
Generative Aspect Sentiment Quad Prediction with Self-Inference Template


Abstract
1. Introduction
- We designed a Self-Inference Template that guides the model in step-by-step reasoning and significantly improves the results of aspect sentiment quadruplet prediction. To our knowledge, this work is the first to approach aspect sentiment quadruplet prediction from the perspective of encouraging the model to contemplate and reason gradually.
- We created prompt texts based on the training tasks to help the model train on small datasets. Experiments on both Paraphrase and SIT models demonstrated the effectiveness of prompts.
- We boldly experimented with applying MASK operations to ABSA text data to help the model effectively identify sentiment elements, providing more possibilities for future research on ABSA tasks.
2. Related Work
3. Methodology
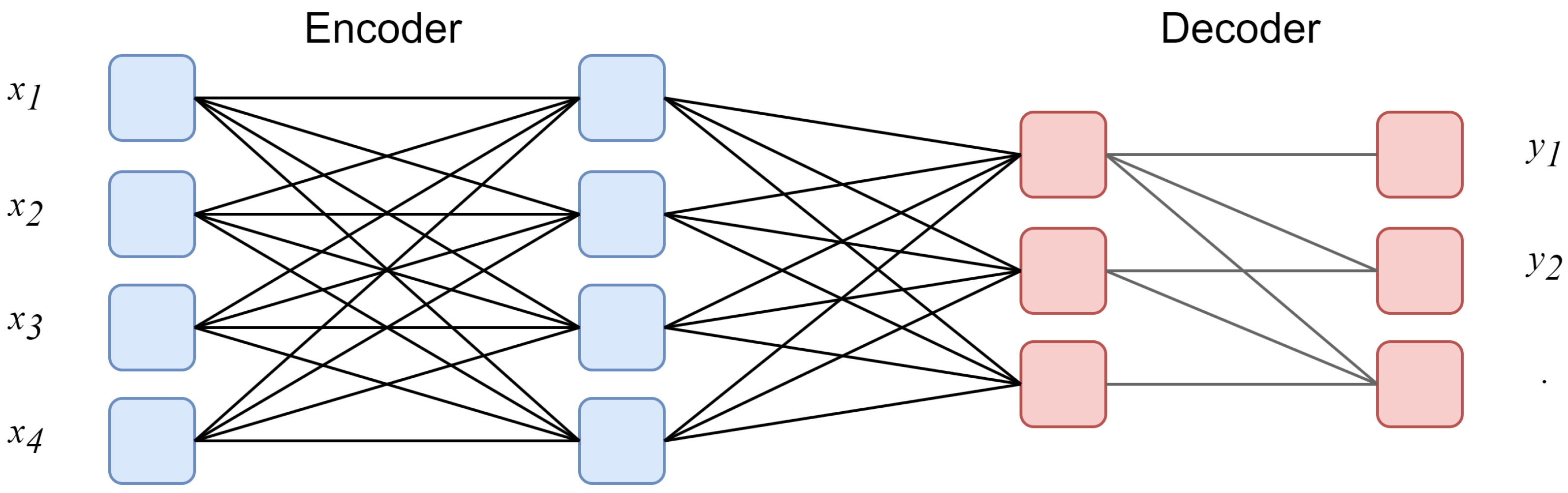
3.1. Aspect Sentiment Quad Prediction Based on the Generative Paradigm
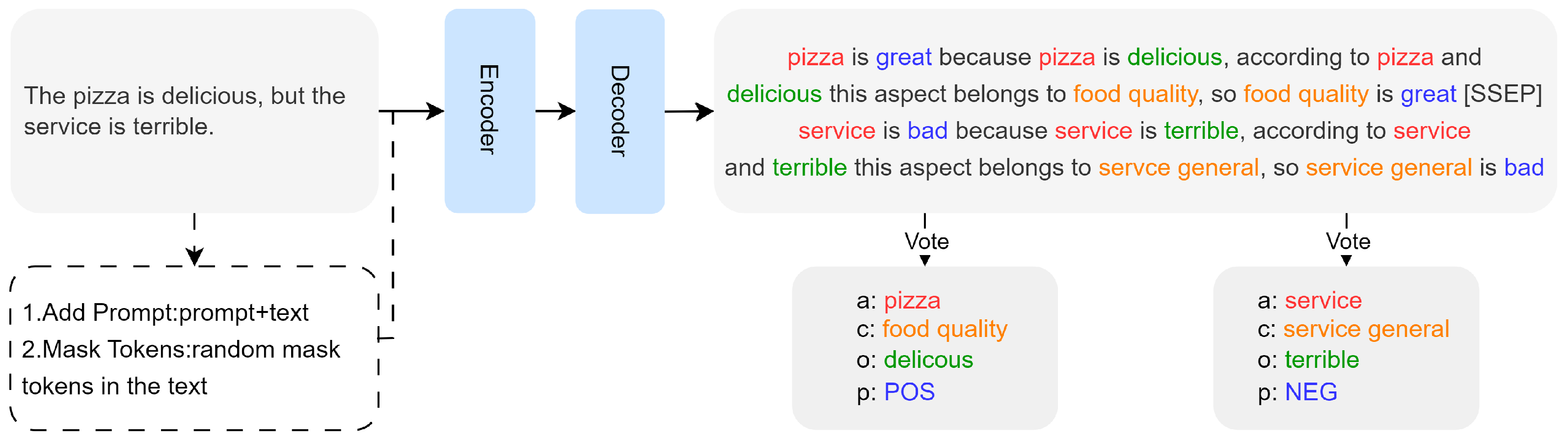
3.2. Self-Inference Template
3.3. Addition Prompt
3.4. Mask Tokens
4. Experimental Setup
4.1. Dataset
4.2. Experiment Details
4.3. Baselines
- HGCN-BERT+BERT-TFM Modification of the above model with the final linear layer replaced by Transformer blocks (BERT-TFM).
- TASO-BERT-Linear TAS [8], originally designed for extracting unified triples of aspect categories, aspect terms, and sentiment polarities, is extended to TASO for handling ASQP tasks. Linear classification layers are used for prediction.
- TASO-BERT-CRF A variant of the TASO model with a Conditional Random Field layer in the prediction stage.
- TAS-BERT-ACOS On the basis of the TAS method, cai [9] designed a two-step pipeline approach that incorporates BERT to extract quadruples from ACOS data.
- Extract-Classify-ACOS This method first extracts aspect terms and opinion terms from the original sentence and then classifies aspect categories and sentiment polarities based on these extracted terms [9].
- Seq2Path Transforming the generation order of sentiments into the path of a tree, using a constrained beam search, automatically selecting valid paths with the help of additional tokens [24].
