


Data Mining and Augmented Reality: An Application to the Fashion Industry



Abstract
:Featured Application
Abstract
1. Introduction
2. Materials and Methods
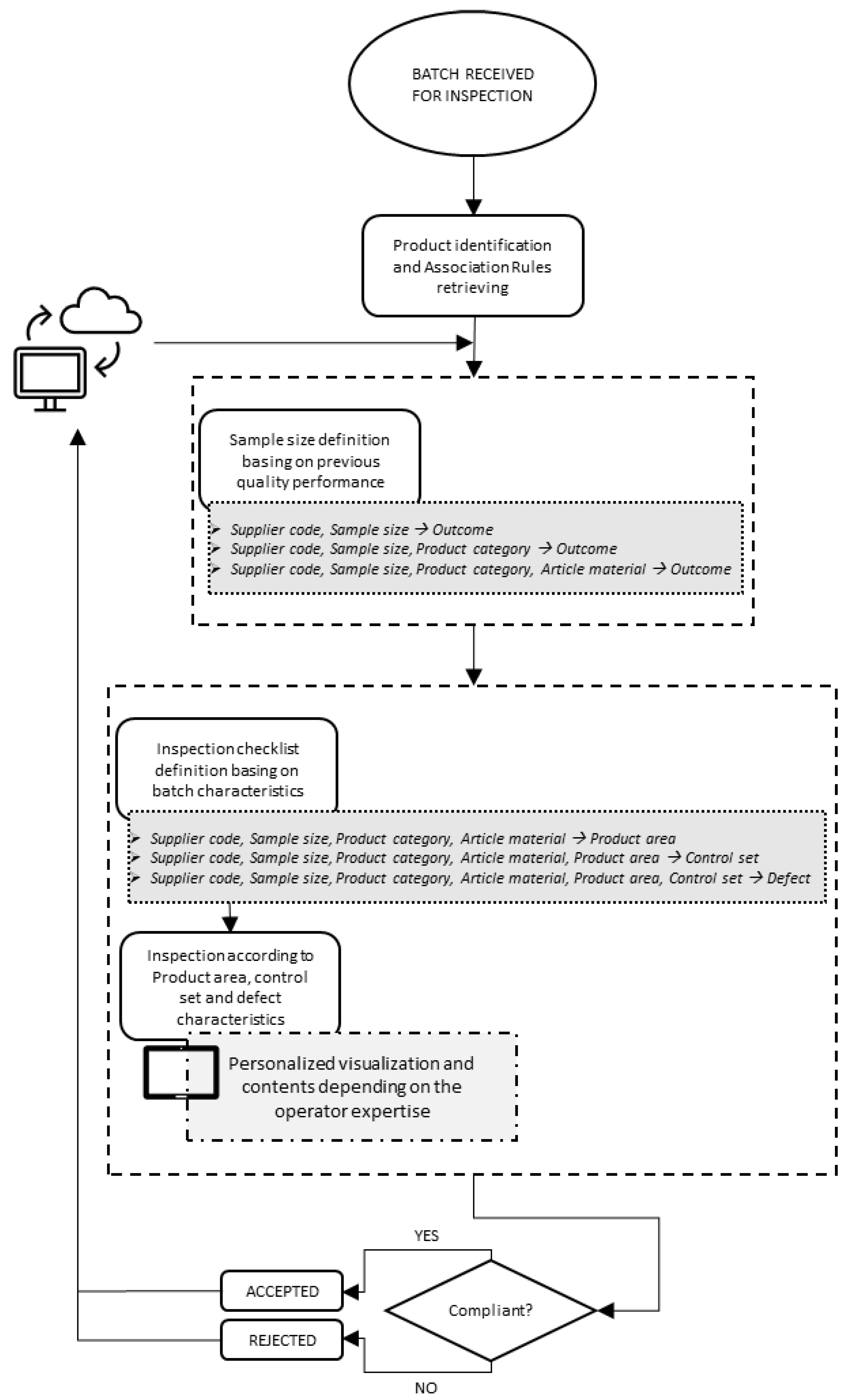
2.1. Research Approach
- Relating a supplier and the associated sample size to the outcome of the quality inspections: in this way, the ability to provide compliant lots is verified at a general level. In particular, if the supplier is able to provide an acceptance rate of 100% in all cases, then there is no need to analyze furtherly the performance in order to identify virtuous and vicious products. On the other end, it should be discussed whether a lower sample size could be selected to hasten the quality control phase;
- Relating a supplier, the associated sample size per product category to the outcome of the quality inspections: this group of rules is focused on identifying the impact of the product category on the performance of the supplier: this should be the case for suppliers producing a variety of product categories, but having specific expertise only on manufacturing a selection of them. If the supplier provides an acceptance rate of 100% for a specific product category, then the same remarks made at point 1 can be repeated, i.e., the sample size can be reduced, and the analysis should not be reiterated;
- Relating a supplier, the associated sample size per product category and article material to the outcome of the quality inspections: indeed, recurrent non-compliance can regard the characteristics of the main material composing the article. Being able to quantify such impact represents a valuable input.
