


A Novel Dual Mixing Attention Network for UAV-Based Vehicle Re-Identification

Abstract
:1. Introduction
- We introduce a novel DMANet designed to handle the challenges of unmanned aerial vehicle UAV-based vehicle ReID. DMANet effectively addresses issues related to shooting angles, occlusions, top–down features, and scale variations, resulting in enhanced viewpoint robust feature extraction.
- Our proposed DMAM employs SMA and CMA to capture pixel-level pairwise relationships and channel dependencies. This modular design fosters comprehensive feature interactions, improving discriminative feature extraction under varying viewpoints.
- The versatility of DMAM allows its seamless integration into existing backbone networks at varying depths, significantly enhancing vehicle discrimination performance. Our approach demonstrates superior performance through extensive experiments compared to representative methods in the UAV-based vehicle re-identification task, affirming its efficacy in challenging aerial scenarios.
2. Related Work
2.1. Vehicle Re-Identification
2.2. Attention Mechanism
3. Proposed Method
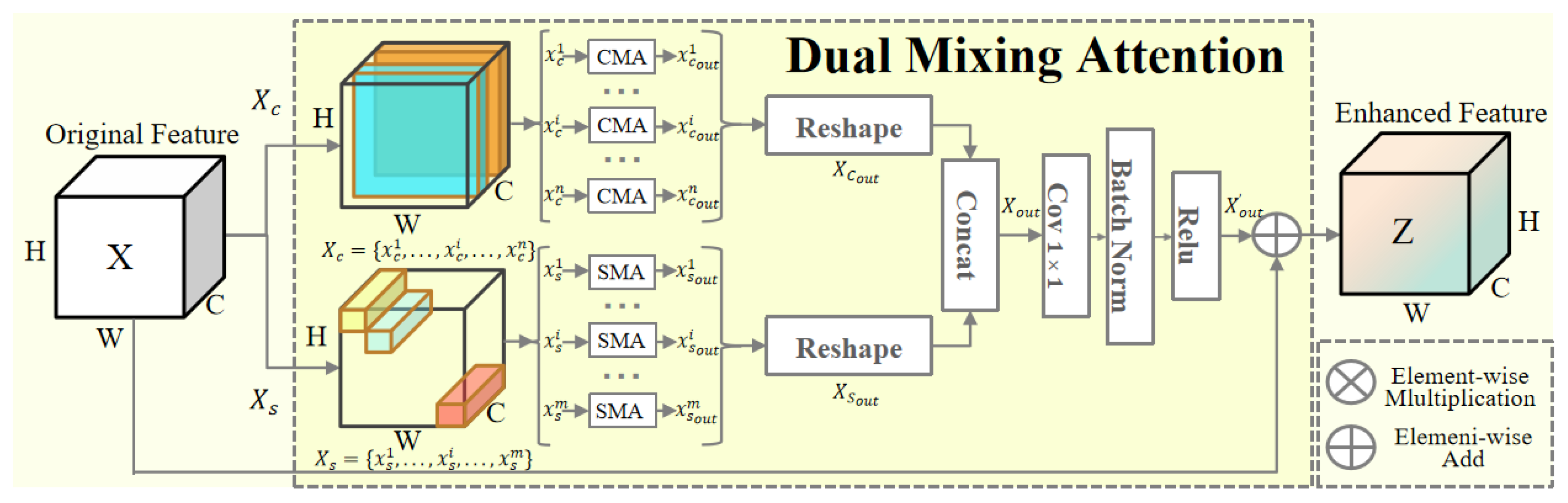
3.1. Dual Mixing Attention Module
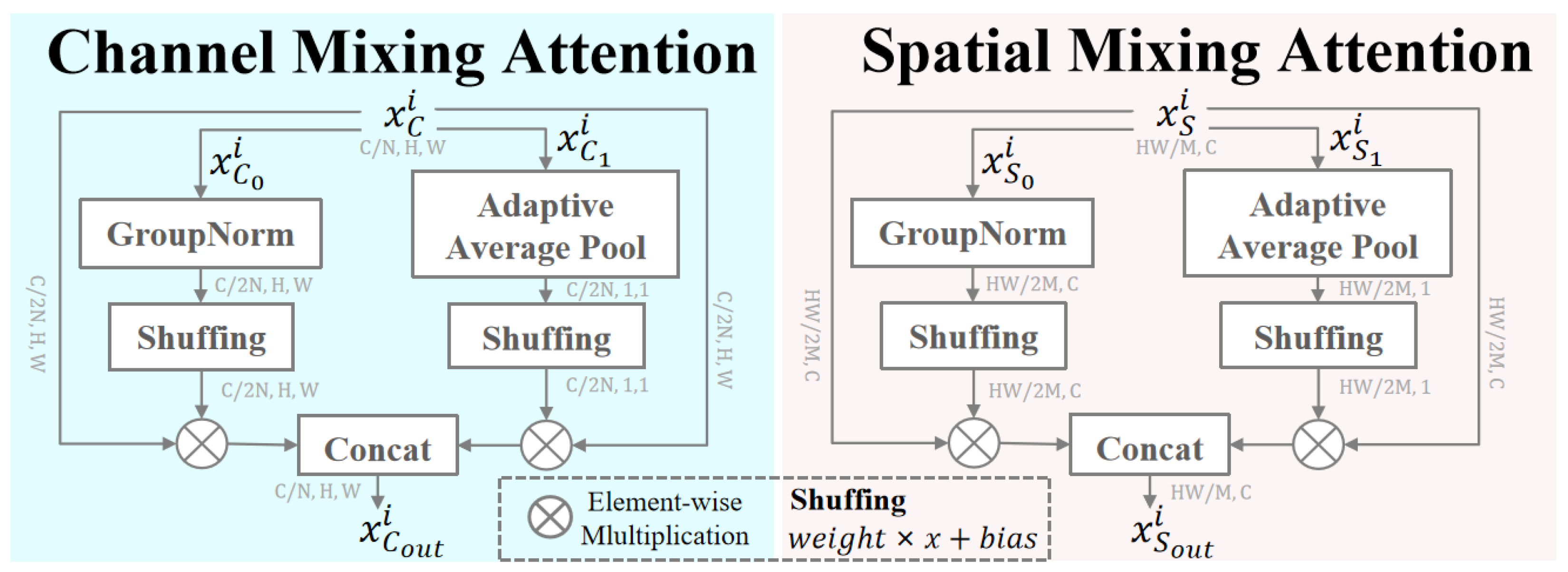
3.2. Channel Mixing Attention
3.3. Spatial Mixing Attention
4. Analysis and Experiments
4.1. Datasets
4.2. Implementation Details
4.3. Comparison with State of the Art
4.3.1. Experiments on VeRi-UAV
4.3.2. Experiments on UAV-VeID
4.4. Ablation Experiment and Analysis
4.4.1. The Role of Dual Mixing Attention Module
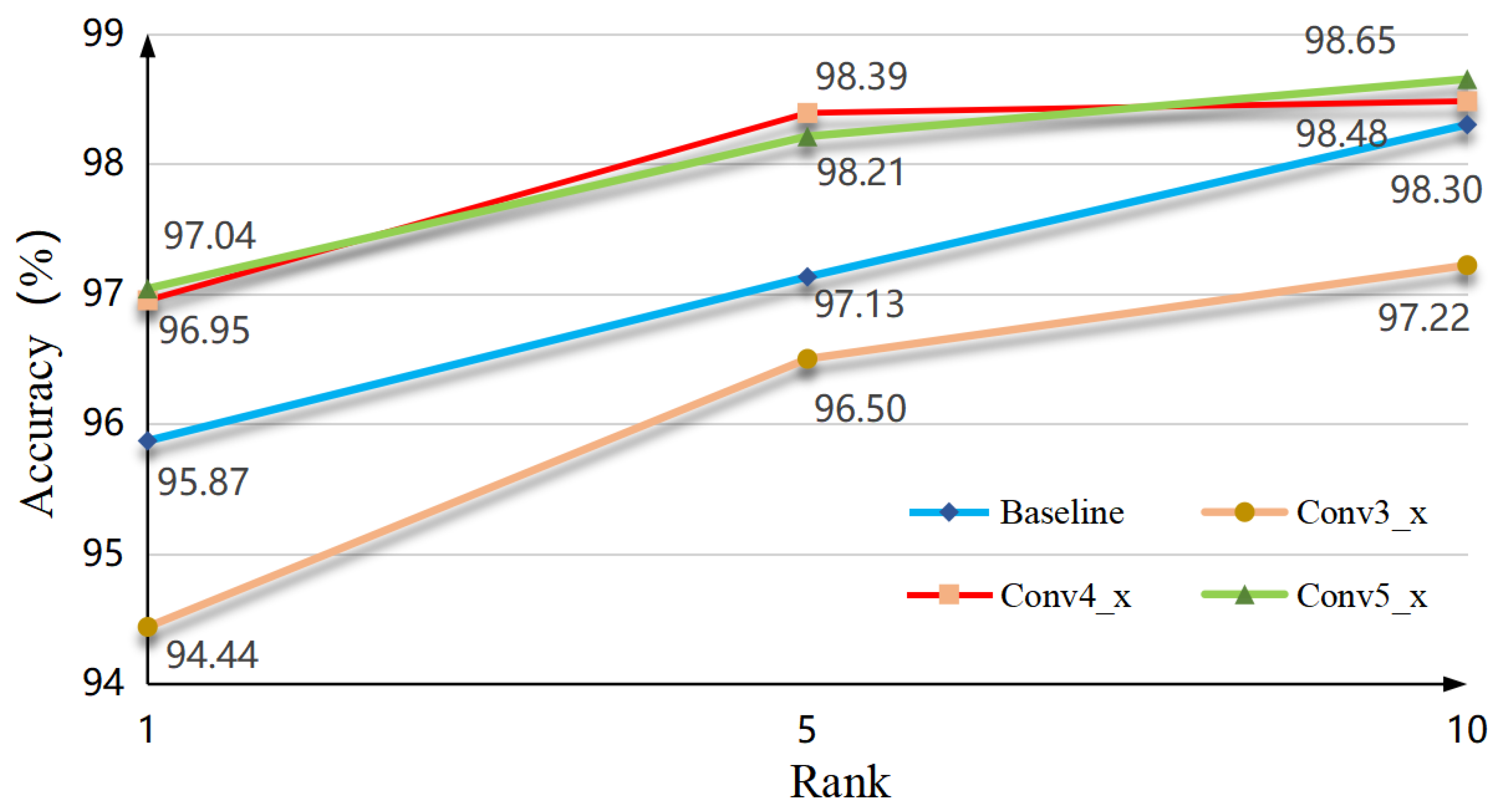
4.4.2. The Effectiveness on Which Stage to Plug the Dual Mixing Attention Module
4.4.3. The Effect of Normalized Strategy in Dual Mixing Attention Module
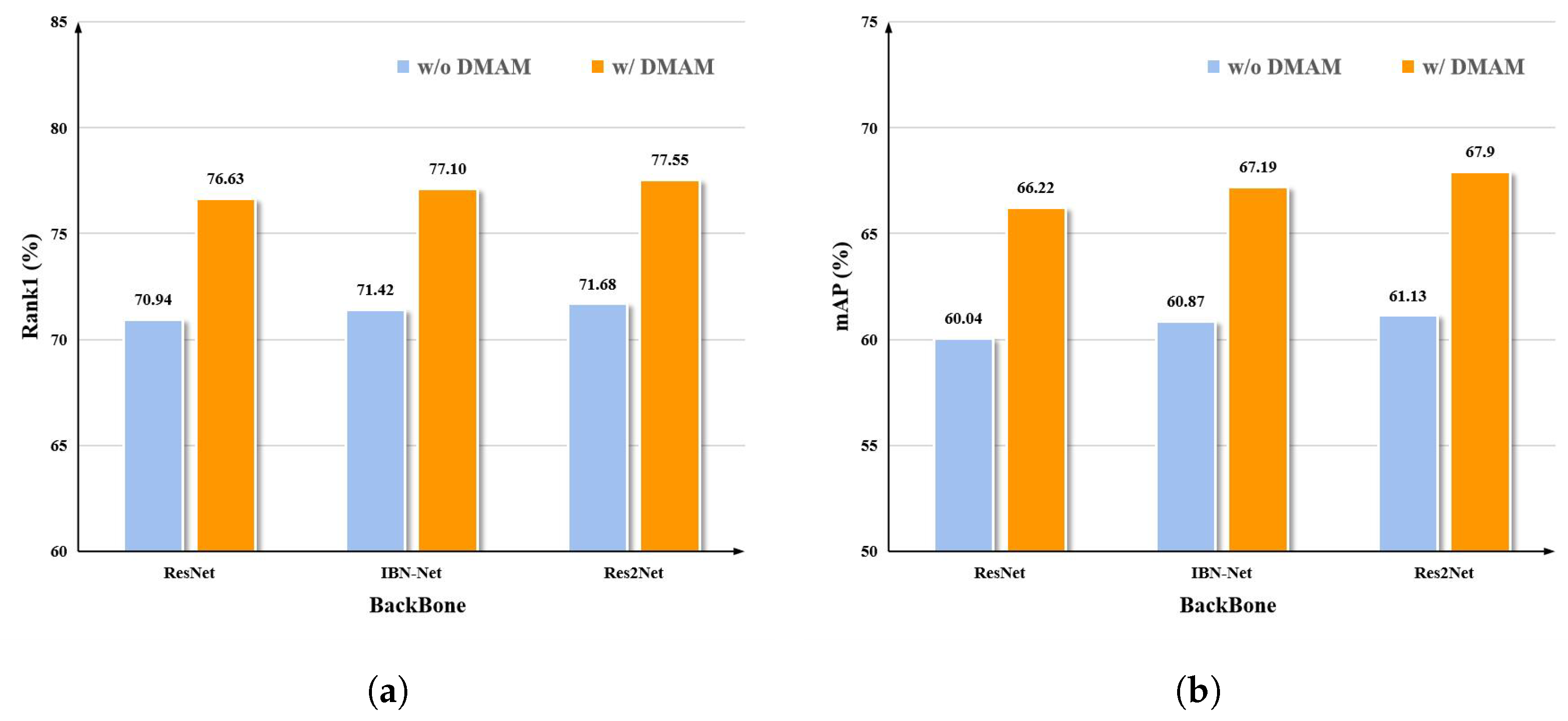
4.4.4. The Universality for Different Backbones
4.4.5. Comparison of Different Attention Modules
4.4.6. Visualization of Model Retrieval Results
