1. Introduction
The accurate diagnosis of a cancer condition is the first and most important step in deciding the treatment for the prospective patient. After gathering the clinical data, including radiology and other imagistic investigations such as US (ultrasonography) and the complementary US-based technique 2D-SWE (2D-shear wave elastography), CT, or MRI, the process of correlating the results is more and more frequently left to artificial intelligence models. There currently exist many models based on artificial intelligence for both lung cancers (see the review in [
1]) and for prostate cancers (see the review in [
2]) that provide assistance during prospective diagnosis consultations. But, mostly due to the fact that typically, the training datasets with real patients are relatively small in size, the accuracy levels of these models are usually low when used in clinical practice. Therefore, herein, we propose a method to improve the management of cancer risk groups by coupling a features attention mechanism with a deep supervised neural network.
The attention mechanism is a key component of many modern machine learning algorithms, including neural machine translation, image captioning, and speech recognition [
3]. While attention mechanisms have primarily been used in natural language processing and computer vision tasks, recent research has shown their effectiveness in improving the performances of models on tabular datasets as well. In this context, attention mechanisms can be used to help models selectively focus on the most important features of the input data. This can be particularly useful in cases where the input data contains a large number of features or when some features may be more important than others for making accurate predictions. It grants the models the ability to concentrate on specific aspects of input data by assigning degrees of importance to different elements. This mechanism functions through a series of transformations that convert input into query, key, and value vectors. Queries specify the components to focus on, keys identify the elements within the input, and values contain relevant information for retrieval or amplification. Attention scores are computed to determine the relative significance of queries with respect to keys, and these scores are subsequently converted into attention weights through a SoftMax function. The ultimate outcome is achieved by computing a weighted sum of values based on these attention weights. This dynamic approach empowers models to capture intricate dependencies and context-aware information within input sequences, proving to be highly beneficial in tasks such as comprehending natural language, analyzing images in computer vision, and facilitating datasets that are difficult to analyze. To design the deep neural network model, we used layers of the Dense and BatchNormalization types [
4]. A dense layer is often used to compute the attention scores. The dense layer takes in the input embeddings, which could be the hidden states of the previous layer or the input features, and applies a set of learnable weights to compute a score for each embedding. These scores represent the relevance of each embedding to the current context. The output of the dense layer is then passed through a SoftMax function to obtain a probability distribution over the embeddings [
5]. This distribution represents the attention weights, which indicate how much each embedding should be attended to in the next layer. The attention weights are then used to compute a weighted sum of the input embeddings, which forms the context vector. The context vector represents the attended information from the input and is used as the input to the next layer in the model [
3].
On the other hand, LIME (local interpretable model-agnostic explanations) is a post-hoc explainability algorithm that works by approximating the behavior of the model in a local region around a specific input instance [
6]. This generates an interpretable model that approximates the predictions of the original model, allowing the user to understand which features were important in making the prediction. LIME is highly relevant due to its capacity to make intricate machine learning models understandable, thus addressing the need for transparency and accountability in AI systems. Its significance extends to building trust, ensuring adherence to regulations, detecting and mitigating errors and biases, enabling collaboration between humans and AI, guiding model enhancements, and broadening the application of AI across diverse sectors, all of which collectively contribute to the responsible and trustworthy deployment of AI technologies. Attention mechanisms and LIME (local interpretable model-agnostic explanations) can be used together to improve the accuracy of deep neural networks. By using LIME to explain the behavior of a model in a local region, it can be easier to understand how the attention mechanism is used to focus on specific parts of the input [
7]. After applying the LIME method to the dataset, we were able to observe the relevant features for the model inference. We retained only the relevant characteristics and applied the attention mechanism only to them. Thus, we managed to increase the accuracy of the prediction by a relevant value of 20%, compared to the moment when we did not apply the method of paying attention to the relevant characteristics.
4. Artificial Intelligence Algorithm
The LIME algorithm [
8,
9,
10], works in the following manner: first, it selects a random subset of instances from the dataset that represents the population of interest. Next, it trains a black-box model, such as a neural network or support vector machine, on the dataset. This model should be able to make accurate predictions with new, unseen data. Then, it chooses an instance from the dataset that we want to explain. It creates a new dataset by sampling instances similar to the instance which we want to explain. This can be achieved by perturbing the instance, such as by adding noise or dropping features, to create new instances [
11,
12]. The selection of LIME as an explainability method in AI models, in preference to other techniques, hinges on the specific context and objectives of the application. LIME’s inherent model-agnostic nature makes it an appealing choice, as it can be seamlessly applied to a wide array of machine learning models, including complex black-box ones (which is illustrated in detail in
Figure 4), without needing prior knowledge of the model’s architecture. Additionally, LIME specializes in providing localized explanations for individual predictions, catering to scenarios where understanding the rationale behind a single prediction holds more significance than explaining the entire model’s behavior. This becomes especially beneficial in applications where high-stakes decisions rely on individual instances, as it allows for pinpointed insights into why a specific prediction was made. Furthermore, the simplicity of LIME-generated explanations, which approximate intricate models with more interpretable ones, offers clarity and ease of understanding, which can be pivotal in scenarios where stakeholders and end-users require straightforward, human-intuitive explanations. On the other hand, the choice of LIME is also influenced by its transparency, as it reveals the most influential features behind a given prediction. This feature is vital in domains like healthcare and finance, where comprehending the impact of different input variables is of paramount importance. LIME is instrumental in error detection, enabling the identification of errors and biases in AI models, a crucial step towards ensuring fairness and accuracy. Moreover, in applications where human experts are actively involved in the decision-making process and need to both understand and potentially correct model predictions, LIME’s capacity to generate localized explanations fosters effective collaboration between human expertise and AI capabilities. Lastly, LIME helps to meet regulatory requirements that demand explanations for AI model decisions, making it a prudent choice for compliance in heavily regulated sectors.
Nevertheless, the selection of the most suitable explainability method should always be contingent on the specific use case, the nature of the AI model, and the unique needs of the stakeholders, as other methods like SHAP, integrated gradients, and decision trees may offer distinct advantages in differing contexts. Evaluating the strengths and limitations of each approach is key to ensuring that the chosen method aligns with the interpretability prerequisites of the application at hand. For our case, after several analyses related to these techniques, we came to the conclusion that the most advantages are provided by the use of LIME. This method excels in providing localized explanations. It focuses on explaining individual predictions rather than the global behavior of the model.
This granularity is especially valuable in situations where understanding the rationale behind specific predictions is more important than having a holistic view of the model’s behavior. For instance, in healthcare, it can offer insights into why a particular diagnosis was made, which can be vital for both medical professionals and patients. After we achieved this, the training of an interpretable model followed, in this case a decision tree using the newly created dataset. This model should approximate the behavior of the black-box model in the local region around the instance we want to explain. Calculating the feature importance scores for the prediction by analyzing the coefficients or decision paths of the interpretable model is the next step. These feature importance scores explain how each feature contributed to the prediction [
13]. The last step is to use the feature importance scores to create an explanation for the prediction. This explanation can be in the form of a visual or textual description that highlights the most important features and their contributions to the prediction. This can help us to better understand the dataset and to improve the performance of the black-box model. We assume that the perturbed samples are generated by perturbing the input instance x using some perturbation method. The kernel fn is a function that computes a similarity score between two data points. The num features parameter specifies the number of features to select in the local linear model [
14].
Specifically, the application of the LIME algorithm consists of the following computations: (1) Generate new perturbed samples by applying a perturbation method to the input instance x. (2) Compute kernel weights for each perturbed sample using the kernel function. (3) Train a local linear model using the perturbed samples, kernel weights, and labels for the black-box model’s predictions. (4) Compute feature importance weights using the local linear model. (5) Generate an explanation of the black-box model’s prediction for the input instance x using the local linear model and feature importance weights.
