
Tor Anonymous Traffic Identification Based on Parallelizing Dilated Convolutional Network

Abstract
1. Introduction
- (1)
- In the data processing stage, the directional features are enhanced through cropping and adding data. We then combine the methods used in previous studies to identify anonymous traffic using a single directional feature or timestamp feature.
- (2)
- In the model training stage, we use parallelizing dilated convolutional networks and multi-layer RBMs to extract features and classify web pages. A multi-core convolutional network parallelizing architecture is built to extract the sequential features of cell packets and the expanded convolutions make it possible to expand the sensory field of the model without pooling operations, enhancing the sensory range of a single cell packet for continuous positive/negative traffic data with neighboring timestamps, compared to the traditional CNN architecture.
- (3)
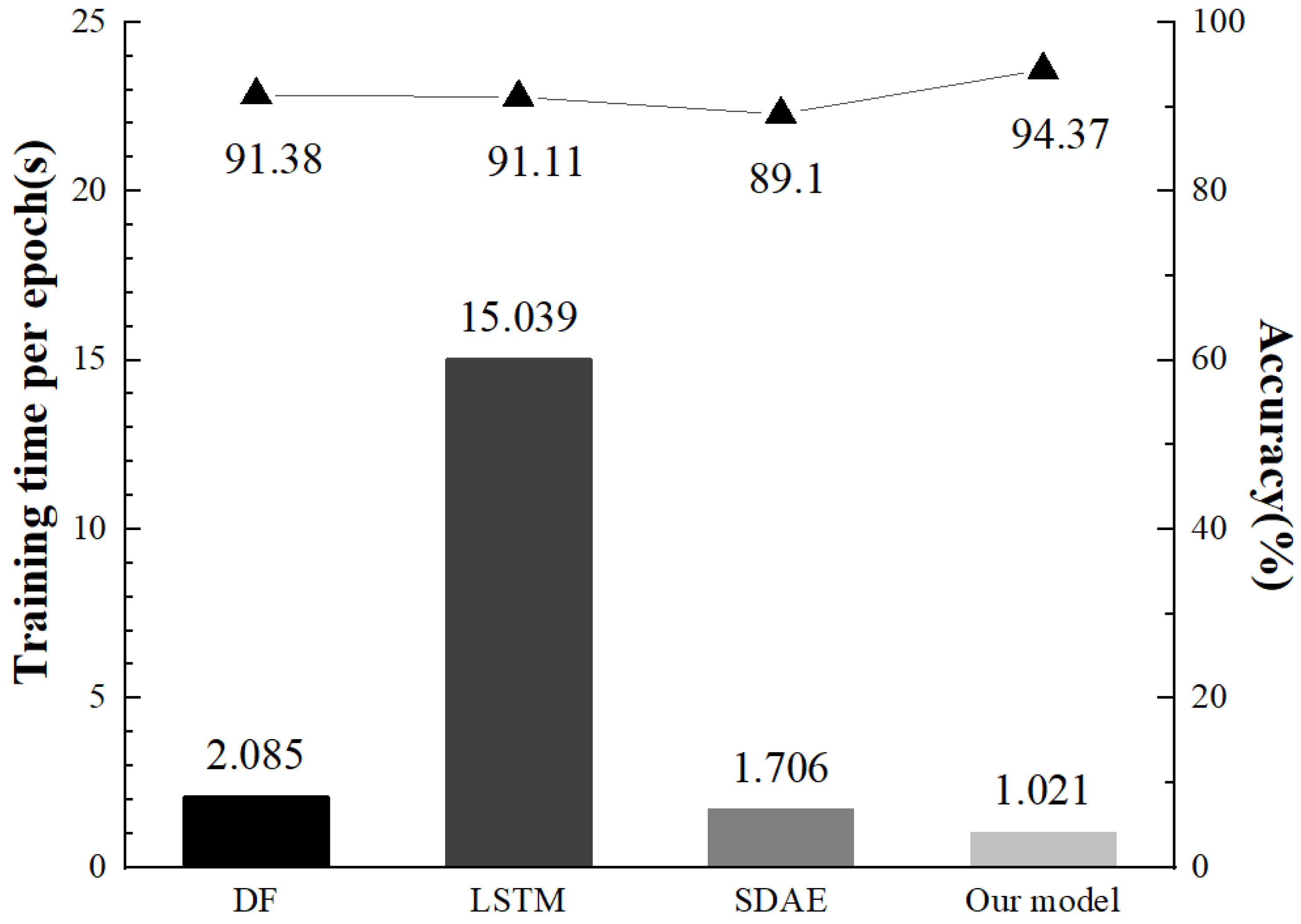
- In the model implementation stage, we provide the possibility of bi-directional deployment of the traffic identification model over the Tor communication link and improve the robustness of the model. Experiments are conducted on the collected dataset to compare with the DF model, LSTM model, SDAE model, etc. The experiments show that our method alleviates the problem of insufficient generalization