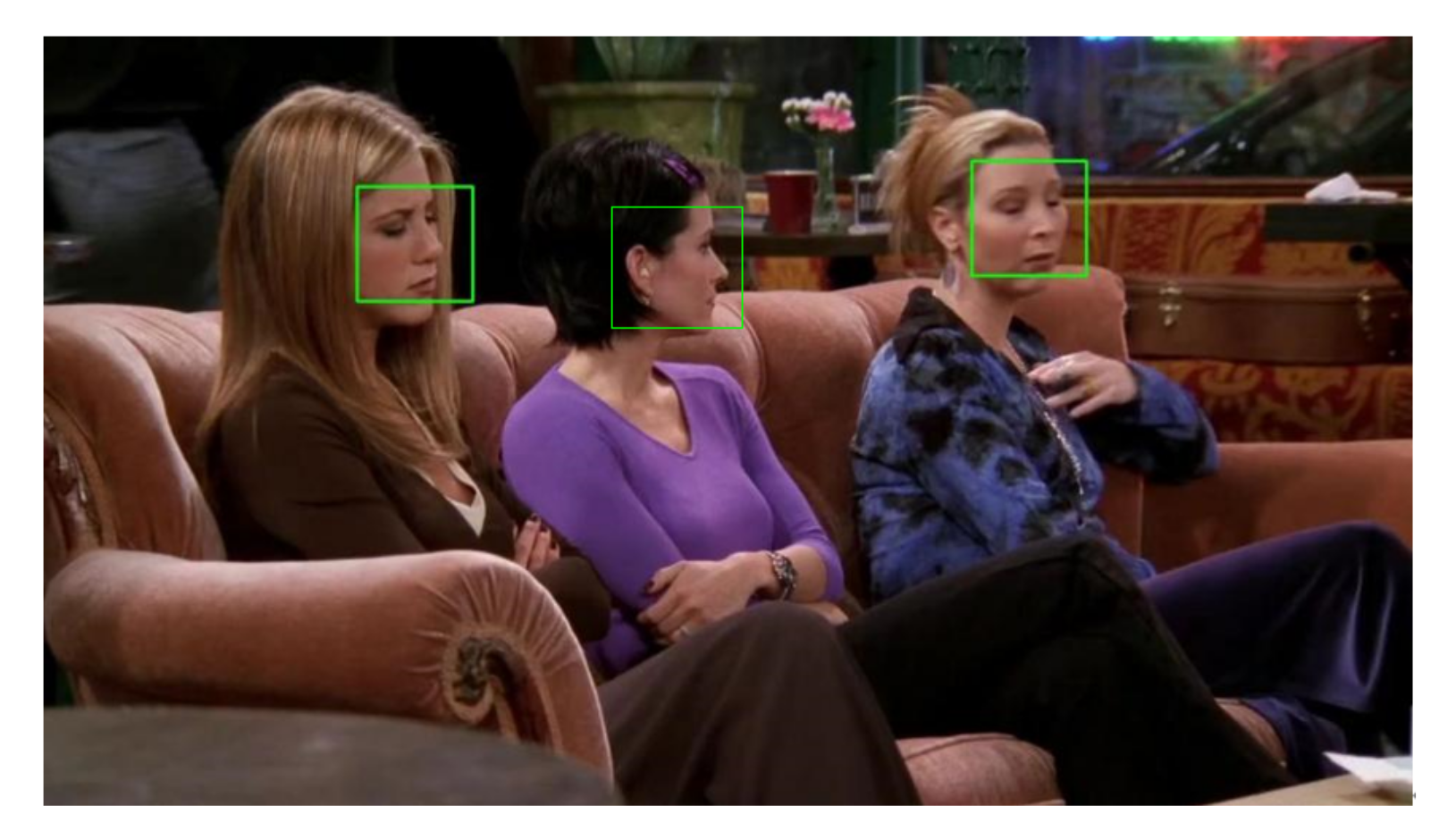
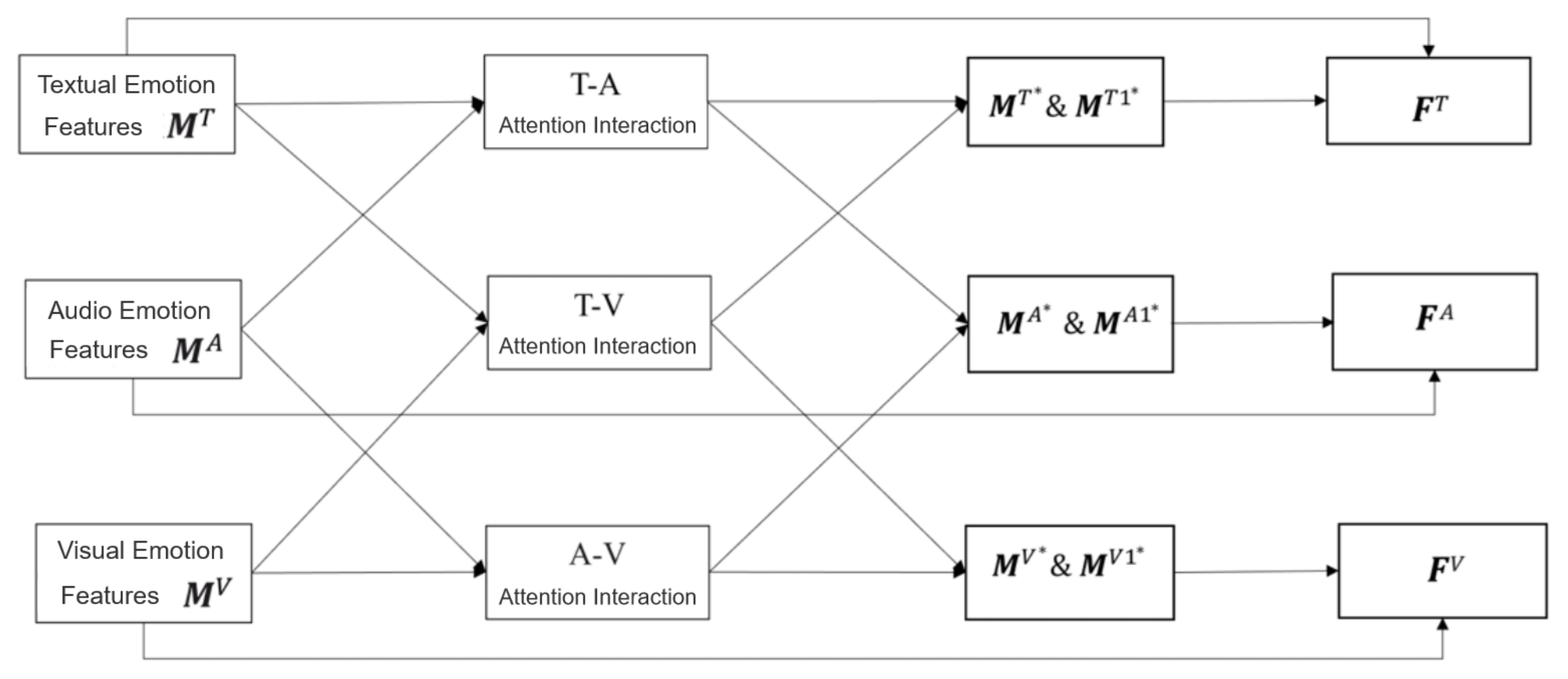
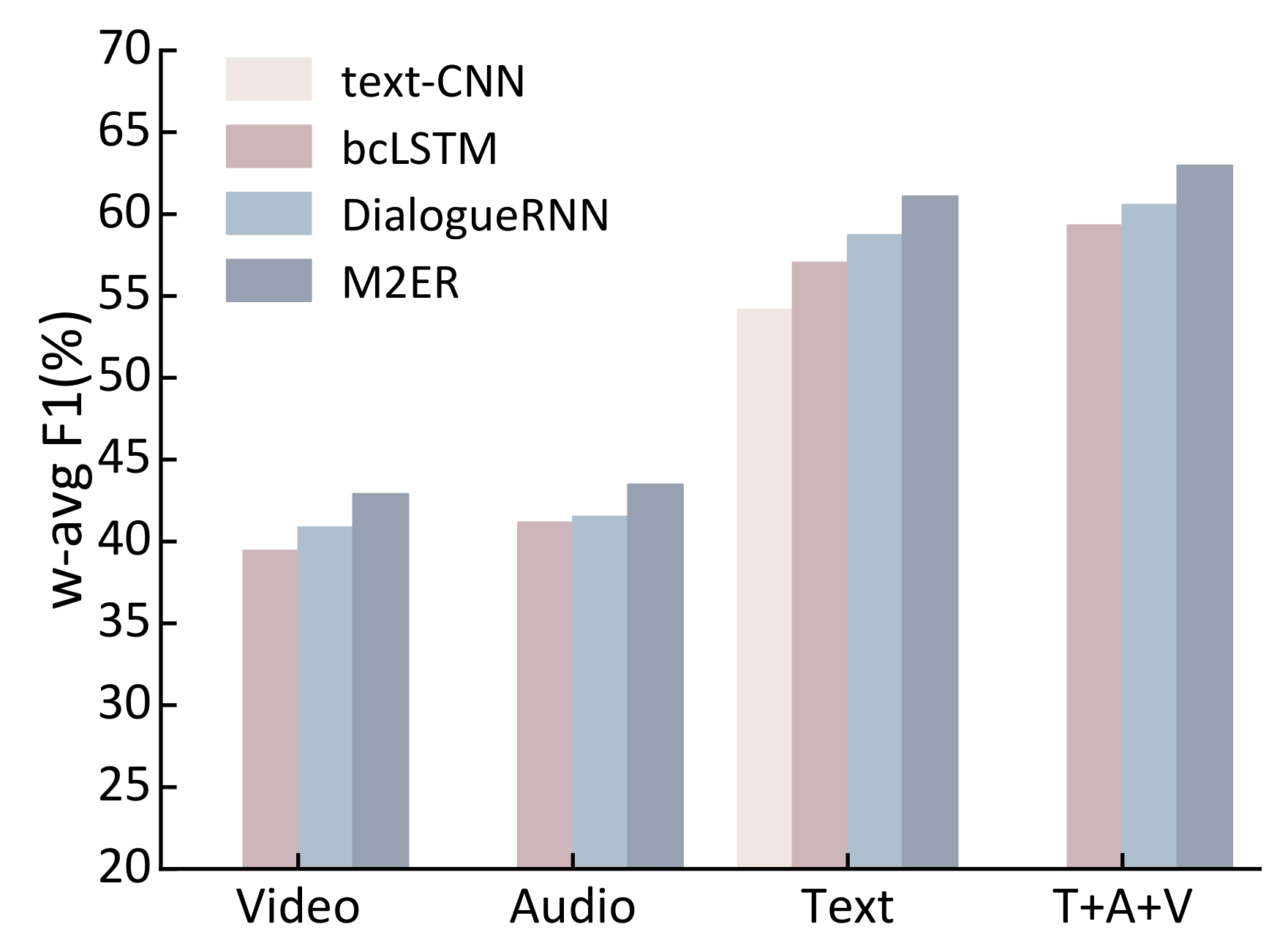
1. Introduction
Emotions are unique and important forms of human expression [
1]. When conducting early research on emotions, Ekman [
2] classified people’s basic emotions according to their needs. In 1977, Picard proposed the concept of emotional computing [
3], aiming to equip computers with the ability to recognize, understand, express, and adapt to human emotions. An important direction in emotional computing research is emotion recognition, which can create more intelligent and harmonious user entities for applications such as lie detection, audiovisual monitoring, online conferences, and human–computer interaction (HCI) [
4].
