
CA-CGNet: Component-Aware Capsule Graph Neural Network for Non-Rigid Shape Correspondence


Abstract
1. Introduction
- We design a novel network structure called CA-CGNet, which enhances the expressive ability of the network to represent object spatial pose and orientation changes by adding local mesh pose details to achieve high-precision shape correspondence.
- To reduce the interference of noisy patch assignments, we propose a dynamic clustering algorithm to cluster the over-segmented meshes dynamically according to feature similarity to form components. By adding a component constraint to the functional maps and integrating component-based semantic constraint loss into the regularization term, the accuracy of shape correspondence is further improved.
- The component-aware graph routing treats capsules as nodes in a graph neural network by adding component constraints to obtain more accurate relationships between capsules. In addition, the knowledge distillation strategy is used to reduce the number of parameters while maintaining network performance.
- Experiments on four challenging datasets show qualitatively and quantitatively that the CA-CGNet has stronger robustness and better generalization. The ablation study demonstrates that component pair constraint, component-aware graph routing, and knowledge distillation strategy have a great improvement in network performance.
2. Related Work
2.1. Non-Rigid Shape Correspondence
2.2. Capsule Graph Neural Network
2.3. Correspondence with Functional Maps
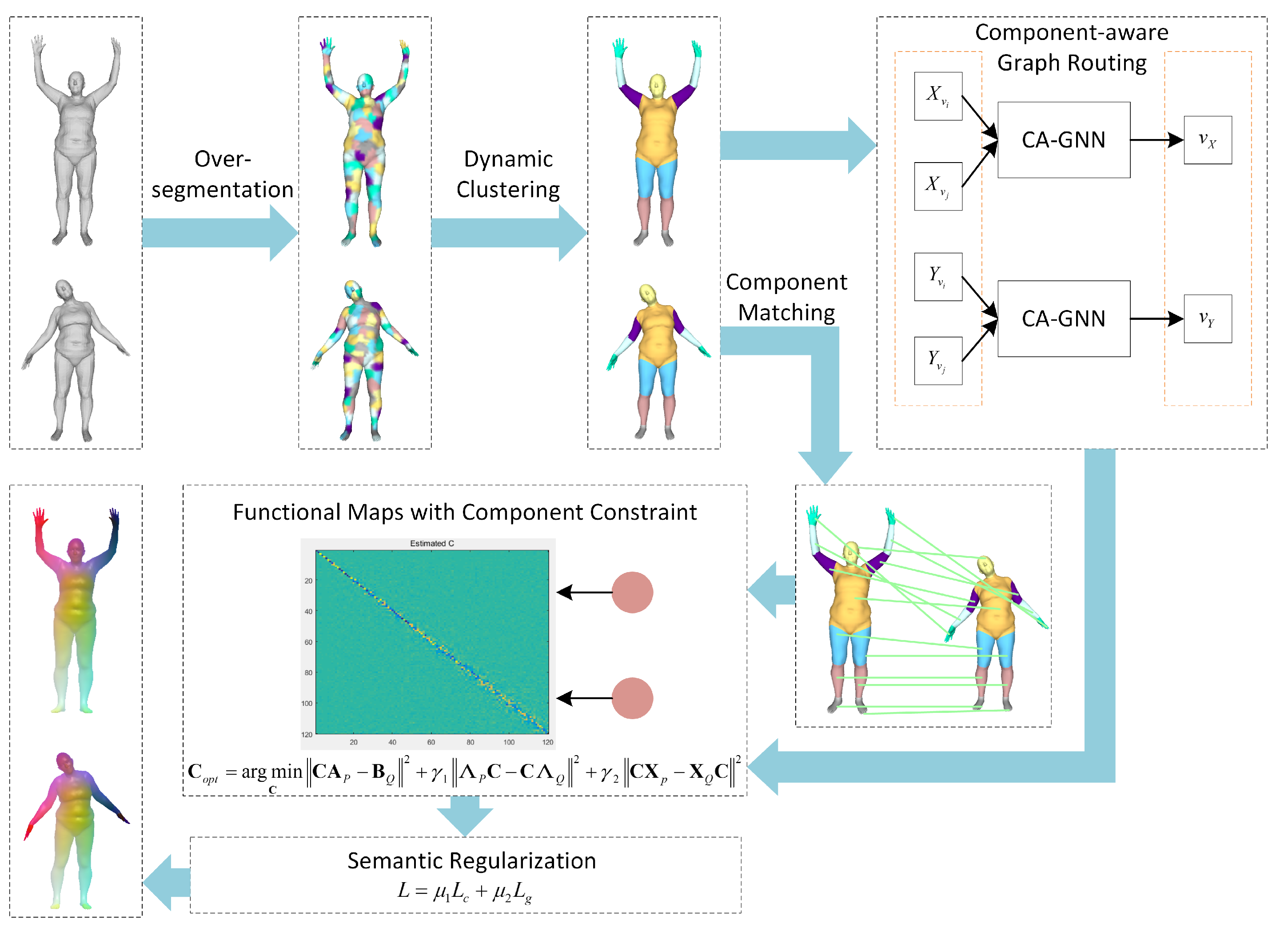
3. Proposed Method
3.1. CA-CGNet
3.2. Component Extraction
3.2.1. Dynamic Clustering
3.2.2. Component Matching
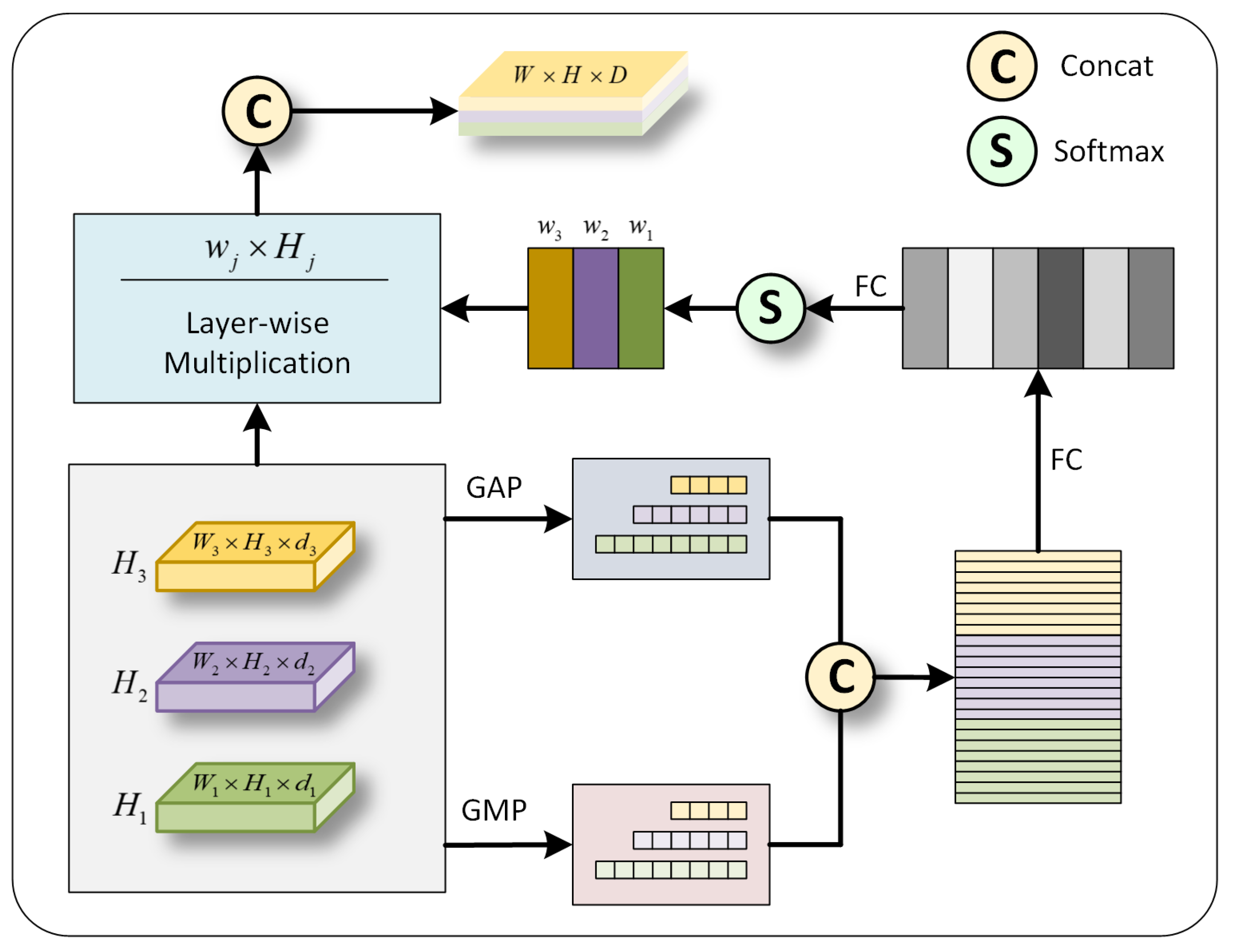
3.3. Component-Aware Graph Routing
3.3.1. Multi-Layer Attention Graph Routing
| Algorithm 1: The Algorithm of the Component-aware Graph Routing |
 |
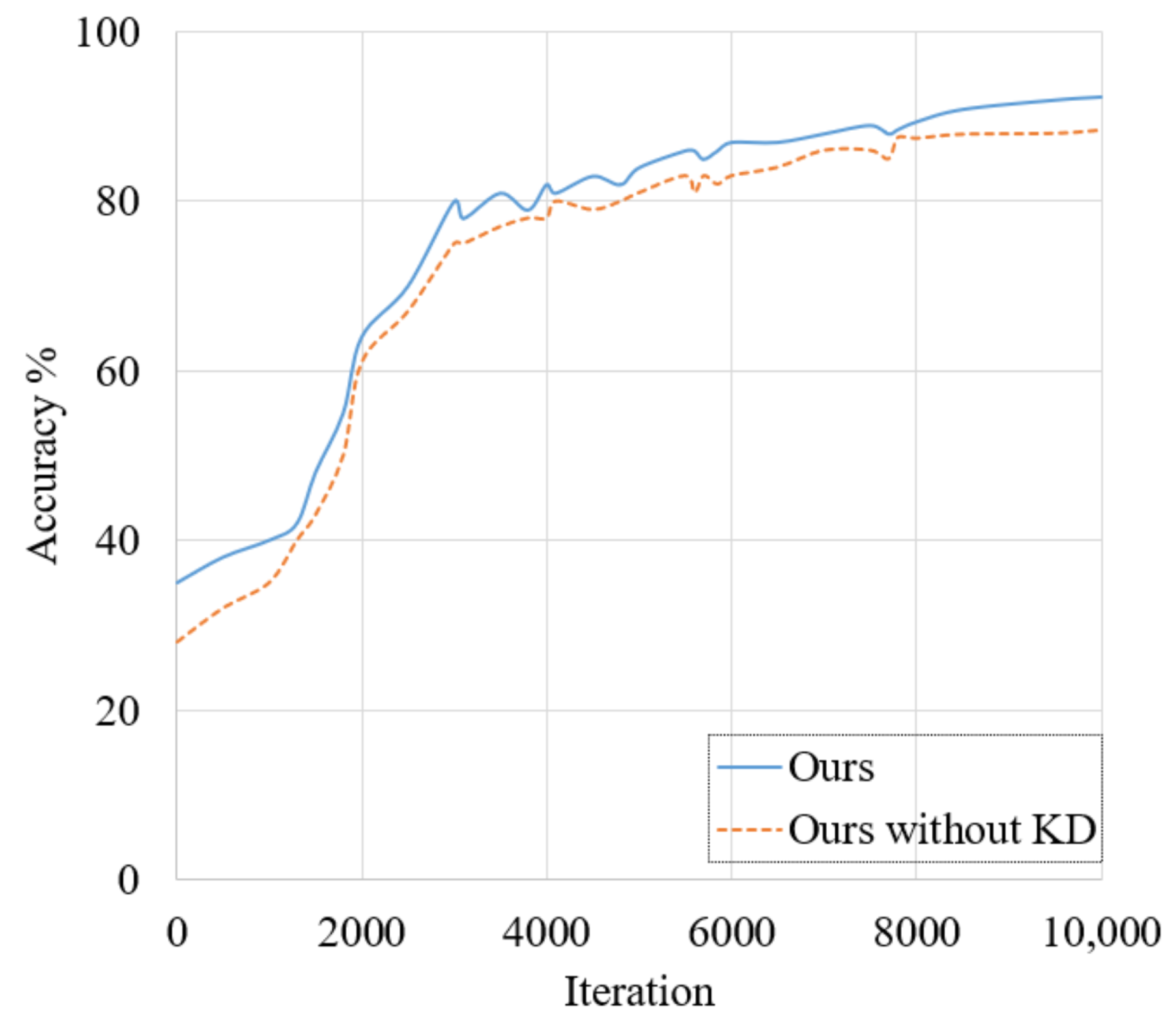
3.3.2. Knowledge Distillation Strategy
3.4. Functional Maps with Component Constraint
3.5. Semantic Regularization
4. Experiments and Evaluation
4.1. Dataset
4.2. Component Matching
4.3. Correspondence Results
4.4. Ablation Study
