
Custom Anchorless Object Detection Model for 3D Synthetic Traffic Sign Board Dataset with Depth Estimation and Text Character Extraction


Abstract
1. Introduction
2. Related Work
3. Traffic Sign Board Dataset
3.1. 3D Modeling
3.2. Render Images and Extract Labels
3.3. Generate Ground-Truth Labels
4. Proposed Method
4.1. Modified Hourglass Network
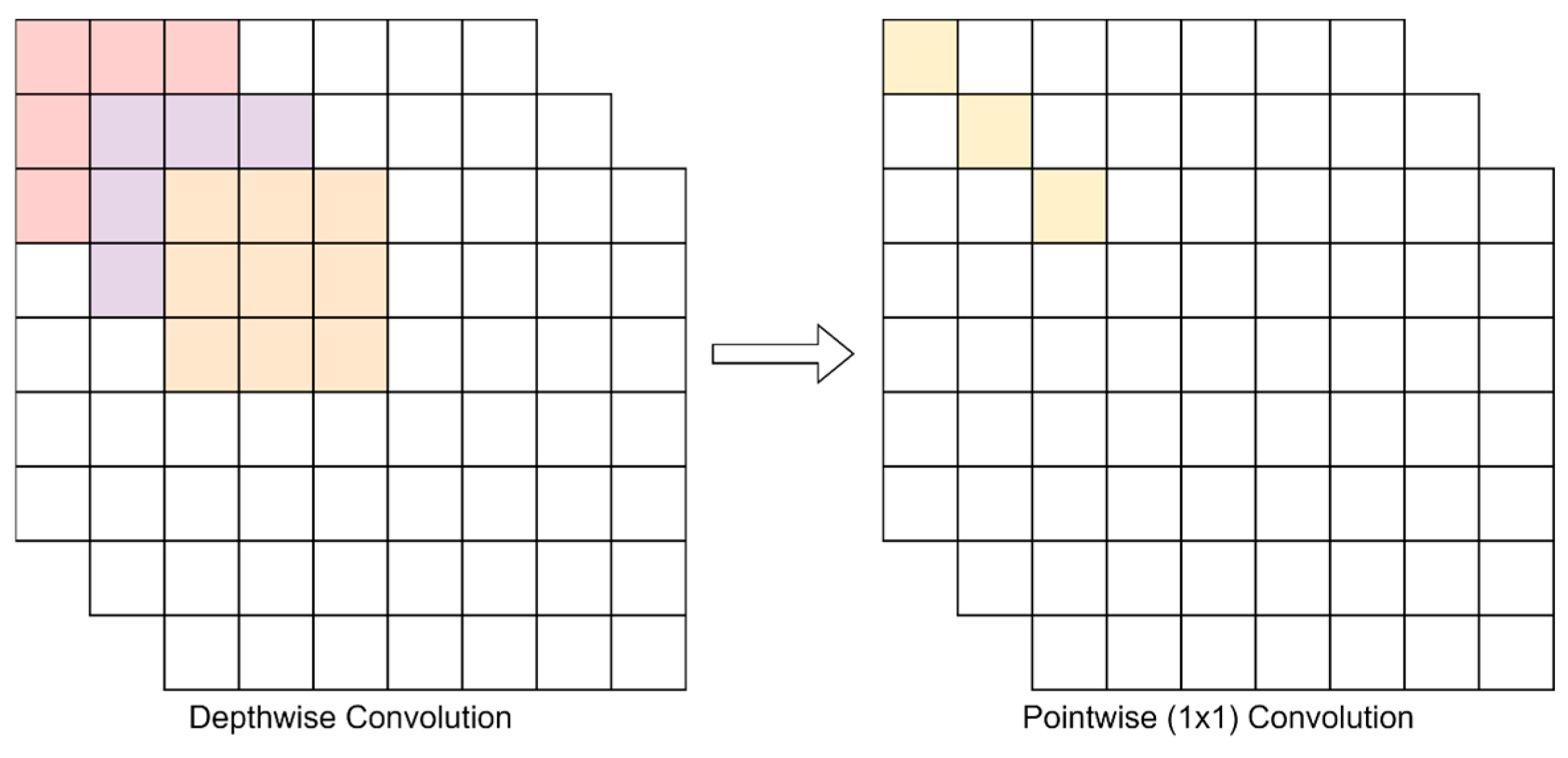
4.1.1. Depthwise Separable Convolution
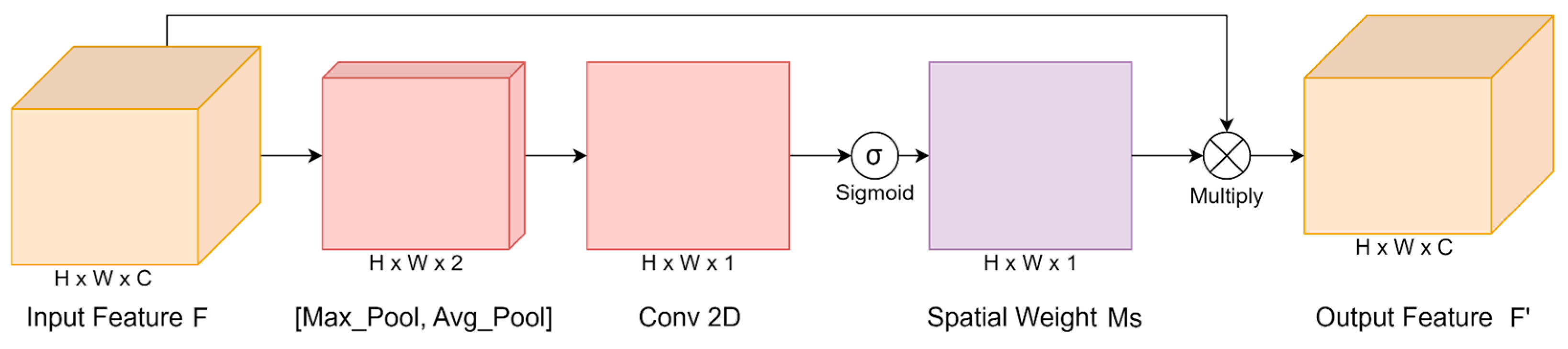
4.1.2. Spatial and Channel Attention Modules
