
Syn2Real Detection in the Sky: Generation and Adaptation of Synthetic Aerial Ship Images

 , and
, and
Abstract
1. Introduction
- The Introduction section describes the problem of aerial object detection and our solution using synthetic images, and it also discusses the problem of the interaction of the synthetic domain with the real domain, which needs to be solved by domain-adaptive algorithms to apply synthetic image datasets for object detection.
- The Related Works section describes existing real-world image datasets, synthetic image datasets, and domain-adaptation algorithms for object detection.
- The Methods section describes how we built the synthetic image datasets and knowledge about the domain-adaptive algorithms.
- The Experiments section describes the synthetic-to-real domain, adaptive object detection experiments, including the implements, real datasets, detailed data, and experimental conclusions.
- The Conclusion section describes the contributions of the full paper and the shortcomings of this study, and it also points out directions for future improvements.
2. Related Works
2.1. Real-World Image Datasets
2.2. Synthetic Image Datasets
2.3. Object Detection from the Synthetic World to the Real World
3. Methods
3.1. Engine-Based Generation
3.2. Image Generation with Models
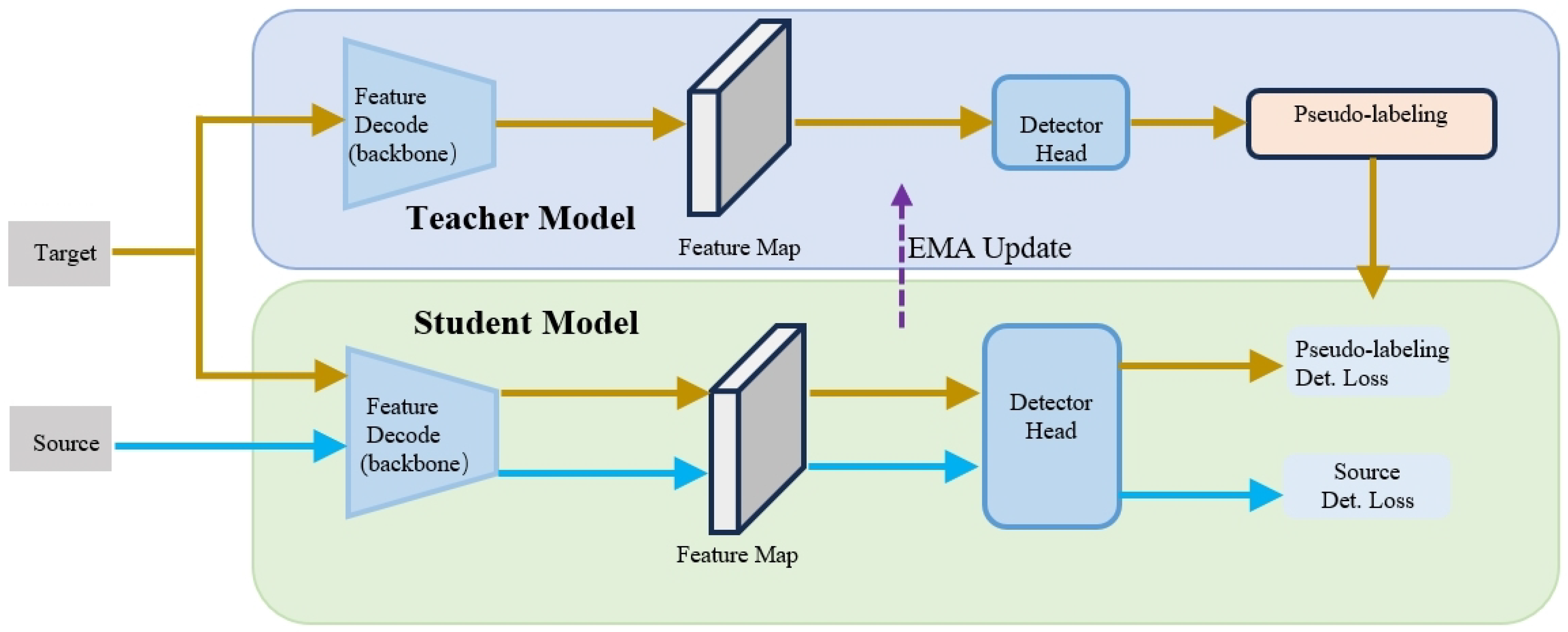
3.3. Syn2Real Object Detection Framework
4. Experiments
4.1. Target Datasets
4.2. Implements
4.3. DAOD Experiments
4.4. Observation and Analysis
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Deng, J.; Dong, W.; Socher, R.; Li, L.-J.; Li, K.; Fei-Fei, L. Imagenet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Everingham, M.; Van Gool, L.; Williams, C.K.; Winn, J.; Zisserman, A. The pascal visual object classes (voc) challenge. Int. J. Comput. Vis. 2010, 88, 303–338. [Google Scholar] [CrossRef]
- Lin, T.-Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In Proceedings of the Computer Vision—ECCV 2014: 13th European Conference, Zurich, Switzerland, 6–12 September 2014; pp. 740–755. [Google Scholar]
- Kuznetsova, A.; Rom, H.; Alldrin, N.; Uijlings, J.; Krasin, I.; Pont-Tuset, J.; Kamali, S.; Popov, S.; Malloci, M.; Kolesnikov, A. The open image dataset v4: Unified image classification, object detection, and visual relationship detection at scale. Int. J. Comput. Vis. 2020, 128, 1956–1981. [Google Scholar] [CrossRef]
- Xia, G.-S.; Bai, X.; Ding, J.; Zhu, Z.; Belongie, S.; Luo, J.; Datcu, M.; Pelillo, M.; Zhang, L. DOTA: A large-scale dataset for object detection in aerial images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 3974–3983. [Google Scholar]
- Zhu, H.; Chen, X.; Dai, W.; Fu, K.; Ye, Q.; Jiao, J. Orientation robust object detection in aerial images using deep convolutional neural network. In Proceedings of the 2015 IEEE International Conference on Image Processing (ICIP), Quebec City, QC, Canada, 27–30 September 2015; pp. 3735–3739. [Google Scholar]
- Cheng, G.; Han, J. A survey on object detection in optical remote sensing images. ISPRS J. Photogramm. Remote Sens. 2016, 117, 11–28. [Google Scholar] [CrossRef]
- Li, K.; Wan, G.; Cheng, G.; Meng, L.; Han, J. Object detection in optical remote sensing images: A survey and a new benchmark. ISPRS J. Photogramm. Remote Sens. 2020, 159, 296–307. [Google Scholar] [CrossRef]
- Zhang, Y.; Yuan, Y.; Feng, Y.; Lu, X. Hierarchical and robust convolutional neural network for very high-resolution remote sensing object detection. IEEE Trans. Geosci. Remote Sens. 2019, 57, 5535–5548. [Google Scholar] [CrossRef]
