


Formation Control of Nonlinear Multi-Agent Systems with Nested Input Saturation



Abstract
:Featured Application
Abstract
1. Introduction
1.1. Motivation
1.2. State of the Art and Contributions
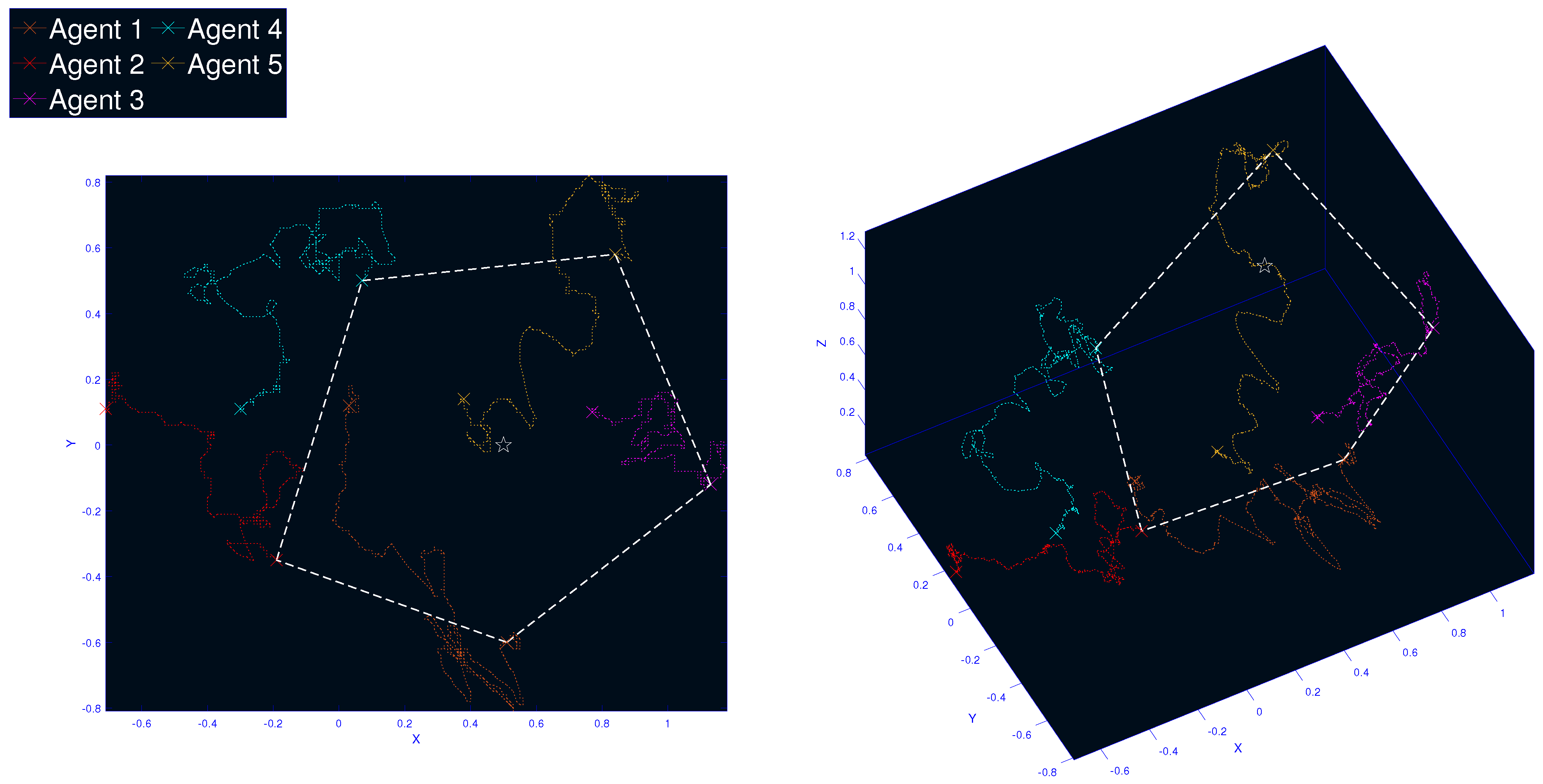
- The control protocol is decentralized with easy gain tuning, which facilitates its integration on a real robotic swarm, as illustrated in Figure 1.
