
Meta-Learning-Based Incremental Nonlinear Dynamic Inversion Control for Quadrotors with Disturbances


Abstract
:1. Introduction
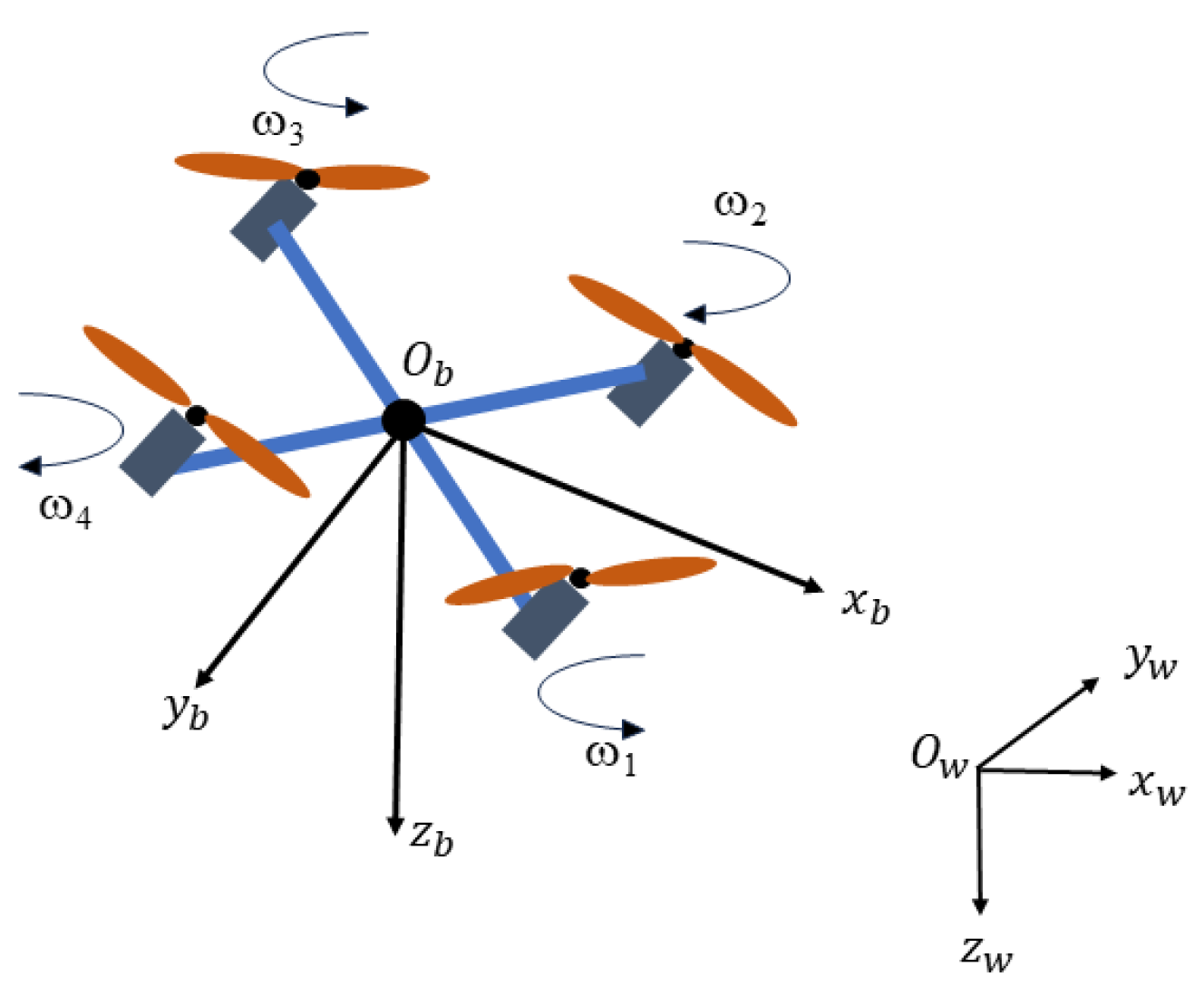
2. Quadrotor Dynamic Model
3. Incremental Nonlinear Dynamic Inversion Control Design
3.1. Incremental Nonlinear Dynamic Inversion
3.2. INDI Acceleration Controller
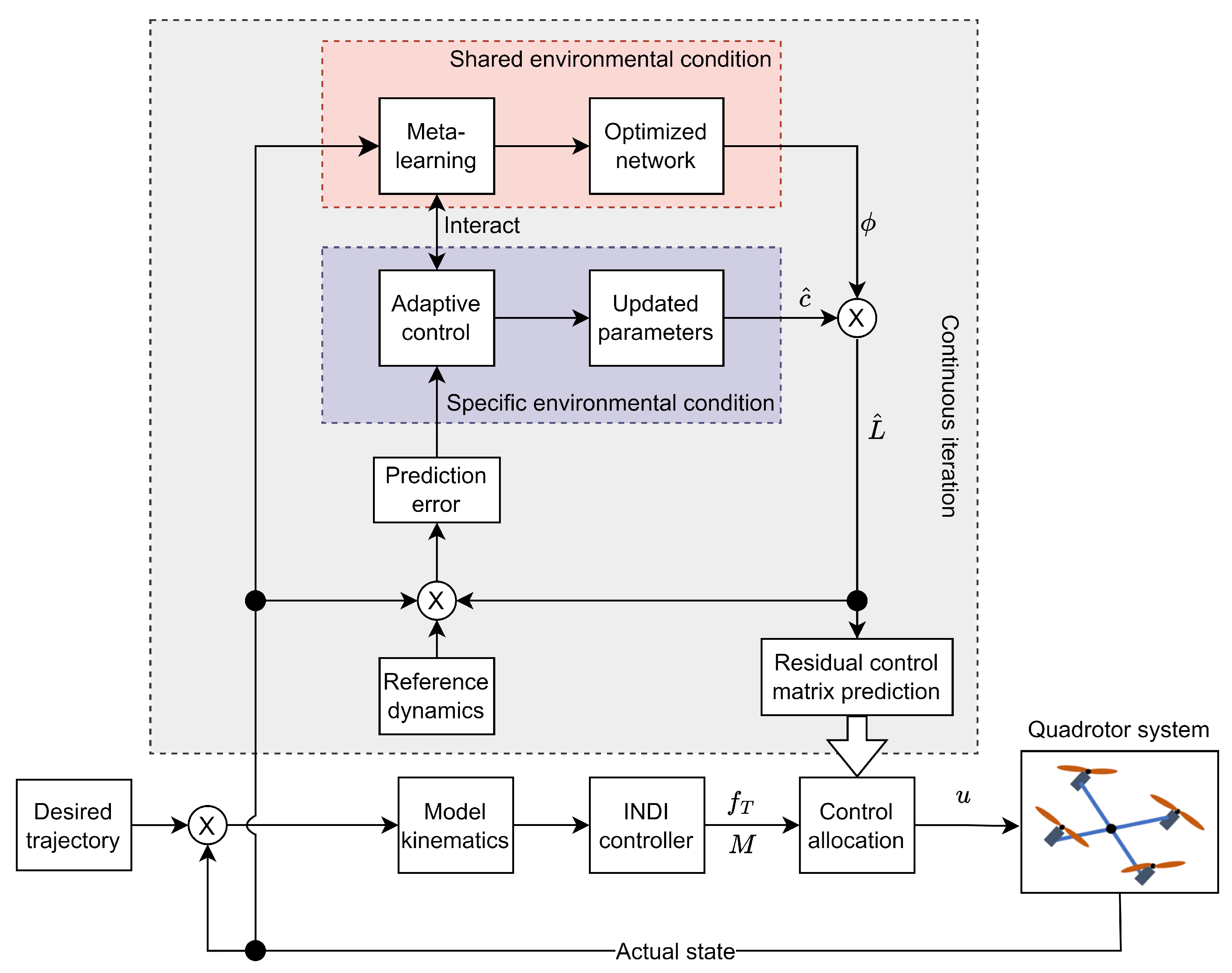
4. Meta-Learning-Based INDI Control and Convergence Analysis
4.1. Meta-Learning-Based INDI Control with Wind Disturbances
4.2. Convergence Analysis
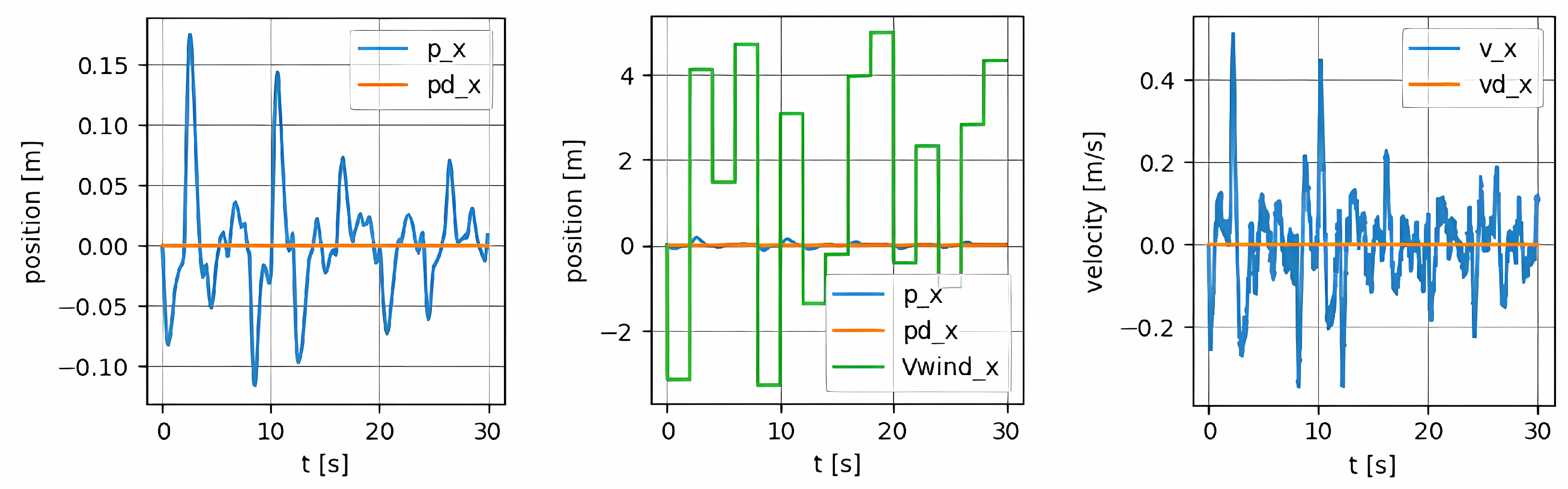
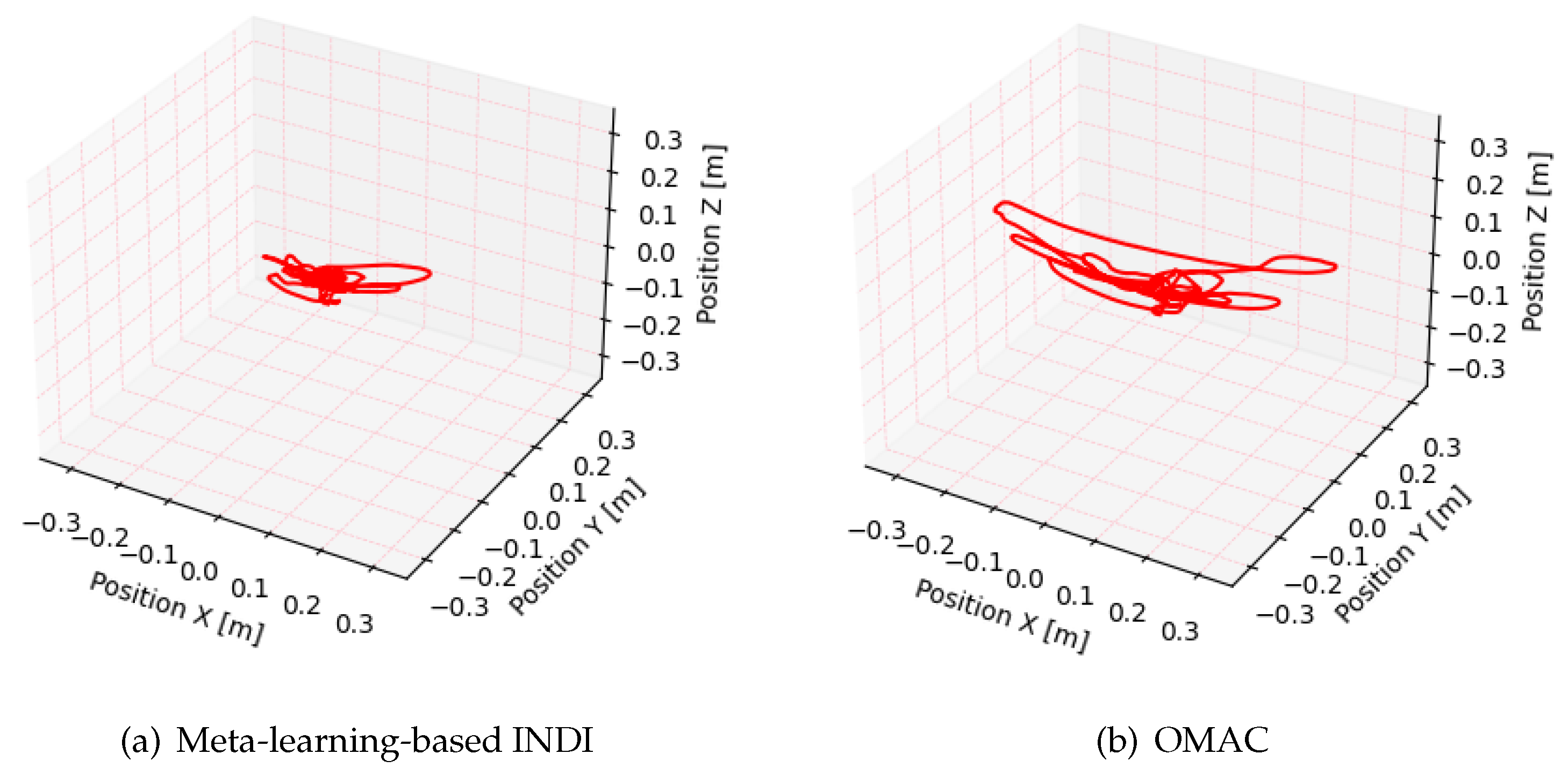
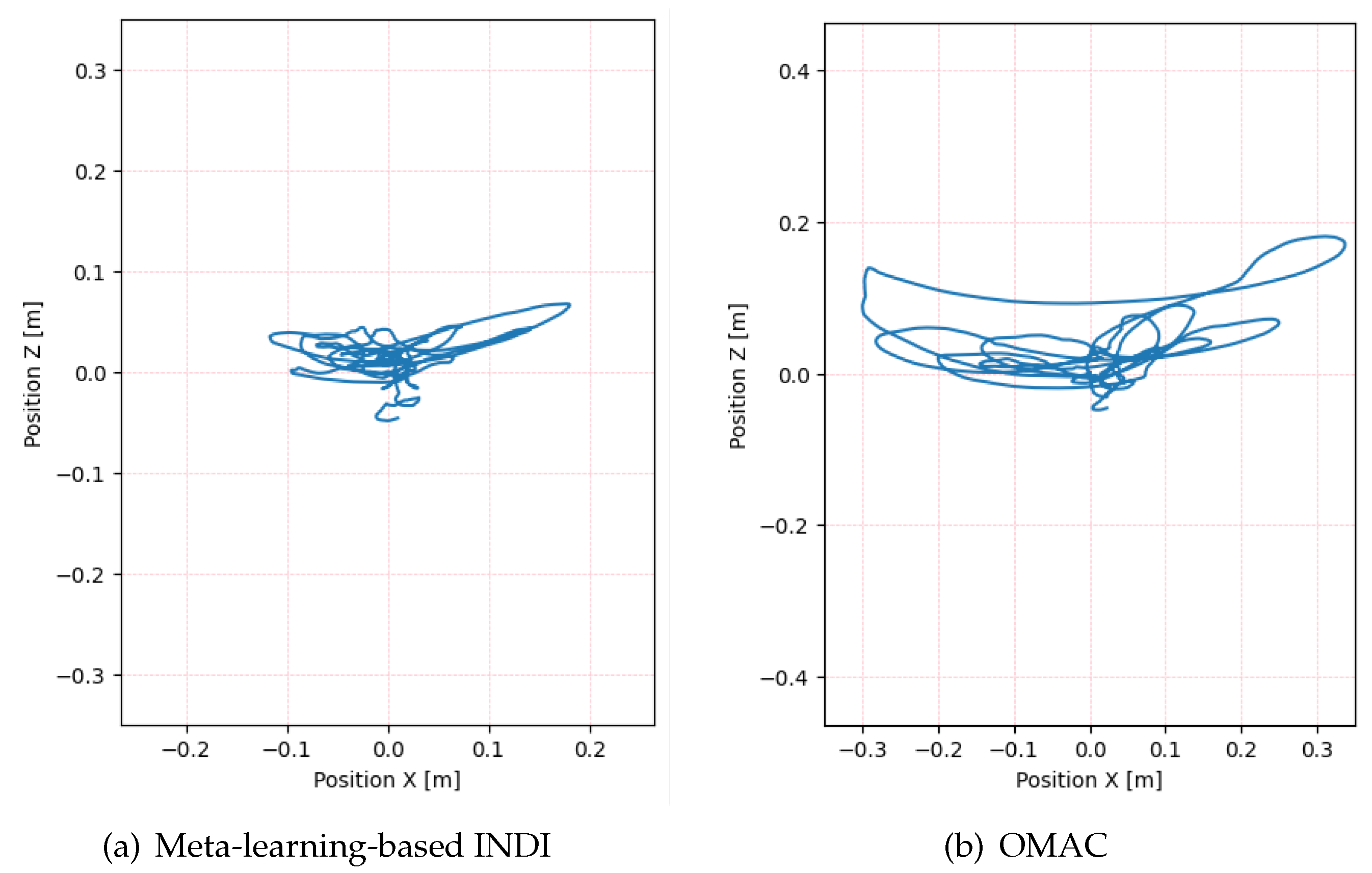
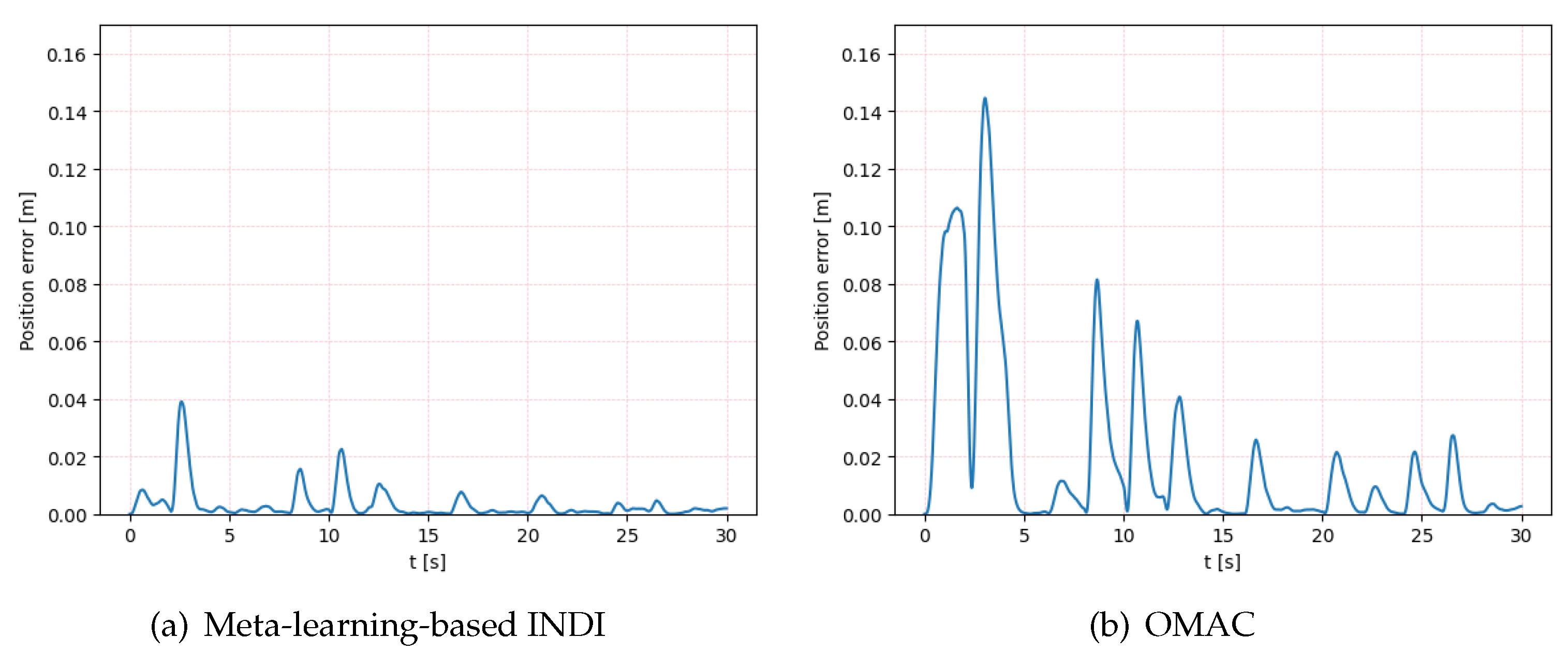
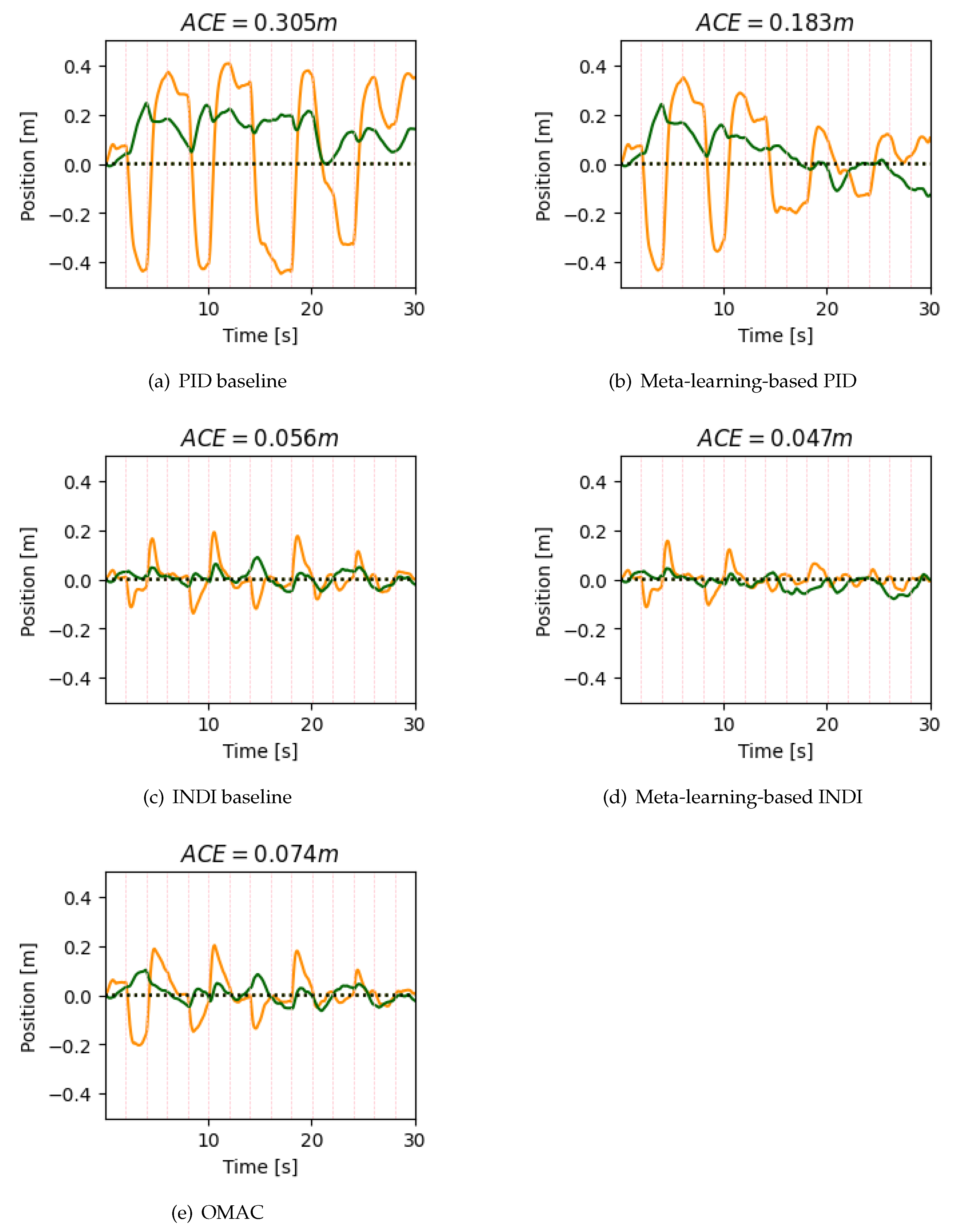
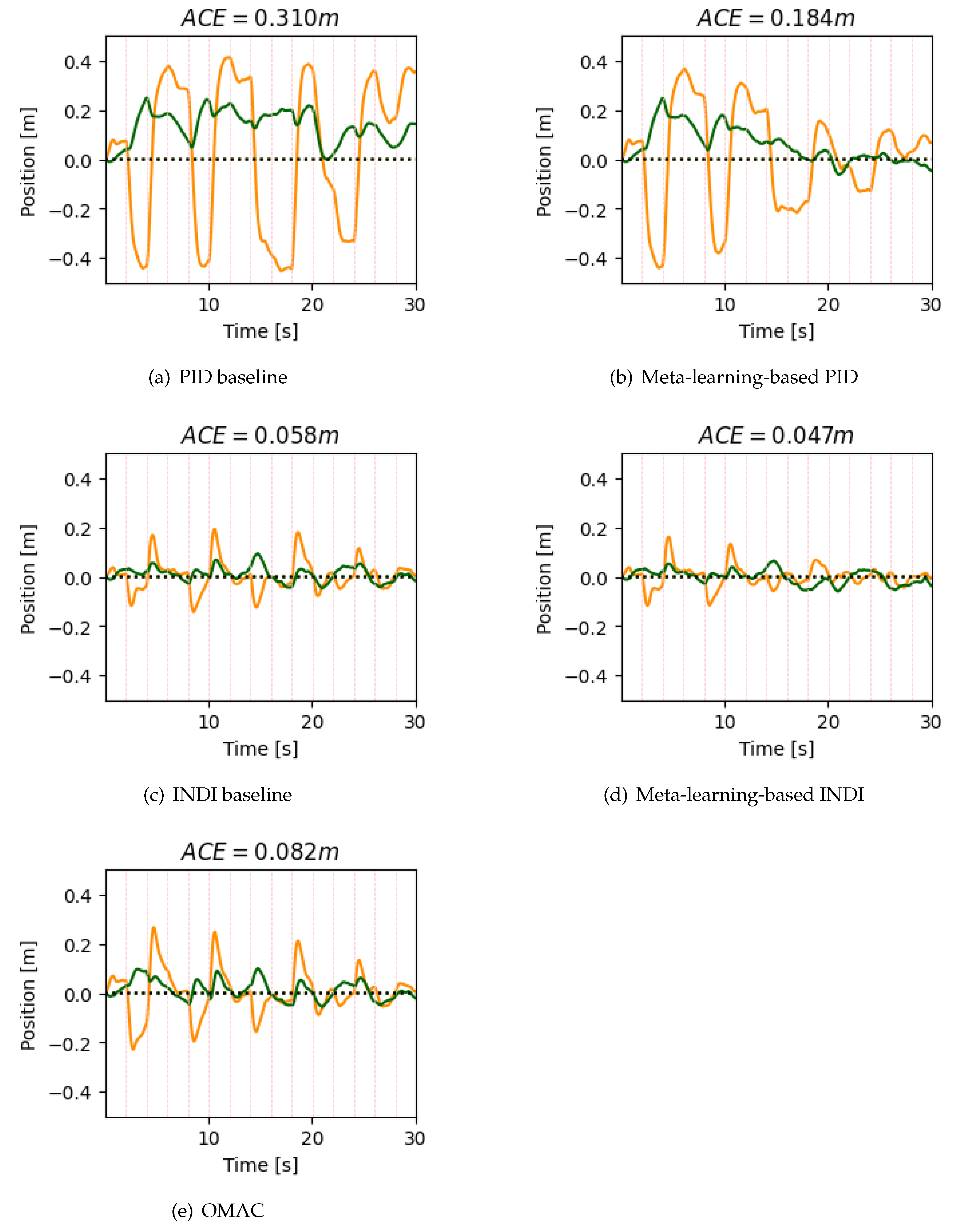
