

Real-Time Stereo Visual Odometry Based on an Improved KLT Method

Abstract
1. Introduction
- By analyzing the relationship between the motion experienced by the feature, the average disparity, the translation velocity, the yaw angle, and the adaptive window size for the AKT must by necessity be jointly determined, which can significantly improve the tracking accuracy in the presence of scale distortion and affine transformation.
- The AKT tracks the inherited features between only the left images of two consecutive frames, and the SKM is performed in a new stereo frame, which can avoid computationally expensive feature detection and feature-based stereo matching processes as much as possible.
- To limit the drift error, an effective veer chain matching (VCM) scheme is introduced.
- A systematic evaluation using the KITTI dataset [17] was performed. The experimental results show that the proposed SVO can achieve better real-time performance in comparison to the other state-of-the-art approaches without deteriorating the localization accuracy.
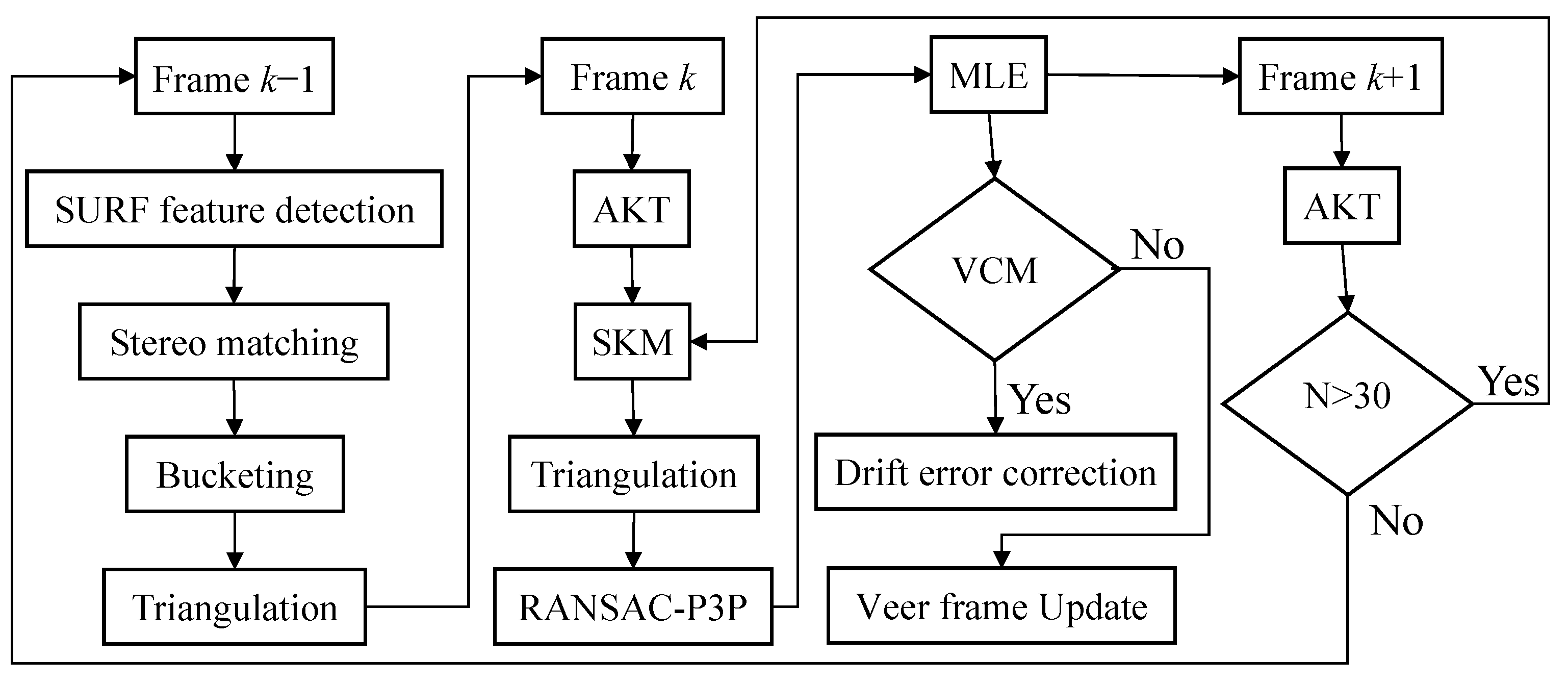
2. Method Overview
- Searching for a series of SURF key points in the first stereo frame and computing their normalized descriptors with 64 dimensions.
- With the epipolar constraint, stereo matching is performed using the Euclidean distance between the SURF descriptors.
- A subset of the matched features is selected by means of bucketing to ensure the features are uniformly distributed over the image plane.
- The three-dimensional (3-D) coordinates of the selected features are computed using triangulation.
- The two-dimensional (2-D) features are tracked between the left images in frames and using the AKT.
