
Lightweight, Trust-Managing, and Privacy-Preserving Collaborative Intrusion Detection for Internet of Things


Abstract
1. Introduction
2. Related Works
- This study proposes FL-DNN with a binary classification mode for a collaborative anomaly detection model in CIDS to analyze diverse attacks in heterogeneous devices and networks with realistic traffic from IoT.
- This research used the combination of the Ethereum blockchain and interplanetary file system (IPFS) for trust management to distribute a training model for real-time traffic analysis in CIDS.
- The proposed model underwent testing using the CICIoT2023 dataset that simulates multiple heterogeneous devices and networks with realistic traffic from the IoT for comprehensive analysis.
- The proposed model uses a combination of edge–fog–cloud architecture and FL to create a hierarchical and lightweight architecture for a CIDS in IoT systems.
3. Methodology
3.1. CIDS Architecture
3.2. FL with DNN
3.3. Dataset Preprocessing
| Algorithm 1: Load and Distribute CICIoT2023 Data Train |
Input: client_id Output: , # Create non-IID splits based on client_id Set random seed using client_id Generate array of indices Shuffle the indices # Choose a fraction of the data for this client Set fraction = 0.04 Calculate client data size = Select client indices from shuffled indices based on client data size = [client_indices] = .iloc[client_indices] return , |
3.4. Performance Parameters
- Accuracy (%): The accuracy of an IDS is crucial for effectively identifying and responding to malicious activity while minimizing false positives. High accuracy indicates correct identification of true positives and true negatives. Accuracy is computed as in Formula (7) [31].where TP is true positive, TN is true negative, FP is false positive, and FN is false negative.