of the model due to irregular updates of web content in real-life situations. The reduced number of parameters speeds up the convergence of the model and the proposed method improves the recognition accuracy compared to previous Tor anonymous traffic identification methods.
2. Related Work
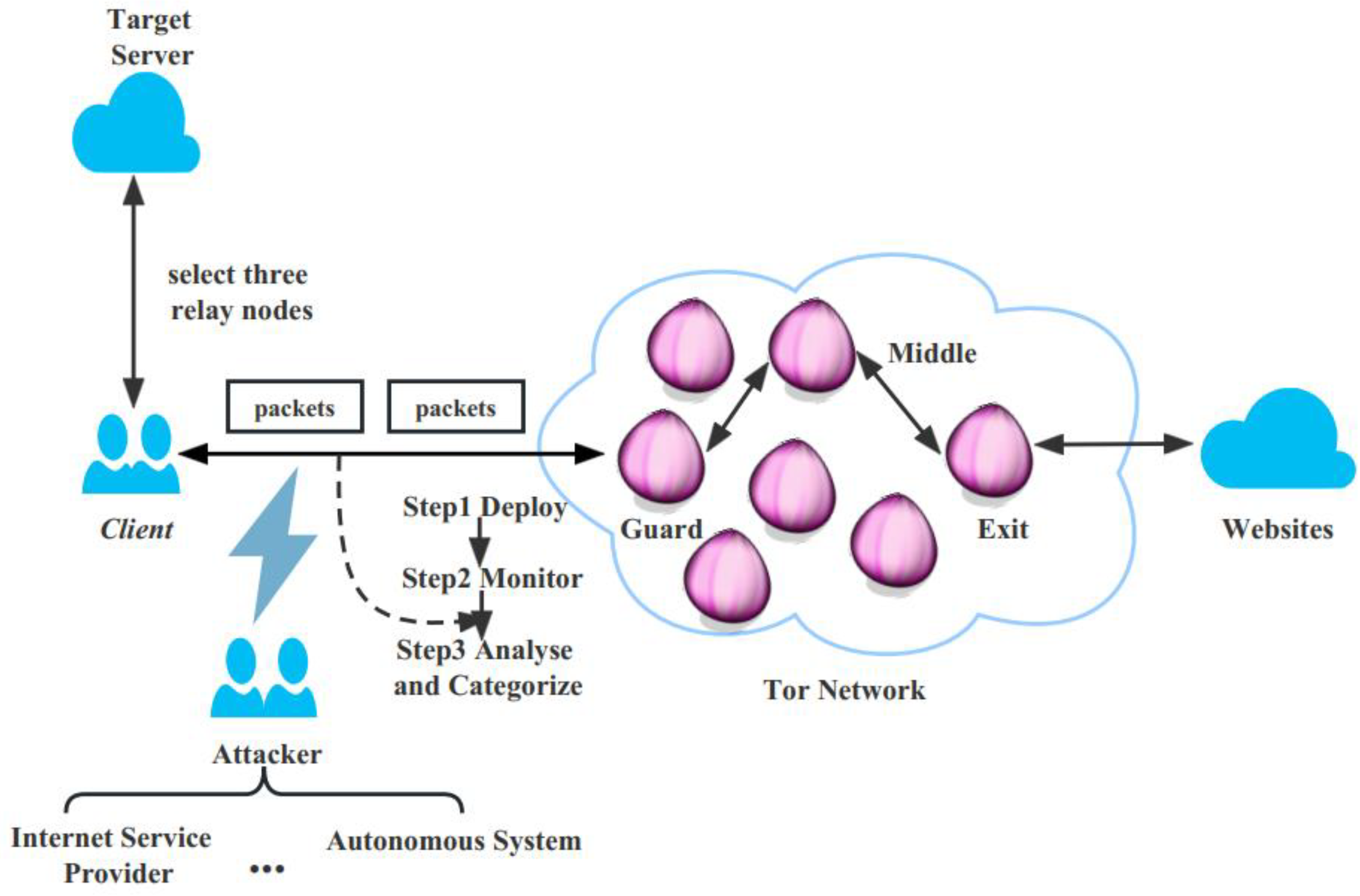
2.1. Tor Website Fingerprinting Attack Architecture
2.2. Overview of Website Fingerprinting Attacks
3. Model Design of This Paper
3.1. Tor Anonymous Traffic Identification Architecture
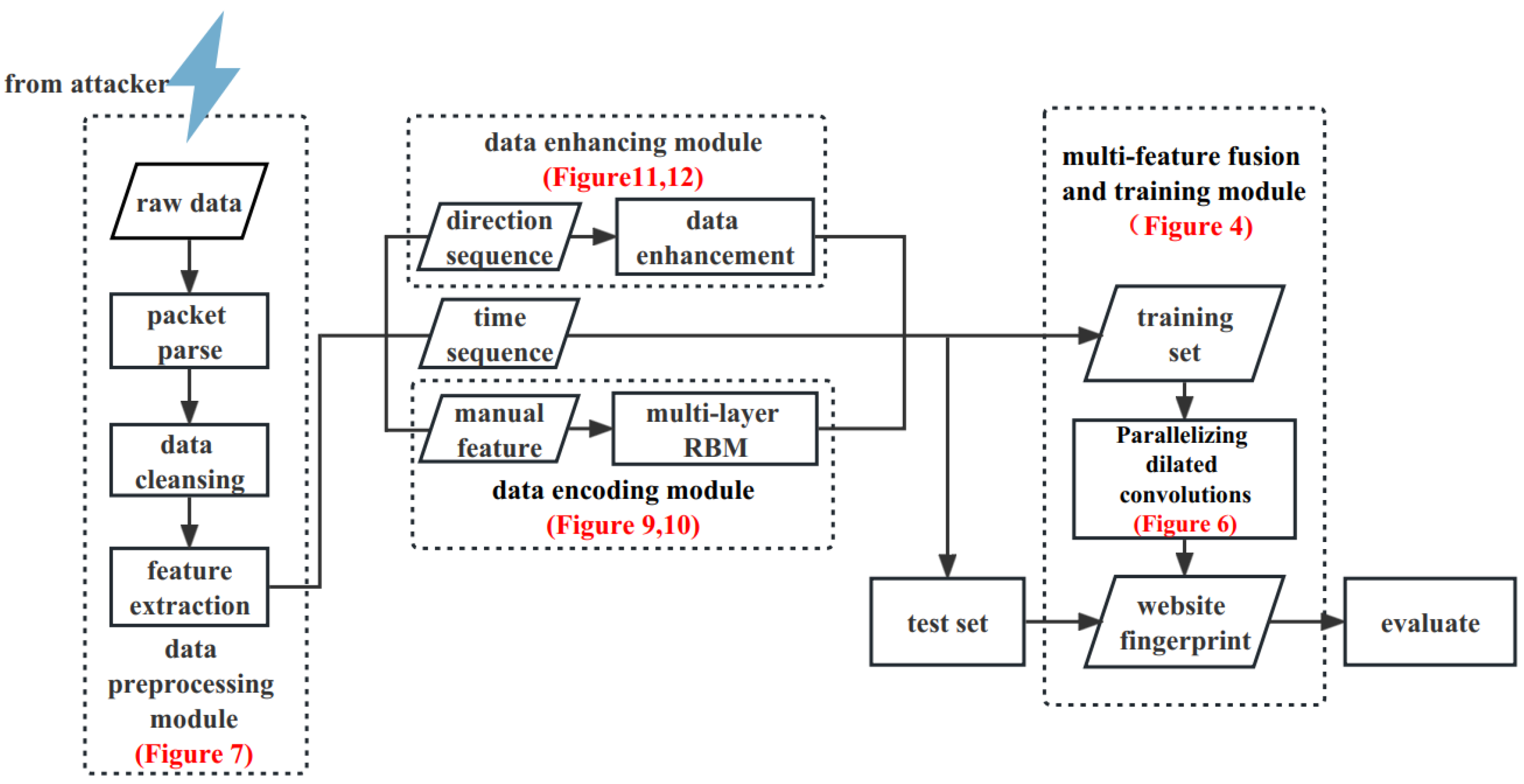
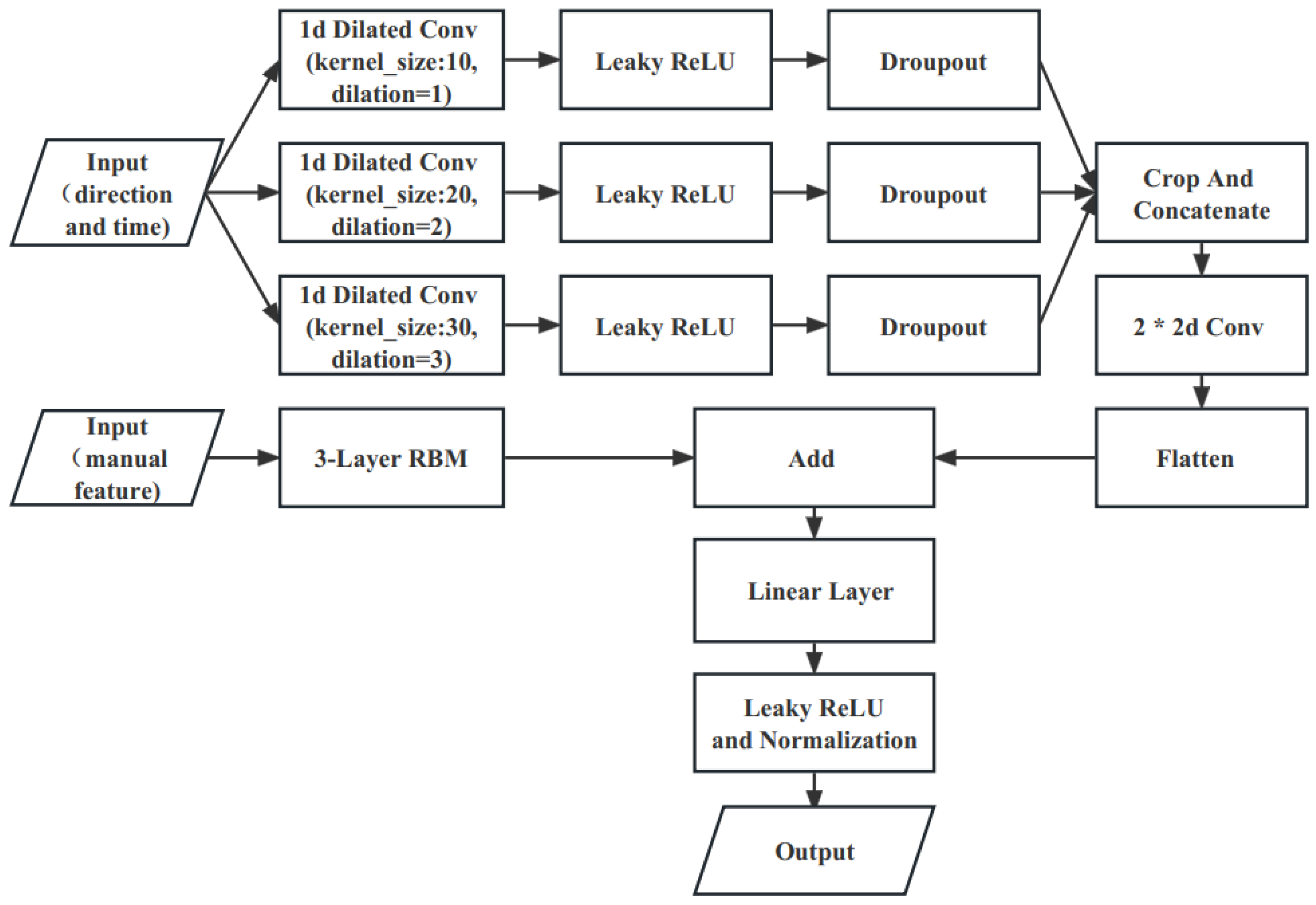
3.1.1. Overall Architecture and Tor Anonymous Traffic Identification Process
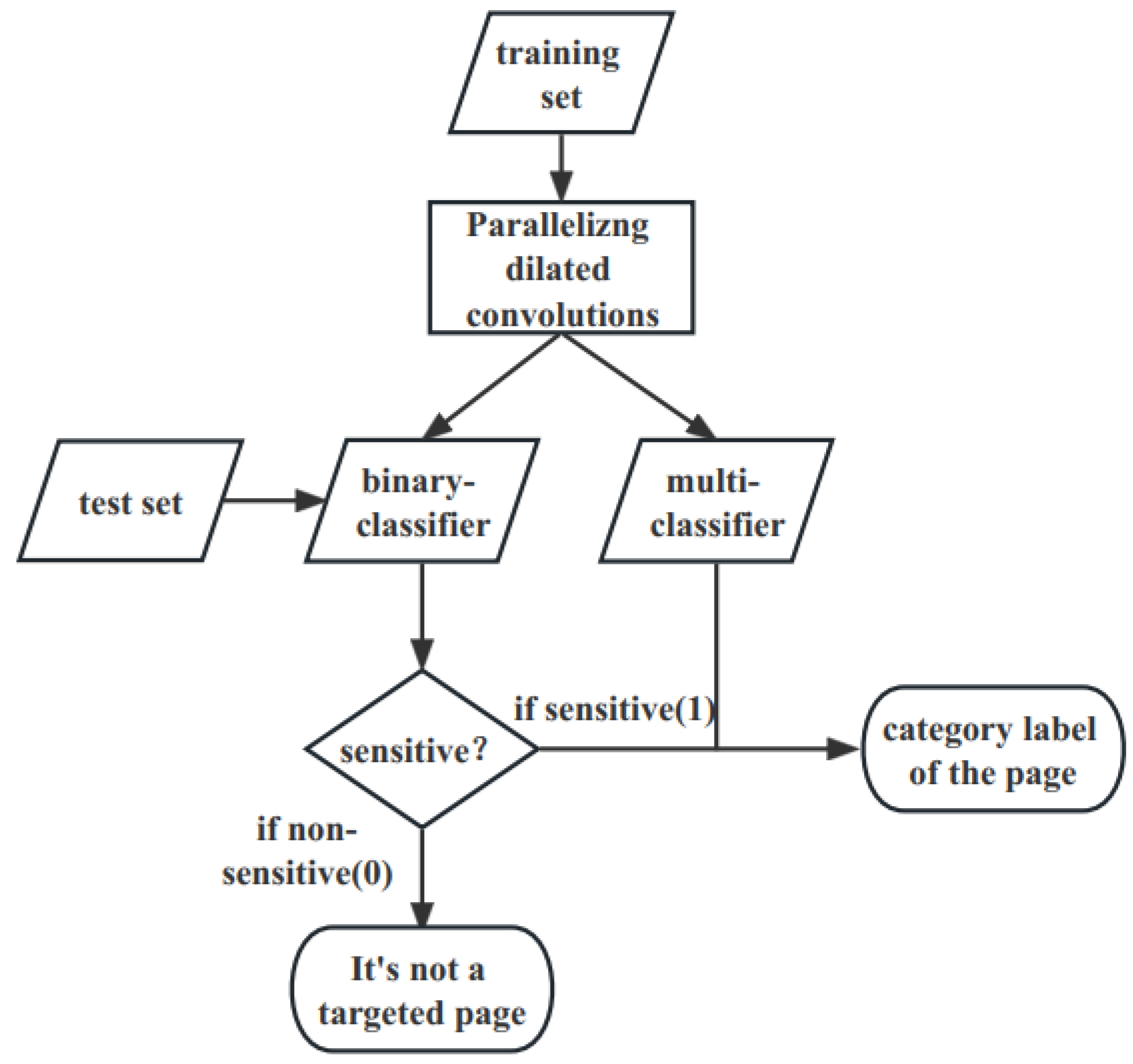
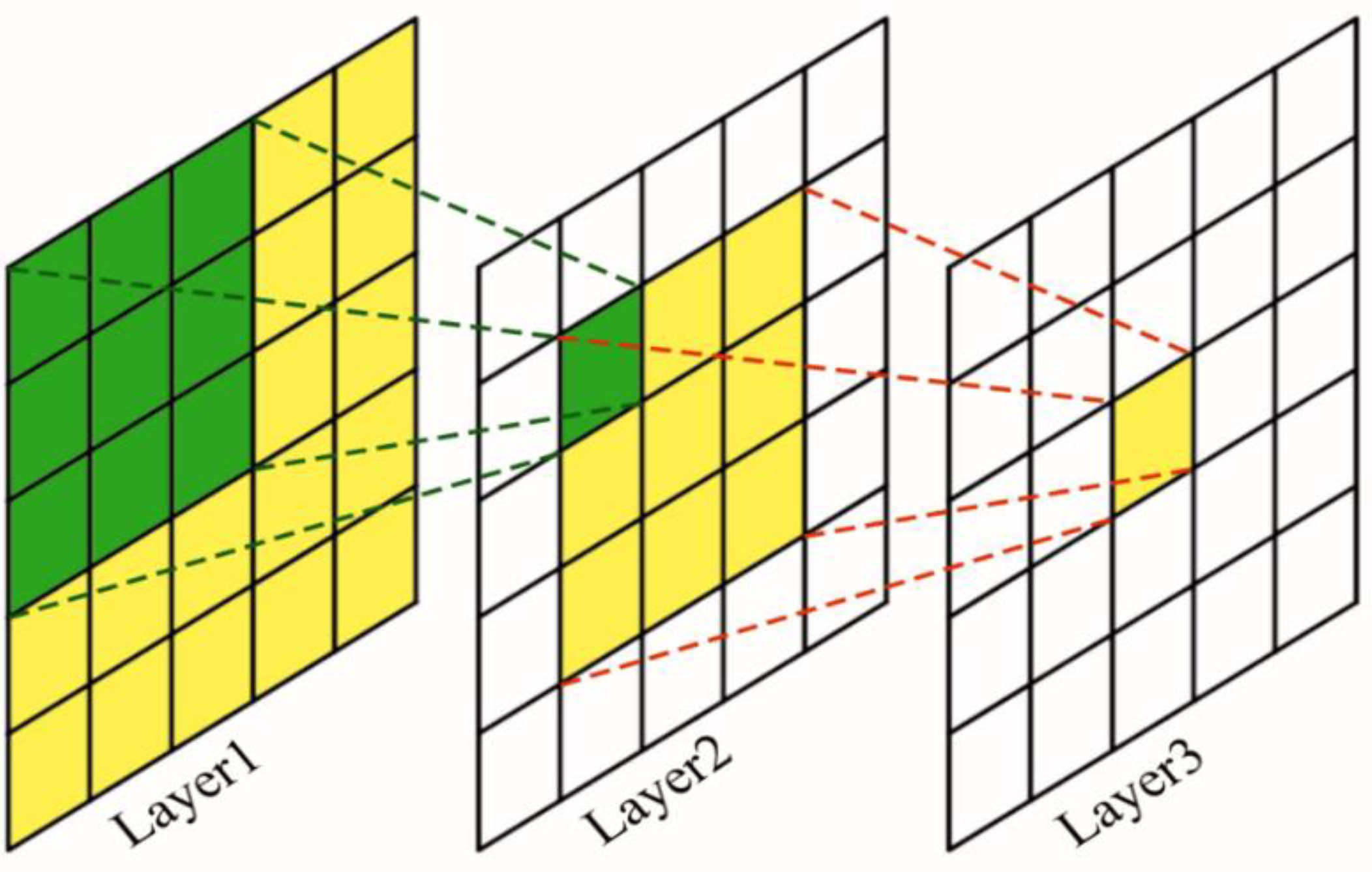
3.1.2. Parallelizing Dilated Convolutions Networks
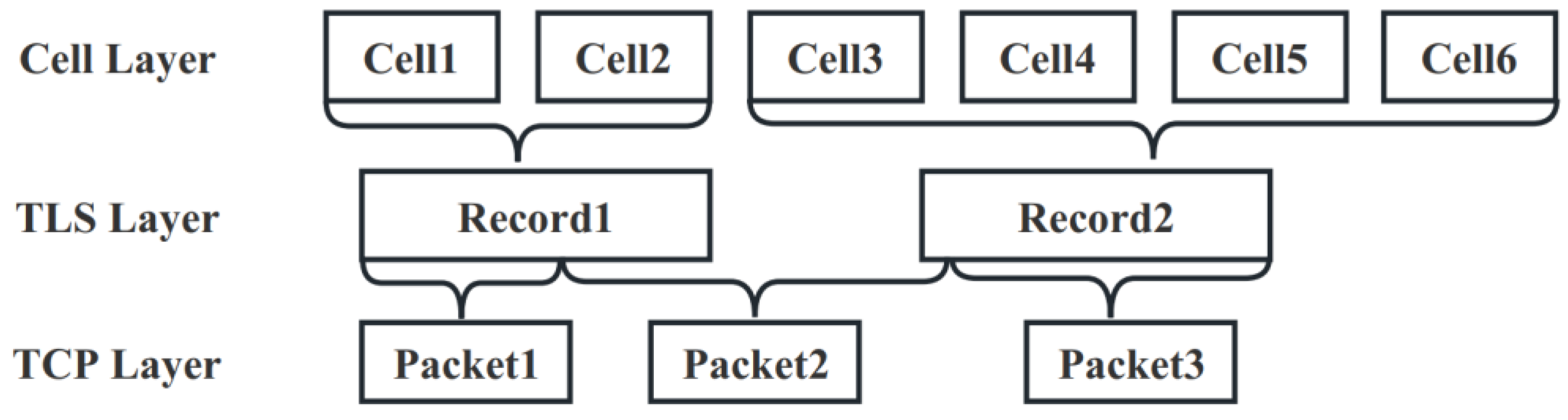
3.2. Tor Traffic Data Pre-Processing
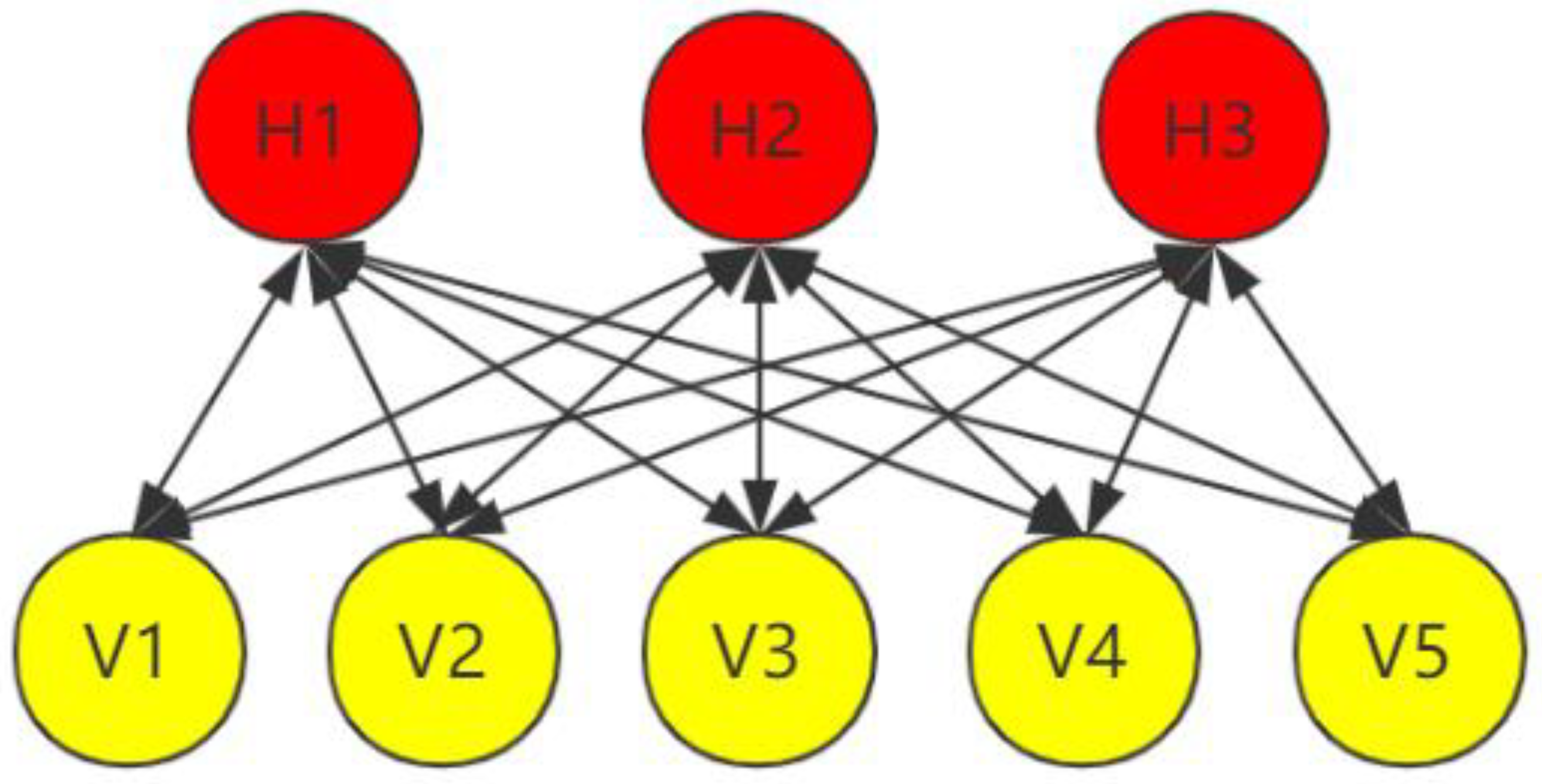
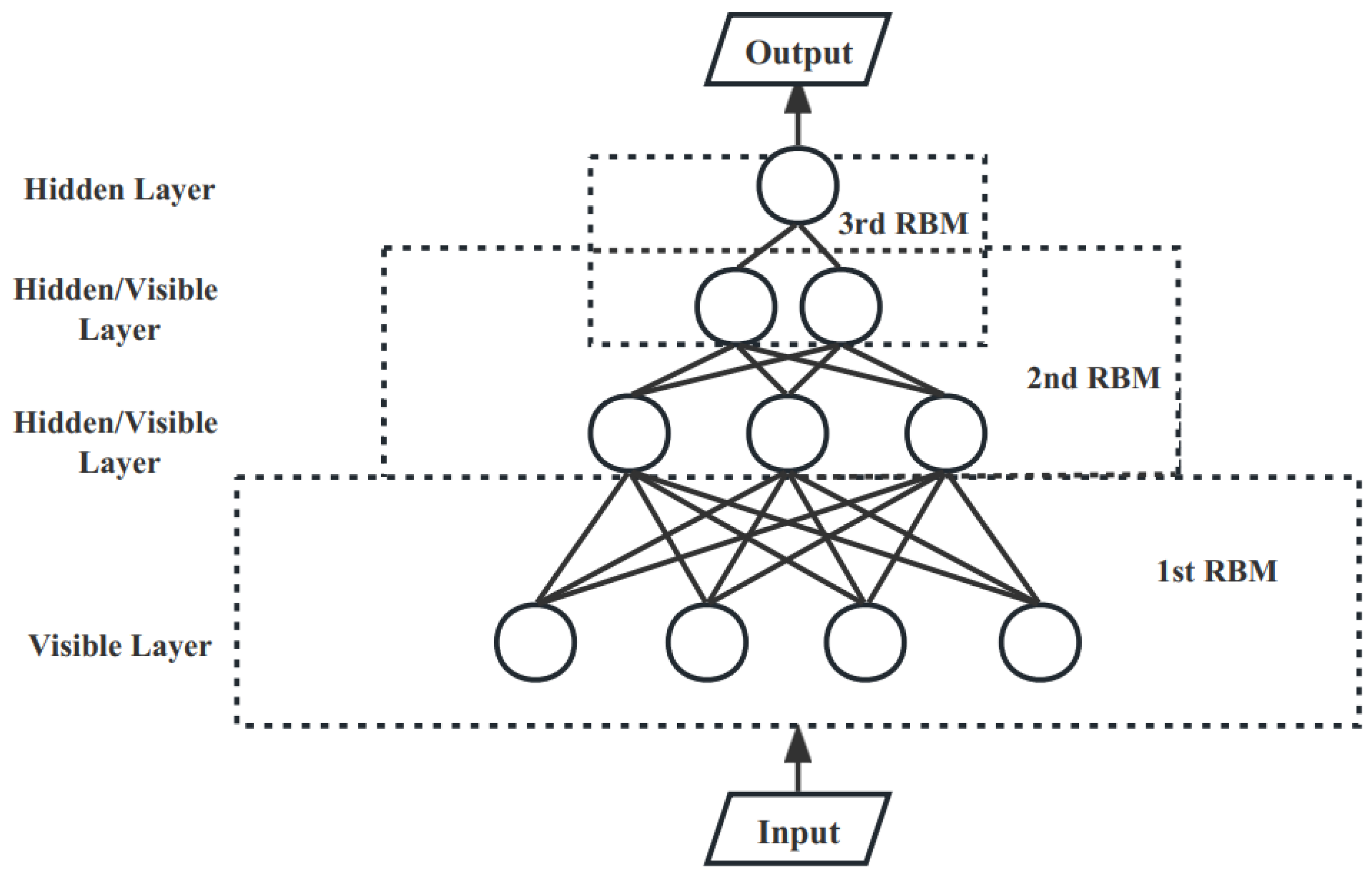
3.3. Multilayer Restricted Boltzmann Machine Coding Module
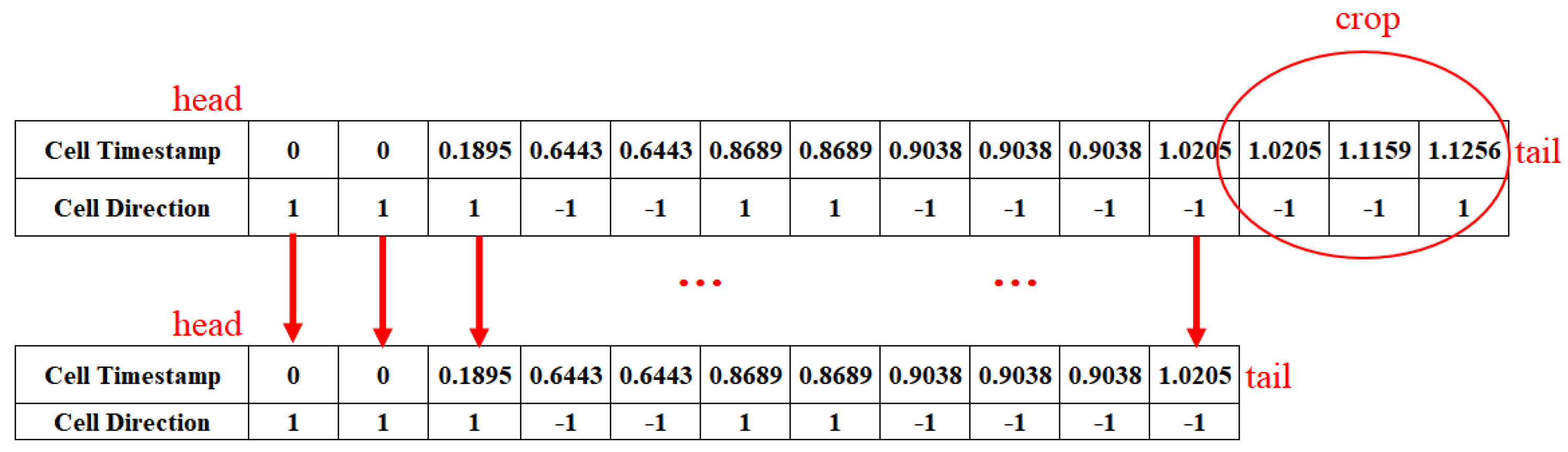
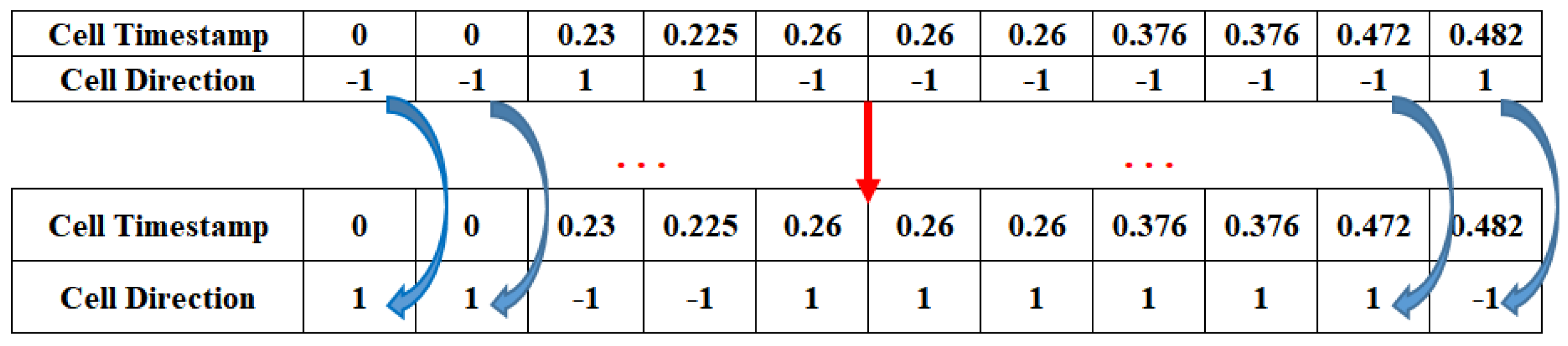
3.4. Data Enhancement and Multi-Feature Fusion Module
4. Experimental Analysis
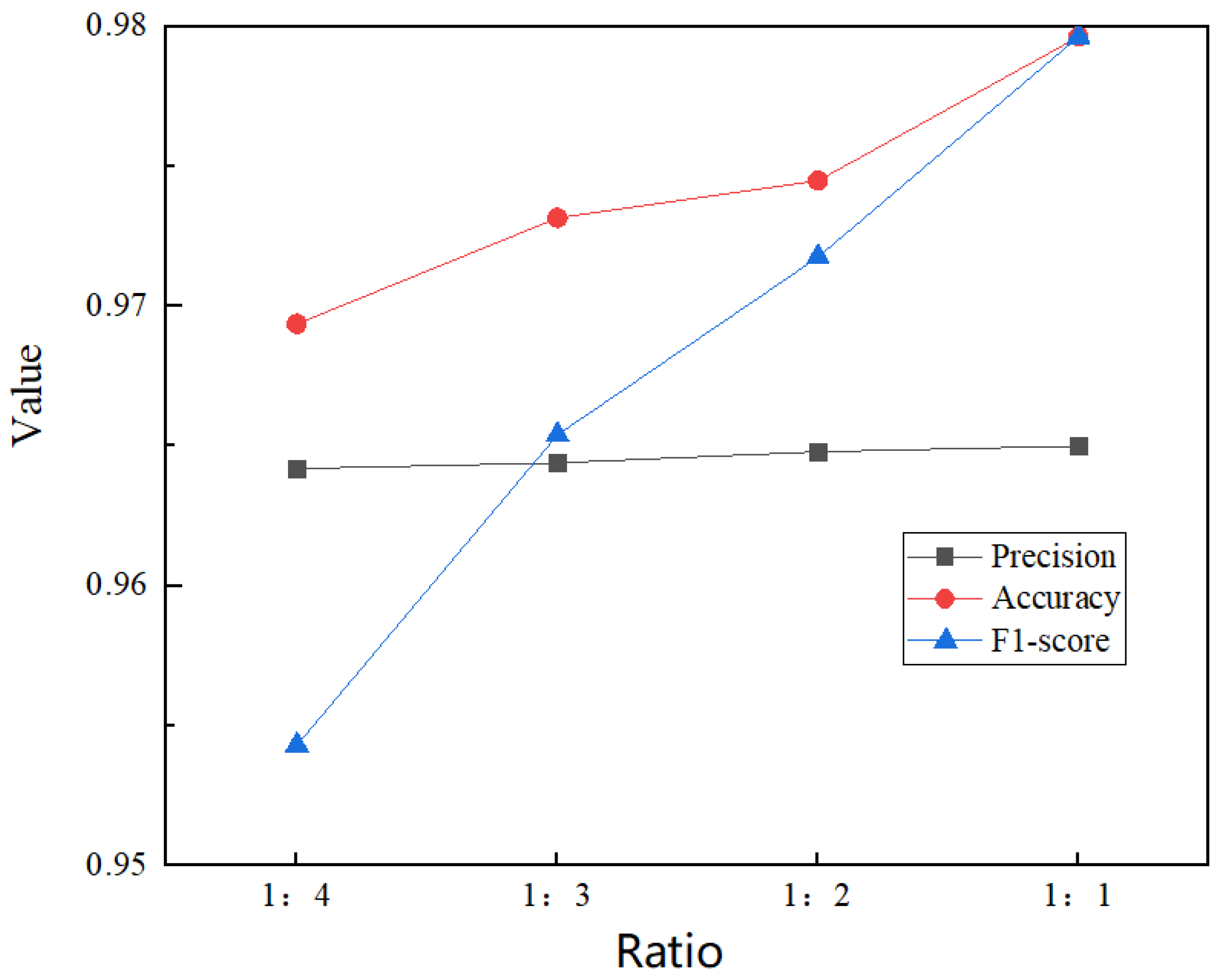
4.1. Dataset Partitioning and Hyperparameter Selection
4.2. Assessment Indicators
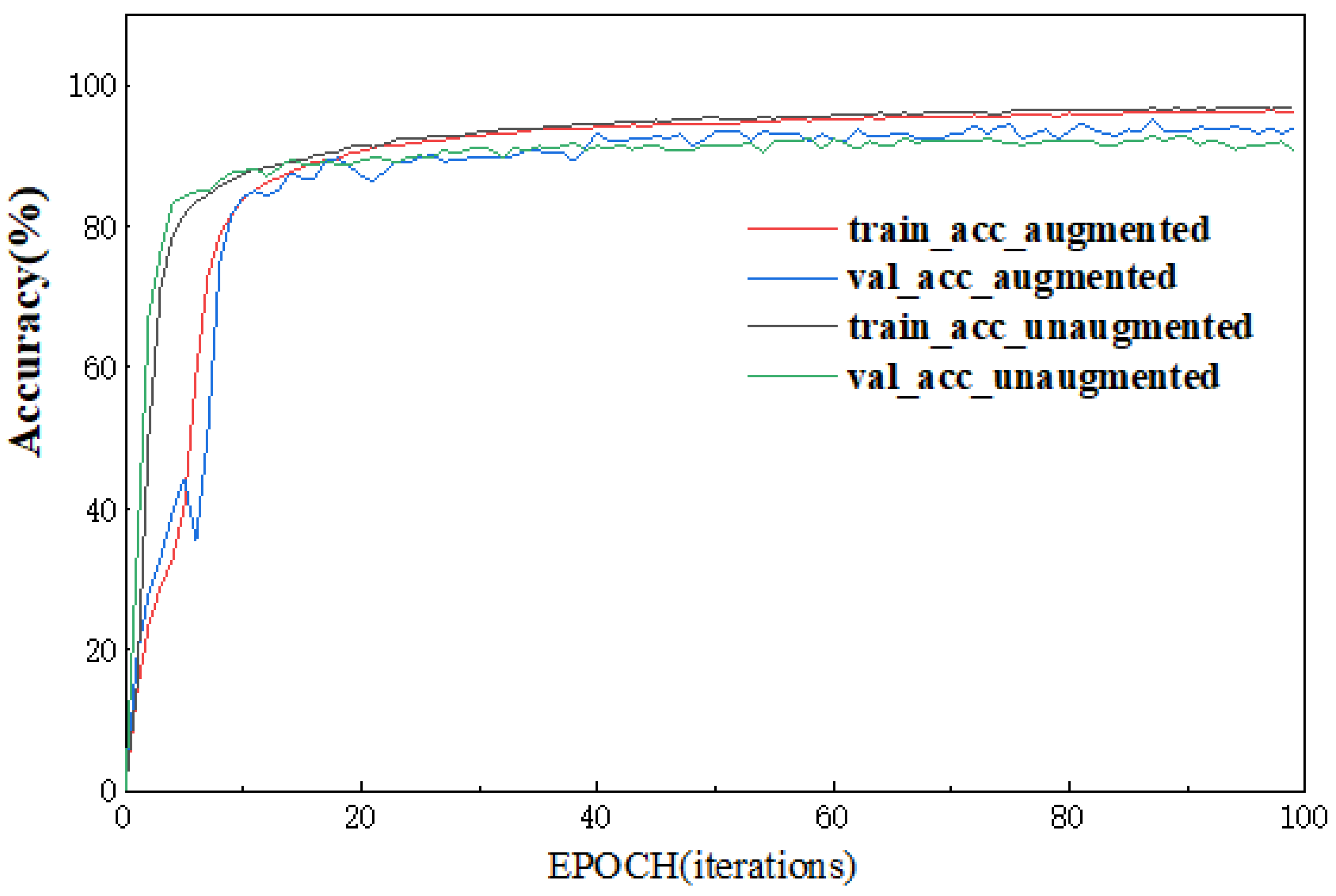
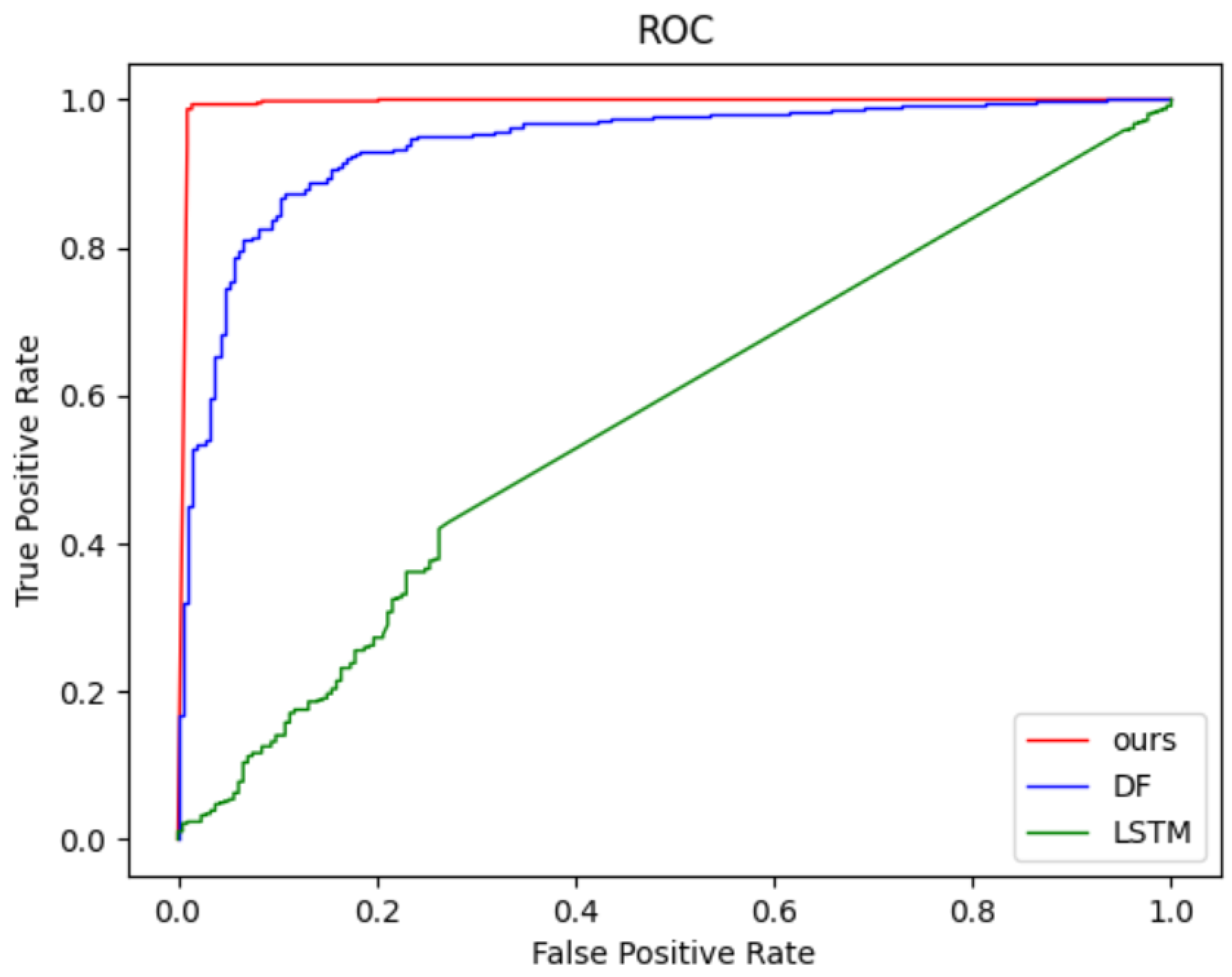
