Abstract
The limited computing resources on edge devices such as Unmanned Aerial Vehicles (UAVs) mean that lightweight object detection algorithms based on convolution neural networks require significant development. However, lightweight models are challenged by small targets with few available features. In this paper, we propose an LC-YOLO model that uses detailed information about small targets in each layer to improve detection performance. The model is improved from the one-stage detector, and contains two optimization modules: Laplace Bottleneck (LB) and Cross-Layer Attention Upsampling (CLAU). The LB module is proposed to enhance shallow features by integrating prior information into the convolutional neural network and maximizing knowledge sharing within the network. CLAU is designed for the pixel-level fusion of deep features and shallow features. Under the combined action of these two modules, the LC-YOLO model achieves better detection performance on the small object detection task. The LC-YOLO model with a parameter quantity of 7.30M achieves an mAP of 94.96% on the remote sensing dataset UCAS-AOD, surpassing the YOLOv5l model with a parameter quantity of 46.61M. The tiny version of LC-YOLO with 1.83M parameters achieves 94.17% mAP, which is close to YOLOv5l. Therefore, the LC-YOLO model can replace many heavyweight networks to complete the small target high-precision detection task under limited computing resources, as in the case of mobile edge-end chips such as UAV onboard chips.
1. Introduction
As one of the basic tasks in the field of computer vision, object detection aims to locate and classify objects in images. Object detection algorithms based on convolutional neural networks have made great breakthroughs in accuracy. In practical applications such as remote sensing and aerial photography, it is often necessary to detect small targets in images. Much information is lost after multiple convolutions and pooling in the network, which leads to small object detection being a hot research topic with many challenges. Much research [1,2,3,4,5,6,7] has been conducted on improving network extraction ability. In the same direction, it has been found that increasing the width, depth, and complexity of the network structure can improve network detection performance. The fusion of semantic and detail features [8,9,10,11,12,13] is carried out to improve the precision of small object detection by backtracking the detailed information of the shallow network. Researchers in this area are constantly facing the challenge of limited computing resources. In recent years, the UAV industry has become increasingly prosperous, and people have begun to deploy and use them on edge chips and mobile devices. These computing resources are limited, leading to another development direction of convolutional neural networks: lightweight networks [14,15,16,17,18,19,20], that is, those with maximized reasoning speed and reduced use of computing resources, though this comes at the expense of network detection accuracy.
Small targets require a more complex network in order to obtain more relevant information in the image and assist in the detection task. However, lightweight networks have fewer parameters, and their feature extraction and feature fusion capability need to be improved, resulting in its limited fitting capacity. Therefore, exploring how to improve the performance of lightweight networks used in small object detection tasks is of great significance for the deployment and practical application of object detection algorithms based on convolutional neural networks on mobile edge chips.
In this paper, we propose a lightweight model called LC-YOLO that can be widely used in practical projects and performs better on small object detection tasks. First, we propose Laplace Bottleneck (LB), which takes the classical Laplace operator as prior knowledge and integrates a filter with a fixed weight designed by adjusting the element value into the bottleneck structure through a shortcut. The maximum sharing of previous expertise in the network enhances the feature detail and improves the feature extraction ability of the backbone. Then, to improve the feature fusion ability of the deep network structure, we propose Cross-Layer Attention Upsampling (CLAU). This module takes the shallow feature map as the query tensor and uses the deep feature diagram of the nearest sampling as the key tensor and value tensor. Using the attention mechanism, it obtains the pixel-level weight representing the correlation between the shallow feature and the deep feature, realizes their adaptive fusion, and generates fusion features conducive to small target detection. This can dramatically improve the detection accuracy of the network for small targets. Finally, we obtain the LC-YOLO model by adjusting the function position of the two modules, which uses the extracted features efficiently. When verifying the model’s validity on the UCAS-AOD dataset, the mAP was 94.96%. This is 3.3% higher than YOLOv5s, and exceeds the performance of heavier versions of YOLOv5 such as YOLOv5m and YOLOv5l. The LC-YOLO model can be deployed with lower computing resource consumption on the edge to achieve high-precision detection of small targets that only a heavier existing networks can achieve. The main contributions of this work can be summarized as:
1. We propose Laplace Bottleneck (LB); our experiments prove that the traditional operator can be skillfully integrated into a lightweight neural network as a priori knowledge to maximize knowledge sharing and improve the network’s feature extraction ability.
2. We propose Cross-Layer Attention Upsampling (CLAU). Our experience shows that the practical guidance of shallow features for obtaining in-depth features at the pixel level can significantly improve network performance for small target detection.
3. We obtain the LC-YOLO model by integrating LB and CLAU and adjusting their function position, which makes efficient use of the features extracted and stored in the current network and realizes better performance on small targets.
