
Point–Line-Aware Heterogeneous Graph Attention Network for Visual SLAM System


Abstract
1. Introduction
- To solve the problem of weak point–line extraction ability in complex scenes, a point–line synchronous geometric feature extraction network, PL-Net, is proposed. We use an optimized residual block-feature pyramid network (ORB-FPN) to extract the feature map of the input image. In the point extraction branch, based on the point-aware module, the multiscale context is aggregated to obtain features with rich receptive fields. Moreover, the edge information is used for the line extraction branch to improve the accuracy of the line-segment detection. In order to make the network lightweight, a transfer-aware knowledge distillation method is proposed to compress the model for generating the point–line feature in the extraction task.
- Targeting a high accuracy and efficiency, a heterogeneous attention graph neural network (HAGNN) is presented, which uses an edge-aggregated graph attention network (EAGAT) to iterate the vertices of the heterogeneous graph constructed from points and lines. To enhance the performance of the point–line matching, a cross-heterogeneous graph interaction (CHGI) is used for harmonizing heterogeneous information between graphs.
- By transforming the point–line matching process into an optimal transport problem, a greedy inexact proximal point method for optimal transport, GIPOT, is proposed, which calculates the optimal feature assignment matrix to find the global optimal solution for the point–line matching problem.
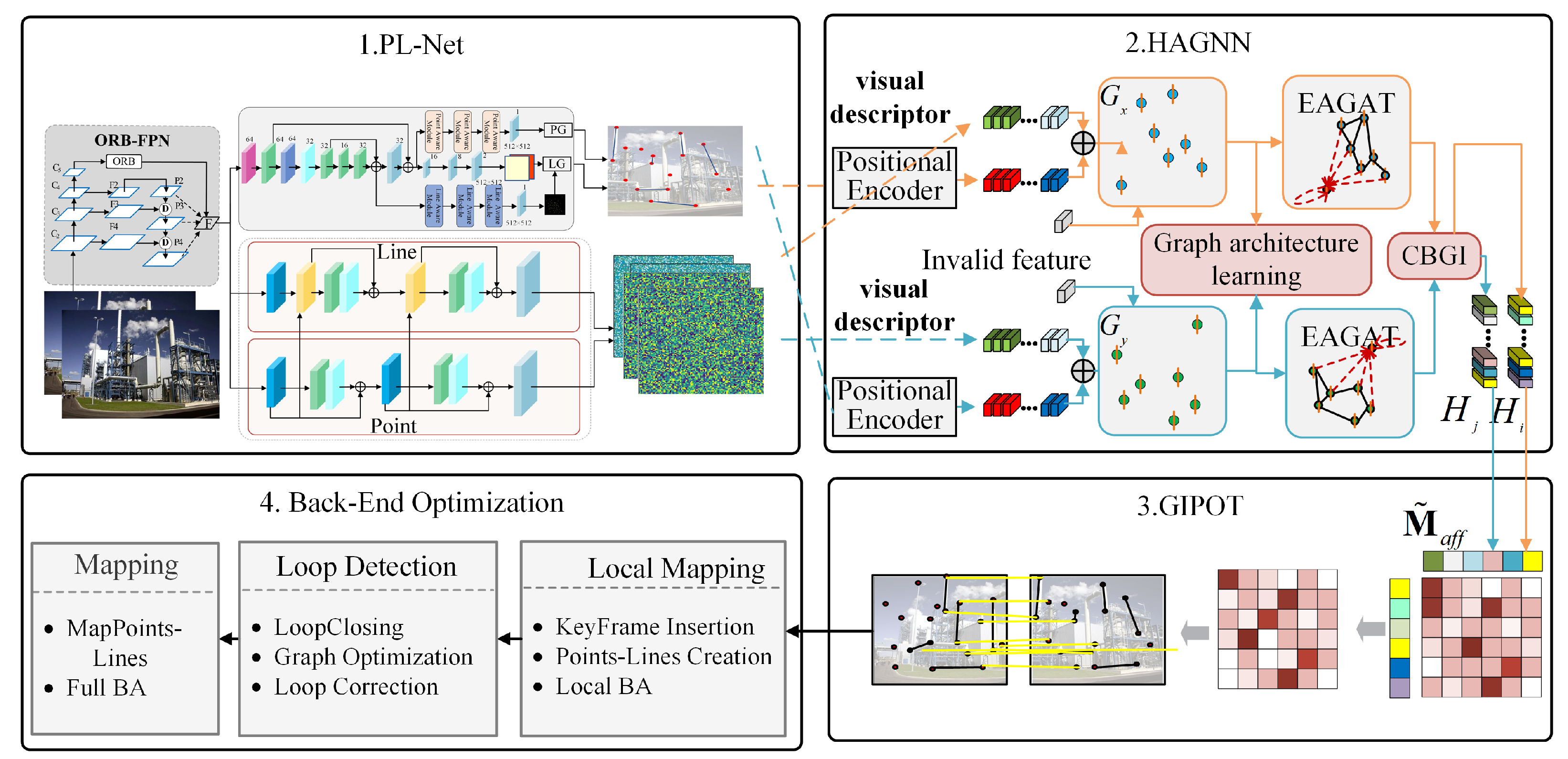
2. SLAM System Framework
3. Methodology
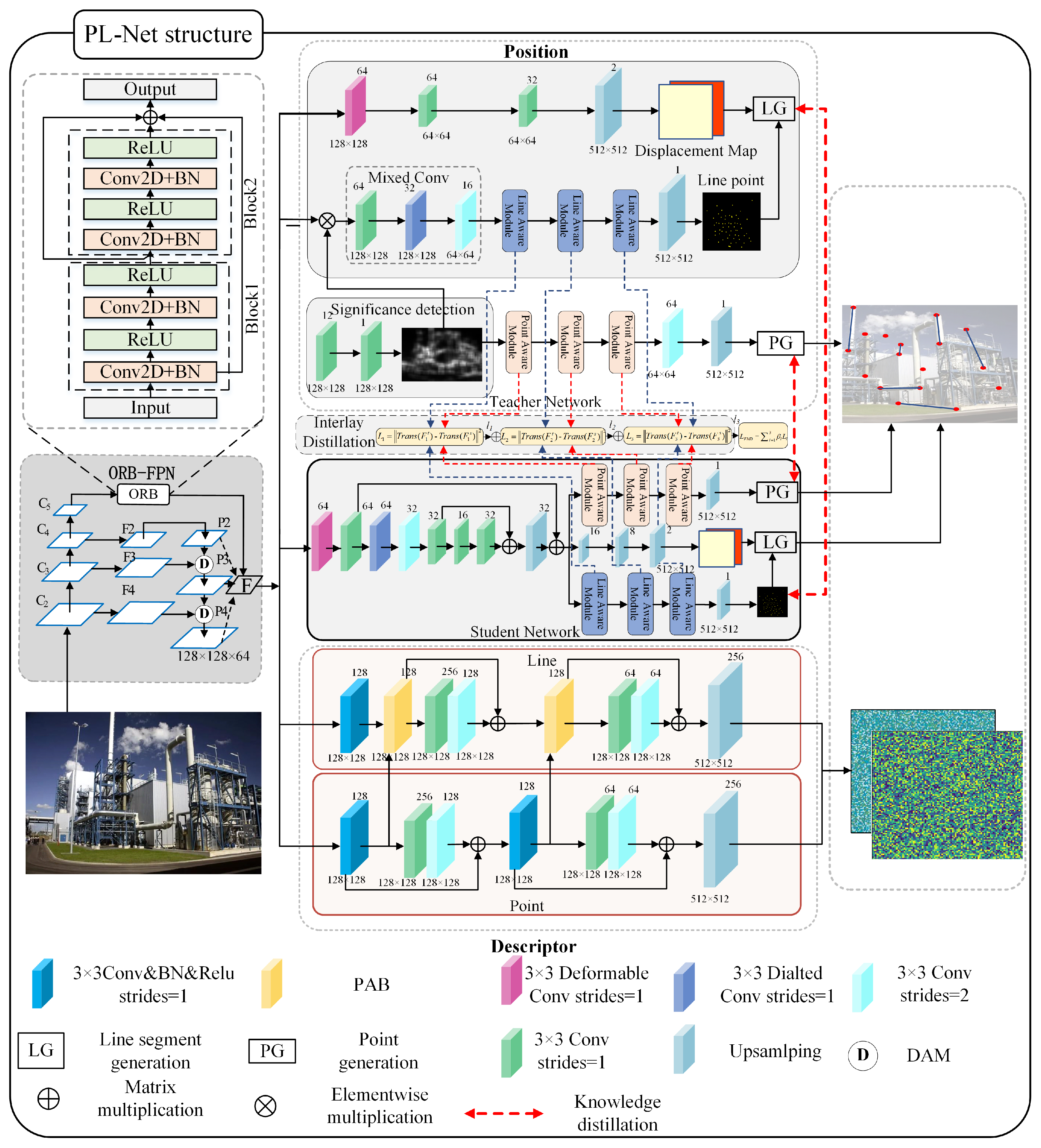
3.1. Point–Line Feature Extraction Network
3.1.1. ORB-FPN Module
