
A Malware Detection Framework Based on Semantic Information of Behavioral Features


Abstract
:1. Introduction
- We propose an approach to malware detection that is based on natural language processing and behavioral features, which can achieve high accuracy just by analyzing API call sequences;
- We design a feature vectorization representation method based on the Skip-Gram algorithm for better learning of contextual behavior information. We demonstrate the results of the experiments and validate the experimental effect of the feature method for word vector representation;
- We design a method that combines API calls’ semantic information and statistical characteristics. Numerous experiments verify the effectiveness of the approach we propose;
- We propose a CNNs-BiGRU based deep learning approach to implement malware detection and evaluate it. The results demonstrate that our model superior to other malware detection models.
2. Related Work
2.1. Static Analysis
2.2. Dynamic Analysis
2.3. Natural Language Processing and Deep Learning for Malware Detection

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Paper | Year | Analysis Type | Feature Info | Method |
|---|---|---|---|---|
| Moskovitch et al. [33] | 2008 | Static | N-grams | ML |
| Shabtai et al. [34] | 2009 | Static | N-gram | ML |
| Sami et al. [36] | 2010 | Static | frequency characteristic | ML |
| Kang et al. [30] | 2019 | Static | semantic information | DL |
| Chai et al. [35] | 2022 | Static | malware images | DL |
| Arzu et al. [44] | 2022 | Static | semantic information | DL |