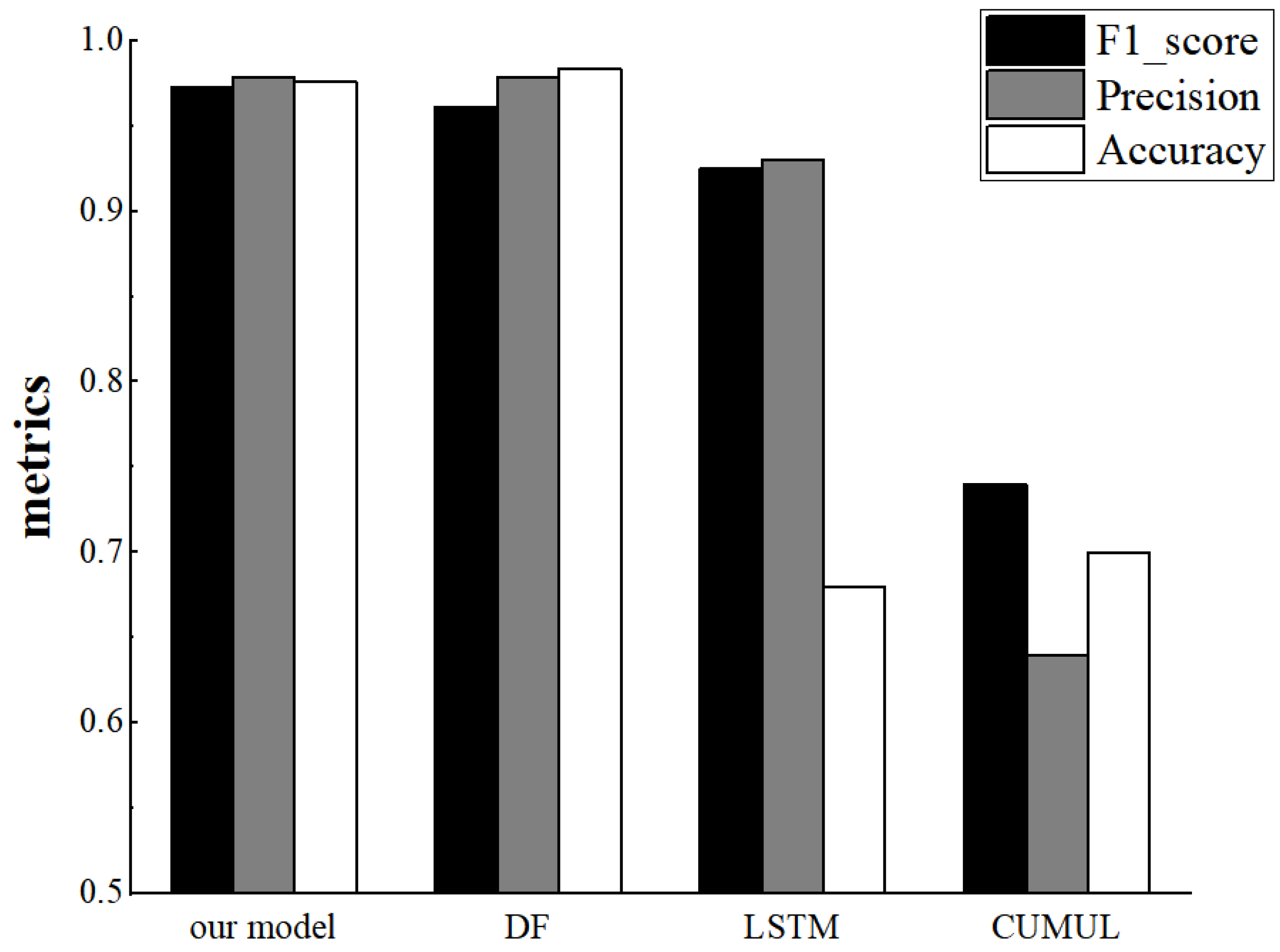
4.3. Closed-World Performance
4.4. Open-World Performance
5. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Zou, H.; Wei, Z.; Su, J.; Zhao, B.; Xia, Y.; Zhao, N. A review of website fingerprinting and defense research. J. Comput. Sci. 2022, 45, 2243–2278. [Google Scholar]
- Hintz, A. Fingerprinting websites using traffic analysis. In Privacy Enhancing Technologies; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2003; pp. 171–178. [Google Scholar]
- Sun, Q.; Simon, D.R.; Wang, Y.M.; Russell, W.; Padmanabhan, V.N.; Qiu, L. Statistical identification of encrypted web browsing traffic. In Proceedings of the 2002 IEEE Symposium on Security and Privacy, Berkeley, CA, USA, 12–15 May 2002. [Google Scholar] [CrossRef]
- Bissias, G.D.; Liberatore, M.; Jensen, D.; Levine, B.N. Privacy vulnerabilities in encrypted HTTP streams. In Privacy Enhancing Technologies; Danezis, G., Martin, D., Eds.; Springer: Berlin/Heidelberg, Germany, 2005. [Google Scholar]
- Panchenko, A.; Niessen, L.; Zinnen, A.; Engel, T. Website fingerprinting in onion routing based anonymization networks. In Proceedings of the 10th Annual ACM Workshop on Privacy in the Electronic Society, Chicago, IL, USA, 17 October 2011; pp. 103–114. [Google Scholar] [CrossRef]
