Abstract
Sarcasm is a mode of expression whereby individuals communicate their positive or negative sentiments through words contrary to their intent. This communication style is prevalent in news headlines and social media platforms, making it increasingly challenging for individuals to detect sarcasm accurately. To mitigate this challenge, developing an intelligent system that can detect sarcasm in headlines and news is imperative. This research paper proposes a deep learning architecture-based model for sarcasm identification in news headlines. The proposed model has three main objectives: (1) to comprehend the original meaning of the text or headlines, (2) to learn the nature of sarcasm, and (3) to detect sarcasm in the text or headlines. Previous studies on sarcasm detection have utilized datasets of tweets and employed hashtags to differentiate between ordinary and sarcastic tweets depending on the limited dataset. However, these datasets were prone to noise regarding language and tags. In contrast, using multiple datasets in this study provides a comprehensive understanding of sarcasm detection in online communication. By incorporating different types of sarcasm from the Sarcasm Corpus V2 from Baskin Engineering and sarcastic news headlines from The Onion and HuffPost, the study aims to develop a model that can generalize well across different contexts. The proposed model uses LSTM to capture temporal dependencies, while the proposed model utilizes a GlobalMaxPool1D layer for better feature extraction. The model was evaluated on training and test data with an accuracy score of 0.999 and 0.925, respectively.
1. Introduction
The Oxford Language Dictionary defines sarcasm as the use of irony to mock or express contempt. It is a commonly used form of expression that presents a challenge in identifying sarcasm in the written text [1,2]. The challenge in detecting sarcasm arises from the ambiguity of the language employed and the intention of the speaker or writer, which can be in opposition to the literal meaning. Sarcasm is often used as a tool to attract attention and to express negative sentiments more unequivocally. With the widespread use of online platforms such as Facebook, Instagram, and Twitter, people can express their opinions on various topics such as politics, entertainment, and products. The complex structure of sentences in these online messages makes it difficult for both machines and humans to understand their meaning, making sentiment analysis and sarcasm detection a rapidly growing area of interest in machine learning [3].
Previous research on sarcasm detection has primarily focused on using Twitter data, such as tweets. The methods used in these studies have varied from rule-based to more advanced approaches, and a rule-based method was employed to categorize text incongruity. However, previous studies were constrained due to limitations arising from unclear labelling, and the data were not explicitly collected to detect sarcasm.
Recently, researchers have tried to accurately identify sarcasm by exploring the characteristics of sarcastic phrases compared to non-sarcastic ones. Despite these efforts, the field of sarcasm detection remains under investigation. Neural Networks have been used to develop sarcasm detectors for different types of content, including tweets, Flickr photos, etc.
This study proposes an improved version of the Long Short-Term Memory (LSTM) model for sarcasm detection, called the GMP-LSTM. The GMP-LSTM incorporates a GlobalMaxPooling layer, which allows the model to capture essential features from temporal sequences. The GMP-LSTM is designed to capture higher-level patterns in the data compared to the original LSTM. The proposed model was evaluated on two sarcasm datasets and achieved a higher accuracy than the original LSTM. These results suggest that the GMP-LSTM can be a useful tool for detecting sarcasm in textual data. The paper is structured as follows: In Section 2, we review previous works on sarcasm detection using machine learning. In Section 3, we outline the approach used in this study, where we propose a deep learning architecture-based model to detect sarcasm in news headlines. In Section 4, the implementation of the classifier and the results of the implemented classifies are presented. Finally, in Section 5, we summarize the findings of this study and discuss its implications.
2. Literature Review
Previous research on sarcasm detection mainly focused on utilizing Twitter datasets, but more advanced techniques have since been developed, including obtaining written news headlines from formal journalists and utilizing headlines exclusively containing sarcastic content from The Onion. Currently, researchers are utilizing convolutional neural networks (CNNs) and Long Short-Term Memory (LSTM) neural networks as methodologies in natural language processing (NLP) [4]. M. S. Razali [5] proposed the use of a multi-channel attention-based Bidirectional Long Short-Term Memory (BLSTM) technique for detecting sarcasm in news headlines. In addition, some researchers have applied the naive Bayes classifier and support vector machines to analyze data by identifying sarcasm. The accuracy of existing solutions, which were based on features such as punctuation, phrase structure, and hashtags, was reported to be over 75% when applied to datasets from various social media networks. The latest research has adopted deep learning techniques, which have proven to be superior to shallow modeling techniques in detecting sarcasm in text [6]. Most researchers currently prefer deep learning methods over manual feature extraction methods [5].
Previously, research has primarily focused on the use of tweets as input data for sarcasm detection. To distinguish sarcasm, contextual clues such as hashtags are often used as indicators, with keywords such as “#sarcasm”, “#sarcastic”, “#notsarcasm”, and “#not” believed to provide the best indication of a sarcastic tweet [3,7,8]. In previous studies, researchers have extracted feature sets from Twitter datasets consisting of 9400 tweets, with 5800 expressing a positive sentiment, 3100 expressing a negative sentiment, and 500 expressing a neutral sentiment [9]. Convolutional neural networks (CNNs) and long-term and short-term memory (LSTM) neural networks are two commonly used methodologies for natural language processing (NLP) in sarcasm detection [10]. A multi-channel attention-based mechanism using the Bidirectional Long Short-Term Memory (BLSTM) technique has also been proposed for detecting sarcasm in news headlines [11].
Researchers have also added additional rules based on patterns of sarcasm, such as counting positive/negative words and emotional words, as well as collecting tweets that included recurring words such as “sarcasm”, “sarcastic”, “being sarcastic”, “yay!”, and “nay!” [12]. Pawar and Bhingarkar [13] state that the twitter has been a very big network in terms of active users and tweets made per day [14]. The limitations of tweet analysis for sarcasm detection include the 140-character limit of tweets, which can make it difficult to understand the intended meaning and even more challenging to detect sarcasm [15,16]. In previous studies, tweets have been analyzed and classified according to mood, predefined sets (such as events, opinion, transactions, and private messages), and non-contextual characteristics such as slang and sentiments expressed by words [17].
Most of the previous work on sarcasm detection in tweets was based on the polarity of the users’ sentiments, with a focus on the content of the tweets. Burfoot and Baldwin [18] proposed a set of attributes, including profanity, use of slang, and their “semantic action”, and used an SVM classifier to classify humorous tweets [19]. Researchers rely on hashtags to classify the tone of a tweet. Researchers have used public modeling [20] to detect the original tone of tweets by classifying the variety of the tone as well as the manifestation on Twitter. This highlights the importance of historical data gathered from a user’s past tweets, although this approach is effective only if a historical record of a user exists.
RNNs and other DL neural networks that use pre-trained word embeddings to tackle FL have been successful because of word embeddings, or trained maps of words to real-valued vectors. In fact, Kumar et al. and Ghosh and Veale combined word embeddings with convolutional neural networks (CNN), known as CNN-LSTM units, and reached state-of-the-art performance. Additionally, attentive RNNs perform well when used with Word2Vec embeddings that have already undergone training and have contextual data.
Reference [21] proposed a methodology for a news headline dataset was in a JSON file format consisting of 26,700 headlines, with sarcastic headlines (11,700) and non-sarcastic headlines (14,900) from the Orion and HuffPost, respectively. The proposed ML model is a supervised learning model consisting of headlines and a label indicating whether the headline is sarcastic or not. The first step was performed by Tokenizer of Keras, which converts initial headlines/sentences into a much more suitable form where sentences are converted into sequences of 300 words. There were 29.6 k unique words, and after removing spaces, 20 k words were left. The next step was to prepare an embedding matrix using pre-trained embeddings of words by Stanford. The shape of this matrix was [20,000, 300] which then was fed to the BLSTM by flattening all LSTM sequences and feeding it to a normal NN layer to output the label.
In work of [22], the model took pre-trained user embedding as context and tweets as a dataset to output a binary value classifying the tweet as sarcastic or not sarcastic. However, the authors removed the context path because the nature of sarcasm does not dependent on the author of the news. LSTM, which is new, was implemented for encoding the context of words occurring in sentences. The forward LSTM reads the sequence of the hidden states in forward order, whereas the backward LSTM reads the given sequence in backwards or reverse order to calculate hidden words in the reverse direction. By removing context/word-embeddings, the author was not considered, and the use of embeddings were considered as a baseline. The dataset was then separated into train, validate, and test data which was done in an 80:10:10 ratio. The baseline had an accuracy of 84.88%, whereas this model has accuracy of 89.7%. This model has improved upon the baseline by ~5%.
Reference [23] proposed a hybrid deep learning model for sarcasm detection in Indian indigenous languages using word-emoji embeddings. The model is a supervised learning model that uses a combination of word embeddings and emoji embeddings to detect sarcasm. The dataset used in the study was collected from social media platforms such as Twitter, Facebook, and Reddit. The authors preprocessed the data and created a corpus of 23,000 sentences. The dataset was then split into training, validation, and testing sets in the ratio of 70:15:15. The proposed model uses a hybrid architecture of CNN and LSTM for feature extraction and classification. The model achieved an accuracy of 85.68% on the test set, which outperformed the baseline model that achieved an accuracy of 75.44%. This study demonstrated the effectiveness of using a hybrid deep learning model for sarcasm detection in Indian indigenous languages.
Reference [24] presented a machine learning approach to analyze the effect of hyperboles on sarcasm detection using negative sentiment tweets. The authors collected a dataset of 8000 negative sentiment tweets, out of which 2000 tweets were labeled as sarcastic using manual annotation. The authors preprocessed the data by removing stop words, stemming, and tokenizing the tweets. They then used a combination of traditional machine learning algorithms such as support vector machines (SVM), naive Bayes, and random forest to classify the tweets as sarcastic or not sarcastic. The authors also introduced a hyperbole score metric to capture the degree of hyperbole present in the tweets. The experimental results showed that SVM outperformed the other classifiers with an accuracy of 85.8%. The authors found that hyperbole had a significant impact on sarcasm detection, and their study provides valuable insights for the development of more accurate sarcasm detection models.