5. Simulation Results
6. Discussion
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Mohd Basri, M.A.; Husain, A.R.; Danapalasingam, K.A. Enhanced backstepping controller design with application to autonomous quadrotor unmanned aerial vehicle. J. Intell. Robot. Syst. 2015, 79, 295–321. [Google Scholar] [CrossRef]
- Emran, B.J.; Najjaran, H. A review of quadrotor: An underactuated mechanical system. Annu. Rev. Control 2018, 46, 165–180. [Google Scholar] [CrossRef]
- Al Tahtawi, A.R.; Yusuf, M. Low-cost quadrotor hardware design with PID control system as flight controller. Telecommun. Comput. Electron. Control 2019, 17, 1923–1930. [Google Scholar] [CrossRef]
- Dydek, Z.T.; Annaswamy, A.M.; Lavretsky, E. Adaptive control of quadrotor UAVs: A design trade study with flight evaluations. IEEE Trans. Control Syst. Technol. 2012, 21, 1400–1406. [Google Scholar] [CrossRef]
- Zhang, X.; Wang, Y.; Zhu, G.; Chen, X.; Li, Z.; Wang, C.; Su, C. Compound adaptive fuzzy quantized control for quadrotor and its experimental verification. IEEE Trans. Cybern. 2020, 51, 1121–1133. [Google Scholar] [CrossRef] [PubMed]
- Sieberling, S.; Chu, Q.P.; Mulder, J.A. Robust flight control using incremental nonlinear dynamic inversion and angular acceleration prediction. J. Guid. Control. Dyn. 2010, 33, 1732–1742. [Google Scholar] [CrossRef]
- Yang, J.; Cai, Z.; Zhao, J.; Wang, Z.; Ding, Y.; Wang, Y. INDI-based aggressive quadrotor flight control with position and attitude constraints. Robot. Auton. Syst. 2023, 159, 104292. [Google Scholar] [CrossRef]