- Precision (%): Precision in IDS is the ratio of true-positive predictions to the total positive predictions made by the model, measuring the accuracy of positive predictions. It calculates the proportion of correctly predicted positive instances out of all instances predicted as positive. Precision is computed as in Formula (8) [31].
- Recall (%): The recall metric, also known as sensitivity or the true-positive rate, is the ratio of true-positive predictions to the total actual positive instances in the dataset. It gauges the model’s ability to correctly identify positive instances, regardless of some instances being wrongly predicted as negative. Recall is computed as in Formula (9) [31].
- F1-Score (%): The F1-score, a widely used metric in machine learning for classification tasks, combines precision and recall into a single value to measure the model’s accuracy. It offers a balanced evaluation of the model’s performance, especially when false positives and false negatives are equally significant. F1 is computed as in Formula (10) [31].
- TPS: Measuring TPS for DLT involves assessing the system’s transaction processing rate within a one-second time frame, serving as a crucial metric for evaluating a DLT’s performance and scalability. TPS is determined by tracking the successful recording and confirmation of transactions on the ledger, reflecting the system’s efficiency and capacity to accommodate a growing number of participants and transactions without compromising speed and reliability. This metric is influenced by factors such as the DLT’s technology, consensus mechanism, network capabilities, and data-handling processes. In terms of hardware resources, TPS is closely tied to both CPU and RAM. The CPU is responsible for processing and validating incoming transactions, while RAM aids in efficient data storage and retrieval. An effective combination of CPU and RAM resources is vital for achieving and sustaining high TPS rates in a DLT system, as they