

Deep Neural Network Modeling for CFD Simulations: Benchmarking the Fourier Neural Operator on the Lid-Driven Cavity Case

 ,
, 
 ,
,  ,
, 

Abstract
1. Introduction
2. Materials and Methods
2.1. Data Generation
2.2. Models’ Architecture Setup
2.2.1. ConvLSTM
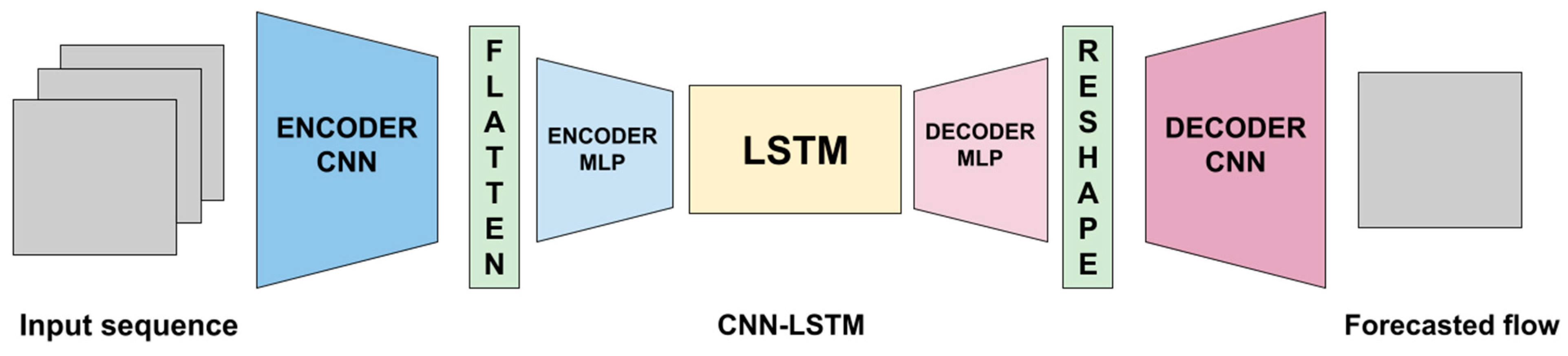
2.2.2. Two-dimensional CNN + LSTM
2.2.3. Fourier Neural Operator
