1. Introduction
With the increase in model parameters, the fitting capacity of neural networks becomes stronger. However, when the joint distribution of the training set samples and labels differs from that of the evaluation/testing set, the training set is considered biased [
1]. In the case of biased data, deep neural networks tend to overfit [
2], leading to a decline in model performance. Thus, effectively utilizing biased data can reduce the high cost of data re-collection or annotation.
Class imbalance [
3] refers to a situation where the number of samples in one or more classes is significantly different from the number of samples in other classes. This situation is prevalent in many real-world problems, such as spam email classification and telephone fraud detection. Class imbalance can affect the performance of classifiers, causing them to predict the majority class, which would achieve decent accuracy without truly learning the essence of the problem. However, such training does not serve the purpose of building a reliable classifier, as the model’s generalization ability is compromised, leading to poor performance in real-world applications.
Corrupted labels [
4] refer to instances where the labels in the training data do not match the true labels. This issue often arises during data collection or annotation [
5] and may result from automated annotation, non-expert labeling, or adversarial label tampering [
6]. The existence of corrupted labels in the dataset can negatively impact the model’s performance [
7], as it learns from erroneous information.
In the real world, both types of bias often coexist and influence each other. A dataset may suffer from class imbalance, which, in turn, could lead to the presence of corrupted labels. Additionally, due to the bias in sample distribution, the model may more easily learn features that favor the majority class, neglecting features from other classes, further exacerbating the class imbalance and corrupted label issues. Therefore, research focusing on effectively handling and utilizing class imbalanced data and corrupted labels is crucial [
1,
8].
Currently, many studies have attempted to address the issue of biased data, mainly employing two methods: sample re-sampling and sample reweighting. Sample re-sampling includes over-sampling [
9], under-sampling, and data augmentation. Sample reweighting, on the other hand, assigns weights to each sample based on a weighted function, adjusting the impact of each sample on the model through weighted losses. In sample reweighting, a weight function along with its associated hyperparameters during model training is predefined in advance to assign different weights to samples based on their loss values, reflecting the significance of each sample in the training set. By utilizing importance weighting, the negative impact of biased samples on the model can be reduced.
However, the bias type in the data is unknown. Traditional weighting methods tend to assign high weights to samples with small loss to reduce the misleading effect of label noise samples on the model when label noise exists [
10]. Conversely, another scenario might emerge where high loss samples are assigned high weights, as these large loss samples could belong to minority classes and need to be forcefully learned by the classifier as hard boundary samples [
