Abstract
This paper is primarily focused on the robust control of an inverted pendulum system based on policy iteration in reinforcement learning. First, a mathematical model of the single inverted pendulum system is established through a force analysis of the pendulum and trolley. Second, based on the theory of robust optimal control, the robust control of the uncertain linear inverted pendulum system is transformed into an optimal control problem with an appropriate performance index. Moreover, for the uncertain linear and nonlinear systems, two reinforcement-learning control algorithms are proposed using the policy iteration method. Finally, two numerical examples are provided to validate the reinforcement learning algorithms for the robust control of the inverted pendulum systems.
1. Introduction
In the last decade, there has been increased interest in the robust control of the inverted pendulum system (IPS) owing to its high potential in testing a variety of advanced control algorithms. Robust control is widely used in power electronics, flight control, motion control, network control, and IPSs, in addition to other fields [1,2]. Research on the robust control of an IPS has provided advantageous results in recent years. An inverted pendulum is an experimental device that has insufficient drive, absolute instability, and uncertainty. It has become an excellent benchmark in the field of automatic control over the last few decades as it provides better explanations for model-based nonlinear control techniques and is a typical experimental platform for verifying classical and modern control theories.
Although the earliest research on IPSs can be traced back to 1908 [3], there is almost no literature on this subject between 1908 and 1960. In 1960, a number of tall, slender structures survived the Chilean earthquake, while structures that appeared more stable were severely damaged. Therefore, some scholars conducted more in-depth research to obtain a suitable explanation [4]. A pendulum structure under the effect of an earthquake was modeled as a base and rigid block system, and block overturning was studied by applying a horizontal acceleration, sinusoidal pulses, and seismic-type excitations to the system. It was observed that there is an unexpected scaling effect that makes the large block more stable than the small block among two geometrically similar blocks. Furthermore, tall blocks exhibit greater stability during earthquakes when exposed to horizontal forces. Since then, with the development of modern control theory, various control methods have been applied to different types of IPSs, such as proportional–integral–derivative control, cloud model control, fuzzy control, sliding mode control, and neural network control methods [5,6,7]. These methods provide different ideas for the control of IPSs.
As is known, the IPS is an uncertain system, and the uncertainty of its model is naturally within the scope of consideration. The aim of the robust control of an IPS is to find a controller capable of addressing system uncertainties. When the system is disturbed by uncertainty, robust control laws can stabilize the system. Because it is difficult to directly solve the robust control problem, some scholars transformed the robust control problem into an optimal control problem. In [8], the authors proposed a robust optimal control method for linear systems with matching uncertainty. However, the situation where the uncertainty does not meet matching conditions has not been considered. Lin et al. [9,10] conducted research on the robust optimal control of uncertain systems by adjusting the value of the weighting matrix and solving an algebraic Riccati equation (ARE) to obtain robust control laws. Zhang et al. [11] presented a unified framework for studying robust optimal control problems with adjustable uncertainty sets. Wang et al. [12] developed a novel adaptive critical learning approach for robust optimal control of a class of uncertain affine nonlinear systems with matching uncertainties. And the data-based adaptive critical designs were developed to solve the Hamilton–Jacobi–Bellman (HJB) equation corresponding to the transformed optimal control problem.
In fact, the pioneering methods for solving optimal control problems mainly include dynamic programming [13] and maximum principles [14]. With the dynamic programming method, solving the HJB equation yields optimal control of the system. As for the optimal control problem of a linear system with a quadratic performance index, irrespective of whether it is a continuous system or a discrete system, it finally comes down to solving an ARE. However, when the dimension of the state vector or control input vector in the dynamic system is large, the so-called “curse of dimensionality” appears when the dynamic programming method is used to solve the optimal control problem [15]. To overcome this weakness, some scholars have used the reinforcement learning (RL) policy to solve the optimal control problem [16,17].