2.3. Application of Physical Information to the Models
2.4. Number of Timesteps (Moving Time Window)
3. Results
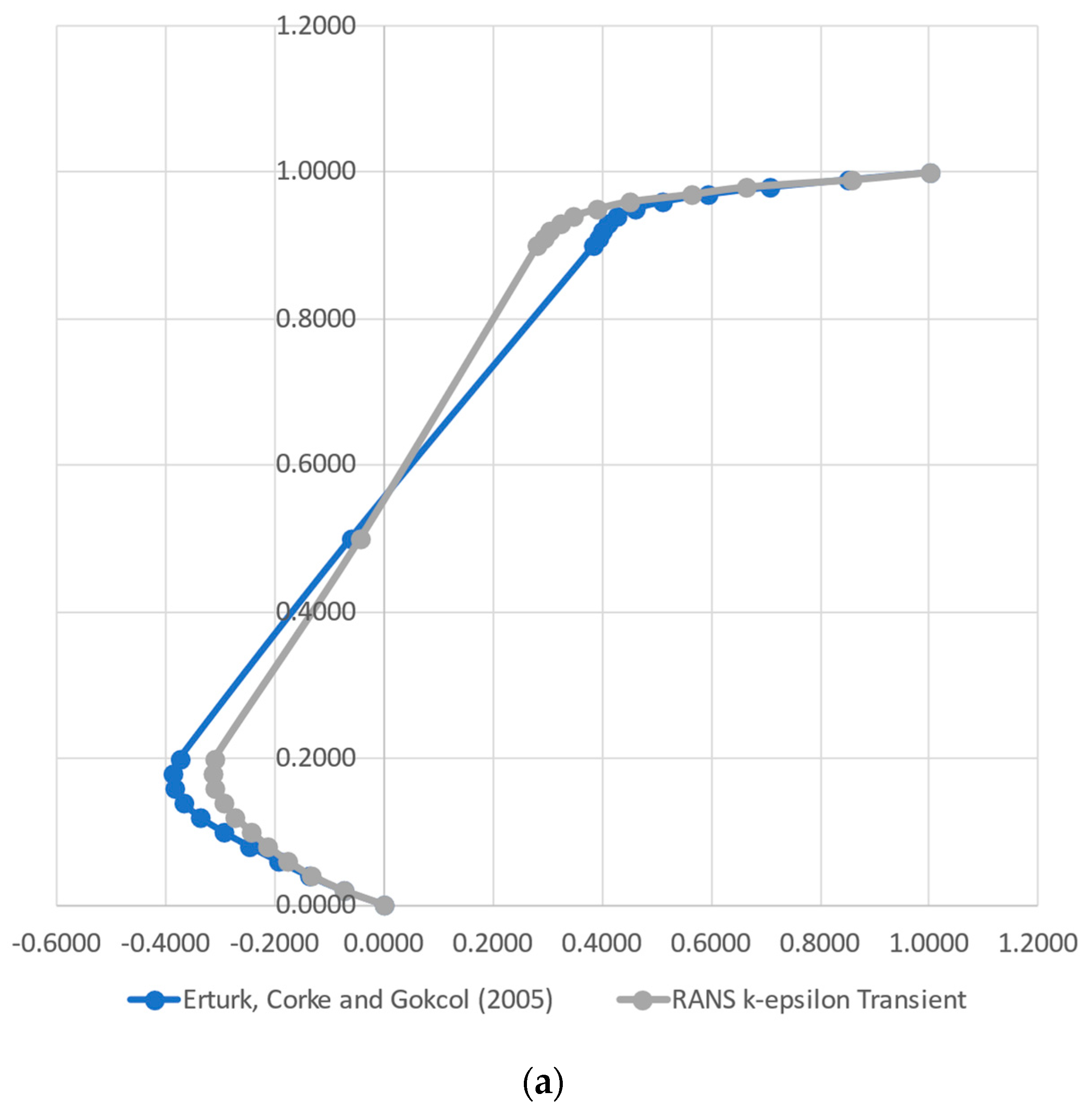
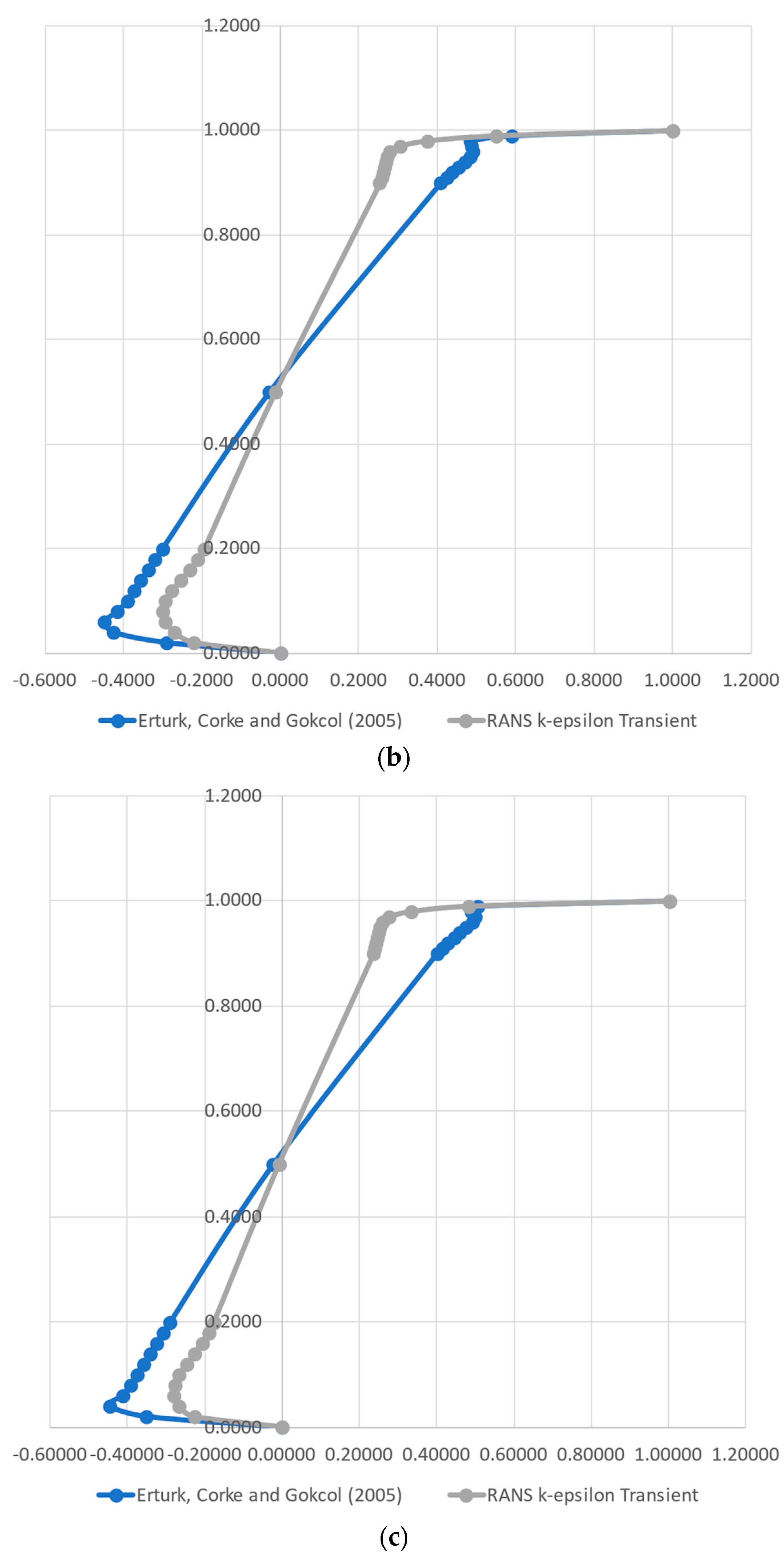
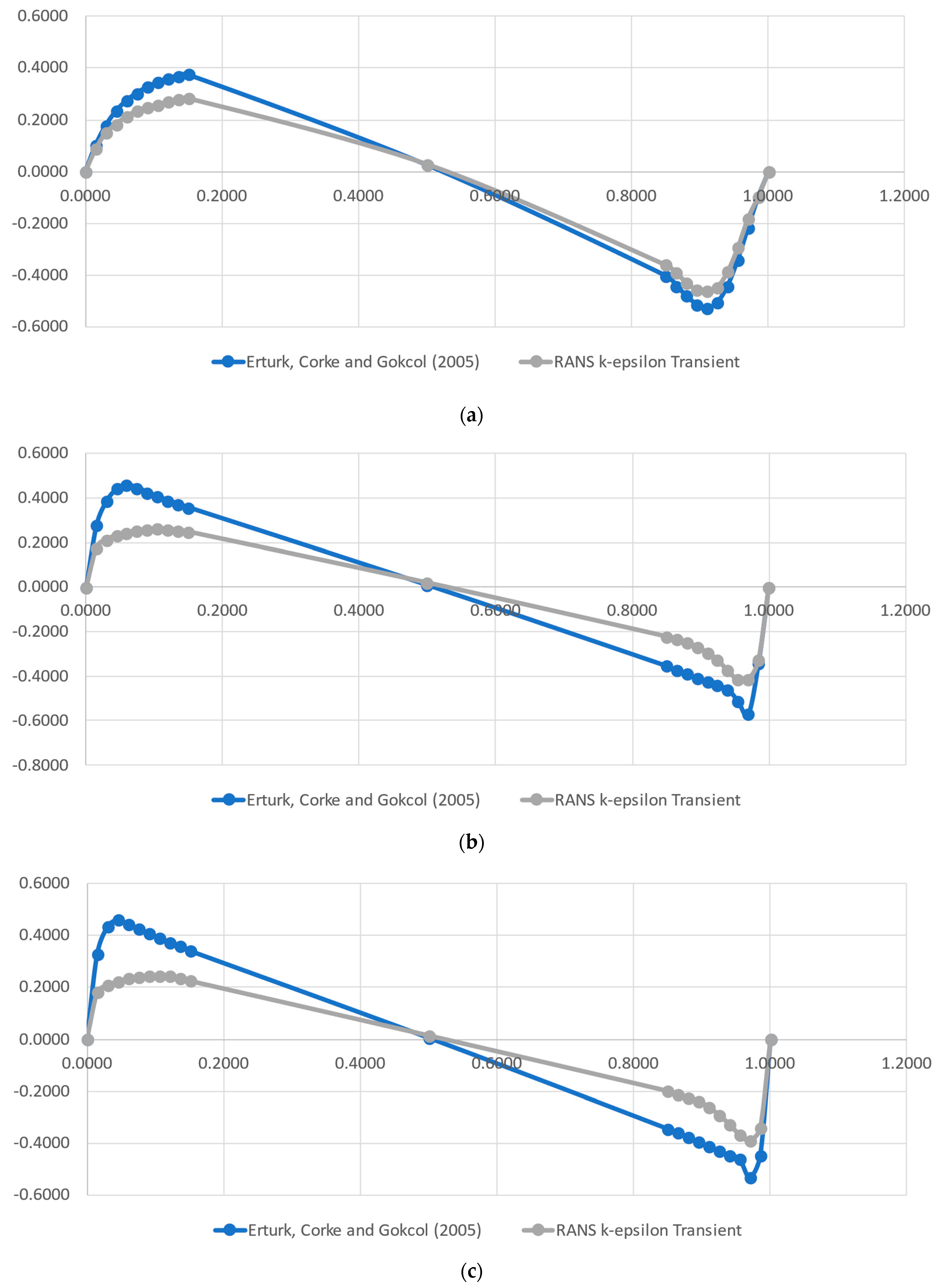
3.1. Numerical Data Validation
3.2. Models’ Architecture Setup
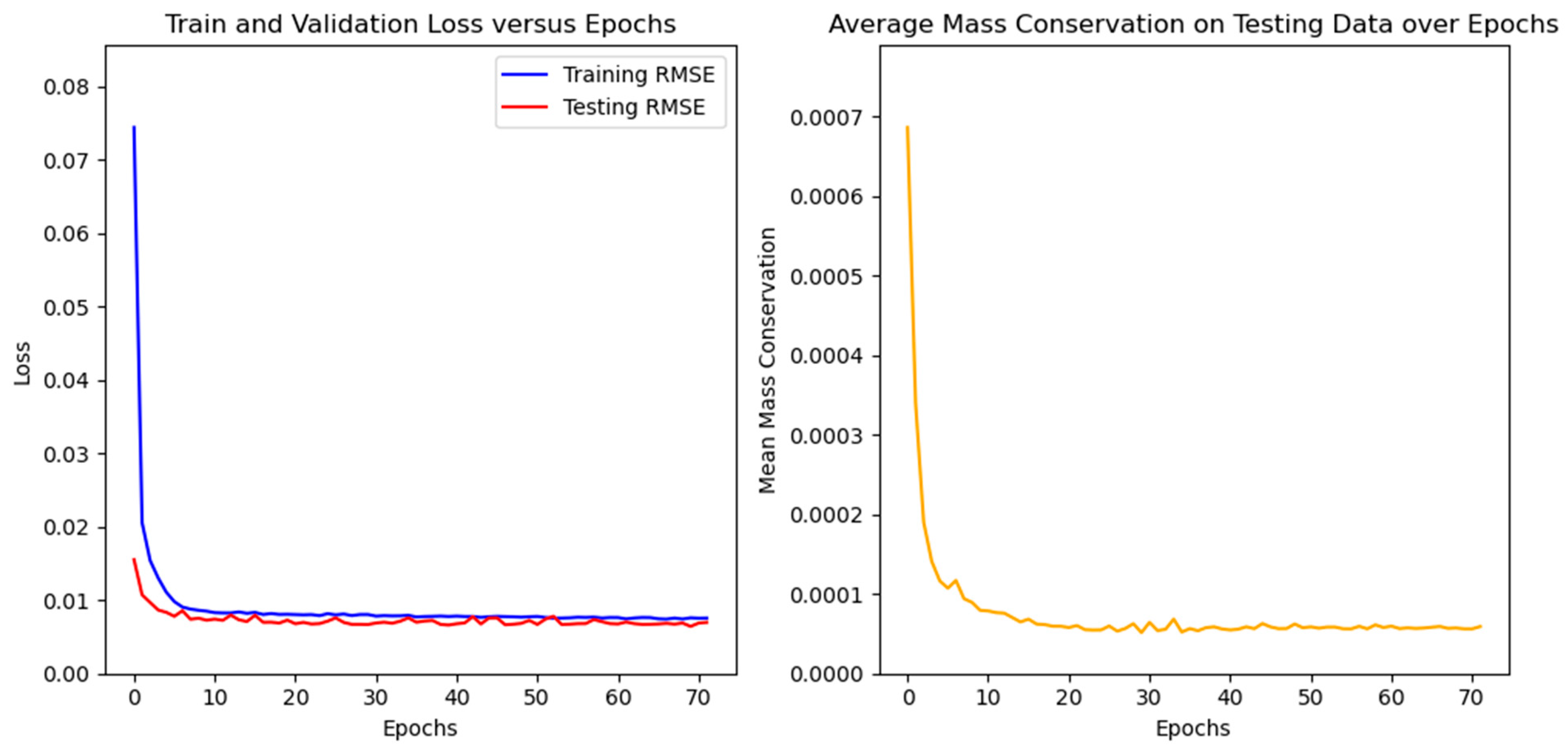
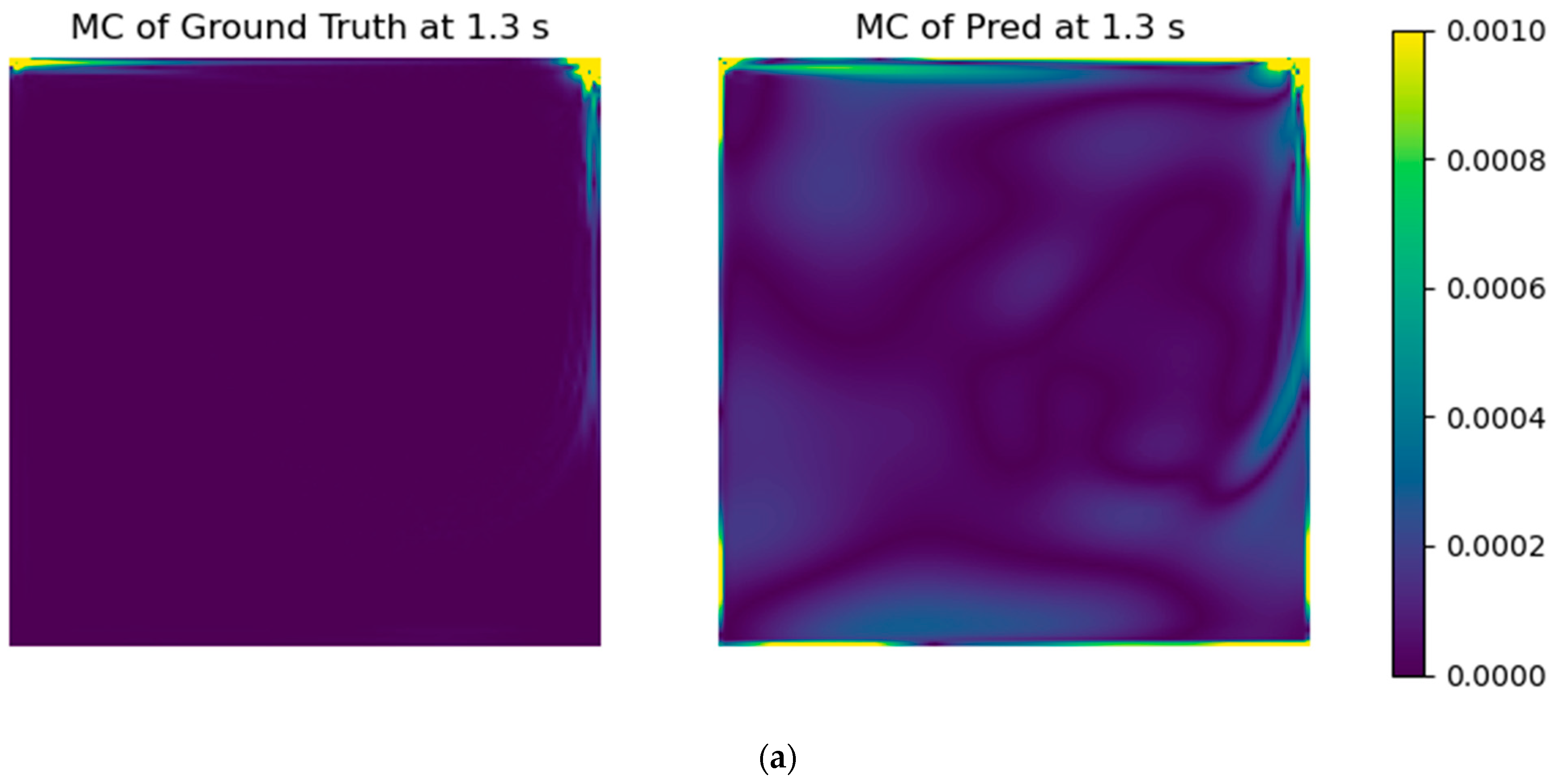