11]. As a result, these weighting methods fail to accommodate both scenarios effectively.
In addition, on the one hand, bias types in the data can be diverse, and the degree of bias is difficult to predict. On the other hand, the utilization of bias data’s inherent information in the reweighting method is not high enough to effectively enhance the discrimination between samples. Meta-learning refers to enabling models to “learn to learn” and quickly adapt to new tasks with minimal training data. In recent years, the use of meta-learning has demonstrated high generalization in meta-neural networks across different tasks [
12], acquiring more generalized weights than manual hyperparameter tuning [
13]. To address the aforementioned challenges and drawing inspiration from the work of [
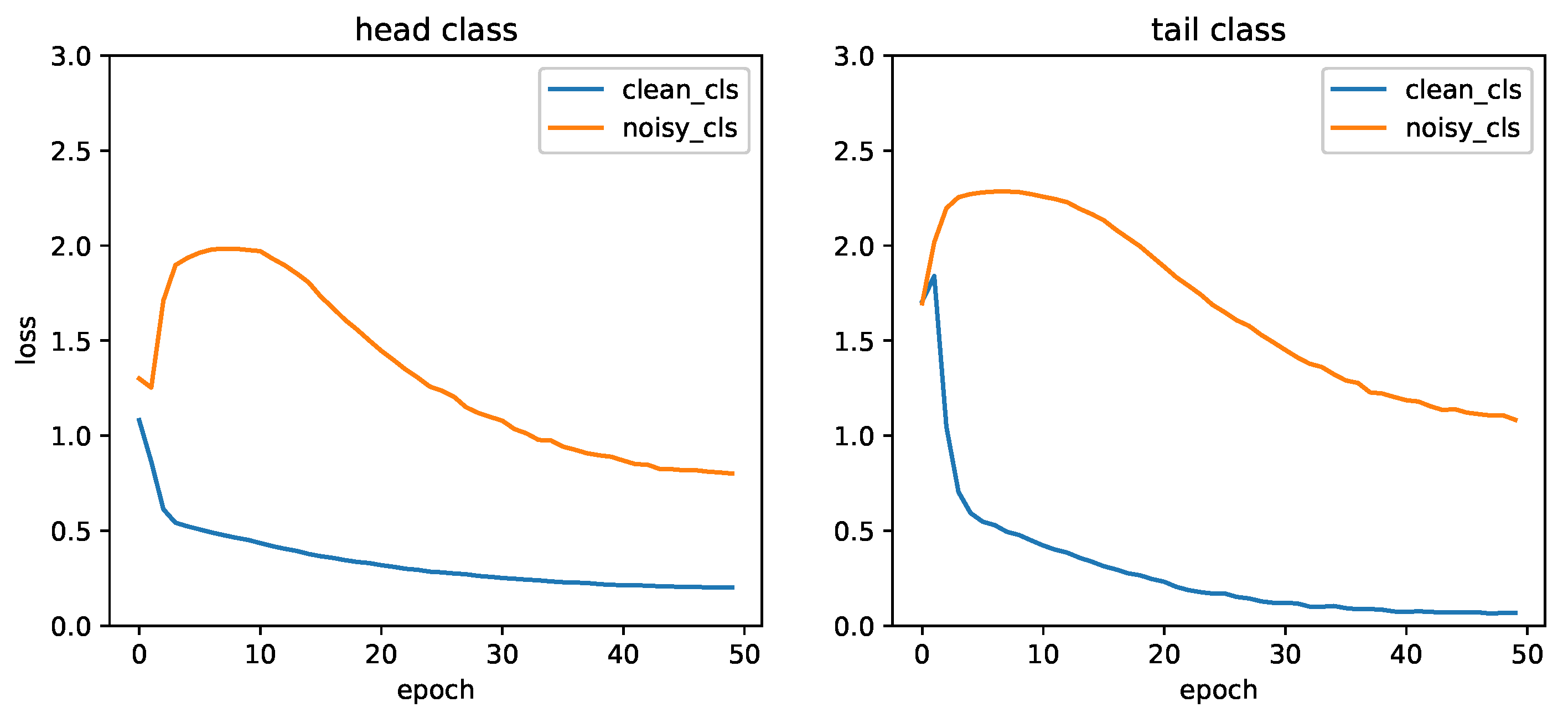
14], we adopt a two-stage training strategy. In the first stage, we employ a pre-trained model to obtain multiple loss variation values for each epoch of all samples and fuse these values with attention features, which are semantic features extracted by multi-head self-attention layers, to enhance the discrimination among samples. We observe that the variation pattern of the pre-collected average training loss values (as illustrated in
Figure 1) is similar to the findings of [
14]. In the second stage, leveraging the high generalization capability of meta-learning, MLRNet calculates weights based on the fused sample features and analyzes the loss variation for each sample, assigning more reasonable weights and obtaining the final weighted loss values through a bi-level optimization problem with the classifier.
In summary, our contributions are as follows:
We propose a Meta-Loss Reweighting Network (MLRNet) based on the concept of meta-learning with attention features, which performs well on complex biased situations.
We embed the labels of samples, concatenate them with the features extracted by self-attention layers, and fuse it with pre-collected sample multi-loss variation values. This fused representation is referred to as the discriminative feature (or DF). Through MLRNet analysis of discriminative features, we identify the bias type of each sample and automatically assign appropriate weights to biased data.
We conduct experiments on several English and Chinese benchmark datasets, including artificially generated and real-world biased datasets. The results demonstrate that our approach achieves better and more generalizable performance than prior works.
The structure of the paper is organized as follows:
Section 2 discusses related work,
Section 3 presents our proposed method,
Section 4 demonstrates the experimental results and analysis, and
Section 5 concludes the paper.
4. Experiments
To evaluate the proposed algorithm’s performance, we conduct experiments on benchmark datasets in both English and Chinese. These datasets comprise both synthetic and real-world biased datasets, allowing us to assess the algorithm’s generalizability in various scenarios. We compared the algorithm against existing methods under different imbalance factors and noise levels to gauge its effectiveness.