2. Related Work
2.1. Backbone for Feature Extraction
To fit fewer computing resources, previous researchers have reduced the number of model parameters at the cost of reduced detection accuracy. For example, SqueezeNet [14] uses 1 × 1 convolution to compress the number of feature maps. MobileNet [15] proposes depth-separable convolution to replace ordinary convolution, which greatly reduces the number of parameters. ShuffleNet [16] uses packet convolution to replace dense ordinary convolutions. ChannelNets [17] uses channel-wise convolution to compress the depth model, and replaces dense connections between feature maps with sparse connections in the CNN. IGCV1 [18] relies on interlaced group convolution to make full use of grouped convolution. GhostNet [19] uses a linear transformation to achieve a similar characteristic graph, saving calculation effort. However, a significant reduction in the number of parameters inevitably reduces the detection accuracy of the network. Researchers have explored many ways of achieving higher detection accuracy with fewer parameters. In this paper, we use prior knowledge to enhance the feature extraction ability of a lightweight network without increasing the number of learning parameters.
2.2. Neck for Feature Fusion
When the convolutional neural network is deepened, many details are lost, which makes the detection accuracy of the network for small objects unsatisfactory. The pioneering feature pyramid network (FPN) [8] uses upsampling to improve the resolution of the deep feature map, forming a pyramid structure from top to bottom; in combination with horizontal connection, this approach realizes the fusion of deep features and shallow features. PANet [9] adds a bottom-up path aggregation network on the basis of FPN. STDL [10] proposes a scale conversion module combined with DenseNet, enabling feature mapping with both low-level detail features and high-level semantic features. In M2det [11], a set of alternating connection simplified U-shaped modules is designed to achieve the goal of feature fusion. G-FRNet [12] proposes a gated feedback refinement network that uses deep features to assist shallow features in filtering out the fuzziness and ambiguity of information. BiFPN [13] proposes a weighted special fusion mechanism to realize the organic fusion of deep and shallow features. The feature fusion process inevitably increases the number of parameters in the model and the required memory consumption.
2.3. Head for Object Detection
Existing object detectors mainly consist of an anchor-based detector and an anchor-free detector. The anchor-based detectors can be subdivided into two-stage detectors and one-stage detectors. The classical two-stage detector is Faster-RCNN [21], which has superior detection performance; however, it cannot realize real-time detection. The one-stage detector RetinaNet [22] surpasses the second-stage detectors in detection accuracy by weighting the sample loss. YOLOv3 [4] inherits the idea of YOLOv1 [23] and YOLOv2 [24] and adds the FPN structure to achieve multi-scale prediction. While retaining the advantages of real-time monitoring of one-stage detectors, the detection accuracy is greatly improved. RoI-Trans [25], DAL [26], and others add attributes such as rotation angle to the anchor to increase the proportion of effective pixels in the ground truth, thereby improving the detection performance of the network for small targets; however, due to its large network volume and complex structure it has not been widely used in practical projects. Anchor-free detectors such as CenterNet [27], FCOS [28], RepPoints [29], and Orientated RepPoints [30] have advantages in small target detection due to their pixel-level prediction of feature maps; however, their huge amount of computation makes the reasoning speed of the network very slow.
YOLOv5 simplifies the backbone of YOLOv4 [6], adds the PANet structure to achieve the fusion of deep and shallow features, uses k-means clustering to obtain the appropriate anchor frame size, and improves the problem of missed detection of small targets by eliminating grid sensitivity. In addition, similar to EfficienctNet, YOLOv5 sets two parameters, the depth multiple and width multiple, to control the depth and width of the network, that is, the number of convolution layers and channels, respectively. YOLOv5s, YOLOv5m, YOLOv5l, and YOLOv5x, representing the four versions of model volume and accuracy in increasing order, have been released to adapt to different task requirements. YOLOv5 has been applied to various visual tasks after several iterations as an efficient one-stage object detection model. Unless otherwise specified, the YOLOv5 model mentioned in this paper refers specifically to the 5.0 version.
3. Methodology
In this section, we first review the overall structure of the YOLOv5 network. Then, we analyze the structural characteristics of the bottleneck and the nearest upsampling and introduce our Laplace Bottleneck (LB) and Cross-Layer Attention Upsample (CLAU) structure. Finally, we show the details of the joint action of Laplace Bottleneck (LB) and Cross-Layer Attention Upsample (CLAU) in the model proposed in this paper.
