



Comparative Analysis of AI-Based Facial Identification and Expression Recognition Using Upper and Lower Facial Regions


Abstract
1. Introduction
2. Related Works
2.1. Facial Expression Recognition of Upper and Lower Facial Regions
2.2. Face Identification of Upper and Lower Facial Regions
2.3. Models
3. Methods
3.1. Preprocessing Dataset
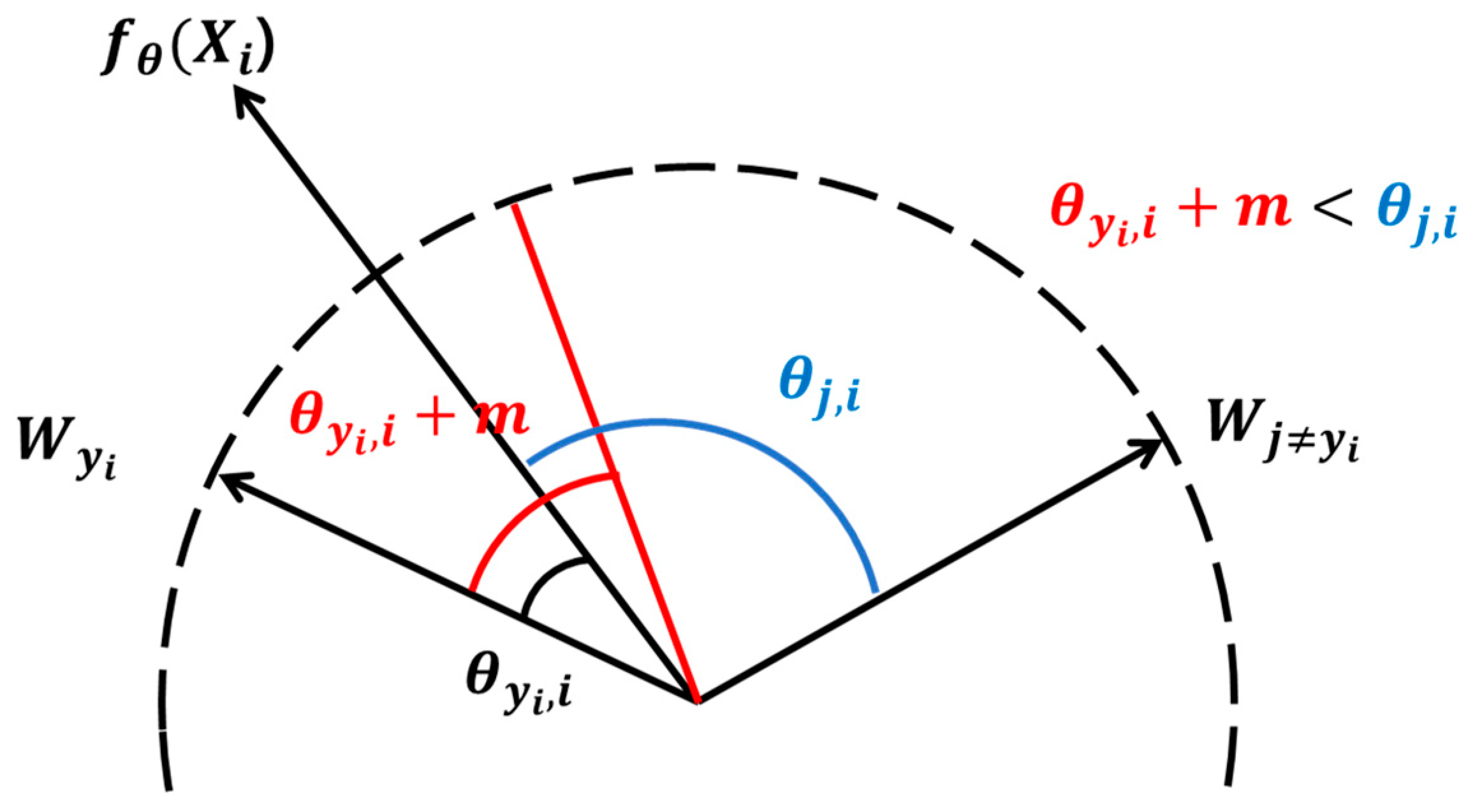