contribute to accelerated transaction processing and reduced latency. The formula for calculating TPS can be expressed as Formula (11) [32].where is the transactions per second, represents the total number of transactions processed during the chosen time period, and is the duration over which the transactions are measured in seconds.
- Latency (s): Measuring latency in an edge–fog–cloud architecture involves assessing the time it takes for data or a computational task to travel through the various layers of the architecture. Latency in this context refers to the delay introduced at different stages of processing, from the edge devices to the fog nodes and ultimately to the cloud servers. For network latency measurement, this research uses the following Formula (12) [33]:where is the round-trip time it takes for data to travel from the source to the destination and back. It is measured in seconds. is the size of the data being transmitted, expressed in kilobytes (KB). The measurement ensures that the size is consistent with the units used for network transmission speed. represents the capacity of the network to transmit data and is typically measured in kilobits per second (Kbps) [34].
- CPU and memory (%): Measuring the average CPU and memory usage during a learning process is crucial for assessing the computational demands of a machine learning model. This research utilizes system monitoring tools like ‘psutil’ in Python to provide real-time insights into CPU and memory usage [35].
3.5. Benchmarking Scenario
- Detection performance: The first scenario involves benchmarking the performance of the FL-DNN model to test it using testing data from all devices. The parameters analyzed in this measurement are accuracy, precision, recall, and F1-score.
- Transaction performance: The second scenario aims to evaluate the performance of the DLT when handling transactions in the proposed CIDS model. The parameter analyzed in this measurement is transactions per second (TPS).
