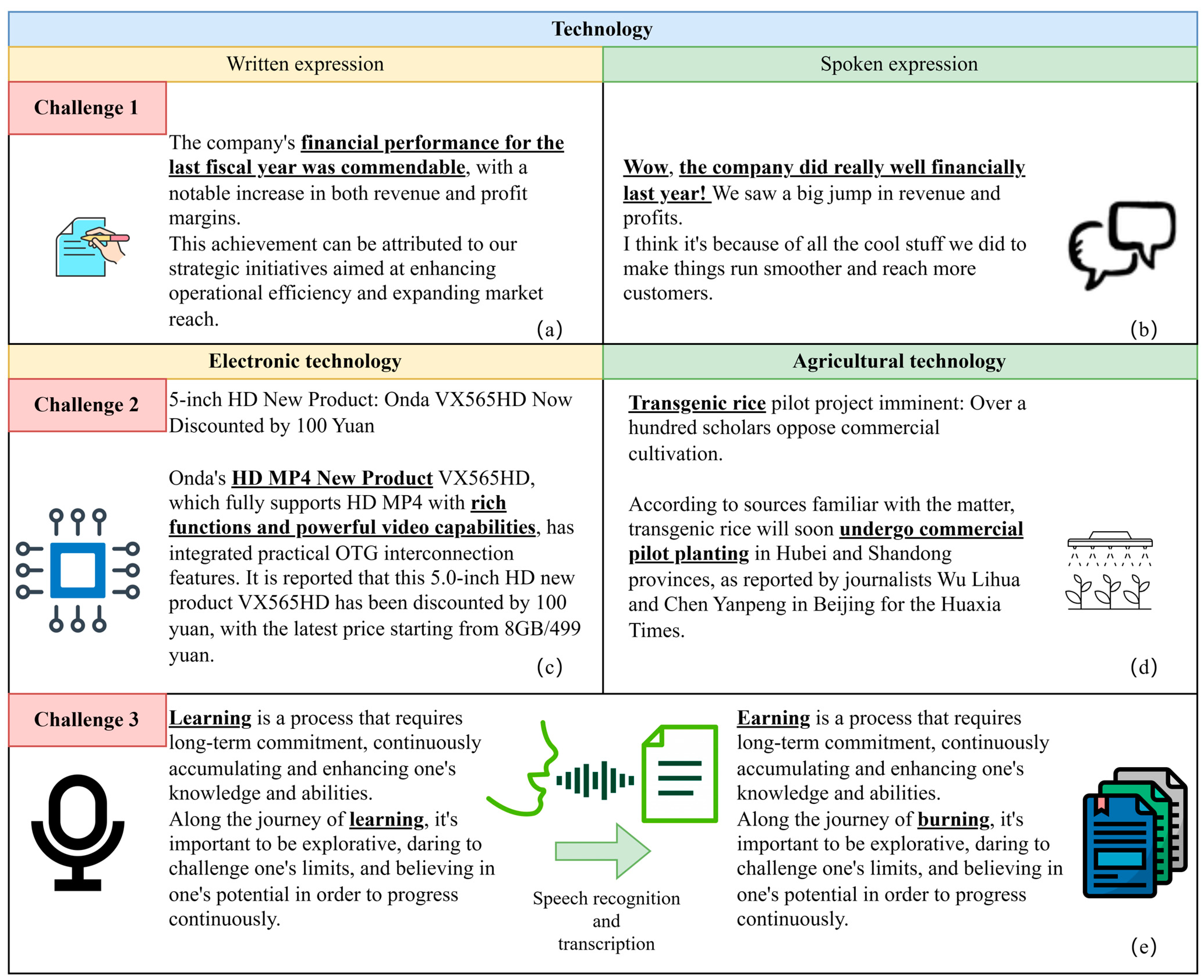
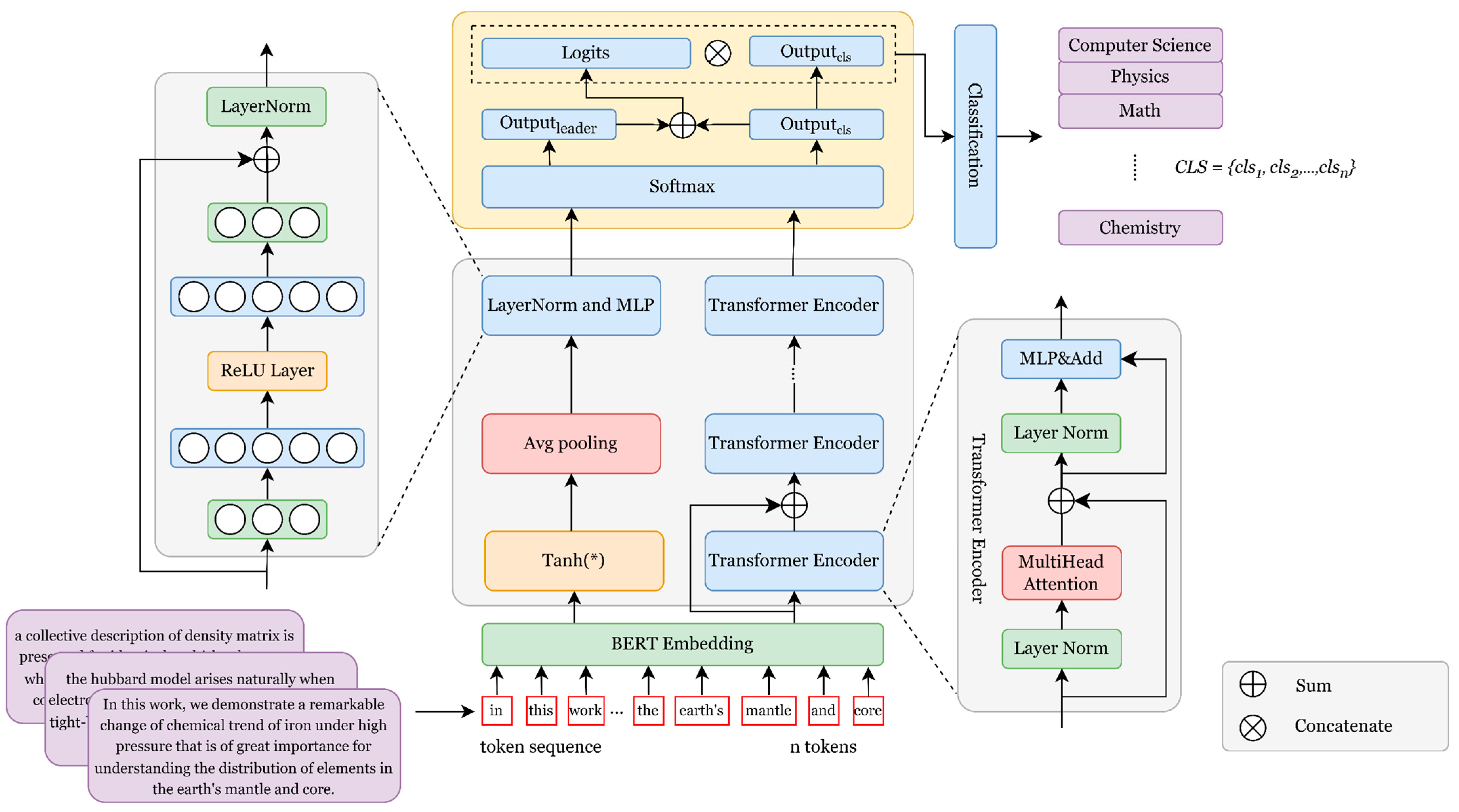
The overall architecture of RQ-OSPTrans consists of three parts: BERT word embedding learning, repeat question learning, and overall semantic perception. With regard to a word sequence S with an arbitrary number of characters
, RQ-OSPTrans inputs these parts into the BERT word embedding learning module to extract sentence feature states
and word vector representations
. In a word sequence S, each of them,
, represents a word-level semantics vector, as well as the elements in
. S represents the sentence-level semantics and
represents the overall semantics of the text. In other words, the sentence-level semantic representation and the overall semantic representation of each piece of text will be used as model inputs to implement the key insights in
Section 1.2, holistic semantic learning guided classification and joint semantic learning, to extract key clues. Thereafter, the repeat question learning module further extracts the implicit associated features of the text, introducing a masking mechanism and residual connections to enhance feature integrity during propagation and obtaining the classification output
of the text sequence. Subsequently, RQ-OSPTrans uses the global feature state pooler, introducing a multi-layer feedforward network with layer normalization to perceive the overall semantics of the sequence, obtaining the guiding output
using ReLU activation. Finally, the weighted average of the two types of outputs is calculated to obtain the final prediction output.
