
Individualized Stress Mobile Sensing Using Self-Supervised Pre-Training



Abstract
:1. Introduction
- We introduce a novel “personalized SSL” paradigm to address the common real-world situation of large datasets with few training labels. This solution enables mobile sensing systems to predict traditionally subjective classes such as stress. This interaction paradigm is similar to how Apple’s Face ID works: once the face recognition system is provided with only a few examples provided by the end users, it can be used repeatedly to unlock the device. In this case, the labels are stress predictions, rather than identity predictions, and the model input is wearable biosignals, rather than a face image.
- We evaluated this novel mobile sensing methodology on a real-world biosignal dataset with stress labels: the Wearable Stress and Affect Detection (WESAD) dataset.
2. Related Work
2.1. Stress Assessment Using Biosignals
2.2. SSL on Biosignals
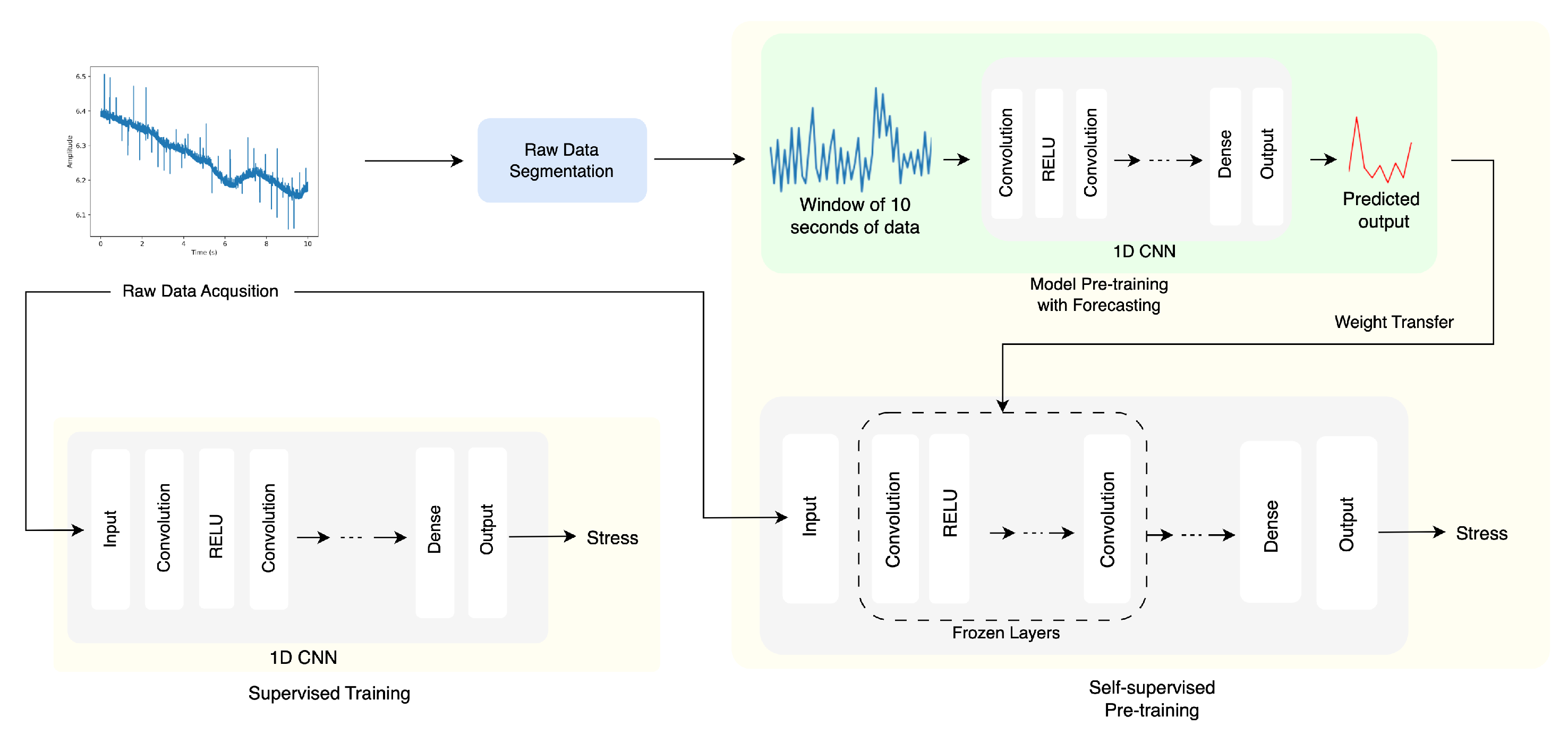
3. Methodology
- Model A: stress prediction via supervised learning;
- Model B: stress prediction with a model pre-trained with SSL and fine-tuned using the same supervised learning strategy as Model A.
