

BWLM: A Balanced Weight Learning Mechanism for Long-Tailed Image Recognition


Abstract
1. Introduction
- We propose the BFS loss function that combines the weight balance characteristics of common and rare classes. By adjusting the weights between the loss functions, the balance proportion of common and rare classes can be adjusted, which correspondingly affects the accuracy of common and rare classes.
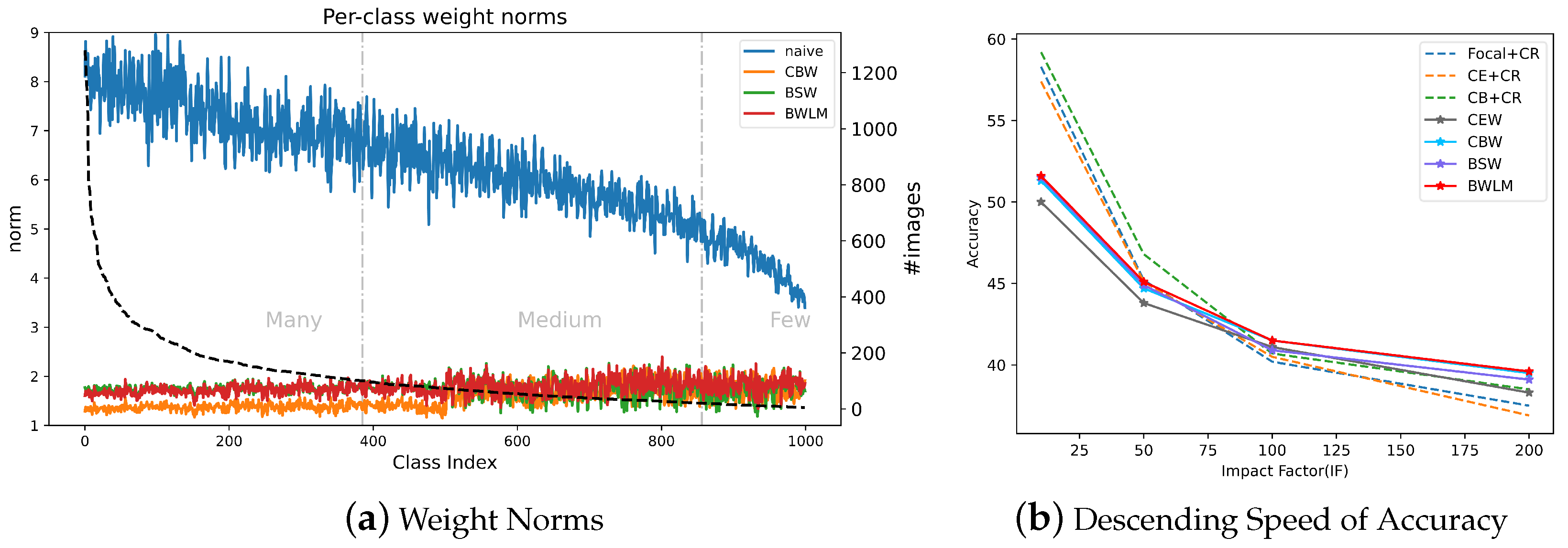
- We propose BWLM to balance network weights, and investigate the weight balancing effect of weight decay on multiple balanced loss functions. We prove that weight decay also learns smaller balanced weights to make the model more balanced and improve the accuracy of multiple balanced loss functions, especially for BFS; BWLM performs better when the Imbalance Factor (i.e., the ratio of common classes with the most instances to rare classes with the least instances) is large. We use five long-tailed distributions including the large-scale dataset ImageNet-LT with Imbalance Factor (IF) = 256 and the dataset CIFAR100-LT with IF = [10, 50, 100, 200] to prove that our method achieves optimal results with increasing IF. Therefore, it proves that our method BWLM can handle more complex long-tailed image recognition problems.
- We adopt two-stage learning, which can narrow the weight norms gap between common and rare classes in the native model.