3.1. Word Sequence Embedding
In the word sequence embedding of the text, BERT demonstrates a superior word-level and paragraph-level feature representation performance compared with Glove [
39] and Word2Vec [
40]. This peculiarity aligns well with the requirements of the word embedding learning module in RQ-OSPTrans, making BERT the chosen core component for this module. After learning through multiple layers of the Transformer encoder, it outputs the last hidden state of the text sequence as the semantic word embedding matrix:
where
represents the hidden state of the word, and
denotes the computation function in the BERT model. This model then passes through a linear layer with Tanh activation and uses average pooling to aggregate all word features into a sentence semantic feature vector
:
Here, we pool each sentence-level semantic representation matrix
evenly in its text length, and fairly consider the semantic representation of each word while ensuring the word embedding dimension, and the semantic capture degree depends on all the dimensions and sentence lengths represented by the word embedding vector of each paragraph, so as to ensure that the overall semantic matrix captures the semantic information of all words. The Tanh activation function is used for nonlinear mapping:
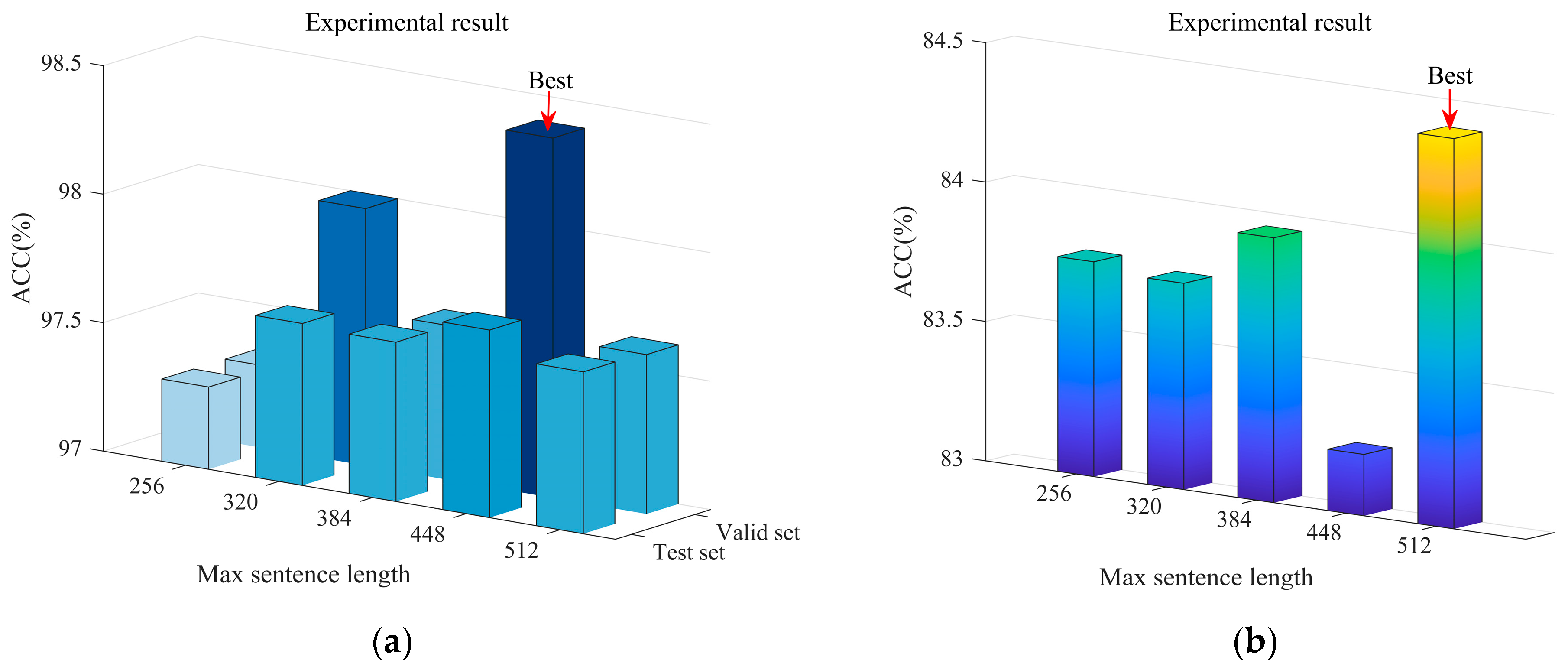
We uniformly expand the semantic matrix of word embeddings to the length of to enhance the effectiveness of word vector masking and residual connections. With regard to shorter sentences, we fill the missing parts with zeros. Meanwhile, we truncate the longer sentences to the length of . Finally, this module adds positional association features to the semantic matrix using positional information embedding from the Transformer based on the word embedding semantic matrix output by BERT, completing the output of this module.
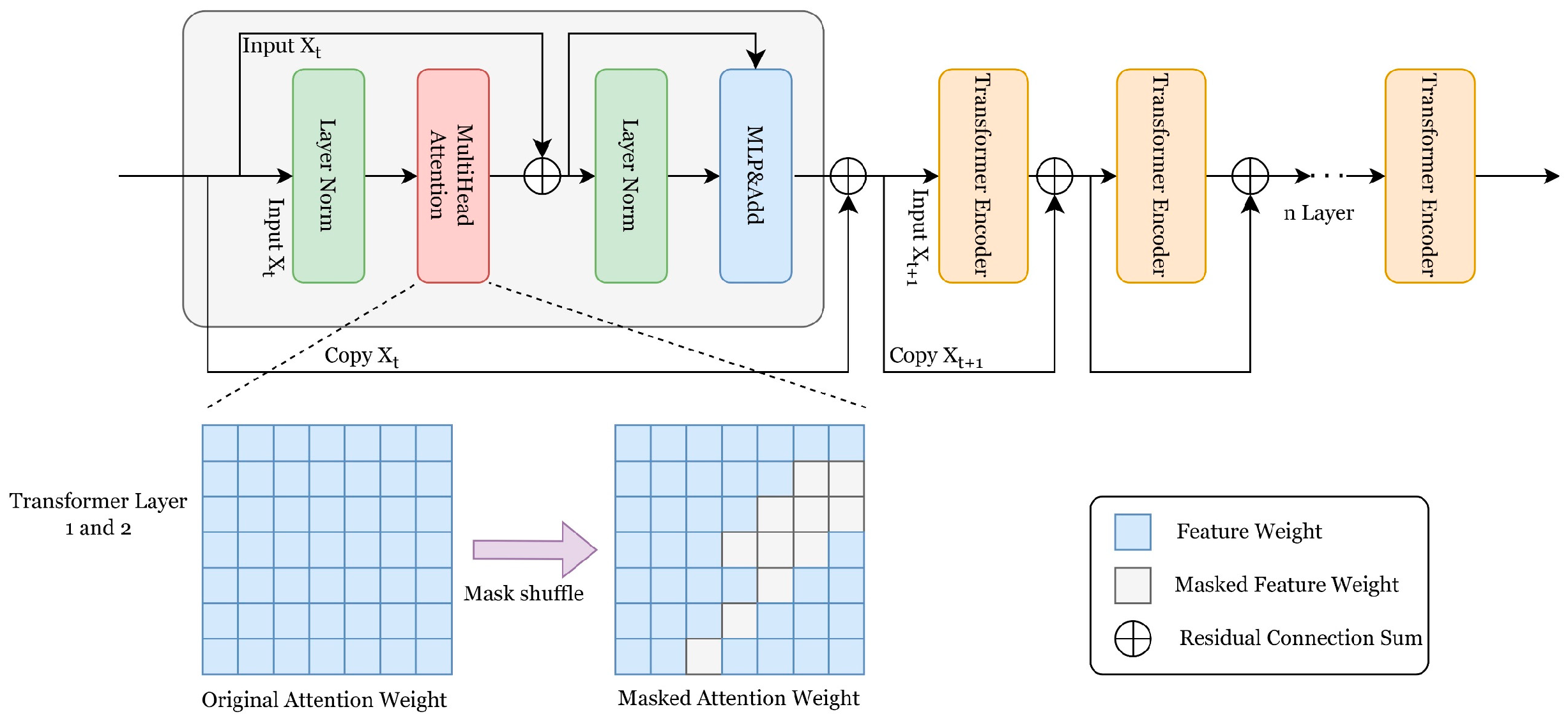
