1. Introduction
With the rapid development of artificial intelligence and big data, emerging technologies have become the core force driving innovation and development in education. These technologies are widely used to assist teaching [
1,
2], manage classrooms, and analyze student behavior. For example, applications like the “Rain Classroom” mini-program make attendance and questioning more convenient, while advanced monitoring technologies simplify classroom management and provide accurate data for teaching evaluations. In particular, student behavior detection technology, through deep learning models, offers new perspectives for understanding student performance and teaching quality in classrooms. Despite challenges in data collection and technical application in university settings, this research holds great potential and significant value in improving educational management efficiency and teaching quality. Future research in this field is expected to elevate the quality of education to new levels [
3,
4].
The rapid advancement of object detection technology in the field of computer vision has garnered widespread attention in academia, especially methods based on deep learning. These methods can be broadly categorized into three types: two-stage algorithms, single-stage algorithms, and recently emerging Transformer-based algorithms. Since the introduction of the AlexNet network with ReLU activation function and Dropout technology, deep learning has achieved significant progress in image recognition accuracy, marking a major breakthrough in the field [
5]. Subsequently, the OverFeat algorithm demonstrated the potential of convolutional networks in object detection. The advent of R-CNN [
6] and its derivative algorithms, Fast R-CNN [
7] and Faster R-CNN [
8], significantly improved object detection accuracy and speed by integrating convolutional neural networks with region proposal techniques, highlighting the application of deep learning in object detection. Following this, algorithms such as Mask R-CNN [
9], Cascade R-CNN [
10], and Libra R-CNN [
11] further enhanced instance segmentation accuracy and the ability to handle complex scenes. In the realm of single-stage algorithms, the YOLO series [
12,
13,
14,
15,
16] transformed the detection task into a regression problem, achieving fast and efficient object detection. Algorithms like SSD [
17], RetinaNet [
18], and EfficientDet [
19] adopted various strategies to improve detection performance, especially in handling small objects and class imbalance issues. Recently, Transformer-based object detection algorithms, such as DETR [
20] and its improved versions, Deformable DETR [
21] and Conditional DETR [
22], have demonstrated strong capabilities in processing global information and complex scenes by simplifying detection processes and optimizing training efficiency. Particularly, RT-DETR [
23], designed for real-time object detection, enhances performance in accuracy and speed through optimized computational complexity and inference speed, making it highly suitable for detecting student classroom behaviors in complex scenes.
In recent years, student classroom behavior detection has become a research hotspot, focusing on three deep learning-based methods: sensor analysis, skeleton key point detection, and convolutional network detection. Sensor methods, for instance, use Kinect One to capture 2D and 3D data and evaluate student attention through machine learning techniques [
24]. Skeleton key point detection identifies specific behaviors by tracking changes in student skeletal points, such as the OpenPose model recognizing hand-raising behavior [
25,
26,
27]. Convolutional network detection methods, like YOLO, have improved behavior recognition accuracy and speed through algorithm enhancements [
28,
29,
30,
31].
Despite progress in student classroom behavior detection, the field still faces multiple challenges, such as outdated algorithms, insufficient detection efficiency, and a lack of diverse public datasets. The complexity of student behaviors, irregular seating arrangements, small object recognition difficulties, and variations in lighting and background need to be addressed. Additionally, existing studies often fail to cover student behaviors across various grades and scenes, limiting model generalization and practical applicability. Given these challenges, this study proposes using the RT-DETR algorithm for student classroom behavior detection and analysis. The algorithm aims to achieve efficient and accurate object detection through optimized computational complexity and inference speed, particularly suited for applications in complex scenes.
2. Dataset
2.1. Constructing the Fusion Student Classroom Behavior Dataset
To address the limitations of existing student behavior detection datasets in terms of singularity and scarcity, this study proposes an innovative data construction strategy—the fusion dataset method (FSCB dataset). By combining AI-generated data and actual student classroom behavior observation data, the FSCB dataset diversifies data sources. This method is similar to the Quality Function Deployment approach applied by Shvetsova et al. in product design concept selection, effectively enriching data resources and providing strong support for further behavior analysis and educational interventions [
32]. The FSCB dataset includes 4711 images with 10,185 labels of student behaviors, covering actions such as focusing, raising hands, writing, sleeping, and using phones.
Figure 1 illustrates the specific content and structure of the FSCB dataset, highlighting its broad scope and detail in capturing and labeling diverse classroom behaviors. This fusion dataset enriches the data resources for student behavior detection, providing strong support for further behavior analysis and educational interventions.
2.2. Image Generation
During the construction of this fusion dataset, we leveraged cutting-edge text-to-image generation technologies, particularly the Stable Diffusion [
33] and DALL-E 3 [
34] models, to create simulated images that closely match actual student behavior data. This approach not only significantly expanded the scale of the dataset but also enhanced its diversity and coverage. By utilizing these advanced image generation techniques, we were able to produce highly realistic images that accurately reflect student behavior patterns and classroom environments.
Specifically, the Stable Diffusion and DALL-E 3 models, through advanced deep learning algorithms, generated images with a high degree of realism, depicting various classroom behaviors such as focusing, raising hands, writing, sleeping, and using phones.
Figure 2 illustrates the diversity and detail level of these generated images, showcasing the models’ capability to accurately recreate student behaviors in different scenarios.
These simulated images provided a rich data foundation for the research, greatly enhancing the depth and breadth of the dataset. This not only helped improve the accuracy and efficiency of student behavior detection but also provided strong support for further behavior analysis and educational interventions. With this enriched data resource, we can gain a more comprehensive understanding and analysis of student behavior patterns in the classroom, thereby providing data support for improving teaching methods and enhancing educational quality.