2. Related Work
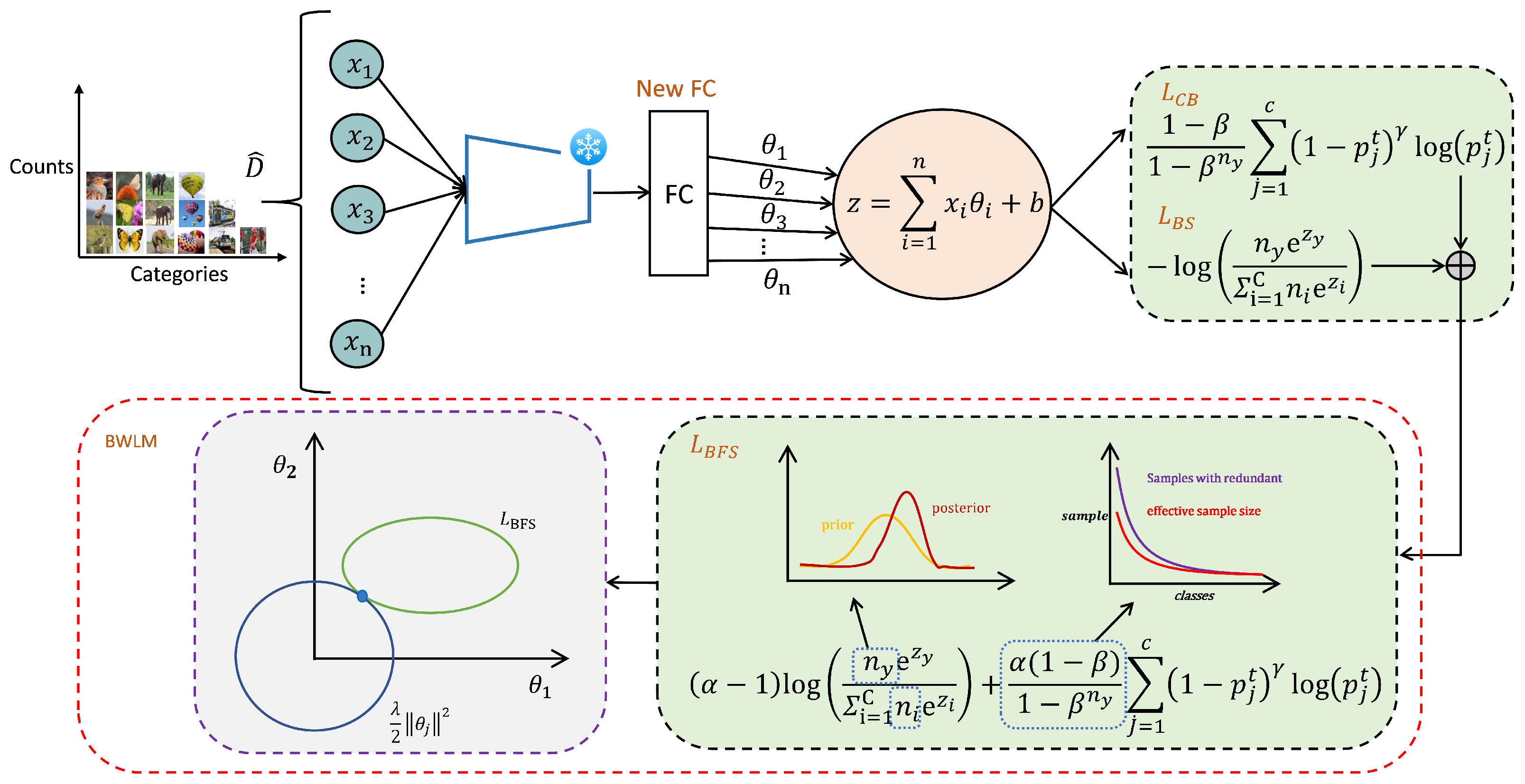
3. Method
3.1. Preliminaries
3.2. Weights Transfer
3.3. BWLM
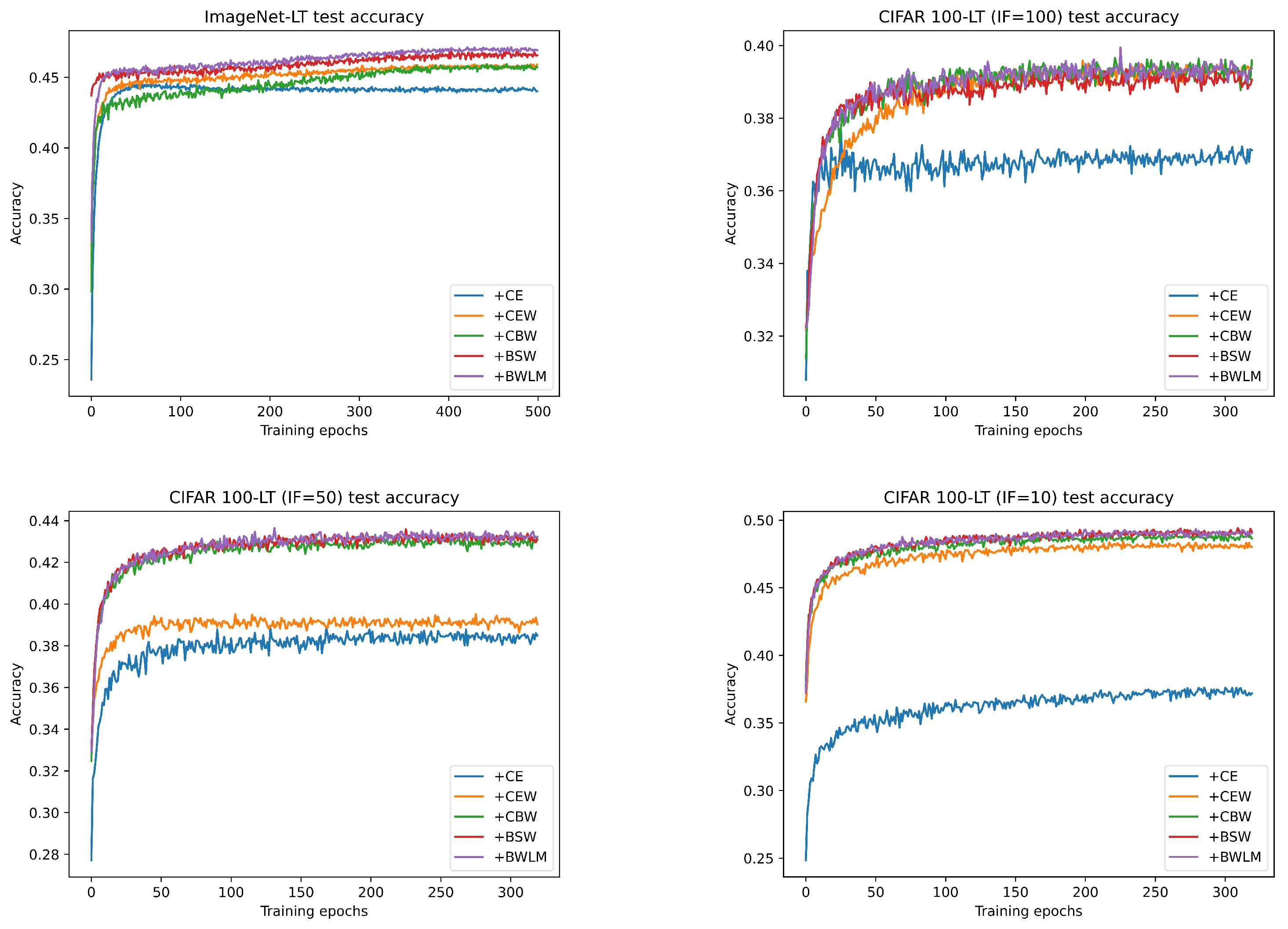
4. Experiments
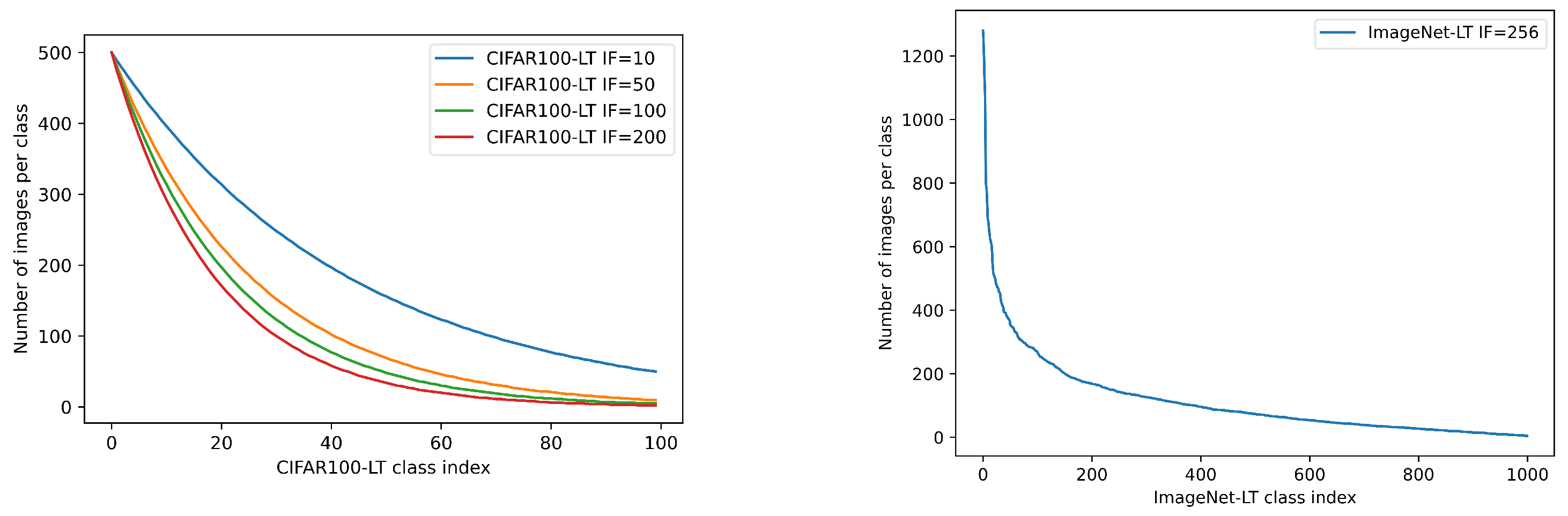
4.1. Datasets
4.2. Implementation
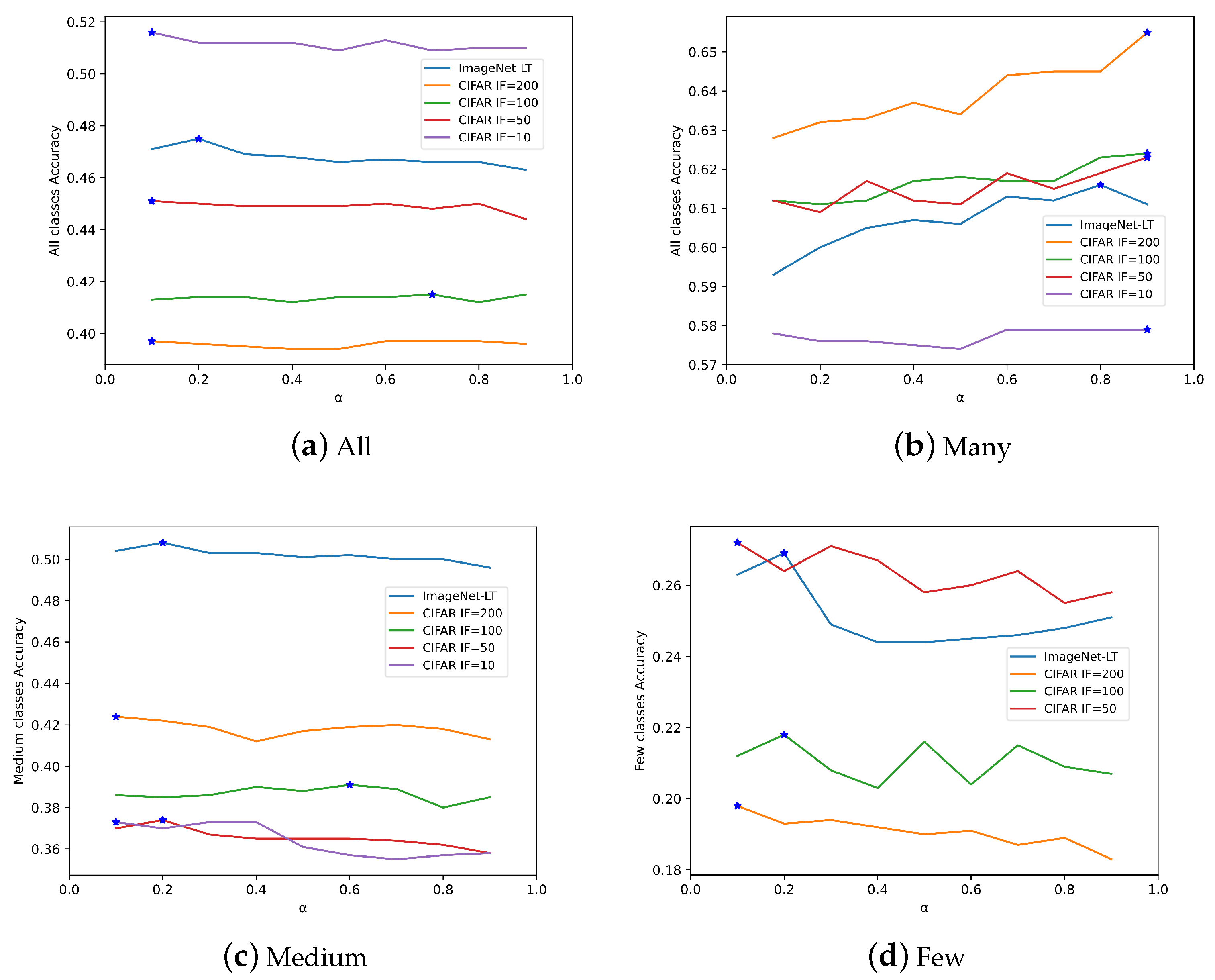
4.3. Ablation Study
4.4. Long-Tailed Image Recognition
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Cao, K.; Wei, C.; Gaidon, A.; Arechiga, N.; Ma, T. Learning imbalanced datasets with label-distribution-aware margin loss. In Proceedings of the Advances in Neural Information Processing Systems 32: Annual Conference on Neural Information Processing Systems 2019, NeurIPS 2019, Vancouver, BC, Canada, 8–14 December 2019. [Google Scholar]
- Kang, B.; Xie, S.; Rohrbach, M.; Yan, Z.; Gordo, A.; Feng, J.; Kalantidis, Y. Decoupling representation and classifier for long-tailed recognition. arXiv 2019, arXiv:1910.09217. [Google Scholar]
- Yang, Y.; Xu, Z. Rethinking the value of labels for improving class-imbalanced learning. Adv. Neural Inf. Process. Syst. 2020, 33, 19290–19301. [Google Scholar]
- Shafiq, M.; Gu, Z. Deep residual learning for image recognition: A survey. Appl. Sci. 2022, 12, 8972. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Proceedings of the Advances in Neural Information Processing Systems 25: 26th Annual Conference on Neural Information Processing Systems 2012, Lake Tahoe, NV, USA, 3–6 December 2012. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Chouhan, V.; Singh, S.K.; Khamparia, A.; Gupta, D.; Tiwari, P.; Moreira, C.; Damaševičius, R.; De Albuquerque, V.H.C. A novel transfer learning based approach for pneumonia detection in chest X-ray images. Appl. Sci. 2020, 10, 559. [Google Scholar] [CrossRef]
- Alzubaidi, L.; Fadhel, M.A.; Al-Shamma, O.; Zhang, J.; Santamaría, J.; Duan, Y.; Oleiwi, S.R. Towards a better understanding of transfer learning for medical imaging: A case study. Appl. Sci. 2020, 10, 4523. [Google Scholar] [CrossRef]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Li, F.-F. Imagenet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In Proceedings of the Computer Vision—ECCV 2014: 13th European Conference, Zurich, Switzerland, 6–12 September 2014; Proceedings, Part V 13. Springer: Berlin/Heidelberg, Germany, 2014; pp. 740–755. [Google Scholar]