Reference [25] proposed an intelligent machine learning-based sarcasm detection and classification model for social networks. The model uses a supervised learning approach to detect and classify sarcastic tweets. The dataset used in the study was collected from Twitter, and it consisted of 10,000 tweets with an equal distribution of sarcastic and non-sarcastic tweets. The authors preprocessed the data and used feature extraction techniques to create a set of relevant features. The model used in this study is based on ensemble learning, which combines the predictions of multiple models to improve accuracy. The study evaluated the model’s performance on various classification algorithms such as decision tree, random forest, naive Bayes, and support vector machine. The model achieved an accuracy of 92.14% using the random forest algorithm, which outperformed the other classifiers. This study demonstrates the effectiveness of ensemble learning techniques for detecting sarcasm and classification on social networks.
Reference [26] proposed a deep learning-based model for sarcasm detection in news headlines. The authors used a dataset of 26,700 headlines, including 11,700 sarcastic and 14,900 non-sarcastic headlines collected from the Orion and HuffPost. The dataset was in a JSON file format. This supervised learning model uses a Bidirectional Long Short-Term Memory (BLSTM) network and a convolutional neural network (CNN) for feature extraction and classification. The authors used the Keras Tokenizer to convert the headlines into sequences of 300 words to prepare the embedding matrix. The embedding matrix used pre-trained embeddings of words by Stanford, and its shape was [20,000, 300]. The authors evaluated the performance of the proposed model and reported an accuracy of 90.19%. They compared the performance of the proposed model with the state-of-the-art models and reported that their model outperformed others in terms of accuracy and computational time. This study demonstrates the effectiveness of using a deep learning-based model for sarcasm detection in news headlines.
Reference [27] proposed a multilingual approach to fake news detection that takes into account the presence of satire. The authors use a dataset of news articles in multiple languages and developed a machine learning model to classify them as real or fake. They also trained the model to identify satirical elements in the articles. The model is based on a convolutional neural network (CNN) and a Long Short-Term Memory (LSTM) network and was trained using a combination of word embeddings and character-level embeddings. The results of the experiments show that the proposed method outperforms several state-of-the-art methods in fake news detection, achieving an accuracy of over 90% on some datasets. The authors also show that their method is effective in detecting satirical elements in news articles, which is a significant contribution to the field.
Reference [28] proposed a deep multi-task learning approach to tackle both tasks simultaneously. The authors used a dataset of tweets to develop a model that combines a convolutional neural network (CNN) and a Long Short-Term Memory (LSTM) network. The model was trained using a multi-task learning framework that jointly optimizes both sentiment analysis and sarcasm detection. The authors also experimented with different ways of combining the two tasks, including using a shared encoder or separate encoders. The results of these experiments show that the proposed method outperforms several state-of-the-art methods in both sentiment analysis and sarcasm detection. The authors also show that the multi-task learning approach is effective in leveraging the shared information between the two tasks, resulting in better performance than training the tasks separately.
Reference [29] presents a systematic review of machine learning techniques for stance detection and their applications. The authors surveyed the literature on stance detection and identified the different machine learning techniques that have been used for this task. They also discussed the different applications of stance detection in various fields. The authors highlighted the challenges in stance detection, including a lack of labeled data and the difficulty of identifying the context in which a statement is made. The results of the review show that machine learning techniques have been effective in stance detection, with several methods achieving state-of-the-art performance on benchmark datasets. The authors also identified several areas for future research, including developing better methods for handling the context of statements and improving the generalization of models across different domains.
Reference [30] proposed a novel approach to sarcasm detection using deep learning and ensemble learning techniques. The proposed method uses a convolutional neural network (CNN) to extract features from the text, followed by a Bidirectional Long Short-Term Memory (BiLSTM) network to capture temporal dependencies in the sequence. The authors also introduced an ensemble learning approach that combines multiple models to improve the performance of the system. Experiments were conducted on a dataset of sarcastic and non-sarcastic tweets. The results showed that the proposed method outperforms several state-of-the-art approaches in terms of accuracy, precision, recall, and F1-score. The authors also analyzed the contribution of different features, and showed that the combination of lexical, syntactic, and semantic features yields the best performance. Table 1 presents a review of select research available on sarcasm detection.

Table 1.
Datasets and classifiers used in earlier work.
3. Materials and Methods
The methodology of this study consists of several components, from data collection to evaluation. The methods for sarcasm detection are illustrated comprehensively in Figure 1. This study conducted a comprehensive review of the relevant literature and evaluated the currently available techniques for sarcasm detection.
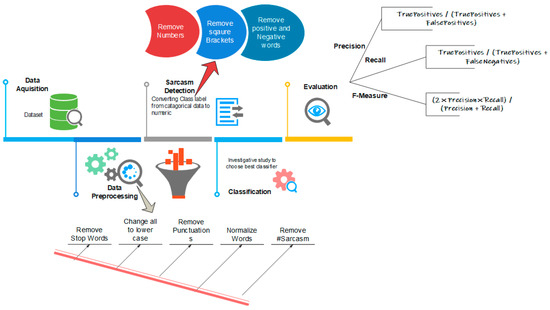
Figure 1.
Methodology for sarcasm detection.
3.1. Data Acquisition
Our news headlines dataset offers several advantages over the Twitter dataset, including formal language with minimal spelling errors, higher-quality labels due to The Onion’s exclusive focus on satirical news, and independent headlines that do not reply to other tweets. Each entry in the dataset has three properties, including whether the headline is sarcastic and a link to the corresponding article [31]. The second dataset used in this study was The Sarcasm Corpus V2 [32]; a subset of the Internet Argument Corpus (IAC). It includes posts annotated for sarcasm and represents three categories: general sarcasm, hyperbole, and rhetorical questions. We selected this dataset for its diverse range of sarcastic language and annotated markers, which makes it ideal for training and testing a model for sarcasm detection.
3.2. Data Preprocessing
The data preprocessing phase involved cleaning and merging both datasets. The News Headlines dataset contained 26,709 headlines, including 14,985 neutral headlines from HuffPost and 11,724 satirical headlines from The Onion. We preprocessed the headlines by removing the article link and text in square brackets, converting them to lowercase, and removing punctuation and numerals. We sorted them in ascending order based on their length. For the second dataset, The Sarcasm Corpus V2, the data already contained sarcasm labels, so no preprocessing was necessary. We merged both datasets and assigned a “GEN” corpus label to all headlines. Merging both datasets allowed for diversity in the corpus, as the News Headlines dataset provided a more formal and structured language, while The Sarcasm Corpus V2 provided sarcastic and humorous speech. This diversity in the corpus helped in training a robust sarcasm detection model.
3.3. Sarcasm Detection
The News Headlines dataset, comprising 26,709 headlines, includes 14,985 neutral headlines from Huff-Post and 11,724 satirical headlines from The Onion. We sorted headlines in ascending order according to length and removed text in square brackets. We removed punctuation and numerals from the text and converted the headlines to lowercase. The dataset has an average headline length of 12.5 words and a standard deviation of 4.3 words, as presented in Table 2. The dataset features three columns: the headline, a binary indicator of whether the headline is sarcastic (1 for sarcastic, 0 for non-sarcastic), and the source organization (HuffPost or The Onion). Table 3 presents information on the Sarcasm Corpus V2 dataset, which consists of 9386 headlines, of which 4693 are sarcastic and 4693 are non-sarcastic. We divided the dataset into three tasks: Generic Sarcasm (GEN), Hyperbole Sarcasm (HYP), and Rhetorical Sarcasm (RQ). Figure 2 provides a graphical representation of the distribution of sarcastic and non-sarcastic headlines in the dataset.
Table 2.
Statistics on the Huffpost and Onion datasets.
Table 3.
Statistics on the Sarcasm Corpus V2 dataset.
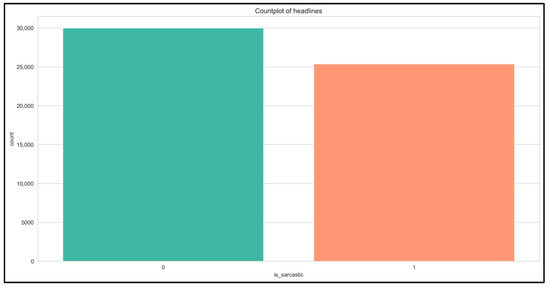
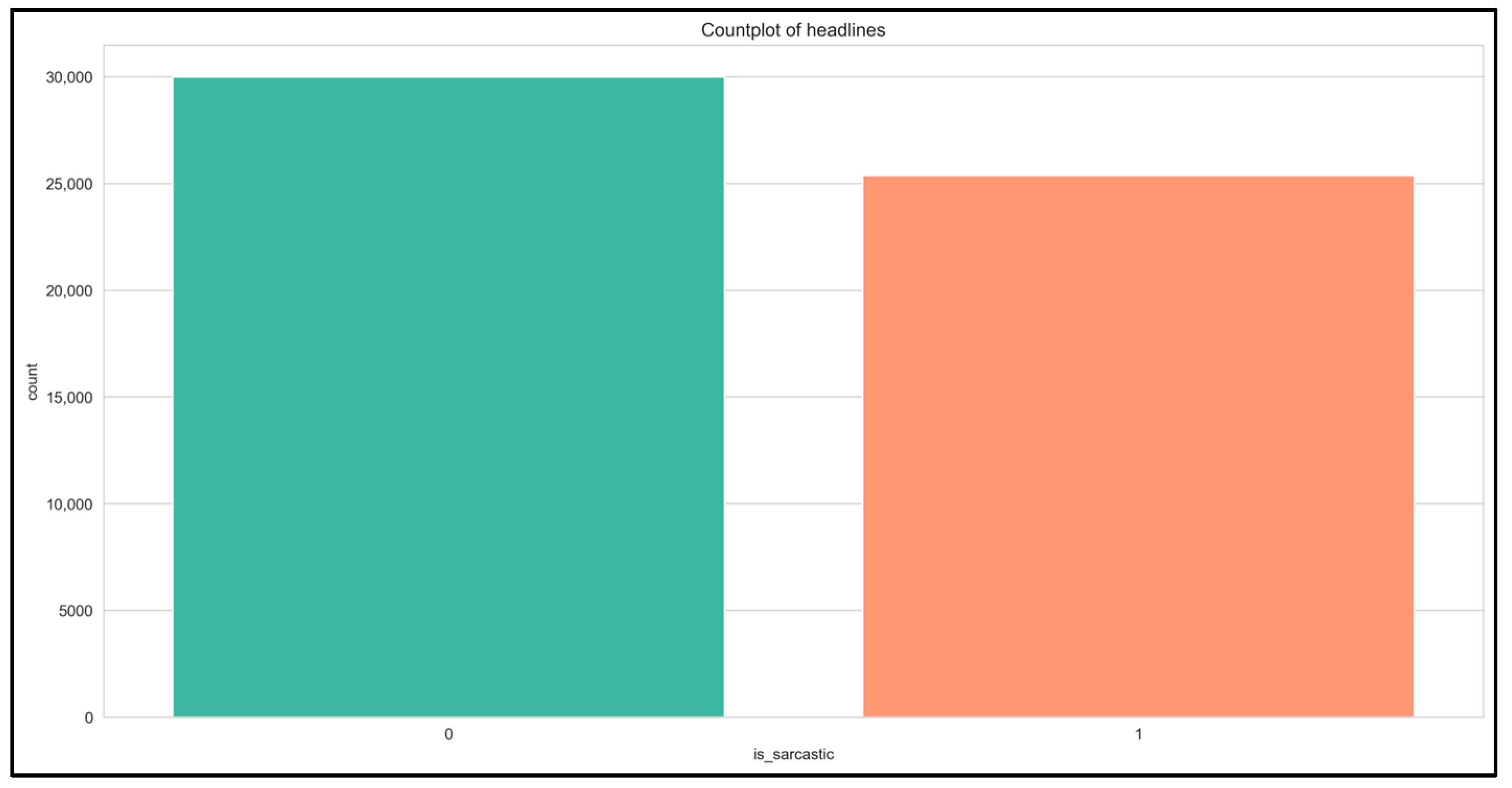
Figure 2.