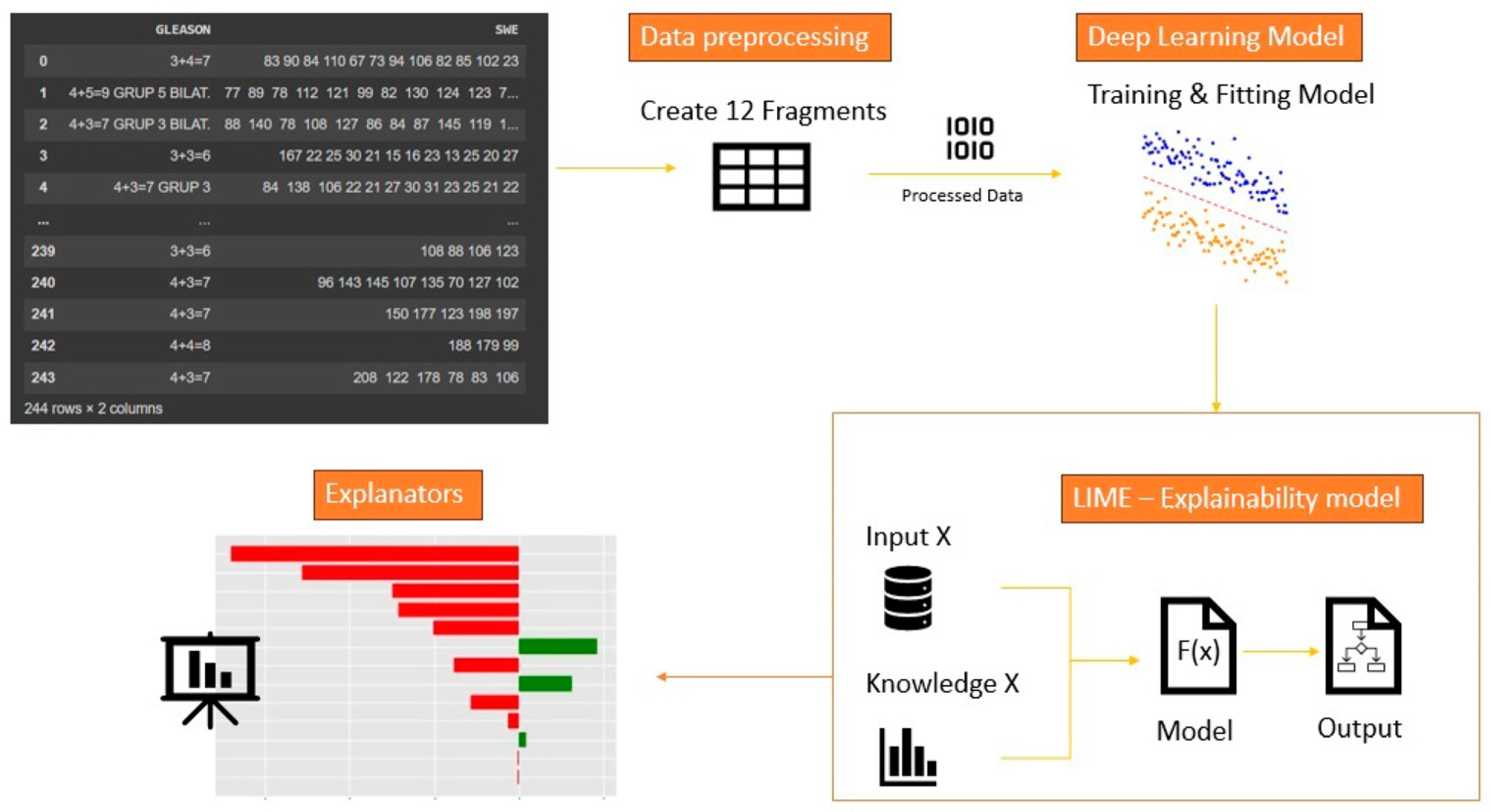
We trained a four-layer-deep neural network, and we evaluated the performance of the model using fourfold cross-validation with the task of binary classification. We designed from scratch a six-layer-deep neural network for the urology dataset using, again, a fourfold cross-validation for the multi-class case. Here, we included an extra step, namely, the encoding of the data. The values that were retained in y were encoded as a list of three binary values using one-hot encoding. This is a widely used technique in data preprocessing that plays a crucial role in converting categorical data into a numerical format suitable for machine learning algorithms. This technique works by taking categorical features, which are often represented as strings or labels, and transforming them into binary vectors. Each category is assigned a unique binary column, and the presence of a particular category is denoted by a ‘1’ in its respective column, while all other columns hold ‘0 s’. One-hot encoding ensures that categorical data does not introduce any ordinal relationship or magnitude, thus making it suitable for models that require numerical input. This method is advantageous in classification and regression as it helps models to interpret and utilize categorical information effectively. We used this in order to be able to apply the classification algorithms for later extraction, with the help of the LIME explainability method the characteristics that were relevant in predicting urological malignancies.
The classifier we used was a fully connected dense neural network for both datasets, because we aimed to use the same neural network architecture for both datasets. After training the model, we obtained a prediction accuracy of approximately 60% for the characteristics of the dataset. We aimed to visualize the impact and the way the developed model behaved with different data of different volumes of information and of different classes. After reaching this accuracy level, we were able to observe the relevant and least relevant characteristics for the prediction of thoracic diseases.
The architecture of the model was developed until we were able to extract the relevant characteristics and interpret the result as in the
Figure 5:
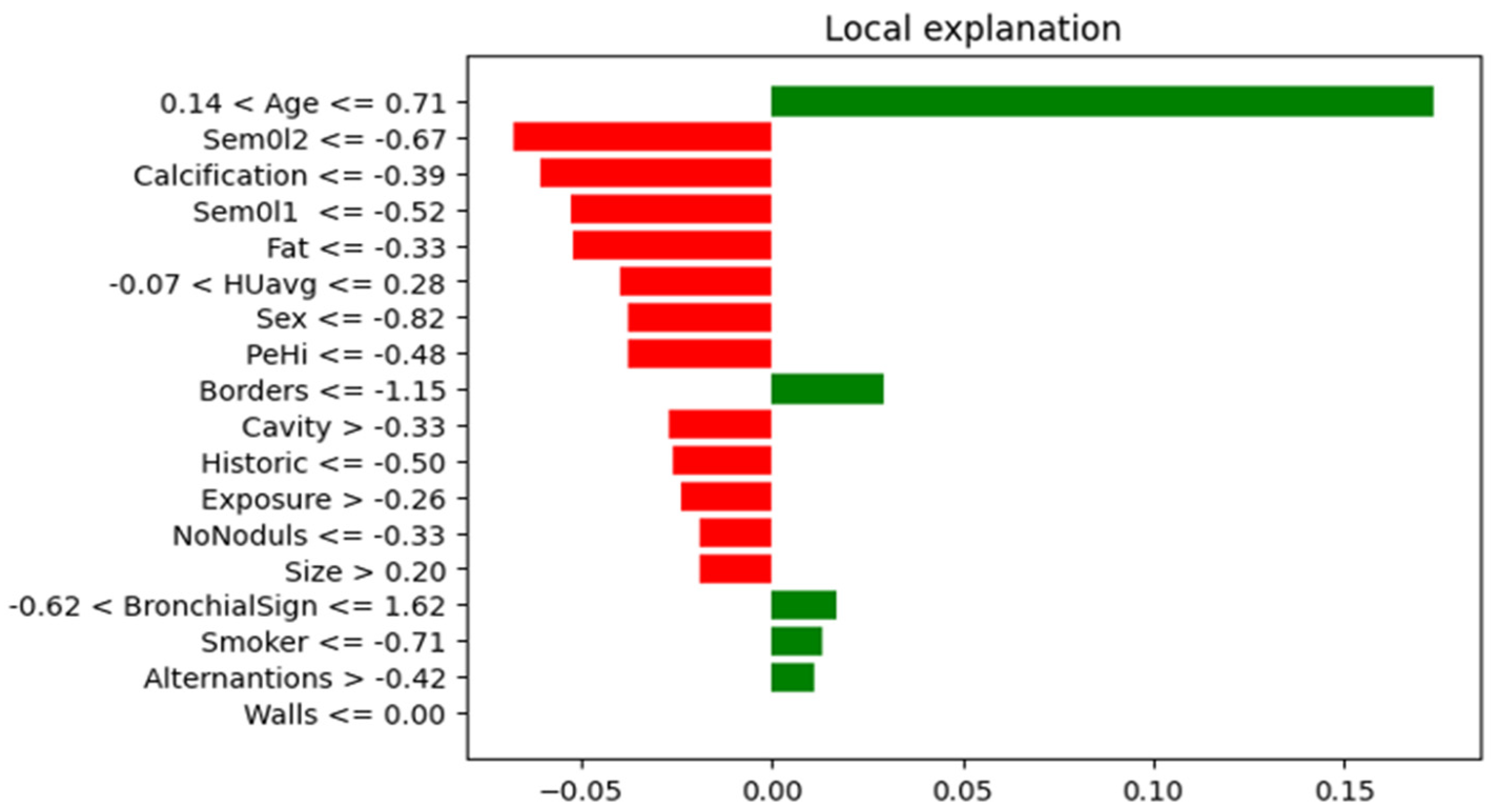
In
Figure 6, it can be observed that the most important characteristics for the thoracic dataset were: Age, Borders, BronchicalSign, Smoker, Alternations, and Walls.