| Christodorescu et al. [37] | 2007 | Dynamic | dependency graph | Data Mining |
| David et al. [43] | 2015 | Dynamic | 1-g | DL |
| Tobiyama et al. [38] | 2016 | Dynamic | relationship between API calls | DL |
| Kolosnjaji et al. [46] | 2016 | Dynamic | One-Hot | DL |
| Rosenberg et al. [41] | 2018 | Dynamic | frequency characteristic | DL |
| Ndibanje et al. [39] | 2019 | Dynamic | statistical information | ML |
| Liu et al. [45] | 2019 | Dynamic | semantic information | DL |
| Amer and Zelinka [31] | 2020 | Dynamic | Markov | DL |
| Zhang et al. [40] | 2020 | Dynamic | API-Graph | DL |
| Wang et al. [32] | 2021 | Dynamic | semantic information | DL |
| Zhang et al. [29] | 2020 | Dynamic | hash encoding | DL |
| Catak et al. [47] | 2020 | Dynamic | relationship between API calls | DL |
| Chen et al. [42] | 2022 | Dynamic | semantic clustering | DL |
| Li et al. [48] | 2022 | Dynamic | intrinsic features | DL |
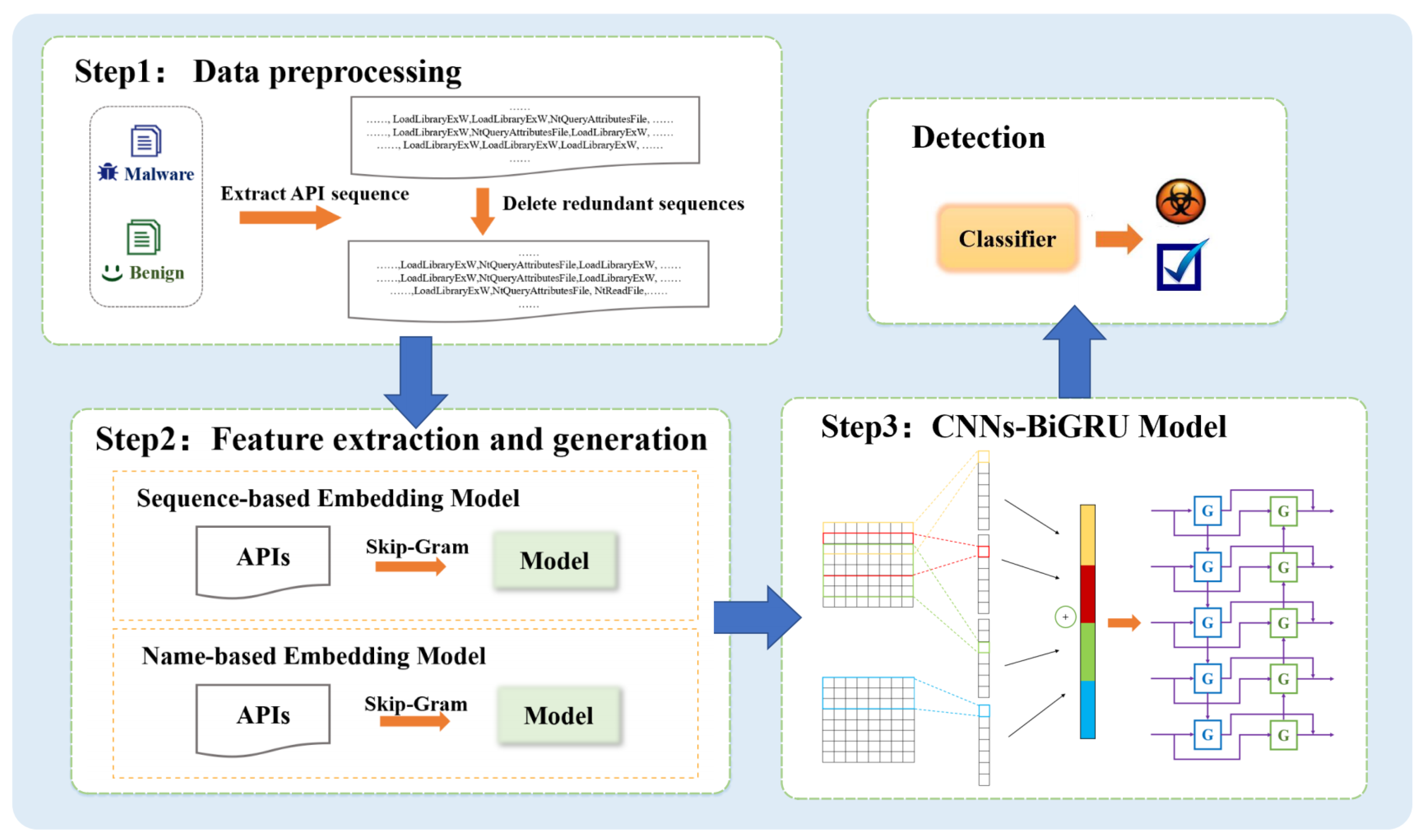
3. Methodology
3.1. Data Preprocessing
3.2. Feature Extraction and Generation
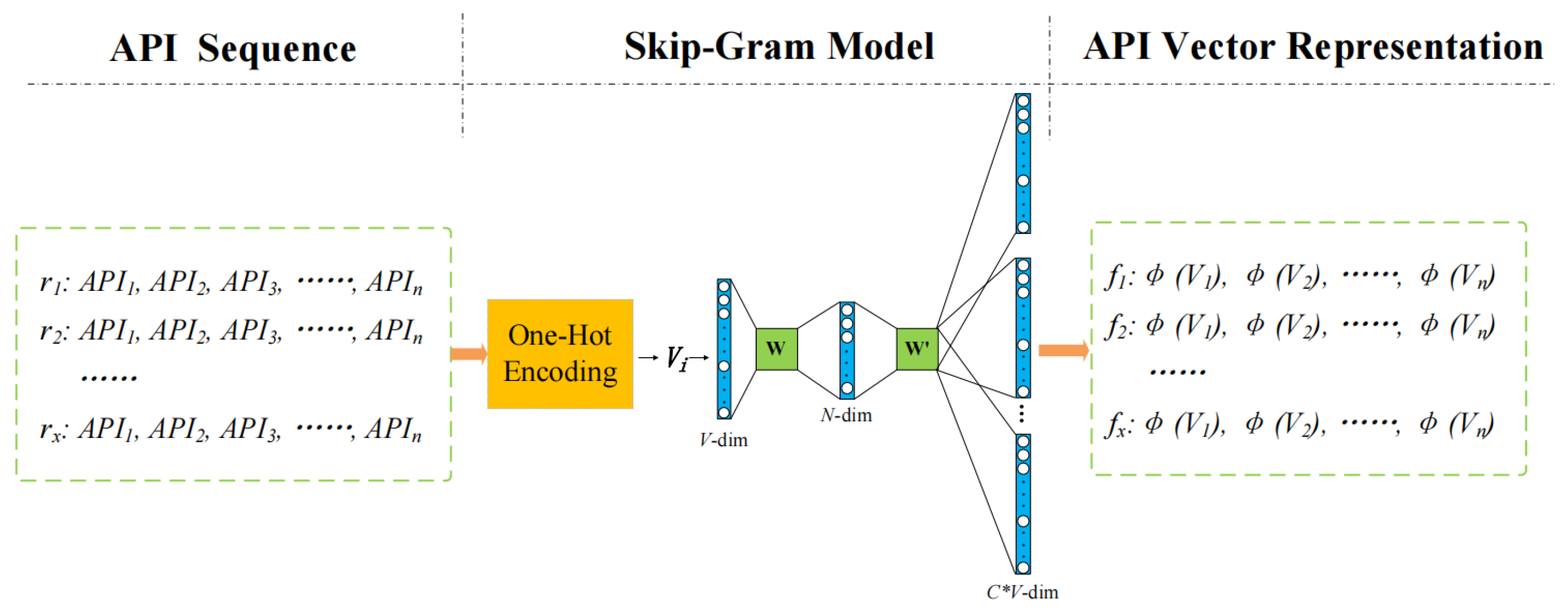
3.2.1. Sequence-Based Embedding
3.2.2. Name-Based Embedding
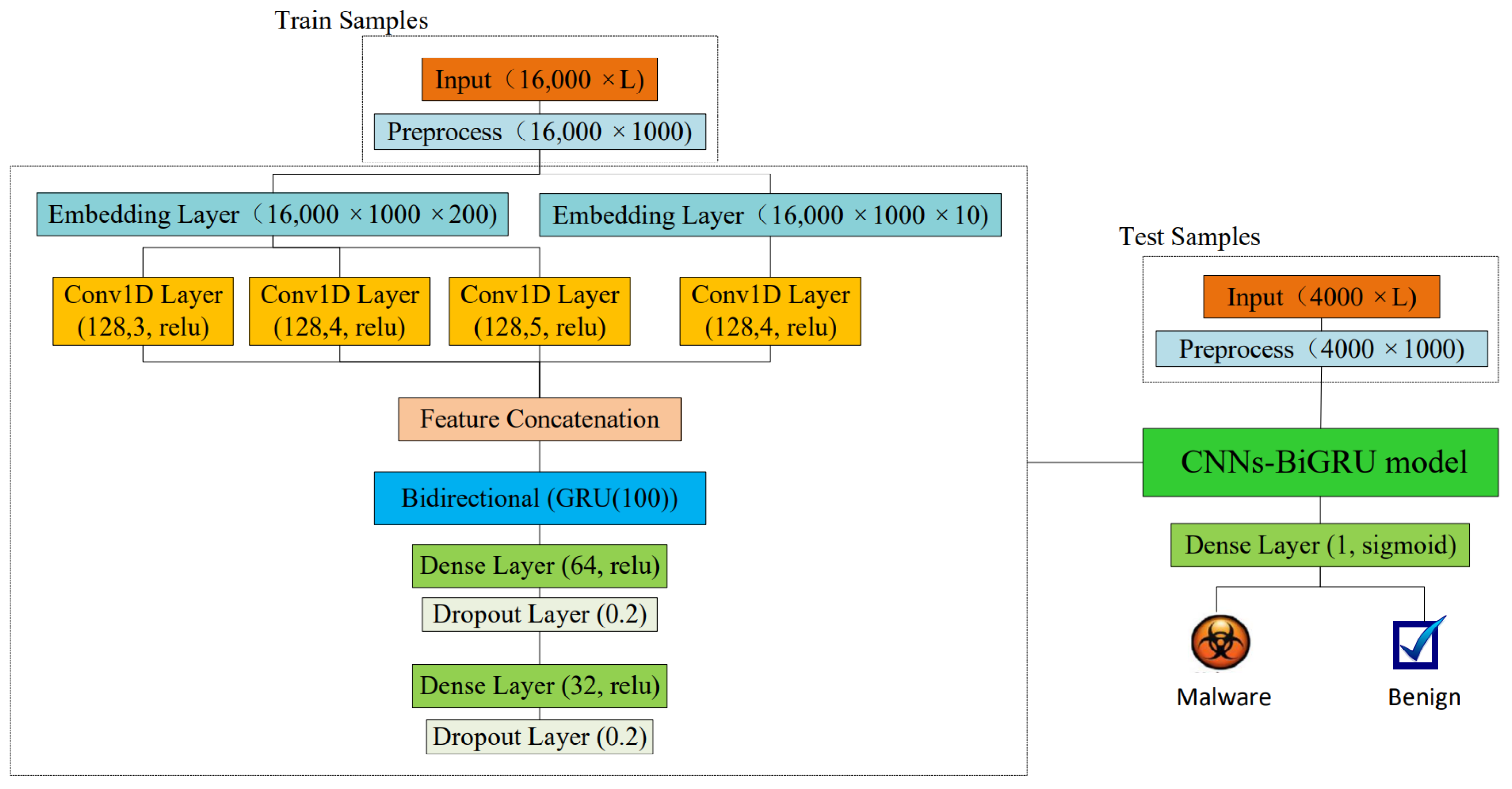
3.3. CNNs-BiGRU Model
4. Dataset and Evaluation Methods
4.1. Experimental Design
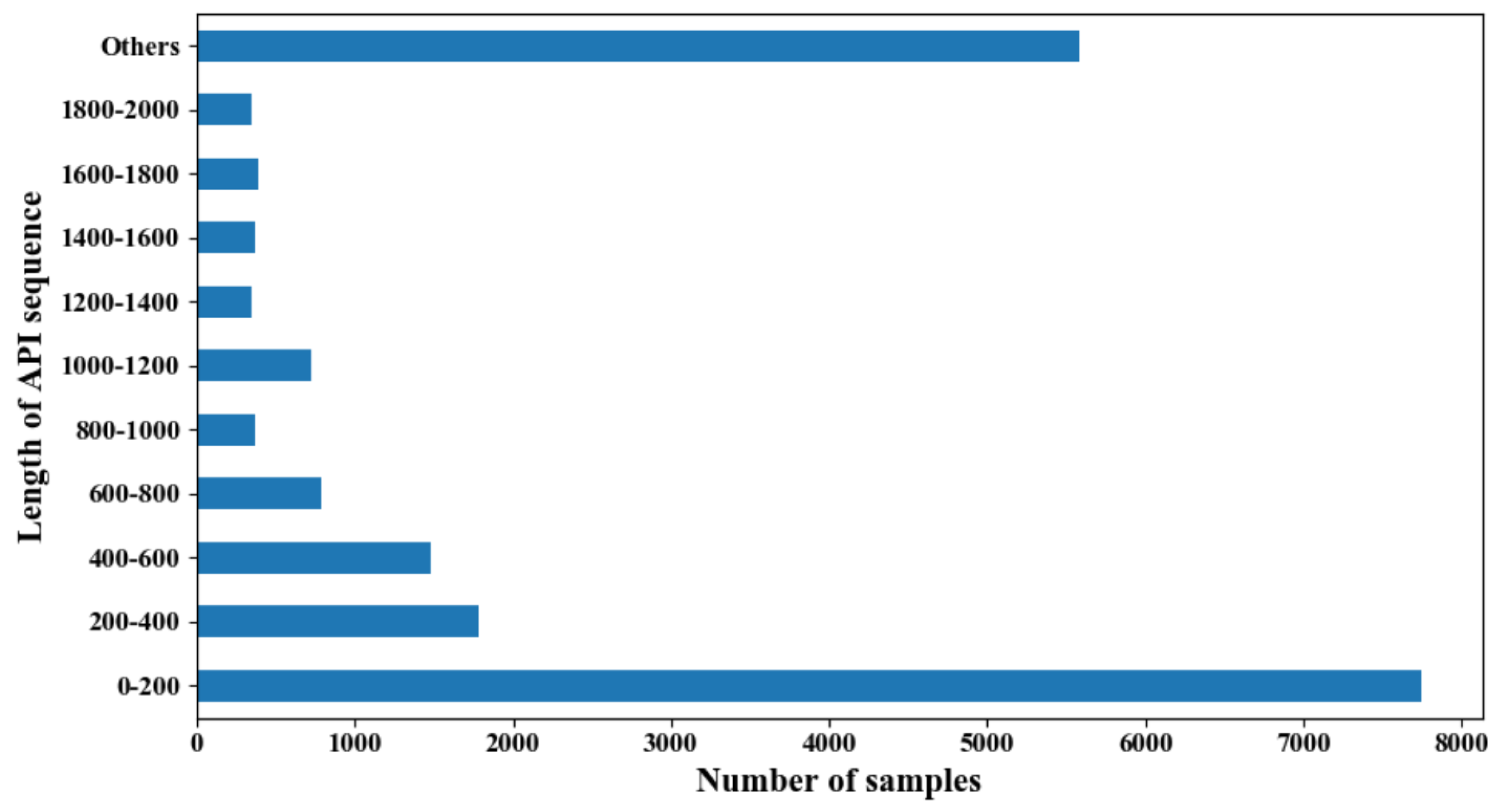
4.1.1. Dataset
4.1.2. Experimental Setup
4.2. Evaluation Metrics
4.3. Experimental Results
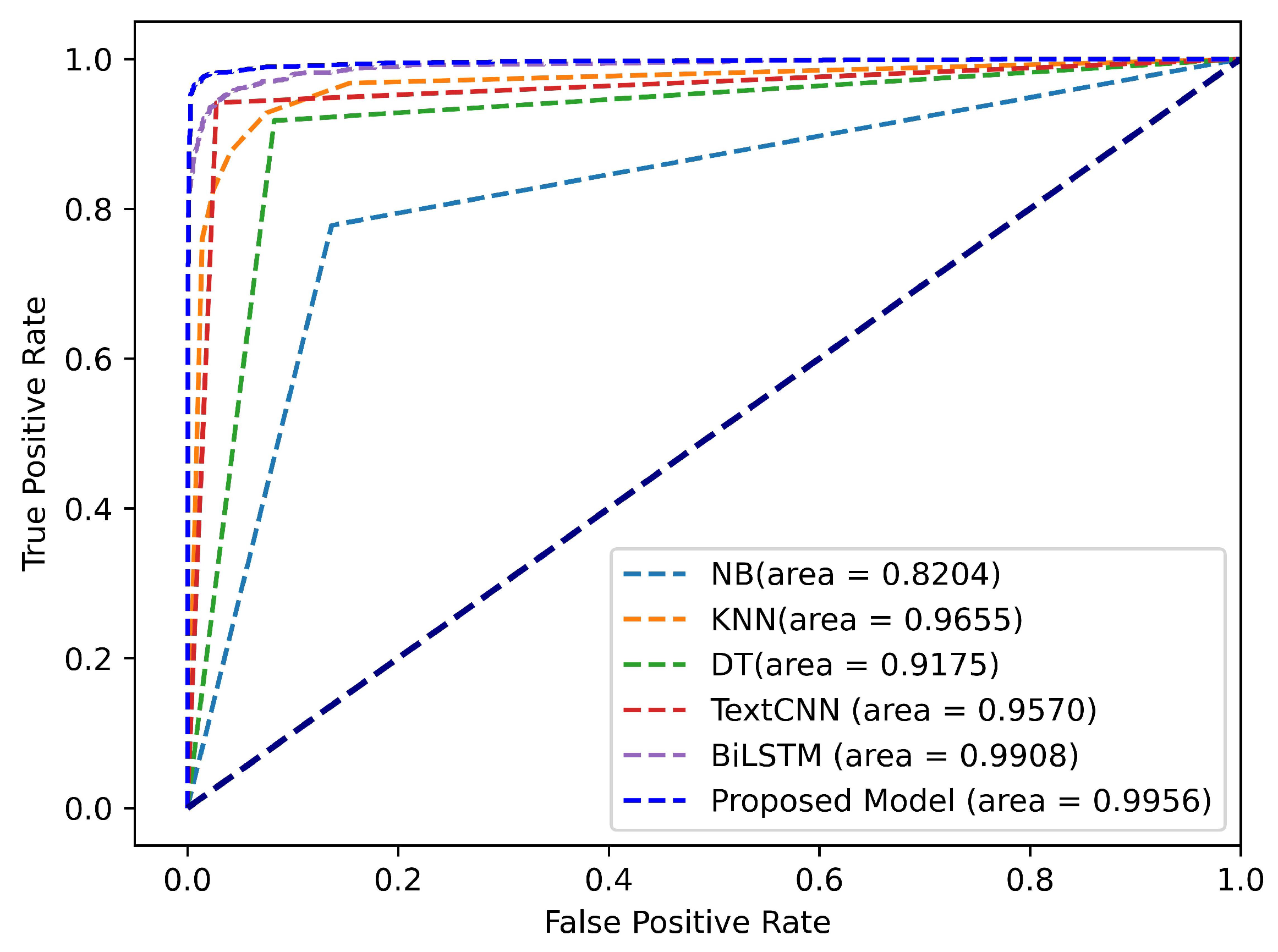
4.3.1. Comparison with Baselines
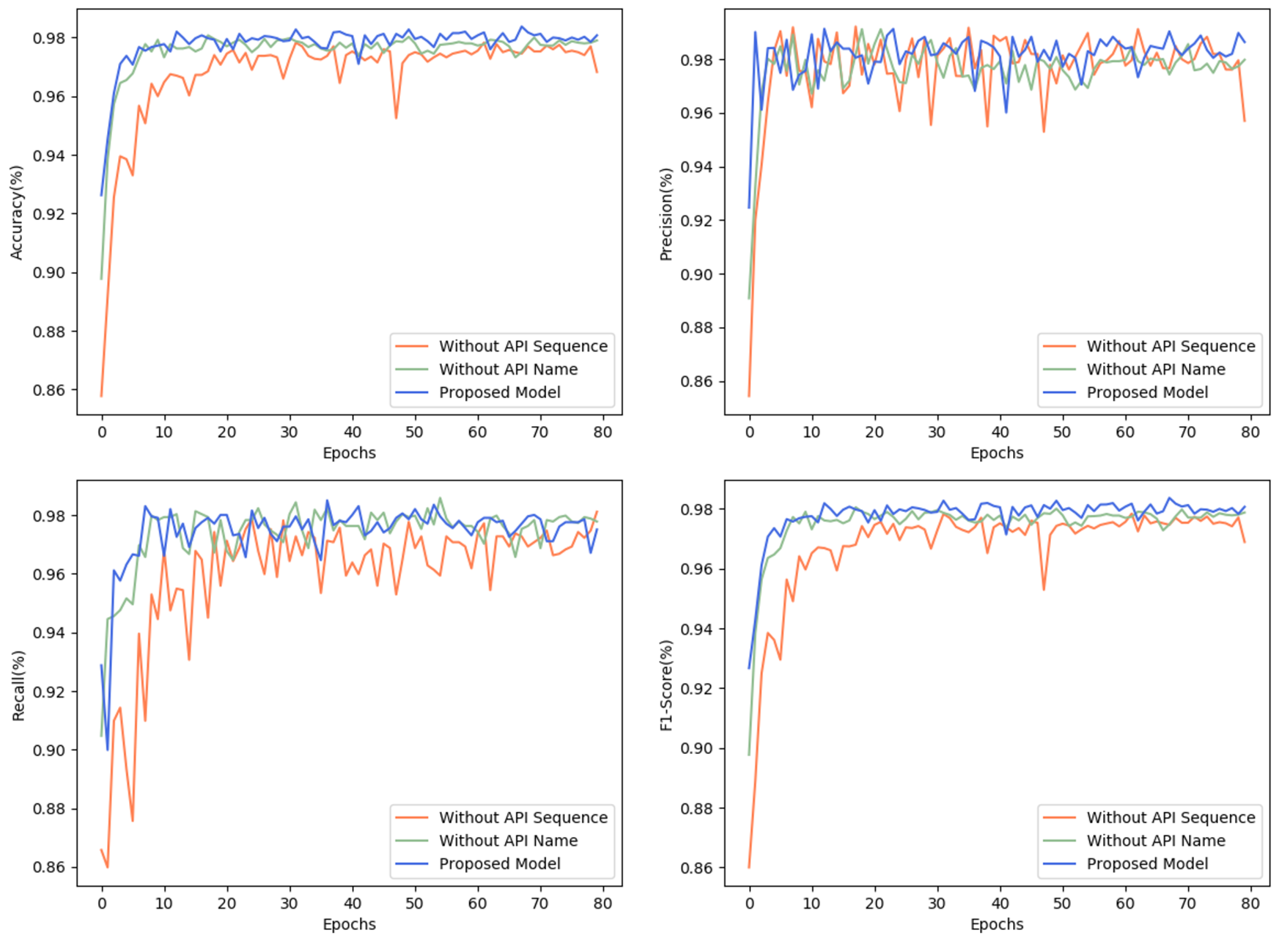
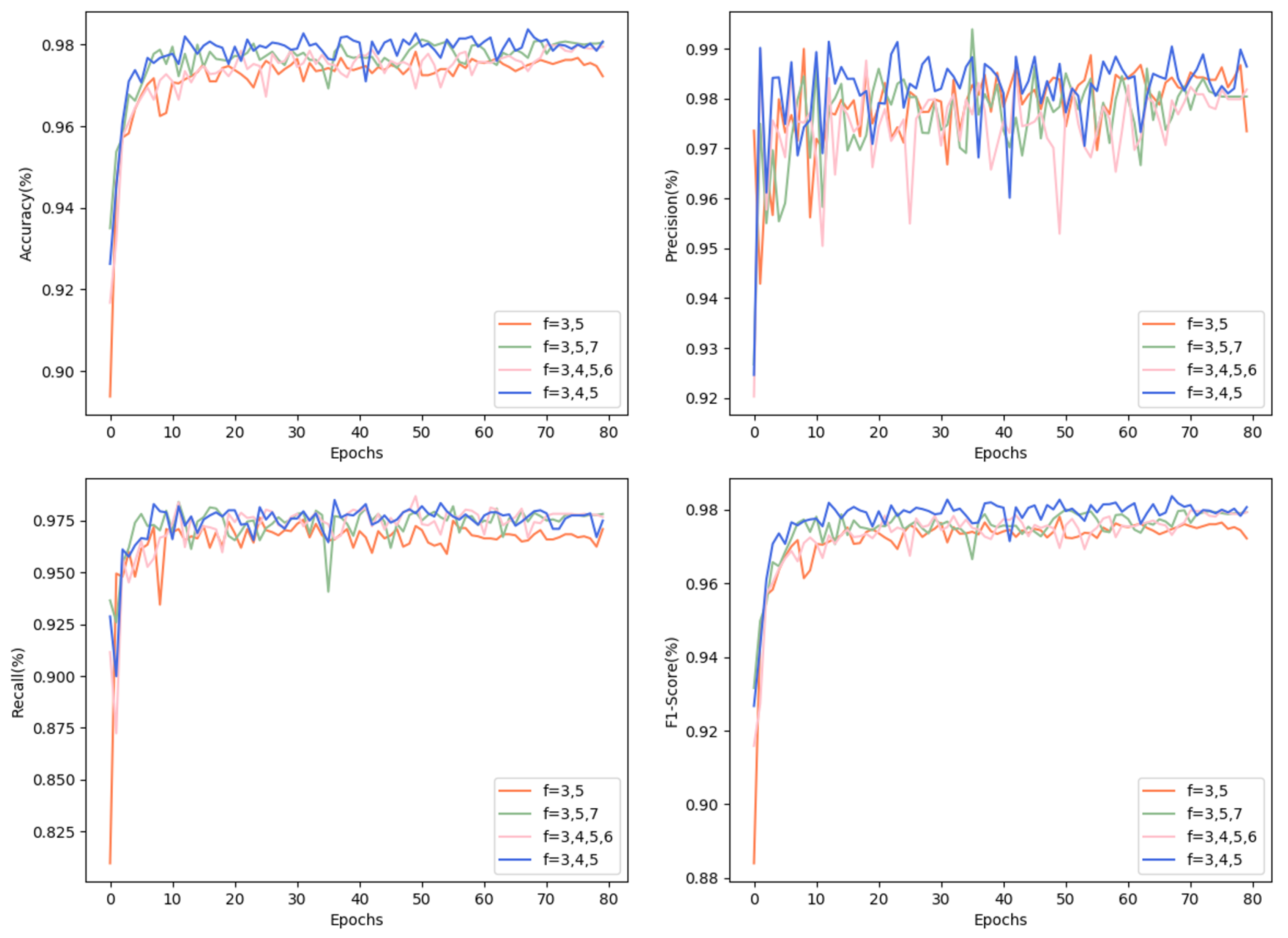
4.3.2. Ablation Studies
- Feature processing: a set of experiments is used to verify the detection effectiveness of various feature processing methods, networks only the contextual semantic information about the sequence of API calls, networks only the semantic structure for the names of API calls and statistical features, and networks with both.
- CNNs: by a set of experiments to observe the model effects of API sequences of different lengths, two convolutional layers with the first filter stride of 3 and the second filter stride of 5; three convolutional layers with kernel strides of 3, 4, and 5; three convolutional layers with kernel strides of 3, 5, and 7; and four convolutional layers with kernel strides of 3, 4, 5, and 6.
- BiGRU: a set of experiments are to understand the impact of the pact of the BiGRU layer, the model has no BiGRU, only one unidirectional GRU, and BiGRU.