3.1. Review of YOLOv5 Model
YOLOv5 network can be divided into three parts, the backbone, the neck, and the head, which are used for feature extraction, feature fusion, and classification and regression, respectively. In the backbone, YOLOv5 improves on the CSPBottleneck in CSPnet and incorporates the C3 module by removing the residual block’s output and replacing the activation function. The module continues CSPnet’s idea of dividing gradient flow to enrich the gradient combination of the network; the result is simpler, faster, and lighter, with similar performance and better fuse characteristics. In the feature fusion stage, YOLOv5 uses nearest neighbor upsampling and a concatenation operation to build the bottom-up and top-down dual path feature fusion structure proposed by the PANet model, which realizes the fusion of detail and semantic features. This design improves the severe problem of small target feature information loss in the deep network transmission process, and enhances the model’s representation ability. The YOLOv5 model contains three outputs responsible for predicting the location and category information of the target in various scales, and is optimized on the loss function and the positive sample matching strategy.
3.2. Laplace Bottleneck (LB)
3.2.1. Laplace Operator
As a typical high-pass filter, the Laplace operator enhances the edge contour of an image by increasing the difference between adjacent pixels. The Laplace operator is the sum of second-order differentials in the x and y directions, as shown in (1). When applied to a digital image, we can extend it to the discrete domain and obtain (2), the filter template of which is shown as Figure 1a. The filter template with diagonal terms is expanded as shown in Figure 1b, for which the version used in practical applications is Figure 1c.
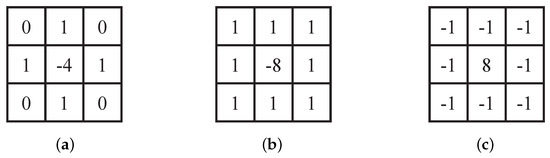
Figure 1.
Common Laplace filter templates: (a) filter for Formula (2), (b) diagonal expansion, and (c) practical application.
In practical applications, the Laplace operator is often inverted. For this, we need to superimpose the filtered image onto the original image, as shown in (3), where and are the input image and sharpened image, respectively. When using templates such as Figure 1a,b for filtering, the constant c = 1. When a template such as Figure 1c is used for filtering, the constant c = −1.
3.2.2. Bottleneck
YOLOv5 contains two kinds of C3 structures, with the critical difference being whether shortcuts are present in the bottleneck structure. As shown in Figure 2, the C3 module has two branches. The first passing through a CBL module containing a convolution layer, a batch normalization layer, and an activation function. Then, N bottlenecks are calculated (where N is calculated from the parameters that control the network width, as mentioned above), and the CBL module calculates another branch. The two components are used in the concatenation operation, and a CBL module is finally used for feature fusion.
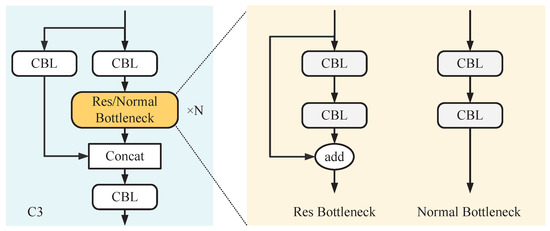
Figure 2.
C3, Res Bottleneck, and Normal Bottleneck module network structures.
As the main component of C3, the Bottleneck has two structures, as shown in Figure 2. We call the structure containing a shortcut a Res Bottleneck, which is only used for the backbone network; the other is called a Normal Bottleneck, which is used for the neck network. The Bottleneck includes 1 × 1 convolution and 3 × 3 convolution. Its core idea is to use multiple small convolutions to replace a large convolution to significantly reduce the number of model parameters and floating point operations (FLOPs).
3.2.3. Laplace Bottleneck
By visualizing the output tensors of each layer of the network, we can find a shallow feature map that contains rich details. As the number of network layers increases, the details are lost and the features become more abstract. The Laplace Bottleneck (LB) module is designed to enhance the elements of shallow features. In this study, we design the convolution kernel weight using the Laplace operator as a priori knowledge and integrate it into the residual structure of the Bottleneck to obtain the LB structure for enhancing the feature map. Specifically, we replace the original residual bottleneck module in C3 with the LB module to obtain an LB–C3 structure. The structure of the LB-C3 module is shown in Figure 3.
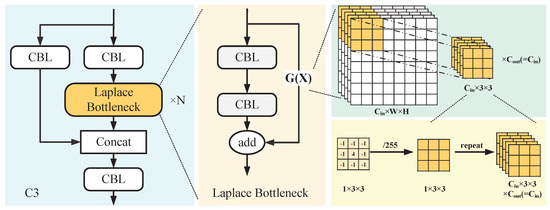
Figure 3.
Laplace Bottleneck (LB) module network stucture.
Specifically, we first modify the Laplace operator mentioned above by changing the central element +8 to +4 and readjusting the difference between pixels, allowing the gradient to spread stably during neural network training. Further, following the normalization operation in the image pre-processing of the deep neural network, each element value in the filter template is divided by 255, as expressed in Formulas (4) and (5). We then expand the filter into a 3 × 3 convolutional kernel parameter. Finally, the convolution kernel with fixed parameters is integrated into the bottleneck structure to obtain the Laplace Bottleneck (LB) (Figure 3), which adds the sharpening tensor based on the original tensor. The value mutation feature of the shallow feature tensor containing small object profile information is enhanced.