- Bordes, F.; Shekhar, S.; Ibrahim, M.; Bouchacourt, D.; Vincent, P.; Morcos, A. Pug: Photorealistic and semantically controllable synthetic data for representation learning. Adv. Neural Inf. Process. Syst. 2024, 36, 45020–45054. [Google Scholar]
- Reiher, L.; Lampe, B.; Eckstein, L. A sim2real deep learning approach for the transformation of images from multiple vehicle-mounted cameras to a semantically segmented image in bird’s eye view. In Proceedings of the 2020 IEEE 23rd International Conference on Intelligent Transportation Systems (ITSC), Rhodes, Greece, 20–23 September 2020; pp. 1–7. [Google Scholar]
- Khan, S.; Phan, B.; Salay, R.; Czarnecki, K. ProcSy: Procedural Synthetic Dataset Generation towards Influence Factor Studies of Semantic Segmentation Networks. In Proceedings of the CVPR Workshops, Long Beach, CA, USA, 16–20 June 2019; p. 4. [Google Scholar]
- Chen, Y.; Li, W.; Sakaridis, C.; Dai, D.; Van Gool, L. Domain adaptive faster r-cnn for object detection in the wild. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 3339–3348. [Google Scholar]
- Saito, K.; Ushiku, Y.; Harada, T.; Saenko, K. Strong-weak distribution alignment for adaptive object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 6956–6965. [Google Scholar]
- Deng, J.; Li, W.; Chen, Y.; Duan, L. Unbiased mean teacher for cross-domain object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021; pp. 4091–4101. [Google Scholar]
- Khodabandeh, M.; Vahdat, A.; Ranjbar, M.; Macready, W.G. A robust learning approach to domain adaptive object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 480–490. [Google Scholar]
- Yao, X.; Zhao, S.; Xu, P.; Yang, J. Multi-source domain adaptation for object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 3273–3282. [Google Scholar]
- Li, W.; Liu, X.; Yuan, Y. Sigma: Semantic-complete graph matching for domain adaptive object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 5291–5300. [Google Scholar]
- Li, Y.-J.; Dai, X.; Ma, C.-Y.; Liu, Y.-C.; Chen, K.; Wu, B.; He, Z.; Kitani, K.; Vajda, P. Cross-domain adaptive teacher for object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 7581–7590. [Google Scholar]
- Razakarivony, S.; Jurie, F. Vehicle detection in aerial imagery: A small target detection benchmark. J. Vis. Commun. Image Represent. 2016, 34, 187–203. [Google Scholar] [CrossRef]
- Zou, Z.; Shi, Z. Random access memories: A new paradigm for target detection in high resolution aerial remote sensing images. IEEE Trans. Image Process. 2017, 27, 1100–1111. [Google Scholar] [CrossRef] [PubMed]
- Liu, Z.; Yuan, L.; Weng, L.; Yang, Y. A high resolution optical satellite image dataset for ship recognition and some new baselines. In Proceedings of the International Conference on Pattern Recognition Applications and Methods, Porto, Portugal, 24–26 February 2017; pp. 324–331. [Google Scholar]
- Mundhenk, T.N.; Konjevod, G.; Sakla, W.A.; Boakye, K. A large contextual dataset for classification, detection and counting of cars with deep learning. In Proceedings of the Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Proceedings, Part III 14. 2016; pp. 785–800. [Google Scholar]
- Li, J.; Qu, C.; Shao, J. Ship detection in SAR images based on an improved faster R-CNN. In Proceedings of the 2017 SAR in Big Data Era: Models, Methods and Applications (BIGSARDATA), Beijing, China, 13–14 November 2017; pp. 1–6. [Google Scholar]
- Long, Y.; Gong, Y.; Xiao, Z.; Liu, Q. Accurate object localization in remote sensing images based on convolutional neural networks. IEEE Trans. Geosci. Remote Sens. 2017, 55, 2486–2498. [Google Scholar] [CrossRef]
- Airbus. Airbus Ship Detection Challenge. 2019. Available online: https://www.kaggle.com/c/airbus-ship-detection (accessed on 31 July 2018).
