



Self-Improved Learning for Salient Object Detection

Abstract
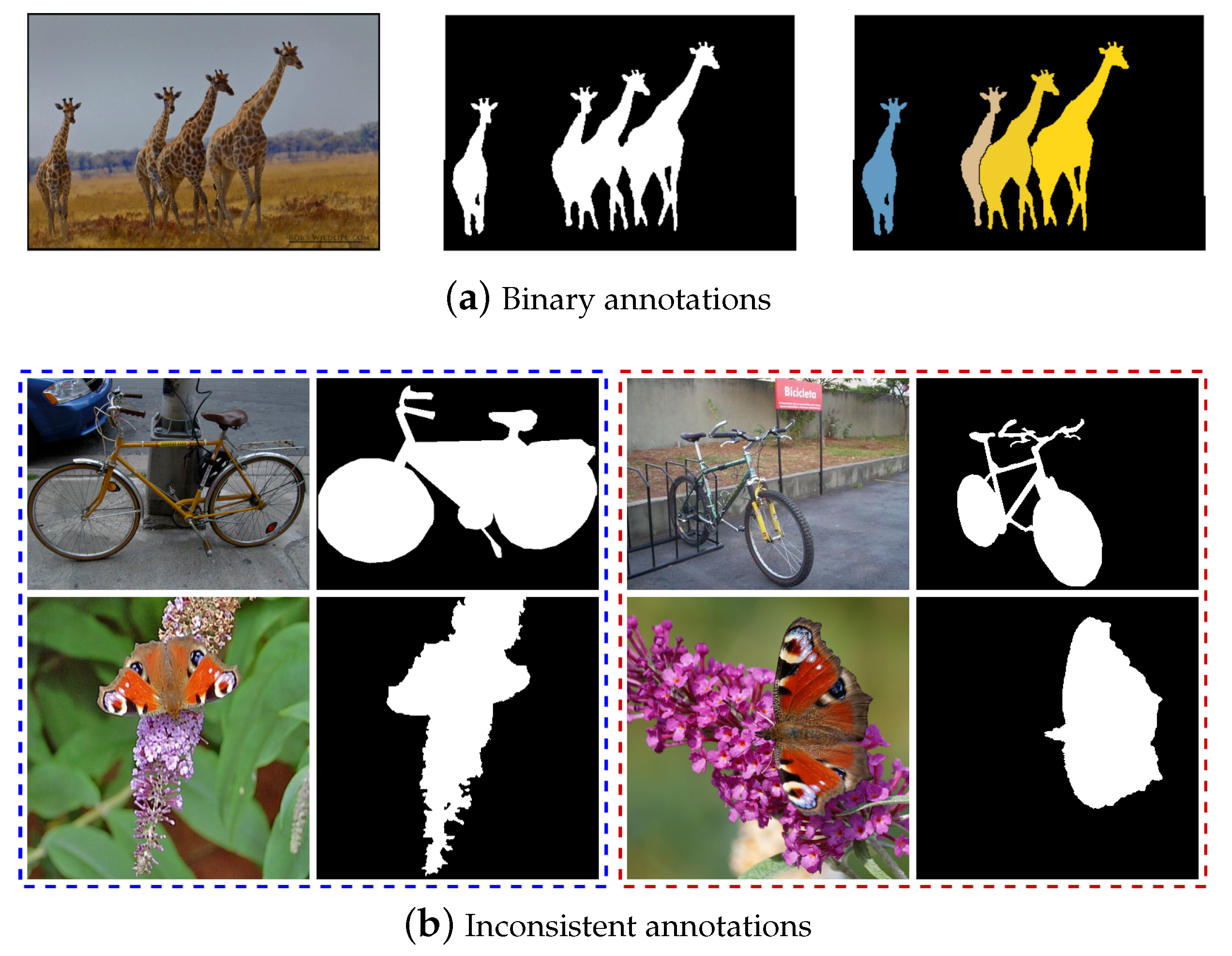
:1. Introduction
- We propose a novel Self-Improved Training strategy for SOD, which reduces the learning difficulty and effectively improves the performance.
- We present an Augmentation-based Consistent Learning scheme that regularizes the consistency between raw images and their corresponding augmented images at training time and improves the robustness of the models.
- The proposed method is model independent, which can be applied to existing prevalent methods without modifying the architecture to gain considerable improvements.
