
Iteratively Refined Multi-Channel Speech Separation


Abstract
1. Introduction
- The structure of the original neural beamforming is revised. Specifically, two main changes are made. First, the number of the time-frequency domain path scanning blocks in the neural network is reduced to three from the original six. This simplification improves the training efficiency and inference speed of the model, while reducing the complexity and resource consumption of the model. Second, an iteratively refined separation method is proposed, which combines the initially separated speech with the original mixed signal as an auxiliary input for the iterative network. By repeating this process in N iteration stages, the MVDR beamformer and post-separation network are mutually promoted. As a result, the separation results are effectively improved;
- The proposed method not only evaluates each stage of the multi-stage iterative processes, but also uses more evaluation metrics to obtain a more comprehensive evaluation. The experimental results show that the proposed method worked well on the spatialized version of the WSJ0-2mix data corpus and greatly outperformed the current popular methods. In addition, it is noted that our proposed method also performed well in the dereverberation task.
2. Proposed Method
2.1. Signal Model
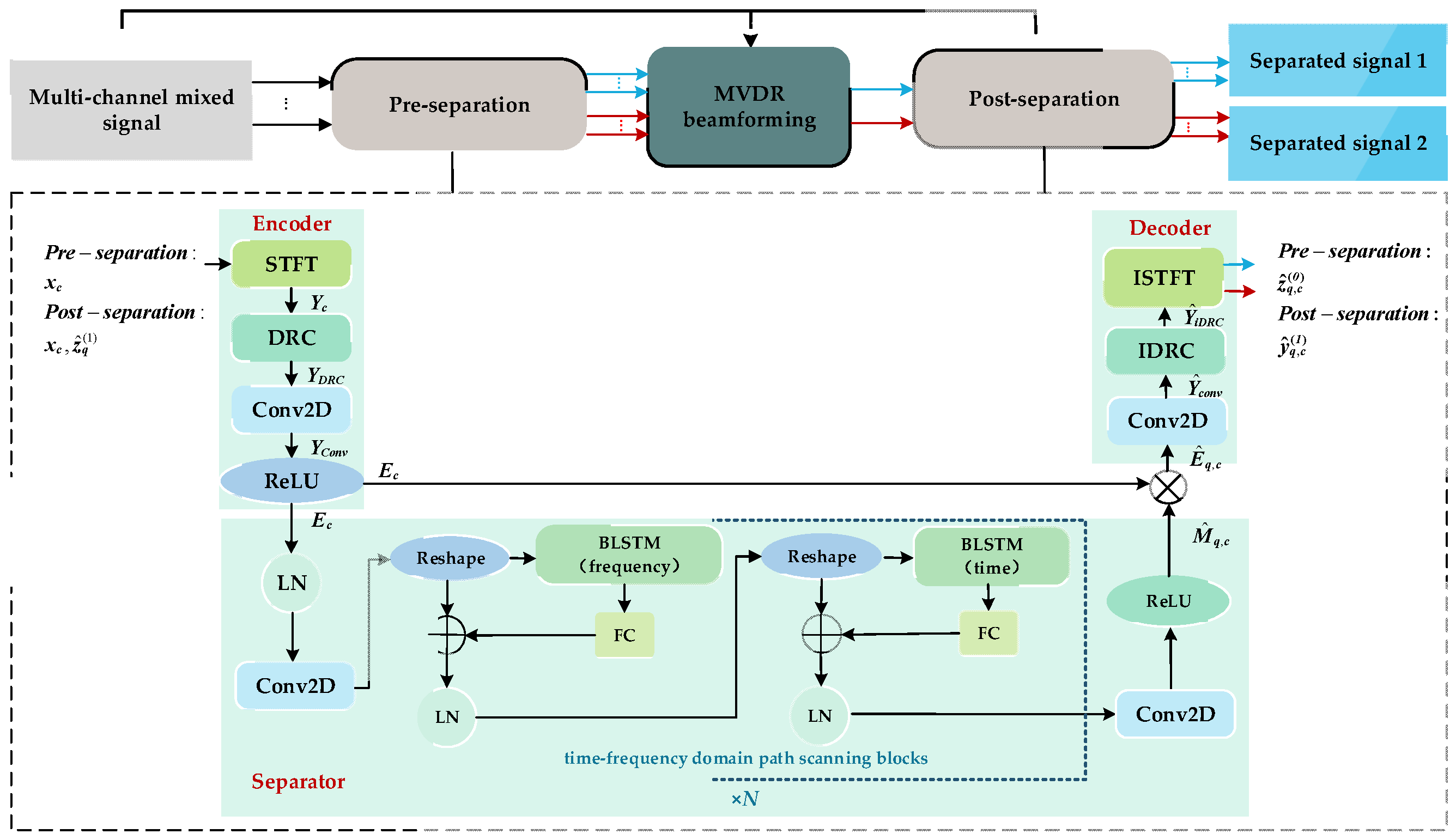
2.2. Initial Separation
- (a)
