



Dense-HR-GAN: A High-Resolution GAN Model with Dense Connection for Image Dehazing in Icing Wind Tunnel Environment



Abstract
1. Introduction
- We proposed the development of a novel generative image super-resolution dehazing model, which is suitable for the icing wind tunnel environment. We validated the model using real-world images captured in the icing environment, and the results showed excellent dehazing performance.
- The proposed model involves the incorporation of sub-pixel convolution and instance normalization into the network architecture to generate high-resolution dehazed images while preserving the structural information of ice on the wings. Sub-pixel convolution is employed to mitigate artifacts arising from traditional deconvolution, while instance normalization is used to enhance image style transformation. The model enables the capture of both content and style information from hazy and haze-free images, leading to a more effective restoration of the haze-free appearance.
2. Materials and Methods
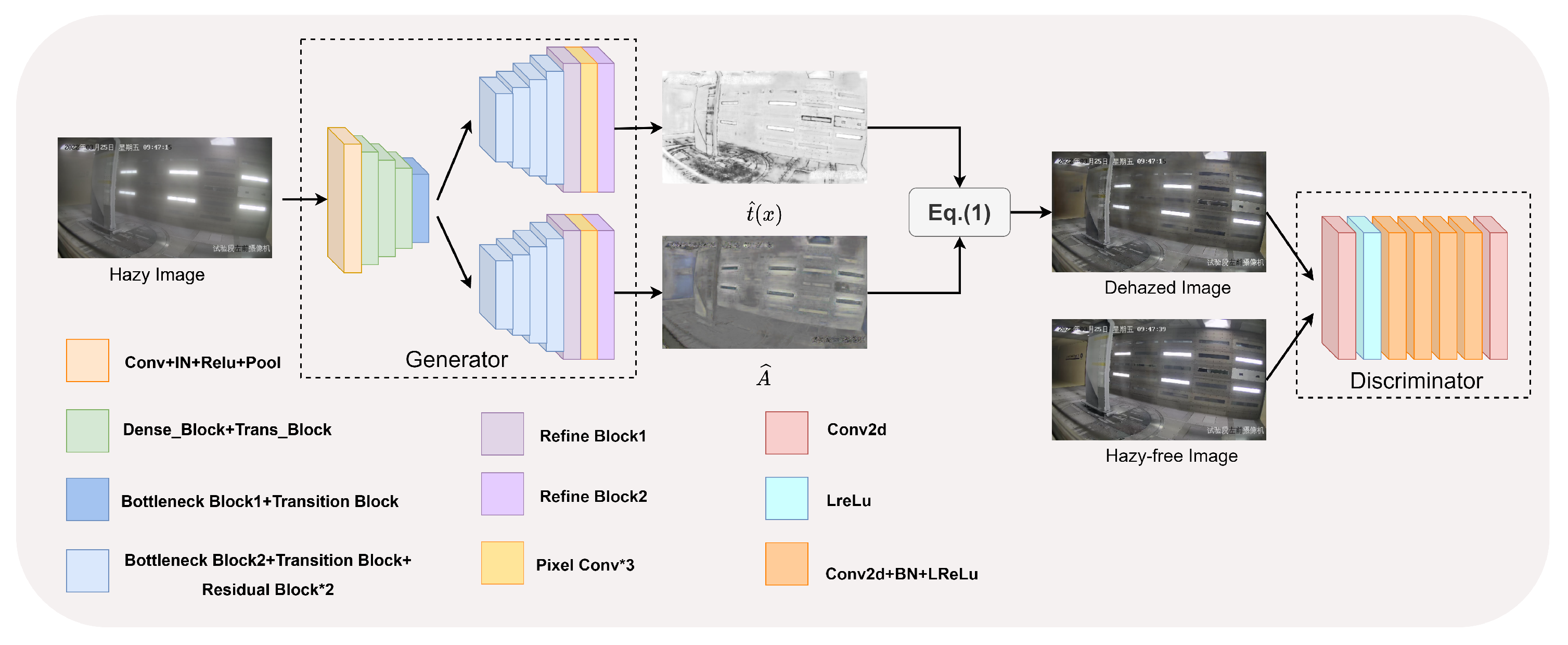
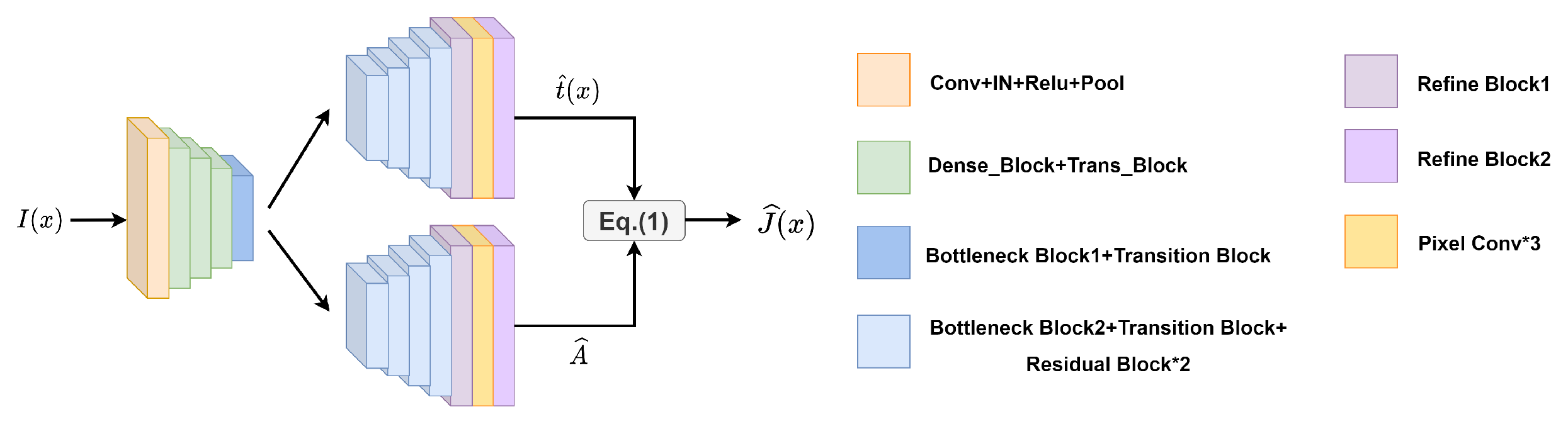
2.1. Generator
2.1.1. Instance Normalization
2.1.2. Sub-Pixel Convolution
2.2. Image Restoration
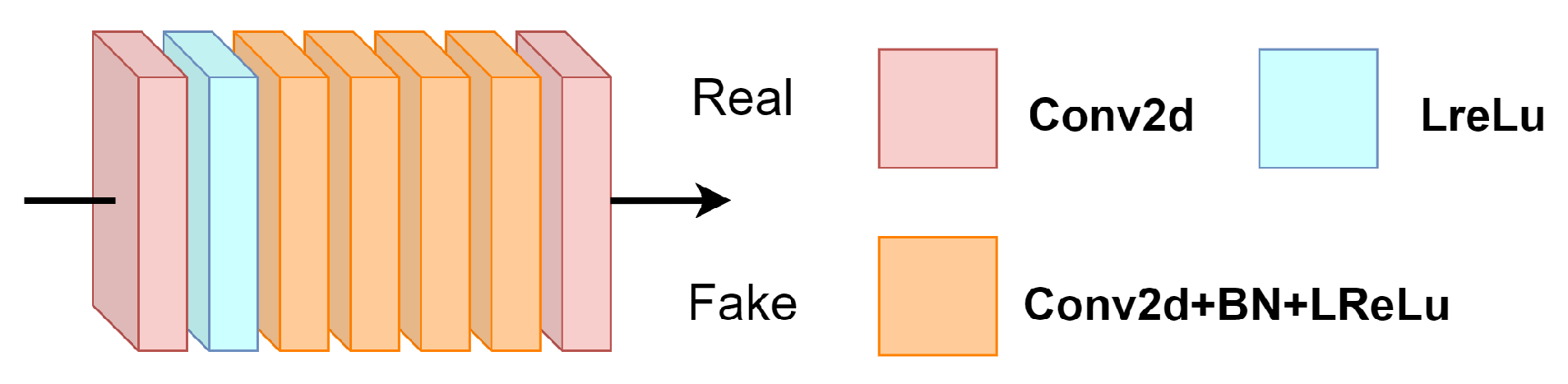
2.3. Discriminator
2.4. Loss Function
2.4.1. Reconstruction Loss
2.4.2. Perceptual Loss
2.4.3. Adversarial Loss
2.4.4. Overall Loss Function
3. Results
3.1. Settings
3.2. Evaluation Metrics
3.3. Comparative Experiments
3.4. Ablation Experiments
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- McCartney, E.J. Optics of the Atmosphere: Scattering by Molecules and Particles; John Wiley and Sons, Inc.: New York, NY, USA, 1976. [Google Scholar]
- He, K.; Sun, J.; Tang, X. Single image haze removal using dark channel prior. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 33, 2341–2353. [Google Scholar] [PubMed]
- Zhu, Q.; Mai, J.; Shao, L. A fast single image haze removal algorithm using color attenuation prior. IEEE Trans. Image Process. 2015, 24, 3522–3533. [Google Scholar] [PubMed]
- Jobson, D.J.; Rahman, Z.U.; Woodell, G.A. A multiscale retinex for bridging the gap between color images and the human observation of scenes. IEEE Trans. Image Process. 1997, 6, 965–976. [Google Scholar] [CrossRef]