- PARAPHRASE This method extracts (at, ac, sp, ot) by paraphrasing the original sentence as “ac is sp because at is ot” [10].
- DLO Considering the impact of the order of generating each element in the quadruplet in generative models [11], 24 template orders were experimented with. The final template order was chosen based on the overall quadruplet extraction performance on the dataset.
- ILO Similar to DLO, after experimenting with 24 template orders, the template order for each instance was chosen individually based on its own performance.
5. Results and Discussion
5.1. Main Results
5.2. Determination of Prefix Prompts
5.3. Ablation Study
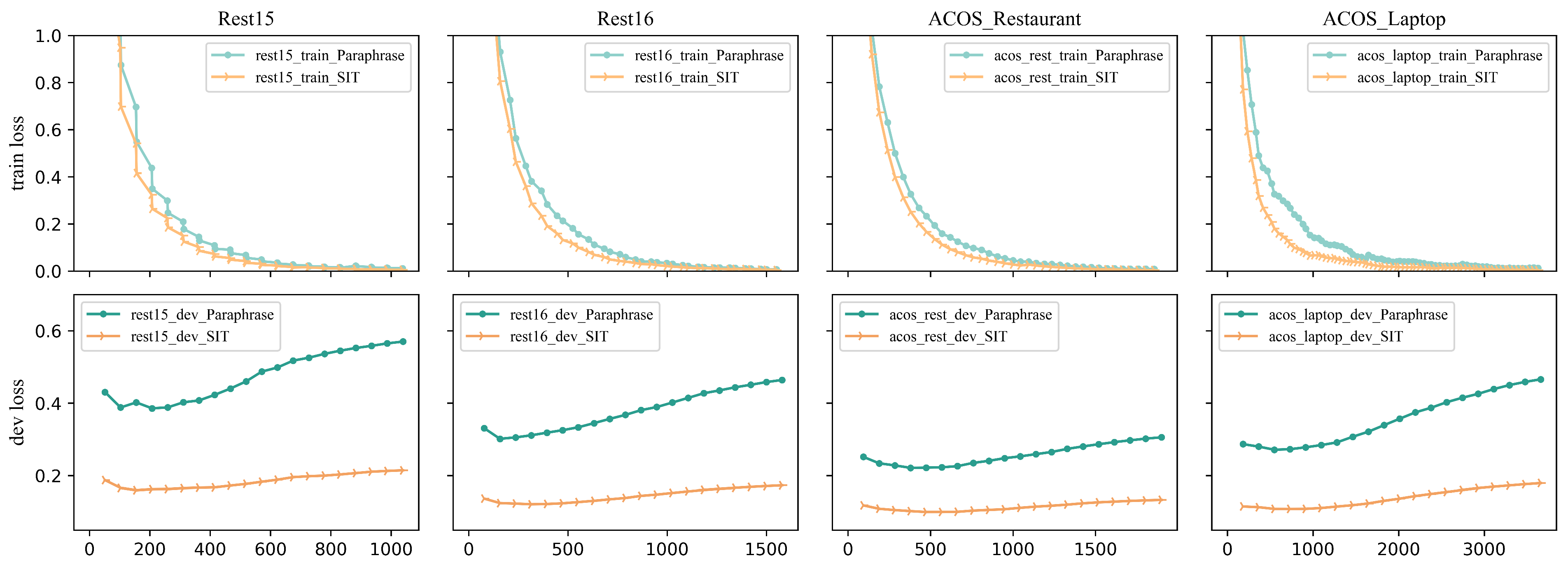
5.4. Model Overfitting Analysis
5.5. Error Analysis and Case Study
5.6. Practical Insights
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Liu, P.; Joty, S.; Meng, H. Fine-grained opinion mining with recurrent neural networks and word embeddings. In Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing, Lisbon, Portugal, 17–21 September 2015; pp. 1433–1443. [Google Scholar]
- He, R.; Lee, W.S.; Ng, H.T.; Dahlmeier, D. An unsupervised neural attention model for aspect extraction. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Vancouver, BC, Canada, 30 July–4 August 2017; pp. 388–397. [Google Scholar]
- Pontiki, M.; Galanis, D.; Papageorgiou, H.; Androutsopoulos, I.; Manandhar, S.; AL-Smadi, M.; Al-Ayyoub, M.; Zhao, Y.; Qin, B.; De Clercq, O.; et al. Semeval-2016 task 5: Aspect based sentiment analysis. In Proceedings of the ProWorkshop on Semantic Evaluation (SemEval-2016). Association for Computational Linguistics, San Diego, CA, USA, 16–17 June 2016; pp. 19–30. [Google Scholar]
- Zhou, X.; Wan, X.; Xiao, J. Representation learning for aspect category detection in online reviews. In Proceedings of the AAAI Conference on Artificial Intelligence, Austin, TX, USA, 25–30 January 2015; Volume 29. [Google Scholar]