3.2. Repeat Question Module
Similar to the ViT [
41] model, we consider a Transformer encoder as a Transformer layer. The repeat question learning module consists of
similar layers with residual connections (
Figure 3). In the attention part, we utilize nonlinear scaled dot-product attention. The attention score input comprises the key and value from the input. We scale each attention score by the input dimension
, with the scaling factor being
. Here, a Tanh activation function is applied to project the attention scores into the nonlinear range of (−1, 1), with the aim of fitting the nonlinear sequence space and separate positive and negative feature weights. This approach helps in reducing the amplification effect of scores for ineffective blocks on the total weight when the input dimension is large, assigning higher weights to effective blocks in the Softmax classification output. The attention score and attention algorithm are shown as follows:
In the first and second layers, an auxiliary masking mechanism is applied for the attention weights of the multi-head attention mechanism. This mechanism helps each attention head to focus on text sequence blocks with high attention scores while minimizing weight waste on ineffective words as much as possible. After obtaining
, this mechanism masks elements below the threshold
in the attention score matrix
. Elements with values lower than the threshold
are masked to
:
In the subsequent layers, this masking mechanism is removed. The encoder network layers can fully learn from the input while passing a copy of the input to the next layer. The predictions of the current layer are additively fused with the input copy of this layer.
In this work,
is projected to dimensions
,
, and
