1. Introduction
Despite recent rapid advances, fine-grained visual recognition (FGVR) is still one of the nontrivial tasks in the computer vision community. Unlike conventional recognition tasks, FGVR aims to predict subordinate categories of a given object, e.g., subcategories of birds [
1], flowers [
2,
3], and cars [
4,
5]. It is a highly challenging task due to inherently subtle inter-class differences caused by similar subordinate categories and large intraclass variations caused by object pose, scale, or deformation.
The most common solution for FGVR is to decompose the target object into multiple local parts [
6,
7,
8,
9,
10]. Due to subtle differences between fine-grained categories mostly residing in the unique properties of object parts [
11], decomposed local parts provide more discriminative clues of the target object. For example, a given bird object can be decomposed into its beak, wing, and head parts. At this time, ‘Glaucous Winged Gull’ and ‘California Gull’ can be distinguished by comparing their corresponding object parts. Early approaches of these part-based methods find discriminative local parts using manual part annotations [
6,
7,
11]. However, curating manual annotations for all possible object parts is labor-intensive and carries the risk of human error [
12]. Therefore, the research focus has consequently shifted to a weakly supervised manner [
8,
9,
10,
13,
14,
15]. Researchers use additional tricks such as attention mechanisms [
9,
14,
16] or region proposal networks (RPNs) [
13,
15,
17] to estimate local parts with only category-level labels. However, the part proposal process greatly increases the overall computational cost. Additionally, they tend not to deeply consider the interactions between estimated local parts that are essential for accurate recognition [
18].
Recently, Vision Transformers (ViTs) [
19] are being actively applied to FGVR [
18,
20,
21,
22,
23,
24,
25,
26,
27]. Relying exclusively on the Transformer [
28] architecture, ViTs have shown competitive image classification performance on a large scale. Similar to token sequences in NLP, ViTs embed the input images into fixed-size image patches, and the patches pass through multiple Transformer encoder blocks. Patch-by-patch processing is highly suitable for FGVR because each image patch can be considered as a local part. This means that the cumbersome part proposal is no longer necessary. Additionally, the self-attention mechanism [
28] inherent in each encoder block facilitates the modeling of global interactions between patch-divided local parts. ViT-based FGVR methods use patch selection to further boost performance [
18,
20,
21,
22]. Because ViTs deal with all patch-divided image regions equally, many irrelevant patches may lead to inaccurate recognition. Similar to part proposals, patch selection selects the most salient patches from a set of generated image patches based on the computed importance ranking, i.e., accumulated attention weights [
21,
29]. As a result, redundant patch information is filtered out, and only selected salient patches are considered for the final decision.
However, the existing ViT-based FGVR methods suffer from their single-scale limitations. ViTs use fixed-size image patches throughout the entire network, ensuring that the receptive fields remain the same across all layers and preventing ViTs from obtaining multiscale feature representations [
30,
31,
32]. On the other hand, Convolutional Neural Networks (CNNs) are suitable for multiscale feature representations thanks to their staged architecture, where feature resolution decreases as layer depth increases [
33,
34,
35,
36,
37]. In the early stages, spatial details of an object are encoded on high-resolution feature maps, and as the stages deepen, the receptive field expands with decreasing feature resolution, and higher-order semantic patterns are encoded into low-resolution feature maps. Multiscale features are important for most vision tasks, especially pixel-level dense prediction tasks, e.g., object detection [
38,
39,
40], and segmentation [
41,
42,
43]. In the same context, single-scale processing can cause two failure cases in FGVR, which leads to suboptimal recognition performance. (i) First, it is vulnerable to scale changes in fine-grained objects [
32,
35,
38]. Fixed patch size may be insufficient to capture very subtle features of small-scale objects due to too coarse patches, and conversely, discriminative features may be over-decomposed for large-scale objects due to too finely split patches. (ii) Second, single-scale processing limits representational richness for objects [
30,
39]. Compared with a CNN that explores rich feature hierarchies from multiscale features, ViT considers only monotonic single-scale features due to its fixed receptive field.