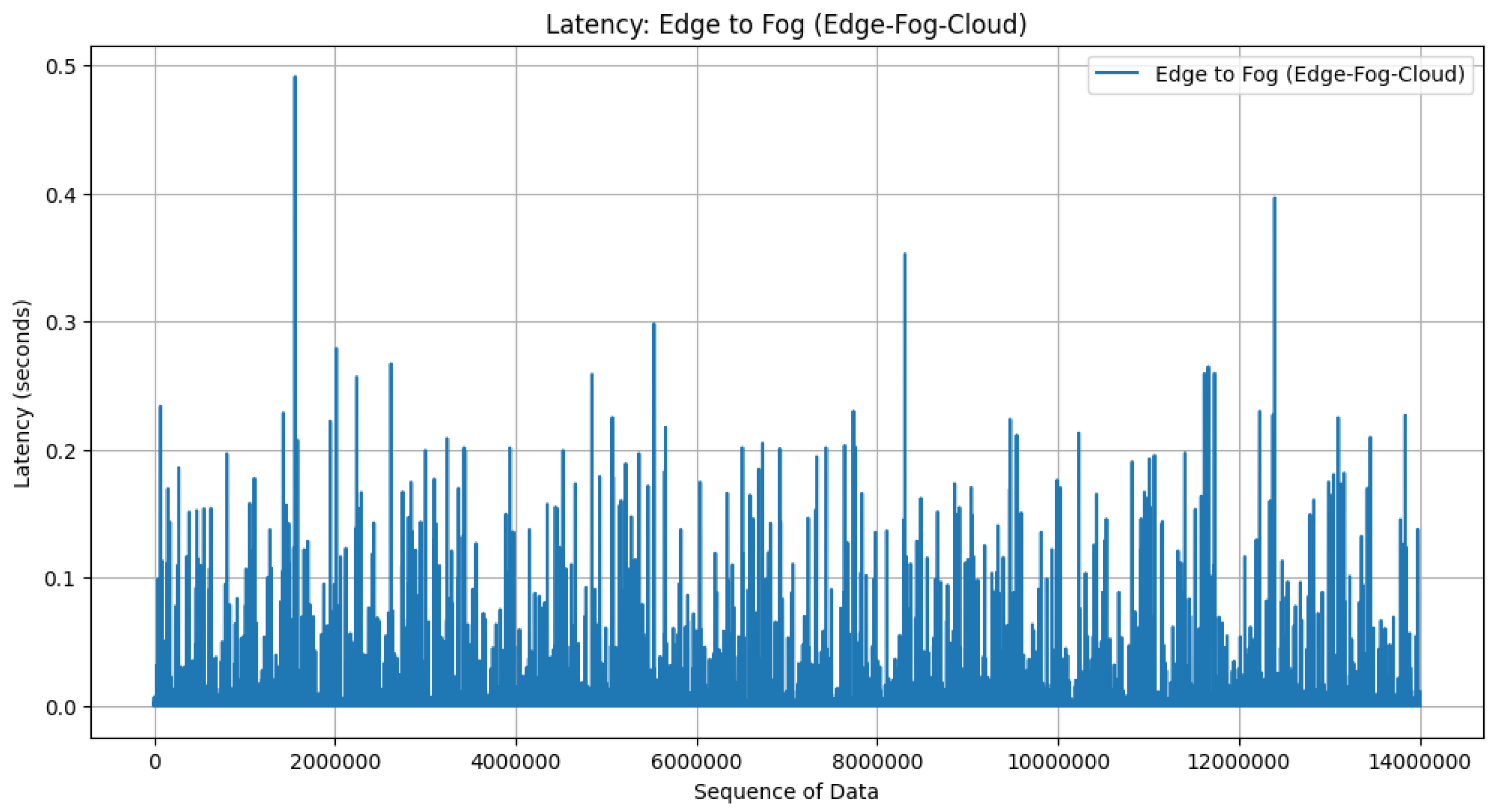
- Network latency performance: The third scenario is calculating network latency in an edge–fog–cloud architecture. This scenario involves assessing the time it takes for data to traverse the communication layers within the system. Beginning with edge latency, the duration for data to move from edge devices to local processing units is measured, considering local network dynamics. Moving to fog latency, the time taken for data processing at fog nodes, which offer additional computational capabilities closer to the edge, is evaluated. Cloud latency assessment follows, considering the round-trip time for data to travel from the edge and fog layers to centralized cloud servers and back. End-to-end latency encapsulates the total time for data or tasks to traverse the entire architecture, encompassing edge, fog, and cloud layers. Network latency, an essential component, examines the delays introduced during data transmission between these layers.
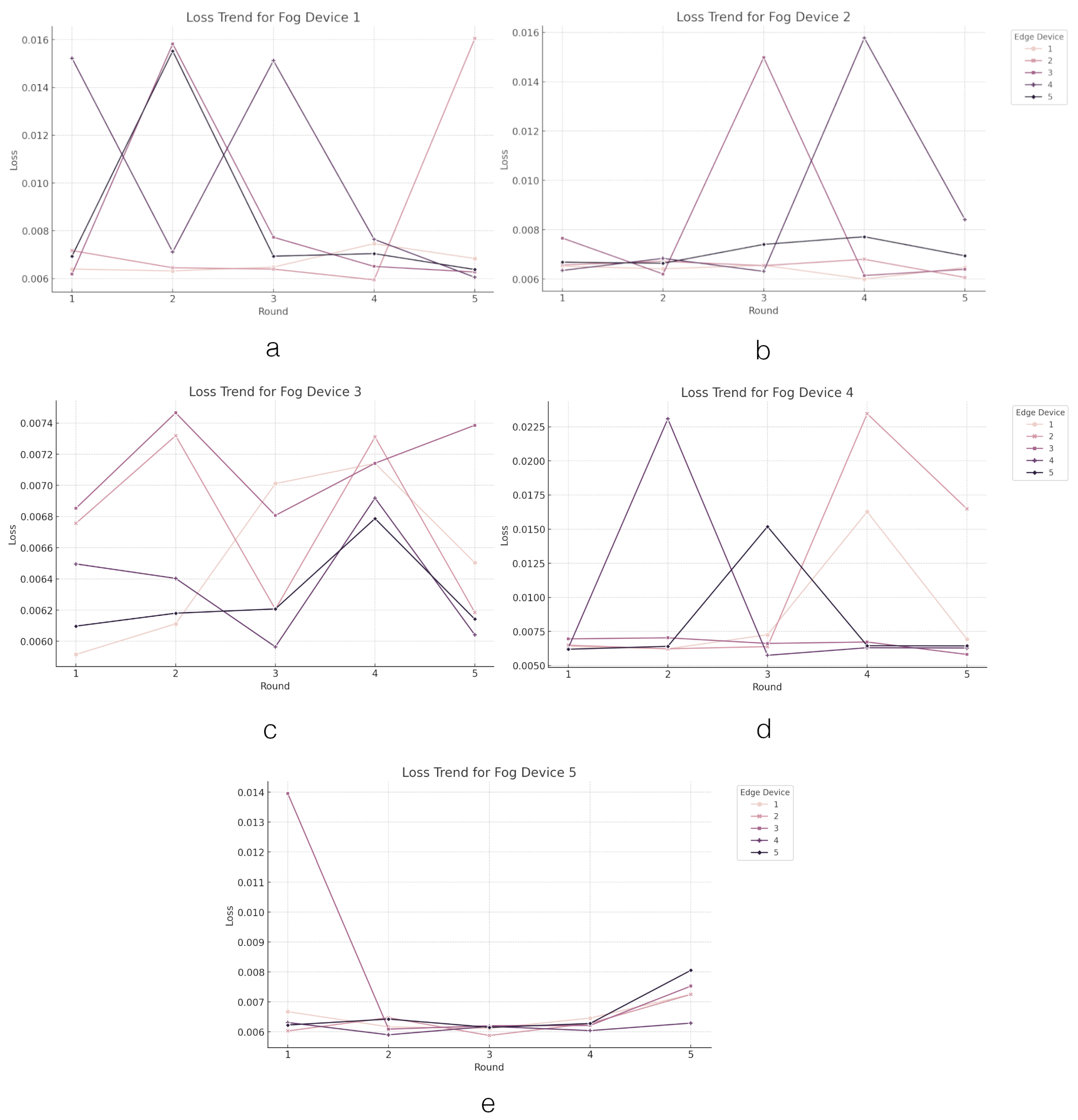
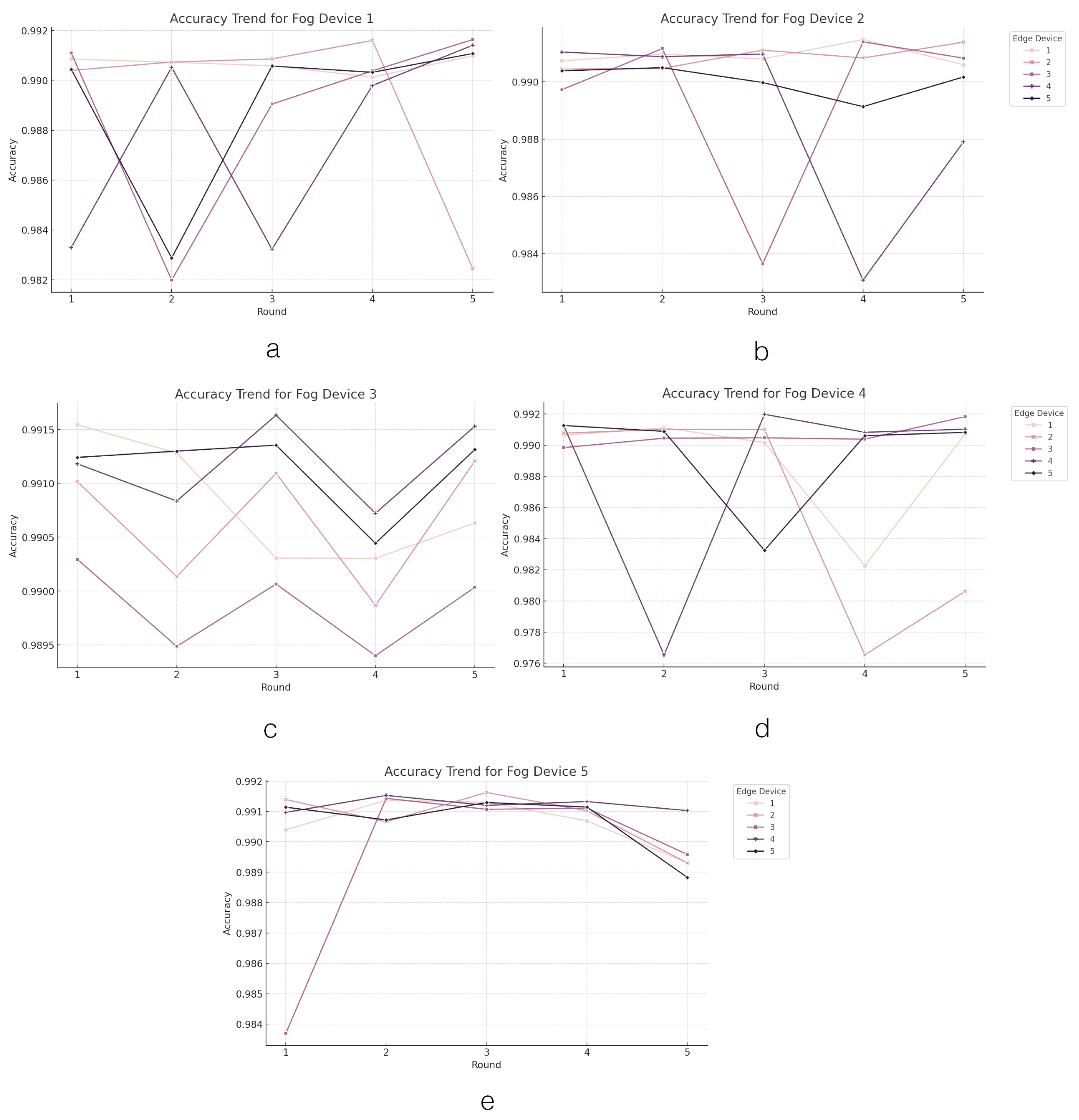
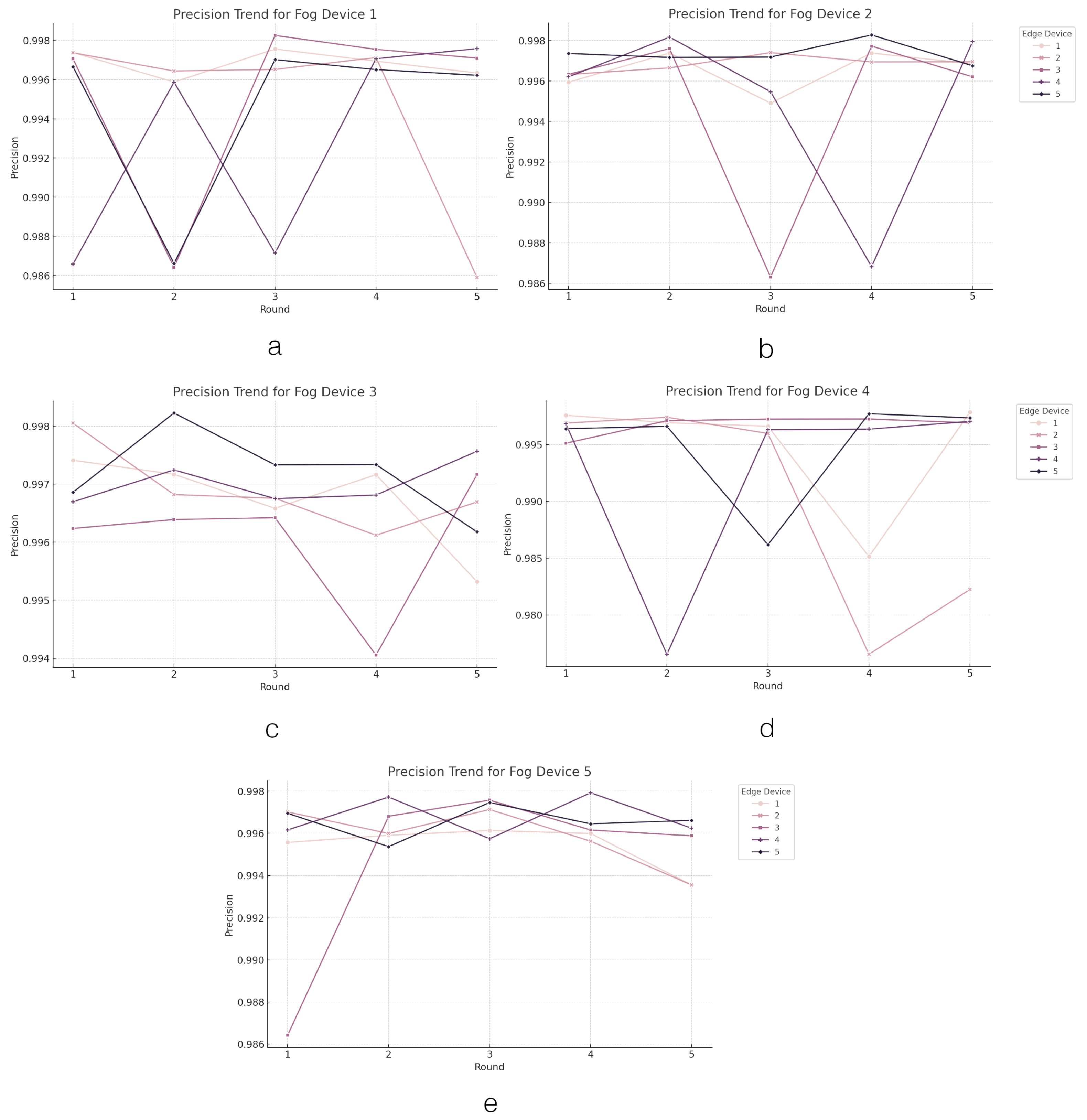
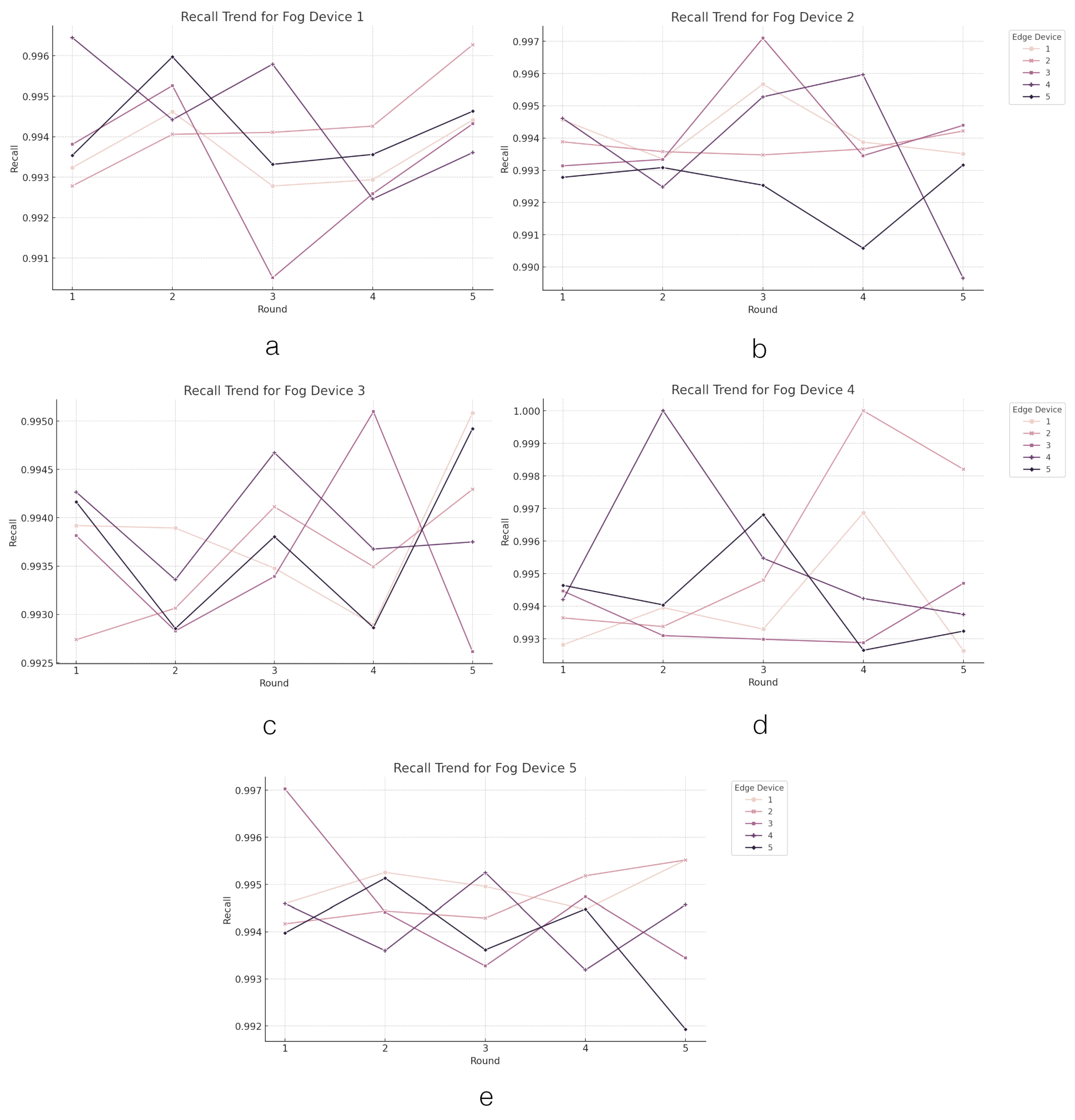
- Resource consumption performance: The fourth testing scenario involves measuring resource consumption. The performance of resource consumption focuses on CPU and memory consumption during the training process. In this research, we compare the learning process between centralized learning and federated learning when distributed in edge computing. We monitor the CPU and memory consumption every second during the learning process, then average all the captured values from CPU and memory consumption to calculate the CPU and memory consumption in a single learning process. In FL based on edge–fog–cloud architecture, we monitor the learning process in 5 rounds.