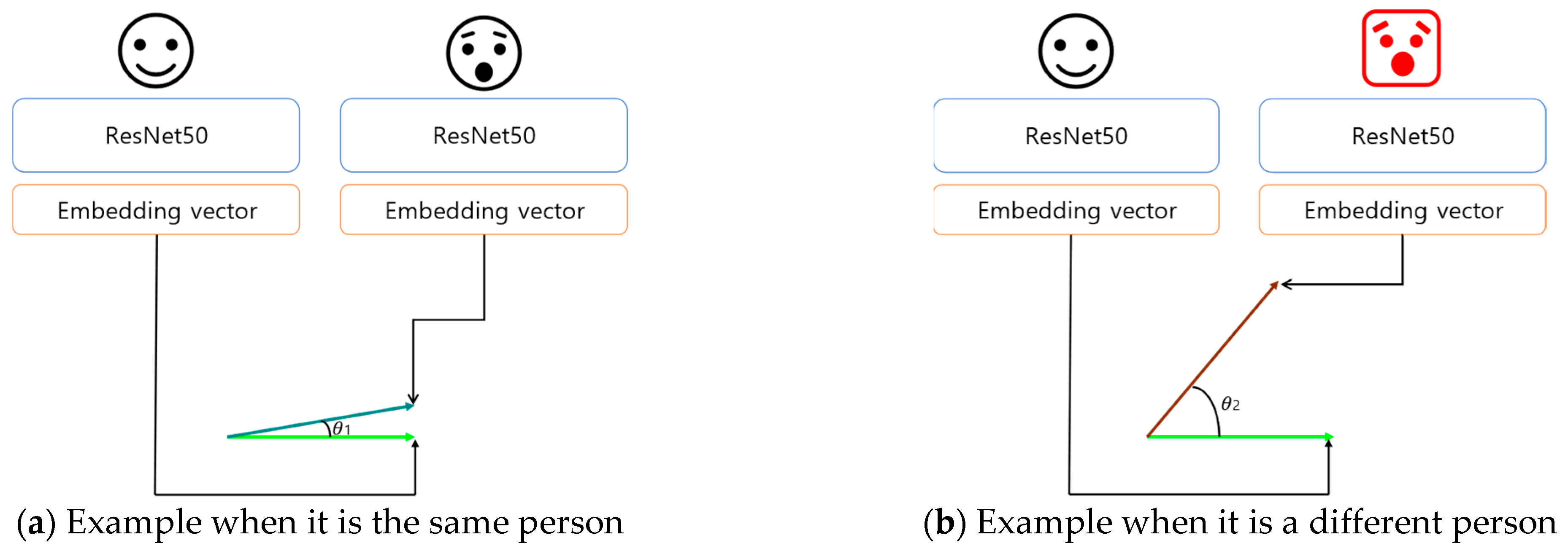
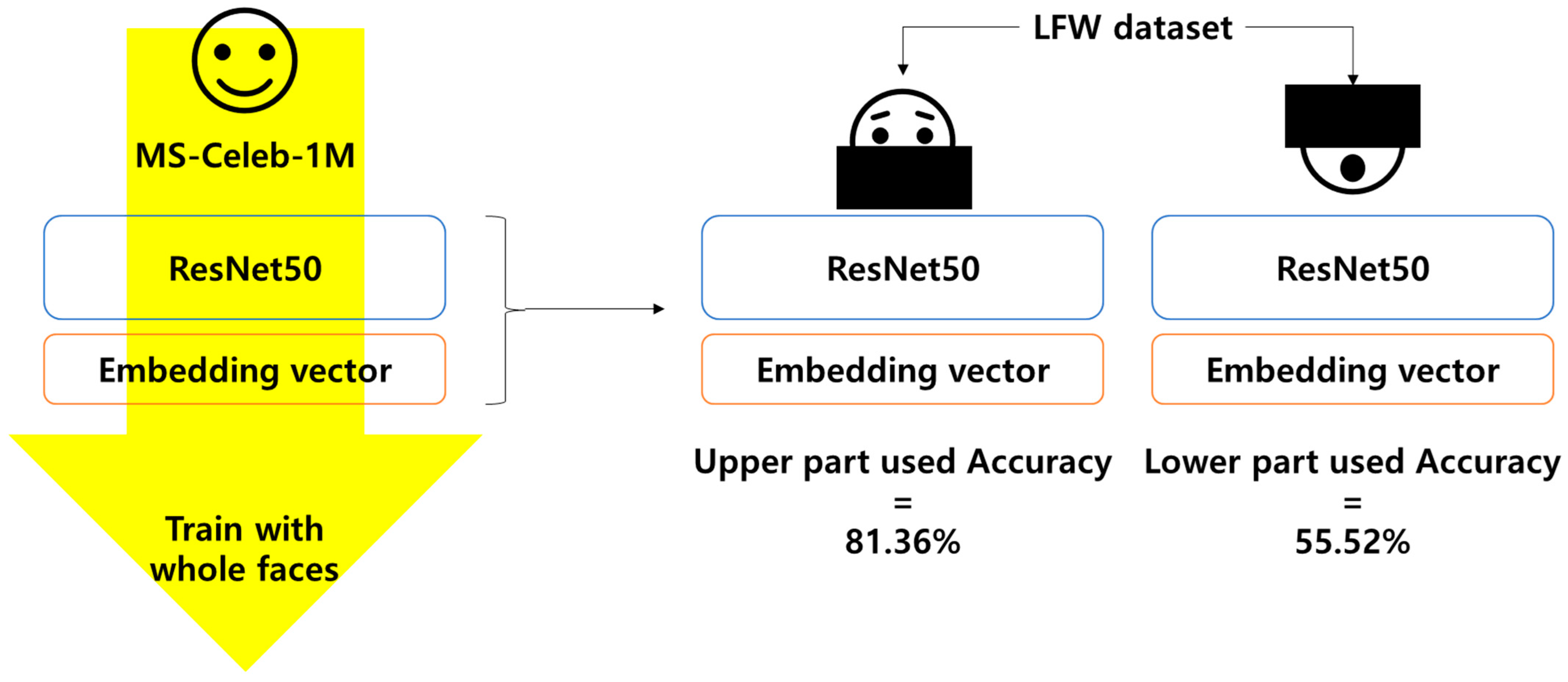
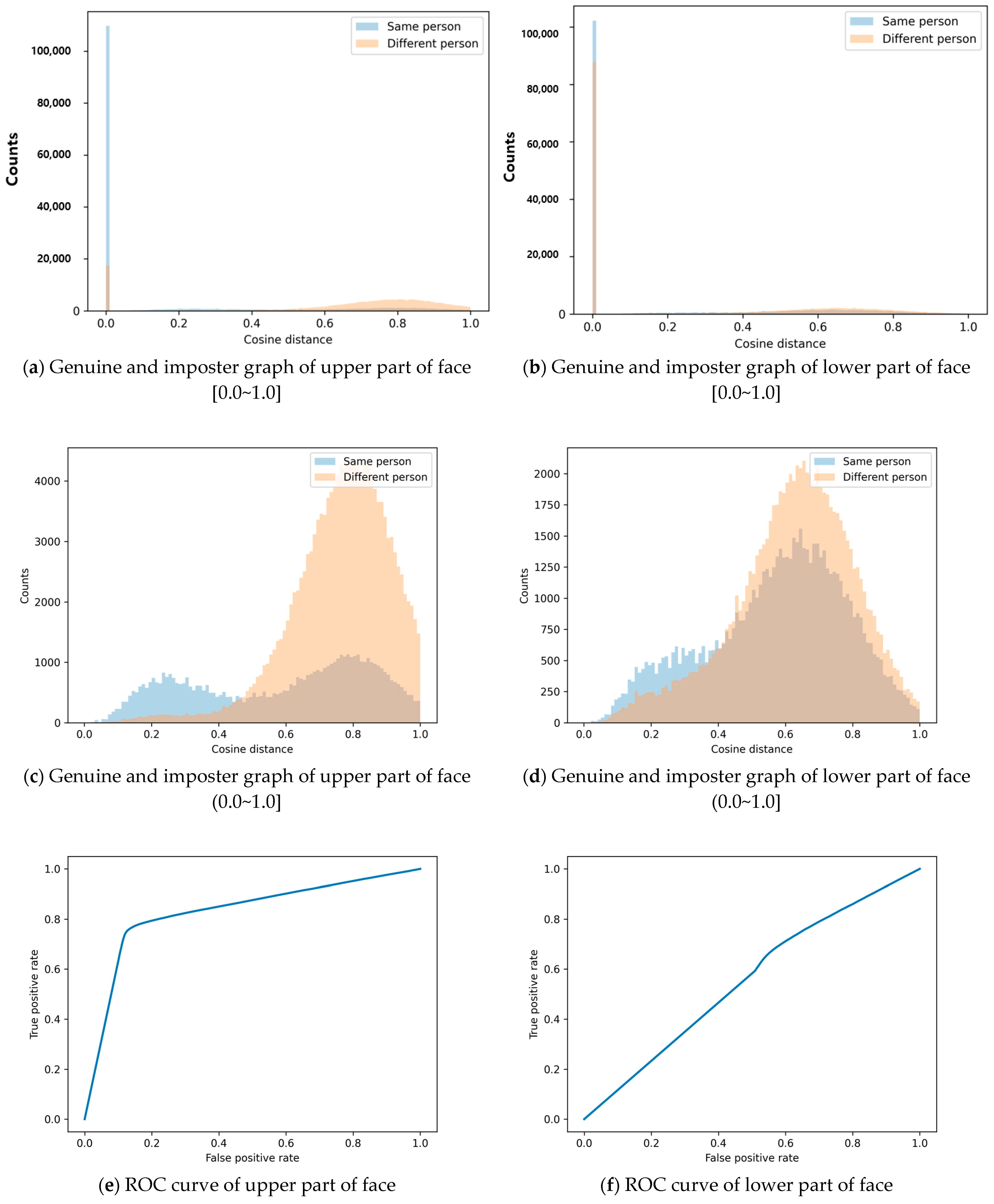
3.2. Face Identification
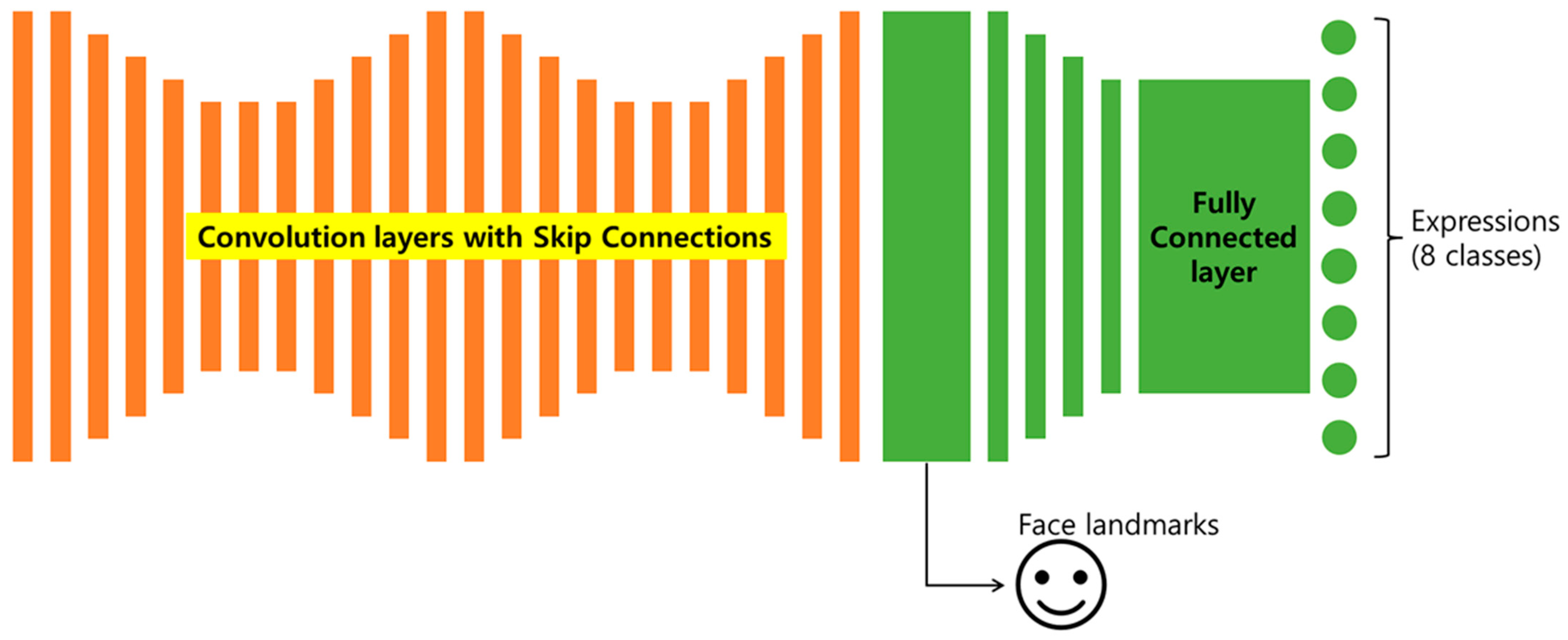
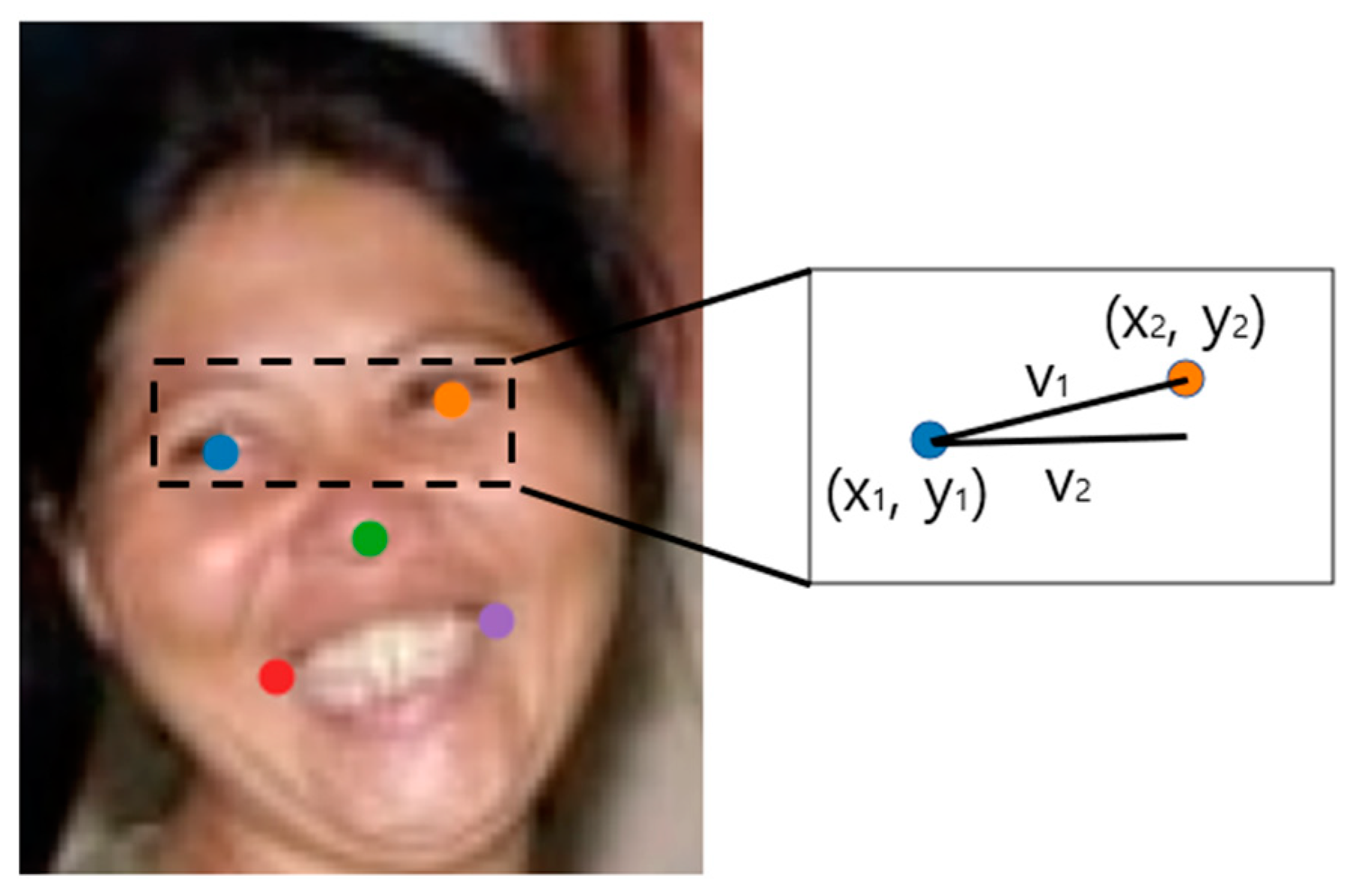
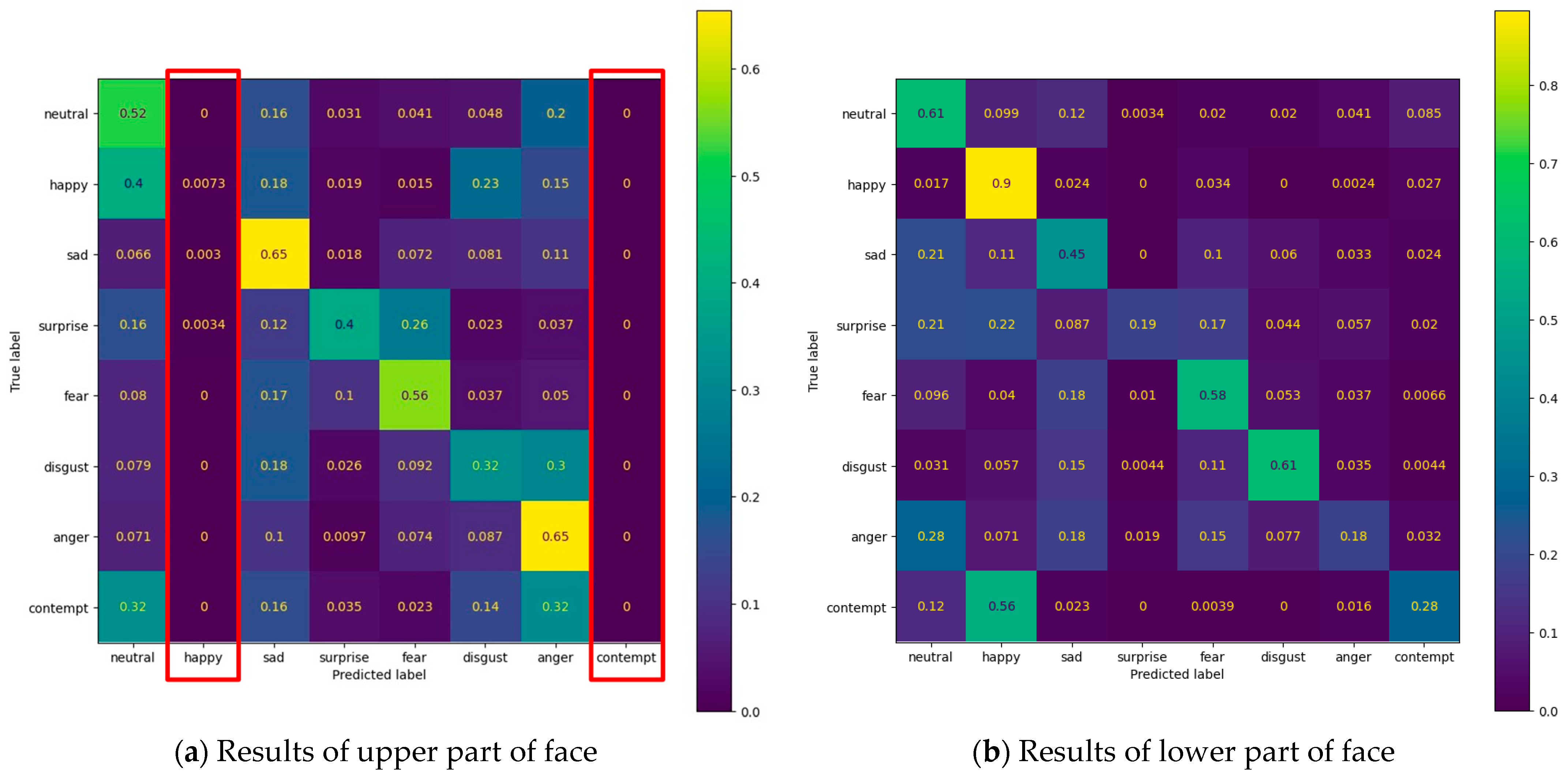
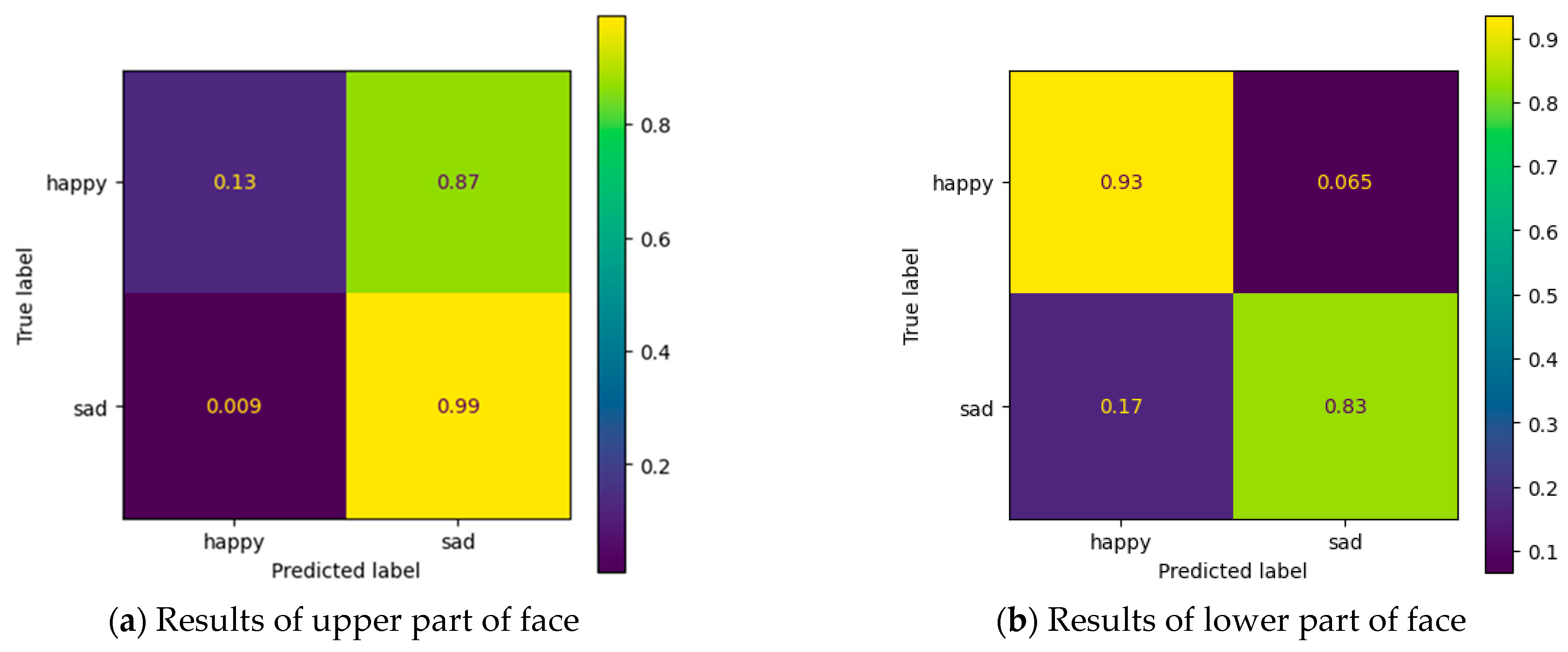
3.3. Facial Expression Recognition
4. Results
