
Automatic Vulgar Word Extraction Method with Application to Vulgar Remark Detection in Chittagonian Dialect of Bangla




Abstract
:1. Introduction
- Collect a comprehensive dataset of 2500 comments and posts exclusively from publicly accessible Facebook accounts in the Chittagonian dialect.
- Develop a simple keyword-matching-based baseline method for vulgar remark detection using a hand-crafted vulgar word lexicon.
- Create a method for automatically expanding the vulgar word lexicon to ensure future-proofing of the baseline method.
- Implement various matching algorithms to detect sentences containing vulgar remarks, beginning with a simple method using a manually crafted vulgar word lexicon, an automatic method using simple TF-IDF statistics for vulgar term extraction with no additional filtering of non-vulgar words, as well as a more robust method applying additional filtering of words with a high probability of being non-vulgar.
- Evaluate various ML- and DL-based approaches to identify vulgar remarks in Chittagonian social media posts, aiming for over 90% accuracy for practical applicability.
- Conduct a thorough comparison between the keyword-matching baseline method and machine learning (ML) and deep learning (DL) models to achieve the highest possible performance in vulgar remark detection.
2. Literature Review

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Paper | Classifier | Highest Score | Language | Sample Size | Class and Ratio | Data Sources |
|---|---|---|---|---|---|---|
| [29] | Multinomial Naive Bayes, Random Forest, Support Vector Machines, | 80% (Accuracy) | Bengali | 2.5K | - | F |
| [30] | Support Vector Machines, Naive Bayes, Decision Tree, K-Nearest Neighbors | 97% (Accuracy) | Bengali | 2.4 K | Non-Bullying Bullying (10%) | F, T |
| [31] | Linear Support Vector Classification, Logistic Regression, Multinomial Naive Bayes, Random Forest Artificial Neural Network, RNN + LSTM | 82.2% (Accuracy) | Bengali | 4.7 K | Slang (19.57%), Religious, Politically, Positive, Neutral, violated (13.28%), Anti- feminism (0.87%), Hatred (13.15%), Personal attack (12.36%) | F, Y, News portal |
| [32] | Naive Bayes | 80.57% (Accuracy) | Bengali | 2.665 K | Non-Abusive, Abusive (45.55%) | Y |
| [33] | Root-Level approach | 68.9% (Accuracy) | Bengali | 300 | Not Bullying, Bullying | F, Y News portal |
| [35] | Logistic Regression, Support Vector Machines, Stochastic Gradient Descent, Bidirectional LSTM | 89.3% (F1 Score) 82.4% (F1 Score) | Bengali | 7.245 K | Non Vulgar, Vulgar | Y |
| [36] | Support Vector Machines, RF, Adaboost | 72.14% (Accuracy) 80% (Precision) | Bengali | 2 K | Non Abusive, Abusive (78.41%) | F |
| [37] | Gated Recurrent Units, Support Vector Classification, LinearSVC, Random Forest, Naive Bayes | 70.1% (Accuracy) | Bengali | 5.126 K | Religious comment (14.9%), Hate speech (19.2%), Inciteful (10.77%), Communal hatred (15.67%), Religious hatred (15.68%), Political comment (23.43%) | F |
| [38] | Logistic Regression, Support Vector Machines, Convolutional Neural Network, BIdirectional LSTM, BERT, LSTM | 78% 91% 89% 84% (F1 Score) | Bengali | 8.087 K | Personal (43.44%), Religious (14.97%), Geopolitical (29.23%), Political (12.35%) | F |
| [39] | Logistic Regression, Support Vector Machines, Random Forest, Bidirectional LSTM | 82.7% (F1 Score) | Bengali | 3 K | Non abusive, Abusive (10%) | Y |
| [41] | Long Short-term Memory, Bidirectional LSTM | 87.5% (Accuracy) | Bengali | 30 K | Not Hate speech, Hate speech (33.33%) | F, Y |
| [42] | Multinomial Naive Bayes, Multilayer Perceptron, Support Vector Machines, Decision Tree, Random Fores, Stochastic Gradient Descent, K-Nearest Neighbors | 88% (Accuracy) | Bengali | 9.76 K | Non Abusive, abusive (50%) | F, Y |
| [43] | ELECTRA, Deep Neural Network, BERT | 85% (Accuracy) (BERT), 84.92% (Accuracy) (ELECTRA) | Bengali | 44.001 K | Troll (23.78%), Religious (17.22%), Sexual (20.29%), Not Bully (34.86%), Threat (3.85%) | F |
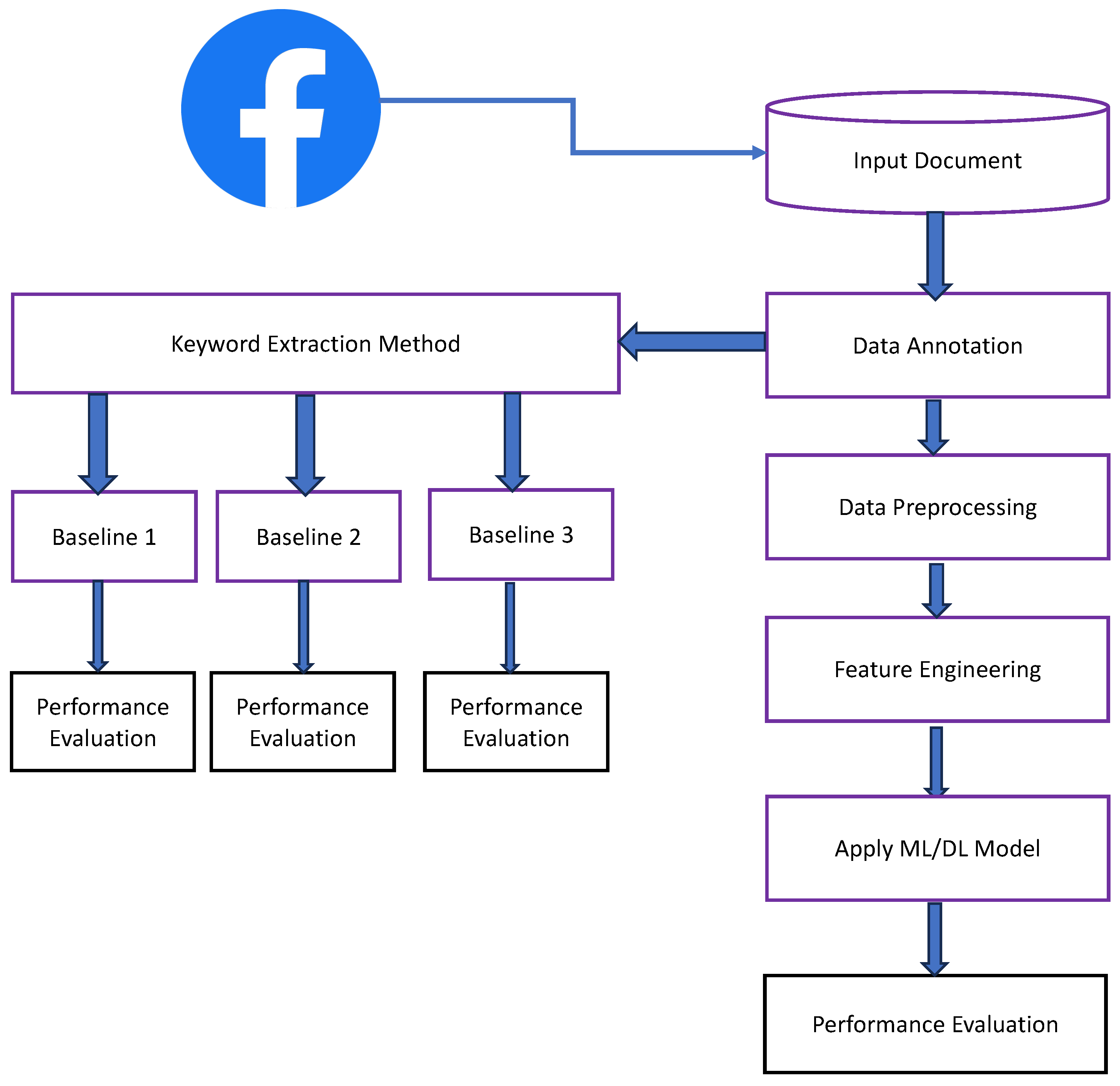
3. Proposed Methodology
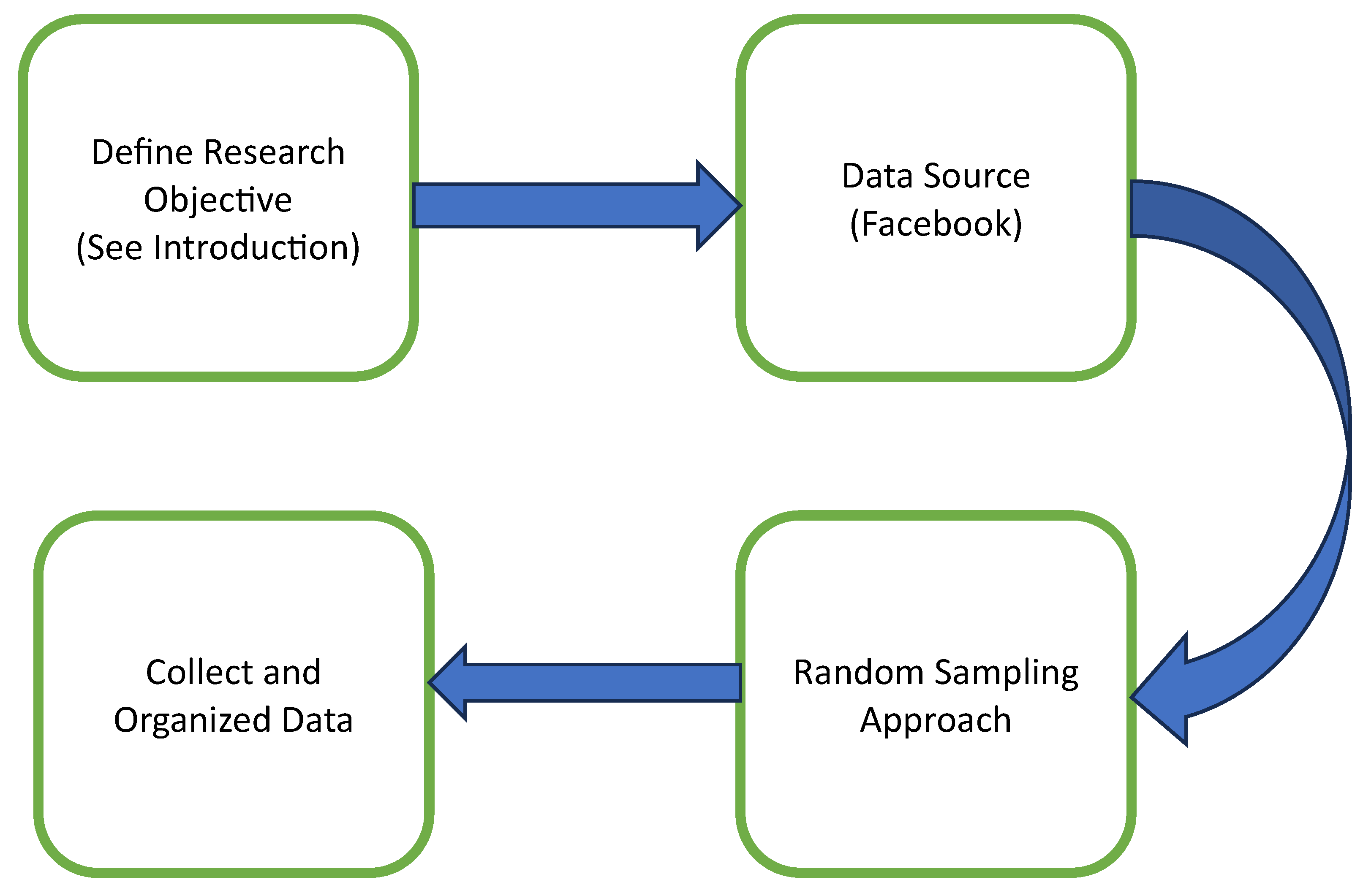
3.1. Data Collection
- The dataset used in this study was made up of text excerpts from social media sites and open comment sections. A dataset with a wide range of topics, writing styles, and user demographics was intended to be both diverse and representative.