4. Results
4.1. Experiment Environment and Configuration
| Algorithm 2: Transaction in FL-DNN based on DLT |
 |
4.2. Centralized Learning vs. FL Based on Edge–Fog–Cloud Architecture
4.2.1. Centralized Learning Performance
4.2.2. FL on Edge Layer Performance
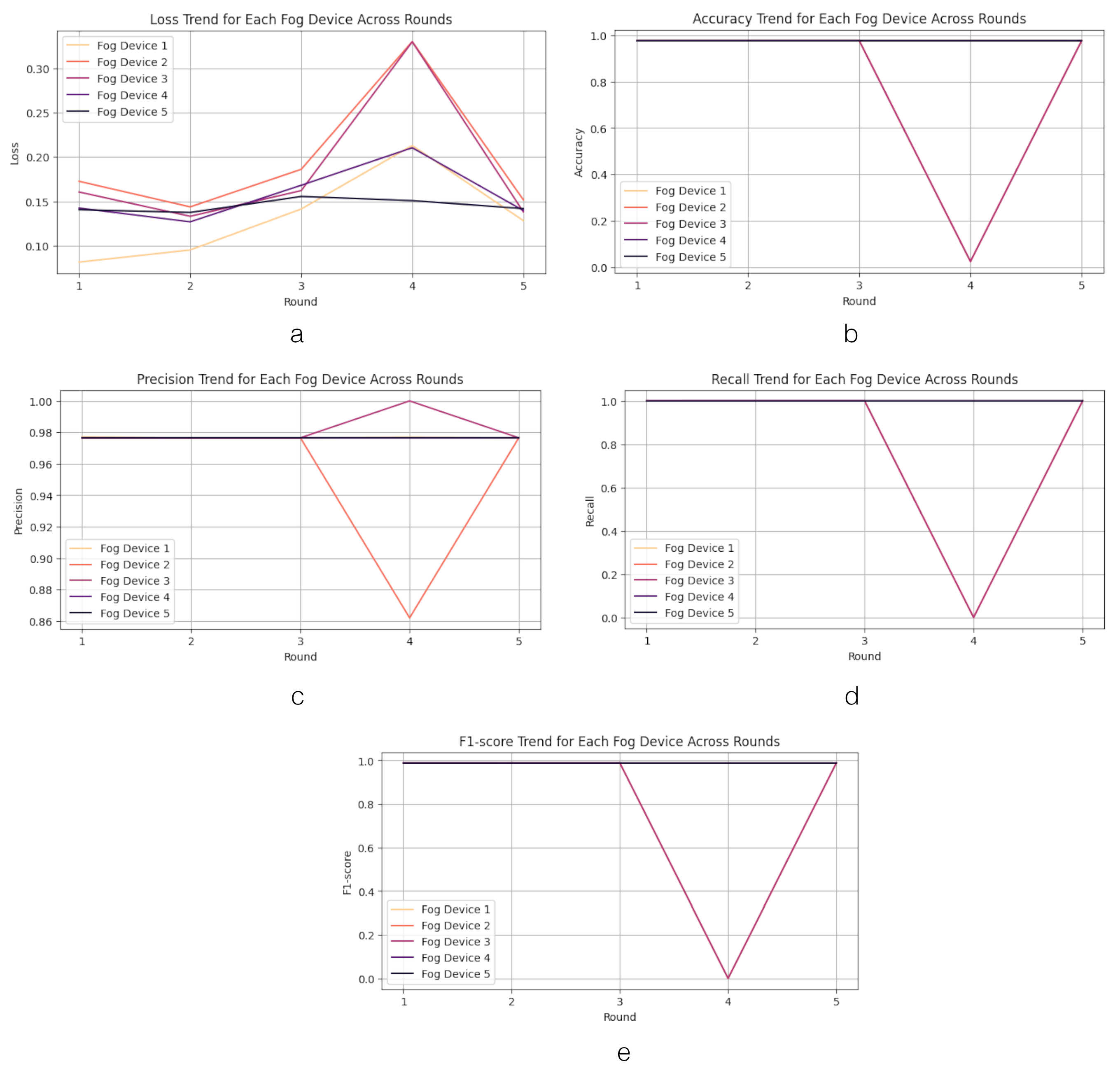
4.2.3. FL on Fog Layer Performance
4.2.4. FL on Cloud Layer Performance
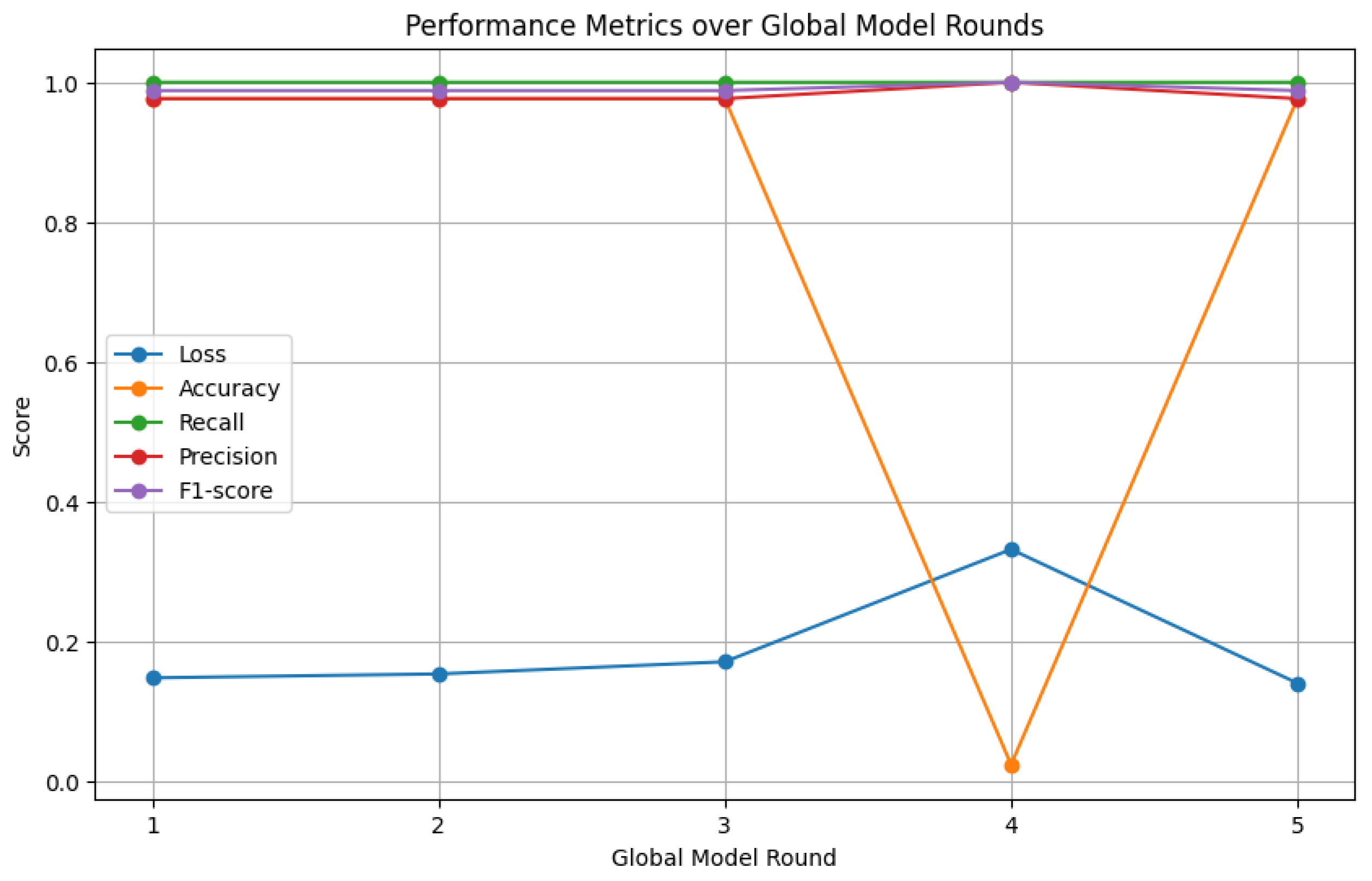
4.2.5. FL Based on Edge–Fog–Cloud Architecture (Training Time)
4.2.6. FL Based on Edge–Fog–Cloud Architecture (Resource Consumption)
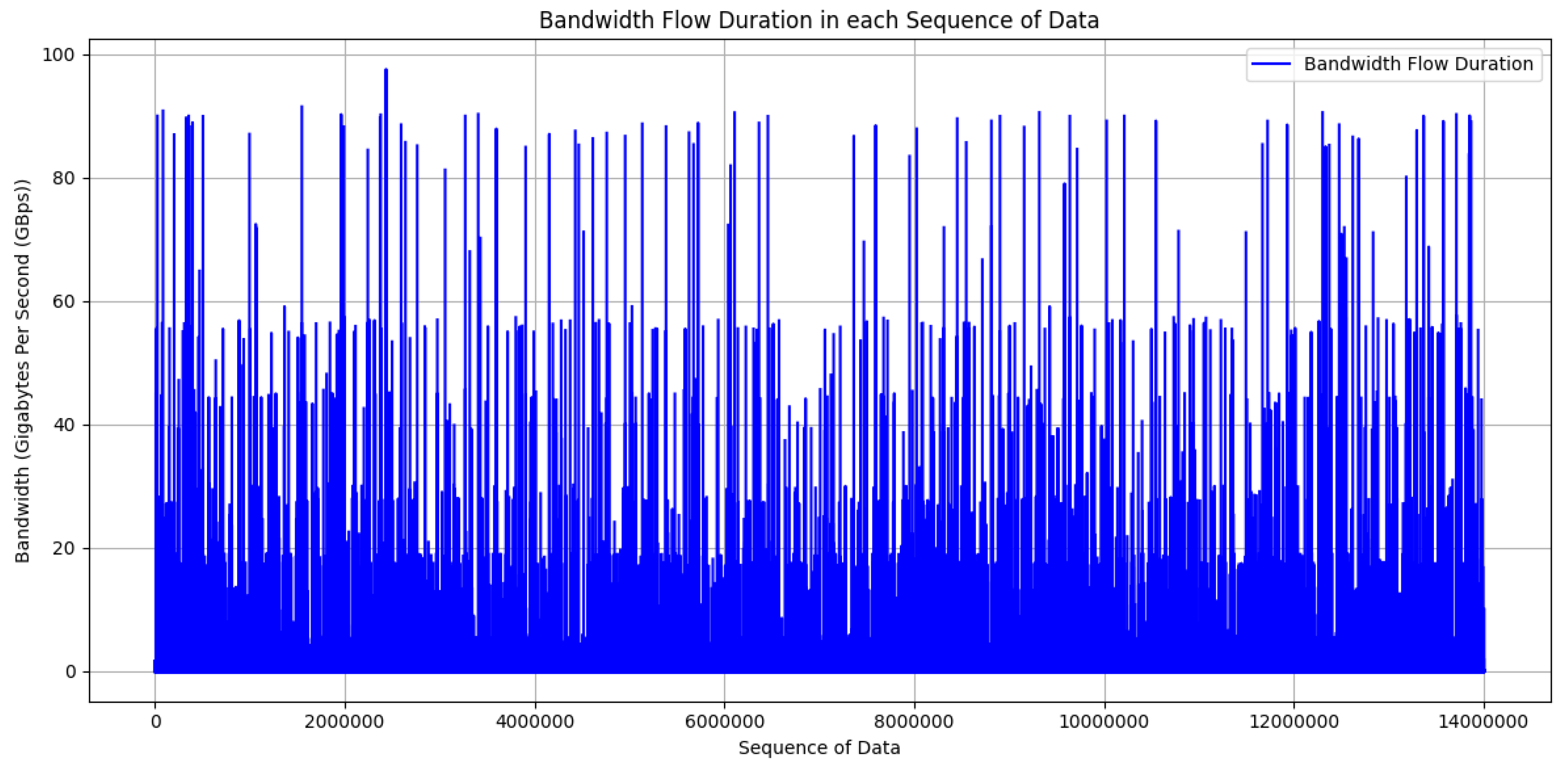
4.2.7. Latency Performance
| Algorithm 3: Latency Simulation |
Data: CSV CICIoT2023 dataset Result: latency_edge_to_fog, latency_fog_to_cloud, and latency_edge_to_cloud Load the CSV dataset Calculate the average speed of data transfer for each task BFD ← df[’Tot size’] / df[’flow_duration’] Determine the size of a model model_size ← 46 KB Divide the devices into different groups num_edge_devices ← 5 num_fog_devices ← 5 num_total_edge_devices_cloud_centric ← 25 Assign data transfer speed to each group trnsSPD_edge_to_fog ← BFD / num_edge_devices trnsSPD_fog_to_cloud ← BFD / num_fog_devices trnsSPD_edge_to_cloud ← BFD / num_total_edge_devices_cloud_centric Calculate the time taken for data transfer between different groups latency_edge_to_fog ← model_size / trnsSPD_edge_to_fog latency_fog_to_cloud ← model_size / trnsSPD_fog_to_cloud latency_edge_to_cloud ← model_size / trnsSPD_edge_to_cloud |
4.2.8. Performance Comparison
4.3. DLT Performance
4.4. CIDS Trust and Privacy-Preserving Analysis
5. Discussion and Future Works
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Sarker, I.H.; Khan, A.I.; Abushark, Y.B.; Alsolami, F. Internet of Things (IoT) Security Intelligence: A Comprehensive Overview, Machine Learning Solutions and Research Directions. Mob. Netw. Appl. 2023, 28, 296–312. [Google Scholar] [CrossRef]
- Wardana, A.A.; Kołaczek, G.; Warzyński, A.; Sukarno, P. Ensemble averaging deep neural network for botnet detection in heterogeneous Internet of Things devices. Sci. Rep. 2024, 14, 3878. [Google Scholar] [CrossRef]
- Li, W.; Au, M.H.; Wang, Y. A fog-based collaborative intrusion detection framework for smart grid. Int. J. Netw. Manag. 2021, 31, e2107. [Google Scholar] [CrossRef]
- de Souza, C.A.; Westphall, C.B.; Machado, R.B.; Loffi, L.; Westphall, C.M.; Geronimo, G.A. Intrusion detection and prevention in fog based IoT environments: A systematic literature review. Comput. Netw. 2022, 214, 109154. [Google Scholar] [CrossRef]
- Wardana, A.A.; Kołaczek, G.; Sukarno, P. Collaborative Intrusion Detection System for Internet of Things Using Distributed Ledger Technology: A Survey on Challenges and Opportunities. In Intelligent Information and Database Systems; Springer: Cham, Switzerland, 2022; pp. 339–350. [Google Scholar]
- Awan, K.A.; Din, I.U.; Almogren, A.; Rodrigues, J.J.P.C. AutoTrust: A privacy-enhanced trust-based intrusion detection approach for internet of smart things. Future Gener. Comput. Syst. 2022, 137, 288–301. [Google Scholar] [CrossRef]
- Li, W.; Meng, W.; Kwok, L.F. Surveying Trust-Based Collaborative Intrusion Detection: State-of-the-Art, Challenges and Future Directions. IEEE Commun. Surv. Tutorials 2022, 24, 280–305. [Google Scholar] [CrossRef]
