1. Introduction
Many image-processing applications perform localization of target objects in the first place. For instance, detecting and inferring objects (such as road signs, pedestrians and vehicles) in road scene videos are the essential tasks of an autonomous driving system [
1]. Representative features are estimated from image pixels, generally under the assumption that the image is acquired with good visibility. High quality images are also important for remote sensing and surveillance. For instance, ground settlement monitoring in construction sites, or structural health assessments of buildings, demand an accurate survey and geometric reconstruction of the scene. Liu et al. [
2] employed time series synthetic-aperture-radar interferometry (InSAR) to estimate the deformation of land reclamation. Remote sensing can also be achieved through the use of image processing techniques such as structure from motion (SfM) photogrammetry.
One main problem of image-based applications is that the acquired images are of low quality. Remote sensing images are often captured in outdoor environments. The visibility in the images depends on the weather conditions. When there is haze, rain or fog, the acquired images are seriously degraded. As a result, the image feature is distorted and the image-processing algorithm will fail to reach the expected accuracy. To address this problem, image dehazing is often employed. Many image processing algorithms assume that the image records the scene’s radiance. If the image dehazing method restores the image radiance, representative features can be extracted using the subsequent processing steps of the algorithm. Image dehazing is an important and foremost module in many applications, e.g., auto-driving [
3], scene surveillance [
4] and remote sensing [
5]. These studies demonstrated that image dehazing can address some common problems faced by various image-based applications. Image dehazing has become a popular research topic. The amount of image dehazing papers has increased over recent years (see a recent review [
6]). We aim to propose an image dehazing algorithm that can improve the visibility in images, particularly images that are degraded by rain and fog. Moreover, we demonstrate the benefit of using the proposed method on a popular image-based application of object detection.
We propose a new image dehazing model based on a convolutional neural network (CNN). The single network can be trained end-to-end to transform a hazy image into a haze-free image. A quantitative evaluation of the proposed model, with respect to some metrics, was performed on various image datasets. As demonstrated from the numerical results, our model outperformed other image dehazing methods. Moreover, the visual results illustrated the improvement of visibility in the degraded images. The dehazed images look very similar to the haze-free images. In the research of object detection, we observed that outdoor images degraded by rain and fog produced predictions with lower accuracy than those obtained from clearer images. We, therefore, utilized the proposed image dehazing method to enhance the visibility of the degraded images before the object detection task. We investigated the impact of dehazed images with respect to the detection of five target objects captured in road scene videos. Following thorough experimentation, we demonstrated that the objects detected in images enhanced by our proposed dehazing model were significantly improved over those detected in the degraded images. Our main contributions are as follows:
We adopt the conditional generative adversarial network (cGAN) and propose a novel image dehazing model. The network, which is comprised of a generator and discriminator, demands no pre-processing step. Therefore, the single network learns the dehazing function via end-to-end training. The generator module has an encoder–decoder structure. We strengthened the analytical power of the network via the adoption of convolutional blocks with progressively more layers. Moreover, the entire dehazing framework was enhanced with the utilization of a new activation function in both the generator and discriminator modules. Thorough experimentation was carried out to illustrate the superiority of the proposed model over other image dehazing methods on various image dehazing datasets.
Image enhancement was beneficial to various image processing tasks. One practical application was the detection of objects in degraded images. To the best of our knowledge, our research is the first to propose a new cGAN-based image dehazing method for the enhancement of images for object detection. For this investigation, we created a dataset of road scene videos. Five target objects (pedestrian, bicycle, car, bus and truck) were annotated. Two common weather conditions (rain and fog) were adopted for the synthesis of degraded images.
We adopted the object detector You Only Look Once (YOLO). Experimentation was performed on clear images, images degraded by rain, images degraded by fog and images enhanced using our proposed image dehazing method. The numeric results showed that our proposed image dehazing method can lead to target detection with higher accuracy. The visual results also illustrated that, with the use of images dehazed using our method, the object detector was able to detect objects which may have been missed in images processed using other image dehazing methods.
