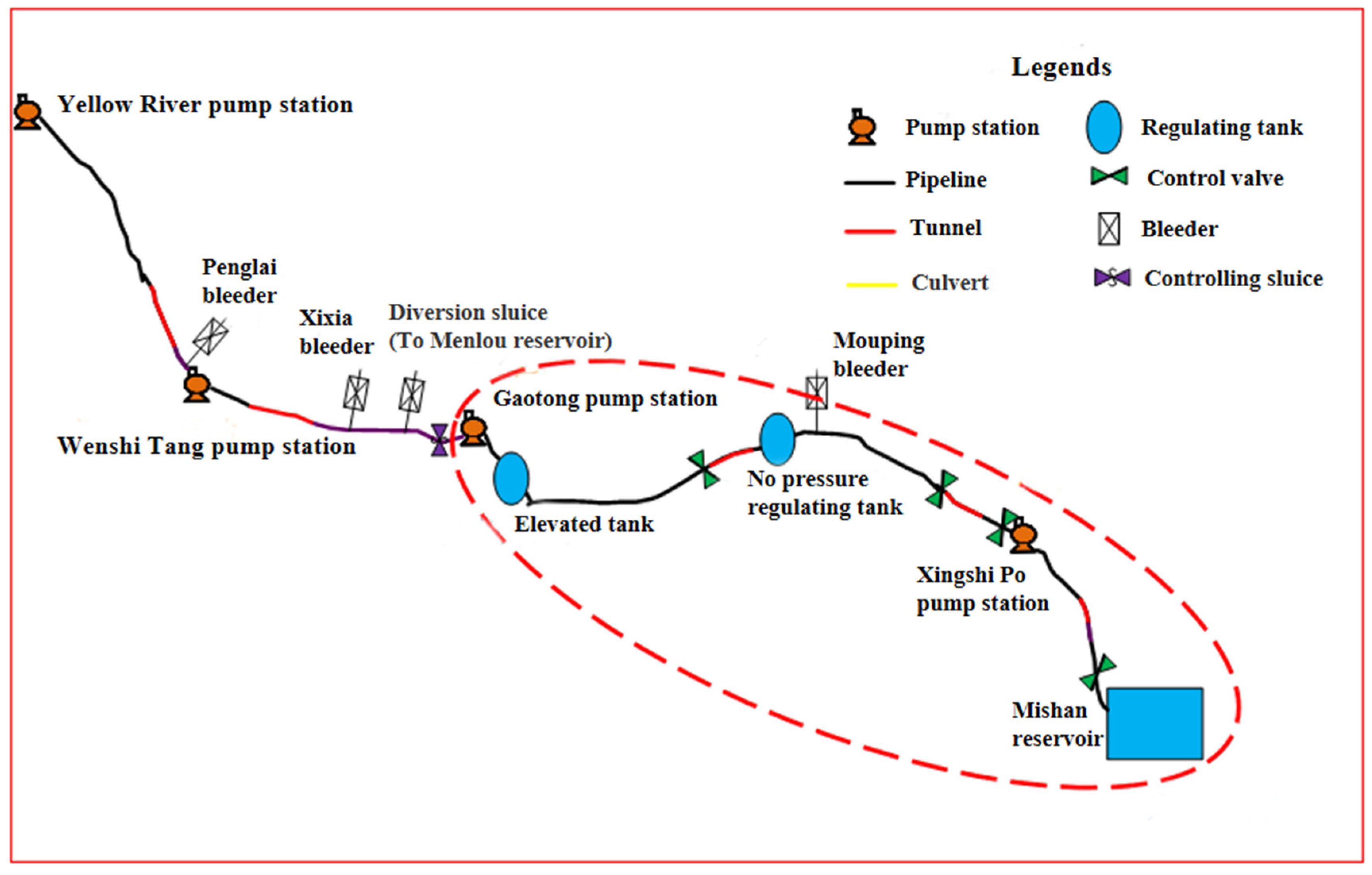
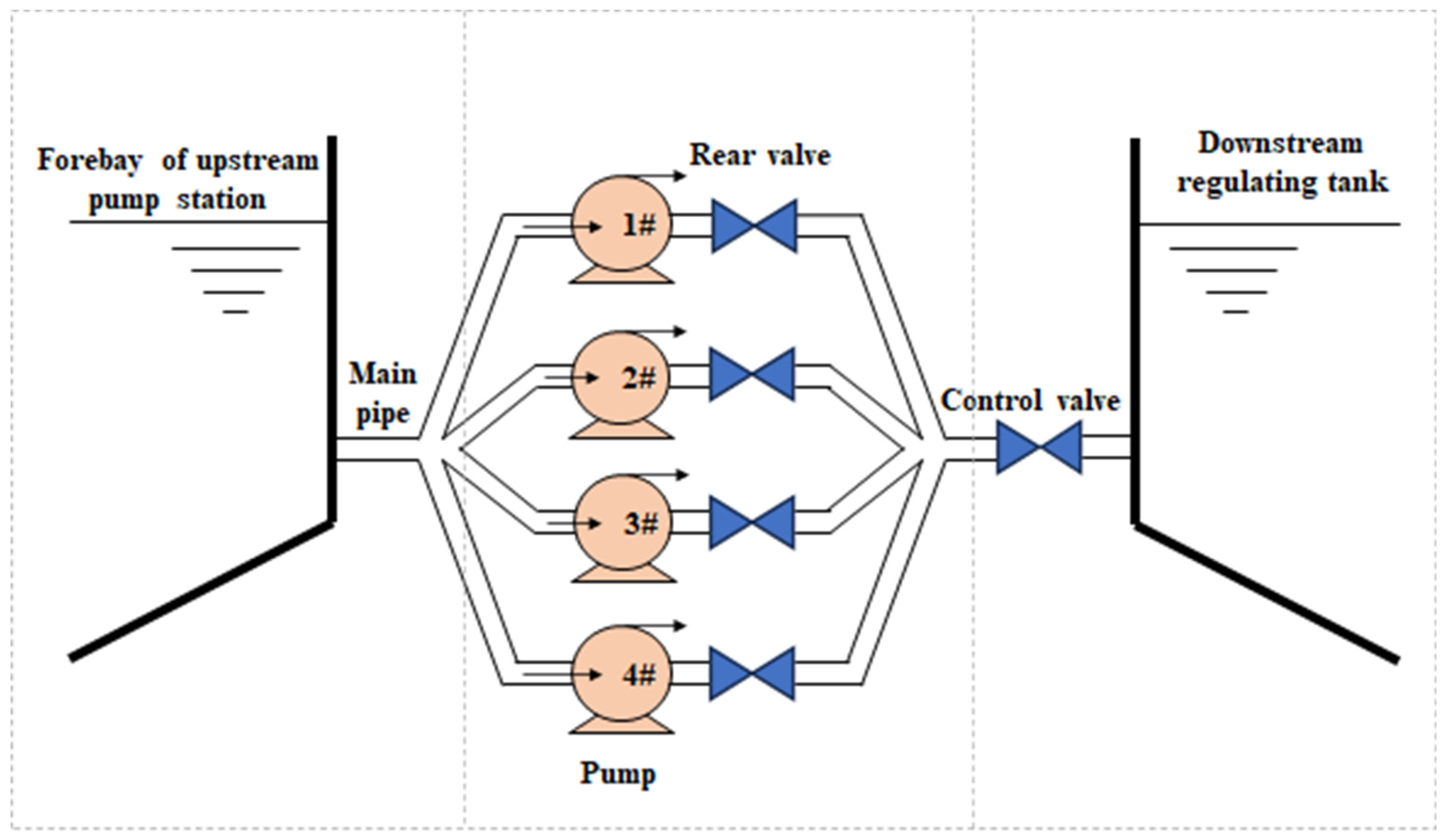
2.2.1. Identification Method
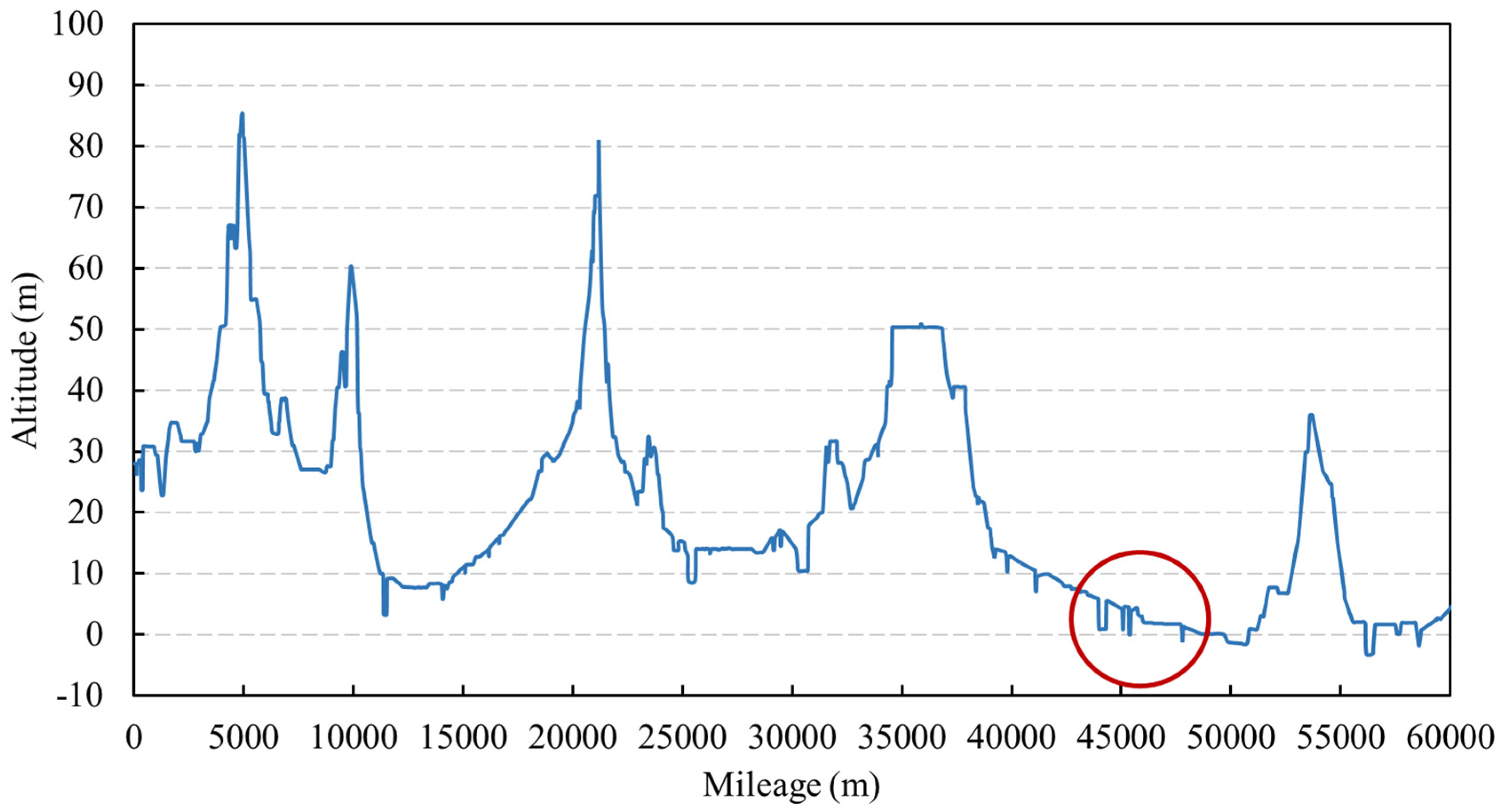
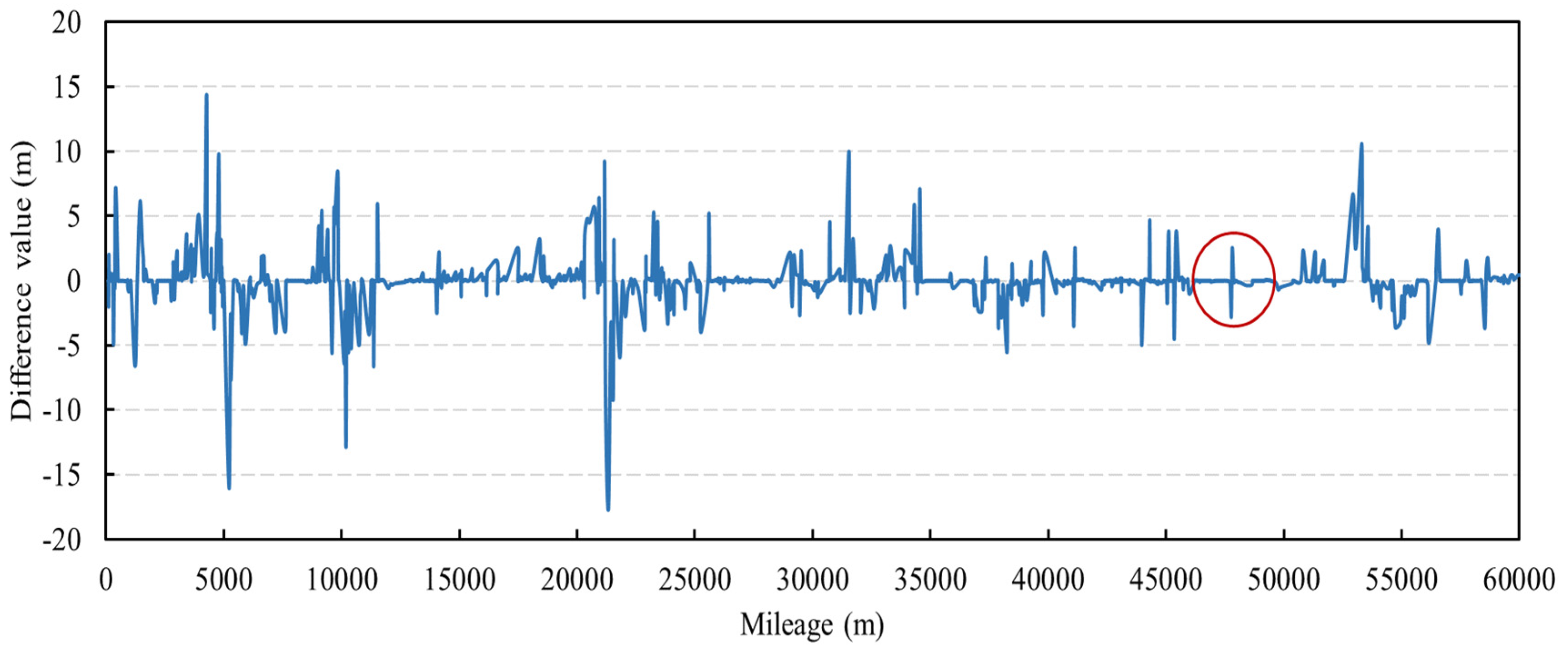
Data-driven methods are used to identify abnormal data and restore them. For the collected data on the elevation of pipeline, some of the data are judged and identified via expert knowledge, and the labels 0 and 1 are assigned to abnormal data and normal data. The classification model is then trained based on the labeled data, which are used to identify other data for the elevation of pipeline. Before model training, additional input features are constructed to assist the training of the classification model. The difference method is used to construct the new feature, i.e., the difference between the data and the last data. The nearby data of the data point are used as input features at the same time to give the model a better understanding of the sequential data. The support vector machine classifier is used in this model.