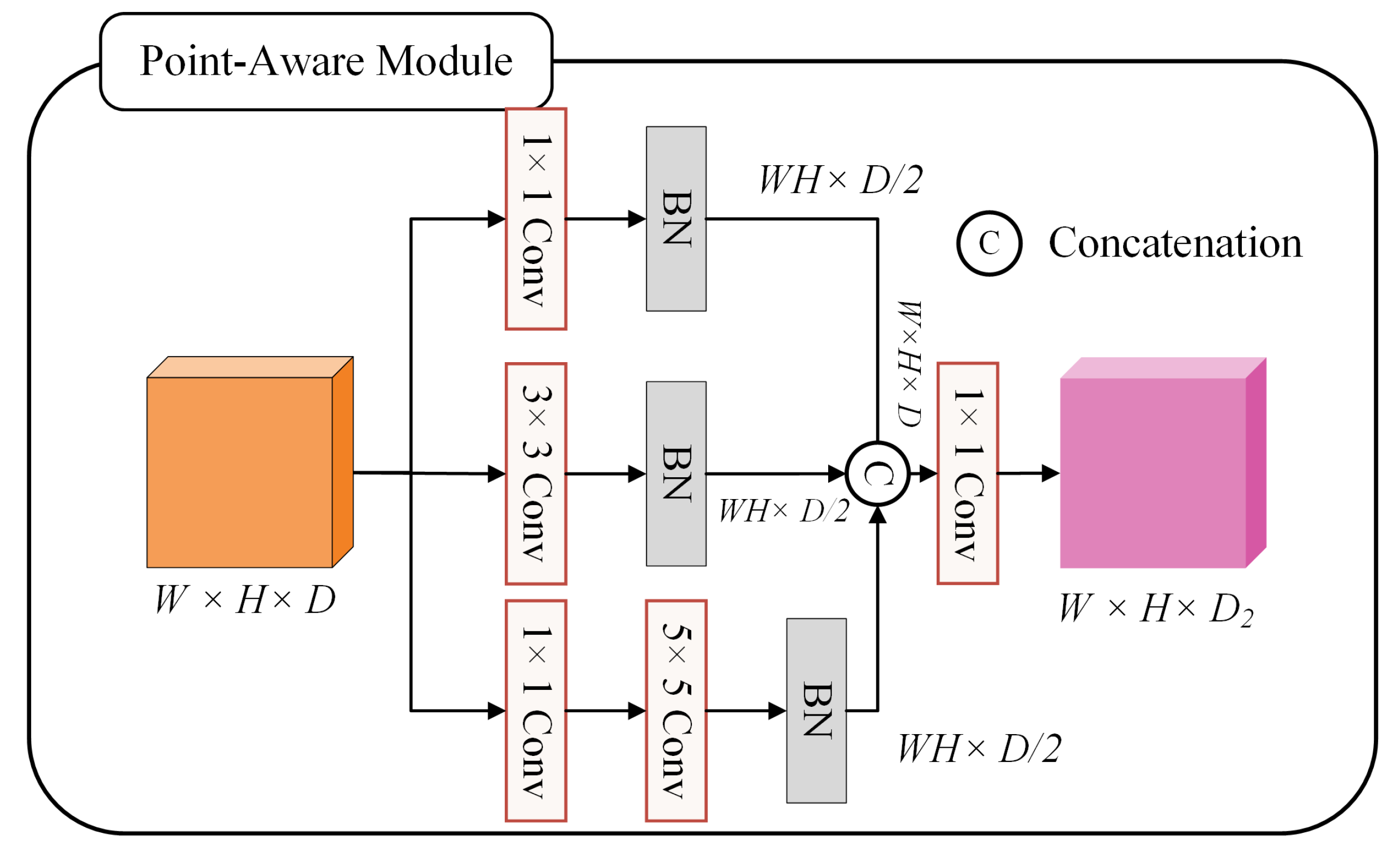
3.1.2. Key-point Detection Module
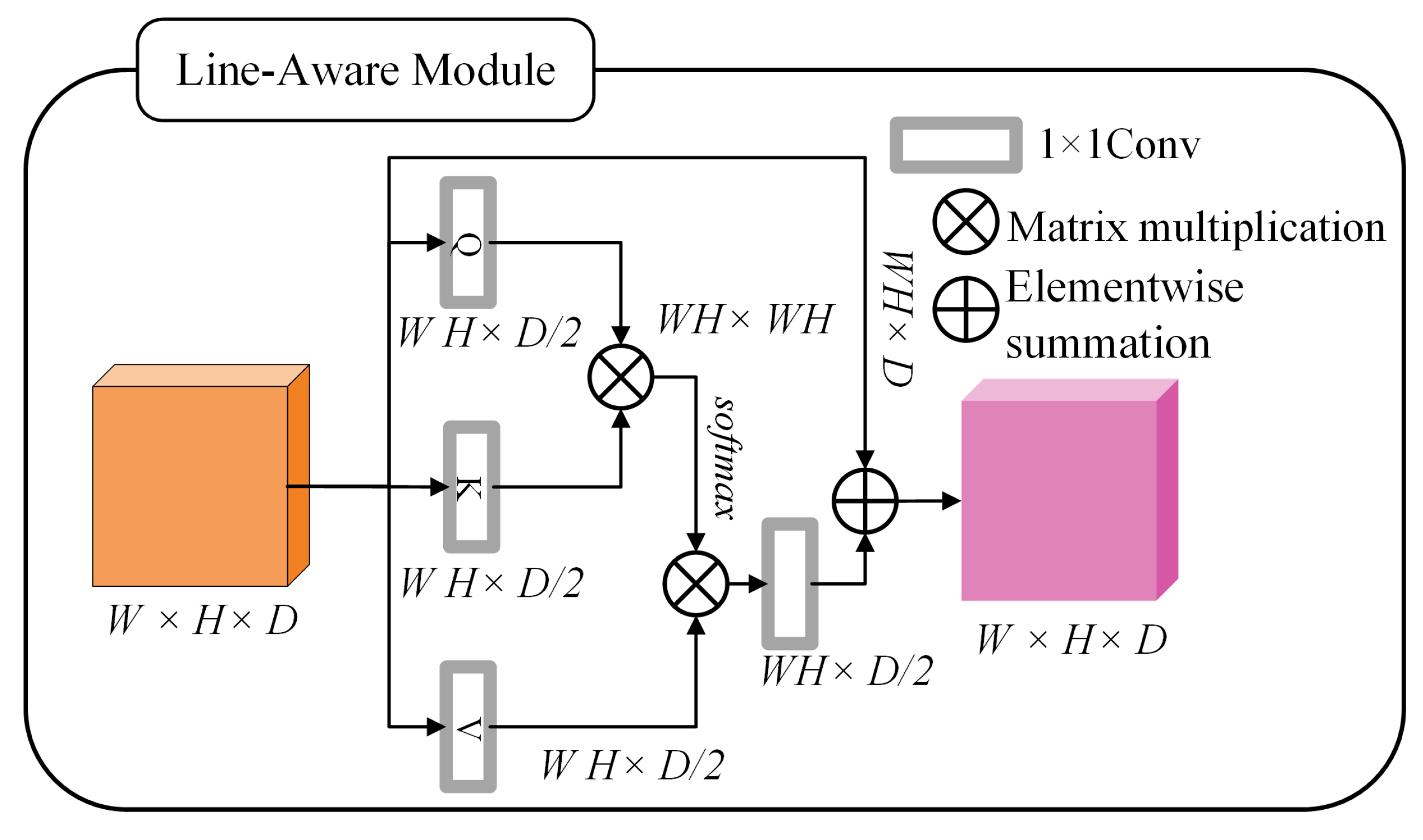
3.1.3. Line-Segment Detection Module
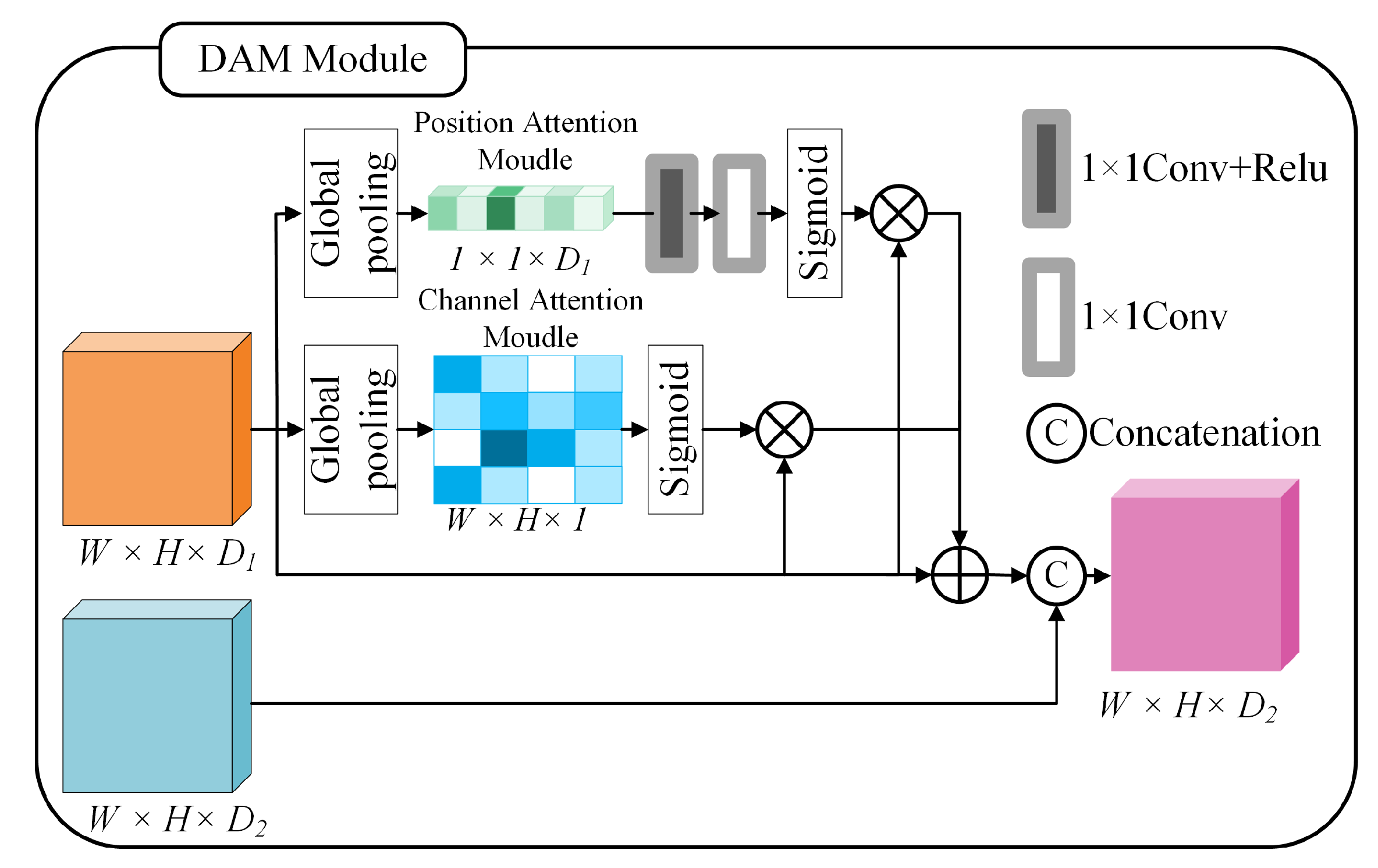
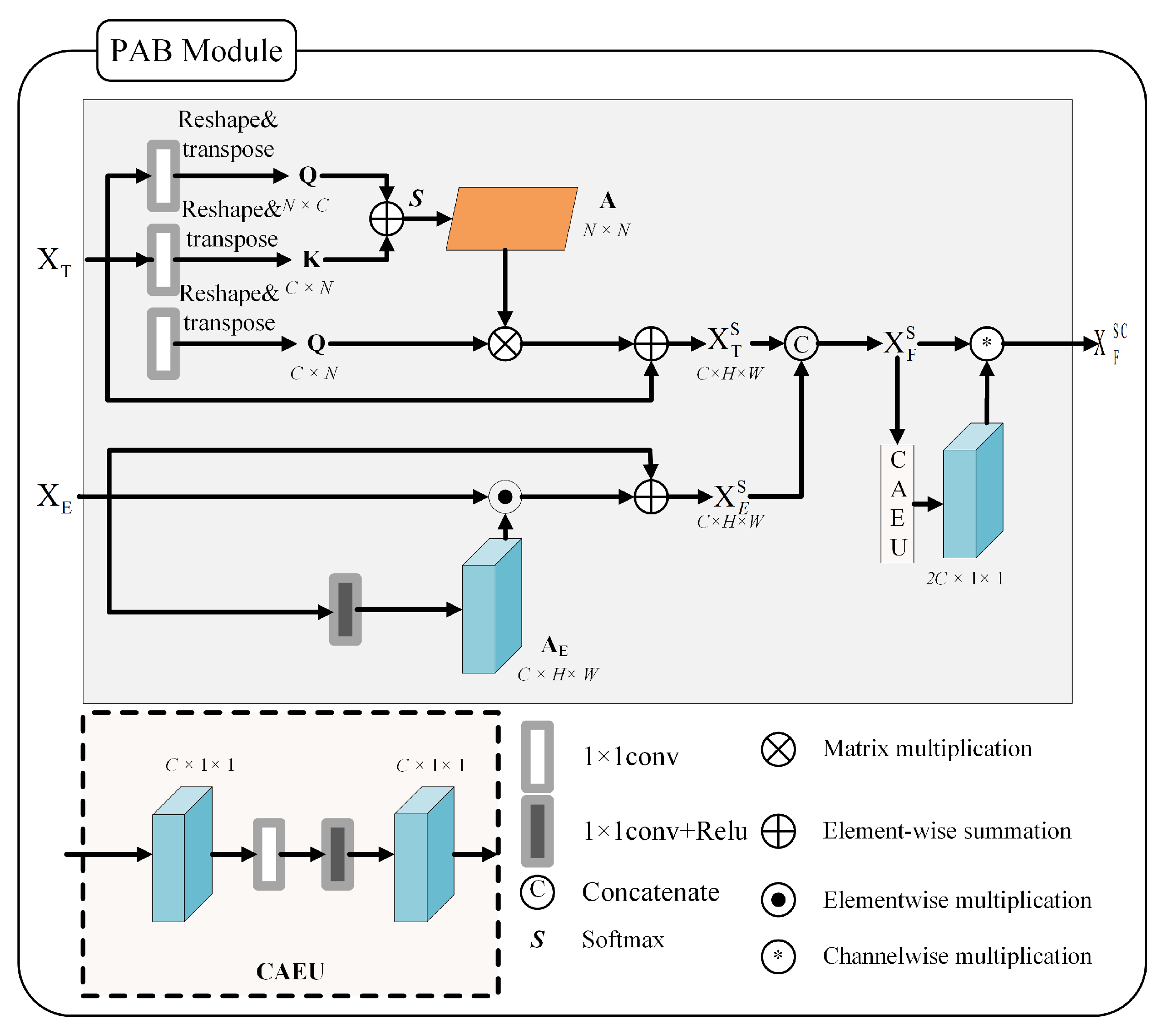
3.1.4. Parallel Attention Module
3.1.5. Network Output Distillation
3.1.6. Interlayer Knowledge Distillation
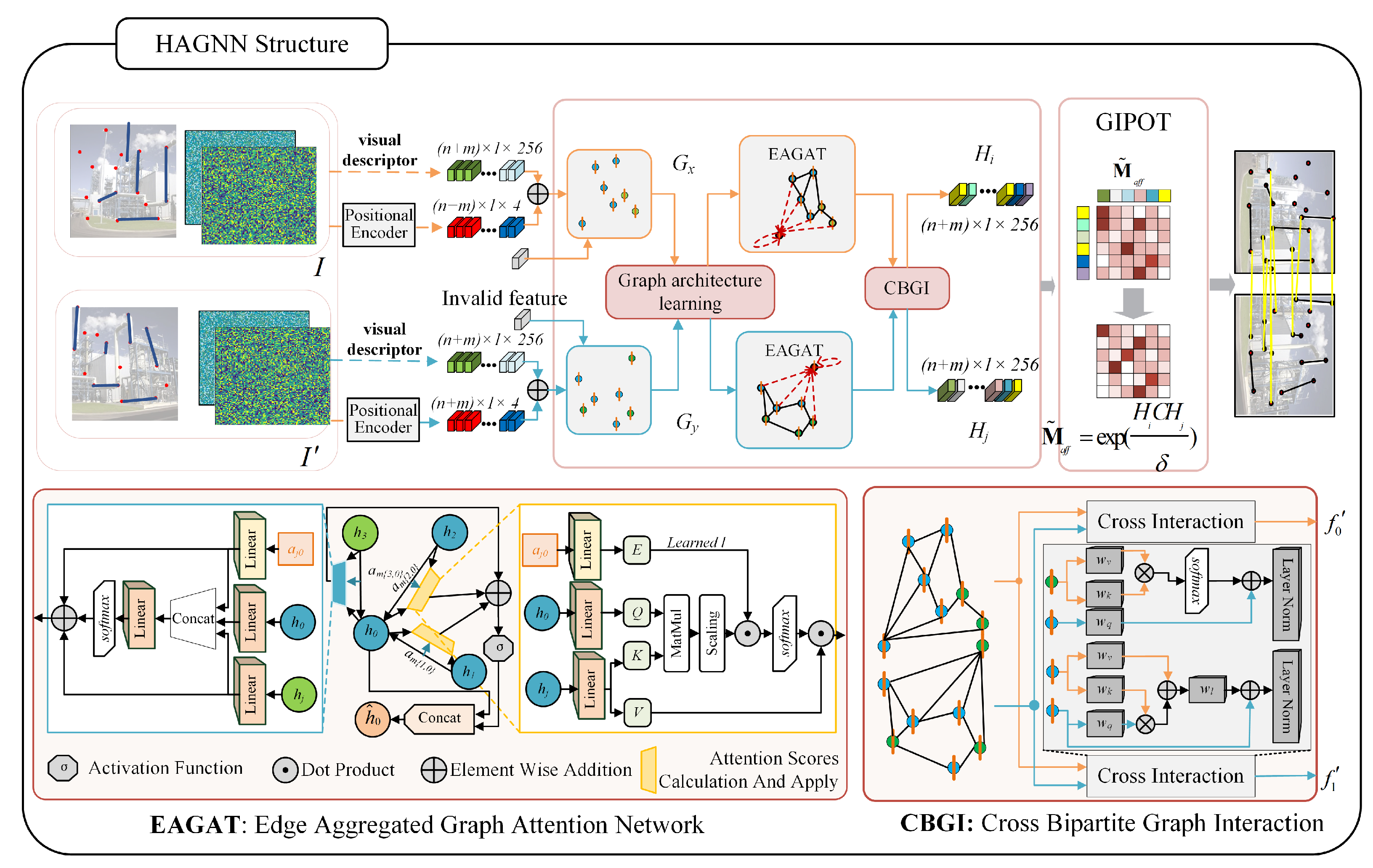
3.2. Heterogeneous Graph Attention Network
3.2.1. Edge-Clustering Graph Attention Module
3.2.2. Cross-Heterogeneous Graph Iteration Module
3.3. Greedy near Iterative Matching Module

3.4. Loss Function
3.4.1. Point–Line Extraction Loss
3.4.2. Point–Line Descriptor Loss
3.4.3. Matching Loss
3.4.4. Normalization
4. Experiments and Evaluation
4.1. Model Training Details
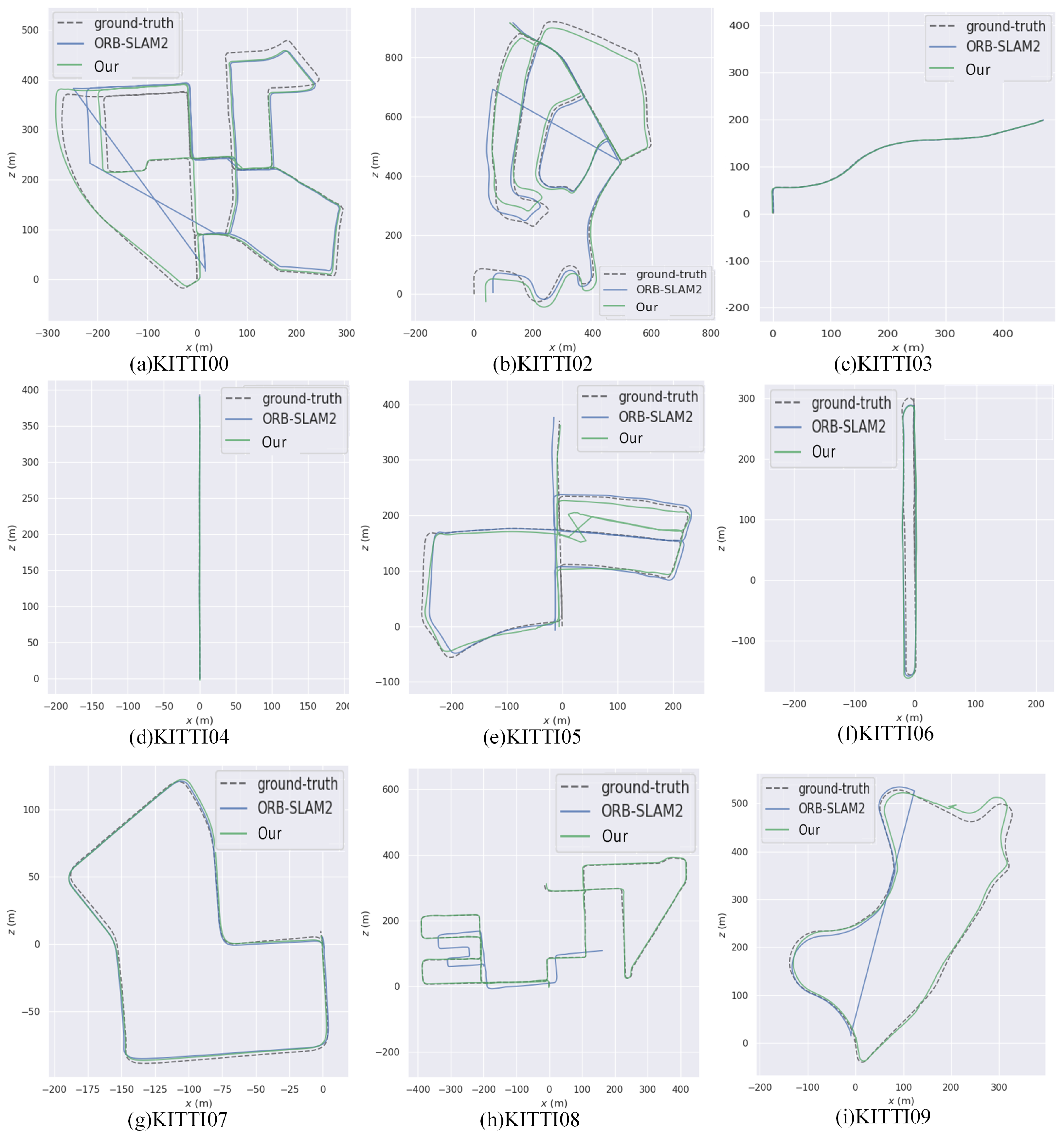
4.2. KITTI Dataset Evaluation
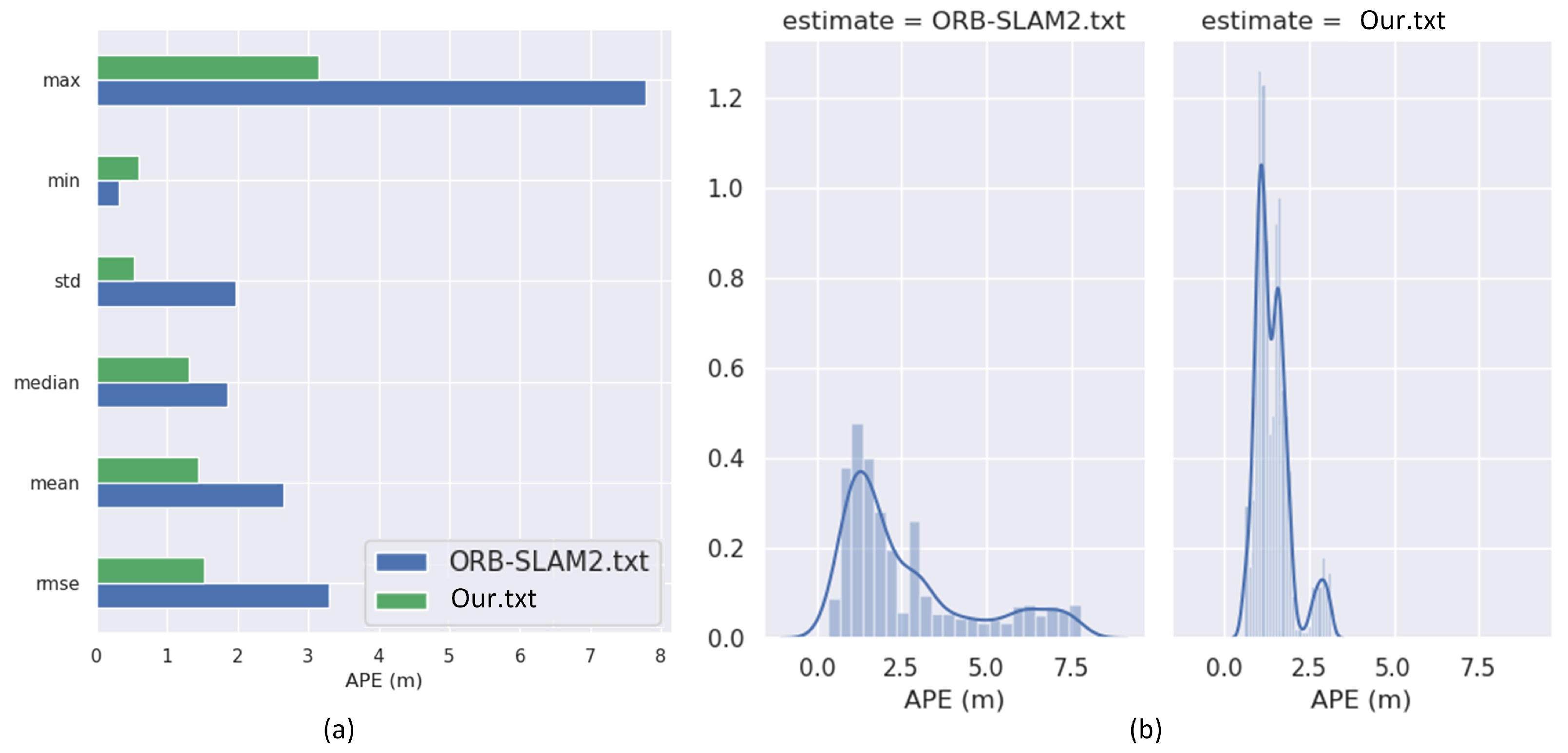
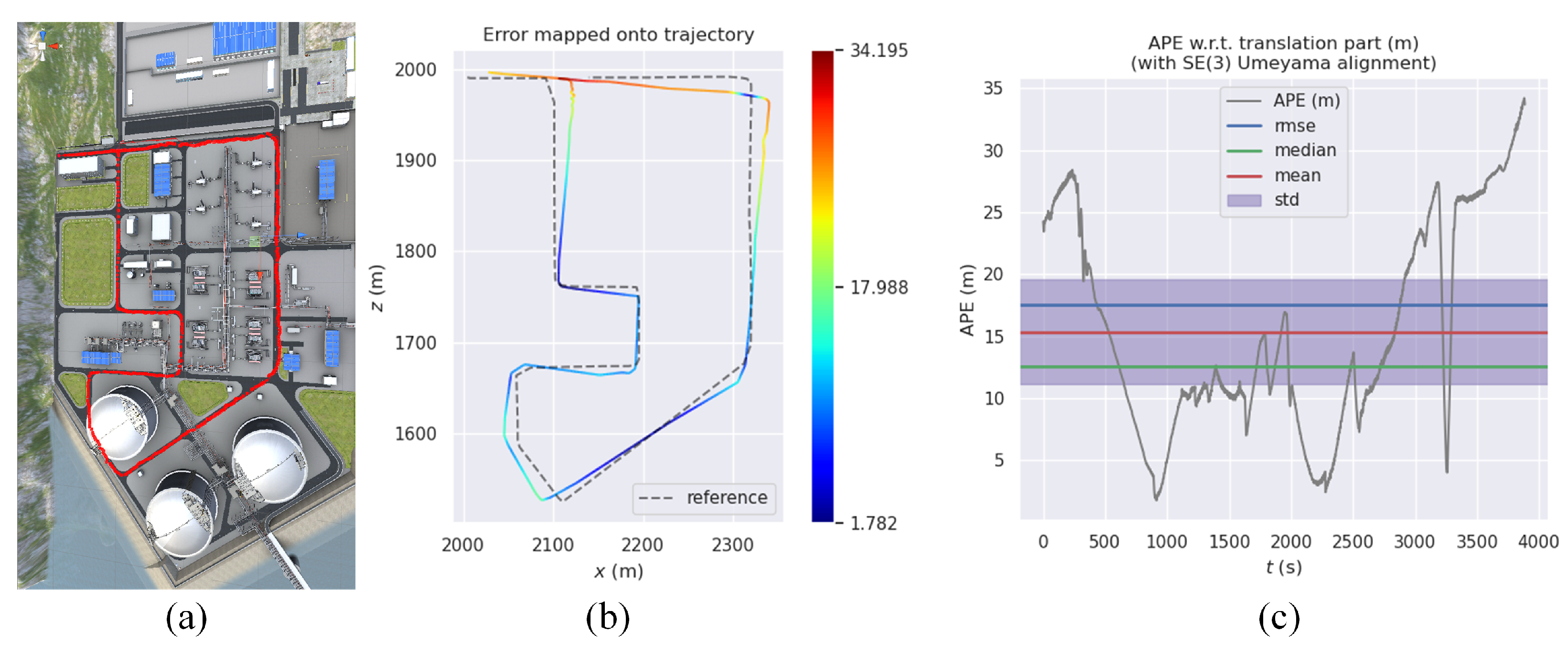
4.3. Real Data Evaluation
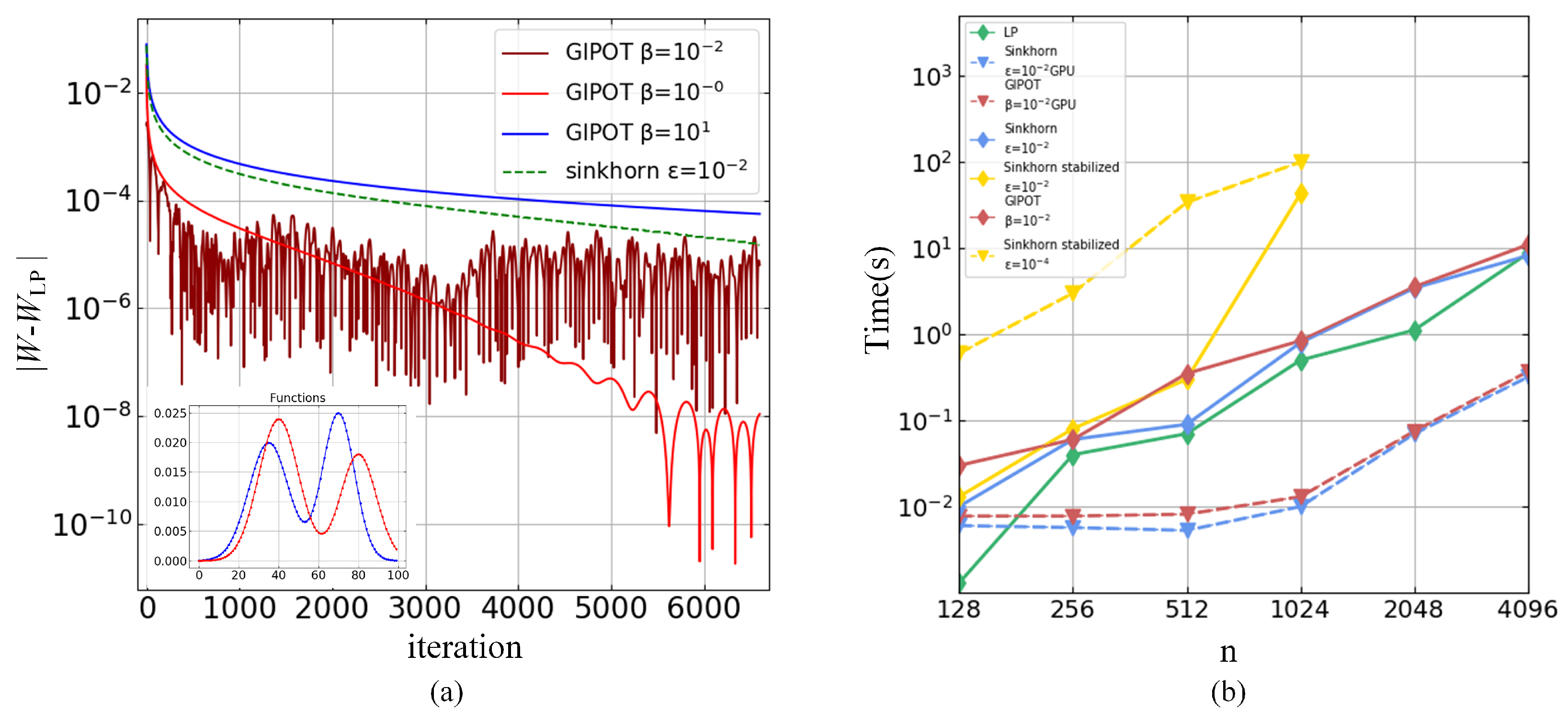
4.4. GIPOT Experiment
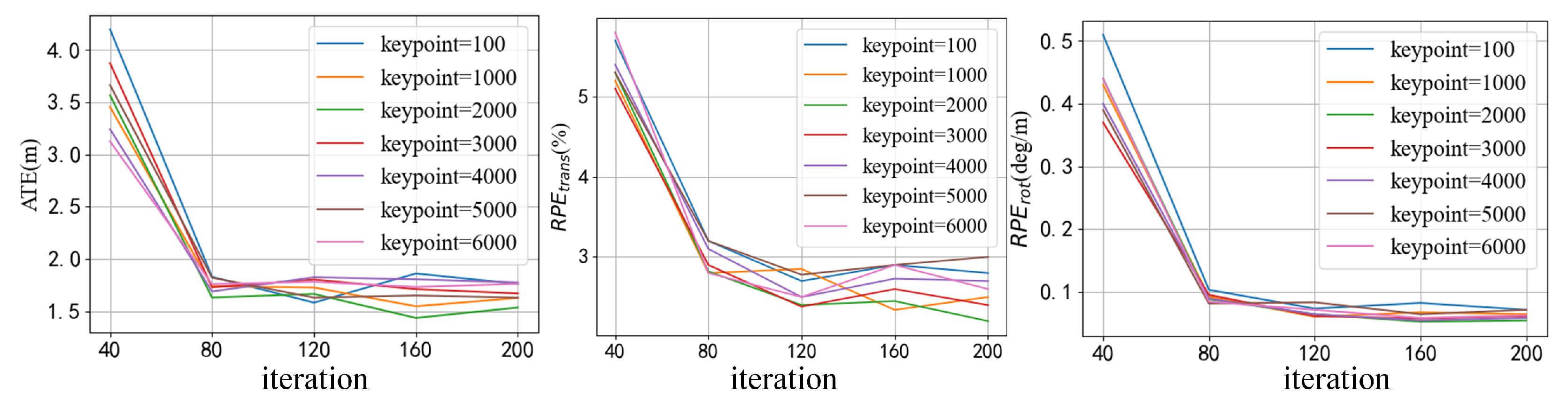
4.5. Ablation Study
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Yousif, K.; Bab-Hadiashar, A.; Hoseinnezhad, R. An overview to visual odometry and visual SLAM: Applications to mobile robotics. Intell. Ind. Syst. 2015, 1, 289–311. [Google Scholar] [CrossRef]
- Demim, F.; Nemra, A.; Boucheloukh, A.; Louadj, K.; Hamerlain, M.; Bazoula, A. Robust SVSF-SLAM algorithm for unmanned vehicle in dynamic environment. In Proceedings of the 2018 International Conference on Signal, Image, Vision and Their Applications (SIVA), Guelma, Algeria, 26–27 November 2018; pp. 1–5. [Google Scholar]
- Demim, F.; Nemra, A.; Boucheloukh, A.; Kobzili, E.; Hamerlain, M.; Bazoula, A. SLAM based on adaptive SVSF for cooperative unmanned vehicles in dynamic environment. IFAC-PapersOnLine 2019, 52, 73–80. [Google Scholar] [CrossRef]