2. Related Work
2.1. Network Designs for SOD
2.2. Non-Fully Supervised Learning for SOD
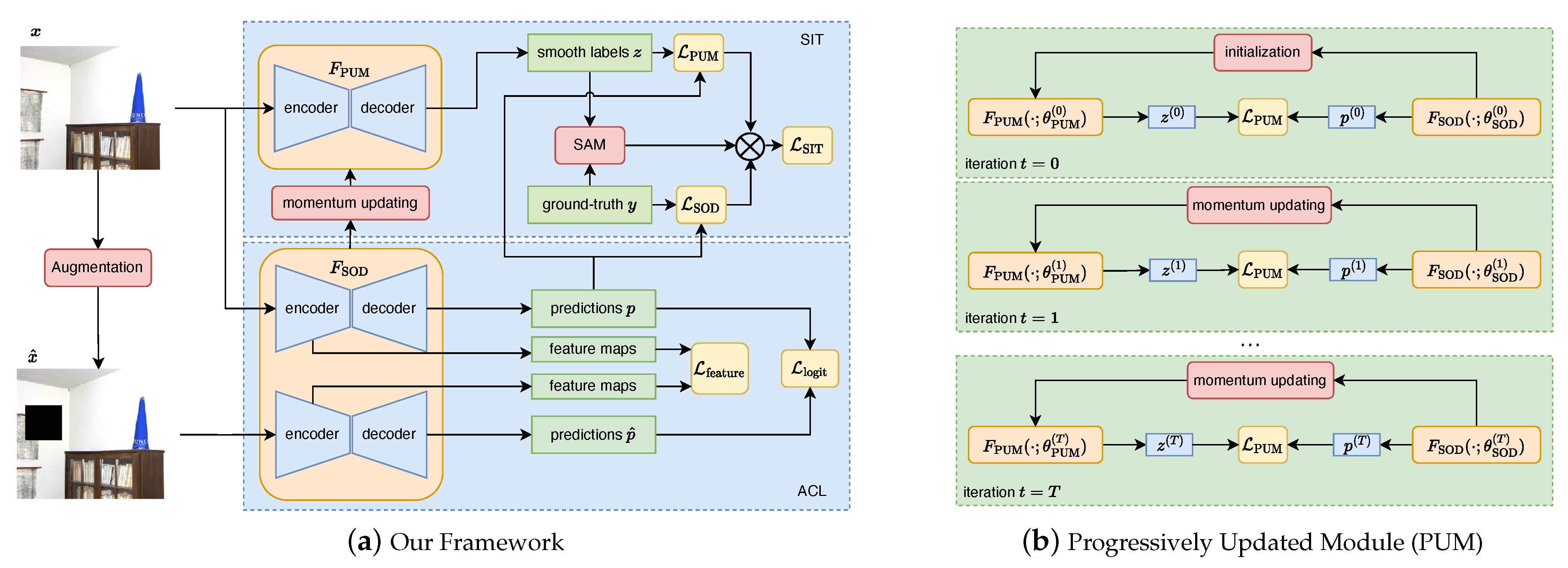
3. Method
3.1. Self-Improvement Training Strategy
3.1.1. PUM: Progressively Updated Module
3.1.2. SAM: Sample Adaptive Module
3.2. Augmentation-Based Consistent Learning
3.2.1. Regularizing with Prediction Consistency
3.2.2. Regularizing with Feature Consistency
3.3. The Training Procedure
| Algorithm 1 SIT and ACL training strategy at the t iteration |
| Input: x, an input images; y, its ground-truth |
| Networks: , an SOD network with its parameters; , a PUM network with its parameters |
| Output: , . |
|
4. Experiment
4.1. Experiment Setup
4.1.1. Datasets
4.1.2. Evaluation Metrics
4.1.3. Implementation Details
4.2. Ablation Study
4.2.1. Effectiveness of SIT
4.2.2. Effectiveness of ACL
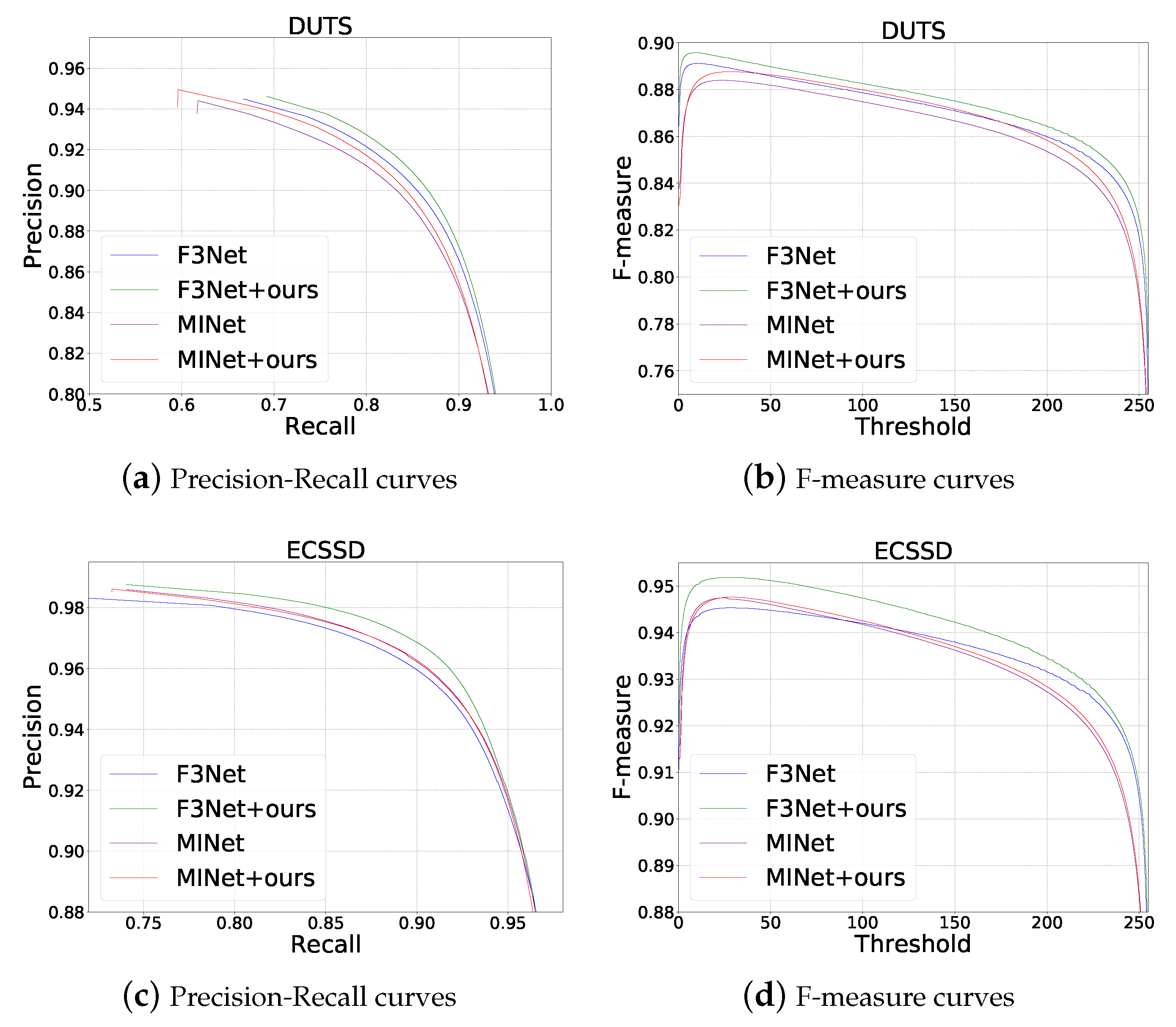
4.2.3. The Whole Framework
4.3. Analysis on Design Choices
4.3.1. Updating Strategy of PUM
4.3.2. The Selection of Momentum Coefficient
4.3.3. Effect of Sample Adaptive Module
4.4. Visualization Analysis
4.4.1. Visualization of Smooth Labels
4.4.2. Visualization of Feature Attention Maps
4.4.3. Visual Comparison with Baseline Methods
4.5. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Mahadevan, V.; Vasconcelos, N. Saliency-based discriminant tracking. In Proceedings of the IEEE Conference of Computer Vision and Pattern Recognition (CVPR), Miami Beach, FL, USA, 20–25 June 2009; pp. 1007–1013. [Google Scholar]
- Fang, H.; Gupta, S.; Iandola, F.N.; Srivastava, R.K.; Deng, L.; Dollár, P.; Gao, J.; He, X.; Mitchell, M.; Platt, J.C.; et al. From captions to visual concepts and back. In Proceedings of the IEEE Conference of Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 1473–1482. [Google Scholar]
- Zhang, W.; Liu, H. Study of Saliency in Objective Video Quality Assessment. IEEE Trans. Image Process. 2017, 26, 1275–1288. [Google Scholar] [CrossRef] [PubMed]
- Zhao, R.; Ouyang, W.; Wang, X. Unsupervised Salience Learning for Person Re-identification. In Proceedings of the IEEE Conference of Computer Vision and Pattern Recognition (CVPR), Portland, OR, USA, 25–27 June 2013; pp. 3586–3593. [Google Scholar]
- Liu, G.; Fan, D. A Model of Visual Attention for Natural Image Retrieval Computing Companion. In Proceedings of the International Conference on Information Science and Cloud, Guangzhou, China, 7–8 December 2013; pp. 728–733. [Google Scholar]
- Hou, Q.; Jiang, P.; Wei, Y.; Cheng, M. Self-Erasing Network for Integral Object Attention. Adv. Neural Inf. Process. Syst. 2018, 31, 547–557. [Google Scholar]
- Zhang, D.; Han, J.; Zhao, L.; Meng, D. Leveraging Prior-Knowledge for Weakly Supervised Object Detection under a Collaborative Self-Paced Curriculum Learning Framework. Int. J. Comput. Vis. 2019, 127, 363–380. [Google Scholar] [CrossRef]