4.4.1. Effectiveness of the Component Pair Constraint
4.4.2. Effectiveness of the Component-Aware Graph Routing
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Jain, V.; Zhang, H.; Van Kaick, O. Non-rigid spectral correspondence of triangle meshes. Int. J. Shape Model. 2007, 13, 101–124. [Google Scholar] [CrossRef]
- Jian, B.; Vemuri, B.C. Robust point set registration using gaussian mixture models. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 33, 1633–1645. [Google Scholar] [CrossRef] [PubMed]
- Ma, J.; Zhao, J.; Tian, J.; Yuille, A.L.; Tu, Z. Robust point matching via vector field consensus. IEEE Trans. Image Process. 2014, 23, 1706–1721. [Google Scholar] [CrossRef] [PubMed]
- Ma, J.; Zhao, J.; Yuille, A.L. Non-rigid point set registration by preserving global and local structures. IEEE Trans. Image Process. 2015, 25, 53–64. [Google Scholar] [PubMed]
- Bronstein, A.M.; Bronstein, M.M.; Kimmel, R. Generalized multidimensional scaling: A framework for isometry-invariant partial surface matching. Proc. Natl. Acad. Sci. USA 2006, 103, 1168–1172. [Google Scholar] [CrossRef] [PubMed]
- Coifman, R.R.; Lafon, S.; Lee, A.B.; Maggioni, M.; Nadler, B.; Warner, F.; Zucker, S.W. Geometric diffusions as a tool for harmonic analysis and structure definition of data: Diffusion maps. Proc. Natl. Acad. Sci. USA 2005, 102, 7426–7431. [Google Scholar] [CrossRef] [PubMed]
- Litman, R.; Bronstein, A.M. Learning spectral descriptors for deformable shape correspondence. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 36, 171–180. [Google Scholar] [CrossRef] [PubMed]
- Groueix, T.; Fisher, M.; Kim, V.G.; Russell, B.C.; Aubry, M. 3d-coded: 3d correspondences by deep deformation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 230–246. [Google Scholar]
- Wang, W.; Ceylan, D.; Mech, R.; Neumann, U. 3dn: 3d deformation network. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 1038–1046. [Google Scholar]
- Kovnatsky, A.; Bronstein, M.M.; Bresson, X.; Vandergheynst, P. Functional correspondence by matrix completion. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 905–914. [Google Scholar]