- In the encoder section, firstly, the mixed signal xc is transformed into the time–frequency representation Yc by short-time Fourier transform (STFT). Then, this representation Yc is applied to the dynamic range compression (DRC) module to obtain YDRC. Subsequently, the local features YConv are extracted from YDRC through a 2D convolutional (Conv2D) layer. Finally, these features YConv are passed through a rectified linear unit (ReLU) activation function to obtain the encoded feature Ec. The whole encoder section can be expressed as:where corresponds to the encoder of the cth microphone and Ec denotes the representation of encoder of the cth microphone.
- (b)
- In the separator section, firstly, the encoded feature Ec is sent to the layer normalization (LN) for standardization, followed by a Conv2D layer to obtain the feature . Subsequently, the feature is sent to N time–frequency domain scanning blocks using a time–frequency scanning mechanism [21,22]. Each scanning block consists of two recurrent modules, where the first recurrent module utilizes a bi-directional LSTM (BLSTM) network layer along the frequency axis and the second recurrent module utilizes BLSTM along the time axis. Both modules include reshaping, LN, and fully connected (FC) operations. Finally, after processing through these modules, the features are further refined through a Conv2D layer and the ReLU activation function, resulting in the separated mask . The whole separator section can be expressed as:where Separator{.}c denotes the separator corresponding to the signal of the cth microphone and denotes the mask of the qth speaker in the cth microphone.Thus, the separated masks are multiplied element-wise with the encoded feature Ec to obtain the separated feature representation :where Ec denotes the encoded feature representation in the cth microphone, ☉ denotes the Hadamard product.
- (c)
- In the decoder section, the separated feature passes through a Conv2D layer, inverse DRC (IDRC), and inverse STFT (ISFFT) to obtain the finally separated waveforms , where the superscript (0) denotes the first stage. The whole decoder section can be expressed as:where Decoder{.}q denotes the decoder of the qth speaker and denotes the separated waveform of the qth speaker in the cth microphone.
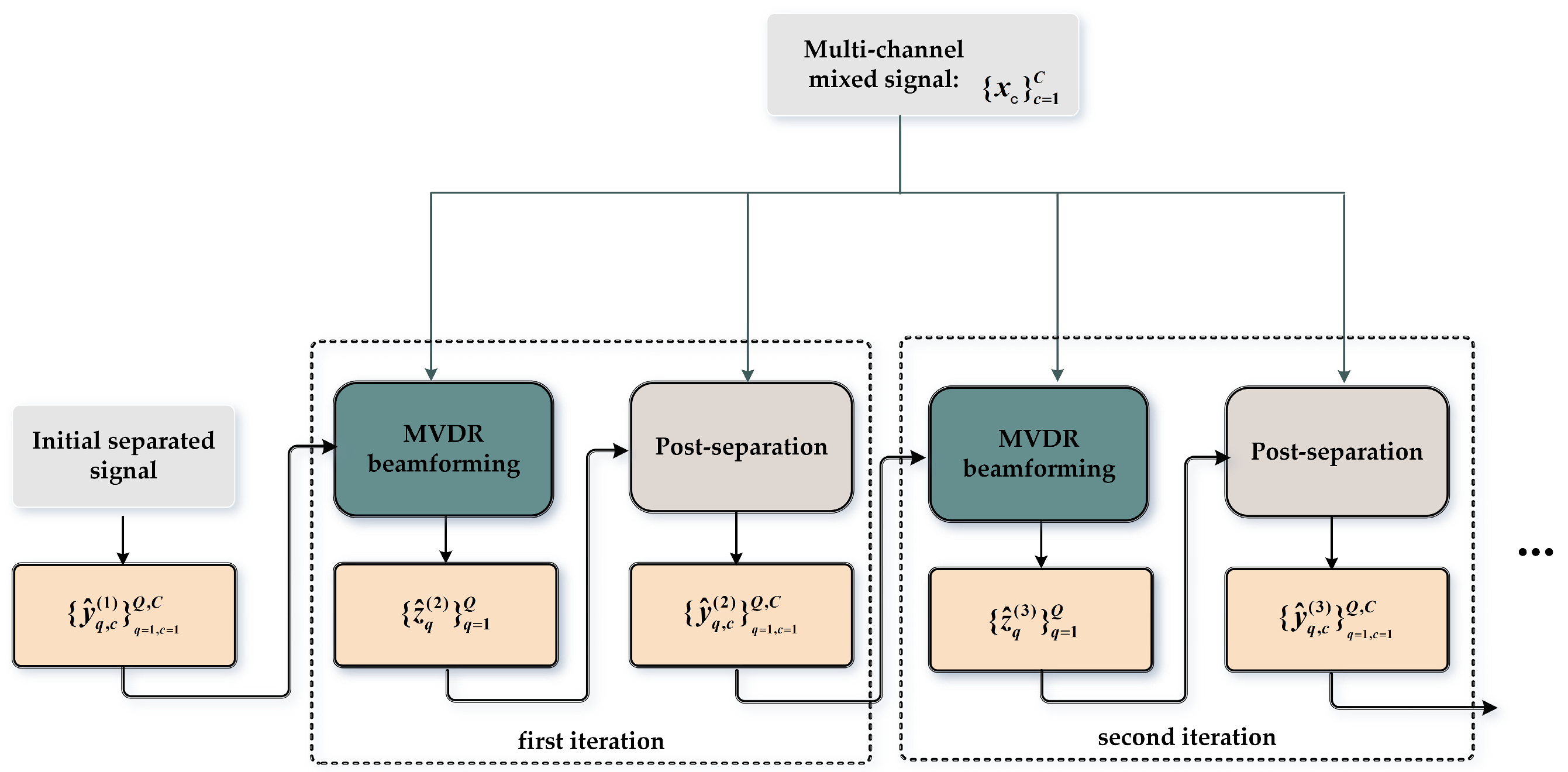
2.3. Iterative Separation
2.4. Loss Function
3. Experimental
3.1. Datasets and Microphone Structure
3.2. Model Configuration
3.3. Training Configuration
3.4. Evaluation Metrics
4. Results
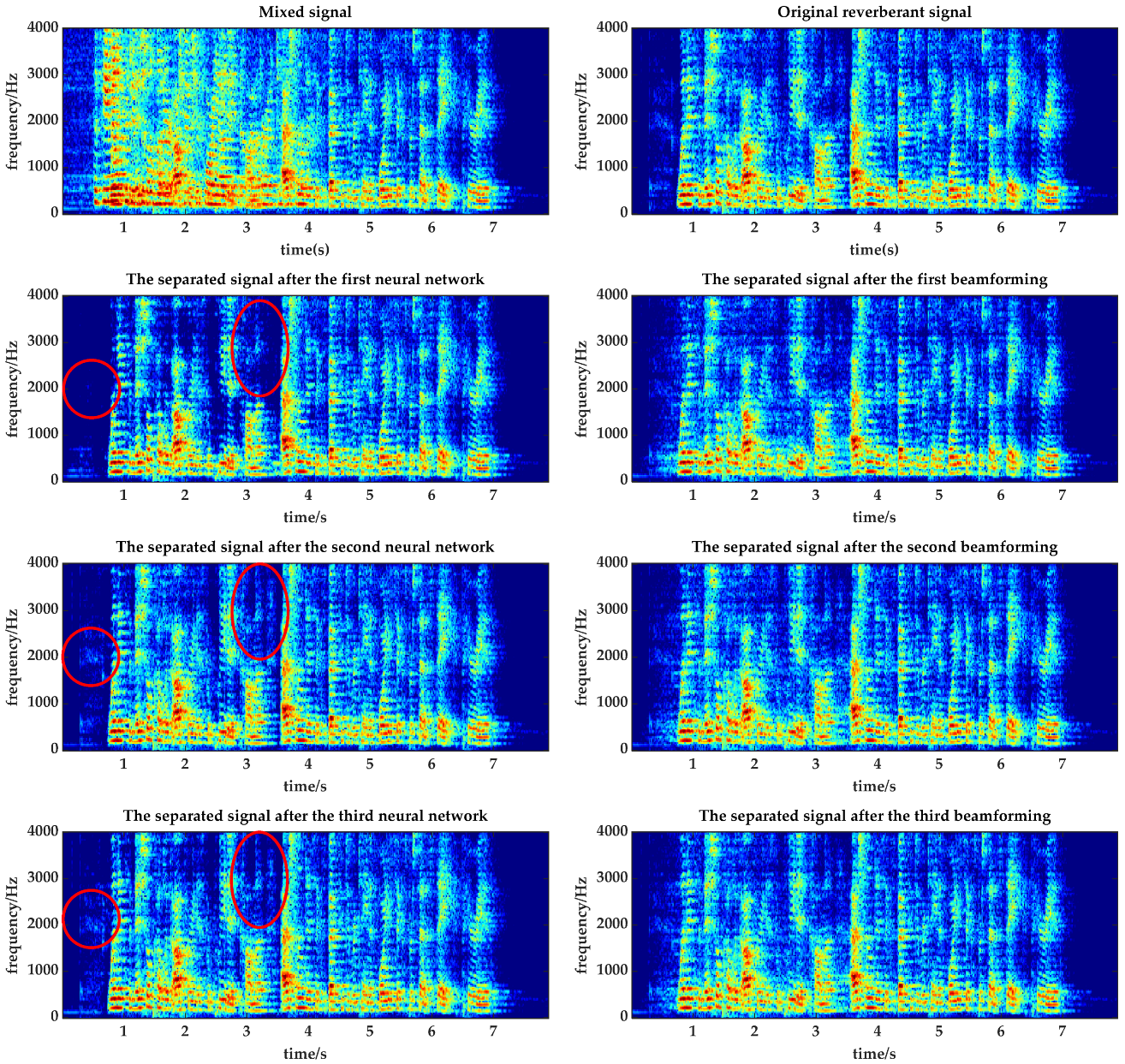
4.1. Analysis of Iterative Results
4.2. Comparison with Reference Methods
- (a)
- Filter-and-sum networking (FaSNet) [26] is a time-domain method that uses a neural network to implement beamforming technology. This method utilizes deep learning to automatically learn and optimize the weights and parameters of the beamformer. The core advantage of this method is its adaptability, allowing the network to adjust according to the complexity and diversity of the speech signal;
- (b)
- Narrow-band (NB) BLSTM [27] is a frequency-domain method using the BLSTM network, which is specially focused on narrow-band frequency processing and is trained by full-band methods to improve its performance. By processing each narrow-band frequency component separately in the frequency domain, this method can effectively identify and separate individual speakers in overlapped speech;
- (c)
- Beam-TasNet [9] is a classical speech separation method that combines time-domain and frequency-domain approaches. First, the time-domain neural network is used for pre-separation. Subsequently, these pre-separated speech signals are used to calculate the SCM of the beamformer. Finally, the separated signal is obtained by the beamformer;
- (d)
- Beam-guided TasNet [19] is a two-stage speech separation method that also combines both time-domain and frequency-domain approaches. In the first stage, the initial speech separation is performed using Beam-TasNet. In the second stage, the network structure remains the same as Beam-TasNet, but the input includes the output from the first stage. This iterative process helps to further refine the separation of the initial speech.