2. Problem Formulation and Preliminaries
2.1. Preliminaries on PPC
3. Main Results
3.1. Sufficient Conditions
3.2. Decentralized Controller Design
3.3. Extension to Multi-Input Multi-Output MASs
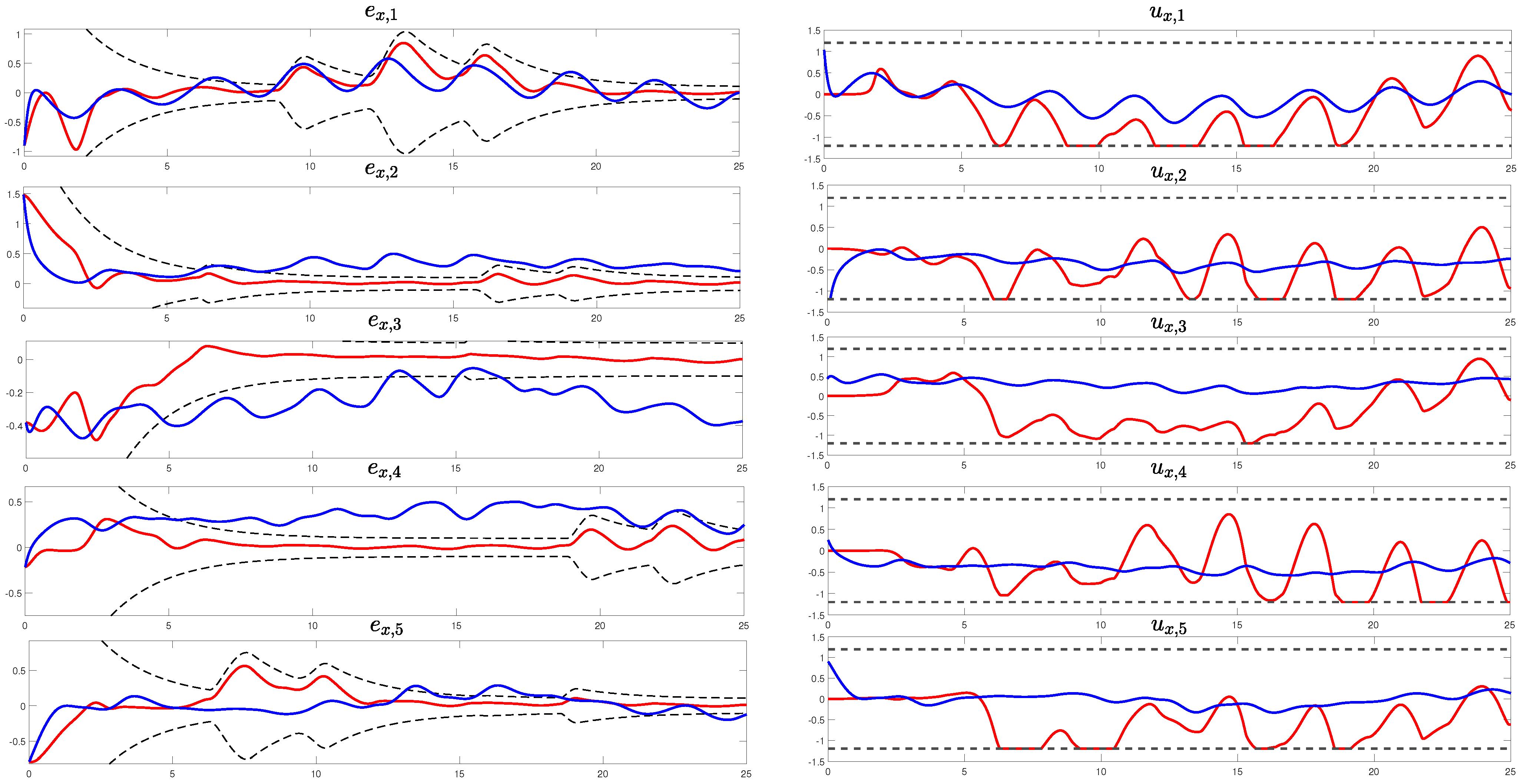
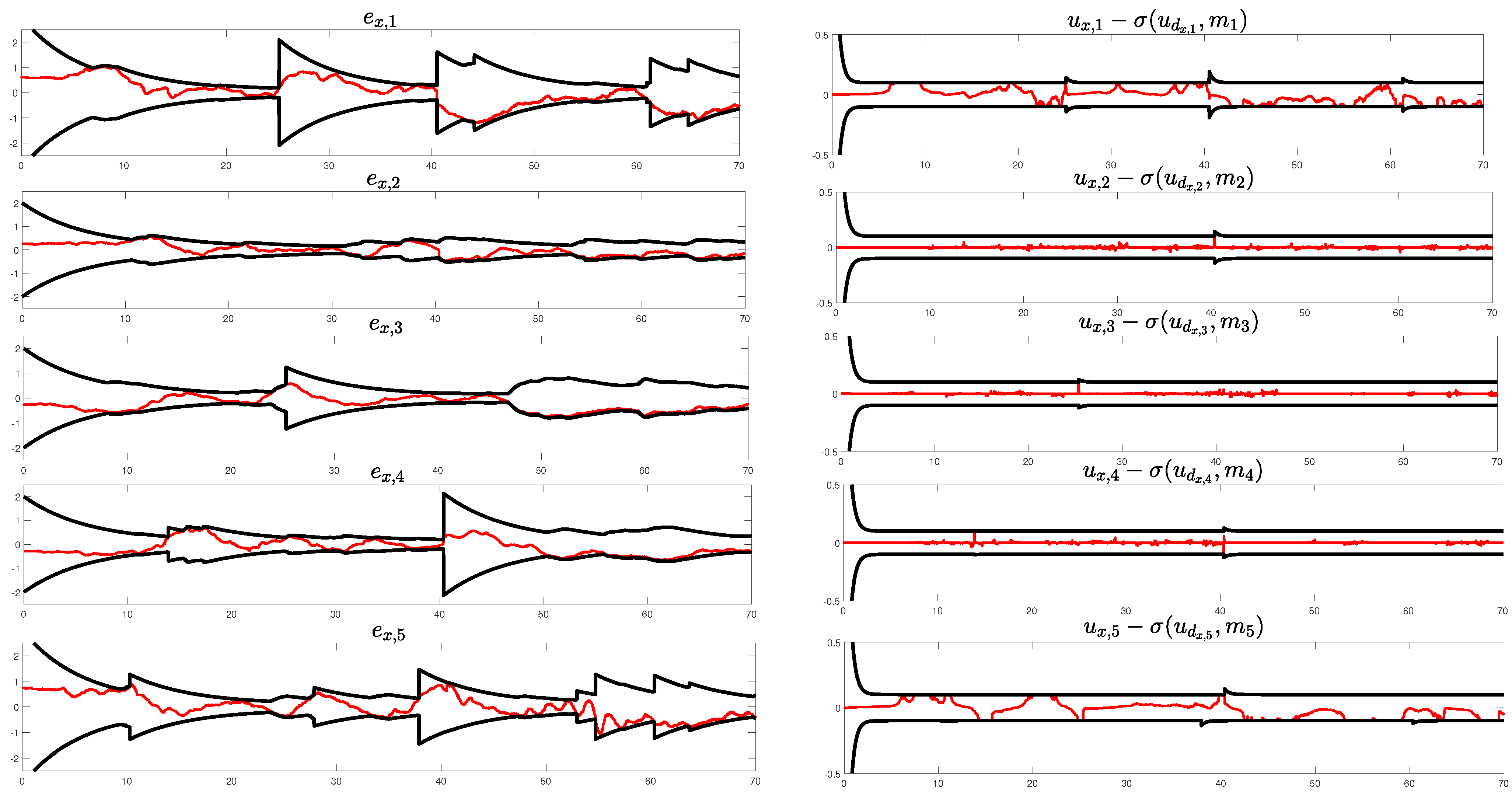
4. Comparative Simulation Results
5. Experimental Results on a Swarm of Aerial Robots
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Darmanin, R.; Bugeja, M. A review on multi-robot systems categorised by application domain. In Proceedings of the 25th Mediterranean Conference on Control and Automation (MED), Valletta, Malta, 3–6 July 2017; pp. 701–706. [Google Scholar]
- Brambilla, M.; Ferrante, E.; Birattari, M.; Dorigo, M. Swarm robotics: A review from the swarm engineering perspective. Swarm Intell. 2013, 7, 1–41. [Google Scholar] [CrossRef]
- Bullo, F.; Cortés, J.; Martínez, S. Distributed Control of Robotic Networks: A Mathematical Approach to Motion Coordination Algorithms; Princeton University Press: Princeton, NJ, USA, 2009; pp. 1–320. [Google Scholar]
- Oh, K.K.; Park, M.C.; Ahn, H.S. A survey of multi-agent formation control. Automatica 2015, 53, 424–440. [Google Scholar] [CrossRef]
- Hacene, N.; Mendil, B. Behavior-based Autonomous Navigation and Formation Control of Mobile Robots in Unknown Cluttered Dynamic Environments with Dynamic Target Tracking. Int. J. Autom. Comput. 2021, 18, 766–786. [Google Scholar] [CrossRef]
- Kuppan Chetty, R.; Singaperumal, M.; Nagarajan, T. Behavior based multi robot formations with active obstacle avoidance based on switching control strategy. Adv. Mater. Res. 2012, 433–440, 6630–6635. [Google Scholar] [CrossRef]
- Antonelli, G.; Arrichiello, F.; Chiaverini, S. Experiments of formation control with multirobot systems using the null-space-based behavioral control. IEEE Trans. Control Syst. Technol. 2009, 17, 1173–1182. [Google Scholar] [CrossRef]