- Li, Y.; Hou, X.; Koch, C.; Rehg, J.M.; Yuille, A.L. The Secrets of Salient Object Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 24–27 June 2014; pp. 280–287. [Google Scholar]
- Yang, C.; Zhang, L.; Lu, H.; Ruan, X.; Yang, M.H. Saliency Detection via Graph-Based Manifold Ranking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Portland, OR, USA, 25–27 June 2013; pp. 3166–3173. [Google Scholar]
- Yan, Q.; Xu, L.; Shi, J.; Jia, J. Hierarchical Saliency Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Portland, OR, USA, 25–27 June 2013; pp. 1155–1162. [Google Scholar]
- Li, G.; Yu, Y. Visual Saliency Based on Multiscale Deep Features. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 5455–5463. [Google Scholar]
- Wang, L.; Lu, H.; Ruan, X.; Yang, M. Deep networks for saliency detection via local estimation and global search. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 3183–3192. [Google Scholar]
- Zhao, R.; Ouyang, W.; Li, H.; Wang, X. Saliency detection by multi-context deep learning. In Proceedings of the IEEE Conference of Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 1265–1274. [Google Scholar]
- Zhang, J.; Sclaroff, S.; Lin, Z.; Shen, X.; Price, B.L.; Mech, R. Unconstrained Salient Object Detection via Proposal Subset Optimization. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 5733–5742. [Google Scholar]
- Lee, G.; Tai, Y.; Kim, J. Deep Saliency with Encoded Low Level Distance Map and High Level Features. In Proceedings of the IEEE Conference of Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 660–668. [Google Scholar]
- He, S.; Lau, R.W.H.; Liu, W.; Huang, Z.; Yang, Q. SuperCNN: A Superpixelwise Convolutional Neural Network for Salient Object Detection. Int. J. Comput. Vis. 2015, 115, 330–344. [Google Scholar] [CrossRef]
- Kim, J.; Pavlovic, V. A Shape-Based Approach for Salient Object Detection Using Deep Learning. In Proceedings of the European Conference on Computer Vision (ECCV), Amsterdam, The Netherlands, 11–14 October 2016; pp. 455–470. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully Convolutional Networks for Semantic Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Fan, D.P.; Cheng, M.M.; Liu, J.J.; Gao, S.H.; Hou, Q.; Borji, A. Salient Objects in Clutter: Bringing Salient Object Detection to the Foreground. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Li, G.; Xie, Y.; Lin, L.; Yu, Y. Instance-Level Salient Object Segmentation. In Proceedings of the IEEE Conference of Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Zhang, P.; Wang, D.; Lu, H.; Wang, H.; Yin, B. Learning Uncertain Convolutional Features for Accurate Saliency Detection. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017. [Google Scholar]