- Nogneng, D.; Melzi, S.; Rodola, E.; Castellani, U.; Bronstein, M.; Ovsjanikov, M. Improved functional mappings via product preservation. In Computer Graphics Forum; Blackwell: Oxford, UK, 2018. [Google Scholar]
- Litany, O.; Remez, T.; Rodola, E.; Bronstein, A.; Bronstein, M. Deep functional maps: Structured prediction for dense shape correspondence. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 5659–5667. [Google Scholar]
- Roufosse, J.M.; Sharma, A.; Ovsjanikov, M. Unsupervised deep learning for structured shape matching. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 1617–1627. [Google Scholar]
- Tombari, F.; Salti, S.; Stefano, L.D. Unique signatures of histograms for local surface description. In Proceedings of the European Conference on Computer Vision, Heraklion, Greece, 5–11 September 2010; Springer: Cham, Switzerland, 2010; pp. 356–369. [Google Scholar]
- Hilaga, M.; Shinagawa, Y.; Kohmura, T.; Kunii, T.L. Topology matching for fully automatic similarity estimation of 3D shapes. In Proceedings of the 28th Annual Conference on Computer Graphics and Interactive Techniques, Los Angeles, CA, USA, 12–17 August 2001; pp. 203–212. [Google Scholar]
- Sun, J.; Ovsjanikov, M.; Guibas, L. A concise and provably informative multi-scale signature based on heat diffusion. In Computer Graphics Forum; Blackwell: Oxford, UK, 2009. [Google Scholar]
- Aubry, M.; Schlickewei, U.; Cremers, D. The wave kernel signature: A quantum mechanical approach to shape analysis. In Proceedings of the 2011 IEEE International Conference on Computer Vision Workshops (ICCV Workshops), Barcelona, Spain, 6–13 November 2011; IEEE: New York, NY, USA, 2011; pp. 1626–1633. [Google Scholar]
- Zuffi, S.; Black, M.J. The stitched puppet: A graphical model of 3d human shape and pose. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3537–3546. [Google Scholar]
- Guo, J.; Wang, H.; Cheng, Z.; Zhang, X.; Yan, D.M. Learning local shape descriptors for computing non-rigid dense correspondence. Comput. Vis. Media 2020, 6, 95–112. [Google Scholar] [CrossRef]