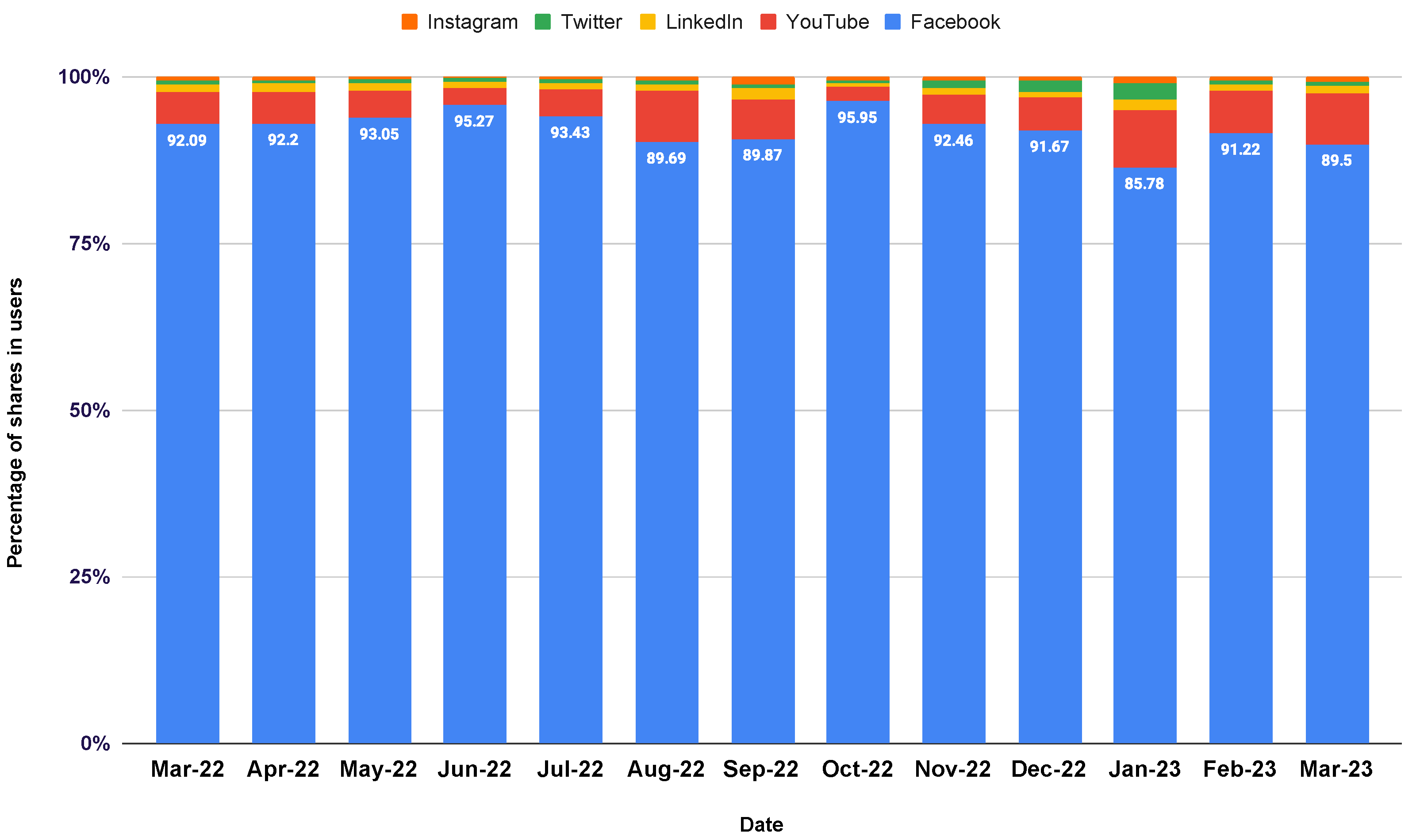
- Facebook comments were manually gathered from a variety of independent sources, such as the public profiles and pages of well-known people.
- Random sampling was used to guarantee a balanced and representative dataset. Each data source’s popularity, user activity, and content suitability had to be taken into account when selecting random text samples from it. The objective was to gather a significant amount of information while keeping a variety of vulgar words and their context.
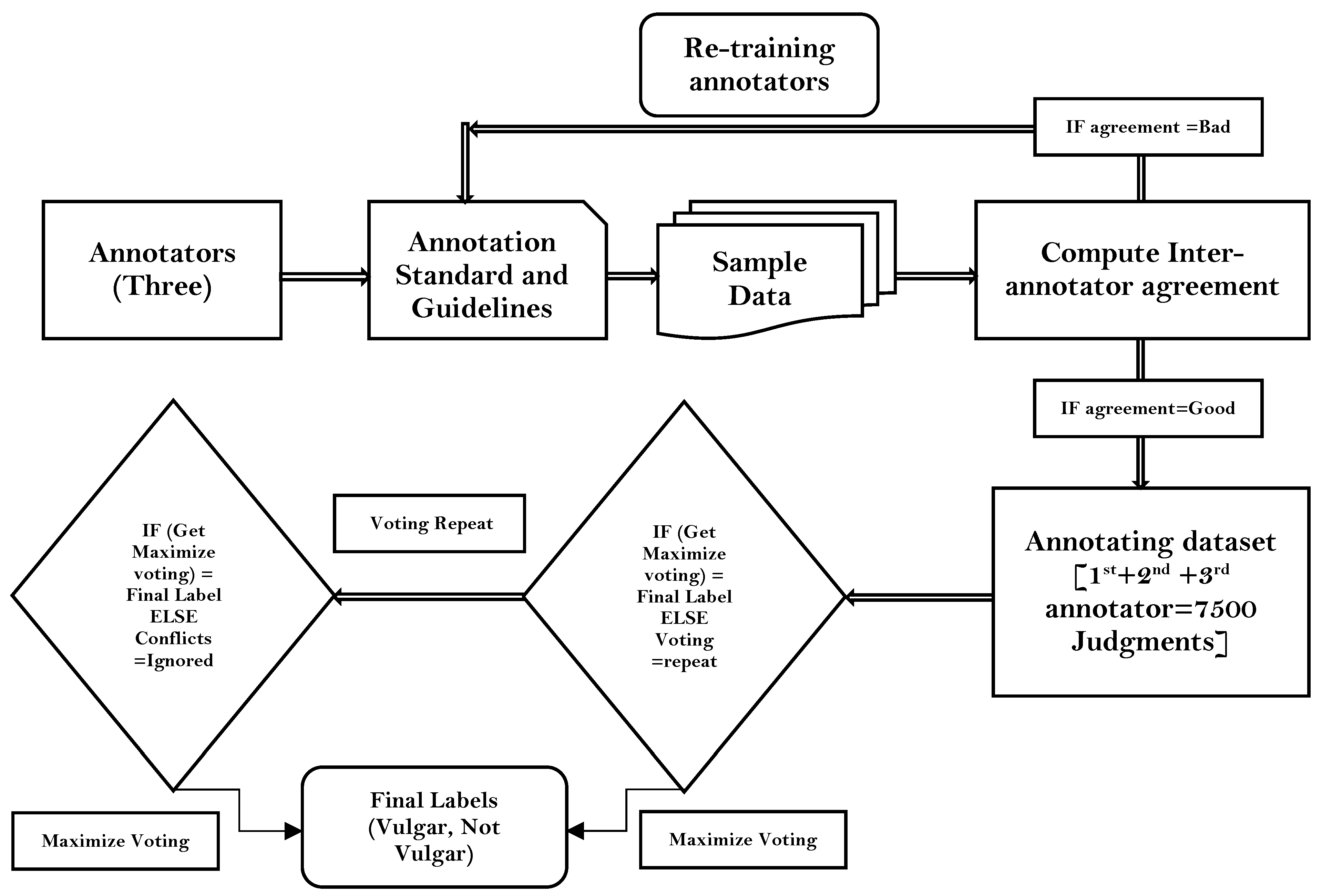
3.2. Data Annotation Process
3.2.1. Standard and Guidelines
- Definition of vulgar words: In this research, we defined vulgar words as unpleasant words such as sl*t, motherf*cker, b*tch, etc., from the Chittagong dialect of Bangla used to harass other people, institutions, groups, and society.
- Severity scale: A number between 1–100 was assigned to each vulgar word from the Chittagong dialect by three language experts.
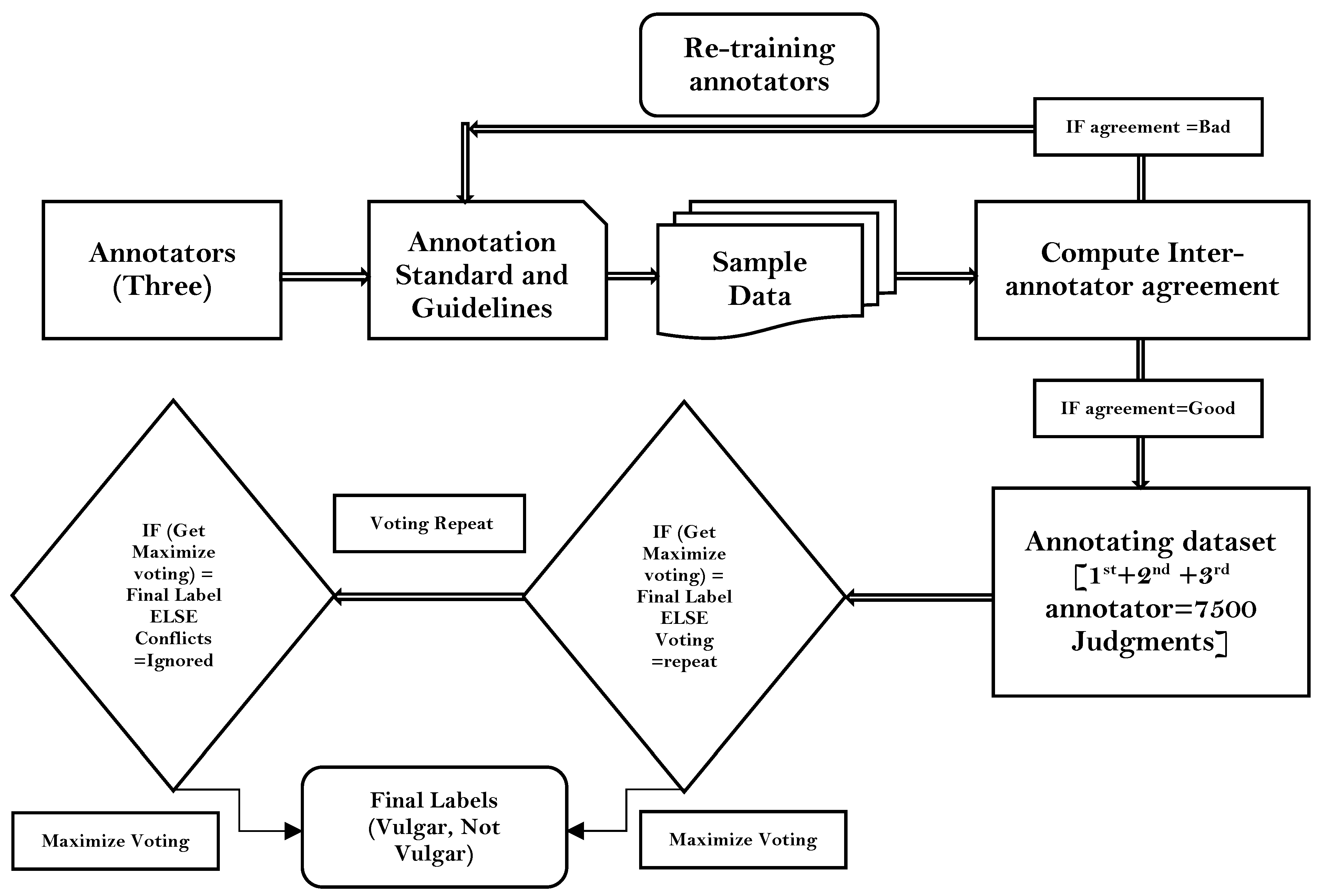
- Annotator training: Three annotators were trained in the interpretation of vulgar words from the Chittagong dialect, so that the annotation process could be conducted properly. This includes training to maintain professional attitude towards the annotated text in all annotations. This includes avoiding any personal bias or judgment.
- Consideration of context: Depending on the context, vulgar words can mean different things and offend people in different ways. The context of the message as well as any cultural or social elements that might affect how a vulgar word is perceived should be taken into account when annotating the text.
- Respect of privacy: Treat any personally identifying information in the annotated text in accordance with any applicable laws or policies and respect the individual’s privacy.
3.2.2. Data Annotation Evaluation
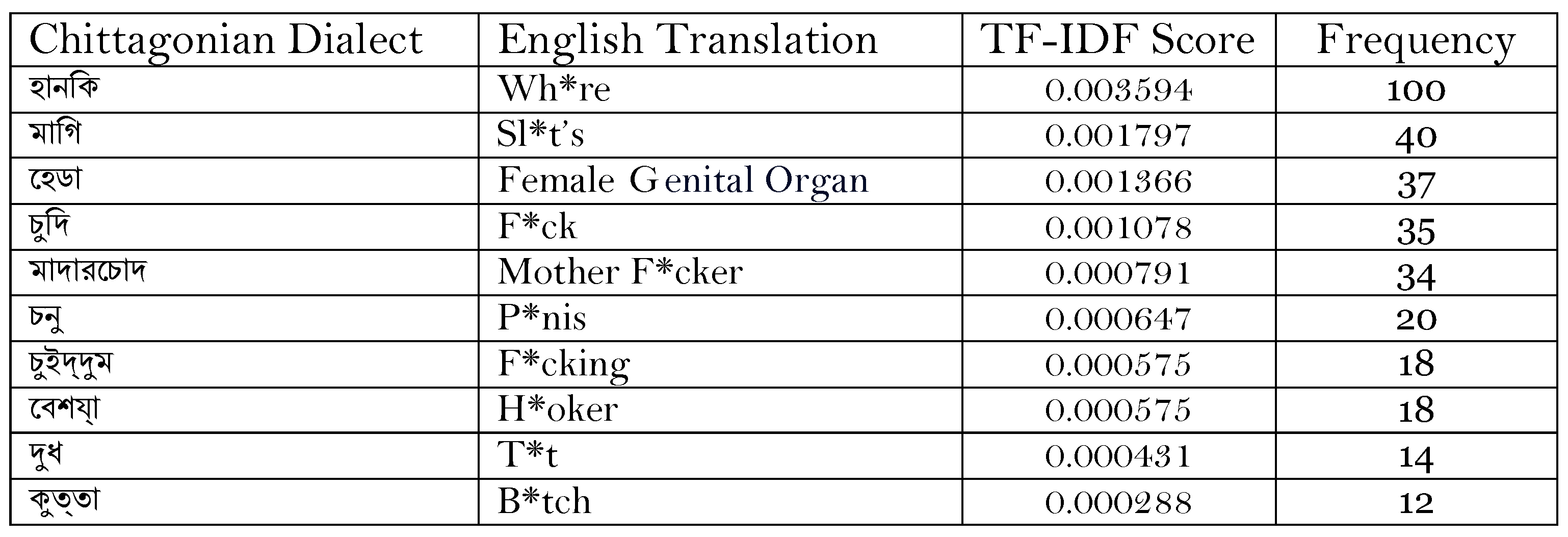
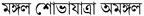 (English translation: “Mangal shovajatra (Mass procession) is inauspicious”). Three annotators gave three different judgments to this comment, i.e., the first judged this comment as non-vulgar, the second as judged this comment as vulgar, and the third could not reach a decision. Three people have given three types of judgments on this comment by looking at the word Mangal from a different religious point of view. Since this was a more difficult problem, surpassing the notion of vulgarity, we decided to not include it in the study this time but will consider it for separate research in the future. Figure 6 displays some of the most typical vulgar words in the dataset.