- Soni, B.; Mathur, P. An improved image dehazing technique using CLAHE and guided filter. In Proceedings of the 2020 7th International Conference on Signal Processing and Integrated Networks (SPIN), Noida, India, 27–28 February 2020; pp. 902–907. [Google Scholar]
- Ren, W.; Liu, S.; Zhang, H.; Pan, J.; Cao, X.; Yang, M.H. Single image dehazing via multi-scale convolutional neural networks. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 154–169. [Google Scholar]
- Cai, B.; Xu, X.; Jia, K.; Qing, C.; Tao, D. Dehazenet: An end-to-end system for single image haze removal. IEEE Trans. Image Process. 2016, 25, 5187–5198. [Google Scholar] [CrossRef]
- Zhang, H.; Patel, V.M. Densely connected pyramid dehazing network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 3194–3203. [Google Scholar]
- Dong, Y.; Liu, Y.; Zhang, H.; Chen, S.; Qiao, Y. FD-GAN: Generative adversarial networks with fusion-discriminator for single image dehazing. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 10729–10736. [Google Scholar]
- Liu, X.; Ma, Y.; Shi, Z.; Chen, J. Griddehazenet: Attention-based multi-scale network for image dehazing. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 7314–7323. [Google Scholar]
- Qin, X.; Wang, Z.; Bai, Y.; Xie, X.; Jia, H. FFA-Net: Feature fusion attention network for single image dehazing. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 11908–11915. [Google Scholar]
- Song, Y.; He, Z.; Qian, H.; Du, X. Vision Transformers for Single Image Dehazing. arXiv 2022, arXiv:2109.12564. [Google Scholar] [CrossRef] [PubMed]
- Guo, T.; Li, X.; Cherukuri, V.; Monga, V. Dense scene information estimation network for dehazing. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Long Beach, CA, USA, 16–20 June 2019; pp. 2122–2130. [Google Scholar]
- Ancuti, C.O.; Ancuti, C.; Sbert, M.; Timofte, R. Dense Haze: A benchmark for image dehazing with dense-haze and haze-free images. arXiv 2019, arXiv:1904.02904v1. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- Ulyanov, D.; Vedaldi, A.; Lempitsky, V. Instance Normalization: The Missing Ingredient for Fast Stylization. arXiv 2016, arXiv:1607.08022. [Google Scholar]
