
Query Optimization in Distributed Database Based on Improved Artificial Bee Colony Algorithm



Abstract
1. Introduction
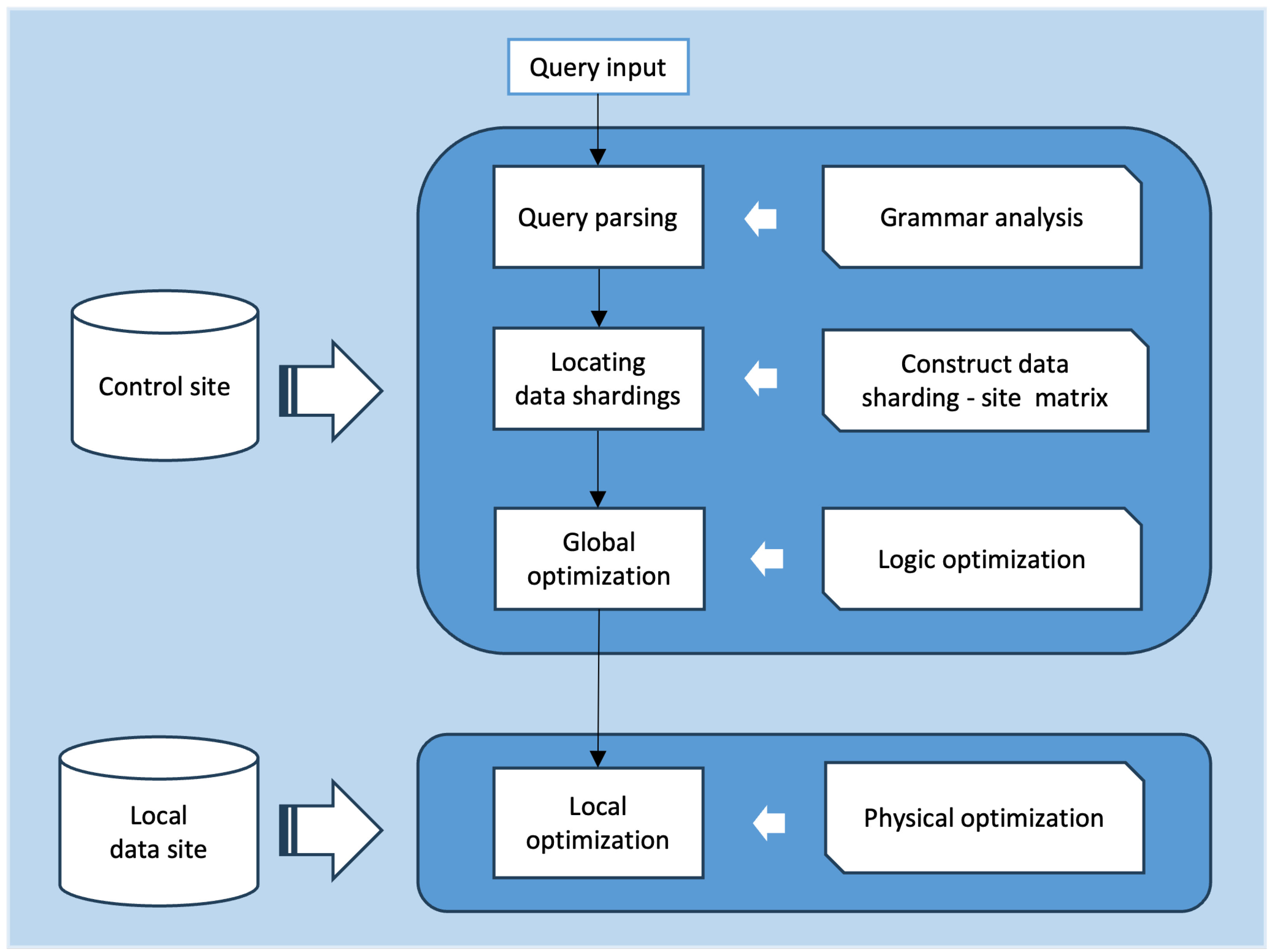
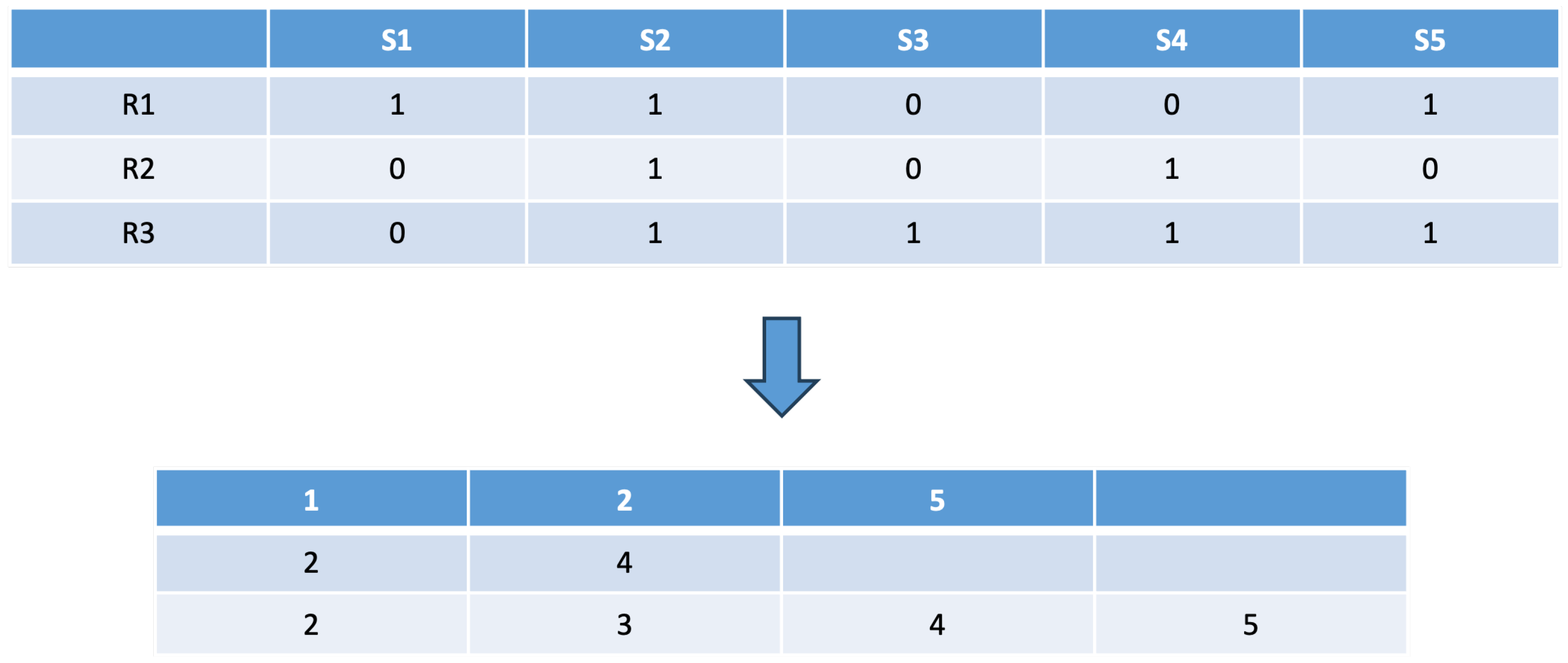
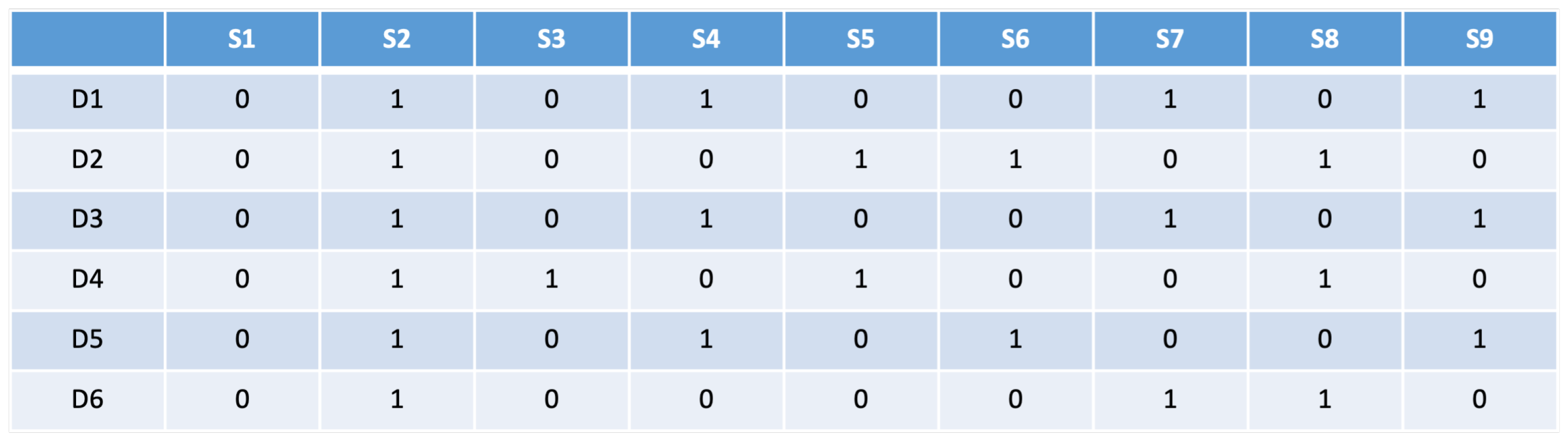
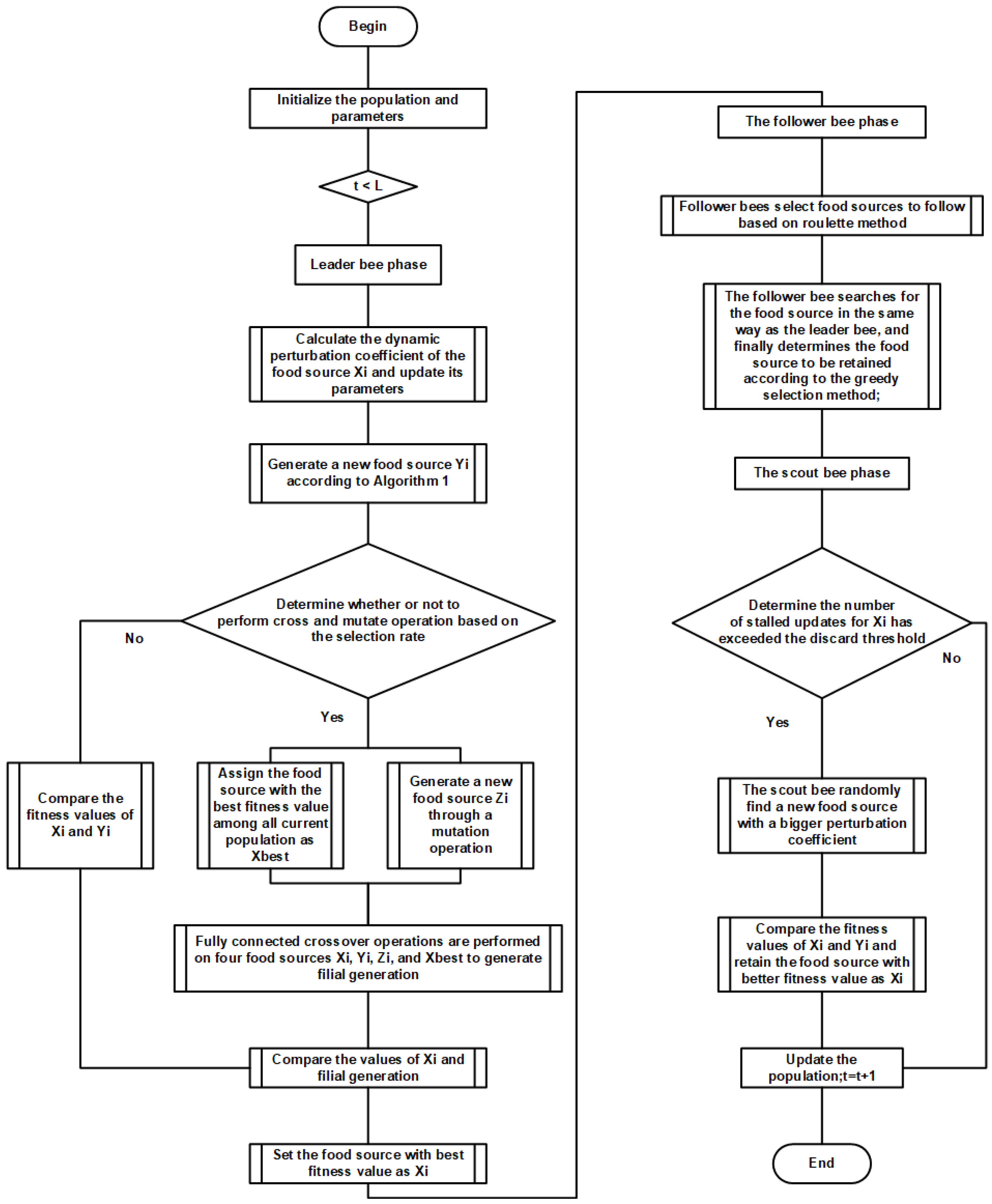
2. Proposed Method
2.1. Improved Artificial Bee Colony Algorithm
| Algorithm 1 Improved Optimization Strategy Logical Pseudo-Code |
| Input: X and ▹ A food source in the population and the perturbation coefficient Output: Y ▹ A new food source generated by X
|
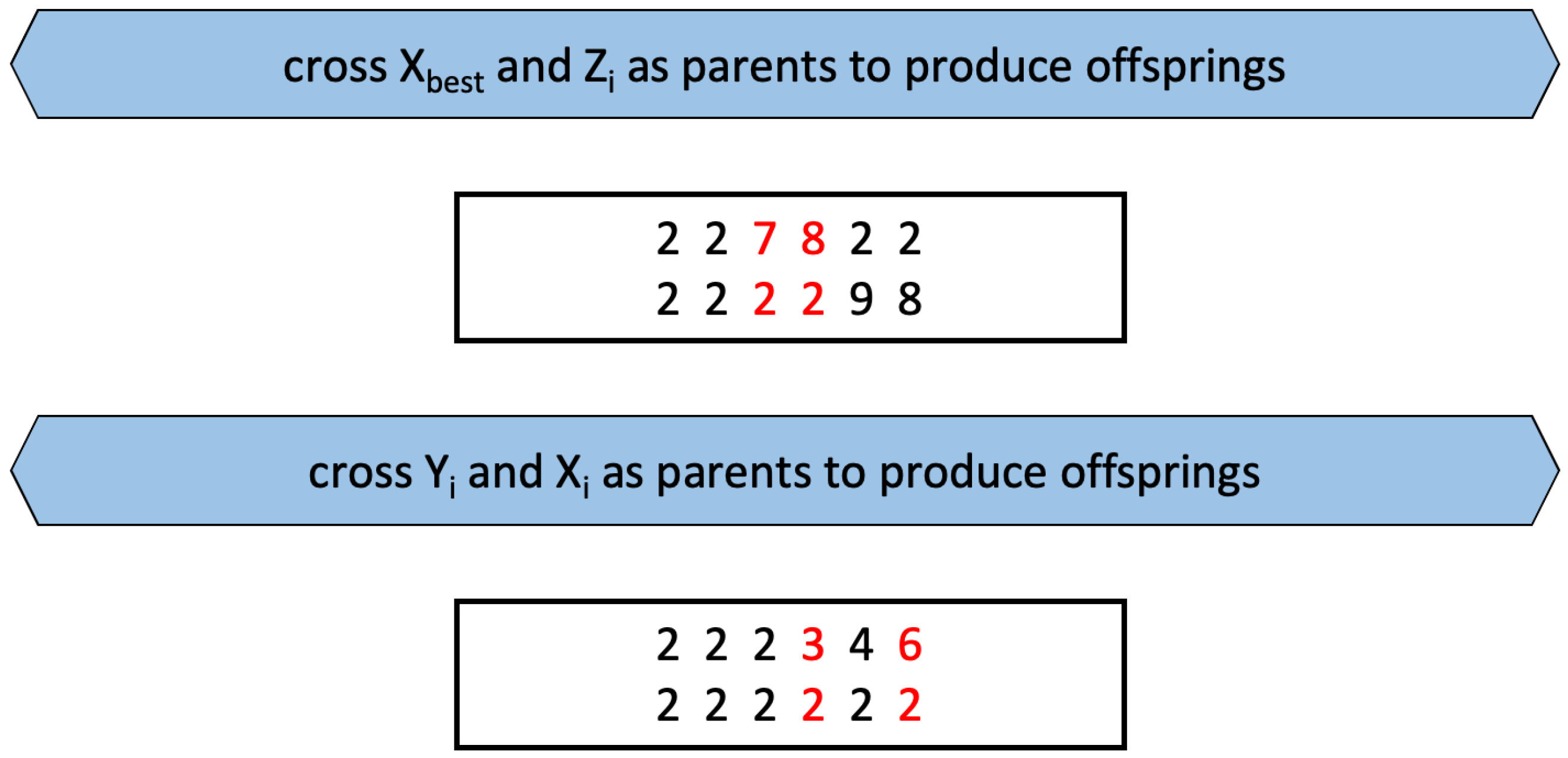
2.2. Genetic Operators
2.3. A Hybrid Model of the Dynamic Artificial Bee Colony Algorithm Combined with Genetic Operators
2.4. Time and Space Complexity of the Hybrid Model
| Algorithm 2 DYABC-GO Logical Pseudo-Code |
| Input: Data sharding-site matrix (DSM) for query statement and the number of output query plans k Output: Top-k query execution plans and their query execution costs
|
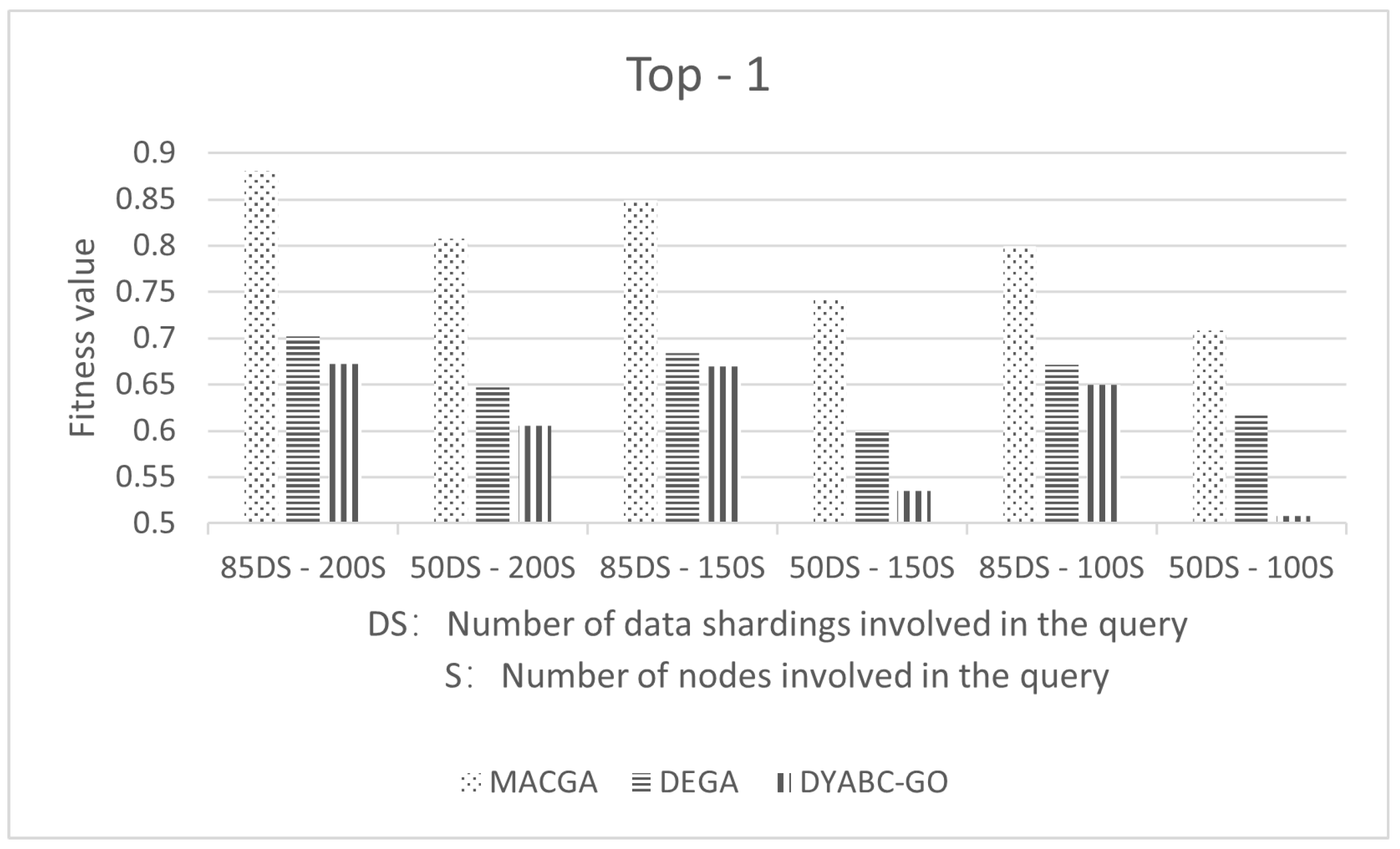
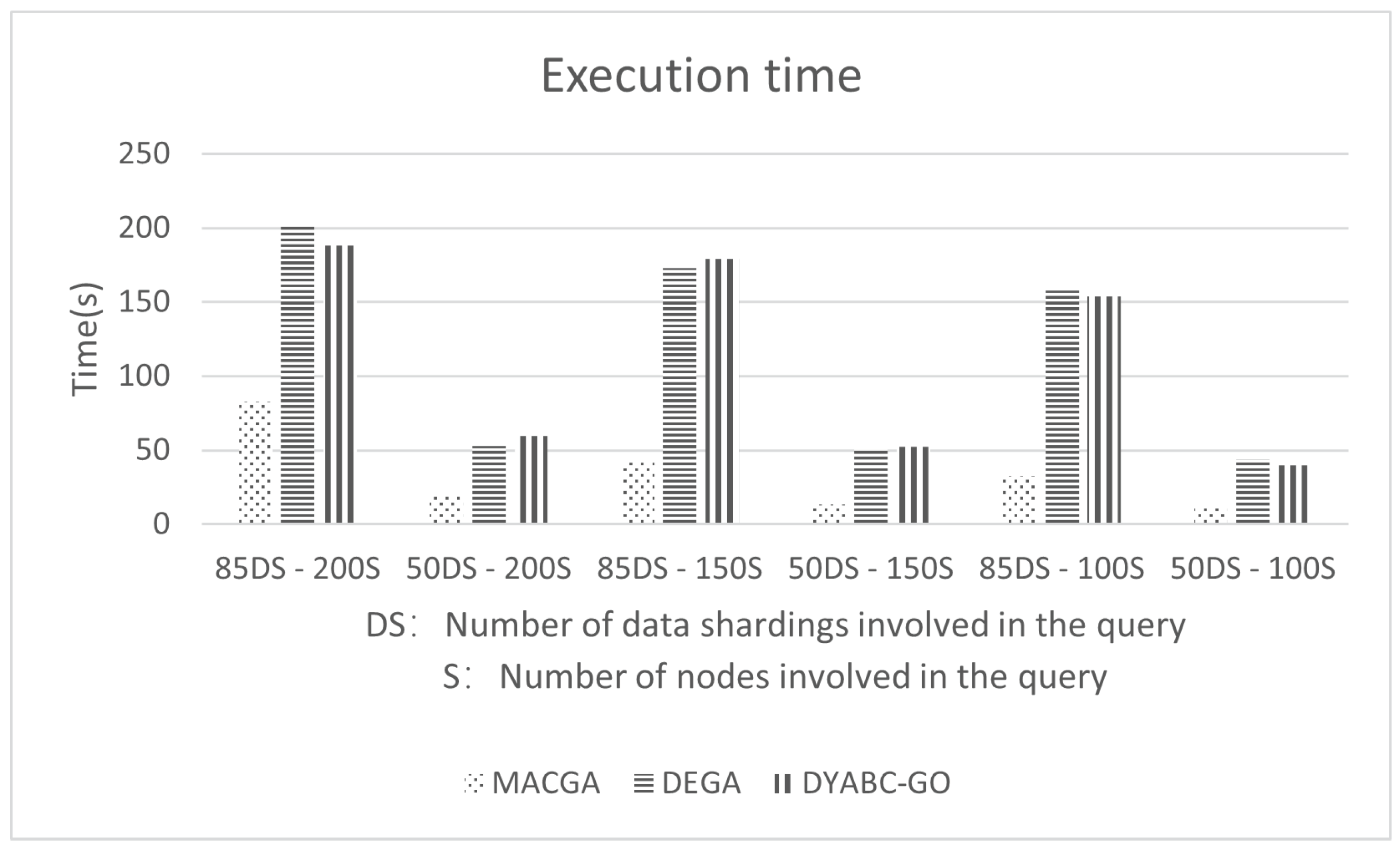
3. Experiment Results and Analysis
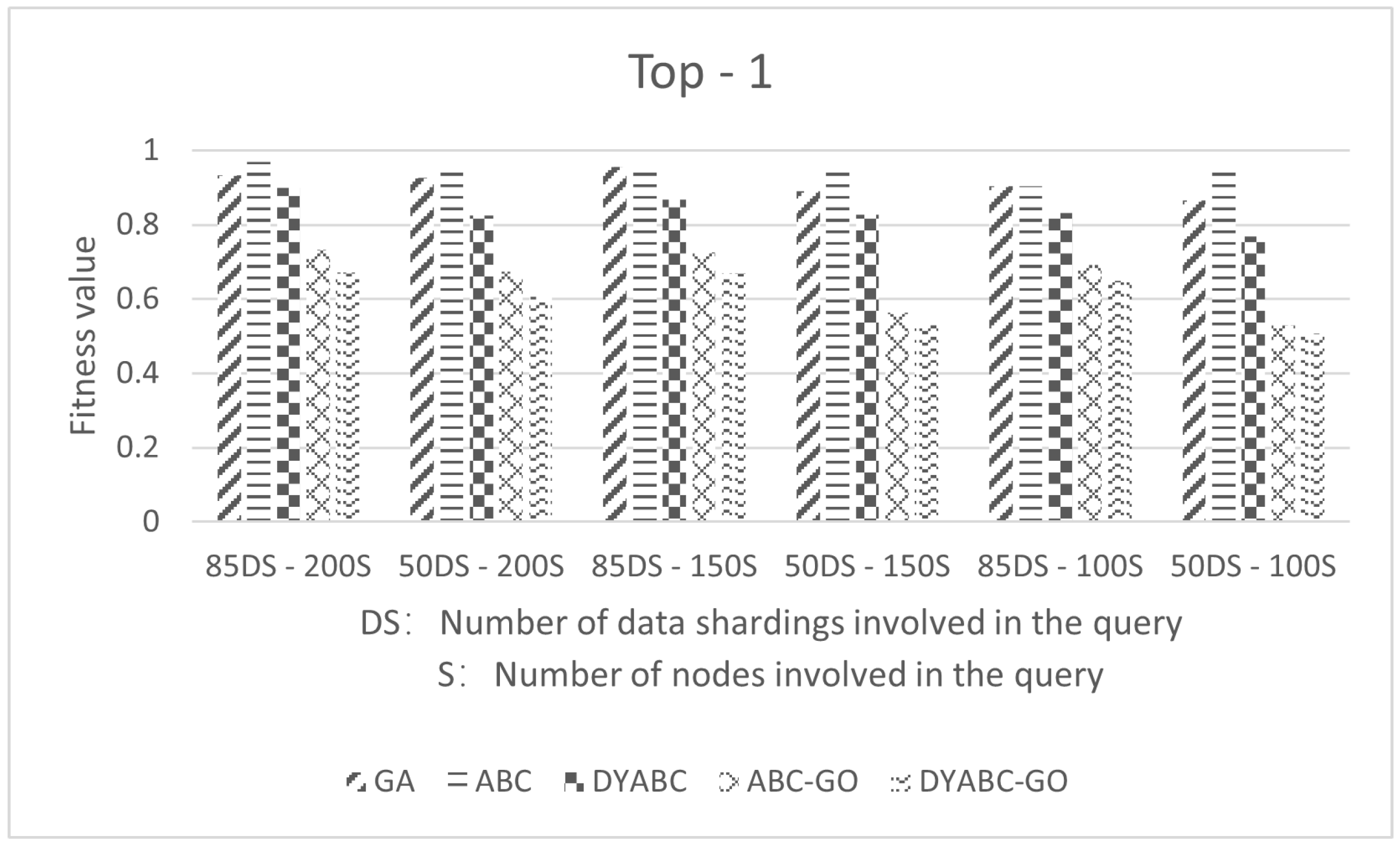
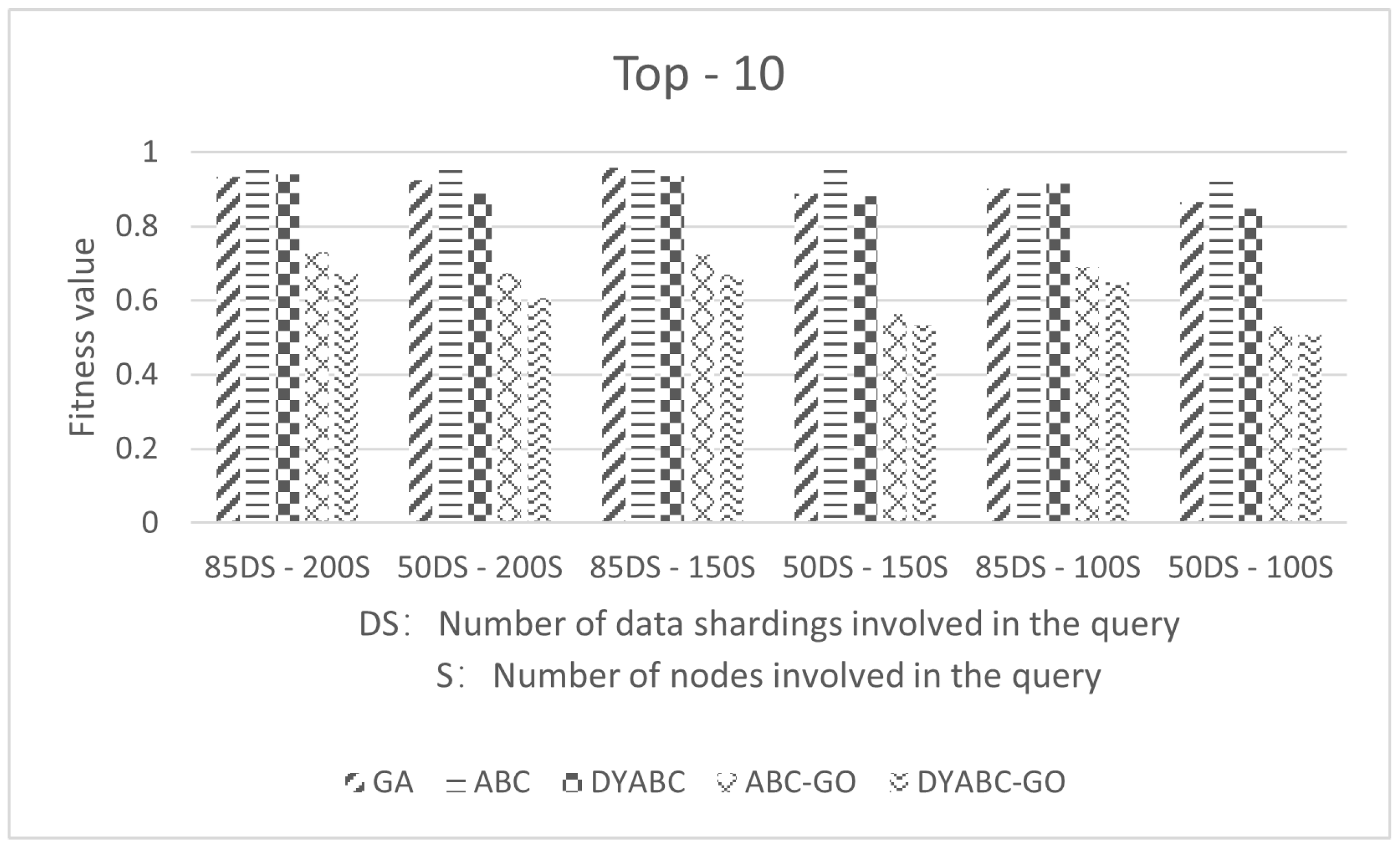
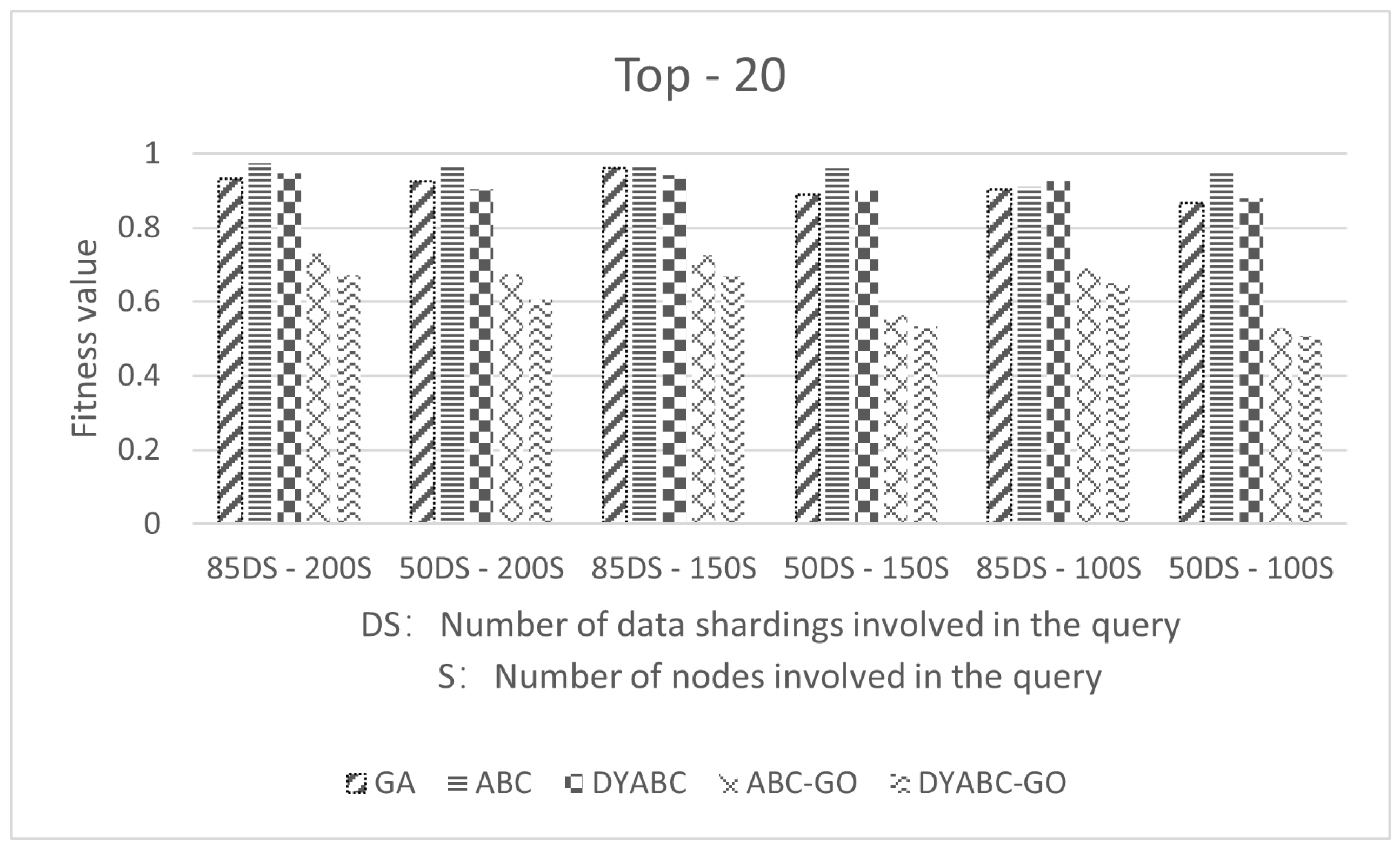
3.1. Experimental Parameters and Data
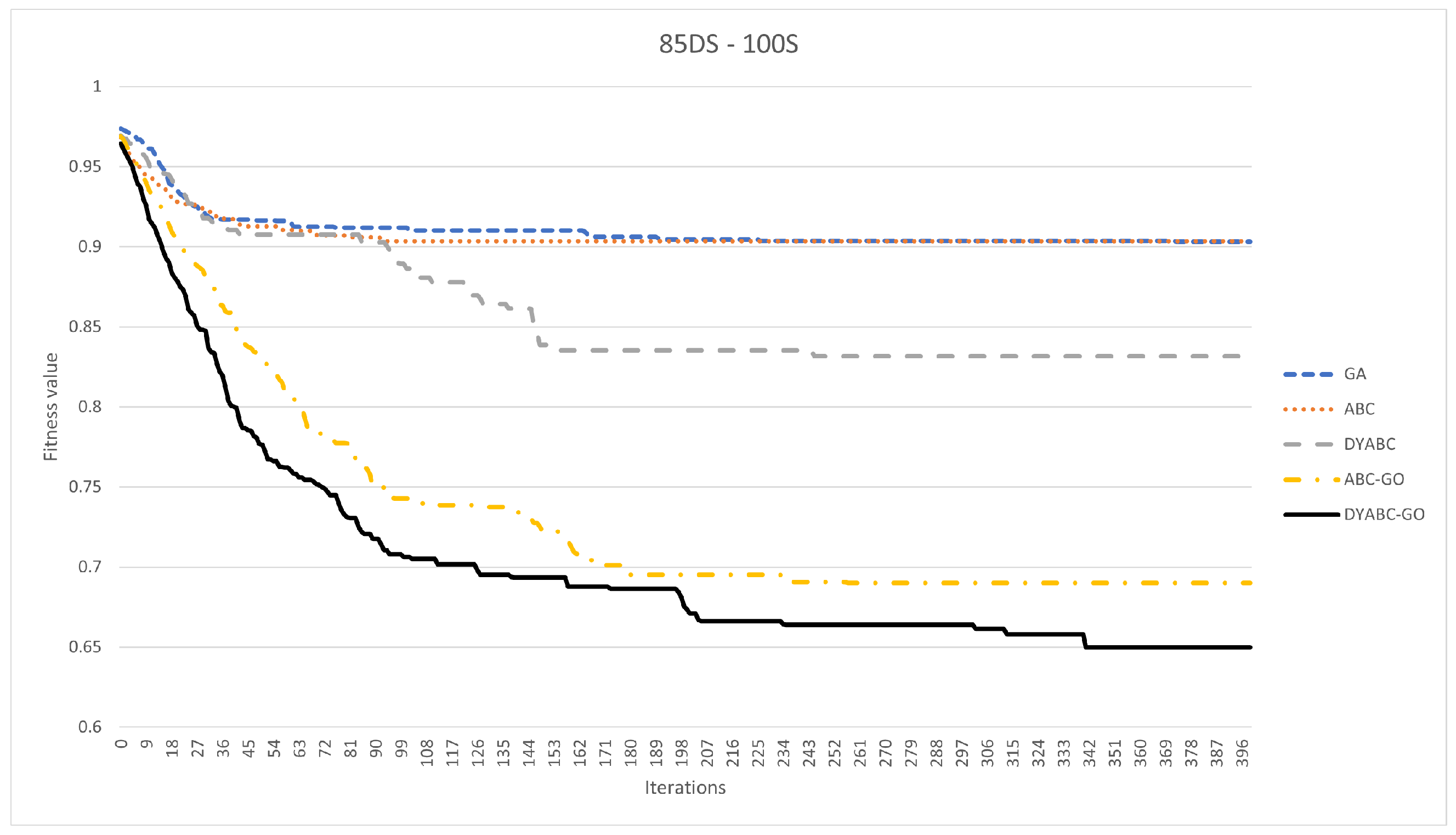
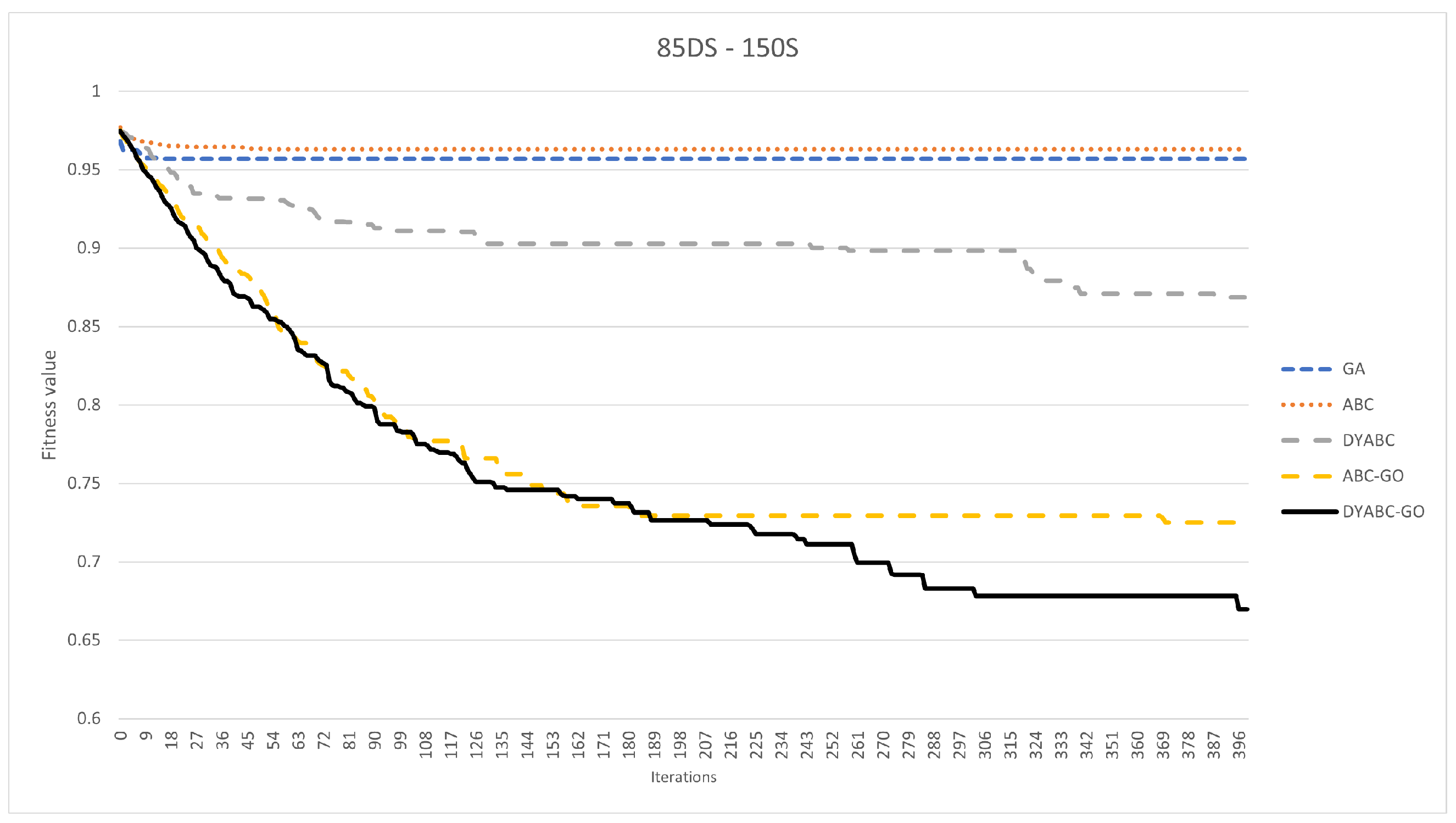
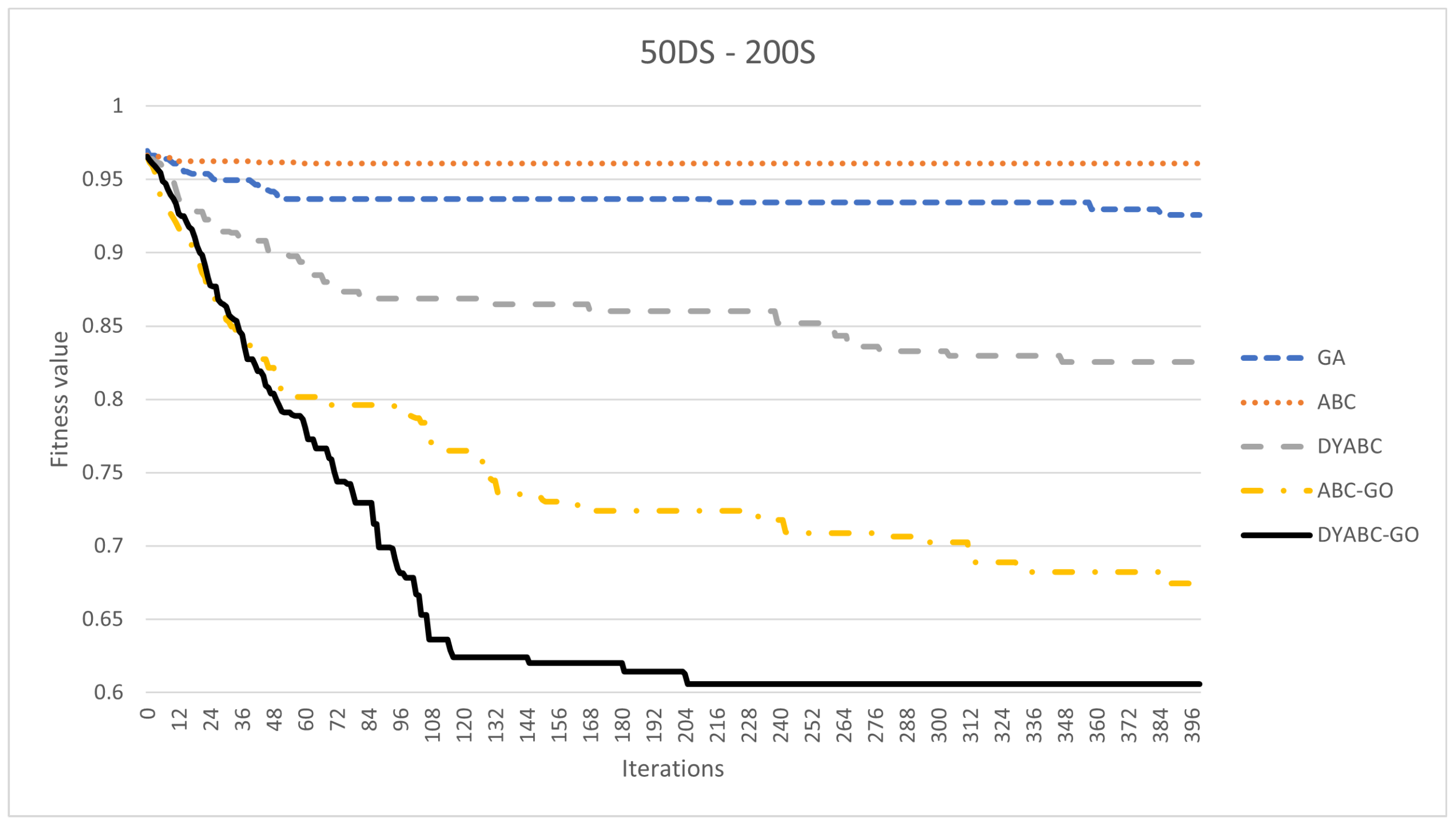
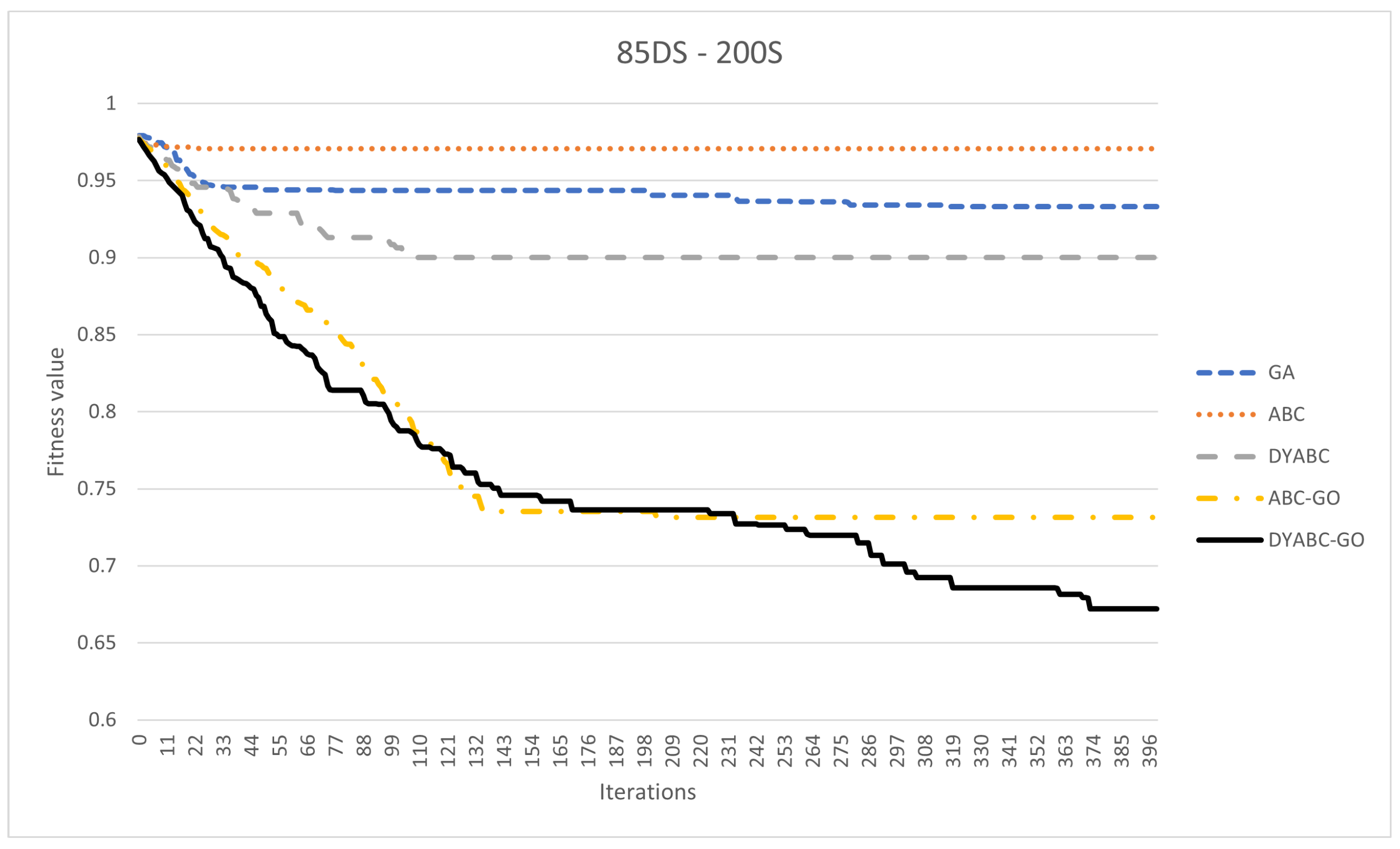
3.2. Results and Discussion
4. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- IDC. Global Data Volume Trends [EB/OL]. 2018. Available online: https://www.seagate.com/files/www-content/our-StoryAmazon/trends/files/idc-seagate-dataage-chine-whitepaper.pdf (accessed on 16 October 2018).