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Li, M.; Wei, M.; He, X.; Shen, F. Enhancing Part Features via Contrastive Attention Module for Vehicle Re-identification. In Proceedings of the 2022 IEEE International Conference on Image Processing (ICIP), Bordeaux, France, 16–19 October 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 1816–1820. [Google Scholar]
- Shen, F.; Peng, X.; Wang, L.; Zhang, X.; Shu, M.; Wang, Y. HSGM: A Hierarchical Similarity Graph Module for Object Re-identification. In Proceedings of the 2022 IEEE International Conference on Multimedia and Expo (ICME), Taipei, Taiwan, 18–22 July 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 1–6. [Google Scholar]
- Han, K.; Wang, Q.; Zhu, M.; Zhang, X. PVTReID: A Quick Person Re-Identification Based Pyramid Vision Transformer. Appl. Sci. 2023, 13, 9751. [Google Scholar] [CrossRef]
- Qiao, W.; Ren, W.; Zhao, L. Vehicle re-identification in aerial imagery based on normalized virtual Softmax loss. Appl. Sci. 2022, 12, 4731. [Google Scholar] [CrossRef]
- Li, H.; Lin, X.; Zheng, A.; Li, C.; Luo, B.; He, R.; Hussain, A. Attributes guided feature learning for vehicle re-identification. IEEE Trans. Emerg. Top. Comput. Intell. 2021, 6, 1211–1221. [Google Scholar] [CrossRef]
- Shen, F.; Wei, M.; Ren, J. HSGNet: Object Re-identification with Hierarchical Similarity Graph Network. arXiv 2022, arXiv:2211.05486. [Google Scholar]
- Shen, F.; Shu, X.; Du, X.; Tang, J. Pedestrian-specific Bipartite-aware Similarity Learning for Text-based Person Retrieval. In Proceedings of the 31th ACM International Conference on Multimedia, Ottawa, ON, Canada, 29 October–3 November 2023. [Google Scholar]
- Zhou, T.; Li, L.; Li, X.; Feng, C.M.; Li, J.; Shao, L. Group-wise learning for weakly supervised semantic segmentation. IEEE Trans. Image Process. 2021, 31, 799–811. [Google Scholar] [CrossRef] [PubMed]