2.3. Generalizability Analysis of the Fusion Dataset
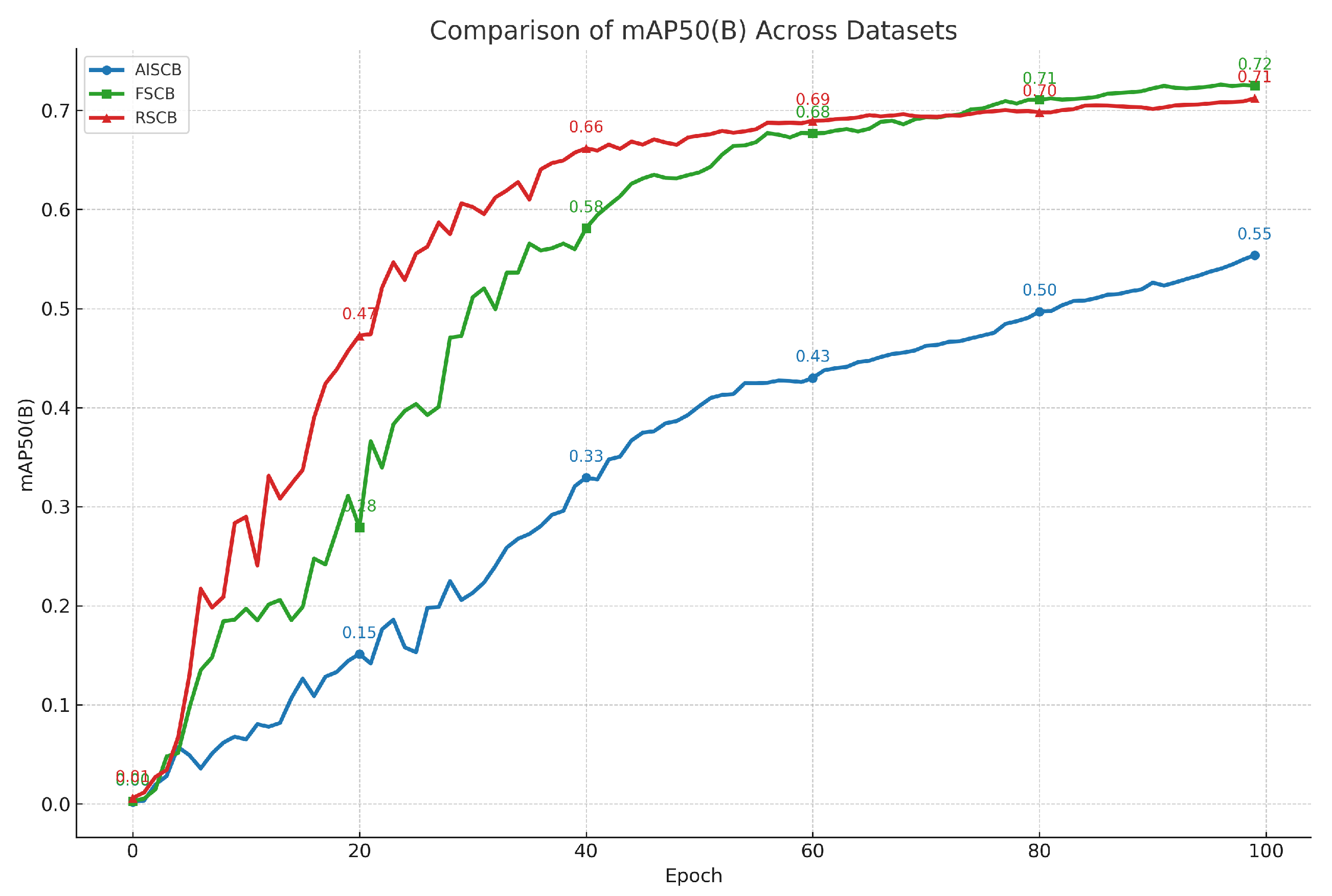
To further enhance the dataset’s practicality and application scope, we conducted a comprehensive comparative analysis of three different datasets: a dataset containing 1200 purely real-captured images (RSCB), a dataset containing 1200 completely AI-generated images (AISCB), and a fusion dataset (FSCB) containing 1200 images that combined AI-generated and real images. Each dataset included five different student behaviors, with 300 images for each behavior.
As shown in
Figure 3, the experimental results indicated that the fusion dataset demonstrated similar accuracy and reliability to the purely real-captured dataset. This finding highlights the high applicability of the fusion dataset in student classroom behavior detection, showing that combining AI-generated images with real images can effectively enhance the diversity and coverage of the dataset.
Moreover, the fusion dataset provides an effective solution to the challenges of dataset scarcity, student privacy protection, and rapid dataset construction. Traditional real-captured image datasets are often limited by high data collection costs, lengthy collection times, and privacy concerns. By incorporating AI-generated images, we can rapidly expand the dataset’s scale while providing rich training data without infringing on student privacy.
Additionally, the high accuracy and reliability of the fusion dataset lay a solid foundation for subsequent behavior analysis and educational interventions. Utilizing such a multi-source dataset enables researchers to gain a more comprehensive understanding and analysis of student behavior patterns in the classroom, thereby providing critical data support for improving teaching methods and enhancing educational quality. This innovative dataset construction method showcases the immense potential of AI technology in the education sector, paving the way for future educational technology research and applications.
3. Methods
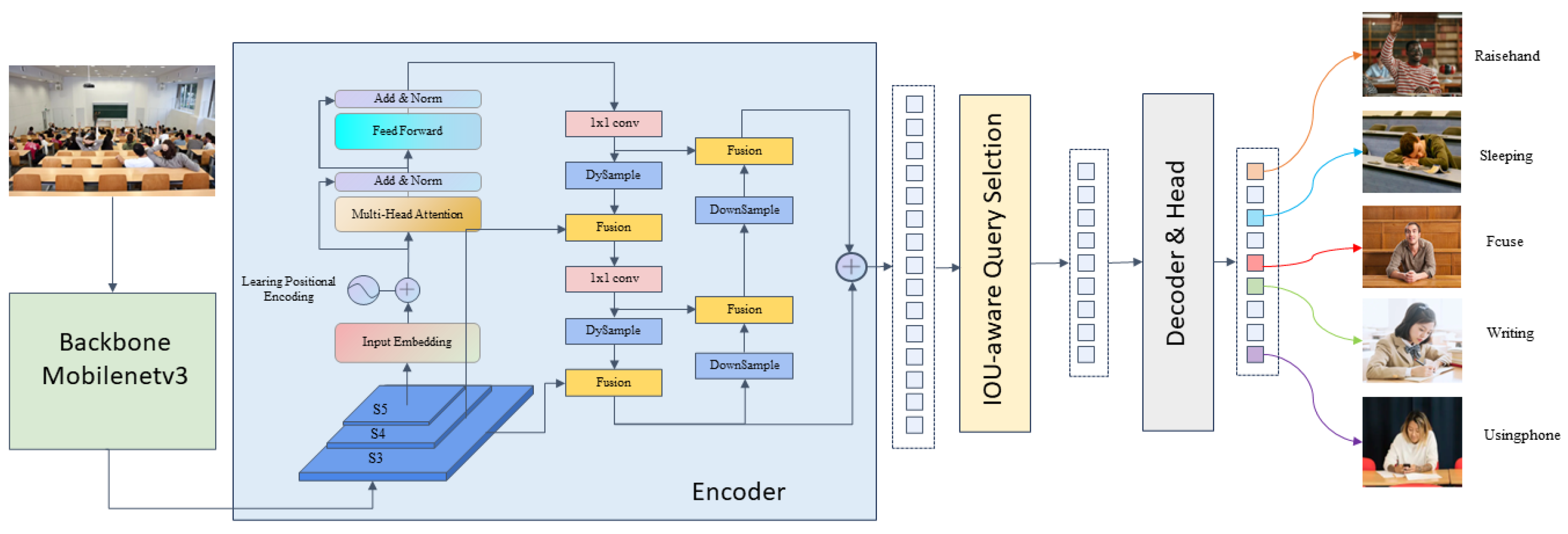
As shown in the algorithm flowchart in
Figure 4, the FSCB dataset is input into the RT DETR algorithm, which processes the data through multiple steps to accurately recognize student behaviors. First, the algorithm uses a backbone network to extract fundamental features from the images, ensuring that key information is effectively captured. Next, the Encoder processes these extracted features using self-attention mechanisms and feature fusion, enhancing the richness and diversity of the feature representations. Finally, the Decoder merges and interprets all the information through object queries, enabling accurate localization and classification of objects in the images. Through this series of processing steps, the RT DETR algorithm can accurately identify five types of student behaviors in the classroom, including focusing, raising hands, writing, sleeping, and using a phone.