3.3. Cross-Layer Attention Upsampling (CLAU)
3.3.1. Nearest Neighbor Sampling
To fuse the low-resolution in-depth features with high-resolution shallow features, the deep feature map needs to be upsampled before performing the concatenation operation in order to achieve resolution alignment in the spatial dimension. The YOLOv5 network uses nearest neighbor upsampling, meaning that it directly copies the value of the pixel closest to the current location. This method does not involve any learning behavior, and memory consumption increases without any increase in the amount of feature information.
3.3.2. Scaled Dot Product Attention
The scaled dot product attention mechanism proposed in [31] has shown impressive performance in sequential-to-sequential modeling tasks, and is summarized here. The attention mechanism takes tensor queries and keys of dimension and values of dimension dv as inputs, which can be expressed as Q, K, and V, respectively. Then, the dot products of the query are computed with all keys, each is divided by , and a softmax function is applied to obtain the weights of the values. The formula is expressed as follows (6):
In recent years, attention mechanisms have been widely used in the visual field to replace or improve upon convolutional neural networks (CNNs). However, because the input tensor of the model is the output of a certain layer of convolution in the neural network, the global information of the current layer can be fully learned after the self-attention model to make up for the deficiency that convolution can only obtain local information. However, the details lost in the current layer cannot be retrieved, meaning that the resulting models have only a limited effect on improving the performance of network detection of small targets.
3.3.3. Cross-Layer Attention Upsampling
To further enhance the feature fusion capability of our lightweight network, we propose a learnable upsampling model called “Cross-Layer Attention Upsampling (CLAU)” (Figure 4). The inputs to the model consist of two tensors, X and Y ; X is a low-resolution deep feature map that contains rich semantic information while losing many details, while Y is a high-resolution shallow feature map that has detailed information and can help the network to detect small targets. We implement a nearest-neighbor upsampling operation on X to achieve resolution alignment and obtain the tensor X. Here, C represents the number of channels, while S is the coefficient required for upsampling. Next, three standard 1 × 1 convolution operations are used to obtain the query, key, and value tensors:
where Q, K, V , and W, W, W are the respective weight tensors of the three 1 × 1 convolutions. Then, we reshape Q, K, V and obtain the output Z according to the Formula (6). We use the attention mechanism to help the deep network obtain the shallow feature information. The shallow feature map with small target details guides the up-sampling of the deep feature map, allowing the network to selectively adjust its attention and obtain the details of small targets.
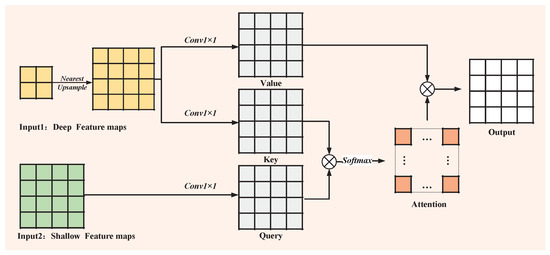
Figure 4.
Cross-Layer Attention Upsampling (CLAU) module network structure.
3.4. LC-YOLO Model Network Structure
We propose LB to enhance the details of the shallow features in the feature extraction stage and CLAU in the neck to improve the feature fusion capability of the network. Further, we combine the two modules as shown in Figure 5. For the sake of illustration, we have numbered each network layer. There are two LC–C3 modules, placed in the network’s second and fourth layers, and the network’s eleventh and fifteenth layers are CLAU models. The input of layer 11 is the preceding layer (layer 10) and the detail-enhanced layer 5. We set layer 5 as the guiding layer to provide detailed information for the deep network and use the attention mechanism to guide the network to extract more small target features, then splice these with the characteristics of layer 6 in the channel dimension. Finally, convolution is used for feature fusion. The structure of layer 15 is similar to that of layer 11, and its input is the output of layer 3 and layer 14.
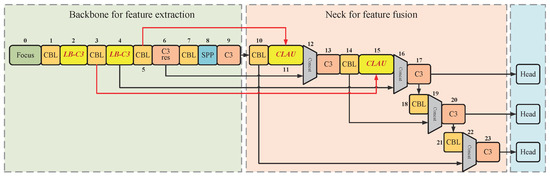
Figure 5.
LC-YOLO model network structure.
Overall, we enhanced the details of the network in layers 2 and 4. All the feature information of layers 3, 4, 5, 6, 10, and 14 were fused in the Neck stage. This significantly improved the utilization of the feature information extracted and stored by the entire current network in the lightweight network with limited parameters, allowing the network to generate new features conducive to small target detection.
