1. Introduction
In the description of classical image classification problems based on machine learning, images typically belong to a specific category. However, in some practical scenarios, a label is assigned after observing multiple images. This process is analogous to analyzing a video, where the judgment is made only after a comprehensive view. This scenario aligns with the general concept of multi-instance learning (MIL). In 1997, Dietterich et al. proposed the concept of multi-instance learning to address the challenge of drug activity prediction. They employed the axis-parallel rectangle (APR) learning algorithm in conjunction with multi-instance learning to tackle this issue. Within the framework of multi-instance learning, a method for handling weakly supervised problems is elucidated. In this process, labels are not assigned to individual samples. Instead, based on the problem’s specifications, a subset of instances (samples) meeting the problem’s criteria is grouped into a bag, and a label is then assigned to each bag. If at least one positive instance exists within a bag, the label of the bag is defined as positive; otherwise, if all instances are negative, the bag is considered negative [
1]. The primary advantage of multi-instance learning lies in its simplification of dataset construction for the respective problem, thereby reducing the workload for professionals. This advantage is particularly pronounced in medical imaging tasks, such as computer histopathology, X-ray imaging, or CT imaging screening. Given the potential existence of various associations and features among different image data, organizing these related images into bags enables multi-instance learning to better capture this information. Consequently, this approach enhances the performance and accuracy of the model [
2].
Currently, numerous medical models rely on multi-instance learning frameworks to predict bag labels. Another crucial task involves assigning prediction weights to the outcomes within the bag. This process helps identify key instances that contribute to the bag label, which holds significant importance in certain medical clinical tasks. It plays a pivotal role in enabling doctors to locate the disease and formulate precise treatment plans accordingly [
3]. To address this challenge, researchers have proposed various solutions. One approach involves making judgments based on the similarity at the bag level. This method utilizes the difference vector between the bag and all other bags as the feature representation, followed by prediction using this representation [
4]. Another method entails embedding all instances within a bag into a compact representation, subsequently employing a bag-level classifier for prediction [
5]. The third approach involves predicting low-dimensional embedded features via an instance-level classifier [
6]. Among these methods, only the third can offer interpretable results. However, many researchers note that the instance-level classifier often exhibits lower prediction accuracy compared to the bag-level classifier [
7]. Furthermore, in cases where there is a strong correlation among instances, employing this method may lead the model to detect abnormalities in different data segments with minor variations in the training data. Consequently, this can result in discrepancies in disease localization [
8].
Computed tomography (CT) scan images currently serve as an effective method for clinically examining various diseases, including lung tumors, pneumonia, and others. According to the American Cancer Society, patients detected with lung cancer at an early stage through CT scan images have a 47% survival rate, while 80% of patients can be accurately diagnosed and treated at the central or advanced stages of cancer. A notable feature of CT scan images is their unobtrusiveness. The scanning process is relatively quiet, and compared to other imaging techniques like parallel imaging, changes in angles seldom draw attention [
9]. When X-rays capture parts with a 3D structure, they are projected onto a 2D view. In some severe cases, this method may not offer effective information for professional radiologists. This is because the geometric structure overlaps during the projection process, leading to confusion regarding the actual structure. Therefore, the reconstruction of 3D scan images emerges as the preferred solution for visualizing the structural information of the patient’s lesion site, facilitating clinical analysis [
10]. Three-dimensional CT scan images exhibit high-resolution features. Presently, the thickness of high-resolution CT scans can range from 1 to 1.5 mm, enabling clear observation of tissue structures and lesion sites. Typically, a single scan generates dozens to hundreds of slices based on the patient’s condition. However, disease diagnosis based on CT images relies on analyzing various permutations and combinations of features. This task proves exceedingly challenging even for experienced physicians. In recent years, the advancement of artificial intelligence and deep learning has significantly contributed to image classification. This technology has matured substantially, capable of extracting subtle features imperceptible to the human eye from different angles. Common examples include histogram features, texture features, shape features, and more [
11].
The features of 3D CT scan images can be categorized into high-frequency and low-frequency features. High-frequency features typically represent fine structures within the image, such as edges and textures. These features correspond to rapidly changing or high-gradient areas in the image, such as object boundaries or structural textures. In CT images, they may manifest as clear contours, small tissue structures, or subtle tissue changes. On the other hand, low-frequency features usually depict the overall shape of the image, encompassing wide-ranging density changes or major tissue structures. These features correspond to slowly changing or low-gradient regions in the image, such as the overall shape or density distribution of the tissue. In CT images, low-frequency features may appear as the general organ shape and variations in tissue density across a wide area. CT images offer diverse levels of feature information at both high and low frequencies. However, accurately discerning these features necessitates considerable time and expertise from professional doctors [
12]. In a 3D CT image, multiple adjacent slices typically comprise the image. The spacing between these slices must be carefully set to ensure that the patient’s disease information is not lost. In three-dimensional space, adjacent slices often overlap to some extent, ensuring the continuity of tissue structure within the CT image. This continuity entails seamless connection and smooth transition between adjacent slices, allowing for the reflection of spatial changes at the lesion site. Such continuity is crucial for doctors to make accurate diagnoses [
13].
In this paper, our objective is to address the practical significance of CT image classification using the concept of multi-instance learning. We meticulously consider the fusion of high- and low-frequency features, as well as the continuity of 3D CT images, aiming to demonstrate its applicability in medical imaging through instances of 3D CT image data. Our experiments will evaluate two extensive public datasets focusing on lung cancer (TCIA) and pneumonia (CCII-CC), aiming to substantiate the superiority of our model over other methods.