- Firstly, the most common areas of the product in which defects are frequently localized should be identified so that the operator focuses on the most critical at first. That said, the occurrences are ranked by confidence, showing at the top of the list the most common ones (i.e., the ones having the highest probability);
- For each of the previous association rules, the list of the controls that should be performed has to be presented so that the operator has a clear idea of all the processes to be carried out before assigning a final outcome to the product. Rules are ranked by confidence, meaning that the controls that are more likely to detect a defect are performed first;
- Once the control set of actions has been selected, the defect that could be identified is selected. In this way, the operators can have a more precise idea of the defect to expect and, hence, can recognize it more easily.
2.2. Association Rule Mining
- I, J ⊆ A;
- I ∩ J = ∅.
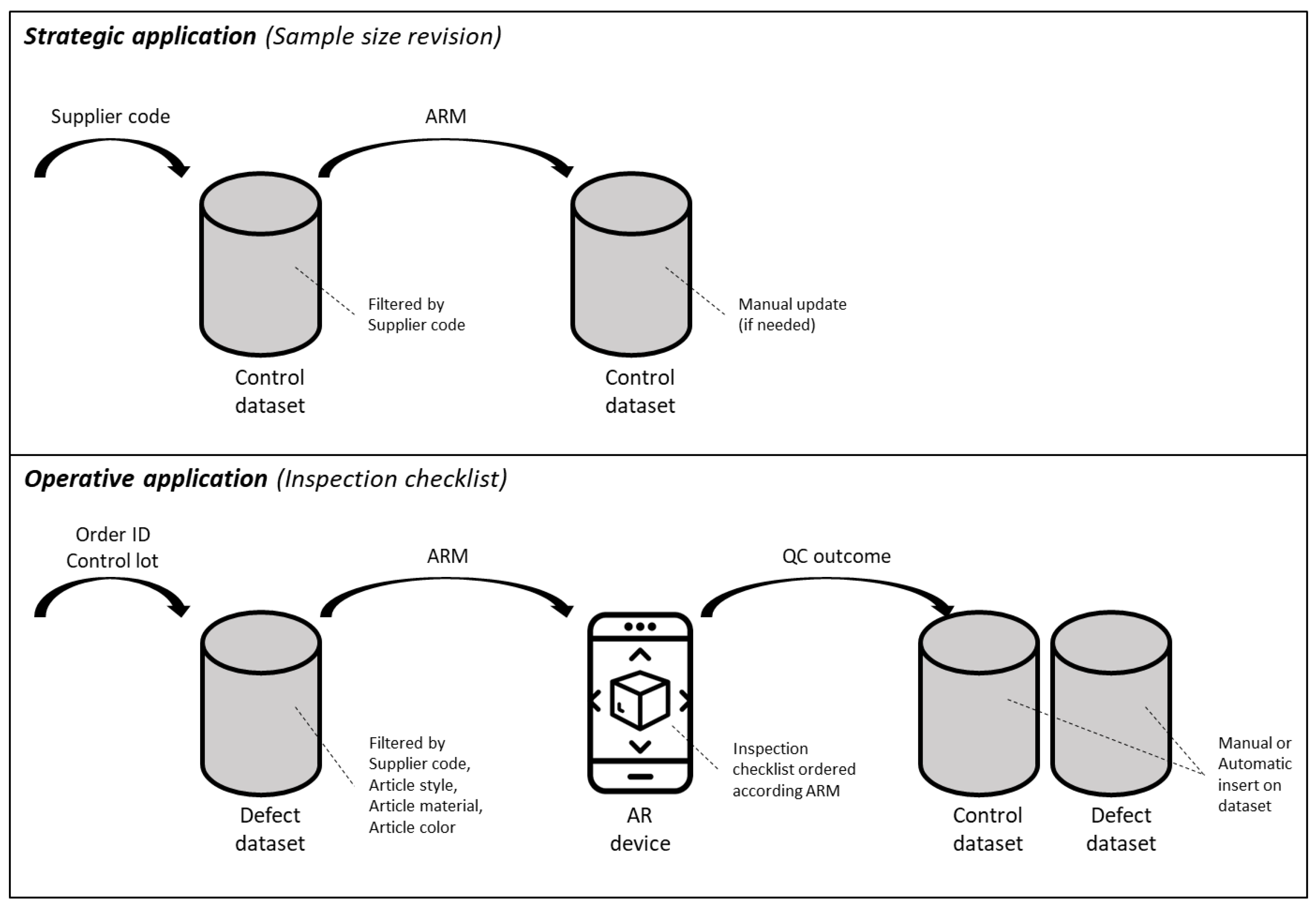
2.3. Dataset Structure and Management
3. Case Study