- Alli, A.A.; Alam, M.M. The fog cloud of things: A survey on concepts, architecture, standards, tools, and applications. Internet Things 2020, 9, 100177. [Google Scholar] [CrossRef]
- Gkogkos, G.; Patsonakis, C.; Drosou, A.; Tzovaras, D. A DLT-based framework for secure IoT infrastructure in smart communities. Technol. Soc. 2023, 74, 102329. [Google Scholar] [CrossRef]
- Imteaj, A.; Thakker, U.; Wang, S.; Li, J.; Amini, M.H. A survey on federated learning for resource-constrained IoT devices. IEEE Internet Things J. 2021, 9, 1–24. [Google Scholar] [CrossRef]
- Sarhan, M.; Lo, W.W.; Layeghy, S.; Portmann, M. HBFL: A hierarchical blockchain-based federated learning framework for collaborative IoT intrusion detection. Comput. Electr. Eng. 2022, 103, 108379. [Google Scholar] [CrossRef]
- Ashraf, E.; Areed, N.F.F.; Salem, H.; Abdelhay, E.H.; Farouk, A. FIDChain: Federated Intrusion Detection System for Blockchain-Enabled IoT Healthcare Applications. Healthcare 2022, 10, 1110. [Google Scholar] [CrossRef] [PubMed]
- He, X.; Chen, Q.; Tang, L.; Wang, W.; Liu, T. CGAN-Based Collaborative Intrusion Detection for UAV Networks: A Blockchain-Empowered Distributed Federated Learning Approach. IEEE Internet Things J. 2023, 10, 120–132. [Google Scholar] [CrossRef]
- Abdel-Basset, M.; Moustafa, N.; Hawash, H.; Razzak, I.; Sallam, K.M.; Elkomy, O.M. Federated Intrusion Detection in Blockchain-Based Smart Transportation Systems. IEEE Trans. Intell. Transp. Syst. 2022, 23, 2523–2537. [Google Scholar] [CrossRef]
- Abdel-Basset, M.; Moustafa, N.; Hawash, H. Privacy-Preserved Cyberattack Detection in Industrial Edge of Things (IEoT): A Blockchain-Orchestrated Federated Learning Approach. IEEE Trans. Ind. Inform. 2022, 18, 7920–7934. [Google Scholar] [CrossRef]
- Neto, E.C.P.; Dadkhah, S.; Ferreira, R.; Zohourian, A.; Lu, R.; Ghorbani, A.A. CICIoT2023: A Real-Time Dataset and Benchmark for Large-Scale Attacks in IoT Environment. Sensors 2023, 23, 5941. [Google Scholar] [CrossRef] [PubMed]
- Le, T.-T.-H.; Wardhani, R.W.; Putranto, D.S.C.; Jo, U.; Kim, H. Toward Enhanced Attack Detection and Explanation in Intrusion Detection System-Based IoT Environment Data. IEEE Access 2023, 11, 131661–131676. [Google Scholar] [CrossRef]
- Zhou, C.V.; Leckie, C.; Karunasekera, S. A survey of coordinated attacks and collaborative intrusion detection. Comput. Secur. 2010, 29, 124–140. [Google Scholar] [CrossRef]
- Marchetti, M.; Messori, M.; Colajanni, M. Peer-to-peer architecture for collaborative intrusion and malware detection on a large scale. In Information Security, Proceedings of the 12th International Conference, ISC 2009, Pisa, Italy, 7–9 September 2009; Springer: Berlin/Heidelberg, Germany, 2009. [Google Scholar]
- Liang, W.; Xiao, L.; Zhang, K.; Tang, M.; He, D.; Li, K.C. Data fusion approach for collaborative anomaly intrusion detection in blockchain-based systems. IEEE Internet Things J. 2021, 9, 14741–14751. [Google Scholar] [CrossRef]
- Shetty, T.; Negi, S.; Kulshrestha, A.; Choudhary, S.; Ramani, S.; Karuppiah, M. Blockchain for intrusion detection systems. In Blockchain Technology for Emerging Applications; Academic Press: Cambridge, MA, USA, 2022; pp. 107–136. [Google Scholar]
- Alevizos, L.; Eiza, M.H.; Ta, V.T.; Shi, Q.; Read, J. Blockchain-Enabled Intrusion Detection and Prevention System of APTs within Zero Trust Architecture. IEEE Access 2022, 10, 89270–89288. [Google Scholar] [CrossRef]
