1. Introduction
Gait defines a distinct pattern of human mobility, strongly influenced by individual biological characteristics such as height, weight, age, and gender. Therefore, it enables differentiation among individuals. Gait analysis has been extensively used to study walking behaviors in both healthy individuals [
1] and those afflicted with neurological conditions such as Huntington’s disease (HD), Amyotrophic Lateral Sclerosis (ALS), and Parkinson’s disease (PD) [
2]. Furthermore, it has been used beyond healthcare, extending to domains such as biometric security systems [
3]. Researchers have devised various techniques for assessing gait, utilizing a range of sensors, including inertial sensors [
4], foot pressure sensors [
5], depth cameras [
6], and motion capture systems [
7].
Wearable and non-wearable sensors are the two primary categories of sensors employed for analyzing human gaits. A typical wearable sensor is the inertial sensor [
8], which can be affixed to the hips, knees, and ankles. OptiTrack and Vicon are also wearable sensors that require users to attach the sensors to their bodies. Wearable sensors provide accurate data; however, they require users to attach the sensors to their bodies, resulting in discomfort during walking [
9]. Another noteworthy sensor is the foot pressure sensor [
10], which comprises an array of sensors that calculate cumulative pressure across the entire surface by measuring pressure on individual cells. With advancements in chip technology, foot pressure sensors [
11] are now integrated into shoe insoles, allowing for more efficient and comfortable data collection.
Recently developed depth cameras, such as Kinect v1, v2, and Azure Kinect by Microsoft (Redmond, DC, USA) [
12], are unintrusive sensors capable of capturing 3D information about human joints. However, they offer lower accuracy. Additionally, one can only capture a few steps at a time while the participant is walking. Nonetheless, the reduced accuracy is generally deemed acceptable owing to the fact that 3D skeleton data are derived as secondary information from depth data. Furthermore, these cameras can cover long distances and are more cost-effective.
Marker-based gait quantification is considered a gold standard by the research and health communities. It reconstructs motion in 3D and provides parameters to measure gait. However, it is an expensive and intrusive technique, limited to soft tissue artifacts, prone to incorrect marker positioning, and associated with skin sensitivity problems. Ref. [
13] illustrated a 3D gait motion analyzer employing impulse radio ultra-wideband (IR-UWB) wireless technology. The prototype can measure 3D motion and determine quantitative parameters considering anatomical reference planes. Knee angles have been calculated from the gait by applying vector algebra. Simultaneously, the model has been corroborated by the popular marker-less camera-based 3D motion-capturing system, the Kinect sensor. Three-dimensional shape information is a crucial clue to understanding the posture and shape of pedestrians. However, most existing person-Re-ID methods learn pedestrian feature representations from images, ignoring the real 3D human body structure and the spatial relationship between pedestrians and interferents. To address this problem, ref. [
14] devised a new point cloud Re-ID network (PointReIDNet), designed to obtain 3D shape representations of pedestrians from point clouds of 3D scenes. The model consists of modules, namely the global semantic guidance and local feature extraction modules. The global semantic guidance module enhances feature representation and reduces the interference caused by 3D shape reconstruction or noise.
The authors in [
15] simulated the depth-wise separable convolution calculation method in the point cloud and proposed a new type of convolution, namely dynamic cover convolution (DC-Conv), to aggregate local features. The core of DC-Conv is the space cover operator (SCOP), which constructs anisotropic spatial geometry in a local area to cover the local feature space to enhance the compactness of local features. DC-Conv achieves the capture of local shapes by dynamically combining multiple SCOPs in the local neighborhood. Among them, the attention coefficients of the SCOPs are adaptively learned from the point position in a data-driven manner. Experiments on the 3D point cloud shape recognition benchmark datasets ModelNet40, ModelNet10, and ScanObjectNN show that this method can effectively improve the performance of 3D point cloud shape recognition and robustness to sparse point clouds, even in the case of a single scale.
Ref. [
16] addressed the problem of gait classification using different pre-trained single- and multi-modal foot pressure and skeleton datasets. This method uses conventional convolutional neural networks (CNNs) for single- and multi-modal methods. However, other methods, such as vision transformers and spatiotemporal graph convolutional network (ST-GCN), exist. Regarding fusion, the method uses only early fusion, which concatenates the best features from both modalities. Similarly, fusion can be performed in other ways, such as by combining the outputs from different modalities with and without weighted summation. Additionally, the accuracies for single-modals, foot pressure, and skeleton datasets were 68.82% and 93.40%, respectively, which are low. However, for the multimodal, the accuracy was 97.60%, which was somewhat adequate. To address these limitations, a classification model other than CNN for single-modal methods is required to effectively classify pathological gaits and achieve improved performance. Other methods for fusing the different multi-modalities are also required.
This study focuses on a more effective approach to classifying one normal gait and five abnormal pathological gaits (antalgic, lurching, steppage, stiff-legged, and Trendelenburg) using datasets from the GIST pathological gait database [
16], which includes foot pressure and skeleton datasets. Single-modal and multi-modal methods were proposed, employing early and late fusion techniques to assess gait classification accuracy. In the single-modal approaches, transfer-based models for the foot pressure dataset and the ST-GCN model for the skeleton dataset were utilized. In the multi-modal approach using early fusion, features from both modalities were concatenated, whereas in the multi-modal approach using late fusion, the outputs from the two modalities were combined in various ways, both with and without different weights. The choice of weights depended on the accuracy of the trained single models. Our early fusion method outperformed the late fusion method. When comparing our single-modal and multi-modal approaches, both in early and late fusion configurations, our models demonstrated state-of-the-art performance with the GIST pathological gait database.
The remainder of the paper is organized as follows:
Section 2 summarizes related works, encompassing sensor-based, vision-based, and multimodal-based methods.
Section 3 discusses the limitations of previous works and our contributions.
Section 4 describes the details of the dataset utilized in this study.
Section 5 first discusses the proposed single-modal models (MViTv2_base and MViTv2_small) and ST-GCN; second, the proposed multi-modal model using early fusion is discussed; and third, the proposed multi-modal using late fusion with and without different weights is discussed.
Section 6 presents potential applications of gaits, conclusions, and some future research directions.
2. Related Works
Related works on machine learning (ML) and deep learning (DL) methods for gait recognition can be categorized into three distinct approaches: sensor-based, vision-based, and multimodal-based approaches.
2.1. Sensor-Based Approaches
Wearable sensors are widely employed in studying the impact and significance of descriptive statistical factors on osteopenia and sarcopenia using artificial intelligence (AI) [
17]. ML techniques have been explored to address natural variations in gaits among different subjects using wearable sensors, with an accuracy rate of 81% [
18]. Furthermore, a DL approach based on long short-term memory (LSTM) has been proposed for the automatic detection of initial contact (IC) and toe-off (TO) using foot-marker kinematics [
19]. Another DL-based study has been reported on the accuracy of various neural networks in modeling lower body joint angles in the sagittal plane, utilizing kinematic records from a single inertial measurement unit (IMU) attached to the foot [
20]. This model demonstrates superior performance compared to ML approaches. Additionally, a paper [
21] delves into gait classification based on CNN using interferometric radar.