- Shi, W.; Caballero, J.; Huszár, F.; Totz, J.; Aitken, A.P.; Bishop, R.; Rueckert, D.; Wang, Z. Real-time single image and video super-resolution using an efficient sub-pixel convolutional neural network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1874–1883. [Google Scholar]
- Zhu, J.Y.; Park, T.; Isola, P.; Efros, A.A. Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017. [Google Scholar]
- Mittal, A.; Soundararajan, R.; Bovik, A.C. Making a “completely blind” image quality analyzer. IEEE Signal Process. Lett. 2012, 20, 209–212. [Google Scholar] [CrossRef]
- Hautiere, N.; Tarel, J.P.; Aubert, D.; Dumont, E. Blind contrast enhancement assessment by gradient ratioing at visible edges. Image Anal. Stereol. 2008, 27, 87–95. [Google Scholar] [CrossRef]
- Zhou, W.; Zhang, R.; Li, L.; Liu, H.; Chen, H. Dehazed Image Quality Evaluation: From Partial Discrepancy to Blind Perception. arXiv 2022, arXiv:2211.12636. [Google Scholar]
- Zhai, G.; Sun, W.; Min, X.; Zhou, J. Perceptual quality assessment of low-light image enhancement. ACM Trans. Multimed. Comput. Commun. Appl. (TOMM) 2021, 17, 1–24. [Google Scholar] [CrossRef]
- Zhou, W.; Jiang, Q.; Wang, Y.; Chen, Z.; Li, W. Blind quality assessment for image superresolution using deep two-stream convolutional networks. Inf. Sci. 2020, 528, 205–218. [Google Scholar] [CrossRef]
- Galdran, A. Image dehazing by artificial multiple-exposure image fusion. Signal Process. 2018, 149, 135–147. [Google Scholar] [CrossRef]
- Raikwar, S.C.; Tapaswi, S. Lower bound on transmission using non-linear bounding function in single image dehazing. IEEE Trans. Image Process. 2020, 29, 4832–4847. [Google Scholar] [CrossRef] [PubMed]
- Li, B.; Peng, X.; Wang, Z.; Xu, J.; Feng, D. Aod-net: All-in-one dehazing network. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 4770–4778. [Google Scholar]
- Yang, Y.; Wang, C.; Liu, R.; Zhang, L.; Guo, X.; Tao, D. Self-Augmented Unpaired Image Dehazing via Density and Depth Decomposition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 2037–2046. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Image 1 | Image 2 | Image 3 | Image 4 | Image 5 | Image 6 | |