4. Experiments
4.1. Experiment Setup
4.1.1. Dataset
In order to evaluate the effectiveness of our Laplace Bottleneck and Cross-Layer Attention Upsampling modules, we conducted several experiments on the UCAS-AOD [32] dataset. The UCAS-AOD dataset contains a total of 1510 images, of which 510 images contain 7114 vehicle samples and 1000 images contain 7428 aircraft samples. The dataset images are cropped from Google Maps, and there are two types of image sizes: 1372 × 941 and 1280 × 659.
4.1.2. Evaluation Criteria
The evaluation metrics in PASCAL VOC [33] are widely used in object detection. First, we calculated the recall and precision, defined as (10) and (11), respectively. Here, TP, FP, and FN mean true positive predictions, false positive predictions, and false negative predictions, respectively. Recall indicates the proportion of positive instances correctly predicted by the model in all positive instances in the dataset, with higher values indicating fewer misses. Precision is a ratio used to calculate how many instances are judged to be positively predicted correctly, with higher values indicating fewer incorrect predictions.
AP is the area bounded by the P(R) curve and the X-axis, with the calculation formula shown in (12). P(R) is a curve based on the above Precision and Recall, while , where N is the number of categories. IOU is the intersection ratio of two bounding boxes, reflecting the coincidence degree between the bounding boxes. The higher the IOU value is, the higher the coincidence degree of the two bounding boxes and the lower the coincidence degree. We set the IoU threshold to 0.5, and used AP@.5 and mAP@.5 as the model performance evaluation indices.
4.1.3. Experiments Details
We randomly divided the UCAS-AOD [32] dataset into a training set and testing set according to a ratio of 7:3. To ensure that the target size conformed to the definition of the absolute and relative scales of the small target, all images padded with zeros were resized to 800 × 800. The target size is shown in Table 1. Small targets were defined on an absolute scale by MSCOCO [34], a large publicly available universal dataset, which considers targets with pixels less than 32 × 32 to be small targets. In addition, There small targets can be defined the on a relative scale, in this case, a target for which the ratio of the target width to the image width and that of the target height to the image height are both less than 0.1.

Table 1.
The size statistics of the target in the images of the UCAS-AOD dataset adjusted to 800 × 800.
From the analysis of Figure 6, it can be seen that the number of instances of cars accounts for more than 50% in the samples meeting the two definitions of absolute scale and relative scale. To a certain extent, the improvement of the detection accuracy of vehicle samples by the network reflects the superiority of the network on the detection task for small targets.
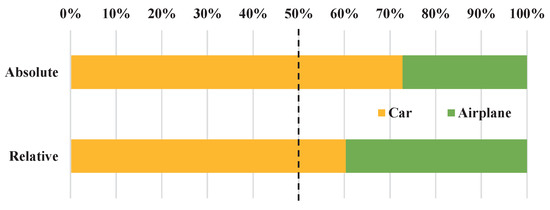
Figure 6.
Category distribution of small targets conforming to the definition in the UCAS-AOD dataset.
To ensure the repeatability of the experimen, we set the initial seed to 0. We used Stochastic Gradient Descent (SGD) to optimize the training, with the weight decay set to 0.0005 and the momentum to 0.937. The initial learning rate was set to 0.01 and attenuated according to the cosine annealing algorithm. We warmed up the training process for the first three iterations and trained the model without pre-trained weights for 300 iterations. For data augmentation, we used random image translation, scaling, left and right flipping, and HSV enhancement to make the model more robust to images obtained from different environments. We implemented the model on Pytorch 1.10.2, and all experiments were completed on a PC with one RTX 3090 GPU and an Intel(R) Core(TM) i7-8700 CPU @3.20 GHz. Unless otherwise stated, the aforementioned training details are used in the experiments.
During post-processing, we applied a confidence threshold of 0.001, indicating that only prediction boxes with a confidence score exceeding 0.001 were included in the sorting process. Moreover, an IOU threshold of 0.6 was set, which meant that if the IOU value between a prediction box with lower confidence and one with higher confidence was greater than 0.6, the prediction box with lower confidence was discarded.
4.2. Ablation Experiments
We performed ablation experiments on the UCAS-AOD dataset to verify the effectiveness of our LB and CLAU modules. The output feature maps of each network layer were visualized, with the results shown in Figure 7 and Figure 8. When detecting vehicle and aircraft samples, both the LB module and CLAU module demonstrate improvements in network performance. According to the optimization scheme presented in Figure 5, when only the LB module was used to optimize the basic network it was able to enhance the detailed features extracted from the shallow layer of the network. Specifically, the second line of the feature maps shows that the contour of the small targets in the second and fourth layer of the network feature map is enhanced (indicated by brighter colors). On the other hand, with only the CLAU module used to optimize the baseline, the location information of small targets appears in the eleventh and fifteenth layer network outputs of the third line, indicating that the CLAU module supplements detailed information in the deep network. With both the LB module and CLAU module used for optimization simultaneously, the detailed features extracted by the shallow network are enhanced and the CLAU model supplements the deep network. The detection effect diagram confirms that the LC-YOLO model improves its missed detection rate for small targets.

