
PMG—Pyramidal Multi-Granular Matching for Text-Based Person Re-Identification


Abstract
:1. Introduction
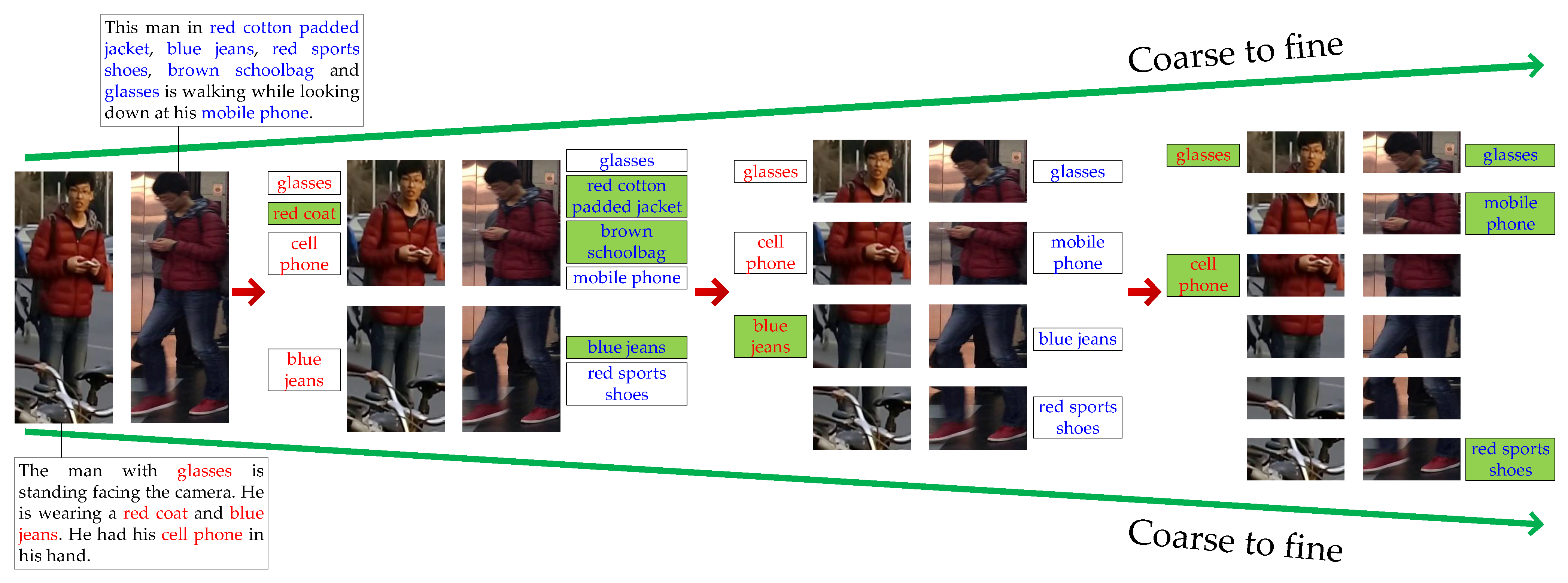
- A coarse-to-fine pyramidal matching method is employed to handle the problem of ineffective local feature extraction from surveillance videos plagued by arbitrariness in existing single-granular methods.
- A Pyramidal Multi-Granular matching network (PMG) is proposed to learn multi-granular cross-modal affinities.
- Comprehensive experiments are conducted on the CUHK-PEDES and RSTPReid datasets, which indicate that PMG outperforms other previous methods significantly and achieves state-of-the-art performance.