Our paper is organized as follows. The related research on image dehazing and object detection are reviewed in the
Section 2. We explain the proposed image dehazing model in detail in
Section 3.
Section 4 presents the experimental set up of detecting target objects in road scene images. Experimental results of image dehazing and object detection are illustrated in
Section 5. We compare our proposed image dehazing model with other methods first on various image dehazing datasets. We then illustrate the performance of object detection using degraded images and images enhanced using our proposed dehazing method. In
Section 6, we draw conclusions and present some future work.
2. Related Work
Many deterministic image dehazing methods have been proposed, with the assumption of prior information or a physical model. Wang and Yuan [
7] reviewed the research on image dehazing. The methods, in accordance with the processing technique used, can be categorized as image enhancement, multi-image fusion or image restoration. Image enhancement methods aim to improve the visibility with image processing algorithms. Multiple input images can be fused to generate the dehazed image. These two approaches do not rely on a physical model of hazy image formation. On the contrary, restoration-based methods adopt a degradation model. Image visibility is improved by reversing the degradation processes. He et al. [
8] proposed a method based on the dark channel prior (DCP) for single image dehazing. They observed the presence of low intensity pixels within local regions in haze-free images. Formulations were then devised for the computation of transmission and airlight. With these parameters and the assumption of the physical model, the scene radiance was restored. As presented in
Section 5, DCP has a problem of color distortion. Dharejo et al. [
9] proposed a method to correct the color and enhance the contrast of hazy images. Galdran [
10] utilized multiple-exposure images and a Laplacian blending scheme for image dehazing. Pixelwise hazy-free color is also estimated from the physical model formulation. Kumar et al. [
11] implemented a multi-exposure framework for haze removal of images represented in the hue saturation value (HSV) color space. To avoid color distortion, the hue channel is not processed. The multiple-exposure images are generated with the gamma factor varied incrementally. Chaudhry et al. [
12] proposed a framework which is comprised of hybrid median filtering for visibility restoration, Laplacian filtering for initial dehazing, and just noticeable difference-based boosting for image detail enhancement. These studies exploit hand-crafted features in image dehazing, while many recently proposed models adopt deep learning approach. In some applications, deterministic algorithms can achieve competitive, or even better performance, than deep learning models. For instance, Khaldi et al. [
13] demonstrated that handcrafted features perform better than CNN-based descriptors in texture analysis.
Recently, more image dehazing research adopted a data-driven approach. The image dehazing model was developed via deep learning from training data. Li et al. [
14] proposed a hybrid method called AOD-Net, in which a CNN is trained to generate a transmission map from the image samples. A haze-free image is then computed with the input of a transmission map and the formulation of an atmospheric scattering model. However, the images generated by AOD-Net may be dark. Zhang and Patel [
15] proposed a two-stream network to predict the transmission map and airlight. The correlation of the generated dehazed image and the estimated transmission map are analyzed with a generative adversarial network (GAN). Dong et al. [
16] also proposed a GAN framework for single image dehazing. The generator network has an encoder–decoder structure. The frequency information, computed from the ground-truthed image and generator output image, is then the input for the discriminator network. Although deep learning models can be trained to produce very good results with benchmark datasets, their performance can deteriorate significantly on unseen images. In summary, these methods either combine a deep learning network with the formulation of the atmospheric scattering model, or embed a deterministic computation module to a CNN. Instead, we propose a novel single network that can be trained end-to-end to generate a haze-free image without pre-processing or additional modules.