- Halimi, O.; Litany, O.; Rodola, E.; Bronstein, A.M.; Kimmel, R. Unsupervised learning of dense shape correspondence. In Proceedings of the PIEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 4370–4379. [Google Scholar]
- Ginzburg, D.; Raviv, D. Cyclic functional mapping: Self-supervised correspondence between non-isometric deformable shapes. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; Springer: Cham, Switzerland, 2020; pp. 36–52. [Google Scholar]
- Marin, R.; Melzi, S.; Rodola, E.; Castellani, U. Farm: Functional automatic registration method for 3d human bodies. In Computer Graphics Forum; Wiley Online Library: Hoboken, NJ, USA, 2020; Volume 39, pp. 160–173. [Google Scholar]
- Wang, Y.; Ren, J.; Yan, D.M.; Guo, J.; Zhang, X.; Wonka, P. Mgcn: Descriptor learning using multiscale gcns. ACM Trans. Graph. (TOG) 2020, 39, 1–122. [Google Scholar] [CrossRef]
- Amor, B.B.; Arguillère, S.; Shao, L. ResNet-LDDMM: Advancing the LDDMM Framework Using Deep Residual Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 3707–3720. [Google Scholar] [CrossRef]
- Sabour, S.; Frosst, N.; Hinton, G.E. Dynamic routing between capsules. Adv. Neural Inf. Process. Syst. 2017, 30, 3859–3869. [Google Scholar]
- Xinyi, Z.; Chen, L. Capsule graph neural network. In Proceedings of the International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Li, J.; Li, S.; Zhao, W.X.; He, G.; Wei, Z.; Yuan, N.J.; Wen, J.R. Knowledge-enhanced personalized review generation with capsule graph neural network. In Proceedings of the 29th ACM International Conference on Information & Knowledge Management, Galway, Ireland, 19–23 October 2020; pp. 735–744. [Google Scholar]
- Lei, Y.; Zhang, J. Capsule Graph Neural Networks with EM Routing. In Proceedings of the 30th ACM International Conference on Information & Knowledge Management (CIKM ’21), Gold Coast, QL, Australia, 1–5 November 2021; Association for Computing Machinery: New York, NY, USA, 2021; pp. 3191–3195. [Google Scholar] [CrossRef]
- Yang, R.; Dai, W.; Li, C.; Zou, J.; Xiong, H. NCGNN: Node-Level Capsule Graph Neural Network for Semisupervised Classification. IEEE Trans. Neural Netw. Learn. Syst. 2022, 3179306. [Google Scholar] [CrossRef] [PubMed]