3.1. Dataset
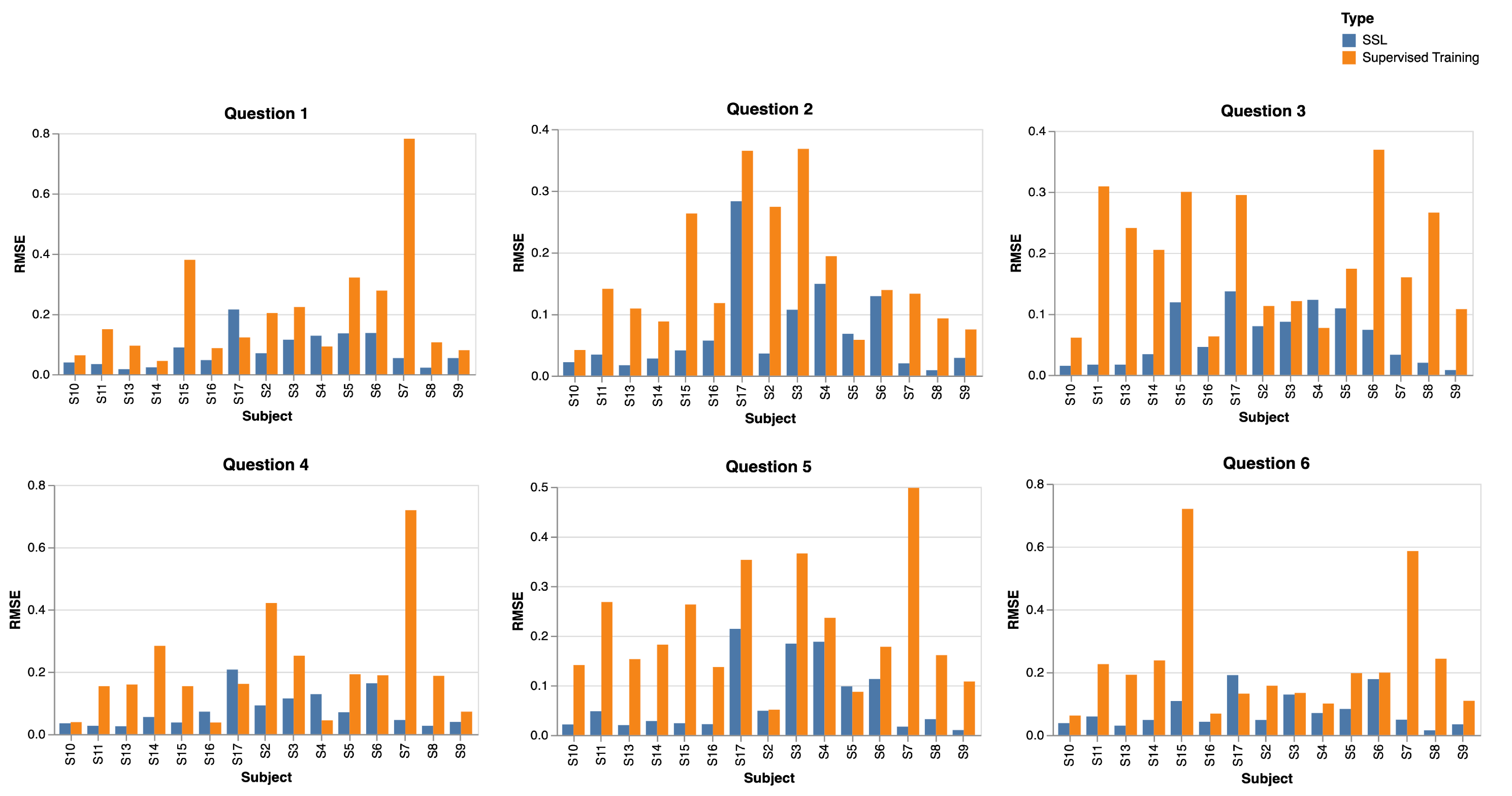
- Question 1: I feel at ease.