- (e)
- Beam-TFDPRNN [15] is our previously proposed time–frequency speech separation method, which, like Beam-TasNet, also uses a neural beamforming structure. This method has more advantages in the reverberant environment, because it uses a time-frequency domain network with more anti-reverberant ability for the pre-separation.
4.3. Performance on the Joint Separation and Dereverberation Tasks
5. Discussion
6. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Chen, Z.; Li, J.; Xiao, X.; Yoshioka, T.; Wang, H.; Wang, Z.; Gong, Y. Cracking the Cocktail Party Problem by Multi-Beam Deep Attractor Network. In Proceedings of the 2017 IEEE Automatic Speech Recognition and Understanding Workshop (ASRU), Okinawa, Japan, 16–20 December 2017; pp. 437–444. [Google Scholar]
- Qian, Y.; Weng, C.; Chang, X.; Wang, S.; Yu, D. Past Review, Current Progress, and Challenges Ahead on the Cocktail Party Problem. Front. Inf. Technol. Electron. Eng. 2018, 19, 40–63. [Google Scholar] [CrossRef]
- Chen, J.; Mao, Q.; Liu, D. Dual-Path Transformer Network: Direct Context-Aware Modeling for End-to-End Monaural Speech Separation. arXiv 2020, arXiv:2007.13975. [Google Scholar]
- Luo, Y.; Mesgarani, N. Conv-TasNet: Surpassing Ideal Time-Frequency Magnitude Masking for Speech Separation. IEEE/ACM Trans. Audio Speech Lang. Process. 2019, 27, 1256–1266. [Google Scholar] [CrossRef] [PubMed]
- Subakan, C.; Ravanelli, M.; Cornell, S.; Bronzi, M.; Zhong, J. Attention Is All You Need in Speech Separation. In Proceedings of the ICASSP 2021—2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Toronto, ON, Canada, 6 June 2021; pp. 21–25. [Google Scholar]
- Zhao, S.; Ma, Y.; Ni, C.; Zhang, C.; Wang, H.; Nguyen, T.H.; Zhou, K.; Yip, J.; Ng, D.; Ma, B. MossFormer2: Combining Transformer and RNN-Free Recurrent Network for Enhanced Time-Domain Monaural Speech Separation. arXiv 2023, arXiv:2312.11825. [Google Scholar]
- Gannot, S.; Vincent, E.; Markovich-Golan, S.; Ozerov, A. A Consolidated Perspective on Multimicrophone Speech Enhancement and Source Separation. IEEE/ACM Trans. Audio Speech Lang. Process. 2017, 25, 692–730. [Google Scholar] [CrossRef]
- Anguera, X.; Wooters, C.; Hernando, J. Acoustic Beamforming for Speaker Diarization of Meetings. IEEE Trans. Audio Speech Lang. Process. 2007, 15, 2011–2022. [Google Scholar] [CrossRef]
- Ochiai, T.; Delcroix, M.; Ikeshita, R.; Kinoshita, K.; Nakatani, T.; Araki, S. Beam-TasNet: Time-Domain Audio Separation Network Meets Frequency-Domain Beamformer. In Proceedings of the ICASSP 2020—2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; pp. 6384–6388. [Google Scholar]
- Zhang, X.; Wang, Z.-Q.; Wang, D. A Speech Enhancement Algorithm by Iterating Single- and Multi-Microphone Processing and Its Application to Robust ASR. In Proceedings of the 2017 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), New Orleans, LA, USA, 5–9 March 2017; pp. 276–280. [Google Scholar]
- Erdogan, H.; Hershey, J.R.; Watanabe, S.; Mandel, M.I.; Roux, J.L. Improved MVDR Beamforming Using Single-Channel Mask Prediction Networks. In Proceedings of the Interspeech 2016, ISCA, San Francisco, CA, USA, 8 September 2016; pp. 1981–1985. [Google Scholar]