- Yang, J.; Zhao, P.; Rong, Y.; Yan, C.; Li, C.; Ma, H.; Huang, J. Hierarchical graph capsule network. In Proceedings of the AAAI Conference on Artificial Intelligence, Vancouver, BC, Canada, 2–9 February 2021; Volume 35, pp. 10603–10611. [Google Scholar]
- He, Z.; Li, W.; Yan, Y. Modeling knowledge proficiency using multi-hierarchical capsule graph neural network. Appl. Intell. 2022, 52, 7230–7247. [Google Scholar] [CrossRef]
- Ovsjanikov, M.; Ben-Chen, M.; Solomon, J.; Butscher, A.; Guibas, L. Functional maps: A flexible representation of maps between shapes. ACM Trans. Graph. (ToG) 2012, 31, 1–11. [Google Scholar] [CrossRef]
- Corman, E.; Ovsjanikov, M.; Chambolle, A. Supervised descriptor learning for non-rigid shape matching. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; Springer: Cham, Switzerland, 2014; pp. 283–298. [Google Scholar]
- Donati, N.; Sharma, A.; Ovsjanikov, M. Deep geometric functional maps: Robust feature learning for shape correspondence. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 8592–8601. [Google Scholar]
- Donati, N.; Corman, E.; Melzi, S.; Ovsjanikov, M. Complex functional maps: A conformal link between tangent bundles. In Proceedings of the Computer Graphics Forum, Eugene, OR, USA, 30 August–1 September 2022; Wiley Online Library: Hoboken, NJ, USA, 2022; Volume 41, pp. 317–334. [Google Scholar]
- Golovinskiy, A.; Funkhouser, T. Consistent segmentation of 3D models. Comput. Graph. 2009, 33, 262–269. [Google Scholar] [CrossRef]
- Huttenlocher, D.P.; Klanderman, G.A.; Rucklidge, W.J. Comparing images using the Hausdorff distance. IEEE Trans. Pattern Anal. Mach. Intell. 1993, 15, 850–863. [Google Scholar] [CrossRef]
- Lian, Y.; Gu, D.; Hua, J. SORCNet: Robust non-rigid shape correspondence with enhanced descriptors by Shared Optimized Res-CapsuleNet. Vis. Comput. 2022, 39, 749–763. [Google Scholar] [CrossRef]
- Kim, V.G.; Lipman, Y.; Funkhouser, T. Blended intrinsic maps. ACM Trans. Graph. (TOG) 2011, 30, 1–12. [Google Scholar]
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Reference | Routing Methods | Outcomes | Limitations |
|---|---|---|---|
