
Document Difficulty Aspects for Medical Practitioners: Enhancing Information Retrieval in Personalized Search Engines




Abstract
:1. Introduction
- Easy to read and high technicalityAutologous hematopoietic stem cell transplantation has emerged as a promising therapeutic intervention for individuals with refractory multiple myeloma. This treatment approach has shown remarkable advancements in terms of progression-free survival and overall response rates, signifying its potential in improving patient outcomes.
- Hard to read and high technicalityThe pathophysiological mechanisms underlying idiopathic pulmonary fibrosis involve aberrant activation of transforming growth factor-beta signaling pathways, leading to excessive deposition of extracellular matrix components and subsequent progressive scarring of lung tissue.
- Easy to read and low technicalityRegular physical exercise has been widely recognized as a key lifestyle intervention for the prevention of cardiovascular diseases, with numerous studies demonstrating its positive impact on reducing the risk of heart attacks, stroke, and hypertension.
- Hard to read and low technicalityCarcinogenesis is a multifactorial process characterized by the dysregulation of cellular homeostasis, involving intricate interactions between oncogenes and tumor suppressor genes that disrupt normal cell growth control mechanisms, resulting in uncontrolled proliferation and the formation of malignant tumors.
2. Literature Review
2.1. Comprehensibility Aspects in Information Retrieval
2.2. Readability Formulas
2.2.1. Simple Measure of Gobbledygook (SMOG)
2.2.2. Dale-Chall Readability Formula
2.3. Readability for Health Consumers
3. Materials and Methods
3.1. Data Collection
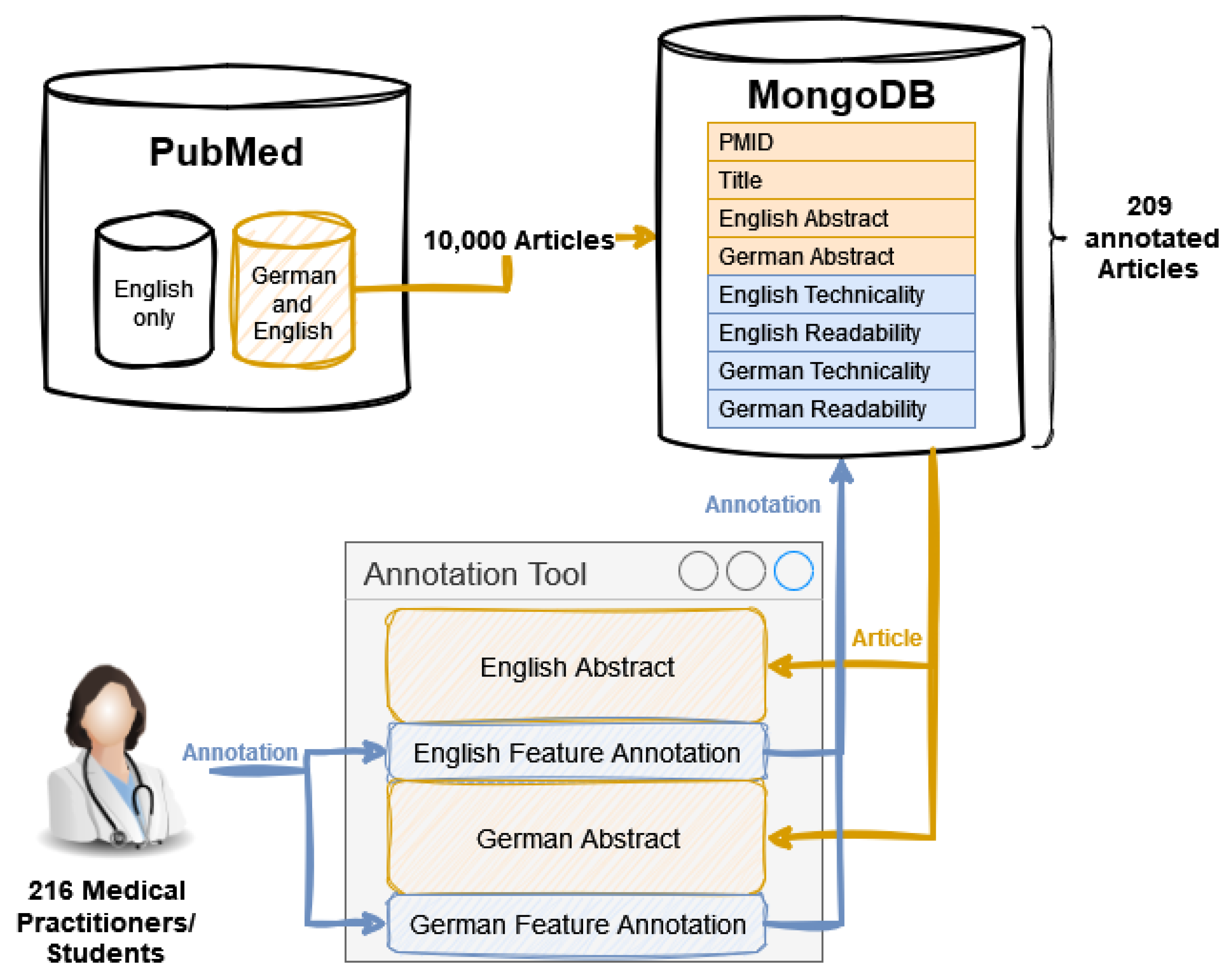
3.1.1. Documents
3.1.2. Participants
3.1.3. Annotation
3.2. Data Analysis
3.2.1. Dataset Overview
3.2.2. Descriptive Statistics
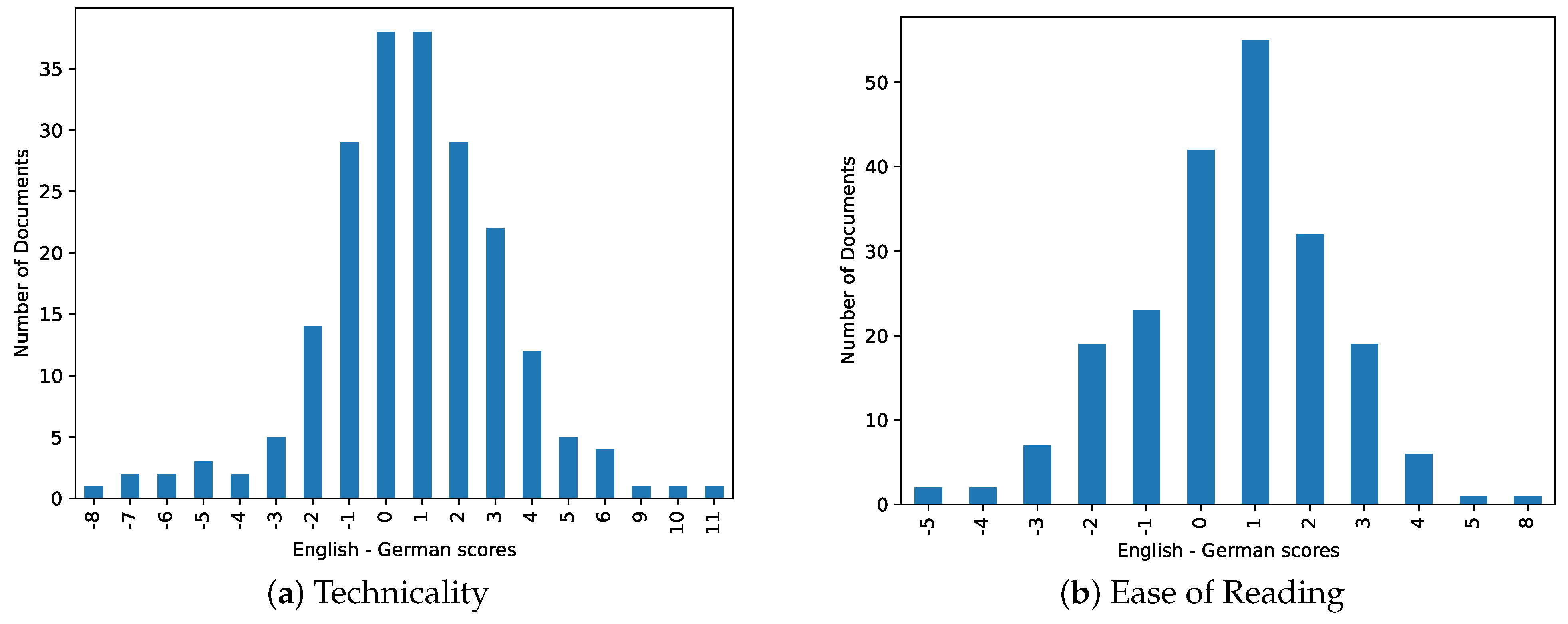
3.2.3. Ease of Reading Analysis
3.2.4. Technicality Analysis
3.2.5. Comparison of German and English Abstracts
3.2.6. Limitations
3.3. Model
3.3.1. Our Model
3.3.2. Common Readability Formulas
4. Results
4.1. Dataset
4.2. BERT-Readability and BERT-Technicality
5. Discussion
5.1. Future Directions
5.2. Limitations
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| IR | Information Retrieval |
| NLP | Natural Language Processing |
| RMSE | Root Mean Square Error |
