
Real-Time SLAM and Faster Object Detection on a Wheeled Lifting Robot with Mobile-ROS Interaction


Abstract
:1. Introduction
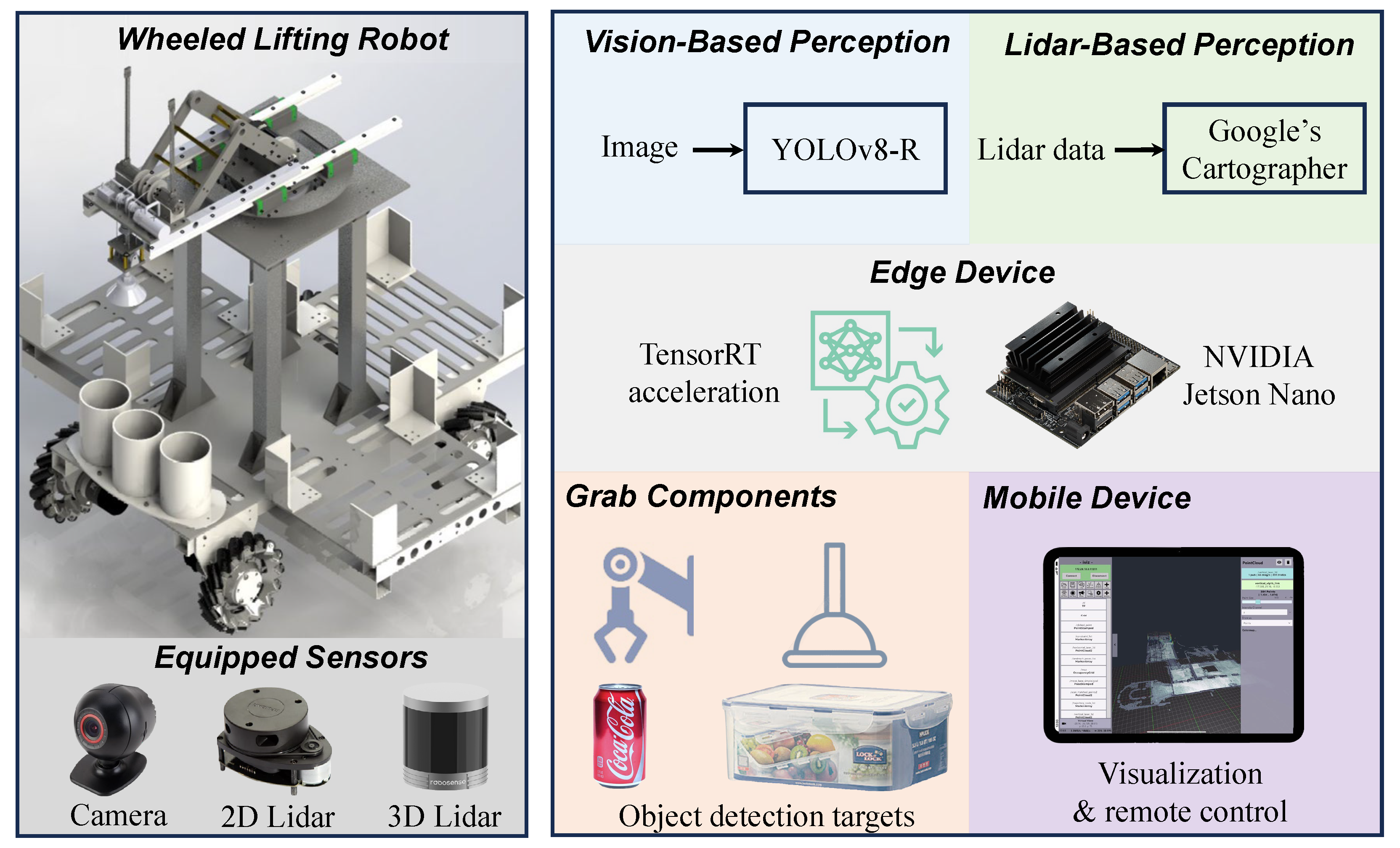
- An autonomous multi-sensor-enabled wheeled lifting robot system, i.e., AMSeWL-R, is proposed to integrate real-time SLAM with faster object detection. By harnessing data from multiple sensors, including LiDAR and cameras, the AMSeWL-R system achieves robust environmental perception and localization accuracy, which is essential for safe and efficient operation in complex environments.