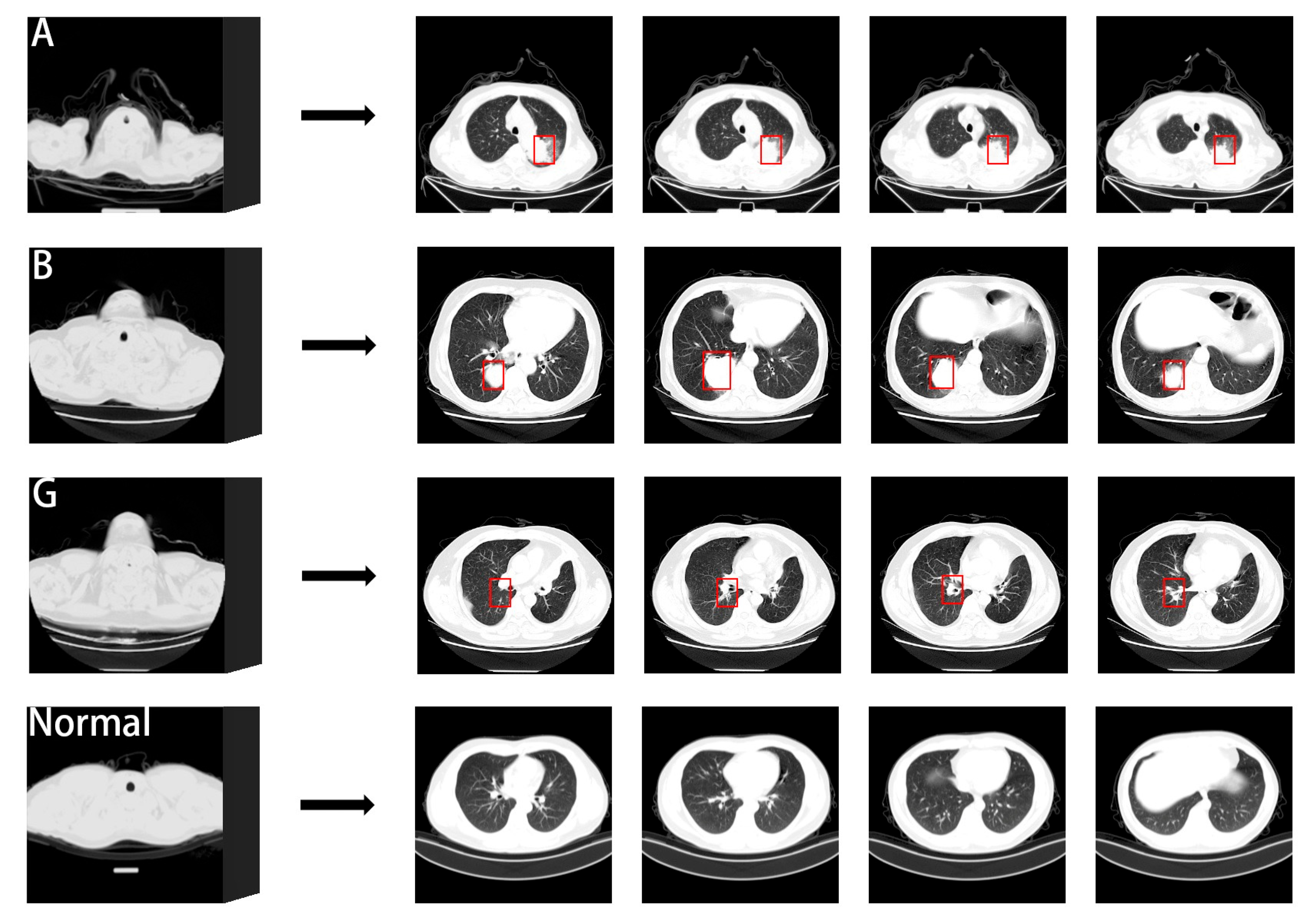
Figure 1 illustrates the comparison of CT slices depicting normal lungs and three types of lung cancer from the dataset utilized in this study. Many medical experts assert that scanning a greater number of CT images decreases the risk of misjudging cancer during examinations. However, CT scan images often contain extensive nodule information. Assessing a larger number of images poses a considerable challenge but is crucial for accurate diagnosis [
14].
In the study, to classify CT images into lung cancer patient and normal categories, we propose a multi-instance learning model called the High–Low Frequency Sliding Recurrent Neural Network (HLFSRNN-MIL) to assist doctors in making a diagnosis of the patient’s condition. HLFSRNN-MIL leverages the principles of multi-instance learning, and the model requires only patient-level labels as input and defines a patient’s 3D CT image as a bag. The size of each bag is determined based on the patient’s specific circumstances, typically ranging from 30 to 300 slices. Each bag undergoes basic feature extraction to obtain feature information. Subsequently, the high- and low-frequency feature information derived from these features is fused, and the prediction probability of each instance within the bag is determined using our modified recurrent neural network. Finally, this information is fed into the MIL classifier to generate bag-level predictions. The paper’s main contributions are summarized below:
We use a wide range of preprocessing techniques to mitigate the noise in the data. In this process, resampling, grayscale standardization, noise reduction, and other technologies are used to reduce the impact of noise on training.
The HLFFF method is used in the process of feature extraction, which can effectively capture and fuse the high- and low-frequency information from the basic feature information, and improve the sensitivity of the network to various distributions of disease data.
The SRNN method is proposed to learn and capture the temporal relationship information in the 2D feature map. This method is based on the Long Short-Term Memory Network (LSTM), which can effectively capture the relationship information between instances and identify the sequential instance fragments that affect the prediction results (that is, the continuous instance fragments of the window size in the package).
We propose a HLFSRNN-MIL model based on the ResNet-50 network. The model adheres to the ‘end-to-end’ architecture concept, and through experiments on TCIA and CC-CCII datasets solves the problem of disease diagnosis using 3D CT images in clinical practice.
2. Related Works
In recent years, numerous models based on various algorithms have emerged to identify and detect specific features, aiming to overcome the limitations of standard CNN methods like AlexNet [
15], Inception [
16], ShuffleNet [
17], and others. These models offer the flexibility to focus on different aspects of CT images by adjusting parameters. However, despite these advancements, the involvement of medical professionals remains crucial in this process, and significant limitations persist in clinical applications [
18]. Hence, researchers in this field are actively exploring ways to enhance feature extraction within models. Improved feature extraction methods have the potential to facilitate accurate diagnosis by medical practitioners in clinical settings. Currently, there is a plethora of studies aimed at enhancing model performance in this domain.
Qin et al. [
19] introduced a deep learning framework that integrates fine-grained features from PET and CT images. This framework utilizes a multi-dimensional attention mechanism to mitigate noise from feature information during the extraction of fine-grained features across multiple imaging modalities. Through experiments on feature fusion and attention concentration, they achieved ROC scores of 0.92 and observed more focused network attention. Raza et al. [
20] proposed the Lung-EffNet framework for lung cancer CT scan image classification. By adapting the classification head of the EfficientNet model and incorporating a predictor based on transfer learning, they achieved an accuracy rate of 99.10% and ROC scores ranging from 0.97 to 0.99 on a public dataset. Compared to other CNN models, Lung-EffNet demonstrated faster training speeds, required fewer parameters, and exhibited model performance comparable to that of general practitioners. Xu et al. [
21] introduced ISANET, a CNN-based classification model that integrates channel attention and spatial attention mechanisms into InceptionV3 to prioritize the lesion area. Compared to traditional models such as AlexNet, VGG-19, and MobileNetV3, ISANET achieved an accuracy of 95.25% in classifying non-small-cell lung cancer data. Siddiqui et al. [
22] addressed the perceived limitations of existing methods in early cancer diagnosis, namely, low performance and long processing times. To overcome these challenges, they proposed E-DBN, a support vector machine based on the deep belief network. This method incorporates an improved Gabor filter with fewer parameters, resulting in reduced processing delays and times.
Chang et al. [
23] proposed a model based on deep multi-instance learning (DMIL), which utilizes a deep convolutional neural network (CNN) as the backbone network for feature extraction. In DMIL, each instance corresponds to a path of the model input. The packet-level features obtained from three different methods—maximum pooling, convolution pooling, and attention mechanism pooling—are expressed as fully connected layers for prediction. This feature fusion technique allows for the estimation of the importance of each instance, thereby enhancing the model’s performance. Fuhrman et al. [
24] used transfer learning to extract more complex and richer feature representations than untrained models. They connected MIL pooling (AMIL) based on an attention mechanism through two fully connected layers, which can evaluate influential slices in CT packages according to attention weights. The powerful classification ability of the model has great potential in clinical implementation. Tang et al. [
25] proposed a shielded hard instance mining model (MHIMMIL) using Exponential Moving Average (EMA), which identifies difficult instances through the instance attention mechanism, and introduces parameter-free momentum into the Siamese structure to obtain more effective and stable instance prediction scores. Meng et al. [
26] proposed an uncertainty-aware consensus-assisted multi-instance learning (UC-MIL) model to deal with any number of CT slices. Through training, a certain number of top instances that contribute the most to the label in the package are selected as the input for subsequent bag prediction. Subsequently, an adaptive bilateral adjacency matrix will be constructed to find vertex relationships at different granularity levels, and a graph inference module (BA-GCN) will be used to predict the patient’s diagnostic probability.