Row count for sarcastic and non-sarcastic headlines.
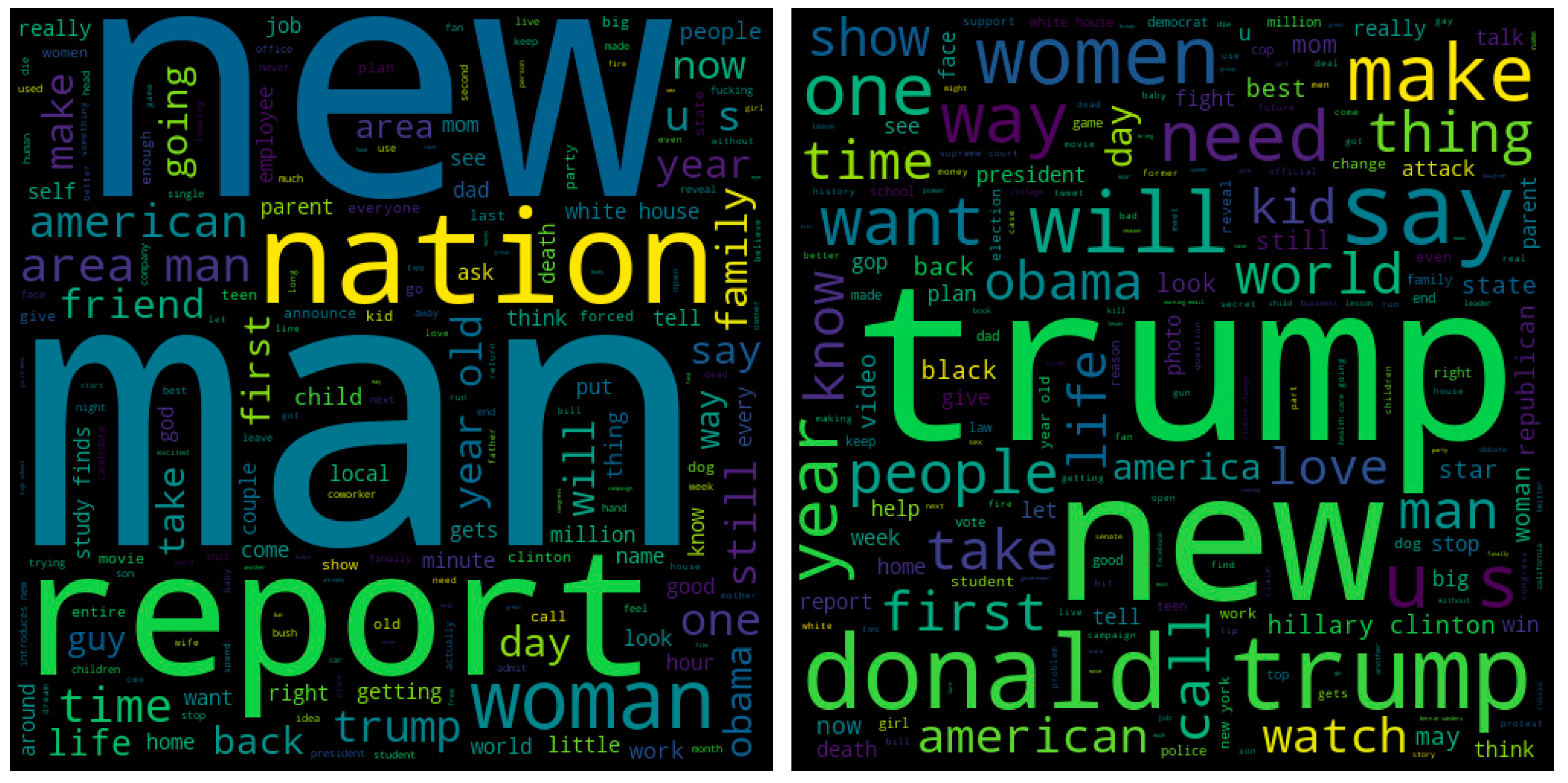
In Figure 3, words are depicted as clouds, wherein the size of each cloud corresponds to the relative frequency of occurrence of the corresponding word compared to the other words.
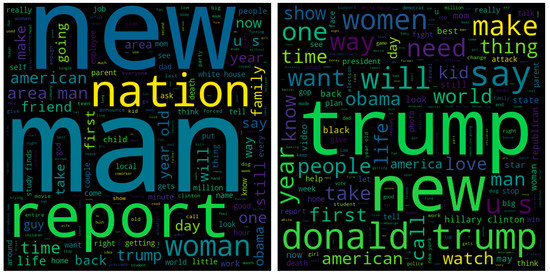
Figure 3.
Word clouds of sarcastic and non-sarcastic headlines.
The dataset comprises three features:
- “Headline”: Textual information from which we need to determine whether the headline is sarcastic.
- “is_sarcastic”: Output column, which indicates the sarcasm status of the headline, where 1 represents sarcasm, and 0 represents non-sarcasm.