Figure 7.
The feature visualization of part of the network layer in different model detection processes in the ablation experiment for car samples.

Figure 8.
The feature visualization of part of the network layer in different model detection processes in the ablation experiment for airplane samples.
In version 6.0 of YOLOv5, YOLOv5n was introduced, which has the same network depth as YOLOv5s with half the network width. The features generated by each channel of the network make different contributions to the network prediction. With training schemes such as random gradient descent and cosine function learning rate adjustment, YOLOv5n effectively extracts features for network prediction with a smaller model size, resulting in slightly lower detection accuracy than YOLOv5s. Consequently, we optimized YOLOv5n with the same scheme to obtain a smaller version of LC-YOLO and conducted ablation experiments.
Corresponding to the above visualization results, Table 2 show the Precision and Recall of our ablation experiments based on YOLOv5s and YOLOv5n. According to conventional understanding, Recall measures a model’s ability to retrieve relevant information compared to the ground truth, while Precision reflects the proportion of retrieved prediction boxes that actually contain the correct target. While there is no inherent relationship between Precision and Recall (as can be seen from the formulas), they are often interdependent in practical applications. Achieving a balance between these metrics is therefore crucial. When using either the LB module or CLAU module to optimize YOLOv5s and YOLOv5n networks, the Recall rate of the network for vehicle samples improved significantly due to effective utilization of details. The combination of the two modules resulted in varying degrees of improvement in Accuracy and Recall for detecting both vehicle and aircraft samples, achieving a relatively good balance.
Table 2.
Precision and Recall in ablation experiments on the UCAS-AOD dataset.
When calculating performance metrics such as Precision, Recall, and mAP, the IOU threshold is commonly set to 0.5. This means that if the IOU value between the predicted box and the ground truth is greater than 0.5, the predicted box is considered a true positive (TP). Figure 9 illustrates that the overall confidence of the TP boxes predicted by the network is improved in the YOLOv5s model optimized by the LB and CLAU modules. Generally, the LC-YOLO model has the highest confidence for TP boxes. The overall improvement in confidence for the true positive (TP) samples indicates that the optimization scheme proposed in this paper enhances the network’s ability to detect the target against complex backgrounds, as evidenced by the improved recall value.
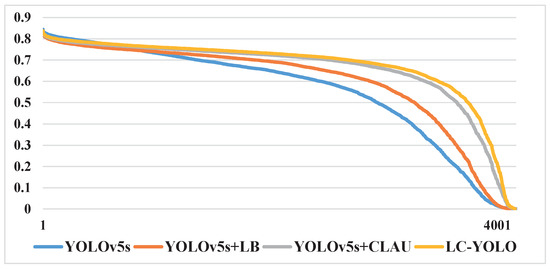
Figure 9.
Comparison of confidence with LB and CLAU on YOLOv5s.
As shown in Table 3, after incorporating LB, the AP@.5 of the car samples (which are smaller) was increased by 3.07% from 87.16% to 90.32% without any additional learnable parameters; furthermore, mAP@.5 achieved a certain degree of improvement. When only CLAU was incorporated into the model, the AP of the car and airplane samples increased by 3.48% and 1.43%, respectively, with only a few parameters increased. It is worth pointing out that the AP of the smaller car samples improved more. At the same time, mAP saw a considerable improvement, from 91.66% to 94.11%. Combining LB and CLAU to obtain the lightweight LC-YOLO model resulted in a 4.66% improvement in the AP of the car samples and a 1.95% improvement in the AP of the plane samples; the mAP@.5 was 94.96%, a significant increase of 3.3%.
Table 3.
The AP@.5 and mAP@.5 results for ablation experiments on the UCAS-AOD dataset.
Table 4 presents the model parameters, forward reasoning time, and computation. It can be seen that the LB model does not increase the number of learnable parameters and the computation remains almost the same, while the reasoning time is increased due to data transfer between the CPU and GPU during the design of convolutional kernel parameters, which can be improved later by optimizing the code. On the other hand, the CLAU module leads to a small increase in learnable parameters, reasoning time consumption, and computation. Nevertheless, its performance results in significantly improvement, as can be seen from Table 2 and Table 3. Overall, the LC-YOLO and Tiny LC-YOLO models can enhance network performance while adding minimal parameters, reasoning time, and computation and maintaining a relatively fast detection speed.
Table 4.
Comparison of parameters, inference time, and computation in ablation experiments on the UCAS-AOD dataset.