3.1. Structure of RT DETR Algorithm
RT DETR is a real-time object detection model that combines two classic object detection methods: Transformer [
35] and DETR [
20] (Detection Transformer). The Transformer is a neural network architecture used for sequence modeling, initially applied in natural language processing but proven effective in computer vision. DETR is an end-to-end object detection model that transforms the object detection task into an object query problem and uses the Transformer to solve it. RT DETR adopts the DETR structure and optimizes it for real-time object detection. It comprises three main components: backbone, Encoder, and Decoder. The backbone network, which uses a CNN network, extracts image features. The CNN network’s powerful feature extraction capability is widely used in image processing tasks, providing necessary image representations for subsequent object detection tasks. The Encoder, based on the Transformer structure, processes the feature maps output by the backbone and captures global dependencies within the image through the self-attention mechanism. Compared to the traditional DETR model, RT DETR optimizes the Encoder design to reduce computational complexity and improve processing speed. These optimizations include reducing the number of self-attention layers and using more efficient attention calculation methods, aiming to maintain high precision while achieving fast inference. Each self-attention layer in the Encoder includes three main components: multi-head self-attention, feed-forward network, and residual connections with layer normalization. This design allows the model to effectively capture long-distance dependencies within the image, enhancing the understanding of complex scenes. The Decoder component receives the Encoder’s output and predefined object queries, combining them through cross-attention and self-attention layers to progressively refine predictions of each object’s location and category. Prediction heads at the end of the model perform object classification and bounding box regression based on the Decoder’s output. These heads are simple and efficient, designed to quickly generate accurate detection results. Classification heads typically use linear layers, while bounding-box regression heads may include more complex network structures to accurately predict object locations.
3.2. Improvements to the RT DETR Algorithm
This study aims to improve the accuracy and efficiency of student classroom behavior recognition by enhancing the RT DETR model in multiple aspects. First, MobileNetV3, a lightweight backbone network, was introduced to reduce the number of model parameters and computational complexity. Second, learned positional encoding (LPE) was used to improve the positional encoding mechanism in AIFI, enhancing the model’s ability to learn positional relationships in training data. Finally, the ultralight and efficient characteristics of DySample were integrated into the CCFM upsampling module to further enhance RT DETR’s performance.
3.2.1. Improving the Backbone of the RT DETR Algorithm
The MobileNet series was proposed to address the issue of traditional convolutional neural networks requiring excessive memory and computational resources when running on mobile and embedded devices. In 2017, MobileNet emerged as a lightweight CNN network designed for mobile and embedded devices, aiming to significantly reduce the number of model parameters and computational load with minimal sacrifice in accuracy. By introducing the latest MobileNetV3, we further advanced efficiency and performance balance in the backbone part of the RT DETR model. Built on the foundations of MobileNetV2 and MobileNetV1, MobileNetV3 inherits and enhances their advantages, optimizing the model to set new standards in fast processing and low resource consumption. This progress means that more efficient models can better serve practical application scenarios, meeting the growing demands for mobile computing [
36,
37,
38].
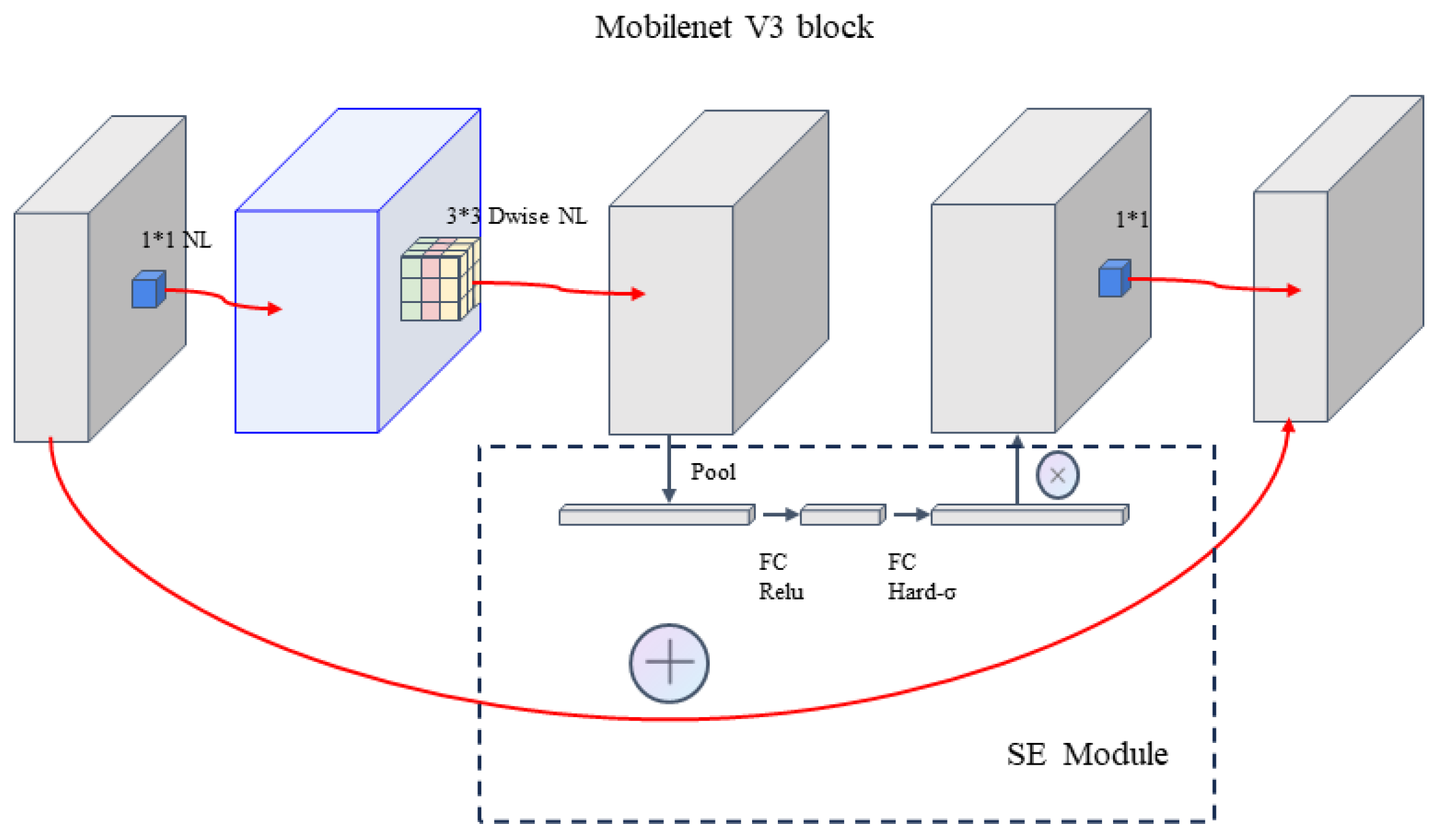
The design improvements in MobileNetV3 are reflected in innovations in the bottleneck blocks. These bottleneck blocks now embed a lightweight attention mechanism called the Squeeze-and-Excitation (SE) module. This mechanism enhances the network’s response to key information by precisely calibrating the importance of each feature channel while naturally suppressing less important information, thereby improving accuracy while keeping the model lightweight. Additionally, the bottleneck block updates include a mixed depthwise separable convolution strategy, which cleverly combines convolution kernels of different sizes. This not only effectively captures multi-scale information in the image but also optimizes computational efficiency.
