
Collaborative Semantic Annotation Tooling (CoAT) to Improve Efficiency and Plug-and-Play Semantic Interoperability in the Secondary Use of Medical Data: Concept, Implementation, and First Cross-Institutional Experiences

 , and
, and
Abstract
Featured Application
Abstract
1. Introduction
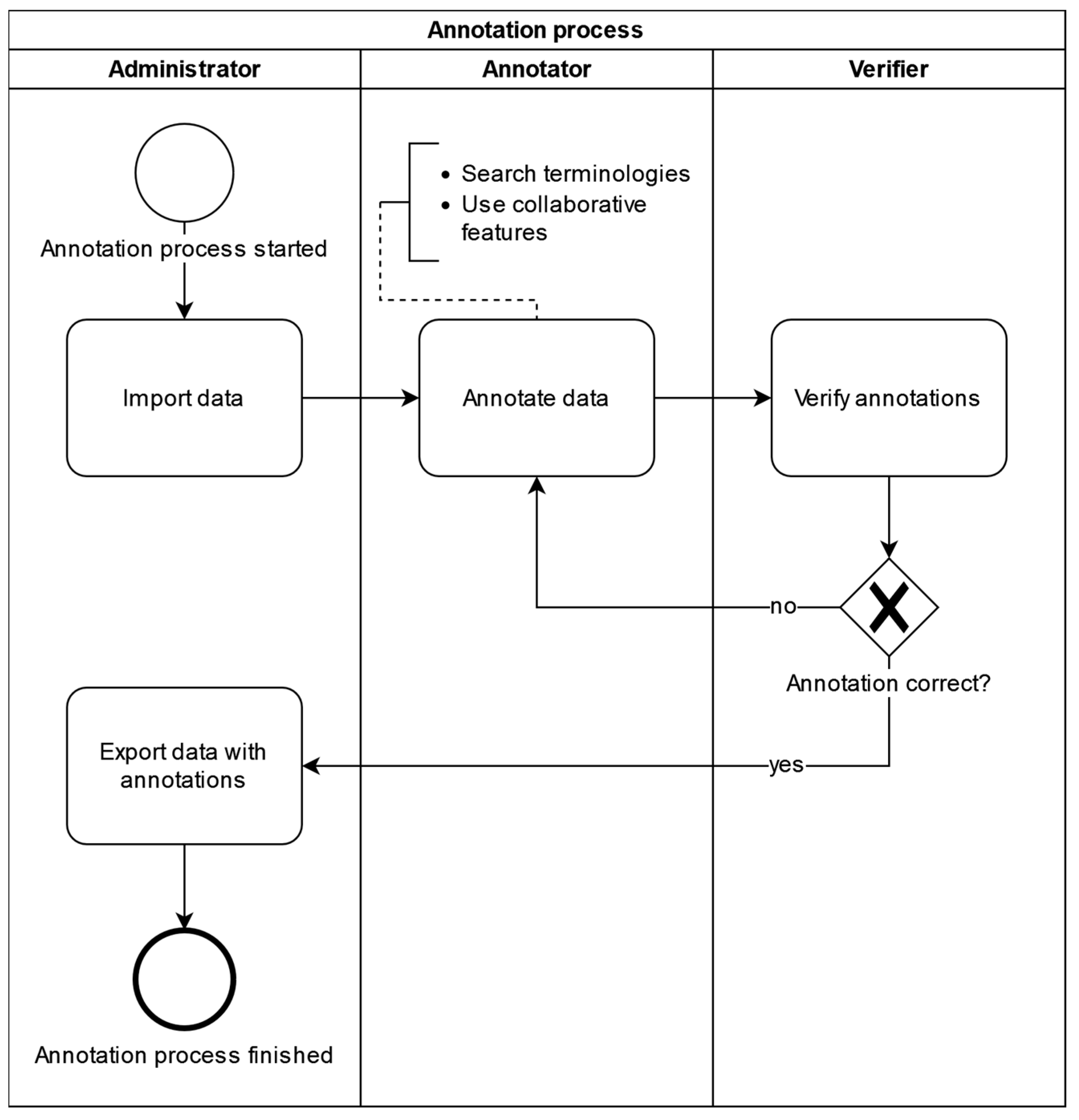
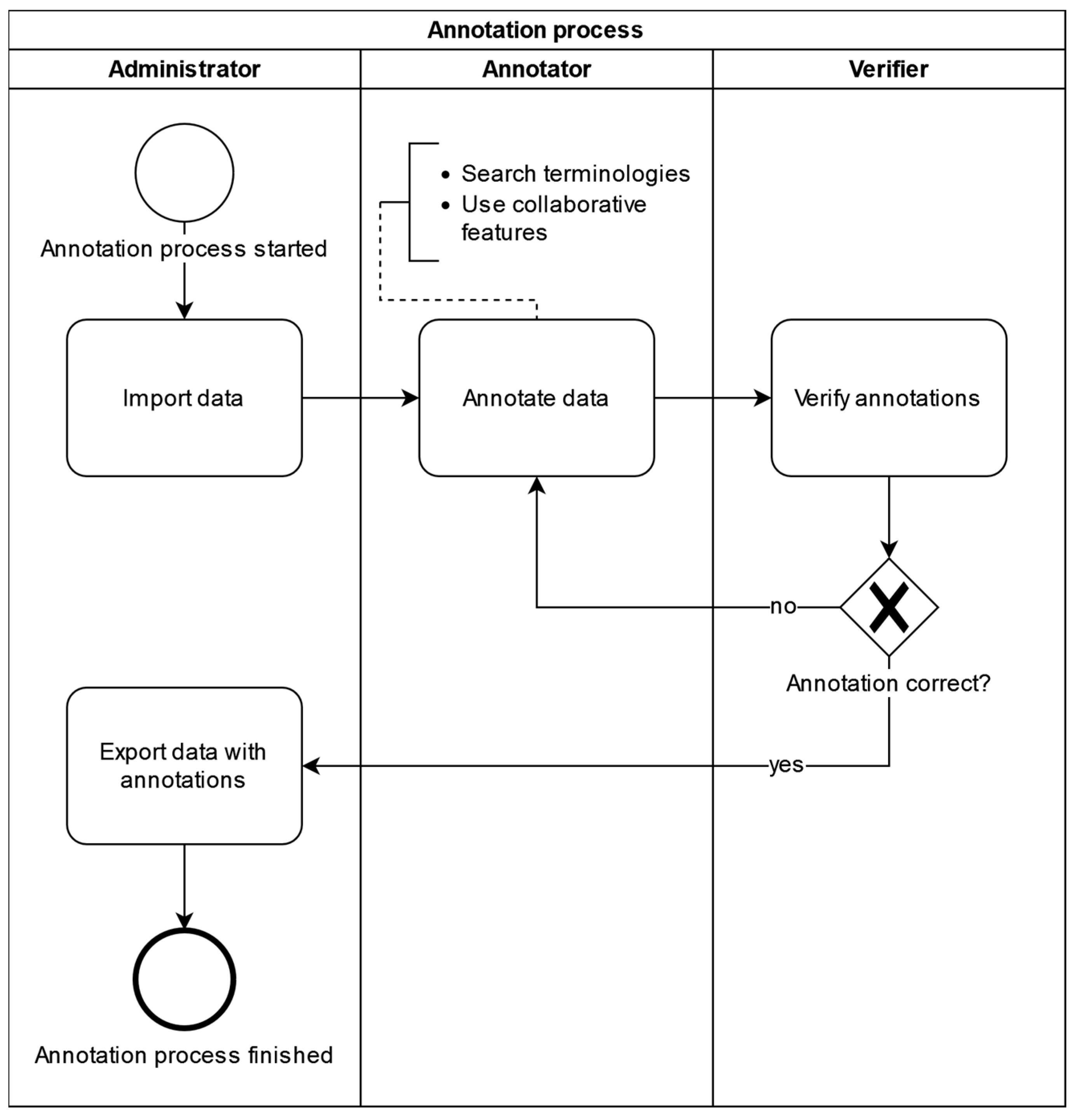