- “article_link”: We removed unnecessary links from the dataset, which was then divided into two categories:
- 0 represents non-sarcastic headlines
- 1 represents sarcastic headlines
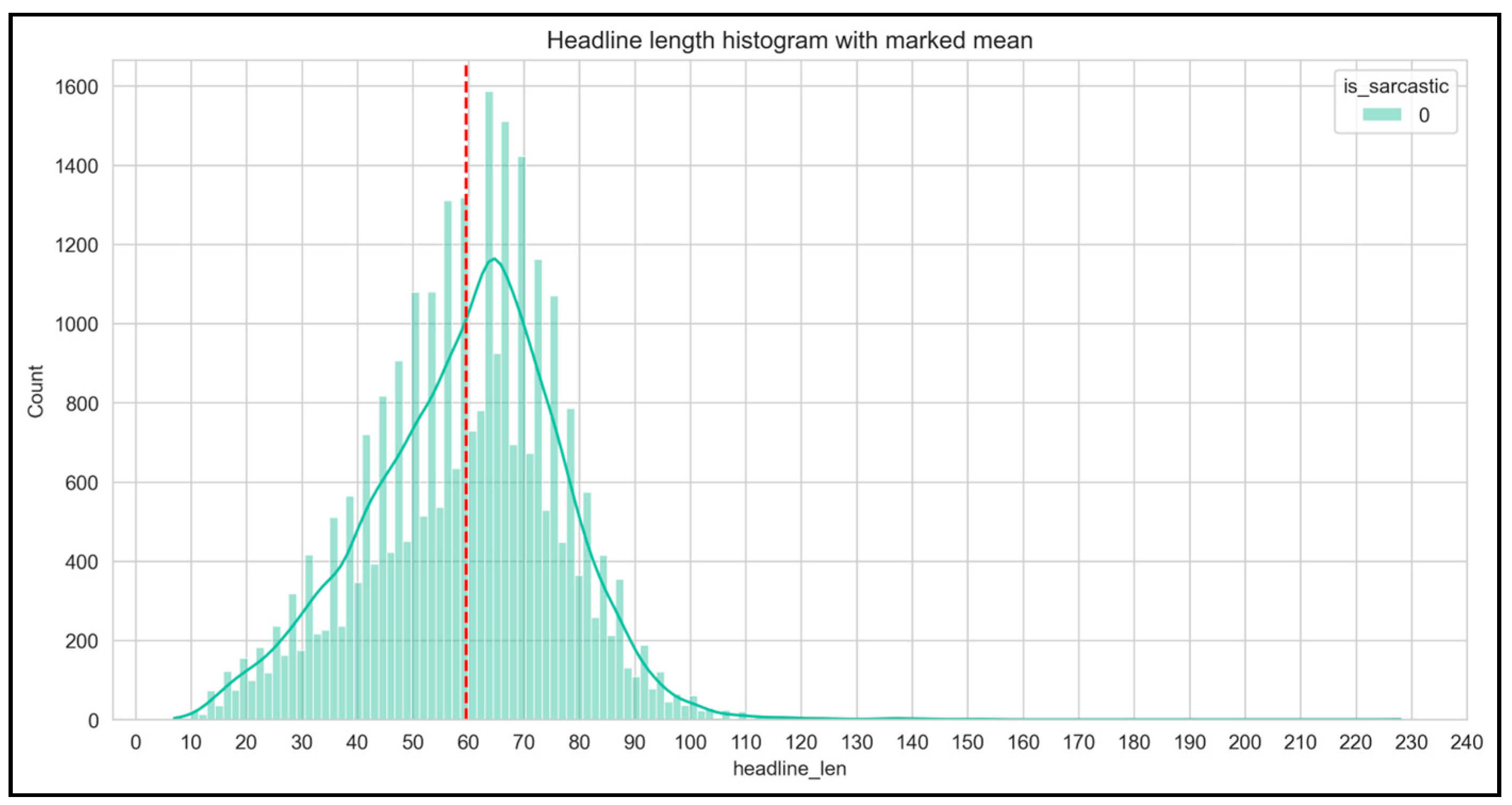
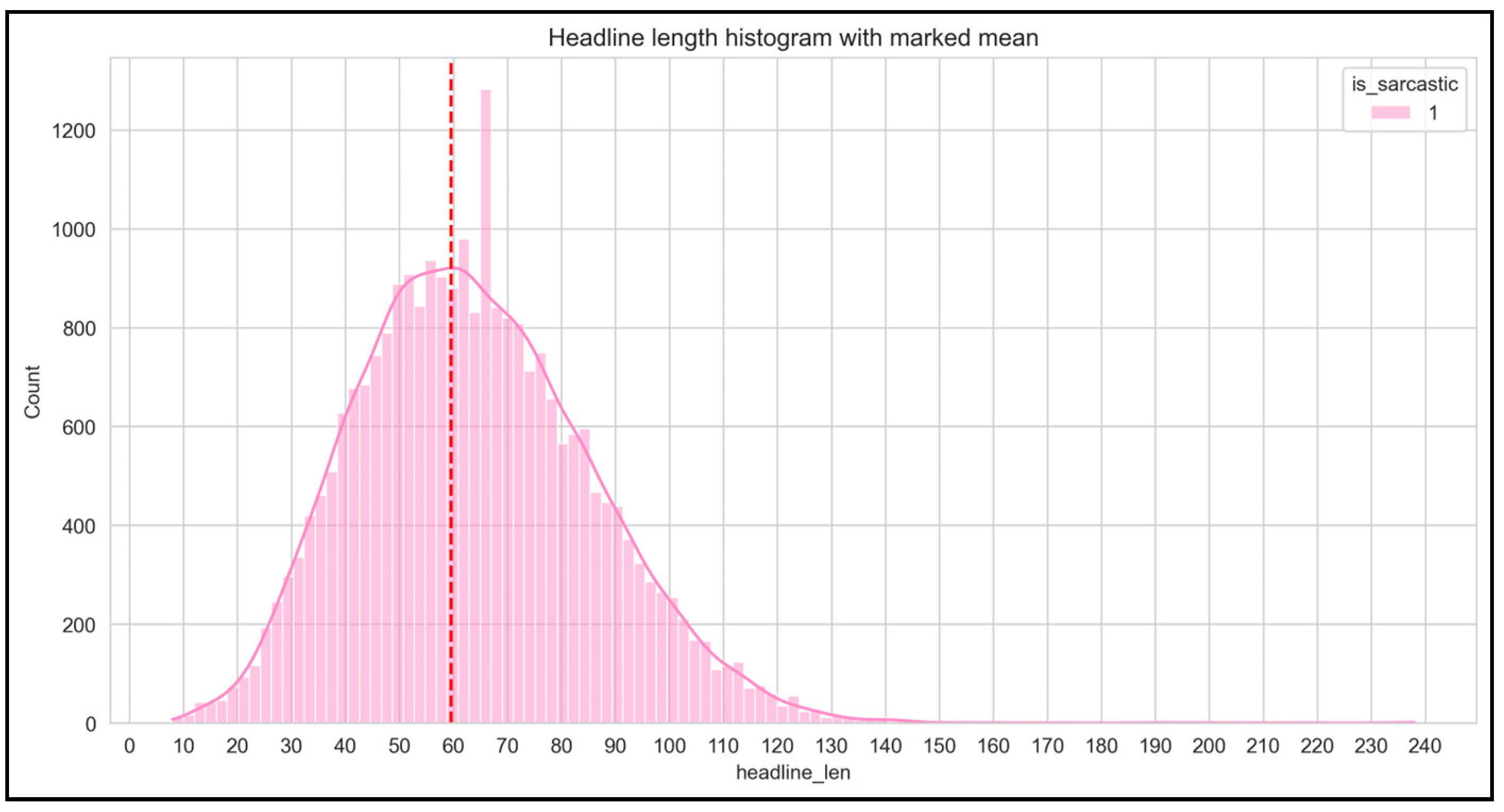
Figure 4 and Figure 5 show the number of headlines (non-sarcastic and sarcastic) with the increasing length of headlines.
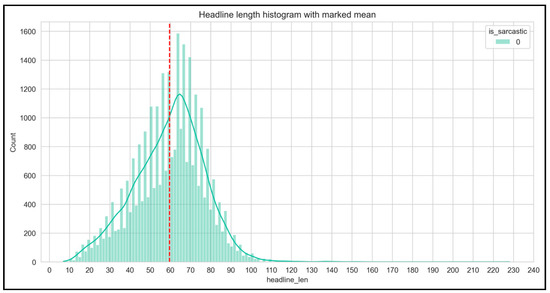
Figure 4.
Non-sarcastic headlines.
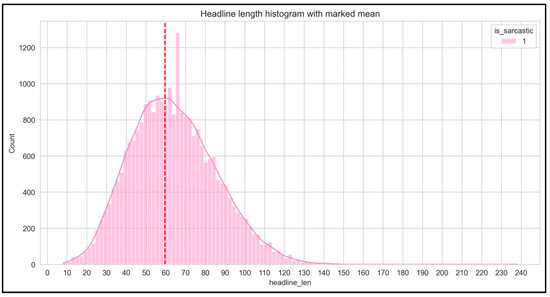
Figure 5.
Sarcastic headlines.
4. Model Selection
In this study, we started experimentation by applying classical machine learning (ML) classifiers to detect sarcastic records among datasets. For classical ML, this study focused on decision tree, random forest, multinomial, Bernoulli, and support vector machines (SVM). The decision tree model is a non-parametric model that partitions the input space into regions corresponding to specific classes. The random forest model is an ensemble of decision trees that combines their predictions to make the final prediction. The multinomial and Bernoulli models are variants of the naive Bayes algorithm that work well for multi-class and binary text classification tasks. The SVM model is a linear model that separates the input space into different classes using a hyperplane. Previous studies have shown that the SVM model works well for text classification tasks.
In addition to the classical classifiers, we also utilized an original Long Short-Term Memory (LSTM) from Sequential Deep Learning Models. This model consisted of an embedding layer, followed by two dense layers with an ReLU activation function, two Dropout layers, and a dense layer with Sigmoid activation function as the output layer. The embedding layer provided a dense representation of the words in the input sequence, while the LSTM layer captured the temporal dependencies of the sequence. The two dense layers were used to capture higher-level patterns in the data. Despite the good performance of these models, with accuracies ranging from 64.87% to 84.25%, we proposed a GMP-LSTM model to improve accuracy further.
We evaluated the model’s performance by comparing accuracy, precision, recall, and F1 scores across all the applied classifiers. F1-measure, precision, recall, and accuracy were the measures employed to assess the technique. Equations (1)–(4) present the formulas for F1-measure, precision, recall, and accuracy:
We commonly evaluate a classification algorithm’s performance using accuracy, defined as the ratio of correctly classified instances to the total number of instances (4). However, accuracy alone might not provide a complete picture of the performance. Precision (2) is the ratio of true positive instances to the total number of true positive and false positive instances. At the same time, recall (3) is the ratio of actual positive instances to the sum of actual positive and false negative instances. We calculated the F1-measure using both precision and recall (1). We then split the dataset into a 70:30 ratio for training and validation sets.
The accuracy results presented in Table 4 indicate that relying solely on classifiers such as decision tree, random forest, multinomial, Bernoulli, support vector, and LSTM may not be sufficient for accurate sarcasm detection in text. To address this limitation, we propose a novel deep learning architecture called GMP-LSTM, which combines Global Max Pooling with Long Short-Term Memory (LSTM) networks. This study introduces the GMP-LSTM model to overcome traditional classifiers’ limitations in detecting sarcasm in text data. The experimental results show that the GMP-LSTM model achieves promising performance with an accuracy of over 90%. This result indicates that the GMP-LSTM model is a practical approach for detecting sarcasm in text data. The subsequent section will provide more details on this novel model and its potential applications. Proposed GMP-LSTM Model.
Table 4.
Classifier scores.
In the proposed model, we replaced the LSTM layer with a GlobalMaxPool1D layer, which performs max pooling operations on the temporal sequences. We added four dense layers with ReLU activation functions, four dropout layers, and a dense layer with a sigmoid activation function as the output layer. The GlobalMaxPool1D layer captures the most important feature from the temporal sequences, and the dense layers capture higher-level patterns in the data. To further improve the model, we used GlobalAveragePool and pruning techniques for better results. We trained the proposed model for 100 epochs consisting of 10 layers.
The hyperparameters used included a vocab size of 1000, an embedding dimension of 32, a maximum length of 50, a learning rate of 0.001, a batch size of 32, and a dropout rate of 0.5. To avoid overfitting the model, we used EarlyStopping with a patience of 10. EarlyStopping is a technique used in deep learning to prevent the overfitting of a model during training. Overfitting occurs when a model becomes too complex and begins to fit the training data too closely, leading to poor performance on new, unseen data. The number of epochs the model is allowed to continue training without improvement on the validation set is known as patience. The value of patience is a hyperparameter that needs to be set by the user. After training, we saved the best model.