(English translation: “Mangal shovajatra (Mass procession) is inauspicious”). Three annotators gave three different judgments to this comment, i.e., the first judged this comment as non-vulgar, the second as judged this comment as vulgar, and the third could not reach a decision. Three people have given three types of judgments on this comment by looking at the word Mangal from a different religious point of view. Since this was a more difficult problem, surpassing the notion of vulgarity, we decided to not include it in the study this time but will consider it for separate research in the future. Figure 6 displays some of the most typical vulgar words in the dataset.3.2.3. Inter-Rater Agreement Evaluation
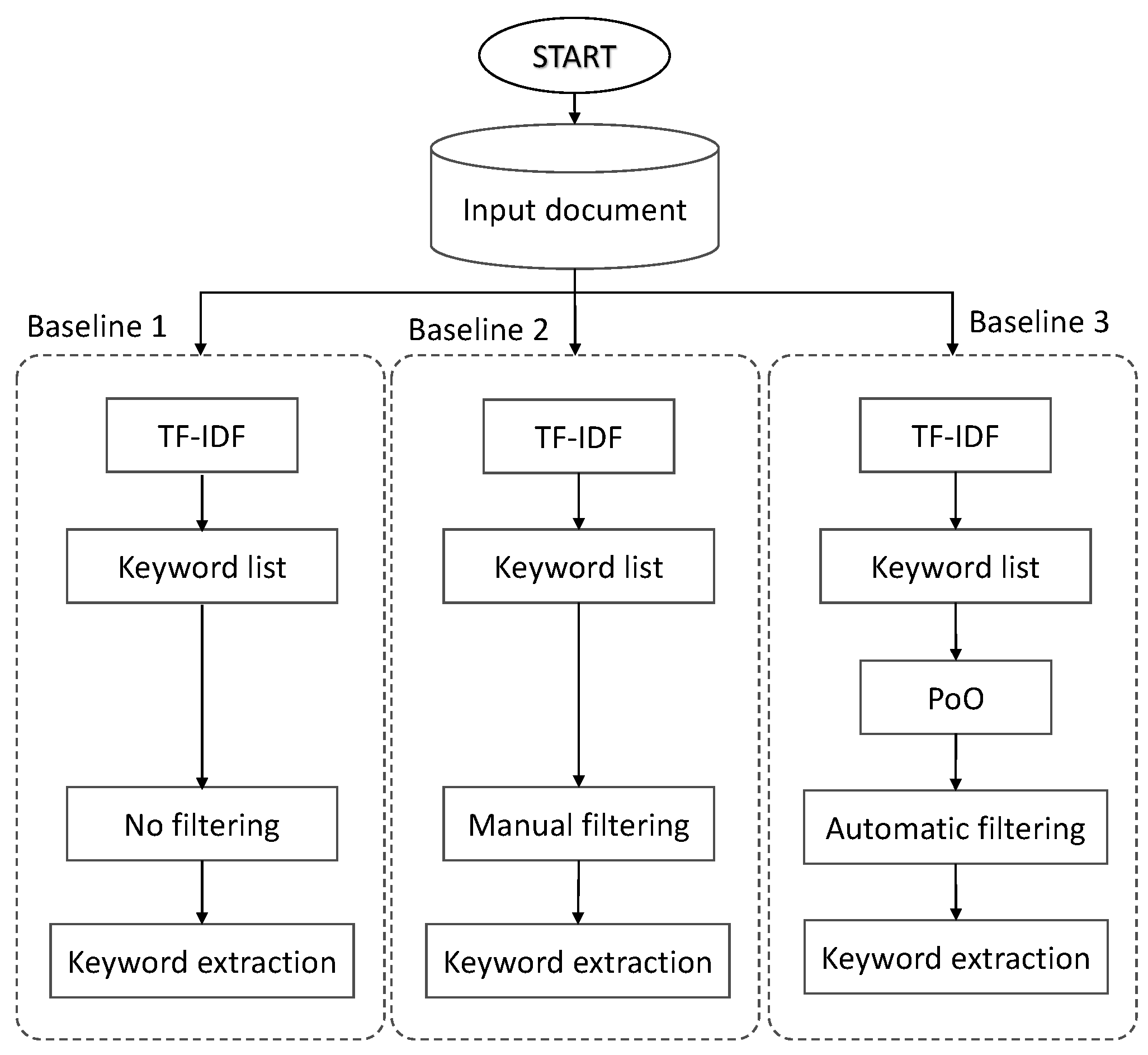
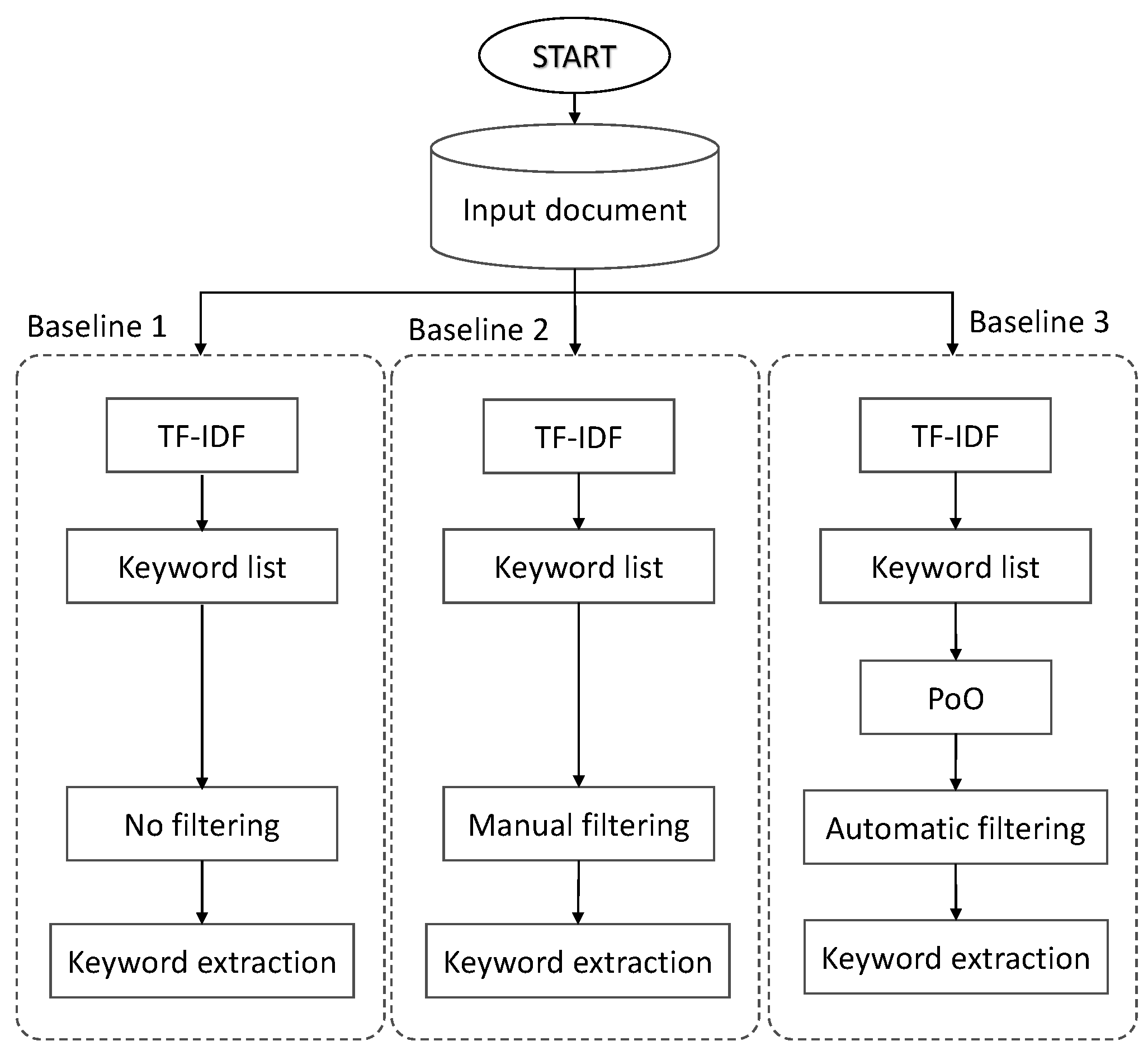
3.3. Baselines
- Automatic keyword extraction method with no additional filtering of non-vulgar words,
- Automatic keyword extraction method with manual filtering of non-vulgar words,
- Automatic keyword extraction method with additional automatic filtering of non-vulgar words.
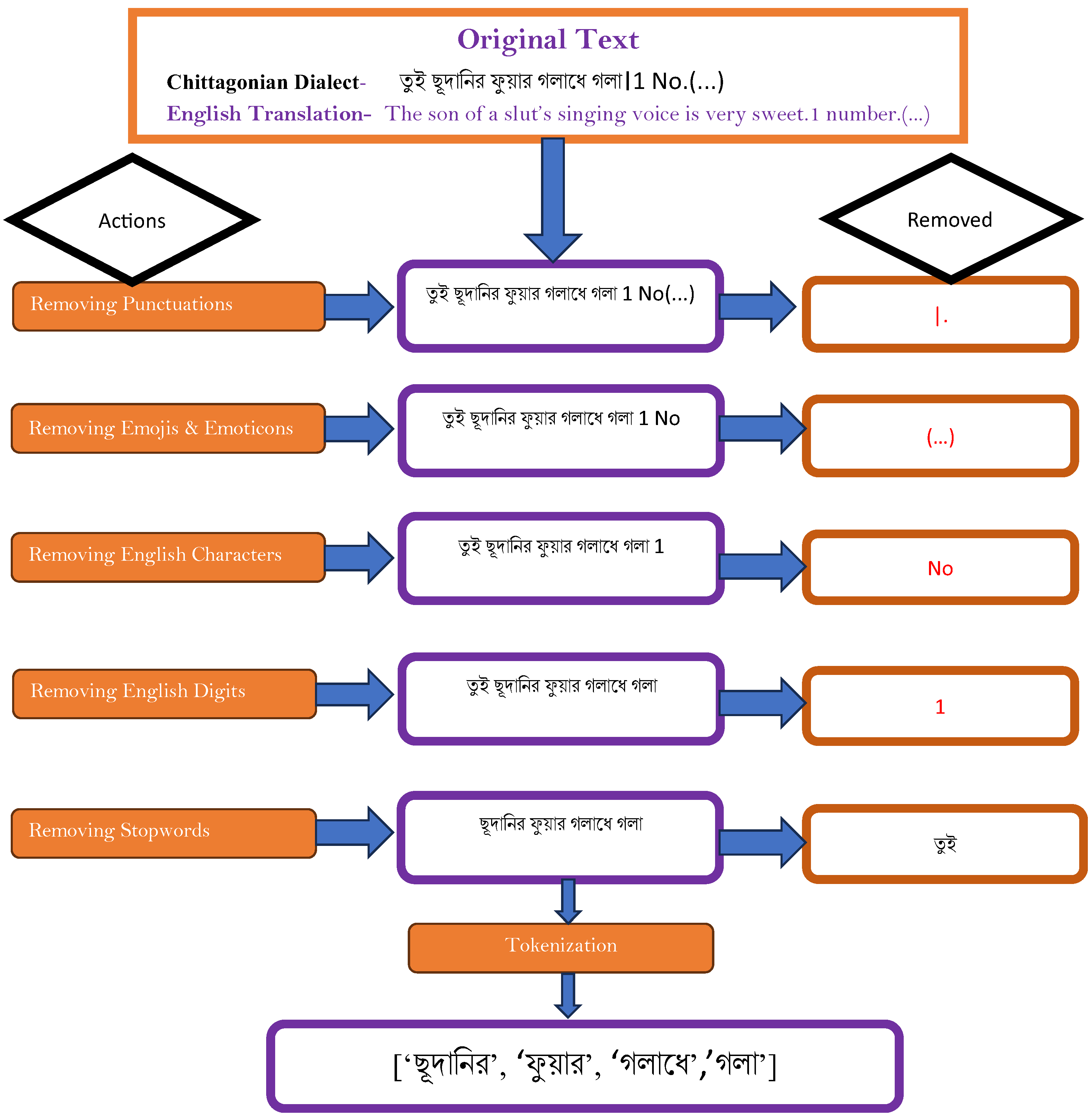
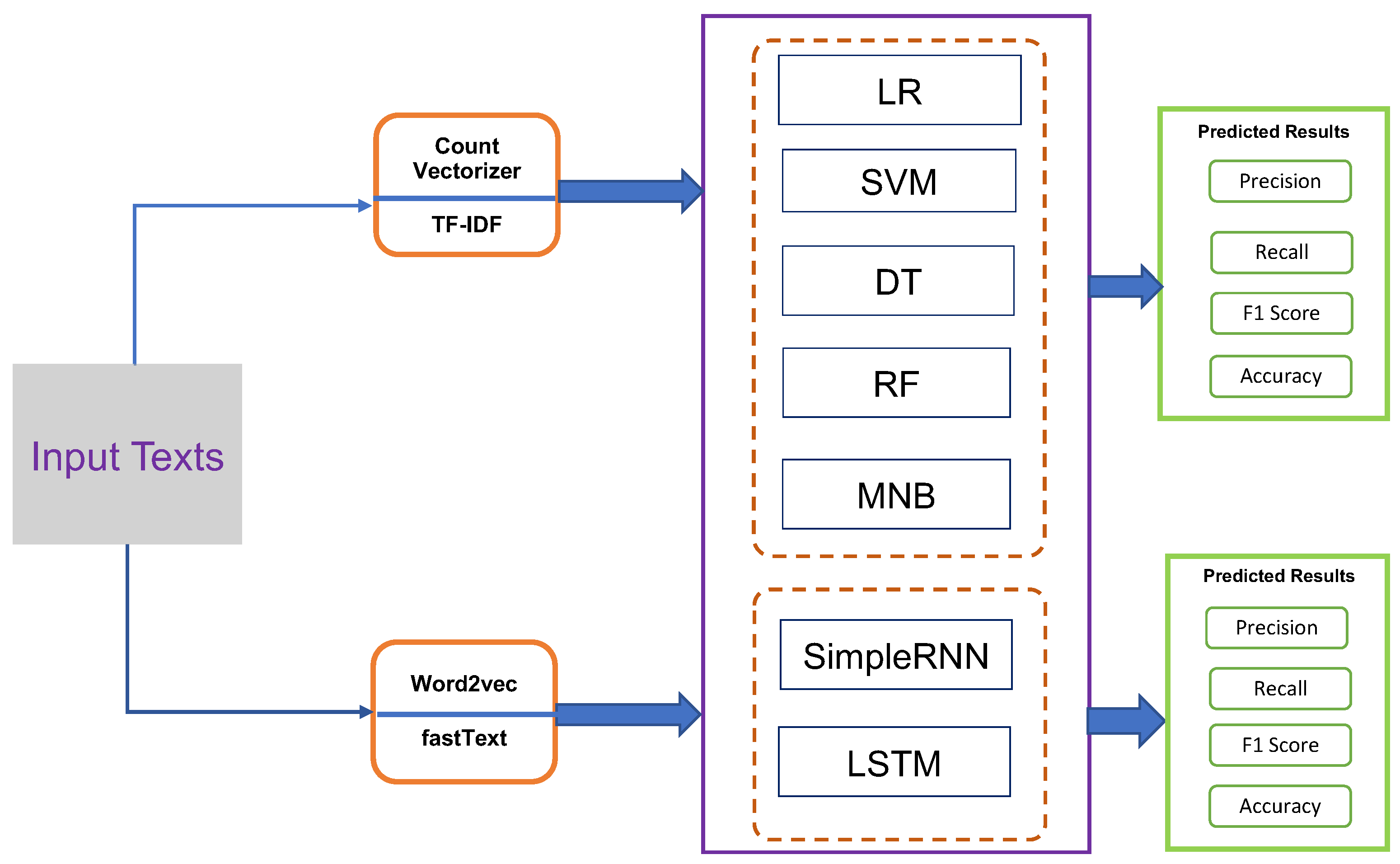
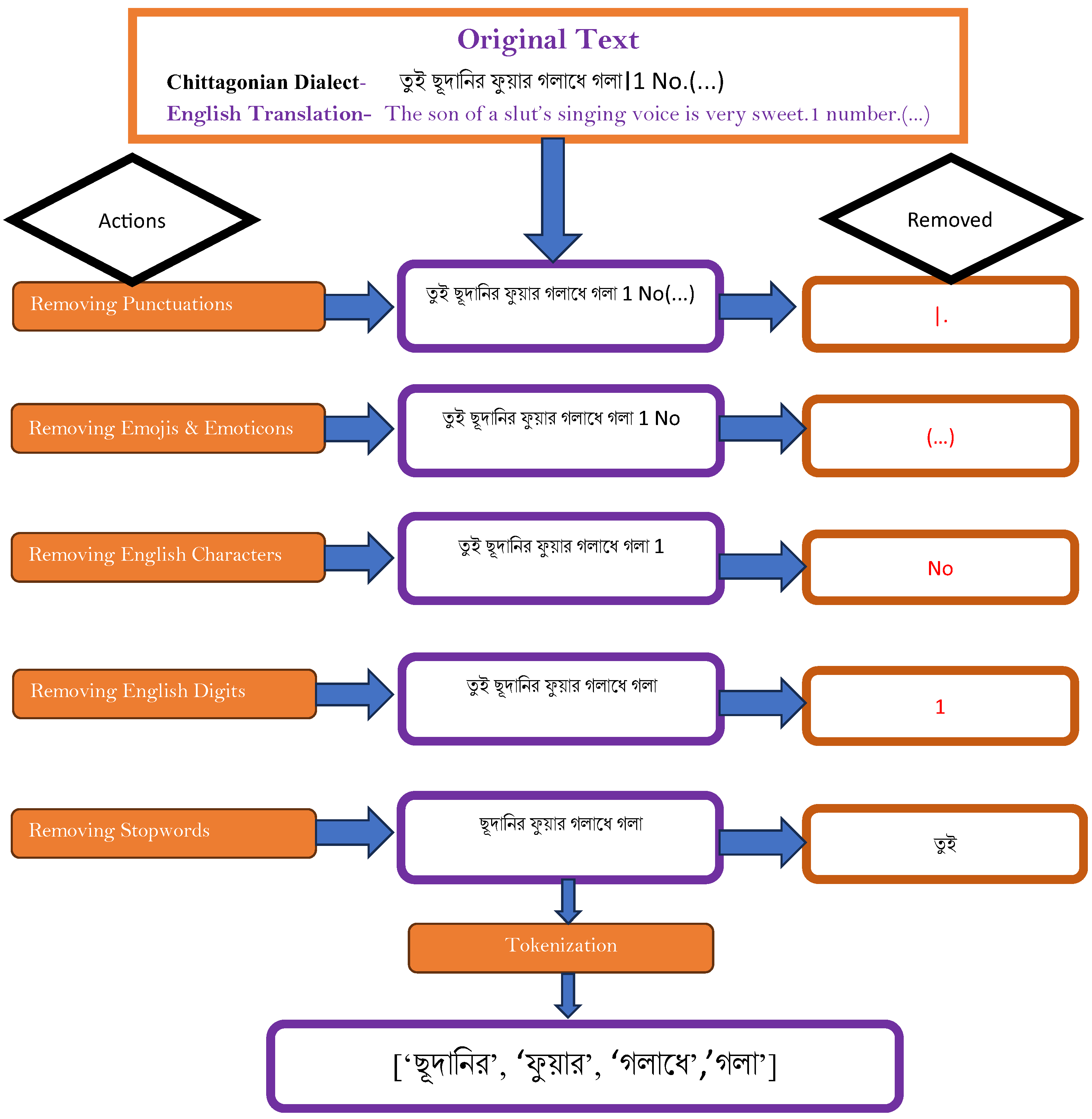
3.4. Data Preprocessing
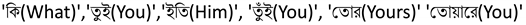 , etc. They are often removed in various natural language processing tasks, like text classification, to reduce the dataset’s dimensionality [62]. Therefore, in order to decrease the dimensionality of the text data and increase the effectiveness and efficiency of the subsequent analysis, we opted to eliminate stopwords from the dataset.
, etc. They are often removed in various natural language processing tasks, like text classification, to reduce the dataset’s dimensionality [62]. Therefore, in order to decrease the dimensionality of the text data and increase the effectiveness and efficiency of the subsequent analysis, we opted to eliminate stopwords from the dataset.3.5. Feature Engineering
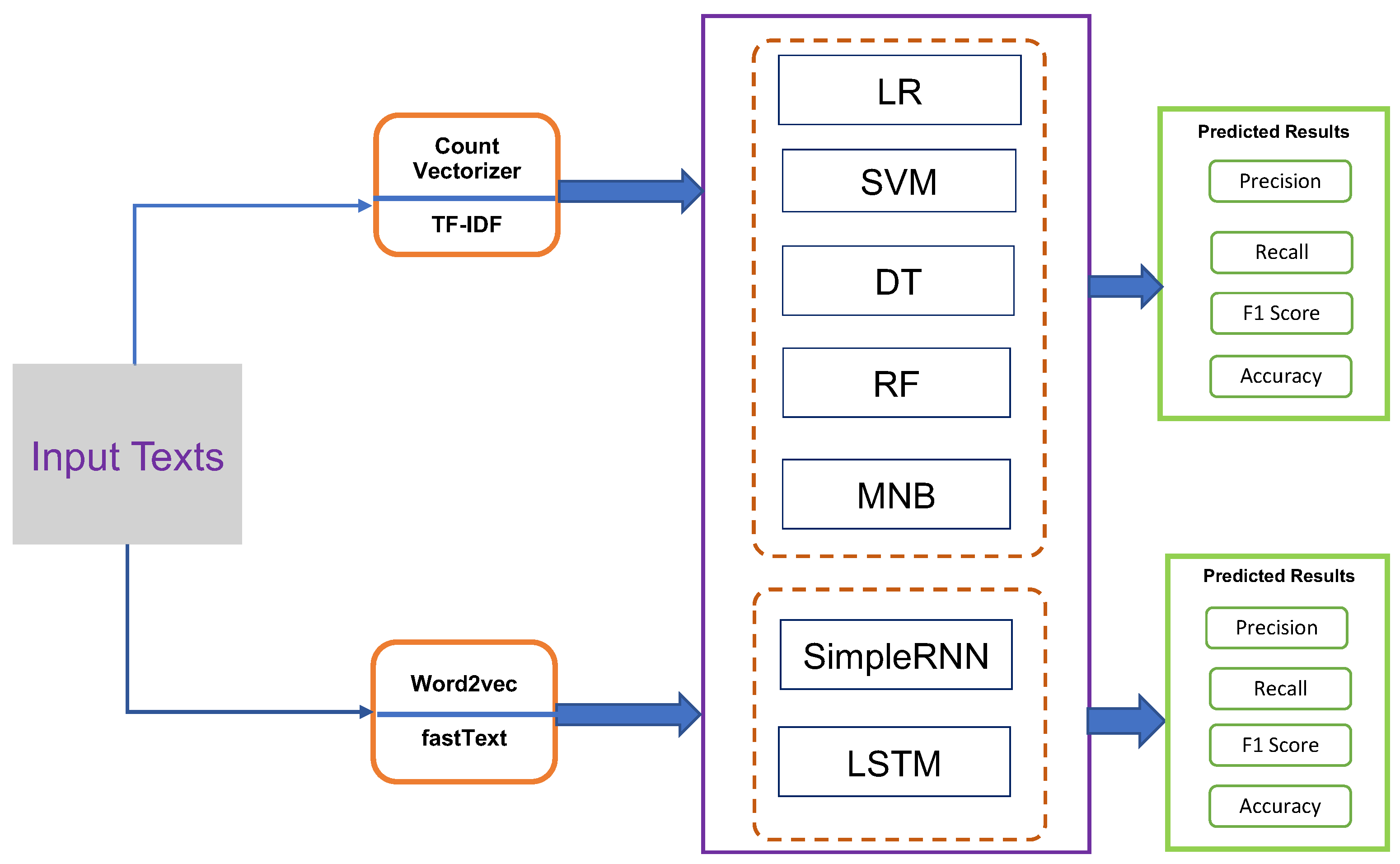
3.5.1. Count Vectorizer
3.5.2. TF-IDF Vectorizer
3.5.3. Word2vec
3.5.4. fastText
3.6. Classification
3.6.1. Logistic Regression
3.6.2. Support Vector Machines
3.6.3. Decision Tree
3.6.4. Random Forest
3.6.5. Multinomial Naive Bayes