- Zhou, B.; Lapedriza, A.; Khosla, A.; Oliva, A.; Torralba, A. Places: A 10 million image database for scene recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 1452–1464. [Google Scholar] [CrossRef]
- Van Horn, G.; Mac Aodha, O.; Song, Y.; Cui, Y.; Sun, C.; Shepard, A.; Adam, H.; Perona, P.; Belongie, S. The inaturalist species classification and detection dataset. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8769–8778. [Google Scholar]
- Buda, M.; Maki, A.; Mazurowski, M.A. A systematic study of the class imbalance problem in convolutional neural networks. Neural Netw. 2018, 106, 249–259. [Google Scholar] [CrossRef]
- Reed, W.J. The Pareto, Zipf and other power laws. Econ. Lett. 2001, 74, 15–19. [Google Scholar] [CrossRef]
- Zhang, Y.; Kang, B.; Hooi, B.; Yan, S.; Feng, J. Deep long-tailed learning: A survey. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 10795–10816. [Google Scholar] [CrossRef]
- Zhao, Y.; Kong, S.; Fowlkes, C. Camera pose matters: Improving depth prediction by mitigating pose distribution bias. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20ߝ25 June 2021; pp. 15759–15768. [Google Scholar]
- Gupta, A.; Dollar, P.; Girshick, R. Lvis: A dataset for large vocabulary instance segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 5356–5364. [Google Scholar]
- Bansal, M.A.; Sharma, D.R.; Kathuria, D.M. A systematic review on data scarcity problem in deep learning: Solution and applications. ACM Comput. Surv. (CSUR) 2022, 54, 208. [Google Scholar] [CrossRef]
- Kong, S.; Ramanan, D. Opengan: Open-set recognition via open data generation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Nashville, TN, USA, 20–25 June 2021; pp. 813–822. [Google Scholar]
- Romero, I.C.; Kong, S.; Fowlkes, C.C.; Jaramillo, C.; Urban, M.A.; Oboh-Ikuenobe, F.; D’Apolito, C.; Punyasena, S.W. Improving the taxonomy of fossil pollen using convolutional neural networks and superresolution microscopy. Proc. Natl. Acad. Sci. USA 2020, 117, 28496–28505. [Google Scholar] [CrossRef] [PubMed]
- Ouyang, W.; Wang, X.; Zhang, C.; Yang, X. Factors in finetuning deep model for object detection with long-tail distribution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 864–873. [Google Scholar]
- Yin, X.; Yu, X.; Sohn, K.; Liu, X.; Chandraker, M. Feature transfer learning for deep face recognition with long-tail data. arXiv 2018, arXiv:1803.09014. [Google Scholar]