- Subathra, G.; Antonidoss, A.; Singh, B.K. Decentralized Consensus Blockchain and IPFS-Based Data Aggregation for Efficient Data Storage Scheme. Secur. Commun. Netw. 2022, 2022, 3167958. [Google Scholar] [CrossRef]
- Munir, A.; Kansakar, P.; Khan, S.U. IFCIoT: Integrated Fog Cloud IoT: A novel architectural paradigm for the future Internet of Things. IEEE Consum. Electron. Mag. 2017, 6, 74–82. [Google Scholar] [CrossRef]
- Roy, S.; Li, J.; Bai, Y. A Two-layer Fog-Cloud Intrusion Detection Model for IoT Networks. Internet Things 2022, 19, 100557. [Google Scholar] [CrossRef]
- Nilsson, A.; Smith, S.; Ulm, G.; Gustavsson, E.; Jirstrand, M. A Performance Evaluation of Federated Learning Algorithms. In Proceedings of the Second Workshop on Distributed Infrastructures for Deep Learning, Rennes, France, 10 December 2018; pp. 1–8. [Google Scholar] [CrossRef]
- Li, T.; Sahu, A.K.; Talwalkar, A.; Smith, V. Federated Learning: Challenges, Methods, and Future Directions. IEEE Signal Process. Mag. 2020, 37, 50–60. [Google Scholar] [CrossRef]
- Lecun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- Aggarwal, C.C. Neural Networks and Deep Learning; Springer: Cham, Switzerland, 2018; Volume 10, pp. 973–978. [Google Scholar]
- Zhu, H.; Xu, J.; Liu, S.; Jin, Y. Federated learning on non-IID data: A survey. Neurocomputing 2021, 465, 371–390. [Google Scholar] [CrossRef]
- Alkasassbeh, M.; Baddar, S.A. Intrusion Detection Systems: A State-of-the-Art Taxonomy and Survey. Arab. J. Sci. Eng. 2023, 48, 10021–10064. [Google Scholar] [CrossRef]
- Ren, K.; Ho, N.M.; Loghin, D.; Nguyen, T.T.; Ooi, B.C.; Ta, Q.T.; Zhu, F. Interoperability in Blockchain: A Survey. IEEE Trans. Knowl. Data Eng. 2023, 35, 12750–12769. [Google Scholar] [CrossRef]
- Hazra, A.; Rana, P.; Adhikari, M.; Amgoth, T. Fog computing for next-generation Internet of Things: Fundamental, state-of-the-art and research challenges. Comput. Sci. Rev. 2023, 48, 100549. [Google Scholar] [CrossRef]
- Zhang, D.G.; Wu, H.; Zhao, P.Z.; Liu, X.H.; Cui, Y.Y.; Chen, L.; Zhang, T. New approach of multi-path reliable transmission for marginal wireless sensor network. Wirel. Netw. 2020, 26, 1503–1517. [Google Scholar] [CrossRef]
- da Silva, L.G.F.; Sadok, D.F.H.; Endo, P.T. Resource optimizing federated learning for use with IoT: A systematic review. J. Parallel Distrib. Comput. 2023, 175, 92–108. [Google Scholar] [CrossRef]
- Lan, K.; Heidemann, J. A measurement study of correlations of Internet flow characteristics. Comput. Netw. 2006, 50, 46–62. [Google Scholar] [CrossRef]
- Sathish, K.; Hamdi, M.; Chinthaginjala, R.; Pau, G.; Ksibi, A.; Anbazhagan, R.; Abbas, M.; Usman, M. Reliable Data Transmission in Underwater Wireless Sensor Networks Using a Cluster-Based Routing Protocol Endorsed by Member Nodes. Electronics 2023, 12, 1287. [Google Scholar] [CrossRef]
- Lee, J.Y.; Lee, W.; Kim, H.; Kim, H. Adaptive TCP Transmission Adjustment for UAV Network Infrastructure. Appl. Sci. 2020, 10, 1161. [Google Scholar] [CrossRef]
- Park, J.-S.; Lee, J.-Y.; Lee, S.-B. Internet traffic measurement and analysis in a high speed network environment: Workload and flow characteristics. J. Commun. Netw. 2000, 2, 287–296. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Feature | ||||
|---|---|---|---|---|
| flow_duration | Header_Length | Protocol Type | Duration | Rate |
| Srate | Drate | fin_flag_number | syn_flag_number | rst_flag_number |