- Question 2: I feel nervous.
- Question 3: I am jittery.
- Question 4: I am relaxed.
- Question 5: I am worried.
- Question 6: I feel pleasant.
3.2. Label Representation
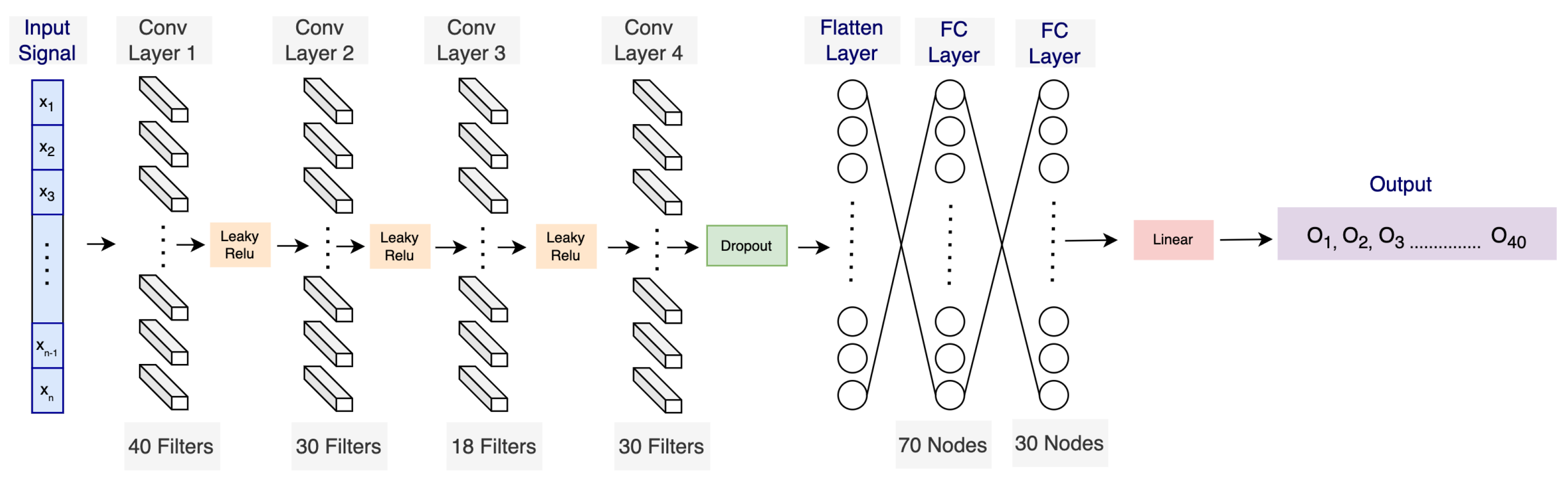
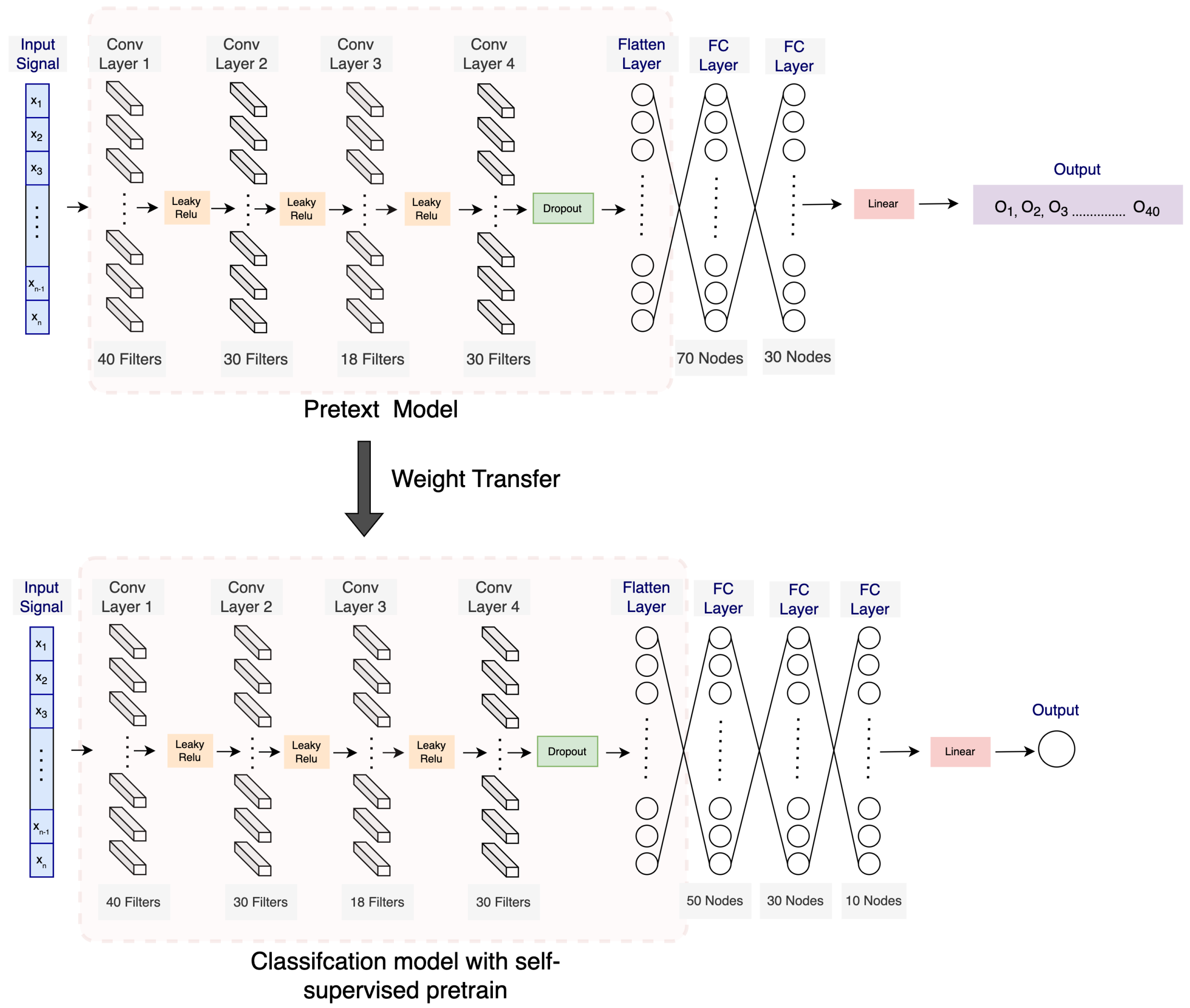
3.3. Self-Supervised Pre-Training
3.4. Downstream Stress-Prediction Task
3.5. Experimental Procedures
4. Results
4.1. Pre-Trained Models
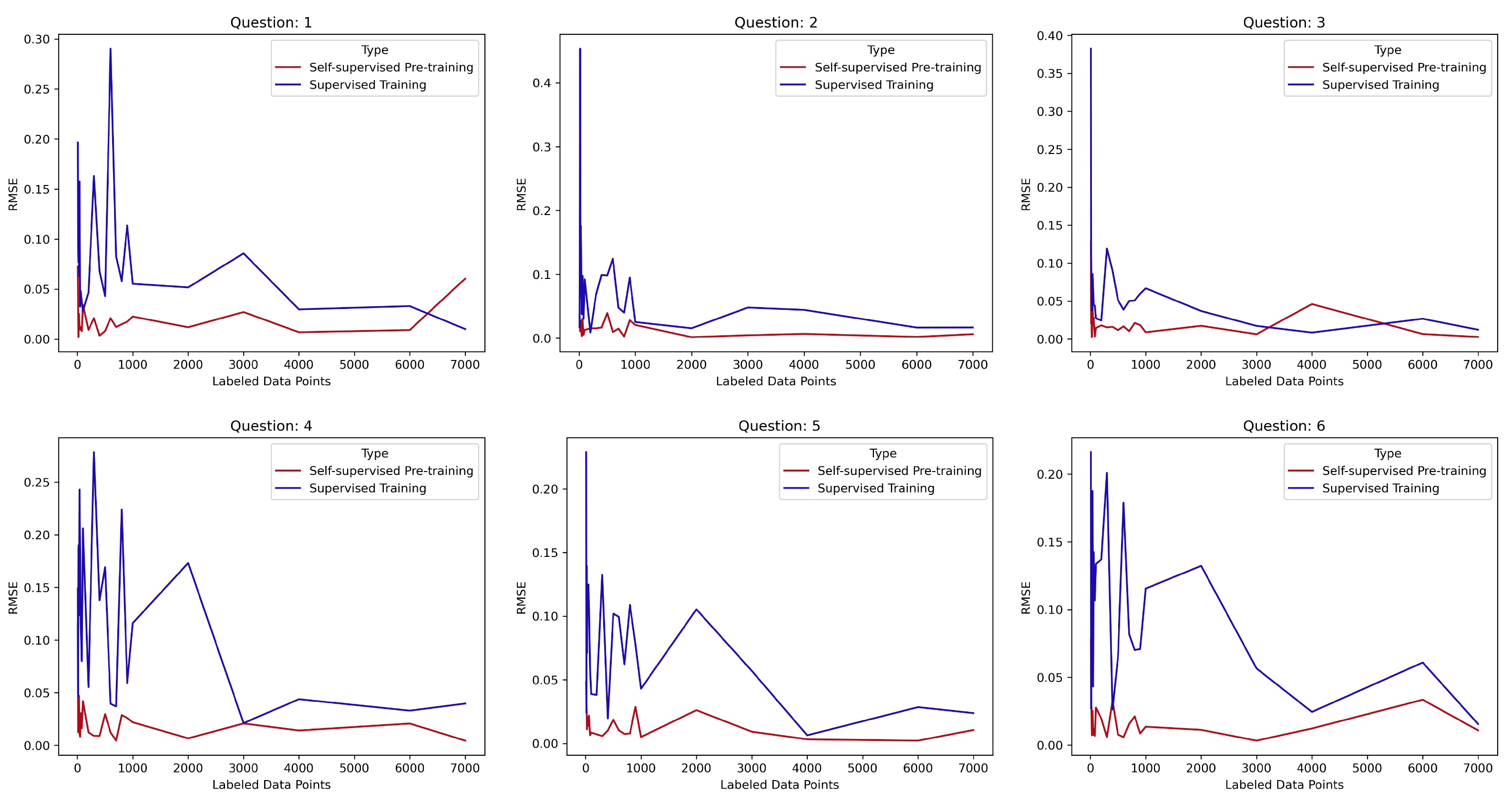
4.2. Evaluation Using Pre-Trained Models
4.3. Results for a Demonstrative User
5. Discussion
5.1. Implications for Mobile Sensing Systems
5.2. Limitations and Future Work
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Cohen, S.; Janicki-Deverts, D.; Miller, G.E. Psychological stress and disease. JAMA 2007, 298, 1685–1687. [Google Scholar] [CrossRef] [PubMed]
- Paredes, P.; Chan, M. CalmMeNow: Exploratory Research and Design of Stress Mitigating Mobile Interventions. In Proceedings of the CHI’11 Extended Abstracts on Human Factors in Computing Systems, Vancouver, BC, Canada, 7–12 May 2011. [Google Scholar] [CrossRef]
- Giannakakis, G.; Grigoriadis, D.; Giannakaki, K.; Simantiraki, O.; Roniotis, A.; Tsiknakis, M. Review on psychological stress detection using biosignals. IEEE Trans. Affect. Comput. 2019, 13, 440–460. [Google Scholar] [CrossRef]
- Healey, J.; Picard, R. Detecting stress during real-world driving tasks using physiological sensors. IEEE Trans. Intell. Transp. Syst. 2005, 6, 156–166. [Google Scholar] [CrossRef]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef]
- Hannun, A.Y.; Rajpurkar, P.; Haghpanahi, M.; Tison, G.H.; Bourn, C.; Turakhia, M.P.; Ng, A.Y. Cardiologist-level arrhythmia detection and classification in ambulatory electrocardiograms using a deep neural network. Nat. Med. 2019, 25, 65–69. [Google Scholar] [CrossRef]
- Schmidt, P.; Reiss, A.; Duerichen, R.; Van Laerhoven, K. Wearable affect and stress recognition: A review. arXiv 2018, arXiv:1811.08854. [Google Scholar]