- Zhou, T.; Qi, S.; Wang, W.; Shen, J.; Zhu, S.C. Cascaded parsing of human-object interaction recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 44, 2827–2840. [Google Scholar] [CrossRef]
- Wu, H.; Shen, F.; Zhu, J.; Zeng, H.; Zhu, X.; Lei, Z. A sample-proxy dual triplet loss function for object re-identification. IET Image Process. 2022, 16, 3781–3789. [Google Scholar] [CrossRef]
- Xie, Y.; Shen, F.; Zhu, J.; Zeng, H. Viewpoint robust knowledge distillation for accelerating vehicle re-identification. EURASIP J. Adv. Signal Process. 2021, 2021, 48. [Google Scholar] [CrossRef]
- Xu, R.; Shen, F.; Wu, H.; Zhu, J.; Zeng, H. Dual modal meta metric learning for attribute-image person re-identification. In Proceedings of the 2021 IEEE International Conference on Networking, Sensing and Control (ICNSC), Xiamen, China, 3–5 December 2021; IEEE: Piscataway, NJ, USA, 2021; Volume 1, pp. 1–6. [Google Scholar]
- Fu, X.; Shen, F.; Du, X.; Li, Z. Bag of Tricks for “Vision Meet Alage” Object Detection Challenge. In Proceedings of the 2022 6th International Conference on Universal Village (UV), Boston, MA, USA, 22–25 October 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 1–4. [Google Scholar]
- Shen, F.; Wang, Z.; Wang, Z.; Fu, X.; Chen, J.; Du, X.; Tang, J. A Competitive Method for Dog Nose-print Re-identification. arXiv 2022, arXiv:2205.15934. [Google Scholar]
- Qiao, C.; Shen, F.; Wang, X.; Wang, R.; Cao, F.; Zhao, S.; Li, C. A Novel Multi-Frequency Coordinated Module for SAR Ship Detection. In Proceedings of the 2022 IEEE 34th International Conference on Tools with Artificial Intelligence (ICTAI), Macao, China, 31 October–2 November 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 804–811. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Li, X.; Wang, W.; Hu, X.; Yang, J. Selective kernel networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 510–519. [Google Scholar]
- Wang, Q.; Wu, B.; Zhu, P.; Li, P.; Zuo, W.; Hu, Q. ECA-Net: Efficient channel attention for deep convolutional neural networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 11534–11542. [Google Scholar]