| psh_flag_number | ack_flag_number | ece_flag_number | cwr_flag_number | ack_count |
| syn_count | fin_count | urg_count | rst_count | HTTP |
| HTTPS | DNS | Telnet | SMTP | SSH |
| IRC | TCP | UDP | DHCP | ARP |
| ICMP | IPv | LLC | Tot sum | Min |
| Max | AVG | Std | Tot size | IAT |
| Number | Magnitue | Radius | Covariance | Variance |
| Weight | Label |
| No | Traffic Type | Number |
|---|---|---|
| 1 | DDoS | 10,197,039 |
| 2 | DoS | 2,426,635 |
| 3 | Mirai | 790,305 |
| 4 | Benign | 328,597 |
| 5 | Spoofing | 145,999 |
| 6 | Recon | 105,957 |
| 7 | Web | 7462 |
| 8 | BruteForce | 3980 |
| Hyperparameter | Details |
|---|---|
| Hidden layer | 4 |
| Input dimension | 46 |
| Optimization algorithm | SGD |
| Output dimension | 1 (binary) |
| Batch size | 1000 |
| Output layer activation function | Sigmoid |
| Epochs | 10 |
| Metrics | Accuracy, precision, and recall |
| Loss function | Mean squared error |
| Hidden Layer | Number of Node | Activation Function |
|---|---|---|
| 1 | 21 | ReLU |
| 2 | 13 | ReLU |
| 3 | 7 | ReLU |
| 4 | 5 | ReLU |
| No | Parameter | Result |
|---|---|---|
| 1 | Loss | 0.0045648 |
| 2 | Accuracy (%) | 0.9936 |
| 3 | Precision (%) | 0.9955 |
| 4 | Recall (%) | 0.9979 |
| 5 | F1-score (%) | 0.9967 |
| 6 | Training time (s) | 4041.07 |
| 7 | Average CPU (%) | 4.7 |
| 8 | Average memory (GB) | 40.78 |
| 9 | Model size (Kb) | 46 |
| Number of Transactions | Latency (s) | Transactions per Second |
|---|---|---|
| 1000 | 6 | 166.67 |
| 2000 | 12 | 166.67 |
| 3000 | 18 | 166.67 |
| 4000 | 25 | 160 |
| 5000 | 30 | 166.67 |
| 6000 | 36 | 166.67 |
| 7000 | 42 | 166.67 |
| 8000 | 49 | 163.26 |
| 9000 | 56 | 160.71 |
| 10,000 | 62 | 161.29 |
| Average | 33.6 | 164.52 |
| Number of Transactions | CPU (%) | RAM (Mb) |
|---|---|---|
| 1000 | 3.26 | 217.39 |
| 2000 | 3.42 | 217.42 |
| 3000 | 2.98 | 217.39 |
| 4000 | 2.84 | 217.37 |
| 5000 | 2.82 | 217.36 |
| 6000 | 3.75 | 217.71 |
| 7000 | 2.9 | 217.38 |
| 8000 | 2.85 | 217.4 |
| 9000 | 3.43 | 217.57 |
| 10,000 | 2.85 | 217.18 |
| Average | 3.11 | 217.41 |
| Number of Transactions | CPU (%) | RAM (Mb) |
|---|---|---|
| 1000 | 15.42 | 138.17 |
| 2000 | 17.55 | 140.27 |
| 3000 | 15.13 | 144.24 |
| 4000 | 15.34 | 144.52 |
| 5000 | 15.48 | 144.62 |
| 6000 | 15.64 | 144.09 |
| 7000 | 17.36 | 144.39 |
| 8000 | 17.1 | 144.66 |
| 9000 | 17.86 | 145.11 |
| 10,000 | 19.223 | 147.43 |
| Average | 16.61 | 143.75 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wardana, A.A.; Kołaczek, G.; Sukarno, P. Lightweight, Trust-Managing, and Privacy-Preserving Collaborative Intrusion Detection for Internet of Things. Appl. Sci. 2024, 14, 4109. https://doi.org/10.3390/app14104109
Wardana AA, Kołaczek G, Sukarno P. Lightweight, Trust-Managing, and Privacy-Preserving Collaborative Intrusion Detection for Internet of Things. Applied Sciences. 2024; 14(10):4109. https://doi.org/10.3390/app14104109
Chicago/Turabian StyleWardana, Aulia Arif, Grzegorz Kołaczek, and Parman Sukarno. 2024. "Lightweight, Trust-Managing, and Privacy-Preserving Collaborative Intrusion Detection for Internet of Things" Applied Sciences 14, no. 10: 4109. https://doi.org/10.3390/app14104109
APA StyleWardana, A. A., Kołaczek, G., & Sukarno, P. (2024). Lightweight, Trust-Managing, and Privacy-Preserving Collaborative Intrusion Detection for Internet of Things. Applied Sciences, 14(10), 4109. https://doi.org/10.3390/app14104109