3.6.6. Simple Recurrent Neural Network
3.6.7. Long Short-Term Memory Network
3.7. Performance Evaluation Metrics
4. Results and Discussion
4.1. Discussion on Performance of Keyword-Based Vulgarity Extraction and Classification Baselines
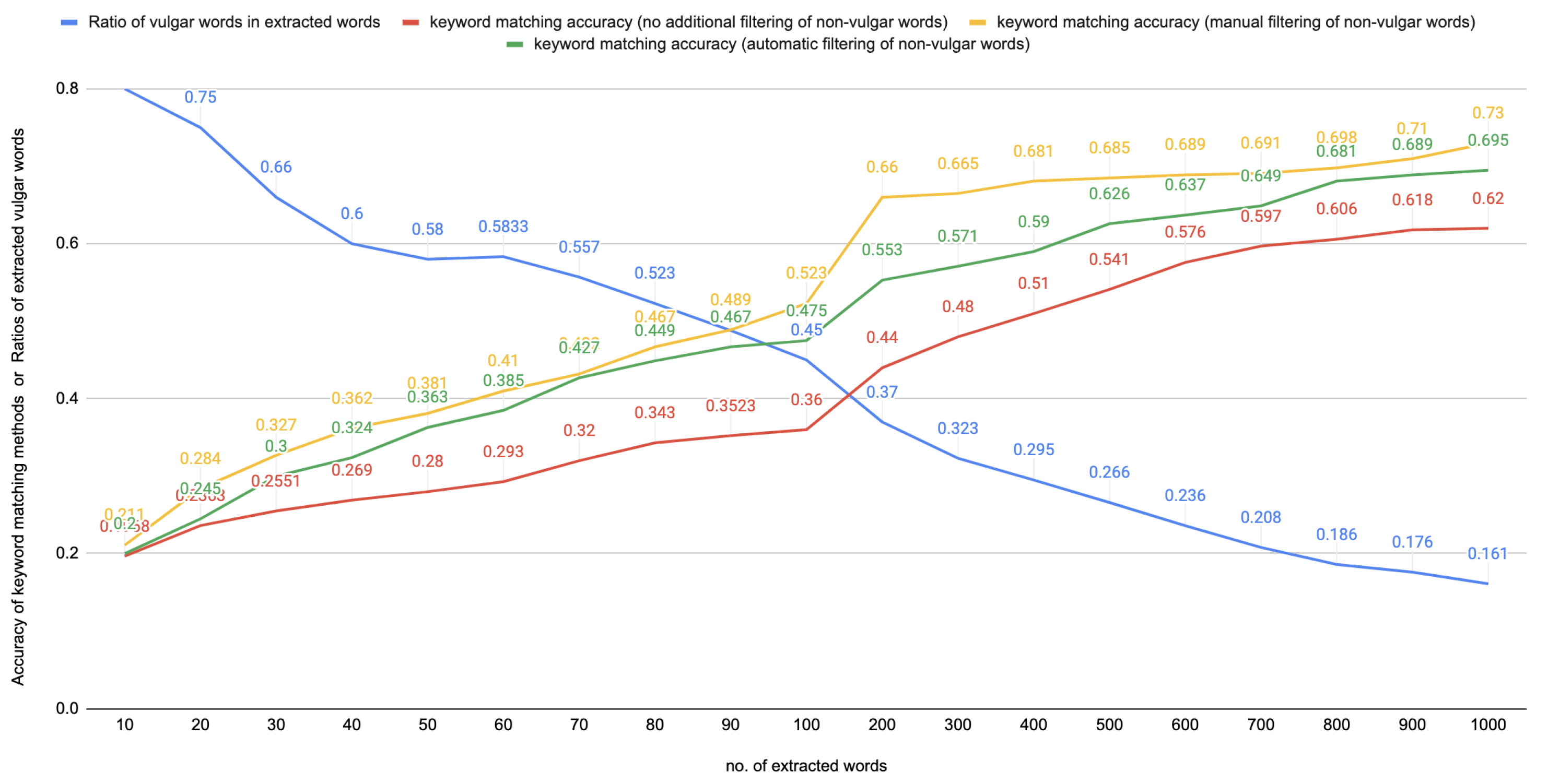
4.1.1. Discussion on Ratio of Vulgar Words Extracted with TF-IDF Weighting
4.1.2. Baseline 1: Keyword-Matching Method Based on TF-IDF Term Extraction with No Additional Filtering
4.1.3. Baseline 2: Keyword-Matching Method Based on TF-IDF Term Extraction with Only Manual Filtering
4.1.4. Baseline 3: Keyword-Matching Method Based on TF-IDF Term Extraction with Automatic Filtering of Non-Vulgar Words
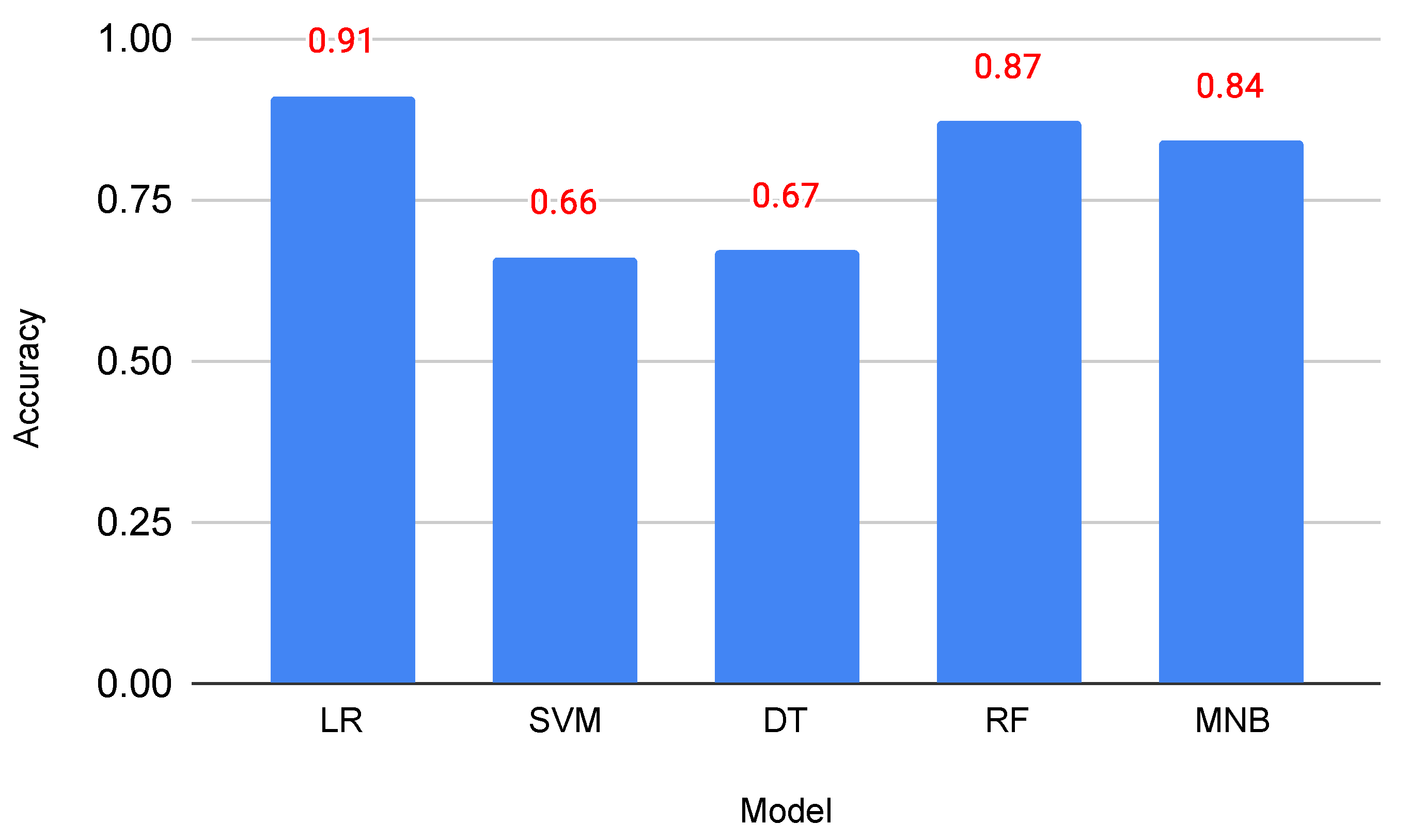
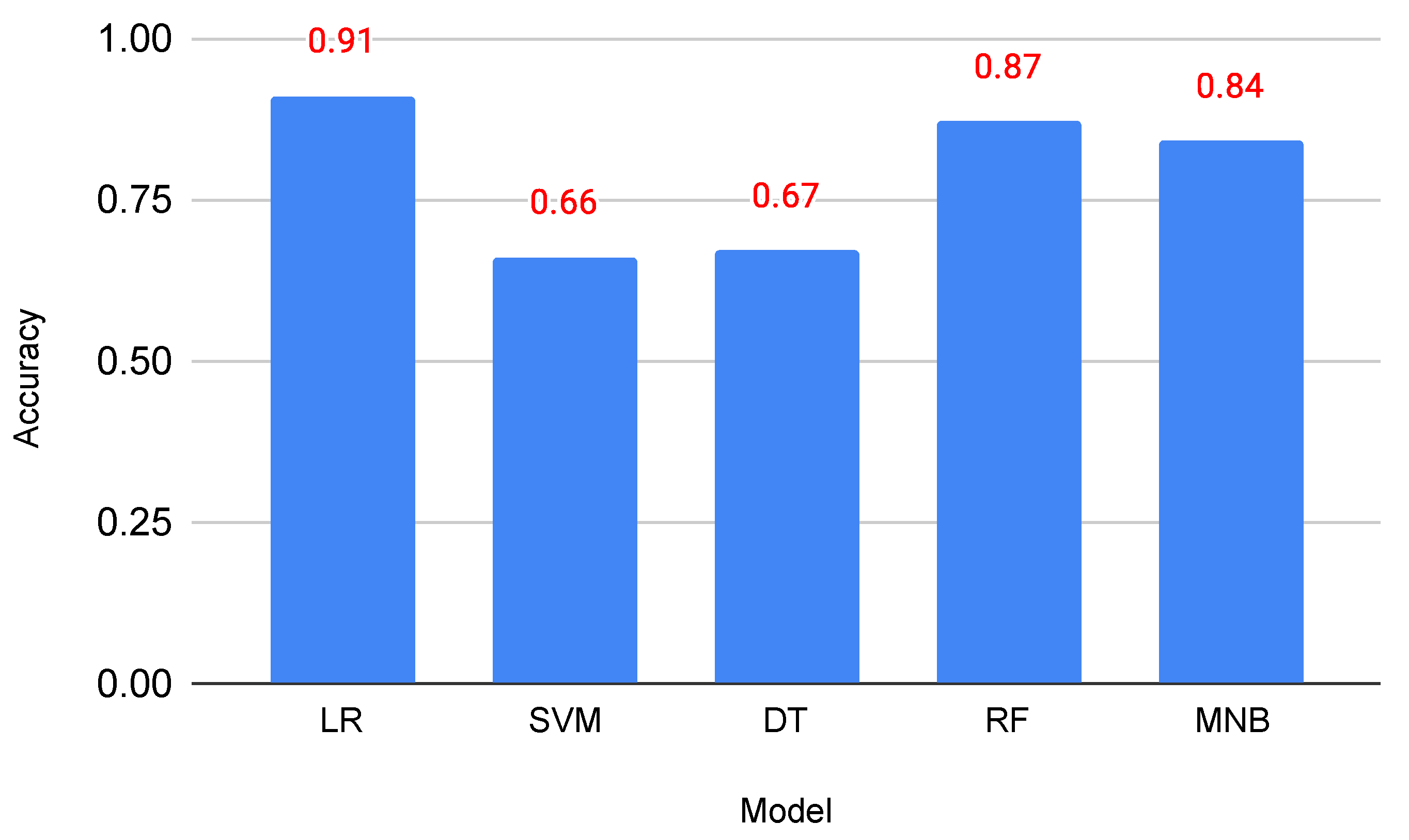
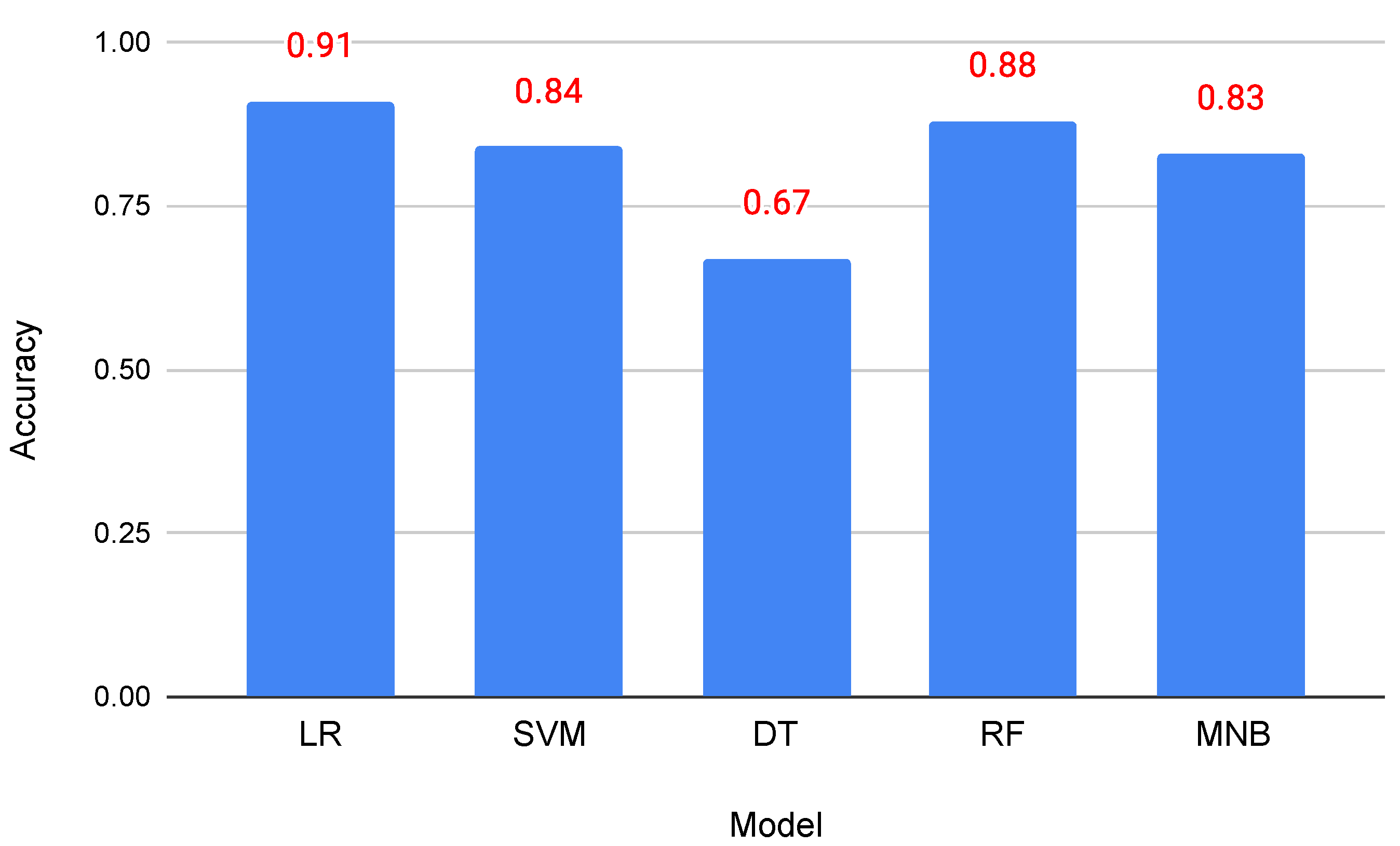
4.2. Machine Learning Models for Vulgarity Detection
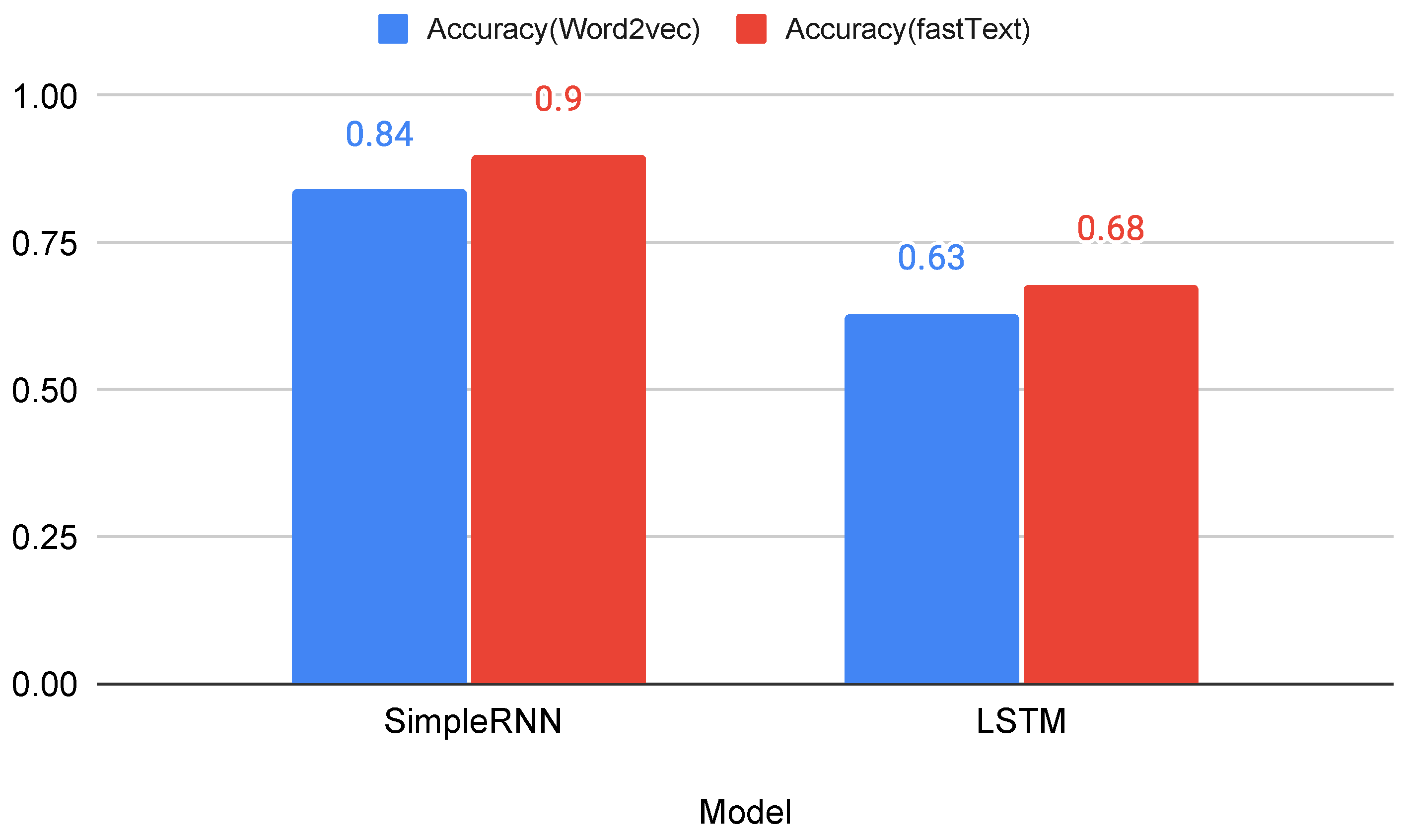
4.3. Deep Learning Models for Vulgarity Detection
4.4. Comparison with Keyword-Matching Baseline
4.5. Comparison with Previous Studies
- Our research language domain is the Chittagong dialect of Bangla, while previous work focused on Bengali/Bangla. Working with dialects has many challenges such as data collection, data annotation, data processing, dataset validation, model creation, etc. By overcoming all these challenges, we successfully completed the research.
- We carried out the research in two steps. Firstly, we reported the performance of the three keyword-matching baselines. No previous research has tried this type of method.
- Then, we built machine learning and deep learning models and compared them with baseline methods. We observed that our models gave comparatively better results then previous studies [35].
4.6. Limitations of Study
4.7. Ethical Considerations
- As the source for our dataset, we primarily used social media groups. Therefore, while gathering the data, we verified and complied with those groups’ terms and conditions.
- We performed anonymization of posts containing such sensitive information as names of private persons, organizations, religious groups, institutions, and states.
- We deleted personal information such as phone numbers, home addresses, etc.
5. Conclusions and Future Work
5.1. Conclusions