In this paper, we improve existing ViT-based FGVR methods by enhancing multiscale capabilities. One simple solution is to use the recent MultiScale Vision Transformers (MS-ViTs) [
30,
31,
32,
44,
45,
46,
47,
48,
49]. In fact, we can achieve satisfactory results simply by using MS-ViTs. However, we further boost the performance by adapting patch selection to MS-ViTs. Specifically, we propose a MultiScale Patch Selection (MSPS) that extends the previous Single-Scale Patch Selection (SSPS) [
18,
20,
21,
22] to multiscale. MSPS selects salient patches of different scales from different stages of the MS-ViT backbone. As shown in
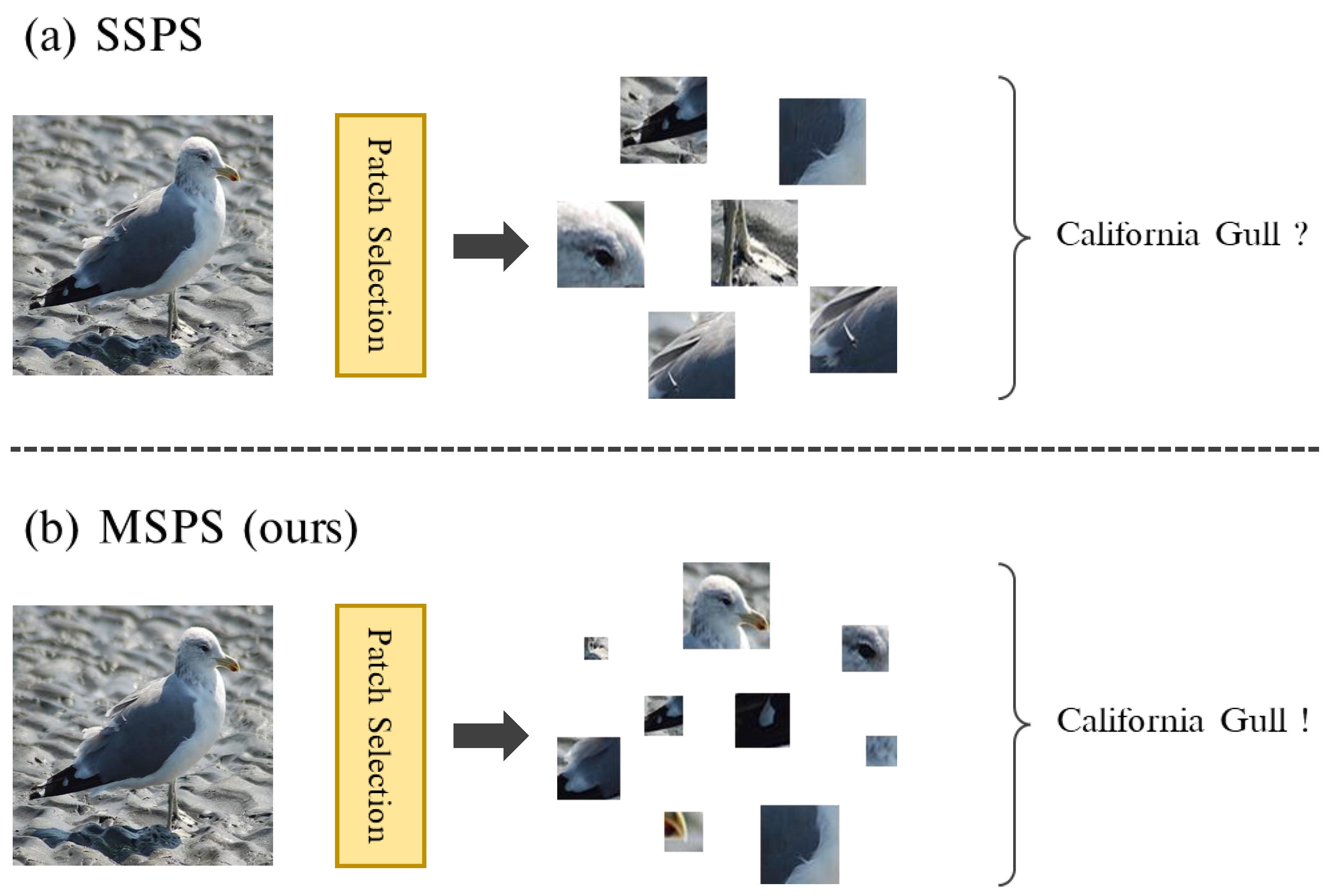
Figure 1, multiscale salient patches selected through MSPS include both large-scale patches that capture object semantics and small-scale patches that capture fine-grained details. Compared with single-scale patches in SSPS, feature hierarchies in multiscale patches provide richer representations of objects, which leads to better recognition performance. In addition, the flexibility of multiscale patches is useful for handling extremely large/small objects through multiple receptive fields.