When RL was initially used for system control, it was primarily focused on discrete-time systems or discretized continuous-time systems in research on problems such as the billiard game problem [18], scheduling problem [19], and robot navigation problem [20]. Furthermore, the application of RL algorithms to continuous-time and continuous-state systems was initially extended by Doya et al. [21]. They used the known system model to learn the optimal control policy. In the context of control engineering, RL and adaptive dynamic programming link traditional optimal control methods to adaptive control methods [22,23,24]. Vrabie et al. [25] used the RL algorithm to solve the optimal control problem of the continuous time system. In the case of the linear system, system data are collected, and the solution of the HJB equation is obtained via online policy iteration (PI) using the least squares method. Xu et al. [26,27] proposed an RL algorithm based on linear continuous-time systems to solve the robust control and robust tracking problems through online PI. The algorithm takes into consideration the uncertainty in the system’s state and input matrices and improves the method for solving robust control.
The IPS demonstrates a positive impact in the validation of RL algorithms. There are some literatures on RL to solve the control problem of inverted pendulum systems. Bates [28] harnessed GPUs to quickly train a simulation of an inverted pendulum to balance itself. Israilov et al. [29] used two model-free RL algorithms to control targets and proposed a general framework to reproduce successful experiments and simulations based on the inverted pendulum. In addition, there are still many studies of this kind, for example [30,31,32]. However, the results of these studies focused more on reducing the time to reach equilibrium, without fully considering uncertainty in the system. We attempt to solve the robust control problem of an uncertain IPS using RL algorithms. Only the input and output data need to be collected when using the RL control algorithm and the state matrix of the nominal system need not be known. This study lays out a theoretical foundation for the wide application of the RL control algorithm in engineering systems. The main contributions of this study are as follows.
(1) The state-space model of the IPS with uncertainty is established and a robust optimal control method is applied to the IPS model. By constructing an appropriate performance index, the optimal control method is used to design a robust control law for an uncertain IPS.
(2) A PI algorithm in the RL has been designed to realize the robust optimal control of an IPS. The use of the RL algorithm to solve the robust control problem of IPS does not require knowing the state matrix, only collecting input and output data. The application of the RL for solving the control problem of an IPS has significance for its potential application in practical engineering.
The organization of this paper is as follows. In Section 2, the state-space equation of the IPS and a linearization model are established. The robust control and RL algorithm for linearizing the IPS are presented in Section 3 and Section 4. In Section 5, we establish the nonlinear state-space model of the IPS and propose the corresponding RL algorithm. The RL algorithm is then verified via a simulation in Section 6. Finally, we summarize the work of this paper and potential future research directions.
2. Model Formulation
In this section, we established a physical model of a first-order linear IPS according to Newton’s second law. By selecting appropriate state variables, the state-space model with uncertainty is derived.
2.1. Modeling of Inverted Pendulum System
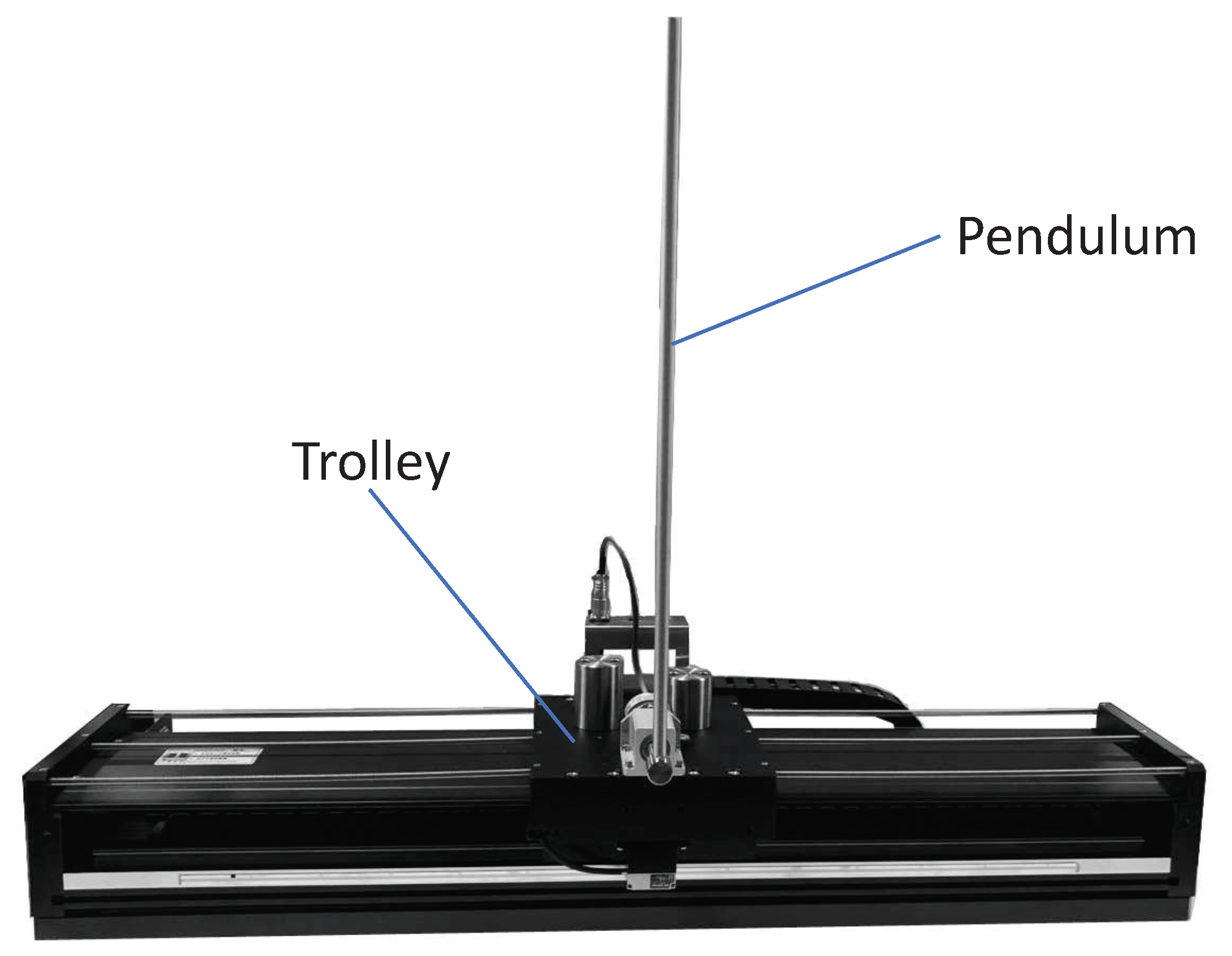
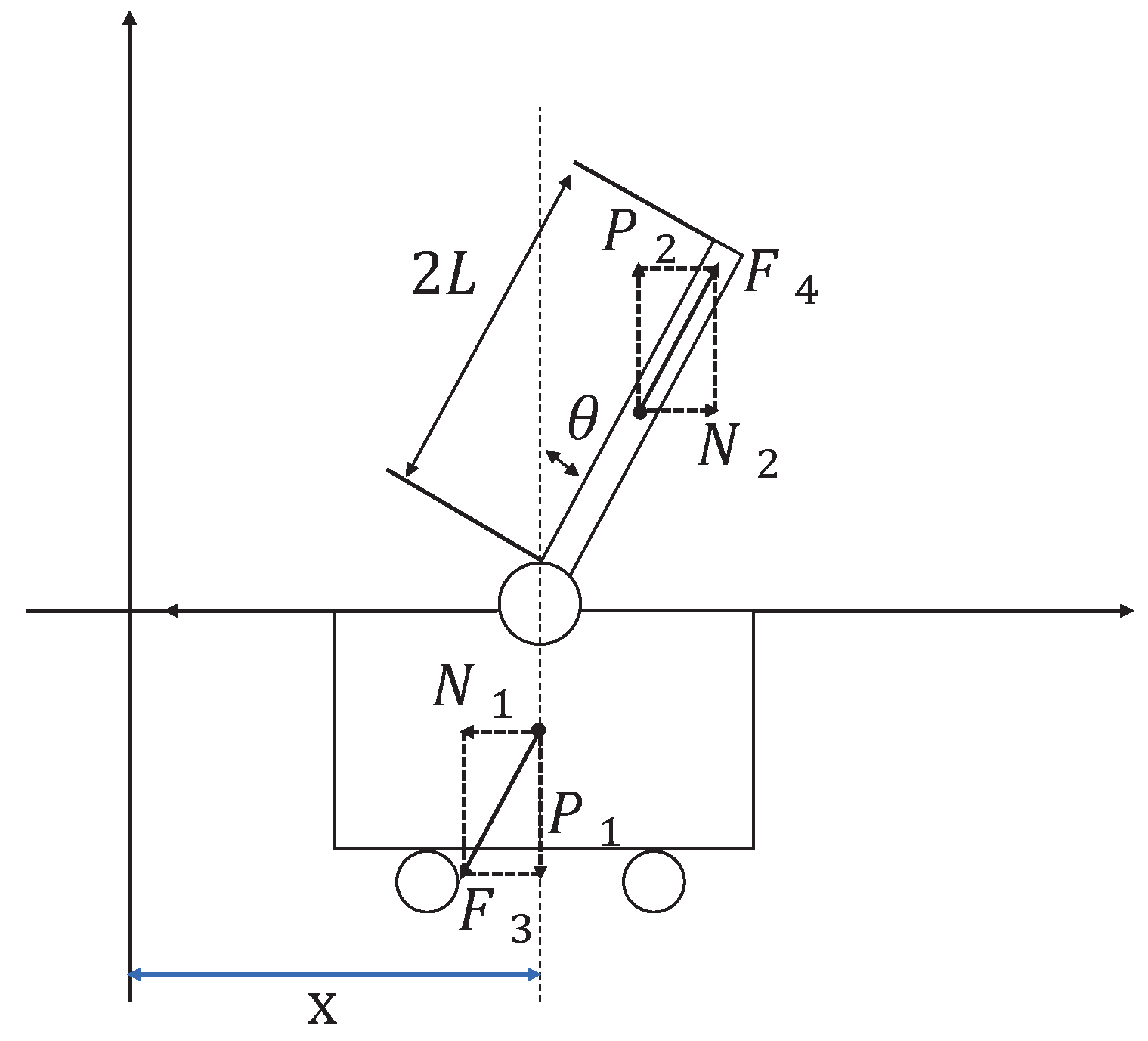
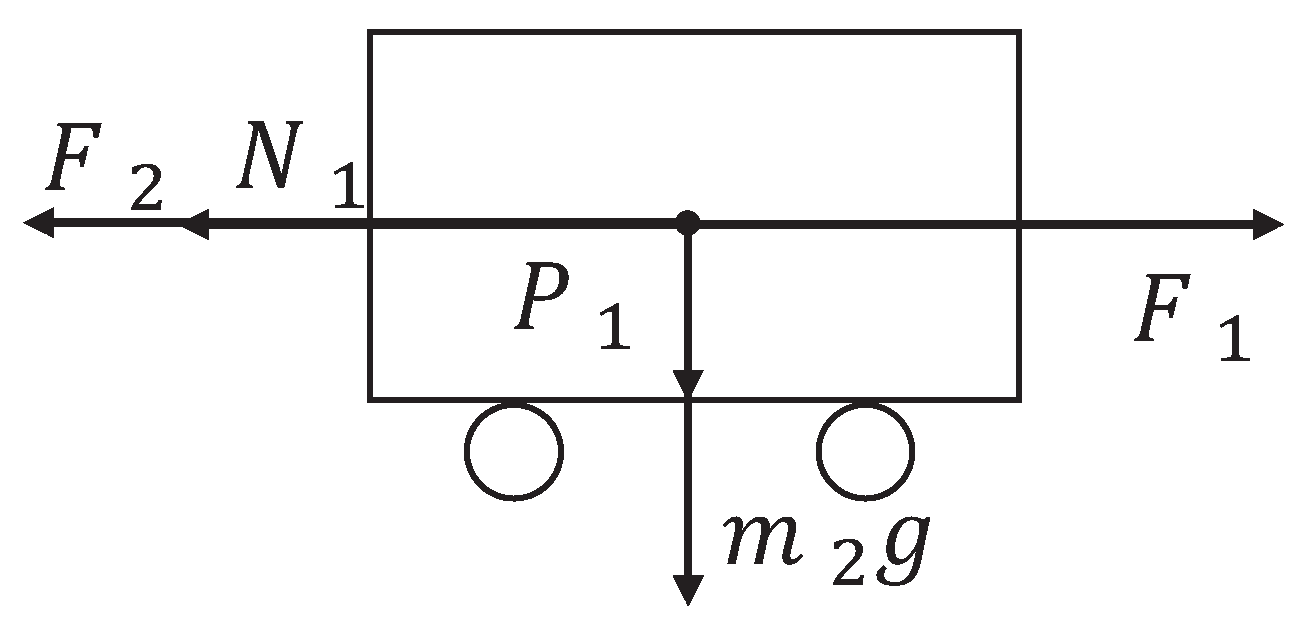
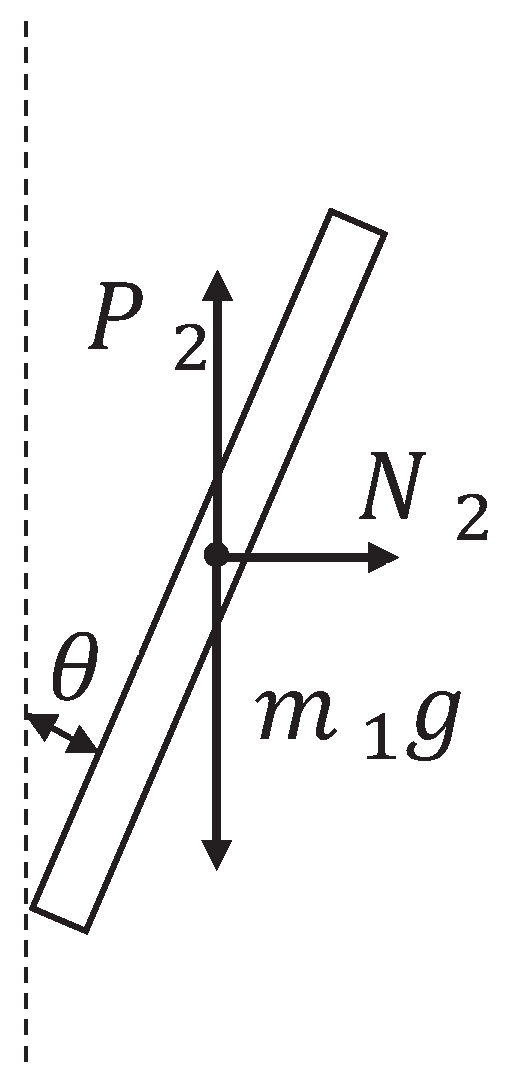
The inverted pendulum experimental device comprises a pendulum and a trolley [33]. Its structure is presented in Figure 1. The encoder is a photoelectric rotary one, and the motor is a direct-current servo motor. For a detailed information on the experimental platform, see [34]. Moreover, its simplified physical model is presented in Figure 2, which mainly includes the pendulum and trolley. In Figure 2, owing to the interaction between the trolley and pendulum, the trolley is subjected to a force from the pendulum, which acts in the lower left direction. Furthermore, the pendulum is subjected to a force from the trolley, which acts in the upper right direction. In addition, the pendulum and trolley are also subjected to other forces, as shown in Figure 3 and Figure 4, respectively. The trolley is driven by a motor to perform horizontal movements on the guide rail. In Figure 3, the trolley is subjected to the force from the motor and gravity. represents the resistance between the trolley and guide rail. Furthermore, and are the two components of force . In Figure 4, the pendulum is subjected to gravity , and and are the two components of force .