Xue et al. [
27] proposed a multi-instance learning approach based on two-stage attention combined with transfer learning (TSA-MIL), which adjusts the attention weight of each instance by determining the distance between the key instance and the current instance. During the feature space processing, they adopted a clustering constraint method to refine the classification features, thereby enhancing the classification performance of TSA-MIL. Wang et al. [
28] proposed a self-tuning module to mitigate the impact of unbalanced label distribution in positive packets. The confidence-based regularization strategy generates pseudo-labels for each weak input through prediction. By incorporating a Student–Teacher architecture, the model can leverage unlabeled data for training, thereby enhancing the model’s recognition ability in a cost-effective manner. Liu et al. [
29] proposed an adversarial multi-instance learning (AdvMIL) model, which enhances the distribution estimation performance of AdvMIL by employing time-adversarial instances. This approach eliminates the necessity of fully supervised learning for data in the model, effectively reducing the computational cost of AdvMIL and enhancing the robustness of mainstream survival analysis methods. Schmidt et al. [
30] introduced the Attention Gaussian Process (AGP) method in multi-instance learning, which leverages a combination of the Gaussian process and attention mechanism to predict the probability of instance-level labels. The packet-level predictions can be elucidated by the instance-level prediction results. This approach effectively ensures accurate fitting and predictive estimation performance of the model even when the data are unbalanced. Wang et al. [
31] proposed an Iteratively Coupled Multi-Instance Learning (ICMIL) framework, which fine-tunes the parameters of the feature-extracted instance embedder using packet-level category information. This framework facilitates information exchange between the low-cost coupled instance embedder and the packet classifier, thus aiding in generating improved instance representations. In addressing the challenge of early clinical diagnosis of low-level characteristic symptoms, Li et al. [
32] introduced a multi-instance learning framework based on a causal-driven graph neural network. This framework encodes spatial proximity and feature similarity between instances while emphasizing the causal components of instance features through a causal comparison mechanism, thus enhancing the diagnostic performance of the model.
These methods have played a significant role in advancing multi-instance learning, and a common trend among them is the exploration of more complex feature extraction techniques. Many current methods rely on feature extraction modules based on deep neural networks, such as ResNet [
33], MobileNetV3 [
34], and GoogleNet [
35], among others. These network models have great differences in design concepts and performance. ResNet connects residual blocks through identity mapping to solve the problem of gradient explosion and vanishing in training. Using the inverted residual structure and separable convolution, MobileNetV3 reduces the required computing resources, enhances the feature relationship between channels, and further improves the performance of the model. GoogleNet uses a combination of convolution kernels of different shapes and pooling methods to extract features from multiple scales, which improves the utilization of computing resources. However, lesions in CT images often exhibit complex characteristics such as uncertain location, blurred shape, and varying sizes. Therefore, further research is necessary to effectively enhance the classification performance of multi-instance learning methods in CT image settings. This entails developing more sophisticated feature extraction methods that can accurately capture the nuanced characteristics of lesions in CT images, ultimately leading to improved diagnostic accuracy and clinical utility.
3. Proposed Methods
The designed method of HLFSRNN-MIL draws on the current popular network architecture concept, and combines more advanced and effective methods on the basis of a variety of feature extractors to solve the problem of 3D CT images. This design pattern is more conducive to training and subsequent parameter adjustment of the model, demonstrating high-intensity feature selection ability and excellent performance in multi-instance learning problems.
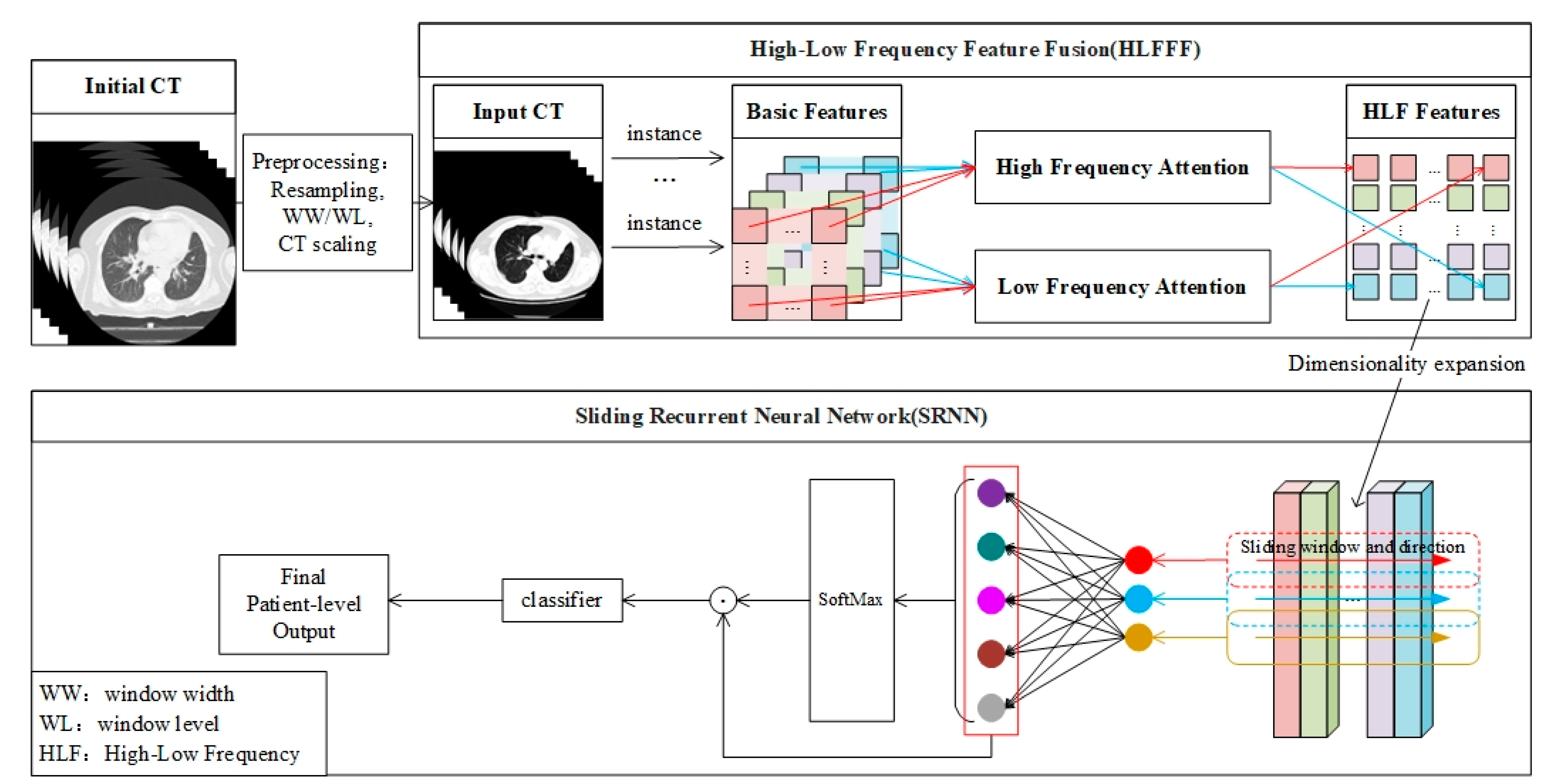
Figure 2 shows an overview of the classification model proposed in this paper, which can be explained in three parts: (1) The preprocessing of 3D CT image data; (2) The extraction of the high- and low-frequency features (HLFFF) of the instance at the 2D level; (3) The search for key package segments for classification at the 2D and 3D levels (SRNN). To input a patient’s 3D CT image with any number of slices, the original CT data need to be preprocessed first, and then the processed data are sent to the HLFFF module to extract the high- and low-frequency features of each instance in a packet as a unit, and then the representation of the feature space is improved by increasing the dimension. Then, as the input of the proposed SRNN, SRNN learns the time information of the instance in the 3D space. It is worth noting that the output of SRNN can be considered as finding a packet fragment with a high contribution based on the size W of the sliding window, which is set to 5 according to the empirical hyperparameter
. The development details and detailed explanations of each part are given as follows.
