
Towards a Method to Enable the Selection of Physical Models within the Systems Engineering Process: A Case Study with Simulink Models




Abstract
:1. Introduction
2. Related Work
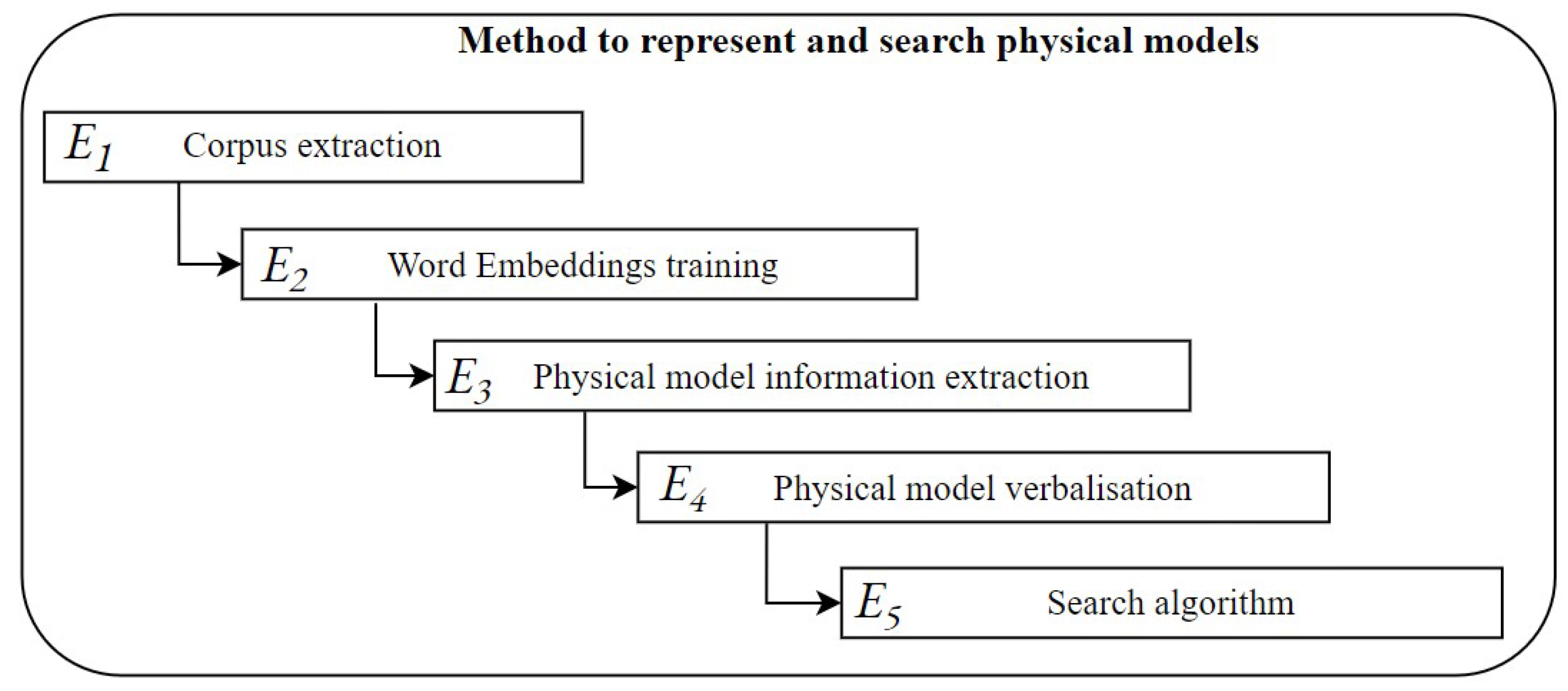
3. Proposed Method for Representing and Searching Physical Models
3.1. Corpus Extraction
3.2. Word Embeddings Training
- Data Collection: in this initial step, we employ a pretrained model, denoted as M and available from [29]. This model is typically constructed using a substantial corpus, such as the 2021 Wikipedia dump. This corpus forms the foundation for the subsequent stages of the process.
- Corpus Preprocessing: the text corpus C obtained in the prior stage undergoes a series of essential preprocessing steps. These steps are vital for cleaning and preparing the data for further training. Preprocessing can include operations such as tokenisation, which involves breaking text into individual words or tokens; normalisation, which often entails converting text to singular to ensure consistent representation; and the removal of stopwords, which are common words that do not significantly contribute to the semantic meaning of the text. These preprocessing steps serve to enhance the quality of the input data and ensure the effectiveness of the subsequent training process.
- Training with Pretrained Model: with the preprocessed corpus C at hand, the next phase involves training the word vectors in the pretrained model M. This training process necessitates adjusting the existing word vectors within the pretrained model to better reflect the specific vocabulary and semantics relevant to the given application or domain. The result of this phase is the creation of a new word embeddings model, denoted as .
- Generating New Word Embeddings: the outcome of the training process in the previous step is a set of word vectors that have been tailored to align with the new terminology and semantics derived from the particular corpus C associated with Simulink models. These adapted word vectors now closely correspond with the domain-specific context, rendering them better suited for tasks such as text comprehension and interpretation related to Simulink models.