3.1. Company Profile
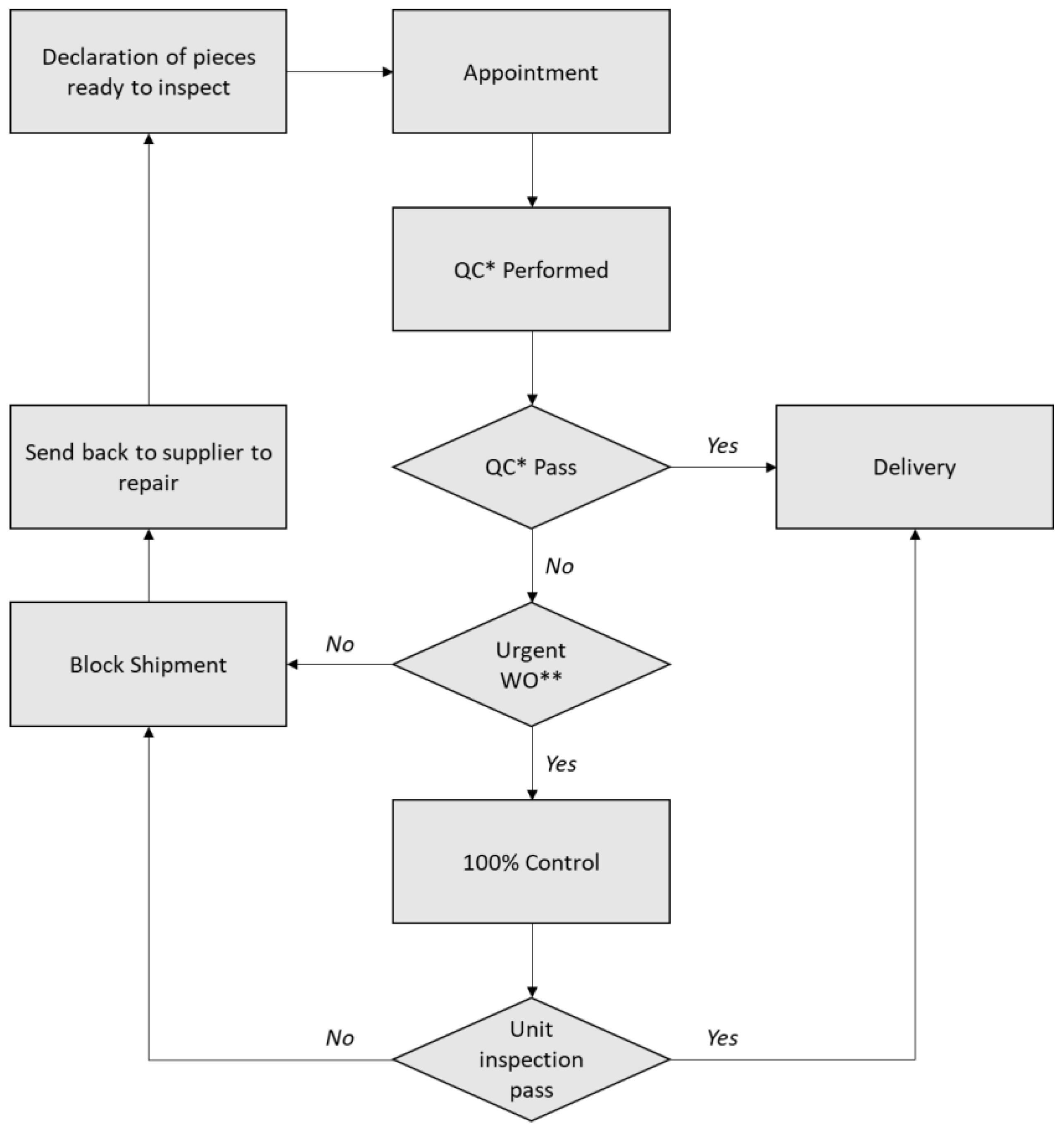
3.2. Quality Control Process
4. Results
4.1. Association Rule Mining
4.1.1. Sampling Rules
4.1.2. Defect Identification
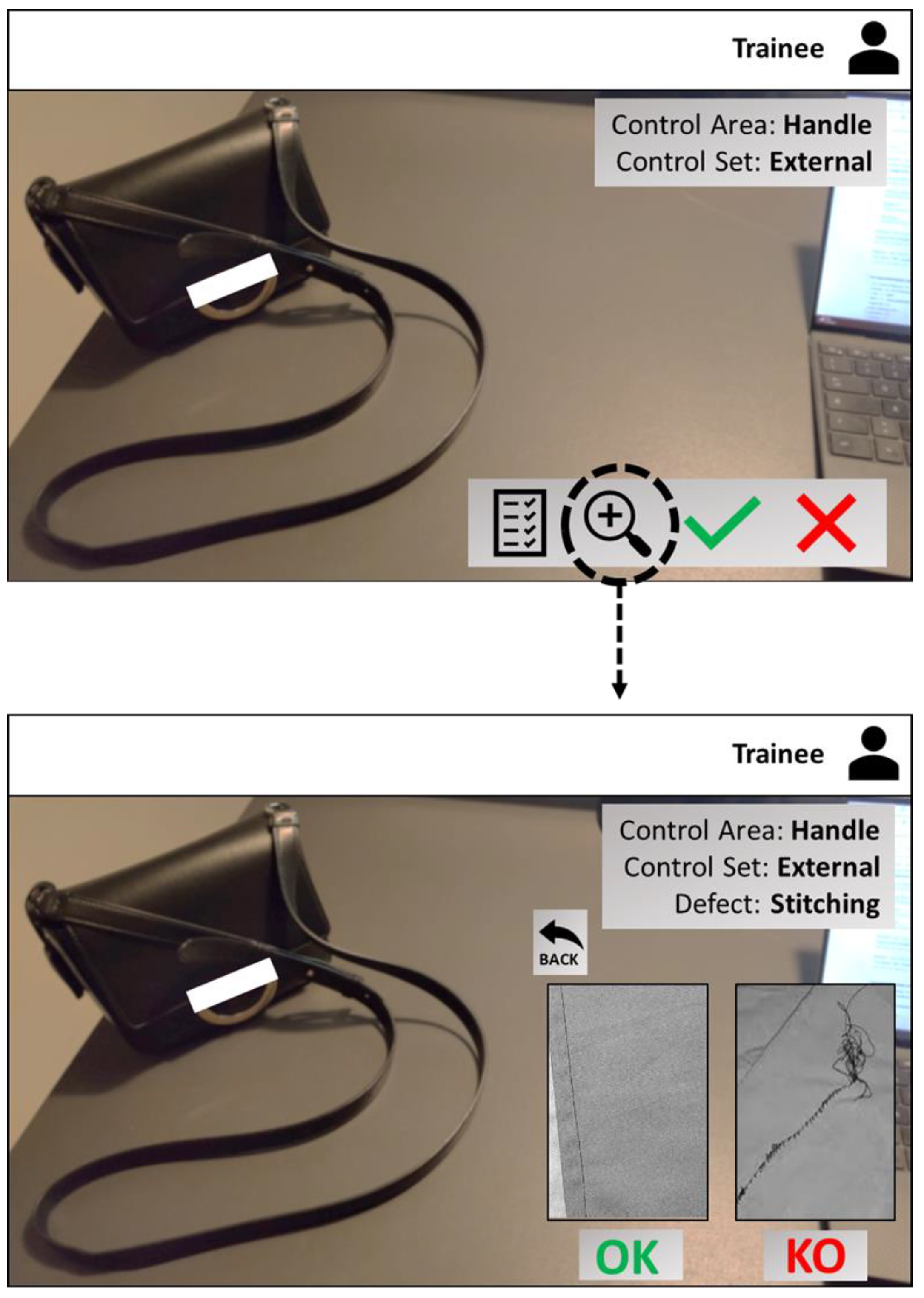
4.2. Augmented Reality Support
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Alcácer, V.; Cruz-Machado, V. Scanning the Industry 4.0: A Literature Review on Technologies for Manufacturing Systems. Eng. Sci. Technol. Int. J. 2019, 22, 899–919. [Google Scholar] [CrossRef]
- Naqvi, R.; Soomro, T.R.; Alzoubi, H.M.; Ghazal, T.M.; Alshurideh, M.T. The Nexus Between Big Data and Decision-Making: A Study of Big Data Techniques and Technologies. In Proceedings of the International Conference on Artificial Intelligence and Computer Vision (AICV2021); Hassanien, A.E., Haqiq, A., Tonellato, P.J., Bellatreche, L., Goundar, S., Azar, A.T., Sabir, E., Bouzidi, D., Eds.; Springer International Publishing: Cham, Switzerland, 2021; pp. 838–853. [Google Scholar]