- Lam, D.; Kuzma, R.; McGee, K.; Dooley, S.; Laielli, M.; Klaric, M.; Bulatov, Y.; McCord, B. xview: Objects in context in overhead imagery. arXiv 2018, arXiv:1802.07856. [Google Scholar]
- Yang, M.Y.; Liao, W.; Li, X.; Cao, Y.; Rosenhahn, B. Vehicle detection in aerial images. Photogramm. Eng. Remote Sens. 2019, 85, 297–304. [Google Scholar] [CrossRef]
- Xian, S.; Zhirui, W.; Yuanrui, S.; Wenhui, D.; Yue, Z.; Kun, F. AIR-SARShip-1.0: High-resolution SAR ship detection dataset. J. Radars 2019, 8, 852–863. [Google Scholar]
- Wei, S.; Zeng, X.; Qu, Q.; Wang, M.; Su, H.; Shi, J. HRSID: A high-resolution SAR image dataset for ship detection and instance segmentation. IEEE Access 2020, 8, 120234–120254. [Google Scholar] [CrossRef]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. Adv. Neural Inf. Process. Syst. 2014, 27, 2672–2680. [Google Scholar]
- Kingma, D.P.; Welling, M. Auto-encoding variational bayes. arXiv 2013, arXiv:1312.6114. [Google Scholar]
- Ho, J.; Jain, A.; Abbeel, P. Denoising diffusion probabilistic models. Adv. Neural Inf. Process. Syst. 2020, 33, 6840–6851. [Google Scholar]
- Song, J.; Meng, C.; Ermon, S. Denoising diffusion implicit models. arXiv 2020, arXiv:2010.02502. [Google Scholar]
- BwandoWando. Face Dataset Using Stable Diffusion v.1.4. 2022. Available online: https://www.kaggle.com/dsv/4185294 (accessed on 8 September 2022).
- Meijia-Escobar, C.; Cazorla, M.; Martinez-Martin, E. Fer-Stable-Diffusion-Dataset. 2023. Available online: https://www.kaggle.com/dsv/6171791 (accessed on 21 July 2023).
- Johnson-Roberson, M.; Barto, C.; Mehta, R.; Sridhar, S.N.; Rosaen, K.; Vasudevan, R. Driving in the matrix: Can virtual worlds replace human-generated annotations for real world tasks? arXiv 2016, arXiv:1610.01983. [Google Scholar]
- Sun, X.; Zheng, L. Dissecting person re-identification from the viewpoint of viewpoint. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 608–617. [Google Scholar]
- Hu, Y.-T.; Chen, H.-S.; Hui, K.; Huang, J.-B.; Schwing, A.G. Sail-vos: Semantic amodal instance level video object segmentation-a synthetic dataset and baselines. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 3105–3115. [Google Scholar]
- Wang, Q.; Gao, J.; Lin, W.; Yuan, Y. Learning from synthetic data for crowd counting in the wild. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 8198–8207. [Google Scholar]
- Wang, Z.J.; Montoya, E.; Munechika, D.; Yang, H.; Hoover, B.; Chau, D.H. Diffusiondb: A large-scale prompt gallery dataset for text-to-image generative models. arXiv 2022, arXiv:2210.14896. [Google Scholar]
- Doan, A.-D.; Jawaid, A.M.; Do, T.-T.; Chin, T.-J. G2D: From GTA to Data. arXiv 2018, arXiv:1806.07381. [Google Scholar]
