Abstract
Recent advances in convolutional neural network (CNN)-based object detection have a trade-off between accuracy and computational cost in various industrial tasks and essential consideration. However, the fully convolutional one-stage detector (FCOS) demonstrates low accuracy compared with its computational costs owing to the loss of low-level information. Therefore, we propose a module called a dual-path lightweight module (DLM) that efficiently utilizes low-level information. In addition, we propose a DLMFCOS based on DLM to achieve an optimal trade-off between computational cost and detection accuracy. Our network minimizes feature loss by extracting spatial and channel information in parallel and implementing a bottom-up feature pyramid network that improves low-level information detection. Additionally, the structure of the detection head is improved to minimize the computational cost. The proposed method was trained and evaluated by fine-tuning parameters through experiments and using public datasets PASCAL VOC 07 and MS COCO 2017 datasets. The average precision (AP) metric is used for our quantitative evaluation matrix for detection performance, and our model achieves an average 1.5% accuracy improvement at about 33.85% lower computational cost on each dataset than the conventional method. Finally, the efficiency of the proposed method is verified by comparing the proposed method with the conventional method through an ablation study.
1. Introduction
In recent years, convolutional neural networks (CNNs) have been actively investigated in computer vision fields for object detection [1,2,3], semantic segmentation [1], and super-resolution [4]. Among the computer vision tasks, object detection, which is a fundamental task, is mainly used in autonomous driving, CCTV, crack detection [5,6], and industrial fields.
Deep learning object detection methods are two-stage or one-stage methods; in detail, models can be anchor-based or anchor-free. The two-step method performs localization and classification based on region-of-interest (RoI) selection using a region proposal network that searches for regions in an image that is likely to contain the desired object. Region-based CNN (R-CNN) [7,8,9] is a representative two-stage method. The one-stage method performs localization and classification simultaneously, providing favorable detection accuracy. However, it is less accurate than the two-stage method. Representative one-stage methods include SSD [10] and YOLO series [11,12]. In addition, the one-stage method is improved by extending the network depth by adding a feature pyramid [13] that utilizes feature maps at different scales. However, this method has a class imbalance problem. Therefore, RetinaNet appears, which solves this by assigning different weights to easy and hard samples. Another method, FCOS [14], improves the class imbalance problem due to space constraints, such as anchor-free methods, that do not predefine anchors. Recently, object detection has been studied for lightweight networks to be applied to various industrial environments. As a representative method, two networks, DualNet [15], which utilizes high and low-resolution features, and DPNet [16,17], a lightweight network that utilizes different resolutions and feature convergence, have been proposed. As such, object detection is a method of high accuracy with low computational cost.
In this paper, we propose an anchor-free method based on FCOS, called dual-path lightweight module FCOS, which achieves an optimal trade-off between computational cost and accuracy. DLMFCOS comprises a DLM, FPN, and lightweight detection head. First, the proposed DLM minimized feature loss by calculating the spatial and channel information in parallel to improve detection accuracy. Second, bottom-up and top-down structures are added to the conventional FPN to minimize the low-level feature loss of the baseline FCOS. Finally, the lightweight detection head maintains accuracy and minimizes computation. The proposed method was compared with the baseline FCOS in the public datasets PASCAL VOC and MS COCO datasets. The result is an average 1.5% improvement in detection accuracy at a 2.4M lower computational cost. Furthermore, the ablation study usefulness between the proposed methods was verified. The main contributions of this study are as follows:
- The proposed DLM optimal trade-off computational cost and accuracy compared to standard convolution by minimizing spatial and channel information loss.
- The proposed feature pyramid structure achieves a balance between accuracy and computational cost by improving the feature loss compared to the conventional methods.
- The proposed method minimizes computational costs by improving the conventional detection head structure.
2. Related Works
2.1. Fully Convolutional One-Stage Detector
Object detection classifies instances in images as objects and predicts their locations. The conventional detector anchor-based methods generally place many anchors densely within an image to increase the recall. However, a class imbalance problem between the foreground and background occurs because most samples are classified as background. In addition, a predefined anchor-based detector has hyperparameters of size, aspect ratio, and number, and model detection performance varies significantly depending on this definition. Actually, the performance of SSD and YOLO one-stage object detection networks is greatly influenced by the hyperparameter settings. Therefore, its hyperparameters must be reset according to the target to be learned to reduce performance deviations. An example of RetinaNet exhibits a performance deviation of approximately on the MS COCO dataset when changing its anchor hyperparameters. As such, the generalization performance varies greatly depending on the setting of the anchor-based object detection hyperparameters. Therefore, FCOS was proposed as an object detection method that does not use an anchor by utilizing the method of FCN [18], which showed good performance in semantic segmentation and depth estimation. Figure 1 shows the structure of FCOS.