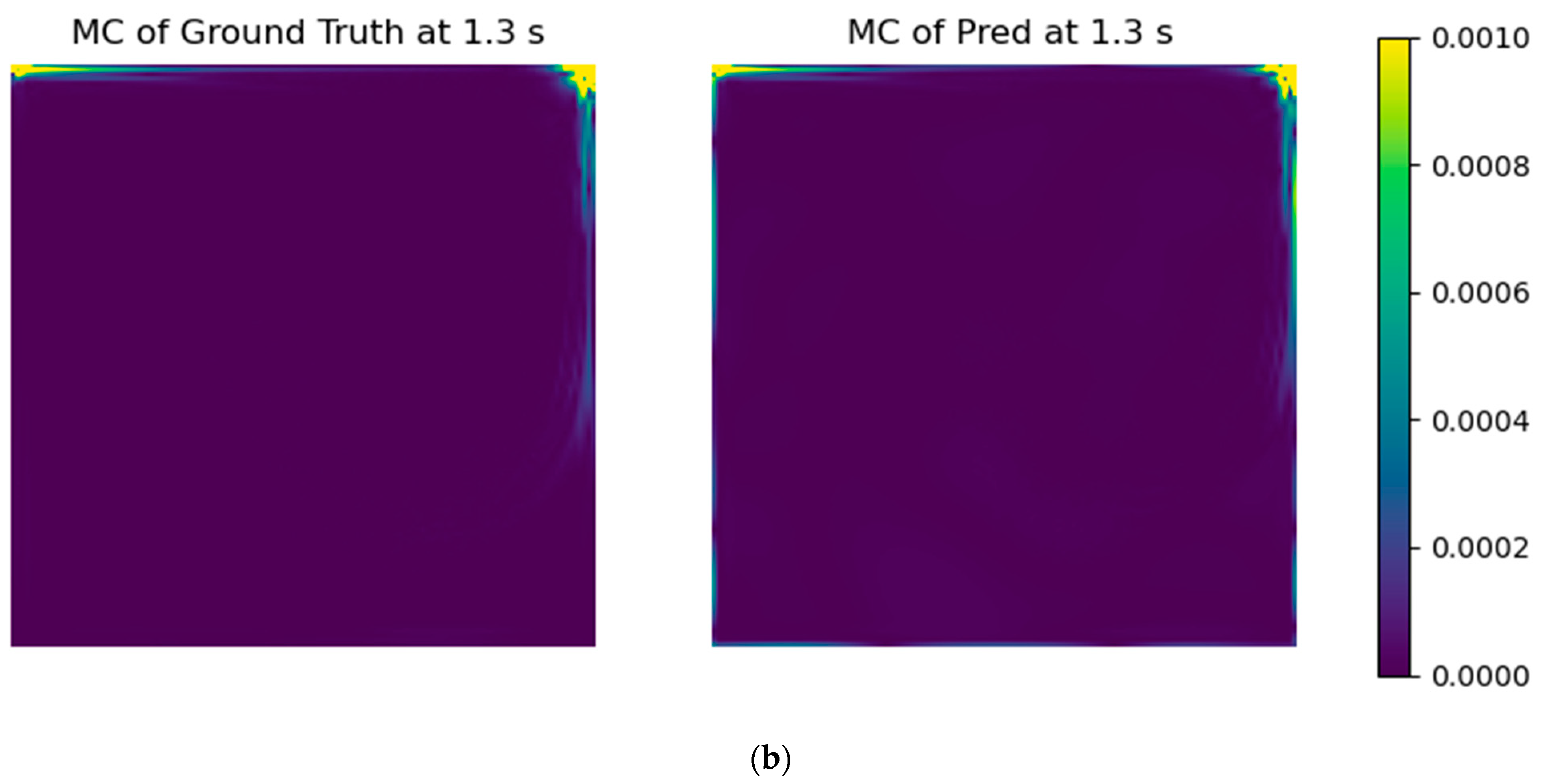
3.3. Application of Physical Error Metrics to the Models
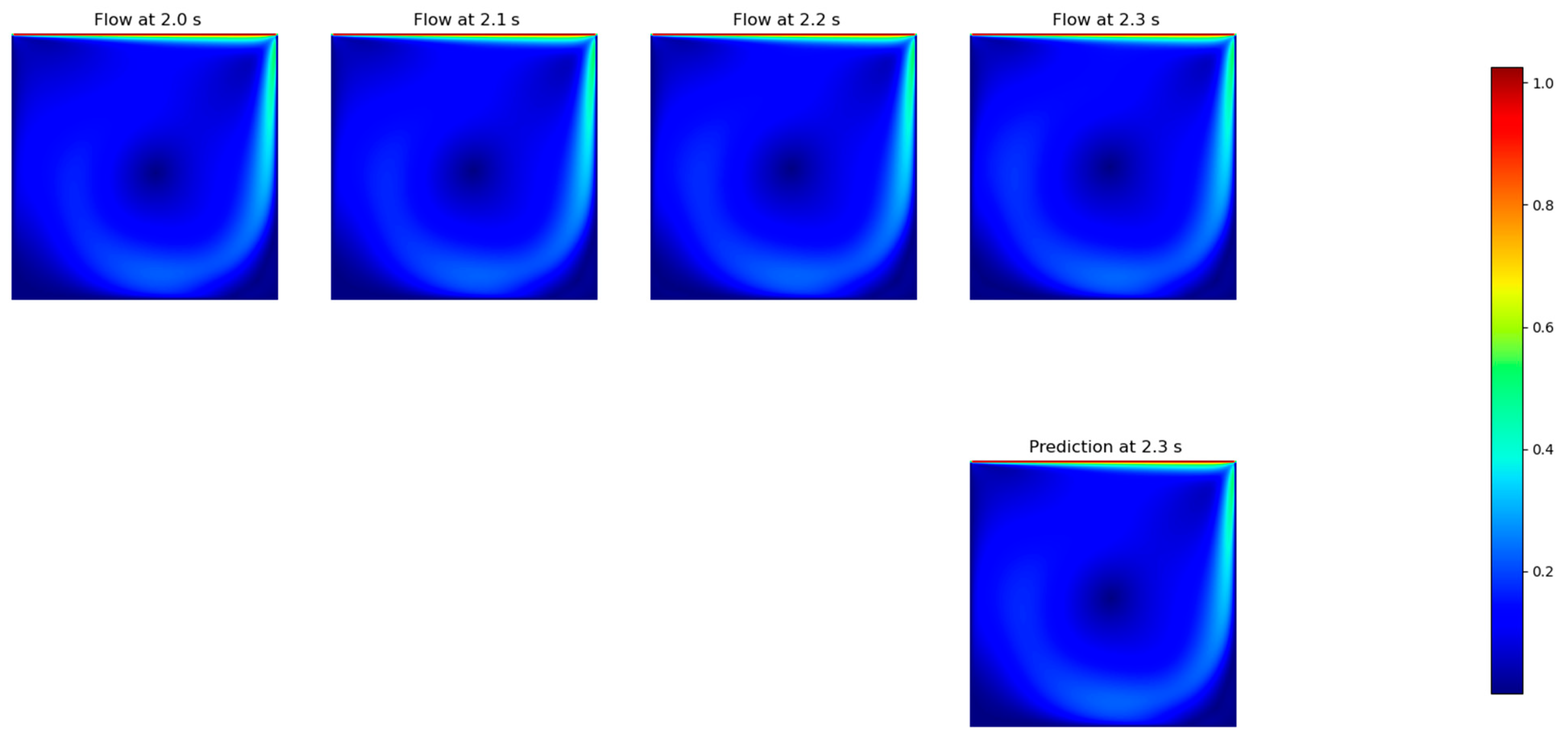
3.4. Accuracy Assessment
3.4.1. Input Time Window Size
3.4.2. Output Time Window Size
4. Discussion
5. Conclusions
- A RANS k-ε CFD solution was performed to generate data (training and testing) to be fed to the models. A comparison with the results found in the literature was able to attest the data quality. The evaluation of the k-ε turbulence model against a full Direct Numerical Simulation indicated that the simpler CFD model, for this simple case, accurately represented the turbulence phenomena.
- After the tests for the models’ architectures setup, the FNO and ConvLSTM paradigms performed better, with a consistent small advantage of FNO.
- With the selected models’ architectures, a custom error parcel regarding the mass conservation error was added to the training step, using several weight values. Even though the RMSE of the test case did not improve, the resultant fields presented a notable improvement in physical coherence.