4.2. Text Character Recognition
4.2.1. Generate OCR Data
4.2.2. Optical Character Recognition Model
4.2.3. CTC Loss
5. Experiments and Results
5.1. Training
5.2. Qualitative Analysis
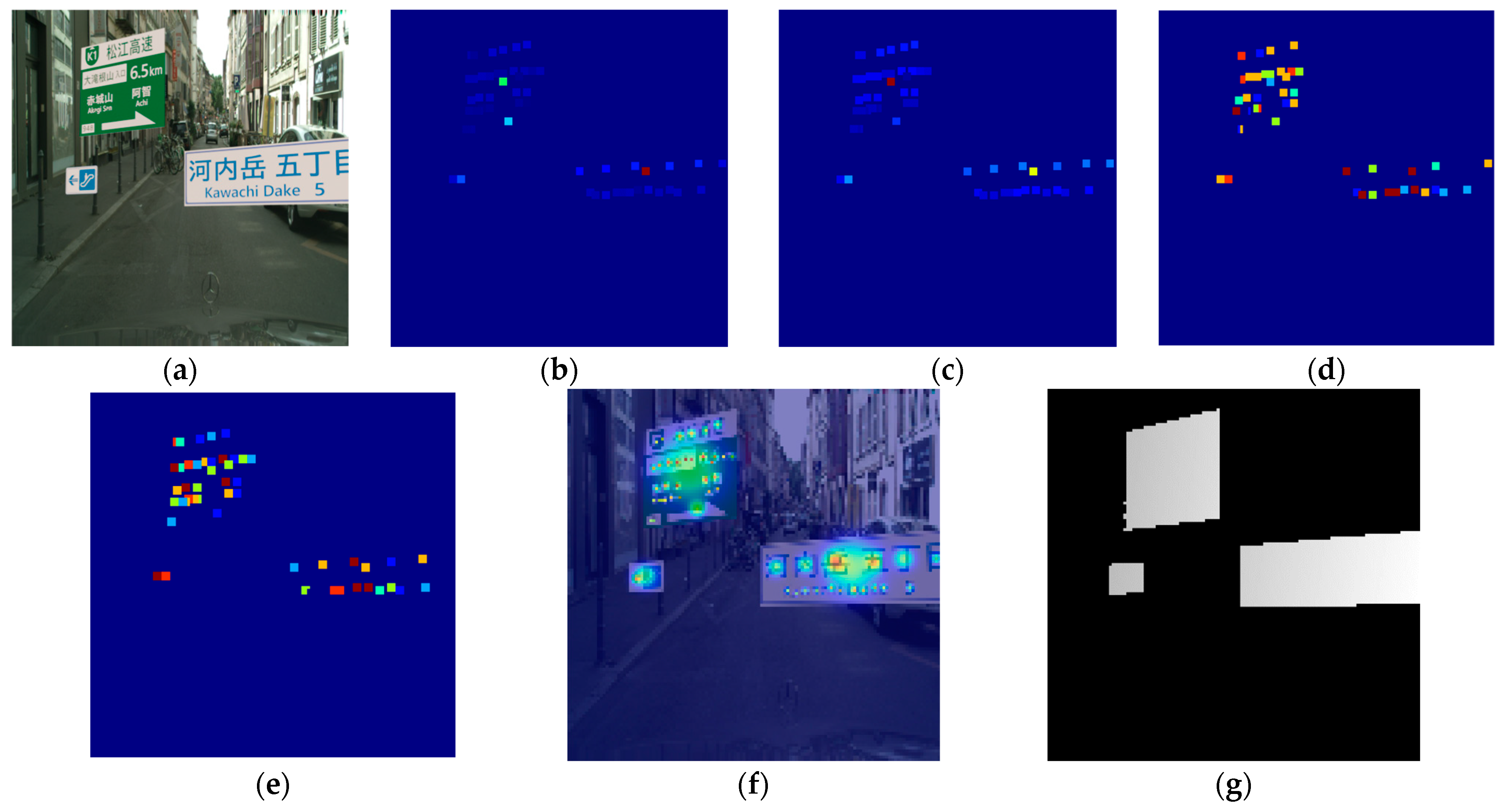
5.2.1. Heatmap Regression and Bounding Box Predictions
5.2.2. Text Recognition
5.3. Quantitative Analysis
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Denninger, M.; Winkelbauer, D.; Sundermeyer, M.; Boerdijk, W.; Knauer, M.W.; Strobl, K.H.; Humt, M.; Triebel, R. BlenderProc2: A Procedural Pipeline for Photorealistic Rendering. J. Open Source Softw. 2023, 8, 4901. [Google Scholar] [CrossRef]
- Community, B.O. Blender—A 3D Modelling and Rendering Package. Stichting Blender Foundation, Amsterdam: Blender Foundation. 2018. Available online: https://www.blender.org (accessed on 15 April 2022).
- Haas, J.K. A History of the Unity Game Engine. Ph.D. Thesis, Worcester Polytechnic Institute, Worcester, MA, USA, 2014. Available online: https://www.unity.com (accessed on 15 April 2022).