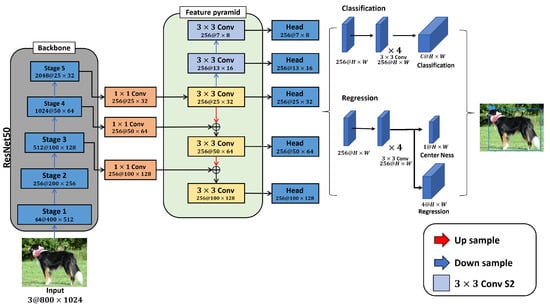
Figure 1.
Fully convolutional one-stage detector structure. FCOS consists of a ResNet-50 [19] backbone network, FPN, and detection head. The extracted features were adjusted to 256 channels by a convolution. Ordinarily, if a plurality of objects exists in an input image, erroneous detection may occur, especially with overlaps. To avoid this, the FCOS detector utilizes feature maps of different resolutions in the feature pyramids. Performance is improved by weighting candidate objects and removing the least-probable candidates via center loss. Conv: convolution.
2.2. Feature Pyramid
The deep learning-based object detector used an image pyramid, a single feature map, and a hierarchical feature pyramid structure to detect objects of different sizes. Generally, when using feature maps as independent units, semantic gaps and slow inference speeds can cause the loss of important feature information. Thus, FPN was invented to handle feature maps of different scales from a single-scale image. Features are extracted layer-by-layer on the backbone network instead of relying on a newly designed model. By using extracted features of different resolutions, the scale of the feature map is adjusted in a top-down structure, such as a pyramid. Thus, the feature loss that would otherwise occur during upsampling is mitigated with a lateral connection. Thus, the scale invariance problem is resolved by using different feature maps. Figure 2 illustrates the FPN structure.
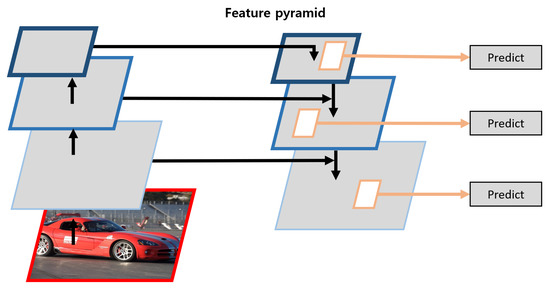
Figure 2.
Feature pyramid network structure.
3. Proposed Method
This section describes the proposed method. The FPN comprises a DLM with up- and down-sampling, and the detection head comprises and convolutions.
Figure 3 shows the proposed DLFCOS structure. The proposed DLM consists of a lightweight spatial module (LSM) comprising a standard convolution, dilated depth-wise convolution [20], and channel attention (CA). The CA extracts channel vectors from input feature maps and processes the generated features in parallel. The proposed lightweight detection head consists of and convolutions to maximize accuracy with fewer calculations than a conventional detection head. Finally, we use FCOS, which has a low impact on hyperparameters, for both regression and classification.
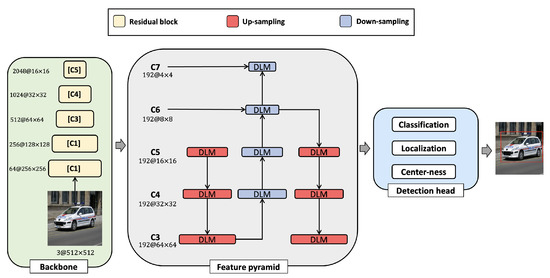
Figure 3.
Proposed method architecture. The proposed method used ResNet-50 as the backbone input to the DLM-reconstructed FPN, which is designed to minimize feature map loss. Subsequently, to minimize the overall computational burden, the feature map extracted from the backbone is adjusted to 192 channels using a convolution. DLM: dual-path lightweight module.
3.1. Proposed Feature Pyramid Structure
The FPN method uses a single-resolution image and outputs a feature map of different resolutions. Its structure is a top-down CNN, and the deeper the network, the more difficult it is to transmit low-level information to deeper layers. Thus, the proposed method is designed to minimize low-level information loss by transferring the features used in previous layers to deeper ones for sampling. The proposed FPN structure is constructed as a DLM to minimize feature loss with minimized computational overhead by calculating the spatial and channel information in parallel. In detail, the proposed DLM consists of LSM and CA and extracts spatial information efficiently with LSM and important information between channels with CA. Figure 4 shows the proposed FPN structure.