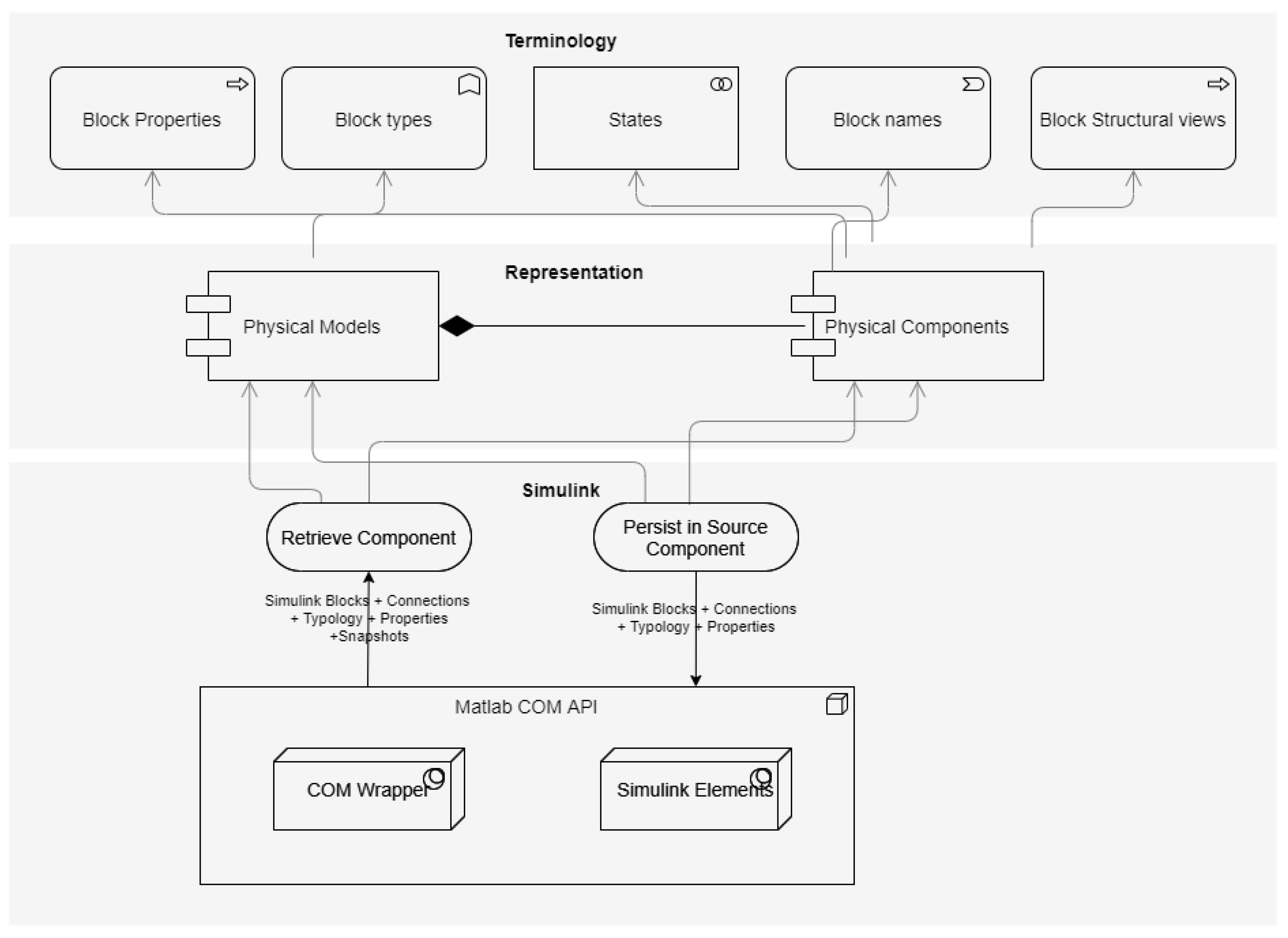
3.3. Physical Model Information Extraction
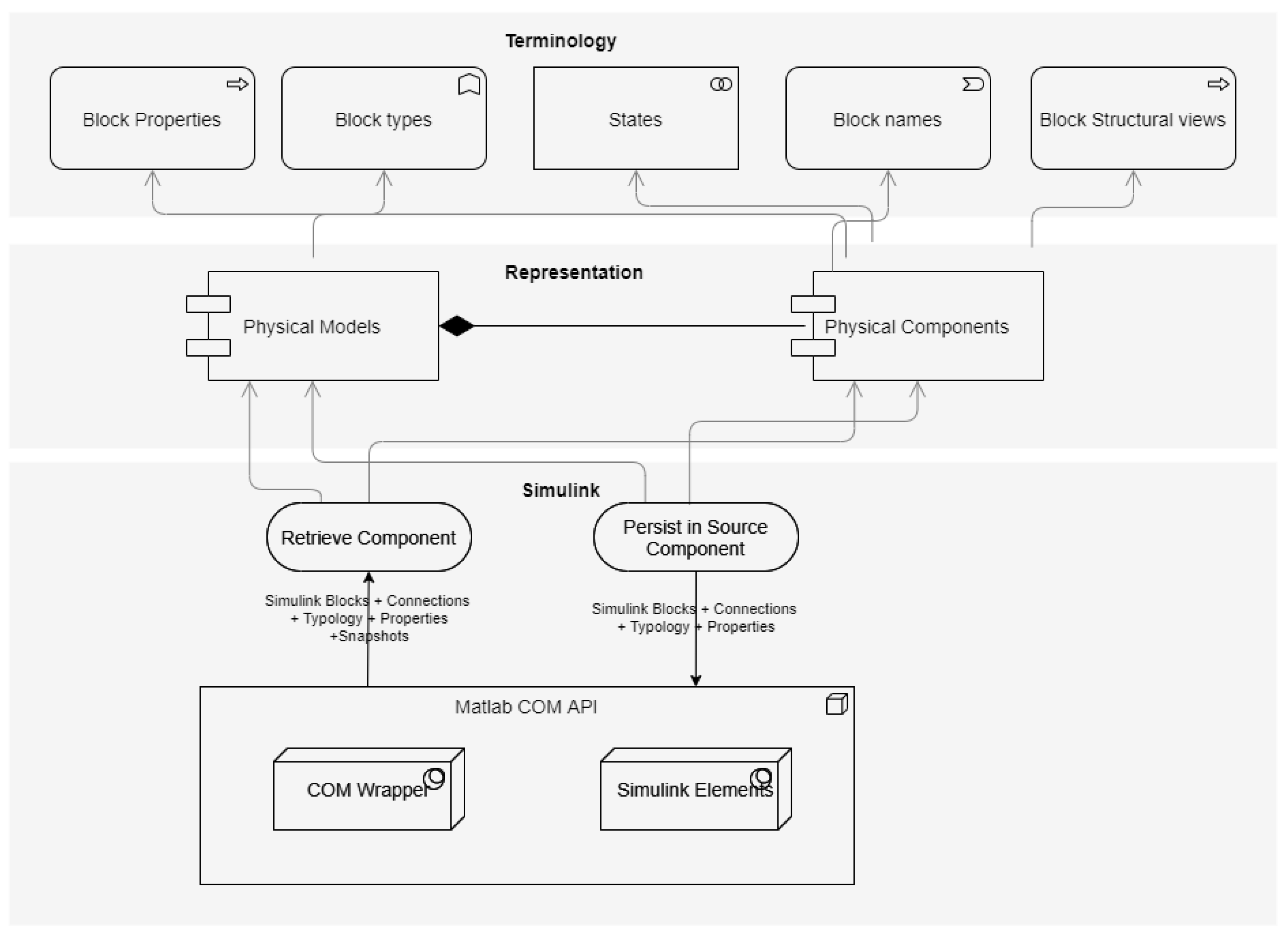
- Model Layer: this layer represents a critical component that enables interaction with the different modelling frameworks and platforms. It facilitates the retrieval of relevant data from physical models, encompassing elements such as blocks, systems, subsystems, properties, and even visual representations. Within this layer, a connector must be customised to harness platform-specific technologies and Application Programming Interfaces (APIs), facilitating the retrieval of data associated with the models. Subsequently, these data are processed and organised in accordance with the data model established within the rendering