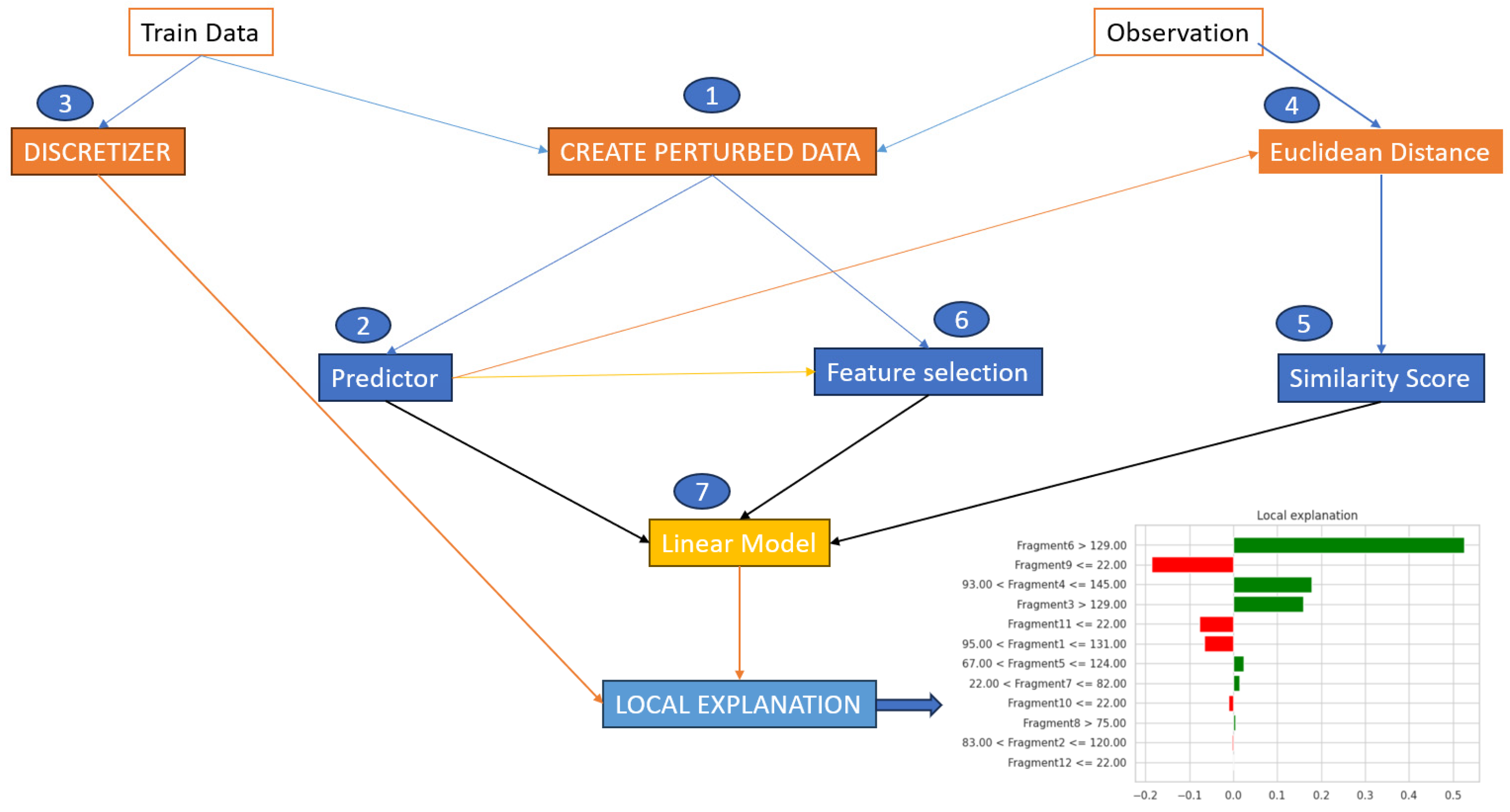
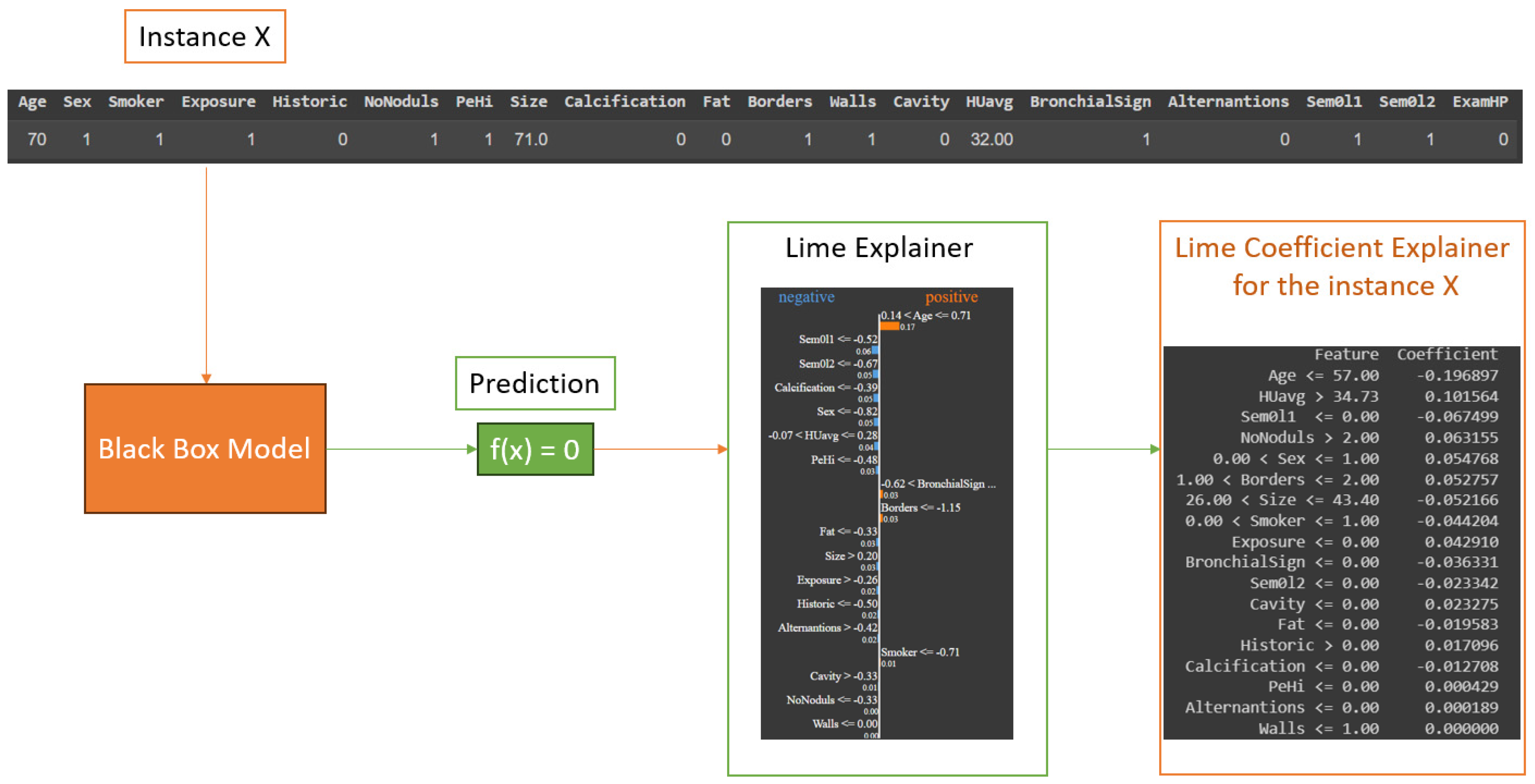
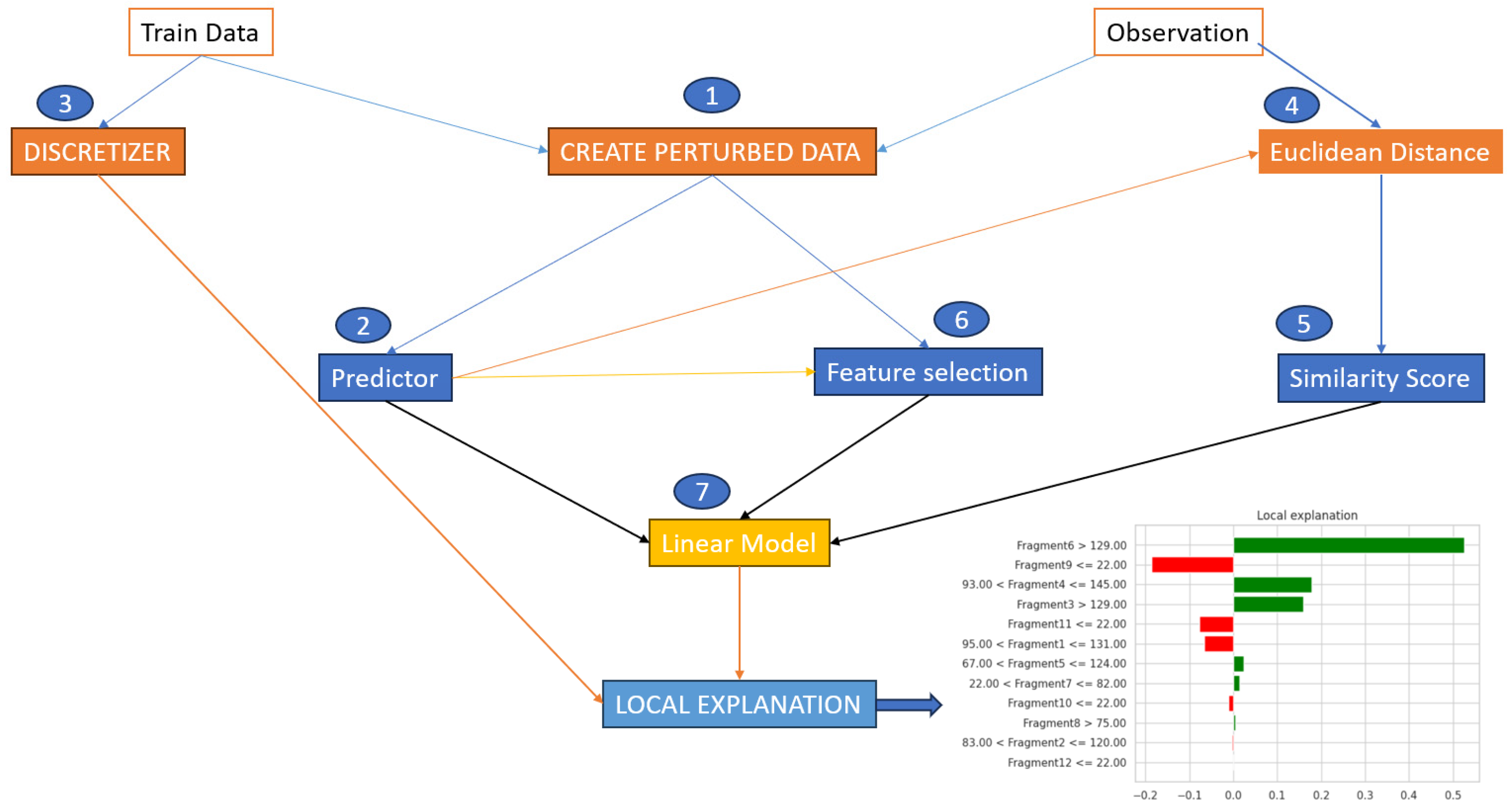
Although we have observed and extracted the most important characteristics from the thoracic dataset, it is also important to specify how the LIME algorithm works to reach the result presented above. For this, we chose to represent in
Figure 7 the entire process that each instance in our dataset underwent. This should be coupled with the process from
Figure 4, in which we explained in detail the black box process and what exactly occurred at that point. The steps for each instance were as follows: take instance X, apply each point from
Figure 4 in the specified order, and check the obtained result. If the prediction was correct or not, then, we analyzed the obtained result and collected the conclusions.