- Kuo, X.Y.; Liu, C.; Lin, K.C.; Lee, C.Y. Dynamic attention-based visual odometry. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Seattle, WA, USA, 14–19 June 2020; pp. 36–37. [Google Scholar]
- Teixeira, B.; Silva, H.; Matos, A.; Silva, E. Deep learning for underwater visual odometry estimation. IEEE Access 2020, 8, 44687–44701. [Google Scholar] [CrossRef]
- Lee, T.; Kim, C.-H.; Cho, D.-i.D. A monocular vision sensor-based efficient SLAM method for indoor service robots. IEEE Trans. Ind. Electron. 2018, 66, 318–328. [Google Scholar] [CrossRef]
- Zhang, L.; Koch, R. An efficient and robust line segment matching approach based on LBD descriptor and pairwise geometric consistency. J. Vis. Commun. Image Represent. 2013, 24, 794–805. [Google Scholar] [CrossRef]
- Cho, H.; Kim, E.K.; Kim, S. Indoor SLAM application using geometric and ICP matching methods based on line features. Robot. Auton. Syst. 2018, 100, 206–224. [Google Scholar] [CrossRef]
- Han, R.; Li, W.F. Line-feature-based SLAM algorithm. Acta Autom. Sin. 2006, 32, 43–46. [Google Scholar]
- Zhou, D.; Dai, Y.; Li, H. Ground-plane-based absolute scale estimation for monocular visual odometry. IEEE Trans. Intell. Transp. Syst. 2019, 21, 791–802. [Google Scholar] [CrossRef]
- Yang, S.; Scherer, S. Monocular object and plane slam in structured environments. IEEE Robot. Autom. Lett. 2019, 4, 3145–3152. [Google Scholar] [CrossRef]
- Cho, H.; Yeon, S.; Choi, H.; Doh, N. Detection and compensation of degeneracy cases for imu-kinect integrated continuous slam with plane features. Sensors 2018, 18, 935. [Google Scholar] [CrossRef]
