. Sensitivity to Hyperparameters
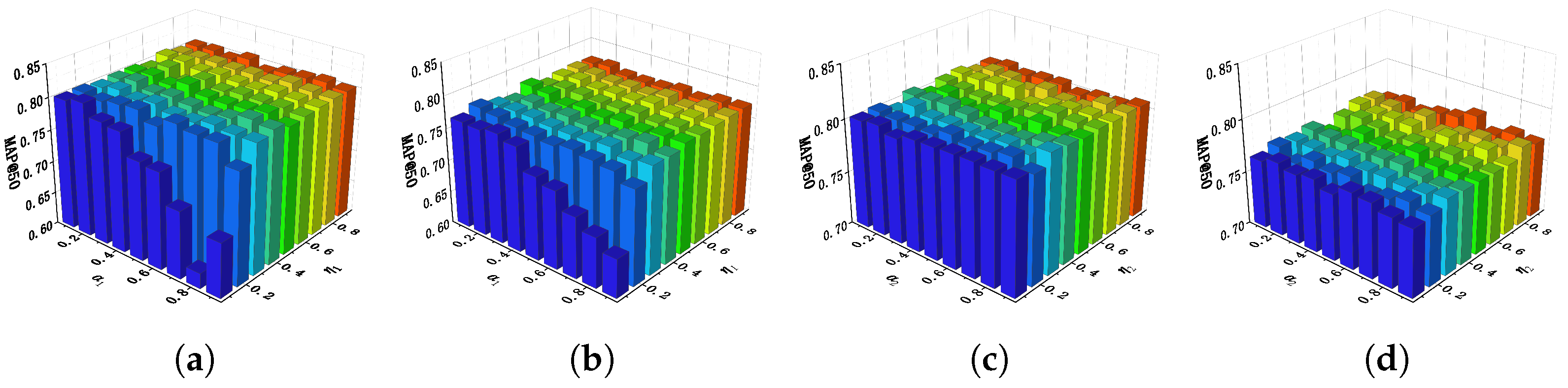
This section, we conduct an analysis of the sensitivity of all hyperparameters used in the model: . To explore the comprehensive impact of them, the accuracy of I2T and T2I task is used to visualize the trend of cross-modal hash performance. All these analysis are carried out in 16 bit hash code length on NUS-WIDE dataset.
Hyperparameter . In semantic similarity matrix updating module,
are used to construct the refined similarity matrix
,
are used to execute the updating strategy to generate semantic similarity matrix
. We observe the performance change of MGSPU by varying
and
. According to the experimental results in
Figure 7, it is clearly that the retrieval accuracy is more susceptible to changes of
when the value of
is small. We speculate that this phenomenon is caused by the noises that are injected in refined similarity matrix when the value of
is small. On the other hand, when we change the
and
, the fluctuations in model performance are relatively less severe, which still shows that our model performs a bit better if
is set to a large value (r.g.,
). The reason behind this results is understandable: if a larger threshold
is taken, the discrimination of whether
and
are dissimilar will be more rigorous. Under this circumstance, the semantic similarity matrix updating will be executed more cautiously to preserve robust.