- Wang, T.; Zhang, L.; Wang, S.; Lu, H.; Yang, G.; Ruan, X.; Borji, A. Detect Globally, Refine Locally: A Novel Approach to Saliency Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Liu, N.; Han, J.; Yang, M.H. PiCANet: Learning Pixel-Wise Contextual Attention for Saliency Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Zhang, L.; Dai, J.; Lu, H.; He, Y.; Wang, G. A Bi-Directional Message Passing Model for Salient Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Ji, W.; Li, X.; Wei, L.; Wu, F.; Zhuang, Y. Context-Aware Graph Label Propagation Network for Saliency Detection. IEEE Trans. Image Process. 2020, 29, 8177–8186. [Google Scholar] [CrossRef] [PubMed]
- Liu, Z.; Wang, Y.; Tu, Z.; Xiao, Y.; Tang, B. TriTransNet: RGB-D Salient Object Detection with a Triplet Transformer Embedding Network. In Proceedings of the ACM International Conference on Multimedia, Chengdu, China, 20–24 October 2021; pp. 4481–4490. [Google Scholar]
- Wang, X.; Jiang, B.; Wang, X.; Luo, B. MTFNet: Mutual-Transformer Fusion Network for RGB-D Salient Object Detection. arXiv 2021, arXiv:2112.01177. [Google Scholar]
- Mao, Y.; Zhang, J.; Wan, Z.; Dai, Y.; Li, A.; Lv, Y.; Tian, X.; Fan, D.; Barnes, N. Transformer Transforms Salient Object Detection and Camouflaged Object Detection. arXiv 2021, arXiv:2104.10127. [Google Scholar]
- Qiu, Y.; Liu, Y.; Zhang, L.; Xu, J. Boosting Salient Object Detection with Transformer-based Asymmetric Bilateral U-Net. arXiv 2021, arXiv:2108.07851. [Google Scholar] [CrossRef]
- Liu, N.; Zhang, N.; Wan, K.; Shao, L.; Han, J. Visual Saliency Transformer. In Proceedings of the International Conference on Computer Vision (ICCV), Montreal, BC, Canada, 11–17 October 2021; pp. 4722–4732. [Google Scholar]
- Zhang, X.; Wang, T.; Qi, J.; Lu, H.; Wang, G. Progressive Attention Guided Recurrent Network for Salient Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 714–722. [Google Scholar]
- Wang, W.; Zhao, S.; Shen, J.; Hoi, S.C.H.; Borji, A. Salient Object Detection With Pyramid Attention and Salient Edges. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 1448–1457. [Google Scholar]
- Feng, M.; Lu, H.; Ding, E. Attentive Feedback Network for Boundary-Aware Salient Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Zhao, X.; Pang, Y.; Zhang, L.; Lu, H.; Zhang, L. Suppress and Balance: A Simple Gated Network for Salient Object Detection. In Proceedings of the European Conference on Computer Vision (ECCV), Glasgow, UK, 23–28 August 2020. [Google Scholar]
- Hou, Q.; Cheng, M.; Hu, X.; Borji, A.; Tu, Z.; Torr, P.H.S. Deeply Supervised Salient Object Detection with Short Connections. TPAMI 2019, 41, 815–828. [Google Scholar] [CrossRef] [PubMed]
- Zhang, P.; Wang, D.; Lu, H.; Wang, H.; Ruan, X. Amulet: Aggregating Multi-level Convolutional Features for Salient Object Detection. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 202–211. [Google Scholar]