layer. In the case of Simulink, this layer facilitates all interactions with MATLAB Simulink. It utilises COM technology to retrieve information about the elements that constitute the physical models, including blocks, systems, subsystems, properties, and even image snapshots. Within this layer, two components were developed that leverage the MATLAB interop engine [30] to execute commands from the MATLAB console and perform Simulink model component recovery operations. The retrieved information is then processed and represented in the data model defined in the rendering layer.
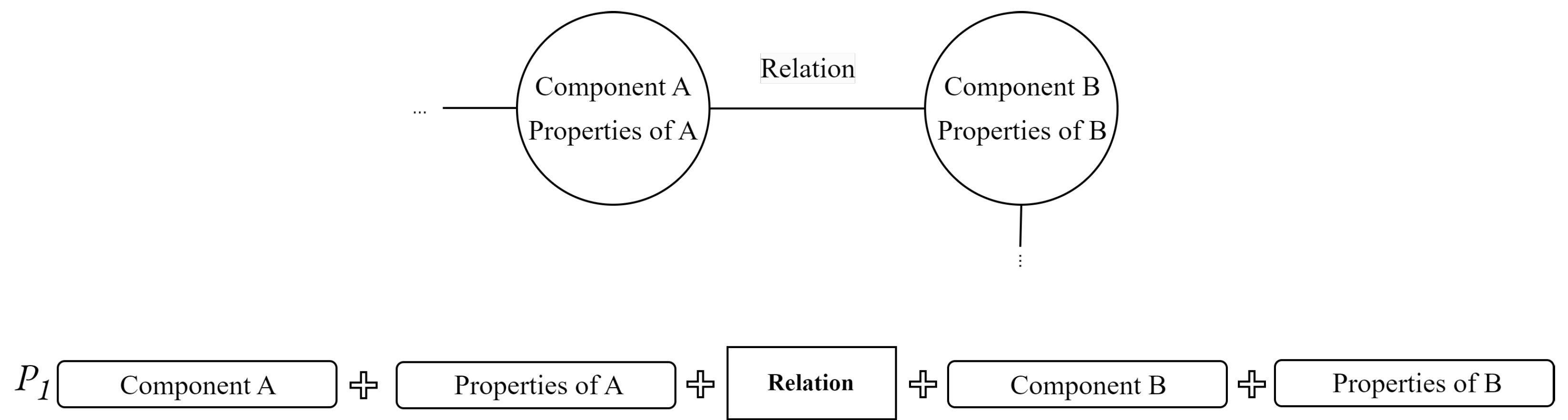
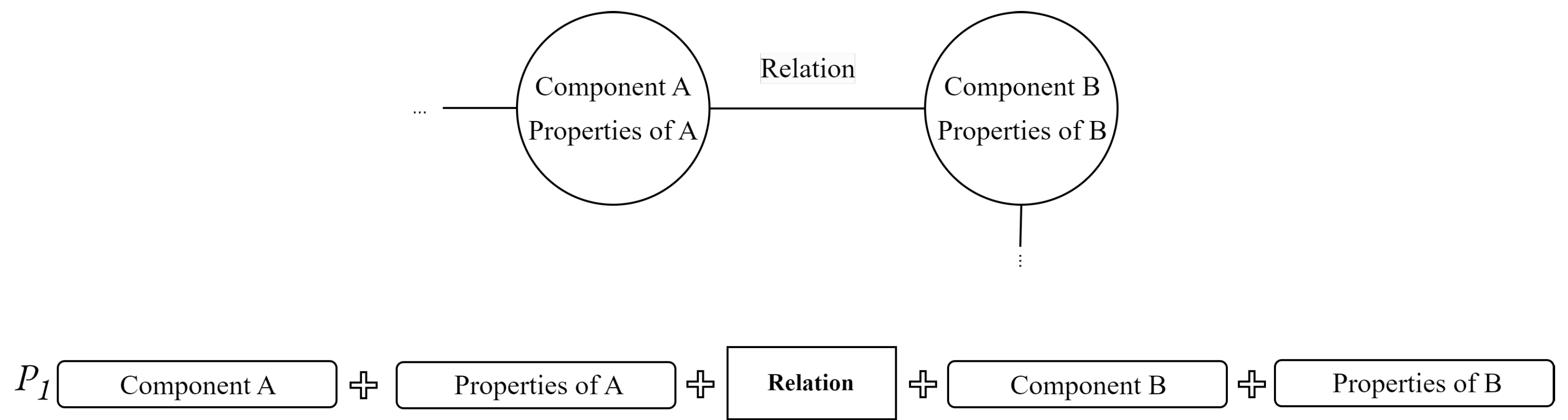