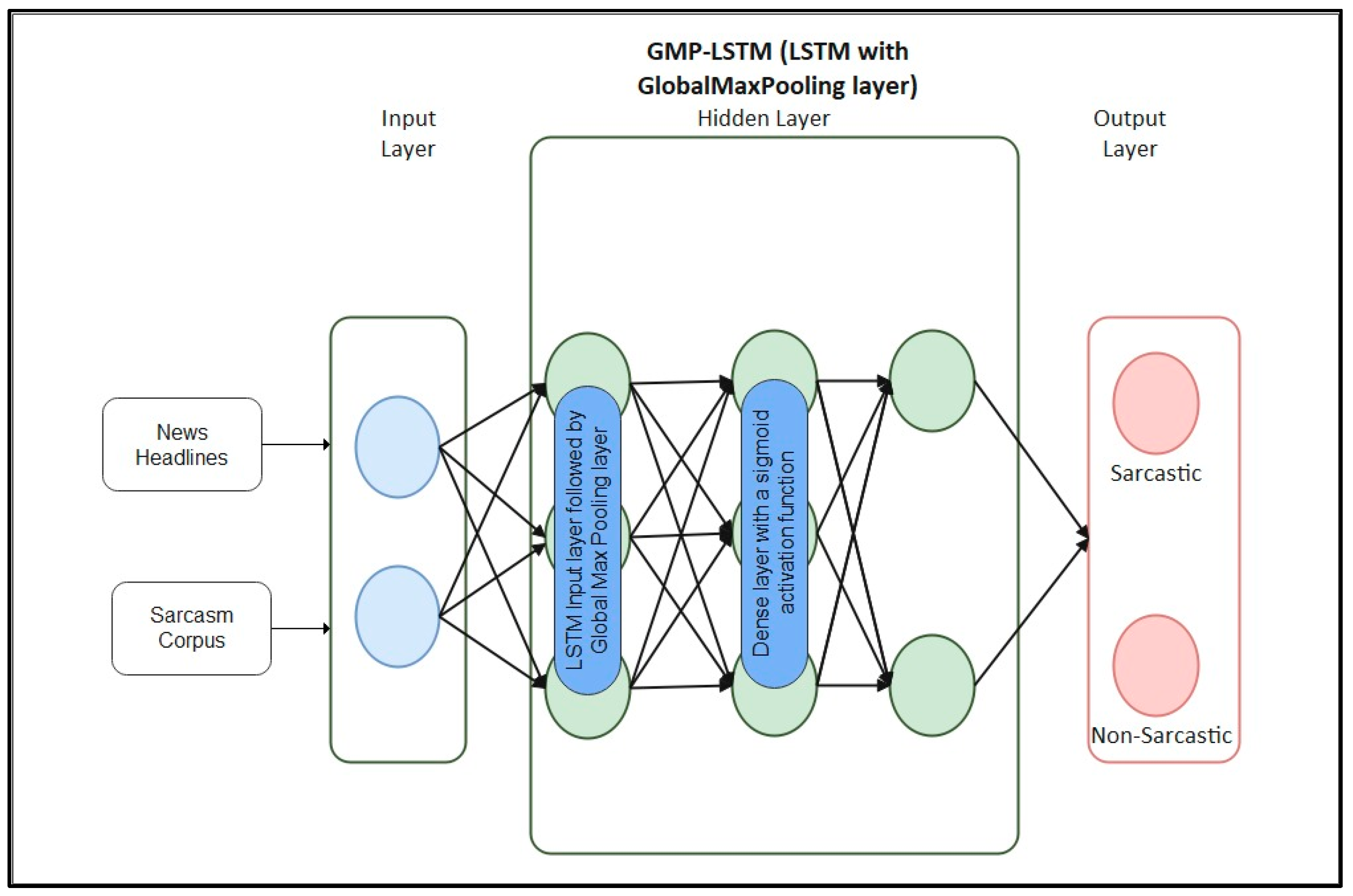
The loss function used during training was binary cross-entropy, and we employed the Adam optimizer. The loss function was evaluated on both training and validation datasets to assess the model’s performance, achieving accuracy scores of 0.999 and 0.925, respectively. Figure 6 represents the overall structure of the proposed GMP-LSTM model.
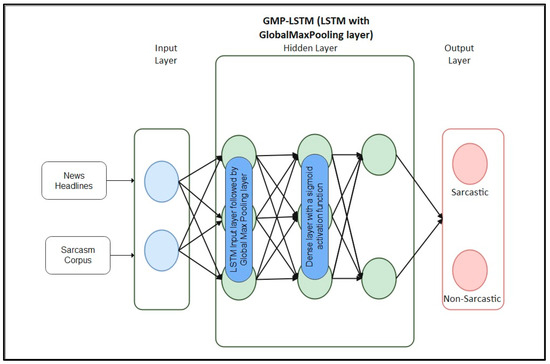
Figure 6.
Structure of the GMP-LSTM model.
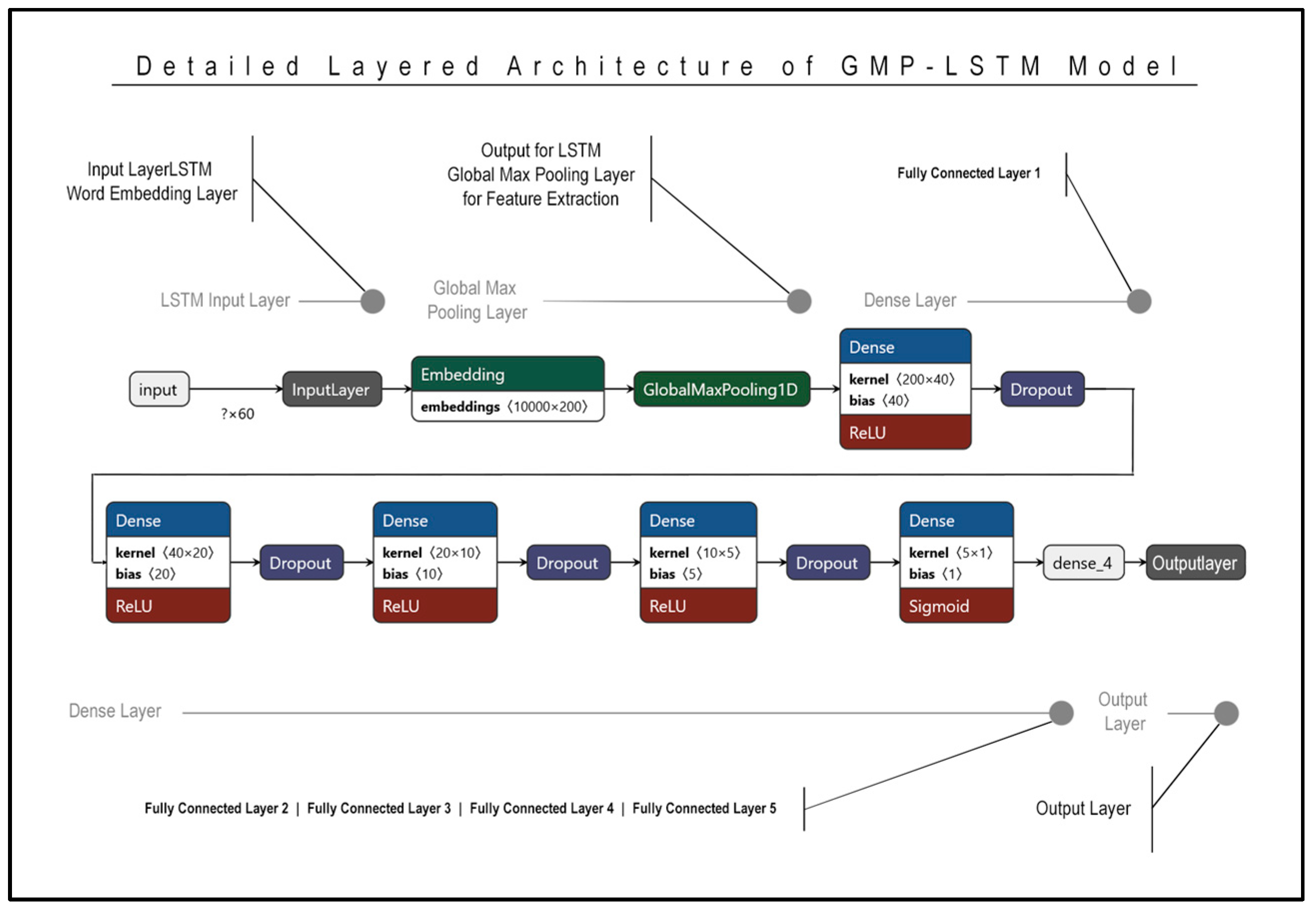
Figure 7 describes the detailed layered architecture of the GMP-LSTM model, in which the model is divided in three sections: embedding, GlobalMaxPooling and dense layers. The embedding layer is the first layer in the model and is responsible for mapping the input text data to a continuous vector space. This is done by assigning a unique vector representation to each word in the input text, such that words that are semantically similar have similar vectors. The embedding layer helps the model to understand the underlying meaning of the text and is often pre-trained using large text corpora. The global max pooling layer is used to reduce the dimensionality of the output of the LSTM layer. It works by taking the maximum value across all the output values of each feature map, resulting in a single value for each feature. This reduces the output dimension of the LSTM layer and captures the most important features of the input sequence. The dense layers are fully connected layers that perform nonlinear transformations on the output of the global max pooling layer. These layers help to further abstract the features learned by the model and are often used for classification tasks. The model has five dense layers, which may be used to capture increasingly complex features of the input sequence.