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Schneider, J.; Sandoz, V.; Equey, L.; Williams-Smith, J.; Horsch, A.; Graz, M.B. The Role of Face Masks in the Recognition of Emotions by Preschool Children. JAMA Pediatr. 2022, 176, 96. [Google Scholar] [CrossRef] [PubMed]
- Philippot, P.; Feldman, R.S. Age and social competence in preschoolers’ decoding of facial expression. Br. J. Soc. Psychol. 1990, 29, 43–54. [Google Scholar] [CrossRef] [PubMed]
- Ejaz, S.; Islam, R.; Sifatullah; Sarker, A. Implementation of Principal Component Analysis on Masked and Non-masked Face Recognition. In Proceedings of the 2019 1st International Conference on Advances in Science, Engineering and Robotics Technology, Dhaka, Bangladesh, 3–5 May 2019; pp. 1–5. [Google Scholar] [CrossRef]
- Tian, Y.-I.; Kanade, T.; Cohn, J. Recognizing action units for facial expression analysis. IEEE Trans. Pattern Anal. Mach. Intell. 2001, 23, 97–115. [Google Scholar] [CrossRef] [PubMed]
- Park, S.; Wallraven, C. Comparing Facial Expression Recognition in Humans and Machines: Using CAM, GradCAM, and Extremal Perturbation. In Proceedings of the Pattern Recognition: 6th Asian Conference, ACPR 2021, Jeju Island, Republic of Korea, 9–12 November 2021. [Google Scholar] [CrossRef]
- Nam, H.-H.; Kang, B.-J.; Park, K.-R. Comparison of Computer and Human Face Recognition According to Facial Components. J. Korea Multimedia Soc. 2012, 15, 40–50. [Google Scholar] [CrossRef]
- Comparison of Human and Computer Performance across Face Recognition Experiments—ScienceDirect. Available online: https://www.sciencedirect.com/science/article/pii/S0262885613001741 (accessed on 21 April 2023).