Researchers often rely on unimodal emotion recognition [
5]. Recently, significant progress has been made in the research of unimodal approaches for text, audio, and video. Particularly, facial emotion recognition (FER) technology has a wide range of applications, including HCI, emotional chat, psychological diagnosis, and other tasks [
6]. AffectNet [
7] is a widely recognized corpus for video modality emotion recognition. Currently, the top three models in terms of accuracy for seven-class emotion recognition on AffectNet are POSTER++ (67.49%) [
8], Emotion-GCN (66.46%) [
9], and EmoAffectNet (66.37%) [
10]. Other studies related to FER are as follows: Bakariya et al. [
11] created a real-time system that can recognize human faces, assess human emotions, and recommend music to users. Meena et al. [
12] proposed a facial image sentiment analysis model based on a CNN. It is discovered that more convolution layers, a strong dropout, a large batch size, and many epochs can obtain better effects. Savchenko [
13] studied lightweight convolutional neural networks (CNNs) for FER task learning and verified the effectiveness of CNNs for FER. Meena et al. [
14] utilized Inception-v3, along with additional deep features, to enhance image categorization performance. A CNN-based Inception-v3 architecture was used for emotion detection and classification. In a study by Saravanan [
15], they found that CNNs are highly effective for image recognition tasks due to their ability to capture spatial features using numerous filters. They proposed a model consisting of six convolutional layers, two max-pooling layers, and two fully connected layers, which performed better than decision trees and feed-forward neural networks on the FER-2013 dataset. Li [
16] used a CNN, which extracts geometric and appearance features, and LSTM, which captures temporal and contextual information on facial expressions. This CNN–LSTM architecture allows for a more comprehensive representation of facial expressions by combining spatial and temporal information. Ming et al. [
17] presented a facial expression recognition method that included an attention mechanism based on a CNN and LSTM. This model was able to effectively extract information on important regions, better than general CNN–LSTM-based models. Sang [
18] focused on reducing intra-class variation in facial expression depth features and introduced a dense convolutional network [
19] for the FER task.
There has been an increase in the combination of transformers in various FER methods. Xue [
20] was the first to use the vision transformer for FER and achieved state-of-the-art results. VTFF [
21] excels in dealing with facial expression recognition tasks in the wild due to its feature fusion. Chen et al. [
22] introduced CrossViT, which uses dual branches to combine image patches of different sizes to produce more reliable features. Heo et al. [
23] examined the benefits of pooling layers in ViT, similar to their advantages in CNNs.
However, in real-world scenarios, the video modality often presents complex data formats. For example, multiple faces often appear in the same frame in multi-party dialogue scenarios, and the presence of non-speaking individuals’ faces can interfere with the final emotion recognition. This is the reason why most of the existing research on multimodal emotion recognition in multi-party dialogues has not utilized the video modality. Challenges such as speaker recognition, significant intra-class facial expression variations, and subtle inter-class differences further highlight the room for improvement in emotion recognition. Thus, there is still considerable scope for further research and exploration in the field of emotion recognition.
It is hard to obtain accurate emotional information only through a single modality [
24,
25]. Compared with unimodal emotion recognition, multimodal emotion recognition can make up for the noise interference caused by the single modality and make full use of the complementary features between different modalities. Zadeh [
26] conducted multimodal sentiment analysis on three modalities of text, audio, and video for the first time and released the first dataset containing text, audio, and video modalities—the YouTube dataset. Rosas [
27] proposed a multimodal research dataset—Moud—and conducted sentiment analysis in sentences. Zadeh [
28] constructed a large-scale multimodal dataset CMU-MOSEI. In recent years, based on the above datasets, researchers have carried out many classic multimodal emotion analysis methods based on text, audio, and video modalities. Dai [
29] combined multimodal feature extraction and fusion into a model and optimized it at the same time, which improved the accuracy of emotion recognition in real-time performance. Ren [
30] used the self-supervised training model to fuse the features of text, audio, and video modalities into non-standard classes and achieved better results than the baseline model.