- Chawla, N.V.; Bowyer, K.W.; Hall, L.O.; Kegelmeyer, W.P. SMOTE: Synthetic minority over-sampling technique. J. Artif. Intell. Res. 2002, 16, 321–357. [Google Scholar] [CrossRef]
- Feng, C.; Zhong, Y.; Huang, W. Exploring classification equilibrium in long-tailed object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 3417–3426. [Google Scholar]
- Estabrooks, A.; Jo, T.; Japkowicz, N. A multiple resampling method for learning from imbalanced data sets. Comput. Intell. 2004, 20, 18–36. [Google Scholar] [CrossRef]
- Mahajan, D.; Girshick, R.; Ramanathan, V.; He, K.; Paluri, M.; Li, Y.; Bharambe, A.; Van Der Maaten, L. Exploring the limits of weakly supervised pretraining. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 181–196. [Google Scholar]
- Mikolov, T.; Sutskever, I.; Chen, K.; Corrado, G.S.; Dean, J. Distributed representations of words and phrases and their compositionality. In Proceedings of the Advances in Neural Information Processing Systems 26, Lake Tahoe, NV, USA, 5–10 December 2013. [Google Scholar]
- Zhang, X.; Fang, Z.; Wen, Y.; Li, Z.; Qiao, Y. Range loss for deep face recognition with long-tailed training data. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 5409–5418. [Google Scholar]
- Cui, Y.; Jia, M.; Lin, T.Y.; Song, Y.; Belongie, S. Class-balanced loss based on effective number of samples. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 9268–9277. [Google Scholar]
- Ren, J.; Yu, C.; Ma, X.; Zhao, H.; Yi, S. Balanced meta-softmax for long-tailed visual recognition. Adv. Neural Inf. Process. Syst. 2020, 33, 4175–4186. [Google Scholar]
- Jamal, M.A.; Brown, M.; Yang, M.H.; Wang, L.; Gong, B. Rethinking class-balanced methods for long-tailed visual recognition from a domain adaptation perspective. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 7610–7619. [Google Scholar]
- Liu, Z.; Miao, Z.; Zhan, X.; Wang, J.; Gong, B.; Yu, S.X. Large-scale long-tailed recognition in an open world. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 2537–2546. [Google Scholar]
- Wang, Y.X.; Ramanan, D.; Hebert, M. Learning to model the tail. In Proceedings of the Advances in Neural Information Processing Systems 30, Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Zhong, Y.; Deng, W.; Wang, M.; Hu, J.; Peng, J.; Tao, X.; Huang, Y. Unequal-training for deep face recognition with long-tailed noisy data. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 7812–7821. [Google Scholar]