- Richter, S.R.; Vineet, V.; Roth, S.; Koltun, V. Playing for Data: Ground Truth from Computer Games. In Computer Vision—ECCV 2016, Proceedings of the 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Leibe, B., Matas, J., Sebe, N., Welling, M., Eds.; Lecture Notes in Computer Science; Springer International Publishing: Cham, Switzerland, 2016; pp. 102–118. [Google Scholar]
- Tremblay, J.; Prakash, A.; Acuna, D.; Brophy, M.; Jampani, V.; Anil, C.; To, T.; Cameracci, E.; Boochoon, S.; Birchfield, S. Training Deep Networks with Synthetic Data: Bridging the Reality Gap by Domain Randomization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Salt Lake City, UT, USA, 18–22 June 2018; pp. 1082–10828. [Google Scholar]
- Baek, Y.; Lee, B.; Han, D.; Yun, S.; Lee, H. Character Region Awareness for Text Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 9357–9366. [Google Scholar]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft COCO: Common Objects in Context. In Proceedings of the 13th European Conference on Computer Vision (ECCV), Zurich, Switzerland, 6–12 September 2014; pp. 740–755. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.B.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Law, H.; Deng, J. CornerNet: Detecting Objects as Paired Keypoints. Int. J. Comput. Vis. 2018, 128, 642–656. [Google Scholar] [CrossRef]
- Duan, K.; Bai, S.; Xie, L.; Qi, H.; Huang, Q.; Tian, Q. CenterNet: Keypoint Triplets for Object Detection. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 6568–6577. [Google Scholar]
- Zhou, X.; Zhuo, J.; Krahenbuhl, P. Bottom-up object detection by grouping extreme and center points. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 850–859. [Google Scholar]
- Zhou, X.; Wang, D.; Krähenbühl, P. Objects as points. arXiv 2019, arXiv:1904.07850. [Google Scholar]
- Liu, C.; Li, S.; Chang, F.; Wang, Y. Machine Vision Based Traffic Sign Detection Methods: Review, Analyses and Perspectives. IEEE Access 2019, 7, 86578–86596. [Google Scholar] [CrossRef]
- Zakir, U.; Leonce, A.N.J.; Edirisinghe, E. Road Sign Segmentation Based on Colour Spaces: A Comparative Study. In Proceedings of the 11th Iasted International Conference on Computer Graphics and Imgaing, Innsbruck, Austria, 17–19 February 2010; pp. 17–19. [Google Scholar]
- Youssef, A.; Albani, D.; Nardi, D.; Bloisi, D.D. Fast Traffic Sign Recognition Using Color Segmentation and Deep Convolutional Networks. In Advanced Concepts for Intelligent Vision Systems; Blanc-Talon, J., Distante, C., Philips, W., Popescu, D., Scheunders, P., Eds.; Lecture Notes in Computer Science; Springer International Publishing: Cham, Switzerland, 2016; Volume 10016, pp. 205–216. [Google Scholar]
- Prisacariu, V.A.; Timofte, R.; Zimmermann, K.; Reid, I.; Van Gool, L. Integrating Object Detection with 3D Tracking towards a Better Driver Assistance System. In Proceedings of the 2010 20th International Conference on Pattern Recognition, Istanbul, Turkey, 23–26 August 2010; pp. 3344–3347. [Google Scholar]
- Saadna, Y.; Behloul, A. An Overview of Traffic Sign Detection and Classification Methods. Int. J. Multimed. Inf. Retr. 2017, 6, 193–210. [Google Scholar] [CrossRef]
- Rajendran, S.P.; Shine, L.; Pradeep, R.; Vijayaraghavan, S. Real-Time Traffic Sign Recognition Using YOLOv3 Based Detector. In Proceedings of the 2019 10th International Conference on Computing, Communication and Networking Technologies (ICCCNT), Kanpur, India, 6–8 July 2019; pp. 1–7. [Google Scholar]