- Wang, Y.; Wang, R.; Fan, X.; Wang, T.; He, X. Pixels, Regions, and Objects: Multiple Enhancement for Salient Object Detection. In Proceedings of the IEEE Conference Computer Vision and Pattern Recognition (CVPR), Vancouver, Canada, 18–22 June 2023; pp. 10031–10040. [Google Scholar]
- Zhao, J.; Liu, J.; Fan, D.; Cao, Y.; Yang, J.; Cheng, M. EGNet: Edge Guidance Network for Salient Object Detection. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 8778–8787. [Google Scholar]
- Li, X.; Yang, F.; Cheng, H.; Liu, W.; Shen, D. Contour Knowledge Transfer for Salient Object Detection. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 355–370. [Google Scholar]
- Qin, X.; Zhang, Z.; Huang, C.; Gao, C.; Dehghan, M.; Jagersand, M. BASNet: Boundary-Aware Salient Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Chen, Z.; Zhou, H.; Lai, J.; Yang, L.; Xie, X. Contour-Aware Loss: Boundary-Aware Learning for Salient Object Segmentation. IEEE Trans. Image Process. 2021, 30, 431–443. [Google Scholar] [CrossRef] [PubMed]
- Wang, L.; Lu, H.; Wang, Y.; Feng, M.; Wang, D.; Yin, B.; Ruan, X. Learning to Detect Salient Objects with Image-Level Supervision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 2017; pp. 136–145. [Google Scholar]
- Li, G.; Xie, Y.; Lin, L. Weakly Supervised Salient Object Detection Using Image Labels. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018. [Google Scholar]
- Zeng, Y.; Zhuge, Y.; Lu, H.; Zhang, L.; Qian, M.; Yu, Y. Multi-source weak supervision for saliency detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 6074–6083. [Google Scholar]
- Zhang, J.; Xie, J.; Barnes, N. Learning Noise-Aware Encoder-Decoder from Noisy Labels by Alternating back-propagation for saliency detection. In Proceedings of the European Conference on Computer Vision (ECCV), Glasgow, UK, 23–28 August 2020; pp. 349–366. [Google Scholar]
- Piao, Y.; Wang, J.; Zhang, M.; Lu, H. MFNet: Multi-filter directive network for weakly supervised salient object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Virtual, 19–25 June 2021; pp. 4136–4145. [Google Scholar]
- Zhang, J.; Yu, X.; Li, A.; Song, P.; Liu, B.; Dai, Y. Weakly-Supervised Salient Object Detection via Scribble Annotations. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 2020; pp. 12546–12555. [Google Scholar]
- Yu, S.; Zhang, B.; Xiao, J.; Lim, E.G. Structure-consistent weakly supervised salient object detection with local saliency coherence. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtual, 4–7 February 2021; pp. 3234–3242. [Google Scholar]
- Gao, S.; Zhang, W.; Wang, Y.; Guo, Q.; Zhang, C.; He, Y.; Zhang, W. Weakly-Supervised Salient Object Detection Using Point Supervision. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtual, 22 February–1 March 2022; pp. 670–678. [Google Scholar]
- Wu, Z.; Wang, L.; Wang, W.; Xia, Q.; Chen, C.; Hao, A.; Li, S. Pixel is All You Need: Adversarial Trajectory-Ensemble Active Learning for Salient Object Detection. In Proceedings of the AAAI Conference on Artificial Intelligence, Washington, DC, USA, 7–14 February 2023; pp. 2883–2891. [Google Scholar]