As shown in the Figure 10, the LB module has a more significant impact on YOLOv5n when detecting smaller samples such as cars. This means that the maximum sharing of prior knowledge in a neural network can to a certain extent make up for the problem of insufficient feature extraction ability in lightweight networks due to the low number of learnable parameters. Compared to the LB model, CLAU improves the performance of YOLOv5s and YOLOv5n more significantly in the detection of small cars. Shallow networks have output characteristics that contain a large amount of detailed information, which can be lost after multiple convolutions and pooling. While the LB model uses prior knowledge to set fixed convolution kernel weights to enhance the details of the network with the least parameters in the shallow network, details can be lost as the network becomes deeper. The CLAU module is applied in the deep network to supplement detailed information and guide the network to independently integrate semantic and detailed features. Therefore, a single LB module alone cannot solve the issue of detail loss in the deep network, and a single CLAU module alone can only supplement the details of the deep network. Consequently, combining the LB module and CLAU module allows the LC-YOLO and Tiny LC-YOLO models to use the enhanced detailed features in the shallow network to supplement the deep network at the cost of adding only a few parameters, thereby significantly improving detection performance.
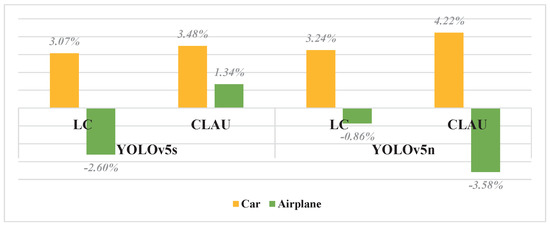
Figure 10.
Comparison of effects of LB and CLAU on YOLOv5s and YOLOv5n.
4.3. Comparison with State-of-Art Models
To more extensively evaluate the superiority of our lightweight LC-YOLO model for small target detection tasks, we compared it with current state-of-the-art target detection network models; the results are shown in Table 5. It can be seen that our LC-YOLO model was the best among all the compared networks, surpassing the classical algorithms [4,21,22] that are widely used in current practical projects and even exceeding advanced rotating target detection algorithms [25,26,30]. It is undeniable that the network structure of YOLOv5 has tremendous advantages. The mAP of YOLOv5n with parameters of only 1.77M reaches 91.36%, and the mAP of YOLOv5m with parameters of 21.04M under the same frame reaches 94.24%. Tiny LC-YOLO can achieve detection performance of 94.17% mAP with only 1.83M parameters, and its detection performance for small targets is very close to that of YOLOv5m and YOLOv5l with more extensive parameters. The detection performance of LC-YOLO with 7.30M parameters exceeds YOLOv5m and YOLOv5l under the same framework, and the mAP reaches 94.96%.
Table 5.
Performance comparison of different models on the UCAS-AOD dataset.
Furthermore, among the models listed in the table our LC-YOLO model exhibits the highest recall value in small target detection tasks, demonstrating the effectiveness of the proposed optimization scheme in significantly enhancing the model’s target retrieval ability. In practical engineering applications, LC-YOLO can complete high-precision small target detection tasks that only the heavyweight networks have previously been able to complete while requiring extremely low computing and storage costs.
5. Conclusions
This paper uses LB to enhance shallow detail features and CLAU to achieve pixel-level adaptive fusion of detail and semantic features. Both modules show improved network performance in small target detection to varying degrees. Further, we combine the two modules to obtain the LC-YOLO model. With only a few parameters added, the model efficiently uses the extracted features to realize high-precision detection of small targets. Experiments on the UCAS-AOD dataset show that our lightweight LC-YOLO network has advantages in small target detection tasks. Its mAP is 3.30% better than that of the YOLOv5s network, surpassing the heavy networks and advanced target detection models widely used in many projects, and even exceeding heavier networks such YOLOv5m and YOLOv5l under the same framework. In small target detection tasks, LC-YOLO and Tiny LC-YOLO demonstrate exceptional detection performance with minimal parameters and memory consumption while exhibiting strong target retrieval capabilities. This is advantageous for deploying and utilizing small target detection networks on mobile edge chips in practical projects.
Author Contributions
Conceptualization, M.C.; methodology, M.C.; software, M.J.; validation, M.C., H.W. and G.G.; formal analysis, M.C.; investigation, M.C.; resources, G.C. and H.L.; data curation, M.C.; writing—original draft preparation, M.C. and H.W.; writing—review and editing, G.G.; visualization, M.C.; supervision, W.M.; project administration, G.C. and H.L.; funding acquisition, M.J. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the National Natural Science Foundation of China (U19A2080) and the Strategic Priority Research Program of the Chinese Academy of Sciences (XDA27040303, XDA18040400, XDB44000000).
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The data presented in this study are available on request from the corresponding authors.