However, we argue that patch selection alone cannot fully explain the object, and consideration is required for how to model interactions between selected patches and effectively reflect them in the final decision. It is more complicated than considering only single-scale patches. Therefore, we introduce Class Token Transfer (CTT) and MultiScale Cross-Attention (MSCA) to effectively deal with selected multiscale patches. First, CTT aggregates the multiscale patch information by transferring the global CLS token to each stage. Each stage-specific patch information is shared through transferred global CLS tokens, which generate richer network-level representations. In addition, we propose MSCA to model direct interactions between selected multiscale patches. In the MSCA block, cross-scale interactions in both spatial and channel dimensions are computed for selected patches of all stages. Finally, our MultiScale Vision Transformer with MultiScale Patch Selection (M2Former) obtains improved FGVR performance over other ViT-based SSPS models, as well as CNN-based models.
Our main contributions can be summarized as follows:
We propose MultiScale Patch Selection (MSPS) that further boosts the multiscale capabilities of MS-ViTs. Compared with Single-Scale Patch Selection (SSPS), MSPS generates richer representations of fine-grained objects with feature hierarchies, and obtains flexibility for scale changes with multiple receptive fields.
We propose Class Token Transfer (CTT) that effectively shares the selected multiscale patch information. Stage-specific patch information is shared through transferred global CLS tokens to generate enhanced network-level representations.
We design a MultiScale Cross-Attention (MSCA) block to capture the direct interactions of selected multiscale patches. In the MSCA block, the spatial-/channel-wise cross-scale interdependencies can be captured.
Extensive experimental results on widely used FGVR benchmarks show the superiority of our M2Former over conventional methods. In short, our M2Former achieves an accuracy of 92.4% on Caltech-UCSD Birds (CUB) [
1] and 91.1% on NABirds [
50].
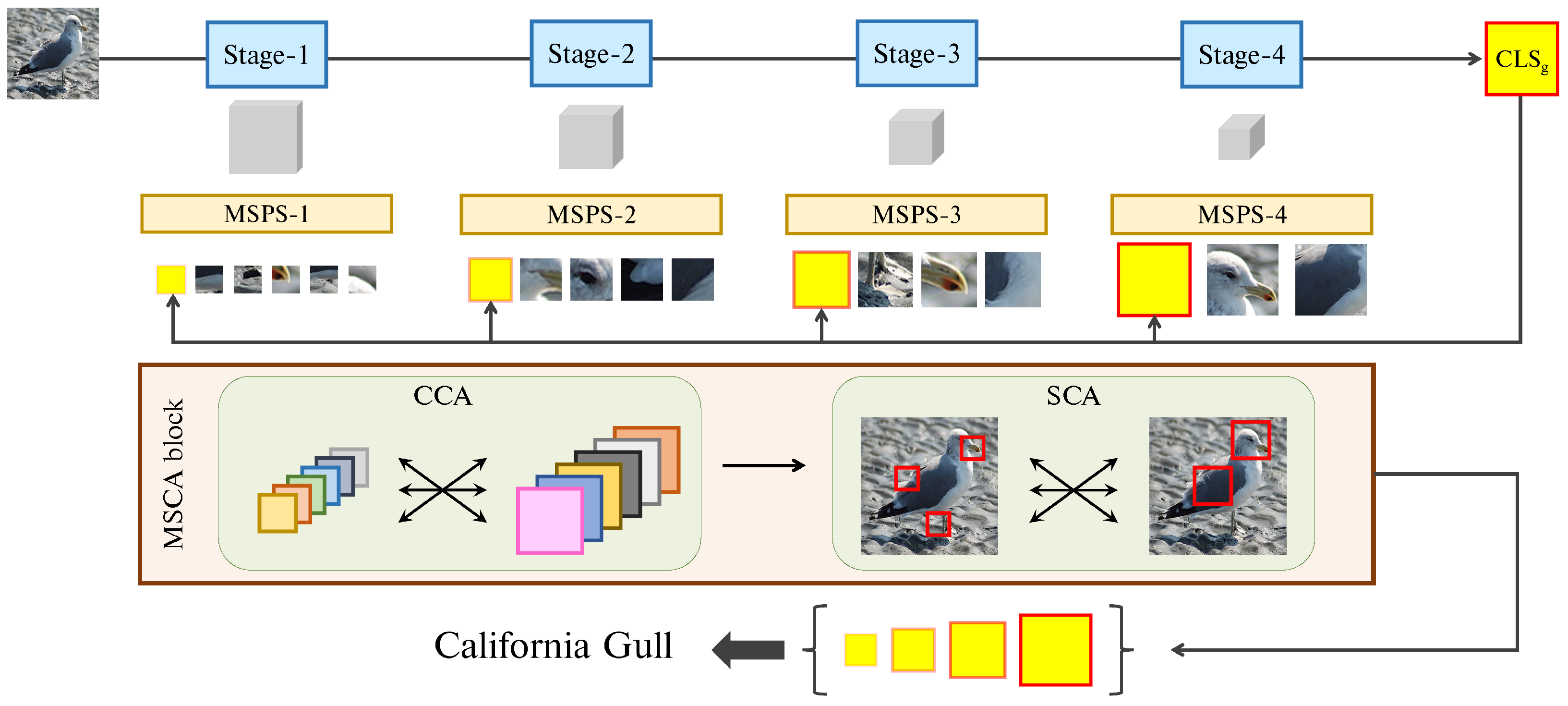
3. Our Method
The overall framework of our method is presented in
Figure 2. First, we use MultiScale Vision Transformers (MS-ViTs) as our backbone network (
Section 3.1). After that, MultiScale Patch Selection (MSPS) is equipped on different stages of MS-ViT to extract multiscale salient patches (
Section 3.2). Class Token Transfer (CTT) aggregates multiscale patch information by transferring the global
CLS token to each stage. MultiScale Cross-Attention (MSCA) blocks are used to model spatial-/channel-wise interactions of selected multiscale patches (
Section 3.4). Finally, we use additional training strategies for better optimization (
Section 3.5). More details are described as follows.
3.1. Multiscale Vision Transformer
To enhance the multiscale capability, we use MS-ViT as our backbone network, specifically the recent Multiscale Vision Transformer (MViT) [
30,
45]. MViT constructs a four-stage pyramid structure for low-level to high-level visual modeling instead of single-scale processing. To produce a hierarchical representation, MViT introduces Pooling Attention (PA), which pools query tensors to control the downsampling factor. We refer the interested reader to the original work [
30,
45] for details.