- Liberatore, M.; Levine, B.N. Inferring the source of encrypted HTTP connections. In Proceedings of the 13th ACM Conference on Computer and Communications Security, Alexandria, VA, USA, 30 October–3 November 2006. [Google Scholar]
- Shahbar, K.; Zincir-Heywood, A.N. Benchmarking two techniques for Tor classification: Flow level and circuit level classification. In Proceedings of the 2014 IEEE Symposium on Computational Intelligence in Cyber Security (CICS), Orlando, FL, USA, 9–12 December 2014; pp. 1–8. [Google Scholar] [CrossRef]
- Cai, Z.; Jiang, B.; Lu, Z.; Liu, J.; Ma, P. isAnon: Flow-based anonymity network traffic identification using extreme gradient boosting. In Proceedings of the 2019 International Joint Conference on Neural Networks (IJCNN), Budapest, Hungary, 14–19 July 2019. [Google Scholar]
- Wang, T.; Goldberg, I. Improved website fingerprinting on Tor. In Proceedings of the 12th ACM Workshop on Privacy in the Electronic Society, Dallas, TX, USA, 3 November 2013; pp. 201–212. [Google Scholar]
- Hinton, G.E.; Salakhutdinov, R.R. Reducing the dimensionality of data with neural networks. Science 2006, 313, 504–507. [Google Scholar] [CrossRef] [PubMed]
- Abe, K.; Goto, S. Fingerprinting attack on Tor anonymity using deep learning. Proc. Asia Pac. Adv. Netw. 2016, 42, 15–20. [Google Scholar]
- Rimmer, V.; Preuveneers, D.; Juarez, M.; Van Goethem, T.; Joosen, W. Automated website fingerprinting through deep learning. arXiv 2018, arXiv:1708.06376. [Google Scholar] [CrossRef]