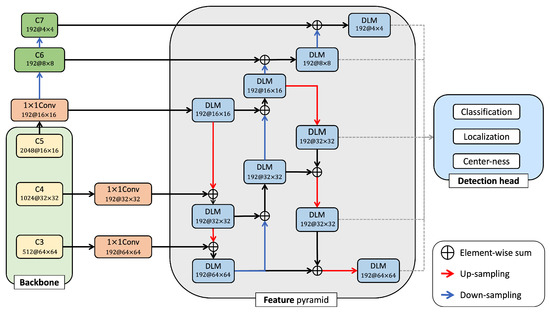
Figure 4.
Proposed dual-path lightweight module (DLM) feature pyramid structure. Conv: convolution.
3.1.1. Dual Path Lightweight Module
A CNN extracts features and classifies objects using various convolution techniques. In other words, this is to extract foreground information and background information of the input image and use them as feature information. Therefore, kernels of various sizes are billed to convolutions that are needed for accurate object detection. However, this method’s computational cost increases. Therefore, in this paper, we proposed the dual-path lightweight module (DLM) that minimizes feature loss with a few computations. Figure 5 illustrates its structure. First, the input feature map is compressed to half the size of the input channel using convolution to minimize the increased computation. Second, the LSM consists of a dilated depth-wise convolution that efficiently extracts spatial information by taking a wide receptive field with a few computational costs. Simultaneously, the channel information of the input feature map is extracted by the CA. The dual lightweight module combines features by concatenating the spatial and channel information to minimize feature loss. Third, the combined feature maps are compressed with a convolution and the feature loss is minimized by concatenating the initially compressed features. Finally, the feature maps are extracted by a convolution to minimize feature loss. Equation (1) shows the proposed dual-path lightweight module.
where refers to the convolution, LSM is the lightweight spatial modulus, CA is the channel attention, and ⨂ implies concatenation.
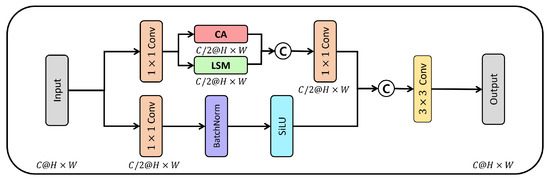
Figure 5.
Proposed dual-path lightweight module structure. BatchNorm: batch normalization; (C): concatenation; Conv: convolution; CA: channel attention; H × W: (H: height, W: width) input feature map size; LSM: lightweight spatial model; SiLU: sigmoid linear unit.
3.1.2. Lightweight Spatial Module
Figure 6 illustrates the structure of the proposed LSM, which efficiently extracts spatial information with a small amount of computation. With a conventional convolution, the kernel processes the spatial and channel dimensions simultaneously to extract features. However, the LSM extracts spatial information between each channel through the depth-extended convolution, which expands the receptive field with minimized computation. For the extracted spatial information, channel information is extracted by compressing and expanding the channel 0.5 times through convolutions. Unlike general convolution modules, the proposed method improves the convergence speed of the network by extracting spatial information and performing batch normalization without using batch normalization or activation functions after convolution. Finally, when the channel is compressed and expanded, the feature map is activated. Residual learning is used to minimize the feature loss that otherwise occurs during compression and expansion. Equations (2)–(4) detail the dilated [21], depth-wise, and dilated depth-wise convolutions, respectively:
where i, j represent the elements of the feature map, is the input feature map, is the output feature map, is the convolution kernel, is the expansion ratio, k, l is the kernel size, and is the channel.
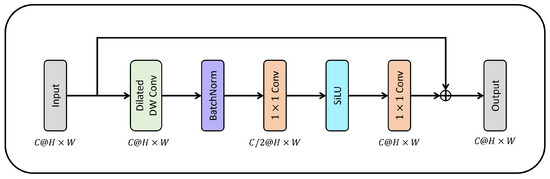
Figure 6.
Structure of the proposed lightweight spatial module. The proposed LSM used kernel size 5 and dilated rate 2. BatchNorm (BN): batch normalization; dilated DW: dilated depth-wise Conv; : (H: height, W: width) input feature map size; SiLU: sigmoid linear unit; (+): elemental wise sum.