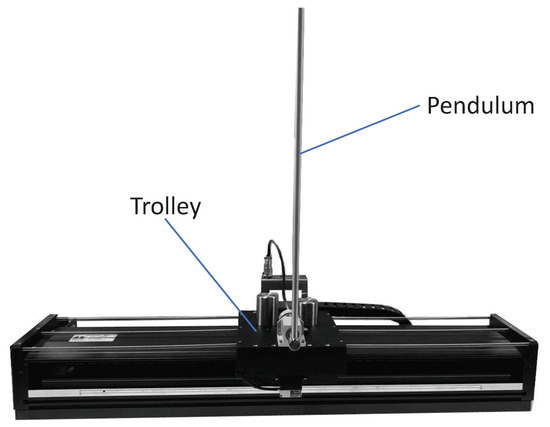
Figure 1.
Inverted pendulum system diagram.
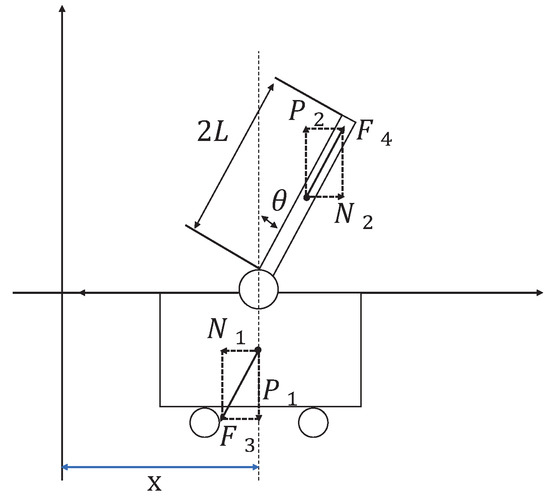
Figure 2.
First-order inverted pendulum physical model.
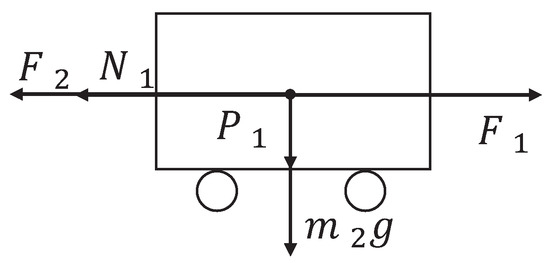
Figure 3.
Force analysis of the trolley.
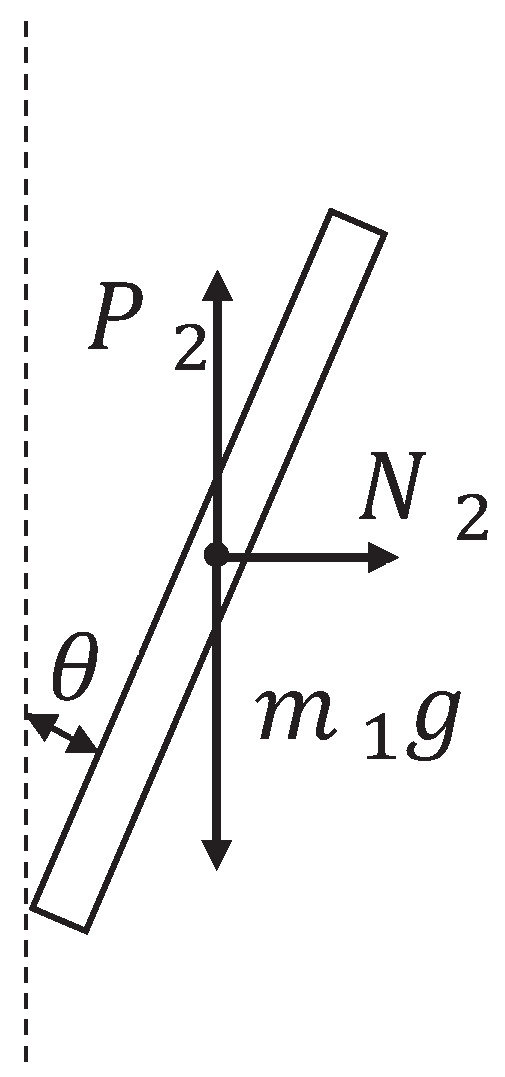
Figure 4.
Force analysis of the pendulum.
To facilitate subsequent calculations, we define the parameter of the first-order IPS, as shown in Table 1. The time parameter symbol is omitted, which indicates that x represents . In Figure 3, according to Newton’s second Law, the trolley satisfies the following equation in the horizontal direction:

Table 1.
IPS parameter symbols.
We assume that the resistance is proportional to the speed of the trolley. Therefore, , z is the proportional coefficient. Moreover, in Figure 4, the pendulum satisfies the following equation in the horizontal direction:
Considering that in Figure 2, and on substituting (2) into (1), we obtain
Next, in Figure 4, we analyze the resultant force in the vertical direction of the pendulum, and the following equation can be obtained.
The component force of in the direction perpendicular to the pendulum is
Based on the torque balance, we can obtain the following equation
where I is the moment of inertia of the pendulum. On substituting Equations (4) and (5) into Equation (6),
Thus far, Equations (3) and (7) constitute the dynamic model of the IPS. Moreover, it can be assumed that the rotation angle of the pendulum is very small, that is, . Therefore, it can be approximated that
Therefore, it follows from Equations (3) and (7),
2.2. State-Space Model with Uncertainty
In Section 2.1, we established the dynamic model of the IPS as shown in Equation (8). Next, we will derive the state-space model of the IPS.
As the rotation angle of the pendulum is very small, it can be approximated that , . It follows from (8) that
Equation (9) is the linearized dynamic model of the system. The first equation comes from (1)–(3), which is the equilibrium force equation of the system in the horizontal direction. The second equation comes from (4)–(7), which is the equilibrium force equation of the system in the vertical direction. The state variables of the system can be defined as
Therefore, the following state-space equation can be derived.
where u represents the force from the motor. Using , Equation (10) can be written as
where
However, the accurate model of the IPS is difficult to obtain, and all its parameters have uncertainties. In this paper, the friction coefficient z between the trolley and guide rail is selected as an uncertain parameter. The numerical values of the other parameters in Table 1 are known, where and . Therefore, the state-space model of the uncertain IPS can be abbreviated as
where
Here we choose as the nominal value and denote the nominal matrix of the system as . Therefore, the nominal system corresponding to the uncertain system (11) is
where
3. Robust Control of Uncertain Linear System
This section mainly presents the robust optimal control methods for the uncertain IPS modeled in the previous section by selecting the appropriate performance index function and solving an ARE to construct the robust control law. When the uncertain parameters of the system change within a certain range, this robust control law can cause the system to become asymptotically stable.
The following lemmas are proposed to prove the main results of this paper.
Lemma 1.
The nominal system (12) corresponding to system (11) is stabilizeable.
Proof.
For the four-dimensional continuous time-invariant system presented in system (12), the controllability matrix is constructed as
Therefore, we have
Therefore, system (12) is completely controllable, which means that the system can be stabilized. This completes the proof. □
Lemma 2.
There is an matrix , such that the system matrices and satisfy the following matched condition.
Proof.
where
This completes the proof. □
Lemma 3.
For any , there exists a positive semidefinite matrix F, such that satisfies
where .
Proof.
According to Lemma 2, we can obtain
This completes the proof. □
For nominal system (12), we construct the following ARE.
where . According to the above three lemmas and ARE (18), we propose the following theorem.
Theorem 1.
Let us suppose that S is a symmetric positive definite solution to ARE (18). Then, for all uncertainties , the feedback control , can make system (11) asymptotically stable.
Proof.
We define the following Lyapunov function.
We set and take the time derivative of Lyapunov Function (19) along system (11). We can then obtain
According to Lemma 2, we can obtain
On substituting ARE (18) into the above equation, we obtain
because ,
As
we can obtain
Therefore,
According to the Lyapunov stability theorem [35], the uncertain system (11) is asymptotically stable. Theorem 1 has thus been proved. □
4. RL Algorithm for Robust Optimal Control
In this section, we propose an RL algorithm for solving the robust control problem of an IPS through online PI. According to ARE (18), the following optimal control problem is constructed. For the nominal system,
we find a control u, such that the following performance index reaches a minimum.
where . For any initial time t, the optimal cost can be written as
From Lyapunov Function (19), we obtain
where S is the solution to ARE (18). We propose the following RL algorithm for solving a robust controller.