- Gu, R.; Zhang, S.-X.; Zou, Y.; Yu, D. Towards Unified All-Neural Beamforming for Time and Frequency Domain Speech Separation. IEEE/ACM Trans. Audio Speech Lang. Process. 2023, 31, 849–862. [Google Scholar] [CrossRef]
- Xiao, X.; Zhao, S.; Jones, D.L.; Chng, E.S.; Li, H. On Time-Frequency Mask Estimation for MVDR Beamforming with Application in Robust Speech Recognition. In Proceedings of the 2017 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), New Orleans, LA, USA, 5–9 March 2017; pp. 3246–3250. [Google Scholar]
- Luo, Y. A Time-Domain Real-Valued Generalized Wiener Filter for Multi-Channel Neural Separation Systems. IEEE/ACM Trans. Audio Speech Lang. Process. 2022, 30, 3008–3019. [Google Scholar] [CrossRef]
- Zhang, X.; Bao, C.; Zhou, J.; Yang, X. A Beam-TFDPRNN Based Speech Separation Method in Reverberant Environments. In Proceedings of the 2023 IEEE International Conference on Signal Processing, Communications and Computing (ICSPCC), Zhengzhou, China, 14 November 2023; pp. 1–5. [Google Scholar]
- Kavalerov, I.; Wisdom, S.; Erdogan, H.; Patton, B.; Wilson, K.; Roux, J.L.; Hershey, J.R. Universal Sound Separation. arXiv 2019, arXiv:1905.03330. [Google Scholar]
- Tzinis, E.; Wisdom, S.; Hershey, J.R.; Jansen, A.; Ellis, D.P.W. Improving Universal Sound Separation Using Sound Classification. In Proceedings of the ICASSP 2020—2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; pp. 96–100. [Google Scholar]
- Shi, Z.; Liu, R.; Han, J. LaFurca: Iterative Refined Speech Separation Based on Context-Aware Dual-Path Parallel Bi-LSTM. arXiv 2020, arXiv:2001.08998. [Google Scholar]
- Chen, H.; Yi, Y.; Feng, D.; Zhang, P. Beam-Guided TasNet: An Iterative Speech Separation Framework with Multi-Channel Output. arXiv 2022, arXiv:2102.02998. [Google Scholar]
- Wang, Z.-Q.; Erdogan, H.; Wisdom, S.; Wilson, K.; Raj, D.; Watanabe, S.; Chen, Z.; Hershey, J.R. Sequential Multi-Frame Neural Beamforming for Speech Separation and Enhancement. In Proceedings of the 2021 IEEE Spoken Language Technology Workshop (SLT), Shenzhen, China, 19 January 2021; pp. 905–911. [Google Scholar]
- Yang, L.; Liu, W.; Wang, W. TFPSNet: Time-Frequency Domain Path Scanning Network for Speech Separation. In Proceedings of the ICASSP 2022—2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Singapore, 23–27 May 2022. [Google Scholar] [CrossRef]
- Yang, X.; Bao, C.; Zhang, X.; Chen, X. Monaural Speech Separation Method Based on Recurrent Attention with Parallel Branches. In Proceedings of the INTERSPEECH 2023, ISCA, Dublin, Ireland, 20 August 2023; pp. 3794–3798. [Google Scholar]
- Wang, Z.-Q.; Le Roux, J.; Hershey, J.R. Multi-Channel Deep Clustering: Discriminative Spectral and Spatial Embeddings for Speaker-Independent Speech Separation. In Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018; pp. 1–5. [Google Scholar]
- Allen, J.B.; Berkley, D.A. Image Method for Efficiently Simulating Small-Room Acoustics. J. Acoust. Soc. Am. 1979, 65, 943–950. [Google Scholar] [CrossRef]
- Févotte, C.; Gribonval, R.; Vincent, E. BSS_EVAL Toolbox User Guide Revision 2.0; IRISA: Rennes, France, 2011; p. 22. [Google Scholar]