3.1.3. Channel Attention
Figure 7 illustrates the Channel attention (CA) [22,23] entails compression and readjustment. First, the input feature map is compressed into a one-dimensional vector with a GAP-weighted channel. Second, after compressing the channel 0.25 times via the convolution of a compressed vector, the network’s expression performance is improved via the addition of non-linearity to the feature map using the SiLU activation function. The channel is then expanded to its original size by convolution. Subsequently, the feature map extracted by the SiLU is converted into a value between zero and one, and an emphasis vector representing the importance of each channel is created. Finally, channels with high importance are emphasized in the input feature map by multiplying the channel weight vector and the input feature map. Equations (5)–(7) show the GAP, convolution, and CA
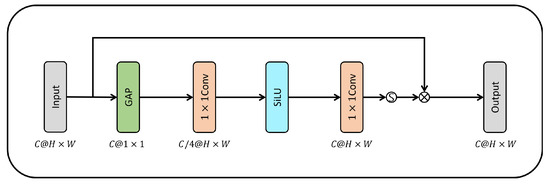
Figure 7.
Channel attention structure. GAP: global average pooling; H W: input feature map size; SiLU: sigmoid linear unit; (s): sigmoid function; (): matrix multiplication.
3.2. Lightweight Detection Head
The detection head extracts the feature map from the FPN, and the required feature information for object detection is extracted from the feature maps at different resolutions via the FPN. Figure 8 illustrates the detection head structure. Figure 8a presents the conventional detection head, and Figure 8b shows the improved version. Conventional detection heads repeat a standard convolution four times, as shown in Figure 8a. However, this repetition entails high computational complexity. Because this structure greatly simplifies detection head feature extraction, the input channel through the convolution is extended, as shown in Figure 8b. Thus, the proposed lightweight detection head is capable of feature extraction with minimized computational overhead.
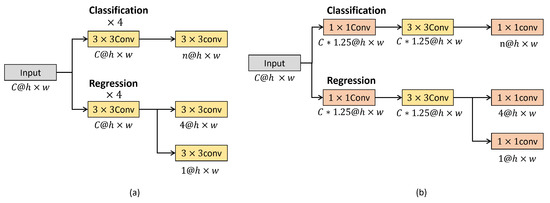
Figure 8.
Detection head structures: (a) conventional method, (b) the proposed method. C = Conv: convolution.
3.3. Loss Function
The loss function of the proposed method consists of classification, regression, and centrality types. Focal loss [24], generalized intersection over union (GIoU) [25], and center loss are used, respectively.
The purpose of classification loss is to mitigate the increased recall in object detection resulting from the imbalanced foreground and background sampling. We use focus loss as the classification loss, which improves cross-entropy, as formulated in Equation (8):
where p and y represent the output value of the network and the ground truth, where the input value is , respectively. The cross-entropy loss function compares the classification value generated by the deep learning model with the correct value and outputs the error. In this case, if cross-entropy is used, the entire loss is dominated by a sample that is relatively easy to classify (easy sample). Therefore, the focus loss provides the needed relative increase in the loss of hard samples by assigning weights to easy samples. Equations (9) and (10) formulate the focus loss:
where is either the correct or approximately correct value. As this value increases, the loss function becomes smaller compared with the conventional cross-entropy loss function. Conversely, the loss increases as the value gets farther away from correct. If the value is zero, the function becomes the standard cross-entropy function in which the hyperparameters limit the contribution of focus loss. The proposed method uses optimal values and based on the data analyzed by Tsung-Yi and Priya [24].
GIoU is used as the regression loss function. The contemporary version uses a smooth L1 loss that regresses the distance between the predicted and correct coordinates. However, calculating a precise regression loss is difficult when the distance is constant. Therefore, the intersection-over-union (IoU) becomes attractive. However, when IoU is used as a regression loss function, if there is no intersection between the predicted coordinates and the correct answer, or if a large error occurs, the loss may lead to a local minimum. Therefore, the GIoU is constructed as shown in Equation (11):
where C is the smallest bounding box that encompasses the predicted and correct values. This is the area obtained by subtracting the union of the two areas by transforming the warning value and correct answer into the bounding box. The variant was used, and its maximum value was set to two. The minimum was zero.
Finally, we use centerness loss, which weighs whether objects are centered during inference. The centerness loss determines whether an object is centered or not. Therefore, the loss is calculated using binary cross entropy (BCE), a special form of cross entropy.
In this case, l, r, t, and b denote the left, right, top, and bottom of the predicted coordinates, respectively. Equation (12) [14]: shows that the center loss approaches one as the predicted bounding box approximates the center; otherwise, it approaches zero. Therefore, the center loss is calculated using binary cross-entropy, which is the binary form of cross-entropy, as shown in Equation (13).
In this case, p is the predicted value, and y is the correct answer value.