- Gomez-Ojeda, R.; Moreno, F.A.; Zuniga-Noël, D.; Scaramuzza, D.; Gonzalez-Jimenez, J. PL-SLAM: A stereo SLAM system through the combination of points and line segments. IEEE Trans. Robot. 2019, 35, 734–746. [Google Scholar] [CrossRef]
- Zhang, X.; Wang, W.; Qi, X.; Liao, Z.; Wei, R. Point-plane slam using supposed planes for indoor environments. Sensors 2019, 19, 3795. [Google Scholar] [CrossRef] [PubMed]
- Grant, W.S.; Voorhies, R.C.; Itti, L. Efficient Velodyne SLAM with point and plane features. Auton. Robot. 2019, 43, 1207–1224. [Google Scholar] [CrossRef]
- Sun, Q.; Yuan, J.; Zhang, X.; Duan, F. Plane-Edge-SLAM: Seamless fusion of planes and edges for SLAM in indoor environments. IEEE Trans. Autom. Sci. Eng. 2020, 18, 2061–2075. [Google Scholar] [CrossRef]
- Chen, X.; Cai, Y.; Tang, Y. A visual SLAM algorithm based on line point invariants. Robot 2020, 42, 485–493. [Google Scholar]
- Li, H.; Hu, Z.; Chen, X. PLP-SLAM: A visual SLAM method based on point-line-plane feature fusion. Jiqiren 2017, 39, 214–220. [Google Scholar]
- Simo-Serra, E.; Trulls, E.; Ferraz, L.; Kokkinos, I.; Fua, P.; Moreno-Noguer, F. Discriminative learning of deep convolutional feature point descriptors. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 118–126. [Google Scholar]
- Fu, K.; Liu, Z.; Wu, X.; Sun, C.; Chen, W. An Effective End-to-End Image Matching Network with Attentional Graph Neural Networks. In Proceedings of the 2022 IEEE 17th Conference on Industrial Electronics and Applications (ICIEA), Chengdu, China, 15–18 April 2022; pp. 1628–1633. [Google Scholar]
- Zhang, J.; Marszałek, M.; Lazebnik, S.; Schmid, C. Local features and kernels for classification of texture and object categories: A comprehensive study. Int. J. Comput. Vis. 2007, 73, 213–238. [Google Scholar] [CrossRef]