- Zhou, H.; Chen, P.; Yang, L.; Xie, X.; Lai, J. Activation to saliency: Forming high-quality labels for unsupervised salient object detection. IEEE Trans. Circuits Syst. Video Technol. 2022, 33, 743–755. [Google Scholar] [CrossRef]
- Zhou, H.; Qiao, B.; Yang, L.; Lai, J.; Xie, X. Texture-Guided Saliency Distilling for Unsupervised Salient Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2023; pp. 7257–7267. [Google Scholar]
- Song, Y.; Gao, S.; Xing, H.; Cheng, Y.; Wang, Y.; Zhang, W. Towards End-to-End Unsupervised Saliency Detection with Self-Supervised Top-Down Context. In Proceedings of the ACM International Conference on Multimedia, Ottawa, Canada, 29 October–3 November 2023; pp. 5532–5541. [Google Scholar]
- Wu, Z.; Su, L.; Huang, Q. Cascaded Partial Decoder for Fast and Accurate Salient Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Fan, D.; Cheng, M.; Liu, Y.; Li, T.; Borji, A. Structure-Measure: A New Way to Evaluate Foreground Maps. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 4558–4567. [Google Scholar]
- Fan, D.; Gong, C.; Cao, Y.; Ren, B.; Cheng, M.; Borji, A. Enhanced-alignment Measure for Binary Foreground Map Evaluation. In Proceedings of the International Joint Conference on Artificial Intelligence, Stockholm, Sweden, 13–19 July 2018; pp. 698–704. [Google Scholar]
- Wei, J.; Wang, S.; Huang, Q. F3Net: Fusion, Feedback and Focus for Salient Object Detection. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020. [Google Scholar]
- Pang, Y.; Zhao, X.; Zhang, L.; Lu, H. Multi-Scale Interactive Network for Salient Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference of Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- DeVries, T.; Taylor, G.W. Improved Regularization of Convolutional Neural Networks with Cutout. arXiv 2017, arXiv:1708.04552. [Google Scholar]
- Deng, Z.; Hu, X.; Zhu, L.; Xu, X.; Qin, J.; Han, G.; Heng, P. R3Net: Recurrent Residual Refinement Network for Saliency Detection. In Proceedings of the International Joint Conference on Artificial Intelligence, Stockholm, Sweden, 13–19 July 2018; pp. 684–690. [Google Scholar]
- Wang, W.; Shen, J.; Cheng, M.; Shao, L. An Iterative and Cooperative Top-Down and Bottom-Up Inference Network for Salient Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 5968–5977. [Google Scholar]
- Liu, J.; Hou, Q.; Cheng, M.; Feng, J.; Jiang, J. A Simple Pooling-Based Design for Real-Time Salient Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 3917–3926. [Google Scholar]
- Chen, S.; Tan, X.; Wang, B.; Hu, X. Reverse Attention for Salient Object Detection. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 236–252. [Google Scholar]
