4.1. Performance Comparison
Table 4 presents the performance results of various models tested on three real-world datasets. These experimental results showcase the superiority of our model in comparison to all other baseline models across the entirety of the datasets.
Compared to the other baseline models, VAR and SVR exhibited inferior performance, primarily due to their sole focus on the temporal dimension while neglecting the spatial correlations inherent in traffic flow. This underscores the critical importance of considering temporal and spatial correlations simultaneously when modeling traffic flow.
In contrast, spatial–temporal deep-learning models generally demonstrated superior performance. DCRNN, ASTGCN, and STSGCN are three models that concurrently process information across both temporal and spatial dimensions. DCRNN, which is based on the RNN in the temporal dimension, encounters a limit in capturing long-range temporal correlations. ASTGCN employs a standard convolution layer to aggregate information only from neighboring time slices, which makes it difficult to gain a promising ability to model temporal dependency. In the spatial dimension, both DCRNN and ASTGCN utilize predefined adjacency matrices to learn spatial dependency. In comparison, STSGCN employs a temporal embedding matrix and a spatial embedding matrix, both of which are learnable. It also utilizes spatial–temporal convolution modules to extract features, thus enhancing performance. However, it only captures local spatial–temporal correlations, limiting its ability to discover global information in traffic flow.
Both AGCRN and Z-GCNETs utilize GRUs to learn temporal patterns, yet they fall short of efficiently capturing dynamic and long-range temporal correlations. In terms of spatial dependency learning, AGCRN and Z-GCNETs adopt distinct approaches. AGCRN learns unique parameters for each node based on matrix factorization and accordingly constructs an adaptive graph generation module capable of autonomously inferring dependencies among different traffic series. On the other hand, Z-GCNETs design time-aware graph convolutions to capture topological attributes in traffic data.
In the spatial dimension, GMAN develops a spatial embedding which is similar to AGCRN but employs a spatial attention mechanism instead of graph convolution. In the temporal dimension, it develops temporal embedding and a temporal attention mechanism. However, the embeddings are not comprehensive enough. Moreover, an encoder–decoder architecture is utilized to explore spatial–temporal correlations.
Both STFGNN and DSTAGNN rely on mining historical data to construct data-driven graph structures as opposed to using predefined graphs, thereby enhancing the exploration of previously unexposed spatial correlations. Moreover, DSTAGNN leverages an attention mechanism and a gated convolution module, augmenting its capability to capture dynamic spatial correlations. In the temporal dimension, STFGNN employs a gated dilated convolution module with extensive dilation to broaden its receptive field in time series, capturing temporal correlations. DSTAGNN introduces a multi-scale gated tanh unit to explore temporal information. Both methods lack the ability to capture dynamic temporal correlations.