- MGI. Big Data: The Next Frontier for Innovation, Competition, and Productivity [EB/OL]. 2011. Available online: https://www.mckinsey.com/business-Functions/mckinsey-digital/our-insights/big-data-the-next-frontier-for-innovation (accessed on 13 May 2011).
- Vivekrabinson, K.; Muneeswaran, K. Fault-tolerant based group key servers with enhancement of utilizing the contributory server for cloud storage applications. IETE J. Res. 2021, 69, 2487–2502. [Google Scholar] [CrossRef]
- Sharma, M.; Singh, G.; Singh, R. Design and analysis of stochastic DSS query optimizers in a distributed database system. Egypt. Inform. J. 2016, 17, 161–173. [Google Scholar] [CrossRef]
- Özsu, M.T.; Valduriez, P. Principles of Distributed Database Systems, 2nd ed.; Prentice-Hall, Inc.: Upper Saddle River, NJ, USA, 1999. [Google Scholar]
- Özsu, M.T.; Valduriez, P. Principles of Distributed Database Systems; Springer Science and Business Media: New York, NY, USA, 2011. [Google Scholar]
- Golshanara, L.; Rankoohi, S.M.T.R.; Shah-Hosseini, H. A multi-colony ant algorithm for optimizing join queries in distributed database systems. Knowl. Inf. Syst. 2014, 39, 175–206. [Google Scholar]
- Ren, K.; Thomson, A.; Abadi, D.J. VLL: A lock manager redesign for main memory database systems. VLDB J. 2015, 24, 681–705. [Google Scholar] [CrossRef]
- Morsali, R.; Ghadimi, N.; Karimi, M.; Mohajeryami, S. Solving a novel multiobjective placement problem of recloser and distributed generation sources insimultaneous mode by improved harmony search algorithm. Complexity 2015, 21, 328–339. [Google Scholar] [CrossRef]