In [
22], a smart insole equipped with various sensor arrays is discussed for gait classification based on DL. The results encompass seven types of gaits: walking, fast walking, running, stair climbing, stair descending, hill climbing, and hill descending. The method achieves a high classification rate of 90%. In [
23], two models are presented, one hardware-based, consisting of multiple sensor modules (MSM), and another software-based, composed of a biomedical and inertial sensor algorithm, along with the leg health classification net (LCNet) model. These models achieve an impressive accuracy of 94.41%. Ref. [
24] introduces a DL-based model that conducts a comprehensive examination of ground reaction force (GRF) patterns to detect normal gait and gait abnormalities. Another model, described in [
25], employs five classifiers (K-Nearest Neighbors (KNN), Random Forest (RF), Decision Tree (DT), Logistic Regression (LR), and Stochastic Gradient Descent (SGD)) for the electromyography (EMG) dataset. The results demonstrate 99% accuracy using KNN and RF, whereas the DT classifier achieves 97% accuracy. In [
26], a model is discussed for classifying numerous anatomical regions and their combinations using a vast and highly unbalanced dataset. Furthermore, ref. [
27] presents a model that employs Shapley’s additive explanations to select important parameters with the Support Vector Machine (SVM), RF, and multilayer perceptron. The highest accuracy of 95% was achieved using an SVM classifier.
These sensor-based approaches sometimes achieve high accuracy in gait classification. However, they demand specialized hardware sensors and possess limitations in their general applicability, particularly for gait classification in cases of sarcopenia.
2.2. Vision-Based Approaches
In [
28], the Kinect motion system is utilized to collect spatiotemporal gait data from seven healthy subjects across three walking trials: normal, pelvic-obliquity, and knee-hyperextension walking. Four classifiers—LSTM, SVM, KNN, and CNN—are employed. Notably, SVM and KNN perform well, achieving classification accuracies of 94.9% and 94.0%, respectively. Ref. [
29] introduces a deep CNN that employs 3D convolutions for gait recognition from multiple viewpoints, capturing spatiotemporal features. This approach is evaluated across three different datasets, accounting for variations in clothing, walking speeds, and viewing angles. Additionally, ref. [
30] proposes gait recognition using an enhanced CNN with the incorporation of a Gabor filter.
In [
31], the researchers propose a model based on Gait Energy Images (GEIs) to automatically extract robust and discriminative spatial gait features for human identification. They leverage deep 3-dimensional CNNs to learn the temporal gait features, referred to as Convolutional 3D (C3D) representations. In [
32], a classifier based on Gated Recurrent Units (GRUs) is proposed. It is used to classify six different gaits, including one normal and five pathological gaits (antalgic, stiff-legged, lurching, steppage, and Trendelenburg), achieving an accuracy of 93.67%.
A study detailed in [
33] that introduces an RNN-based model for the classification of pathological gaits based on skeleton data has garnered significant attention. Utilizing bidirectional LSTM, the model achieves an accuracy of 88.90%. It categorizes gaits into six categories: normal, in-toeing, out-toeing, drop foot, pronation, and supination. Furthermore, in [
34], features extracted by an LSTM-based autoencoder are employed in a GRU classifier. This approach accurately distinguishes between normal, limping, and knee-stiff gaits across various levels, achieving an impressive accuracy rate of 95.90%.
2.3. Multimodal-Based Approaches
In [
35], an automated knee osteoarthritis (KOA) classification algorithm based on the Kellgren–Lawrence (KL) grading system is examined utilizing radiographic imaging and gait analysis data. The model achieves an F1-score, sensitivity, and precision of 0.70, 0.76, and 0.71, respectively.
In [
16], a DL-based multimodal model is presented for classifying six gait types, including one normal and five pathological (antalgic, lurch, steppage, stiff-legged, and Trendelenburg) gaits. This model uses both skeletal and foot pressure data. To efficiently extract features from these two different data types for classification, the model inputs sequential skeletal data into recurrent neural network (RNN)-based encoding layers and average foot pressure data into a CNN. The classification accuracy for the pressure-based and skeleton-based single models is 68.82% and 93.40%, respectively. However, the hybrid model outperforms them with an accuracy of 95.66%. Subsequently, the model underwent improvement, achieving an accuracy of 97.60% through a three-step training process.
In [
36], gait freezing episodes were classified with an accuracy of 98.1% through the data fusion of scalograms from Wi-Fi sensing and spectrograms from radar sensors. Additionally, ref. [
37] explores sensor fusion using data from ambulatory inertial sensors (AISs) and plastic optical fiber-based floor sensors (FSs). The model attains an accuracy of 88% with ANN and 91% with CNN, as it learns optimal data representations from both sensor modalities.
3. Limitations of Previous Works and Contributions
Table 1 outlines the issues with existing works, which often exhibit one or more of the following limitations:
The system outlined in [
16] is intricate, despite its high accuracy, as it involves processing double instances of each dataset.
The model presented in [
21] boasts good accuracy but offers fewer classes and limited datasets from various sources.
In contrast to the work described in [
24], which achieves high accuracy but lacks diversified datasets, the approach addressed in [
19] only achieves 81%, a comparatively lower result.
Whereas the model mentioned in [
17] provides good accuracy, its applicability is restricted to specific age groups. Moreover, it is gender-specific and suitable only for slow speeds.
The model in [
25] conducted experiments with fewer classes.
Achieving a deep understanding of image properties is imperative when relying on a fixed set of handcrafted features [
17,
18,
25]. These methods rely on texture analysis, where classifiers like RF are fed a limited number of locally computed descriptors from the image. Whereas some studies have demonstrated the high accuracy of these strategies, they are constrained in terms of generalizability and inter-dataset variability.
Some of the aforementioned models have demonstrated exceptional accuracy in their respective work. However, they are often tested in a limited number of classes. Others may have a sufficient number of classes but are limited to specific age or gender groups and can only operate within certain speed limits.
Additionally, some researchers have employed diverse datasets, but they often belong to the same modality. In light of the challenges outlined in
Table 1, this study makes the following significant contributions:
Transformer-based single-modal models, MViTv2_base and MViTv2_small, were introduced using the original instances of the foot pressure dataset. These models exhibit enhanced performance in gait classification from foot pressure data.
A single-modal approach, the ST-GCN model, utilizing the original instances of the skeletal dataset, was presented.
To enhance the accuracy of the foot pressure dataset, various augmentations were introduced.
The proposed single-modal models outperform the baseline single-modal models.
A multi-modal approach employing early fusion was proposed, which utilizes the original instances of both foot pressure and skeletal data simultaneously.
Additionally multi-modal methods utilizing late fusion were introduced, where the outputs from both modalities were combined, both without and with varying weights.
The proposed multi-modal method using early fusion performed better than our proposed late fusion methods.
Our proposed multi-modal models show state-of-the-art performance on the GIST pathological database.
4. Dataset Used
In this study, a publicly available foot pressure and skeleton dataset was utilized from [
16]. This dataset comprises one normal gait and five abnormal pathological gaits (antalgic, lurching, steppage, stiff-legged, and Trendelenburg). Twelve healthy males participated in the data collection. All of them were laboratory staff members and fully understood the data collection system. They had watched videos of each pathological gait and trained until they became familiar with simulating them. Data collection was conducted under strict supervision. The data were acquired using a recently released single-depth camera (Azure Kinect, Microsoft, USA), along with foot pressure data collected from a pressure plate (GW1100, GHiWell, Yangju-si, Republic of Korea). Although the size of the dataset was sufficient, it had certain limitations. For example, for the DL models, the size is low. Additionally, the dataset was created for only one gender. Moreover, there are no details about the dataset regarding which age groups participated, and the dataset was not created by real patients.
