

Deep Feature Retention Module Network for Texture Classification



Abstract
1. Introduction
2. Related Works
2.1. Model for Texture Classification
2.2. Multiple Structure to Obtain Features
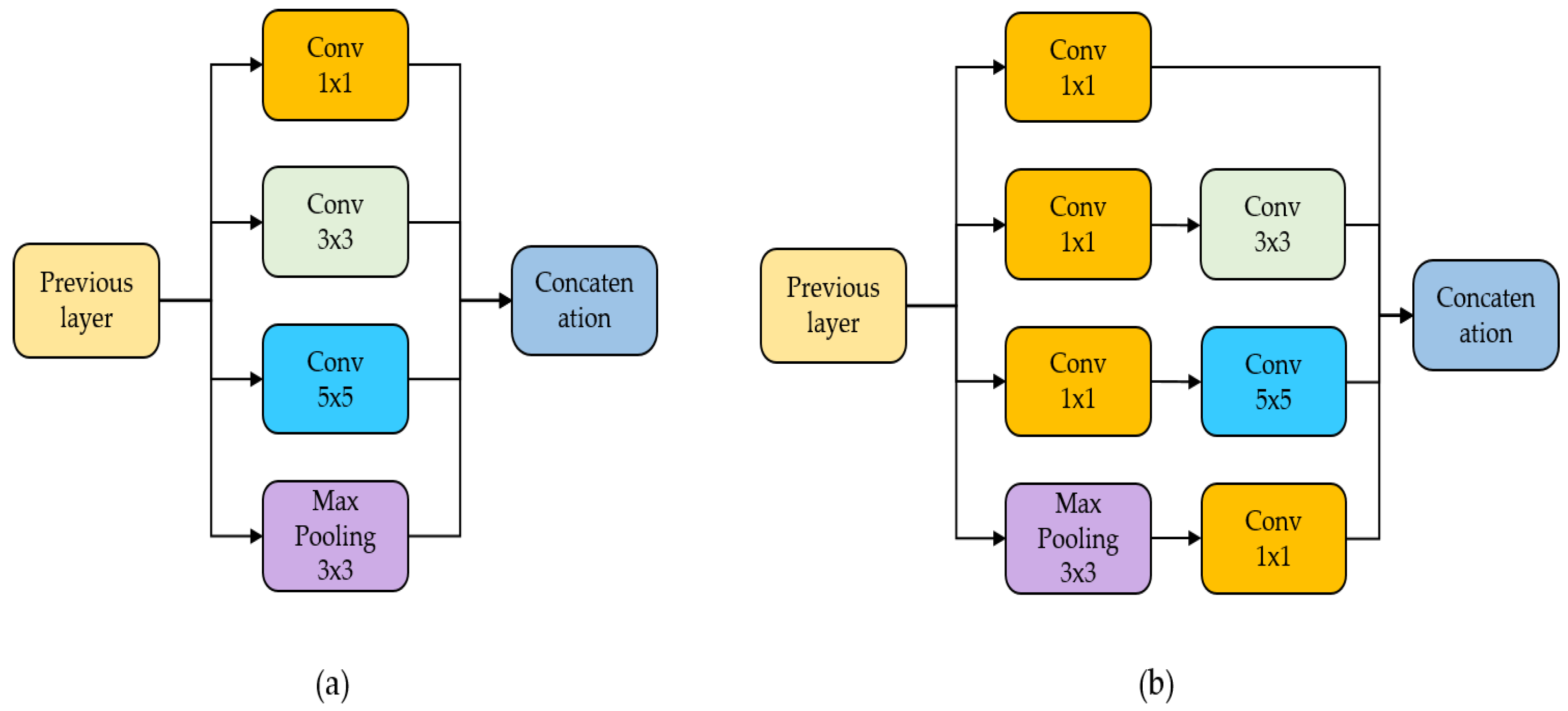
2.3. Feature Module for CNN
3. Proposed Method
3.1. Model Architecture
- DenseNet has a structural characteristic that uses information from the input layer connected to the output layer in the feed-forward process. Therefore, it can consider the advantages of features and continually learn all feature information from low to high levels.
- FRM was used for each DenseBlock to minimize the loss of information as the layers of the backbone model deepened. This is expected to have an important influence on the use of the detailed features of textures for learning.
- We aimed to use various detailed features of the texture dataset for learning. Therefore, the structural characteristics of the model proposed in [18] were referred to. By combining the FRM with the backbone, it is expected that the outputs through the FRM from low to high levels are aggregated and can help distinguish classes with high probability.