- A novel mobile-ROS interaction method is introduced to establish seamless real-time communication and control between a mobile device and a ROS host. This innovative method bridges the gap between mobile platforms and robotic systems, enabling users to interact with AMRs from their mobile devices remotely.
- An innovative lightweight object detection algorithm, i.e., YOLOv8-R, is proposed to improve real-time object detection speed, with notably significant enhancements achieved through TensorRT acceleration. Real-world tests conducted on a Jetson Nano in real-world deployment scenarios not only validate its efficacy but also boost the practical applicability of our system. The code is available at https://github.com/Lei00764/AMSeWL-R (accessed on 1 June 2024).
2. Related Work
2.1. SLAM
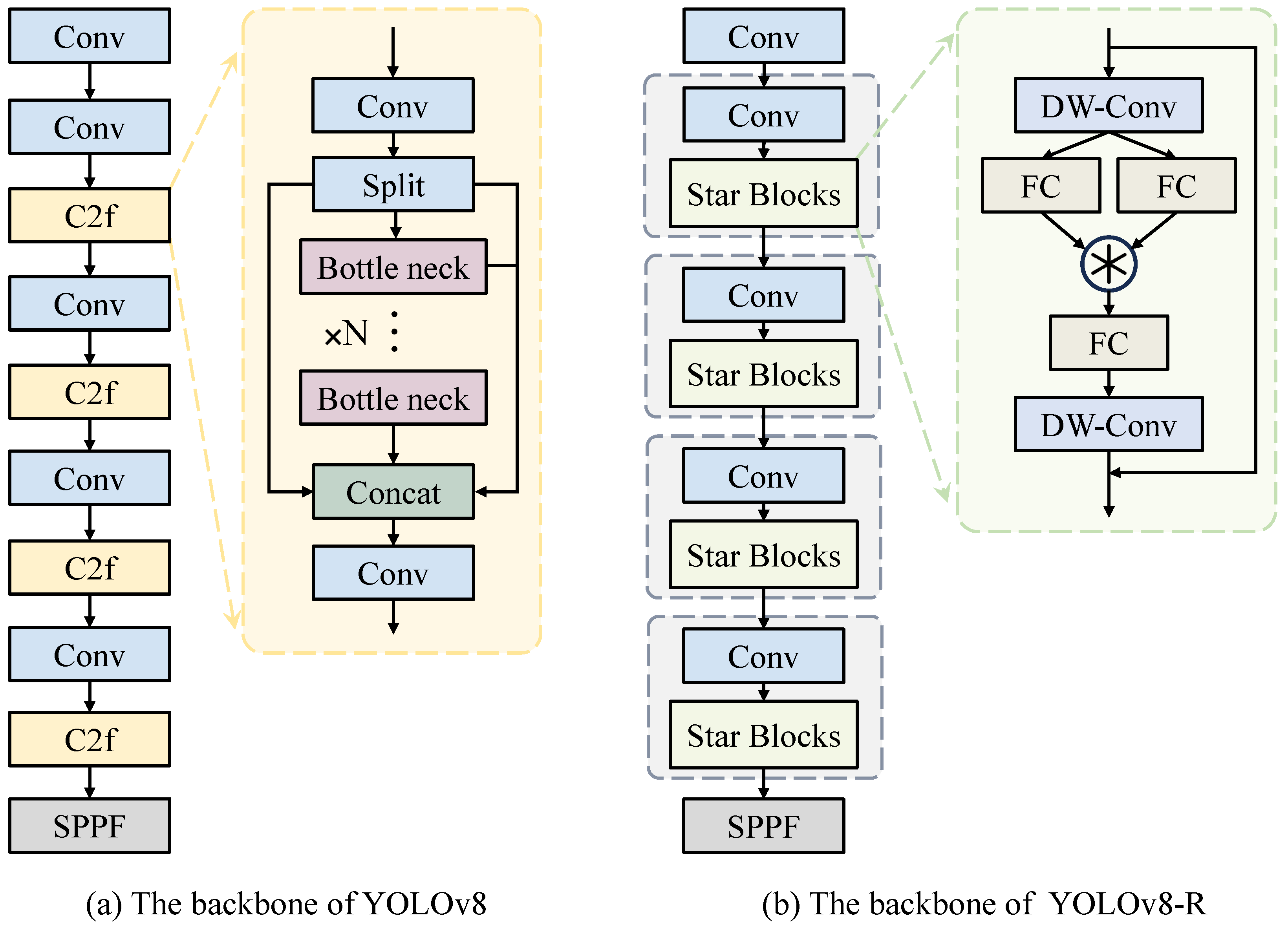
2.2. Lightweight Object Detection
3. Proposed Method
3.1. Overview
3.2. Mobile-ROS Interaction
| Algorithm 1: Mobile-ROS Interaction |
| Input: LiDAR data from a ROS-running host (PC or embedded board), mobile device with Iviz Output: Real-time map visualization and control actions 1 while True do 2 Bind socket to the specified port and listen for incoming connections; 3 Accept incoming connection from the mobile device; 4 while connected do 5 Receive and decode command from the mobile device; 6 if command is “kill” then 7 Terminate the current roslaunch process; 8 else if command is “switch 2D/3D” then 9 Start to play the 2D/3D data bag collected in advance; 10 else if command is “switch real-time mapping” then 11 Start real-time mapping script; 12 end 13 Close the connection with the mobile device; 14 Close the socket; 15 end |