Guo et al. [
17] proposed an image dehazing model combining transformer and CNN modules. The transformer, with the use of prior 3D information, aims for global modeling. The CNN encoder is capable of local modeling. The activation function in each convolution block is ReLU. Transformer features and CNN features are fused. The dehazed image is generated by the CNN decoder module. Qin et al. [
18] proposed FFA-Net, which is an end-to-end feature fusion network. There is no input of a clear image during training. The feature attention (FA) block combines the channel attention (uneven haze) and pixel attention (low intensity color channel). The training process adopted only an L1 loss function. Wu et al. [
19] proposed an autoencoder network with contrastive regularization for image dehazing. The idea was to generate a dehazed image closer to the ground-truthed image and further from a hazy image. The model, consisting of 2.61 M parameters, has a simpler structure than FFA-Net. Dong et al. [
20] proposed an image dehazing network based on U-Net. The decoder module was modified with the incorporation of a strengthen–operate–subtract (SOS) boosting strategy which generates the dehazed image progressively from the multi-scale features. However, as presented in [
19], the network is far more complex than other models, such as AOD-Net and FFA-Net, with lower performance.
GAN is a well-known CNN for image synthesis. Many researchers have adopted it for image-to-image translation, single-image dehazing, etc. However, GAN may suffer from training failure. To address this problem, cGAN was proposed, with constraints added to the GAN architecture. Some cGAN models have been proposed recently for single-image dehazing. For instance, Su et al. [
21] proposed a prior guided cGAN framework which contains an encoder–decoder-based generator and a multi-scale discriminator. Features are extracted using an attention-based encoder and parameters are shared with the generator. Kan et al. [
22] proposed a cGAN framework, which adopts a U-shaped residual network as the generator. Li et al. [
23] proposed the cGAN model based on the generator network with an encoder–decoder structure of the U-Net. They adopted the summation method to skip connections. The activation functions were ReLU and LeakyReLU. They evaluated the model only using a synthetic dataset. The performance on real degraded images is not known. We adopted the cGAN structure for our proposed image dehazing model. To strengthen the analytical power of the network, we propose two modifications. First, we designed the framework with convolutional blocks comprising more layers in the encoder output. We used the concatenation method to forward the detail features from the encoder to the decoder. According to Li et al.’s results [
23], the PSNR of the concatenation method is higher than the summation method for most of the training epochs. Second, for the activation function in the generator and discriminator, we selected a new nonlinear activation function Mish. As will be explained in
Section 3.1, Mish is better than ReLU in allowing gradient flow. We also inserted dropout layers in the generator to provide more variety of network configuration during training.
To facilitate image dehazing research, many synthetic or real image datasets have been created. The acquisition of haze-free and hazy images, e.g., in the indoor environment, can be made under control. For instance, Ancuti et al. [
24] utilized a professional machine to generate haze in a scene. Therefore, clear and hazy image pairs can be captured. However, the acquisition of haze-free outdoor images is a tedious task. One possible approach is to add the hazy effect to a clear image via simulation. For instance, Tarel et al. created two synthetic datasets, the Foggy Road Image Database (FRIDA) [
3] and FRIDA2 [
25]. Sakaridis et al. [
26] constructed two foggy datasets to facilitate foggy scene understanding and image dehazing. They applied fog synthesis on the Cityscapes dataset and generated Foggy Cityscapes with 20,550 images. Alternatively, Zhao et al. [
27] created BeDDE, which contains real outdoor images. The haze-free and hazy image pairs were acquired in slightly different positions. A quantitative measure was computed on the common region of interest (ROI) of the image pair which was manually segmented by the authors. As we did not a find haze-free and hazy real road scene image pair dataset, we collected and annotated real road scene videos for our research. The degraded images were synthesized through the addition of rain and fog effects to the clear images.