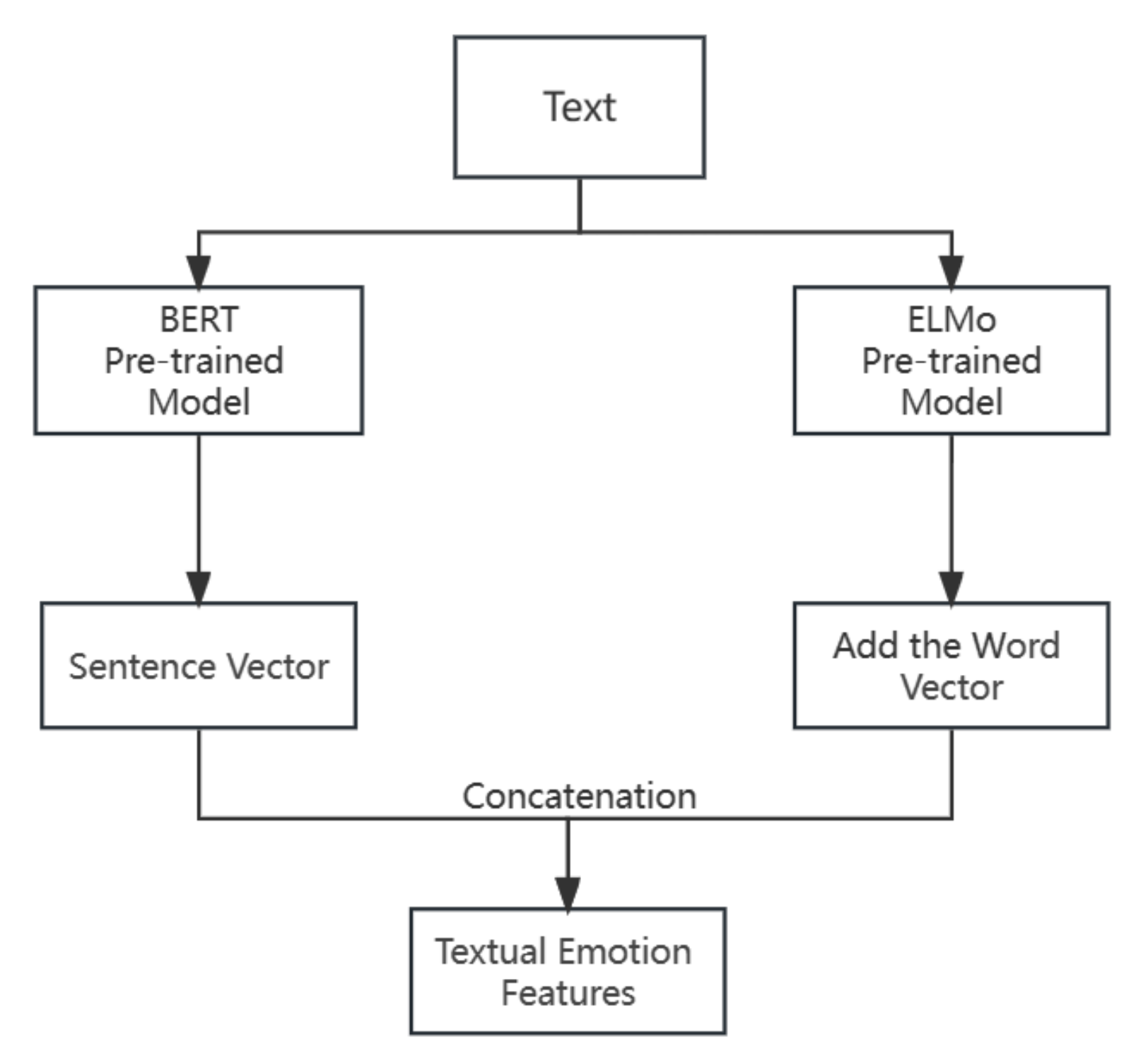