2. Related Works
2.1. Person Re-Identification
2.2. Text-Based Person Re-Identification
3. Proposed Method
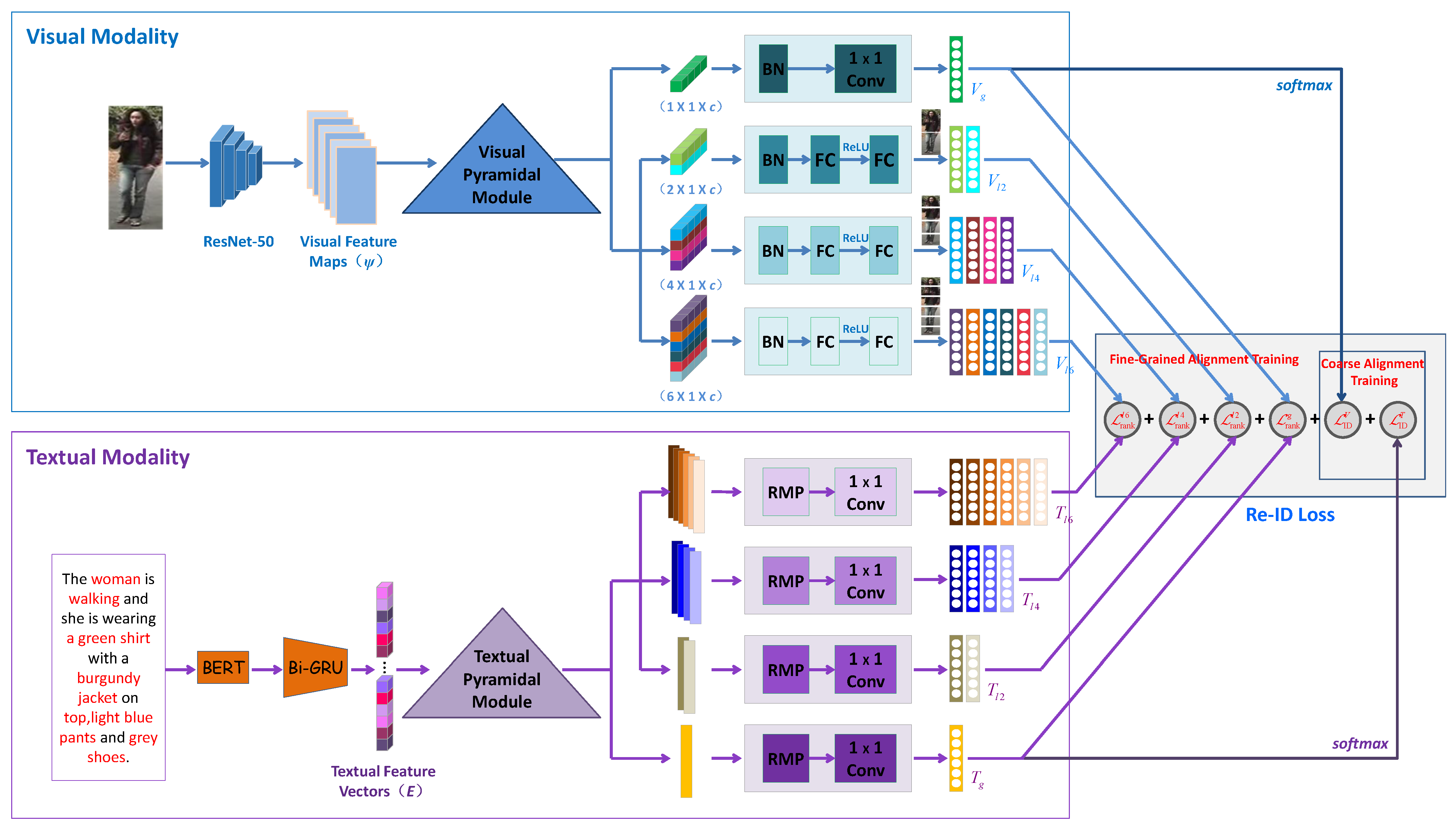
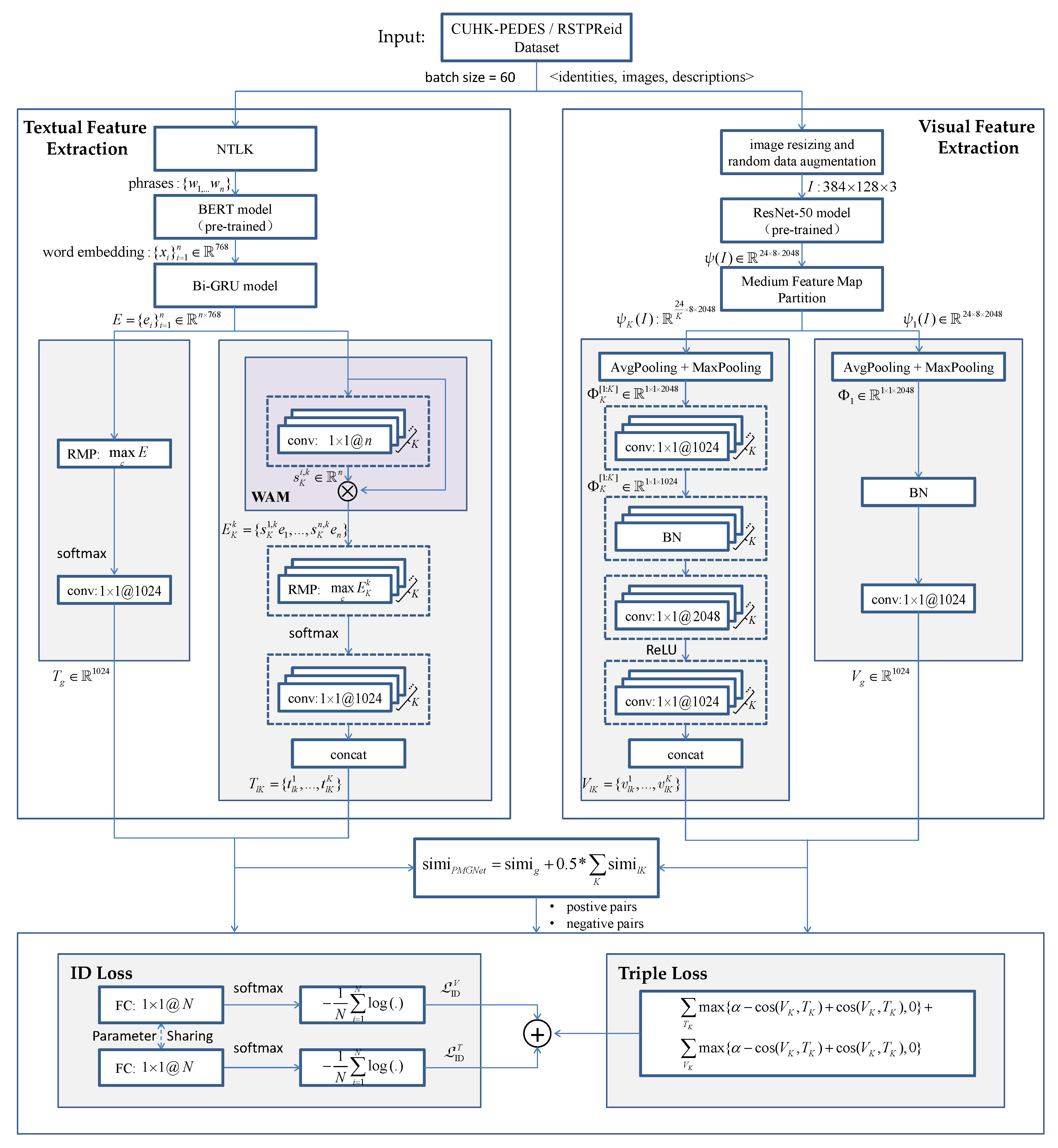
3.1. Pyramidal Multi-Granular Feature Extraction
3.1.1. Visual Feature Extraction
3.1.2. Textual Feature Extraction
3.2. Image-Text Matching
3.3. Loss Functions and Training Strategy
4. Experiment Details
4.1. Experiment Setup
4.1.1. Experiment Preparations
4.1.2. Dataset and Evaluation Metrics
4.1.3. Implementation Details
4.2. Comparison with SOTA
4.3. Ablation Study
4.3.1. Pyramidal Scales
4.3.2. Fused Pooling Method
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Sun, Y.; Zheng, L.; Yang, Y.; Tian, Q.; Wang, S. Beyond part models: Person retrieval with refined part pooling (and A strong convolutional baseline). In Proceedings of the 15th European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 480–496. [Google Scholar]
- Yao, H.; Zhang, S.; Hong, R.; Zhang, Y.; Xu, C.; Tian, Q. Deep Representation Learning with Part Loss for Person Re-identification. IEEE Trans. Image Process. 2019, 28, 2860–2871. [Google Scholar] [CrossRef] [PubMed]
- Xiong, M.; Gao, Z.; Hu, R.; Chen, J.; He, R.; Cai, H.; Peng, T. A Lightweight Efficient Person Re-Identification Method Based on Multi-Attribute Feature Generation. Appl. Sci. 2022, 12, 4921. [Google Scholar] [CrossRef]
- Xie, H.; Luo, H.; Gu, J.; Jiang, W. Unsupervised Domain Adaptive Person Re-Identification via Intermediate Domains. Appl. Sci. 2022, 12, 6990. [Google Scholar] [CrossRef]
- Wang, C.; Zhang, C.; Feng, Y.; Ji, Y.; Ding, J. Learning Visible Thermal Person Re-identification via Spatial Dependence and Dual-constraint Loss. Entropy 2022, 24, 443. [Google Scholar] [CrossRef] [PubMed]