- The SKM is performed by combining the standard KLT method [16] with the epipolar constraint. Then, the 3-D coordinates of the matched features are computed through triangulation.
- The features inherited from Step 5 between the left images in frames and are continuously tracked. If the number of new tracked features is smaller than a predefined threshold , repeat from Step 1. Otherwise, the features are inherited successfully and repeat from Step 6. The threshold is set to 30 to ensure both computational accuracy and efficiency. This process is called FI.
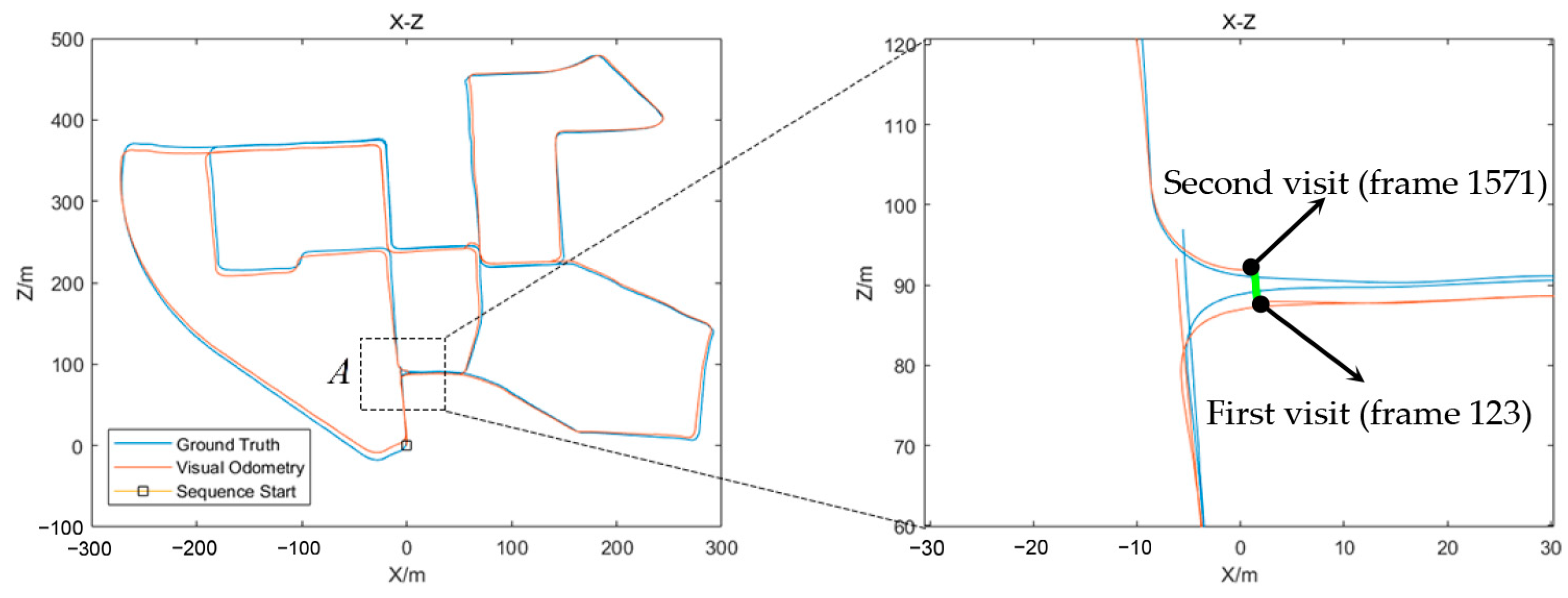
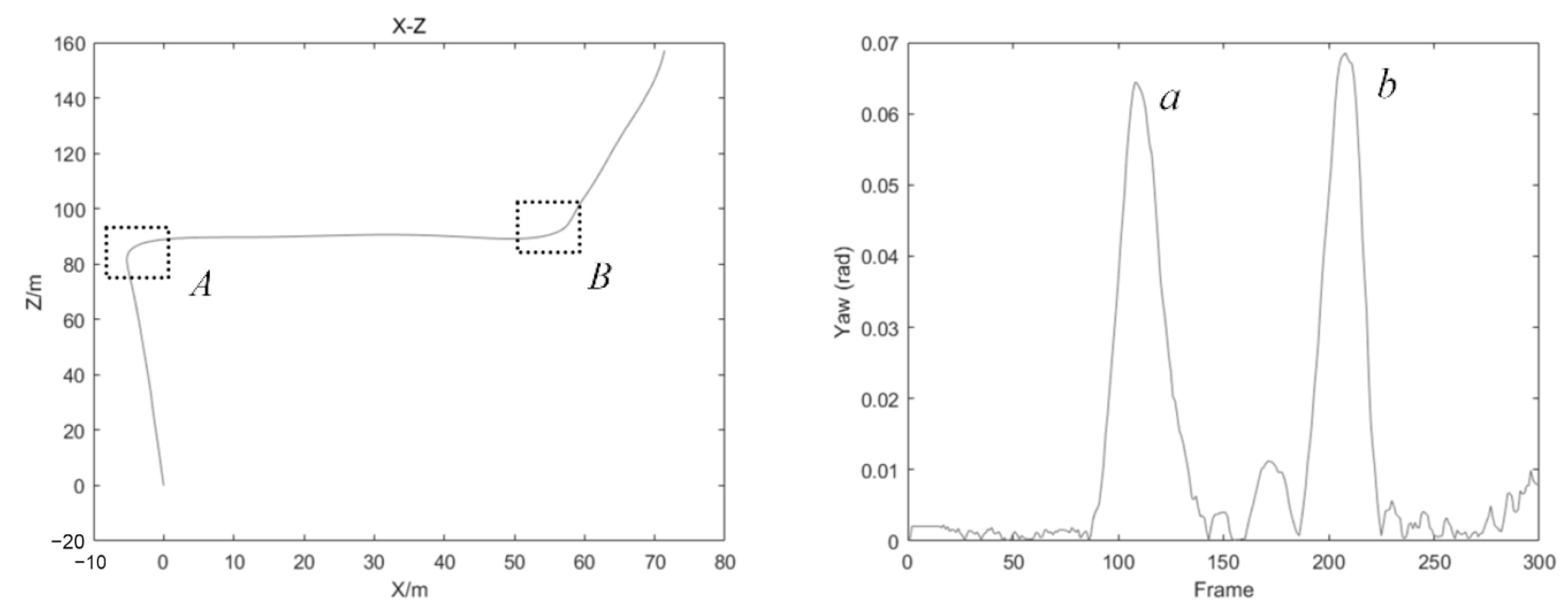
- After Step 8, for a turning maneuver, the drift error is reduced via a