Figure 5 shows the structural details of the improved bottleneck block, revealing its superior performance in executing multi-scale feature extraction.
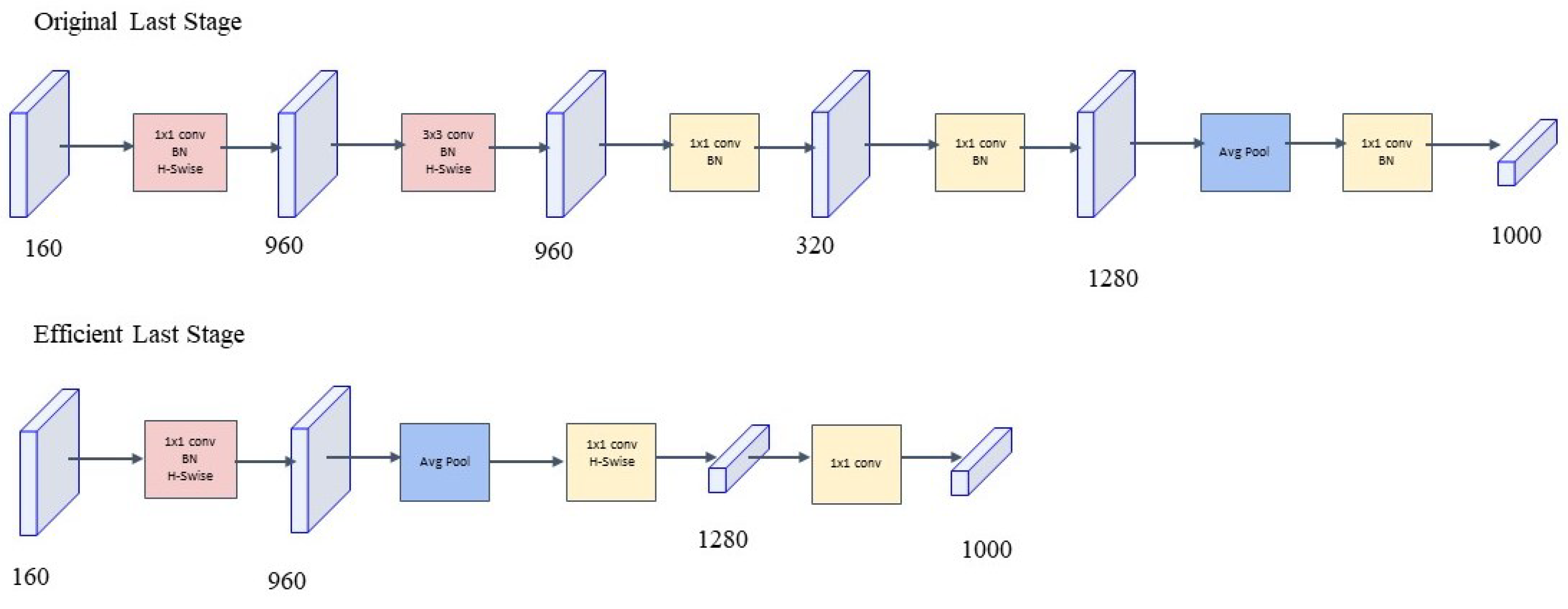
MobileNetV3 reconstructs and optimizes the most computationally intensive layers in the model to reduce their computational costs while maintaining or improving model accuracy. This includes optimizing the first and last layers of the model, which are typically the most computationally expensive parts in many deep learning architectures. MobileNetV3’s specific designs, such as adjusting the convolution kernel size, stride, and filter numbers, aim to reduce the computational burden of these layers.
Figure 6 illustrates the streamlined design of time-efficient layers.
In the design of MobileNetV3, researchers redesigned the activation function to adapt to mobile devices’ computational constraints while enhancing performance, using h-swish instead of the swish function. The swish non-linear activation function, an alternative to ReLU, significantly improves neural network accuracy. Its definition is as follows:
where
x is the input, and
is the sigmoid function of the input
x, defined as
. The swish function increases non-linearity by multiplying the sigmoid function by
x, thus enhancing the model’s expressive power.
Although this non-linearity improves accuracy, swish’s complex derivative calculation is not friendly to the quantization process. The improved h-swish function is defined as follows:
where
is a piecewise linear function, defined as
. The h-swish function can be implemented as a piecewise function, reducing memory accesses and thereby significantly lowering latency costs.
Replacing the RT DETR model’s backbone from ResNet to MobileNetV3 can significantly reduce the model’s computational load to one-tenth of the original. Simultaneously, this substitution has a negligible impact on detection accuracy, almost not diminishing the model’s performance.
3.2.2. Improving Positional Encoding in the AIFI Module of the RT DETR Algorithm
To enhance the model’s positional information encoding capability, this study used learned positional encoding (LPE) to improve the positional encoding mechanism in AIFI. In transformer-based models, positional encoding is an essential mechanism to maintain the order information of sequence data.
Traditional fixed positional encoding uses fixed positional encoding (FPE) calculated by the following Formulas (3) and (4):
where
is the dimension of the model,
is the position, and
i is the dimension. In this way, the positional encoding of each position is a fixed vector that does not change with model training.
Compared to fixed positional encoding, learned positional encoding (LPE) provides a more flexible method for encoding positional information [
39]. In this mechanism, positional encoding is part of the model parameters, learned through the model training process rather than predefined. Specifically, each positional encoding is randomly initialized at the start of model training and adjusted through optimization algorithms like backpropagation and gradient descent during training.
Learned positional encoding (LPE) is obtained during the model training process, where each position’s encoding is part of the model parameters and can dynamically adjust according to the task and data. Fundamentally, LPE increases the model’s flexibility and adaptability in encoding positional information, allowing the model to better capture and utilize positional information in sequence data. This can improve performance, particularly in tasks where the sequence’s structure or pattern is not very regular, or the model needs a finer-grained understanding of positional information.
3.2.3. Improving the Upsampling in the CCFM Module of the RT DETR Algorithm
In the RT DETR algorithm, the CCFM upsampling module plays a crucial role by effectively restoring the spatial resolution of feature maps, significantly enhancing the accuracy of object detection tasks. This module’s upsampling process ensures consistency in spatial dimensions between low-resolution and high-resolution feature maps, promoting effective integration of multi-scale features.
DySample represents a significant advancement in dynamic upsampling technology [
40]. By avoiding the complexity of dynamic convolution and adopting a point sampling strategy, it achieves efficient resource utilization. This method considerably reduces the computational burden compared to traditional dynamic upsampling techniques while demonstrating better performance in object detection tasks. Its mathematical representation can be summarized in the following steps:
Feature map representation: let the input low-resolution feature be , where H, W, and C represent height, width, and channels, respectively.