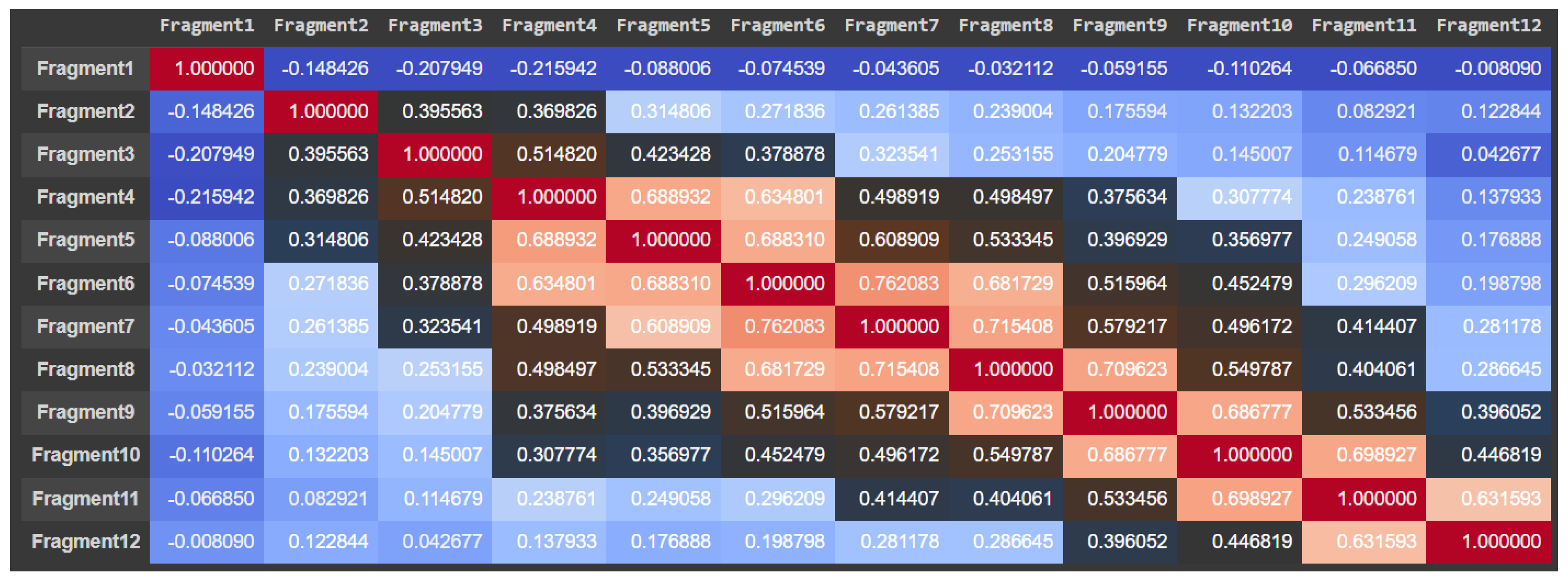
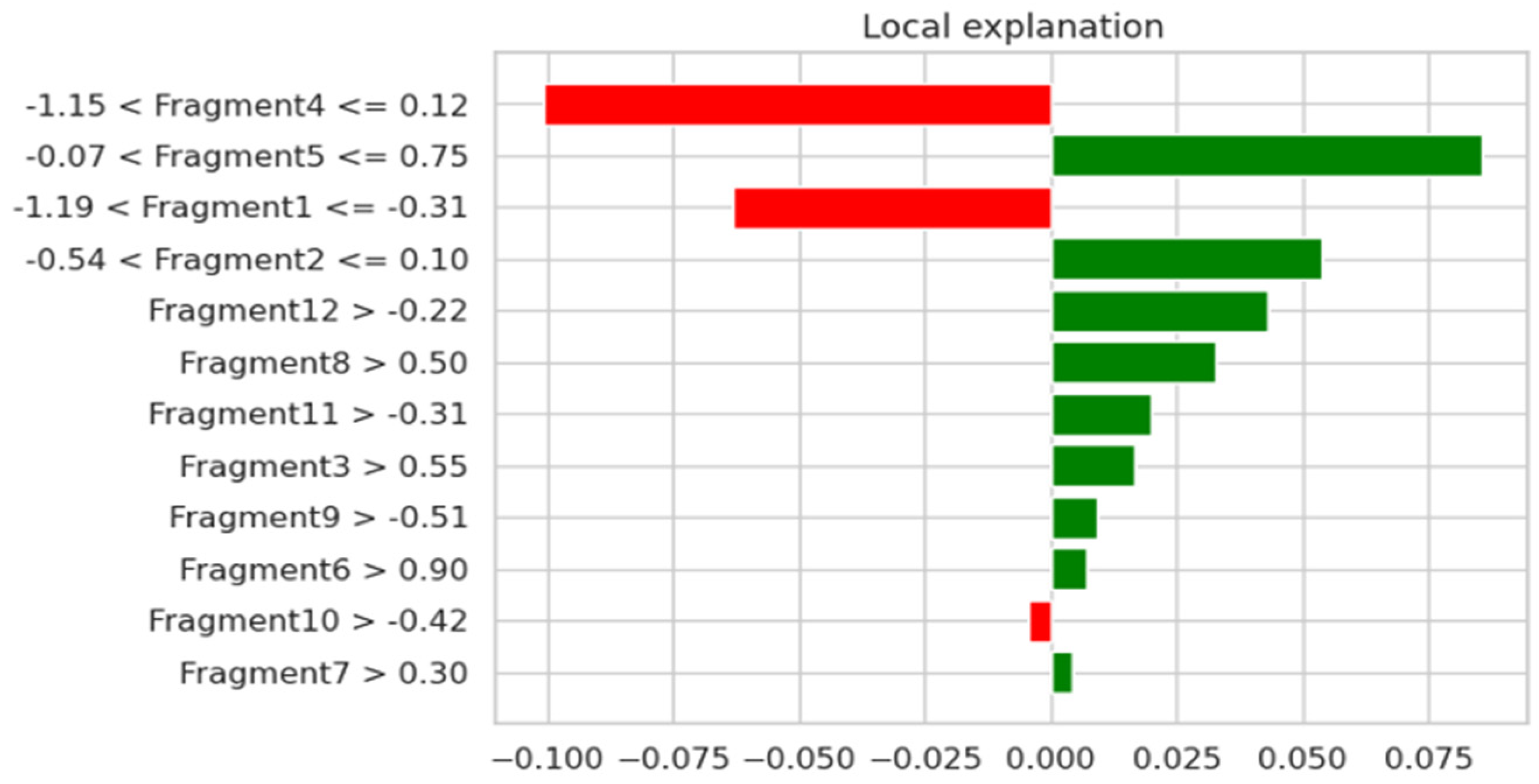
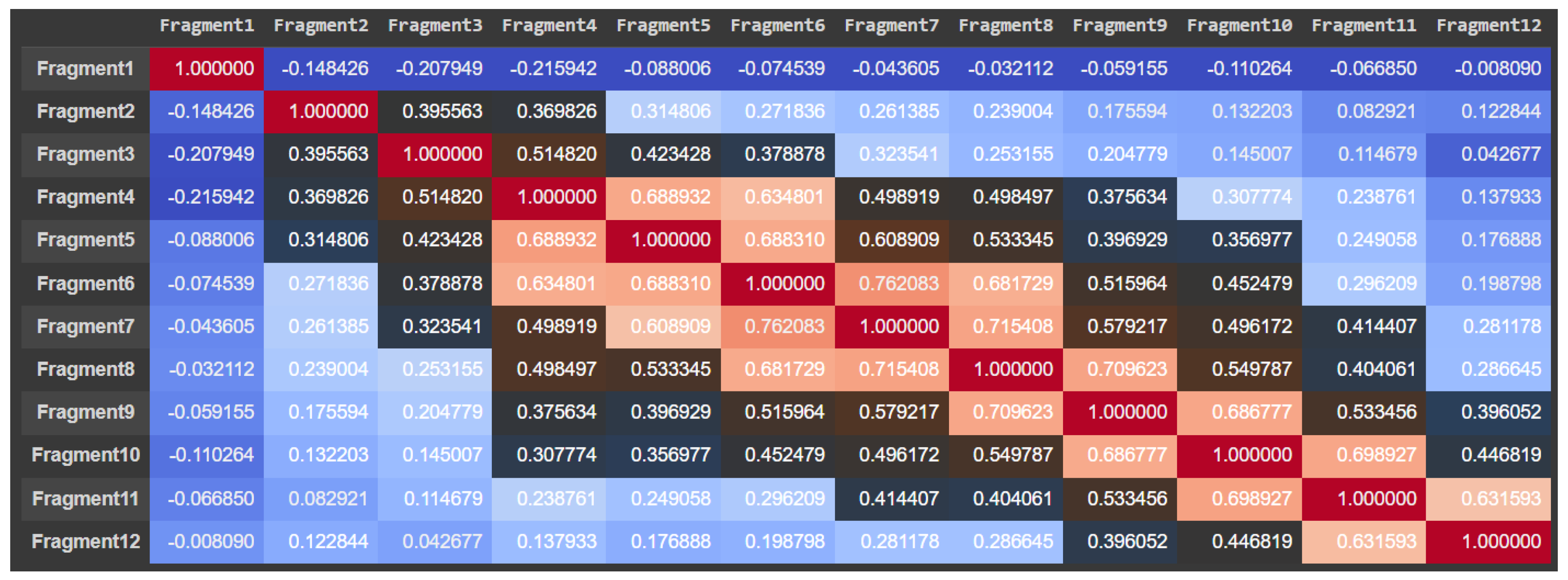
For the urology dataset, the most relevant characteristics were: Fragment3, Fragment5, Fragment6, Fragment7, Fragment8, Fragment9, Fragment11, and Fragment12, which are illustrated in
Figure 8. By using the attention mechanism, we focused our deep neural network encoder on the characteristics listed above in order to obtain a prediction as relevant as possible for the considered dataset. If we were to analyze the result obtained only after applying the LIME explainability method, we could support the fact that the result was slightly different. In the case of the thoracic dataset, out of 18 independent characteristics, the model identified only 5 as relevant for the dataset, while for the urologic dataset, we obtained many more important characteristics. More precisely, for the urology dataset, we noticed that there were nine relevant features.