- Sarlin, P.E.; DeTone, D.; Malisiewicz, T.; Rabinovich, A. Superglue: Learning feature matching with graph neural networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 4938–4947. [Google Scholar]
- Tang, J.; Ericson, L.; Folkesson, J.; Jensfelt, P. GCNv2: Efficient correspondence prediction for real-time SLAM. IEEE Robot. Autom. Lett. 2019, 4, 3505–3512. [Google Scholar] [CrossRef]
- Tang, J.; Folkesson, J.; Jensfelt, P. Geometric correspondence network for camera motion estimation. IEEE Robot. Autom. Lett. 2018, 3, 1010–1017. [Google Scholar] [CrossRef]
- Pautrat, R.; Lin, J.T.; Larsson, V.; Oswald, M.R.; Pollefeys, M. SOLD2: Self-supervised occlusion-aware line description and detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 11368–11378. [Google Scholar]
- Li, H.; Yang, Y.; Chen, D.; Lin, Z. Optimization algorithm inspired deep neural network structure design. In Proceedings of the Asian Conference on Machine Learning, Beijing, China, 14–16 November 2018; pp. 614–629. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30, 1–11. [Google Scholar]
- Duan, K.; Bai, S.; Xie, L.; Qi, H.; Huang, Q.; Tian, Q. Centernet: Keypoint triplets for object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 6569–6578. [Google Scholar]
- Zhang, H.; Luo, Y.; Qin, F.; He, Y.; Liu, X. ELSD: Efficient Line Segment Detector and Descriptor. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 2969–2978. [Google Scholar]
- Hinton, G.; Vinyals, O.; Dean, J. Distilling the knowledge in a neural network. arXiv 2015, arXiv:1503.02531. [Google Scholar]
- Zhang, K.; Zhang, C.; Li, S.; Zeng, D.; Ge, S. Student network learning via evolutionary knowledge distillation. IEEE Trans. Circuits Syst. Video Technol. 2021, 32, 2251–2263. [Google Scholar] [CrossRef]