3.2. Feature Retention Module
4. Experiment
4.1. Dataset
4.2. Implementation Setting
4.3. Experiment Method and Result
4.4. Dataset Analysis
4.5. Ablation Study
5. Extended Study
5.1. Overview of Modified Module
5.2. Experiment Result
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Liu, L.; Chen, J.; Fieguth, P.; Zhao, G.; Chellappa, R.; Pietikäinen, M. From BoW to CNN: Two decades of texture representation for texture classification. Int. J. Comput. Vis. 2019, 127, 74–109. [Google Scholar] [CrossRef]
- Liu, L.; Fieguth, P.; Guo, Y.; Wang, X.; Pietikäinen, M. Local binary features for texture classification: Taxonomy and experimental study. Pattern Recognit. 2017, 62, 135–160. [Google Scholar] [CrossRef]
- Fradi, H.; Fradi, A.; Dugelay, J.L. Multi-layer Feature Fusion and Selection from Convolutional Neural Networks for Texture Classification. In Proceedings of the VISIGRAPP (4: VISAPP), Vienna, Austria, 8–10 February 2021; pp. 574–581. [Google Scholar]
- Chen, Z.; Li, F.; Quan, Y.; Xu, Y.; Ji, H. Deep texture recognition via exploiting cross-layer statistical self-similarity. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 5231–5240. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. Imagenet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Krizhevsky, A.; Hinton, G. Learning Multiple Layers of Features from Tiny Images; Technical Report; University of Toronto: Toronto, ON, Canada, 2009. [Google Scholar]
- Wah, C.; Branson, S.; Welinder, P.; Perona, P.; Belongie, S. The Caltech-Ucsd Birds-200-2011 Dataset; Technical Report; California Institute of Technology: Pasadena, CA, USA, 2011. [Google Scholar]
- Cimpoi, M.; Maji, S.; Kokkinos, I.; Mohamed, S.; Vedaldi, A. Describing textures in the wild. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 3606–3613. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2012, 25, 1097–1105. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. In Proceedings of the International Conference on Learning Representations, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- Tan, M.; Le, Q. Efficientnet: Rethinking model scaling for convolutional neural networks. In Proceedings of the International Conference on Machine Learning, Long Beach, CA, USA, 9–15 June 2019; pp. 6105–6114. [Google Scholar]
- Chai, J.; Zeng, H.; Li, A.; Ngai, E.W. Deep learning in computer vision: A critical review of emerging techniques and application scenarios. Mach. Learn. Appl. 2021, 6, 100134. [Google Scholar] [CrossRef]
- Guo, Y.; Liu, Y.; Oerlemans, A.; Lao, S.; Wu, S.; Lew, M.S. Deep learning for visual understanding: A review. Neurocomputing 2016, 187, 27–48. [Google Scholar] [CrossRef]
- Zhuang, F.; Qi, Z.; Duan, K.; Xi, D.; Zhu, Y.; Zhu, H.; Xiong, H.; He, Q. A comprehensive survey on transfer learning. Proc. IEEE 2020, 109, 43–76. [Google Scholar] [CrossRef]
- Dai, X.; Yue-Hei Ng, J.; Davis, L.S. Fason: First and second order information fusion network for texture recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7352–7360. [Google Scholar]
- Hu, Y.; Long, Z.; AlRegib, G. Multi-Level Texture Encoding and Representation (Multer) Based on Deep Neural Networks. In Proceedings of the 2019 IEEE International Conference on Image Processing (ICIP), Taipei, Taiwan, 22–25 September 2019; pp. 4410–4414. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Csurka, G.; Dance, C.; Fan, L.; Willamowski, J.; Bray, C. Visual categorization with bags of keypoints. In Proceedings of the Workshop on Statistical Learning in Computer Vision, ECCV, Prague, Czech Republic, 11–14 May 2004; Volume 1, pp. 1–2. [Google Scholar]
- Sivic, J.; Zisserman, A. Video Google: A text retrieval approach to object matching in videos. In Proceedings of the Ninth IEEE International Conference on Computer Vision, Nice, France, 13–16 October 2003; pp. 1470–1477. [Google Scholar]
- Vasconcelos, N.; Lippman, A. A probabilistic architecture for content-based image retrieval. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. CVPR 2000 (Cat. No. PR00662), Head Island, SC, USA, 13–15 June 2000; Volume 1, pp. 216–221. [Google Scholar]