Both STGODE and ASTGCN enhance performance in traffic flow prediction by integrating the structure of Ordinary Differential Equations (ODEs). Specifically, STGODE constructs a semantic adjacency matrix to capture the semantic associations between nodes via Dynamic Time Warping (DWT). It also designs a spatial–temporal graph convolution based on an ODE structure to simultaneously handle spatial and temporal information. ASTGCN, based on node-adaptive parameters, constructs an adaptive graph and further combines it with an attention mechanism to explore local spatial–temporal features. Moreover, STGODE employs two TCN blocks to extract long-range temporal correlations, while ASTGCNs adopt both TCNs and ODEs to further explore global spatial–temporal features.
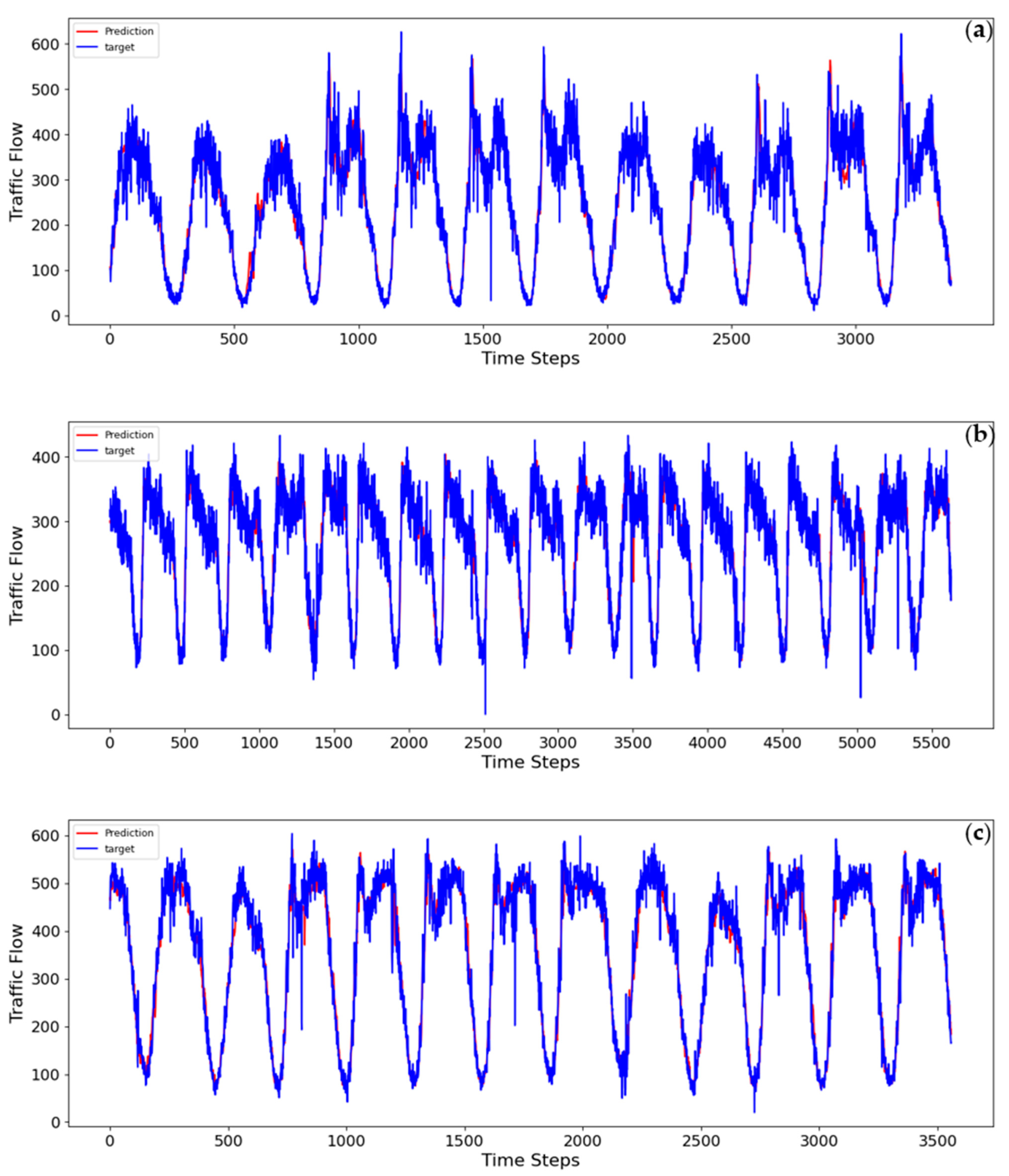
Our model, STFEformer, exhibited superior prediction performance on all three real-world datasets. Specifically, on the PeMS04 dataset, STFEformer’s MAE was 18.98, surpassing the second-best model, DSTAGNN, which had an MAE of 19.30. Additionally, STFEformer presented a lower RMSE of 30.94 compared to DSTAGNN’s RMSE of 31.46, and a lower MAPE of 12.65% compared to DSTAGNN’s MAPE of 12.70%. Similarly, on the PeMS07 dataset, STFEformer achieved an MAE of 20.50, an RMSE of 33.87, and an MAPE of 8.75%, while DSTAGNN obtained an MAE of 21.42, an RMSE of 34.51, and an MAPE of 9.01%. On the PeMS08 dataset, STFEformer achieved an MAE of 14.80, an RMSE of 24.22, and an MAPE of 9.85%, while DSTAGNN exhibited an MAE of 15.67, an RMSE of 24.77, and an MAPE of 9.94%.
These improvements are attributed to the combination of short-term features and periodic features in the temporal dimension, the use of data-driven adaptive spatial embeddings without predefined graphs, and native feature extraction from raw data. Then, our model utilizes a spatial self-attention module which integrates an adaptive similarity matrix, thereby highlighting interactions between similar nodes and capturing dynamic and long-range spatial correlations. To explore dynamic temporal dependencies, a temporal self-attention module is also employed. In conclusion, our model effectively captures complex features in traffic data.
4.2. Ablation Study Results
To assess the efficacy of each component in STFEformer, ablation experiments with five variants of our model were conducted:
w/o MaskSSA. This removes the mask spatial self-attention.
w/o mask. This removes the binary mask matrix.
w/o . This removes the adaptive spatial embedding, .
w/o . This removes the native feature embedding, .
w/o . This removes the temporal embedding, .