3.3. Vision Subsystem
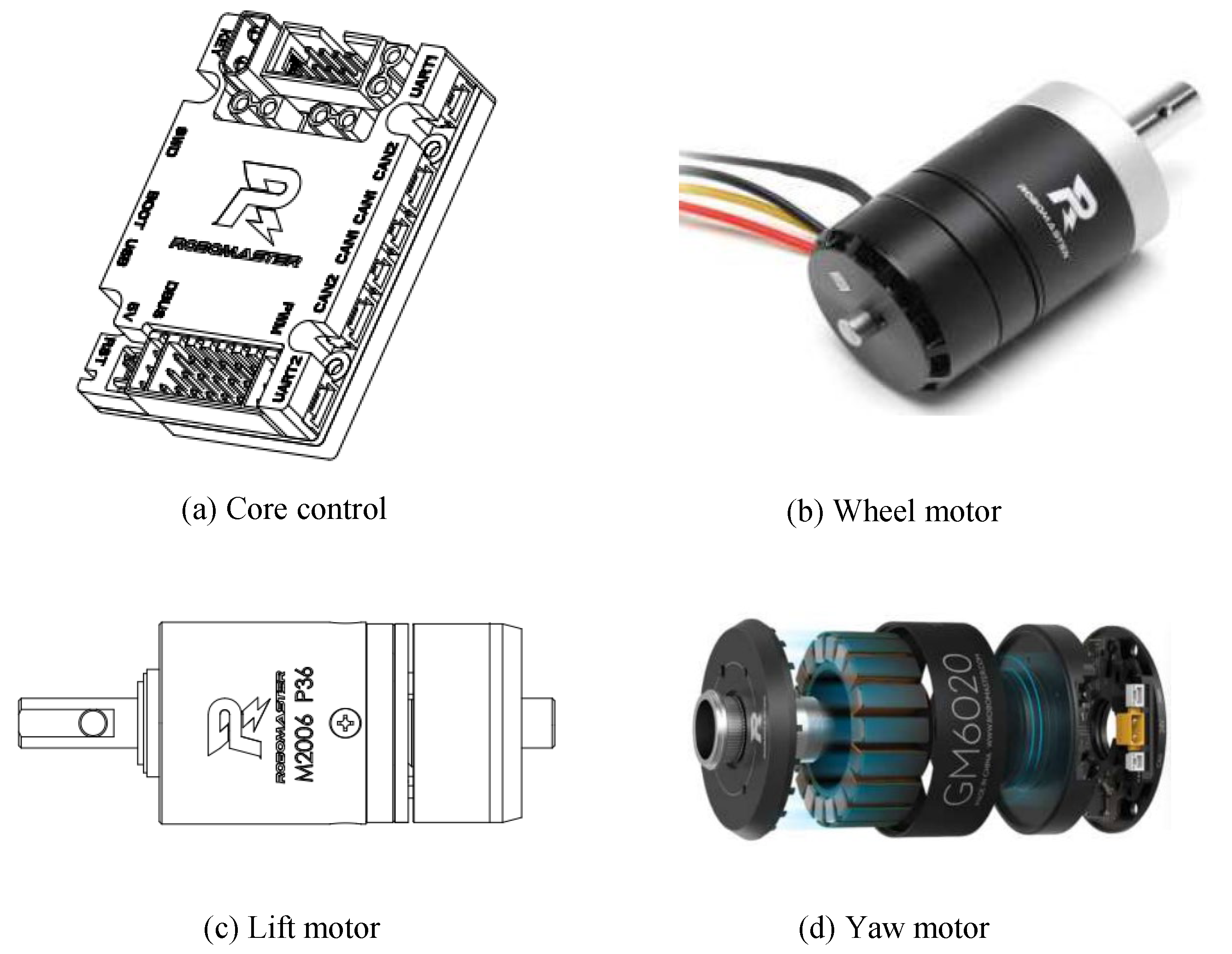
3.4. Mechanical and Electronic Control Subsystem
4. Experiments
4.1. Implementation Details
4.2. Evaluation Metrics
4.3. Comparative Analysis
4.4. Ablation Study
5. Real-World Tests
5.1. Mobile-ROS Interaction Test
5.2. Onboard Object Detection Test
6. Discussion
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Siegwart, R.; Nourbakhsh, I.R.; Scaramuzza, D. Introduction to Autonomous Mobile Robots; MIT Press: Cambridge, MA, USA, 2011. [Google Scholar]
- Fragapane, G.; Ivanov, D.; Peron, M.; Sgarbossa, F.; Strandhagen, J.O. Increasing Flexibility and Productivity in Industry 4.0 Production Networks with Autonomous Mobile Robots and Smart Intralogistics. Ann. Oper. Res. 2022, 308, 125–143. [Google Scholar] [CrossRef]
- Balakrishnan, S.; Azman, A.D.; Nisar, J.; Ejodame, O.E.; Cheng, P.S.; Kin, T.W.; Yi, Y.J.; Das, S.R. IoT-Enabled Smart Warehousing with AMR Robots and Blockchain: A Comprehensive Approach to Efficiency and Safety. In Proceedings of the International Conference on Mathematical Modeling and Computational Science (ICMMCS), Madurai, Tamilnadu, India, 24–25 February 2023; pp. 261–270. [Google Scholar]
- Chen, Y.; Luo, Y.; Yang, C.; Yerebakan, M.O.; Hao, S.; Grimaldi, N.; Li, S.; Hayes, R.; Hu, B. Human Mobile Robot Interaction in the Retail Environment. Sci. Data 2022, 9, 673. [Google Scholar] [CrossRef] [PubMed]