- Zhang, Q.L.; Yang, Y.B. Sa-net: Shuffle attention for deep convolutional neural networks. In Proceedings of the ICASSP 2021–2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Toronto, ON, Canada, 6–11 June 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 2235–2239. [Google Scholar]
- Park, J.; Woo, S.; Lee, J.Y.; Kweon, I.S. Bam: Bottleneck attention module. arXiv 2018, arXiv:1807.06514. [Google Scholar]
- Fu, J.; Liu, J.; Tian, H.; Li, Y.; Bao, Y.; Fang, Z.; Lu, H. Dual attention network for scene segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 3146–3154. [Google Scholar]
- Shen, F.; Du, X.; Zhang, L.; Tang, J. Triplet Contrastive Learning for Unsupervised Vehicle Re-identification. arXiv 2023, arXiv:2301.09498. [Google Scholar]
- Lin, W.H.; Tong, D. Vehicle re-identification with dynamic time windows for vehicle passage time estimation. IEEE Trans. Intell. Transp. Syst. 2011, 12, 1057–1063. [Google Scholar] [CrossRef]
- Kwong, K.; Kavaler, R.; Rajagopal, R.; Varaiya, P. Arterial travel time estimation based on vehicle re-identification using wireless magnetic sensors. Transp. Res. Part C Emerg. Technol. 2009, 17, 586–606. [Google Scholar] [CrossRef]
- Silva, S.M.; Jung, C.R. License plate detection and recognition in unconstrained scenarios. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 580–596. [Google Scholar]
- Watcharapinchai, N.; Rujikietgumjorn, S. Approximate license plate string matching for vehicle re-identification. In Proceedings of the 2017 14th IEEE International Conference on Advanced Video and Signal Based Surveillance (AVSS), Lecce, Italy, 29 August–1 September 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 1–6. [Google Scholar]
- Feris, R.S.; Siddiquie, B.; Petterson, J.; Zhai, Y.; Datta, A.; Brown, L.M.; Pankanti, S. Large-scale vehicle detection, indexing, and search in urban surveillance videos. IEEE Trans. Multimed. 2011, 14, 28–42. [Google Scholar] [CrossRef]