- The FNO paradigm was finally assessed to predict the solutions of the flow under several input/output situations, giving a testing RMSE of 0.008792 m/s for the best configuration (three timesteps for the input and three timesteps for the output), which was at least two orders of magnitude of the reference lid velocity (1.0 m/s).
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Nguyen, N.T.; Bochnia, D.; Kiehnscherf, R.; Dötzel, W. Investigation of Forced Convection in Microfluid Systems. Sens. Actuators A Phys. 1996, 55, 49–55. [Google Scholar] [CrossRef]
- Wang, Z.; Li, B.; Luo, Q.-Q.; Zhao, W. Effect of Wall Roughness by the Bionic Structure of Dragonfly Wing on Microfluid Flow and Heat Transfer Characteristics. Int. J. Heat Mass Transf. 2021, 173, 121201. [Google Scholar] [CrossRef]
- Castorrini, A.; Gentile, S.; Geraldi, E.; Bonfiglioli, A. Increasing Spatial Resolution of Wind Resource Prediction Using NWP and RANS Simulation. J. Wind Eng. Ind. Aerodyn. 2021, 210, 104499. [Google Scholar] [CrossRef]
- Machniewski, P.; Molga, E. CFD Analysis of Large-Scale Hydrogen Detonation and Blast Wave Overpressure in Partially Confined Spaces. Process Saf. Environ. Prot. 2022, 158, 537–546. [Google Scholar] [CrossRef]
- Li, R.; Wang, Y.; Lin, H.; Du, H.; Wang, C.; Chen, X.; Huang, M. A Mesoscale CFD Simulation Study of Basic Wind Pressure in Complex Terrain—A Case Study of Taizhou City. Appl. Sci. 2022, 12, 10481. [Google Scholar] [CrossRef]
- Carneiro, F.O.M.; Moura, L.F.M.; Costa Rocha, P.A.; Pontes Lima, R.J.; Ismail, K.A.R. Application and Analysis of the Moving Mesh Algorithm AMI in a Small Scale HAWT: Validation with Field Test’s Results against the Frozen Rotor Approach. Energy 2019, 171, 819–829. [Google Scholar] [CrossRef]
- Menter, F.; Hüppe, A.; Matyushenko, A.; Kolmogorov, D. An Overview of Hybrid RANS–LES Models Developed for Industrial CFD. Appl. Sci. 2021, 11, 2459. [Google Scholar] [CrossRef]
- Waschkowski, F.; Zhao, Y.; Sandberg, R.; Klewicki, J. Multi-Objective CFD-Driven Development of Coupled Turbulence Closure Models. J. Comput. Phys. 2022, 452, 110922. [Google Scholar] [CrossRef]
- Kumar, G.; Mondal, P.K. Application of Artificial Neural Network for Understanding Multi-Layer Microscale Transport Comprising of Alternate Newtonian and Non-Newtonian Fluids. Colloids Surf. A Physicochem. Eng. Asp. 2022, 642, 128664. [Google Scholar] [CrossRef]
- Ismayeel, M.; Mehta, S.K.; Mondal, P.K. Prediction of Electrodiffusio-Osmotic Transport of Shear-Thinning Fluids in a Nanochannel Using Artificial Neural Network. Phys. Fluids 2023, 35, 012018. [Google Scholar] [CrossRef]
- Kumar, G.; Saha, S.P.; Ghosh, S.; Mondal, P.K. Artificial Neural Network-Based Modelling of Optimized Experimental Study of Xylanase Production by Penicillium Citrinum Xym2. Proc. Inst. Mech. Eng. Part E: J. Process Mech. Eng. 2022, 236, 1340–1348. [Google Scholar] [CrossRef]
- Kumar, G.; Thampi, G.; Mondal, P.K. Predicting Performance of Briquette Made from Millet Bran: A Neural Network Approach. Adv. J. Grad. Res. 2020, 9, 1–13. [Google Scholar] [CrossRef]
- Zhao, Y.; Akolekar, H.D.; Weatheritt, J.; Michelassi, V.; Sandberg, R.D. RANS Turbulence Model Development Using CFD-Driven Machine Learning. J. Comput. Phys. 2020, 411, 109413. [Google Scholar] [CrossRef]
- Guo, Y.; Cao, X.; Liu, B.; Gao, M. Solving Partial Differential Equations Using Deep Learning and Physical Constraints. Appl. Sci. 2020, 10, 5917. [Google Scholar] [CrossRef]
- Iskhakov, A.S.; Dinh, N.T.; Chen, E. Integration of Neural Networks with Numerical Solution of PDEs for Closure Models Development. Phys. Lett. A 2021, 406, 127456. [Google Scholar] [CrossRef]
- Bhatnagar, S.; Afshar, Y.; Pan, S.; Duraisamy, K.; Kaushik, S. Prediction of Aerodynamic Flow Fields Using Convolutional Neural Networks. Comput Mech 2019, 64, 525–545. [Google Scholar] [CrossRef]
- Ringstad, K.E.; Banasiak, K.; Ervik, Å.; Hafner, A. Machine Learning and CFD for Mapping and Optimization of CO2 Ejectors. Appl. Therm. Eng. 2021, 199, 117604. [Google Scholar] [CrossRef]
- Mohammadpour, J.; Husain, S.; Salehi, F.; Lee, A. Machine Learning Regression-CFD Models for the Nanofluid Heat Transfer of a Microchannel Heat Sink with Double Synthetic Jets. Int. Commun. Heat Mass Transf. 2022, 130, 105808. [Google Scholar] [CrossRef]