- Jeong, B.; Park, J.; Kwak, S. ASMR: Learning attribute-based Person search with adaptive semantic margin regularizer. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 12016–12025. [Google Scholar]
- Wang, Z.; Zhu, A.; Xue, J.; Jiang, D.; Liu, C.; Li, Y.; Hu, F. SUM: Serialized Updating and Matching for text-based person retrieval. Knowl.-Based Syst. 2022, 248, 108891. [Google Scholar]
- Jing, Y.; Si, C.; Wang, J.; Wang, W.; Wang, L.; Tan, T. Pose-guided multi-granularity attention network for text-based Person search. In Proceedings of the 34th AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 11189–11196. [Google Scholar]
- Wang, Z.; Zhu, A.; Xue, J.; Wan, X.; Liu, C.; Wang, T.; Li, Y. CAIBC: Capturing all-round information beyond color for text-based person retrieval. In Proceedings of the 30th ACM International Conference on Multimedia, Lisboa, Portugal, 10–14 October 2022; pp. 5314–5322. [Google Scholar]
- Li, S.; Xiao, T.; Li, H.; Zhou, B.; Yue, D.; Wang, X. Person search with natural language description. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 1970–1979. [Google Scholar]
- Chen, T.; Xu, C.; Luo, J. Improving text-based Person search by spatial matching and adaptive threshold. In Proceedings of the IEEE Winter Conference on Applications of Computer Vision (WACV), Waikola, HI, USA, 21–15 March 2018; pp. 1879–1887. [Google Scholar]
- Niu, K.; Huang, Y.; Ouyang, W.; Wang, L. Improving Description-based Person Re-identification by Multi-granularity Image-text Alignments. IEEE Trans. Image Process. 2020, 29, 5542–5556. [Google Scholar] [CrossRef] [PubMed]
- Ding, Z.; Ding, C.; Shao, Z.; Tao, D. Semantically Self-Aligned Network for Text-to-Image Part-aware Person Re-identification. arXiv 2021, arXiv:2107.12666. [Google Scholar]