VCM scheme. This scheme consists of a veer frame detection process and a veer frame matching process. If this is the first time through the corner or the intersection, a veer frame update will collect the current frame as the unique keyframe of this corner. If not, the motion between the current veer frame and the first veer frame of this corner is estimated and the drift error is corrected. This novel scheme will be described in Section 3.
3. Detailed Description of the Method
3.1. Feature Detection and Stereo Matching
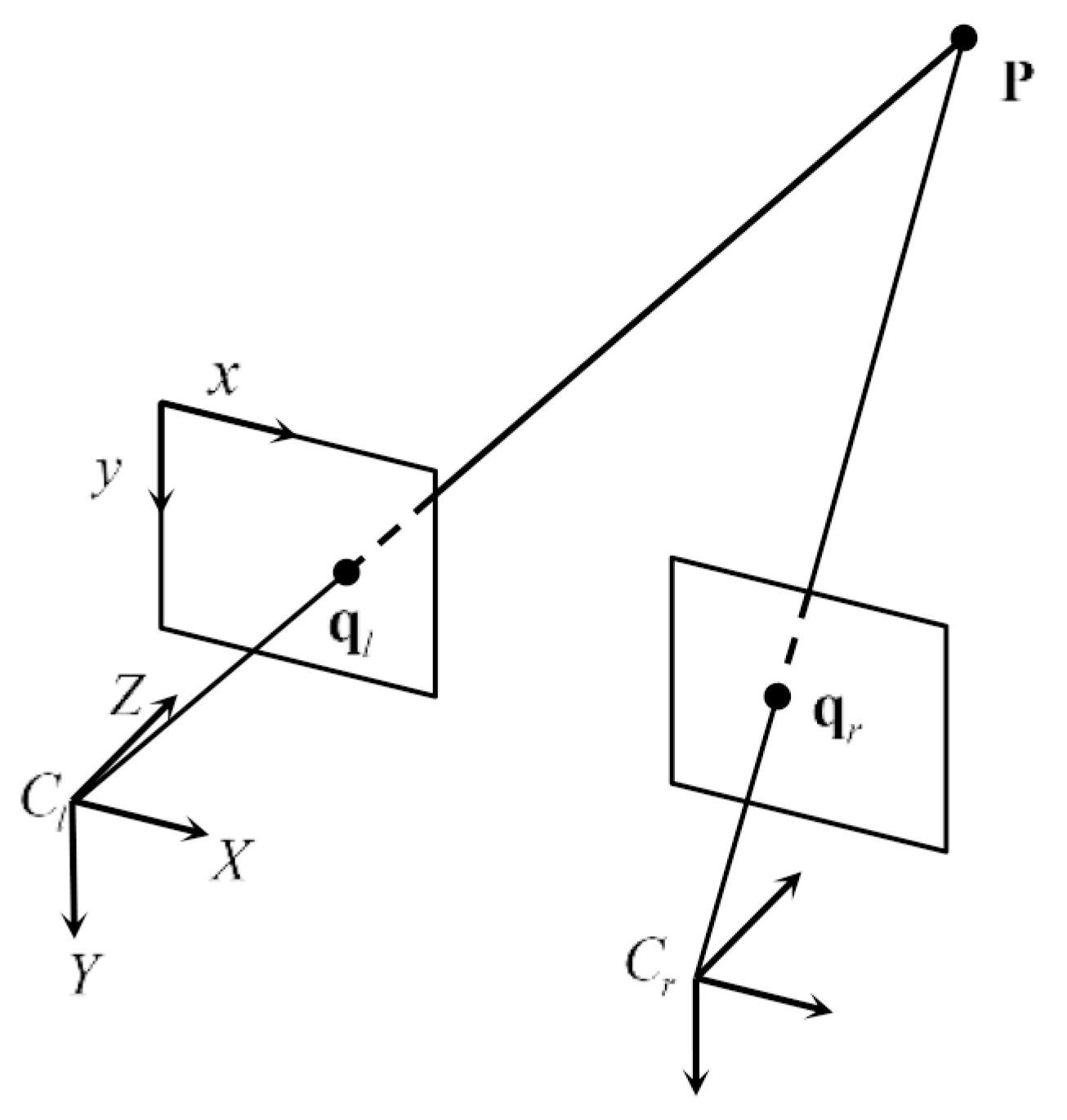
3.2. Bucketing and Triangulation
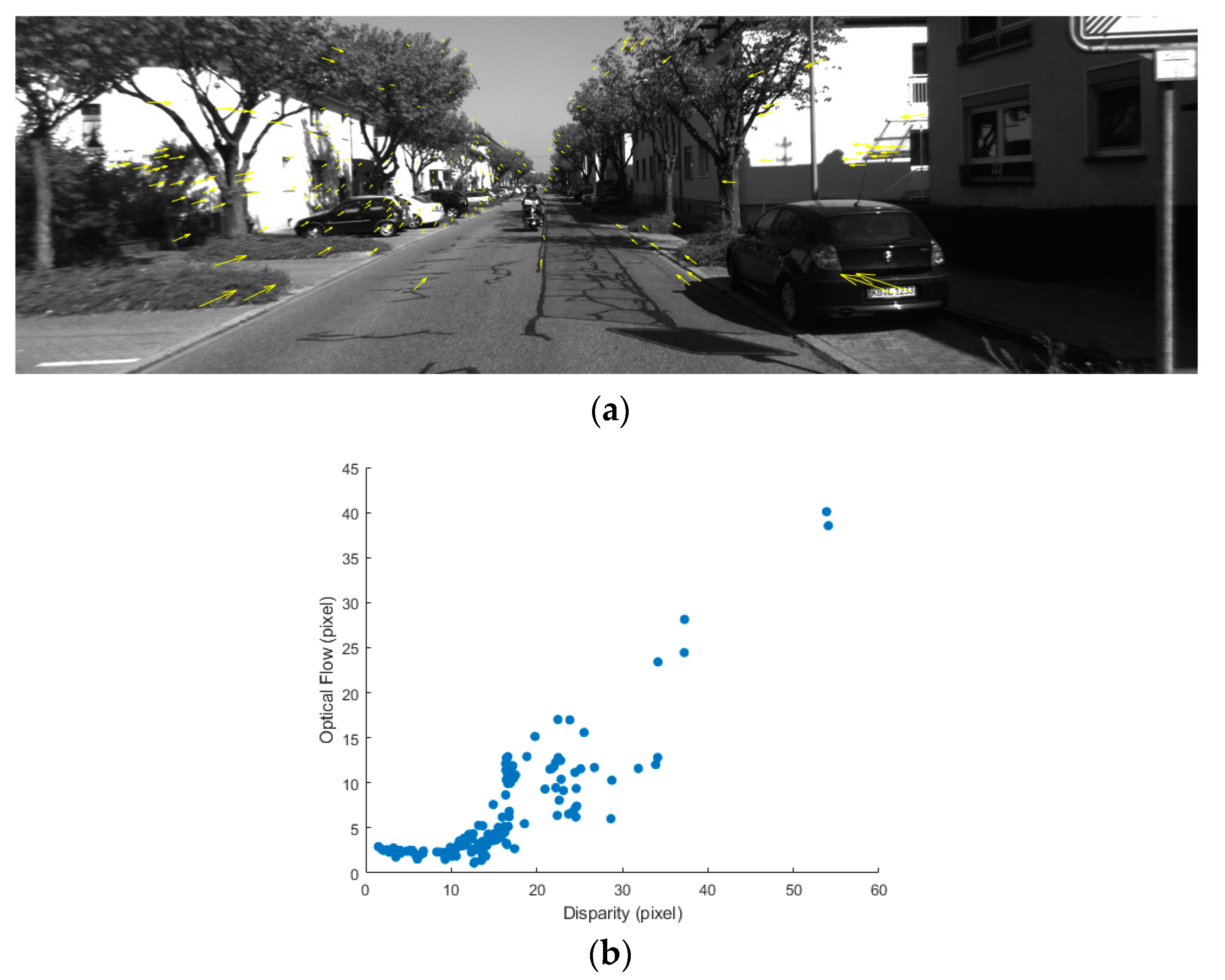
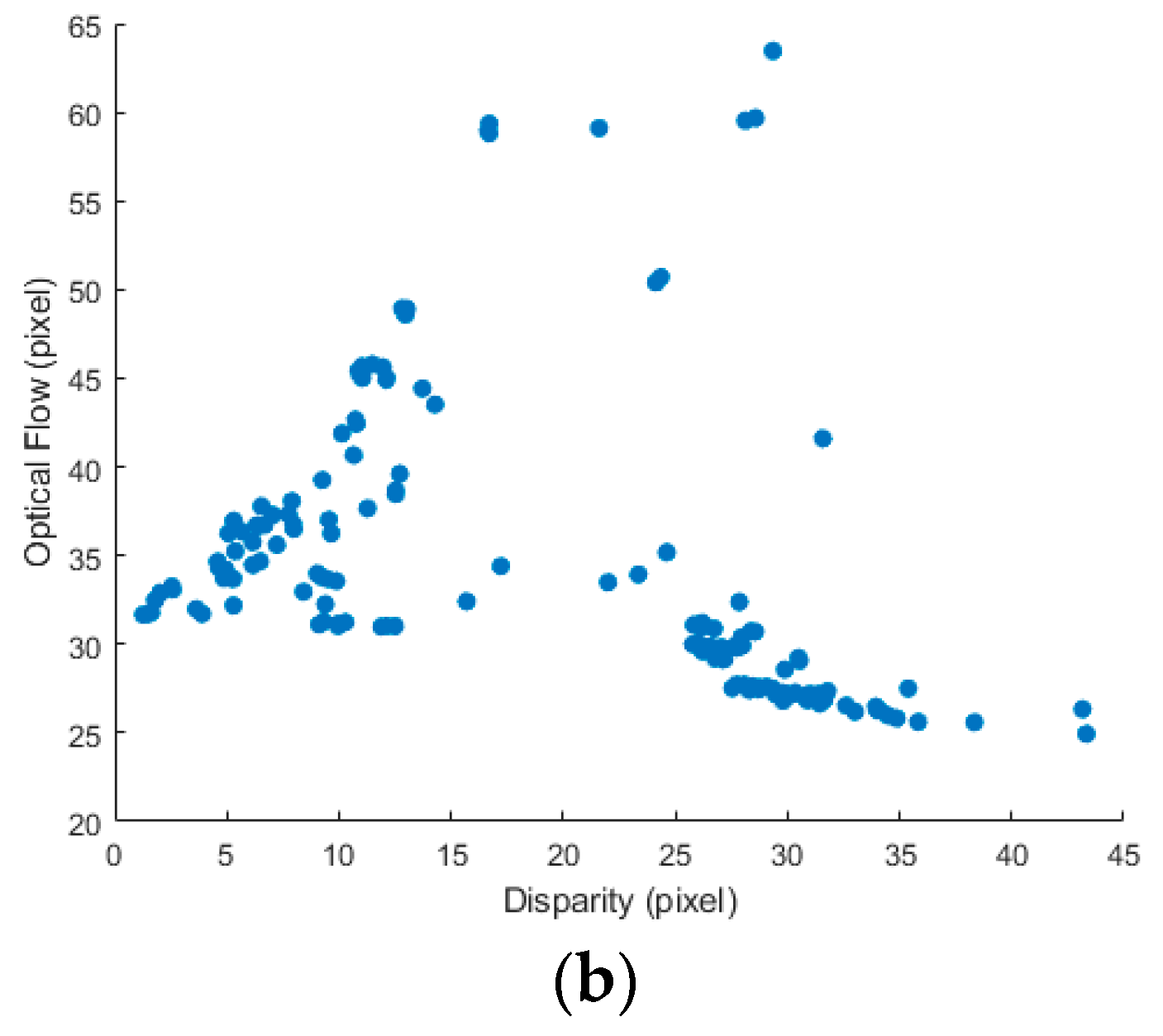
3.3. Adaptive KLT Tracker and Simplified KLT Matcher