- Hwang, J.; Lee, J.; Park, C. Collision avoidance control for formation flying of multiple spacecraft using artificial potential field. Adv. Space Res. 2022, 69, 2197–2209. [Google Scholar] [CrossRef]
- Ren, W.; Beard, R. Formation feedback control for multiple spacecraft via virtual structures. IEE Proc. Control Theory Appl. 2004, 151, 357–368. [Google Scholar] [CrossRef]
- Wang, D.; Wei, W.; Wang, X.; Gao, Y.; Li, Y.; Yu, Q.; Fan, Z. Formation control of multiple mecanum-wheeled mobile robots with physical constraints and uncertainties. Appl. Intell. 2022, 52, 2510–2529. [Google Scholar] [CrossRef]
- Gao, Z.; Guo, G. Velocity free leader-follower formation control for autonomous underwater vehicles with line-of-sight range and angle constraints. Inf. Sci. 2019, 486, 359–378. [Google Scholar] [CrossRef]
- Ghommam, J.; Saad, M. Adaptive Leader-Follower Formation Control of Underactuated Surface Vessels under Asymmetric Range and Bearing Constraints. IEEE Trans. Veh. Technol. 2018, 67, 852–865. [Google Scholar] [CrossRef]
- Verginis, C.K.; Nikou, A.; Dimarogonas, D.V. Robust formation control in SE(3) for tree-graph structures with prescribed transient and steady state performance. Automatica 2019, 103, 538–548. [Google Scholar] [CrossRef]
- Dimarogonas, D.; Egerstedt, M.; Kyriakopoulos, K. A leader-based containment control strategy for multiple unicycles. In Proceedings of the 45th IEEE Conference on Decision and Control, San Diego, CA, USA, 13–15 December 2006; pp. 5968–5973. [Google Scholar]
- Zhang, X.; Wu, J.; Zhan, X.; Han, T.; Yan, H. Observer-Based Adaptive Time-Varying Formation-Containment Tracking for Multiagent System with Bounded Unknown Input. IEEE Trans. Syst. Man Cybern. Syst. 2023, 53, 1479–1491. [Google Scholar] [CrossRef]
- Cheah, C.; Hou, S.; Slotine, J. Region-based shape control for a swarm of robots. Automatica 2009, 45, 2406–2411. [Google Scholar] [CrossRef]