- Representation Layer: this layer creates a connection between the underlying object model of the source tool and a structured data shape based on a semantic graph known as Mappeable Elements (MEs). MEs offer a standardised representation [28] of the model artefacts, decoupling the representation of entities from the specific object model of the source tool. In the case of Simulink, this layer transforms the Simulink object model into a set of MEs. This representation facilitates the creation of an underlying knowledge graph that can integrate information from different sources.
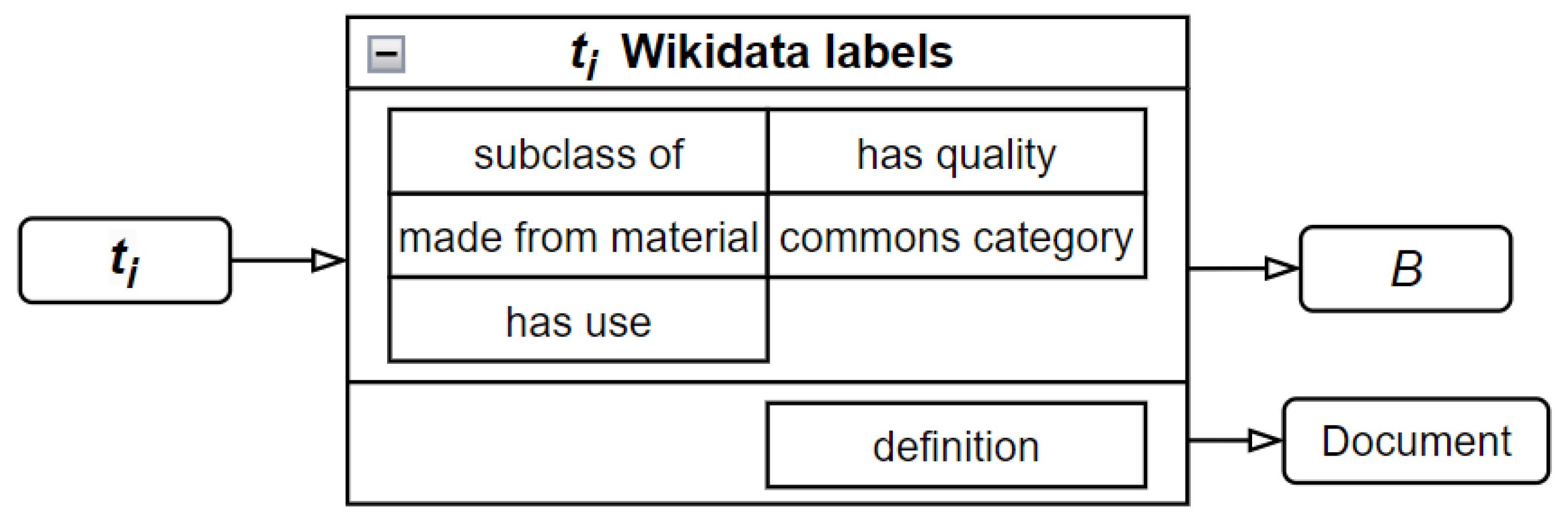
- Terminology Layer: this layer facilitates the extraction of terminology from various information sources. In the case of Simulink models, it retrieves component names, component types, properties, and even images of the subsystems.