- Laine, S.; Aila, T. Temporal Ensembling for Semi-Supervised Learning. In Proceedings of the International Conference on Learning Representations, Toulon, France, 24–26 April 2017. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Datasets | Training Images | Testing Images |
|---|---|---|
| DUTS [42] | 10,533 | 5019 |
| ECSSD [10] | – | 1000 |
| DUT-OMRON [9] | – | 5168 |
| HKU-IS [11] | – | 4447 |
| PASCAL-S [8] | – | 850 |
| SIT | ACL | MAE ↓ | mF ↑ | ↑ | ↑ |
|---|---|---|---|---|---|
| — | — | 0.035 | 0.840 | 0.888 | 0.902 |
| ✓ | — | 0.035 | 0.847 | 0.891 | 0.904 |
| — | ✓ | 0.035 | 0.845 | 0.888 | 0.905 |
| ✓ | ✓ | 0.034 | 0.846 | 0.891 | 0.904 |
| Algorithm | ECSSD | PASCAL-S | DUTS-TE | HKU-IS | DUT-OMRON | |||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| MAE ↓ | MAE ↓ | ↑ | ↑ | ↑ | MAE ↓ | ↑ | ↑ | ↑ | MAE ↓ | ↑ | ↑ | ↑ | MAE ↓ | ↑ | ↑ | ↑ | ||||
| C2SNet | 0.059 | 0.853 | 0.882 | 0.906 | 0.086 | 0.761 | 0.822 | 0.835 | 0.066 | 0.710 | 0.817 | 0.841 | 0.051 | 0.839 | 0.873 | 0.919 | 0.079 | 0.664 | 0.780 | 0.817 |
| RAS | 0.055 | 0.890 | 0.894 | 0.916 | 0.102 | 0.782 | 0.792 | 0.832 | 0.060 | 0.750 | 0.838 | 0.861 | 0.045 | 0.874 | 0.888 | 0.931 | 0.063 | 0.711 | 0.812 | 0.843 |
| RNet | 0.051 | 0.883 | 0.910 | 0.914 | 0.101 | 0.775 | 0.809 | 0.824 | 0.067 | 0.716 | 0.837 | 0.827 | 0.047 | 0.853 | 0.894 | 0.921 | 0.073 | 0.690 | 0.819 | 0.814 |
| PiCA-R | 0.046 | 0.886 | 0.917 | 0.913 | 0.075 | 0.798 | 0.849 | 0.833 | 0.051 | 0.759 | 0.869 | 0.862 | 0.043 | 0.870 | 0.904 | 0.936 | 0.065 | 0.717 | 0.832 | 0.841 |
| BMPM | 0.044 | 0.894 | 0.911 | 0.914 | 0.073 | 0.803 | 0.840 | 0.838 | 0.049 | 0.762 | 0.861 | 0.859 | 0.039 | 0.875 | 0.906 | 0.937 | 0.063 | 0.698 | 0.809 | 0.839 |
| DGRL | 0.043 | 0.903 | 0.906 | 0.917 | 0.074 | 0.807 | 0.834 | 0.836 | 0.051 | 0.764 | 0.846 | 0.863 | 0.037 | 0.881 | 0.896 | 0.941 | 0.063 | 0.709 | 0.810 | 0.843 |
| PAGE | 0.042 | 0.906 | 0.912 | 0.920 | 0.077 | 0.810 | 0.835 | 0.841 | 0.052 | 0.777 | 0.854 | 0.869 | 0.037 | 0.882 | 0.903 | 0.940 | 0.062 | 0.736 | 0.824 | 0.853 |
| AFNet | 0.042 | 0.908 | 0.913 | 0.918 | 0.070 | 0.821 | 0.844 | 0.846 | 0.046 | 0.792 | 0.867 | 0.879 | 0.036 | 0.888 | 0.905 | 0.942 | 0.057 | 0.738 | 0.826 | 0.853 |
| TDBU | 0.041 | 0.880 | 0.918 | 0.922 | 0.071 | 0.779 | 0.844 | 0.852 | 0.048 | 0.767 | 0.865 | 0.879 | 0.038 | 0.878 | 0.907 | 0.942 | 0.061 | 0.739 | 0.837 | 0.854 |
| PoolNet | 0.039 | 0.915 | 0.921 | 0.924 | 0.074 | 0.822 | 0.845 | 0.850 | 0.040 | 0.809 | 0.883 | 0.889 | 0.032 | 0.899 | 0.916 | 0.949 | 0.055 | 0.747 | 0.835 | 0.863 |
| BASNet | 0.037 | 0.880 | 0.916 | 0.921 | 0.076 | 0.775 | 0.832 | 0.847 | 0.048 | 0.791 | 0.866 | 0.884 | 0.032 | 0.895 | 0.909 | 0.946 | 0.056 | 0.756 | 0.836 | 0.869 |
| CPD-R | 0.037 | 0.917 | 0.918 | 0.925 | 0.072 | 0.824 | 0.842 | 0.849 | 0.043 | 0.805 | 0.869 | 0.886 | 0.034 | 0.891 | 0.905 | 0.944 | 0.056 | 0.747 | 0.825 | 0.866 |