- Matei, B.C.; Sawhney, H.S.; Samarasekera, S. Vehicle tracking across nonoverlapping cameras using joint kinematic and appearance features. In Proceedings of the CVPR 2011, Colorado Springs, CO, USA, 20–25 June 2011; IEEE: Piscataway, NJ, USA, 2011; pp. 3465–3472. [Google Scholar]
- Huang, P.; Huang, R.; Huang, J.; Yangchen, R.; He, Z.; Li, X.; Chen, J. Deep Feature Fusion with Multiple Granularity for Vehicle Re-identification. In Proceedings of the CVPR Workshops, Long Beach, CA, USA, 16–20 June 2019; pp. 80–88. [Google Scholar]
- Shen, F.; Zhu, J.; Zhu, X.; Xie, Y.; Huang, J. Exploring spatial significance via hybrid pyramidal graph network for vehicle re-identification. IEEE Trans. Intell. Transp. Syst. 2021, 23, 8793–8804. [Google Scholar]
- Shen, F.; Xie, Y.; Zhu, J.; Zhu, X.; Zeng, H. Git: Graph interactive transformer for vehicle re-identification. IEEE Trans. Image Process. 2023, 32, 1039–1051. [Google Scholar] [CrossRef] [PubMed]
- Shen, F.; Zhu, J.; Zhu, X.; Huang, J.; Zeng, H.; Lei, Z.; Cai, C. An Efficient Multiresolution Network for Vehicle Reidentification. IEEE Internet Things J. 2021, 9, 9049–9059. [Google Scholar] [CrossRef]
- Zhou, T.; Li, J.; Wang, S.; Tao, R.; Shen, J. Matnet: Motion-attentive transition network for zero-shot video object segmentation. IEEE Trans. Image Process. 2020, 29, 8326–8338. [Google Scholar] [CrossRef]
- Khorramshahi, P.; Kumar, A.; Peri, N.; Rambhatla, S.S.; Chen, J.C.; Chellappa, R. A dual-path model with adaptive attention for vehicle re-identification. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 6132–6141. [Google Scholar]
- Teng, S.; Liu, X.; Zhang, S.; Huang, Q. Scan: Spatial and channel attention network for vehicle re-identification. In Proceedings of the Advances in Multimedia Information Processing—PCM 2018: 19th Pacific-Rim Conference on Multimedia, Hefei, China, 21–22 September 2018; Proceedings, Part III 19. Springer: Berlin/Heidelberg, Germany, 2018; pp. 350–361. [Google Scholar]