- Valverde, F.R.; Hurtado, J.V.; Valada, A. There is more than meets the eye: Self-supervised multi-object detection and tracking with sound by distilling multimodal knowledge. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Virtual, 19–25 June 2021; pp. 11612–11621. [Google Scholar]
- Veličković, P.; Cucurull, G.; Casanova, A.; Romero, A.; Lio, P.; Bengio, Y. Graph attention networks. arXiv 2017, arXiv:1710.10903. [Google Scholar]
- Cuturi, M. Sinkhorn distances: Lightspeed computation of optimal transport. Adv. Neural Inf. Process. Syst. 2013, 26, 1–9. [Google Scholar]
- Xie, Y.; Wang, X.; Wang, R.; Zha, H. A fast proximal point method for computing exact wasserstein distance. In Proceedings of the Uncertainty in Artificial Intelligence, Online, 3–6 August 2020; pp. 433–453. [Google Scholar]
- Geiger, A.; Lenz, P.; Stiller, C.; Urtasun, R. Vision meets robotics: The kitti dataset. Int. J. Robot. Res. 2013, 32, 1231–1237. [Google Scholar] [CrossRef]
- Huang, K.; Wang, Y.; Zhou, Z.; Ding, T.; Gao, S.; Ma, Y. Learning to parse wireframes in images of man-made environments. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 626–635. [Google Scholar]
- Chen, B.B.; Gao, Y.; Guo, Y.B.; Liu, Y.; Zhao, H.H.; Liao, H.J.; Wang, L.; Xiang, T.; Li, W.; Xie, Z. Automatic differentiation for second renormalization of tensor networks. Phys. Rev. B 2020, 101, 220409. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J.A.; Adam, J. A method for stochastic optimization. arXiv 2020, arXiv:1412.6980. [Google Scholar]
- Schubert, D.; Goll, T.; Demmel, N.; Usenko, V.; Stückler, J.; Cremers, D. The TUM VI benchmark for evaluating visual-inertial odometry. In Proceedings of the 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Madrid, Spain, 1–5 October 2018; pp. 1680–1687. [Google Scholar]