3.1. 3D CT Datasets and Datasets Preprocessing
This paper will verify the feasibility of the method on two datasets, the Cancer Imaging Archive (TCIA) and the China Consortium of Chest CT Image Investigation (CC-CCII), and the number of slices per package is controlled between 30 and 300.
Table 1 presents the CT image acquisition parameter information of the two datasets.
TCIA is a large public dataset on lung cancer. A total of 300 3D CT packages were used for 234 patients with lung cancer, including 216 packages of adenocarcinoma, 41 packages of small-cell carcinoma, and 43 packages of squamous-cell carcinoma. Patients needed to be fasted for at least 6 h before the examination. Whole-body emission scanning was performed within 12 min after injection of 60F-FDG (18.4 MBq/kg, 44.0 mCi/kg). During the scan, the blood glucose of each patient was less than 11 mmol/L. The original CT image was composed of anisotropic voxels with different in-plane resolutions. Due to the differences between different scanners or acquisition protocols, the voxel spacing of the CT dataset was also inconsistent. To facilitate training, we resampled all medical images according to the voxel spacing information provided by the DICOM file to ensure consistent resolution. The slice thickness range was usually between 0.625 mm and 5 mm, and the scanning mode includes plane, contrast, and 3D reconstruction.
CC-CCII is a dataset of novel coronavirus pneumonia established by Zhang et al. [
36], comprising both cases of novel coronavirus pneumonia (COVID-19) and cases of common pneumonia resulting from the SARS-CoV-2 virus. A total of 300 3D CT scans of COVID-19 and common pneumonia were included, with each scan acquired during the patient’s admission examination. This dataset is essential for distinguishing between COVID-19 and other types of pneumonia, providing valuable data for developing and validating diagnostic models.
Since X-ray absorption varies among different tissues or substances within the human body, Hounsfield Unit (HU) values require adjustment based on varying conditions. By referencing the absorption of water, a positive HU value signifies greater X-ray absorption by tissues or substances compared to water, while a negative HU value indicates lesser absorption than water. To delineate diverse types of abnormal tissues and lesions in the lungs, it is crucial to establish appropriate window width (WW) and window level (WL) settings to achieve clear lung features. In our experiment, we configured WW to 1050 HU and WL to −475 HU. The disparity between initial CT and modified input CT is illustrated in
Figure 1.
Voxel spacing denotes the distance between adjacent volume pixels in the patient’s CT image within three-dimensional space. This spacing determines the minimum spatial unit discernible within the image. Smaller voxel spacing implies higher spatial resolution. Typically, the size of voxel spacing is governed by the parameter settings of the scanning device. In our experiment, the voxel spacing range of the original CT image data spanned from 0.585937 to 0.841796, while the spatial resolution range of the resampled images fell between 300 and 431. To streamline subsequent training processes, standardizing the resolution of all CT images becomes necessary. Hence, employing the OpenCV tool, the resolution of all images was uniformly scaled to 256 × 256.
3.2. Extraction of Deep Features
The fine-tuned ResNet-50 serves as the foundational network for the deep feature extraction process. The input channel of the ResNet-50 network was adjusted to 1, and the final global average pooling layer and fully connected layer were omitted. The retained portion functions as a feature extractor devoid of a classifier, thereby preserving the spatial structure of image features and encompassing feature information across various depth levels.
After the final layer, a series of feature maps was obtained, which represent image features at various levels within the network and encompass information at differing abstract levels. In the context of this paper’s problem, the number of channels in the last layer determined the quantity of features captured by each instance in the package across different aspects, corresponding to distinct feature extractors. The dimensions of the feature map depend on the size of the input image. Following convolution and pooling operations, the size transitions from the original 256 × 256 resolution to 8 × 8. Throughout this process, the feature map’s dimensions decreased while the semantic information contained within them increased.
In general, the process of acquiring CT images can be influenced by the scanning equipment and parameters, necessitating consideration of the model’s flexibility and generalization capability. The adapted ResNet-50 network effectively addresses these challenges, enabling adaptation to various tasks and application scenarios during subsequent processing.
3.3. Multiple Instance Learning
Unlike typical binary supervised learning problems, the objective of prediction in the Multiple Instance Learning (MIL) problem involves a collection of instances comprising numerous instances, denoted as
. Instances within the collection exhibit no interdependence or ordering among each other. Throughout this process, it is presumed that the value of
may vary across different collections, with a package label
associated with each collection, existing independently and denoted as
. Traditional multi-instance learning assumes that each instance in the bag possesses an individual label
and
[
37]. The assumption underlying the MIL problem can be articulated as follows:
However, obtaining labels at the instance level can be challenging and time-consuming in many practical scenarios. For instance, in CT images of lung cancer and COVID-19, medical professionals must examine all slices to identify lesion locations, where a lesion may span across a contiguous series of adjacent slices. Therefore, it becomes imperative to define an aggregation function
that aggregates the spatial features of instances within a specified range, such as:
where
is the result of the
-th instance aggregation,
denotes the number of primary aggregations within the package, with
, where
is a hyperparameter signifying the range requiring particular attention for the instance.
In many cases, the number of instances with actual corresponding labels in the positive bag may be limited and non-contiguous, influenced by factors such as slice thickness during CT scanning and the actual number of lesions present in the patient. Given this scenario, it becomes essential to adapt the two requisite transformation functions
and
, of the prediction model for the MIL problem, as follows:
In the current study, the selection of types for
and
is approached from different perspectives to address the problem [
38]. Firstly, the focus lies on the instance-based method. Here, the transformation function
is regarded as an instance-level classifier, while
is considered an identity function that consolidates instance scores. While this method offers high interpretability, scholars [
39] have observed its inferior effectiveness compared to the embedding-based approach across all facets. The embedding method utilizes
as a low-dimensional embedding feature extractor, with
serving as a packet-level aggregation operator. By aggregating sample-level features into packet-level features, predictions for package labels can be made.