3.4. RANSAC-P3P and Maximum Likelihood Estimator
3.5. Veer Chain Matching
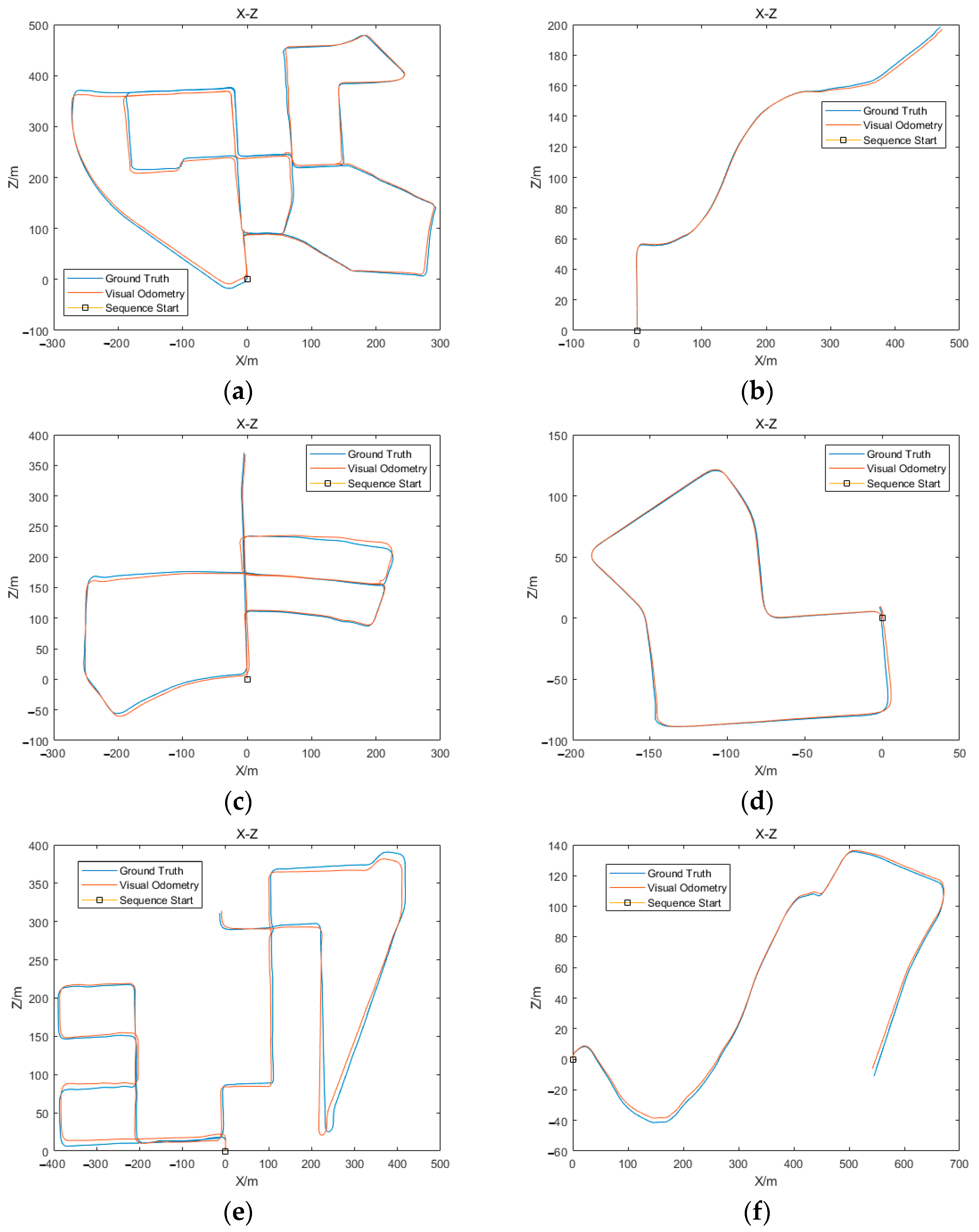
4. Experimental Results
- , , and represent no significant difference in runtime, and , between the two versions, respectively.
- , , and represent a significant difference in runtime, and , between the two versions, respectively.