- Nistér, D.; Stewénius, H. Scalable Recognition with a Vocabulary Tree. In Proceedings of the Computer Vision and Pattern Recognition, New York, NY, USA, 17–22 June 2006. [Google Scholar]
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Seq | ORB-SLAM2 | Our | ||||
|---|---|---|---|---|---|---|
| ATE (m) | (%) | (deg/m) | ATE (m) | (%) | (deg/m) | |
| 00 | 1.266 | 52.5 | 0.363 | 1.233 | 2.9 | 0.122 |
| 01 | 4.296 | 3.4 | 0.420 | 2.616 | 4.8 | 0.044 |
| 02 | 12.790 | 4.3 | 0.107 | 12.721 | 3.6 | 0.077 |
| 03 | 0.403 | 0.8 | 0.072 | 0.385 | 2.0 | 0.055 |
| 04 | 0.466 | 2.2 | 0.055 | 0.192 | 2.1 | 0.040 |
| 05 | 0.348 | 2.3 | 0.144 | 0.402 | 1.7 | 0.056 |
| 06 | 1.184 | 3.9 | 0.089 | 0.572 | 1.8 | 0.042 |
| 07 | 0.439 | 1.3 | 0.076 | 0.436 | 1.6 | 0.046 |
| 08 | 3.122 | 12.1 | 0.076 | 2.874 | 3.9 | 0.054 |
| 09 | 3.319 | 15.0 | 0.104 | 1.537 | 2.2 | 0.054 |
| 10 | 0.927 | 2.6 | 0.090 | 0.989 | 2.1 | 0.060 |
| Method | Wireframe Dataset | YorkUrban Dataset | FPS | ||||
|---|---|---|---|---|---|---|---|
| Student | 77.5 | 58.9 | 59.8 | 64.6 | 25.9 | 32.0 | 12.5 |
| Teacher | 80.6 | 57.6 | 61.3 | 67.2 | 27.6 | 34.3 | 7.2 |
| Seq | P-SLAM | L-SLAM | PL-SLAM | ORB-SLAM2 | LSD-SLAM | PTAM |
|---|---|---|---|---|---|---|
| 00 | 1.203 | 6.233 | 1.233 | 1.266 | 5.347 | 2.842 |
| 01 | 3.934 | 12.367 | 2.616 | 4.296 | — | 3.358 |
| 02 | 7.689 | — | 12.721 | 12.790 | — | 13.742 |
| 03 | 0.393 | 5.457 | 0.385 | 0.403 | 7.431 | 2.302 |
| 04 | 0.347 | 13.824 | 0.192 | 0.466 | — | 2.773 |
| 05 | 0.863 | — | 0.402 | 0.348 | 1.293 | 0.456 |
| 06 | 0.884 | — | 0.572 | 1.184 | — | 1.024 |
| 07 | 0.255 | — | 0.436 | 0.439 | — | 0.423 |
| 08 | 3.122 | — | 2.874 | 3.122 | — | 3.358 |