In Algorithm 1, by providing an initial stabilizing control law, repeated iterations are performed between steps 3 and 4 until convergence. We can then obtain the robust control gain K of system (11).
| Algorithm 1 RL Algorithm for Uncertain Linear IPS |
|
Remark 1.
Step 3 in Algorithm 1 is the policy evaluation, and step 4 is the policy improvement. Equivalently, the solving of the equation in step 3 is actually solving a least squares problem. In the integral interval, if sufficient data are obtained in the system, the least square method can be used to solve .
Next, we prove the convergence of Algorithm 1. However, it is necessary to prove the following Lemma first.
Lemma 4.
On assuming that the matrix is stable, solving the matrix from step 3 of Algorithm 1 becomes equivalent to solving the following equation.
Proof.
We rewrite the equation of step 3 in Algorithm 1 as follows
According to the definition of the derivative, it can be observed that the first term of Equation (23) is the derivative of with respect to time t. We thus obtain
Further re-arranging Equation (24) yields
which means that (22) is established. Next, we reverse the process.
Along the stable system , the time derivative of the Lyapunov function is calculated. We can then obtain
On integrating both sides of the Equation (26) in the interval , we obtain
This completes the proof.
According to the existing conclusions [36], iterative relations (22) and step 3 of Algorithm 1 converge to form the solution of ARE (18). □
Remark 2.
The behavior of the control is evaluated using a cost function, which is similar to the reward in RL. The agent corresponds to the controller in optimal control, and the control process corresponds to the environmental model in RL. In control engineering, maximizing rewards is equivalent to minimizing the cost function, so the ultimate goal of the controller is to develop an optimal control policy by learning.
5. Robust Control of Nonlinear IPS
In this section, a nonlinear state-space model of the IPS is established. Moreover, we construct a suitable auxiliary system and corresponding performance index. The problem of the robust control of the IPS is then transformed into the optimal control problem of the auxiliary system. We finally propose the corresponding RL algorithm.
5.1. Nonlinear State-Space Representation of IPS
Based on the uncertain linear inverted pendulum model (11) established in Section 2.1, we consider the following uncertain nonlinear system.
where represents the nonlinear perturbation of the system and can be used to represent various nonlinearity factors in the system. Based on the modeling process in Section 2 and [8], it is assumed that
where the parameters I, , L, and W are the same as those in (10). On rewriting system (27), we obtain
where
On substituting the parameter values into system (28), we can obtain
5.2. Robust Control of Nonlinear IPS
To obtain the robust control law for an uncertain nonlinear IPS, we propose the following two lemmas.
Lemma 5.
There exists an uncertain function such that can be decomposed into the following form.
Proof.