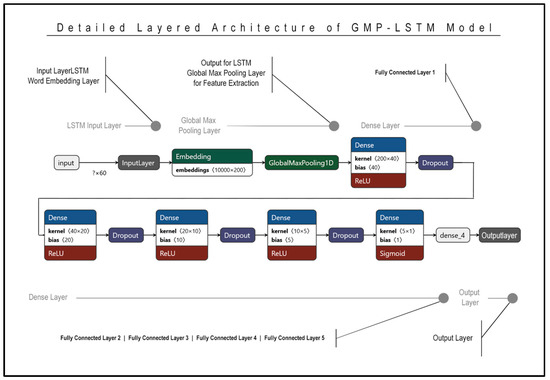
Figure 7.
Detailed layered architecture of GMP-LSTM.
5. Results
In this study, we utilized machine learning techniques to detect sarcastic headlines, including several classifiers such as random forest, multinomial naïve Bayes, Bernoulli naïve Bayes, decision tree, and support vector. We prepared the data by employing tokenization techniques on a dataset of news headlines and used the Keras tokenizer to convert the headlines into a form suitable for analysis. We created an embedding matrix and constructed a GMP-LSTM model with binary crossentropy as the loss function and the Adam optimizer.
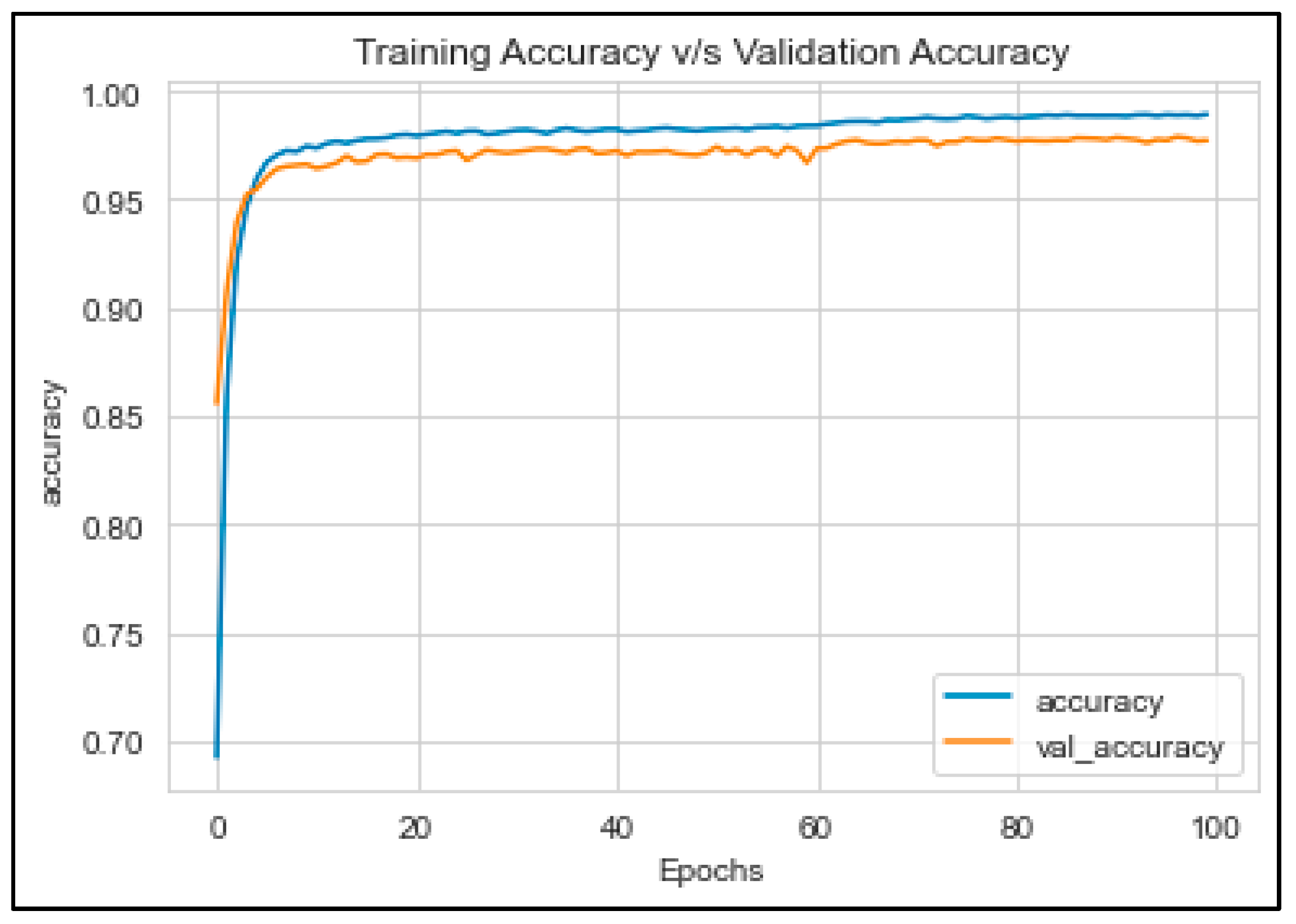
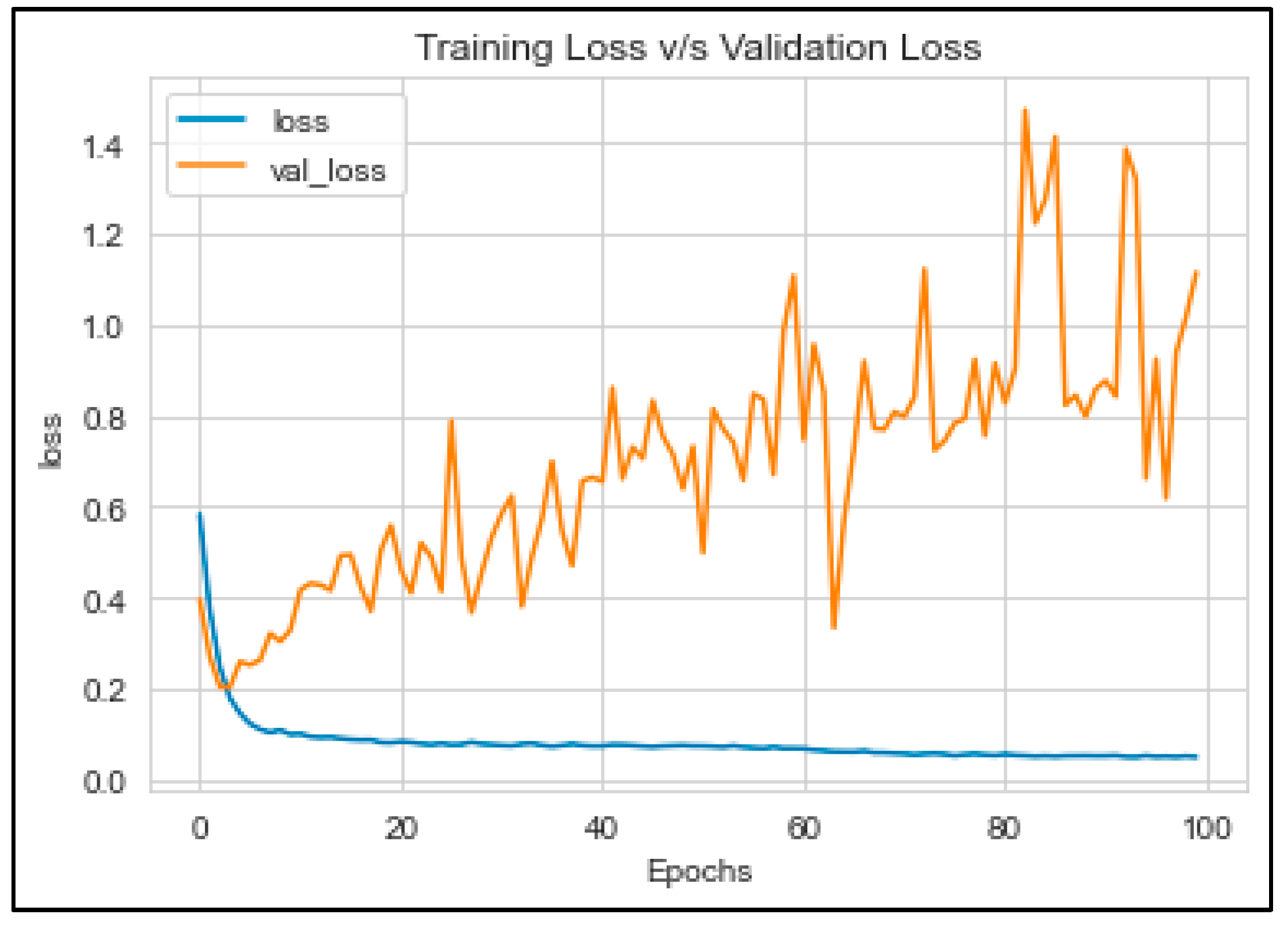
This study evaluated the performance of a GMP-LSTM model in detecting sarcastic headlines using various evaluation metrics. The training accuracy score, testing accuracy score, and validation accuracy score was calculated and presented in Table 5. The GMP-LSTM model achieved the highest accuracy of 92%, which outperformed Bernoulli naive Bayes and support vector classifiers. The precision, recall, F1, and accuracy metrics were calculated and presented in Table 6. The results show that the GMP-LSTM model demonstrated high accuracy in predicting both sarcastic and non-sarcastic headlines. Figure 8 and Figure 9 present the relationship between accuracy and loss for the training, validation, and testing sets. These findings highlight the potential of deep learning techniques in text classification and sentiment analysis tasks, particularly in detecting sarcastic headlines.
Table 5.
GMP-LSTM model evaluation scores.
Table 6.
Performance matrix for applied classifiers.
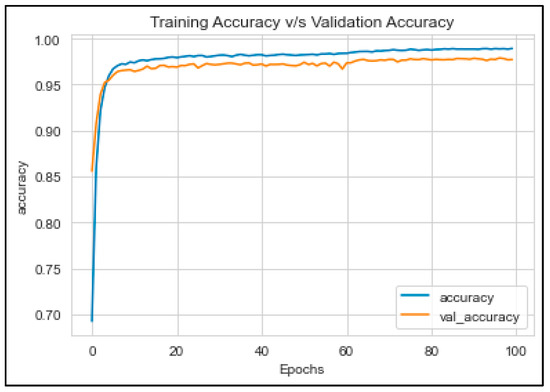
Figure 8.