- Li, Y.; Li, J.; Meng, P. Attention-YOLOV4: A Real-Time and High-Accurate Traffic Sign Detection Algorithm; Springer: Berlin/Heidelberg, Germany, 2022; pp. 1–16. [Google Scholar]
- Newell, A.; Yang, K.; Deng, J. Stacked Hourglass Networks for Human Pose Estimation. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 483–499. [Google Scholar]
- Soans, R.V.; Fukumizu, Y. Improved Facial Keypoint Regression Using Attention Modules. In Proceedings of the Communi-cations in Computer and Information Science, Frontiers of Computer Vision, Hiroshima, Japan, 21–22 February 2022; pp. 182–196. [Google Scholar]
- Shivanna, V.M.; Guo, J. Object Detection, Recognition, and Tracking Algorithms for ADASs—A Study on Recent Trends. Sensors 2023, 24, 249. [Google Scholar] [CrossRef]
- Diwan, T.; Anirudh, G.S.; Tembhurne, J.V. Object detection using YOLO: Challenges, architectural successors, datasets and applications. Multimed. Tools Appl. 2022, 82, 9243–9275. [Google Scholar] [CrossRef] [PubMed]
- Wang, J.; Chen, Y.; Dong, Z.; Gao, M. Improved YOLOv5 network for real-time multi-scale traffic sign detection. Neural Comput. Appl. 2021, 35, 7853–7865. [Google Scholar] [CrossRef]
- Chu, J.; Zhang, C.; Yan, M.; Zhang, H.; Ge, T. TRD-YOLO: A Real-Time, High-Performance Small Traffic Sign Detection Algorithm. Sensors 2023, 23, 3871. [Google Scholar] [CrossRef]
- Liu, H.; Zhou, K.; Zhang, Y.; Zhang, Y. ETSR-YOLO: An improved multi-scale traffic sign detection algorithm based on YOLOv5. PLoS ONE 2023, 18, e0295807. [Google Scholar] [CrossRef] [PubMed]
- Wang, Y.; Bai, M.; Wang, M.; Zhao, F.; Guo, J. Multiscale Traffic Sign Detection Method in Complex Environment Based on YOLOv4. In Computational Intelligence and Neuroscience; John Wiley & Sons Ltd.: Hoboken, NJ, USA, 2022; p. 5297605. [Google Scholar]
- Liu, Y.; Shi, G.; Li, Y.; Zhao, Z. M-YOLO: Traffic Sign Detection Algorithm Applicable to Complex Scenarios. Symmetry 2022, 14, 952. [Google Scholar] [CrossRef]
- Shen, J.; Zhang, Z.; Luo, J.; Zhang, X. YOLOv5-TS: Detecting traffic signs in real-time. Front. Phys. 2023, 11, 1297828. [Google Scholar] [CrossRef]
- Zhang, K.; Chen, J.; Zhang, R.; Hu, C. A Hybrid Approach for Efficient Traffic Sign Detection Using Yolov8 and SAM. In Proceedings of the 2024 3rd Asia Conference on Algorithms, Computing and Machine Learning, Shanghai, China, 22–24 March 2024; pp. 298–302. [Google Scholar]
- Luo, Y.; Ci, Y.; Jiang, S.; Wei, X. A novel lightweight real-time traffic sign detection method based on an embedded device and YOLOv8. J. Real Time Image Process. 2024, 21, 24. [Google Scholar] [CrossRef]
- Liu, X.; Yan, W.Q. Traffic-light sign recognition using capsule network. Multimed. Tools Appl. 2021, 80, 15161–15171. [Google Scholar] [CrossRef]
- Kumar, A.D. Novel Deep Learning Model for Traffic Sign Detection Using Capsule Networks. arXiv 2018, arXiv:1805.04424. [Google Scholar]
- Yalamanchili, S.; Kodepogu, K.; Manjeti, V.B.; Mareedu, D.; Madireddy, A.; Mannem, J.; Kancharla, P.K. Optimizing Traffic Sign Detection and Recognition by Using Deep Learning. Int. J. Transp. Dev. Integr. 2024, 8, 131–139. [Google Scholar] [CrossRef]