Acknowledgments
The authors would like to thank the creators of the open access UCAS-AOD remote sensing image dataset.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. Computer Science. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Computer Society, Boston, MA, USA, 7–12 June 2014. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Wang, C.Y.; Liao, H.; Wu, Y.H.; Chen, P.Y.; Yeh, I.H. CSPNet: A New Backbone that can Enhance Learning Capability of CNN. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Seattle, WA, USA, 14–19 June 2020. [Google Scholar]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Tan, M.; Le, Q.V. Efficientnet: Rethinking model scaling for convolutional neural networks. In Proceedings of the International Conference on Machine Learning, Long Beach, CA, USA, 10–15 June 2019; pp. 6105–6114. [Google Scholar]
- Lin, T.Y.; Dollar, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path aggregation network for instance segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Peng, Z.; Cong, G. Scale-Transferrable Object Detection. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Zhao, Q.; Sheng, T.; Wang, Y.; Tang, Z.; Chen, Y.; Cai, L.; Ling, H. M2det: A single-shot object detector based on multi-level feature pyramid network. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019. [Google Scholar]
- Islam, M.A.; Rochan, M.; Bruce, N.; Yang, W. Gated Feedback Refinement Network for Dense Image Labeling. In Proceedings of the Computer Vision & Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Tan, M.; Pang, R.; Le, Q.V. EfficientDet: Scalable and Efficient Object Detection. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Iandola, F.N.; Han, S.; Moskewicz, M.W.; Ashraf, K.; Dally, W.J.; Keutzer, K. SqueezeNet: Alexnet-level accuracy with 50x fewer parameters and <0.5 mb model size. arXiv 2016, arXiv:1602.07360. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Wey, T.; Andreetto, M.; Adam, H. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Zhang, X.; Zhou, X.; Lin, M.; Sun, J. Shufflenet: An extremely efficient convolutional neural network for mobile devices. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 6848–6856. [Google Scholar]
- Gao, H.; Wang, Z.; Cai, L.; Ji, S. Channelnets: Compact and efficient convolutional neural networks via channel-wise convolutions. Adv. Neural Inf. Process. Syst. 2020, 31. [Google Scholar] [CrossRef] [PubMed]
- Zhang, T.; Qi, G.J.; Xiao, B.; Wang, J. Interleaved group convolutions for deep neural networks. arXiv 2017, arXiv:1707.02725. [Google Scholar]
- Han, K.; Wang, Y.; Tian, Q.; Guo, J.; Xu, C. GhostNet: More Features From Cheap Operations. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Li, Y.; Chen, Y.; Dai, X.; Chen, D.; Liu, M.; Yuan, L.; Liu, Z.; Zhang, L.; Vasconcelos, N. MicroNet: Improving Image Recognition with Extremely Low FLOPs. In Proceedings of the International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. Adv. Neural Inf. Process. Syst. 2015, 28, 91–99. [Google Scholar] [CrossRef] [PubMed]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, Faster, Stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 6517–6525. [Google Scholar]
- Ding, J.; Xue, N.; Long, Y.; Xia, G.-S.; Lu, Q. Learning RoI transformer for oriented object detection in aerial images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 2849–2858. [Google Scholar]
- Ming, Q.; Zhou, Z.; Miao, L.; Zhang, H.; Li, L. Dynamic anchor learning for arbitrary-oriented object detection. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; pp. 2355–2363. [Google Scholar]
- Duan, K.; Bai, S.; Xie, L.; Qi, H.; Huang, Q.; Tian, Q. Centernet: Keypoint triplets for object detection. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 6568–6577. [Google Scholar]
- Tian, Z.; Shen, C.; Chen, H.; He, T. FCOS: Fully Convolutional One-Stage Object Detection. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019. [Google Scholar]
- Yang, Z.; Liu, S.; Hu, H.; Wang, L.; Lin, S. RepPoints: Point Set Representation for Object Detection. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019. [Google Scholar]
- Li, W.; Zhu, J. Oriented reppoints for aerial object detection. arXiv 2021, arXiv:2105.11111. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N. Attention is all you need. arXiv 2017, arXiv:1706.03762. [Google Scholar]
- Zhu, H.; Chen, X.; Dai, W.; Fu, K.; Ye, Q.; Jiao, J. Orientation robust object detection in aerial images using deep convolutional neural network. In Proceedings of the 2015 IEEE International Conference on Image Processing (ICIP), Quebec City, QC, Canada, 27–30 September 2015; pp. 3735–3739. [Google Scholar]
- Everingham, M.; Van Gool, L.; Williams, C.K.; Winn, J.; Zisserman, A. The pascal visual object classes (voc) challenge. Int. J. Comput. Vis. 2010, 88, 303–338. [Google Scholar] [CrossRef]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; pp. 740–755. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).