- Teng, S.; Zhang, S.; Huang, Q.; Sebe, N. Viewpoint and scale consistency reinforcement for UAV vehicle re-identification. Int. J. Comput. Vis. 2021, 129, 719–735. [Google Scholar] [CrossRef]
- Song, Y.; Liu, C.; Zhang, W.; Nie, Z.; Chen, L. View-Decision Based Compound Match Learning for Vehicle Re-identification in UAV Surveillance. In Proceedings of the 2020 39th Chinese Control Conference (CCC), Shenyang, China, 27–30 July 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 6594–6601. [Google Scholar]
- Shen, F.; He, X.; Wei, M.; Xie, Y. A competitive method to vipriors object detection challenge. arXiv 2021, arXiv:2104.09059. [Google Scholar]
- Shen, Y.; Xiao, T.; Li, H.; Yi, S.; Wang, X. Learning deep neural networks for vehicle re-id with visual-spatio-temporal path proposals. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 1900–1909. [Google Scholar]
- Chatfield, K.; Simonyan, K.; Vedaldi, A.; Zisserman, A. Return of the devil in the details: Delving deep into convolutional nets. arXiv 2014, arXiv:1405.3531. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Liu, X.; Zhang, S.; Huang, Q.; Gao, W. Ram: A region-aware deep model for vehicle re-identification. In Proceedings of the 2018 IEEE International Conference on Multimedia and Expo (ICME), San Diego, CA, USA, 23–27 July 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 1–6. [Google Scholar]
- Yao, H.; Zhang, S.; Zhang, Y.; Li, J.; Tian, Q. One-shot fine-grained instance retrieval. In Proceedings of the 25th ACM International Conference on Multimedia, Mountain View, CA, USA, 23–27 October 2017; pp. 342–350. [Google Scholar]
- Yao, A.; Huang, M.; Qi, J.; Zhong, P. Attention mask-based network with simple color annotation for UAV vehicle re-identification. IEEE Geosci. Remote Sens. Lett. 2021, 19, 1–5. [Google Scholar] [CrossRef]