- Bhat, S.; Lu, D.; Kwon, A.; Devadas, S. Var-CNN: A data-efficient website fingerprinting attack based on deep learning. Proc. Priv. Enhancing Technol. 2019, 2019, 292–310. [Google Scholar] [CrossRef]
- Wang, M.; Li, Y.; Wang, X.; Liu, T.; Shi, J.; Chen, M. 2ch-TCN: A website fingerprinting attack over tor using 2-channel temporal convolutional networks. In Proceedings of the 2020 IEEE Symposium on Computers and Communications (ISCC), Rennes, France, 7–10 July 2020. [Google Scholar]
- Ma, C.; Du, X.; Cao, L.; Wu, B. Website fingerprint attack method based on deep neural network burst feature analysis. Comput. Res. Dev. 2020, 57, 21. [Google Scholar]
- Sirinam, P.; Imani, M.; Juarez, M.; Wright, M. Deep fingerprinting: Undermining website fingerprinting defenses with deep learning. In Proceedings of the 2018 ACM SIGSAC Conference on Computer and Communications Security, Toronto, ON, Canada, 15–19 October 2018. [Google Scholar]
- Yu, F.; Koltun, V. Multi-scale context aggregation by dilated convolutions. arXiv 2015, arXiv:1511.07122. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 12 June 2015. [Google Scholar]
- Benna, M.K.; Fusi, S. Computational principles of synaptic memory consolidation. Nat. Neurosci. 2016, 19, 1697–1706. [Google Scholar] [CrossRef] [PubMed]