- Shen, L.; Lin, Z.; Huang, Q. Relay backpropagation for effective learning of deep convolutional neural networks. In Proceedings of the Computer Vision—ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Proceedings, Part VII 14. Springer: Berlin/Heidelberg, Germany, 2016; pp. 467–482. [Google Scholar]
- Zhong, Q.; Li, C.; Zhang, Y.; Sun, H.; Yang, S.; Xie, D.; Pu, S. Towards good practices for recognition & detection. In Proceedings of the CVPR Workshops, Las Vegas, NV, USA, 27–30 June 2016; Volume 1, p. 3. [Google Scholar]
- He, H.; Garcia, E.A. Learning from imbalanced data. IEEE Trans. Knowl. Data Eng. 2009, 21, 1263–1284. [Google Scholar]
- Japkowicz, N.; Stephen, S. The class imbalance problem: A systematic study. Intell. Data Anal. 2002, 6, 429–449. [Google Scholar] [CrossRef]
- Huang, C.; Li, Y.; Loy, C.C.; Tang, X. Learning deep representation for imbalanced classification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 5375–5384. [Google Scholar]
- Huang, C.; Li, Y.; Loy, C.C.; Tang, X. Deep imbalanced learning for face recognition and attribute prediction. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 42, 2781–2794. [Google Scholar] [CrossRef]
- Sinha, S.; Ohashi, H.; Nakamura, K. Class-wise difficulty-balanced loss for solving class-imbalance. In Proceedings of the Asian Conference on Computer Vision, 2020, Kyoto, Japan, 30 November–4 December 2020. [Google Scholar]
- Wang, T.; Zhu, Y.; Zhao, C.; Zeng, W.; Wang, J.; Tang, M. Adaptive class suppression loss for long-tail object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 3103–3112. [Google Scholar]
- Wang, J.; Zhang, W.; Zang, Y.; Cao, Y.; Pang, J.; Gong, T.; Chen, K.; Liu, Z.; Loy, C.C.; Lin, D. Seesaw loss for long-tailed instance segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 9695–9704. [Google Scholar]
- Li, B.; Yao, Y.; Tan, J.; Zhang, G.; Yu, F.; Lu, J.; Luo, Y. Equalized focal loss for dense long-tailed object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 6990–6999. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Tan, J.; Wang, C.; Li, B.; Li, Q.; Ouyang, W.; Yin, C.; Yan, J. Equalization loss for long-tailed object recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 11662–11671. [Google Scholar]