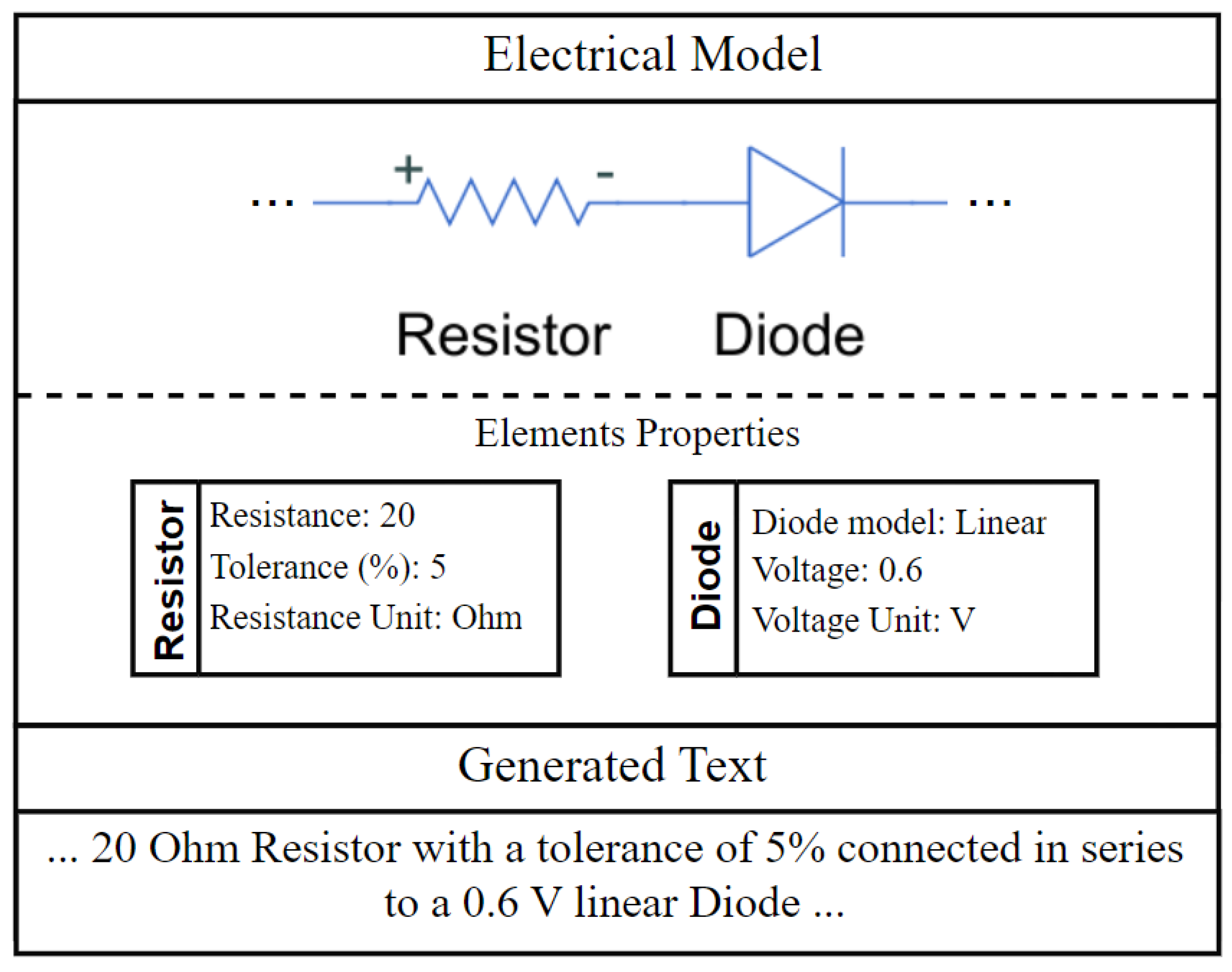
3.4. Physical Model Verbalisation
3.5. Search Algorithm
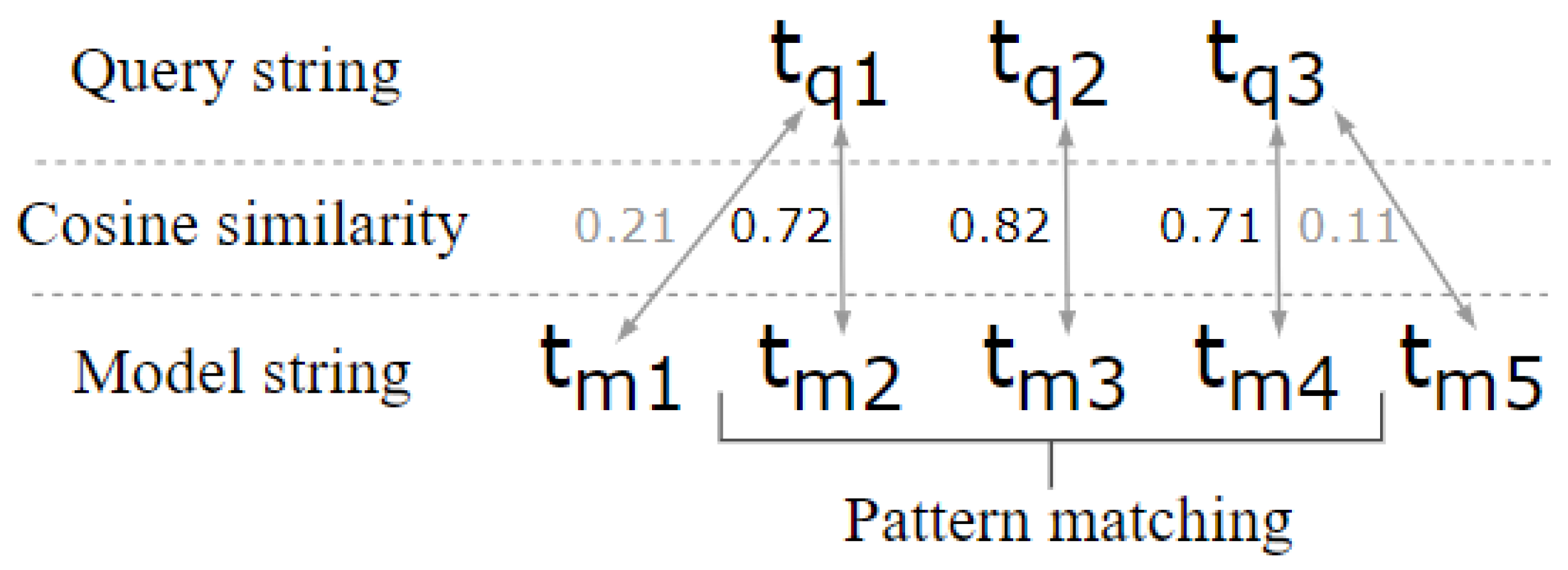
- Pattern Matching: in this step, the algorithm searches for the semantic pattern of the input query to be matched in the models. The model text and the query text are processed using NLP techniques, such as tokenisation and normalisation, to calculate the cosine similarity d between the resulting terms of the query and model . If the cosine similarity of in is consecutively higher than the value of set in the algorithm, then the model is assigned a weight . In this way, the models that match the pattern return a higher similarity than the others (see Figure 6).The threshold value of 0.7 was selected after an empirical experimentation process in which we tested different values ranging from 0.4 to 0.9. The selected threshold consistently yielded the most accurate and relevant results while effectively balancing precision and recall. When setting the threshold at 0.7, the algorithm assigns a significant weight to highly relevant models that closely match the query’s semantic pattern, thereby optimising the trade-off between capturing meaningful matches and avoiding excessive false positives. Similarly, the assigned weight for matching models was determined through experimentation, where it was found to provide a desirable emphasis on pattern matches while boosting the similarity scores. This weighted approach prioritises models that closely align with the query pattern, thereby refining the retrieval process. The combination of the threshold and weight parameters ensures that the algorithm generates meaningful and relevant results, facilitating the semantic reuse of physical models with improved precision and effectiveness.