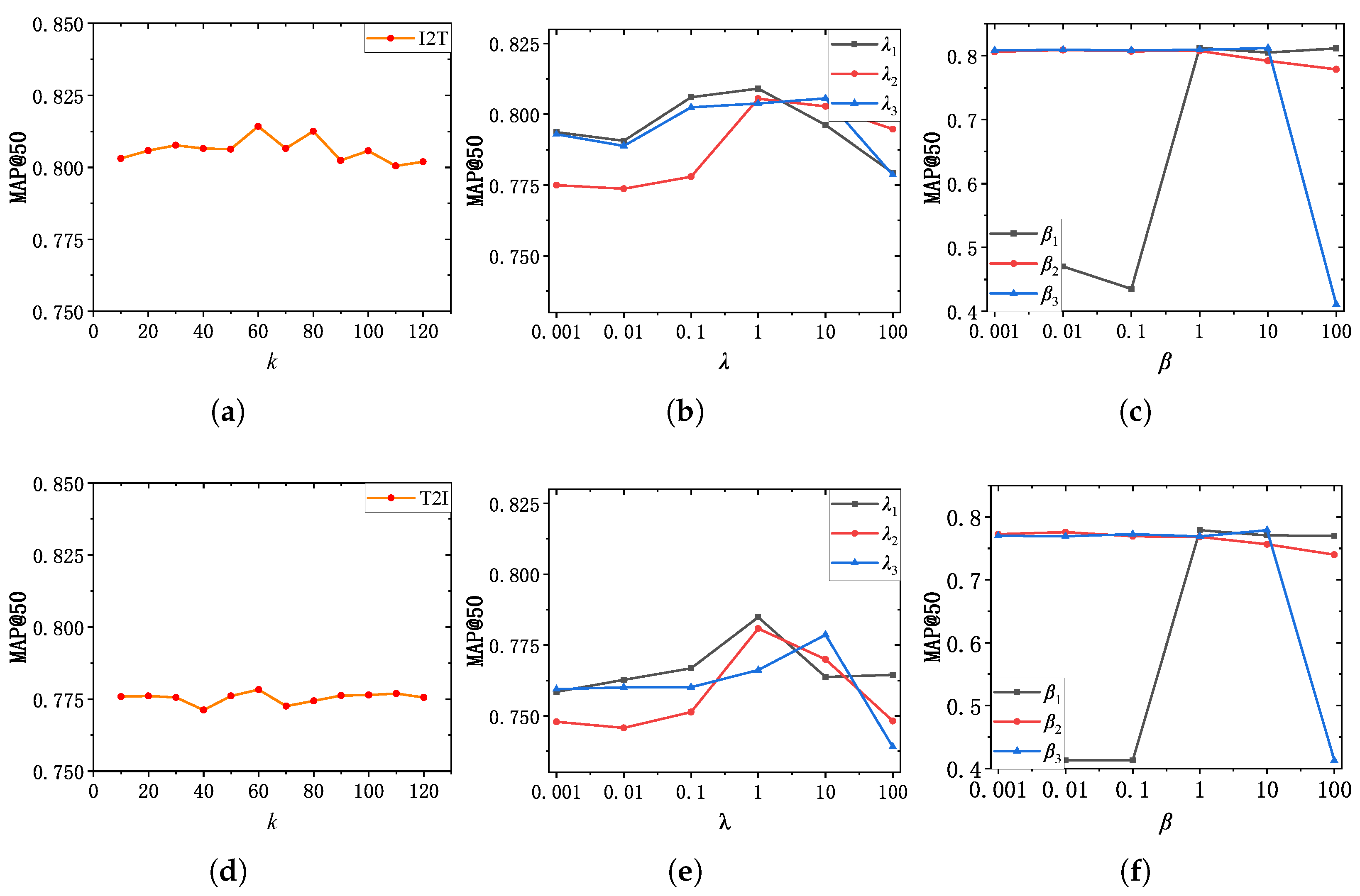
Hyperparameter k. We recorded the performance change by varying the value of
k on NUS-WIDE dataset to evaluate the effect by the the number of neighbors in
kNN algorithm. As demonstrated in
Figure 8, when
, the curve changes sharply, while the curve changes more modestly in the rest of the interval. We conjecture that when too many or too few neighbors we selected, noise will be introduced into the intra-modal similarity relationship representation, thereby affecting the latent similarity relationship learning within modality. Particularly, if
k is set to 60, MGSPU achieves the highest mAP@50 score for both I2T and T2I task. It indicates that by selecting an appropriate number of neighbors, high-quality intra-modal similarity structure information can be aggregated by GCN to improve intra-modal similarity consistency preserving.
Hyperparameter. As presented in Equation (
20),
are used to balance three components, i.e.,
,
and
of hash code learning loss function. To analyze the effect by these three losses, we recorded the performance change of our method in
Figure 8 by varying
from 0.001 to 100 with a 10-fold increase. It is noteworthy that our method obtains the best performance if we set
. Among these three losses, we found that the new designed loss
has a relatively greater effect on the learning of hash code. We argue that this is mainly due to the indispensability of a reliable similarity matrix for unsupervised hash learning.
Hyperparameter . As depicted in Equation (
21),
serves as weight factor to balance
,
, and
. The observations in
Figure 8 indicates that
and
contributes more than
. We infer that although the duty of
is to ensure numerical consistency between the generated hash codes
and trained hash codes and
, the main goal of cross-modal hash learning is still to eliminate cross-modal heterogeneity, which is only achieved by
. Besides, the quantization error is cannot reduced by other losses but
. In addition, by setting
, our method achieves the best performance.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}