- Zhao, H.; Huang, L.; Zhang, R.; Lu, Q.; Xue, H. Spanmlt: A span-based multi-task learning framework for pair-wise aspect and opinion terms extraction. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020; pp. 3239–3248. [Google Scholar]
- Chen, S.; Liu, J.; Wang, Y.; Zhang, W.; Chi, Z. Synchronous double-channel recurrent network for aspect-opinion pair extraction. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020; pp. 6515–6524. [Google Scholar]
- Peng, H.; Xu, L.; Bing, L.; Huang, F.; Lu, W.; Si, L. Knowing what, how and why: A near complete solution for aspect-based sentiment analysis. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 8600–8607. [Google Scholar]
- Wan, H.; Yang, Y.; Du, J.; Liu, Y.; Qi, K.; Pan, J.Z. Target-aspect-sentiment joint detection for aspect-based sentiment analysis. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 9122–9129. [Google Scholar]
- Cai, H.; Xia, R.; Yu, J. Aspect-category-opinion-sentiment quadruple extraction with implicit aspects and opinions. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), Virtual Event, 1–6 August 2021; pp. 340–350. [Google Scholar]
- Zhang, W.; Deng, Y.; Li, X.; Yuan, Y.; Bing, L.; Lam, W. Aspect sentiment quad prediction as paraphrase generation. arXiv 2021, arXiv:2110.00796. [Google Scholar]
- Hu, M.; Wu, Y.; Gao, H.; Bai, Y.; Zhao, S. Improving aspect sentiment quad prediction via template-order data augmentation. arXiv 2022, arXiv:2210.10291. [Google Scholar]
- Peper, J.J.; Wang, L. Generative aspect-based sentiment analysis with contrastive learning and expressive structure. arXiv 2022, arXiv:2211.07743. [Google Scholar]
- Wei, J.; Wang, X.; Schuurmans, D.; Bosma, M.; Xia, F.; Chi, E.; Le, Q.V.; Zhou, D. Chain-of-thought prompting elicits reasoning in large language models. Adv. Neural Inf. Process. Syst. 2022, 35, 24824–24837. [Google Scholar]
- Liu, P.; Yuan, W.; Fu, J.; Jiang, Z.; Hayashi, H.; Neubig, G. Pre-train, prompt, and predict: A systematic survey of prompting methods in natural language processing. ACM Comput. Surv. 2023, 55, 1–35. [Google Scholar] [CrossRef]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Fei, H.; Li, B.; Liu, Q.; Bing, L.; Li, F.; Chua, T.S. Reasoning Implicit Sentiment with Chain-of-Thought Prompting. arXiv 2023, arXiv:2305.11255. [Google Scholar]