- Mu, C.; Wang, D.; He, H. Novel iterative neural dynamic programming for data-based approximate optimal control design. Automatica 2017, 81, 240–252. [Google Scholar] [CrossRef]
- Li, Y.; Chen, X.; Li, N. Online optimal control with linear dynamics and predictions: Algorithms and regret analysis. Adv. Neural Inf. Process. Syst. 2019, 32, 1–13. [Google Scholar]
- Saviolo, A.; Loianno, G. Learning quadrotor dynamics for precise, safe, and agile flight control. Annu. Rev. Control 2023, 55, 45–60. [Google Scholar] [CrossRef]
- Finn, C.; Abbeel, P.; Levine, S. Model-agnostic meta-learning for fast adaptation of deep networks. In Proceedings of the 34th International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017; pp. 1126–1135. [Google Scholar]
- Shi, G.; Azizzadenesheli, K.; O’Connell, M.; Chung, S.; Yue, Y. Meta-adaptive nonlinear control: Theory and algorithms. Adv. Neural Inf. Process. Syst. 2021, 34, 10013–10025. [Google Scholar]
- Bouabdallah, S. Design and Control of Quadrotors with Application to Autonomous Flying; Epfl: Lausanne, Switzerland, 2007. [Google Scholar]
- Monteiro, J.; Lizarralde, F.; Hsu, L. Optimal control allocation of quadrotor UAVs subject to actuator constraints. In Proceedings of the 2016 American Control Conference, Boston, MA, USA, 6–8 July 2016; pp. 500–505. [Google Scholar]
- Lee, T.; Leok, M.; McClamroch, N.H. Nonlinear robust tracking control of a quadrotor UAV on SE (3). Asian J. Control 2013, 15, 391–408. [Google Scholar] [CrossRef]