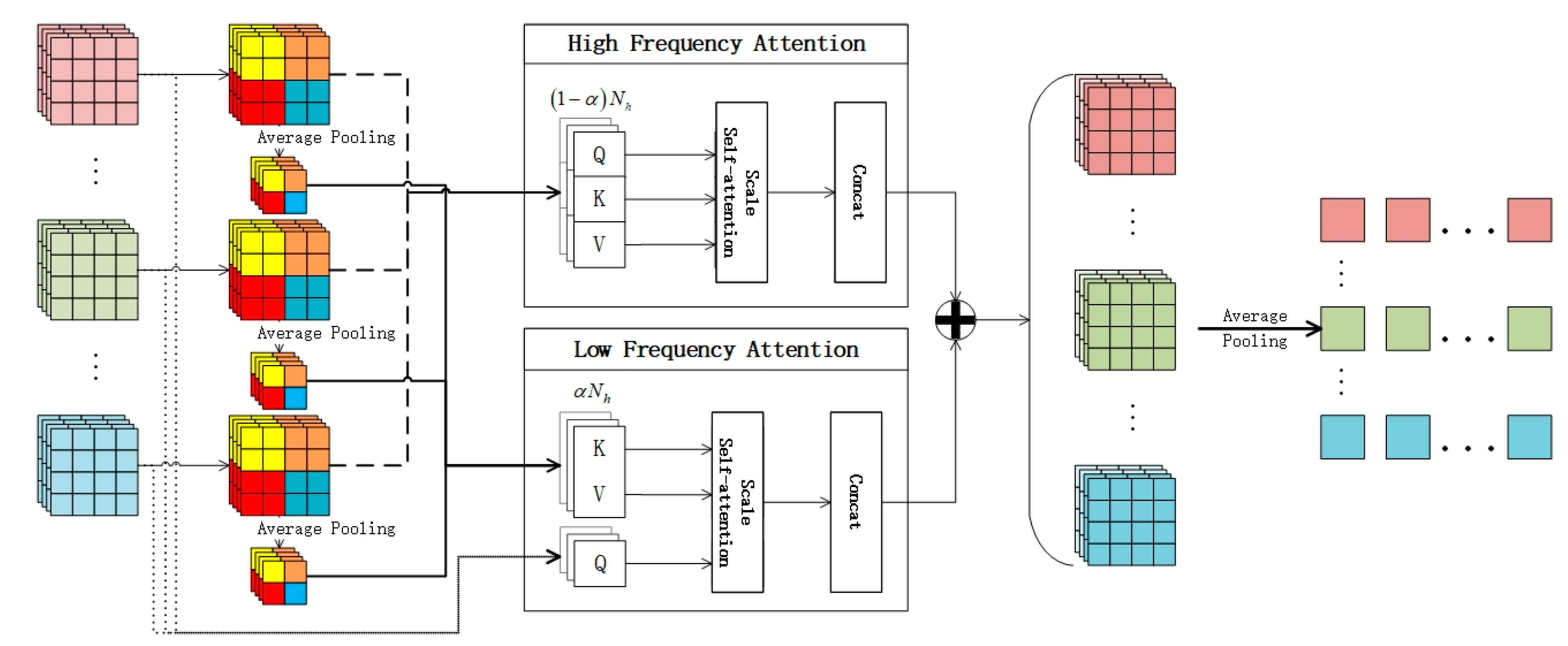
3.4. HLFFF Method for Processing High-Frequency and Low-Frequency Features
For the MIL problem parameterized by the neural network,
is used as a feature extractor. This paper proposes an HLFFF method that combines the basic feature extraction network with Hilo attention [
40], as shown in
Figure 3. In the face of the complex problems of high-resolution images, the semantic information of features can be re-added from the perspective of high frequency and low frequency. This section will explain the HLFFF method with the feature extraction network based on ResNet-50.
The output vector from the last residual block of ResNet-50 is preserved. Here, represents the feature matrix acquired from each instance under identical conditions, where denotes the number of instances in the package, and signifies the size of the hidden dimension. Subsequently, dimensionality reduction is applied to the feature vector of each instance, followed by global average pooling over a specified window size. The data before pooling and the data after pooling are utilized as inputs for high-frequency attention and low-frequency attention.
Initially, leveraging the multi-head self-attention mechanism (MSA) [
41],
self-attention heads are designated, each assigned with Query matrices (
), Key matrices (
), and Value matrices (
):
where
and
denote the high-frequency and low-frequency attention branches, respectively.
are the attention weights that
can learn. The input for
and
is
, where
represents the number of hidden weight matrices, and
is the number of hidden weight matrices corresponding to each self-attention head. Subsequently, the weighted sum of the output vectors from each head is computed:
Then, combine the output of each head:
In the formula, denotes a linear projection layer for series output. Here, represents the total number of self-attention heads in this layer, harmonizing the dimensions of output and input.
In this process, a hyperparameter is defined to regulate the number of self-attention heads participating in high frequency and low frequency, respectively. denotes the number of self-attention heads assigned to high frequency, while denotes the number of self-attention heads allocated to low frequency. Depending on the nature of the problem at hand, the value of α can be adjusted to prioritize either high frequency or low frequency, thereby potentially reducing computational complexity to some extent.
High-frequency attention (): The intuitive concept here involves utilizing high-frequency components to encode local details of the target. This is achieved by capturing high-frequency information through the establishment of a local self-attention window (for example, a 2 × 2 window). Low-frequency attention (): Each window employs average pooling to acquire down-sampled feature information , which is then mapped to and , while utilizes the original feature information . This approach not only captures abundant low-frequency information but also alleviates the complexity of Formulas (5) and (7).
Finally, the output of HLFFF is obtained through concatenating each attention result:
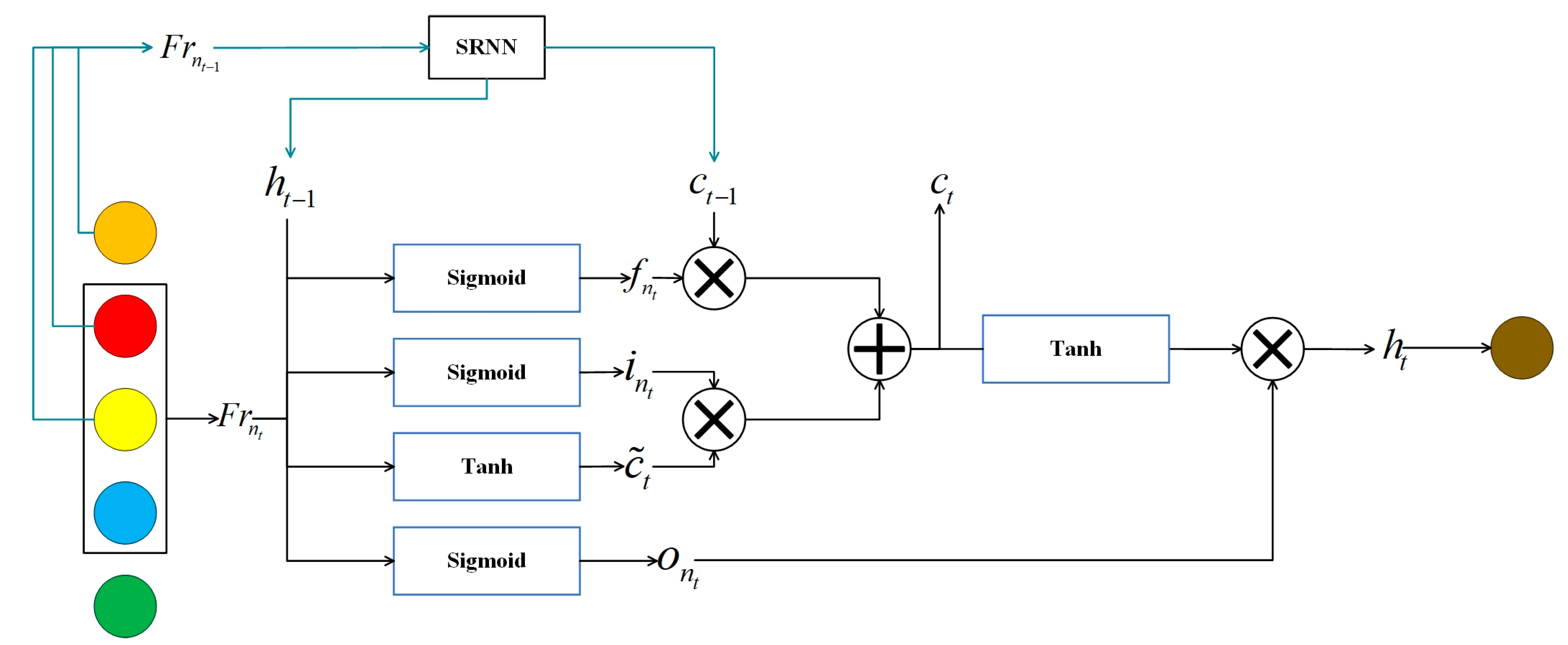
3.5. SRNN Method for Processing Instance with Temporal Relationships
In the classic MIL scenario, there is a fundamental assumption that each instance within a package is independent of one another. However, when a patient’s 3D CT image is employed as a MIL package, there exists a contiguous relationship between each slice. In this context, the target lesion at the same position might consecutively appear across several adjacent slices. Given that these lesions actually pertain to the same morphologically similar structure, we propose the utilization of a recurrent neural network to process a certain length of the instance sequence. In doing so, it is crucial to maintain the spatial order of instance upon input. A sequence of sequentially continuous instances is termed a sequence.