- Hart, S.; Kamenetsky, J.; Kitts, C. Dynamic Elliptical Shaping Control for Swarm Robots. IEEE Access 2023, 11, 17454–17470. [Google Scholar] [CrossRef]
- Wei, C.; Wu, X.; Xiao, B.; Wu, J.; Zhang, C. Adaptive leader-following performance guaranteed formation control for multiple spacecraft with collision avoidance and connectivity assurance. Aerosp. Sci. Technol. 2022, 120, 107266. [Google Scholar] [CrossRef]
- Wu, X.; Luo, S.; Yang, S.; Wei, C. Adaptive appointed-time formation tracking control for multiple spacecraft with collision avoidance under a dynamic event-triggered mechanism. Adv. Space Res. 2022, 70, 3552–3567. [Google Scholar] [CrossRef]
- Cheng, W.; Zhang, K.; Jiang, B. Fixed-Time Fault-Tolerant Formation Control for a Cooperative Heterogeneous Multiagent System with Prescribed Performance. IEEE Trans. Syst. Man Cybern. Syst. 2023, 53, 462–474. [Google Scholar] [CrossRef]
- Cui, Y.; Cao, L.; Gong, X.; Basin, M.V.; Shen, J.; Huang, T. Resilient Output Containment Control of Heterogeneous Multiagent Systems Against Composite Attacks: A Digital Twin Approach. IEEE Trans. Cybern. 2023, 1–14. [Google Scholar] [CrossRef]
- Cui, Y.; Luo, B.; Feng, Z.; Huang, T.; Gong, X. Resilient state containment of multi-agent systems against composite attacks via output feedback: A sampled-based event-triggered hierarchical approach. Inf. Sci. 2023, 629, 77–95. [Google Scholar] [CrossRef]
- Di, F.Q.; Li, A.J.; Guo, Y.; Xie, C.Q.; Wang, C.Q. Event-triggered sliding mode attitude coordinated control for spacecraft formation flying system with disturbances. Acta Astronaut. 2021, 188, 121–129. [Google Scholar] [CrossRef]
- Xiao, C.; Guo, Y.; Xie, C.Q.; Li, A.J.; Wang, C.Q. Adaptive super-twisting sliding mode attitude coordination control for spacecraft formation flying with actuator saturation. Adv. Space Res. 2023, 72, 4244–4255. [Google Scholar] [CrossRef]