4.1. Gait Types
The publicly accessible foot pressure and 3D skeleton datasets used in this study include normal, antalgic, lurch, steppage, and stiff-legged gait types. In a normal gait, the spine and pelvis play crucial roles. Antalgic gait is characterized by pain resulting from a specific disease or leg injury. Steppage gait occurs when the toes of the foot avoid contact with the ground due to muscle and motor nerve abnormalities in the front shin. Lurch gait is induced by hip area abnormalities, such as weakness or paralysis of the gluteus maximus. Stiff-legged gait, also known as stiff-knee gait, is often due to quadriceps weakness, caused by joint abnormalities in the knee region. In contrast, Trendelenburg gait results from weakness or paralysis of the blunt middle force, often due to a weak gluteus medius muscle, causing the torso to tilt in the direction of the symptoms during walking [
32].
4.2. Foot Pressure Dataset
The GW1100 pressure plate, capable of measuring pressure up to 100 N/cm
2, is equipped with 6144 high-voltage matrix sensors and is 1080 mm × 480 mm in size [
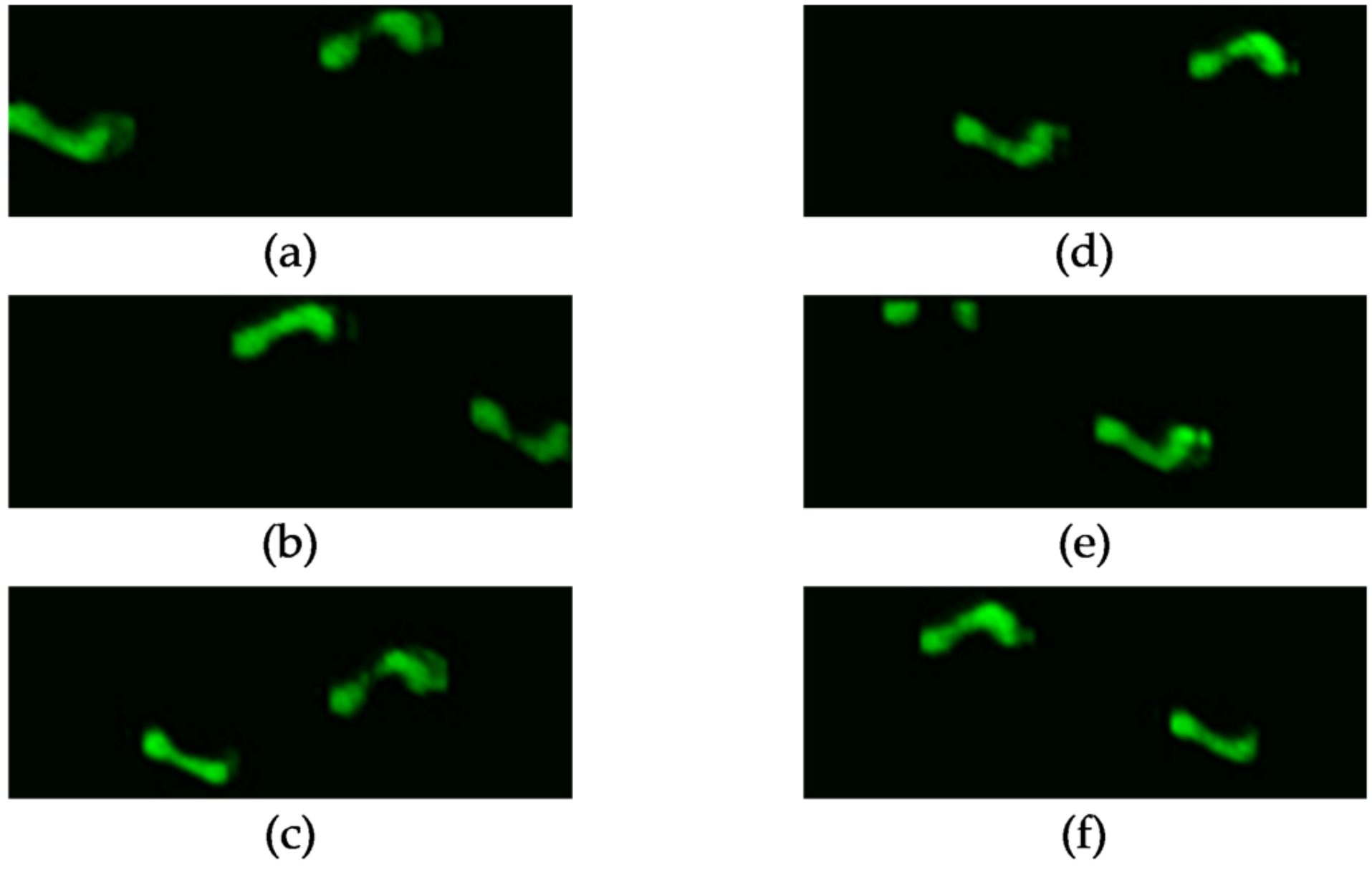
12]. Typically, this sensor can capture data for two walking steps. To create the dataset utilized in this study, which measures average foot pressure, the planar foot pressures from all time sequences were averaged. The foot pressure dataset, encompassing normal, antalgic, lurch, steppage, and Trendelenburg gaits, is depicted in
Figure 1. A single-channel image suffices to represent the average foot pressure. For data collection, gait datasets were compiled from 12 subjects, encompassing six different gait types and 20 trials, resulting in a total of 12 × 6 × 20 = 1440 foot pressure samples.
4.3. The 3D Skeleton Dataset
The most recent Kinect sensor available is the Azure Kinect. In [
16], researchers utilized the Azure Kinect sensor along with the associated Microsoft software development kit (SDK) to collect skeleton data. This enabled them to capture the 3D XYZ coordinates for 32 joints, including the hips, knees, ankles, feet, nose, clavicles, shoulders, elbows, wrists, hands, hand tips, and thumbs.
Figure 2 illustrates the skeleton dataset encompassing normal, antalgic, lurch, steppage, stiff-legged, and Trendelenburg gaits. The skeletal gaits of the walkers were recorded on a 4 m boardwalk. Similar to the foot-pressure dataset, gait datasets were collected for 12 subjects, comprising six different gait types and 20 trials, resulting in a total of 12 × 6 × 20 = 1440 skeleton data samples.