- Chen, M.-Y.; Chen, C.-C. The contribution of the upper and lower face in happy and sad facial expression classification. Vis. Res. 2010, 50, 1814–1823. [Google Scholar] [CrossRef] [PubMed]
- Abrosoft FantaMorph—Photo Morphing Software for Creating Morphing Photos and Animations. Available online: https://www.fantamorph.com/ (accessed on 21 April 2023).
- Itoh, M.; Yoshikawa, S. Relative importance of upper and lower parts of the face in recognizing facial expressions of emotion. J. Hum. Environ. Stud. 2011, 9, 89–95. [Google Scholar] [CrossRef]
- Seyedarabi, H.; Lee, W.-S.; Aghagolzadeh, A.; Khanmohammadi, S. Facial Expressions Recognition in a Single Static as well as Dynamic Facial Images Using Tracking and Probabilistic Neural Networks. Adv. Image Video Technol. 2006, 4319, 292–304. [Google Scholar] [CrossRef]
- Khoeun, R.; Chophuk, P.; Chinnasarn, K. Emotion Recognition for Partial Faces Using a Feature Vector Technique. Sensors 2022, 22, 4633. [Google Scholar] [CrossRef] [PubMed]
- Deng, H.; Feng, Z.; Qian, G.; Lv, X.; Li, H.; Li, G. MFCosface: A Masked-Face Recognition Algorithm Based on Large Margin Cosine Loss. Appl. Sci. 2021, 11, 7310. [Google Scholar] [CrossRef]
- Mukhiddinov, M.; Djuraev, O.; Akhmedov, F.; Mukhamadiyev, A.; Cho, J. Masked Face Emotion Recognition Based on Facial Landmarks and Deep Learning Approaches for Visually Impaired People. Sensors 2023, 23, 1080. [Google Scholar] [CrossRef] [PubMed]
- Pann, V.; Lee, H.J. Effective Attention-Based Mechanism for Masked Face Recognition. Appl. Sci. 2022, 12, 5590. [Google Scholar] [CrossRef]
- Stajduhar, A.; Ganel, T.; Avidan, G.; Rosenbaum, R.S.; Freud, E. Face masks disrupt holistic processing and face perception in school-age children. Cogn. Res. Princ. Implic. 2022, 7, 9. [Google Scholar] [CrossRef] [PubMed]
- Wang, M.; Deng, W. Deep face recognition: A survey. Neurocomputing 2020, 429, 215–244. [Google Scholar] [CrossRef]
- Schroff, F.; Kalenichenko, D.; Philbin, J. FaceNet: A Unified Embedding for Face Recognition and Clustering. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 815–823. [Google Scholar]
- Parkhi, O.M.; Vedaldi, A.; Zisserman, A. Deep Face Recognition. In Proceedings of the British Machine Vision Conference 2015, Swansea, UK, 7–10 September 2015; British Machine Vision Association: Swansea, UK, 2015; p. 41. [Google Scholar]
- Deng, J.; Guo, J.; Yang, J.; Xue, N.; Kotsia, I.; Zafeiriou, S. ArcFace: Additive Angular Margin Loss for Deep Face Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 44, 5962–5979. [Google Scholar] [CrossRef] [PubMed]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar] [CrossRef]
- Guo, Y.; Zhang, L.; Hu, Y.; He, X.; Gao, J. MS-Celeb-1M: A Dataset and Benchmark for Large-Scale Face Recognition. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; Leibe, B., Matas, J., Sebe, N., Eds.; Max Welling Springer: Cham, Switzerland, 2016; pp. 87–102. [Google Scholar]
- Mollahosseini, A.; Hasani, B.; Mahoor, M.H. AffectNet: A Database for Facial Expression, Valence, and Arousal Computing in the Wild. IEEE Trans. Affect. Comput. 2017, 10, 18–31. [Google Scholar] [CrossRef]
- Antoine, T.; Kossaifi, J.; Bulat, A.; Tzimiropoulos, G.; Pantic, M. Estimation of Continuous Valence and Arousal Levels from Faces in Naturalistic Conditions. Nat. Mach. Intell. 2021, 3, 42–50. [Google Scholar] [CrossRef]
- Savchenko, A.V.; Savchenko, L.V.; Makarov, I. Classifying Emotions and Engagement in Online Learning Based on a Single Facial Expression Recognition Neural Network. IEEE Trans. Affect. Comput. 2022, 13, 2132–2143. [Google Scholar] [CrossRef]
- The Latest in Machine Learning|Papers with Code. Available online: https://paperswithcode.com/ (accessed on 11 April 2023).