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Chen, Y.; Mei, Y.; Wan, S. Visual Odometry for Self-Driving with Multihypothesis and Network Prediction. Math. Probl. Eng. 2021, 2021, 1930881. [Google Scholar] [CrossRef]
- He, M.; Zhu, C.; Huang, Q.; Ren, B.; Liu, J. A review of monocular visual odometry. Vis. Comput. 2020, 36, 1053–1065. [Google Scholar] [CrossRef]
- Fraundorfer, F.; Scaramuzza, D. Visual odometry: Part II: Matching, robustness, optimization, and applications. IEEE Robot. Autom. Mag. 2012, 19, 78–90. [Google Scholar] [CrossRef]
- Cvišić, I.; Marković, I.; Petrović, I. Recalibrating the KITTI Dataset Camera Setup for Improved Odometry Accuracy. In Proceedings of the 2021 European Conference on Mobile Robots (ECMR), Bonn, Germany, 31 August–3 September 2021; pp. 1–6. [Google Scholar]
- Fraundorfer, F.; Scaramuzza, D. Visual odometry: Part I: The first 30 years and fundamentals. IEEE Robot. Autom. Mag. 2011, 18, 80–92. [Google Scholar]
- Wu, M.; Lam, S.K.; Srikanthan, T. A Framework for Fast and Robust Visual Odometry. IEEE T. Intell. Transp. 2017, 18, 3433–3448. [Google Scholar] [CrossRef]
- Geiger, A.; Ziegler, J.; Stiller, C. Stereoscan: Dense 3d reconstruction in real-time. In Proceedings of the IEEE Intelligent Vehicles Symposium (IV), Baden-Baden, Germany, 5–9 June 2011; pp. 963–968. [Google Scholar]
- Wan, W.; Liu, Z.; Di, K.; Wang, B.; Zhou, J. A Cross-Site Visual Localization Method for Yutu Rover. In Proceedings of the International Archives of the Photogrammetry, Remote Sensing and Spatial Information Sciences (ISPRS), Suzhou, China, 14–16 May 2014; Volume XL-4. [Google Scholar]
- Cheng, Y.; Maimone, M.; Matthies, L. Visual odometry on the Mars exploration rovers. In Proceedings of the 2005 IEEE International Conference on Systems, Man and Cybernetics, Waikoloa, HI, USA, 12 October 2005; pp. 903–910. [Google Scholar]
- Maimone, M.; Cheng, Y.; Matthies, L. Two years of visual odometry on the mars exploration rovers. J. Field Robot. 2007, 24, 169–186. [Google Scholar] [CrossRef]
- Mur-Artal, R.; Tardós, J.D. ORB-SLAM2: An Open-Source SLAM System for Monocular, Stereo, and RGB-D Cameras. IEEE Trans. Robot. 2017, 33, 1255–1262. [Google Scholar] [CrossRef]
- Chien, C.H.; Hsu, C.C.J.; Chien, C.J. Multiple Master-Slave FPGA Architecture of a Stereo Visual Odometry. IEEE Access 2021, 9, 103266–103278. [Google Scholar] [CrossRef]
- Min, Z.; Yang, Y.; Dunn, E. VOLDOR: Visual Odometry From Log-Logistic Dense Optical Flow Residuals. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 4898–4909. [Google Scholar]
- Ferrera, M.; Eudes, A.; Moras, J.; Sanfourche, M.; Le Besnerais, G. OV2SLAM: A Fully Online and Versatile Visual SLAM for Real-Time Applications. IEEE Robot. Autom. Lett. 2021, 6, 1399–1406. [Google Scholar] [CrossRef]
- Moreno, F.A.; Blanco, J.L.; González, J. An efficient closed-form solution to probabilistic 6D visual odometry for a stereo camera. In Proceedings of the International Conference on Advanced Concepts for Intelligent Vision Systems (ACIVS), Delft, The Netherlands, 28–31 August 2007; Springer: Berlin/Heidelberg, Germany, 2007; Volume 4678, pp. 932–942. [Google Scholar]
- Shi, J. Good features to track. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 21–23 June 1994; pp. 593–600. [Google Scholar]
- Geiger, A.; Lenz, P.; Stiller, C.; Urtasun, R. Vision meets robotics: The kitti dataset. Ind. Robot. 2013, 32, 1231–1237. [Google Scholar] [CrossRef]
- Alismail, H.; Browning, B.; Dias, M.B. Evaluating pose estimation methods for stereo visual odometry on robots. In Proceedings of the 11th International Conference on Intelligent Autonomous Systems (IAS-11), Ottawa, ON, Canada, 30 August–1 September 2010; pp. 101–110. [Google Scholar]
- Fischler, M.A.; Bolles, R.C. Random sample consensus: A paradigm for model fitting with applications to image analysis and automated cartography. Commun. ACM 1981, 24, 381–395. [Google Scholar] [CrossRef]
- Harris, C.G.; Pike, J. 3D positional integration from image sequences. Image Vision Comput. 1988, 6, 87–90. [Google Scholar] [CrossRef]