- Geiger, R.S.; Cope, D.; Ip, J.; Lotosh, M.; Shah, A.; Weng, J.; Tang, R. “Garbage in, Garbage out” Revisited: What Do Machine Learning Application Papers Report about Human-Labeled Training Data? Quant. Sci. Stud. 2021, 2, 795–827. Available online: https://direct.mit.edu/qss/article-pdf/2/3/795/1970760/qss_a_00144.pdf (accessed on 5 November 2021). [CrossRef]
- Dharmawan, Z. Analysis of Computer Games Player Stress Level Using EEG Data. In Proceedings of the 11th International Conference on Computer Games: AI, Animation, Mobile, Educational and Serious Games, La Rochelle, France, 21–23 November 2007; The University of Wolverhampton: Wolverhampton, UK, 2007. [Google Scholar]
- Wickramasuriya, D.S.; Qi, C.; Faghih, R.T. A state-space approach for detecting stress from electrodermal activity. In Proceedings of the 2018 40th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Honolulu, HI, USA, 18–21 July 2018. [Google Scholar]
- Spathis, D.; Perez-Pozuelo, I.; Brage, S.; Wareham, N.J.; Mascolo, C. Self-supervised transfer learning of physiological representations from free-living wearable data. In Proceedings of the Conference on Health, Inference, and Learning, Virtual, 8–10 April 2021. [Google Scholar]
- Zhu, L.; Ng, P.C.; Yu, Y.; Wang, Y.; Spachos, P.; Hatzinakos, D.; Plataniotis, K.N. Feasibility study of stress detection with machine learning through eda from wearable devices. In Proceedings of the ICC 2022—IEEE International Conference on Communications, Seoul, Republic of Korea, 16–20 May 2022. [Google Scholar]
- Yadav, M.; Sakib, M.N.; Nirjhar, E.H.; Feng, K.; Behzadan, A.; Chaspari, T. Exploring Individual Differences of Public Speaking Anxiety in Real-Life and Virtual Presentations. IEEE Trans. Affect. Comput. 2020, 13, 1168–1182. [Google Scholar] [CrossRef]
- Schmidt, P.; Reiss, A.; Duerichen, R.; Marberger, C.; Van Laerhoven, K. Introducing wesad, a multimodal dataset for wearable stress and affect detection. In Proceedings of the ICMI ’18: International Conference on Multimodal Interaction, Boulder, CO, USA, 16–20 October 2022. [Google Scholar]