- Yi, D.; Lei, Z.; Liao, S.; Li, S.Z. Deep metric learning for person re-identification. In Proceedings of the 22nd IEEE International Conference on Pattern Recognition (ICPR), Stockholm, Sweden, 24–28 August 2014; pp. 34–39. [Google Scholar]
- Zheng, Z.; Yang, X.; Yu, Z.; Zheng, L.; Yang, Y.; Kautz, J. Joint discriminative and generative learning for person re-identification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 2138–2147. [Google Scholar]
- Liu, Y.; Yang, H.; Zhao, Q. Hierarchical Feature Aggregation from Body Parts for Misalignment Robust Person Re-Identification. Appl. Sci. 2019, 9, 2255. [Google Scholar] [CrossRef]
- Zhang, Z.; Lan, C.; Zeng, W.; Jin, X.; Chen, Z. Relation-aware global attention for person re-identification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 3186–3195. [Google Scholar]
- Li, H.; Wu, G.; Zheng, W.S. Combined depth space based architecture search for Person re-identification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 6729–6738. [Google Scholar]
- Bak, S.; Carr, P. One-shot metric learning for person Re-identification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 2990–2999. [Google Scholar]
- Liu, J.; Zha, Z.J.; Hong, R.; Wang, M.; Zhang, Y. Deep adversarial graph attention convolution network for text-based person search. In Proceedings of the 27th ACM International Conference on Multimedia, Nice, France, 21–25 October 2019; pp. 665–673. [Google Scholar]
- Sarafianos, N.; Xu, X.; Kakadiaris, I.A. Adversarial representation learning for text-to-image matching. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 5814–5824. [Google Scholar]