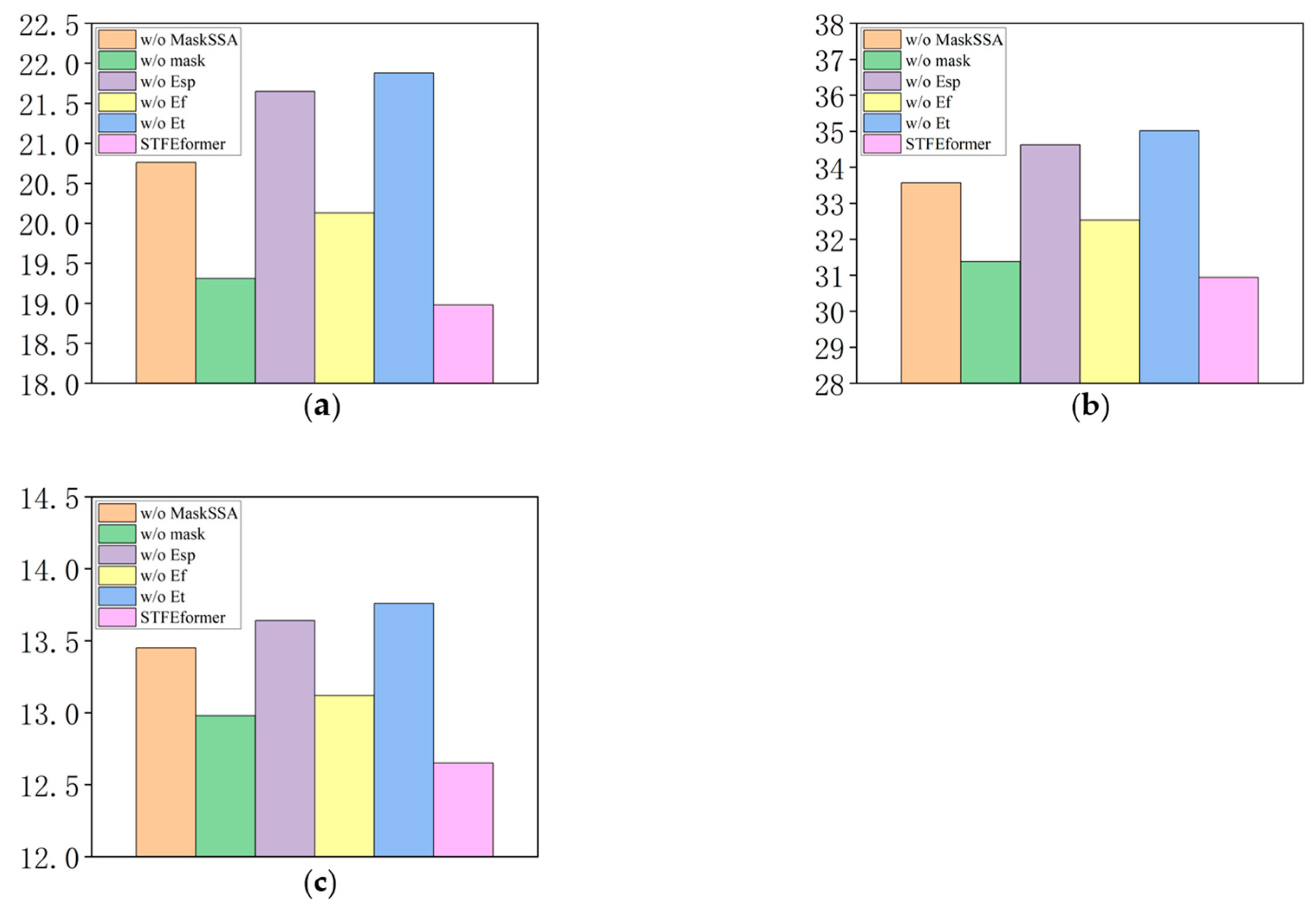
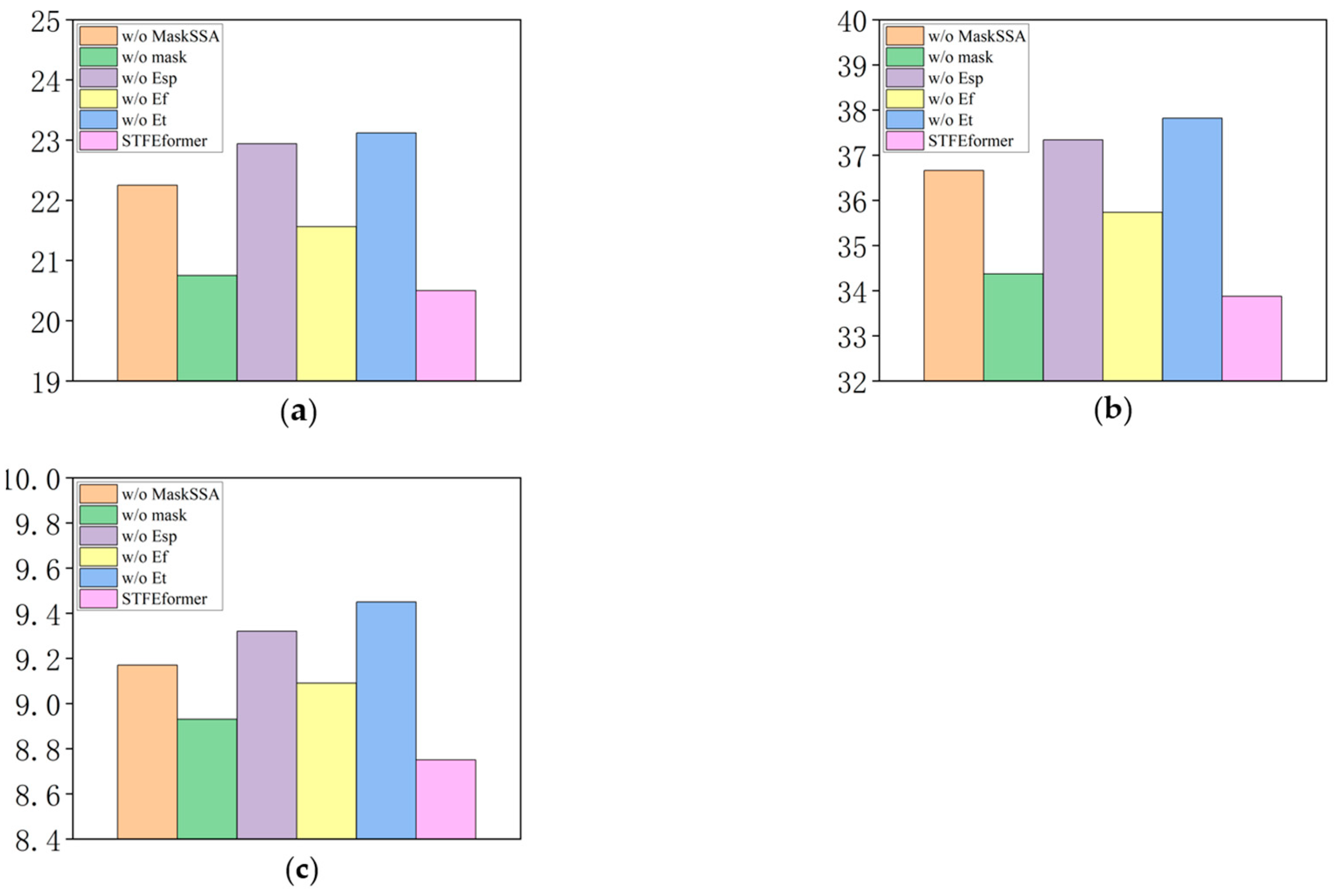
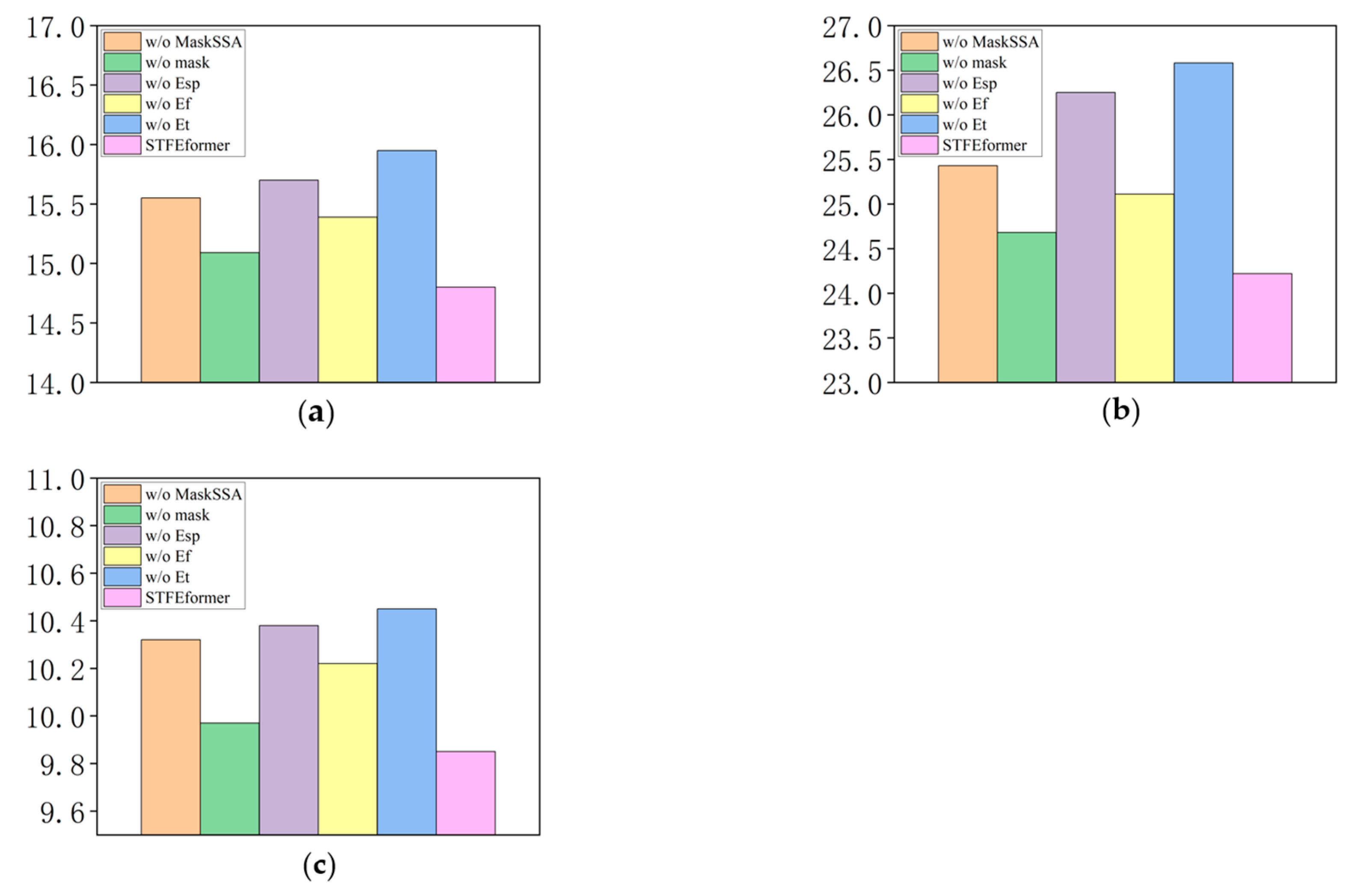
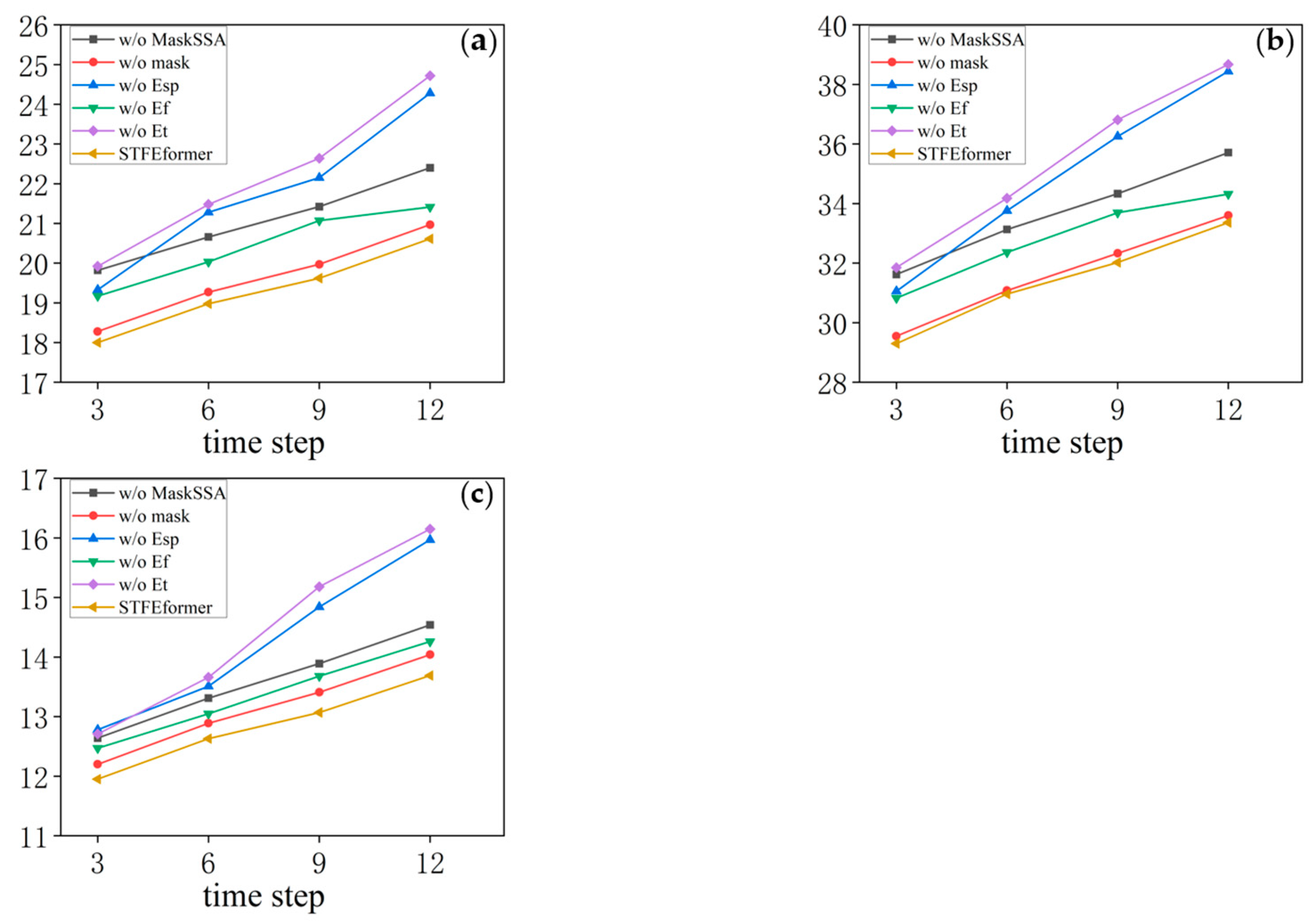
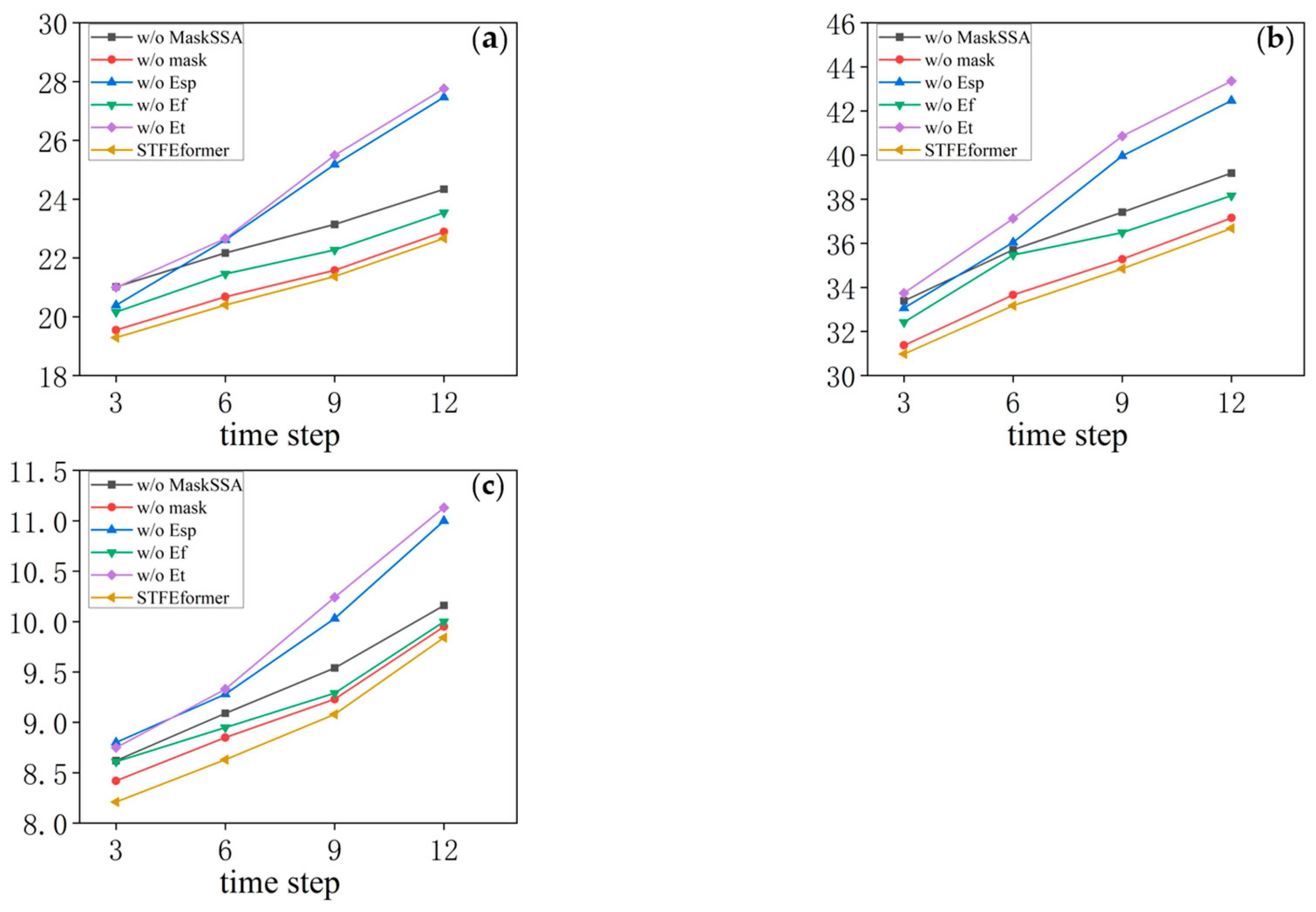
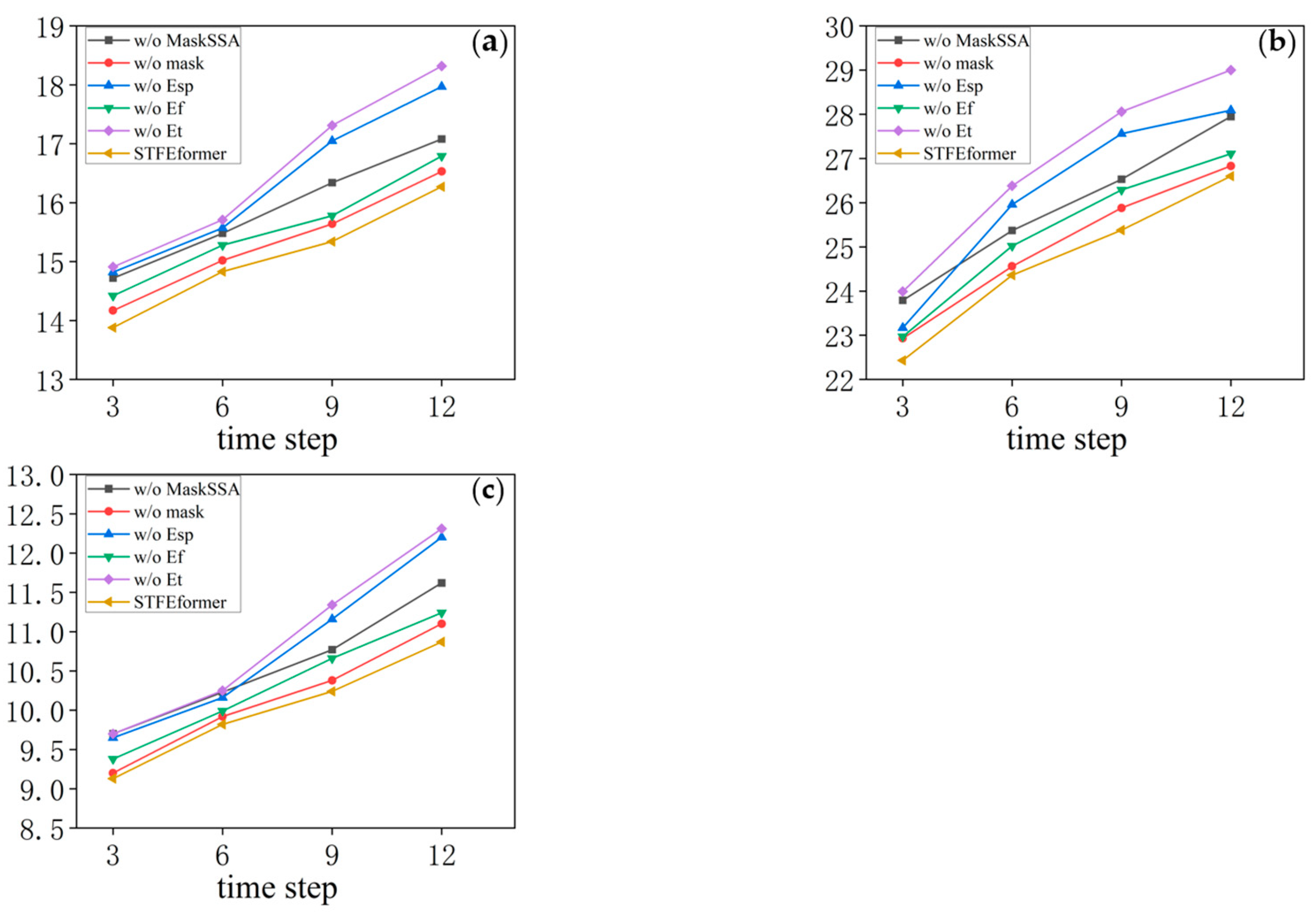
The experiments were carried out on the PeMS04, PeMS07, and PeMS08 datasets. The results are as shown in
Table 5,
Table 6,
Table 7 and
Table 8 and
Figure 2,
Figure 3,
Figure 4,
Figure 5,
Figure 6 and