- Chen, J.; Cheng, G.; Mei, H. F-ACCUMUL: A Protocol fingerprint and accumulative payload length sample-based tor-snowflake traffic-identifying framework. Appl. Sci. 2023, 13, 622. [Google Scholar] [CrossRef]
- Zhang, Y.; Li, P.; Wang, X. Intrusion detection for IoT based on improved genetic algorithm and deep belief network. IEEE Access 2019, 7, 31711–31722. [Google Scholar] [CrossRef]
- Hinton, G.E. A practical guide to training restricted Boltzmann machines. In Neural Networks: Tricks of the Trade; Springer: Berlin/Heidelberg, Germany, 2012; pp. 599–619. [Google Scholar]
- Panchenko, A.; Lanze, F.; Pennekamp, J.; Engel, T.; Zinnen, A.; Henze, M.; Wehrle, K. Website Fingerprinting at Internet Scale; NDSS (National Down Syndrome Society): Manhattan, NY, USA, 2016. [Google Scholar]
- De la Cadena, W.; Mitseva, A.; Hiller, J.; Pennekamp, J.; Reuter, S.; Filter, J.; Engel, T.; Wehrle, K.; Panchenko, A. Trafficsliver: Fighting website fingerprinting attacks with traffic splitting. In Proceedings of the 2020 ACM SIGSAC Conference on Computer and Communications Security, Virtual, 9–13 November 2020. [Google Scholar]
- Ling, Z.; Xiao, G.; Wu, W.; Gu, X.; Yang, M.; Fu, X. Towards an efficient defense against deep learning based website fingerprinting. In Proceedings of the IEEE INFOCOM 2022-IEEE Conference on Computer Communications, London, UK, 2–5 May 2022. [Google Scholar]