The significance of the SRNN method lies in its ability to identify an instance similarity vector that aligns with the target variations within a sequence. However, the uncertainty regarding the number of instance in each package presents a challenge. One existing approach is to employ a fixed-length sequence template. In this method, the length of the template must exceed the length of each package used. When the size of the package falls short of this length, the vacant portion is filled with zeros. However, this approach gives rise to two issues. Firstly, it can lead to inefficient utilization of computational resources when dealing with packages containing a small number of instances (with the largest package approximately 10 times the size of the smallest package). Secondly, the padding of zeros may degrade the learning performance of the network, particularly in cases of highly unbalanced data.
This paper proposes to employ a sliding window
to encode sequential packages. The selection of
entails additional configuration, yet within packages of varying sizes,
encoded sample fragments emerge:
After such processing, the sequence length of each input to the recurrent neural network equals
, resulting in:
Here,
is a sliding encoder, and then the recurrent neural network uses a long short-term memory (LSTM) network. The input is a feature map obtained by the HLFFF method, as shown in
Figure 4. Here, the
-th instance sequence obtained by
in order is considered to be the state at time
, and the gated unit at time
is calculated by referring to the mathematical calculation formula of LSTM:
Here, represents the sigmoid function, while , , , , , and denote the weight matrices that can be learned within the LSTM. signifies the sequence vector of the -th time step of the -th sequence, denotes the hidden state at the -th time step, and represents the memory unit at the -th time step. Particularly, represents the weight matrix employed to calculate the memory unit required for the next sequence. It is utilized to map the hidden state of the current time input and the previous time to the memory unit needed for the subsequent sequence.
4. Experiments and Results
In this chapter, the effectiveness of the proposed method will be validated using two large public datasets. The first dataset comprises lung cancer data from TCIA, while the second dataset is the CC-CCII dataset, which currently holds a prominent position in COVID-19 research.
4.1. Datasets and Experimental Settings
The TCIA lung cancer dataset comprises comprehensive lung cancer images updated in 2020, encompassing adenocarcinoma (A), small-cell carcinoma (B), and squamous-cell carcinoma (G). It provides DICOM format medical data files, facilitating the adjustment of imaging parameters as per specific requirements. On the other hand, the CC-CCII novel coronavirus pneumonia dataset, released in 2020, consists of 3D CT images of novel coronavirus pneumonia (NCP) and common pneumonia (CP). This dataset offers processed PNG format data files suitable for direct training.
In the experiment of this project, the learning ability and generalization ability of the proposed model will be assessed on these two datasets separately. Detailed information on the two datasets is provided in
Table 2, with the number of slices ranging from 30 to 300. The TCIA dataset comprises 36,031 slices, while the CC-CCII dataset contains 36,950 slices. To evaluate the model’s performance, a 5-fold cross-validation is employed during the training and testing phases. All packages are approximately split into training and test sets in a 4:1 ratio. During each batch’s training process, four-fifths of the training set is utilized to learn the weight parameters in the model, while the remaining one-fifth is used to assess the model’s generalization ability. The experimental results will be averaged across five experiments.
When transforming the data content into the tensor format required for the experiment, each 512 × 512 resolution CT image is scaled down to 256 × 256, representing only one-quarter of the initial CT image size. This resizing reduces the file size and training time of the training data overall, while also alleviating the demand on video memory to some extent. Importantly, there is minimal disparity between the data after model testing and the data before modification.
All experiments of this evaluation model will be conducted on a local workstation equipped with an Intel® Core™ i9-12900H CPU and an NVIDIA GeForce RTX 3070 Ti Laptop GPU. The manufacturers of CPU and GPU are Intel and NVIDIA, both of which are purchased in China. Given the large dataset, 32 GB of memory is utilized. The initial learning rate of the model is configured to 0.0005, and subsequently, the learning rate of the Adam optimizer is decayed using the cosine annealing method. The number of training epochs for each model is set to 50.
4.2. Evaluation Metrics
The problem solved in this paper is a binary classification problem. To evaluate the performance of the classification model in practical scenarios, typical classification evaluation indicators are usually used for evaluation, including Sensitivity (
SEN), Specificity
(SPE), Precision, F1 score, accuracy (
ACC), and area under the receiver operating characteristic (ROC) curve (
AUC). Here, the area under the ROC curve is used to assess the model’s ability to predict positive and negative instances across various thresholds. When the data category distribution is unbalanced, the use of AUC and ACC can more comprehensively evaluate the comprehensive performance of the model. Different classification models are evaluated by the above six evaluation indicators:
In the formulas, TP represents true positives, TN represents true negatives, FP represents false positives, and FN represents false negatives. Recall is calculated in the same way as Sensitivity (SEN). By computing these six indicators on the actual dataset, we can compare them with those of currently popular models to demonstrate the effectiveness of the proposed method.
4.3. Ablation Experiments on TCIA
This paper aims to investigate the contribution of the HLFFF and SRNN methods to the classification network. The FLFFF method requires setting the value of
to adjust the weight distribution of high frequency and low frequency in the method. Initially, ResNet-50 is utilized as the fundamental feature extraction method of the model. The value of
is set in the range of 0.1 to 0.9, with an interval of 0.1, yielding a total of nine values. The benchmark model of ResNet-50 combined with the HLFFF method is tested on the TCIA dataset.
Table 3 summarizes the performance indicators under different
values.