- Dosovitskiy, A.; Ros, G.; Codevilla, F.; Lopez, A.; Koltun, V. CARLA: An open urban driving simulator. In Proceedings of the Conference on Robot Learning, Mountain View, CA, USA, 13–15 November 2017; pp. 1–16. [Google Scholar]
- Savva, M.; Chang, A.X.; Dosovitskiy, A.; Funkhouser, T.; Koltun, V. MINOS: Multimodal indoor simulator for navigation in complex environments. arXiv 2017, arXiv:1712.03931. [Google Scholar]
- Cabezas, R.; Straub, J.; Fisher, J.W. Semantically-aware aerial reconstruction from multi-modal data. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 2156–2164. [Google Scholar]
- Gao, Q.; Shen, X.; Niu, W. Large-scale synthetic urban dataset for aerial scene understanding. IEEE Access 2020, 8, 42131–42140. [Google Scholar] [CrossRef]
- Kiefer, B.; Ott, D.; Zell, A. Leveraging synthetic data in object detection on unmanned aerial vehicles. In Proceedings of the 2022 26th International Conference on Pattern Recognition (ICPR), Montreal, QC, Canada, 21–25 August 2022; pp. 3564–3571. [Google Scholar]
- Shermeyer, J.; Hossler, T.; Van Etten, A.; Hogan, D.; Lewis, R.; Kim, D. Rareplanes: Synthetic data takes flight. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Virtual, 5–9 January 2021; pp. 207–217. [Google Scholar]
- Barisic, A.; Petric, F.; Bogdan, S. Sim2air-synthetic aerial dataset for uav monitoring. IEEE Robot. Autom. Lett. 2022, 7, 3757–3764. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Bochkovskiy, A.; Wang, C.-Y.; Liao, H.-Y.M. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Li, C.; Li, L.; Jiang, H.; Weng, K.; Geng, Y.; Li, L.; Ke, Z.; Li, Q.; Cheng, M.; Nie, W. YOLOv6: A single-stage object detection framework for industrial applications. arXiv 2022, arXiv:2209.02976. [Google Scholar]
- Wang, C.-Y.; Bochkovskiy, A.; Liao, H.-Y.M. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 7464–7475. [Google Scholar]
- Lin, T.-Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Tian, Z.; Shen, C.; Chen, H.; He, T. Fcos: Fully convolutional one-stage object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 9627–9636. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. Adv. Neural Inf. Process. Syst. 2015, 28, 1137–1149. [Google Scholar] [CrossRef]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Li, Y.; Chen, Y.; Wang, N.; Zhang, Z. Scale-aware trident networks for object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 6054–6063. [Google Scholar]
- He, Z.; Zhang, L. Domain adaptive object detection via asymmetric tri-way faster-rcnn. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; pp. 309–324. [Google Scholar]
- Shen, Z.; Maheshwari, H.; Yao, W.; Savvides, M. Scl: Towards accurate domain adaptive object detection via gradient detach based stacked complementary losses. arXiv 2019, arXiv:1911.02559. [Google Scholar]