- McGuan, C. Practical and Lightweight Defense Against Website Fingerprinting. Ph.D. Thesis, Cleveland State University, Cleveland, OH, USA, 2022. [Google Scholar]


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Number | Manual Feature |
|---|---|
| 1 | The number of cells |
| 2 | The number of incoming cells (+1) |
| 3 | The number of outcoming cells (−1) |
| 4 | The number of bursts |
| 5 | The number of forward bursts |
| 6 | The number of backward bursts |
| 7 | Total transmission time |
| 8 | Average time to send each burst |
| Configuration | Parameters |
|---|---|
| OS | Linux64 (Ubuntu 16.04.7 LTS) |
| GPU Video memory | NVIDIA GeForce GTX 1080 Ti 16 GB |
| Python | 3.8.13 |
| PyTorch | 1.8.1 |
| CPU Memory | Intel(R) Xeon(R) CPU E5-2650 v4 @2.20GHz 128 GB |
| Name of Hyperparameters | Range | Size |
|---|---|---|
| Input dimension | 500, 1000, 1500, 2000, 3000, 5000 | 2000 |
| Optimizer | Adam, Adamax, RMSProp, SGD | Adam |
| Number of RBM layers | [2,5] | 3 |
| Learning rate | 0.0005, 0.001, 0.002, 0.005, 0.01 | 0.002 |
| Training Epoch | [30,200] | 100 |
| decay | [0,0.8] | 0 |
| Hidden units of RBM | [5,30] | 20, 10, 5 |
| Number of out_channels | [5,15] | 10 |
| Dilation coefficient | [1,10] | (1, 2, 3) |
| Kernel_size(Conv1d) | [5,20] | 10, 20, 30 |
| Kernel_size(Conv2d) | [1,30] | (5, 10), (1, 1) |
| Activation function | Sigmoid, ReLu, Leaky ReLu, tanh | Leaky ReLU |