- Fragapane, G.; Hvolby, H.H.; Sgarbossa, F.; Strandhagen, J.O. Autonomous Mobile Robots in Hospital Logistics. In Proceedings of the IFIP International Conference on Advances in Production Management Systems (APMS), Novi Sad, Serbia, 30 August–3 September 2020; pp. 672–679. [Google Scholar]
- Saleh, S.A.M.; Suandi, S.A.; Ibrahim, H.; Hamad, Q.S.; Al Amoudi, I. AGVs and AMRs Robots: A Brief Overview of the Differences and Navigation Principles. In Proceedings of the International Conference on Robotics, Vision, Signal Processing and Power Applications (RoViSP), Penang, Malaysia, 28–29 August 2023; pp. 255–260. [Google Scholar]
- Loganathan, A.; Ahmad, N.S. A Systematic Review on Recent Advances in Autonomous Mobile Robot Navigation. Eng. Sci. Technol. Int. J. 2023, 40, 101343. [Google Scholar] [CrossRef]
- Tadić, S.; Krstić, M.; Dabić-Miletić, S.; Božić, M. Smart Material Handling Solutions for City Logistics Systems. Sustainability 2023, 15, 6693. [Google Scholar] [CrossRef]
- Padilla, R.; Netto, S.L.; Da Silva, E.A. A Survey on Performance Metrics for Object-Detection Algorithms. In Proceedings of the IEEE International Conference on Systems, Signals and Image Processing (IWSSIP), Niteroi, Brazil, 1–3 July 2020; pp. 237–242. [Google Scholar]
- Joseph, K.; Khan, S.; Khan, F.S.; Balasubramanian, V.N. Towards Open World Object Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 5830–5840. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single Shot Multibox Detector. In Proceedings of the European Conference on Computer Vision (ECCV), Amsterdam, The Netherlands, 11–14 October 2016; pp. 21–37. [Google Scholar]