- Aggarwal, S.; Radhakrishnan, V.B.; Chakraborty, A. Text-based Person search via attribute-aided matching. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), Snowmass Village, CO, USA, 1–5 March 2020; pp. 2617–2625. [Google Scholar]
- Hao, X.; Zhao, S.; Ye, M.; Shen, J. Cross-modality person re-identification via modality confusion and center aggregation. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Montreal, BC, Canada, 11–17 October 2021; pp. 16403–16412. [Google Scholar]
- Gao, C.; Cai, G.; Jiang, X.; Zheng, F.; Zhang, J.; Gong, Y.; Peng, P.; Guo, X.; Sun, X. Contextual Non-Local Alignment over Full-Scale Representation for Text-Based Person Search. arXiv 2021, arXiv:2101.03036. [Google Scholar]
- Zheng, K.; Liu, W.; Liu, J.; Zha, Z.J.; Mei, T. Hierarchical gumbel attention network for text-based person search. In Proceedings of the 28th ACM International Conference on Multimedia, Seattle, WA, USA, 12–16 October 2020; pp. 3441–3449. [Google Scholar]
- Wang, Z.; Fang, Z.; Wang, J.; Yang, Y. Vitaa: Visual-textual attributes alignment in person search by natural language. In Proceedings of the 16th European Conference on Computer Vision (ECCV), Glasgow, UK, 23–28 August 2020; pp. 402–420. [Google Scholar]
- Zhu, A.; Wang, Z.; Li, Y.; Wan, X.; Jin, J.; Wang, T.; Hu, F.; Hua, G. DSSL: Deep surroundings-person separation learning for text-based person retrieval. In Proceedings of the 29th ACM International Conference on Multimedia, Virtual, 20–24 October 2021; pp. 209–217. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30, 15. [Google Scholar]
- Wang, Z.; Zhu, A.; Zheng, Z.; Jin, J.; Xue, Z.; Hua, G. IMG-Net: Inner-cross-modal Attentional Multigranular Network for Description-based Person Re-identification. J. Electron. Imaging 2020, 29, 043028. [Google Scholar] [CrossRef]