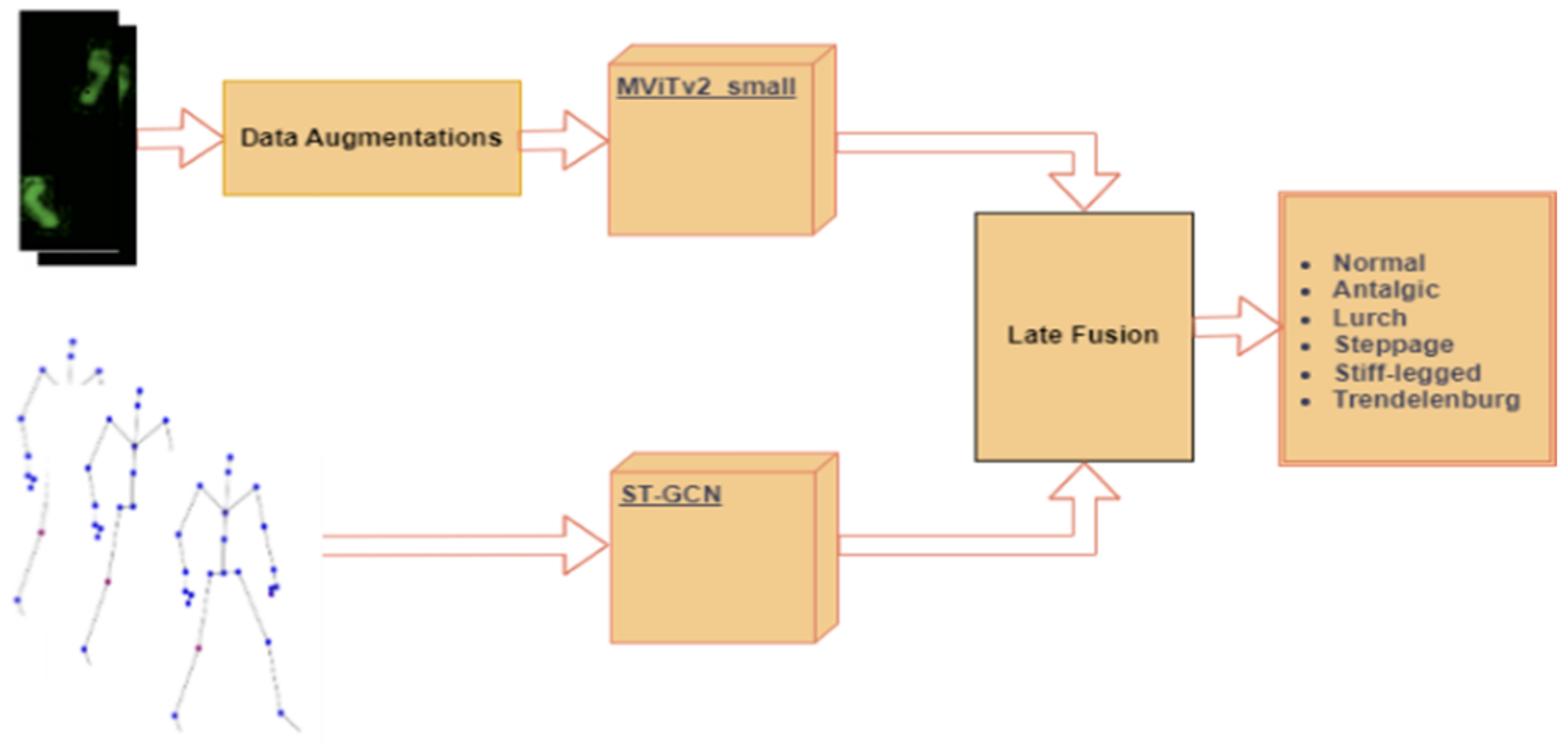
5. Proposed Models
In this section, various aspects of our approach were covered. First, two single-modal models, MViTv2_base, and MViTv2_small, both of which are transformer-based and utilize the foot pressure dataset were introduced. Following that, another single-modal model, ST-GCN, tailored for the skeleton dataset was discussed. Moving into multi-modal methods, the early fusion approach, which concatenates features from both the foot pressure and the skeleton datasets, was explained. Finally, the multi-modal technique was explored using late fusion, both with and without different weights, where the outputs from both modalities are combined.
5.1. Single-Modals (MViTv2_Base and MViTv2_Small) for Foot Pressure Dataset
Recent advancements in image and video classification have been propelled by models based on vision transformers [
38]. This unified architecture caters to image and video classification, along with object recognition, demonstrating remarkable performance in image processing and classification tasks. For our purposes, the pre-trained MViTv2_base and MViTv2_small models from MViTv2, which are already trained on ImageNet [
39], were employed. Both the pre-trained models were fine-tuned according to a new dataset. The model’s evaluation included ImageNet classification and Kinetics video recognition, incorporating decomposed relative positional embeddings and residual pooling connections. MViTv2 stands at the forefront in three key areas: image classification (achieving 88.8% accuracy), COCO object detection (achieving 58.7% accuracy), and video classification (achieving 86.1% accuracy).
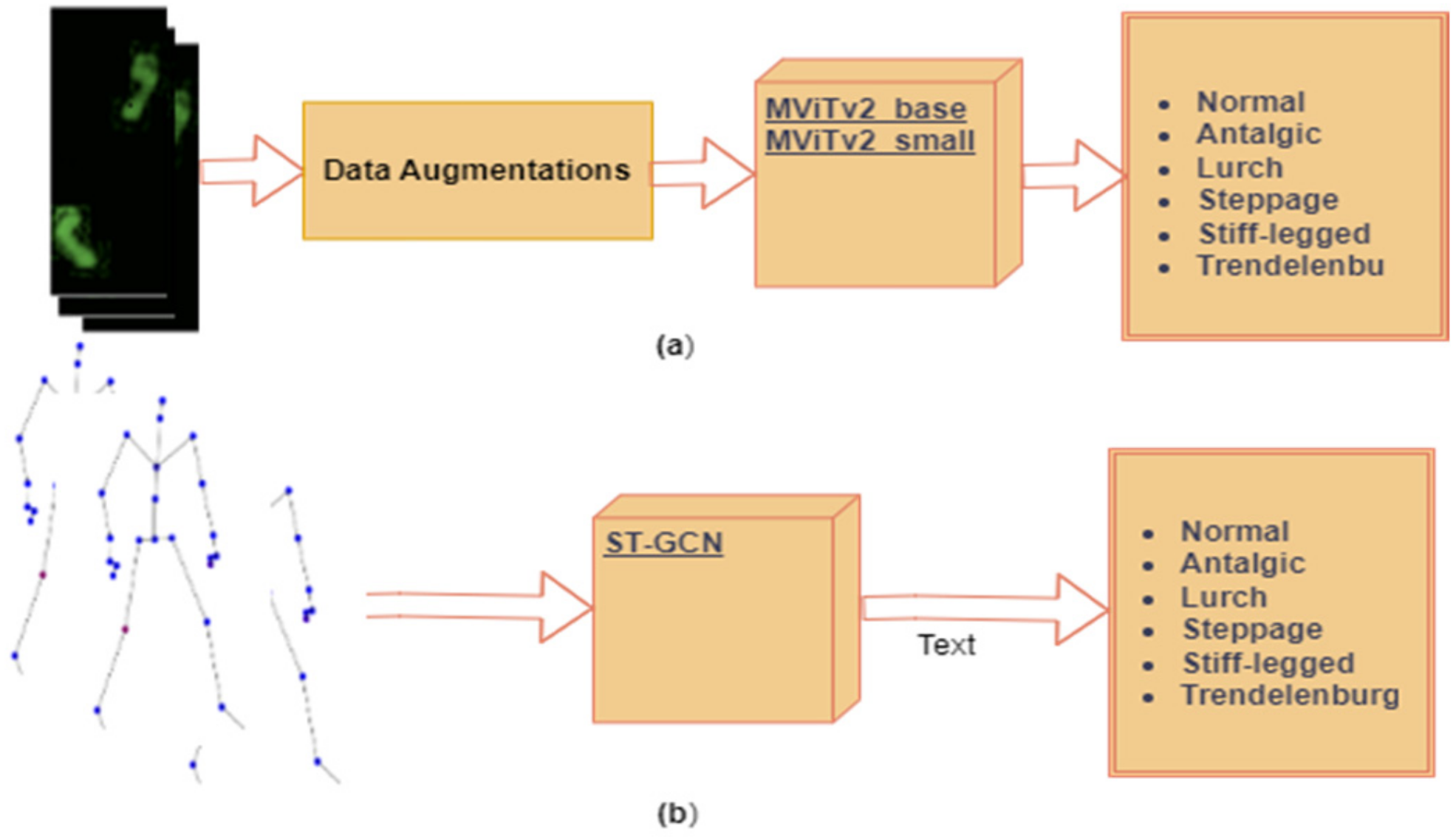
Figure 3a illustrates the block diagram for the single-modal models, MViTv2_base and MViTv2_small, employed with the foot pressure dataset after undergoing data augmentation, as detailed in
Section 5.1.1. These models were employed for the classification of six pathological gaits, including one normal gait and five abnormal ones (antalgic, lurch, steppage, stiff-legged, and Trendelenburg).