- Yuan, Z.; Yan, Y.; Jin, R.; Yang, T. Stagewise training accelerates convergence of testing error over sgd. In Proceedings of the Advances in Neural Information Processing Systems 32, Vancouver, BC, Canada, 8–14 December 2019. [Google Scholar]
- Zhao, Y.; Kong, S.; Shin, D.; Fowlkes, C. Domain decluttering: Simplifying images to mitigate synthetic-real domain shift and improve depth estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 3330–3340. [Google Scholar]
- Xiang, L.; Ding, G.; Han, J. Learning from multiple experts: Self-paced knowledge distillation for long-tailed classification. In Proceedings of the Computer Vision—ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Proceedings, Part V 16. Springer: Berlin/Heidelberg, Germany, 2020; pp. 247–263. [Google Scholar]
- Alshammari, S.; Wang, Y.X.; Ramanan, D.; Kong, S. Long-tailed recognition via weight balancing. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 6897–6907. [Google Scholar]
- Fan, B.; Liu, Y.; Cuthbert, L. Improvement of DGA Long Tail Problem Based on Transfer Learning. In Proceedings of the International Conference on Computer and Information Science, Zhuhai, China, 26–28 June 2022; Springer: Berlin/Heidelberg, Germany, 2022; pp. 139–152. [Google Scholar]
- Olken, F. Random Sampling from Databases. Ph.D. Thesis, University of California, Berkeley, CA, USA, 1993. [Google Scholar]
- Liu, B.; Li, H.; Kang, H.; Hua, G.; Vasconcelos, N. Gistnet: A geometric structure transfer network for long-tailed recognition. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 8209–8218. [Google Scholar]
- Berger, J. The case for objective Bayesian analysis. Bayesian Anal. 2006, 1, 385–402. [Google Scholar] [CrossRef]
- Krogh, A.; Hertz, J. A simple weight decay can improve generalization. In Proceedings of the Advances in Neural Information Processing Systems 4, Denver, CO, USA, 2–5 December 1991. [Google Scholar]
- Moody, J.E. Note on generalization, regularization and architecture selection in nonlinear learning systems. In Proceedings of the Neural Networks for Signal Processing Proceedings of the 1991 IEEE Workshop, Princeton, NJ, USA, 30 September–2 October 1991; pp. 1–10. [Google Scholar]
- Yue, C.; Long, M.; Wang, J.; Han, Z.; Wen, Q. Deep quantization network for efficient image retrieval. In Proceedings of the 13th Association for the Advancement of Artificial Intelligence, Phoenix, AZ, USA, 12–17 February 2016; pp. 3457–3463. [Google Scholar]