| BERT | Bidirectional Encoder Representations from Transformers |
| CEFR | Common European Framework of Reference |
| SD | Standard Deviation |
| ICC | Intraclass Correlation Coefficient |
| WPM | Words Per Minute |
| SMOG | Simple Measure Of Gobbledygook |
References
- Entin, E.B.; Klare, G.R. Relationships of Measures of Interest, Prior Knowledge, and Readability to Comprehension of Expository Passages. Adv. Read./Lang. Res. 1985, 3, 9–38. [Google Scholar]
- Vydiswaran, V.V.; Mei, Q.; Hanauer, D.A.; Zheng, K. Mining consumer health vocabulary from community-generated text. In Proceedings of the AMIA Annual Symposium Proceedings, American Medical Informatics Association, San Diego, CA, USA, 30 October–3 November 2014; Volume 2014, p. 1150. [Google Scholar]
- Chall, J. Readability: An Appraisal of Research and Application; Bureau of Educational Research Monographs: Columbus, OH, USA, 1958. [Google Scholar]
- Hätty, A.; Schlechtweg, D.; Dorna, M.; im Walde, S.S. Predicting degrees of technicality in automatic terminology extraction. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, London, UK, 5–10 July 2020; pp. 2883–2889. [Google Scholar]
- Hedman, A.S. Using the SMOG formula to revise a health-related document. Am. J. Health Educ. 2008, 39, 61–64. [Google Scholar] [CrossRef]
- Liu, Y.; Ji, M.; Lin, S.S.; Zhao, M.; Lyv, Z. Combining readability formulas and machine learning for reader-oriented evaluation of online health resources. IEEE Access 2021, 9, 67610–67619. [Google Scholar] [CrossRef]
- Goeuriot, L.; Jones, G.J.; Kelly, L.; Leveling, J.; Hanbury, A.; Müller, H.; Salanterä, S.; Suominen, H.; Zuccon, G. ShARe/CLEF eHealth Evaluation Lab 2013, Task 3: Information retrieval to address patients’ questions when reading clinical reports. CLEF Online Work. Notes 2013, 4, 191–201. [Google Scholar]
- O’Sullivan, L.; Sukumar, P.; Crowley, R.; McAuliffe, E.; Doran, P. Readability and understandability of clinical research patient information leaflets and consent forms in Ireland and the UK: A retrospective quantitative analysis. BMJ Open 2020, 10, e037994. [Google Scholar] [CrossRef]
- Veltri, L.W.; Milton, D.R.; Delgado, R.; Shah, N.; Patel, K.; Nieto, Y.; Kebriaei, P.; Popat, U.R.; Parmar, S.; Oran, B.; et al. Outcome of autologous hematopoietic stem cell transplantation in refractory multiple myeloma. Cancer 2017, 123, 3568–3575. [Google Scholar] [CrossRef]