Deep learning-based object detection methods can be grouped into two categories—one stage and two stage. A one-stage detector conducts target classification and target positioning in one pass. For instance, YOLO [
28] directly calculates the position and category of objects in the output layer. SSD [
29] uses a multi-scale feature map to return the location and category of the objects. A two-stage detector produces a target bounding box first. Then, for each candidate box, classification and regression are carried out. For instance, R-CNN [
30] adopts the region proposal method to generate the ROIs. The ROIs are then converted into fixed-size images and fed into the CNN to achieve target classification and refinement of the bounding box. Faster R-CNN [
31] extracts the image feature only once, instead of extracting a feature for each ROI. It achieves target classification and refinement of the bounding box based on ROI pooling which converts each of the feature maps with various sizes into a fixed-size feature map. Mask R-CNN [
32] performs instance segmentation. It is a two-stage method that divides instance segmentation into object detection and mask representation. It adopts ResNet [
33] as the backbone to extract feature maps. A pyramidal network is used to combine the feature maps from the low layer to the high layer and produce the prediction feature maps. Chen et al. [
34] proposed a Faster R-CNN-based object detector with the addition of image-level adaptation, instance-level adaptation and consistency regularization of the two domain classifiers. The challenges are that the target domain has no annotation and its distribution is different from the source domain. The augmented model can tackle both image-level and instance-level shifts. The authors evaluated the proposed model on various datasets with different domain shift scenarios. For instance, Cityscapes was used as the source domain, while Foggy Cityscapes was used as the target domain. Wang et al. [
35] also tackled the domain adaptation problem with two modules, DQFA (to reduce domain discrepancy in global feature representation) and TDA (to reduce the domain gaps in instance-level feature representation), which were added to the backbone Deformable DETR. They evaluated the proposed unsupervised domain adaptive object detector (DAOD) on three scenarios, e.g., Cityscapes to Foggy Cityscapes. In summary, a two-stage detector can achieve higher accuracy (e.g., 0.7 mean average precision (mAP)) at the expense of higher computational load (e.g., 0.1 s per image). A one-stage detector has a faster speed (e.g., 50 frames per second (fps)) with a slightly lower accuracy (e.g., 0.6 mAP). The accuracy is further decreased with the use of degraded images. In order to improve the object detection accuracy of the one-stage object detector, we utilized the proposed image dehazing method to pre-process the images.
3. Image Dehazing Model
Image dehazing is considered a generative problem. A network learns from the training samples how to transform the degraded image into a clear image. As compared with the traditional methods that rely on a physical model, a deep learning-based generative model does not demand explicit computation of parameters such as a transmission map and atmospheric light. Model optimization is driven by the hazy/clear-image-pair dataset. To strengthen the learning algorithm for better dehazing, the realness of the generator result is challenged using a discriminator which is adversarially trained.
We adopted the structure of cGAN, as shown in
Figure 1, as our proposed image dehazing model. cGAN is a supervised learning model with two major modules—generator and discriminator. Like GAN, the generator module
G learns the mapping from a random noise vector z to the output y (
G:
z →
y). The generator output (fake data), together with the real data, is then passed to the discriminator module
D. The discriminator is trained to determine whether the generator output is real or fake. The generator and discriminator, formed as an adversarial pair, work together in optimizing the realness of the generated image. The structure of cGAN is almost the same as GAN but with the additional information of “label”. This additional input will guide/constrain the generator module to generate the desired kind of output. Bharath Raj and Venketeswaran proposed Dehaze-GAN [
36] for image-to-image translation. We selected it as the base model. We then modified and extended the network for it to become our proposed image dehazing model. In the proposed model, the real data are the clear image and the label is the hazy input. With the random noise vector
z and output
y, an additional variable
x is added such that
G: {
x,
z} →
y. The details of the generator network and discriminator are explained in the following sub-sections.
3.1. Generator Network
In the base model Dehaze-GAN, each dense block (DB) contains four composite layers (CLs). The activation function is ReLU.