Sampling point generation: The sampling point generator in DySample dynamically selects sampling points based on the input . Let the generated set of sampling points be , where N is the number of sampling points, and is the coordinate of the ith sampling point.
Upsampling operation: through the sampling points S and corresponding interpolation algorithms like bilinear interpolation, a high-resolution feature map is generated from , where and are the target high-resolution dimensions.
DySample’s upsampling technology significantly improves computational efficiency and optimizes the recovery of high-resolution feature maps through fine sampling point selection, effectively enhancing object detection accuracy. Moreover, DySample technology does not rely on specific hardware acceleration, increasing its practicality and flexibility in student classroom scenarios.
3.3. Experimental Environment Configuration, Training Setup, and Data Augmentation
3.3.1. Experimental Environment Configuration
The experimental environment for training the RT DETR model was configured as follows: the operating system was Ubuntu 20.04, the programming language was Python 3.8, and the deep learning framework used was PyTorch 1.10.0 with CUDA version 11.3. The hardware setup included an NVIDIA RTX 3090 GPU with 24 GB of memory, an Intel(R) Xeon(R) Platinum 8352V CPU with 12 cores @ 2.10 GHz, and 90 GB of RAM.
3.3.2. Training Setup
Learning Rate: The initial learning rate (lr0) was set to 0.0001. During the first 2000 iterations, it gradually decreased from 0.1 to 0.0001 to ensure training stability. After this warm-up phase, the learning rate remained constant at 0.0001, facilitating stable and effective learning of data features.
Optimizer: The Adam optimizer was used, with initial parameters set as follows: β1 = 0.9, β2 = 0.999, and ɛ = 1 × 10 −8. Adam was chosen for its excellent performance in handling sparse gradients and large datasets.
Batch size: A batch size of 8 was used during training. This setting ensured efficient GPU memory utilization while also aiding in the stable updating of model weights.
Number of epochs: The model was trained on the training set for a total of 100 epochs. Early stopping was implemented by monitoring the performance on the validation set to prevent overfitting.
Loss function: The RT DETR model’s loss function consists of several key components to optimize detection performance. The main components include the box regression loss (Box Loss, weight 7.5), which uses the mean squared error (MSE) or Intersection over Union (IoU) loss to measure the difference between predicted and ground-truth bounding boxes; the classification loss (Classification Loss, weight 0.5), which uses cross-entropy loss to assess the accuracy of predicted class probabilities; and the objectness loss (Objectness Loss, weight 1.0), which employs binary cross-entropy loss to evaluate the confidence of predicted bounding boxes. Additionally, the Distribution Focal Loss (DFL, weight 1.5) was introduced to improve the accuracy of bounding box predictions.
3.3.3. Data Augmentation Techniques
In this study, we employed various data augmentation techniques to enhance the generalization and robustness of the model. These techniques include HSV color space augmentation (random adjustments of hue, saturation, and brightness), geometric transformations (rotation, translation, scaling, shearing, and perspective transformations), flipping (horizontal and vertical flips), as well as composite augmentation techniques (Mosaic and Mixup). The specific parameter settings were as follows: a hue adjustment range of 0.015, a saturation adjustment range of 0.7, a brightness adjustment range of 0.4; for geometric transformations, the translation range was ±0.1, and the scaling range was ±0.5; the probability of horizontal flipping was 0.5. These data augmentation techniques generated more diverse training samples during the training process, thereby significantly improving the model’s performance in practical applications.
4. Experiment and Analysis
4.1. Comparison Experiments of Algorithms on the SCB-Dataset-S
Table 1 presents the comparison results of different algorithms on the SCB-Dataset-S. The SCB-Dataset-S is a publicly available dataset of real student classroom behaviors, containing a total of 5010 images with annotations for three types of behaviors: hand raising, reading, and writing. Specifically, the dataset includes 10,078 labels for hand raising, 5882 labels for reading, and 2539 labels for writing. The models evaluated included YOLOv5n, YOLOv8n, RT DETR-ResNet18, and RT DETR-ResNet18+LPE+DySample. Their performance was assessed using four standard object detection metrics: precision, recall, mAP50, and mAP50-95. The results were as follows:
The results clearly indicated that the RT DETR-ResNet18+LPE+DySample model outperformed the others across all evaluated metrics, demonstrating superior precision, recall, and consistency in object detection. This highlighted the model’s enhanced capability in handling complex scenes and detecting small targets, making it particularly suitable for practical applications such as monitoring student behavior in classrooms.
4.2. Comparison Experiments of Algorithms on the FSCB-Dataset
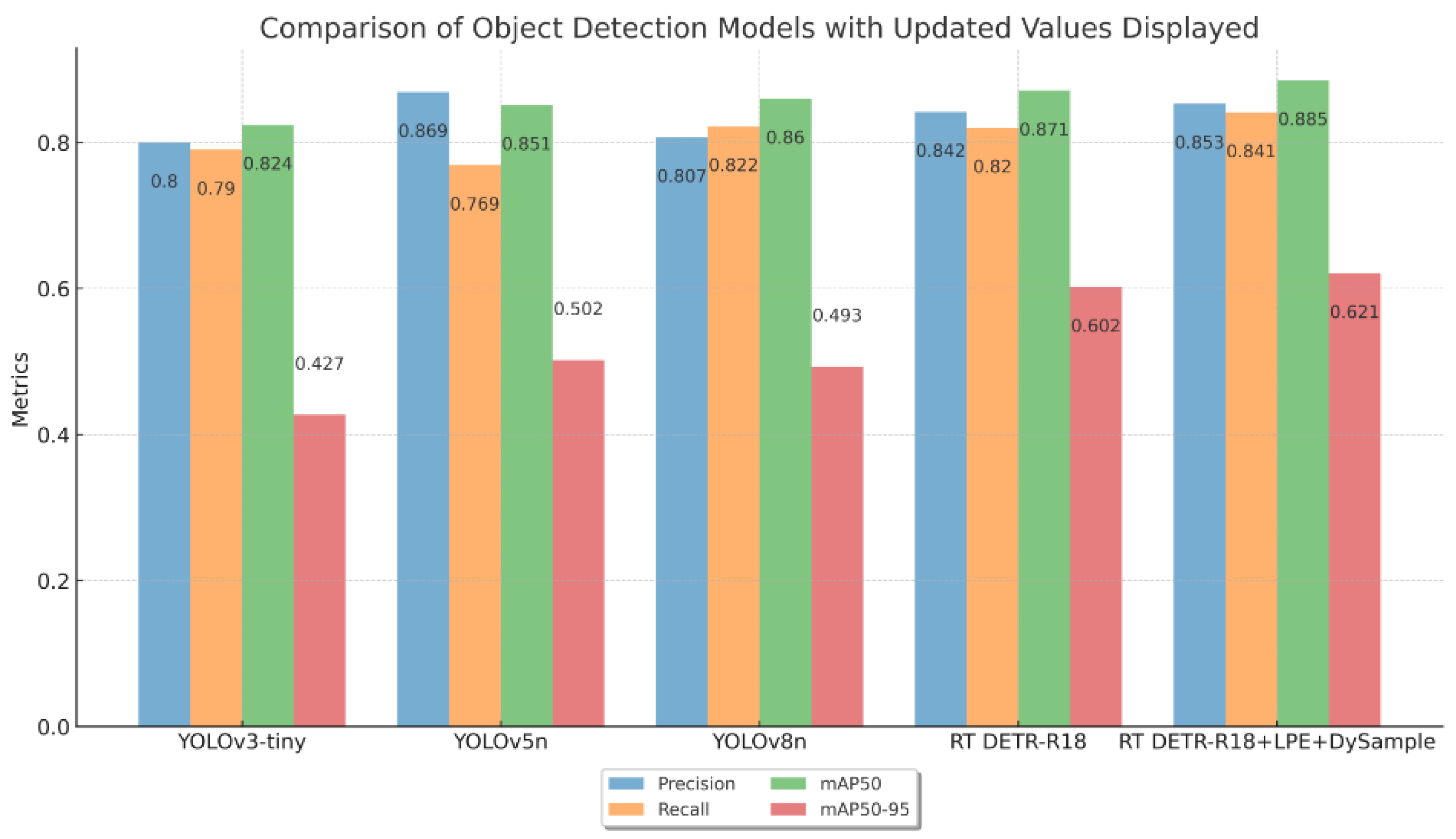
This section details the comparison experiment results of the improved RT DETR-18+LPE+DySample model and existing object detection models (YOLOv3-tiny, YOLOv5n, YOLOv8n) on the FSCB-dataset. All models were trained under the same hardware configuration and training epochs, using standard object detection metrics to evaluate performance, including precision, recall, mAP50, and mAP50-95. The results are shown in
Figure 7.