, serving as the input for h attention learners. Nonlinear dot-product scaling attention is applied to each attention learner, allowing the model to focus on feature information in various subspaces of the sequence samples. The granularity of feature extraction is finer compared with a single self-attention mechanism. This module employs a multi-head attention mechanism with h attention heads, where
, requiring the word embedding dimension from
Section 3.1 to be evenly distributed across h subspaces. The joint feature learning matrix, denoted as
, is utilized for this purpose. The computation process of the multi-head attention mechanism is as follows. Here, we refer to the output of this part as
.
After the attention network, a scaled MLP with a residual connection to the attention input is introduced. The scaling perceptron maps the output of the attention network to a high-dimensional space of dimension and performs the first linear partitioning. Thereafter, the dimension of the matrix mapped by the first-dimension increment is flipped and mapped back to the original dimension , with a ReLU activation function inserted in the middle of the scaling perception for linear feature correction.
The presence of bias terms in the linear mapping operation affects the feature space distribution of the information. Accordingly, a layer normalization mechanism is established to address this issue. This mechanism calculates the mean and variance of each dimension of the input matrix based on the sample features, stabilizing the data distribution during forward propagation and the gradient during backward propagation. Layer normalization is more suitable for handling long data compared with batch normalization. Normalization focuses on individual sample feature spaces rather than the sentence length and batch size, stabilizing the feature space. The input dimension here is
, and the dimension after incrementing is
. Considering the integrity of the module, we will introduce the computational logic of this module in
Section 3.3.