- Rosten, E.; Drummond, T. Machine learning for high-speed corner detection. In European Conference on Computer Vision (ECCV); Springer: Berlin/Heidelberg, Germany, 2006; Volume 3951, pp. 430–443. [Google Scholar]
- Lowe, D.G. Distinctive image features from scale-invariant keypoints. Int. J. Comput. Vision 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Bay, H.; Tuytelaars, T.; Van Gool, L. SURF: Speeded Up Robust Features. In European Conference on Computer Vision (ECCV); Springer: Berlin/Heidelberg, Germany, 2006; Volume 3951, pp. 404–417. [Google Scholar]
- Cvišić, I.; Petrović, I. Stereo odometry based on careful feature selection and tracking. In Proceedings of the 2015 European Conference on Mobile Robots (ECMR), Lincoln, UK, 2–4 September 2015; pp. 1–6. [Google Scholar]
- Silva, H.; Bernardino, A.; Silva, E. Probabilistic egomotion for stereo visual odometry. J. Intell. Robot. Syst. 2015, 77, 265–280. [Google Scholar] [CrossRef]
- Ramakrishnan, N.; Srikanthan, T.; Lam, S.K.; Tulsulkar, G.R. Adaptive Window Strategy for High-Speed and Robust KLT Feature Tracker. In Image and Video Technology; PSIVT 2015; Lecture Notes in Computer Science; Bräunl, T., McCane, B., Rivera, M., Yu, X., Eds.; Springer: Cham, Switzerland, 2015; Volume 9431, pp. 355–367. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| SVO + FI + AKT + SKM + VCM + JAF | SVO + FI AKT + SKM + VCM + Disparity | |||||
|---|---|---|---|---|---|---|
| Sequence | Runtime (s) | (%) | Runtime (s) | |||
| 00 | 0.0729 | 0.9496 | 0.0008 | 0.0703 | 1.3844 | 0.0012 |
| 02 | 0.0734 | 1.2011 | 0.0013 | 0.0650 | 1.2042 | 0.0009 |
| 03 | 0.0358 | 1.0257 | 0.0005 | 0.0397 | 1.7008 | 0.0010 |
| 04 | 0.0546 | 0.5361 | 0.0001 | 0.0600 | 1.6663 | 0.0001 |
| 05 | 0.0597 | 0.5957 | 0.0016 | 0.0599 | 1.0291 | 0.0015 |
| 06 | 0.0978 | 1.1253 | 0.0006 | 0.0922 | 1.7430 | 0.0011 |
| 07 | 0.0585 | 0.6460 | 0.0055 | 0.0612 | 0.8742 | 0.0068 |
| 08 | 0.0635 | 2.1540 | 0.0004 | 0.0674 | 2.9020 | 0.0011 |
| 09 | 0.0670 | 1.3569 | 0.0015 | 0.0711 | 1.9772 | 0.0015 |
| 10 | 0.0744 | 1.7708 | 0.0091 | 0.0752 | 1.7731 | 0.0075 |
| avg | 0.0658 | 1.1361 | 0.0021 | 0.0662 | 1.6254 | 0.0023 |
| Test Data | Runtime | ||
|---|---|---|---|
| Mann–Whitney U | 46.0000 | 25.0000 | 43.5000 |
| Wilcoxon W | 101.0000 | 80.0000 | 99.5000 |
| Z | −0.3024 | −1.8898 | −0.4925 |
| Asymp. Sig. (2-tailed) | 0.7624 | 0.0059 | 0.6224 |
| Our Method | SVO | |||
|---|---|---|---|---|
| (Without FI and VCM) | ||||
| Stage | Seq. 05 | Seq. 07 | Seq. 05 | Seq. 07 |
| Feature detection | 20.4340 | 19.8128 | 61.0502 | 62.4008 |
| Stereo matching | 1.8556 | 1.8549 | 5.6062 | 6.3031 |
| AKT | 4.1532 | 3.6080 | 2.6890 | 2.8666 |
| SKM | 2.5029 | 2.5025 | 2.5195 | 2.5339 |
| VCM | 18.1453 | 17.9953 | \ | \ |
| Motion estimation | 4.1176 | 5.0820 | 22.3288 | 16.9736 |
| Total | 59.7044 | 59.4217 | 103.0680 | 100.0306 |
| Method | Runtime (s) | et (%) | er (deg/m) | Environment |
|---|---|---|---|---|
| SOFT2 | 0.1 | 0.71 | 0.0024 | 2.5 GHz (C/C++) |
| ORB-SLAM2 | 0.06 | 0.73 | 0.0022 | 3.6 GHz (C/C++) |
| FRVO | 0.03 (excluding the time for disparity map computation) | 0.98 | 0.0056 | 3.5 GHz (C/C++) |
| SVO-FPGA | 0.0301 | 2.7 | \ | 4.2 GHz +FPGA |
| VOLDOR | 0.1 | 1.32 | 0.0042 | GPU |
| Proposed | 0.0658 | 1.14 | 0.0021 | 3.0 GHz (MATLAB) |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Guo, G.; Dai, Z.; Dai, Y. Real-Time Stereo Visual Odometry Based on an Improved KLT Method. Appl. Sci. 2022, 12, 12124. https://doi.org/10.3390/app122312124
Guo G, Dai Z, Dai Y. Real-Time Stereo Visual Odometry Based on an Improved KLT Method. Applied Sciences. 2022; 12(23):12124. https://doi.org/10.3390/app122312124
Chicago/Turabian StyleGuo, Guangzhi, Zuoxiao Dai, and Yuanfeng Dai. 2022. "Real-Time Stereo Visual Odometry Based on an Improved KLT Method" Applied Sciences 12, no. 23: 12124. https://doi.org/10.3390/app122312124
APA StyleGuo, G., Dai, Z., & Dai, Y. (2022). Real-Time Stereo Visual Odometry Based on an Improved KLT Method. Applied Sciences, 12(23), 12124. https://doi.org/10.3390/app122312124