Experimental results showed that the improved RT DETR-18+LPE+DySample model performed excellently on various performance metrics. The precision increased to 0.853, and the recall rate was 0.841, indicating superior positive sample detection ability. The mAP50 and mAP50-95 metrics achieved 0.885 and 0.621, respectively, demonstrating consistency and high precision across different IoU thresholds. These optimizations significantly enhanced the model’s ability to handle complex scenes and small target detection, suitable for practical applications like student classroom behavior detection. Overall, the correctness of the optimization strategies and their potential application value were validated.
4.3. Backbone Improvement Experiments
In this experiment, we explored the impact of replacing different backbone networks within the RT DETR framework on model performance. Four configurations were compared: RT DETR-ResNet18, RT DETR-Faster, RT DETR-EfficientViT, and RT DETR-MobileNetv3. We evaluated these models in terms of total parameters, GFLOPs, FPS, and two accuracy metrics, mAP50 and mAP50-95, to assess their performance in resource consumption, speed, and accuracy.
The experimental results, as shown in
Table 2, indicated that RT DETR-MobileNetv3 was the lightest in terms of total parameters, with 9,546,660 parameters and 23.6 GFLOPs, indicating higher computational efficiency. In terms of real-time performance (FPS), this model ranked first with a result of 76.4. Despite having fewer parameters, the MobileNetv3 version showed strong performance with a mAP50 of 0.857, surpassing RT DETR-EfficientViT and being close to RT DETR-Faster’s 0.879. For the more comprehensive accuracy metric mAP50-95, RT DETR-MobileNetv3 achieved 0.591, which was very close to RT DETR-Faster. This result demonstrated MobileNetv3’s contribution to overall model performance when replacing the backbone, especially in maintaining high efficiency and good accuracy while ensuring real-time performance.
4.4. Ablation Experiments
To comprehensively evaluate the effectiveness of different configurations in the RT-DETR model for classroom behavior detection, we conducted ablation experiments, including enhancements such as backbone network replacement, learned positional encoding (LPE), and dynamic upsampling (DySample). The results are summarized in
Table 3.
The RT DETR-ResNet18, serving as the baseline model, demonstrated significant capabilities in various behavior classifications, achieving an overall accuracy of 87.2%. The introduction of learned positional encoding (LPE) improved the detection accuracy of specific categories such as “Writing” and “Sleeping,” raising the overall accuracy to 87.8%, with an increased frame rate of 60.2 FPS, indicating a notable enhancement in processing efficiency. Particularly, the RT DETR-ResNet18+LPE+DySample configuration achieved the highest accuracy in detecting “Raising Hand” and “Writing” behaviors, with an overall accuracy of 88.5%. This configuration also exhibited outstanding real-time processing capabilities, recording the highest frame rate of 57.6 FPS.
The final model configuration, RT DETR-MobileNetV3+LPE+DySample, while not entirely surpassing its predecessors in accuracy, significantly reduced computational resource consumption, with only 9.67 M parameters and 26.3 GFLOPs. Despite an increased frame rate of 72.3 FPS, this configuration demonstrated strong potential for application scenarios where computational efficiency is critical, particularly suitable for deployment in mobile devices or embedded systems with limited resources.
The ablation study highlighted the significant impact of various architectural enhancements on the performance of the RT-DETR model. Specifically, the RT DETR-MobileNetV3+LPE+DySample configuration effectively reduced the model’s computational requirements and improved processing speed while maintaining reasonable accuracy, providing an excellent solution for real-time behavior detection in computationally constrained environments.