For water level data, there are many influence factors (e.g., water flow, water level, pump frequency and valve opening at nearby nodes) and various operation patterns, so it is difficult to directly identify abnormal data. Therefore, in the judgment of abnormal water level data, the clustering algorithm is used to cluster the data first, and then the abnormal data are identified by the 3-sigma method according to different operation patterns.
The clustering algorithm uses the K-medoids algorithm, which is an improvement on K-means clustering. Instead of using the mean, K-medoids clustering uses the most central object in the cluster, that is, the medoid, as the reference point, and that of each selection must be a sample point.
When there are noise and isolated points, K-medoids is more robust than K-means, but the time complexity of calculating the centroid step is O(n2), and the running speed is relatively slow. The basic idea of the algorithm is to divide the observed objects into several subsets, and each subset is regarded as a class, so the objects within the class are similar and the objects between the classes are not similar. The steps are as follows:
Input the data to be clustered and randomly select K points in the data as the centroids.
Aggregate all data points in the dataset into the closest cluster based on the distance to the centroid.
Compute the distance between each cluster point as a centroid, and then choose the point with the smallest distance as the new centroid. Repeat steps 2 and 3 until the centroids of every cluster no longer change or the sum of squared errors (convergence function) is minimized. The sum of squared errors (SSE) is calculated as follows:
where
is the ith cluster, p is sample data points in
, and