|---|---|---|---|---|---|---|
| MVD (μm) | 25 | 25 | 20 | 20 | 20 | 20 |
| LWC (g/m) | 1.31 | 1.31 | 1.0 | 1.0 | 0.5 | 0.5 |
| Metric | Image | DCP [2] | CAP [3] | AMEDF [24] | LBF [25] | Ours |
|---|---|---|---|---|---|---|
| e | Image 1 | 1.67 | 3.51 | 1.59 | 1.81 | 2.03 |
| Image 2 | 6.73 | 14.64 | 4.54 | 11.80 | 3.47 | |
| Image 3 | 1.33 | 3.36 | 1.41 | 2.52 | 1.31 | |
| Image 4 | 1.21 | 2.35 | 1.18 | 1.80 | 1.82 | |
| Image 5 | 2.60 | 3.12 | 2.41 | 4.41 | 0.64 | |
| Image 6 | 3.74 | 4.98 | 2.48 | 4.41 | 0.52 | |
| Average | 2.88 | 5.33 | 2.27 | 4.46 | 1.63 | |
| Image 1 | 1.22 | 1.21 | 2.35 | 1.19 | 4.45 | |
| Image 2 | 1.16 | 1.46 | 2.48 | 1.84 | 5.34 | |
| Image 3 | 1.04 | 1.17 | 2.50 | 1.24 | 3.82 | |
| Image 4 | 1.13 | 1.11 | 2.49 | 1.17 | 4.03 | |
| Image 5 | 1.34 | 1.50 | 2.06 | 1.94 | 2.28 | |
| Image 6 | 1.24 | 1.24 | 2.23 | 1.47 | 1.79 | |
| Average | 1.19 | 1.28 | 2.35 | 1.48 | 3.62 | |
| Image 1 | 3.43 | 7.48 | 3.45 | 7.48 | 3.17 | |
| Image 2 | 2.80 | 3.33 | 2.81 | 3.33 | 2.86 | |
| Image 3 | 3.65 | 4.21 | 3.30 | 4.21 | 3.03 | |
| Image 4 | 3.31 | 4.22 | 3.10 | 4.22 | 2.95 | |
| Image 5 | 3.04 | 2.84 | 2.88 | 2.84 | 2.54 | |
| Image 6 | 3.34 | 3.58 | 3.70 | 3.58 | 3.11 | |
| Average | 3.26 | 4.28 | 3.21 | 4.28 | 2.94 |
| Metric | Image | AOD-NET [26] | MSCNN [6] | FFA-Net [11] | D4 [27] | Ours |
|---|---|---|---|---|---|---|
| e | Image 1 | 2.38 | 0.46 | 1.30 | 1.77 | 2.03 |
| Image 2 | 5.41 | 0.76 | 1.40 | 5.47 | 3.47 | |
| Image 3 | 1.75 | 0.30 | 0.86 | 1.56 | 1.31 | |
| Image 4 | 1.39 | 0.26 | 0.63 | 1.23 | 1.82 | |
| Image 5 | 2.00 | 1.16 | 1.40 | 1.09 | 0.64 | |
| Image 6 | 2.94 | 0.68 | 0.72 | 1.73 | 0.52 | |
| Average | 2.65 | 0.60 | 1.05 | 2.14 | 1.63 | |
| Image 1 | 1.70 | 1.22 | 1.34 | 1.49 | 4.45 | |
| Image 2 | 2.18 | 1.29 | 1.45 | 1.60 | 5.34 | |
| Image 3 | 1.73 | 1.20 | 1.43 | 1.53 | 3.82 | |
| Image 4 | 1.69 | 1.19 | 1.35 | 1.52 | 4.03 | |
| Image 5 | 1.74 | 1.37 | 1.48 | 1.44 | 2.28 | |
| Image 6 | 1.53 | 1.15 | 1.26 | 1.36 | 1.79 | |
| Average | 1.76 | 1.24 | 1.22 | 1.49 | 3.62 | |