| PoolNet | 0.039 | 0.915 | 0.921 | 0.924 | 0.075 | 0.810 | 0.836 | 0.847 | 0.040 | 0.809 | 0.883 | 0.889 | 0.033 | 0.893 | 0.913 | 0.946 | 0.056 | 0.747 | 0.836 | 0.863 |
| PoolNet+ours | 0.039 | 0.918 | 0.922 | 0.924 | 0.074 | 0.815 | 0.841 | 0.848 | 0.039 | 0.814 | 0.884 | 0.892 | 0.031 | 0.899 | 0.915 | 0.950 | 0.052 | 0.752 | 0.838 | 0.870 |
| FNet | 0.033 | 0.925 | 0.924 | 0.927 | 0.062 | 0.840 | 0.855 | 0.859 | 0.035 | 0.840 | 0.888 | 0.902 | 0.028 | 0.910 | 0.917 | 0.953 | 0.053 | 0.766 | 0.838 | 0.870 |
| FNet+ours | 0.032 | 0.930 | 0.927 | 0.929 | 0.061 | 0.837 | 0.855 | 0.861 | 0.034 | 0.846 | 0.891 | 0.904 | 0.027 | 0.916 | 0.921 | 0.955 | 0.052 | 0.769 | 0.842 | 0.870 |
| MINet | 0.033 | 0.924 | 0.925 | 0.927 | 0.063 | 0.829 | 0.850 | 0.851 | 0.037 | 0.828 | 0.884 | 0.898 | 0.029 | 0.909 | 0.919 | 0.953 | 0.055 | 0.755 | 0.833 | 0.865 |
| MINet+ours | 0.033 | 0.926 | 0.925 | 0.927 | 0.059 | 0.835 | 0.857 | 0.859 | 0.036 | 0.834 | 0.887 | 0.901 | 0.029 | 0.910 | 0.920 | 0.954 | 0.054 | 0.756 | 0.834 | 0.869 |
| GateNet | 0.040 | 0.916 | 0.920 | 0.924 | 0.067 | 0.819 | 0.851 | 0.851 | 0.040 | 0.807 | 0.885 | 0.889 | 0.033 | 0.899 | 0.915 | 0.949 | 0.055 | 0.746 | 0.838 | 0.861 |
| GateNet+ours | 0.038 | 0.915 | 0.924 | 0.924 | 0.065 | 0.820 | 0.856 | 0.857 | 0.039 | 0.808 | 0.888 | 0.891 | 0.031 | 0.901 | 0.921 | 0.951 | 0.055 | 0.746 | 0.839 | 0.862 |
| Updating Strategy | MAE ↓ | ↑ | ↑ | ↑ | |
|---|---|---|---|---|---|
| Epoch Based | — | 0.038 | 0.833 | 0.882 | 0.895 |
| Iteration Based | 0.9 | 0.035 | 0.843 | 0.891 | 0.901 |
| Iteration Based | 0.99 | 0.034 | 0.846 | 0.891 | 0.904 |
| Iteration Based | 0.999 | 0.035 | 0.846 | 0.889 | 0.903 |
| Iteration Based | 0.9999 | 0.035 | 0.841 | 0.888 | 0.902 |
| MAE ↓ | ↑ | ↑ | ↑ | |
|---|---|---|---|---|
| 0.3 | 0.035 | 0.841 | 0.889 | 0.901 |
| 0.5 | 0.036 | 0.838 | 0.885 | 0.899 |
| 0.7 | 0.040 | 0.829 | 0.883 | 0.891 |
| SAM | 0.034 | 0.846 | 0.891 | 0.904 |
| MAE ↓ | ↑ | ↑ | ↑ | |
|---|---|---|---|---|
| 30 | 0.035 | 0.843 | 0.889 | 0.901 |
| 70 | 0.034 | 0.846 | 0.891 | 0.904 |
| 110 | 0.037 | 0.839 | 0.885 | 0.898 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, S.; Zeng, H.; Wang, H.; Li, X. Self-Improved Learning for Salient Object Detection. Appl. Sci. 2023, 13, 12966. https://doi.org/10.3390/app132312966
Li S, Zeng H, Wang H, Li X. Self-Improved Learning for Salient Object Detection. Applied Sciences. 2023; 13(23):12966. https://doi.org/10.3390/app132312966
Chicago/Turabian StyleLi, Songyuan, Hao Zeng, Huanyu Wang, and Xi Li. 2023. "Self-Improved Learning for Salient Object Detection" Applied Sciences 13, no. 23: 12966. https://doi.org/10.3390/app132312966
APA StyleLi, S., Zeng, H., Wang, H., & Li, X. (2023). Self-Improved Learning for Salient Object Detection. Applied Sciences, 13(23), 12966. https://doi.org/10.3390/app132312966