- Reed, S.; Akata, Z.; Lee, H.; Schiele, B. Learning deep representations of fine-grained visual descriptions. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 49–58. [Google Scholar]
- Vinyals, O.; Toshev, A.; Bengio, S.; Erhan, D. Show and tell: A neural image caption generator. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 3156–3164. [Google Scholar]
- Li, S.; Xiao, T.; Li, H.; Yang, W.; Wang, X. Identity-aware textual-visual matching with latent co-attention. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 1890–1899. [Google Scholar]
- Zheng, Z.; Zheng, L.; Garrett, M.; Yang, Y.; Xu, M.; Shen, Y.D. Dual-Path Convolutional Image-Text Embeddings with Instance Loss. ACM Trans. Multimed. Comput. Commun. Appl. (TOMM) 2020, 16, 1–23. [Google Scholar] [CrossRef]
- Chen, D.; Li, H.; Liu, X.; Shen, Y.; Shao, J.; Yuan, Z.; Wang, X. Improving deep visual representation for person re-identification by global and local image-language association. In Proceedings of the 15th European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 54–70. [Google Scholar]
- Zhang, Y.; Lu, H. Deep cross-modal projection learning for image-text matching. In Proceedings of the 15th European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 686–701. [Google Scholar]
- Wang, Z.; Xue, J.; Zhu, A.; Li, Y.; Zhang, M.; Zhong, C. AMEN: Adversarial multi-space embedding network for text-based Person re-identification. In Proceedings of the 4th Chinese Conference on Pattern Recognition and Computer Vision (PRCV), Beijing, China, 29 October–1 November 2021; pp. 462–473. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Network Architecture | Attention Mechanism | Aiding Information | Local Feature Alignments |