- Lowe, D.G. Distinctive image features from scale-invariant keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Bay, H.; Tuytelaars, T.; Van Gool, L. Surf: Speeded up robust features. In Proceedings of the Computer Vision–ECCV 2006: 9th European Conference on Computer Vision, Graz, Austria, 7–13 May 2006; Proceedings, Part I 9. Springer: Berlin/Heidelberg, Germany, 2006; pp. 404–417. [Google Scholar]
- Bruna, J.; Mallat, S. Invariant scattering convolution networks. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 1872–1886. [Google Scholar] [CrossRef] [PubMed]
- Chan, T.H.; Jia, K.; Gao, S.; Lu, J.; Zeng, Z.; Ma, Y. PCANet: A simple deep learning baseline for image classification? IEEE Trans. Image Process. 2015, 24, 5017–5032. [Google Scholar] [CrossRef] [PubMed]
- Jolliffe, I. Principal Component Analysis; Springer: New York, NY, USA, 2002. [Google Scholar]
- Sharan, L.; Rosenholtz, R.; Adelson, E. Material perception: What can you see in a brief glance? J. Vis. 2009, 9, 784. [Google Scholar] [CrossRef]
- Caputo, B.; Hayman, E.; Mallikarjuna, P. Class-specific material categorisation. In Proceedings of the Tenth IEEE International Conference on Computer Vision (ICCV’05) Volume 1, Beijing, China, 17–21 October 2005; Volume 2, pp. 1597–1604. [Google Scholar]
- Lin, T.Y.; Maji, S. Visualizing and understanding deep texture representations. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2791–2799. [Google Scholar]
- Cimpoi, M.; Maji, S.; Vedaldi, A. Deep filter banks for texture recognition and segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3828–3836. [Google Scholar]
- Song, Y.; Zhang, F.; Li, Q.; Huang, H.; O’Donnell, L.J.; Cai, W. Locally-transferred fisher vectors for texture classification. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 4912–4920. [Google Scholar]
- Zhang, H.; Xue, J.; Dana, K. Deep ten: Texture encoding network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 708–717. [Google Scholar]
- Bu, X.; Wu, Y.; Gao, Z.; Jia, Y. Deep convolutional network with locality and sparsity constraints for texture classification. Pattern Recognit. 2019, 91, 34–46. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Backbone | DTD | FMD | KTH-TIP2b |
|---|---|---|---|---|
| BP-CNN [30] | VGG19 | 69.6 | 77.8 | 75.1 |
| FV-CNN [31] | VGG19 | 72.3 | 79.8 | 75.4 |
| LFV [32] | VGG19 | 73.8 | 82.1 | 82.6 |
| FASON [17] | VGG19 | 72.9 | 82.1 | 76.5 |
| DeepTEN [33] | ResNet50 | 69.6 | 80.2 | 82.0 |
| LSCNet [34] | VGG16 | 71.1 | 82.4 | 76.9 |
| CLASSNet [4] | ResNet18 | 71.5 | 82.5 | 85.4 |
| CLASSNet [4] | ResNet50 | 74.0 | 86.2 | 87.7 |
| Block 14 (Ours) | DenseNet161 | 74.53 | 82.76 | 92.97 |
| Block 24 (Ours) | DenseNet161 | 74.52 | 82.07 | 91.55 |
| Block 34 (Ours) | DenseNet161 | 74.35 | 81.72 | 91.83 |
| Block 4 (Ours) | DenseNet161 | 74.35 | 81.72 | 91.76 |
| Method | DTD | FMD | KTH-TIP2b |
|---|---|---|---|
| DenseNet161 (Backbone) | 70.57 | 79.67 | 81.89 |
| Block 14 (Ours) | 74.53 | 82.76 | 92.97 |
| Method | Backbone | DTD | FMD | KTH-TIP2b | |
|---|---|---|---|---|---|
| Method 1 | Block 14 | DenseNet161 | 74.53 | 82.76 | 92.97 |
| Block 24 | DenseNet161 | 74.52 | 82.07 | 91.55 | |
| Block 34 | DenseNet161 | 74.35 | 81.72 | 91.83 | |
| Block 4 | DenseNet161 | 74.35 | 81.72 | 91.76 | |
| Method 2 | Block 14 | DenseNet161 | 74.83 | 82.76 | 91.19 |
| Block 24 | DenseNet161 | 74.47 | 82.07 | 91.48 | |
| Block 34 | DenseNet161 | 74.89 | 82.41 | 91.76 | |
| Block 4 | DenseNet161 | 74.71 | 83.45 | 92.12 | |
| Method 3 | Block 14 | DenseNet161 | 75.26 | 83.79 | 91.62 |
| Block 24 | DenseNet161 | 75.50 | 81.03 | 91.97 | |
| Block 34 | DenseNet161 | 75.14 | 81.72 | 92.26 | |
| Block 4 | DenseNet161 | 74.77 | 82.41 | 92.40 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Park, S.-H.; Ahn, S.-Y.; Lee, S.-W. Deep Feature Retention Module Network for Texture Classification. Appl. Sci. 2024, 14, 4011. https://doi.org/10.3390/app14104011
Park S-H, Ahn S-Y, Lee S-W. Deep Feature Retention Module Network for Texture Classification. Applied Sciences. 2024; 14(10):4011. https://doi.org/10.3390/app14104011
Chicago/Turabian StylePark, Sung-Hwan, Sung-Yoon Ahn, and Sang-Woong Lee. 2024. "Deep Feature Retention Module Network for Texture Classification" Applied Sciences 14, no. 10: 4011. https://doi.org/10.3390/app14104011
APA StylePark, S.-H., Ahn, S.-Y., & Lee, S.-W. (2024). Deep Feature Retention Module Network for Texture Classification. Applied Sciences, 14(10), 4011. https://doi.org/10.3390/app14104011