- Bromley, J.; Guyon, I.; LeCun, Y.; Säckinger, E.; Shah, R. Signature verification using a “siamese” time delay neural network. Adv. Neural Inf. Process. Syst. 1993, 6. [Google Scholar] [CrossRef]
- Liao, S.; Hu, Y.; Zhu, X.; Li, S.Z. Person re-identification by local maximal occurrence representation and metric learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 2197–2206. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Pan, X.; Ge, C.; Lu, R.; Song, S.; Chen, G.; Huang, Z.; Huang, G. On the integration of self-attention and convolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 815–825. [Google Scholar]
- Li, Y.; Yao, T.; Pan, Y.; Mei, T. Contextual transformer networks for visual recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 45, 1489–1500. [Google Scholar] [CrossRef]
- Liu, H.; Liu, F.; Fan, X.; Huang, D. Polarized self-attention: Towards high-quality pixel-wise regression. arXiv 2021, arXiv:2107.00782. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | Rank-1 | Rank-5 | Rank-10 |
|---|---|---|---|
| Siamese-Visual [39] | 25.98 | 41.98 | 50.61 |
| VGG CNN M [40] | 28.34 | 39.27 | 43.48 |
| SCAN [35] | 40.49 | 53.74 | 60.55 |
| GoogleLeNet [41] | 45.23 | 64.88 | 70.38 |
| RAM [42] | 45.26 | 59.35 | 64.07 |
| CN-Nets [43] | 55.91 | 76.54 | 82.46 |
| TCRL [22] | 56.44 | 77.21 | 82.98 |
| EMRN [32] | 63.47 | 79.84 | 84.66 |
| CANet [1] | 63.68 | 80.73 | 85.40 |
| HPGN [30] | 64.18 | 82.19 | 85.88 |
| HSGNet [6] | 64.22 | 85.31 | 86.36 |
| AM + WTL [44] | 69.11 | 87.23 | 91.64 |
| GiT [31] | 72.48 | 85.83 | 89.61 |
| Baseline | 70.94 | 84.56 | 88.22 |
| Ours | 76.63 | 88.54 | 91.75 |
| Methods | Rank-1 | Rank-5 | Rank-10 | mAP |
|---|---|---|---|---|
| BOW-SIFT [45] | 36.2 | 52.6 | 61.0 | 9.0 |
| LOMO [46] | 69.3 | 77.8 | 82.3 | 34.1 |
| VGGNet [47] | 56.0 | 72.4 | 78.6 | 44.4 |
| ResNet50 [48] | 58.7 | 74.0 | 79.5 | 47.3 |
| VD-CML (VGGNet) [37] | 62.5 | 76.2 | 81.3 | 49.7 |
| VD-CML (ResNet50) [37] | 67.3 | 78.8 | 83.0 | 54.6 |