- Term Similarity: The last step of the algorithm consists of calculating the similarity between and . The cosine distance d is calculated for each element and , then multiplied by a weight function provided by Equation 1, where x is the number of distance calculations with a value larger than a and less or equal to b and y is the number of distance calculations with a value smaller or equal to a. After conducting different tests and evaluations, the values of and were determined to offer the best precision in the algorithm. This weight function was implemented to take into account the relevance of terms in a query within a model.
4. Case Study: Searching Physical Models in MATLAB Simulink
- A dataset of Simulink models covering electronic models and physical models in the automotive and aerospace domains was defined. This dataset comprised 40 models.
- A query dataset for evaluating the retrieval capabilities of the proposed solution was created. Queries were automatically designed by mixing the available terms in the physical models with other related terms that do not appear in the generated text of the model, such as the term circuit (see Table 1).
- The indexing and retrieval process was executed. For each query defined in the previous step, we analysed the models retrieved via the implemented method, taking into account all matching term distances and patterns between the query and models.
- The results were analysed and validated using the schema proposed in [35]. Specifically, the performance metrics used to evaluate the method were (1) precision (the proportion of retrieved information that is relevant); (2) recall (the proportion of relevant information that is retrieved); and (3) the F1 score, which is a combination of the first two metrics.
Analysis of Results
5. Conclusions and Future Directions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Micouin, P. Model-Based Systems Engineering: Fundamentals and Methods; Control, Systems and Industrial Engineering Series; ISTE: London, UK, 2014. [Google Scholar]
- Madni, A.; Madni, C.; Lucero, S. Leveraging Digital Twin Technology in Model-Based Systems Engineering. Systems 2019, 7, 7. [Google Scholar] [CrossRef]
- Henderson, K.; Salado, A. Value and benefits of model-based systems engineering (MBSE): Evidence from the literature. Syst. Eng. 2021, 24, 51–66. [Google Scholar] [CrossRef]
- Zeigler, B.P.; Mittal, S.; Traore, M.K. MBSE with/out Simulation: State of the Art and Way Forward. Systems 2018, 6, 40. [Google Scholar] [CrossRef]
- Mili, H.; Mili, F.; Mili, A. Reusing software: Issues and research directions. IEEE Trans. Softw. Eng. 1995, 21, 528–562. [Google Scholar] [CrossRef]
- Smolárová, M.; Návrat, P. Software reuse: Principles, patterns, prospects. J. Comput. Inf. Technol. 1997, 5, 33–49. [Google Scholar]
- Kim, Y.; Stohr, E.A. Software reuse: Survey and research directions. J. Manag. Inf. Syst. 1998, 14, 113–147. [Google Scholar] [CrossRef]
- Krueger, C.W. Software reuse. ACM Comput. Surv. (CSUR) 1992, 24, 131–183. [Google Scholar] [CrossRef]
- Hogan, A.; Blomqvist, E.; Cochez, M.; d’Amato, C.; de Melo, G.; Gutiérrez, C.; Kirrane, S.; Labra Gayo, J.E.; Navigli, R.; Neumaier, S.; et al. Knowledge Graphs; Number 22 in Synthesis Lectures on Data, Semantics, and Knowledge; Springer: Berlin/Heidelberg, Germany, 2021. [Google Scholar] [CrossRef]
- Madni, A.M.; Erwin, D.; Madni, C.C. Digital twin-enabled MBSE testbed for prototyping and evaluating aerospace systems: Lessons learned. In Proceedings of the 2021 IEEE Aerospace Conference (50100), Big Sky, MT, USA, 6–13 March 2021; pp. 1–8. [Google Scholar]
- Wikidata. 2023. Available online: https://www.wikidata.org/wiki/Wikidata:WikidataCon_2023 (accessed on 10 January 2022).