5.1.1. Data Augmentations
Insufficient training data can lead to improper training or overfitting problems. Data augmentation, achieved by generating modified data from the original dataset, can effectively augment the dataset’s size to mitigate the issue of data scarcity. The foot pressure dataset utilized in our experiment also possesses a relatively limited amount of data (14 to 40 samples). For each foot pressure image, the following successive transforms were performed:
For MViTv2_base and MViTv2_small, the results both without and with augmentation, specifically flipping and rotating images, were evaluated as detailed in
Table 2. Without any augmentation, an accuracy of 71.74% for MViTv2_base and 70.83% for MViTv2_small were achieved. For flipping, random horizontal flips with a probability of 0.5 were employed, resulting in an accuracy of 72.43% for MViTv2_base and 73.47% for MViTv2_small. Additionally, random rotations were applied at angles of 15, 30, and 45 degrees, respectively. With a probability of 0.5, these rotations were applied, and the highest accuracy was achieved with a 30-degree rotation: 76.46% for MViTv2_base and 78.24% for MViTv2_small. Notably, applying the 30-degree rotation augmentation led to a substantial accuracy increase of 7.41% (from 70.83% to 78.24%) for the MViTv2_small model.
5.2. Single-Modal ST-GCN for Skeleton Data
Skeleton data consists of sequential time series data. Notably, the field of skeleton-based action detection has witnessed a surge in the adoption of graph convolutional networks (GCNs) [
40,
41]. The ST-GCN-based model enhances expressive power and exhibits stronger generalization capabilities. Recently, pathological gait categorization has employed ST-GCN, incorporating attention mechanisms with 3D skeletal data [
42]. This innovative technique introduces an attention mechanism for spatiotemporal GCNs, enabling a focus on crucial joints within the current gait. There are two types of edges, namely the spatial edges that conform to the natural connectivity of joints and the temporal edges that connect the same joints across consecutive time steps. Multiple layers of ST-GCN are constructed thereon, which allow information to be integrated along both the graph and the temporal dimension. This is achieved after initially extracting spatiotemporal features from 3D skeletal data through joint linkages and subsequently applying these features to GCNs. The ST-GCN attention mechanism facilitates the concentration on significant joints during pathological gait classification based on skeleton data (refer to
Figure 3b for the block diagram illustrating a single-modal ST-GCN). Here, our previously proposed ST-GCN model from [
43] was utilized, which uses an attention technique applied to pathological gait classification from the skeleton information. Our focus was twofold. The first objective was to extract spatiotemporal features from skeletal information presented by joint connections and to apply these features to graph convolutional neural networks. The second objective was to develop an attention mechanism for spatiotemporal graph convolutional neural networks to focus on important joints in the current gait. This model establishes a pathological gait classification system for diagnosing sarcopenia.
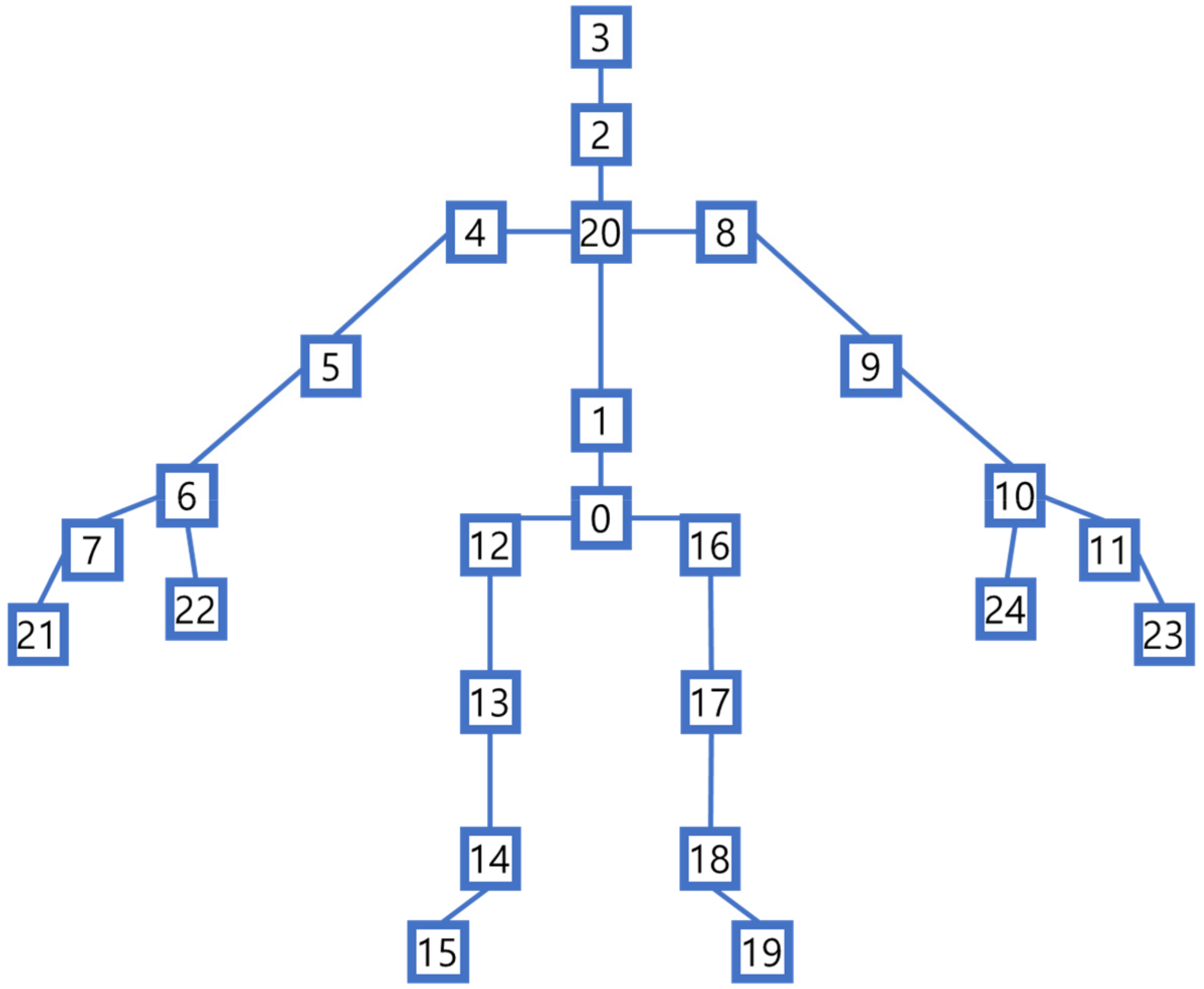
As detailed in
Section 4.3, Azure Kinect was employed to capture the 3D skeleton dataset, which encompasses 32 joints representing the human skeleton [
44]. However, in this study, joints were selectively utilized as input data for the ST-GCN model. Specifically, joints such as the nose, left eye, right eye, left clavicle, and right clavicle were excluded. Instead, only 25 joints (as shown in
Figure 4) sourced from Azure Kinect, which align with the same 25 joints found in Kinect v2, were used.