- Wang, R.; Kuru, E.; Yan, Y.; Yang, X.; Yan, X. Sensitivity Analysis of Factors Controlling the Cement Hot Spot Temperature and the Corresponding Well Depth Using a Combined CFD Simulation and Machine Learning Approach. J. Pet. Sci. Eng. 2022, 208, 109617. [Google Scholar] [CrossRef]
- Sirignano, J.; MacArt, J.F.; Freund, J.B. DPM: A Deep Learning PDE Augmentation Method with Application to Large-Eddy Simulation. J. Comput. Phys. 2020, 423, 109811. [Google Scholar] [CrossRef]
- Xu, X.; Waschkowski, F.; Ooi, A.S.H.; Sandberg, R.D. Towards Robust and Accurate Reynolds-Averaged Closures for Natural Convection via Multi-Objective CFD-Driven Machine Learning. Int. J. Heat Mass Transf. 2022, 187, 122557. [Google Scholar] [CrossRef]
- Kochkov, D.; Smith, J.A.; Alieva, A.; Wang, Q.; Brenner, M.P.; Hoyer, S. Machine Learning–Accelerated Computational Fluid Dynamics. Proc. Natl. Acad. Sci. USA 2021, 118, e2101784118. [Google Scholar] [CrossRef]
- Kashinath, K.; Mustafa, M.; Albert, A.; Wu, J.-L.; Jiang, C.; Esmaeilzadeh, S.; Azizzadenesheli, K.; Wang, R.; Chattopadhyay, A.; Singh, A.; et al. Physics-Informed Machine Learning: Case Studies for Weather and Climate Modelling. Phil. Trans. R. Soc. A. 2021, 379, 20200093. [Google Scholar] [CrossRef] [PubMed]
- Wu, H.; Niu, S.; Zhang, Y.; Fu, W. Physics-Informed Generative Adversarial Network-Based Modeling and Simulation of Linear Electric Machines. Appl. Sci. 2022, 12, 10426. [Google Scholar] [CrossRef]
- Raissi, M.; Perdikaris, P.; Karniadakis, G.E. Physics-Informed Neural Networks: A Deep Learning Framework for Solving Forward and Inverse Problems Involving Nonlinear Partial Differential Equations. J. Comput. Phys. 2019, 378, 686–707. [Google Scholar] [CrossRef]
- Jiang, C.M.; Esmaeilzadeh, S.; Azizzadenesheli, K.; Kashinath, K.; Mustafa, M.; Tchelepi, H.A.; Marcus, P.; Prabhat, M.; Anandkumar, A. MESHFREEFLOWNET: A Physics-Constrained Deep Continuous Space-Time Super-Resolution Framework. In Proceedings of the SC20: International Conference for High Performance Computing, Networking, Storage and Analysis, Atlanta, GA, USA, 9–19 November 2020; pp. 1–15. [Google Scholar]
- Li, Z.; Kovachki, N.; Azizzadenesheli, K.; Liu, B.; Bhattacharya, K.; Stuart, A.; Anandkumar, A. Fourier Neural Operator for Parametric Partial Differential Equations. In Proceedings of the International Conference on Learning (ICLR), Vienna, Austria, 3–7 May 2021; pp. 1–16. [Google Scholar]
- Lu, L.; Meng, X.; Cai, S.; Mao, Z.; Goswami, S.; Zhang, Z.; Karniadakis, G.E. A Comprehensive and Fair Comparison of Two Neural Operators (with Practical Extensions) Based on FAIR Data. Comput. Methods Appl. Mech. Eng. 2022, 393, 114778. [Google Scholar] [CrossRef]
- Carlberg, K.T.; Jameson, A.; Kochenderfer, M.J.; Morton, J.; Peng, L.; Witherden, F.D. Recovering Missing CFD Data for High-Order Discretizations Using Deep Neural Networks and Dynamics Learning. J. Comput. Phys. 2019, 395, 105–124. [Google Scholar] [CrossRef]
- Hanna, B.N.; Dinh, N.T.; Youngblood, R.W.; Bolotnov, I.A. Machine-Learning Based Error Prediction Approach for Coarse-Grid Computational Fluid Dynamics (CG-CFD). Prog. Nucl. Energy 2020, 118, 103140. [Google Scholar] [CrossRef]
- Feldman, Y.; Gelfgat, A.Y. From Multi- to Single-Grid CFD on Massively Parallel Computers: Numerical Experiments on Lid-Driven Flow in a Cube Using Pressure–Velocity Coupled Formulation. Comput. Fluids 2011, 46, 218–223. [Google Scholar] [CrossRef]
- Rajakumar, S.B.; Perumal, D.A.; Yadav, A.K. Computation of Fluid Flow in Double Sided Cross-Shaped Lid-Driven Cavities Using Lattice Boltzmann Method. Eur. J. Mech.-B/Fluids 2018, 70, 46–72. [Google Scholar] [CrossRef]
- Bayareh, M.; Nourbakhsh, A.; Rouzbahani, F.; Jouzaei, V. Explicit Incompressible SPH Algorithm for Modelling Channel and Lid-Driven Flows. SN Appl. Sci. 2019, 1, 1040. [Google Scholar] [CrossRef]
- Filali, A.; Khezzar, L.; Semmari, H.; Matar, O. Application of Artificial Neural Network for Mixed Convection in a Square Lid-Driven Cavity with Double Vertical or Horizontal Oriented Rectangular Blocks. Int. Commun. Heat Mass Transf. 2021, 129, 105644. [Google Scholar] [CrossRef]
- Jasak, H. OpenFOAM: Open Source CFD in Research and Industry. Int. J. Nav. Archit. Ocean Eng. 2009, 1, 89–94. [Google Scholar] [CrossRef]
- OpenFOAM. Available online: https://www.openfoam.com/ (accessed on 13 January 2023).