5.2. Contributions of this Study
- Gathered a dataset of 2500 comments and posts from publicly accessible Facebook accounts.
- Ensured dataset reliability through rigorous manual annotation and validated the annotations using Cohen’s Kappa statistics and Krippendorff’s alpha.
- Introduced a keyword-matching-based baseline method using a hand-crafted vulgar word lexicon.
- Developed an automated method for augmenting the vulgar word lexicon, ensuring adaptability to evolving language.
- Introduced various sentence-level vulgar remark detection methods, from lexicon matching to advanced techniques.
- Conducted comprehensive comparisons between keyword-matching and machine learning (ML) and deep learning (DL) models to achieve high detection accuracy.
- Achieved over 90% accuracy in detecting vulgar remarks in Chittagonian social media posts, demonstrating a performance acceptable for real-world applications.
5.3. Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| NLP | Natural Language Processing |
| ML | Machine Learning |
| DL | Deep Learning |
| RNN | Recurrent Neural Networks |
| BTRC | Bangladesh Telecommunication Regulatory Commission |
| NGO | Non-governmental Organization |
| TF-IDF | Term Frequency-Inverse Document Frequency |
| LR | Logistic Regression |
| SVM | Support Vector Machine |
| DT | Decision Tree |
| RF | Random Forest |
| MNB | Multinomial Naive Bayes |
| LSTM | Long Short-Term Memory network |
| BiLSTM | Bidirectional Long Short-Term Memory network |
| BERT | Bidirectional Encoder Representations from Transformers |
| ELECTRA | Pre-training Text Encoders as Discriminators Rather Than Generators |
References
- Bangladesh Telecommunication Regulatory Commission. Available online: http://www.btrc.gov.bd/site/page/347df7fe-409f-451e-a415-65b109a207f5/- (accessed on 15 January 2023).
- United Nations Development Programme. Available online: https://www.undp.org/bangladesh/blog/digital-bangladesh-innovative-bangladesh-road-2041 (accessed on 20 January 2023).
- Chittagong City in Bangladesh. Available online: https://en.wikipedia.org/wiki/Chittagong (accessed on 1 April 2023).
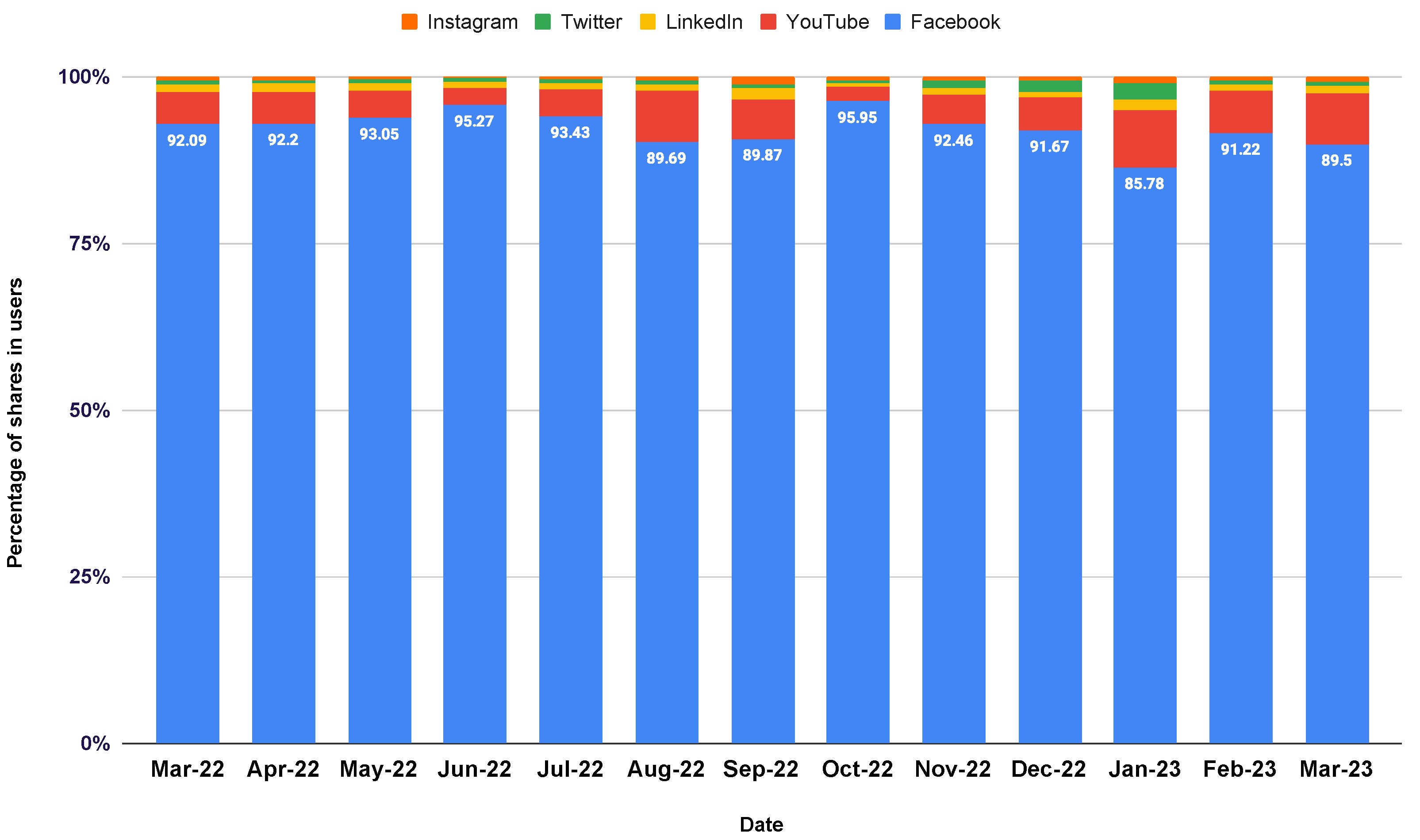