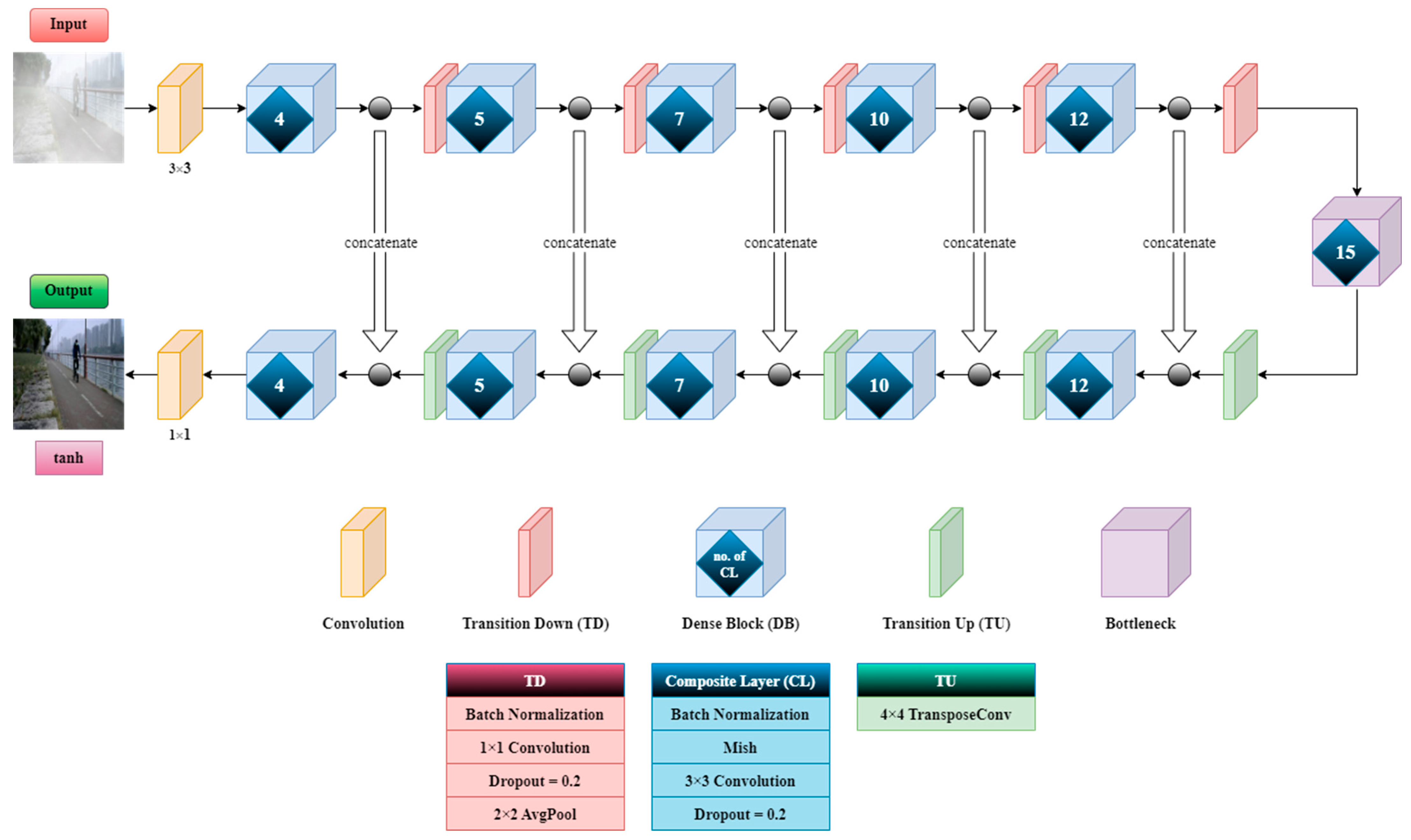
Figure 2 shows the generator network (
G) of our proposed image dehazing model. There are five DBs in the encoder and five DBs in the decoder. On the encoder side, each DB is followed by a down-sampling layer. Similarly, on the decoder side, each DB is followed by an up-sampling layer. The decoder can generate a high-resolution image due to the concatenation of detailed features from the encoder side. We substantially extended the generator network from the base model of 56 layers to 103 layers. In deep learning, more layers do not imply better results and accuracy. The performance of the model depends on various factors such as the number of training samples, regularization technique, etc. For instance, a complex network trained with insufficient data may lead to overfitting. Oppositely, a shallow network may suffer from the underfitting problem when it is trained with a large amount of data. Through thorough experimentation, and as demonstrated in our superior results, we designed
G with 103 layers.