The total loss function in this study is composed of the sum of classification, regression, and centrality losses, as formulated in Equation (14):
In this case, p and g are the predicted values of the network (prior) and ground thrust (GT).
4. Experiment Results and Discussion
The experimental environment of the proposed method is discussed in Section 4.1, and the existing method is compared with PASCAL VOC07 [26] and MS COCO2017 [27] in Section 4.2. Finally, in Section 4.3, an ablation study was conducted to verify the utility of the proposed method’s constituent modules.
4.1. Implementation Details
The hyperparameters and data augmentation used in the experiments are listed in Table 1. The backbone network (ResNet-50) was pretrained using the ILSVRC 2012 dataset [28]. Specifically, the optimizer used stochastic gradient descent (SGD), with a momentum and weight decay of 0.9 and 0.0001, respectively. PASCAL VOC and MS COCO datasets’ batch size was 32 and 8. The input resolution of the proposed method for each dataset was and . The initialized learning rate (LR) was set to 0.02. We used a multistep learning rate (multistepLR) as the LR scheduler for each dataset. PASCAL VOC decreased LR by 0.1 per iteration, 2K and 2.1K. In addition, MS COCO reduced LR by 0.1 at every 60K and 90K. The data augmentation for the training to DLMFCOS included color jitter, random rotation, and random resized crop. Table 2 shows the hardware and software environments.

Table 1.
Implementation details.
Table 2.
Hardware and software environment.
As an evaluation matrix, we used average precision (AP) [29], a standard metric for quantitative comparison of object detection. AP calculates the mAP of the recall value from the precision-recall curve (PR curve). In addition, the computational cost is measured using FLOPs and params. Equations (15)–(18) show the precision, recall, AP, and mAP [30].
where , , , r, , N, and denote the true positive (TP), false positive (FP), false negative (FN), recall, the precision value of each recall, the total number of classes, and AP value of the ith class, respectively.
4.2. Comparison with Other Networks
In this paper, public data sets PASCAL VOC (07 + 12) and MS COCO2017 were used for training and evaluation. PASCAL VOC consists of 20 classes. It consists of a total of 8324 training images, 11,227 validated datasets, and 4952 testing images. In this paper, the performance of the proposed and conventional method was compared with the PASCAL VOC dataset, which is often used for object detection performance comparison. For comparison, , which is an input resolution frequently used in the one-stage method of PASCAL VOC, was used. The MS COCO dataset consists of 80 classes, which are composed of more detailed categories compared to PASCAL VOC. It consists of a total of 118,287 training images, 4952 validated images, and 5000 test images. This study was used to compare a conventional network with other methods. The performances for the MS COCO dataset were evaluated with average values between 50% and 95% based on the threshold value of the IoU.
4.2.1. PASCAL VOC07
Table 3 shows the accuracies and numbers of computations of the compared methods on the PASCAL VOC07 test dataset. The proposed method achieves high accuracy with low computation overhead compared to the two-step method. Compared with the standard FCOS detector, our improved model showed a accuracy improvement with fewer computations. There was also a improvement in inference time.
Table 3.
Comparison of PASCAL VOC07 test dataset detection results.
Compared with other one-stage backbone networks (e.g., VGG-16, ResNet, and DarkNet), our ResNet-50 method achieves high accuracy with only a small amount of computation. Moreover, the spatial and channel feature losses are minimized by the DLM, which enables more efficient feature extraction. By strengthening the lateral connections between feature maps with the proposed FPN structure, low-level information was supplemented. Thus, we can confirm that the detection performance and inferencing speed of the proposed method clearly improved, resulting in a good balance between the amount of computation and accuracy.
Figure 9 compares the detection results of the baseline FCOS detector, and the proposed method using the PASCAL VOC07 test dataset, which includes occluded object detection. The proposed method demonstrated better detection results than the baseline FCOS detector because it overcame the low-level information loss, which enabled it to detect occluded objects better, as illustrated in Figure 9.
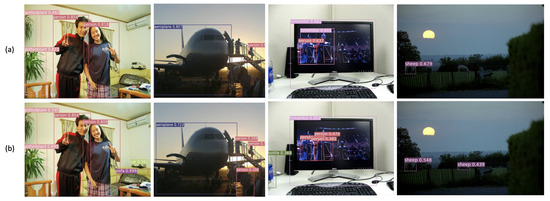
Figure 9.
Detection results with the PASCAL VOC07 testing dataset by (a) the baseline FCOS and (b) the proposed method.