- Jiang, P.; Ergu, D.; Liu, F.; Cai, Y.; Ma, B. A Review of YOLO Algorithm Developments. Procedia Comput. Sci. 2022, 199, 1066–1073. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-time Object Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Durrant-Whyte, H.; Bailey, T. Simultaneous Localization and Mapping: Part I. IEEE Robot. Autom. Mag. 2006, 13, 99–110. [Google Scholar] [CrossRef]
- Chen, C.W.; Lin, C.L.; Hsu, J.J.; Tseng, S.P.; Wang, J.F. Design and Implementation of AMR Robot Based on RGBD, VSLAM and SLAM. In Proceedings of the International Conference on Orange Technology (ICOT), Tainan, Taiwan, 16–17 December 2021; pp. 1–5. [Google Scholar] [CrossRef]
- Cadena, C.; Carlone, L.; Carrillo, H.; Latif, Y.; Scaramuzza, D.; Neira, J.; Reid, I.; Leonard, J.J. Past, Present, and Future of Simultaneous Localization and Mapping: Toward the Robust-Perception Age. IEEE Trans. Robot. 2016, 32, 1309–1332. [Google Scholar] [CrossRef]
- Hess, W.; Kohler, D.; Rapp, H.; Andor, D. Real-Time Loop Closure in 2D LIDAR SLAM. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), Stockholm, Sweden, 16–21 May 2016; pp. 1271–1278. [Google Scholar] [CrossRef]
- Zea, A.; Hanebeck, U.D. Iviz: A ROS Visualization App for Mobile Devices. Softw. Impacts 2021, 8, 100057. [Google Scholar] [CrossRef]
- RViz. Available online: https://wiki.ros.org/rviz (accessed on 1 June 2024).