Training and validation accuracy of the GMP-LSTM model.
Figure 9.
Training loss and validation loss of the GMP-LSTM model.
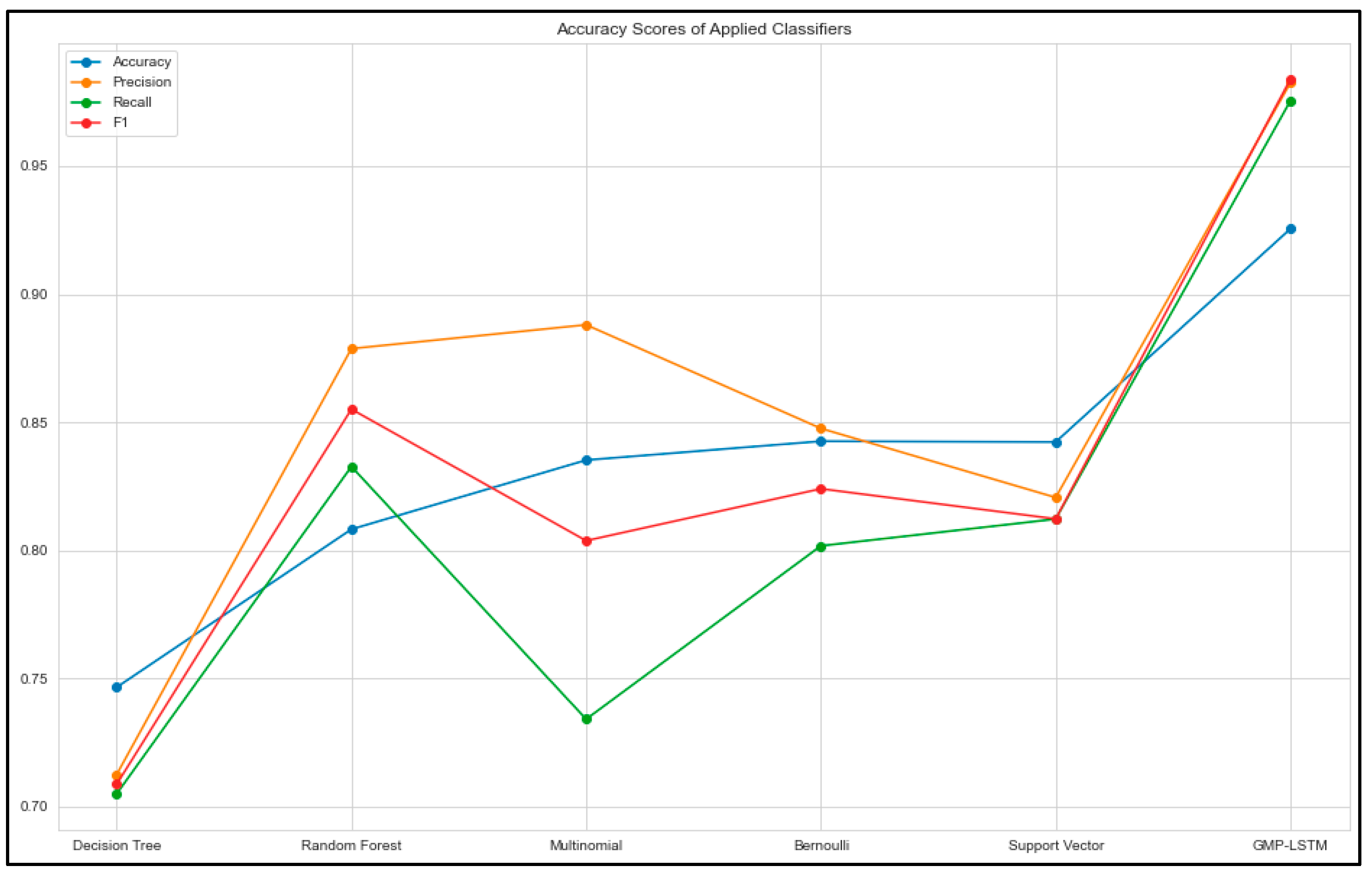
Performance evaluation of different classifiers was conducted using a dataset, and the results are presented in Table 6. The evaluation metrics used included precision, re-call, F1, and accuracy. Precision is a measure of the number of true positive predictions made by the classifier, out of all positive predictions. Recall is a measure of the number of true positive predictions made by the classifier, out of all actual positive instances. F1 is the harmonic mean of precision and recall and is a commonly used overall measure of classifier performance. Accuracy is a simple measure of the number of correct predictions made by the classifier, out of all predictions. The results show that the GMP-LSTM model had the highest accuracy of 92.5486%, with high precision, recall, and F1 scores as well. The other classifiers showed varying degrees of accuracy, with the decision tree and random forest classifiers having the lowest accuracy scores of 74.6462% and 80.8162%, respectively. These findings suggest that the GMP-LSTM model is a promising approach for text classification and sentiment analysis tasks.
Figure 10 serves as a graphical representation of the performance evaluation of various classifiers based on four key metrics: precision, recall, F1, and accuracy. Each classifier is represented by a separate bar, and the bar’s height corresponds to the metric’s value for that particular classifier. The graph aids in interpreting and comparing the results, facilitating the identification of the most effective classifier for the given problem.
Figure 10.
Evaluation of the applied classifiers.
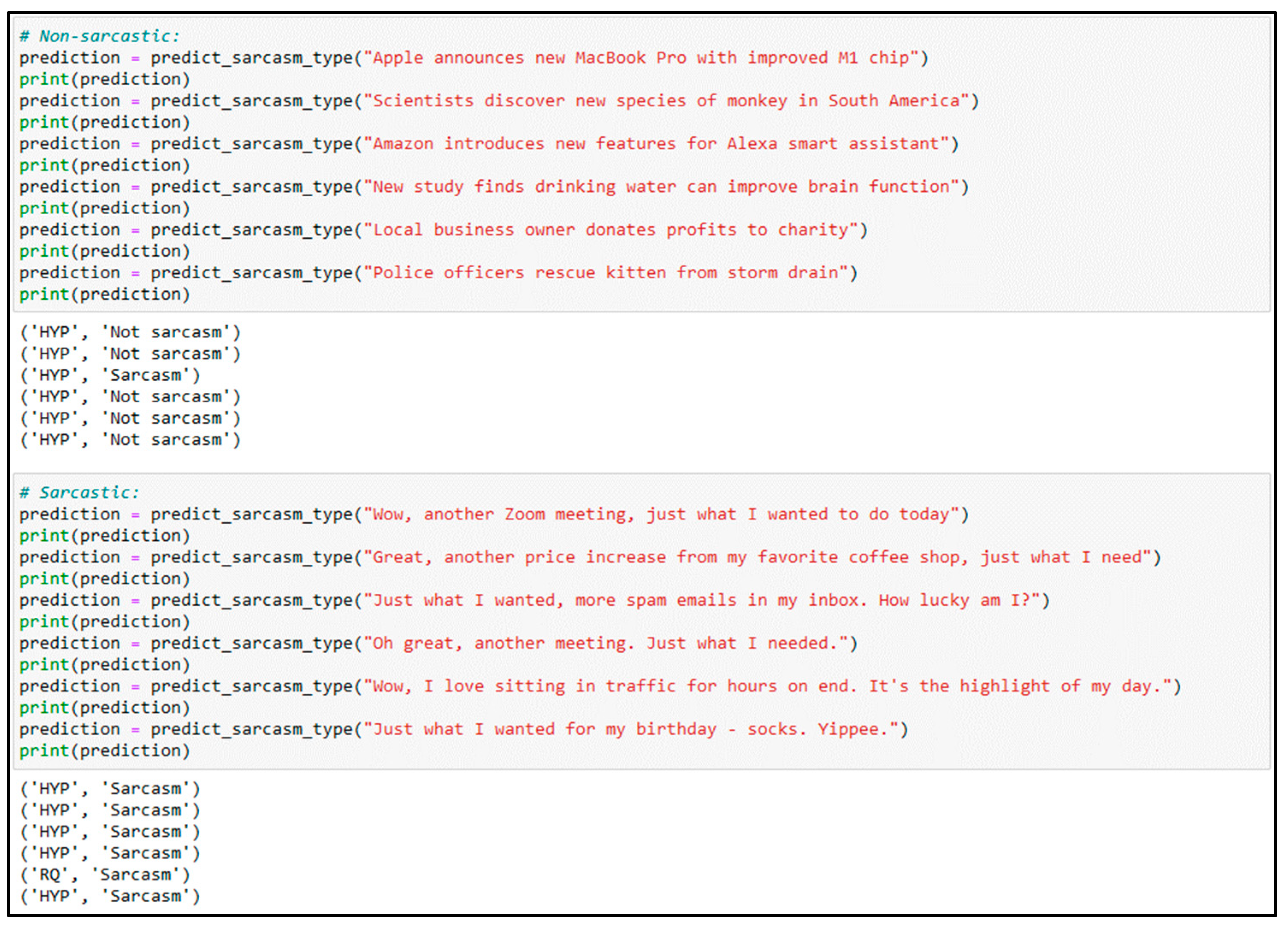
Figure 11 presents the results of manual testing performed on the proposed GMP-LSTM model, which was evaluated on a dataset containing sarcastic and non-sarcastic sentences. The testing revealed that the model demonstrated remarkable accuracy in distinguishing between the two types of sentences. Specifically, for the non-sarcastic sentences, the model accurately classified all test cases as non-sarcastic. Moreover, for the sarcastic sentences, the model correctly identified all but one as being sarcastic. These findings suggest that the proposed GMP-LSTM model can effectively discern between sarcastic and non-sarcastic sentences. Overall, the model’s performance in this manual testing was exemplary, indicating its potential to be a reliable tool for sentiment analysis in real-world applications.
Figure 11.
Manual testing results of the GMP-LSTM model.