- Miyato, T.; Kataoka, T.; Koyama, M.; Yoshida, Y. Spectral normalization for generative adversarial networks. In Proceedings of the 12th International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Kinga, D.; Adam, J.B. A method for stochastic optimization. In Proceedings of the 3rd International Conference on Learning Representations, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Zhang, Z. Improved adam optimizer for deep neural networks. In Proceedings of the 2018 IEEE/ACM 26th International Symposium on Quality of Service, Banff, AT, Canada, 4–6 June 2018; pp. 1–2. [Google Scholar]
- Gomes, L.L.; Leal, L.; Oliveira, T.R.; Cunha, J.P.V.S.; Revoredo, T.C. Unmanned quadcopter control using a motion capture system. IEEE Lat. Am. Trans. 2016, 14, 3606–3613. [Google Scholar] [CrossRef]
- Ran, M.; Li, J.; Xie, L. A new extended state observer for uncertain nonlinear systems. Automatica 2021, 131, 109772. [Google Scholar] [CrossRef]
- Ran, M.; Li, J.; Xie, L. Reinforcement learning-based disturbance rejection control for uncertain nonlinear systems. IEEE Trans. Cybern. 2022, 52, 9621–9633. [Google Scholar] [CrossRef] [PubMed]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Value |
|---|---|
| g | 9.81 |
| m (kg) | 2.4 |
| J (kg· m2) |
| Random Seed Number | PID Baseline | Meta-Learning-Based PID | INDI Baseline | Meta-Learning-Based INDI |
|---|---|---|---|---|
| 1 | 0.303 m | 0.225 m | 0.054 m | 0.043 m |
| 2 | 0.282 m | 0.217 m | 0.054 m | 0.047 m |
| 3 | 0.320 m | 0.230 m | 0.069 m | 0.057 m |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, X.; Ran, M. Meta-Learning-Based Incremental Nonlinear Dynamic Inversion Control for Quadrotors with Disturbances. Appl. Sci. 2023, 13, 11844. https://doi.org/10.3390/app132111844
Zhang X, Ran M. Meta-Learning-Based Incremental Nonlinear Dynamic Inversion Control for Quadrotors with Disturbances. Applied Sciences. 2023; 13(21):11844. https://doi.org/10.3390/app132111844
Chicago/Turabian StyleZhang, Xinyue, and Maopeng Ran. 2023. "Meta-Learning-Based Incremental Nonlinear Dynamic Inversion Control for Quadrotors with Disturbances" Applied Sciences 13, no. 21: 11844. https://doi.org/10.3390/app132111844
APA StyleZhang, X., & Ran, M. (2023). Meta-Learning-Based Incremental Nonlinear Dynamic Inversion Control for Quadrotors with Disturbances. Applied Sciences, 13(21), 11844. https://doi.org/10.3390/app132111844