4.2.2. MS COCO2017
MS COCO2017 has 80 detailed categories, which is four times the number of classifications, and small objects (e.g., scissors and toothbrushes). Therefore, when applying the same detection method used with the PASCAL VOC07 dataset, P and R were both low. Table 4 lists the comparison results for the MS COCO2017 validation dataset. In this case, the proposed method used the same input resolution as the baseline FCOS detector. Compared with the existing two-step method, our method shows higher detection accuracy with approximately six times fewer computations. Compared with the one-stage YOLOv3, the proposed method has nearly three times fewer parameters and a higher accuracy. We confirmed that the detection accuracy improved by with 2.5M fewer computations than the baseline FCOS.
Table 4.
Comparison of MS COCO2017 minval dataset detection results.
Figure 10 shows the detection results of the occluded objects in the MS COCO2017 minival dataset. The baseline FCOS detector has difficulty with this, owing to the loss of low-level information, as illustrated in Figure 9a. The proposed method minimizes false detections by improving the FPN and transferring low-level information to deeper layers with high-level information. As shown in Figure 9b, the proposed FPN structure improves occluded object detection.

Figure 10.
Detection results with the MS COCO2017 minival dataset by (a) the baseline FCOS and (b) the proposed method.
4.3. Ablation Study
In this section, we report the results of our ablation study, which compared the improvements provided by each part of the divided lightweight module: the DLM, mobile bottleneck block (MBConv), and standard convolutions. In addition, a moderation study was conducted on the expansion and kernel sizes of the proposed LSM. Moreover, a study on the proposed FPN and the excision of the conventional feature pyramid was conducted. Finally, a cross-class comparison with baseline FCOS and DLMFCOS. PASCAL VOC07 was the test and validation dataset, and the baseline FCOS was compared unless otherwise noted.
4.3.1. Ablation Study of the Proposed Module
Table 5 and Table 6 present the results of a comparative analysis of FCOS methods. It is clear that the proposed module is efficient, with improved accuracy and less computation. First, to verify the utility of the split lightweight module, we compared MBConv with the proposed network and found that the proposed method showed higher accuracy with 1.1M more computations. Compared with the standard convolution method, ours had 2.4M fewer calculations and a high accuracy. Therefore, it is clearly shown that the proposed method is efficient, with improved accuracy and fewer computations.
Table 5.
Ablation study of the proposed module.
Table 6.
Ablation study of the proposed lightweight spatial module (LSM).
Table 6 presents the results of the comparative analysis of kernel size and the LSM expansion ratio. Here, K denotes the kernel size, and D denotes the expansion factor. The lower the expansion ratio, the narrower the accommodation area; the larger the expansion ratio, the wider the accommodation area. According to the ablation study, if the expansion ratio increases beyond a certain level, the object information will be lost because of the empty area inside. The FCOS style of object detection, which is similar to semantic segmentation, leads to damaged adjacent pixels. Hence, the tests show the appropriate kernel size (K) and expansion ratio (D) needed to maximize the LSM detection accuracy. This shows that an inappropriate kernel size with an incorrect number of extensions leads to lower accuracy.
4.3.2. Analysis of the Proposed FPN Structure
Table 7 shows the ablation study results of the proposed model vs. FPN. The proposed FPN produced 2.5M fewer computations and improved the mAP by . The FPN has a bottom-up structure, making it difficult for low-level information to reach deeper layers. A path aggregation network (PAN) has both top-down and bottom-up structures, which improves the low-level information shortage problem as the network depth increases. However, considering PAN’s side connections, the number of computations is much higher than that of the proposed method. Therefore, the proposed method minimizes feature loss better while achieving a good balance between efficiency and accuracy.
Table 7.
Ablation study of the proposed feature pyramid structure.
4.3.3. Analysis of Conventional Network
Table 8 shows the detection accuracy of each class of DLMFCOS and FCOS for the PASCAL VOC 07 test dataset; it is evident that the detection accuracy of DLMFCOS is better than that of FCOS. Through the proposed DLM, the spatial information extraction performance was improved by reconstructing the feature pyramid, and the loss of contextual information was minimized through the proposed feature fusion module to achieve an optimal trade-off between detection accuracy and computational cost. Compared to FCOS, DLFCOS improved the detection accuracy for difficult-to-detect objects, such as boat, potted plant, and train. This confirmed that there was spatial information loss owing to the dilated depth-wise convolution, which required a wide receptive area and low computational cost.
Table 8.
The ablation study for DLMFCOS analysis on the PASCAL VOC 2007 test dataset.