- Peres, R.S.; Jia, X.; Lee, J.; Sun, K.; Colombo, A.W.; Barata, J. Industrial artificial intelligence in industry 4.0-systematic review, challenges and outlook. IEEE Access 2020, 8, 220121–220139. [Google Scholar] [CrossRef]
- Brown, T.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.D.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; et al. Language models are few-shot learners. arXiv 2020, arXiv:2005.14165. [Google Scholar]
- Liu, R.; Fu, R.; Xu, K.; Shi, X.; Ren, X. A Review of Knowledge Graph-Based Reasoning Technology in the Operation of Power Systems. Appl. Sci. 2023, 13, 4357. [Google Scholar] [CrossRef]
- Lehmann, J.; Isele, R.; Jakob, M.; Jentzsch, A.; Kontokostas, D.; Mendes, P.N.; Bizer, C. DBpedia—A large-scale, multilingual knowledge base extracted from Wikipedia. Semant. Web 2015, 6, 167–195. [Google Scholar] [CrossRef]
- Pennington, J.; Socher, R.; Manning, C. Glove: Global vectors for word representation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; pp. 1532–1543. [Google Scholar]
- TensorFlow. Word2Vec. Available online: https://www.tensorflow.org/text/tutorials/word2vec (accessed on 1 March 2023).
- Stein, R.A.; Jaques, P.A.; Valiati, J.F. An analysis of hierarchical text classification using word embeddings. Inf. Sci. 2019, 471, 216–232. [Google Scholar] [CrossRef]
- Tang, J.; Xue, Y.; Wang, Z.; Hu, S.; Gong, T.; Chen, Y.; Zhao, H.; Xiao, L. Bayesian estimation-based sentiment word embedding model for sentiment analysis. CAAI Trans. Intell. Technol. 2022, 7, 144–155. [Google Scholar] [CrossRef]
- Satapathy, S.C.; Peer, P.; Tang, J.; Bhateja, V.; Ghosh, A. Machine Translation System Combination with Enhanced Alignments Using Word Embeddings. In Intelligent Data Engineering and Analytics; Smart Innovation, Systems and Technologies; Springer Singapore Pte. Limited: Singapore, 2022; Volume 266, pp. 19–29. [Google Scholar]
- Berenguer, A.; Mazón, J.N.; Tomás, D. A Tabular Open Data Search Engine Based on Word Embeddings for Data Integration. In New Trends in Database and Information Systems; Chiusano, S., Cerquitelli, T., Wrembel, R., Nørvåg, K., Catania, B., Vargas-Solar, G., Zumpano, E., Eds.; Springer International Publishing: Cham, Switzerland, 2022; pp. 99–108. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Advances in Neural Information Processing Systems 30, Proceedings of the 31st Annual Conference on Neural Information Processing Systems (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017; Neural Information Processing Systems Foundation, Inc. (NeurIPS): La Jolla, CA, USA, 2017. [Google Scholar]
- Safavi, T.; Koutra, D. Relational world knowledge representation in contextual language models: A review. arXiv 2021, arXiv:2104.05837. [Google Scholar]
- Huang, B.; Zhang, S.; Huang, R.; Li, X.; Zhang, Y. An effective retrieval approach of 3D CAD models for macro process reuse. Int. J. Adv. Manuf. Technol. 2019, 102, 1067–1089. [Google Scholar] [CrossRef]
- Cibrián, E.; Mendieta, R.; Rodríguez, J.M.Á.; Morillo, J.L. Towards the reuse of physical models within the development life-cycle: A case study of Simulink models. In Proceedings of the NOMS 2022-2022 IEEE/IFIP Network Operations and Management Symposium, Budapest, Hungary, 25–29 April 2022; pp. 1–6. [Google Scholar]
- Cibrian, E.; Alvarez-Rodriguez, J.M.; Mendieta, R.; Llorens, J. Discovering traces between textual requirements and logical models in the functional design of Printed Circuit Boards. In Proceedings of the 2022 IEEE 5th International Conference on Industrial Cyber-Physical Systems (ICPS), Coventry, UK, 24–26 May 2022; pp. 1–6. [Google Scholar]
- ISO 10303-243:2021; Industrial Automation Systems and Integration—Product Data Representation and Exchange. International Organization for Standardization: Geneva, Switzerland, 2021.
- Rodríguez, J.M.Á.; Mendieta, R.; de la Vara, J.L.; Fraga, A.; Morillo, J.L. Enabling System Artefact Exchange and Selection through a Linked Data Layer. J. Univers. Comput. Sci. 2018, 24, 1536–1560. [Google Scholar]
- NLPL Word Embeddings Repository. Available online: http://vectors.nlpl.eu/repository/ (accessed on 20 June 2022).
- MathWorks. Llamar a MATLAB desde NET-MATLAB & Simulink-MathWorks España. 2023. Available online: https://es.mathworks.com/help/matlab/call-matlab-from-net.html (accessed on 28 June 2023).