2. Materials and Methods
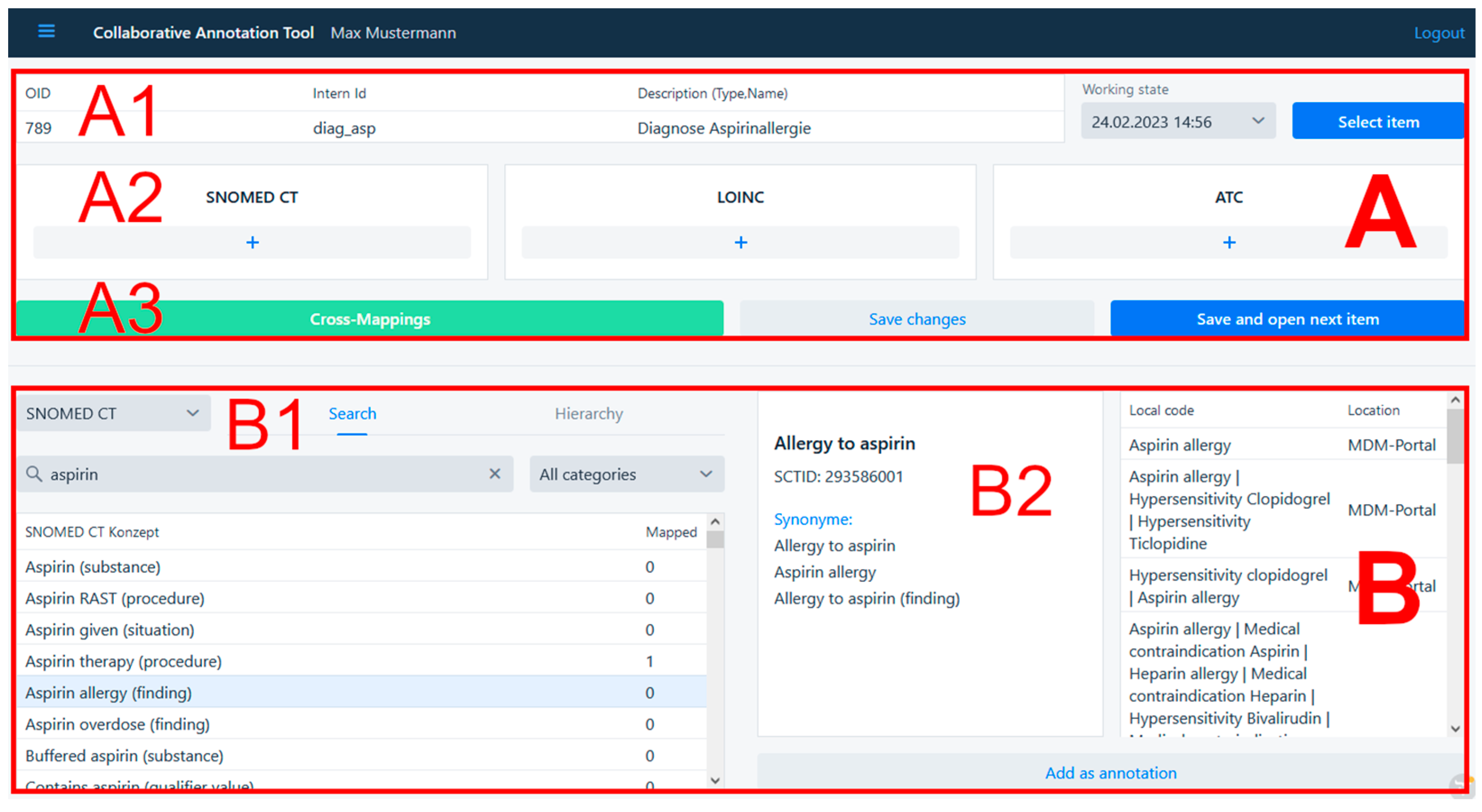
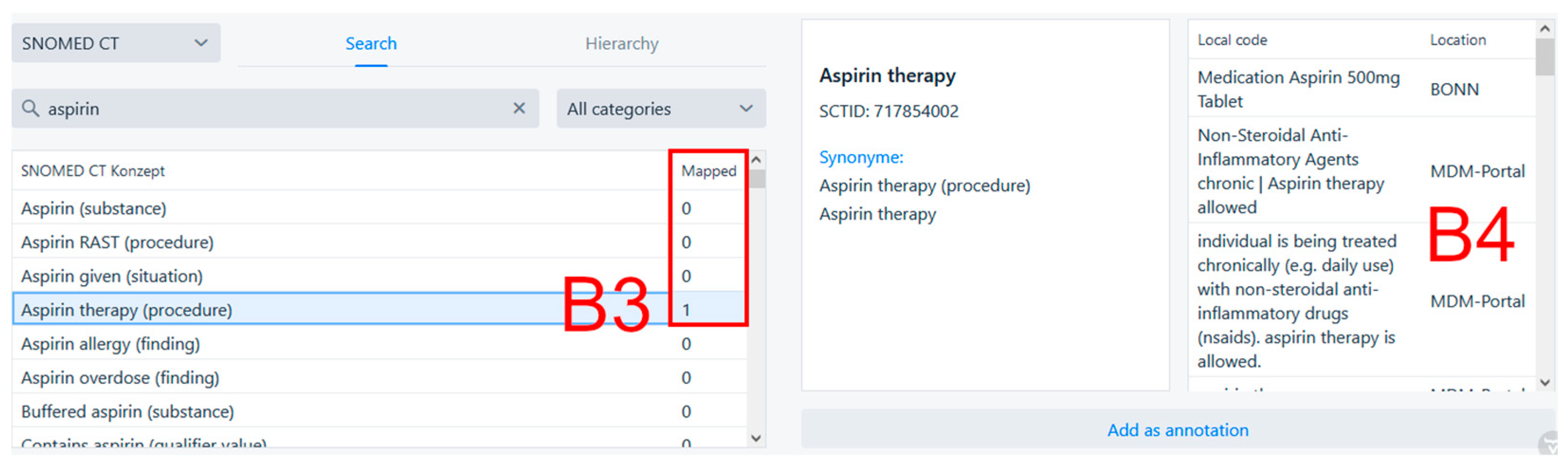
- Collaborative annotation: Searching for pre-existing annotations from local sites or other participating sites for fitting terminology codes as a seamlessly integrated part of the annotation process itself allows users to see what local codes from the same or other participating sites have previously been annotated using these terminology codes. Annotators can profit from comparing their local codes to other local codes previously annotated with a terminology code to determine if the terminology code is fitting based on the equivalence or similarity of the local codes under consideration.