4.3.3. Model Evaluation
5. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Zhao, D.; Xiao, G.; Wang, Z.; Wang, L.; Xu, L. Minimum dominating set of multiplex networks: Definition, application, and identification. IEEE Trans. Syst. Man Cybern. Syst. 2020, 51, 7823–7837. [Google Scholar] [CrossRef]
- Xu, L.; Wang, B.; Wu, X.; Zhao, D.; Zhang, L.; Wang, Z. Detecting Semantic Attack in SCADA System: A Behavioral Model Based on Secondary Labeling of States-Duration Evolution Graph. IEEE Trans. Netw. Sci. Eng. 2021, 9, 703–715. [Google Scholar] [CrossRef]
- Han, W.; Xue, J.; Wang, Y.; Huang, L.; Kong, Z.; Mao, L. MalDAE: Detecting and explaining malware based on correlation and fusion of static and dynamic characteristics. Comput. Secur. 2019, 83, 208–233. [Google Scholar] [CrossRef]
- Korczynski, D.; Yin, H. Capturing malware propagations with code injections and code-reuse attacks. In Proceedings of the 2017 ACM SIGSAC Conference on Computer and Communications Security, Dallas, TX, USA, 30 October–3 November 2017; pp. 1691–1708. [Google Scholar]
- Xu, L.; Wang, B.; Yang, M.; Zhao, D.; Han, J. Multi-Mode Attack Detection and Evaluation of Abnormal States for Industrial Control Network. J. Comput. Res. Dev. 2021, 58, 2333–2349. [Google Scholar]
- Cesare, S.; Xiang, Y.; Zhou, W. Control flow-based malware variantdetection. IEEE Trans. Dependable Secur. Comput. 2013, 11, 307–317. [Google Scholar] [CrossRef]
- Galal, H.S.; Mahdy, Y.B.; Atiea, M.A. Behavior-based features model for malware detection. J. Comput. Virol. Hacking Tech. 2016, 12, 59–67. [Google Scholar] [CrossRef]
- Ijaz, M.; Durad, M.H.; Ismail, M. Static and dynamic malware analysis using machine learning. In Proceedings of the 2019 16th International Bhurban Conference on Applied Sciences and Technology (IBCAST), Islamabad, Pakistan, 8–12 January 2019; pp. 687–691. [Google Scholar]
- Zhao, Z.; Yang, S.; Zhao, D. A New Framework for Visual Classification of Multi-Channel Malware Based on Transfer Learning. Appl. Sci. 2023, 13, 2484. [Google Scholar] [CrossRef]
- Moser, A.; Kruegel, C.; Kirda, E. Limits of static analysis for malware detection. In Proceedings of the Twenty-Third Annual Computer Security Applications Conference (ACSAC 2007), Miami Beach, FL, USA, 10–14 December 2007; pp. 421–430. [Google Scholar]
- Ye, Y.; Li, T.; Adjeroh, D.; Iyengar, S.S. A survey on malware detection using data mining techniques. ACM Comput. Surv. (CSUR) 2017, 50, 1–40. [Google Scholar] [CrossRef]
- Burnap, P.; French, R.; Turner, F.; Jones, K. Malware classification using self organising feature maps and machine activity data. Comput. Secur. 2018, 73, 399–410. [Google Scholar] [CrossRef]
- Ucci, D.; Aniello, L.; Baldoni, R. Survey of machine learning techniques for malware analysis. Comput. Secur. 2019, 81, 123–147. [Google Scholar] [CrossRef]
- Bazrafshan, Z.; Hashemi, H.; Fard, S.M.H.; Hamzeh, A. A survey on heuristic malware detection techniques. In Proceedings of the 5th Conference on Information and Knowledge Technology, Shiraz, Iran, 22–24 May 2013; pp. 113–120. [Google Scholar]
- Cesare, S.; Xiang, Y. Software Similarity and Classification; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2012. [Google Scholar]
- Egele, M.; Scholte, T.; Kirda, E.; Kruegel, C. A survey on automated dynamic malware-analysis techniques and tools. ACM Comput. Surv. (CSUR) 2008, 44, 1–42. [Google Scholar] [CrossRef]
- Ki, Y.; Kim, E.; Kim, H.K. A novel approach to detect malware based on API call sequence analysis. Int. J. Distrib. Sens. Netw. 2015, 11, 659101. [Google Scholar] [CrossRef]
- Pektaş, A.; Acarman, T. Classification of malware families based on runtime behaviors. J. Inf. Secur. Appl. 2017, 37, 91–100. [Google Scholar] [CrossRef]
- Palumbo, P.; Sayfullina, L.; Komashinskiy, D.; Eirola, E.; Karhunen, J. A pragmatic android malware detection procedure. Comput. Secur. 2017, 70, 689–701. [Google Scholar] [CrossRef]
- Ding, Y.; Yuan, X.; Tang, K.; Xiao, X.; Zhang, Y. A fast malware detection algorithm based on objective-oriented association mining. Comput. Secur. 2013, 39, 315–324. [Google Scholar] [CrossRef]
- Miao, Q.; Liu, J.; Cao, Y.; Song, J. Malware detection using bilayer behavior abstraction and improved one-class support vector machines. Int. J. Inf. Secur. 2016, 15, 361–379. [Google Scholar] [CrossRef]
- Shalaginov, A.; Franke, K. Automated intelligent multinomial classification of malware species using dynamic behavioural analysis. In Proceedings of the 2016 14th Annual Conference on Privacy, Security and Trust (PST), Auckland, New Zealand, 12–14 December 2016; pp. 70–77. [Google Scholar]
- Xu, L.; Wang, B.; Wang, L.; Zhao, D.; Han, X.; Yang, S. PLC-SEIFF: A programmable logic controller security incident forensics framework based on automatic construction of security constraints. Comput. Secur. 2020, 92, 101749. [Google Scholar] [CrossRef]
- Tran, T.K.; Sato, H. NLP-based approaches for malware classification from API sequences. In Proceedings of the 2017 21st Asia Pacific Symposium on Intelligent and Evolutionary Systems (IES), Hanoi, Vietnam, 15–17 November 2017; pp. 101–105. [Google Scholar]