| Image 1 | 4.31 | 4.06 | 2.92 | 3.99 | 3.17 | |
| Image 2 | 3.55 | 3.85 | 2.76 | 3.41 | 2.86 | |
| Image 3 | 3.78 | 3.67 | 2.91 | 3.54 | 3.03 | |
| Image 4 | 3.56 | 3.52 | 2.76 | 2.32 | 2.95 | |
| Image 5 | 3.25 | 3.01 | 3.01 | 2.99 | 2.54 | |
| Image 6 | 4.24 | 3.84 | 3.43 | 3.84 | 3.11 | |
| Average | 3.78 | 3.66 | 2.97 | 3.35 | 2.94 |
| Metric | Image | Design 1 | Design 2 | Design 3 |
|---|---|---|---|---|
| e | Image 1 | 0.88 | 2.13 | 2.03 |
| Image 2 | 1.45 | 2.15 | 3.47 | |
| Image 3 | 0.82 | 1.54 | 1.31 | |
| Image 4 | 0.72 | 2.09 | 1.82 | |
| Image 5 | 0.44 | 0.91 | 0.64 | |
| Image 6 | 0.63 | 0.45 | 0.52 | |
| Average | 0.82 | 1.55 | 1.63 | |
| Image 1 | 2.91 | 4.08 | 4.45 | |
| Image 2 | 3.38 | 4.40 | 5.34 | |
| Image 3 | 2.56 | 3.63 | 3.82 | |
| Image 4 | 2.60 | 3.88 | 4.03 | |
| Image 5 | 2.02 | 2.40 | 2.28 | |
| Image 6 | 1.83 | 1.85 | 1.79 | |
| Average | 2.55 | 3.37 | 3.62 | |
| Image 1 | 2.95 | 2.81 | 3.17 | |
| Image 2 | 3.09 | 2.71 | 2.86 | |
| Image 3 | 3.00 | 2.72 | 3.03 | |
| Image 4 | 2.86 | 2.61 | 2.95 | |
| Image 5 | 2.80 | 2.49 | 2.54 | |
| Image 6 | 3.33 | 2.94 | 3.11 | |
| Average | 3.01 | 2.71 | 2.94 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhou, W.; Yang, X.; Zuo, C.; Wang, Y.; Peng, B. Dense-HR-GAN: A High-Resolution GAN Model with Dense Connection for Image Dehazing in Icing Wind Tunnel Environment. Appl. Sci. 2023, 13, 5171. https://doi.org/10.3390/app13085171
Zhou W, Yang X, Zuo C, Wang Y, Peng B. Dense-HR-GAN: A High-Resolution GAN Model with Dense Connection for Image Dehazing in Icing Wind Tunnel Environment. Applied Sciences. 2023; 13(8):5171. https://doi.org/10.3390/app13085171
Chicago/Turabian StyleZhou, Wenjun, Xinling Yang, Chenglin Zuo, Yifan Wang, and Bo Peng. 2023. "Dense-HR-GAN: A High-Resolution GAN Model with Dense Connection for Image Dehazing in Icing Wind Tunnel Environment" Applied Sciences 13, no. 8: 5171. https://doi.org/10.3390/app13085171
APA StyleZhou, W., Yang, X., Zuo, C., Wang, Y., & Peng, B. (2023). Dense-HR-GAN: A High-Resolution GAN Model with Dense Connection for Image Dehazing in Icing Wind Tunnel Environment. Applied Sciences, 13(8), 5171. https://doi.org/10.3390/app13085171