6. Conclusions
This research article presents an effective approach for detecting sarcasm in text. As demonstrated by the experimental results, the proposed GMP-LSTM model achieved high accuracy in distinguishing between sarcastic and non-sarcastic sentences. The model outperformed several other classifiers, including decision tree, random forest, multinomial, Bernoulli, and support vectors. The findings of this study highlight the potential of machine learning techniques in detecting sarcasm in text and offer insights into the development of more accurate and efficient models for this task. The proposed model can be applied to various applications, such as social media monitoring, sentiment analysis, and online customer service, to enhance their effectiveness and efficiency. Future research could improve the model’s performance by exploring different features and optimization techniques. Overall, the proposed approach contributes to natural language processing and machine learning.
Author Contributions
R.A., T.F. and S.A. (Sanya Abdullah), conceived the idea and designed the methodology. R.A., T.F., S.A. (Sanya Abdullah), S.A. (Sheeraz Akram), M.A., A.M. and M.A.I. performed implementation. R.A., T.F. and S.A. (Sanya Abdullah) wrote the introduction and literature review. S.A. (Sheeraz Akram), M.A., A.M. and M.A.I. analyzed the results. All authors have read and agreed to the published version of the manuscript.
Funding
Researchers supporting project number (RSP2022R458), King Saud University, Riyadh, Saudi Arabia.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Dataset is already available on Kaggle and at Natural Language and Dialogue Systems from University of California, Santa Cruz.
Acknowledgments
Researchers supporting project number (RSP2022R458), King Saud University, Riyadh, Saudi Arabia.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Dave, A.D.; Desai, N.P. A comprehensive study of classification techniques for sarcasm detection on textual data. In Proceedings of the 2016 International Conference on Electrical, Electronics, and Optimization Techniques (ICEEOT), Chennai, India, 3–5 March 2016; pp. 1985–1991. [Google Scholar]
- Cheang, H.S.; Pell, M.D. The sound of sarcasm. Speech Commun. 2008, 50, 366–381. [Google Scholar] [CrossRef]
- Riloff, E.; Qadir, A.; Surve, P.; De Silva, L.; Gilbert, N.; Huang, R. Sarcasm as contrast between a positive sentiment and negative situation. In Proceedings of the 2013 Conference on Empirical Methods in Natural Language Processing, Seattle, DC, USA, 18–21 October 2013; pp. 704–714. [Google Scholar]
- Mandal, P.K.; Mahto, R. Deep CNN-LSTM with word embeddings for news headline sarcasm detection. In Proceedings of the 16th International Conference on Information Technology-New Generations (ITNG 2019), Las Vegas, NV, USA, 1–3 April 2019; pp. 495–498. [Google Scholar]
- Razali, M.S.; Halin, A.A.; Ye, L.; Doraisamy, S.; Norowi, N.M. Sarcasm Detection Using Deep Learning With Contextual Features. IEEE Access 2021, 9, 68609–68618. [Google Scholar] [CrossRef]
- Porwal, S.; Ostwal, G.; Phadtare, A.; Pandey, M.; Marathe, M.V. Sarcasm detection using recurrent neural network. In Proceedings of the 2018 Second International Conference on Intelligent Computing and Control Systems (ICICCS), Madurai, India, 14–15 June 2018; pp. 746–748. [Google Scholar]
- Davidov, D.; Tsur, O.; Rappoport, A. Semi-supervised recognition of sarcasm in Twitter and Amazon. In Proceedings of the Fourteenth Conference on Computational Natural Language Learning, Uppsala, Sweden, 15–16 July 2010; pp. 107–116. [Google Scholar]
- Bamman, D.; Smith, N. Contextualized sarcasm detection on twitter. In Proceedings of the International AAAI Conference on Web and Social Media, Online, 8–10 June 2021; pp. 574–577. [Google Scholar]
- Poria, S.; Cambria, E.; Hazarika, D.; Vij, P. A deeper look into sarcastic tweets using deep convolutional neural networks. arXiv 2016, arXiv:1610.08815. [Google Scholar]
- Ilić, S.; Marrese-Taylor, E.; Balazs, J.A.; Matsuo, Y. Deep contextualized word representations for detecting sarcasm and irony. arXiv 2018, arXiv:1809.09795. [Google Scholar]
- Ptáček, T.; Habernal, I.; Hong, J. Sarcasm detection on czech and english twitter. In Proceedings of the COLING 2014, the 25th International Conference on Computational Linguistics: Technical Papers, Dublin, Ireland, 23–29 August 2014; pp. 213–223. [Google Scholar]
- Tsur, O.; Davidov, D.; Rappoport, A. ICWSM—A great catchy name: Semi-supervised recognition of sarcastic sentences in online product reviews. In Proceedings of the Fourth International AAAI Conference on Weblogs and Social Media, Washington, DC, USA, 23–26 May 2010. [Google Scholar]
- Pawar, N.; Bhingarkar, S. Machine learning based sarcasm detection on Twitter data. In Proceedings of the 2020 5th International Conference on Communication and Electronics Systems (ICCES), Coimbatore, India, 10–12 June 2020; pp. 957–961. [Google Scholar]
- Bouazizi, M.; Ohtsuki, T.O. A pattern-based approach for sarcasm detection on twitter. IEEE Access 2016, 4, 5477–5488. [Google Scholar] [CrossRef]
- Tay, Y.; Tuan, L.A.; Hui, S.C.; Su, J. Reasoning with sarcasm by reading in-between. arXiv 2018, arXiv:1805.02856. [Google Scholar]
- Joshi, A.; Bhattacharyya, P.; Carman, M.J. Sarcasm Detection Using Incongruity within Target Text. In Investigations in Computational Sarcasm; Springer: Berlin/Heidelberg, Germany, 2018; pp. 59–91. [Google Scholar]
- Sriram, B.; Fuhry, D.; Demir, E.; Ferhatosmanoglu, H.; Demirbas, M. Short text classification in twitter to improve information filtering. In Proceedings of the 33rd International ACM SIGIR Conference on Research and Development in Information Retrieval, Geneva, Switzerland, 18–23 July 2010; pp. 841–842. [Google Scholar]
- Burfoot, C.; Baldwin, T. Automatic satire detection: Are you having a laugh? In Proceedings of the ACL-IJCNLP 2009 Conference Short Papers, Suntec, Singapore, 4 August 2009; pp. 161–164. [Google Scholar]
- Campbell, J.D.; Katz, A.N. Are there necessary conditions for inducing a sense of sarcastic irony? Discourse Process. 2012, 49, 459–480. [Google Scholar] [CrossRef]
- Rajadesingan, A.; Zafarani, R.; Liu, H. Sarcasm detection on twitter: A behavioral modeling approach. In Proceedings of the Eighth ACM International Conference on Web Search and Data Mining, Shanghai China, 2–6 February 2015; pp. 97–106. [Google Scholar]
- Shrikhande, P.; Setty, V.; Sahani, A. Sarcasm detection in newspaper headlines. In Proceedings of the 2020 IEEE 15th International Conference on Industrial and Information Systems (ICIIS), Rupnagar, India, 26–28 November 2020; pp. 483–487. [Google Scholar]
- Misra, R.; Arora, P. Sarcasm detection using hybrid neural network. arXiv 2019, arXiv:1908.07414. [Google Scholar]
- Kumar, A.; Sangwan, S.R.; Singh, A.K.; Wadhwa, G. Hybrid deep learning model for sarcasm detection in Indian indigenous language using word-emoji embeddings. Trans. Asian Low-Resour. Lang. Inf. Process. 2022. [Google Scholar] [CrossRef]
- Govindan, V.; Balakrishnan, V. A machine learning approach in analysing the effect of hyperboles using negative sentiment tweets for sarcasm detection. J. King Saud Univ.-Comput. Inf. Sci. 2022, 34, 5110–5120. [Google Scholar] [CrossRef]
- Vinoth, D.; Prabhavathy, P. An intelligent machine learning-based sarcasm detection and classification model on social networks. J. Supercomput. 2022, 78, 10575–10594. [Google Scholar] [CrossRef]
- Nayak, D.K.; Bolla, B.K. Efficient deep learning methods for sarcasm detection of news headlines. In Machine Learning and Autonomous Systems, Proceedings of ICMLAS 2021, Tamil Nadu, India, 24–25 September 2021; Springer: Singapore, 2022; pp. 371–382. [Google Scholar]
- Guibon, G.; Ermakova, L.; Seffih, H.; Firsov, A.; Noe-Bienvenu, G.L. Multilingual fake news detection with satire. In Proceedings of the Computational Linguistics and Intelligent Text Processing: 20th International Conference, CICLing 2019, La Rochelle, France, 7–13 April 2019; Revised Selected Papers, Part II. pp. 392–402. [Google Scholar]
- Tan, Y.Y.; Chow, C.-O.; Kanesan, J.; Chuah, J.H.; Lim, Y. Sentiment Analysis and Sarcasm Detection using Deep Multi-Task Learning. Wirel. Pers. Commun. 2023, 129, 2213–2237. [Google Scholar] [CrossRef] [PubMed]
- Alturayeif, N.; Luqman, H.; Ahmed, M. A systematic review of machine learning techniques for stance detection and its applications. Neural Comput. Appl. 2023, 35, 5113–5144. [Google Scholar] [CrossRef] [PubMed]
- Goel, P.; Jain, R.; Nayyar, A.; Singhal, S.; Srivastava, M. Sarcasm detection using deep learning and ensemble learning. Multimed. Tools Appl. 2022, 81, 43229–43252. [Google Scholar] [CrossRef]
- Misra, R. (Ed.) News Headlines Dataset For Sarcasm Detection; Kaggle: San Francisco, CA, USA, 2019; Available online: https://www.kaggle.com/datasets/rmisra/news-headlines-dataset-for-sarcasm-detection (accessed on 3 February 2022).
- Oraby, S.; Harrison, V.; Reed, L.; Hernandez, E.; Riloff, E.; Walker, M. Creating and characterizing a diverse corpus of sarcasm in dialogue. arXiv 2017, arXiv:1709.05404. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).