In this study, to design the model, we used four and six layers of the types Dense and BatchNormalization. We chose a value of seven as the input shape for the thoracic dataset and eight for urology dataset, because we excluded the last feature, and the activation functions used were ReLU and Sigmoid. The input shape value for a Dense layer in a neural network depends on the specific architecture and the preceding layers in the network. In a Dense layer, each neuron is connected to every neuron in the previous layer, which means that the input shape of the Dense layer should match the output shape of the preceding layer. To optimize the model, we used Adam optimized, and the number of epochs chosen was 250. The number of 250 epochs was chosen because we noticed that, once we reached this epoch, the model was trained better and the result was a very good one for datasets with small volumes of information. We attempted to increase the number of epochs, but in doing so, we caused overfitting, so we chose to use a volume of 250 epochs. The main purpose of a dense layer is to learn complex relationships between the input and output data [
15]. The layer applies a linear transformation to the input data, followed by a non-linear activation function. The output of the layer can then be fed into another dense layer or a different type of layer in the neural network. The number of neurons in a dense layer is a hyperparameter that can be tuned to optimize the performance of the neural network [
16]. Increasing the number of neurons in the layer can increase the capacity of the network to learn complex data.
ReLU stands for rectified linear unit and is a commonly used activation function in neural networks. It is a simple and efficient non-linear activation function that is widely used in deep learning models. The ReLU activation function applies the rectification operation to the input, which simply sets any negative values to zero and leaves the positive values unchanged [
17].
Mathematically, the function can be expressed as:
The sigmoid function is a popular activation function used in artificial neural networks. It is a smooth, S-shaped function that maps any real-valued number to a value between 0 and 1. The sigmoid function is defined mathematically as:
The sigmoid function is often used in the output layer of a neural network to produce a probability value that can be interpreted as the likelihood of a certain class [
18]. The main idea behind Adam is to adapt the learning rate for each weight in the neural network based on the average of the first and second moments of the gradients. The first moment is the mean of the gradients, while the second moment is the variance of the gradients. The algorithm calculates the adaptive learning rates for each weight in the network based on the moving averages of the first and second moments of the gradients [