4.1. Datasets
AG News: This is a large-scale multi-class text classification benchmark dataset containing 496,835 news articles from over 2000 different news sources. Following the work of [
41], we focused on the four classes with the most samples and used the article titles along with their corresponding descriptions. In the training set, each class has 30,000 samples, while in the test set, each class has 1900 samples. For fair comparison (MLC), we randomly selected 100 samples from each class to form a clean and unbiased meta-dataset.
CLUE: A Chinese language understanding evaluation benchmark [
42]. For our experiments, we selected two datasets from the classification tasks, TNEWS and IFLYTEK. TNEWS is a dataset that contains 73,360 news headlines for short text classification. It covers 15 categories, and the training, validation, and test sets consist of 53.3 k, 10 k, and 10 k samples, respectively. IFLYTEK is a dataset that includes 17,332 app descriptions for long text classification. It has 119 categories, and the dataset is split into 12.1 k, 2.6 k, and 2.6 k samples for training, validation, and test sets, respectively.
Real-World Noise: DataCLUE is a benchmark that replaces the traditional model-centric approach with a data-centric approach for Chinese text classification [
43]. We used the CIC Electronic Commerce 118-classification dataset from DataCLUE because it contains a high proportion of mislabeled data and a large number of label categories with certain imbalances in the label distribution. This dataset is used as a real-world biased dataset. The data are split into 10,000 samples for training, 2000 samples for validation, and 2000 samples for the test set. Notably, more than 1/3 of the training set and more than 1/5 of the validation set have mislabeled data, while the test set has ground-truth labels with an accuracy exceeding 95%.
It is worth noting that AG News is a large-scale dataset without biased data, but the other three datasets, THNEWS, IFLYTEK, CIC, are all naturally biased and have smaller scales than AG NEWS. Therefore, we additionally set the bias for the AG News dataset and experimentally verified the performance of our method on the large-scale dataset under different bias combinations. Thus, we constructed a biased training set for the AG news dataset using the two types of bias settings mentioned in
Section 4.2 and conducted experiments on it.
4.2. Bias Setup
Class Imbalance: To create a class-imbalanced dataset, we gradually reduced the number of samples for each class using an exponential function , where i is the index of the class, is the original number of samples for each class, and . The imbalance level of the dataset is defined by an imbalance factor, which is the ratio of the number of training samples in the largest class to the number of training samples in the smallest class. For example, when the imbalance factor is 100, assuming the class with the most samples has 1200 samples, the class with the fewest samples contains only 12 samples.
Label Noise: We used two commonly used methods to introduce label noise: uniform noise and flipping noise. Both methods change the label of a sample to another label with a probability of noise level p.
UNIFORM: Suppose the dataset contains
C classes. In the uniform noise setting, the sample’s label is preserved with a probability of
. The label is randomly corrupted to other labels with equal probability
for each class. The UNIFORM noise matrix is defined as follows: for each element
in the matrix, it represents the probability that the label with index
i is corrupted to the label with index
j.
FLIP: In the FLIP noise setting, we also assume a dataset with C classes. Similar to the uniform noise, the label is preserved with a probability of . However, with a probability of p, the label is corrupted to one of the remaining classes specified randomly. For example, for the label with index 0, the FLIP noise matrix may look like . Due to its randomness, the complete FLIP noise matrix is not provided here.