- Medical Data Models (MDM) portal integration: As terminologies like SNOMED CT contain hundreds of thousands of codes, many existing annotations originating from many participating sites would be needed to regularly benefit from this feature while using CoAT. To give annotators access to more input in this early pilot phase of implementation, a web service with access to annotations from the Medical Data Models portal (MDM portal) was integrated [18,19], effectively turning MDM into a large contributing annotation collaborator. The MDM portal is an online resource providing over 25,000 semantically annotated structured data acquisition forms [20], with coverage ranging from numerous electronic case report forms from clinical studies to documentation forms from clinical information systems including fully annotated versions of the 2015 state of intensive care documentation systems from both Bonn and Munster [21]. MDM integration was realized using its REST API.
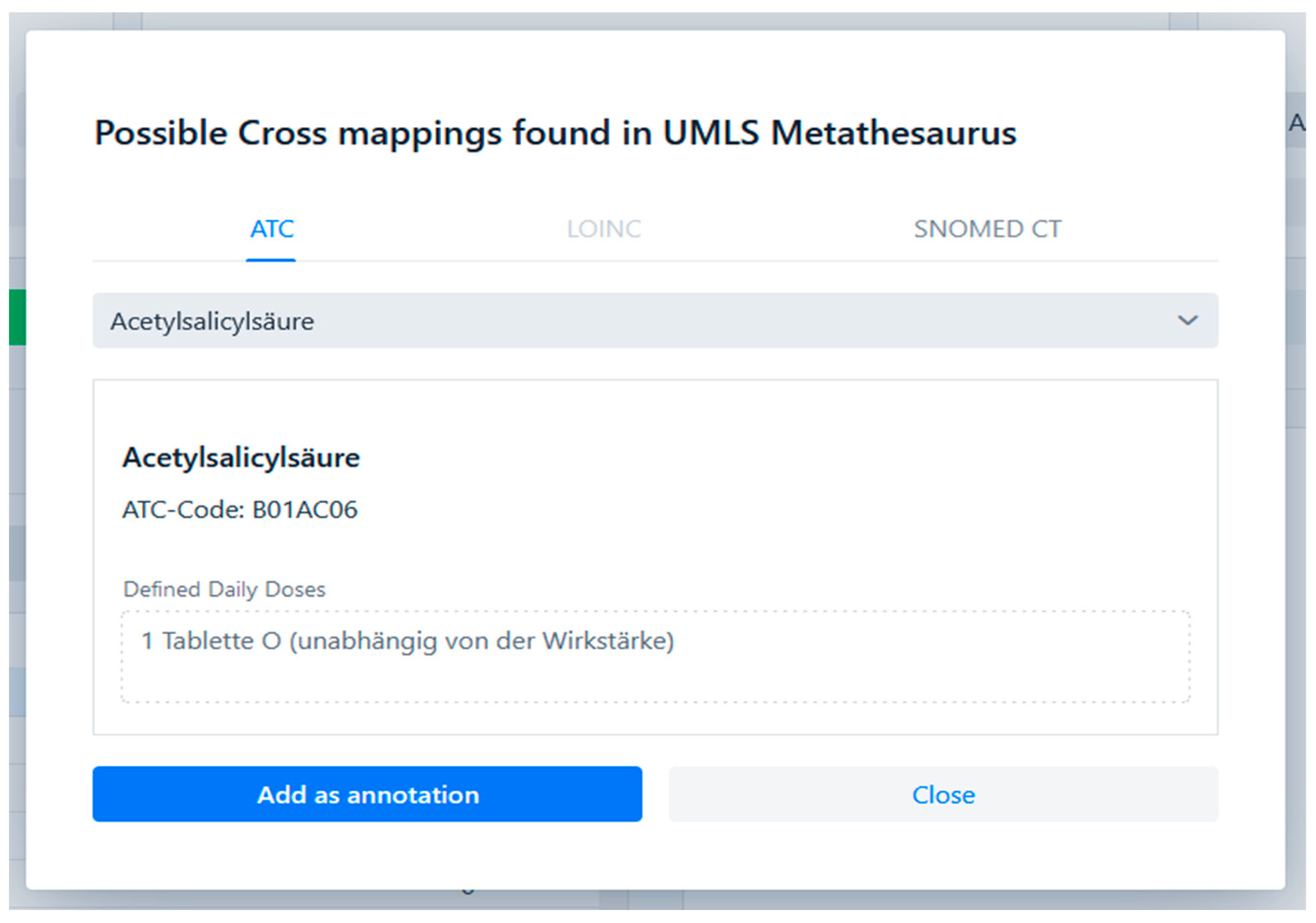
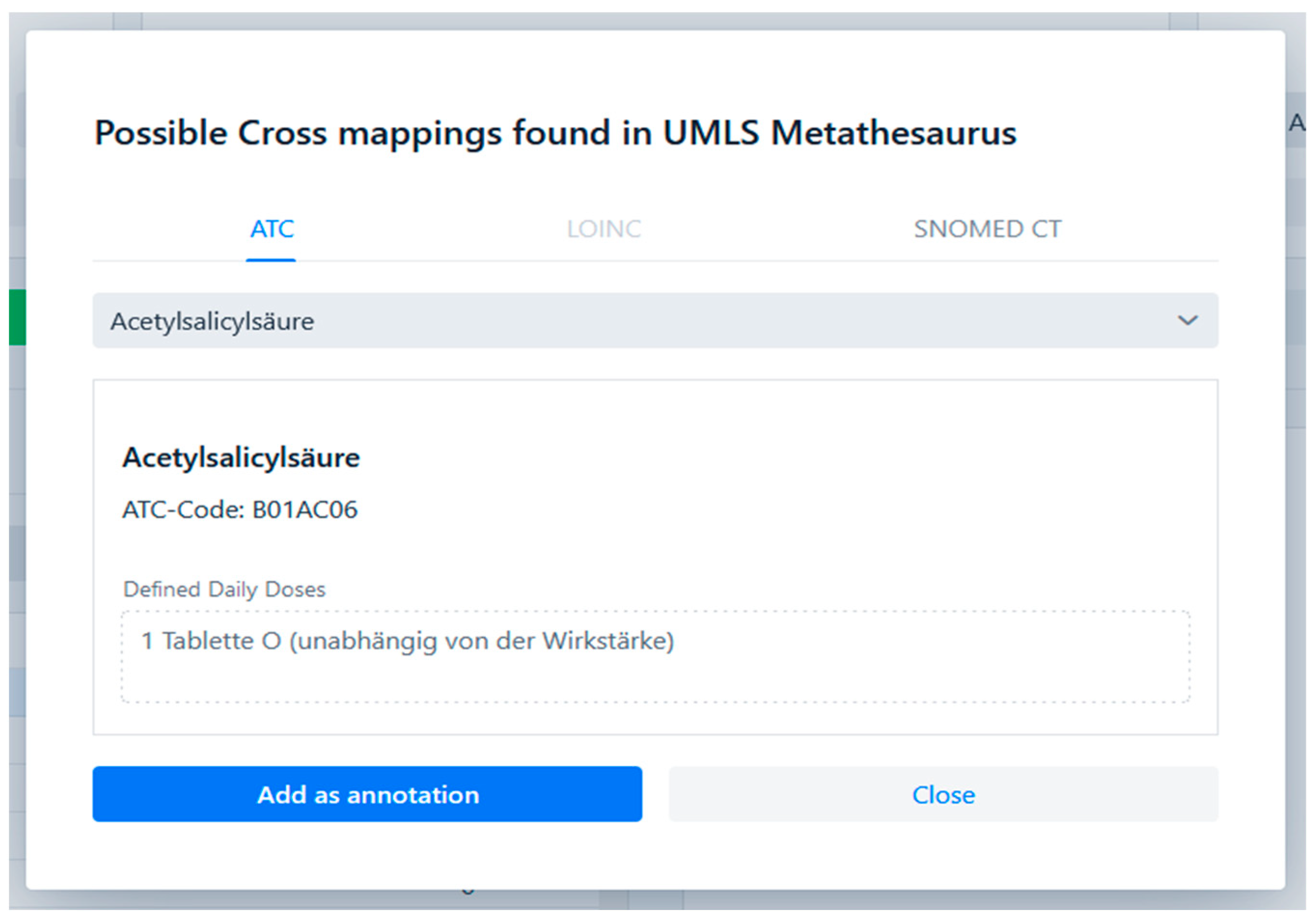
- Cross-terminology mapping: Medical ontologies and terminologies typically describe overlapping knowledge domains and are used to support different application scenarios, implying that annotating source data items with multiple semantic codes from different ontologies and/or terminologies may make annotation results more broadly applicable and practically useful. We therefore enabled CoAT to facilitate cross-/multi-terminology annotation by seamlessly integrating the cross-terminology mapping information from the UMLS Metathesaurus [22] into CoAT for semi-automatic multi-terminology annotation.