- Zhang, W.; Li, X.; Deng, Y.; Bing, L.; Lam, W. A survey on aspect-based sentiment analysis: Tasks, methods, and challenges. IEEE Trans. Knowl. Data Eng. 2022, 35, 11019–11038. [Google Scholar] [CrossRef]
- Raffel, C.; Shazeer, N.; Roberts, A.; Lee, K.; Narang, S.; Matena, M.; Zhou, Y.; Li, W.; Liu, P.J. Exploring the limits of transfer learning with a unified text-to-text transformer. J. Mach. Learn. Res. 2020, 21, 5485–5551. [Google Scholar]
- Wang, X.; Wei, J.; Schuurmans, D.; Le, Q.; Chi, E.; Narang, S.; Chowdhery, A.; Zhou, D. Self-consistency improves chain of thought reasoning in language models. arXiv 2022, arXiv:2203.11171. [Google Scholar]
- Brown, T.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.D.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; et al. Language models are few-shot learners. Adv. Neural Inf. Process. Syst. 2020, 33, 1877–1901. [Google Scholar]
- Cai, H.; Tu, Y.; Zhou, X.; Yu, J.; Xia, R. Aspect-category based sentiment analysis with hierarchical graph convolutional network. In Proceedings of the 28th International Conference on Computational Linguistics, Online, 8–13 December 2020; pp. 833–843. [Google Scholar]
- Li, X.; Bing, L.; Zhang, W.; Lam, W. Exploiting BERT for end-to-end aspect-based sentiment analysis. arXiv 2019, arXiv:1910.00883. [Google Scholar]
- Zhang, W.; Li, X.; Deng, Y.; Bing, L.; Lam, W. Towards generative aspect-based sentiment analysis. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 2: Short Papers), Virtual Event, 1–6 August 2021; pp. 504–510. [Google Scholar]
- Mao, Y.; Shen, Y.; Yang, J.; Zhu, X.; Cai, L. Seq2path: Generating sentiment tuples as paths of a tree. In Proceedings of the Findings of the Association for Computational Linguistics: ACL 2022, Dublin, Ireland, 22–27 May 2022; pp. 2215–2225. [Google Scholar]
- Li, S.; Zhang, Y.; Lan, Y.; Zhao, H.; Zhao, G. From Implicit to Explicit: A Simple Generative Method for Aspect-Category-Opinion-Sentiment Quadruple Extraction. In Proceedings of the 2023 International Joint Conference on Neural Networks (IJCNN), Gold Coast, Australia, 18–23 June 2023; IEEE: Piscataway, NJ, USA, 2023; pp. 1–8. [Google Scholar]