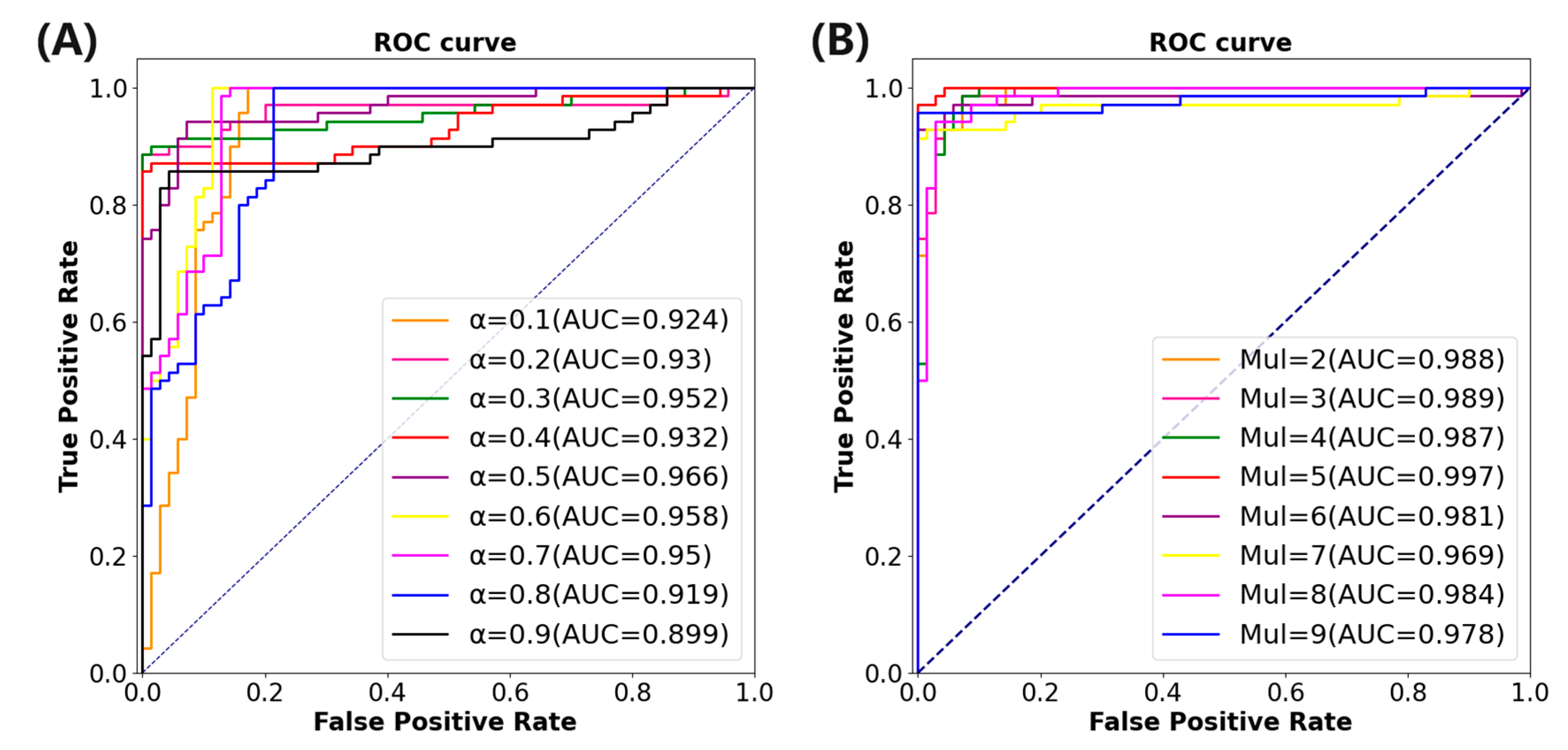
Figure 5A illustrates the area under the ROC curve under varying
values. The results indicate that when
, the model performs optimally, with the AUC and ACC increasing by 7.8% and 6.7%, respectively, compared to the classification model utilizing only ResNet-50.
The SRNN method needs to set the value of
to adjust the length of the instance fragment processed by the method. The experiment will be carried out on the basis of the combination of ResNet-50 and HLFFF methods. The value of
is set between 2 and 9 and the interval is 1, a total of 9 values. The benchmark model combining ResNet-50 and the HLFFF and SRNN methods is also tested on the TCIA dataset.
Table 4 shows the performance indicators of the model under different w values.
Figure 5B shows the area under the ROC curve under different w values. The results show that the performance of the model is optimal when
, which means that each time the sample fragment with a length of five is input into the SRNN method, the AUC and ACC are increased by 3.3% and 3.5%, respectively, compared with the model using only the HLFFF method.
In particular, we evaluated the accuracy of the model predictions based on the le-sion site annotations in the original TCIA dataset. By generating weight heat maps for each sample fragment after applying the SRNN method,
Figure 6 displays the weight heat maps for four packages. Each weight represents a fragment of length 5. The re-sults demonstrate that the SRNN method adeptly identifies the fragment with the highest lesion weight. The red boxes in the graph denote annotation boxes marked ac-cording to corresponding annotation information, highlighting the lesion sites identi-fied by the SRNN method.
4.4. HLFSRNN-MIL Method and Its Performance on TCIA
In order to eliminate the influence of the feature extraction network on the proposed method, the experiment will use the current popular feature extraction networks and the proposed method for performance evaluation.
Table 5 shows the basic information of the network used. The initial learning rate is set to 0.0005, and the learning rate reduction method is optimized by the cosine annealing algorithm.
Table 6 corresponding to
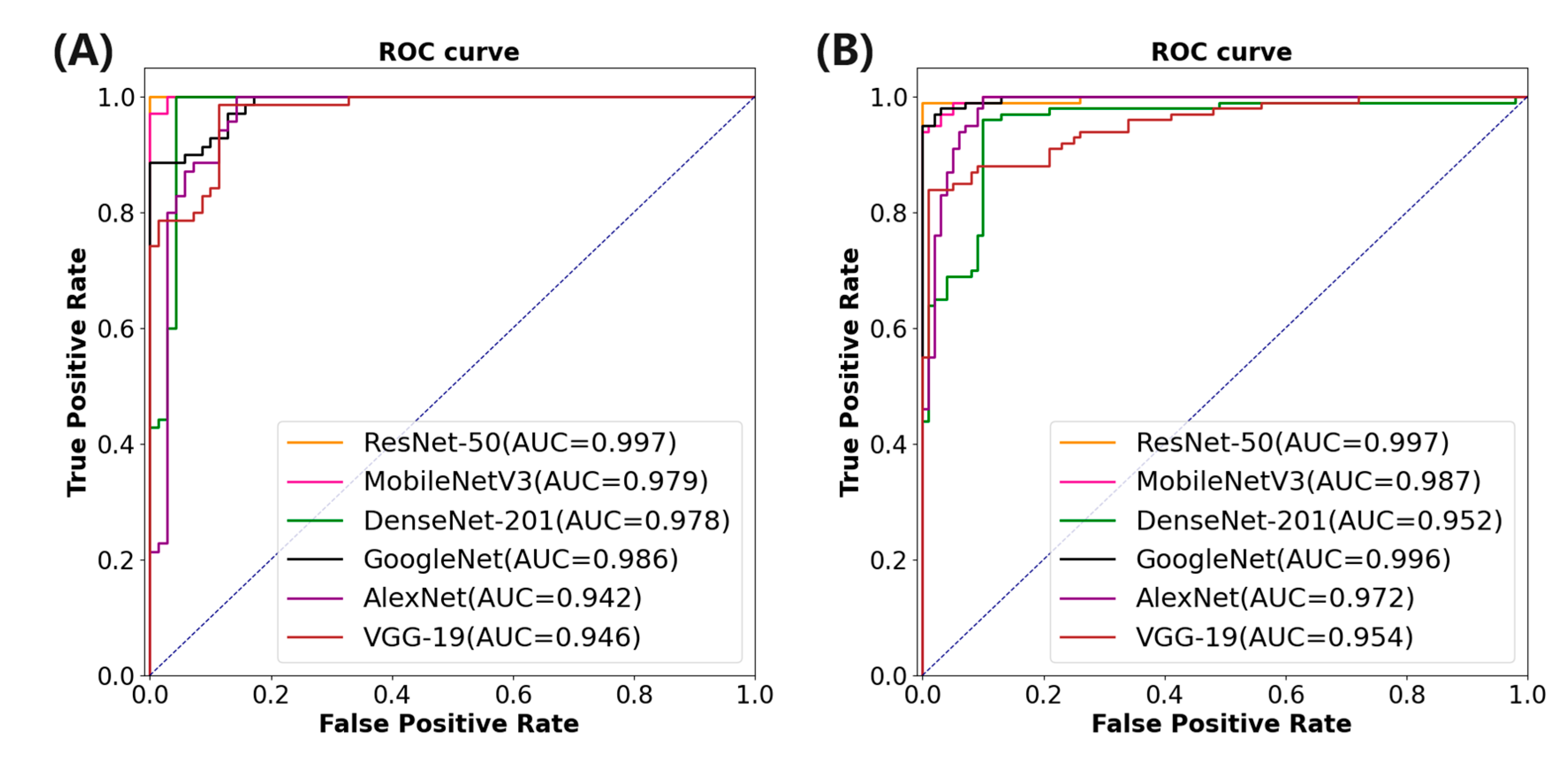
Table 5 shows the performance index of the proposed method combined with different feature extraction networks. It is evident that although AlexNet boasts a shorter training time, its performance across all metrics is notably poorer compared to ResNet-50, which exhibits the best performance metrics. Specifically, ResNet-50 achieves an AUC of 0.997, ACC of 0.992, SEN of 0.995, SPE of 0.997, and F1 score of 0.995.