- StatCounter Global Stats. Available online: https://gs.statcounter.com/social-media-stats/all/bangladesh/#monthly-202203-202303 (accessed on 24 April 2023).
- Facebook. Available online: https://www.facebook.com/ (accessed on 28 January 2023).
- imo. Available online: https://imo.im (accessed on 28 January 2023).
- WhatsApp. Available online: https://www.whatsapp.com (accessed on 28 January 2023).
- Addiction Center. Available online: https://www.addictioncenter.com/drugs/social-media-addiction/ (accessed on 28 January 2023).
- Prothom Alo. Available online: https://en.prothomalo.com/bangladesh/Youth-spend-80-mins-a-day-in-Internet-adda (accessed on 28 January 2023).
- United Nations. Available online: https://www.un.org/en/chronicle/article/cyberbullying-and-its-implications-human-rights (accessed on 28 January 2023).
- ACCORD—African Centre for the Constructive Resolution of Disputes. Available online: https://www.accord.org.za/conflict-trends/social-media/ (accessed on 28 January 2023).
- Cachola, I.; Holgate, E.; Preoţiuc-Pietro, D.; Li, J.J. Expressively vulgar: The socio-dynamics of vulgarity and its effects on sentiment analysis in social media. In Proceedings of the 27th International Conference on Computational Linguistics, Santa Fe, NM, USA, 20–26 August 2018; pp. 2927–2938. [Google Scholar]
- Wang, N. An analysis of the pragmatic functions of “swearing” in interpersonal talk. Griffith Work. Pap. Pragmat. Intercult. Commun. 2013, 6, 71–79. [Google Scholar]
- Mehl, M.R.; Vazire, S.; Ramírez-Esparza, N.; Slatcher, R.B.; Pennebaker, J.W. Are women really more talkative than men? Science 2007, 317, 82. [Google Scholar] [CrossRef] [PubMed]
- Wang, W.; Chen, L.; Thirunarayan, K.; Sheth, A.P. Cursing in English on twitter. In Proceedings of the 17th ACM Conference on Computer Supported Cooperative Work & Social Computing, Baltimore, MD, USA, 15–19 February 2014; pp. 415–425. [Google Scholar]
- Holgate, E.; Cachola, I.; Preoţiuc-Pietro, D.; Li, J.J. Why swear? Analyzing and inferring the intentions of vulgar expressions. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, Brussels, Belgium, 31 October–4 November 2018; pp. 4405–4414. [Google Scholar]
- Chittagonian Language. Available online: https://en.wikipedia.org/wiki/Chittagonian_language (accessed on 11 February 2023).