- Wynn, T.A.; Ramalingam, T.R. Mechanisms of fibrosis: Therapeutic translation for fibrotic disease. Nat. Med. 2012, 18, 1028–1040. [Google Scholar] [CrossRef]
- Ott, N.; Meurers, D. Information retrieval for education: Making search engines language aware. Themes Sci. Technol. Educ. 2011, 3, 9–30. [Google Scholar]
- Tomažič, T.; Čelofiga, A.K. The Role of Different Behavioral and Psychosocial Factors in the Context of Pharmaceutical Cognitive Enhancers’ Misuse. Healthcare 2022, 10, 972. [Google Scholar] [CrossRef]
- Frihat, S. Context-sensitive, personalized search at the Point of Care. In Proceedings of the 22nd ACM/IEEE Joint Conference on Digital Libraries, Cologne, Germany, 20–24 June 2022; pp. 1–2. [Google Scholar]
- Basch, C.H.; Fera, J.; Garcia, P. Readability of influenza information online: Implications for consumer health. Am. J. Infect. Control 2019, 47, 1298–1301. [Google Scholar] [CrossRef]
- Klare, G.R. The formative years. In Readability: Its Past, Present, and Future; International Reading Association: Newark, DE, USA, 1988; pp. 14–34. [Google Scholar]
- Yan, X.; Song, D.; Li, X. Concept-based document readability in domain specific information retrieval. In Proceedings of the 15th ACM International Conference on Information and Knowledge Management, Arlington, VA, USA, 13–16 August 2006; pp. 540–549. [Google Scholar]
- Ceri, S.; Bozzon, A.; Brambilla, M.; Della Valle, E.; Fraternali, P.; Quarteroni, S.; Ceri, S.; Bozzon, A.; Brambilla, M.; Della Valle, E.; et al. An introduction to information retrieval. Web Inf. Retr. 2013, 3, 3–11. [Google Scholar]
- Selvaraj, P.; Burugari, V.K.; Sumathi, D.; Nayak, R.K.; Tripathy, R. Ontology based recommendation system for domain specific seekers. In Proceedings of the 2019 Third International Conference on I-SMAC (IoT in Social, Mobile, Analytics and Cloud) (I-SMAC), Palladam, India, 12–14 December 2019; pp. 341–345. [Google Scholar]
- Jameel, S.; Qian, X. An unsupervised technical readability ranking model by building a conceptual terrain in LSI. In Proceedings of the 2012 Eighth International Conference on Semantics, Knowledge and Grids, Beijing, China, 22–24 October 2012; pp. 39–46. [Google Scholar]
- Palotti, J.; Goeuriot, L.; Zuccon, G.; Hanbury, A. Ranking health web pages with relevance and understandability. In Proceedings of the 39th International ACM SIGIR Conference on Research and Development in Information Retrieval, Pisa, Italy, 17–21 July 2016; pp. 965–968. [Google Scholar]