is the centroid of
. The smaller the SSE of each cluster, the higher the overall compactness of the data around the centroid in each cluster under this clustering condition, and the better the clustering effect.
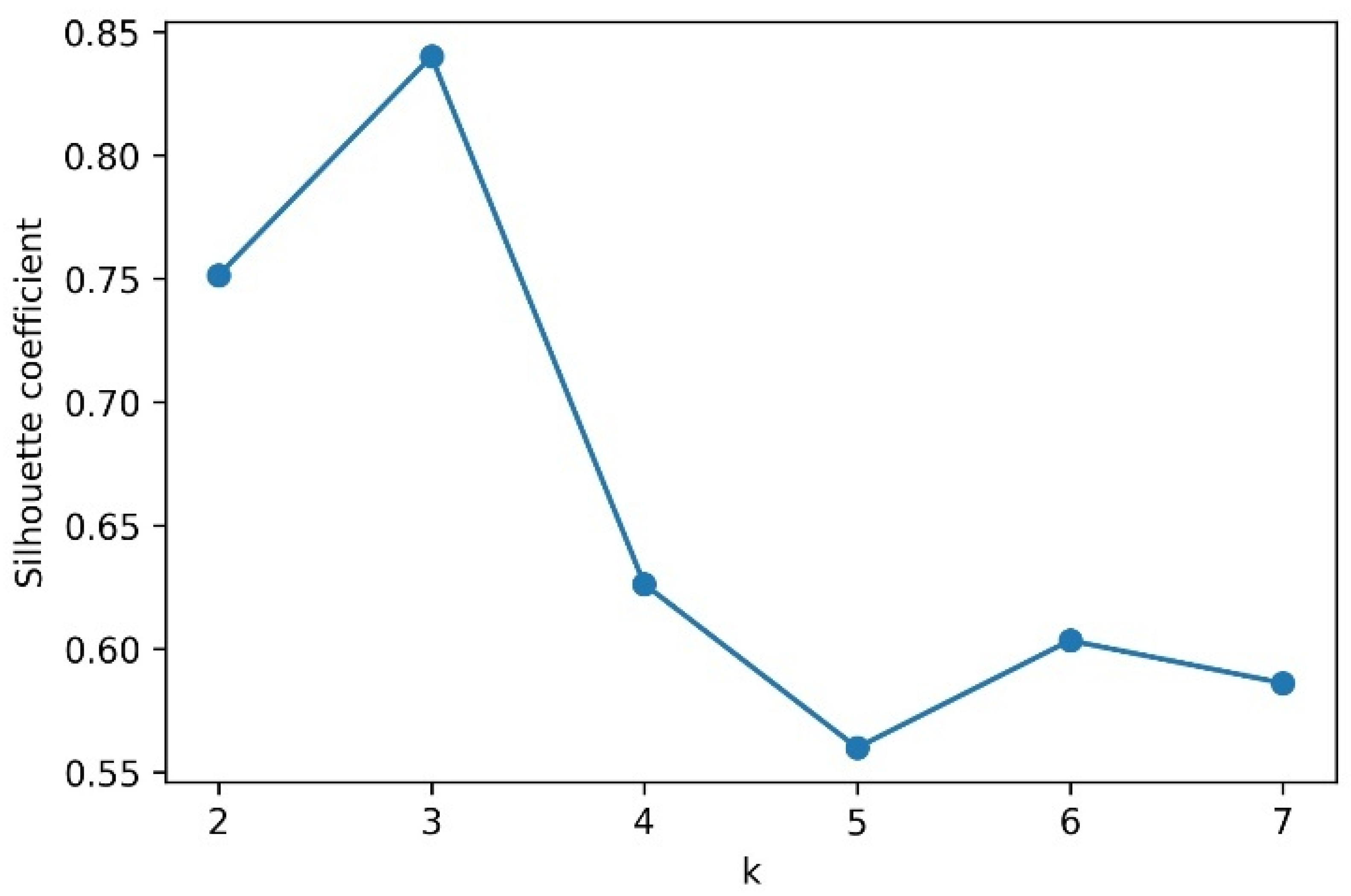
It is very important to find the optimal value of K for the k-medoids algorithm. The silhouette coefficient is adopted in this paper, and its basic principle is as follows: first, the intra-cluster similarity
of the sample is calculated, which represents the average distance between the sample and other sample points in the same cluster. The smaller the value, the more correct the classification. Then, the dissimilarity measure
is computed, which is the average distance between the sample and the other clusters. Higher values indicate better classification. Therefore, the calculation method of
is as follows:
where
and