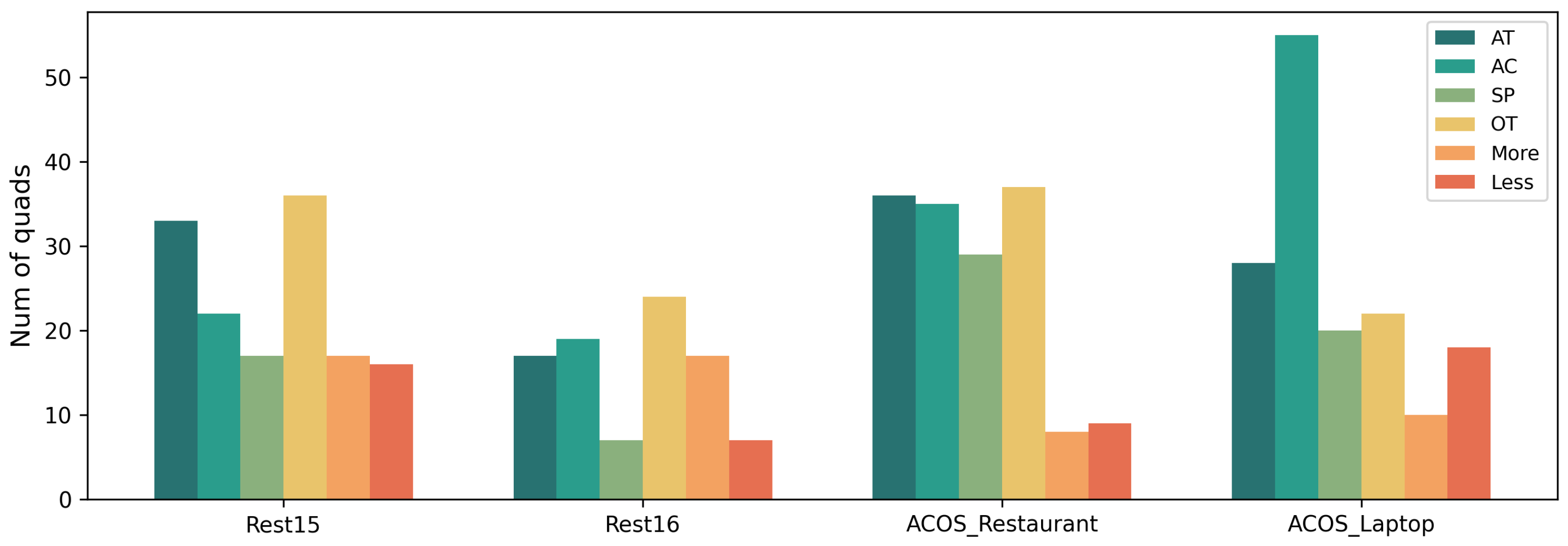


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Train | Dev | Test | ||
|---|---|---|---|---|
| Rest15 | #C | 13 | 12 | 12 |
| #S | 834 | 209 | 537 | |
| #+ | 1005 | 252 | 453 | |
| #0 | 34 | 14 | 37 | |
| #− | 315 | 81 | 305 | |
| Rest16 | #C | 12 | 13 | 12 |
| #S | 1264 | 316 | 544 | |
| #+ | 1369 | 341 | 583 | |
| #0 | 62 | 23 | 40 | |
| #− | 558 | 143 | 176 | |
| ACOS_Restaurant | #C | 12 | 13 | 12 |
| #S | 1530 | 171 | 583 | |
| #+ | 1656 | 180 | 667 | |
| #0 | 95 | 12 | 44 | |
| #− | 733 | 69 | 205 | |
| ACOS_Laptop | #C | 114 | 71 | 81 |
| #S | 2934 | 326 | 816 | |
| #+ | 2583 | 279 | 716 | |
| #0 | 227 | 24 | 65 | |
| #− | 1362 | 137 | 380 | |
| Methods | Rest15 | Rest16 | ACOS_Restaurant | ACOS_Laptop | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Pre | Rec | F1 | Pre | Rec | F1 | Pre | Rec | F1 | Pre | Rec | F1 | |
| HGCN-BERT+BERT-Linear * | 24.43 | 20.25 | 22.15 | 25.36 | 24.03 | 24.68 | - | - | - | - | - | - |
| HGCN-BERT+BERT-TFM * | 25.55 | 22.01 | 23.65 | 27.40 | 26.41 | 26.90 | - | - | - | - | - | - |
| TASO-BERT-Linear * | 41.86 | 26.50 | 32.46 | 49.73 | 40.70 | 44.77 | - | - | - | - | - | - |
| TASO-BERT-CRF * | 44.24 | 28.66 | 34.78 | 48.65 | 39.68 | 43.71 | - | - | - | - | - | - |
| TAS-BERT-ACOS ♠ | - | - | - | - | - | - | 26.29 | 46.29 | 33.53 | 47.15 | 19.22 | 27.31 |
| Extract-Classify-ACOS ⋆♠ | 35.64 | 37.25 | 36.42 | 38.40 | 50.93 | 43.77 | 38.54 | 52.96 | 44.61 | 45.56 | 29.48 | 35.80 |
| GAS *▴ | 45.31 | 46.70 | 45.98 | 54.54 | 57.62 | 56.04 | 53.57 | 54.34 | 53.95 | 40.70 | 40.17 | 40.43 |
| Seq2Path ♣ | - | - | - | - | - | - | 62.38 | 55.02 | 58.47 | 41.46 | 41.00 | 41.23 |
| Paraphrase *▾ | 46.16 | 47.72 | 46.93 | 56.63 | 59.30 | 57.93 | 61.02 | 59.73 | 60.37 | 44.87 | 44.10 | 44.48 |
| DLO ⋆ | 47.07 | 49.33 | 48.18 | 57.92 | 61.80 | 59.79 | - | - | - | - | - | - |
| ILO ⋆ | 47.78 | 50.38 | 49.05 | 57.58 | 61.17 | 59.32 | - | - | - | - | - | - |