- UNI ISO. Procedimenti di Campionamento Nell’ispezione per Attributi-Parte 1: Schemi di Campionamento Indicizzati Secondo il Limite di Qualità Accettabile (AQL) Nelle Ispezioni Lotto per lotto. Available online: https://store.uni.com/p/UNII285901-2007/uni-iso-2859-12007-11390/UNII285901-2007_EEN (accessed on 27 December 2022).
- Rivera-Gómez, H.; Gharbi, A.; Kenné, J.-P.; Montaño-Arango, O.; Corona-Armenta, J.R. Joint optimization of production and maintenance strategies considering a dynamic sampling strategy for a deteriorating system. Comput. Ind. Eng. 2020, 140, 106273. [Google Scholar] [CrossRef]
- Hajej, Z.; Rezg, N.; Gharbi, A. Joint production preventive maintenance and dynamic inspection for a degrading manufacturing system. Int. J. Adv. Manuf. Technol. 2021, 112, 221–239. [Google Scholar] [CrossRef]
- Samohyl, R.W. Acceptance sampling for attributes via hypothesis testing and the hypergeometric distribution. J. Ind. Eng. Int. 2018, 14, 395–414. [Google Scholar] [CrossRef]
- Bindi, B.; Bandinelli, R.; Fani, V.; Pero, M.E.P. Supply chain strategy in the luxury fashion industry: Impacts on performance indicators. Int. J. Product. Perform. Manag. 2021; ahead-of-print. [Google Scholar] [CrossRef]
- Antomarioni, S.; Lucantoni, L.; Ciarapica, F.E.; Bevilacqua, M. Data-driven decision support system for managing item allocation in an ASRS: A framework development and a case study. Expert Syst. Appl. 2021, 185, 115622. [Google Scholar] [CrossRef]
- Ur-Rahman, N.; Harding, J.A. Textual data mining for industrial knowledge management and text classification: A business oriented approach. Expert Syst. Appl. 2012, 39, 4729–4739. [Google Scholar] [CrossRef]
- Fani, V.; Antomarioni, S.; Bandinelli, R.; Bevilacqua, M. Data-driven decision support tool for production planning: A framework combining association rules and simulation. Comput. Ind. 2023, 144, 103800. [Google Scholar] [CrossRef]
- Kotu, V.; Deshpande, B. Data Science-Concepts and Practice, 2nd ed.; Morgan Kaufmann: Burlington, MA, USA, 2018; ISBN 978-0-12-814761-0. Available online: https://www.elsevier.com/books/data-science/kotu/978-0-12-814761-0 (accessed on 27 December 2022).