- Hsu, C.-C.; Tsai, Y.-H.; Lin, Y.-Y.; Yang, M.-H. Every pixel matters: Center-aware feature alignment for domain adaptive object detector. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; pp. 733–748. [Google Scholar]
- Cai, Q.; Pan, Y.; Ngo, C.-W.; Tian, X.; Duan, L.; Yao, T. Exploring object relation in mean teacher for cross-domain detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 11457–11466. [Google Scholar]
- Ramesh, A.; Dhariwal, P.; Nichol, A.; Chu, C.; Chen, M. Hierarchical text-conditional image generation with clip latents. arXiv 2022, arXiv:2204.06125. [Google Scholar]
- Betker, J.; Goh, G.; Jing, L.; Brooks, T.; Wang, J.; Li, L.; Ouyang, L.; Zhuang, J.; Lee, J.; Guo, Y. Improving image generation with better captions. Comput. Sci. 2023, 2, 8. [Google Scholar]
- Rombach, R.; Blattmann, A.; Lorenz, D.; Esser, P.; Ommer, B. High-resolution image synthesis with latent diffusion models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 10684–10695. [Google Scholar]
- Radford, A.; Kim, J.W.; Hallacy, C.; Ramesh, A.; Goh, G.; Agarwal, S.; Sastry, G.; Askell, A.; Mishkin, P.; Clark, J. Learning transferable visual models from natural language supervision. In Proceedings of the International Conference on Machine Learning, Online, 18–24 July 2021; pp. 8748–8763. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention–MICCAI 2015: 18th International Conference, Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar]
- Ho, J.; Salimans, T. Classifier-free diffusion guidance. arXiv 2022, arXiv:2207.12598. [Google Scholar]
- Chen, K.; Wang, J.; Pang, J.; Cao, Y.; Xiong, Y.; Li, X.; Sun, S.; Feng, W.; Liu, Z.; Xu, J. MMDetection: Open mmlab detection toolbox and benchmark. arXiv 2019, arXiv:1906.07155. [Google Scholar]
- Tarvainen, A.; Valpola, H. Mean teachers are better role models: Weight-averaged consistency targets improve semi-supervised deep learning results. Adv. Neural Inf. Process. Syst. 2017, 30, 1195–1204. [Google Scholar]
- Yang, Y.; Soatto, S. Fda: Fourier domain adaptation for semantic segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 4085–4095. [Google Scholar]
- Risser, E.; Wilmot, P.; Barnes, C. Stable and controllable neural texture synthesis and style transfer using histogram losses. arXiv 2017, arXiv:1701.08893. [Google Scholar]

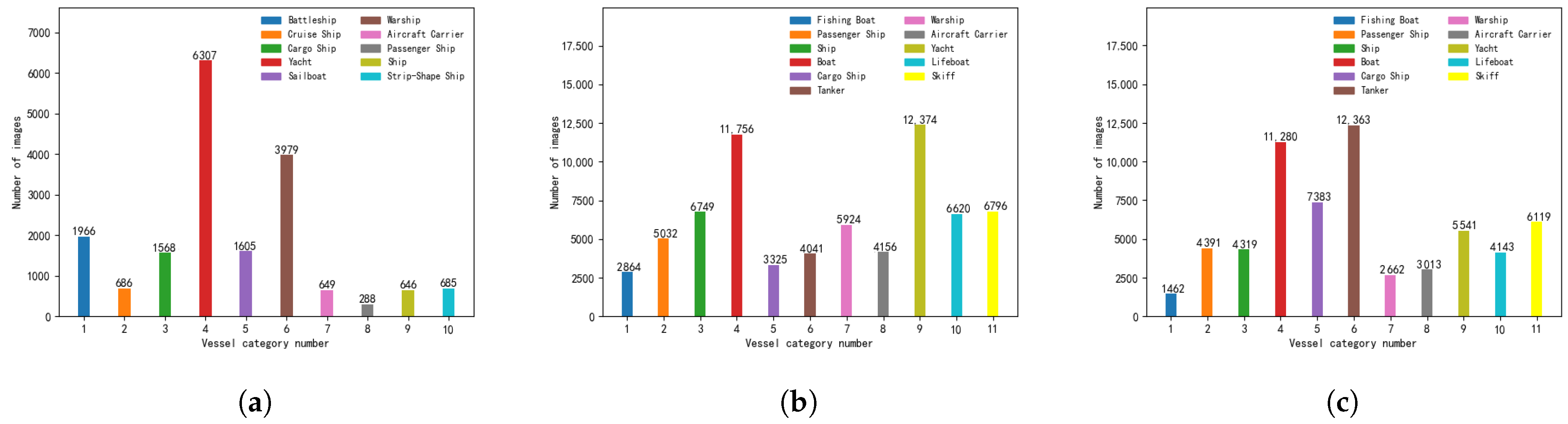
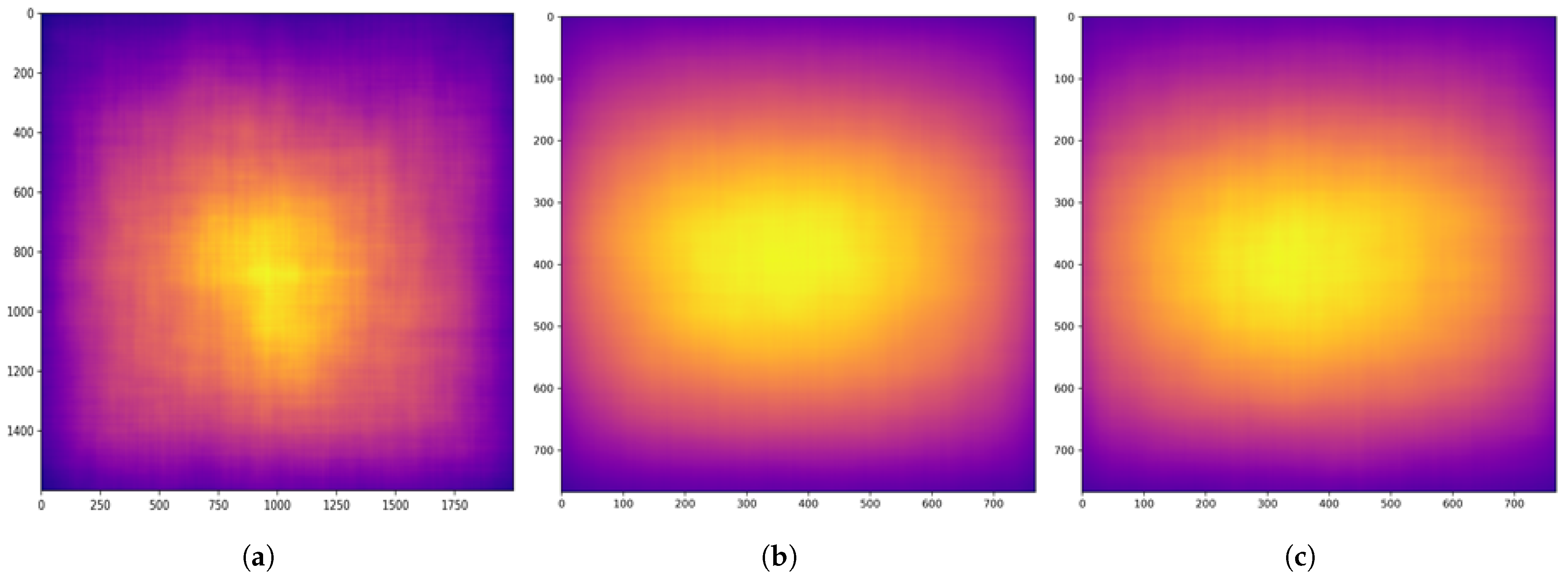
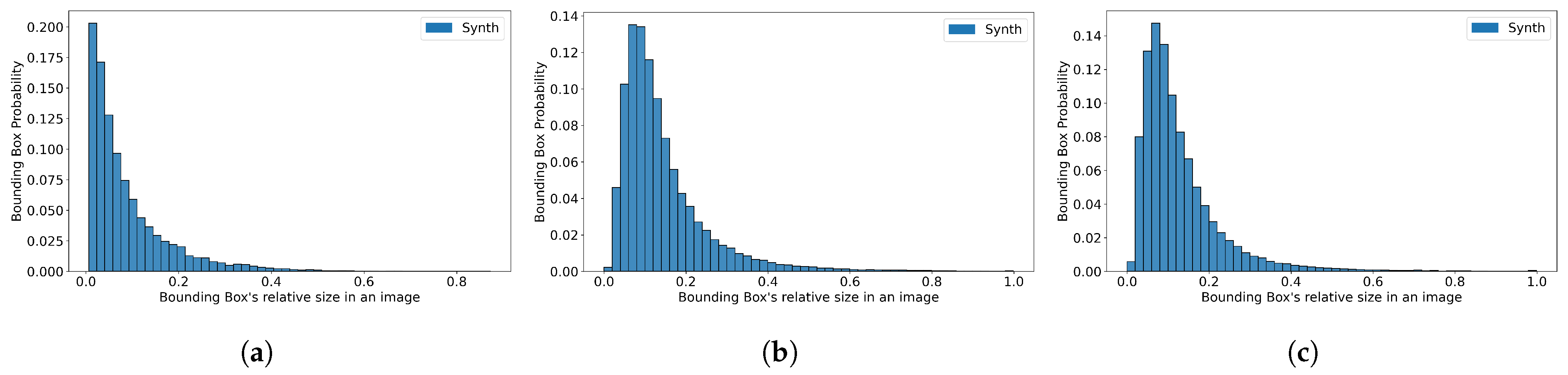

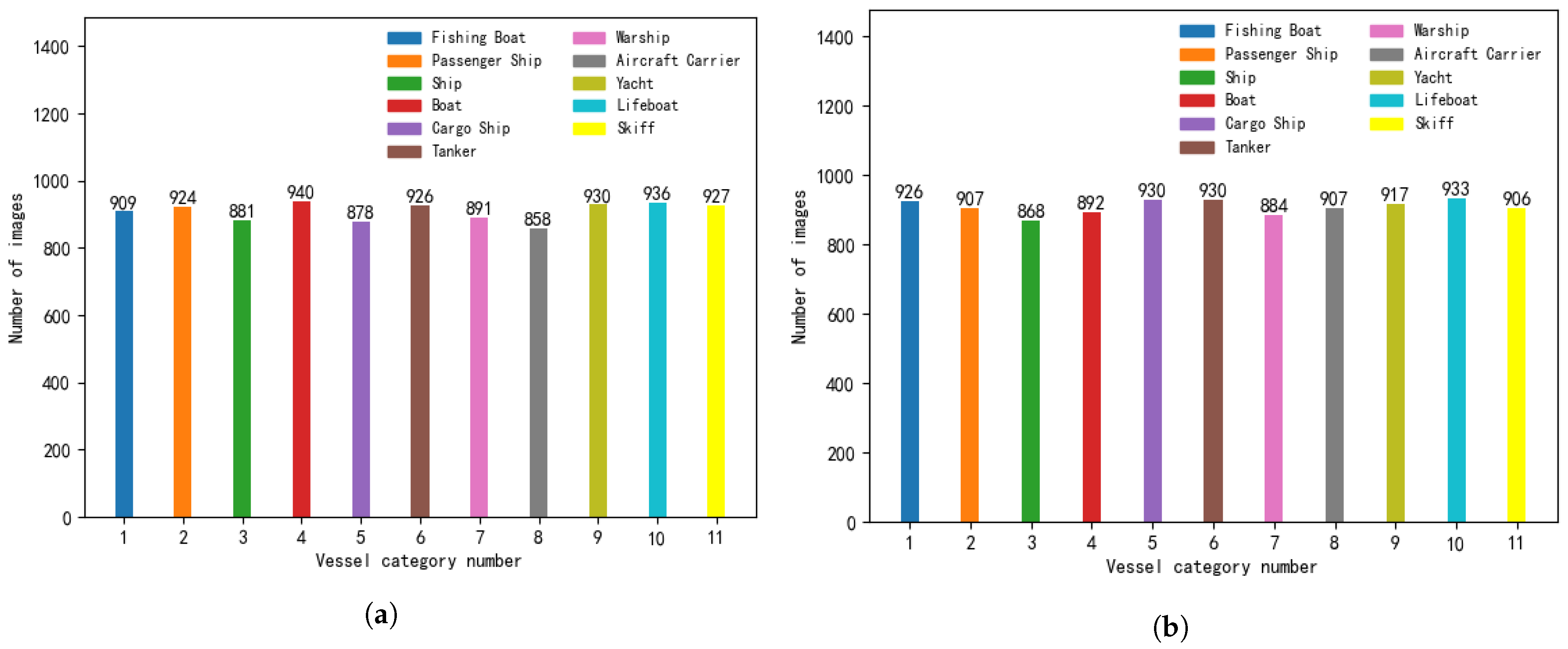



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Type | Name | Images | Categories | Instances | Year |
|---|---|---|---|---|---|
| General Dataset | ImageNet [1] | 14,197,122 | 21,841 | / | 2009 |