4.3. Hyperparameter Configuration for the MLRNet
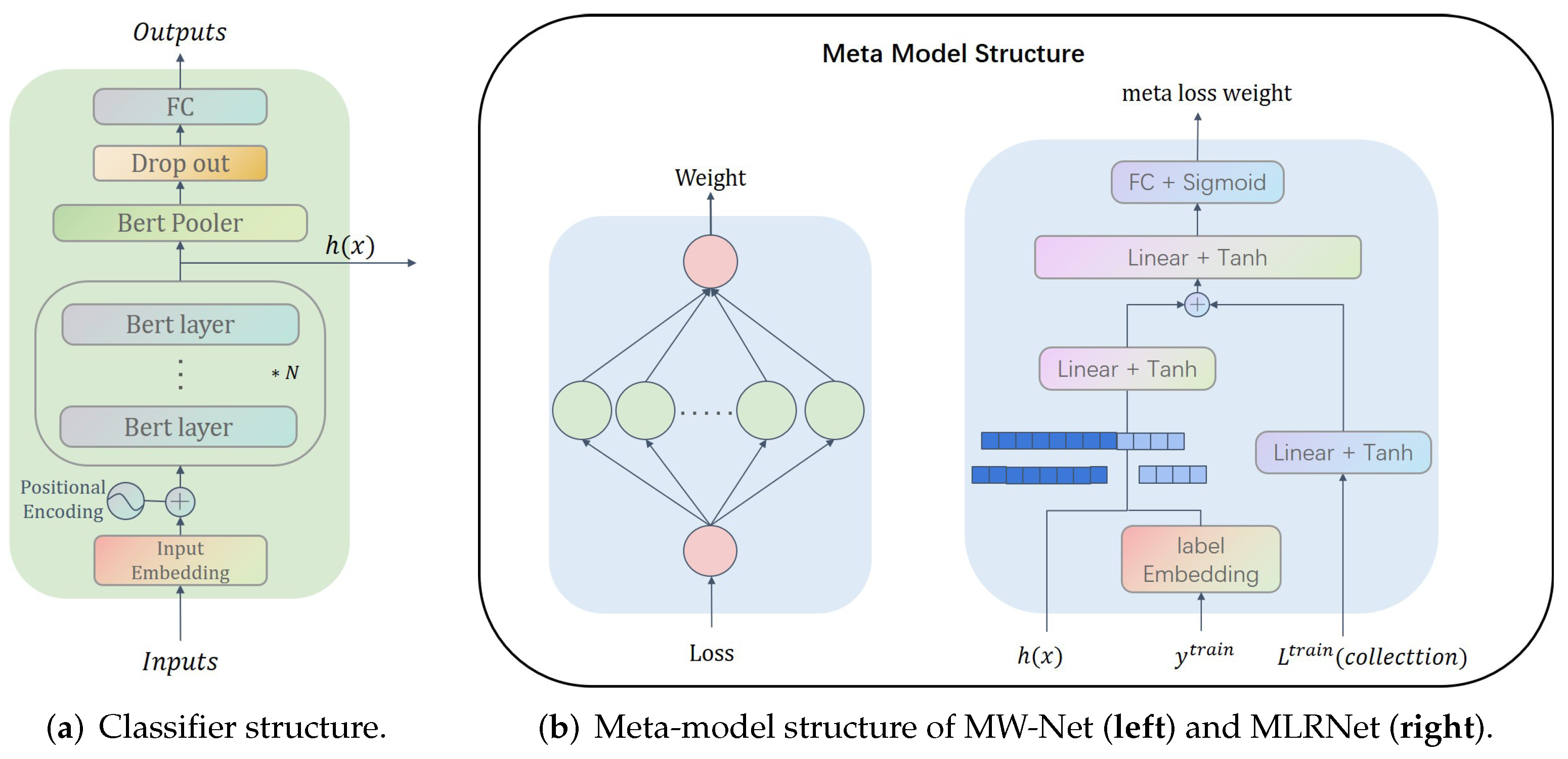
We maintained a consistent configuration similar to MLC by setting the dimensionality of the attention features extracted by the classifier to 768. Simultaneously, we established the size of the label embedding layer as , where C represents the number of classes in the dataset. We then processed through three layers of Tanh activation functions, resulting in an output dimensionality equivalent to that of the discriminative features.
Given that attention features are concatenated with label embedding vectors, the concatenated representation subsequently passes through two layers of Tanh activation functions. The input dimensionality here is the sum of the feature dimension and the label embedding dimension, while the output dimension matches that of the discriminative features. Summation is performed to obtain the discriminative features .
Following this, a three-layer feedforward network with Tanh activation functions is employed, which is followed by a final layer with a sigmoid activation function. This ensures that the computed weights fall within the [0, 1] range. The structural visualization of this model can be referenced in
Figure 3.
4.4. Implement Details
AG News: We constructed datasets with different bias proportions by artificially reducing the number of samples in each category and corrupting the labels with noise using the noise matrices. The model was trained for 10 epochs on an NVIDIA RTX A5000 GPU. We utilized the pre-trained BERT-base-uncased model as the backbone network with a batch size of 30. The learning rate for the classifier was set to 1 × and we set the random seed to 1 to ensure the results are replicable in multiple runs.