- Zhang, K.; Zhang, Z.; Li, Z.; Qiao, Y. Joint Face Detection and Alignment Using Multitask Cascaded Convolutional Networks. IEEE Signal Process. Lett. 2016, 23, 1499–1503. [Google Scholar] [CrossRef]
- Huang, G.B.; Ramesh, M.; Berg, T.; Learned-Miller, E. Labeled Faces in the Wild: A Database for Studying Face Recognition in Unconstrained Environments; University of Massachusetts: Amherst, MA, USA, 2007. [Google Scholar]
- Chen, X.; Duan, Y.; Houthooft, R.; Schulman, J.; Sutskever, I.; Abbeel, P. InfoGAN: Interpretable Representation Learning by In-formation Maximizing Generative Adversarial Nets. Adv. Neural Inf. Process. Syst. 2016, 29, 2180–2188. [Google Scholar] [CrossRef]
- Moschoglou, S.; Papaioannou, A.; Sagonas, C.; Deng, J.; Kotsia, I.; Zafeiriou, S. AgeDB: The First Manually Collected, In-the-Wild Age Database. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Honolulu, HI, USA, 21–26 July 2017; pp. 1997–2005. [Google Scholar] [CrossRef]
- Ekman, P.; Friesen, W. Facial Action Coding System: A Technique for the Measurement of Facial Movement. 1978. Available online: https://www.paulekman.com/facial-action-coding-system/ (accessed on 23 April 2023).













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Summary | Limitations |
|---|---|---|
| Che et al. [8] | Using the FantaMorph 4.0 dataset, the sad and happy facial expressions were divided into 7 steps. | Lack of test data set and classifying only happy and sad emotions. |
| Mika Itoh at el. [10] | The six emotions were tested by changing only the upper part of the face, and the relationship between each emotion was analyzed. | The lack of access to a diverse demographic pool based on the opinion of a female college student.The data used in the experiment were small and self-generated. |
| Seyedarabi et al. [11] | In the faces extracted from images and videos, the effect of Action Unit on upper and lower facial expression classification was analyzed. | The characteristics of action units were classified for the entire face. Characteristics by region of the face were not analyzed. |
| Khoeun et al. [12] | Using the CK+ and RAF-DB datasets, this study generated a face wearing a mask and calculated the accuracy through CNN. | Only the upper part of the face was used to analyze the effect of the upper part. |
| Method | Summary | Limitations |
|---|---|---|
| Deng et al. [13] | This uses MTCNN to synthesize the mask on the face. Face recognition is performed using the Att-Inception module. | An effect of mask type on accuracy cannot be ruled out. |
| Mukhiddinov et al. [14] | After converting the AffectNet data set into a high-contrast image, the experiment was conducted. After generating a mask with the MaskTheFace algorithm, the result was derived through CNN. | Face recognition accuracy cannot be guaranteed in a wild environment through high-contrast conversion. |
| Pann et al. [15] | The image preprocessed through CBAM and ArcFace was used for upper part recognition through mask synthesis. | Only the upper part of the face was studied. |
| Stajduhar et al. [16] | After presenting faces in forward and reverse directions, face recognition was performed on children. | Only male faces were used as the dataset. |
| Upper Parts | Lower Parts | |
| Face identification | 81.36% | 55.52% |
| Facial Expression Recognition (8 classes) | 39% | 49% |
| Facial Expression Recognition (2 classes) | 51% | 88% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kim, S.; An, B.S.; Lee, E.C. Comparative Analysis of AI-Based Facial Identification and Expression Recognition Using Upper and Lower Facial Regions. Appl. Sci. 2023, 13, 6070. https://doi.org/10.3390/app13106070
Kim S, An BS, Lee EC. Comparative Analysis of AI-Based Facial Identification and Expression Recognition Using Upper and Lower Facial Regions. Applied Sciences. 2023; 13(10):6070. https://doi.org/10.3390/app13106070
Chicago/Turabian StyleKim, Seunghyun, Byeong Seon An, and Eui Chul Lee. 2023. "Comparative Analysis of AI-Based Facial Identification and Expression Recognition Using Upper and Lower Facial Regions" Applied Sciences 13, no. 10: 6070. https://doi.org/10.3390/app13106070
APA StyleKim, S., An, B. S., & Lee, E. C. (2023). Comparative Analysis of AI-Based Facial Identification and Expression Recognition Using Upper and Lower Facial Regions. Applied Sciences, 13(10), 6070. https://doi.org/10.3390/app13106070