Figure 7 illustrating the visualization of the experimental results. The outcomes of the ablation experiments provide a comprehensive perspective on the performance of STFEformer following the removal of different components. Overall, considering 12-time-step prediction, STFEformer performed the best, while w/o
ranked the lowest. Compared to the STFEformer model, the performance sequentially decreased for w/o mask, w/o
, w/o MaskSSA, and w/o
.
Compared to w/o , STFEformer demonstrated a significant improvement in next overall 12-time-step prediction and showed enhancements in MAE, RMSE, and MAPE. For example, STFEformer improved by 13.2%, 11.6%, and 8.0% on the PeMS04 dataset; on the PeMS07 dataset, the improvements were 11.3%, 10.4%, and 7.4%; and on the PeMS08 dataset, the improvements were 7.2%, 8.8%, and 5.7%.
In predicting the next overall 12 time steps, STFEformer achieved enhancements in MAE, RMSE, and MAPE when contrasted with w/o . On the PeMS04 dataset, STFEformer demonstrated enhancements of 12.3% in MAE, 10.6% in RMSE, and 7.2% in MAPE. Similarly, on the PeMS07 dataset, the enhancements were 10.6%, 9.2%, and 6.1% in MAE, RMSE, and MAPE, respectively. On the PEMS08 dataset, the enhancements were 5.7%, 7.7%, and 5.1% in MAE, RMSE, and MAPE.
Moreover, in the prediction of the next overall 12 time steps, STFEformer exhibited enhancements on different datasets when contrasted with w/o . For instance, the improvements were 5.7%, 4.8%, and 3.5% in MAE, RMSE, and MAPE on the PeMS04 dataset; on the PEMS07 dataset, the improvements were 4.9%, 5.2%, and 3.7; and the improvements were 3.8%, 3.5%, and 3.6% on the PEMS08 dataset, respectively.
Furthermore, compared to w/o mask, STFEformer showed an improvement in next overall 12-time-step prediction. Specifically, on the PeMS04 dataset, STFEformer improved by 1.7%, 1.4%, and 2.5% in MAE, RMSE, and MAPE, respectively. The enhancements were 1.9%, 1.8%, and 1.2% on the PeMS07 dataset, while STFEformer improved by 1.2%, 1.4%, and 2.0% on the PeMS08 dataset.