- Moradi Pari, H.; Bolandi, H. Discrete time multiple spacecraft formation flying attitude optimal control in presence of relative state constraints. Chin. J. Aeronaut. 2021, 34, 293–305. [Google Scholar] [CrossRef]
- Zhang, D.W.; Liu, G.P.; Cao, L. Proportional Integral Predictive Control of High-Order Fully Actuated Networked Multiagent Systems with Communication Delays. IEEE Trans. Syst. Man Cybern. Syst. 2023, 53, 801–812. [Google Scholar] [CrossRef]
- Zhu, Z.; Guo, Y. Adaptive coordinated attitude control for spacecraft formation with saturating actuators and unknown inertia. J. Frankl. Inst. 2019, 356, 1021–1037. [Google Scholar] [CrossRef]
- Zhou, W.; Wang, Y.; Ahn, C.K.; Cheng, J.; Chen, C. Adaptive Fuzzy Backstepping-Based Formation Control of Unmanned Surface Vehicles with Unknown Model Nonlinearity and Actuator Saturation. IEEE Trans. Veh. Technol. 2020, 69, 14749–14764. [Google Scholar] [CrossRef]
- Lu, Y.; Wen, C.; Shen, T.; Zhang, W. Bearing-Based Adaptive Neural Formation Scaling Control for Autonomous Surface Vehicles with Uncertainties and Input Saturation. IEEE Trans. Neural Netw. Learn. Syst. 2021, 32, 4653–4664. [Google Scholar] [CrossRef]
- Trakas, P.S.; Bechlioulis, C.P. Robust Adaptive Prescribed Performance Control for Unknown Nonlinear Systems with Input Amplitude and Rate Constraints. IEEE Control Syst. Lett. 2023, 7, 1801–1806. [Google Scholar] [CrossRef]
- Qu, Z.; Wang, J.; Hull, R.A. Cooperative Control of Dynamical Systems with Application to Autonomous Vehicles. IEEE Trans. Autom. Control 2008, 53, 894–911. [Google Scholar] [CrossRef]
- Wen, C.; Zhou, J.; Liu, Z.; Su, H. Robust Adaptive Control of Uncertain Nonlinear Systems in the Presence of Input Saturation and External Disturbance. IEEE Trans. Autom. Control 2011, 56, 1672–1678. [Google Scholar] [CrossRef]
- Bechlioulis, C.P.; Rovithakis, G.A. A low-complexity global approximation-free control scheme with prescribed performance for unknown pure feedback systems. Automatica 2014, 50, 1217–1226. [Google Scholar] [CrossRef]