Let denote the input image, where , , and refer to the height, width, and the number of channels, respectively. first goes through a patch embedding layer to produce initial feature maps with a patch size of . As the stage deepens, the resolution of the feature maps decreases and the channel dimension increases proportionally. As a result, at each stage , we can extract the feature maps with resolutions and channel dimensions . We can also flatten into 1D patch sequence as , where . In fact, after patch embedding, we attach a trainable class token (CLS token) to the patch sequence, and all patches are fed into consecutive encoder blocks, where . After the last block, the CLS token is detached from the patch sequence and used for class prediction through a linear classifier.
3.2. Multiscale Patch Selection
Single-Scale Patch Selection (SSPS) has limited representations due to its fixed receptive field. Therefore, we propose MultiScale Patch Selection (MSPS) that extends SSPS to multiscale. With multiple receptive fields, the proposed MSPS encourages rich representations of objects from deep semantic information to fine-grained details. We design MSPS based on the MViT backbone. Specifically, we select salient patches from the intermediate feature maps produced at each stage of MViT.
Given the patch sequence , we start by detaching the CLS token and reshaping it into 2D feature maps to . And then we group neighboring patches, reshaping into . This means neighboring patch groups are generated. Afterwards, we apply a per-group average to merge patch groups, producing , where . We set to merge patches within a local region. This merging process removes the redundancies of neighboring patches, which forces MSPS to search for salient patches in wider areas of the image.
Now, we produce a score map
using a predefined scoring function
. Then, patches with top-
k scores are selected from
,
where
. We set
k differently for each stage to consider hierarchical representations. Since the high-resolution feature maps of the lower stage capture the detailed shape of the object with a small receptive field, we set
k to be large so that enough patches are selected to sufficiently represent the details of the object. On the other hand, low-resolution feature maps of the higher stage capture the semantic information of objects with a large receptive field, so small
k is sufficient to represent the overall semantics.
For patch selection, we decided how to define the scoring function
. Attention roll-out [
29] has been mainly used as a scoring function for SSPS [
18,
20]. Attention roll-out aggregates the attention weights of the Transformer blocks through successive matrix multiplications, and the patch selection module selects the most salient patches based on the aggregated attention weights. However, since we use MS-ViT as the backbone, we cannot use attention roll-out because the size of attention weights is different for each stage, even each block. Instead, we propose a simple scoring function based on mean activation, where the score for the
j-th patch of
is calculated by
where
c is the channel index
. Mean activation measures how strongly the channels in each patch are activated on average. After computing the score map, our MSPS conducts patch selection based on it. This is implemented through top-
k and gather operations. We extract
patch indices with the highest scores from the
through the top-
k operation, and patches corresponding to the patch indices
are selected from
,
where
, and
.