- Luo, Y.; Ceolini, E.; Han, C.; Liu, S.-C.; Mesgarani, N. FaSNet: Low-Latency Adaptive Beamforming for Multi-Microphone Audio Processing. arXiv 2019, arXiv:1909.13387. [Google Scholar]
- Quan, C.; Li, X. Multi-Channel Narrow-Band Deep Speech Separation with Full-Band Permutation Invariant Training. In Proceedings of the ICASSP 2022—2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Singapore, 23 May 2022; pp. 541–545. [Google Scholar]
- Chen, Z.; Yoshioka, T.; Lu, L.; Zhou, T.; Meng, Z.; Luo, Y.; Wu, J.; Xiao, X.; Li, J. Continuous Speech Separation: Dataset and Analysis. In Proceedings of the ICASSP 2020—2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020. [Google Scholar]
- Maciejewski, M.; Wichern, G.; McQuinn, E.; Roux, J.L. WHAMR!: Noisy and Reverberant Single-Channel Speech Separation. In Proceedings of the ICASSP 2020—2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; pp. 696–700. [Google Scholar]

{kind=link}
{kind=link}
{kind=link}
| Dataset | Number of Samplers | Total Duration (h) |
|---|---|---|
| Training | 20,000 | 30 |
| Development | 5000 | 10 |
| Testing | 3000 | 5 |
| Stage | RTF | SDR | SI-SDR | SIR | PESQ | STOI | |||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0.024 | - | 14.41 | - | 13.91 | - | 30.67 | - | 4.13 | - | 0.98 |
| 1 | 0.049 | 18.79 | 21.84 | 17.08 | 21.13 | 27.21 | 30.67 | 3.93 | 4.13 | 0.99 | 0.98 |
| 2 | 0.074 | 22.07 | 24.17 | 20.95 | 23.48 | 33.21 | 33.21 | 3.93 | 4.23 | 0.99 | 0.99 |
| 3 | 0.104 | 22.10 | 24.48 | 21.07 | 23.84 | 33.23 | 33.93 | 3.99 | 4.25 | 0.99 | 0.99 |
| 4 | 0.125 | 22.21 | 24.91 | 21.20 | 24.26 | 33.80 | 34.36 | 3.98 | 4.26 | 0.99 | 0.99 |
| 5 | 0.148 | 22.31 | 24.60 | 21.34 | 23.98 | 34.05 | 34.24 | 4.00 | 4.25 | 0.99 | 0.99 |
| Method | Param | SDR | SI-SDR | PESQ | SIR | STOI |
|---|---|---|---|---|---|---|
| FaSNet | 2.8 M | 11.96 | 11.69 | 3.16 | 18.97 | 0.93 |
| NB-BLSTM | 1.2 M | 8.22 | 6.90 | 2.44 | 12.13 | 0.83 |
| Beam-TasNet | 5.4 M | 17.40 | - | - | - | - |
| Beam-guided TasNet | 5.5 M | 20.52 | 19.49 | 3.88 | 27.49 | 0.98 |
| Beam-TFDPRNN | 2.7 M | 17.20 | 16.80 | 3.68 | 26.77 | 0.96 |
| iBeam-TFDPRNN | 2.8 M | 24.17 | 23.48 | 4.23 | 33.21 | 0.99 |
| Method | SDR | |
|---|---|---|
| Beam TasNet | 10.8 | 14.6 |
| Beam-guided TasNet | 16.5 | 17.1 |
| iBeam-TFDPRNN | 20.2 | 19.7 |
| Oracle mask-based MVDR | 11.4 | 12.0 |
| Oracle signal-based MVDR | ∞ | 21.1 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, X.; Bao, C.; Yang, X.; Zhou, J. Iteratively Refined Multi-Channel Speech Separation. Appl. Sci. 2024, 14, 6375. https://doi.org/10.3390/app14146375
Zhang X, Bao C, Yang X, Zhou J. Iteratively Refined Multi-Channel Speech Separation. Applied Sciences. 2024; 14(14):6375. https://doi.org/10.3390/app14146375
Chicago/Turabian StyleZhang, Xu, Changchun Bao, Xue Yang, and Jing Zhou. 2024. "Iteratively Refined Multi-Channel Speech Separation" Applied Sciences 14, no. 14: 6375. https://doi.org/10.3390/app14146375
APA StyleZhang, X., Bao, C., Yang, X., & Zhou, J. (2024). Iteratively Refined Multi-Channel Speech Separation. Applied Sciences, 14(14), 6375. https://doi.org/10.3390/app14146375