| VOC [2] | 33,043 | 20 | 79,540 | 2007+2012 | |
| COCO [3] | 330 K | 80 | 1.5 M | 2014 | |
| Open Images V7 [4] | 1.9 M | 600 | 15.4 M | 2022 | |
| Aerial Dataset | NWPU VHR-10 [7] | 800 | 10 | / | 2014 |
| UCAS-AOD [6] | 910 | 2 | 6029 | 2014 | |
| VEDAI [20] | 1210 | 9 | 3640 | 2015 | |
| HRSC2016 [22] | 1070 | 1 | 2976 | 2016 | |
| COWC [23] | 53 | 4 | 32,716 | 2016 | |
| SSDD [24] | 1160 | 1 | 2358 | 2017 | |
| RSOD-Dataset [25] | 976 | 4 | 6950 | 2017 | |
| airbus-ship-detection [26] | 42,556 | 1 | 81,011 | 2018 | |
| DIOR [8] | 23,463 | 20 | 192,472 | 2018 | |
| xView [27] | 1413 | 60 | 800,636 | 2018 | |
| DOTA [5] | 2806 | 15 | 188,282 | 2018 | |
| ITCVD [28] | 173 | 1 | 29,088 | 2018 | |
| LEVIR [21] | 21,952 | 3 | 10,467 | 2018 | |
| TGRS-HRRSD-Dataset [9] | 21,761 | 13 | 55,740 | 2019 | |
| AIR-SARShip-1.0 [29] | 31 | 1 | 461 | 2019 | |
| HRSID [30] | 5604 | 1 | 16,951 | 2020 |
| Model | Method | mAP | |||||
|---|---|---|---|---|---|---|---|
| Faster R-CNN | Source | 25.6 | 49.8 | 24.2 | 0.6 | 24.6 | 27.0 |
| FDA | 22.3 | 45.7 | 19.0 | 0.3 | 18.8 | 26.4 | |
| HM | 22.5 | 47.1 | 18.7 | 0.2 | 20.9 | 24.4 | |
| PDA | 27.8 | 55.4 | 25.2 | 2.2 | 24.6 | 31.6 | |
| FDA+HM+PDA | 26.2 | 53.9 | 22.4 | 0.9 | 24.3 | 28.8 | |
| MT | 43.1 | 77.9 | 42.0 | 23.0 | 47.8 | 40.7 | |
| FCOS | Source | 22.9 | 47.3 | 20.8 | 3.2 | 23.7 | 23.7 |
| FDA | 23.8 | 50.5 | 19.7 | 3.4 | 21.9 | 26.9 | |
| HM | 22.5 | 50.0 | 15.8 | 1.1 | 18.7 | 27.9 | |
| PDA | 27.6 | 56.7 | 24.3 | 4.2 | 25.8 | 30.8 | |
| FDA+HM+PDA | 23.9 | 52.6 | 18.2 | 2.0 | 21.7 | 27.6 | |
| MT | 42.6 | 79.3 | 41.4 | 0.7 | 34.5 | 52.9 |
| Model | Method | mAP | |||||
|---|---|---|---|---|---|---|---|
| Faster R-CNN | Source | 33.1 | 57.7 | 34.6 | 2.1 | 18.9 | 45.4 |
| FDA | 33.1 | 58.8 | 34.0 | 2.1 | 21.1 | 43.8 | |
| HM | 27.0 | 52.5 | 25.5 | 0.3 | 16.5 | 37.4 | |
| PDA | 36.0 | 62.6 | 37.4 | 0.9 | 23.0 | 47.7 | |
| FDA+HM+PDA | 28.0 | 51.7 | 26.7 | 0.2 | 15.2 | 39.4 | |
| MT | 44.2 | 80.7 | 43.0 | 4.5 | 40.5 | 50.3 | |
| FCOS | Source | 34.6 | 62.0 | 34.3 | 0.8 | 22.1 | 45.6 |
| FDA | 31.7 | 59.1 | 30.9 | 0.9 | 19.2 | 42.7 | |
| HM | 29.7 | 59.1 | 26.6 | 0.1 | 18.2 | 41.1 | |
| PDA | 34.9 | 64.2 | 33.5 | 0.2 | 21.6 | 47.0 | |
| FDA+HM+PDA | 31.3 | 60.5 | 29.1 | 0.3 | 19.0 | 42.8 | |
| MT | 53.6 | 86.8 | 61.2 | 2.1 | 45.3 | 62.2 |
| Model | Method | mAP | |||||
|---|---|---|---|---|---|---|---|
| Faster R-CNN | Source | 33.3 | 56.9 | 35.1 | 2.0 | 19.2 | 45.9 |
| FDA | 32.9 | 58.6 | 34.5 | 1.6 | 19.8 | 44.3 | |
| HM | 27.9 | 55.9 | 23.8 | 0.6 | 15.8 | 39.4 | |
| PDA | 35.9 | 64.7 | 36.3 | 1.0 | 22.9 | 47.8 | |
| FDA+HM+PDA | 30.3 | 57.6 | 27.9 | 0.3 | 16.7 | 42.6 | |
| MT | 52.9 | 81.0 | 63.8 | 1.9 | 45.0 | 61.5 | |