- Ninh, V.T.; Smyth, S.; Tran, M.T.; Gurrin, C. Analysing the performance of stress detection models on consumer-grade wearable devices. arXiv 2022, arXiv:2203.09669. [Google Scholar]
- Eren, E.; Navruz, T.S. Stress Detection with Deep Learning Using BVP and EDA Signals. In Proceedings of the 2022 International Congress on Human-Computer Interaction, Optimization and Robotic Applications (HORA), Ankara, Turkey, 9–11 June 2022. [Google Scholar]
- Pakarinen, T.; Pietilä, J.; Nieminen, H. Prediction of Self-Perceived Stress and Arousal Based on Electrodermal Activity. In Proceedings of the 2019 41st Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Berlin, Germany, 23–27 July 2019. [Google Scholar] [CrossRef]
- Kalimeri, K.; Saitis, C. Exploring multimodal biosignal features for stress detection during indoor mobility. In Proceedings of the 18th ACM International Conference on Multimodal Interaction, Tokyo, Japan, 12–16 November 2016. [Google Scholar]
- Chen, T.; Kornblith, S.; Norouzi, M.; Hinton, G. A simple framework for contrastive learning of visual representations. In Proceedings of the 37th International Conference on Machine Learning, Vienna, Austria, 13–18 July 2020. [Google Scholar]
- Grill, J.B.; Strub, F.; Altché, F.; Tallec, C.; Richemond, P.; Buchatskaya, E.; Doersch, C.; Avila Pires, B.; Guo, Z.; Gheshlaghi Azar, M.; et al. Bootstrap your own latent-a new approach to self-supervised learning. Adv. Neural Inf. Process. Syst. 2020, 33, 21271–21284. [Google Scholar]
- Zhang, J.; Ma, K. Rethinking the augmentation module in contrastive learning: Learning hierarchical augmentation invariance with expanded views. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022. [Google Scholar]
- Pöppelbaum, J.; Chadha, G.; Schwung, A. Contrastive learning based self-supervised time series analysis. Appl. Soft Comput. 2022, 117, 108397. [Google Scholar] [CrossRef]