| Dropout | [0.05,0.5] | 0.2 |
| Batch_size | [16,24,32,64,128] | 32 |
| Name of State-of-the-Art Approaches | Accuracy |
|---|---|
| Panchenko-CUMUL | 91.38% |
| Rimmer-CNN | 71.43% |
| Rimmer-SDAE | 87.78% |
| Rimmer-LSTM | 91.11% |
| Deep fingerprinting | 91.38% |
| Bhat-Var-CNN-dir | 93.20% |
| Bhat-Var-CNN | 93.33% |
| Wang-2ch-TCN | 93.73% |
| Our model | 94.37% |
| Accuracy | Loss | |
|---|---|---|
| Direction-Augmented data model | 93.17% | 0.468919 |
| Unaugmented data model | 3.78% | 10.002669 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lu, Y.; Cai, M.; Zhao, C.; Zhao, W. Tor Anonymous Traffic Identification Based on Parallelizing Dilated Convolutional Network. Appl. Sci. 2023, 13, 3243. https://doi.org/10.3390/app13053243
Lu Y, Cai M, Zhao C, Zhao W. Tor Anonymous Traffic Identification Based on Parallelizing Dilated Convolutional Network. Applied Sciences. 2023; 13(5):3243. https://doi.org/10.3390/app13053243
Chicago/Turabian StyleLu, Yunan, Manchun Cai, Ce Zhao, and Weiyi Zhao. 2023. "Tor Anonymous Traffic Identification Based on Parallelizing Dilated Convolutional Network" Applied Sciences 13, no. 5: 3243. https://doi.org/10.3390/app13053243
APA StyleLu, Y., Cai, M., Zhao, C., & Zhao, W. (2023). Tor Anonymous Traffic Identification Based on Parallelizing Dilated Convolutional Network. Applied Sciences, 13(5), 3243. https://doi.org/10.3390/app13053243