19]. These moving averages are computed using exponential decay rates, which allows the algorithm to give more weight to recent gradients and less weight to older ones [
20]. We chose to use such a large number of epochs because the dataset was very small, and, thus, we wanted to learn more about the model to correctly predict the result. Thus, based on the combination of LIME and the Attention mechanism, our newly developed algorithm, to be used to increase the prediction accuracy, could be summarized in Algorithm 1:
| Algorithm 1: The features attention coupling algorithm |
| 1. | Input: clinical features dataset; |
| 2. | Output: features-attention retrained neural network; |
| 3. | Specify the architecture of the network; |
| 4. | Perform k-fold cross-validation to evaluate the network; |
| 5. | Call the LIME explainability method on the network; |
| 6. | Analyze the explanations from LIME and select the relevant features; |
| 7. | Activate the attention mechanism in the network; |
| 8. | Modify the network based on insights gained and retrain the network; |
| 9. | Return improved network. |
5. Medical Discussion
After training the dataset that included only the characteristics with positive impacts that were relevant to our analysis, we managed to increase its accuracy by 20%, compared to the instance when we used the entire dataset. The accuracy value obtained following the use of the LIME method and the application of the attention mechanism on both datasets was approximately 80%.
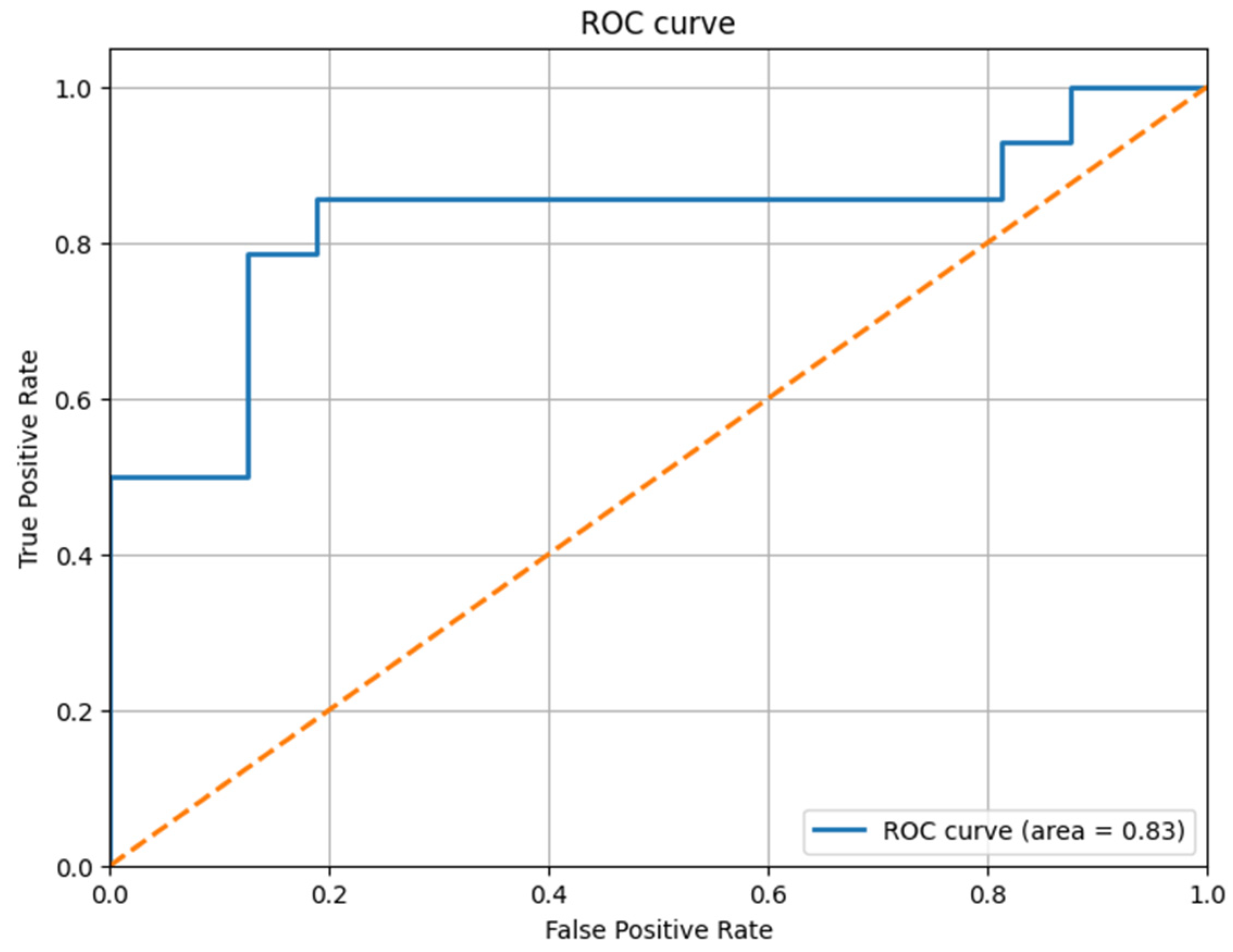
All the obtained results are illustrated with the help of the confusion matrix and the ROC curve, illustrated in
Figure 9 for the thoracic dataset and in
Figure 10 and
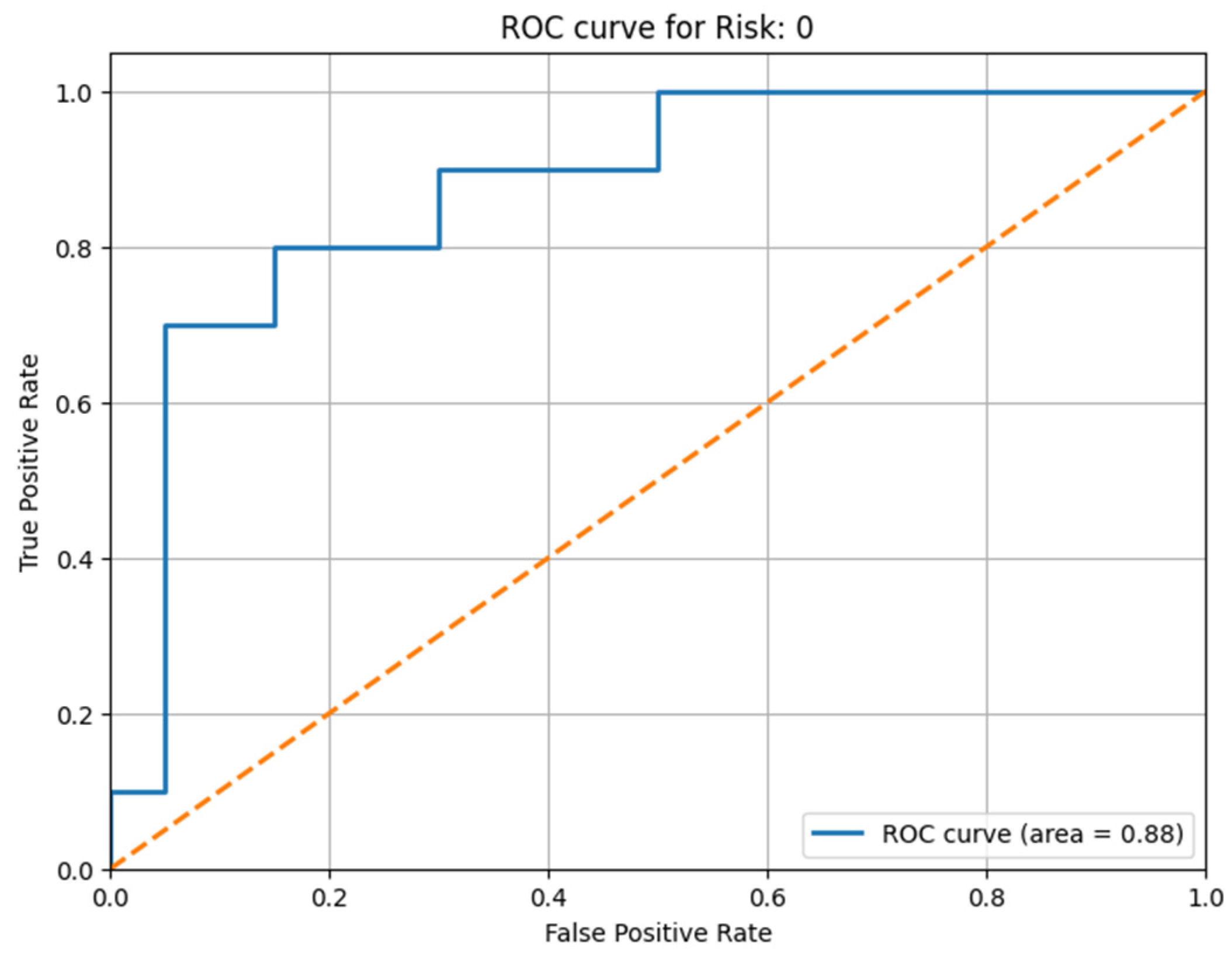
Figure 11 for the urology dataset. We noticed that, after the prediction, the obtained ROC curve was ascending and quite linear for such a small volume of data (see
Figure 9). Therefore, we confirmed the assumption that, by extracting only the relevant information, the model can be trained more correctly, and we can obtain a better result that is closer to reality. We present the results before and after using our method for the thoracic dataset in
Table 2.
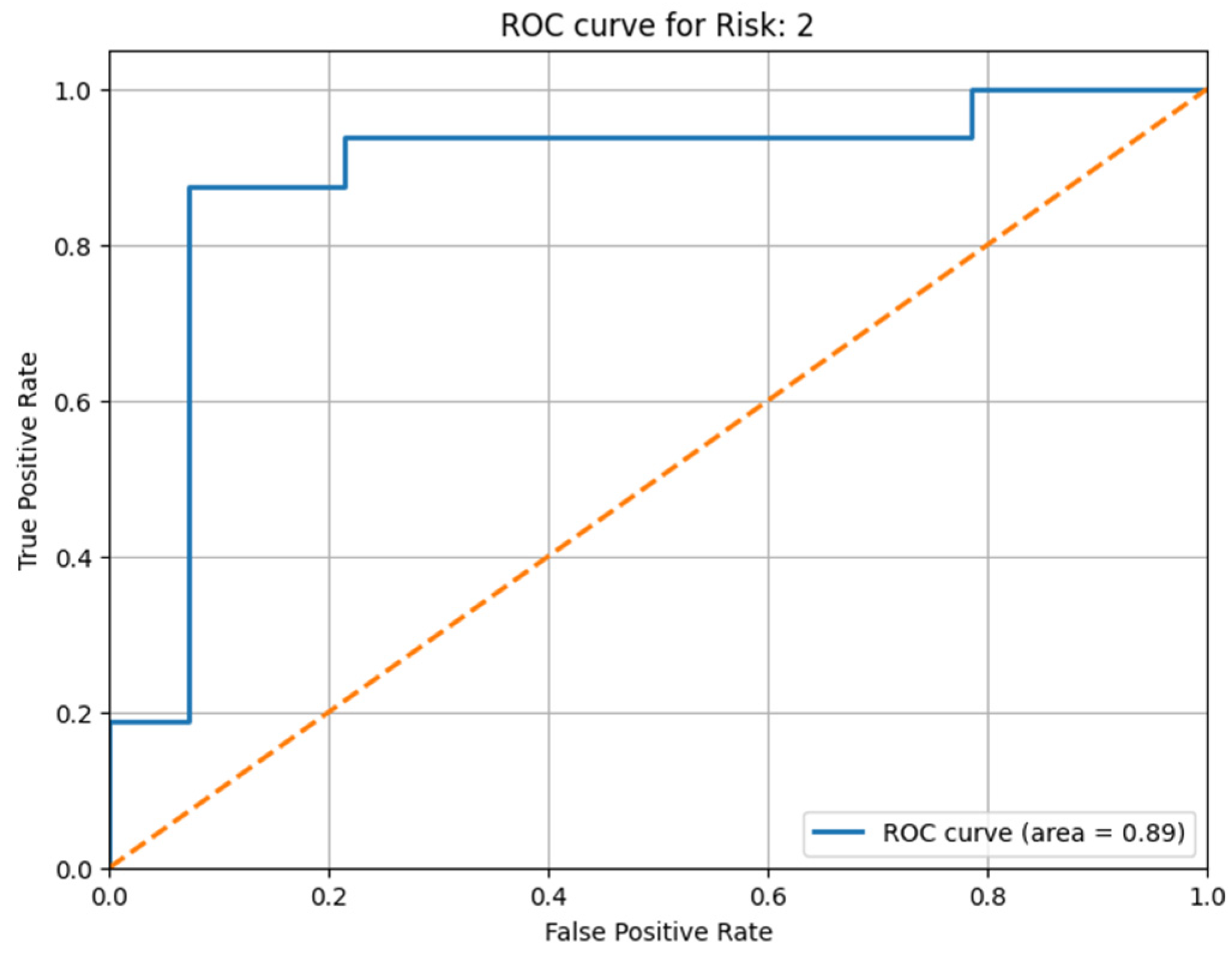
For the multi-class case, the result was even better. We illustrate in
Figure 10 and
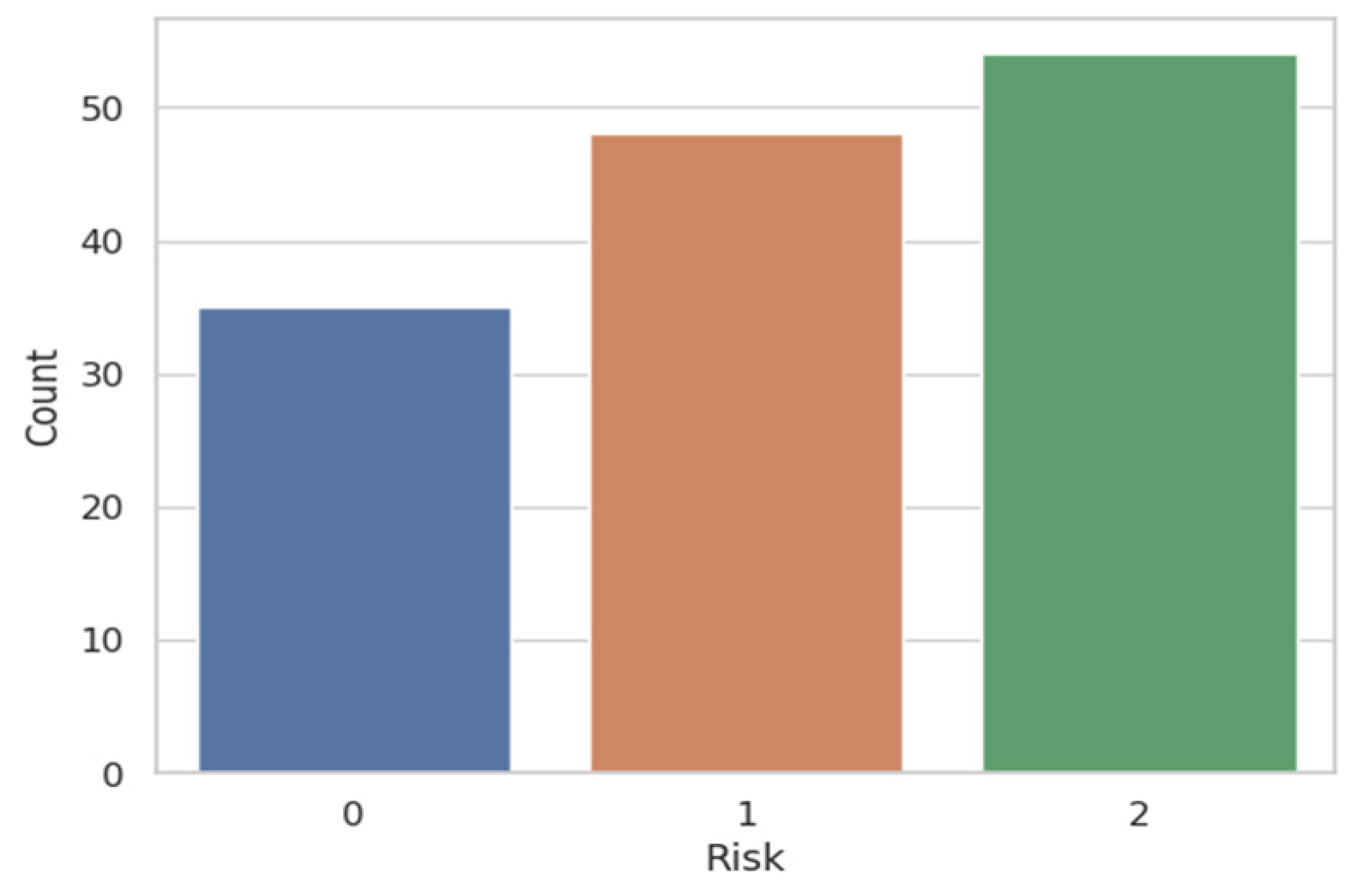
Figure 11 the result obtained after applying the attention mechanism to the urology prostate cancer dataset. We chose to illustrate the results for Risk 0 and for Risk 2, because from
Figure 2, we can observe that approximately 35 patients were classified with Risk 0 and over 50 patients with Risk 2. Patients with Risk 1 were under 50, so they fell in the middle as a volume of patients with intermediate risk of prostate cancer. To extend the ROC-AUC performance metric to multi-class classification for Risk 0 and Risk 2, which are the most interesting clinical cases, we have used a One-vs.-Rest (OvR) approach. Therefore, a separate ROC curve was plotted for each class against all other classes, effectively treating the multi-class problem as a multiple binary classification problem. Following the obtained result, we can state that the developed model worked very well on the multi-class case and on a larger volume of information.