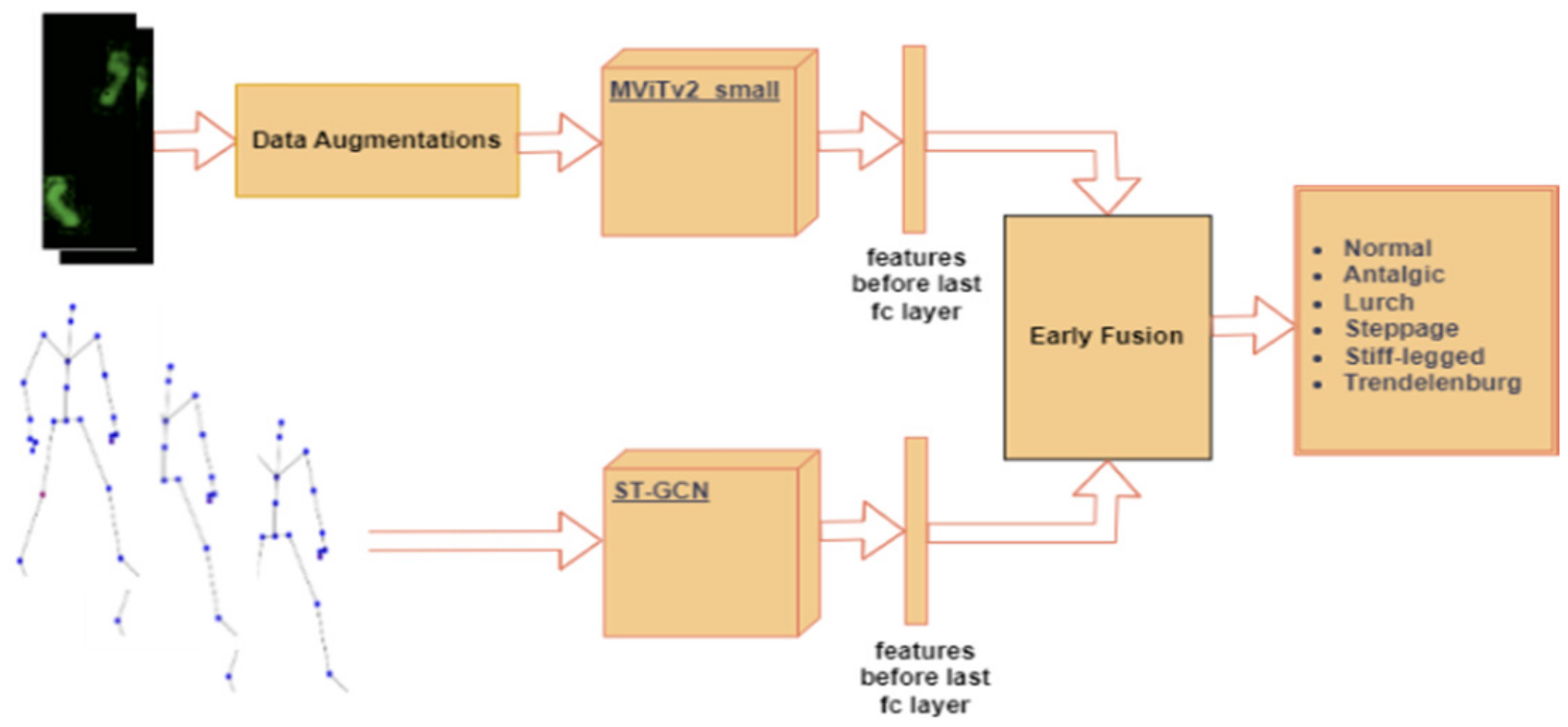
5.3. Multi-Modal Using Early Fusion
In this section, the multi-modal approach, employing early fusion by concatenating features from the foot pressure and 3D skeleton data, was introduced as illustrated in
Figure 5. These features were extracted from the second-to-last fully connected (fc) layers of both MViTv2_small and ST-GCN. For the foot pressure data, MViTv2_small was used due to its superior performance. Feature extraction plays a pivotal role in uncovering valuable information, which is subsequently harnessed for image classification tasks. To illustrate this, feature extraction allows us to identify facial features such as the eyes, nose, and mouth when presented with an image of a human face. Through concatenation, the performance of these combined models was fused, thereby enhancing the accuracy of individual models.
5.4. Multi-Modal Using Late Fusion with and without Different Weights
In this section, the multi-modal approach employing late fusion, which involves the combination of both the skeleton and foot pressure datasets, was introduced by utilizing various weight configurations. Data fusion techniques have been extensively explored across diverse domains, including medical applications, as multimodal data fusion holds the potential to enhance the performance of ML models [
45,
46]. Once again, the MViTv2_small model for the foot pressure dataset was used due to its superior performance.
Similarly, for ST-GCN, our previously proposed model was employed as detailed in [
43].
Figure 6 illustrates the block diagram of the late fused method, both without and with varying weights, showcasing the combination of outputs from the two single-modal models, MViTv2_small and ST-GCN, utilizing diverse weighting schemes. These weight selections were made in accordance with the accuracy levels achieved by the already-trained single-modal models, wherein higher accuracy corresponded to greater weights and vice versa. During the evaluation process, different late fusion techniques, including maximum, average, and multiplication, were employed both with and without varying weights.
6. Results and Discussions
In this section, a comprehensive evaluation and discussion of our approach are presented. First, the performance of our single-modal models, namely MViTv2_base and MViTv2_small, is assessed and discussed using the foot pressure dataset. Second, the ST-GCN architecture, focusing on the skeleton dataset, is evaluated and discussed. Third, the outcomes of our proposed multi-modal approach are scrutinized and discussed, employing early fusion. Lastly, the results of our proposed multi-modal technique, which employed late fusion, considering various weight configurations, are examined and discussed.
To assess the performance of our proposed single-modal and multi-modal classification models, a leave-one-subject-out cross-validation approach was employed. This entailed using data from one subject as the validation set, whereas the remaining data served as the training set. Consequently, the training procedure was performed 12 times, and the resultant average validation accuracy was calculated. The training process for both the foot-pressure and ST-GCN models was conducted independently for 200 epochs. For the foot-pressure model, the AdamW (Adam with Weight decay) optimizer was employed, whereas the ST-GCN model was optimized using the Adam optimizer. Additionally, in the case of the transformer-based model, the learning rate was set to 0.00006 with a weight decay of 0.01, and the batch size was set to eight. For ST-GCN, the learning rate was set at 0.1, with a weight decay of 0.0001, and a batch size of 16. The cross-entropy loss function was used.
The system specifications utilized for the evaluation in our study consist of an Intel (Santa Clara, CA, USA) CPU with 32 GB of RAM and an NVIDIA (Santa Clara, CA, USA) GeForce RTX 3060 GPU. The implementation of the models in this study was executed using PyTorch 2.1. For the 118 frames of the skeleton dataset, the system takes 11.31 s to evaluate, which processes ten frames per second, so it is applicable in the real world.
6.1. Performance of Single-Modals (MViTv2_Base and MViTv2_Small) for Foot Pressure Dataset
In this context, the foot pressure dataset to train both the MViTv2_base and MViTv2_small models was utilized. Validation accuracies for each individual subject were computed and subsequently calculated the average validation accuracy across all subjects.