Figure 7A depicts the area under the ROC curve of different feature extraction networks combined with the proposed method.
4.5. Attention Heat Maps Visualization for HLFSRNN-MIL on TCIA
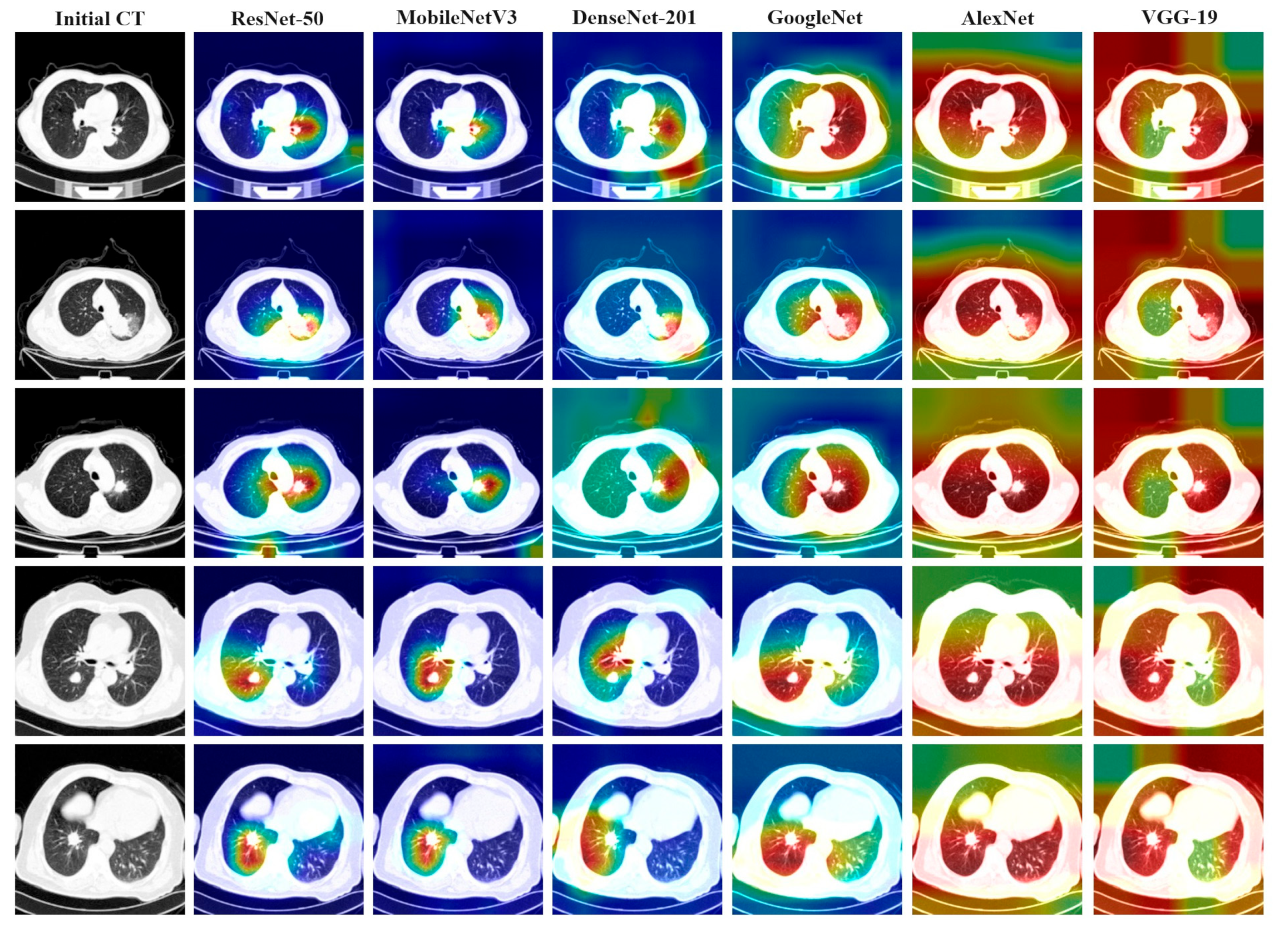
Figure 8 illustrates the thermal image generated under various conditions of different feature extraction networks, alongside the attention heat map generated by the gradient category activation mapping (Grad-CAM) method. The first column in the figure represents the result of a lung cancer patient’s slice, with each row displaying the original CT slice image and the Grad-CAM results depicted under different network models. Observations reveal that models exhibiting better performance metrics tend to focus their attention on more concentrated and accurate areas, whereas models with lower indicators often concentrate attention on areas unrelated to the lesion site. Notably, the areas of interest for ResNet-50, MobileNetV3, and GoogleNet are predominantly centered on the lesion.
4.6. Comparison of HLFSRNN-MIL with Other Methods on CC-CCII
Finally, the performance of the proposed HLFSRNN-MIL on the CC-CCII dataset is evaluated in terms of generalization and robustness. Firstly, we select the most outstanding performance indicators based on different feature extraction networks. The results are presented in
Table 7, revealing that ResNet-50 exhibits superior performance with an
AUC of 0.997,
ACC of 0.994,
SEN of 0.996,
SPE of 0.995, and F1 score of 0.992. To gain a more intuitive understanding of the classification effect across various feature networks,
Figure 7B illustrates the area under the ROC curve associated with each model.
In order to validate the efficacy of our proposed approach, we employ the HLFSRNN-MIL model on the CC-CCII dataset and compare it with state-of-the-art research.
Table 8 presents the performance index results of the relevant research compared with our study from 2021 to 2023. However, what needs special attention is that, due to actual conditions (video memory and memory), many studies have selected a part of CC-CCII for experimental testing, but we divided CC-CCII into several parts and trained them separately, and ultimately obtained very good results.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}