3. Results
3.1. Requirements Analysis
3.2. Implementation Process and Results
3.3. Usability Evaluation
3.4. Cross-Site Evaluation
3.4.1. Evaluation at Jena University Hospital
3.4.2. Evaluation at the University of Leipzig
4. Discussion
4.1. CoAT Performance Relative to Identified User Needs and Pre-Existent Tooling
4.2. Value of Collaborative Features
4.3. Limitations
4.4. Future Work
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Meystre, S.M.; Lovis, C.; Bürkle, T.; Tognola, G.; Budrionis, A.; Lehmann, C.U. Clinical Data Reuse or Secondary Use: Current Status and Potential Future Progress. Yearb. Med. Inform. 2017, 26, 38–52. [Google Scholar] [CrossRef] [PubMed]
- Sorensen, H.T.; Sabroe, S.; Olsen, J. A Framework for Evaluation of Secondary Data Sources for Epidemiological Research. Int. J. Epidemiol. 1996, 25, 435–442. [Google Scholar] [CrossRef] [PubMed]
- Semler, S.C.; Wissing, F.; Heyder, R. German Medical Informatics Initiative. Methods Inf. Med. 2018, 57, e50–e56. [Google Scholar] [CrossRef] [PubMed]
- Zenker, S.; Strech, D.; Ihrig, K.; Jahns, R.; Müller, G.; Schickhardt, C.; Schmidt, G.; Speer, R.; Winkler, E.; von Kielmansegg, S.G.; et al. Data Protection-Compliant Broad Consent for Secondary Use of Health Care Data and Human Biosamples for (Bio)Medical Research: Towards a New German National Standard. J. Biomed. Inform. 2022, 131, 104096. [Google Scholar] [CrossRef]
- Medizininformatik-Initiative. Arbeitsgruppe Interoperabilität. Available online: https://www.medizininformatik-initiative.de/de/zusammenarbeit/arbeitsgruppe-interoperabilitaet (accessed on 2 November 2023).
- Medizininformatik-Initiative. Arbeitsgruppe Data Sharing. Available online: https://www.medizininformatik-initiative.de/de/zusammenarbeit/arbeitsgruppe-data-sharing (accessed on 2 November 2023).
- Medizininformatik-Initiative. Der Kerndatensatz Der Medizininformatik-Initiative. Available online: https://www.medizininformatik-initiative.de/de/der-kerndatensatz-der-medizininformatik-initiative (accessed on 2 November 2023).