| FCOS | Source | 32.6 | 62.0 | 31.1 | 2.9 | 23.6 | 41.2 |
| FDA | 33.2 | 62.3 | 32.9 | 1.9 | 20.7 | 44.1 | |
| HM | 30.4 | 59.1 | 27.2 | 0.3 | 17.5 | 41.8 | |
| PDA | 36.0 | 66.3 | 35.4 | 1.6 | 25.5 | 46.5 | |
| FDA+HM+PDA | 32.3 | 62.5 | 31.4 | 0.8 | 20.2 | 43.4 | |
| MT | 47.4 | 81.6 | 49.7 | 4.0 | 38.2 | 59.9 |
| Model | Method | mAP | |||||
|---|---|---|---|---|---|---|---|
| Faster R-CNN | Source | 8.0 | 21.2 | 4.9 | 0.9 | 9.1 | 11.6 |
| FDA | 8.2 | 21.1 | 5.2 | 1.7 | 8.6 | 11.1 | |
| HM | 8.4 | 22.2 | 4.7 | 1.5 | 9.3 | 10.9 | |
| PDA | 8.4 | 22.6 | 5.3 | 1.2 | 9.3 | 11.5 | |
| FDA+HM+PDA | 7.7 | 20.6 | 4.5 | 1.3 | 8.5 | 11.0 | |
| MT | 12.3 | 32.9 | 8.4 | 8.4 | 13.1 | 14.4 | |
| FCOS | Source | 9.2 | 23.6 | 5.5 | 1.4 | 11.2 | 10.6 |
| FDA | 9.2 | 24.2 | 5.3 | 2.9 | 11.0 | 11.1 | |
| HM | 9.0 | 23.2 | 4.8 | 2.1 | 11.0 | 10.8 | |
| PDA | 8.8 | 22.9 | 4.7 | 2.1 | 10.0 | 10.9 | |
| FDA+HM+PDA | 9.7 | 24.3 | 5.7 | 2.4 | 11.5 | 11.5 | |
| MT | 11.7 | 30.6 | 6.9 | 6.0 | 14.9 | 10.7 |
| Model | Method | mAP | |||||
|---|---|---|---|---|---|---|---|
| Faster R-CNN | Source | 6.6 | 18.8 | 3.5 | 0.8 | 7.9 | 10.1 |
| FDA | 6.4 | 19.1 | 3.3 | 1.0 | 7.8 | 9.4 | |
| HM | 7.5 | 21.9 | 3.8 | 1.6 | 8.4 | 10.0 | |
| PDA | 7.3 | 21.7 | 3.7 | 1.3 | 8.3 | 10.6 | |
| FDA+HM+PDA | 6.9 | 20.3 | 3.4 | 1.4 | 8.3 | 9.1 | |
| MT | 14.8 | 40.3 | 8.6 | 8.2 | 18.3 | 14.6 | |
| FCOS | Source | 7.2 | 23.6 | 2.5 | 1.9 | 8.7 | 9.4 |
| FDA | 7.8 | 24.8 | 3.0 | 2.5 | 9.4 | 9.8 | |
| HM | 8.7 | 26.1 | 3.8 | 2.7 | 9.8 | 10.6 | |
| PDA | 8.3 | 25.0 | 3.5 | 2.5 | 9.4 | 10.2 | |
| FDA+HM+PDA | 8.2 | 25.5 | 2.8 | 2.5 | 9.1 | 10.6 | |
| MT | 12.2 | 32.6 | 6.8 | 5.7 | 15.2 | 11.8 |
| Model | Method | mAP | |||||
|---|---|---|---|---|---|---|---|
| Faster R-CNN | Source | 6.0 | 17.3 | 3.1 | 0.5 | 7.3 | 9.3 |
| FDA | 6.6 | 19.5 | 3.2 | 1.8 | 7.6 | 9.0 | |
| HM | 7.0 | 20.2 | 3.8 | 0.9 | 8.1 | 9.4 | |
| PDA | 7.2 | 22.2 | 3.3 | 1.4 | 8.7 | 9.7 | |
| FDA+HM+PDA | 7.3 | 20.6 | 4.1 | 1.4 | 8.4 | 10.0 | |
| MT | 15.8 | 42.5 | 10.2 | 9.1 | 19.9 | 15.2 | |
| FCOS | Source | 8.9 | 26.5 | 3.6 | 3.3 | 10.4 | 10.0 |
| FDA | 9.2 | 27.2 | 3.5 | 3.7 | 10.0 | 10.6 | |
| HM | 8.6 | 25.9 | 3.2 | 3.0 | 9.8 | 10.7 | |
| PDA | 8.7 | 24.8 | 4.0 | 2.2 | 9.7 | 10.5 | |
| FDA+HM+PDA | 8.8 | 25.2 | 4.4 | 3.4 | 9.9 | 10.5 | |
| MT | 9.5 | 25.5 | 5.0 | 3.8 | 10.8 | 12.5 |
| Model | Method | mAP | |||||
|---|---|---|---|---|---|---|---|
| Faster R-CNN | Source | 17.1 | 30.1 | 17.6 | 2.0 | 29.4 | 47.6 |
| FDA | 15.2 | 28.0 | 15.5 | 2.4 | 26.2 | 40.6 | |
| HM | 17.4 | 31.5 | 18.4 | 2.5 | 30.3 | 47.0 | |
| PDA | 15.5 | 27.5 | 16.8 | 1.8 | 27.2 | 44.4 | |
| FDA+HM+PDA | 17.6 | 32.5 | 17.9 | 2.7 | 30.4 | 45.9 | |
| MT | 16.7 | 33.0 | 15.7 | 3.1 | 25.5 | 50.9 | |