- Lewis, M.P. Ethnologue: Languages of the World, 16th ed.; SIL International: Dallax, TX, USA, 2009. [Google Scholar]
- Masica, C.P. The Indo-Aryan Languages; Cambridge University Press: Cambridge, UK, 1993. [Google Scholar]
- Cohen, J. A coefficient of agreement for nominal scales. Educ. Psychol. Meas. 1960, 20, 37–46. [Google Scholar] [CrossRef]
- Krippendorff, K. Measuring the reliability of qualitative text analysis data. Qual. Quant. 2004, 38, 787–800. [Google Scholar] [CrossRef]
- Sazzed, S. A lexicon for profane and obscene text identification in Bengali. In Proceedings of the International Conference on Recent Advances in Natural Language Processing (RANLP 2021), Online, 1–3 September 2021; pp. 1289–1296. [Google Scholar]
- Das, S.; Mahmud, T.; Islam, D.; Begum, M.; Barua, A.; Tarek Aziz, M.; Nur Showan, E.; Dey, L.; Chakma, E. Deep Transfer Learning-Based Foot No-Ball Detection in Live Cricket Match. Comput. Intell. Neurosci. 2023, 2023, 2398121. [Google Scholar] [CrossRef]
- Mahmud, T.; Barua, K.; Barua, A.; Das, S.; Basnin, N.; Hossain, M.S.; Andersson, K.; Kaiser, M.S.; Sharmen, N. Exploring Deep Transfer Learning Ensemble for Improved Diagnosis and Classification of Alzheimer’s Disease. In Proceedings of the 2023 International Conference on Brain Informatics, Hoboken, NJ, USA, 1–3 August 2023; Springer: Cham, Switzerland, 2023; pp. 1–12. [Google Scholar]
- Wu, Z.; Luo, G.; Yang, Z.; Guo, Y.; Li, K.; Xue, Y. A comprehensive review on deep learning approaches in wind forecasting applications. CAAI Trans. Intell. Technol. 2022, 7, 129–143. [Google Scholar] [CrossRef]
- Gasparin, A.; Lukovic, S.; Alippi, C. Deep learning for time series forecasting: The electric load case. CAAI Trans. Intell. Technol. 2022, 7, 1–25. [Google Scholar] [CrossRef]
- Pinker, S. The Stuff of Thought: Language as a Window into Human Nature; Penguin: London, UK, 2007. [Google Scholar]
- Andersson, L.G.; Trudgill, P. Bad Language; Blackwell/Penguin Books: London, UK, 1990. [Google Scholar]
- Eshan, S.C.; Hasan, M.S. An application of machine learning to detect abusive bengali text. In Proceedings of the 2017 20th International Conference of Computer and Information Technology (ICCIT), Dhaka, Bangladesh, 22–24 December 2017; pp. 1–6. [Google Scholar]
- Akhter, S.; Abdhullah-Al-Mamun. Social media bullying detection using machine learning on Bangla text. In Proceedings of the 2018 10th International Conference on Electrical and Computer Engineering (ICECE), Dhaka, Bangladesh, 20–22 December 2018; pp. 385–388. [Google Scholar]
- Emon, E.A.; Rahman, S.; Banarjee, J.; Das, A.K.; Mittra, T. A deep learning approach to detect abusive bengali text. In Proceedings of the 2019 7th International Conference on Smart Computing & Communications (ICSCC), Sarawak, Malaysia, 28–30 June 2019; pp. 1–5. [Google Scholar]
- Awal, M.A.; Rahman, M.S.; Rabbi, J. Detecting abusive comments in discussion threads using naïve bayes. In Proceedings of the 2018 International Conference on Innovations in Science, Engineering and Technology (ICISET), Chittagong, Bangladesh, 27–28 October 2018; pp. 163–167. [Google Scholar]
- Hussain, M.G.; Al Mahmud, T. A technique for perceiving abusive bangla comments. Green Univ. Bangladesh J. Sci. Eng. 2019, 4, 11–18. [Google Scholar]
- Das, M.; Banerjee, S.; Saha, P.; Mukherjee, A. Hate Speech and Offensive Language Detection in Bengali. arXiv 2022, arXiv:2210.03479. [Google Scholar]
- Sazzed, S. Identifying vulgarity in Bengali social media textual content. PeerJ Comput. Sci. 2021, 7, e665. [Google Scholar] [CrossRef]
- Jahan, M.; Ahamed, I.; Bishwas, M.R.; Shatabda, S. Abusive comments detection in Bangla-English code-mixed and transliterated text. In Proceedings of the 2019 2nd International Conference on Innovation in Engineering and Technology (ICIET), Dhaka, Bangladesh, 23–24 December 2019; pp. 1–6. [Google Scholar]
- Ishmam, A.M.; Sharmin, S. Hateful speech detection in public facebook pages for the bengali language. In Proceedings of the 2019 18th IEEE International Conference on Machine Learning and Applications (ICMLA), Boca Raton, FL, USA, 16–19 December 2019; pp. 555–560. [Google Scholar]
- Karim, M.R.; Dey, S.K.; Islam, T.; Sarker, S.; Menon, M.H.; Hossain, K.; Hossain, M.A.; Decker, S. Deephateexplainer: Explainable hate speech detection in under-resourced bengali language. In Proceedings of the 2021 IEEE 8th International Conference on Data Science and Advanced Analytics (DSAA), Porto, Portugal, 6–9 October 2021; pp. 1–10. [Google Scholar]
- Sazzed, S. Abusive content detection in transliterated Bengali-English social media corpus. In Proceedings of the Fifth Workshop on Computational Approaches to Linguistic Code-Switching, Online, 11 June 2021; pp. 125–130. [Google Scholar]
- Faisal Ahmed, M.; Mahmud, Z.; Biash, Z.T.; Ryen, A.A.N.; Hossain, A.; Ashraf, F.B. Bangla Text Dataset and Exploratory Analysis for Online Harassment Detection. arXiv 2021, arXiv:2102.02478. [Google Scholar]
- Romim, N.; Ahmed, M.; Talukder, H.; Islam, S. Hate speech detection in the bengali language: A dataset and its baseline evaluation. In Proceedings of the International Joint Conference on Advances in Computational Intelligence, Dhaka, Bangladesh, 20–21 November 2020; Springer: Singapore, 2021; pp. 457–468. [Google Scholar]
- Islam, T.; Ahmed, N.; Latif, S. An evolutionary approach to comparative analysis of detecting Bangla abusive text. Bull. Electr. Eng. Inform. 2021, 10, 2163–2169. [Google Scholar] [CrossRef]
- Aurpa, T.T.; Sadik, R.; Ahmed, M.S. Abusive Bangla comments detection on Facebook using transformer-based deep learning models. Soc. Netw. Anal. Min. 2022, 12, 24. [Google Scholar] [CrossRef]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), Minneapolis, MI, USA, 2–7 June 2019; Association for Computational Linguistics: Minneapolis, MI, USA, 2019; pp. 4171–4186. [Google Scholar]
- Clark, K.; Luong, M.T.; Le, Q.V.; Manning, C.D. Electra: Pre-training text encoders as discriminators rather than generators. In Proceedings of the International Conference on Learning Representations, ICLR 2020, Virtual, 26 April–1 May 2020. [Google Scholar]
- List of Non-Governmental Organisations in Bangladesh. Available online: https://en.wikipedia.org/wiki/List_of_non-governmental_organisations_in_Bangladesh (accessed on 15 February 2023).
- Pradhan, R.; Chaturvedi, A.; Tripathi, A.; Sharma, D.K. A review on offensive language detection. In Advances in Data and Information Sciences, Proceedings of ICDIS 2019, Agra, India, 29–30 March 2019; Springer: Singapore, 2020; pp. 433–439. [Google Scholar]
- Khan, M.M.; Shahzad, K.; Malik, M.K. Hate speech detection in roman urdu. ACM Trans. Asian Low-Resour. Lang. Inf. Process. (TALLIP) 2021, 20, 1–19. [Google Scholar] [CrossRef]
- Novitasari, S.; Lestari, D.P.; Sakti, S.; Purwarianti, A. Rude-Words Detection for Indonesian Speech Using Support Vector Machine. In Proceedings of the 2018 International Conference on Asian Language Processing (IALP), Bandung, Indonesia, 15–17 November 2018; pp. 19–24. [Google Scholar] [CrossRef]
- Kim, S.N.; Medelyan, O.; Kan, M.Y.; Baldwin, T. Automatic keyphrase extraction from scientific articles. Lang. Resour. Eval. 2013, 47, 723–742. [Google Scholar] [CrossRef]
- Li, J.; Jiang, G.; Xu, A.; Wang, Y. The Automatic Extraction of Web Information Based on Regular Expression. J. Softw. 2017, 12, 180–188. [Google Scholar]
- Alqahtani, A.; Alhakami, H.; Alsubait, T.; Baz, A. A survey of text matching techniques. Eng. Technol. Appl. Sci. Res. 2021, 11, 6656–6661. [Google Scholar] [CrossRef]
- Califf, M.E.; Mooney, R.J. Bottom-up relational learning of pattern matching rules for information extraction. J. Mach. Learn. Res. 2003, 4, 177–210. [Google Scholar]
- Ptaszynski, M.; Lempa, P.; Masui, F.; Kimura, Y.; Rzepka, R.; Araki, K.; Wroczynski, M.; Leliwa, G. Brute-force sentence pattern extortion from harmful messages for cyberbullying detection. J. Assoc. Inf. Syst. 2019, 20, 1075–1127. [Google Scholar] [CrossRef]
- Beliga, S. Keyword Extraction: A Review of Methods and Approaches; University of Rijeka, Department of Informatics: Rijeka, Croatia, 2014; Volume 1. [Google Scholar]
- Su, G.y.; Li, J.h.; Ma, Y.h.; Li, S.h. Improving the precision of the keyword-matching pornographic text filtering method using a hybrid model. J. Zhejiang Univ.-Sci. A 2004, 5, 1106–1113. [Google Scholar] [CrossRef]
- Liu, F.; Pennell, D.; Liu, F.; Liu, Y. Unsupervised approaches for automatic keyword extraction using meeting transcripts. In Proceedings of the Human Language Technologies: The 2009 Annual Conference of the North American Chapter of The association for Computational Linguistics, Boulder, CO, USA, 31 May–5 June 2009; pp. 620–628. [Google Scholar]
- Ptaszynski, M.; Yagahara, A. Senmon Yogo Chushutsu Sochi, Senmon yogo Chushutsu hoho Oyobi Puroguramu (Technical Term Extraction Device, Technical Term Extraction Method and Program). 16 December 2021. Available online: https://jglobal.jst.go.jp/en/detail?JGLOBAL_ID=202103002313491840 (accessed on 29 January 2023). (In Japanese).
- Mahmud, T.; Ptaszynski, M.; Eronen, J.; Masui, F. Cyberbullying detection for low-resource languages and dialects: Review of the state of the art. Inf. Process. Manag. 2023, 60, 103454. [Google Scholar] [CrossRef]
- Li, D.; Rzepka, R.; Ptaszynski, M.; Araki, K. HEMOS: A novel deep learning-based fine-grained humor detecting method for sentiment analysis of social media. Inf. Process. Manag. 2020, 57, 102290. [Google Scholar] [CrossRef]
- Haque, M.Z.; Zaman, S.; Saurav, J.R.; Haque, S.; Islam, M.S.; Amin, M.R. B-NER: A Novel Bangla Named Entity Recognition Dataset with Largest Entities and Its Baseline Evaluation. IEEE Access 2023, 11, 45194–45205. [Google Scholar] [CrossRef]
- Eronen, J.; Ptaszynski, M.; Masui, F.; Smywiński-Pohl, A.; Leliwa, G.; Wroczynski, M. Improving classifier training efficiency for automatic cyberbullying detection with feature density. Inf. Process. Manag. 2021, 58, 102616. [Google Scholar] [CrossRef]
- Mahmud, T.; Das, S.; Ptaszynski, M.; Hossain, M.S.; Andersson, K.; Barua, K. Reason Based Machine Learning Approach to Detect Bangla Abusive Social Media Comments. In Intelligent Computing & Optimization, Proceedings of the 5th International Conference on Intelligent Computing and Optimization 2022 (ICO2022), Virtual, 27–28 October 2022; Springer: Cham, Switzerland, 2022; pp. 489–498. [Google Scholar]
- Ahmed, T.; Mukta, S.F.; Al Mahmud, T.; Al Hasan, S.; Hussain, M.G. Bangla Text Emotion Classification using LR, MNB and MLP with TF-IDF & CountVectorizer. In Proceedings of the 2022 26th International Computer Science and Engineering Conference (ICSEC), Sakon Nakhon, Thailand, 21–23 December 2022; pp. 275–280. [Google Scholar]
- sklearn.feature_extraction.text.CountVectorizer. Available online: https://scikit-learn.org/stable/modules/generated/sklearn.feature_extraction.text.CountVectorizer.html (accessed on 23 February 2023).