- Ling, X.; Jihong, L.; Jianchu, Y. Research and Application of Distributed Database Systems. Comput. Eng. 2001, 1, 33–35. [Google Scholar]
- Azhir, E.; Navimipour, N.J.; Hosseinzadeh, M.; Sharifi, A.; Darwesh, A. Query optimization mechanisms in the cloud environments: A systematic study. Int. J. Commun. Syst. 2019, 32, 3940. [Google Scholar] [CrossRef]
- Saranraj, G.; Selvamani, K.; Malathi, P. A novel data aggregation using multi objective based male lion optimization algorithm (DA-MOMLOA) in wireless sensor network. J. Ambient. Intell. Humaniz. Comput. 2021, 13, 5645–5653. [Google Scholar] [CrossRef]
- Hewasinghage, M.; Abelló, A.; Varga, J.; Zimányi, E. A cost model for random access queries in document stores. VLDB J. 2021, 30, 559–578. [Google Scholar] [CrossRef]
- Li, C. Research on Optimization of Distributed Database Query Strategy. Master’s Thesis, Xi’an University of Electronic Science and Technology, Xi’an, China, 2012. [Google Scholar] [CrossRef]
- Ioannidis, Y.E.; Kang, Y. Randomized Algorithms for Optimizing Large Join Queries. ACM Sigmod Rec. 1990, 19, 312–321. [Google Scholar] [CrossRef]
- Forestiero, A.; Mastroianni, C.; Spezzano, G. Antares: An ant-inspired P2P information system for a self-structured grid. In Proceedings of the 2007 2nd Bio-Inspired Models of Network, Information and Computing Systems, Budapest, Hungary, 10–13 December 2007; pp. 151–158. [Google Scholar] [CrossRef]