- Ouyang, W.; Tombari, F.; Mattoccia, S.; Di Stefano, L.; Cham, W.K. Performance evaluation of full search equivalent pattern matching algorithms. IEEE Trans. Pattern Anal. Mach. Intell. 2011, 34, 127–143. [Google Scholar] [CrossRef] [PubMed]
- Roy, D.; Ganguly, D.; Mitra, M.; Jones, G.J. Representing documents and queries as sets of word embedded vectors for information retrieval. arXiv 2016, arXiv:1606.07869. [Google Scholar]
- Jatnika, D.; Bijaksana, M.A.; Suryani, A.A. Word2vec model analysis for semantic similarities in english words. Procedia Comput. Sci. 2019, 157, 160–167. [Google Scholar] [CrossRef]
- Lahitani, A.R.; Permanasari, A.E.; Setiawan, N.A. Cosine similarity to determine similarity measure: Study case in online essay assessment. In Proceedings of the 2016 4th International Conference on Cyber and IT Service Management, Bandung, Indonesia, 26–27 April 2016; pp. 1–6. [Google Scholar]
- Juristo, N.; Moreno, A.M. Basics of Software Engineering Experimentation; Springer Science & Business Media: New York, NY, USA, 2013. [Google Scholar]
- Hayes, J.H.; Dekhtyar, A.; Sundaram, S.K. Improving after-the-fact tracing and mapping: Supporting software quality predictions. IEEE Softw. 2005, 22, 30–37. [Google Scholar] [CrossRef]
- Coïc, C.; Williams, M.; Mendo, J.C.; Alvarez-Rodriguez, J.M.; Richardson, M.K. Linking Design Requirements to FMUs to create LOTAR compliant mBSE models. In Proceedings of the 15th International Modelica Conference, Aachen, Germany, 9–11 October 2023. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Q | Query Description |
|---|---|
| Q1 | Circuits |
| Q2 | Models with a DC power supply of 200 V |
| Q3 | Models with hydraulic transfer functions |
| Q4 | Models with an integrator |
| Q5 | Electrical models using diodes |
| Q6 | Sum operations with integrators |
| Q7 | Resistor connected in series with a resistor |
| Q8 | Models with memory |
| Q9 | Circuits with supercapacitors |
| Q10 | Resistors connected in parallel with diodes |
| Q11 | Models with transfer functions |
| Q12 | Models with switches |
| Q13 | Models with voltages of at least 100 V |
| Q14 | Models with a 3-phase harmonic filter |
| Q15 | Models with SPICE resistors |
| Q16 | Physical models with torque |
| Q17 | Models with logical operations |
| Q18 | A transistor connected in parallel with a resistor |
| Q19 | Circuits with logical operations |
| Q20 | Battery of 12 V |
| Q21 | Models with sum operations |
| Q22 | Bang–bang controller |
| Q23 | AC voltage source of 100 V |
| Q24 | Models with functions |
| Q25 | Physical models with switches |
| Q26 | Models with a signal input |
| Q27 | A transistor in series with a resistor |
| Q28 | Aerospace models |
| Q29 | Capacitor connected with a voltage of 10 V |
| Q30 | Models with thermocouples |
| Level of “Goodness” | Precision | Recall |
|---|---|---|
| Acceptable | ≥20% | ≥60% |
| Good | ≥30% | ≥70% |
| Excellent | ≥50% | ≥80% |
| Precision | Recall | F1 | |
|---|---|---|---|
| Q1 | 1.000 | 1.000 | 1.000 |
| Q2 | 1.000 | 1.000 | 1.000 |
| Q3 | 1.000 | 1.000 | 1.000 |
| Q4 | 1.000 | 0.941 | 0.970 |
| Q5 | 1.000 | 0.800 | 0.889 |
| Q6 | 1.000 | 0.842 | 0.914 |
| Q7 | 0.821 | 0.788 | 0.804 |
| Q8 | 1.000 | 1.000 | 1.000 |
| Q9 | 1.000 | 0.941 | 0.970 |
| Q10 | 0.375 | 0.462 | 0.423 |
| Q11 | 1.000 | 1.000 | 1.000 |
| Q12 | 1.000 | 1.000 | 1.000 |
| Q13 | 1.000 | 0.889 | 0.941 |
| Q14 | 1.000 | 1.000 | 1.000 |
| Q15 | 1.000 | 0.750 | 0.857 |
| Q16 | 1.000 | 1.000 | 1.000 |
| Q17 | 0.682 | 0.621 | 0.650 |
| Q18 | 1.000 | 0.933 | 0.965 |
| Q19 | 1.000 | 1.000 | 1.000 |
| Q20 | 1.000 | 0.571 | 0.727 |
| Q21 | 1.000 | 1.000 | 1.000 |
| Q22 | 1.000 | 1.000 | 1.000 |
| Q23 | 1.000 | 0.889 | 0.941 |
| Q24 | 1.000 | 1.000 | 1.000 |
| Q25 | 1.000 | 0.857 | 0.923 |
| Q26 | 1.000 | 0.889 | 0.941 |
| Q27 | 0.835 | 0.723 | 0.775 |
| Q28 | 1.000 | 0.873 | 0.932 |
| Q29 | 1.000 | 0.922 | 0.959 |
| Q30 | 1.000 | 1.000 | 1.000 |
| Avg | 0.925 | 0.865 | 0.884 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cibrián, E.; Álvarez-Rodríguez, J.M.; Mendieta, R.; Llorens, J. Towards a Method to Enable the Selection of Physical Models within the Systems Engineering Process: A Case Study with Simulink Models. Appl. Sci. 2023, 13, 11999. https://doi.org/10.3390/app132111999
Cibrián E, Álvarez-Rodríguez JM, Mendieta R, Llorens J. Towards a Method to Enable the Selection of Physical Models within the Systems Engineering Process: A Case Study with Simulink Models. Applied Sciences. 2023; 13(21):11999. https://doi.org/10.3390/app132111999
Chicago/Turabian StyleCibrián, Eduardo, Jose María Álvarez-Rodríguez, Roy Mendieta, and Juan Llorens. 2023. "Towards a Method to Enable the Selection of Physical Models within the Systems Engineering Process: A Case Study with Simulink Models" Applied Sciences 13, no. 21: 11999. https://doi.org/10.3390/app132111999
APA StyleCibrián, E., Álvarez-Rodríguez, J. M., Mendieta, R., & Llorens, J. (2023). Towards a Method to Enable the Selection of Physical Models within the Systems Engineering Process: A Case Study with Simulink Models. Applied Sciences, 13(21), 11999. https://doi.org/10.3390/app132111999