- Chakraborty, M.; Huda, M.N. Bangla document categorisation using multilayer dense neural network with tf-idf. In Proceedings of the 2019 1st International Conference on Advances in Science, Engineering and Robotics Technology (ICASERT), Dhaka, Bangladesh, 3–5 May 2019; pp. 1–4. [Google Scholar]
- sklearn.feature_extraction.text.TfidfVectorizer. Available online: https://scikit-learn.org/stable/modules/generated/sklearn.feature_extraction.text.TfidfVectorizer.html (accessed on 23 February 2023).
- Rahman, R. Robust and consistent estimation of word embedding for bangla language by fine-tuning word2vec model. In Proceedings of the 2020 23rd International Conference on Computer and Information Technology (ICCIT), Dhaka, Bangladesh, 19–21 December 2020; pp. 1–6. [Google Scholar]
- Ma, L.; Zhang, Y. Using Word2Vec to process big text data. In Proceedings of the 2015 IEEE International Conference on Big Data (Big Data), Santa Clara, CA, USA, 29 October–1 November 2015; pp. 2895–2897. [Google Scholar]
- facebookresearch/fastText: Library for Fast Text. Available online: https://github.com/facebookresearch/fastText (accessed on 25 February 2023).
- Research—Meta AI. Available online: https://ai.meta.com/research/ (accessed on 25 February 2023).
- Mojumder, P.; Hasan, M.; Hossain, M.F.; Hasan, K.A. A study of fasttext word embedding effects in document classification in bangla language. In Proceedings of the Cyber Security and Computer Science: Second EAI International Conference, ICONCS 2020, Dhaka, Bangladesh, 15–16 February 2020; Proceedings 2. Springer: Cham, Switzerland, 2020; pp. 441–453. [Google Scholar]
- Shah, K.; Patel, H.; Sanghvi, D.; Shah, M. A comparative analysis of logistic regression, random forest and KNN models for the text classification. Augment. Hum. Res. 2020, 5, 12. [Google Scholar] [CrossRef]
- Mahmud, T.; Ptaszynski, M.; Masui, F. Vulgar Remarks Detection in Chittagonian Dialect of Bangla. arXiv 2023, arXiv:2308.15448. [Google Scholar]
- Hasanli, H.; Rustamov, S. Sentiment analysis of Azerbaijani twits using logistic regression, Naive Bayes and SVM. In Proceedings of the 2019 IEEE 13th International Conference on Application of Information and Communication Technologies (AICT), Baku, Azerbaijan, 23–25 October 2019; pp. 1–7. [Google Scholar]
- Hussain, M.G.; Hasan, M.R.; Rahman, M.; Protim, J.; Al Hasan, S. Detection of bangla fake news using mnb and svm classifier. In Proceedings of the 2020 International Conference on Computing, Electronics & Communications Engineering (iCCECE), Southend, UK, 17–18 August 2020; pp. 81–85. [Google Scholar]
- Alam, M.R.; Akter, A.; Shafin, M.A.; Hasan, M.M.; Mahmud, A. Social Media Content Categorization Using Supervised Based Machine Learning Methods and Natural Language Processing in Bangla Language. In Proceedings of the 2020 11th International Conference on Electrical and Computer Engineering (ICECE), Dhaka, Bangladesh, 17–19 December 2020; pp. 270–273. [Google Scholar]
- Joyce, J. Bayes’ theorem. In Stanford Encyclopedia of Philosophy; Stanford University: Stanford, CA, USA, 2003. [Google Scholar]
- Berrar, D. Bayes’ theorem and naive Bayes classifier. Encycl. Bioinform. Comput. Biol. ABC Bioinform. 2018, 403, 412. [Google Scholar]
- Islam, T.; Prince, A.I.; Khan, M.M.Z.; Jabiullah, M.I.; Habib, M.T. An in-depth exploration of Bangla blog post classification. Bull. Electr. Eng. Inform. 2021, 10, 742–749. [Google Scholar] [CrossRef]
- Haydar, M.S.; Al Helal, M.; Hossain, S.A. Sentiment extraction from bangla text: A character level supervised recurrent neural network approach. In Proceedings of the 2018 International Conference on Computer, Communication, Chemical, Material and Electronic Engineering (IC4ME2), Rajshahi, Bangladesh, 8–9 February 2018; pp. 1–4. [Google Scholar]
- Hu, Z.; Zhang, J.; Ge, Y. Handling vanishing gradient problem using artificial derivative. IEEE Access 2021, 9, 22371–22377. [Google Scholar] [CrossRef]
- Mumu, T.F.; Munni, I.J.; Das, A.K. Depressed people detection from bangla social media status using lstm and cnn approach. J. Eng. Adv. 2021, 2, 41–47. [Google Scholar] [CrossRef]
- Dam, S.K.; Turzo, T.A. Social Movement Prediction from Bangla Social Media Data Using Gated Recurrent Unit Neural Network. In Proceedings of the 2021 5th International Conference on Electrical Information and Communication Technology (EICT), Khulna, Bangladesh, 17–19 December 2021; pp. 1–6. [Google Scholar]
- Uddin, A.H.; Bapery, D.; Arif, A.S.M. Depression analysis from social media data in Bangla language using long short term memory (LSTM) recurrent neural network technique. In Proceedings of the 2019 International Conference on Computer, Communication, Chemical, Materials and Electronic Engineering (IC4ME2), Rajshahi, Bangladesh, 11–12 July 2019; pp. 1–4. [Google Scholar]
- Ptaszynski, M.; Dybala, P.; Shi, W.; Rzepka, R.; Araki, K. A system for affect analysis of utterances in Japanese supported with web mining. J. Jpn. Soc. Fuzzy Theory Intell. Inform. 2009, 21, 194–213. [Google Scholar] [CrossRef]
- Ptaszynski, M.; Masui, F.; Dybala, P.; Rzepka, R.; Araki, K. Open source affect analysis system with extensions. In Proceedings of the 1st International Conference on Human–Agent Interaction, iHAI, Sapporo, Japan, 7–9 August 2013. [Google Scholar]
- Ptaszynski, M.; Dybala, P.; Rzepka, R.; Araki, K.; Masui, F. ML-Ask: Open source affect analysis software for textual input in Japanese. J. Open Res. Softw. 2017, 5, 16. [Google Scholar] [CrossRef]
- Ptaszynski, M.; Masui, F.; Fukushima, Y.; Oikawa, Y.; Hayakawa, H.; Miyamori, Y.; Takahashi, K.; Kawajiri, S. Deep Learning for Information Triage on Twitter. Appl. Sci. 2021, 11, 6340. [Google Scholar] [CrossRef]
- Gray, D.E. Doing Research in the Real World; Sage: Newcastle upon Tyne, UK, 2021; pp. 1–100. [Google Scholar]
- Mahoney, J.; Le Louvier, K.; Lawson, S.; Bertel, D.; Ambrosetti, E. Ethical considerations in social media analytics in the context of migration: Lessons learned from a Horizon 2020 project. Res. Ethics 2022, 18, 226–240. [Google Scholar] [CrossRef]





| Annotator Pairs | Cohen’s Kappa |
|---|---|
| 1 and 2 | 0.92 |
| 1 and 3 | 0.90 |
| 2 and 3 | 0.91 |
| Annotator Pairs | Krippendorff’s Alpha |
|---|---|
| 1 and 2 | 0.927 |
| 1 and 3 | 0.898 |
| 2 and 3 | 0.917 |
| Top # Extracted Words | A | B | C | D | E | F | G | H | I | J |
|---|---|---|---|---|---|---|---|---|---|---|
| 10 | 2 | 2 | 8 | 0.800 | 0.197 | 0.211 | 0.200 | 1 | 1 | 0.50 |
| 20 | 3 | 5 | 15 | 0.750 | 0.236 | 0.284 | 0.245 | 3 | 4 | 0.80 |
| 30 | 5 | 10 | 20 | 0.667 | 0.255 | 0.327 | 0.300 | 0 | 4 | 0.40 |
| 40 | 6 | 16 | 24 | 0.600 | 0.269 | 0.362 | 0.324 | 2 | 6 | 0.38 |
| 50 | 5 | 21 | 29 | 0.580 | 0.280 | 0.381 | 0.363 | 2 | 8 | 0.38 |
| 60 | 4 | 25 | 35 | 0.583 | 0.293 | 0.410 | 0.385 | 0 | 8 | 0.32 |
| 70 | 6 | 31 | 39 | 0.557 | 0.320 | 0.432 | 0.427 | 2 | 10 | 0.32 |
| 80 | 7 | 38 | 42 | 0.525 | 0.343 | 0.467 | 0.449 | 1 | 11 | 0.29 |
| 90 | 8 | 46 | 44 | 0.489 | 0.352 | 0.489 | 0.467 | 1 | 12 | 0.26 |
| 100 | 9 | 55 | 45 | 0.450 | 0.360 | 0.523 | 0.475 | 4 | 16 | 0.29 |
| 200 | 71 | 126 | 74 | 0.370 | 0.44 | 0.66 | 0.553 | 30 | 46 | 0.37 |
| 300 | 77 | 203 | 97 | 0.323 | 0.48 | 0.665 | 0.571 | 33 | 79 | 0.39 |
| 400 | 79 | 282 | 118 | 0.295 | 0.510 | 0.681 | 0.59 | 28 | 107 | 0.38 |
| 500 | 85 | 367 | 133 | 0.266 | 0.541 | 0.685 | 0.626 | 42 | 149 | 0.41 |
| 600 | 91 | 458 | 142 | 0.237 | 0.576 | 0.689 | 0.637 | 46 | 195 | 0.43 |
| 700 | 96 | 554 | 146 | 0.209 | 0.597 | 0.691 | 0.649 | 52 | 247 | 0.45 |
| 800 | 97 | 651 | 149 | 0.186 | 0.606 | 0.698 | 0.681 | 50 | 297 | 0.46 |
| 900 | 90 | 741 | 159 | 0.177 | 0.618 | 0.71 | 0.689 | 41 | 338 | 0.46 |
| 1000 | 98 | 839 | 161 | 0.161 | 0.620 | 0.73 | 0.695 | 68 | 406 | 0.48 |
| Model | Vulgar | Non Vulgar | ACC | ||||
|---|---|---|---|---|---|---|---|
| PRE | REC | F1 | PRE | REC | F1 | ||
| Logistic Regression (LR) | 0.800 | 0.921 | 0.860 | 0.910 | 0.761 | 0.833 | 0.910 |
| Support Vector Machines (SVM) | 0.654 | 0.721 | 0.682 | 0.680 | 0.600 | 0.631 | 0.660 |
| Decision Tree (DT) | 0.623 | 0.861 | 0.722 | 0.771 | 0.470 | 0.583 | 0.671 |
| Random Forest (RF) | 0.670 | 0.942 | 0.791 | 0.900 | 0.534 | 0.673 | 0.871 |
| Multinomial Naive Bayes (MNB) | 0.811 | 0.910 | 0.863 | 0.902 | 0.791 | 0.842 | 0.842 |
| Model | Vulgar | Non Vulgar | ACC | ||||
|---|---|---|---|---|---|---|---|
| PRE | REC | F1 | PRE | REC | F1 | ||
| Logistic Regression (LR) | 0.820 | 0.921 | 0.870 | 0.901 | 0.802 | 0.853 | 0.911 |
| Support Vector Machines (SVM) | 0.810 | 0.890 | 0.853 | 0.881 | 0.792 | 0.832 | 0.843 |
| Decision Tree (DT) | 0.561 | 0.963 | 0.712 | 0.852 | 0.211 | 0.341 | 0.671 |
| Random Forest (RF) | 0.643 | 0.971 | 0.770 | 0.942 | 0.453 | 0.612 | 0.881 |
| Multinomial Naive Bayes (MNB) | 0.801 | 0.913 | 0.854 | 0.891 | 0.770 | 0.832 | 0.832 |
| Word2vec | Vulgar | Non Vulgar | ACC | ||||
|---|---|---|---|---|---|---|---|
| PRE | REC | F1 | PRE | REC | F1 | ||
| SimpleRNN | 0.784 | 0.983 | 0.863 | 0.972 | 0.704 | 0.812 | 0.842 |
| Long Short-Term Memory(LSTM) | 0.612 | 0.811 | 0.703 | 0.682 | 0.451 | 0.544 | 0.631 |
| FastText | Vulgar | Non Vulgar | ACC | ||||
| PRE | REC | F1 | PRE | REC | F1 | ||
| SimpleRNN | 0.943 | 0.872 | 0.901 | 0.872 | 0.941 | 0.903 | 0.902 |
| Long Short-Term Memory(LSTM) | 0.632 | 0.893 | 0.744 | 0.792 | 0.452 | 0.573 | 0.681 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mahmud, T.; Ptaszynski, M.; Masui, F. Automatic Vulgar Word Extraction Method with Application to Vulgar Remark Detection in Chittagonian Dialect of Bangla. Appl. Sci. 2023, 13, 11875. https://doi.org/10.3390/app132111875
Mahmud T, Ptaszynski M, Masui F. Automatic Vulgar Word Extraction Method with Application to Vulgar Remark Detection in Chittagonian Dialect of Bangla. Applied Sciences. 2023; 13(21):11875. https://doi.org/10.3390/app132111875
Chicago/Turabian StyleMahmud, Tanjim, Michal Ptaszynski, and Fumito Masui. 2023. "Automatic Vulgar Word Extraction Method with Application to Vulgar Remark Detection in Chittagonian Dialect of Bangla" Applied Sciences 13, no. 21: 11875. https://doi.org/10.3390/app132111875
APA StyleMahmud, T., Ptaszynski, M., & Masui, F. (2023). Automatic Vulgar Word Extraction Method with Application to Vulgar Remark Detection in Chittagonian Dialect of Bangla. Applied Sciences, 13(21), 11875. https://doi.org/10.3390/app132111875