We proposed
G which differs from the base model with two modifications. First, in contrast with the base model, which contained a constant number of CLs in each DB, our generator network has progressively more CLs in the encoder. The number shown in each DB in
Figure 2 is the number of CLs. This structure, with more non-linear computational power towards the end of the encoder, can capture the transformations at the multiple scales needed for artifact removal. In general, more layers in a network means more features can be extracted from the raw data. This can lead to better accuracy, provided that the training dataset is large enough. If the network contains more layers than necessary for the application, those unnecessary layers may try to extract some useless/unrelated features. This problem of overfitting will produce erroneous results. Second, we adopted Mish
f(
x) as the activation function. Mish is a state-of-the-art activation function [
37]. It is a composite function of two existing activation functions,
tanh and
softplus.
Mish has superior performance over other activation functions such as Swish and ReLU. It allows a better gradient flow than ReLU due to the slight allowance for negative values. Instead of a hard zero bound in ReLU, a smoother activation function can also enhance the backpropagation process, which allows more information to flow into the neural network deeply and, thus, leads to a better accuracy and generalization. A drawback of using Mish is the slight increase of network complexity, which leads to a longer training time. However, considering the higher accuracy and better training stability that Mish can accomplish, it was well worth adopting it in our proposed model. We demonstrate the superiority of our proposed generator network with one example of the progression of the generator output in
Figure 3. Our proposed generator network could eventually produce an output which resembled the clear image.
3.2. Discriminator
Figure 4 shows the discriminator of our proposed image dehazing model. It consists of four layers of strided convolution. The inputs were the hazy image concatenated with the clear image and the generated fake image. The activation function at the output layer was sigmoid. The discriminator performed a patch-wise comparison of the clear image with the generated fake image to determine whether the generator output was real or fake. Therefore, the discriminator forced the generator to improve the realness of the output and helped remove the artifacts in the hazy image. In our experimentation, we had two versions of discriminator. The first one (D1) was the same as the base model with the use of LeakyReLU as the activation function. The second one (D2) utilized Mish as the activation function.
3.3. Loss Function and Training
The
G and
D of the image dehazing model were trained simultaneously, where
G minimized the generative objective, and
D maximized the discriminator objective. Therefore, the training process was formulated as a min–max of loss function. The generator objective
LG consisted of three weighted terms—standard objective
Lgan,
L1 loss and perceptual loss
Lp.
where
x is the hazy image,
y′ is the clear image,
V is the VGG-19 network and
Wgan,
WL1 and
Wp are the weights to be determined empirically.
Lp is the mean squared error (
mse) between the VGG-19 outputs of the dehazed image and clear image scaled by the constant
c. The discriminator objective is as follows:
The model was trained on a computer with Intel Xeon Silver 4108 16-core CPU, Nvidia RTX 2080Ti GPU, and 55 GB RAM. In our experimentations, the dataset was partitioned into around 90% training samples and 10% testing samples. To find the best set of hyperparameters, 20% of the training samples were selected as a validation set. The model was trained with a learning rate of 0.001. The training process stopped when there was no improvement in accuracy.
4. Target Detection
Object detection is the foremost process in many image-based applications. It aims to detect the RoIs of the target objects in the image. A one-stage detector conducts target positioning and classification in the last convolutional layer in one pass. It has a faster operating speed with lower accuracy. For instance, You Only Look Once (YOLO) [
28] is a powerful and widely used one-stage object detector. We select YOLO v5s, which is one of the latest versions, as the object detector. The model was the best choice in terms of balancing the requirements of detection accuracy and detection speed in road scene images.