- Trakas, P.S.; Bechlioulis, C.P.; Rovithakis, G.A. Decentralized Global Connectivity Maintenance for Multi-agent Systems using Prescribed Performance Average Consensus Protocols. In Proceedings of the European Control Conference (ECC), London, UK, 12–15 July 2022; pp. 524–529. [Google Scholar]
- Ren, W.; Beard, R.; McLain, T. Coordination Variables and Consensus Building in Multiple Vehicle Systems. In Cooperative Control: A Post-Workshop Volume 2003 Block Island Workshop on Cooperative Control; Lecture Notes in Control and Information Science; Springer: Berlin/Heidelberg, Germany, 2005; Volume 309, pp. 171–188. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Control Protocol |
|---|
| Performance Index | Proposed Scheme | Scheme of [35] |
|---|---|---|
| 0.43835 | 0.83016 | |
| 0.9195 | 2.3677 | |
| 5.0563 | 2.7216 |
| Parameter | Value | Parameter | Value |
|---|---|---|---|
| 3 | |||
| 2 | |||
| 3 | |||
| 2 | 2 | ||
| 2 | |||
| 4 | |||
| 5 | |||
| 1 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Trakas, P.S.; Tantoulas, A.; Bechlioulis, C.P. Formation Control of Nonlinear Multi-Agent Systems with Nested Input Saturation. Appl. Sci. 2024, 14, 213. https://doi.org/10.3390/app14010213
Trakas PS, Tantoulas A, Bechlioulis CP. Formation Control of Nonlinear Multi-Agent Systems with Nested Input Saturation. Applied Sciences. 2024; 14(1):213. https://doi.org/10.3390/app14010213
Chicago/Turabian StyleTrakas, Panagiotis S., Andreas Tantoulas, and Charalampos P. Bechlioulis. 2024. "Formation Control of Nonlinear Multi-Agent Systems with Nested Input Saturation" Applied Sciences 14, no. 1: 213. https://doi.org/10.3390/app14010213
APA StyleTrakas, P. S., Tantoulas, A., & Bechlioulis, C. P. (2024). Formation Control of Nonlinear Multi-Agent Systems with Nested Input Saturation. Applied Sciences, 14(1), 213. https://doi.org/10.3390/app14010213