We illustrate the result for the urology dataset in
Table 3 and represent the values of accuracy, sensitivity, and specificity before and after using our technique.
6. Conclusions
By using the LIME explainability method for the purpose of extracting the relevant features and applying the features attention mechanism to them, we managed to increase the accuracy of the final model by approximately 20% from 60% in the first run to above 80% after the explainability-attention refinement. Thus, we highlighted the importance of extracting only the relevant features from the initial dataset. We managed to apply this method to obtain good predictions, even if the size of the dataset was small, with only 100 real patients in the first dataset and 138 real patients in the second dataset participating in this study.
We compared our novel model, including dense classification layers, with the standard deep neural network that is embedded into it. The results are shown in
Table 2 and
Table 3, where the performance metrics before using the developed method are shown along with the ones computed for the dense neural network embedded in our model. There were two significant improvements over the standard deep learning approaches. One is based on the application of LIME to emphasize the feature importance, and the second is to use this information as a feedback signal for the attention mechanism.
Initially, the model was designed for a small dataset; later, it was tested on a dataset with a larger volume of information, as well as in the multi-class case, where it behaved very well.
Small datasets have unique characteristics and constraints that significantly influence the choice of methods and tools used for analysis and modeling. For instance, in small datasets, there is a higher risk of overfitting when using complex models, as these models might adapt too closely to the limited data available, failing to generalize well to new, unseen data.
At the same time, as a final conclusion, we would like to specify the fact that we were not focused on the volume of the dataset, but whether the developed model would be appropriate or bring a positive contribution to automatic learning. We aimed to analyze the performance of the model and to check whether, by using it, we will be able to improve the predictions. The fact that we followed two sets of data from the clinical field, but from different areas of medicine, furthermore proves the versability and the flexibility of the method in executing different tasks, e.g., binary and multi-class classification.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}