- Antomarioni, S.; Bevilacqua, M.; Potena, D.; Diamantini, C. Defining a data-driven maintenance policy: An application to an oil refinery plant. Int. J. Qual. Reliab. Manag. 2018, 36, 77–97. [Google Scholar] [CrossRef]
- Grabot, B. Rule mining in maintenance: Analysing large knowledge bases. Comput. Ind. Eng. 2020, 139, 105501. [Google Scholar] [CrossRef]
- Yildirim, P.; Birant, D.; Alpyildiz, T. Data mining and machine learning in textile industry. WIREs Data Min. Knowl. Discov. 2018, 8, e1228. [Google Scholar] [CrossRef]
- Lee, C.K.H.; Ho, G.T.S.; Choy, K.L.; Pang, G.K.H. A RFID-based recursive process mining system for quality assurance in the garment industry. Int. J. Prod. Res. 2014, 52, 4216–4238. [Google Scholar] [CrossRef]
- Lee, C.K.H.; Choy, K.L.; Ho, G.T.S.; Chin, K.S.; Law, K.M.Y.; Tse, Y.K. A hybrid OLAP-association rule mining based quality management system for extracting defect patterns in the garment industry. Expert Syst. Appl. 2013, 40, 2435–2446. [Google Scholar] [CrossRef]
- Govender, D.; Moodley, J.; Balmahoon, R. Augmented and Mixed Reality based Decision Support Tool for the Integrated Resource Plan. In Proceedings of the IECON 2021–47th Annual Conference of the IEEE Industrial Electronics Society, Toronto, ON, Canada, 13–16 October 2021; IEEE: Toronto, ON, Canada, 2021; pp. 1–6. [Google Scholar]
- Drath, R.; Horch, A. Industrie 4.0: Hit or Hype? [Industry Forum]. IEEE Ind. Electron. Mag. 2014, 8, 56–58. [Google Scholar] [CrossRef]
- Marques, B.; Santos, B.S.; Araujo, T.; Martins, N.C.; Alves, J.B.; Dias, P. Situated Visualization in The Decision Process Through Augmented Reality. In Proceedings of the 2019 23rd International Conference Information Visualisation (IV), Paris, France, 2–5 July 2019; IEEE: Paris, France, 2019; pp. 13–18. [Google Scholar]
- Cachada, A.; Barbosa, J.; Leitno, P.; Gcraldcs, C.A.S.; Deusdado, L.; Costa, J.; Teixeira, C.; Teixeira, J.; Moreira, A.H.J.; Moreira, P.M.; et al. Maintenance 4.0: Intelligent and Predictive Maintenance System Architecture; IEEE: Piscatvie, NJ, USA, 2018; Volume 1, pp. 139–146. [Google Scholar]
- Martins, N.C.; Marques, B.; Alves, J.; Araújo, T.; Dias, P.; Santos, B.S. Augmented reality situated visualization in decision-making. Multimed. Tools Appl. 2022, 81, 14749–14772. [Google Scholar] [CrossRef]
- Karlsson, I.; Bernedixen, J.; Ng, A.H.C.; Pehrsson, L. Combining Augmented Reality and Simulation-Based Optimization for Decision Support in Manufacturing; IEEE: Piscatvie, NJ, USA, 2017; Volume 1, pp. 3988–3999. [Google Scholar]
- Zheng, M.; Pan, X.; Bermeo, N.V.; Thomas, R.J.; Coyle, D.; O’hare, G.M.P.; Campbell, A.G. STARE: Augmented Reality Data Visualization for Explainable Decision Support in Smart Environments. IEEE Access 2022, 10, 29543–29557. [Google Scholar] [CrossRef]
- Egbert, L.; Quandt, M.; Thoben, K.-D.; Freitag, M. Mobile AR-Based Assistance Systems for Order Picking–Methodical Decision Support in the Early Phases of the Product Life Cycle. In Subject-Oriented Business Process Management. The Digital Workplace–Nucleus of Transformation; Freitag, M., Kinra, A., Kotzab, H., Kreowski, H.-J., Thoben, K.-D., Eds.; Communications in Computer and Information Science; Springer International Publishing: Cham, Switzerland, 2020; Volume 1278, pp. 74–87. ISBN 978-3-030-64350-8. [Google Scholar]
- Mirshokraei, M.; De Gaetani, C.I.; Migliaccio, F. A Web-Based BIM–AR Quality Management System for Structural Elements. Appl. Sci. 2019, 9, 3984. [Google Scholar] [CrossRef]