- Matton, K.; Lewis, R.A.; Guttag, J.; Picard, R. Contrastive Learning of Electrodermal Activity Representations for Stress Detection. In Proceedings of the Conference on Health, Inference, and Learning, Cambridge, MA, USA, 13 June 2023; pp. 410–426. [Google Scholar]
- Kiyasseh, D.; Zhu, T.; Clifton, D.A. Clocs: Contrastive learning of cardiac signals across space, time, and patients. In Proceedings of the International Conference on Machine Learning, Virtual, 18–24 July 2021. [Google Scholar]
- Sarkar, P.; Etemad, A. Self-supervised ECG representation learning for emotion recognition. IEEE Trans. Affect. Comput. 2020, 13, 1541–1554. [Google Scholar] [CrossRef]
- Eldele, E.; Ragab, M.; Chen, Z.; Wu, M.; Kwoh, C.K.; Li, X.; Guan, C. Self-supervised contrastive representation learning for semi-supervised time series classification. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 1–15. [Google Scholar] [CrossRef] [PubMed]
- Yang, X.; Zhang, Z.; Cui, R. TimeCLR: A self-supervised contrastive learning framework for univariate time series representation. Knowl.-Based Syst. 2022, 245, 108606. [Google Scholar] [CrossRef]
- Sunmin, E.; Sunwoo, E.; Peter, W. SIM-CNN: Self-Supervised Individualized Multimodal Learning for Stress Prediction on Nurses Using Biosignals. medRxiv 2023. [Google Scholar] [CrossRef]
- Tanvir, I.; Peter, W. Personalized Prediction of Recurrent Stress Events Using Self-Supervised Learning on Multimodal Time-Series Data. In Proceedings of the AI & HCI Workshop at the 40th International Conference on Machine Learning (ICML), Honolulu, HI, USA, 23–29 July 2023. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Radford, A.; Narasimhan, K.; Salimans, T.; Sutskever, I. Improving language understanding by generative pre-training. OpenAI 2018. [Google Scholar]
- Ancillon, L.; Elgendi, M.; Menon, C. Machine learning for anxiety detection using biosignals: A review. Diagnostics 2022, 12, 1794. [Google Scholar] [CrossRef]
- Washington, P.; Mutlu, C.O.; Kline, A.; Paskov, K.; Stockham, N.T.; Chrisman, B.; Deveau, N.; Surhabi, M.; Haber, N.; Wall, D.P. Challenges and opportunities for machine learning classification of behavior and mental state from images. arXiv 2022, arXiv:2201.11197. [Google Scholar]