3.3. Class Token Transfer
Through MSPS, we can extract salient patches from each stage,
. In
Section 3.2, the
CLS token is detached from the patch sequence before MSPS at each stage. The simplest way to reflect the selected multiscale patches in the model decisions is to concatenate the detached
CLS token
with the
again and feed it into a few additional ViT blocks, consisting of multihead self-attention (MSA) and feed-forward networks (FFN):
where
,
, and
. Finally, predictions for each stage are computed by extracting the
from
and connecting the linear classifier. It should be noted that the
is shared by all stages: the set of
is derived from the global
CLS token and it is detached with different dimensions at each stage. This means that the stage-specific multiscale information is shared through
. However, the current sharing method may cause inconsistency between stage features because the detached
does not equally utilize the representational power of the network. For example,
is detached right after stage-1 and it will always lag behind
, which utilizes representations of all stages.
To this end, we introduce a Class Token Transfer (CTT) strategy that aggregates multiscale information more effectively. The core idea is to use the
CLS token transferred from the global
CLS token
rather than using the detached
at each stage. It should be noted that
is equal to
, so
. We transfer the
according to the dimension of each stage through a projection layer consisting of two linear layers along with Batch Normalization (BN) and ReLU activation:
where
,
are the weight matrices, and
is the transferred
in stage
. Now, (
4) is reformulated as
Compared with conventional approaches, CTT guarantees consistency between stage features as it uses
CLS tokens with the same representational power. Each stage encodes stage-specific patch information into a globally updated
CLS token. CTT is similar to the top-down pathway [
35,
39]: it combines high-level representations of objects with multiscale representations of lower layers to generate richer network-level representations.
3.4. Multiscale Cross-Attention
Although CTT can aggregate multiscale patch information from all stages, it cannot model direct interactions between multiscale patches, which indicates how interrelated they are. Therefore, we propose MultiScale Cross-Attention (MSCA) to model the interactions between multiscale patches.
MSCA takes
as input and models the interactions between selected multiscale salient patches. Specifically, MSCA consists of Channel Cross-Attention (CCA) and Spatial Cross-Attention (SCA), so (
6) is reformulated as
where
.
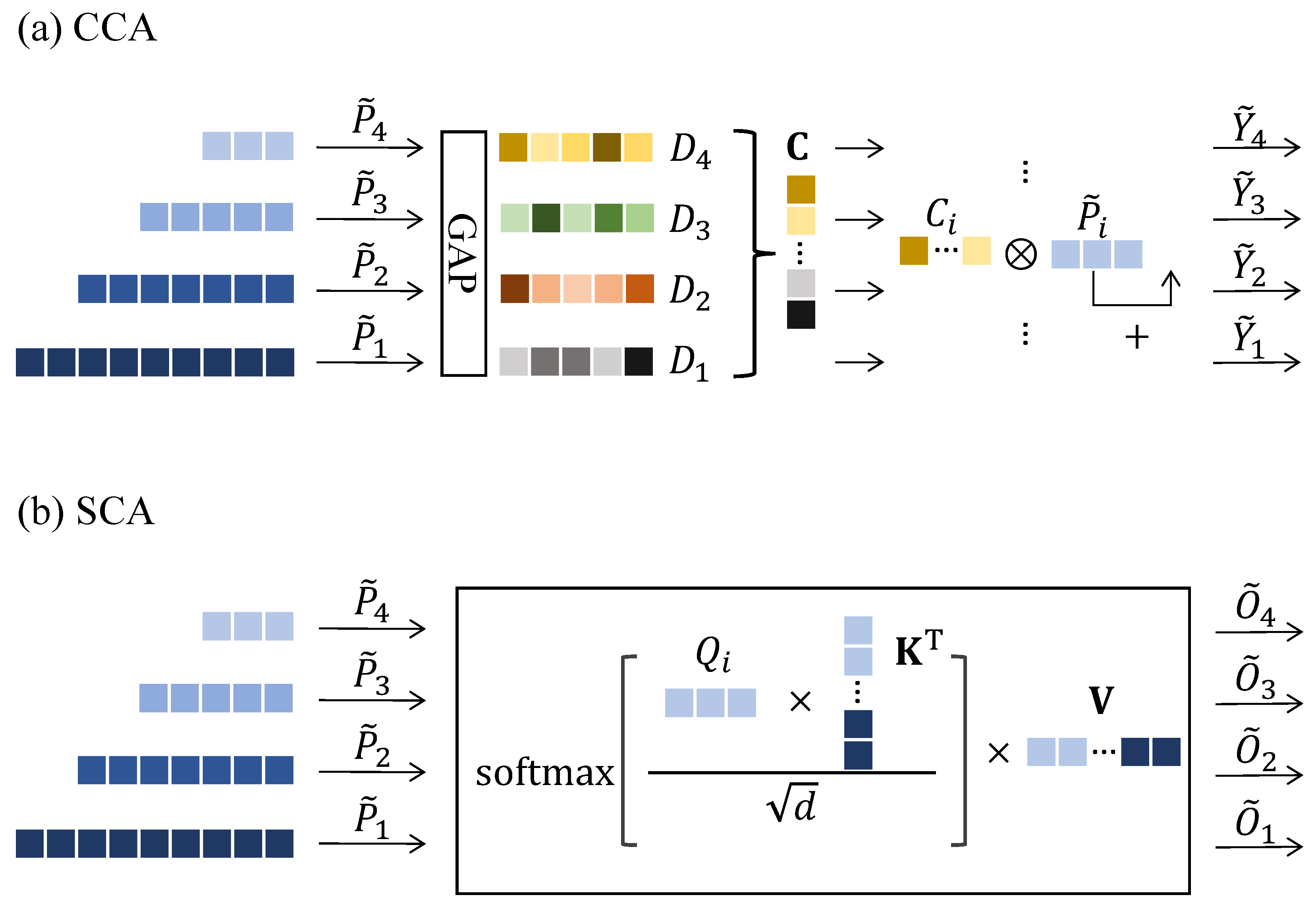
3.4.1. Channel Cross-Attention
Exploring feature channels has been very important in many vision tasks because feature channels encode visual patterns that are strongly related to foreground objects [
10,
53,
59,
70,