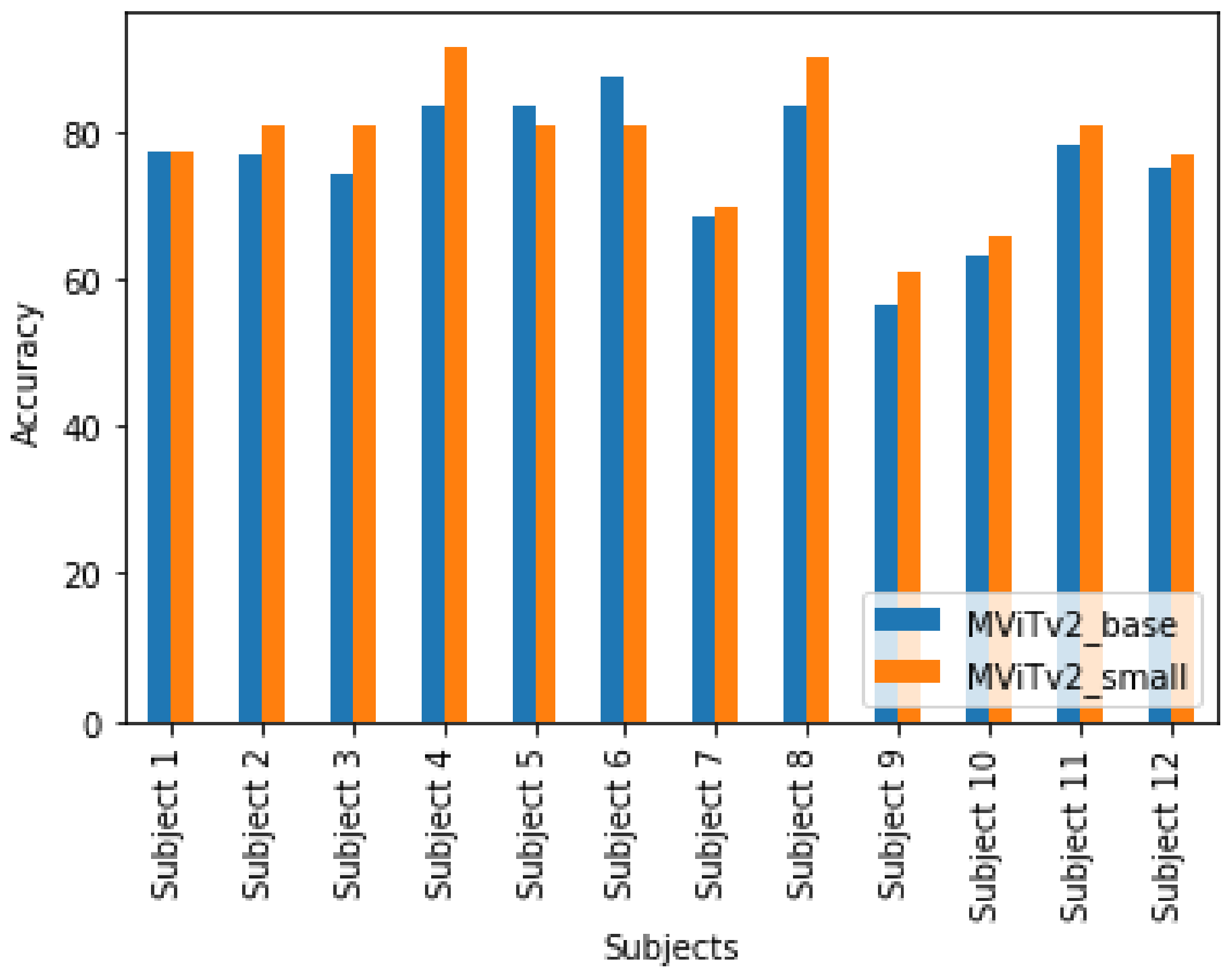
Figure 7 displays subject-specific validation accuracies when training the foot pressure data with MViTv2_base and MViTv2_small, employing a 30° rotation augmentation. For subject 1, both models achieved an accuracy of 77.50%, whereas for subject 2, MViTv2_base reached 76.67%, while MViTv2 achieved a higher accuracy of 80.83%. Notably, subjects 3, 4, 7, 8, 9, 10, and 11 exhibited improved accuracy when using MViTv2_small.
On average, the validation accuracy for MViTv2_base was 76.46%, whereas MViTv2_small achieved a higher average validation accuracy of 78.24%. In summary, our proposed single-modal models outperformed the baseline single-modal models, with one of our proposed single-modal models demonstrating superior performance over the other.
6.2. Performance of Single-Modal ST-GCN for Skeleton Dataset
Here, the model was trained using ST-GCN and subsequently evaluated the validation accuracies for each subject before averaging them. Experiments were conducted involving different numbers of frames for all subjects and then averaged the validation accuracies. Initially, only the last 50 alternate frames were utilized to test our ST-GCN model, and, subsequently, the middle 100 frames were selected to assess its performance. Next, the model’s effectiveness was evaluated using the last 100 frames. Furthermore, the model’s performance was examined with the minimum number of common frames (118). In the final step, our model was tested by employing all available frames (509).
Table 3 shows the subject-wise validation accuracies using various frame combinations for the single-modal ST-GCN model. When the last 50 frames were used, all the subjects except subjects 6 and 7 achieved an accuracy of 100%, and the average validation accuracy was 97.85%. When the middle 100 frames were used, the accuracy for all the subjects dropped a little except for subject 9, and the average validation accuracy was 93.76%. When the last 100 frames were used, the accuracy for all the subjects was 100% except for subjects 6 and 9. The average validation accuracy was 98.90%. There was an increase in accuracy from the middle 100 frames to the last 100 frames. Similarly, when the minimum number of common frames was considered, an accuracy of 100% for all the subjects except subjects 6 and 9 was achieved. The average validation accuracy was 99.04%. Again, there was an increase in accuracy for subjects 6 and 9 when the last 100 frames were chosen from a minimum number of common frames. Finally, there was a decrease in accuracy for subjects 6 and 9 when all the frames were chosen. The accuracy for all other subjects was 100%. Here, the average validation accuracy was 98.68%.
As utilizing the minimum number of common frames resulted in the highest average validation accuracy of 99.04% compared to other combinations, the minimum frame count of 118 was employed for ST-GCN in both the early fusion and late fusion (without and with different weights) methods.
6.3. Performance of Multi-Modal Using Early Fusion
In this subsection, the features from both modalities were combined to determine the ultimate classification accuracy for all subjects.
Table 4 illustrates the subject-wise validation accuracies for the multi-modal approach utilizing early fusion. Remarkably, 100% accuracy for all subjects except for subjects 6 and 9 was achieved. The overall average classification accuracy across all subjects was an impressive 99.86%. Our proposed multi-modal technique using early fusion outperformed the baseline for the multi-modal approach.
6.4. Performance of Multi-Modal Using Late Fusion without and with Different Weights
As discussed in [
40], various strategies have been proposed and modified for sensor fusion. Here, the previously trained single-modals, ST-GCN and MViTv2_small, which correspond to the foot pressure and skeleton data, respectively, were combined to evaluate the classification performance of our proposed multi-modal late fusion method, both with and without applying different weights. The results were computed using the following procedures:
A single vector of the same size by selecting the maximum values from the two input vectors (element-wise) was created.
Two input vectors of the same size (element-wise) were averaged.