| SIT | 47.89 | 50.13 | 48.98 | 58.98 | 61.60 | 60.26 | 63.13 | 63.49 | 63.31 | 44.38 | 44.61 | 44.49 |
| SIT+PT | 48.41 | 49.75 | 49.07 | 60.78 | 63.24 | 61.99 | 63.54 | 63.83 | 63.69 | 43.12 | 42.78 | 42.95 |
| SIT+MT | 47.93 | 49.50 | 48.70 | 58.30 | 60.96 | 59.60 | 61.79 | 63.27 | 62.52 | 44.46 | 44.35 | 44.41 |
| SIT+PM | 49.63 | 50.38 | 50.00 | 59.22 | 61.66 | 60.44 | 62.88 | 63.38 | 63.13 | 45.95 | 45.91 | 45.93 |
| Methods | Running Time | |||
|---|---|---|---|---|
| Rest15 | Rest16 |
ACOS_
Restaurant |
ACOS_
Laptop | |
| Paraphrase | 152.24 | 224.81 | 266.91 | 501.65 |
| SIT | 151.16 | 225.55 | 263.80 | 495.60 |
| SIT+PT | 153.52 | 224.05 | 259.83 | 495.52 |
| SIT+MT | 154.39 | 225.97 | 268.03 | 496.58 |
| SIT+PM | 153.86 | 225.32 | 270.12 | 498.00 |
| Prompt Text | Rest15 | Rest16 | ACOS_Restaurant | ACOS_Laptop | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Pre | Rec | F1 | Pre | Rec | F1 | Pre | Rec | F1 | Pre | Rec | F1 | |
| SIT | 47.89 | 50.13 | 48.98 | 58.98 | 61.60 | 60.26 | 63.13 | 63.49 | 63.31 | 44.38 | 44.61 | 44.49 |
| +Prompt1 | 48.41 | 49.75 | 49.07 | 60.78 | 63.24 | 61.99 | 63.54 | 63.83 | 63.69 | 43.79 | 43.57 | 43.68 |
| +Prompt1+MT | 49.63 | 50.38 | 50.00 | 59.22 | 61.66 | 60.44 | 62.88 | 63.38 | 63.13 | 43.18 | 42.96 | 43.07 |
| +Prompt2 | 48.20 | 48.99 | 48.59 | 58.35 | 61.09 | 59.69 | 62.13 | 62.13 | 62.13 | 44.16 | 43.74 | 43.95 |
| +Prompt2+MT | 48.94 | 49.37 | 49.15 | 58.65 | 60.58 | 59.60 | 62.60 | 62.81 | 62.71 | 45.23 | 44.52 | 44.87 |
| +Prompt3 | 46.99 | 48.11 | 47.54 | 53.50 | 56.15 | 54.79 | 61.43 | 61.22 | 61.33 | 44.20 | 43.74 | 43.97 |
| +Prompt3+MT | 45.41 | 46.10 | 45.75 | 57.89 | 60.46 | 59.14 | 61.20 | 62.59 | 61.88 | 44.70 | 44.70 | 44.70 |
| +Prompt4 | 43.85 | 43.07 | 43.46 | 54.25 | 58.30 | 56.20 | 58.68 | 58.62 | 58.65 | 41.99 | 41.48 | 41.73 |
| +Prompt4+MT | 46.45 | 46.98 | 46.71 | 54.43 | 56.02 | 55.22 | 58.33 | 58.73 | 58.53 | 42.45 | 41.83 | 42.14 |
| +Prompt5 | 47.43 | 48.87 | 48.14 | 59.21 | 61.09 | 60.14 | 63.46 | 63.61 | 63.53 | 43.93 | 43.39 | 43.66 |