| 09 | 2.625 | 4.783 | 1.537 | 3.319 | 11.395 | 2.048 |
| 10 | 0.447 | 5.824 | 0.989 | 0.927 | 2.841 | 0.768 |
| Known | Unknown | |||
|---|---|---|---|---|
| Match Precision | Matching Score | Match Precision | Matching Score | |
| No EAGAT | 79.6 | 29.5 | 55.3 | 15.6 |
| No CHGI | 66.7 | 25.3 | 48.2 | 18.5 |
| No HAGNN | 63.2 | 19.4 | 51.2 | 10.3 |
| Full | 89.3 | 34.2 | 78.3 | 23.8 |
| Feature | Matcher | Pose Estimation AUC | P | MS | ||
|---|---|---|---|---|---|---|
| SIFT | NN | 7.89 | 10.22 | 35.30 | 43.4 | 1.7 |
| SIFT | SuperGlue | 23.68 | 36.44 | 49.44 | 74.1 | 7.2 |
| SuperPoint | NN | 9.80 | 18.99 | 30.88 | 22.5 | 4.9 |
| SuperPoint | SuperGlue | 34.18 | 44.32 | 64.16 | 84.9 | 11.1 |
| LSD + LBD | NN | 5.43 | 7.83 | 28.54 | 32.5 | 1.3 |
| SOLD | NN | 18.34 | 13.22 | 23.51 | 63.6 | 6.2 |
| SuperPoint + SOLD | Ours | 35.86 | 44.73 | 64.43 | 85.3 | 12.3 |
| Ours | Ours | 36.67 | 44.26 | 64.73 | 86.6 | 12.7 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lian, Y.; Sun, H.; Dong, S. Point–Line-Aware Heterogeneous Graph Attention Network for Visual SLAM System. Appl. Sci. 2023, 13, 3816. https://doi.org/10.3390/app13063816
Lian Y, Sun H, Dong S. Point–Line-Aware Heterogeneous Graph Attention Network for Visual SLAM System. Applied Sciences. 2023; 13(6):3816. https://doi.org/10.3390/app13063816
Chicago/Turabian StyleLian, Yuanfeng, Hao Sun, and Shaohua Dong. 2023. "Point–Line-Aware Heterogeneous Graph Attention Network for Visual SLAM System" Applied Sciences 13, no. 6: 3816. https://doi.org/10.3390/app13063816
APA StyleLian, Y., Sun, H., & Dong, S. (2023). Point–Line-Aware Heterogeneous Graph Attention Network for Visual SLAM System. Applied Sciences, 13(6), 3816. https://doi.org/10.3390/app13063816