- Tiwari, P.; Chande, S.V. Optimal Ant and Join Cardinality for Distributed Query Optimization Using Ant Colony Optimization Algorithm. In Emerging Trends in Expert Applications and Security. Advances in Intelligent Systems and Computing; Rathore, V., Worring, M., Mishra, D., Joshi, A., Maheshwari, S., Eds.; Springer: Singapore, 2019; Volume 841. [Google Scholar] [CrossRef]
- Forestiero, A.; Mastroianni, C.; Spezzano, G. QoS-based dissemination of content in grids. Future Gener. Comput. Syst. 2008, 24, 235–244. [Google Scholar]
- Mishra, S.K.; Pattnaik, S.; Patnaik, D. Evaluating query execution plans by implementing join operators using particle swarm optimization. J. Comput. Sci. Appl. 2014, 2, 31–35. [Google Scholar]
- Yao, M. A distributed database query optimization method based on genetic algorithm and immune theory. In Proceedings of the 2017 8th IEEE International Conference on Software Engineering and Service Science (ICSESS), Beijing, China, 24–26 November 2017; pp. 762–765. [Google Scholar] [CrossRef]
- Matysiak, M. Efficient optimization of large join queries using tabu search. Inf. Sci. 1995, 83, 77–88. [Google Scholar] [CrossRef]
- Virk, R.S.; Singh, G. Optimizing Access Strategies for a Distributed Database Design using Genetic Fragmentation. Int. J. Comput. Sci. Netw. Secur. 2011, 11, 180–183. [Google Scholar]
- Yang, W.; Peizhi, W.; Xing, D.; Likun, Z. An improved genetic algorithm for optimization of distributed database query. J. Guilin Univ. Electron. Technol. 2015. [Google Scholar] [CrossRef]
- Dong, H.; Liang, Y. Genetic Algorithms for Large Join Query Optimization. In Proceedings of the 9th Annual Conference on Genetic and Evolutionary Computation, London, UK, 7–11 July 2007. [Google Scholar]