- van der Sluis, F.; van den Broek, E.L. Using complexity measures in information retrieval. In Proceedings of the Third Symposium on Information Interaction in Context, New Brunswick, NJ, USA, 18–21 August 2010; pp. 383–388. [Google Scholar]
- Kane, L.; Carthy, J.; Dunnion, J. Readability applied to information retrieval. In Proceedings of the European Conference on Information Retrieval, London, UK, 4–10 April 2006; Springer: Berlin/Heidelberg, Germany, 2006; pp. 523–526. [Google Scholar]
- Taranova, A.; Braschler, M. Textual complexity as an indicator of document relevance. In Proceedings of the Advances in Information Retrieval: 43rd European Conference on IR Research, ECIR 2021, Virtual Event, 28 March–1 April 2021; Springer: Berlin/Heidelberg, Germany, 2021; Volume 43, Part II. pp. 410–417. [Google Scholar]
- Lopes, C.T. Health Information Retrieval—State of the art report. arXiv 2022, arXiv:2205.09083. [Google Scholar]
- Fung, A.C.H.; Lee, M.H.L.; Leung, L.; Chan, I.H.Y.; Kenneth, W. Internet Health Resources on Nocturnal Enuresis—A Readability, Quality and Accuracy Analysis. Eur. J. Pediatr. Surg. 2023. [Google Scholar] [CrossRef] [PubMed]
- DuBay, W.H. The Principles of Readability; Online Submission; Impact Information: Costa Mesa, CA, USA, 2004. [Google Scholar]
- Mc Laughlin, G.H. SMOG grading-a new readability formula. J. Read. 1969, 12, 639–646. [Google Scholar]
- Wang, L.W.; Miller, M.J.; Schmitt, M.R.; Wen, F.K. Assessing readability formula differences with written health information materials: Application, results, and recommendations. Res. Soc. Adm. Pharm. 2013, 9, 503–516. [Google Scholar] [CrossRef]
- Willis, L.; Gosain, A. Readability of patient and family education materials on pediatric surgical association websites. Pediatr. Surg. Int. 2023, 39, 156. [Google Scholar] [CrossRef]
- Dale, E.; Chall, J.S. A formula for predicting readability: Instructions. Educ. Res. Bull. 1948, 5, 37–54. [Google Scholar]
- Basch, C.H.; Mohlman, J.; Hillyer, G.C.; Garcia, P. Public health communication in time of crisis: Readability of on-line COVID-19 information. Disaster Med. Public Health Prep. 2020, 14, 635–637. [Google Scholar] [CrossRef]
- Diviani, N.; van den Putte, B.; Giani, S.; van Weert, J.C. Low health literacy and evaluation of online health information: A systematic review of the literature. J. Med. Internet Res. 2015, 17, e112. [Google Scholar] [CrossRef]