5. Conclusions
In this study, we proposed a DLMFCOS object detection network that achieves an optimal balance between accuracy and network size for deep-learning object detection. Conventional methods can provide accuracy (two-stage) or speed (one-stage), but normally not both. We propose to overcome this disparity by improving the one-stage FCOS model so that it minimizes the ordinarily high feature loss caused by channel reduction by processing spatial and channel information in parallel with a novel FPN that contains both bottom-up and top-down structures. The DLM comprises an LSM that efficiently extracts spatial information using a dilated depth-wise convolution and a CA, resulting in improved weights for each channel for the GAP. The detection head was expanded, and features were extracted through convolution, maintaining better accuracy than the conventional detection head. Moreover, compared to baseline FCOS, the computational cost was greatly reduced. We compared our models’ mAP with contemporary models using the PASCAL VOC07 and MS COCO2017 open datasets, and the results show that our DLM FCOS object detection network improved the average accuracy by at least , with approximately fewer computations. This method finally achieves a good balance between accuracy and efficiency. We expect that our results will contribute to improved object detection networks. In a future study, it will be necessary to experiment with applying the DLM to other object detection networks. In addition, based on a lightweight backbone network, experiments are planned on devices with limited computational performance, such as embedded devices.
Author Contributions
Conceptualization, B.H. and S.L.; data curation, B.H.; formal analysis, B.H. and S.L.; investigation, B.H.; methodology, B.H. and S.L.; project administration, H.H.; software, B.H. and S.L.; supervision, S.L. and H.H.; validation, B.H. and S.L.; visualization, B.H.; writing—original draft preparation, B.H.; writing—review and editing, S.L. and H.H. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The data presented in this study are openly available online: http://host.robots.ox.ac.uk/pascal/VOC/voc2007/index.html, http://host.robots.ox.ac.uk/pascal/VOC/voc2012/index.html (accessed on 4 December 2022) [26], and https://cocodataset.org/#home (accessed on 4 December 2022) [27].
Acknowledgments
The present Research has been conducted by the Research Grant of Kwangwoon University in 2022.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Shin, S.; Lee, S.; Han, H. EAR-Net: Efficient Atrous Residual Network for Semantic Segmentation of Street Scenes Based on Deep Learning. Appl. Sci. 2021, 11, 9119. [Google Scholar] [CrossRef]
- Park, C.; Lee, S.; Han, H. Efficient Shot Detector: Lightweight Network Based on Deep Learning Using Feature Pyramid. Appl. Sci. 2021, 11, 8692. [Google Scholar] [CrossRef]
- Hwang, B.; Lee, S.; Han, H. LNFCOS: Efficient Object Detection through Deep Learning Based on LNblock. Electronics 2022, 11, 2783. [Google Scholar] [CrossRef]
- Lim, B.; Son, S.; Kim, H.; Nah, S.; Mu Lee, K. Enhanced deep residual networks for single image super-resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Honolulu, HI, USA, 21–26 July 2017; pp. 136–144. [Google Scholar]
- Wang, H.; Chen, Y.; Cai, Y.; Chen, L.; Li, Y.; Sotelo, M.A.; Li, Z. SFNet-N: An Improved SFNet Algorithm for Semantic Segmentation of Low-Light Autonomous Driving Road Scenes. IEEE Trans. Intell. Transp. Syst. 2022, 23, 21405–21417. [Google Scholar] [CrossRef]
- Yu, Y.; Samali, B.; Rashidi, M.; Mohammadi, M.; Nguyen, T.N.; Zhang, G. Vision-based concrete crack detection using a hybrid framework considering noise effect. J. Build. Eng. 2022, 61, 105246. [Google Scholar] [CrossRef]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask R-CNN. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar] [CrossRef]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; Springer: Berlin/Heidelberg, Germany, 2016; pp. 21–37. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar] [CrossRef]
- Redmon, J.; Farhadi, A. YOLO9000: Better, Faster, Stronger. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 6517–6525. [Google Scholar] [CrossRef]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature Pyramid Networks for Object Detection. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 936–944. [Google Scholar] [CrossRef]
- Tian, Z.; Shen, C.; Chen, H.; He, T. FCOS: Fully Convolutional One-Stage Object Detection. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 9626–9635. [Google Scholar] [CrossRef]
- Pan, J.; Sun, H.; Song, Z.; Han, J. Dual-Resolution Dual-Path Convolutional Neural Networks for Fast Object Detection. Sensors 2019, 19, 3111. [Google Scholar] [CrossRef] [PubMed]