- Washington, P.; Voss, C.; Kline, A.; Haber, N.; Daniels, J.; Fazel, A.; De, T.; Feinstein, C.; Winograd, T.; Wall, D. SuperpowerGlass: A wearable aid for the at-home therapy of children with autism. Proc. ACM Interact. Mob. Wearable Ubiquitous Technol. 2017, 1, 1–22. [Google Scholar] [CrossRef]
- Washington, P.; Kalantarian, H.; Kent, J.; Husic, A.; Kline, A.; Leblanc, E.; Hou, C.; Mutlu, C.; Dunlap, K.; Penev, Y.; et al. Training an emotion detection classifier using frames from a mobile therapeutic game for children with developmental disorders. arXiv 2020, arXiv:2012.08678. [Google Scholar]
- Liapis, A.; Faliagka, E.; Katsanos, C.; Antonopoulos, C.; Voros, N. Detection of Subtle Stress Episodes During UX Evaluation: Assessing the Performance of the WESAD Bio-Signals Dataset. In Human-Computer Interaction—INTERACT 2021; Ardito, C., Lanzilotti, R., Malizia, A., Petrie, H., Piccinno, A., Desolda, G., Inkpen, K., Eds.; Springer International Publishing: Cham, Switzerland, 2021; pp. 238–247. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Study | Focus | Opportunities |
|---|---|---|
| Hannun et al. [6] | ECG deep learning | Exploration of hybrid models combining ECG with other biosignals for improved stress prediction. |
| Spathis et al. [11] | Speech-enabled devices | Integration of voice-based feedback mechanisms to provide real-time stress relief interventions. |
| Zhu et al. [12] | EDA wearables | Development of compact and user-friendly wearable devices for mass adoption. |
| Ninh et al. [15] | Consumer EDA devices | Design of consumer-centric applications that utilize EDA data for wellness and mental health tracking. |
| Eren et al. [16] | Empatica E4 device | Incorporation of multi-sensor data for a holistic health-monitoring system. |
| Pakarinen et al. [17] | Mental states | Broadening the scope to include the detection of other mental states like anxiety or excitement. |