represent the coefficient of silhouette and the intra cluster similarity, respectively, and
is the dissimilarity between the sample and other clusters.
is a number in the range [−1, 1], and the closer
is to 1, the more reasonable the cluster is. In general, when the silhouette coefficient > 0.5, the clustering can achieve a relatively ideal effect. When the silhouette coefficient < 0.2, the clustering effect is poor.
2.2.2. Restoration Method
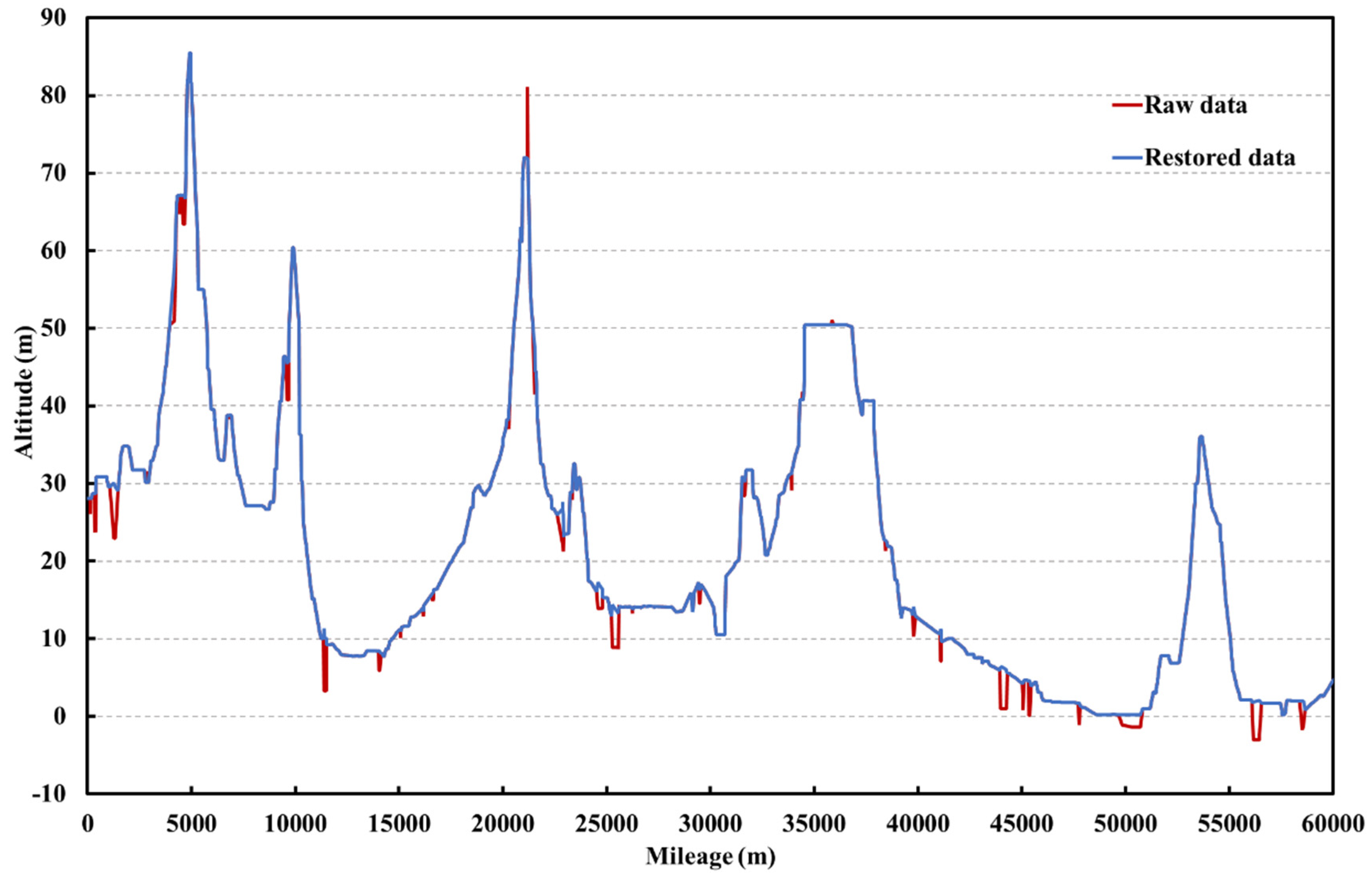
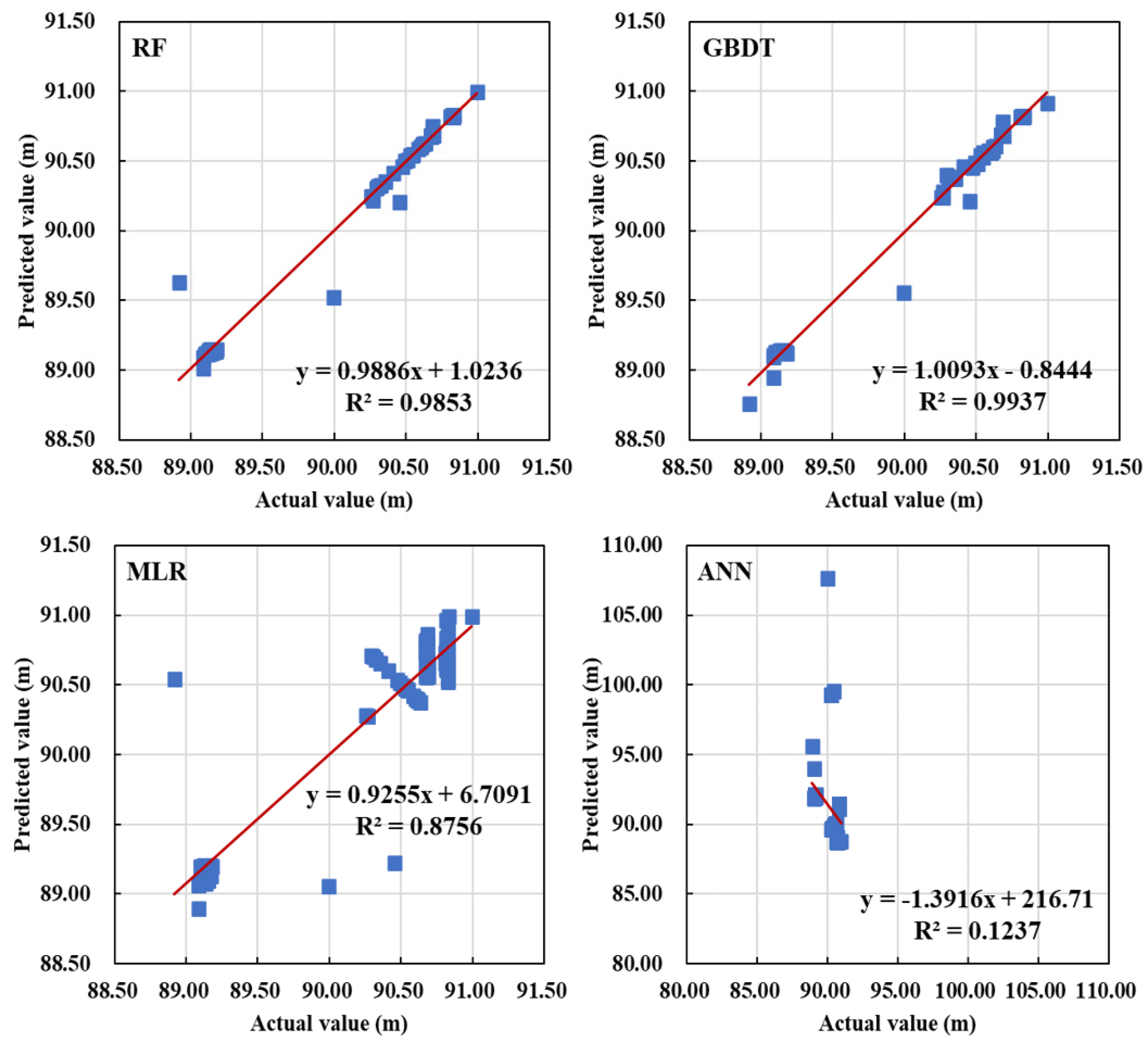
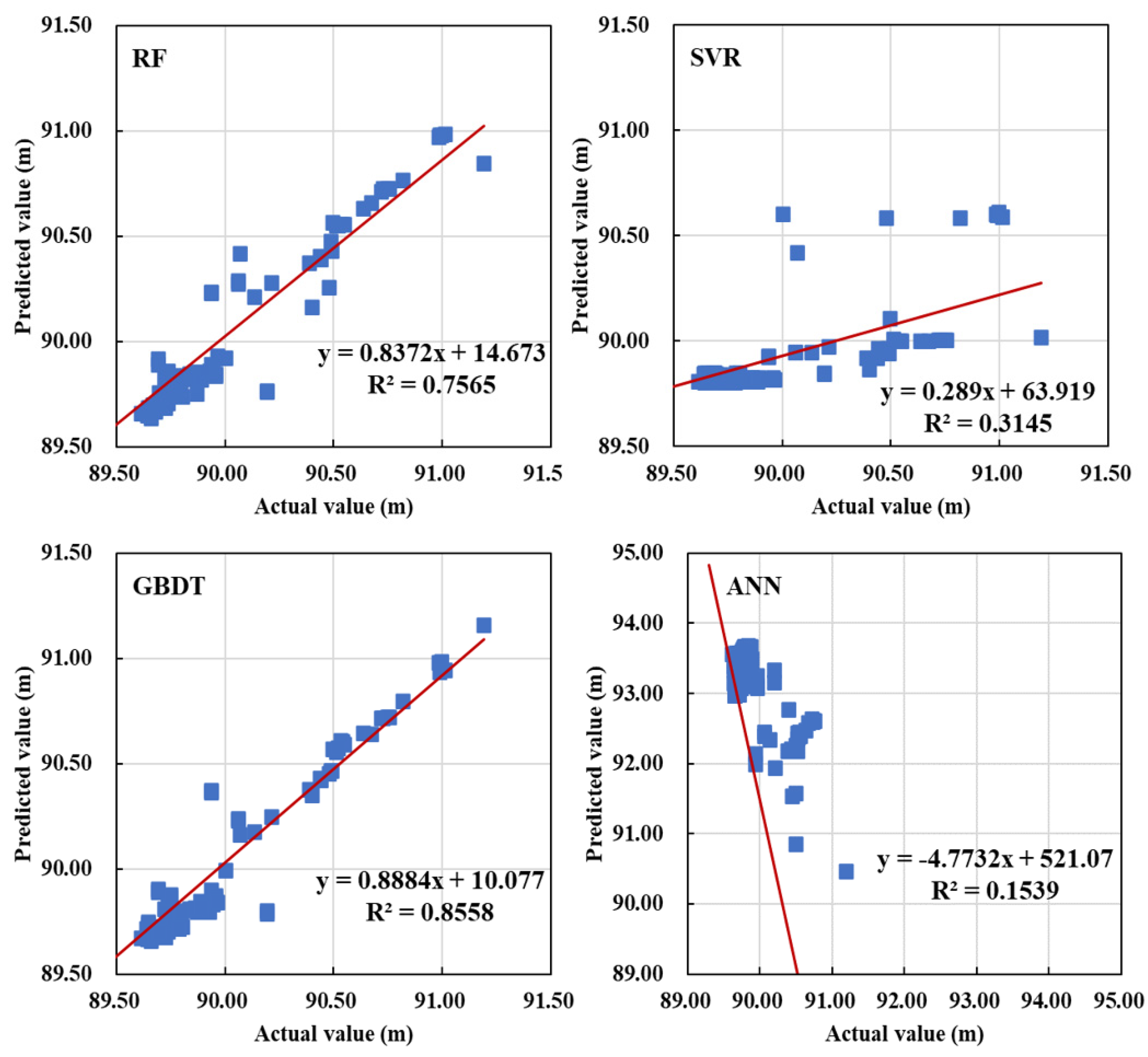
For the single outlier data in the data for the elevation of pipeline (i.e., one-dimensional data), the mean method is used to restore it, and for the continuous outliers, the machine learning prediction model is used to restore it. For the water level data, the prediction model of each cluster is established to restore water level data.