| +Prompt5+MT | 47.27 | 49.12 | 48.18 | 57.95 | 61.47 | 59.66 | 61.88 | 62.59 | 62.23 | 43.46 | 43.30 | 43.38 |
| +Prompt6 | 47.77 | 48.49 | 48.13 | 58.29 | 60.58 | 59.42 | 61.01 | 60.32 | 60.66 | 43.12 | 42.78 | 42.95 |
| +Prompt6+MT | 46.48 | 47.36 | 46.91 | 57.58 | 59.70 | 58.62 | 61.51 | 60.88 | 61.20 | 45.95 | 45.91 | 45.93 |
| Methods | Rest15 | Rest16 | ACOS_Restaurant | ACOS_Laptop | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Pre | Rec | F1 | Pre | Rec | F1 | Pre | Rec | F1 | Pre | Rec | F1 | |
| Paraphrase | 46.16 | 47.72 | 46.93 | 56.63 | 59.30 | 57.93 | 61.02 | 59.73 | 60.37 | 44.87 | 44.10 | 44.48 |
| Paraphrase+PT | 48.46 | 49.56 | 49.00 | 58.99 | 61.58 | 60.26 | 60.07 | 59.40 | 59.73 | 44.51 | 43.32 | 43.91 |
| Paraphrase+MT | 45.51 | 46.54 | 46.02 | 58.19 | 61.33 | 59.72 | 57.71 | 57.84 | 57.78 | 43.53 | 42.89 | 43.21 |
| Paraphrase+PM | 47.58 | 48.30 | 47.94 | 57.11 | 58.82 | 57.95 | 60.09 | 60.29 | 60.19 | 44.54 | 43.24 | 43.88 |
| SIT | 47.89 | 50.13 | 48.98 | 58.98 | 61.60 | 60.26 | 63.13 | 63.49 | 63.31 | 44.38 | 44.61 | 44.49 |
| SIT+PT | 48.41 | 49.75 | 49.07 | 60.78 | 63.24 | 61.99 | 63.54 | 63.83 | 63.69 | 43.12 | 42.78 | 42.95 |
| SIT+MT | 47.93 | 49.50 | 48.70 | 58.30 | 60.96 | 59.60 | 61.79 | 63.27 | 62.51 | 44.46 | 44.35 | 44.41 |
| SIT+PM | 49.63 | 50.38 | 50.00 | 59.22 | 61.66 | 60.44 | 62.88 | 63.38 | 63.13 | 45.95 | 45.91 | 45.93 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Qin, Y.; Lv, S. Generative Aspect Sentiment Quad Prediction with Self-Inference Template. Appl. Sci. 2024, 14, 6017. https://doi.org/10.3390/app14146017
Qin Y, Lv S. Generative Aspect Sentiment Quad Prediction with Self-Inference Template. Applied Sciences. 2024; 14(14):6017. https://doi.org/10.3390/app14146017
Chicago/Turabian StyleQin, Yashi, and Shu Lv. 2024. "Generative Aspect Sentiment Quad Prediction with Self-Inference Template" Applied Sciences 14, no. 14: 6017. https://doi.org/10.3390/app14146017
APA StyleQin, Y., & Lv, S. (2024). Generative Aspect Sentiment Quad Prediction with Self-Inference Template. Applied Sciences, 14(14), 6017. https://doi.org/10.3390/app14146017