| FCOS | Source | 16.6 | 30.1 | 17.3 | 1.8 | 28.7 | 47.3 |
| FDA | 17.5 | 34.9 | 16.0 | 3.6 | 29.0 | 43.1 | |
| HM | 18.4 | 34.3 | 18.5 | 3.4 | 31.5 | 45.2 | |
| PDA | 18.0 | 33.3 | 18.4 | 3.2 | 30.7 | 46.6 | |
| FDA+HM+PDA | 19.2 | 36.7 | 18.4 | 3.7 | 32.3 | 47.5 | |
| MT | 20.6 | 35.1 | 22.2 | 2.4 | 36.0 | 59.5 |
| Model | Method | mAP | |||||
|---|---|---|---|---|---|---|---|
| Faster R-CNN | Source | 17.2 | 32.7 | 17.5 | 1.9 | 27.6 | 51.7 |
| FDA | 17.7 | 35.7 | 16.0 | 2.2 | 28.8 | 50.4 | |
| HM | 19.9 | 38.4 | 19.0 | 2.6 | 32.3 | 54.7 | |
| PDA | 18.6 | 37.2 | 16.9 | 2.3 | 30.2 | 52.9 | |
| FDA+HM+PDA | 18.7 | 36.2 | 18.1 | 2.3 | 30.3 | 53.9 | |
| MT | 13.7 | 30.4 | 10.7 | 1.2 | 18.2 | 57.0 | |
| FCOS | Source | 18.8 | 36.8 | 17.9 | 2.3 | 31.5 | 52.2 |
| FDA | 18.7 | 36.9 | 17.4 | 2.8 | 31.3 | 51.0 | |
| HM | 20.5 | 40.9 | 18.7 | 3.3 | 33.9 | 53.8 | |
| PDA | 19.7 | 39.0 | 18.6 | 2.7 | 32.8 | 53.7 | |
| FDA+HM+PDA | 19.7 | 38.9 | 18.2 | 3.3 | 33.5 | 52.9 | |
| MT | 17.6 | 35.4 | 16.5 | 1.9 | 28.9 | 57.2 |
| Model | Method | mAP | |||||
|---|---|---|---|---|---|---|---|
| Faster R-CNN | Source | 17.6 | 32.5 | 16.8 | 1.7 | 28.4 | 52.3 |
| FDA | 17.3 | 35.7 | 14.5 | 2.7 | 27.8 | 48.1 | |
| HM | 19.1 | 38.3 | 17.3 | 3.0 | 31.3 | 50.9 | |
| PDA | 18.1 | 37.3 | 15.6 | 2.4 | 29.6 | 50.4 | |
| FDA+HM+PDA | 18.4 | 37.7 | 16.1 | 2.8 | 29.8 | 49.8 | |
| MT | 16.3 | 33.2 | 14.4 | 1.4 | 22.4 | 61.9 | |
| FCOS | Source | 18.8 | 37.0 | 17.0 | 3.0 | 31.6 | 48.6 |
| FDA | 18.0 | 37.4 | 14.7 | 3.2 | 29.2 | 48.3 | |
| HM | 19.4 | 39.3 | 17.2 | 3.4 | 32.9 | 49.9 | |
| PDA | 19.1 | 39.4 | 16.7 | 3.3 | 31.5 | 50.0 | |
| FDA+HM+PDA | 19.4 | 39.7 | 16.8 | 3.2 | 31.9 | 50.6 | |
| MT | 19.4 | 37.8 | 18.7 | 2.3 | 32.3 | 57.3 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wu, Y.; Guo, W.; Tan, Z.; Zhao, Y.; Zhu, Q.; Wu, L.; Guo, Z. Syn2Real Detection in the Sky: Generation and Adaptation of Synthetic Aerial Ship Images. Appl. Sci. 2024, 14, 4558. https://doi.org/10.3390/app14114558
Wu Y, Guo W, Tan Z, Zhao Y, Zhu Q, Wu L, Guo Z. Syn2Real Detection in the Sky: Generation and Adaptation of Synthetic Aerial Ship Images. Applied Sciences. 2024; 14(11):4558. https://doi.org/10.3390/app14114558
Chicago/Turabian StyleWu, Yaoyuan, Weijie Guo, Zhuoyue Tan, Yifei Zhao, Quanxing Zhu, Liaoni Wu, and Zhiming Guo. 2024. "Syn2Real Detection in the Sky: Generation and Adaptation of Synthetic Aerial Ship Images" Applied Sciences 14, no. 11: 4558. https://doi.org/10.3390/app14114558
APA StyleWu, Y., Guo, W., Tan, Z., Zhao, Y., Zhu, Q., Wu, L., & Guo, Z. (2024). Syn2Real Detection in the Sky: Generation and Adaptation of Synthetic Aerial Ship Images. Applied Sciences, 14(11), 4558. https://doi.org/10.3390/app14114558