- Pathak, J.; Wang, J.; Kashyap, S.; Basford, M.; Li, R.; Masys, D.R.; Chute, C.G. Mapping Clinical Phenotype Data Elements to Standardized Metadata Repositories and Controlled Terminologies: The eMERGE Network Experience. J. Am. Med. Inform. Assoc. JAMIA 2011, 18, 376–386. [Google Scholar] [CrossRef] [PubMed]
- Aschman, D.J. Snomed® CT: The Fit with Classification in Health. Health Inf. Manag. J. Health Inf. Manag. Assoc. Aust. 2003, 31, 17–25. [Google Scholar] [CrossRef] [PubMed]
- Forrey, A.W.; McDonald, C.J.; De Moor, G.; Huff, S.M.; Leavelle, D.; Leland, D.; Fiers, T.; Charles, L.; Griffin, B.; Stalling, F.; et al. Logical Observation Identifier Names and Codes (LOINC) Database: A Public Use Set of Codes and Names for Electronic Reporting of Clinical Laboratory Test Results. Clin. Chem. 1996, 42, 81–90. [Google Scholar] [CrossRef] [PubMed]
- Skrbo, A.; Zulić, I.; Hadzić, S.; Gaon, I.D. [Anatomic-therapeutic-chemical classification of drugs]. Med. Arh. 1999, 53, 57–60. [Google Scholar] [PubMed]
- Kors, J.A.; Clematide, S.; Akhondi, S.A.; van Mulligen, E.M.; Rebholz-Schuhmann, D. A Multilingual Gold-Standard Corpus for Biomedical Concept Recognition: The Mantra GSC. J. Am. Med. Inform. Assoc. JAMIA 2015, 22, 948–956. [Google Scholar] [CrossRef] [PubMed]
- Lindberg, C. The Unified Medical Language System (UMLS) of the National Library of Medicine. J. Am. Med. Rec. Assoc. 1990, 61, 40–42. [Google Scholar] [PubMed]
- Krishnan, R.; Rajpurkar, P.; Topol, E.J. Self-Supervised Learning in Medicine and Healthcare. Nat. Biomed. Eng. 2022, 6, 1346–1352. [Google Scholar] [CrossRef] [PubMed]
- Buendía, F.; Gayoso-Cabada, J.; Sierra, J.-L. An Annotation Approach for Radiology Reports Linking Clinical Text and Medical Images with Instructional Purposes. In Proceedings of the Eighth International Conference on Technological Ecosystems for Enhancing Multiculturality; Association for Computing Machinery: New York, NY, USA, 22 January 2021; pp. 510–517. [Google Scholar]
- SNOMED CT Browser. Available online: https://browser.ihtsdotools.org/? (accessed on 10 November 2023).
- RELMA. Available online: https://loinc.org/relma/ (accessed on 10 November 2023).
- Hegselmann, S.; Storck, M.; Geßner, S.; Neuhaus, P.; Varghese, J.; Dugas, M. A Web Service to Suggest Semantic Codes Based on the MDM-Portal. Stud. Health Technol. Inform. 2018, 253, 35–39. [Google Scholar] [PubMed]
- Dugas, M.; Neuhaus, P.; Meidt, A.; Doods, J.; Storck, M.; Bruland, P.; Varghese, J. Portal of Medical Data Models: Information Infrastructure for Medical Research and Healthcare. Database J. Biol. Databases Curation 2016, 2016, bav121. [Google Scholar] [CrossRef] [PubMed]
- Dugas, M. Portal für Medizinische Datenmodelle (MDM-Portal). Available online: https://medical-data-models.org (accessed on 26 November 2023).
- Varghese, J.; Bruland, P.; Zenker, S.; Napolitano, G.; Schmid, M.; Ose, C.; Deckert, M.; Jöckel, K.-H.; Böckmann, B.; Müller, M.; et al. Generation of Semantically Annotated Data Landscapes of Four German University Hospitals; German Medical Science GMS Publishing House: Köln, Germany, 2017. [Google Scholar]
- Schuyler, P.L.; Hole, W.T.; Tuttle, M.S.; Sherertz, D.D. The UMLS Metathesaurus: Representing Different Views of Biomedical Concepts. Bull. Med. Libr. Assoc. 1993, 81, 217. [Google Scholar] [PubMed]
- Mcdonald, S.; Edwards, H.; Zhao, T. Exploring Think-Alouds in Usability Testing: An International Survey. IEEE Trans. Prof. Commun. 2012, 55, 2–19. [Google Scholar] [CrossRef]
- Scherag, A.; Andrikyan, W.; Dreischulte, T.; Dürr, P.; Fromm, M.F.; Gewehr, J.; Jaehde, U.; Kesselmeier, M.; Maas, R.; Thürmann, P.A.; et al. POLAR—“POLypharmazie, Arzneimittelwechselwirkungen und Risiken”—Wie können Daten aus der stationären Krankenversorgung zur Beurteilung beitragen? Prävent. Gesundheitsförderung 2022. [Google Scholar] [CrossRef]
- TMF e.V. TMF-School: Fortbildungsreihe für Verbundforschende. Available online: https://www.tmf-ev.de/veranstaltungen/tmf-akademie/tmf-school (accessed on 29 November 2023).