- Kim, C.W. Ntmaldetect: A machine learning approach to malware detection using native api system calls. arXiv 2018, arXiv:1802.05412. [Google Scholar]
- Salehi, Z.; Sami, A.; Ghiasi, M. MAAR: Robust features to detect malicious activity based on API calls, their arguments and return values. Eng. Appl. Artif. Intell. 2017, 59, 93–102. [Google Scholar] [CrossRef]
- Huang, X.; Ma, L.; Yang, W.; Zhong, Y. A method for windows malware detection based on deep learning. J. Signal Process. Syst. 2021, 93, 265–273. [Google Scholar] [CrossRef]
- Pascanu, R.; Stokes, J.W.; Sanossian, H.; Marinescu, M.; Thomas, A. Malware classification with recurrent networks. In Proceedings of the 2015 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), South Brisbane, QLD, Australia, 19–24 April 2015; pp. 1916–1920. [Google Scholar]
- Zhang, Z.; Qi, P.; Wang, W. Dynamic malware analysis with feature engineering and feature learning. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 1210–1217. [Google Scholar]
- Kang, J.; Jang, S.; Li, S.; Jeong, Y.S.; Sung, Y. Long short-term memory-based malware classification method for information security. Comput. Electr. Eng. 2019, 77, 366–375. [Google Scholar] [CrossRef]
- Amer, E.; Zelinka, I. A dynamic Windows malware detection and prediction method based on contextual understanding of API call sequence. Comput. Secur. 2020, 92, 101760. [Google Scholar] [CrossRef]
- Wang, P.; Tang, Z.; Wang, J. A novel few-shot malware classification approach for unknown family recognition with multi-prototype modeling. Comput. Secur. 2021, 106, 102273. [Google Scholar] [CrossRef]
- Moskovitch, R.; Feher, C.; Tzachar, N.; Berger, E.; Gitelman, M.; Dolev, S.; Elovici, Y. Unknown malcode detection using opcode representation. In Proceedings of the European Conference on Intelligence and Security Informatics, Esbjerg, Denmark, 3–5 December 2008; Springer: Berlin/Heidelberg, Germany, 2008; pp. 204–215. [Google Scholar]
- Shabtai, A.; Moskovitch, R.; Elovici, Y.; Glezer, C. Detection of malicious code by applying machine learning classifiers on static features: A state-of-the-art survey. Inf. Secur. Tech. Rep. 2009, 14, 16–29. [Google Scholar] [CrossRef]
- Chai, Y.; Du, L.; Qiu, J.; Yin, L.; Tian, Z. Dynamic prototype network based on sample adaptation for few-shot malware detection. IEEE Trans. Knowl. Data Eng. 2022, 35, 4754–4766. [Google Scholar] [CrossRef]
- Sami, A.; Yadegari, B.; Rahimi, H.; Peiravian, N.; Hashemi, S.; Hamze, A. Malware detection based on mining API calls. In Proceedings of the 2010 ACM Symposium on Applied Computing, Sierre, Switzerland, 22–26 March 2010; pp. 1020–1025. [Google Scholar]
- Christodorescu, M.; Jha, S.; Kruegel, C. Mining specifications of malicious behavior. In Proceedings of the 6th Joint Meeting of the European Software Engineering Conference and the ACM SIGSOFT Symposium on the Foundations of Software Engineering, Dubrovnik, Croatia, 3–7 September 2007; pp. 5–14. [Google Scholar]
- Tobiyama, S.; Yamaguchi, Y.; Shimada, H.; Ikuse, T.; Yagi, T. Malware detection with deep neural network using process behavior. In Proceedings of the 2016 IEEE 40th Annual Computer Software and Applications Conference (COMPSAC), Atlanta, GA, USA, 10–14 June 2016; Volume 2, pp. 577–582. [Google Scholar]
- Ndibanje, B.; Kim, K.H.; Kang, Y.J.; Kim, H.H.; Kim, T.Y.; Lee, H.J. Cross-method-based analysis and classification of malicious behavior by api calls extraction. Appl. Sci. 2019, 9, 239. [Google Scholar] [CrossRef]
- Zhang, X.; Zhang, Y.; Zhong, M.; Ding, D.; Cao, Y.; Zhang, Y.; Zhang, M.; Yang, M. Enhancing state-of-the-art classifiers with api semantics to detect evolved android malware. In Proceedings of the 2020 ACM SIGSAC Conference on Computer and Communications Security, Virtual, 9–13 November 2020; pp. 757–770. [Google Scholar]
- Rosenberg, I.; Shabtai, A.; Rokach, L.; Elovici, Y. Generic black-box end-to-end attack against state of the art API call based malware classifiers. In Proceedings of the International Symposium on Research in Attacks, Intrusions, and Defenses, Crete, Greece, 10–12 September 2018; Springer: Berlin/Heidelberg, Germany, 2018; pp. 490–510. [Google Scholar]
- Chen, X.; Hao, Z.; Li, L.; Cui, L.; Zhu, Y.; Ding, Z.; Liu, Y. CruParamer: Learning on Parameter-Augmented API Sequences for Malware Detection. IEEE Trans. Inf. Forensics Secur. 2022, 17, 788–803. [Google Scholar] [CrossRef]
- David, O.E.; Netanyahu, N.S. Deepsign: Deep learning for automatic malware signature generation and classification. In Proceedings of the 2015 International Joint Conference on Neural Networks (IJCNN), Killarney, Ireland, 12–17 July 2015; pp. 1–8. [Google Scholar]
- Kakisim, A.G.; Gulmez, S.; Sogukpinar, I. Sequential opcode embedding-based malware detection method. Comput. Electr. Eng. 2022, 98, 107703. [Google Scholar] [CrossRef]