- Yavuz Erkek, M.; Erkek, S.; Jamei, E.; Seyedmahmoudian, M.; Stojcevski, A.; Horan, B. Augmented Reality Visualization of Modal Analysis Using the Finite Element Method. Appl. Sci. 2021, 11, 1310. [Google Scholar] [CrossRef]
- Chiang, F.-K.; Shang, X.; Qiao, L. Augmented reality in vocational training: A systematic review of research and applications. Comput. Hum. Behav. 2022, 129, 107125. [Google Scholar] [CrossRef]
- Buddhakulsomsiri, J.; Siradeghyan, Y.; Zakarian, A.; Li, X. Association rule-generation algorithm for mining automotive warranty data. Int. J. Prod. Res. 2006, 44, 2749–2770. [Google Scholar] [CrossRef]
- Han, J.; Cheng, H.; Xin, D.; Yan, X. Frequent pattern mining: Current status and future directions. Data Min. Knowl. Discov. 2007. [Google Scholar] [CrossRef]
- Crespo Márquez, A.; de la Fuente Carmona, A.; Antomarioni, S. A Process to Implement an Artificial Neural Network and Association Rules Techniques to Improve Asset Performance and Energy Efficiency. Energies 2019, 12, 3454. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset Column | Data Type | Example |
|---|---|---|
| Order ID | Int | 20210124101 |
| Control lot | String | ABCD-2021-01241-A |
| Supplier code | Int | 1 |
| Product category | String | Bags |
| Article style | Int | 1233456 |
| Article material | String | 1 |
| Article color | Number | 1000 |
| Article size | String | U |
| Quantity ordered | Int | 24 |
| Quantity controlled | Int | 8 |
| Sample size | Int | 15 |
| Control round | Int | 1 |
| Outcome | String | To be re-checked |
| Dataset Column | Data Type | Example |
|---|---|---|
| Order ID | Int | 20210124101 |
| Control lot | String | ABCD-2021-01241-A |
| Supplier code | Int | 1 |
| Product category | String | Bags |
| Article style | Int | 1233456 |
| Article material | String | 1 |
| Article color | Number | 1000 |
| Article size | String | U |
| Sample size | Int | 15 |
| Control round | Int | 1 |
| Outcome | String | To be re-checked |
| Control area | String | Body |
| Control set | String | Internal |
| Defect | String | Stitching |
| X | Y | Supp | Conf |
|---|---|---|---|
| Supplier code = 7, Sample size = 15%, Product category = Bags, Article material = 118 | Outcome = Non-compliant | <0.001 | 0.143 |
| Supplier code = 7, Sample size = 15%, Product category = Bags Article material = 118 | Outcome = Compliant | <0.001 | 0.857 |
| Supplier code = 7, Sample size = 15%, Product category = Bags Article material = 475 | Outcome = Non-compliant | <0.001 | 0.250 |
| Supplier code = 7, Sample size = 15%, Product category = Bags Article material = 475 | Outcome = Compliant | <0.001 | 0.750 |
| Supplier code = 7, Sample size = 15%, Product category = Bags Article material = 661 | Outcome = To be rechecked | <0.001 | 0.454 |
| Supplier code = 7, Sample size = 15%, Product category = Bags Article material = 661 | Outcome = Compliant | <0.001 | 0.545 |
| X | Y | Supp | Conf |
|---|---|---|---|
| Product category = Bags, Sample size = 15%, Supplier code = 7, Article material = 118 | Control area = Body | <0.001 | 0.600 |
| Product category = Bags, Sample size = 15%, Supplier code = 7, Article material = 118 | Control area = Handle | <0.001 | 0.400 |
| X | Y | Supp | Conf |
|---|---|---|---|
| Product category = Bags, Sample size = 15%, Supplier code = 7, Article material = 118, Control area = Body | Control set = Internal | <0.001 | 1.000 |
| Product category = Bags, Sample size = 15%, Supplier code = 7, Article material = 118, Control area = Handle | Control set = External | <0.001 | 1.000 |
| X | Y | Supp | Conf |
|---|---|---|---|