- Costa, G.d.M.; Petry, M.R.; Moreira, A.P. Augmented Reality for Human-Robot Collaboration and Cooperation in Industrial Applications: A Systematic Literature Review. Sensors 2022, 22, 2725. [Google Scholar] [CrossRef] [PubMed]
- Xiao, Y.; Tian, Z.; Yu, J.; Zhang, Y.; Liu, S.; Du, S.; Lan, X. A Review of Object Detection Based on Deep Learning. Multimed. Tools Appl. 2020, 79, 23729–23791. [Google Scholar] [CrossRef]
- Deng, J.; Xuan, X.; Wang, W.; Li, Z.; Yao, H.; Wang, Z. A Review of Research on Object Detection Based on Deep Learning. J. Phys. Conf. Ser. 2020, 1684, 012028. [Google Scholar] [CrossRef]
- Kaur, R.; Singh, S. A Comprehensive Review of Object Detection with Deep Learning. Digit. Signal Process. 2023, 132, 103812. [Google Scholar] [CrossRef]
- Carranza-García, M.; Torres-Mateo, J.; Lara-Benítez, P.; García-Gutiérrez, J. On the Performance of One-Stage and Two-Stage Object Detectors in Autonomous Vehicles Using Camera Data. Remote Sens. 2020, 13, 89. [Google Scholar] [CrossRef]
- Cheng, M.; Bai, J.; Li, L.; Chen, Q.; Zhou, X.; Zhang, H.; Zhang, P. Tiny-RetinaNet: A One-Stage Detector for Real-Time Object Detection. In Proceedings of the International Conference on Graphics and Image Processing (ICGIP 2019), Hangzhou, China, 12–14 October 2019; Volume 11373, pp. 195–202. [Google Scholar]
- Pham, M.T.; Courtrai, L.; Friguet, C.; Lefèvre, S.; Baussard, A. YOLO-Fine: One-Stage Detector of Small Objects under Various Backgrounds in Remote Sensing Images. Remote Sens. 2020, 12, 2501. [Google Scholar] [CrossRef]
- Diwan, T.; Anirudh, G.; Tembhurne, J.V. Object Detection Using YOLO: Challenges, Architectural Successors, Datasets and Applications. Multimed. Tools Appl. 2023, 82, 9243–9275. [Google Scholar] [CrossRef] [PubMed]
- Dellaert, F.; Contributors, G. borglab/gtsam; Georgia Tech Borg Lab: Atlanta, GA, USA, 2022. [Google Scholar] [CrossRef]
- Jiao, J.; Ye, H.; Zhu, Y.; Liu, M. Robust Odometry and Mapping for Multi-Lidar Systems with Online Extrinsic Calibration. IEEE Trans. Robot. 2021, 38, 351–371. [Google Scholar] [CrossRef]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.C. MobileNetV2: Inverted Residuals and Linear Bottlenecks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 4510–4520. [Google Scholar]
- Howard, A.; Sandler, M.; Chu, G.; Chen, L.C.; Chen, B.; Tan, M.; Wang, W.; Zhu, Y.; Pang, R.; Vasudevan, V.; et al. Searching for MobileNetV3. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 1314–1324. [Google Scholar]
- Zhang, X.; Zhou, X.; Lin, M.; Sun, J. Shufflenet: An Extremely Efficient Convolutional Neural Network for Mobile Devices. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 6848–6856. [Google Scholar]
- Chen, J.; Kao, S.h.; He, H.; Zhuo, W.; Wen, S.; Lee, C.H.; Chan, S.H.G. Run, Don’t Walk: Chasing Higher FLOPS for Faster Neural Networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 17–24 June 2023; pp. 12021–12031. [Google Scholar]
- Ma, X.; Dai, X.; Bai, Y.; Wang, Y.; Fu, Y. Rewrite the Stars. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 17–21 June 2024; pp. 5694–5703. [Google Scholar]
- Liu, Z.; Sun, M.; Zhou, T.; Huang, G.; Darrell, T. Rethinking the Value of Network Pruning. In Proceedings of the International Conference on Learning Representations (ICLR), New Orleans, LA, USA, 6–9 May 2019; pp. 1–21. [Google Scholar]
- Liu, Z.; Li, J.; Shen, Z.; Huang, G.; Yan, S.; Zhang, C. Learning Efficient Convolutional Networks through Network Slimming. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2736–2744. [Google Scholar]
- Molchanov, P.; Mallya, A.; Tyree, S.; Frosio, I.; Kautz, J. Importance Estimation for Neural Network Pruning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 11264–11272. [Google Scholar]
- Lee, J.; Park, S.; Mo, S.; Ahn, S.; Shin, J. Layer-adaptive Sparsity for the Magnitude-based Pruning. In Proceedings of the International Conference on Learning Representations (ICLR), Virtual Event, Austria, Virtual Event, 3–7 May 2021. [Google Scholar]
- FreeRTOS. Available online: https://www.freertos.org (accessed on 1 June 2024).