71]. Many studies have been proposed to enhance the representational power of a network by explicitly modeling the interdependencies between the feature channels [
72,
73,
74,
75,
76]. In the same vein, we propose CCA to further enhance the representational richness of multiscale patches by explicitly modeling their cross-scale channel interactions.
We illustrate CCA in
Figure 3a. First, we apply global average pooling (GAP) to
to obtain a global channel descriptor
for each stage. The
c-th element of
is calculated by
where
j is the patch index
. From the stage-specific channel descriptors, we compute the channel attention score as follows:
where
,
, and
. We then split
back into
and recalibrate the channels of
as follows:
where ⊗ indicates element-wise multiplication. In (
9), we compute the channel attention score by aggregating the channel descriptors of all multiscale patches. It captures channel dependencies in a cross-scale way and reflects them back to each stage-specific piece of channel information.
3.4.2. Spatial Cross-Attention
In addition to channel-wise interactions, we can compute the spatial-wise interdependencies of selected multiscale patches. To this end, we propose SCA, which is a multiscale extension of MSA [
19,
28].
We illustrate SCA in
Figure 3b. First, we compute query, key, and value tensors
,
,
for every
,
where
,
,
, and
,
,
. After that, we concatenate the
and
of all stages to generate global key and value tensors
,
,
where
. Now, we can compute self-attention for
,
,
, and a single linear layer is used to restore the dimension,
where
,
, and
. SCA is also implemented in a multihead manner [
28]. For global key and value, SCA captures how strongly multiscale patches interact spatially with each other. Specifically, SCA models how large-scale semantic patches decompose into more fine-grained views, and conversely, how small-scale fine-grained patches can be identified in more global views.
3.5. Training
After the MSCA block, we can extract
from
and compute the class prediction
using a linear classifier. In addition, we can compute
by concatenating all
tokens. For model training, we compare every
for the ground-truth label
,
where
n is the total number of classes, and
t denotes the element index of the label. To improve model generalization and encourage diversity of representations from specific stages, we employ soft supervision using label smoothing [
8,
77]. We modify the one-hot vector
as follows:
where
denotes index of the ground truth class, and
denotes a smoothing factor
.
controls the magnitude of the ground truth class. As a result, the different predictions are supervised with different labels during training. We set
to increase in equal intervals by
from
to 1, so
has the smallest
.
For inference, we conduct a final prediction considering all of
,
where the maximum entry in
corresponds to the class prediction.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}