- Sheeba, S.; Vamsi, V.M.S.; Sonti, H.; Ramana, P. Intelligent Traffic Sign Detection and Recognition Using Computer Vision. In Intelligent Systems Design and Applications; Abraham, A., Pllana, S., Hanne, T., Siarry, P., Eds.; Springer: Berlin/Heidelberg, Germany, 2024; Volume 1048. [Google Scholar]
- Chi, X.; Luo, D.; Liang, Q.; Yang, J.; Huang, H. Detection and Identification of Text-based Traffic Signs. Sens. Mater. 2023, 35, 153–165. [Google Scholar] [CrossRef]
- Kiefer, B.; Ott, D.; Zell, A. Leveraging Synthetic Data in Object Detection on Unmanned Aerial Vehicles. In Proceedings of the 2022 26th International Conference on Pattern Recognition (ICPR), Montreal, QC, Canada, 21–25 August 2022; pp. 3564–3571. [Google Scholar]
- Premakumara, N.; Jalaeian, B.; Suri, N.; Samani, H.A. Enhancing object detection robustness: A synthetic and natural perturbation approach. arXiv 2023, arXiv:2304.10622. [Google Scholar]
- Clement, N.L.; Schoen, A.; Boedihardjo, A.P.; Jenkins, A. Synthetic Data and Hierarchical Object Detection in Overhead Imagery. ACM Trans. Multimed. Comput. Commun. Appl. 2021, 20, 1–20. [Google Scholar] [CrossRef]
- Adobe Inc. Adobe Illustrator. 2019. Available online: https://adobe.com/products/illustrator (accessed on 7 January 2022).
- Adobe Inc. Adobe Photoshop. 2019. Available online: https://www.adobe.com/products/photoshop.html (accessed on 20 April 2023).
- The GIMP Development Team. GIMP. 2019. Available online: https://www.gimp.org (accessed on 7 January 2022).
- Inkscape Project. Inkscape. 2020. Available online: https://inkscape.org (accessed on 7 January 2022).
- Stallkamp, J.; Schlipsing, M.; Salmen, J.; Igel, C. The German traffic sign recognition benchmark: A multi-class classification competition. In Proceedings of the 2011 International Joint Conference on Neural Networks, San Jose, CA, USA, 31 July–5 August 2011; pp. 1453–1460. [Google Scholar]
- Yang, Y.; Luo, H.; Xu, H.; Wu, F. Towards real-time traffic sign detection and classification. IEEE Trans. Actions Intell. Transp. Syst. 2016, 17, 2022–2031. [Google Scholar] [CrossRef]
- Wang, Q.; Wu, B.; Zhu, P.F.; Li, P.; Zuo, W.; Hu, Q. ECA-Net: Efficient Channel Attention for Deep Convolutional Neural Networks. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 14–19 June 2020; pp. 11531–11539. [Google Scholar]
- Cordts, M.; Omran, M.; Ramos, S.; Rehfeld, T.; Enzweiler, M.; Benenson, R.; Franke, U.; Roth, S.; Schiele, B. The cityscapes dataset for semantic urban scene understanding. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 3213–3223. [Google Scholar]
- Cao, Z.; Hidalgo, G.; Simon, T.; Wei, S.; Sheikh, Y. OpenPose: Realtime Multi-Person 2D Pose Estimation Using Part Affinity Fields. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 43, 172–186. [Google Scholar] [CrossRef] [PubMed]
- Noh, H.; Hong, S.; Han, B. Learning deconvolution network for semantic segmentation. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1520–1528. [Google Scholar]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 39, 2481–2495. [Google Scholar] [CrossRef] [PubMed]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Chollet, F. Xception: Deep learning with depthwise separable convolutions. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 1800–1807. [Google Scholar]
- Hu, J.; Shen, L.; Albanie, S.; Sun, G.; Wu, E. Squeeze-and-Excitation Networks. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7132–7141. [Google Scholar]