- Stillger, M.; Spiliopoulou, M. Genetic Programming in Database Query Optimization. In Proceedings of the First Annual Conference on Genetic Programming, Stanford, CA, USA, 28–31 July 1996. [Google Scholar]
- Bhaskar, N.; Kumar, P.M.; Renjit, J.A. Evolutionary Fuzzy-based gravitational search algorithm for query optimization in crowdsourcing system to minimize cost and latency. Comput. Intell. 2021, 37, 2–20. [Google Scholar]
- Ozger, Z.B.; Uslu, N.Y. An effective discrete artificial bee colony based SPARQL query path optimization by reordering triples. J. Comput. Sci. Technol. 2021, 36, 445–462. [Google Scholar] [CrossRef]
- Kumar, T.V.; Singh, R.; Kumar, A. Distributed query plan generation using ant colony optimization. Int. J. Appl. Metaheuristic Comput. 2015, 6, 1–22. [Google Scholar] [CrossRef]
- Zhou, Y.; Chen, J.H. Query optimization of distributed database based on multiple ant colony genetic algorithm. J. Shanghai Norm. Univ. (Nat. Sci.) 2018, 47, 37–42. [Google Scholar]
- Mohsin, S.A.; Darwish, S.M.; Younes, A. QIACO: A Quantum Dynamic Cost Ant System for Query Optimization in Distributed Database. IEEE Access 2021, 9, 15833–15846. [Google Scholar] [CrossRef]
- Zheng, B.; Li, X.; Tian, Z.; Meng, L. Optimization Method for Distributed Database Query Based on an Adaptive Double Entropy Genetic Algorithm. IEEE Access 2022, 10, 4640–4648. [Google Scholar] [CrossRef]
- Ragmani, A.; Elomri, A.; Abghour, N.; Moussaid, K.; Rida, M. FACO: A hybrid fuzzy ant colony optimization algorithm for virtual machine scheduling in high-performance cloud computing. J. Ambient. Intell. Humaniz. Comput. 2020, 11, 3975–3987. [Google Scholar] [CrossRef]