Two input vectors of the same size (element-wise) were multiplied.
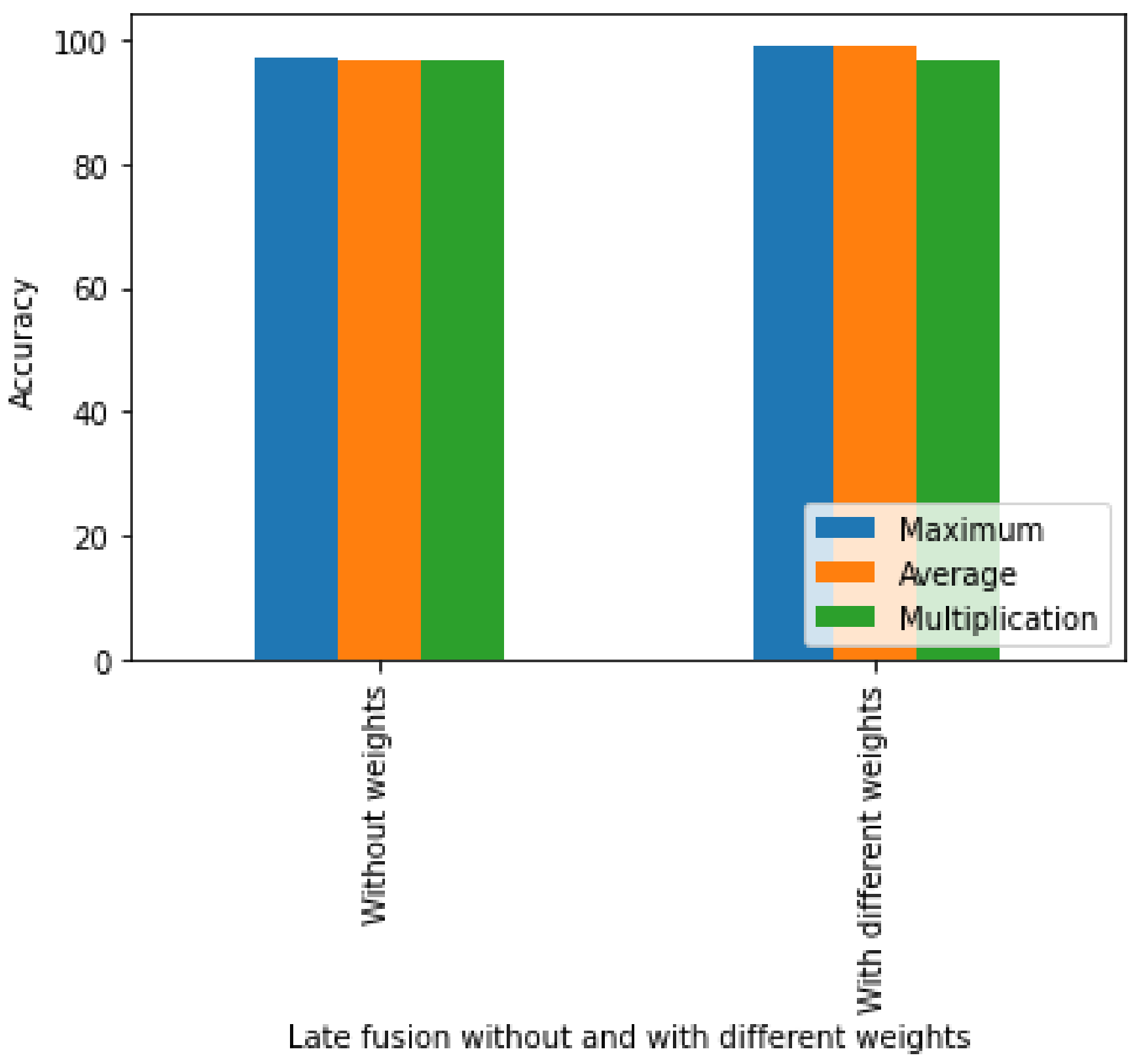
The validation accuracies for our multi-modal method using late fusion with and without different weights, and using the three methods described above, are presented in
Table 5 and
Figure 8. The accuracy using the maximum without weights is 96.95%, whereas the average accuracy with weights is 96.81%. When the outputs of two models were multiplied without weights, the accuracy was 96.67%. In the late fusion method with weight, the outputs with different weights were combined. A weight of 0.9 was assigned to the skeleton dataset due to its high accuracy and 0.1 to the foot pressure dataset due to its low accuracy. In the case of the maximum, an accuracy of 99.10% was achieved, whereas in the case of averaging, a 99.17% accuracy with different weights was achieved. Similarly, for multiplication, an accuracy of 96.67% was achieved. Our proposed multi-modal using late average fusion with different weights shows the highest performance among multi-modal late fusion methods.
A comparison of the suggested models with the baseline is presented in
Table 6. Jun et al. [
16] introduced single-modals using foot pressure and skeleton datasets, achieving accuracies of 68.82% and 93.40%, respectively. In contrast, our proposed single-modals achieved higher accuracies, reaching 78.2% for the foot pressure dataset and an impressive 99.04% for the skeleton dataset. In the realm of multi-modal approaches, Jun et al. reported an accuracy of 97.60%, whereas our proposed multi-modal utilizing early fusion attained an accuracy of 99.86%. Likewise, our proposed multi-modal using late fusion, both with and without different weights, demonstrated superior performance, achieving accuracies of 96.95% and 99.17%, respectively.
Table 6 demonstrates that our multi-modal approach using early fusion outperforms the late fusion method. These results unequivocally establish that our proposed single-modals surpass those in [
16], and our multi-modals using early fusion methods show state-of-the-art results in the pathological gait classification for the GIST dataset. The proposed approach can be applied in real-world scenarios with a simple camera setup. As individuals walk through, the system captures data and classifies specific gait patterns based on their types.
7. Conclusions and Future Directions
In this study, transformer-based single-modals were introduced as the first step to categorize one normal and five abnormal gaits (antalgic, lurch, steppage, stiff-legged, and Trendelenburg), following the application of 30-degree rotation augmentations to foot pressure data. Subsequently, another single-modal approach utilizing the skeleton dataset was presented, referred to as ST-GCN. Next, a multi-modal method employing early fusion was proposed, achieved by concatenating the features from both modalities. In the final step, a multi-modal approach employing late fusion, with and without different weights, was introduced to amalgamate the outputs from both modalities. Our early fusion multi-modal approach exhibited superior performance in comparison to late fusion. Our proposed models underwent a thorough comparison with the baseline, and the results undeniably demonstrate that our work surpassed both single-modal and multi-modal approaches. The findings of this study hold the potential to enhance existing gait analysis programs through the implementation of multimodality, which captures the most important information from all the modalities, thereby offering doctors and physicians more precise results in gait categorization.
In the future, for further study, collaboration with orthopedic, otolaryngology, and rehabilitation medical facilities to collect our datasets will be useful. By utilizing actual patient datasets, the suitability of the proposed hybrid model for real-world applications will be validated.
There are several other potential applications of gait classification. First, it can be used in gait monitoring for abnormal gait detection, the recognition of human activities, fall detection, and sports performance. Second, it can be used as gait-based biometrics with applications in person identification, authentication, and re-identification, as well as gender and race recognition. Third, it can be used as a smart gait device and in environments ranging from smart socks, shoes, and other wearables to smart homes and smart retail stores that incorporate continuous monitoring and control systems.
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}