- Modiri, O.; Guha, D.; Alotaibi, N.M.; Ibrahim, G.M.; Lipsman, N.; Fallah, A. Readability and quality of wikipedia pages on neurosurgical topics. Clin. Neurol. Neurosurg. 2018, 166, 66–70. [Google Scholar] [CrossRef]
- Tan, S.S.L.; Goonawardene, N. Internet health information seeking and the patient-physician relationship: A systematic review. J. Med. Internet Res. 2017, 19, e9. [Google Scholar] [CrossRef] [PubMed]
- Zowalla, R.; Pfeifer, D.; Wetter, T. Readability and topics of the German Health Web: Exploratory study and text analysis. PLoS ONE 2023, 18, e0281582. [Google Scholar] [CrossRef] [PubMed]
- Behrens, H. How Difficult are Complex Verbs? Evidence from German, Dutch and English. Linguistics 1998, 36, 679–712. [Google Scholar] [CrossRef]
- Klatt, E.C.; Klatt, C.A. How much is too much reading for medical students? Assigned reading and reading rates at one medical school. Acad. Med. 2011, 86, 1079–1083. [Google Scholar] [CrossRef] [PubMed]
- Koo, T.K.; Li, M.Y. A guideline of selecting and reporting intraclass correlation coefficients for reliability research. J. Chiropr. Med. 2016, 15, 155–163. [Google Scholar] [CrossRef]
- Hockett, C.F. A Course in Modern Linguistics; The Macmillan Company: New York, NY, USA, 1958. [Google Scholar]
- Grimm, A.; Hübner, J. Nonword repetition by bilingual learners of German: The role of language-specific complexity. Biling. Specif. Lang. Impair. Bi-SLI 2017, 201, 288. [Google Scholar]
- Gu, Y.; Tinn, R.; Cheng, H.; Lucas, M.; Usuyama, N.; Liu, X.; Naumann, T.; Gao, J.; Poon, H. Domain-Specific Language Model Pretraining for Biomedical Natural Language Processing. arXiv 2020, arXiv:2007.15779. [Google Scholar] [CrossRef]
- Deepset-AI. State-of-the-Art German BERT Model Trained from Scratch. Available online: https://www.deepset.ai/german-bert (accessed on 1 August 2023).
- Worrall, A.P.; Connolly, M.J.; O’Neill, A.; O’Doherty, M.; Thornton, K.P.; McNally, C.; McConkey, S.J.; De Barra, E. Readability of online COVID-19 health information: A comparison between four English speaking countries. BMC Public Health 2020, 20, 100231. [Google Scholar] [CrossRef]
- Fajardo, M.A.; Weir, K.R.; Bonner, C.; Gnjidic, D.; Jansen, J. Availability and readability of patient education materials for deprescribing: An environmental scan. Br. J. Clin. Pharmacol. 2019, 85, 1396–1406. [Google Scholar] [CrossRef]