The YOLO model first resizes the input image to a square matrix and partitions it into a number of grid cells. The network contains 24 convolutional layers and 2 fully connected layers. The function of these convolutional layers is to perform feature extraction. Fully connected layers are to generate the position and confidence score of detected objects. Each grid cell will respond to the detected class of object with the predicted bounding box and confidence score. The prediction consists of five values—the x-coordinate, y-coordinate, width and height of the bounding box and confidence score. The x- and y-coordinates are at the center of the box. The width and height are the distance between the boundary and the center of the bounding box. The confidence score represents the probability that the specific object is in the bounding box. The class-specific confidence score is calculated based on the appearance and positional information. Final results are generated after non-maximum suppression (NMS) in order to discard the duplicated detections.
We observed that images degraded by rain and fog produce target object predictions with lower accuracy than those obtained from clear images. Therefore, in this experimentation, we investigated the significance of using dehazed images for road scene target detection. The results of target detection, as presented in
Section 5, were obtained from clear images, degraded images and dehazed images. We illustrate the improvement of target detection in dehazed images over degraded images in terms of the dimension and confidence score of the detected targets.
It is necessary to train the object detector with custom image samples rather than using a pre-trained model. We created the first dataset with 5509 road scene images collected online. Five target objects, as shown in
Table 1, were annotated.
Figure 5 shows some image samples with annotated targets. The images are of good visibility and were considered clear image samples.
We then created two degraded image datasets. Clear images were degraded with two weather conditions (rain and fog). Acquiring real images under raining and foggy weather conditions at the same location and the same time of the day as the clear images would be extremely difficult. Therefore, we adopted the approach of synthesizing and adding the weather conditions to the clear image.
Table 2 shows the steps of the synthesis of rain.
Figure 6 shows some images degraded with rain. Compared with the corresponding clear images, degraded images exhibited long thin white lines simulating the heavy rain. Fog was synthesized by adding two cloud layers with different fill opacities to the clear image.
Table 3 shows the steps and parameter settings for the synthesis of fog.
Figure 7 shows some images degraded with fog. The degraded images are covered with dense fog.
Finally, we created two dehazed datasets from the rain and fog degraded images. Dehazed images were generated using the image dehazing method as described in the
Section 3. Five object detection models (clear, rain, fog, dehazed rain, and dehazed fog) were trained with supervised learning. The models were trained on a computer with AMD R7 3700X CPU, Nvidia RTX 2070s GPU, 16 GB RAM and 2 TB disk memory. Each dataset was partitioned into an 80% training sample and 20% validation sample. Each model was trained with the Adam optimizer and a learning rate of 0.001. The training process stopped when there was no improvement in the last 100 epochs. To find the best set of hyperparameters, we adopted five-fold validation.
6. Conclusions
We designed a novel single end-to-end network based on the cGAN framework for image dehazing. We strengthened the analytical power of the network via the adoption of convolutional blocks with progressively more layers. Moreover, the entire dehazing framework was enhanced with the adoption of a new non-linear activation function in both the generator and discriminator modules. The dehazed image was beneficial for the detection of objects in degraded road scene images. Based on the enhanced framework, we proposed two image dehazing models with two discriminators. Through thorough experimentation, we demonstrated that our proposed image dehazing models improved the visibility of the degraded images and resulted in a higher accuracy of object detection. Our proposed models outperformed not only the hand-crafted and deep learning-based methods, but also the cGAN base model using various datasets.
We will continue our research on image dehazing. In the current work, we investigated the impact of our proposed image dehazing model on object detection performed on images degraded with rain and fog effects. More experimentation will be performed to investigate the capability of our proposed model in tackling other types of image degradation. Besides object detection in 2D images, we will also explore the impact of image dehazing on other applications such as monocular 3D object detection.
For practical applications, we will consider integrating the image dehazing as an optional module within the object detection framework. To save computational costs, there is no need to perform image dehazing when the scene visibility is good. Automatically triggering the execution of the image dehazing module is possible via computation of the similarity between the hazy input image and the dehazed output image. Significant changes in quantitative measures, e.g., SSIM, will enable the continuing function of the image dehazing module. An automatic alert of extreme conditions would be possible when the confidence score of an object detection is low.



























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}