A residual additive connection is utilized in the repeat question learning module (
Figure 3). This approach concatenates the input of the previous layer onto the output of the current layer, prompting the Transformer encoder to focus on every element of the input information. During the forward propagation, this mechanism strengthens the perception of the classification results, similar to prompting the model to confirm the classification answer under repeated questioning, reducing the oscillation caused by the randomness of the weight matrix. Assuming that
represents the output of the current layer,
represents the output of the original Transformer layer, the model retains a copy of this output denoted as
, while
serves as the guiding factor for the next layer. The formula for the residual connection in the next layer’s output is as follows:
At the heart of the repetition mechanism lies Equation (10). In a multi-layer Transformer encoder stack, the output of the pre-sequence network layer will affect the learning of the subsequent network, which may lead to a decrease in classification performance since a very small number of classification cues occupy a large attention score and cause the subsequent network to focus only on these parts. Therefore, it is a way to improve the performance by promoting the model to learn more categorical cues and correct the error of the weight allocation of the pre-order network in the subsequent network, and the “repeated questioning” mechanism proposed by us is derived from the attention information contained in the attention score matrix. First, we look at all the attention scores of a text as a whole and sum all the semantically allocated attention values. Secondly, to avoid overfitting the model by focusing on only a few key cues in multiple rounds of questioning, we use the word embedding dimension to smooth the attention value. After that, the output amplification weight is calculated with the help of the guide factor λ to scale the results of the previous round of attention learning, and the additive combination with the results of this round of learning is completed to complete a repeated question learning.
3.3. Overall Semantic Perception
Considering the BERT model output
, the Tanh activation function has been introduced, which brings nonlinear mapping. Here, in addition to applying the ReLU activation function between the two scaling layers, another ReLU linear correction is applied after completing the perception machine calculation. This connection retains only positive numbers as guiding elements for the classification output and sets the rest of the elements to zero, achieving the calculation of the MLP output:
In each feature sample
, the perception matrices are
and
. A nonlinear improvement using the Mish activation function [
42] is applied in this part to adapt the output feature distribution to the complex feature space of nonlinear activation, mapping the complex feature space to a distribution with minimal gradients. The algorithm for the Mish activation function is as follows:
In the computation of the multi-layer perceptron, the layer norm calculates the mean
and variance
of the features for each sample. The computation method is as follows:
The layer norm will normalize the output of the perceptron based on the
and standard deviation
:
The outputs of the learning modules are calculated separately as follows:
Both outputs are based on the feature space of a sequence of statements as the value set. Normalized feature vectors are calculated based on the feature mean and feature standard deviation.
3.4. Softmax Weight Correction and Loss Function
In our study, two modules are designed to compute the final model classification, handling the processing and loss calculation for the two classification results (
Figure 1). During the training phase, the long-sequence repeat question learning module and the overall semantic perception module are treated as two independent classifiers. These modules will compute losses
and
for the classification and guidance outputs, respectively. Considering the structure and inputs of the two classifiers, we introduce a guiding factor λ for computing the final output loss. Our output loss function is expressed by the following formula:
The design of the loss function aims to leverage the most prominent correlated sequence in the overall semantically reinforced context to contribute to the final classification. These two losses will collaboratively influence the backpropagation process. In either side of the classifier, considering each other’s loss serves as the optimization basis to enhance the model’s performance.
Similar to the design of the loss function, the final output of the model is a weighted average result from both classifiers. The sum of the weights is not directly used as the denominator here. In the two types of outputs
and
, the probabilities for each classification are computed using Softmax. The total classification result of both classifiers is weighted and summed according to the guiding factor. The average operation is then performed across the classifier dimension for the final output
:
Next, this work performs a second averaging operation on
and
to enhance the contribution of classification learning to the overall classification result and focus on optimizing the long-sequence repeat question feature learning module. This operation effectively combines the second amplification of
after an amplification by the guiding factor, resulting in the total weight amplification for each feature sample:
The output after the second amplification is obtained as
:


 ,
, 




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}