- Gao, W.; Liu, S.; Huang, L. A Novel Artificial Bee Colony Algorithm Based on Modified Search Equation and Orthogonal Learning. IEEE Trans. Cybern. 2013, 43, 1011–1024. [Google Scholar]
- Qin, Q.; Cheng, S.; Li, L.; Shi, Y. Survey on Artificial bee colony Algorithm. CAAI Trans. Intell. Syst. 2014, 9, 127–135. [Google Scholar]
- Phongmoo, S.; Leksakul, K.; Charoenchai, N.; Boonmee, C. Artificial Bee Colony Algorithm with Pareto-Based Approach for Multi-Objective Three-Dimensional Single Container Loading Problems. Appl. Sci. 2023, 13, 6601. [Google Scholar] [CrossRef]
- Escamilla-Serna, N.J.; Seck-Tuoh-Mora, J.C.; Medina-Marin, J.; Barragan-Vite, I.; Corona-Armenta, J.R. A Hybrid Search Using Genetic Algorithms and Random-Restart Hill-Climbing for Flexible Job Shop Scheduling Instances with High Flexibility. Appl. Sci. 2022, 12, 8050. [Google Scholar] [CrossRef]
- Mishra, V.; Singh, V. Generating optimal query plans for distributed query processing using teacher-learner based optimization. Procedia Comput. Sci. 2015, 54, 281–290. [Google Scholar] [CrossRef]
- Forestiero, A.; Papuzzo, G. Recommendation platform in Internet of Things leveraging on a self-organizing multiagent approach. Neural Comput. Appl. 2022, 34, 16049–16060. [Google Scholar] [CrossRef]
- Cicirelli, F.; Forestiero, A.; Giordano, A.; Mastroianni, C. Transparent and Efficient Parallelization of Swarm Algorithms. ACM Trans. Auton. Adapt. Syst. 2016, 11, 1–26. [Google Scholar] [CrossRef]