where . This completes the proof. □
Lemma 6.
There exists an upper bound function such that satisfies
Proof.
This completes the proof. □
We construct the optimal control problems for a nominal system.
We determine a controller u, which minimizes the following performance index
Based on the performance index Function (31), the cost function to the admissible control policy is
We define as the gradient of with respect to x. Finding differentiation on both sides of (32) with respect to t yields the following Bellman equation.
Then, we define the following Hamiltonian function.
On assuming that the minimum exists and is unique, the optimal control function for the given problem is then obtained as
On substituting Equation (35) into Equation (33), the HJB equation that satisfies the optimal function can be obtained as
with the initial condition .
On solving the optimal function from Equation (36), the solution of the optimal control problem can be obtained. The solution of the robust control problem can then be obtained. The following theorem shows that the optimal control is a robust controller for a nonlinear IPS.
Theorem 2.
On considering the nominal system (30) with the performance index (31) and assuming that solution of the HJB Equation (36) exists, the optimal control law (35) can then globally stabilize the IPS (28).
Proof.
We select as the Lyapunov function. On considering the performance index function (31), is in evidence, and . Solving the derivative of with respect to t along system (28) yields
According to Lemma 5, it follows that
According to HJB Equation (36), we can obtain
On substituting Equation (38) into Equation (37), we obtain
From Equation (39), we can obtain
where . According to the Lyapunov stability criterion, the optimal controller (35) can asymptotically stabilize the uncertain nonlinear IPS (28) for all the allowable uncertainties. Therefore, for a constant , there exists a neighborhood near the origin, so that, if , then when . However, cannot remain outside the domain forever, or else for all , which implies that
Let , then
This completes the proof. □
5.3. RL Algorithm for Nonlinear IPS
For a nonlinear IPS, we consider the optimal control problems (30) and (31). For any admissible control, the cost function corresponding to the optimal control problem can be expressed as
where is an arbitrarily selected constant. We can then obtain the integral reinforcement relation satisfied by the cost function
According to the integral-based reinforcement relations (41) and the optimal controller (35), the RL algorithm for the robust control of the nonlinear IPS is as follows.
In Algorithm 2, by providing an initial stabilizing control law, the algorithm iterates repeatedly between steps 3 and 4 until convergence. We can then obtain the robust control gain u of system (28).
| Algorithm 2 RL Algorithm of Uncertain Nonlinear IPS |
|
Next, we prove the convergence of Algorithm 2. The following conclusion provides an equivalent form of the integral strengthening relation in step 3.
Lemma 7.