Other datasets: For fairness, for Chinese datasets such as IFLYTEK, TNEWS and CIC, we used different models as classifiers and conducted different experiments on each dataset. Following previous work [
42,
43], we utilized the pre-trained RoBERTa-l3 model as the backbone network with a batch size of 16. This model was trained for 6 epochs on an NVIDIA RTX A5000 GPU. The learning rate for the classifier was set to 2 ×
, and we set the random seed to 42 to ensure the results are replicable in multiple runs.
For the CIC dataset, [
43] used Macro-F1 as the primary evaluation metric. In this paper, we use accuracy as the evaluation metric for the experimental results of all English and Chinese datasets, which is the percentage of the number of correctly predicted samples divided by the total number of samples by the model. To maintain consistency for comparison, we adopted the same hyperparameter settings as [
43].
It is worth noting that in today’s prevalent pre-training models, such as BERT, the Post-Norm structure can lead to the problem of gradient vanishing during backpropagation, especially in deeper layers [
44,
45]. However, this seems to align with the original design intention of pre-trained models, aiming to preserve the effectiveness of pre-trained layers as much as possible. To address this, we used the Adam optimizer for training, and its warm-up mechanism allowed the model to start with a smaller learning rate to familiarize itself with the overall data distribution. For the same dataset, each model was trained with the same number of warm-up steps and epochs.
4.5. Comparison Method
Due to factors such as scale, manual construction, and language differences, AG news is a large-scale English dataset without biased data, while the other datasets are small-scale biased Chinese datasets. Therefore, we use the state-of-the-art comparison methods of the current dataset for comparison.
For the AG News dataset, we conducted experiments with different setting of bias, which included cases of extreme class imbalance and extreme label noise. For example, in
Table 1, an imbalance factor of 200 means that the class with the highest number of samples has 200 times the number of samples compared to the class with the lowest number. The main comparison was made with two SOTA methods: [
36] used meta-learning for sample reweighting (referred to as MW-Net), and [
26] used meta-learning for label correction (referred to as MLC). The label correction model represented by MLC performs poorly on high class imbalance, so we conducted additional experiments under complete label noise settings. The values in
Table 2 represent the average accuracy of 10 noise levels for each of the two bias construction methods (UNIFORM and FLIP); for example, UNIFORM noise level 0.2 and FLIP noise level 0.8 indicates whether to use UNIFORM or FLIP to construct noise, and 20% or 80% of sample labels are replaced with noisy labels. GLC [
5] and MLC are the best models for handling label noise in weakly supervised label correction models.
Result on the Chinese Benchmark Datasets
We further evaluated our approach on the Chinese benchmark datasets, and the results are presented in
Table 3. The experimental outcomes affirm that our methodology also yields commendable results on the Chinese dataset, thus underscoring its versatility and efficacy across diverse tasks.
For other Chinese benchmark datasets, we also follow the work of previous researchers [
42,
43] and use their baseline for comparison, such as RoBERTa-l3 [
39], Bert-wwm-ext [
46] and RoBERTa-wwm-ext [
46]. BERT-WWM is the first pre-training scheme designed for the Chinese language, which uses a whole word mask (WWM) strategy based on Chinese words. Compared to individual Chinese character-based masks, word-based masks enable the model to learn more semantic information. BERT-wwm-ext adopts the same model structure as BERT-wwm, consisting of 12 layers of bert layers. In fact, it is able to increase the training dataset and training steps to improve the effect. RoBERTa changed the pre-training strategy and removed the Next Sentence Prediction (NSP) task; it is trained with dynamic masking. Thus, RoBERTa-wwm-ext is a Roberta model that uses the WWM strategy and increases the training dataset and training steps. RoBERTa-l3 is a RoBERTa-wwm-ext model but with three Bert layers.
In addition, MW-Net [
36], as the state-of-the-art meta-learning reweighting method with strong universality and robustness, runs through all comparison methods.
4.6. Experiments Results and Analysis
4.6.1. Results on the English Benchmark Dataset
We conducted a comparative analysis of model performance on the AG News dataset across various imbalance factors and noise levels. The experimental results presented in
Table 1 demonstrate that when utilizing Bert-base as the backbone network, MLRNet consistently exhibits robust performance across most settings. It is noteworthy that in this context, the noise labels were generated using the UNIFORM method. Importantly, when the noise level is set to 0, the task effectively transforms into a single-class imbalance problem. Similarly, when the imbalance factor is set to 1, it becomes a single-class label corruption problem. The observations reveal that concerning class imbalance, as the imbalance factor gradually increases, MWN outperforms other models, while MLC, functioning as a label correction model, demonstrates relatively weaker performance. Conversely, in terms of label corruption, MLC outperforms MW-Net. Notably, MLRNet consistently achieves favorable results particularly in scenarios characterized by high class imbalance and noise levels.