| Kalimeri et al. [18] | Multimodal framework | Development of adaptive systems for other differently abled individuals beyond the visually impaired. |
| SimCLR [19] and BOYL [20] | Contrastive learning | Application of contrastive learning techniques to other images. |
| Pöppelbaum et al. [22] | Time series analysis | Implementation in real-time systems for quick anomaly detection in biosignals. |
| Robert et al. [23] | EDA stress prediction | Exploration of non-invasive techniques for real-world applications. |
| CLOCS [24] | ECG learning | Expansion to include patient-specific health recommendations based on ECG patterns. |
| Sarkar et al. [26] | ECG emotion | Development of emotion-aware devices and applications for personalized user experiences. |
| Eldede et al. [26] | Time series learning | Application in industries like finance or meteorology where time series data are abundant. |
| Yang et al. [27] | TimeCLR | Incorporation of multivariate time series data for more-complex predictions. |
| Sunmin et al. [28] | Time series representation | Optimized personalized multimodal model |
| Tanvir et al. [29] | Less annotated data | Personalized multimodal machine learning model with least amount of labeled data |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Islam, T.; Washington, P. Individualized Stress Mobile Sensing Using Self-Supervised Pre-Training. Appl. Sci. 2023, 13, 12035. https://doi.org/10.3390/app132112035
Islam T, Washington P. Individualized Stress Mobile Sensing Using Self-Supervised Pre-Training. Applied Sciences. 2023; 13(21):12035. https://doi.org/10.3390/app132112035
Chicago/Turabian StyleIslam, Tanvir, and Peter Washington. 2023. "Individualized Stress Mobile Sensing Using Self-Supervised Pre-Training" Applied Sciences 13, no. 21: 12035. https://doi.org/10.3390/app132112035
APA StyleIslam, T., & Washington, P. (2023). Individualized Stress Mobile Sensing Using Self-Supervised Pre-Training. Applied Sciences, 13(21), 12035. https://doi.org/10.3390/app132112035