- Graves, A.; Fern’andez, S.; Gomez, F.J.; Schmidhuber, J. Connectionist Temporal Classification: Labelling Unsegmented Sequence Data with Recurrent Neural Networks. In Proceedings of the 23rd International Conference on Machine Learning, Pittsburgh, PA, USA, 25–29 June 2006; pp. 369–376. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Shi, B.; Bai, X.; Yao, C. An end-to-end trainable neural network for image-based sequence recognition and its application to scene text recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2298–2304. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Wang, C.; Yeh, I.; Liao, H. YOLOv9: Learning What You Want to Learn Using Programmable Gradient Information. arXiv 2024, arXiv:2402.13616. [Google Scholar]




























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Easy Samples | CTC Output | Decoded Label | Hard Samples | CTC Output | Decoded Label |
|---|---|---|---|---|---|
 | [30, 49, 34, 45] | EXIT |  | [35, 28, 45, 20] | XeV |
 | [53, 53, 36, 12] | 11 Km |  | [28, 42] | CQ |
 | [40, 10, 4, 19, 14] | Oketo |  | [] | |
 | [55, 54, 10, 12] | 32 km |  | [50, 1176] | Y口 |
 | [126, 407] | 五木 |  | [55, 19, 40, 13, 20] | 3tOnu |
 | [362, 564, 407, 1304] | 香ノ木山 |  | [28, 60, 48, 10] | C8Wk |
| Network Architecture | # Params | mAP@0.5 (Mean) |
|---|---|---|
| Hourglass (Baseline) | 192.63 M | 0.783 |
| YOLOv3 | 62.49 M | 0.723 |
| YOLOv9e | 58.1 M | 0.833 |
| Hourglass + Depthwise Separable | 28.20 M | 0.778 |
| Hourglass + Depthwise Separable + Attention | 28.25 M | 0.819 |
| Object Class | AP@0.5 | AP@0.75 |
|---|---|---|
| Japanese Place Names | 0.851 | 0.695 |
| English Place Names | 0.822 | 0.670 |
| Distance Numbers | 0.813 | 0.645 |
| Expressway Numbers | 0.808 | 0.621 |
| General Information | 0.78 | 0.617 |
| Network Architecture | Inference Time |
|---|---|
| Hourglass (Baseline) | 0.174 s |
| YOLOv3 | 0.230 s |
| YOLOv9e | 0.039 s |
| Hourglass + Depthwise Separable | 0.139 s |
| Hourglass + Depthwise Separable + Attention | 0.157 s |
| Hourglass + Depthwise Separable + Attention + Find Peaks | 0.225 s |
| Hourglass + Depthwise Separable + Attention + Find Peaks + Post-Process | 0.267 s |
| Network Architecture | # Params | Accuracy | Inference Time | Inference Time + CTC Decode |
|---|---|---|---|---|
| OCR 1 | 5.95 M | 92.4% | 0.027 s | 0.031 s |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Soans, R.; Fukumizu, Y. Custom Anchorless Object Detection Model for 3D Synthetic Traffic Sign Board Dataset with Depth Estimation and Text Character Extraction. Appl. Sci. 2024, 14, 6352. https://doi.org/10.3390/app14146352
Soans R, Fukumizu Y. Custom Anchorless Object Detection Model for 3D Synthetic Traffic Sign Board Dataset with Depth Estimation and Text Character Extraction. Applied Sciences. 2024; 14(14):6352. https://doi.org/10.3390/app14146352
Chicago/Turabian StyleSoans, Rahul, and Yohei Fukumizu. 2024. "Custom Anchorless Object Detection Model for 3D Synthetic Traffic Sign Board Dataset with Depth Estimation and Text Character Extraction" Applied Sciences 14, no. 14: 6352. https://doi.org/10.3390/app14146352
APA StyleSoans, R., & Fukumizu, Y. (2024). Custom Anchorless Object Detection Model for 3D Synthetic Traffic Sign Board Dataset with Depth Estimation and Text Character Extraction. Applied Sciences, 14(14), 6352. https://doi.org/10.3390/app14146352