- Shi, H.; Zhou, Q.; Ni, Y.; Wu, X.; Latecki, L.J. DPNET: Dual-Path Network for Efficient Object Detectioj with Lightweight Self-Attention. arXiv 2021, arXiv:2111.00500. [Google Scholar]
- Zhou, Q.; Shi, H.; Xiang, W.; Kang, B.; Wu, X.; Latecki, L.J. DPNet: Dual-Path Network for Real-time Object Detection with Lightweight Attention. arXiv 2022, arXiv:2209.13933. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; IEEE Computer Society: Los Alamitos, CA, USA, 2016; pp. 770–778. [Google Scholar] [CrossRef]
- Chollet, F. Xception: Deep Learning with Depthwise Separable Convolutions. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 1800–1807. [Google Scholar] [CrossRef]
- Yu, F.; Koltun, V. Multi-scale context aggregation by dilated convolutions. arXiv 2015, arXiv:1511.07122. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal Loss for Dense Object Detection. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2999–3007. [Google Scholar] [CrossRef]
- Rezatofighi, H.; Tsoi, N.; Gwak, J.; Sadeghian, A.; Reid, I.; Savarese, S. Generalized Intersection Over Union: A Metric and a Loss for Bounding Box Regression. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 658–666. [Google Scholar] [CrossRef]
- Everingham, M.; Van Gool, L.; Williams, C.K.; Winn, J.; Zisserman, A. The Pascal Visual Object Classes (VOC) Challenge; Springer: Berlin/Heidelberg, Germany, 2010; Volume 88, pp. 303–338. [Google Scholar] [CrossRef]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; Springer: Berlin/Heidelberg, Germany, 2014; pp. 740–755. [Google Scholar] [CrossRef]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. Imagenet large scale visual recognition challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef]
- Henderson, P.; Ferrari, V. End-to-end training of object class detectors for mean average precision. In Proceedings of the Asian Conference on Computer Vision, Taipei, Taiwan, 20–24 November 2016; Springer: Berlin/Heidelberg, Germany, 2016; pp. 198–213. [Google Scholar] [CrossRef]
- Chicco, D.; Jurman, G. The advantages of the Matthews correlation coefficient (MCC) over F1 score and accuracy in binary classification evaluation. BMC Genom. 2020, 21, 6. [Google Scholar] [CrossRef] [PubMed]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Shrivastava, A.; Gupta, A.; Girshick, R. Training Region-Based Object Detectors with Online Hard Example Mining. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 761–769. [Google Scholar] [CrossRef]
- Kong, T.; Yao, A.; Chen, Y.; Sun, F. Hypernet: Towards accurate region proposal generation and joint object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 845–853. [Google Scholar]
- Bell, S.; Zitnick, C.L.; Bala, K.; Girshick, R. Inside-outside net: Detecting objects in context with skip pooling and recurrent neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2874–2883. [Google Scholar]
- Dai, J.; Li, Y.; He, K.; Sun, J. R-fcn: Object detection via region-based fully convolutional networks. Adv. Neural Inf. Process. Syst. 2016, 29. [Google Scholar]
- Zhu, Y.; Zhao, C.; Wang, J.; Zhao, X.; Wu, Y.; Lu, H. CoupleNet: Coupling Global Structure with Local Parts for Object Detection. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 4146–4154. [Google Scholar] [CrossRef]
- Fu, C.Y.; Liu, W.; Ranga, A.; Tyagi, A.; Berg, A.C. Dssd: Deconvolutional single shot detector. arXiv 2017, arXiv:1701.06659. [Google Scholar]
- Wang, J.; Sun, K.; Cheng, T.; Jiang, B.; Deng, C.; Zhao, Y.; Liu, D.; Mu, Y.; Tan, M.; Wang, X.; et al. Deep High-Resolution Representation Learning for Visual Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 43, 3349–3364. [Google Scholar] [CrossRef] [PubMed]
- Pang, J.; Chen, K.; Shi, J.; Feng, H.; Ouyang, W.; Lin, D. Libra r-cnn: Towards balanced learning for object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 821–830. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Zhu, C.; He, Y.; Savvides, M. Feature Selective Anchor-Free Module for Single-Shot Object Detection. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 840–849. [Google Scholar] [CrossRef]
- Kong, T.; Sun, F.; Liu, H.; Jiang, Y.; Li, L.; Shi, J. FoveaBox: Beyound Anchor-Based Object Detection. IEEE Trans. Image Process. 2020, 29, 7389–7398. [Google Scholar] [CrossRef]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.C. Mobilenetv2: Inverted residuals and linear bottlenecks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4510–4520. [Google Scholar]
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path aggregation network for instance segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8759–8768. [Google Scholar]










Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).