|---|---|---|---|---|
| SUM [7] | ✓ | - | ||
| PMA [8] | ✓ | ✓ | - | |
| CAIBC [9] | ✓ | ✓ | - | |
| GNA-RNN [10] | ✓ | - | ||
| PWM-ATH [11] | ✓ | - | ||
| MIA [12] | ✓ | ✓ | ✓ | - |
| SSAN [13] | ✓ | - | ||
| A-GANet [20] | ✓ | ✓ | - | |
| TIMAM [21] | ✓ | - | ||
| CMAAM [22] | ✓ | - | ||
| MCLNet [23] | ✓ | - | ||
| NAFS [24] | ✓ | ✓ | - | |
| HGAN [25] | ✓ | - | ||
| ViTAA [26] | ✓ | - | ||
| DSSL [27] | ✓ | - |
| Epoch | ID_Loss () | ID_Loss () | ID_Loss () |
|---|---|---|---|
| 1 | 56.04% | 56.04% | 56.04% |
| 5 | 27.94% | 24.02% | 27.80% |
| 10 | 17.01% | 12.10% | 17.49% |
| Epoch | ID_Loss () | ID_Loss () | ID_Loss () |
|---|---|---|---|
| 20 | 6.24% | 8.47% | 9.57% |
| 30 | 5.43% | 4.32% | 5.80% |
| 40 | 4.36% | 3.50% | 4.14% |
| Epoch | Top-1 | Top-5 | Top-10 |
|---|---|---|---|
| 40 | 62.15% | 80.86% | 87.04% |
| 50 | 64.59% | 83.19% | 89.12% |
| 60 | 63.94% | 82.87% | 88.91% |
| Method | Top-1 | Top-5 | Top-10 |
|---|---|---|---|
| CNN-RNN [30] | 8.07 | - | 32.47 |
| Neural Talk [31] | 13.66 | - | 41.72 |
| GNA-RNN [10] | 19.05 | - | 53.64 |
| IATV [32] | 25.94 | - | 60.48 |
| PWM-ATH [11] | 27.14 | 49.45 | 61.02 |
| Dual Path [33] | 44.40 | 66.26 | 75.07 |
| GLA [34] | 43.58 | 66.93 | 76.26 |
| CMPM-CMPC [35] | 49.37 | 71.69 | 79.27 |
| MIA [12] | 53.10 | 75.00 | 82.90 |
| A-GANet [20] | 53.14 | 74.03 | 81.95 |
| PMA [8] | 54.12 | 75.45 | 82.97 |
| TIMAM [21] | 54.51 | 77.56 | 84.78 |
| ViTAA [26] | 55.97 | 75.84 | 83.52 |
| CMAAM [22] | 56.68 | 77.18 | 84.86 |
| HGAN [25] | 59.00 | 79.49 | 86.62 |
| NAFS [24] | 59.94 | 79.86 | 86.70 |
| DSSL [27] | 59.98 | 80.41 | 87.56 |
| SSAN [13] | 61.37 | 80.15 | 86.73 |
| PMG (ours) | 62.33 | 81.32 | 87.26 |
| PMG + BERT (ours) | 64.59 | 83.19 | 89.12 |