| TCRL [22] | 77.1 | 79.2 | 84.9 | 58.5 |
| EMRN [32] | 87.6 | 88.9 | 92.4 | 65.9 |
| CANet [1] | 94.4 | 95.0 | 95.8 | 77.9 |
| HPGN [30] | 94.7 | 95.6 | 97.4 | 78.4 |
| HSGNet [6] | 94.8 | 95.7 | 97.6 | 78.5 |
| GiT [31] | 95.3 | 95.9 | 97.9 | 80.3 |
| Baseline | 95.1 | 95.6 | 97.5 | 79.6 |
| Ours | 97.0 | 98.7 | 98.8 | 87.0 |
| Methods | Rank-1 | Rank-5 | Rank-10 | mAP |
|---|---|---|---|---|
| Baseline | 95.14 | 95.63 | 97.48 | 79.59 |
| +CMA | 96.34 | 97.25 | 98.03 | 83.63 |
| +SMA | 96.56 | 97.42 | 98.27 | 84.96 |
| Ours | 97.04 | 98.65 | 98.83 | 86.99 |
| No. | Conv3_x | Conv4_x | Conv5_x | Rank-1 | Rank-5 | Rank-10 | mAP |
|---|---|---|---|---|---|---|---|
| 0 | 95.14 | 95.63 | 97.48 | 79.59 | |||
| 1 | ✓ | 95.74 | 96.88 | 97.74 | 82.95 | ||
| 2 | ✓ | 96.52 | 98.01 | 98.24 | 85.18 | ||
| 3 | ✓ | 97.04 | 98.65 | 98.83 | 86.99 |
| Methods | Rank-1 | Rank-5 | Rank-10 | mAP |
|---|---|---|---|---|
| Baseline | 70.94 | 84.56 | 88.22 | 60.04 |
| AAP → AMP | 74.88 | 87.21 | 90.49 | 64.88 |
| GN → IN | 75.98 | 88.03 | 91.25 | 65.62 |
| Ours | 76.63 | 88.54 | 91.75 | 66.22 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yin, W.; Peng, Y.; Ye, Z.; Liu, W. A Novel Dual Mixing Attention Network for UAV-Based Vehicle Re-Identification. Appl. Sci. 2023, 13, 11651. https://doi.org/10.3390/app132111651
Yin W, Peng Y, Ye Z, Liu W. A Novel Dual Mixing Attention Network for UAV-Based Vehicle Re-Identification. Applied Sciences. 2023; 13(21):11651. https://doi.org/10.3390/app132111651
Chicago/Turabian StyleYin, Wenji, Yueping Peng, Zecong Ye, and Wenchao Liu. 2023. "A Novel Dual Mixing Attention Network for UAV-Based Vehicle Re-Identification" Applied Sciences 13, no. 21: 11651. https://doi.org/10.3390/app132111651
APA StyleYin, W., Peng, Y., Ye, Z., & Liu, W. (2023). A Novel Dual Mixing Attention Network for UAV-Based Vehicle Re-Identification. Applied Sciences, 13(21), 11651. https://doi.org/10.3390/app132111651