Furthermore, we investigated two methods for constructing label noise. The values in
Table 2 represent the average results obtained from 20 (2 × 10) different settings with each method (UNIFORM and FLIP) comprising 10 noise levels. Each configuration was run five times to ensure robustness. MLRNet demonstrated robust performance even under extreme label noise conditions.
4.6.2. Ablation Study and Analysis
In order to explore the versatility of MLRNet across different backbone networks, we substituted the backbone network with Bert-base-3l, which comprises only three layers of attention layers, and conducted further experiments on the AG News dataset. We configured imbalance factors for bias data types as [1, 10, 20], employed label noise of the UNIFORM type, and varied noise levels within the range [0.0, 0.2, 0.4, 0.6]. Building upon these settings, we conducted a detailed investigation into our methodology to ascertain its adaptability to diverse bias scenarios. The outcomes of these experiments are presented in
Table 4.
Effects of the number of Meta-Samples. Given the inherent errors in data collection and the substantial cost associated with expertly annotating unbiased datasets, we systematically varied the quantity of meta-samples during training to further validate the robustness of our method. As delineated in
Table 5, our approach demonstrates noteworthy performance, even when the number of meta-samples per class is as low as 10, resulting in a notable improvement of 1.24% (imbalance factor set at 20, noise level at 0.4, and DF feature dimensionality at 128). Interestingly, as the quantity of meta-samples per class gradually increases, this improvement becomes even more pronounced. It is worth noting, however, that when the number of meta-samples per class reaches 500, there is a decline in accuracy, as illustrated in
Figure 4. We attribute this phenomenon to the fact that an excessively large meta-dataset exacerbates the bias within the training set, ultimately leading to a decrease in accuracy. Hence, we emphasize the importance of an appropriately sized meta-dataset in achieving optimal results.
Effects of discriminative feature dimensionality. Given that the dimensionality of discriminative features directly impacts the computational workload and training speed of the meta-model, we conducted experiments by adjusting the dimensionality of discriminative feature embeddings. The results are presented in
Table 6 (imbalance factor set at 20, noise level at 0.4, and 200 meta-samples per class). Concurrently, as evident from
Figure 5, it is apparent that with an increase in DF dimensionality, the average accuracy steadily improves, underscoring the pivotal role of discriminative features. However, the escalation in DF dimensionality also leads to a substantial increase in model parameters, resulting in extended training times and heightened training costs. Consequently, taking into account factors both performance and training time, we opted for a DF dimensionality of 128.
5. Conclusions and Future Work
This paper introduces a novel MLRNet meta-module capable of handling highly biased datasets, which can be applied to various tasks to enhance their performance. It leverages the evolving trends in sample loss values to provide valuable insights for distinguishing different biased samples. Within MLRNet, we propose a meta-loss reweighting network structure that incorporates attention features. We introduce the concept of discriminative features, employing a two-stage training strategy to pre-collect multiple loss variation values for each sample and fuse them with sample feature vectors extracted through self-attention layers. This enhances the discriminative capability of biased data samples. Leveraging meta-learning principles, we train the entire model to assign more reasonable weights to biased samples. Our experimental results on publicly available datasets in both English and Chinese demonstrate the practicality of our approach, particularly in scenarios where dataset is highly biased.
It is important to note that our experiments have been primarily conducted in the domain of text classification. Our future work will explore research in the field of image recognition. However, the meta-learning ideas and dynamic sample weighting methods provided by MLRNet may not be limited to text and image classification. Its architecture and principles may be applicable to other fields, such as speech recognition, medical image analysis, and financial data mining, especially when there is significant bias in the dataset. In the future, it may be used to improve the robustness of models in real-world data and help develop models that are more adaptable to real-world diversity. With data bias becoming a common problem in machine learning, the introduction of MLRNet marks a beneficial exploration of this challenge. Future research may further explore model optimization methods under different types of biases as well as their applications in a wider range of fields.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}