- Krizhevsky, A.; Hinton, G. Learning Multiple Layers of Features from Tiny Images. 2009. Available online: http://www.cs.utoronto.ca/~kriz/learning-features-2009-TR.pdf (accessed on 8 April 2009).
- Paszke, A.; Gross, S.; Chintala, S.; Chanan, G.; Yang, E.; DeVito, Z.; Lin, Z.; Desmaison, A.; Antiga, L.; Lerer, A. Automatic Differentiation in Pytorch. 2017. Available online: https://note.wcoder.com/files/ml/automatic_differentiation_in_pytorch.pdf (accessed on 28 October 2017).
- Xie, S.; Girshick, R.; Dollár, P.; Tu, Z.; He, K. Aggregated residual transformations for deep neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2017, Honolulu, HI, USA, 21–26 July; 2017; pp. 1492–1500. [Google Scholar]
- Loshchilov, I.; Hutter, F.S. Stochastic Gradient Descent with Warm Restarts. In Proceedings of the 5th International Conference on Learning Representations, Toulon, France, 24–26 April 2017; pp. 1–16. [Google Scholar]
- Ma, Y.; Jiao, L.; Liu, F.; Yang, S.; Liu, X.; Li, L. Curvature-Balanced Feature Manifold Learning for Long-Tailed Classification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, Vancouver, BC, Canada, 17–24 June 2023; pp. 15824–15835. [Google Scholar]
- Hinton, G.; Vinyals, O.; Dean, J. Distilling the knowledge in a neural network. arXiv 2015, arXiv:1503.02531. [Google Scholar]
- Zhang, H.; Cisse, M.; Dauphin, Y.N.; Lopez-Paz, D. mixup: Beyond empirical risk minimization. arXiv 2017, arXiv:1710.09412. [Google Scholar]
 denotes training is in progress, while
denotes training is in progress, while  denotes that the transfer weights are frozen and cannot be trained. In the second stage, after obtaining the weights of stage 1, we combine class balanced loss with a balanced softmax loss to obtain BWLM, which is embedded in stage 2.
denotes training is in progress, while denotes that the transfer weights are frozen and cannot be trained. In the second stage, after obtaining the weights of stage 1, we combine class balanced loss with a balanced softmax loss to obtain BWLM, which is embedded in stage 2.
denotes that the transfer weights are frozen and cannot be trained. In the second stage, after obtaining the weights of stage 1, we combine class balanced loss with a balanced softmax loss to obtain BWLM, which is embedded in stage 2.