- Liu, Y.; Wang, Y. A robust malware detection system using deep learning on API calls. In Proceedings of the 2019 IEEE 3rd Information Technology, Networking, Electronic and Automation Control Conference (ITNEC), Chengdu, China, 15–17 March 2019; pp. 1456–1460. [Google Scholar]
- Kolosnjaji, B.; Zarras, A.; Webster, G.; Eckert, C. Deep learning for classification of malware system call sequences. In Proceedings of the Australasian Joint Conference on Artificial Intelligence, Hobart, TAS, Australia, 5–8 December 2016; Springer: Berlin/Heidelberg, Germany, 2016; pp. 137–149. [Google Scholar]
- Catak, F.O.; Yazı, A.F.; Elezaj, O.; Ahmed, J. Deep learning based Sequential model for malware analysis using Windows exe API Calls. PeerJ Comput. Sci. 2020, 6, e285. [Google Scholar] [CrossRef]
- Li, C.; Lv, Q.; Li, N.; Wang, Y.; Sun, D.; Qiao, Y. A novel deep framework for dynamic malware detection based on API sequence intrinsic features. Comput. Secur. 2022, 116, 102686. [Google Scholar] [CrossRef]
- Ketkar, N.; Santana, E. Deep Learning with Python; Springer: Berlin/Heidelberg, Germany, 2017; Volume 1. [Google Scholar]
- Rezaeinia, S.M.; Rahmani, R.; Ghodsi, A.; Veisi, H. Sentiment analysis based on improved pre-trained word embeddings. Expert Syst. Appl. 2019, 117, 139–147. [Google Scholar] [CrossRef]
- Alami, N.; Meknassi, M.; En-nahnahi, N. Enhancing unsupervised neural networks based text summarization with word embedding and ensemble learning. Expert Syst. Appl. 2019, 123, 195–211. [Google Scholar] [CrossRef]
- Martinčić-Ipšić, S.; Miličić, T.; Todorovski, L. The influence of feature representation of text on the performance of document classification. Appl. Sci. 2019, 9, 743. [Google Scholar] [CrossRef]
- Hart, J.M. Windows System Programming; Pearson Education—Addison-Wesley Professional: San Francisco, CA, USA, 2010. [Google Scholar]
- Tang, C.; Xu, L.; Yang, B.; Tang, Y.; Zhao, D. GRU-Based Interpretable Multivariate Time Series Anomaly Detection in Industrial Control System. Comput. Secur. 2023, 127, 103094. [Google Scholar] [CrossRef]
- Invernizzi, L.; Miskovic, S.; Torres, R.; Kruegel, C.; Saha, S.; Vigna, G.; Lee, S.J.; Mellia, M. Nazca: Detecting malware distribution in large-scale networks. In Proceedings of the NDSS, San Diego, CA, USA, 23–26 February 2014; Volume 14, pp. 23–26. [Google Scholar]
- Moreno-Torres, J.G.; Raeder, T.; Alaiz-Rodríguez, R.; Chawla, N.V.; Herrera, F. A unifying view on dataset shift in classification. Pattern Recognit. 2012, 45, 521–530. [Google Scholar] [CrossRef]




| Hyper-Parameter | Value |
|---|---|
| Window sizes in Skip-Gram model | 5 |
| The minimum count in Skip-Gram model | 3 |
| Units of embedding layer in Sequence-based model | 200 |
| Units of embedding layer in Name-based model | 10 |
| Activation function of convolution layers | Relu |
| Bi-GRU layer | 1 |
| Units of Bi-GRU layer | 100 |
| Units of the first dense layer | 64 |
| Units of the second dense layer | 32 |
| Activation function of dense layers | Relu |
| Dropout Ratio | 0.2 |
| Learning rate |
| Embedding Model | Embedding Vector Size | Accuracy | Precision | Recall | F1-Score |
|---|---|---|---|---|---|
| CBOW | 100 | 0.9770 | 0.9793 | 0.9743 | 0.9780 |
| 128 | 0.9720 | 0.9724 | 0.9715 | 0.9719 | |
| 200 | 0.9715 | 0.9709 | 0.9719 | 0.9714 | |
| Skip-Gram | 100 | 0.9775 | 0.9843 | 0.9706 | 0.9773 |
| 128 | 0.9828 | 0.9870 | 0.9789 | 0.9827 | |
| 200 | 0.9755 | 0.9827 | 0.9680 | 0.9754 |
| Accuracy | Precision | Recall | F1-Score | |
|---|---|---|---|---|
| NB | 0.8198 | 0.8518 | 0.7768 | 0.8126 |
| KNN | 0.9175 | 0.9556 | 0.8767 | 0.9145 |
| DT | 0.9178 | 0.9184 | 0.9180 | 0.9182 |
| Text-CNN | 0.9443 | 0.9587 | 0.9298 | 0.9440 |
| BiLSTM | 0.9743 | 0.9766 | 0.9723 | 0.9758 |
| CNNs-BiGRU | 0.9828 | 0.9870 | 0.9789 | 0.9827 |
| Accuracy | Precision | Recall | F1-Score | Structure | Semantic | |
|---|---|---|---|---|---|---|
| Kolosnjaji et al. [46] | 0.9660 | 0.9569 | 0.9775 | 0.9671 | ✗ | ✗ |
| Liu et al. [45] | 0.9668 | 0.9763 | 0.9575 | 0.9668 | ✗ | ✔ |
| Catak et al. [47] | 0.9685 | 0.9720 | 0.9642 | 0.9681 | ✗ | ✗ |
| Li et al. [48] | 0.9738 | 0.9774 | 0.9712 | 0.9743 | ✔ | ✗ |
| Proposed Model | 0.9828 | 0.9870 | 0.9789 | 0.9827 | ✔ | ✔ |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, Y.; Yang, S.; Xu, L.; Li, X.; Zhao, D. A Malware Detection Framework Based on Semantic Information of Behavioral Features. Appl. Sci. 2023, 13, 12528. https://doi.org/10.3390/app132212528
Zhang Y, Yang S, Xu L, Li X, Zhao D. A Malware Detection Framework Based on Semantic Information of Behavioral Features. Applied Sciences. 2023; 13(22):12528. https://doi.org/10.3390/app132212528
Chicago/Turabian StyleZhang, Yuxin, Shumian Yang, Lijuan Xu, Xin Li, and Dawei Zhao. 2023. "A Malware Detection Framework Based on Semantic Information of Behavioral Features" Applied Sciences 13, no. 22: 12528. https://doi.org/10.3390/app132212528
APA StyleZhang, Y., Yang, S., Xu, L., Li, X., & Zhao, D. (2023). A Malware Detection Framework Based on Semantic Information of Behavioral Features. Applied Sciences, 13(22), 12528. https://doi.org/10.3390/app132212528