4.5. Visualization
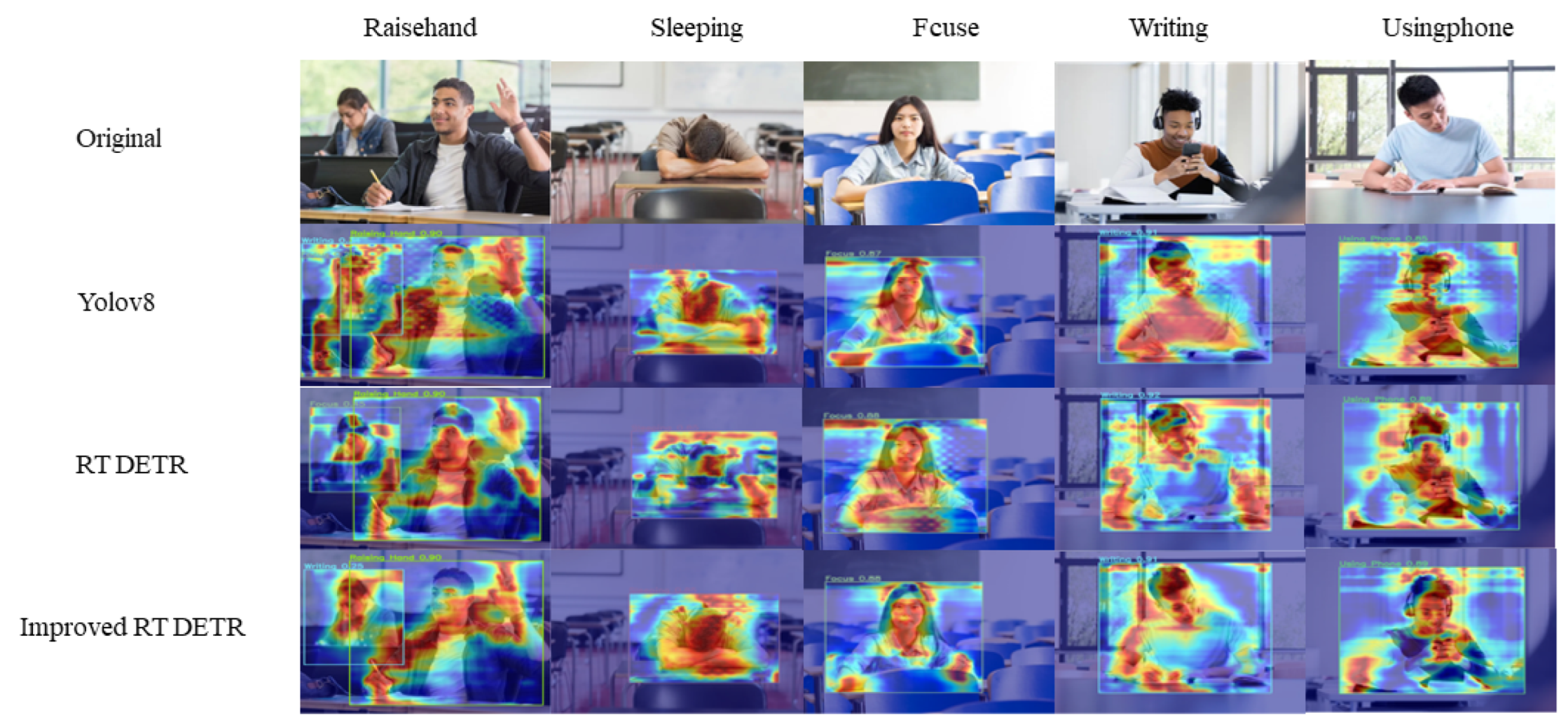
In this study, we conducted an in-depth analysis of the improved RT DETR model’s performance in student classroom behavior detection through heatmap visualization experiments. Heatmaps were generated by the attention weights predicted by the model, visually representing the model’s focus on certain areas of the image, as shown in
Figure 8. This visualization provides intuitive evidence for understanding and interpreting the model’s decision-making process.
In the experiment, we first captured a series of representative classroom scenes involving various typical student behaviors, such as raising hands, sleeping, distraction, writing, and using mobile phones. These scenes were then processed using YOLOv8, the original RT DETR, and our improved RT DETR model to generate the corresponding heatmaps. The improved heatmaps demonstrated the superior performance of the optimized model in the following aspects:
Enhanced attention focus: The improved model exhibited more concentrated attention distribution on the heatmaps. This indicated that the model effectively focused on areas closely related to the behavior detection task, reducing attention dispersion to irrelevant regions.
Optimized spatial resolution: Through improved positional encoding, the model displayed finer spatial resolution on the heatmaps. This was reflected in clearer boundaries of active regions, enhancing behavior detection accuracy.
Improved feature layer fusion: The improved CCFM upsampling strategy demonstrated better multi-scale fusion effects on the heatmaps. This ensured a smoother transition from low-level to high-level features, aiding in capturing detailed information while maintaining overall behavior pattern recognition.
Reduced noise and interference: The improved model produced clearer signals on the heatmaps, effectively suppressing noise and background interference. This is particularly important as it indicates the model’s enhanced robustness to various types of interference in real classroom environments.
5. Discussion
Although this study achieved significant results in detecting student classroom behavior, several limitations still need to be addressed.
1. Dataset diversity and scale: The diversity and scale of the dataset are still insufficient. Although the fusion dataset (FSCB-dataset) combines AI-generated data and actual observation data, enriching the data sources, the scenes and behavior types included in the dataset may not fully cover all possible situations in actual classrooms. The data generated using advanced text-to-image generation techniques (such as Stable Diffusion and DALL-E 3) may not completely reflect the complexity and variability of real scenes in some cases.
2. Real-time performance: Although the RT-DETR model proposed in this paper incorporates the MobileNetV3 backbone network, learned positional encoding (LPE), and dynamic upsampling (DySample) techniques, significantly improving computational efficiency, further optimization is needed to ensure real-time performance, especially in resource-constrained mobile devices or embedded systems.
3. Model explainability: The black-box nature of deep learning models makes their decision-making processes difficult to interpret, which is particularly important in educational settings. Future research can further explore the explainability of behavior detection models, using attention maps and visualization tools to help teachers and researchers better understand the model’s decision-making process, thereby improving the system’s transparency and acceptability.
To further enhance the performance and practicality of the student classroom behavior detection system, future research can explore the following directions:
1. Real-time inference optimization: Investigate methods to further optimize real-time inference, such as edge computing and model compression techniques, to improve deployment efficiency and performance on mobile devices. Techniques such as quantization, pruning, and distillation are feasible approaches [
41].
2. Multimodal data fusion: Combine video, audio, and sensor data to build a multimodal behavior detection system. Multimodal fusion not only provides more comprehensive behavior analysis but also enhances detection robustness and accuracy in various environments. For example, integrating microphone data to detect students’ vocal behaviors, combined with visual data, can improve overall detection performance [
42].
3. Explainability in behavior detection**: Further study the explainability of deep learning models, especially in interpreting detected student behaviors. Using explainability techniques such as attention maps and visualization tools can help teachers and researchers better understand the model’s decision-making process, enhancing the system’s transparency and acceptability [
31].
These research directions not only offer new technical pathways for student behavior detection but also lay a solid foundation for further development in the field of educational technology. Future research can continuously optimize algorithms, enhance the model’s generalization capabilities, and integrate more practical application scenarios, advancing the development and application of intelligent education systems.
6. Conclusions
This study significantly enhanced the performance and practical application of a student classroom behavior detection system through various innovations and optimizations. Firstly, we constructed a fusion dataset (FSCB-dataset) that effectively addressed the issues of limited diversity and scarcity in student behavior detection datasets, providing more varied and realistic data resources for model training. Secondly, we proposed an improved detection model based on the RT DETR algorithm. By incorporating the lightweight MobileNetV3 backbone network, learned positional encoding (LPE), and dynamic upsampling (DySample) techniques, the model’s computational efficiency was significantly improved while maintaining the original detection accuracy despite the lightweight design. Test results on the FSCB-dataset demonstrated that the improved RT DETR model excelled in various performance metrics. The improved lightweight network is also easy to deploy on mobile devices, proving its practicality in resource-constrained environments.
These research outcomes not only offer new technical pathways for student behavior detection but also lay a solid foundation for further development in the field of educational technology. Future research can further optimize the algorithm, enhance the model’s generalization capabilities, and integrate more practical application scenarios, continuously advancing the development and application of intelligent education systems.
Author Contributions
Conceptualization, L.L.; Methodology, H.Y.; Software, H.Y.; Validation, H.Y.; Formal analysis, Q.X., Y.X. and D.L.; Investigation, Q.X., Y.X. and D.L.; Resources, H.Y.; Data curation, H.Y.; Writing—original draft, H.Y.; Writing—review & editing, L.L. and H.Y.; Visualization, H.Y.; Supervision, L.L.; Project administration, L.L.; Funding acquisition, L.L. All authors have read and agreed to the published version of the manuscript.