- Alaya, I.; Solnon, C.; Ghedira, K. Ant Colony Optimization for Multi-objective Optimization Problems. In Proceedings of the IEEE International Conference on Tools with Artificial Intelligence, Boston, MA, USA, 6–8 November 2017; IEEE Computer Society: Washington, DC, USA, 2017. [Google Scholar] [CrossRef]
- Kang, G.; Yang, Z.; Yuan, X.; Wu, J. Fault Reconstruction for a Giant Satellite Swarm Based on Hybrid Multi-Objective Optimization. Appl. Sci. 2023, 13, 6674. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Mechanism | Approach | Advantages | Weaknesses |
|---|---|---|---|
| Ozger et al. [27] | Proposed a discrete artificial bee colony algorithm based on a novel heuristic approach. | •Performing well with a small number of relations | •Terrible performance for a large query •Excess memory and processor consumption |
| Kumar et al. [28] | Proposed an ant colony algorithm optimization for query optimization. | •Improving the average •Quality of query plan | •High overhead •High response time |
| Zhou et al. [29] | Proposed a multi-ant colony genetic algorithm. | •Increasing the convergence speed •Low execution time | •Low variety population •Drop to local optima |
| Mohsin et al. [30] | Designed a quantum-inspired ant colony-based algorithm. | •High convergence speed •High effectiveness | •Terrible performance for a smaller query •Easy to precocity |
| Zheng et al. [31] | Proposed an adaptive genetic algorithm based on double entropy. | •High population diversity •Avoiding getting stuck in local minima | •Low convergence speed •Suffers from long execution time |