- Erturk, E.; Corke, T.C.; Gökçöl, C. Numerical Solutions of 2-D Steady Incompressible Driven Cavity Flow at High Reynolds Numbers. Int. J. Numer. Methods Fluids 2005, 48, 747–774. [Google Scholar] [CrossRef]
- Shi, X.; Chen, Z.; Wang, H.; Yeung, D.-Y.; Wong, W.; Woo, W. Convolutional LSTM Network: A Machine Learning Approach for Precipitation Nowcasting. In Proceedings of the 29th International Conference on Neural Information Processing Systems (NIPS), Montreal, QC, Canada, 7–12 December 2015; pp. 1–9. [Google Scholar]
- Rocha, P.A.C.; Santos, V.O. Global Horizontal and Direct Normal Solar Irradiance Modeling by the Machine Learning Methods XGBoost and Deep Neural Networks with CNN-LSTM Layers: A Case Study Using the GOES-16 Satellite Imagery. Int J Energy Environ. Eng 2022, 13, 1271–1286. [Google Scholar] [CrossRef]
- Larsen, B.E.; Fuhrman, D.R. Simulation of Cross-Shore Breaker Bar Development Utilizing a Stabilized Two-Equation Turbulence Model. Coast. Eng. 2023, 180, 104269. [Google Scholar] [CrossRef]
- He, Z.; Sun, T.; Zou, L.; Jiang, Y.; Duan, L. Ventilated Cavity Flows behind a Backward Facing Step with a Combination Computational Fluid Dynamics and Error Back Propagation Algorithm. Ocean Eng. 2022, 260, 111741. [Google Scholar] [CrossRef]
- Liu, Y.; Hu, R.; Kraus, A.; Balaprakash, P.; Obabko, A. Data-Driven Modeling of Coarse Mesh Turbulence for Reactor Transient Analysis Using Convolutional Recurrent Neural Networks. Nucl. Eng. Des. 2022, 390, 111716. [Google Scholar] [CrossRef]
- Tang, S.; Feng, X.; Wu, W.; Xu, H. Physics-Informed Neural Networks Combined with Polynomial Interpolation to Solve Nonlinear Partial Differential Equations. Comput. Math. Appl. 2023, 132, 48–62. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | CNN-LSTM | ConvLSTM | FNO |
|---|---|---|---|
| RMSE (m·s−1) | 2.26 × 10−2 | 7.36 × 10−3 | 6.83 × 10−3 |
| No MC Error | 0.1 × MC Error | 1.0 × MC Error | 2.0 × MC Error | 5.0 × MC Error | |
|---|---|---|---|---|---|
| FNO | 6.56 × 10−3 | 6.43 × 10−3 | 6.46 × 10−3 | 6.49 × 10−3 | 6.48 × 10−3 |
| CNN-LSTM | 1.82 × 10−2 | 1.91 × 10−2 | 2.57 × 10−2 | 2.58 × 10−2 | 8.09 × 10−2 |
| ConvLSTM | 7.06 × 10−3 | 7.03 × 10−3 | 7.21 × 10−3 | 7.31 × 10−3 | 7.31 × 10−3 |
| No MC Error | 0.1 × MC Error | 1.0 × MC Error | 2.0 × MC Error | 5.0 × MC Error | |
|---|---|---|---|---|---|
| FNO | 1.24 × 10−4 | 5.90 × 10−5 | 4.11 × 10−5 | 4.07 × 10−5 | 3.96 × 10−5 |
| CNN-LSTM | 2.38 × 10−4 | 1.12 × 10−3 | 2.67 × 10−4 | 2.47 × 10−4 | 7.56 × 10−5 |
| ConvLSTM | 7.62 × 10−5 | 5.49 × 10−5 | 5.54 × 10−5 | 4.06 × 10−5 | 3.70 × 10−5 |
| 1:1 | 3:1 | 6:1 | 10:1 | 15:1 | |
|---|---|---|---|---|---|
| RMSE (m·s−1) | 6.07 × 10−3 | 6.43 × 10−3 | 7.15 × 10−3 | 6.81 × 10−3 | 6.70 × 10−3 |
| Mass imbalance (kg·s−1·m2) | 5.71 × 10−5 | 5.89 × 10−5 | 6.10 × 10−5 | 5.14 × 10−5 | 5.27 × 10−5 |
| 1:10 | 3:10 | 6:10 | 10:10 | 15:10 | |
|---|---|---|---|---|---|
| RMSE (m·s−1) | 1.60 × 10−2 | 1.07 × 10−2 | 9.28 × 10−3 | 8.43 × 10−3 | 6.59 × 10−3 |
| Mass imbalance (kg·s−1·m2) | 1.99 × 10−4 | 1.52 × 10−4 | 1.12 × 10−4 | 6.68 × 10−5 | 6.71 × 10−5 |
| 3:1 | 3:3 | 3:10 | |
|---|---|---|---|
| RMSE (m·s−1) | 1.07 × 10−2 | 8.79 × 10−3 | 1.07 × 10−2 |
| Mass imbalance (kg·s−1·m2) | 1.52 × 10−4 | 7.24 × 10−5 | 1.41 × 10−4 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Costa Rocha, P.A.; Johnston, S.J.; Oliveira Santos, V.; Aliabadi, A.A.; Thé, J.V.G.; Gharabaghi, B. Deep Neural Network Modeling for CFD Simulations: Benchmarking the Fourier Neural Operator on the Lid-Driven Cavity Case. Appl. Sci. 2023, 13, 3165. https://doi.org/10.3390/app13053165
Costa Rocha PA, Johnston SJ, Oliveira Santos V, Aliabadi AA, Thé JVG, Gharabaghi B. Deep Neural Network Modeling for CFD Simulations: Benchmarking the Fourier Neural Operator on the Lid-Driven Cavity Case. Applied Sciences. 2023; 13(5):3165. https://doi.org/10.3390/app13053165
Chicago/Turabian StyleCosta Rocha, Paulo Alexandre, Samuel Joseph Johnston, Victor Oliveira Santos, Amir A. Aliabadi, Jesse Van Griensven Thé, and Bahram Gharabaghi. 2023. "Deep Neural Network Modeling for CFD Simulations: Benchmarking the Fourier Neural Operator on the Lid-Driven Cavity Case" Applied Sciences 13, no. 5: 3165. https://doi.org/10.3390/app13053165
APA StyleCosta Rocha, P. A., Johnston, S. J., Oliveira Santos, V., Aliabadi, A. A., Thé, J. V. G., & Gharabaghi, B. (2023). Deep Neural Network Modeling for CFD Simulations: Benchmarking the Fourier Neural Operator on the Lid-Driven Cavity Case. Applied Sciences, 13(5), 3165. https://doi.org/10.3390/app13053165