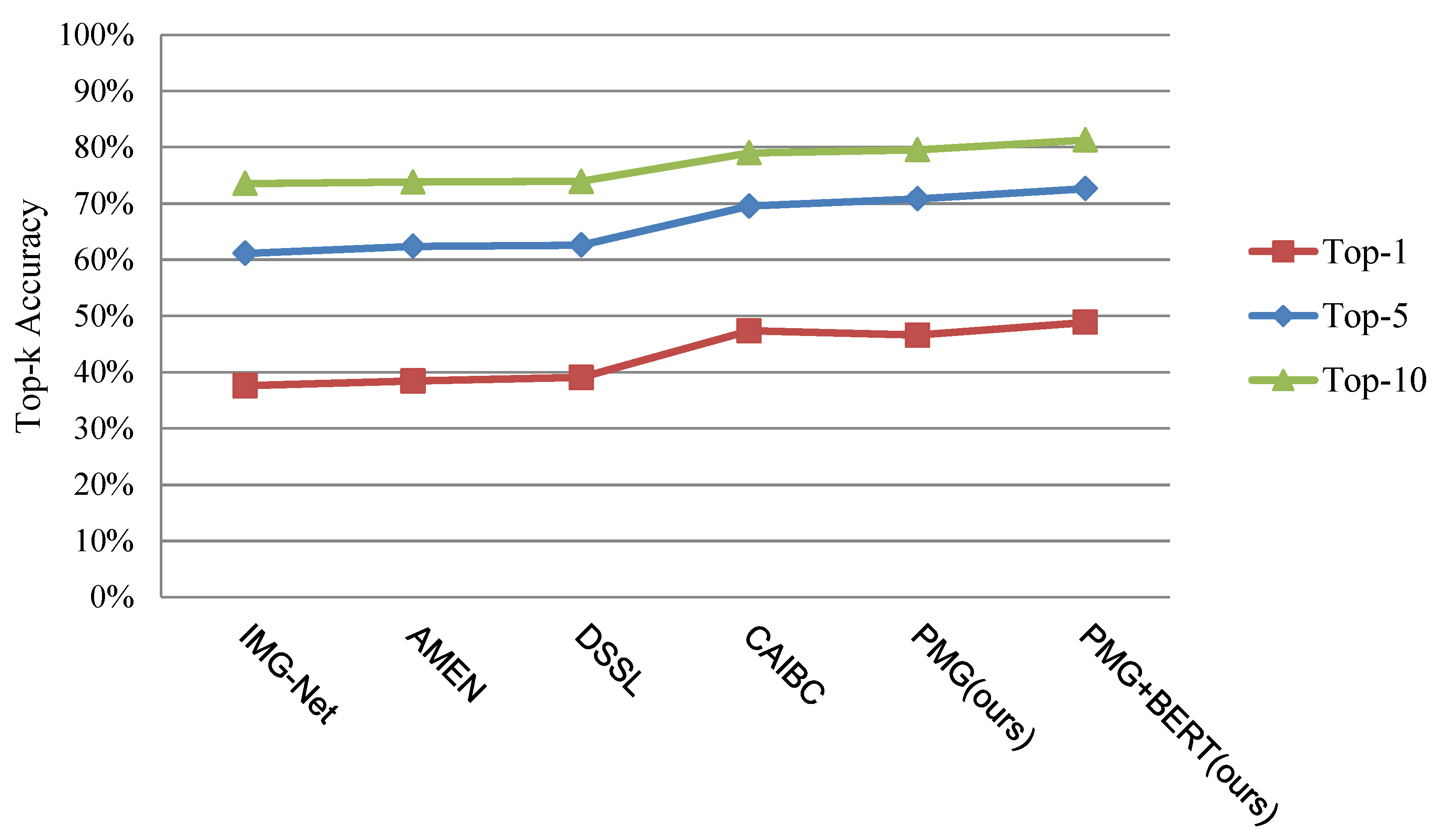
| Method | Top-1 | Top-5 | Top-10 |
|---|---|---|---|
| IMG-Net [29] | 37.60 | 61.15 | 73.55 |
| AMEN [36] | 38.45 | 62.40 | 73.80 |
| DSSL [27] | 39.05 | 62.60 | 73.95 |
| CAIBC [9] | 47.35 | 69.55 | 79.00 |
| PMG (ours) | 46.60 | 70.85 | 79.55 |
| PMG + BERT (ours) | 48.85 | 72.65 | 81.30 |
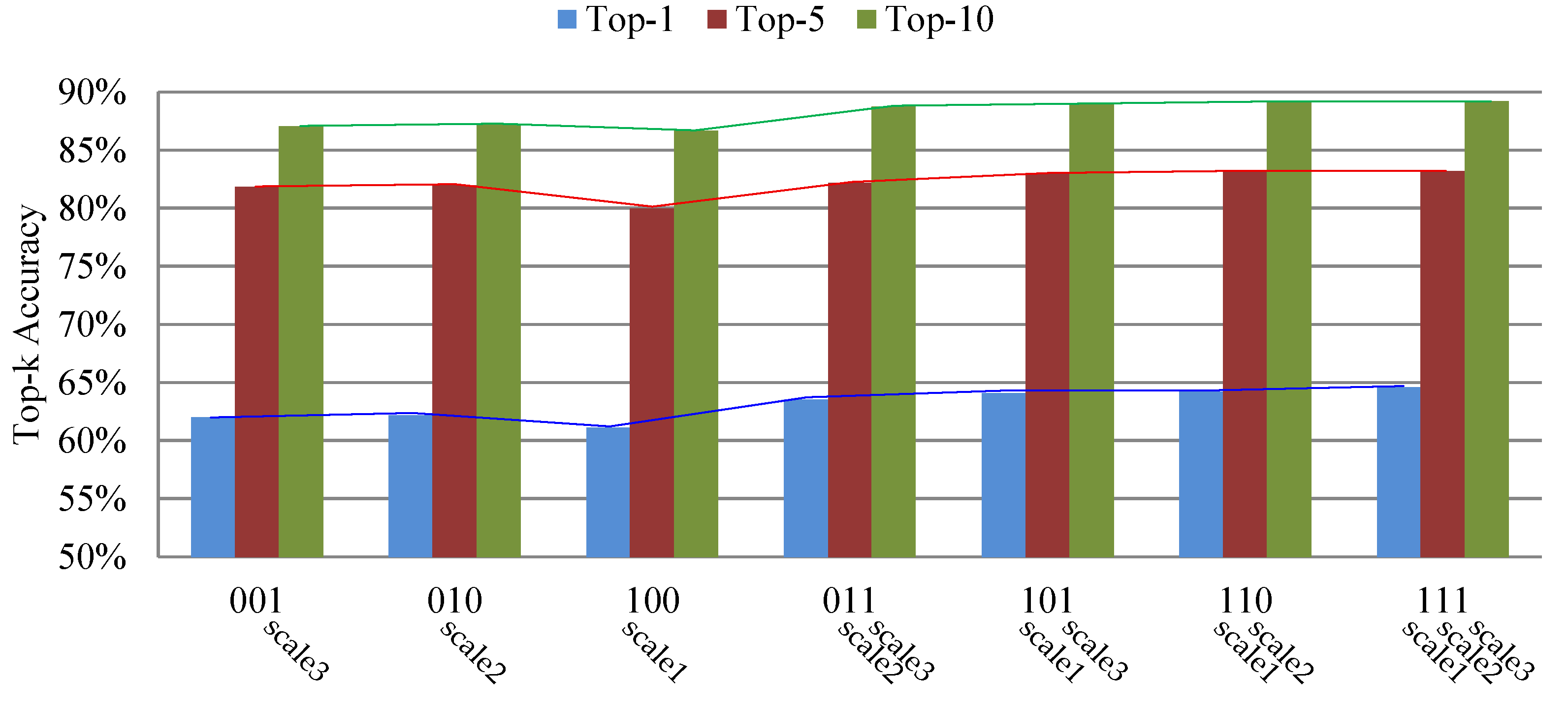
| Method | Top-1 | Top-5 | Top-10 |
|---|---|---|---|
| PMG (001) | 62.02 | 81.82 | 87.04 |
| PMG (010) | 62.18 | 81.93 | 87.17 |
| PMG (011) | 63.52 | 82.16 | 88.73 |
| PMG (100) | 61.08 | 79.98 | 86.65 |
| PMG (101) | 64.04 | 82.95 | 88.94 |
| PMG (110) | 64.20 | 83.13 | 89.08 |
| PMG (111) | 64.59 | 83.19 | 89.21 |
| Method | Top-1 | Top-5 | Top-10 |
|---|---|---|---|
| PMG-AvgPooling | 63.47 | 83.02 | 89.10 |
| PMG-MaxPooling | 63.66 | 83.15 | 89.13 |
| PMG-FusedPooling | 64.59 | 83.19 | 89.21 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, C.; Xue, J.; Wang, Z.; Zhu, A. PMG—Pyramidal Multi-Granular Matching for Text-Based Person Re-Identification. Appl. Sci. 2023, 13, 11876. https://doi.org/10.3390/app132111876
Liu C, Xue J, Wang Z, Zhu A. PMG—Pyramidal Multi-Granular Matching for Text-Based Person Re-Identification. Applied Sciences. 2023; 13(21):11876. https://doi.org/10.3390/app132111876
Chicago/Turabian StyleLiu, Chao, Jingyi Xue, Zijie Wang, and Aichun Zhu. 2023. "PMG—Pyramidal Multi-Granular Matching for Text-Based Person Re-Identification" Applied Sciences 13, no. 21: 11876. https://doi.org/10.3390/app132111876
APA StyleLiu, C., Xue, J., Wang, Z., & Zhu, A. (2023). PMG—Pyramidal Multi-Granular Matching for Text-Based Person Re-Identification. Applied Sciences, 13(21), 11876. https://doi.org/10.3390/app132111876