MLR, RF, ANN, GBDT and SVM are used as prediction models. The algorithm works as follows:
SVM is a supervised machine learning algorithm that can be used for the classification of discrete dependent variables and the prediction of continuous dependent variables. In general, this algorithm will have better prediction accuracy than other single classification algorithms, mainly because it can convert a low-dimensional linearly indivisible space to a high-dimensional linearly separable space by the kernel function. For the nonlinear SVM model, it is necessary to go through two steps; one is to map the sample points in the original space to the new space of high latitude, and the other is to find a linear “hyperplane” in the new space for identifying various sample points.
Common Liner kernel functions:
Polynomial kernel functions:
Sigmoid kernel functions:
In practical applications, the selection of kernel functions is the key to the calculation of support vector machine models. Thus, it is important to combine prior domain knowledge with a cross-validation method to elect a reasonable kernel function. The SVM method has been applied in many fields due to its strong applicability and simple process.
RF is a tree-based algorithm, which builds multiple classification trees and fuses their results to obtain better performance. The results of all decision trees are averaged as the final prediction result of the model for regression problems. Random forest adopts the idea of Bootstrap aggregating (Bagging) in ensemble learning. It randomly extracts samples and features from the sample set and trains a tree based on them, making each tree in the forest unique and different. Random forests are efficient because the trees can be run in parallel, and they overcome the instability problem of a single decision tree. In addition, random forests can handle high-dimensional datasets with high accuracy. The specific calculation steps of RF are as follows:
Construct N decision trees from original samples by Bootstrap method;
Select M features in the m dimension and select the best features as split nodes to establish different decision trees, where m < M;
Do not prune the decision tree, so as to ensure that the decision tree grows as much as possible;
Calculate the average value from the results of each decision tree as the final output result of the random forest, as shown in Equation (7).
GBDT is an iterative decision tree algorithm, which is composed of multiple decision trees, and the final result is made by summing up the results of all trees. The tree in GBDT is a regression tree, not a classification tree, and GBDT is mainly used for regression prediction.
In the training process, it uses the non-positive gradient of loss function as the approximation of the foundation model loss in the mth round of the foundation model, and then uses this approximation value to build the next round of the foundation model. The calculation of the approximate residual of the negative gradient value of the loss function is an expansion of the gradient lifting algorithm on the lifting algorithm, which makes the objective function more convenient to solve.
The steps are as follows:
1. Find a constant that minimizes the loss function and initialize a tree with only the root node.
2. Calculate the negative gradient of the loss function and use it as an estimate of the residual
3. Using the data set
-based model fitting the next round, have corresponding J a leaf node
, J = 1, 2, 3, …, J − 1, J. The residual value
can be estimated using
, namely the optimal fitting value of every single leaf node. The mth base model
predicts the following value at leaf node j.
4. The base model
of the mth round is obtained, and the gradient boosting model is obtained by integrating the base model of the previous m − 1 rounds.
ANN is a network model abstracted from the perspective of information processing by imitating the structure of the human or animal nervous system. The basic structure of a simple neuron consists of a weight vector W, an input vector x and an activation function. The calculation is expressed as follows:
A simple ANN usually contains an input layer, hidden layer, and output layer. In order to obtain high-level abstract features, complex neural networks usually use multiple hidden layers. Neurons in the same layer are not connected to each other, while neurons in adjacent layers are pairwise connected through a weight matrix that reflects the degree of influence of the output of the upper-layer neurons on the input of the lower-layer neurons. This connection method also abstracts the relationship between adjacent layers into the product form of the weight matrix and the input neuron vector. The relationship between the neuron output of layer l − 1 and the neuron output of layer l is expressed as Equations (12) and (13).
where
is the number of neurons in layer l and
is the output vector of neurons in layer L − 1, which is also used as the input vector of layer l.
is the connection weight matrix from layer L − 1 to layer l.
is the bias vector of the
layer,
is the output of the
layer before activation,
is the nonlinear activation function, and
is the activated neuron vector used as the output of layer l, and the input of layer l + 1.
Equations (12) and (13) constitute the feedforward calculation part of the model, that is, the iterative calculation process of the input passing from the input to the output layer in turn. On the basis of feedforward calculation, the model compares the predicted value obtained by feedforward calculation with the actual value through the error backpropagation algorithm to calculate the error gradient, and then backpropagates these errors layer by layer by changing the weight and bias of each neuron to finally produce the output of the network model.
Multiple linear regression (MLR) is a statistical method that describes the linear relationship between variables. Due to the ability to predict the dependent variable by introducing the optimal combination of multiple independent variables, MLR is more effective than univariate linear regression models that only use one independent variable. The prediction model is expressed as follows:
Since the observations of multiple linear regression are a vector instead of a scalar, a matrix is introduced to represent these observations, as shown in Equation (15). The matrix form of multiple linear regression is shown in Equation (16).








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}