On assuming that is the stabilization control function of the nominal system (30), solving the cost function from the equation in step 3 in Algorithm 2 can be equivalent to solving Equation (42).
Proof.
On dividing both sides of the equation in step 3 by and taking the limit, we obtain
Based on the definition of the function limit and L’ Hopital’s rule, we obtain
Therefore,
However, along the stable system , finding the derivative of with respect to t yields
On integrating both sides of the above equation from t to , we obtain
Then, from (42), we obtain
The above equation is consistent with the third step of Algorithm 2. This completes the proof. □
According to the conclusions of [25,37], if the initial control policy can stabilize the system, the control policy taken using the optimal control Function (35) and Equation (42) also can stabilize the system. Furthermore, the iteratively calculated cost function sequence converges to the optimal cost function. From Lemma 7, we know that Equation (42) and the equation of step 3 are equivalent. Therefore, the iterative relationship between steps 3 and 4 in Algorithm 2 converges on the optimal control and optimal cost functions.
6. Numerical Simulation Results
This section includes two simulation examples to illustrate the practical applicability of the theoretical results in the robust control of the uncertain IPS.
6.1. Example 1
Considering system (11), whose state-space model can be referenced in [34], our objective is to obtain a robust control u such that it is stable. Based on Lemmas 1–3, the weighting matrix M is selected as
We present the initial stability control law
The initial state of the nominal system is selected as . The time-step size for the collecting system status and input information is set as 0.01 s. Algorithm 1 converges after six iterations, and the matrix and control gain converge to the following optimal solutions:
and
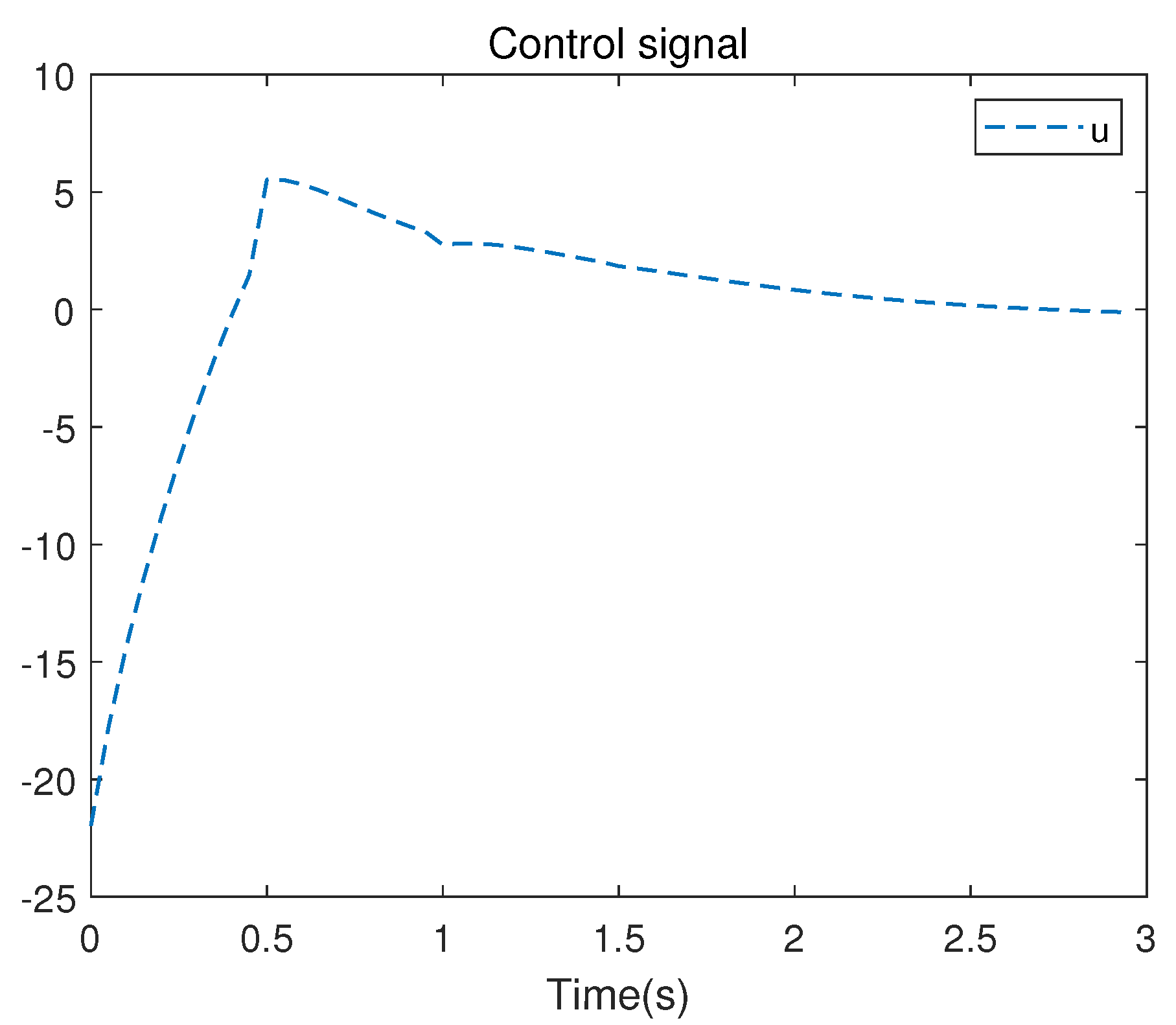
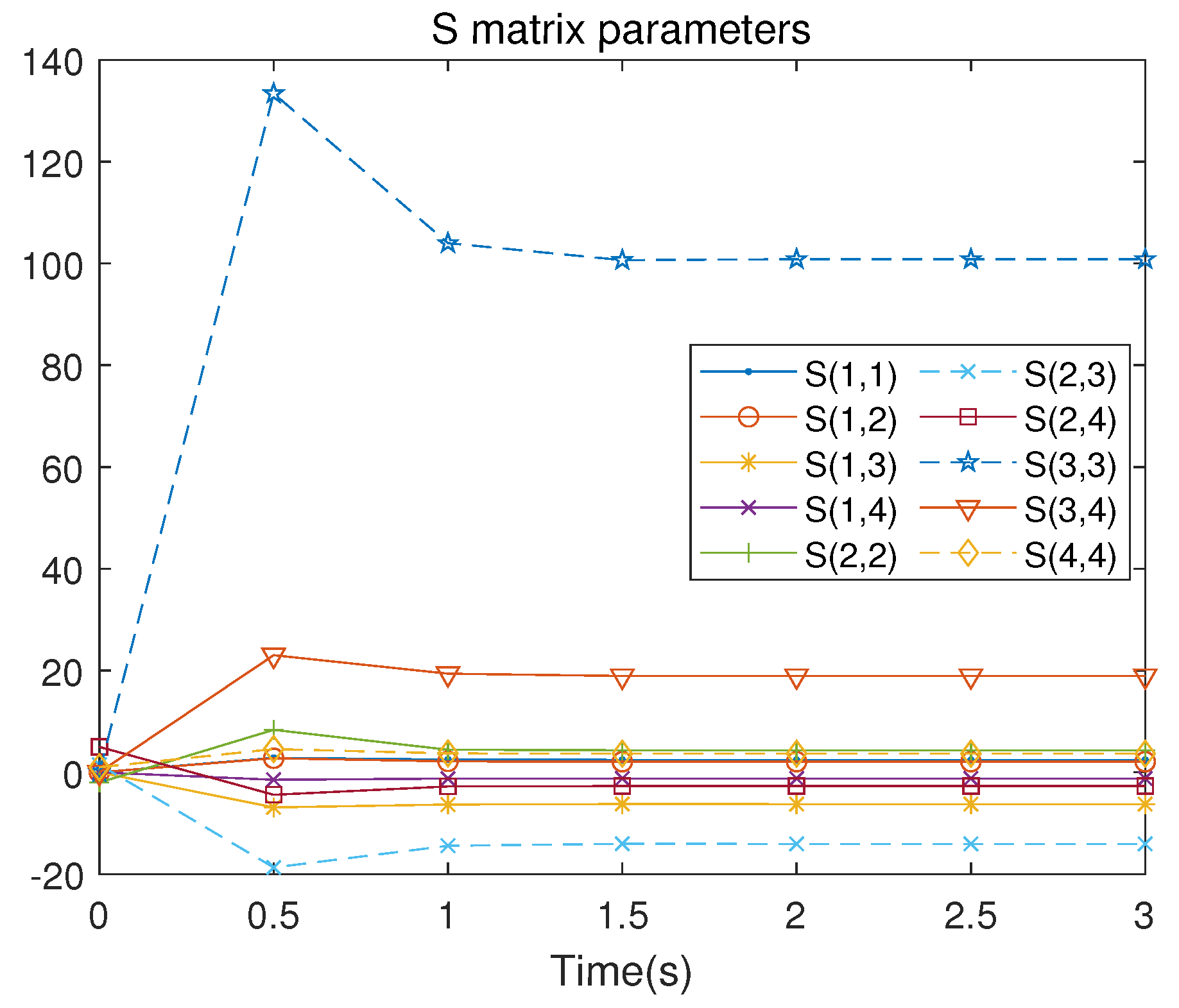
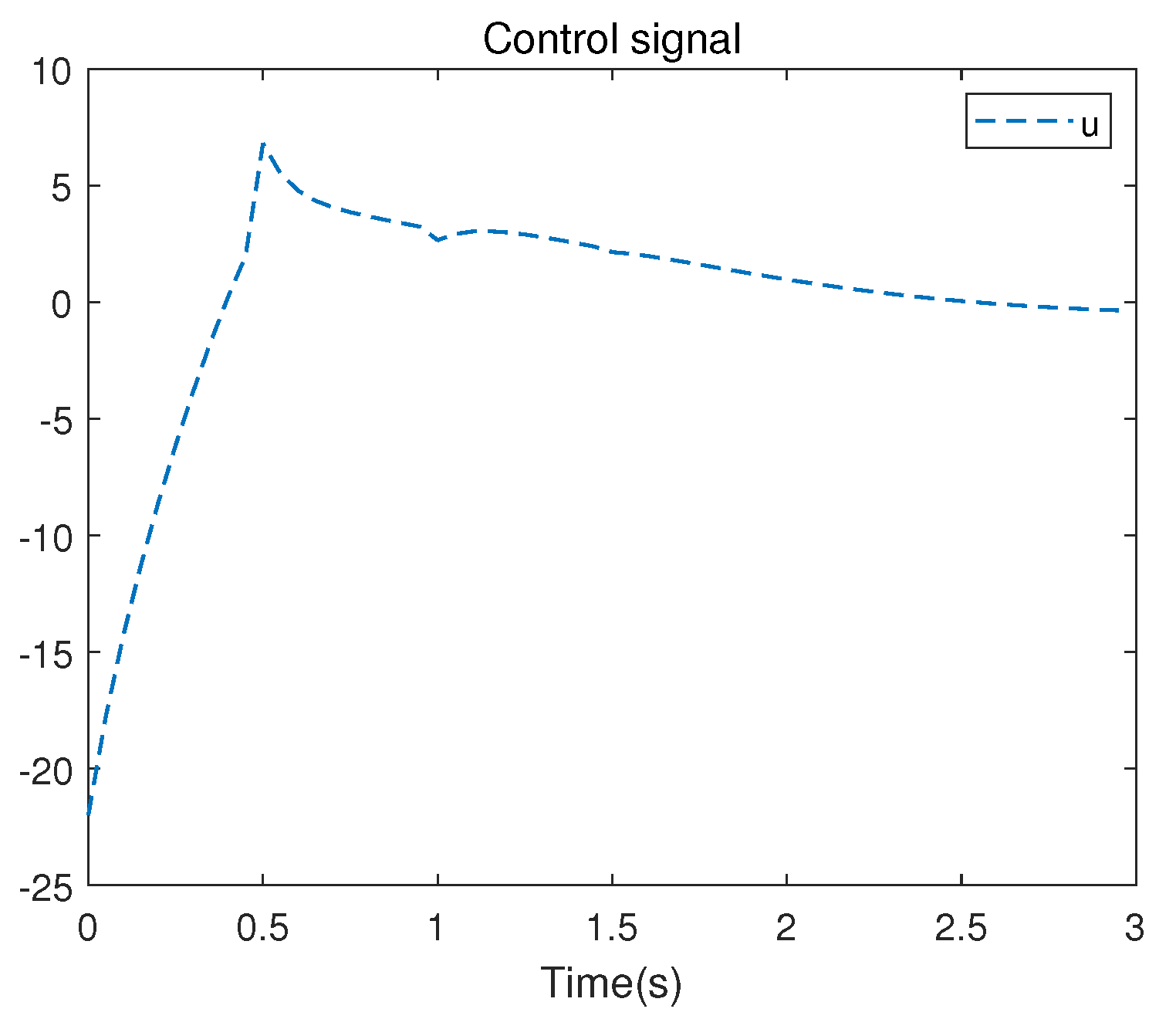
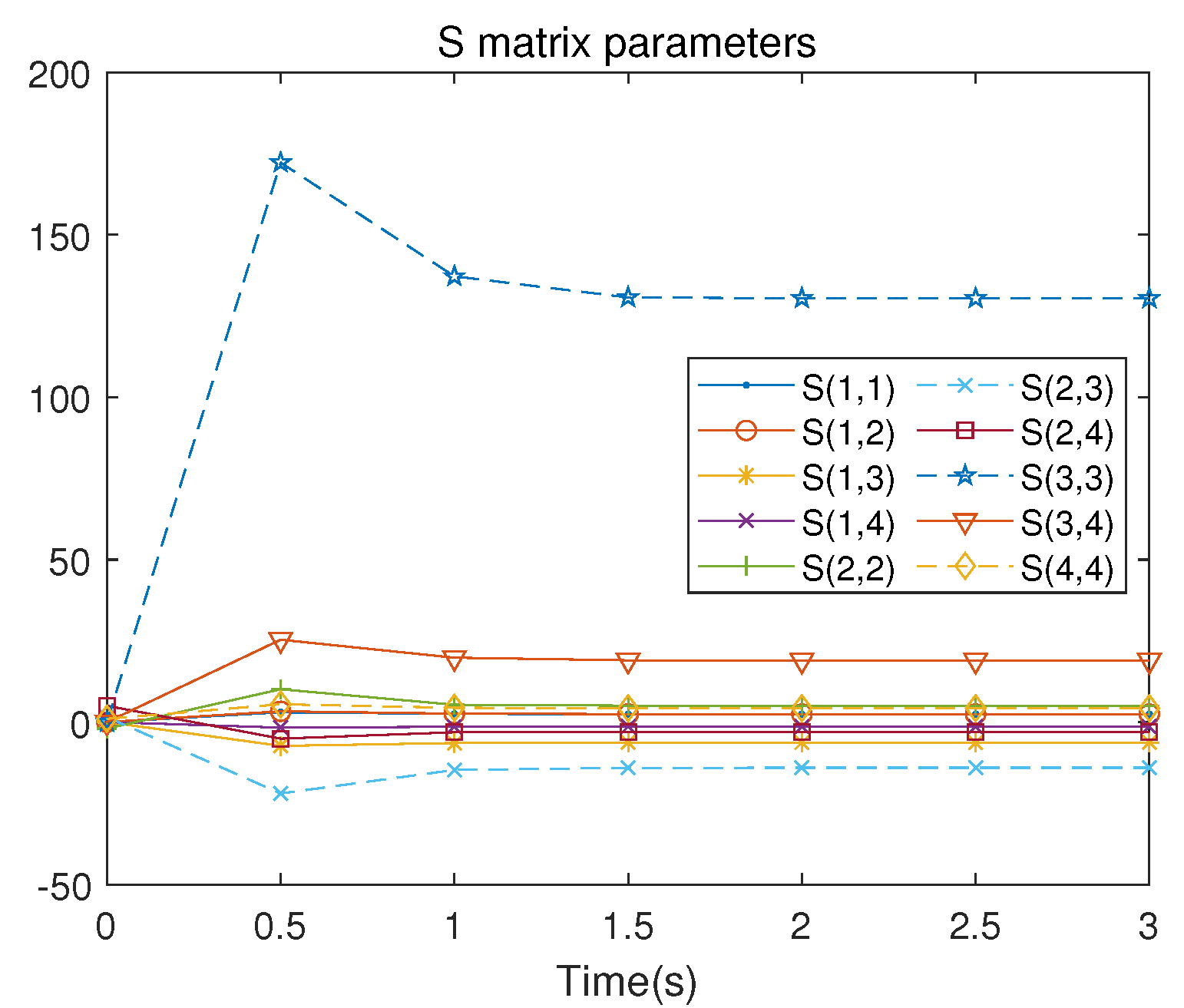
There are 10 independent numerical samples in the matrix . These 10 numerical samples are collected in each iteration to address the least squares problem. The evolution of the control signal u is presented in Figure 5. Figure 6 illustrates the iterative convergence process of the S matrix, where represents the element lying at the intersection of the i-th row and the j-th column in the symmetric matrix S, where , .
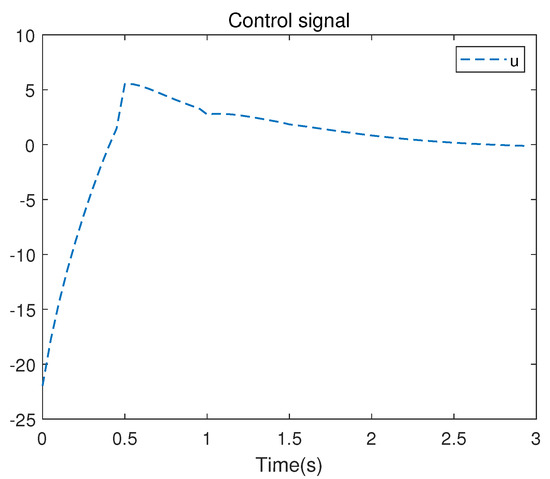
Figure 5.
Control signal u of the linearized system.
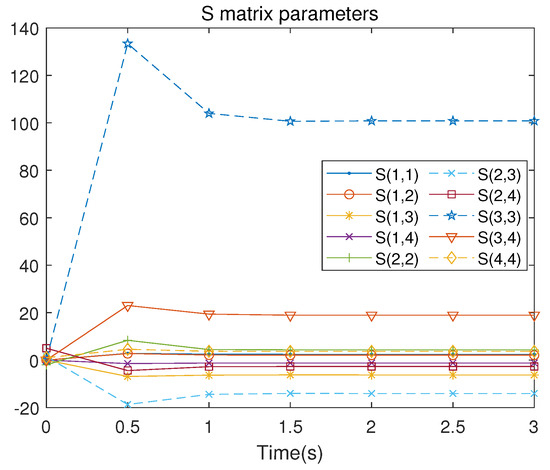
Figure 6.
S-matrix iterative process of the linearized system.
The ARE (18) is solved directly by Matlab, the S matrix and optimal feedback K are obtained as follows.
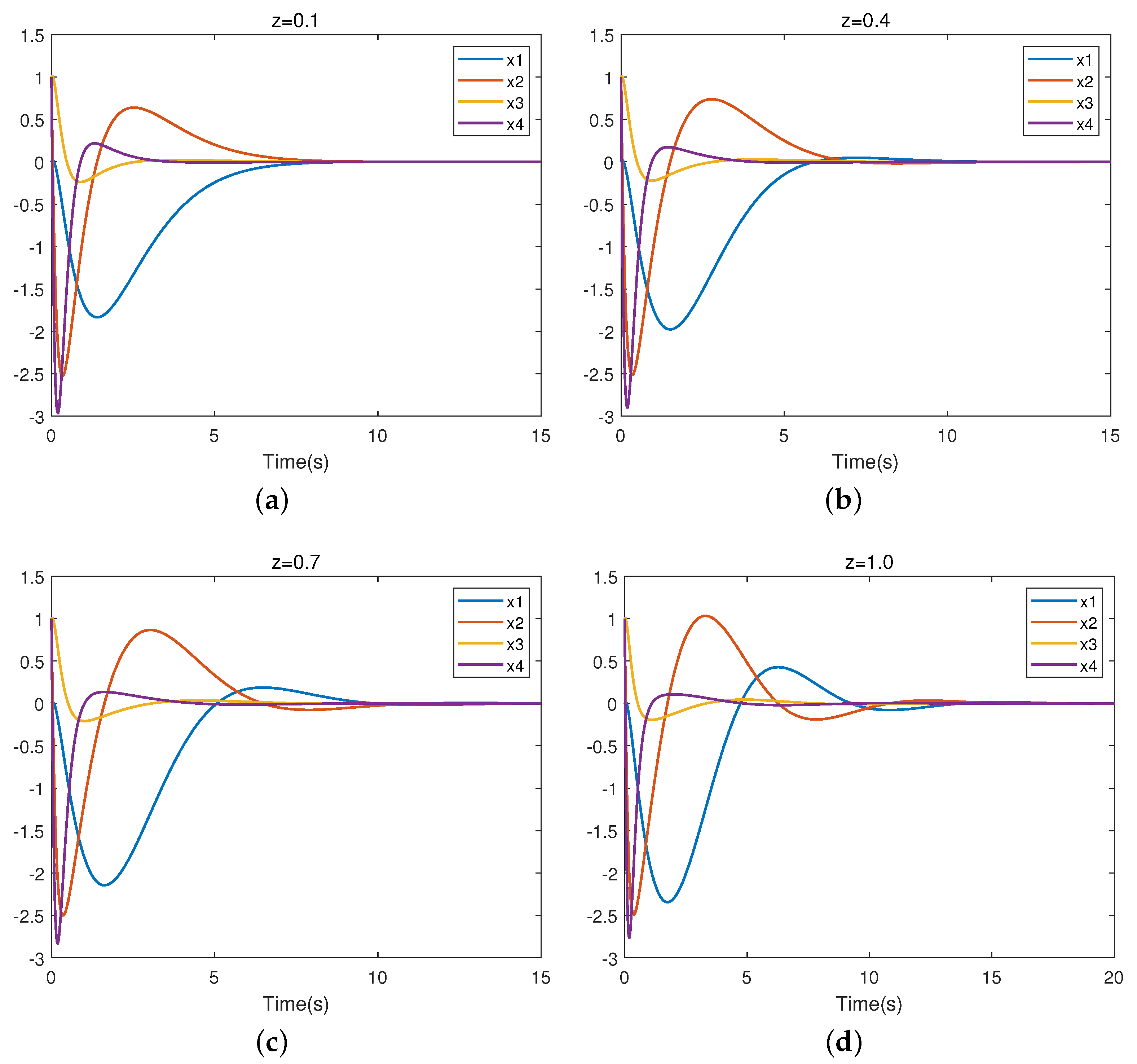
As is apparent, the results from the two methods are very similar. Figure 7 presents the closed-loop trajectory of system (11). Figure 7a–d represent the closed-loop system trajectories for uncertain parameters , respectively. It is easy to observe that the system is stable, which means that the controller is valid
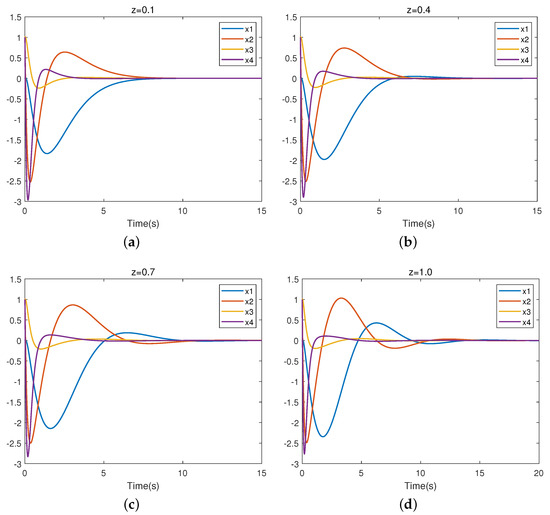
Figure 7.