denotes training is in progress, while denotes that the transfer weights are frozen and cannot be trained. In the second stage, after obtaining the weights of stage 1, we combine class balanced loss with a balanced softmax loss to obtain BWLM, which is embedded in stage 2.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | IF | Training Samples | Testing Samples | Classes | Max Class Size | Min Class Size |
|---|---|---|---|---|---|---|
| ImageNet-LT [34] | 256 | 115,846 | 50,000 | 1000 | 1280 | 5 |
| CIFAR100-LT [59] | 200 | 9502 | 10,000 | 100 | 500 | 2 |
| 100 | 10,847 | 10,000 | 100 | 500 | 5 | |
| 50 | 12,608 | 10,000 | 100 | 500 | 10 | |
| 10 | 19,573 | 10,000 | 100 | 500 | 50 |
| ImageNet-LT | ||||
|---|---|---|---|---|
| Many | Medium | Few | All | |
| naive | 57.6 | 32.5 | 13.4 | 39.6 |
| weight transfer | ||||
| +CE | 55.5 | 48.5 | 19.4 | 44.6 |
| +CB | 51.6 | 45.2 | 18.0 | 41.5 |
| +BS | 52.9 | 47.7 | 25.3 | 44.6 |
| +BFS | 52.8 | 47.7 | 24.3 | 44.5 |
| +CEW | 62.8 | 51.6 | 13.1 | 46.4 |
| +CBW | 61.7 | 50.2 | 26.3 | 47.0 |
| +BSW | 58.2 | 50.1 | 29.7 | 47.3 |
| +BWLM | 60.0 | 50.8 | 26.9 | 47.5 |
| Method | One-stage | Many | Medium | Few | All |
|---|---|---|---|---|---|
| CE [2] | ✓ | 65.9 | 37.5 | 7.7 | 44.4 |
| CE+CB [31] | ✓ | 39.6 | 32.7 | 16.8 | 33.2 |
| KD [65] | ✓ | 58.8 | 26.6 | 3.4 | 35.8 |
| Focal [31] | ✓ | 36.4 | 29.9 | 16.0 | 30.5 |
| OLTR [34] | ✗ | 43.2 | 35.1 | 18.5 | 35.6 |
| LFME [51] | ✗ | 47.1 | 35.0 | 17.5 | 37.2 |
| Range Loss [30] | ✓ | 35.8 | 30.3 | 17.6 | 30.7 |
| Equalization Loss [48] | ✓ | - | - | - | 36.4 |
| BS [32] | ✓ | 50.3 | 39.5 | 25.3 | 41.8 |
| NCM [2] | ✗ | 53.1 | 42.3 | 26.5 | 44.3 |
| -Norm [2] | ✗ | 56.6 | 44.2 | 26.4 | 46.7 |
| cRT [2] | ✗ | 58.8 | 44.0 | 26.1 | 47.3 |
| CE+CR [64] | ✓ | 65.1 | 40.7 | 19.5 | 47.3 |
| Our methods | |||||
| naive | ✓ | 57.6 | 32.5 | 13.4 | 39.6 |
| Weights Transfer | |||||
| +CE | ✗ | 55.5 | 48.5 | 19.4 | 44.6 |
| +CEW | ✗ | 62.8 | 51.6 | 13.1 | 46.4 |
| +CBW | ✗ | 61.7 | 50.2 | 26.3 | 47 |
| +BSW | ✗ | 58.2 | 50.1 | 29.7 | 47.3 |
| +BWLM | ✗ | 60.0 | 50.8 | 26.9 | 47.5 |
| Imbalance Factor (IF) | 10 | 50 | 100 | 200 |
|---|---|---|---|---|
| CE [31] | 55.71 | 43.85 | 38.32 | 34.84 |
| CE+CB [31] | 57.99 | 45.32 | 39.60 | 36.23 |
| KD [65] | 59.22 | 45.49 | 40.32 | - |
| Focal [47] | 55.78 | 44.32 | 38.41 | - |
| LDAM [1] | 56.91 | - | 39.60 | - |
| Mixup [66] | 58.02 | 44.99 | 39.54 | - |
| Focal+CB [31] | 57.99 | 45.17 | 39.60 | 35.62 |
| CE+DRW [1] | 58.10 | 46.50 | 41.00 | 36.90 |
| CE+CR [64] | 57.40 | 45.10 | 40.50 | 36.90 |
| Focal+CR [64] | 58.30 | 45.20 | 40.20 | 37.50 |
| CB+CR [64] | 59.20 | 46.80 | 40.70 | 38.50 |
| Our methods | ||||
| Weights Transfer | ||||
| +CE | 38.8 | 40.5 | 37.8 | 34.8 |
| +CEW | 50.0 | 43.8 | 41.1 | 38.3 |
| +CBW | 51.3 | 44.7 | 41.5 | 39.5 |
| +BSW | 51.5 | 44.9 | 40.9 | 39.1 |
| +BWLM | 51.6 | 45.1 | 41.5 | 39.6 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fan, B.; Ma, H.; Liu, Y.; Yuan, X. BWLM: A Balanced Weight Learning Mechanism for Long-Tailed Image Recognition. Appl. Sci. 2024, 14, 454. https://doi.org/10.3390/app14010454
Fan B, Ma H, Liu Y, Yuan X. BWLM: A Balanced Weight Learning Mechanism for Long-Tailed Image Recognition. Applied Sciences. 2024; 14(1):454. https://doi.org/10.3390/app14010454
Chicago/Turabian StyleFan, Baoyu, Han Ma, Yue Liu, and Xiaochen Yuan. 2024. "BWLM: A Balanced Weight Learning Mechanism for Long-Tailed Image Recognition" Applied Sciences 14, no. 1: 454. https://doi.org/10.3390/app14010454
APA StyleFan, B., Ma, H., Liu, Y., & Yuan, X. (2024). BWLM: A Balanced Weight Learning Mechanism for Long-Tailed Image Recognition. Applied Sciences, 14(1), 454. https://doi.org/10.3390/app14010454