| Product category = Bags, Sample size = 15%, Supplier code = 7, Article material = 118, Control area = Handle, Control set = External | Defect = Stitching | <0.001 | 0.544 |
| Product category = Bags, Sample size = 15%, Supplier code = 7, Article material = 118, Control area = Handle, Control set = External | Defect = Glueing | <0.001 | 0.356 |
| Product category = Bags, Sample size = 15%, Supplier code = 7, Article material = 118, Control area = Handle, Control set = External | Defect = Buckle | <0.001 | 0.100 |
| No Device | |||
|---|---|---|---|
| Expert | Non-Expert | ||
| Time for OK Products | Time for KO Products | Time for OK Products | Time for KO Products |
| 0.10 | 0.50 | 1.00 | 0.64 |
| 1.00 | 0.25 | 1.00 | 0.73 |
| 0.41 | 1.00 | 0.17 | 0.82 |
| 0.72 | 0.75 | 0.33 | 0.36 |
| 0.87 | 0.75 | 0.33 | 0.64 |
| 0.92 | 0.50 | 0.00 | 0.18 |
| 0.52 | 0.00 | 1.00 | 0.73 |
| 0.86 | 0.00 | 0.17 | 0.00 |
| 0.65 | 0.75 | 0.50 | 1.00 |
| 0.31 | 0.25 | 0.17 | 0.55 |
| 0.00 | 0.25 | 0.33 | 0.36 |
| 0.22 | 0.75 | 1.00 | 0.55 |
| 0.93 | 0.25 | 0.83 | 0.73 |
| 0.73 | 0.75 | 0.17 | 0.09 |
| 0.64 | 1.00 | 1.00 | 0.45 |
| 0.04 | 0.00 | 0.50 | 0.64 |
| 0.30 | 0.50 | 0.67 | 0.91 |
| 0.89 | 0.25 | 0.50 | 0.45 |
| 0.43 | 0.40 | 0.17 | 0.36 |
| 0.65 | 0.40 | 0.00 | 0.00 |
| Device | |||
|---|---|---|---|
| Expert | Non-Expert | ||
| Time for OK Products | Time for KO Products | Time for OK Products | Time for KO Products |
| 0.28 | 1.00 | 0.00 | 0.26 |
| 0.83 | 0.00 | 0.67 | 0.11 |
| 0.24 | 1.00 | 0.17 | 0.44 |
| 0.00 | 1.00 | 0.00 | 0.00 |
| 0.91 | 0.67 | 0.33 | 0.26 |
| 0.19 | 0.33 | 0.00 | 0.00 |
| 1.00 | 0.00 | 1.00 | 0.44 |
| 0.20 | 0.33 | 0.17 | 0.78 |
| 0.09 | 0.33 | 0.00 | 0.33 |
| 0.13 | 0.33 | 0.17 | 0.00 |
| 0.33 | 1.00 | 0.00 | 0.44 |
| 0.06 | 0.00 | 0.17 | 0.38 |
| 0.55 | 0.33 | 0.83 | 0.78 |
| 0.56 | 1.00 | 0.17 | 0.00 |
| 0.34 | 0.00 | 0.33 | 0.38 |
| 0.42 | 1.00 | 0.50 | 0.26 |
| 0.82 | 0.33 | 0.33 | 0.00 |
| 0.24 | 0.67 | 0.00 | 1.00 |
| 0.48 | 0.00 | 0.17 | 0.45 |
| 0.01 | 0.00 | 0.00 | 0.11 |
| Sentences | Avg for Expert Operators | Avg for Non-Expert Operators |
|---|---|---|
| The use of the device was complicated [1]/easy [5] | 1.33 | 4.50 |
| The use of the device is not pleasing [1]/pleasing [5] | 1.67 | 5.00 |
| I felt slower [1]/faster in performing my task using the device | 2.67 | 5.00 |
| Using the device was obstructive [1]/supportive [5] of my work | 3.00 | 4.00 |
| I felt demotivated [1]/motivated [5] in using the device | 3.00 | 5.00 |
| The interface was confusing [1]/clear [5] | 3.33 | 3.50 |
| The information displayed was not helpful [1]/helpful [5] | 4.67 | 4.00 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fani, V.; Antomarioni, S.; Bandinelli, R.; Ciarapica, F.E. Data Mining and Augmented Reality: An Application to the Fashion Industry. Appl. Sci. 2023, 13, 2317. https://doi.org/10.3390/app13042317
Fani V, Antomarioni S, Bandinelli R, Ciarapica FE. Data Mining and Augmented Reality: An Application to the Fashion Industry. Applied Sciences. 2023; 13(4):2317. https://doi.org/10.3390/app13042317
Chicago/Turabian StyleFani, Virginia, Sara Antomarioni, Romeo Bandinelli, and Filippo Emanuele Ciarapica. 2023. "Data Mining and Augmented Reality: An Application to the Fashion Industry" Applied Sciences 13, no. 4: 2317. https://doi.org/10.3390/app13042317
APA StyleFani, V., Antomarioni, S., Bandinelli, R., & Ciarapica, F. E. (2023). Data Mining and Augmented Reality: An Application to the Fashion Industry. Applied Sciences, 13(4), 2317. https://doi.org/10.3390/app13042317