| Ragmani et al. [32] | Proposed a hybrid fuzzy ant colony optimization algorithm. | •Decreasing the time •High efficiency | •Easily falls into local optimum for large join query |
| Operator | Probability Value |
|---|---|
| Selection | P· |
| Crossover | P· |
| Mutation | P· |
| Argument\Method | DYABC-GO | DYABC | ABC-GO | ABC | GA |
|---|---|---|---|---|---|
| Maximum iterations | 400 | ||||
| Population size | Data sharding quantity/2 | ||||
| Leader bee population | Data sharding quantity/2 | / | |||
| Follower bee population | Data sharding quantity/2 | / | |||
| Food source abandonment threshold | 5 | / | |||
| Perturbation coefficient | 0.25 | / | |||
| Selection rate | 0.5 | / | 0.5 | ||
| Crossover rate | 0.25 | / | 0.25 | ||
| Mutation rate | 0.1 | / | 0.1 | ||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Du, Y.; Cai, Z.; Ding, Z. Query Optimization in Distributed Database Based on Improved Artificial Bee Colony Algorithm. Appl. Sci. 2024, 14, 846. https://doi.org/10.3390/app14020846
Du Y, Cai Z, Ding Z. Query Optimization in Distributed Database Based on Improved Artificial Bee Colony Algorithm. Applied Sciences. 2024; 14(2):846. https://doi.org/10.3390/app14020846
Chicago/Turabian StyleDu, Yan, Zhi Cai, and Zhiming Ding. 2024. "Query Optimization in Distributed Database Based on Improved Artificial Bee Colony Algorithm" Applied Sciences 14, no. 2: 846. https://doi.org/10.3390/app14020846
APA StyleDu, Y., Cai, Z., & Ding, Z. (2024). Query Optimization in Distributed Database Based on Improved Artificial Bee Colony Algorithm. Applied Sciences, 14(2), 846. https://doi.org/10.3390/app14020846