- Powell, L.; Krivanek, T.; Deshpande, S.; Landis, G. Assessing Readability of FDA-Required Labeling for Breast Implants. Aesthetic Surg. J. Open Forum 2023, 5, ojad027-009. [Google Scholar] [CrossRef]
- Szmuda, T.; Özdemir, C.; Ali, S.; Singh, A.; Syed, M.T.; Słoniewski, P. Readability of online patient education material for the novel coronavirus disease (COVID-19): A cross-sectional health literacy study. Public Health 2020, 185, 21–25. [Google Scholar] [CrossRef] [PubMed]
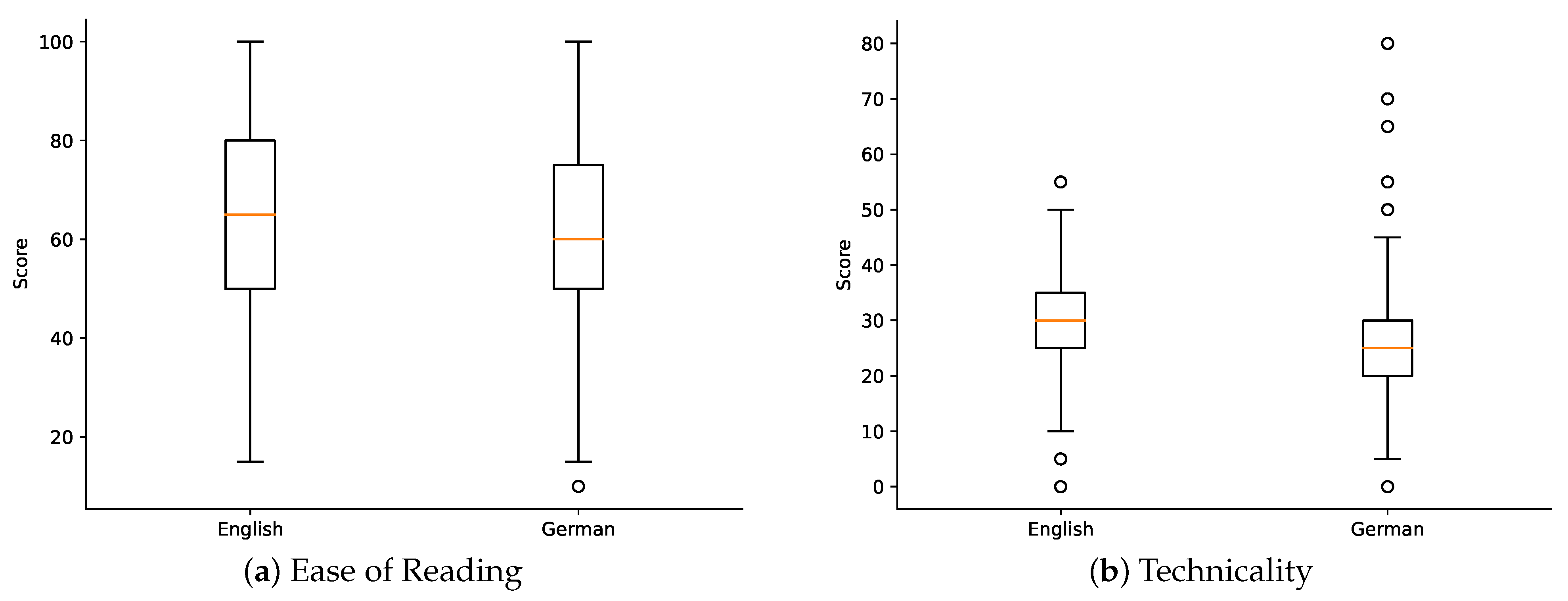

{kind=link}
{kind=link}
{kind=link}
| Category | Med. Student | Med. Doctor | Total | ||
|---|---|---|---|---|---|
| Junior | Senior | Junior | Senior | ||
| Participants | 70 | 59 | 59 | 28 | 216 |
| 32.4% | 27.3% | 27.3% | 13% | 100% | |
| Formula | English | German |
|---|---|---|
| BERT-Technicality | 9.42 | 10.07 |
| BERT-Readability | 10.61 | 11.80 |
| Coleman-Liau Index | 19.96 | 20.22 |
| SMOG Index | 21.28 | 23.59 |
| Gunning Fog Index | 26.13 | 30.66 |
| Dale-Chall Readability Score | 26.77 | 23.61 |
| Flesch-Kincaid Grade Level | 27.93 | 28.38 |
| Automated Readability Index | 30.95 | 30.26 |
| Gutierrez de Polini Index | 33.90 | 31.98 |
| Szigriszt-Pazos Index | 32.93 | 30.94 |
| Fernandez-Huerta Index | 32.30 | 31.17 |
| Flesch Reading Ease | 34.34 | 32.60 |
| Gulpease Index | 34.46 | 35.48 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Frihat, S.; Beckmann, C.L.; Hartmann, E.M.; Fuhr, N. Document Difficulty Aspects for Medical Practitioners: Enhancing Information Retrieval in Personalized Search Engines. Appl. Sci. 2023, 13, 10612. https://doi.org/10.3390/app131910612
Frihat S, Beckmann CL, Hartmann EM, Fuhr N. Document Difficulty Aspects for Medical Practitioners: Enhancing Information Retrieval in Personalized Search Engines. Applied Sciences. 2023; 13(19):10612. https://doi.org/10.3390/app131910612
Chicago/Turabian StyleFrihat, Sameh, Catharina Lena Beckmann, Eva Maria Hartmann, and Norbert Fuhr. 2023. "Document Difficulty Aspects for Medical Practitioners: Enhancing Information Retrieval in Personalized Search Engines" Applied Sciences 13, no. 19: 10612. https://doi.org/10.3390/app131910612
APA StyleFrihat, S., Beckmann, C. L., Hartmann, E. M., & Fuhr, N. (2023). Document Difficulty Aspects for Medical Practitioners: Enhancing Information Retrieval in Personalized Search Engines. Applied Sciences, 13(19), 10612. https://doi.org/10.3390/app131910612