Trajectory of closed-loop linearized system.
Table 2 displays the respective partial eigenvalues of the system (11) with under varying values of z. From Table 2, we can observe that the eigenvalues of the closed-loop system all have negative real parts. Thus, the uncertain linear system (11) with robust control is asymptotically stable for all .
Table 2.
Characteristic root of system (11) when z takes different values.
6.2. Example 2
Let us consider the nonlinear IPS (28). According to Lemma 5, system (28) can be rewritten as
The optimal control problem for the IPS is as follows: for nominal system (30), we find an optimal control u such that the performance index (31) achieves a minimum.
According to Lemma 6, we obtain
then
According to performance index (31), the weight matrix M is selected as
Based on Algorithm 2, we give the initial control policy
The initial state of the system is selected as . Algorithm 2 converges after six iterations, and the matrix and control gain converge to the following optimal solutions.
and
The evolution of the control signal u is presented in Figure 8. Figure 9 presents the convergence process of the matrix.
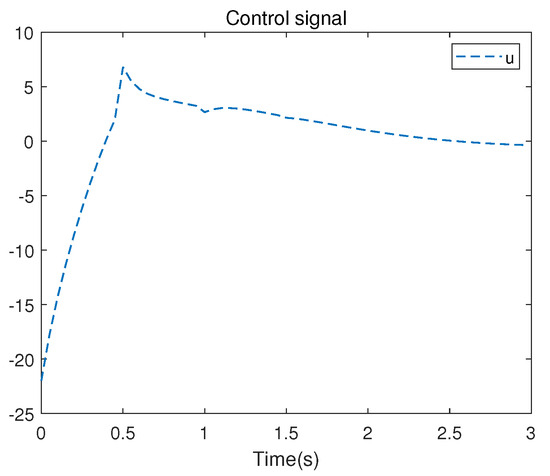
Figure 8.
Control signal u of the nonlinear system.
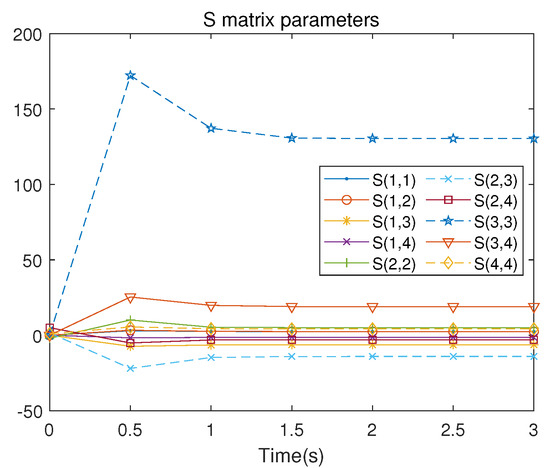
Figure 9.
S-matrix iterative process of the nonlinear system.
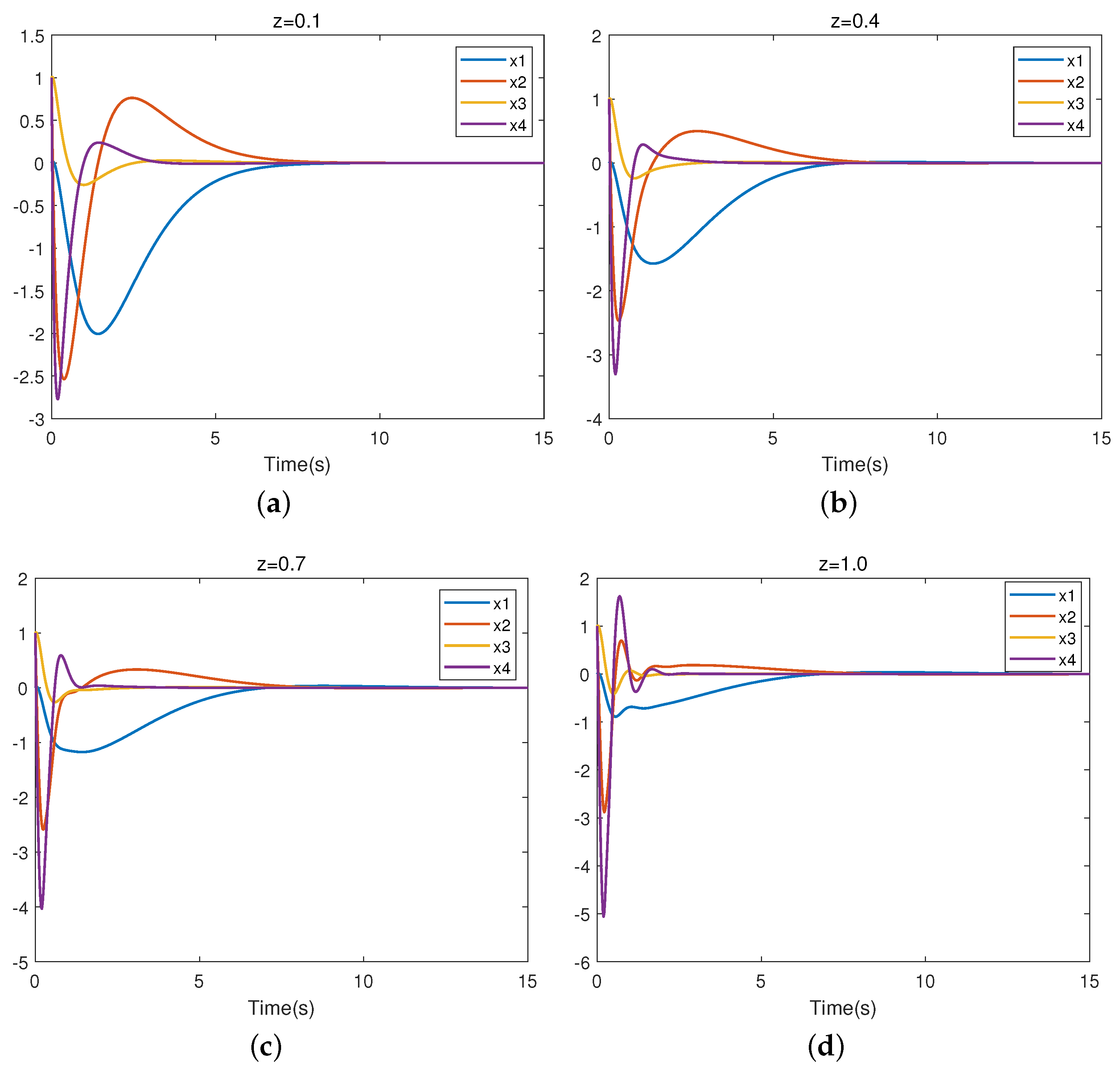
We also selected z = 0.1, 0.4, 0.7, 1.0. Figure 10 presents the closed-loop trajectory of system (28). Figure 10a–d represent the closed-loop system trajectories for uncertain parameters z = 0.1, 0.4, 0.7, and 1.0, respectively. It is easy to observe that the system is stable, which means that the controller is valid.
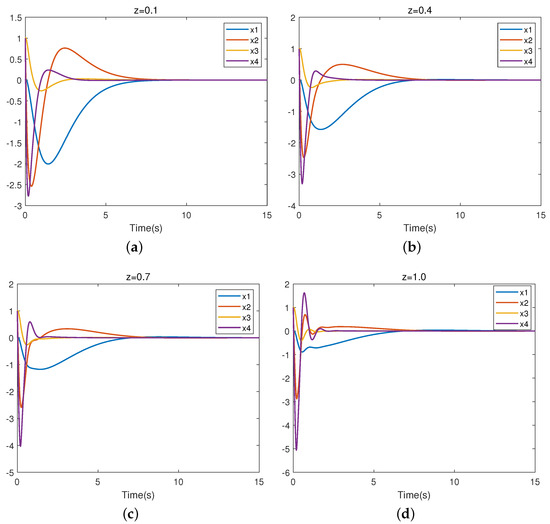
Figure 10.