| CapsGNN [26] (2018) | Dynamic routing | Higher accuracy rate compared to traditional methods | Irrelevant messages from multi-hop neighborhoods has not been restrained |
| Caps-GNN [27] (2020) | Dynamic routing | Higher inference in personalized preference | External knowledge has not been considered |
| HGCN [30] (2021) | Nonlinear function | More effectively capturing the heterogeneous factors under each node. | The over-smoothing issue over graph is ignored |
| CapsGNNEM [28] (2021) | EM routing | Higher graph classification compared to standard methods | Structural information of the graph has not been considered |
| NCGNN [29] (2022) | Dynamic routing | Adaptively identifying a subset of crucial node-level capsules | Unable to preserve structure information of lower-level parts |
| Caps-HAGKT [31] (2022) | Capsule routing | Extracting the latent knowledge structure between levels | Automatic modeling of the complex knowledge structure of the knowledge capsule at same layer is insufficient |
| Ours | Component-aware graph routing | Using component constraints to solve problem of model posture details and low resolution | Performance can be improved with optimizing selection of the number of components |
| Clustering Number | FAUST | SCAPE | KIDS | TOSCA | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| David | Michael | Victoria | Cat | Centaur | Dog | Horse | Wolf | ||||
| 4 | 0.0659 | 0.0872 | 0.0814 | 0.0652 | 0.0796 | 0.0684 | 0.0369 | 0.0427 | 0.0358 | 0.0374 | 0.0335 |
| 5 | 0.0586 | 0.0697 | 0.0705 | 0.0613 | 0.0686 | 0.0529 | 0.0254 | 0.0291 | 0.0216 | 0.0195 | 0.0208 |
| 6 | 0.0403 | 0.0574 | 0.0592 | 0.0486 | 0.0473 | 0.0351 | 0.0263 | 0.0314 | 0.0228 | 0.0199 | 0.0219 |
| 7 | 0.0258 | 0.0261 | 0.0243 | 0.0186 | 0.0195 | 0.0217 | 0.0269 | 0.0316 | 0.0231 | 0.0207 | 0.0231 |
| 8 | 0.0193 | 0.0201 | 0.0189 | 0.0174 | 0.0181 | 0.0203 | 0.0271 | 0.0320 | 0.0235 | 0.0214 | 0.0233 |
| 9 | 0.0206 | 0.0211 | 0.0193 | 0.0176 | 0.0184 | 0.0207 | 0.0277 | 0.0325 | 0.0237 | 0.0223 | 0.0238 |
| 10 | 0.0214 | 0.0219 | 0.0197 | 0.0192 | 0.0187 | 0.0210 | 0.0281 | 0.0326 | 0.0243 | 0.0225 | 0.0241 |
| Method | Intra AE | Inter AE | Average |
|---|---|---|---|