Funding
Industry-University-Research Innovation Fund for Chinese Universities (2021KSA05005).
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The raw data supporting the conclusions of this article will be made available by the authors on request.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Valdés, J.J.; Bonham-Carter, G. Time dependent neural network models for detecting changes of state in complex processes: Applications in earth sciences and astronomy. Neural Netw. 2006, 19, 196–207. [Google Scholar] [CrossRef] [PubMed]
- Lagaris, I.E.; Likas, A.; Fotiadis, D.I. Artificial neural networks for solving ordinary and partial differential equations. IEEE Trans. Neural Netw. 1998, 9, 987–1000. [Google Scholar] [CrossRef] [PubMed]
- Hee Lee, J.; Shvetsova, O.A. The impact of VR application on student’s competency development: A comparative study of regular and VR engineering classes with similar competency scopes. Sustainability 2019, 11, 2221. [Google Scholar] [CrossRef]
- Shvetsova, O.; Feroz, M.; Salkutsan, S.; Efimov, A. Artificial Intelligence Application for Healthcare Industry: Cases of Developed and Emerging Markets. In Proceedings of the International Conference on Expert Clouds and Applications, Bengaluru, India, 9–10 February 2022; Springer: Singapore, 2022; pp. 419–432. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural, NIPS’12. In Proceedings of the 25th International Conference on Neural Information Processing Systems, Lake Tahoe, NV, USA, 3–6 December 2012; pp. 3–6. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Faster, R. Towards real-time object detection with region proposal networks. Adv. Neural Inf. Process. Syst. 2015, 9199, 2969239–2969250. [Google Scholar]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask r-CNN. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Cai, Z.; Vasconcelos, N. Cascade r-cnn: Delving into high quality object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6154–6162. [Google Scholar]
- Pang, J.; Chen, K.; Shi, J.; Feng, H.; Ouyang, W.; Lin, D. Libra r-cnn: Towards balanced learning for object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 821–830. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7263–7271. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Zhu, X.; Lyu, S.; Wang, X.; Zhao, Q. TPH-YOLOv5: Improved YOLOv5 based on transformer prediction head for object detection on drone-captured scenarios. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 2778–2788. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of the Computer Vision—ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Proceedings, Part I 14. Springer: Berlin/Heidelberg, Germany, 2016; pp. 21–37. [Google Scholar]
- Wang, Y.; Wang, C.; Zhang, H.; Dong, Y.; Wei, S. Automatic ship detection based on RetinaNet using multi-resolution Gaofen-3 imagery. Remote Sens. 2019, 11, 531. [Google Scholar] [CrossRef]
- Tan, M.; Pang, R.; Le, Q.V. Efficientdet: Scalable and efficient object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 10781–10790. [Google Scholar]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-end object detection with transformers. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 213–229. [Google Scholar]
- Zhu, X.; Su, W.; Lu, L.; Li, B.; Wang, X.; Dai, J. Deformable detr: Deformable transformers for end-to-end object detection. arXiv 2020, arXiv:2010.04159. [Google Scholar]
- Meng, D.; Chen, X.; Fan, Z.; Zeng, G.; Li, H.; Yuan, Y.; Sun, L.; Wang, J. Conditional detr for fast training convergence. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 28 February 2021; pp. 3651–3660. [Google Scholar]
- Zhao, Y.; Lv, W.; Xu, S.; Wei, J.; Wang, G.; Dang, Q.; Liu, Y.; Chen, J. Detrs beat yolos on real-time object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 21 June 2024; pp. 16965–16974. [Google Scholar]
- Zaletelj, J.; Košir, A. Predicting students’ attention in the classroom from Kinect facial and body features. EURASIP J. Image Video Process. 2017, 2017, 1–12. [Google Scholar] [CrossRef]
- Bai, Y. Research on Video-Based Student Action Recognition Method. Instrum. User 2020, 27, 10–12. [Google Scholar]
- Li, J. Study on Classroom Teacher-Student Behavior Patterns Based on Skeleton Information. Ph.D. Thesis, Northwest University, Kirkland, WA, USA, 2021. [Google Scholar]
- Cao, Z.; Simon, T.; Wei, S.E.; Sheikh, Y. Realtime multi-person 2d pose estimation using part affinity fields. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7291–7299. [Google Scholar]
- Gao, K. Research on Classroom Human Behavior Recognition Based on Convolutional Neural Networks. Ph.D. Thesis, Taiyuan University of Technology, Taiyuan, China, 2020. [Google Scholar]
- Feng, S. Research on Student Classroom Behavior Recognition Based on Deep Convolutional Neural Networks. Ph.D. Thesis, Chang’an University, Xi’an, China, 2020. [Google Scholar]
- Huang, G. Research on Student Classroom Behavior Recognition Based on Deep Learning. Ph.D. Thesis, China University of Mining and Technology, Beijing, China, 2021. [Google Scholar]
- Mahmoudi, S.A.; Amel, O.; Stassin, S.; Liagre, M.; Benkedadra, M.; Mancas, M. A review and comparative study of explainable deep learning models applied on action recognition in real time. Electronics 2023, 12, 2027. [Google Scholar] [CrossRef]
- Shvetsova, O.A.; Park, S.C.; Lee, J.H. Application of quality function deployment for product design concept selection. Appl. Sci. 2021, 11, 2681. [Google Scholar] [CrossRef]
- Rombach, R.; Blattmann, A.; Lorenz, D.; Esser, P.; Ommer, B. High-resolution image synthesis with latent diffusion models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 10684–10695. [Google Scholar]
- Ramesh, A.; Dhariwal, P.; Nichol, A.; Chu, C.; Chen, M. Hierarchical text-conditional image generation with clip latents. arXiv 2022, arXiv:2204.06125. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. arXiv 2017, arXiv:1706.03762. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.C. Mobilenetv2: Inverted residuals and linear bottlenecks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4510–4520. [Google Scholar]
- Howard, A.; Sandler, M.; Chu, G.; Chen, L.C.; Chen, B.; Tan, M.; Wang, W.; Zhu, Y.; Pang, R.; Vasudevan, V.; et al. Searching for mobilenetv3. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 1314–1324. [Google Scholar]
- Ke, G.; He, D.; Liu, T.Y. Rethinking positional encoding in language pre-training. arXiv 2020, arXiv:2006.15595. [Google Scholar]
- Liu, W.; Lu, H.; Fu, H.; Cao, Z. Learning to upsample by learning to sample. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 1–6 October 2023; pp. 6027–6037. [Google Scholar]
- Han, S.; Mao, H.; Dally, W.J. Deep compression: Compressing deep neural networks with pruning, trained quantization and huffman coding. arXiv 2015, arXiv:1510.00149. [Google Scholar]
- Baltrušaitis, T.; Ahuja, C.; Morency, L.P. Multimodal machine learning: A survey and taxonomy. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 41, 423–443. [Google Scholar] [CrossRef] [PubMed]
| Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}