Trajectory of closed-loop nonlinear system.
7. Conclusions
In this paper, the robust control problem of a first-order IPS is studied. The linearization and nonlinear state-space representation are established, and an RL algorithm for the robust control of the IPS is proposed. The controller of the uncertain system is obtained using the method of online PI. The results thus obtained show that the error between the controller obtained using the RL algorithm and by directly solving ARE is very small. Moreover, the algorithm can provide a controller that meets the requirements without the nominal matrix A of the system being known, only collecting input and output data. This improves the current state at which the robust control of the IPS relies excessively on the nominal matrix. In future research, we intend to take into consideration that the input matrix of the system also has uncertainty and extend the RL algorithm to more general systems.
Author Contributions
Y.M.: investigation, methodology, software; D.X.: formal analysis; J.H.: investigation; Y.L.: writing—original draft preparation; All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the Guizhou Province Natural Science Foundation of China under Grant No. Qiankehe Fundamentals—ZK[2021] General 322 and the Doctoral Foundation of Guangxi University of Science and Technology Grant No. Xiaokebo 22z04.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Data is contained within the article.
Acknowledgments
The authors thank to the Journal editors and the reviewers for their helpful suggestions and comments.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Marrison, C.I.; Stengel, R.F. Design of Robust Control Systems for a Hypersonic Aircraft. J. Guid. Control Dyn. 1998, 21, 58–63. [Google Scholar] [CrossRef]
- Yao, B.; Al-Majed, M.; Tomizuka, M. High-Performance Robust Motion Control of Machine Tools: An Adaptive Robust Control Approach and Comparative Experiments. IEEE/ASME Trans. Mechatron. 1997, 2, 63–76. [Google Scholar]
- Stephenson, A. A New Type of Dynamical Stability; Manchester Philosophical Society: Manchester, UK, 1908; Volume 52, pp. 1–10. [Google Scholar]
- Housner, G.W. The behavior of inverted pendulum structures during earthquakes. Bull. Seismol. Soc. Am. 1963, 53, 403–417. [Google Scholar] [CrossRef]
- Wang, J.J. Simulation studies of inverted pendulum based on PID controllers. Simul. Model. Pract. Theory 2011, 19, 440–449. [Google Scholar] [CrossRef]
- Li, D.; Chen, H.; Fan, J.; Shen, C. A novel qualitative control method to inverted pendulum systems. IFAC Proc. Vol. 1999, 32, 1495–1500. [Google Scholar] [CrossRef]
- Nasir, A.N.K.; Razak, A.A.A. Opposition-based spiral dynamic algorithm with an application to optimize type-2 fuzzy control for an inverted pendulum system. Expert Syst. Appl. 2022, 195, 116661. [Google Scholar] [CrossRef]
- Tsay, S.C.; Fong, I.K.; Kuo, T.S. Robust linear quadratic optimal control for systems with linear uncertainties. Int. J. Control 1991, 53, 81–96. [Google Scholar] [CrossRef]
- Lin, F.; Brandt, R.D. An optimal control approach to robust control of robot manipulators. IEEE Trans. Robot. Autom. 1998, 14, 69–77. [Google Scholar]
- Lin, F. An optimal control approach to robust control design. Int. J. Control 2000, 73, 177–186. [Google Scholar] [CrossRef]
- Zhang, X.; Kamgarpour, M.; Georghiou, A.; Goulart, P.; Lygeros, J. Robust optimal control with adjustable uncertainty sets. Automatica 2017, 75, 249–259. [Google Scholar] [CrossRef]
- Wang, D.; Liu, D.; Zhang, Q.; Zhao, D. Data-based adaptive critic designs for nonlinear robust optimal control with uncertain dynamics. IEEE Trans. Syst. Man Cybern. Syst. 2015, 46, 1544–1555. [Google Scholar] [CrossRef]
- Bellman, R. Dynamic programming. Science 1966, 153, 34–37. [Google Scholar] [CrossRef]
- Neustadt, L.W.; Pontrjagin, L.S.; Trirogoff, K. The Mathematical Theory of Optimal Processes; Interscience: London, UK, 1962. [Google Scholar]
- Powell, W.B. Approximate Dynamic Programming: Solving the Curses of Dimensionality; John Wiley & Sons: Hoboken, NJ, USA, 2007; Volume 703. [Google Scholar]
- Li, H.; Liu, D. Optimal control for discrete-time affine non-linear systems using general value iteration. IET Control Theory Appl. 2012, 6, 2725–2736. [Google Scholar] [CrossRef]
- Wei, Q.; Liu, D.; Lin, H. Value iteration adaptive dynamic programming for optimal control of discrete-time nonlinear systems. IEEE Trans. Cybern. 2015, 46, 840–853. [Google Scholar] [CrossRef] [PubMed]
- Tesauro, G. TD-Gammon, a self-teaching backgammon program, achieves master-level play. Neural Comput. 1994, 6, 215–219. [Google Scholar] [CrossRef]
- Singh, S.; Bertsekas, D. Reinforcement learning for dynamic channel allocation in cellular telephone systems. Adv. Neural Inf. Process. Syst. 1996, 9, 974–980. [Google Scholar]
- Maja, J.M. Reward Functions for Accelerated Learning. In Machine Learning Proceedings 1994, 1st ed.; Cohen, W.W., Hirsh, H., Eds.; Morgan Kaufmann: Burlington, MA, USA, 1994; pp. 181–189. [Google Scholar]
- Doya, K. Reinforcement learning in continuous time and space. Neural Comput. 2000, 12, 219–245. [Google Scholar] [CrossRef]
- Krstic, M.; Kokotovic, P.V.; Kanellakopoulos, I. Nonlinear and Adaptive Control Design; John Wiley & Sons, Inc.: Hoboken, NJ, USA, 1995. [Google Scholar]
- Ioannou, P.; Fidan, B. Adaptive Control Tutorial, Vol. 11 of Advances in Design and Control; SIAM: Philadelphia, PA, USA, 2006. [Google Scholar]
- Åström, K.J.; Wittenmark, B. Adaptive Control; Courier Corporation: North Chelmsford, MA, USA, 2013. [Google Scholar]
- Vrabie, D.; Pastravanu, O.; Abu-Khalaf, M.; Lewis, F.L. Adaptive optimal control for continuous-time linear systems based on policy iteration. Automatica 2009, 45, 477–484. [Google Scholar] [CrossRef]
- Xu, D.; Wang, Q.; Li, Y. Adaptive optimal control approach to robust tracking of uncertain linear systems based on policy iteration. Meas. Control 2021, 54, 668–680. [Google Scholar] [CrossRef]
- Xu, D.; Wang, Q.; Li, Y. Optimal guaranteed cost tracking of uncertain nonlinear systems using adaptive dynamic programming with concurrent learning. Int. J. Control Autom. Syst. 2020, 18, 1116–1127. [Google Scholar] [CrossRef]
- Bates, D. A hybrid approach for reinforcement learning using virtual policy gradient for balancing an inverted pendulum. arXiv 2021, arXiv:2102.08362. [Google Scholar]
- Israilov, S.; Fu, L.; Sánchez-Rodríguez, J.; Fusco, F.; Allibert, G.; Raufaste, C.; Argentina, M. Reinforcement learning approach to control an inverted pendulum: A general framework for educational purposes. PLoS ONE 2023, 18, e0280071. [Google Scholar] [CrossRef]
- Lin, B.; Zhang, Q.; Fan, F.; Shen, S. A damped bipedal inverted pendulum for human–structure interaction analysis. Appl. Math. Model. 2020, 87, 606–624. [Google Scholar] [CrossRef]
- Puriel-Gil, G.; Yu, W.; Sossa, H. Reinforcement learning compensation based PD control for inverted pendulum. In Proceedings of the 2018 15th International Conference on Electrical Engineering, Computing Science and Automatic Control (CCE), Mexico City, Mexico, 5–7 September 2018; pp. 1–6. [Google Scholar]
- Surriani, A.; Wahyunggoro, O.; Cahyadi, A.I. Reinforcement learning for cart pole inverted pendulum system. In Proceedings of the 2021 IEEE Industrial Electronics and Applications Conference (IEACon), Penang, Malaysia, 22–23 November 2021; pp. 297–301. [Google Scholar]
- Landry, M.; Campbell, S.A.; Morris, K.; Aguilar, C.O. Dynamics of an inverted pendulum with delayed feedback control. SIAM J. Appl. Dyn. Syst. 2005, 4, 333–351. [Google Scholar] [CrossRef]
- Muskinja, N.; Tovornik, B. Swinging up and stabilization of a real inverted pendulum. IEEE Trans. Ind. Electron. 2006, 53, 631–639. [Google Scholar] [CrossRef]
- Bhatia, N.P.; Szegö, G.P. Stability Theory of Dynamical Systems; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2002. [Google Scholar]
- Kleinman, D. On an iterative technique for Riccati equation computations. IEEE Trans. Autom. Control 1968, 13, 114–115. [Google Scholar] [CrossRef]
- Abu-Khalaf, M.; Lewis, F.L. Nearly optimal control laws for nonlinear systems with saturating actuators using a neural network HJB approach. Automatica 2005, 41, 779–791. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).