- Slamtec. Available online: https://www.slamtec.com (accessed on 1 June 2024).
- Robosense. Available online: https://www.robosense.ai (accessed on 1 June 2024).
- Kirillov, A.; Mintun, E.; Ravi, N.; Mao, H.; Rolland, C.; Gustafson, L.; Xiao, T.; Whitehead, S.; Berg, A.C.; Lo, W.Y.; et al. Segment Anything. In Proceedings of the IEEE/CVF International Conference on Computer Vision (CVPR), Vancouver, BC, Canada, 17–24 June 2023; pp. 4015–4026. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Component | Model No. | Features |
|---|---|---|
| Control Core Board | RoboMaster Development Board C | STM32 main control chip, rich interfaces, compact structure, integrated high-precision IMU sensor, strong protection features |
| Wheel Motor | RoboMaster M3508 | CAN bus control, dual closed-loop, max output power: 220 W, torque: 5 N·m |
| Lifting Motor | RoboMaster M2006 | High precision, small size, max torque: 1000 mN·m, power: 44 W, max speed: 500 rpm |
| Yaw Motor | RoboMaster GM6020 | Powered by 24V DC, speed control via CAN/PWM, built-in angle sensor, FOC technology |
| Model | mAP@0.5/% ↑ | mAP@0.5:0.95/% ↑ | Parameters/M ↓ | FLOPS/B ↓ | FPS ↑ |
|---|---|---|---|---|---|
| YOLOv8n | 0.960 | 0.841 | 3.0 | 8.1 | 283.0 |
| YOLOv8s | 0.965 | 0.842 | 11.1 | 28.4 | 115.3 |
| YOLOv8m | 0.971 | 0.847 | 25.8 | 78.7 | 38.3 |
| YOLOv8l | 0.980 | 0.861 | 43.5 | 164.8 | 26.4 |
| YOLOv8-R (Ours) | 0.973 | 0.821 | 0.1 | 1.0 | 639.8 |
| Model | Parameters/M ↓ | FLOPS/B ↓ | FPS ↑ | |||
|---|---|---|---|---|---|---|
| Baseline (YOLOv8n) | 3.0 | - | 8.1 | - | 283.0 | - |
| + Star Block | 2.2 | −26.7% | 6.5 | −19.8% | 286.2 | +1.1% |
| + LSCDH | 1.4 | −53.3% | 4.5 | −44.4% | 314.9 | +11.3% |
| + LAMP Pruning (YOLOv8-R) | 0.1 | −96.7% | 1.0 | −87.7% | 639.8 | +126.1% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lei, X.; Chen, Y.; Zhang, L. Real-Time SLAM and Faster Object Detection on a Wheeled Lifting Robot with Mobile-ROS Interaction. Appl. Sci. 2024, 14, 5982. https://doi.org/10.3390/app14145982
Lei X, Chen Y, Zhang L. Real-Time SLAM and Faster Object Detection on a Wheeled Lifting Robot with Mobile-ROS Interaction. Applied Sciences. 2024; 14(14):5982. https://doi.org/10.3390/app14145982
Chicago/Turabian StyleLei, Xiang, Yang Chen, and Lin Zhang. 2024. "Real-Time SLAM and Faster Object Detection on a Wheeled Lifting Robot with Mobile-ROS Interaction" Applied Sciences 14, no. 14: 5982. https://doi.org/10.3390/app14145982
APA StyleLei, X., Chen, Y., & Zhang, L. (2024). Real-Time SLAM and Faster Object Detection on a Wheeled Lifting Robot with Mobile-ROS Interaction. Applied Sciences, 14(14), 5982. https://doi.org/10.3390/app14145982