Finally, compared to w/o MaskSSA, STFEformer showed great improvements. For instance, on the PeMS04 dataset, STFEformer improved by 8.5%, 7.8%, and 5.9%; on the PeMS07 dataset, the improvements were 7.8%, 7.6%, and 4.6%; and on the PeMS08 dataset, STFEformer improved by 4.8%, 4.7%, and 4.5%.
In predictions of the next 15, 30, 45, and 60 min, STFEformer also outperformed all the models post-ablation.
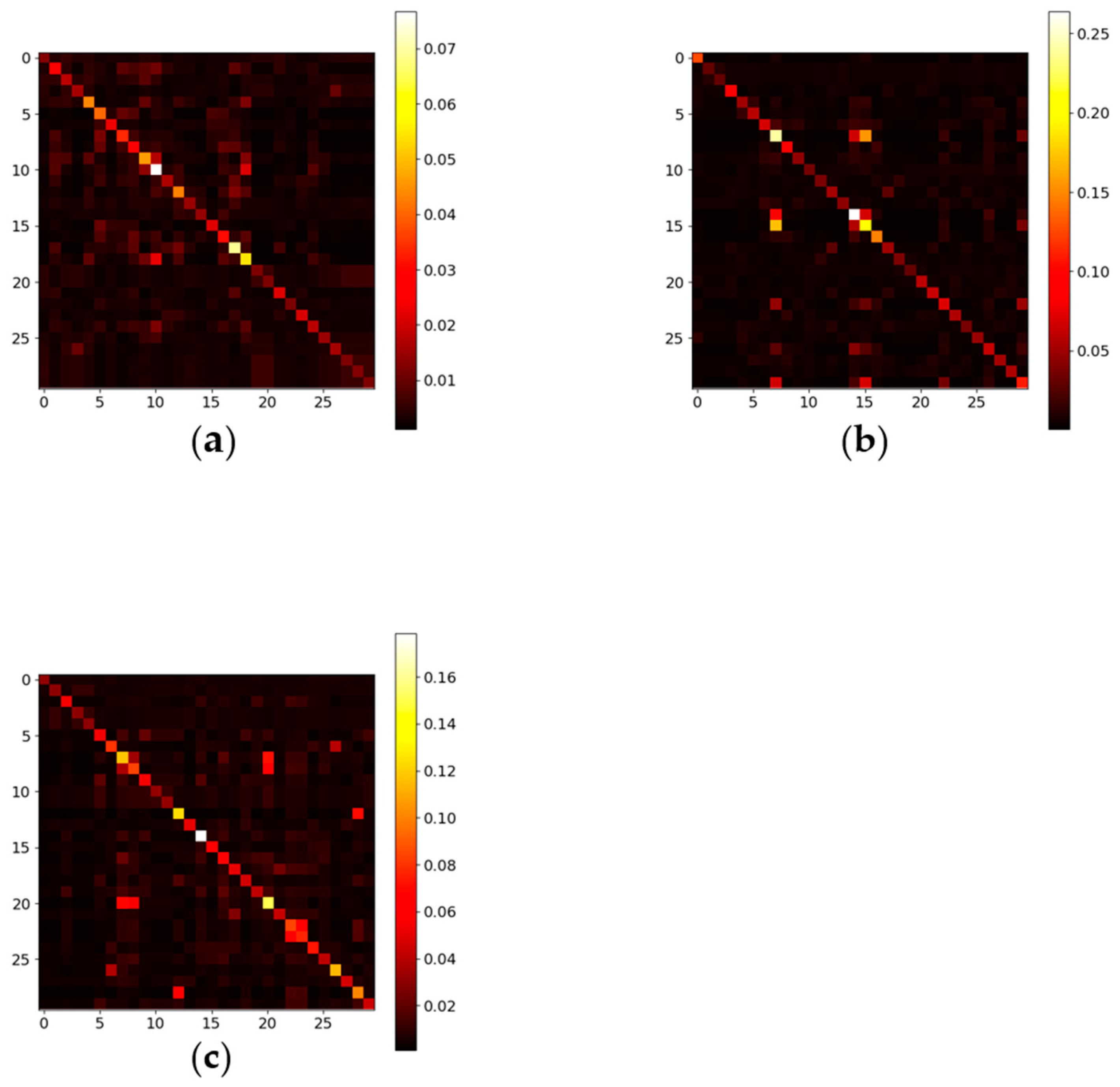
The ablation experiments provide crucial evidence regarding the effectiveness of each component proposed in our research. Through the fusion embedding layer, we successfully achieve comprehensive feature extraction and fusion, significantly enhancing the model’s accuracy for traffic flow prediction tasks. The design of the fusion embedding layer enables the model to extract native information and spatial–temporal characteristics from traffic data more effectively, leading to more accurate prediction. Furthermore, the ablation study underscores the importance of combining an adaptive similarity matrix with spatial self-attention. This method allows the model to concentrate more on the interactions between the similar node pairs during the spatial feature learning process. By accounting for these dynamic and long-range spatial correlations, our model can understand and predict more precisely. Especially when dealing with complex interactions between nodes in urban traffic networks, this mask spatial self-attention mechanism proves particularly crucial.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}