- Yusupov, I.; Vandermorris, S.; Plunkett, C.; Astell, A.; Rich, J.B.; Troyer, A.K. An Agile Development Cycle of an Online Memory Program for Healthy Older Adults-ERRATUM. Can. J. Aging Rev. Can. Vieil. 2022, 41, 669. [Google Scholar] [CrossRef] [PubMed]
- Feldman, A.G.; Moore, S.; Bull, S.; Morris, M.A.; Wilson, K.; Bell, C.; Collins, M.M.; Denize, K.M.; Kempe, A. A Smartphone App to Increase Immunizations in the Pediatric Solid Organ Transplant Population: Development and Initial Usability Study. JMIR Form. Res. 2022, 6, e32273. [Google Scholar] [CrossRef] [PubMed]
- Jovanović, J.; Bagheri, E. Semantic Annotation in Biomedicine: The Current Landscape. J. Biomed. Semant. 2017, 8, 44. [Google Scholar] [CrossRef]
- Erdfelder, F.; Begerau, H.; Meyers, D.; Quast, K.-J.; Schumacher, D.; Brieden, T.; Ihle, R.; Ammon, D.; Kruse, H.M.; Zenker, S. Enhancing Data Protection via Auditable Informational Separation of Powers Between Workflow Engine Based Agents: Conceptualization, Implementation, and First Cross-Institutional Experiences. In Caring Is Sharing—Exploiting the Value in Data for Health and Innovation; IOS Press: Amsterdam, The Netherlands, 2023; pp. 317–321. [Google Scholar]
- HL7 FHIR. Available online: https://www.hl7.org/fhir/ (accessed on 28 November 2023).
- REDCap. Available online: https://www.project-redcap.org/ (accessed on 29 November 2023).
- LibreClinica. Available online: https://www.libreclinica.org/ (accessed on 29 November 2023).



{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Task | Description | Success Rate |
|---|---|---|
| 1. | Import data | 2/3 |
| 2. | Annotate data using SNOMED CT | 3/3 |
| 3. | Annotate data using LOINC | 3/3 |
| 4. | Annotate data using ATC | 3/3 |
| 5. | Delete a medical data item | 3/3 |
| 6. | Vide an annotation | 2/3 |
| 7. | Restore an older working state of an annotation | 1/3 |
| 8. | Use the collaborative search feature | 2/3 |
| 9. | Use the cross mappings feature | 2/3 |
| Internal Code | SNOMED CT |
|---|---|
| 60_va_ECMO | 786451004 |
| 61_vv_ECMO | 786453001 |
| 161_IABP_1:1 | 399217008 |
| 66_PECLA | 233574002 |
| 109_vv-ECMO | 786453001 |
| 109_ECMO | 233573008 |
| 109_va-ECMO | 786451004 |
| 109_vva-ECMO | 786451004 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wiktorin, T.; Grigutsch, D.; Erdfelder, F.; Heidel, A.J.; Bloos, F.; Ammon, D.; Löbe, M.; Zenker, S. Collaborative Semantic Annotation Tooling (CoAT) to Improve Efficiency and Plug-and-Play Semantic Interoperability in the Secondary Use of Medical Data: Concept, Implementation, and First Cross-Institutional Experiences. Appl. Sci. 2024, 14, 820. https://doi.org/10.3390/app14020820
Wiktorin T, Grigutsch D, Erdfelder F, Heidel AJ, Bloos F, Ammon D, Löbe M, Zenker S. Collaborative Semantic Annotation Tooling (CoAT) to Improve Efficiency and Plug-and-Play Semantic Interoperability in the Secondary Use of Medical Data: Concept, Implementation, and First Cross-Institutional Experiences. Applied Sciences. 2024; 14(2):820. https://doi.org/10.3390/app14020820
Chicago/Turabian StyleWiktorin, Thomas, Daniel Grigutsch, Felix Erdfelder, Andrew J. Heidel, Frank Bloos, Danny Ammon, Matthias Löbe, and Sven Zenker. 2024. "Collaborative Semantic Annotation Tooling (CoAT) to Improve Efficiency and Plug-and-Play Semantic Interoperability in the Secondary Use of Medical Data: Concept, Implementation, and First Cross-Institutional Experiences" Applied Sciences 14, no. 2: 820. https://doi.org/10.3390/app14020820
APA StyleWiktorin, T., Grigutsch, D., Erdfelder, F., Heidel, A. J., Bloos, F., Ammon, D., Löbe, M., & Zenker, S. (2024). Collaborative Semantic Annotation Tooling (CoAT) to Improve Efficiency and Plug-and-Play Semantic Interoperability in the Secondary Use of Medical Data: Concept, Implementation, and First Cross-Institutional Experiences. Applied Sciences, 14(2), 820. https://doi.org/10.3390/app14020820