| FMNet [12] | 2.44 | 4.83 | 3.635 |
| Cyclic-FM [21] | 2.12 | 4.07 | 3.095 |
| SP [18] | 1.57 | 3.13 | 2.350 |
| 3D-CODED [8] | 1.98 | 2.88 | 2.430 |
| FARM [22] | 2.81 | 4.12 | 3.465 |
| SURFMNet [13] | 1.73 | 3.63 | 2.680 |
| MGCN [23] | 2.51 | 3.65 | 3.080 |
| ResNet-LDDMM [24] | 1.93 | 2.61 | 2.270 |
| Ours | 1.85 | 2.37 | 2.110 |
| Method | FAUST | SCAPE | KIDS | TOSCA | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| David | Michael | Victoria | Cat | Centaur | Dog | Horse | Wolf | ||||
| FMNet | 0.3601 | 0.3709 | 0.3402 | 0.3413 | 0.3712 | 0.3100 | 0.3752 | 0.3574 | 0.3745 | 0.3522 | 0.0360 |
| SURFMNet | 0.3952 | 0.3895 | 0.3727 | 0.1673 | 0.3485 | 0.3572 | 0.4084 | 0.3659 | 0.3792 | 0.3496 | 0.0545 |
| MGCN | 0.3211 | 0.2755 | 0.2752 | 0.1381 | 0.2631 | 0.2787 | 0.3153 | 0.3015 | 0.3398 | 0.3045 | 0.1779 |
| Ours | 0.1357 | 0.0825 | 0.0596 | 0.0726 | 0.1902 | 0.0864 | 0.1099 | 0.0741 | 0.1158 | 0.0913 | 0.0184 |
| Datasets | Dynamic Routing | Ours without Knowledge Distillation | Ours |
|---|---|---|---|
| david | 0.1153 | 0.1193 | 0.1186 |
| michael | 0.1295 | 0.1136 | 0.1129 |
| victoria | 0.0644 | 0.0612 | 0.0598 |
| cat | 0.1058 | 0.0949 | 0.0941 |
| centaur | 0.1824 | 0.1698 | 0.1605 |
| dog | 0.1625 | 0.1579 | 0.1572 |
| horse | 0.1137 | 0.1182 | 0.1174 |
| wolf | 0.1471 | 0.1354 | 0.1287 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lian, Y.; Chen, M. CA-CGNet: Component-Aware Capsule Graph Neural Network for Non-Rigid Shape Correspondence. Appl. Sci. 2023, 13, 3261. https://doi.org/10.3390/app13053261
Lian Y, Chen M. CA-CGNet: Component-Aware Capsule Graph Neural Network for Non-Rigid Shape Correspondence. Applied Sciences. 2023; 13(5):3261. https://doi.org/10.3390/app13053261
Chicago/Turabian StyleLian, Yuanfeng, and Mengqi Chen. 2023. "CA-CGNet: Component-Aware Capsule Graph Neural Network for Non-Rigid Shape Correspondence" Applied Sciences 13, no. 5: 3261. https://doi.org/10.3390/app13053261
APA StyleLian, Y., & Chen, M. (2023). CA-CGNet: Component-Aware Capsule Graph Neural Network for Non-Rigid Shape Correspondence. Applied Sciences, 13(5), 3261. https://doi.org/10.3390/app13053261