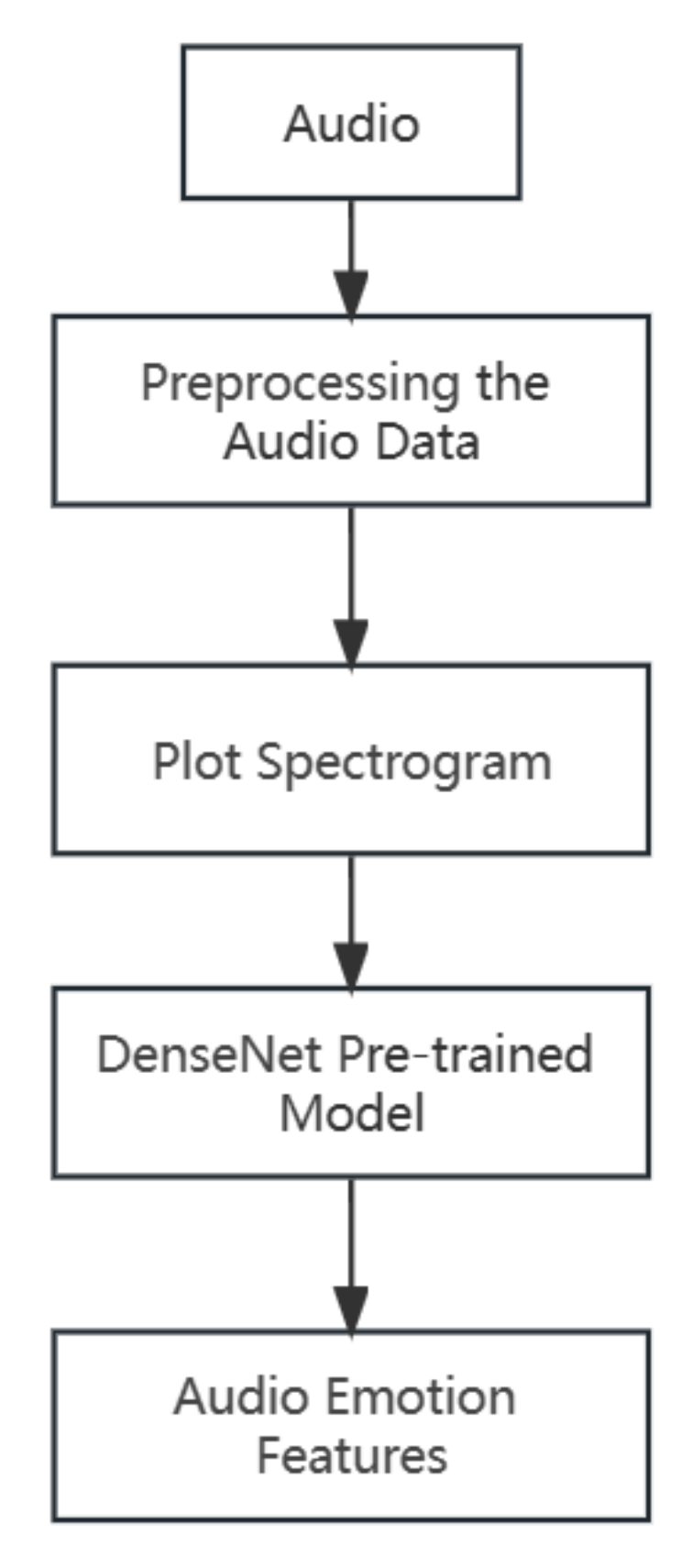
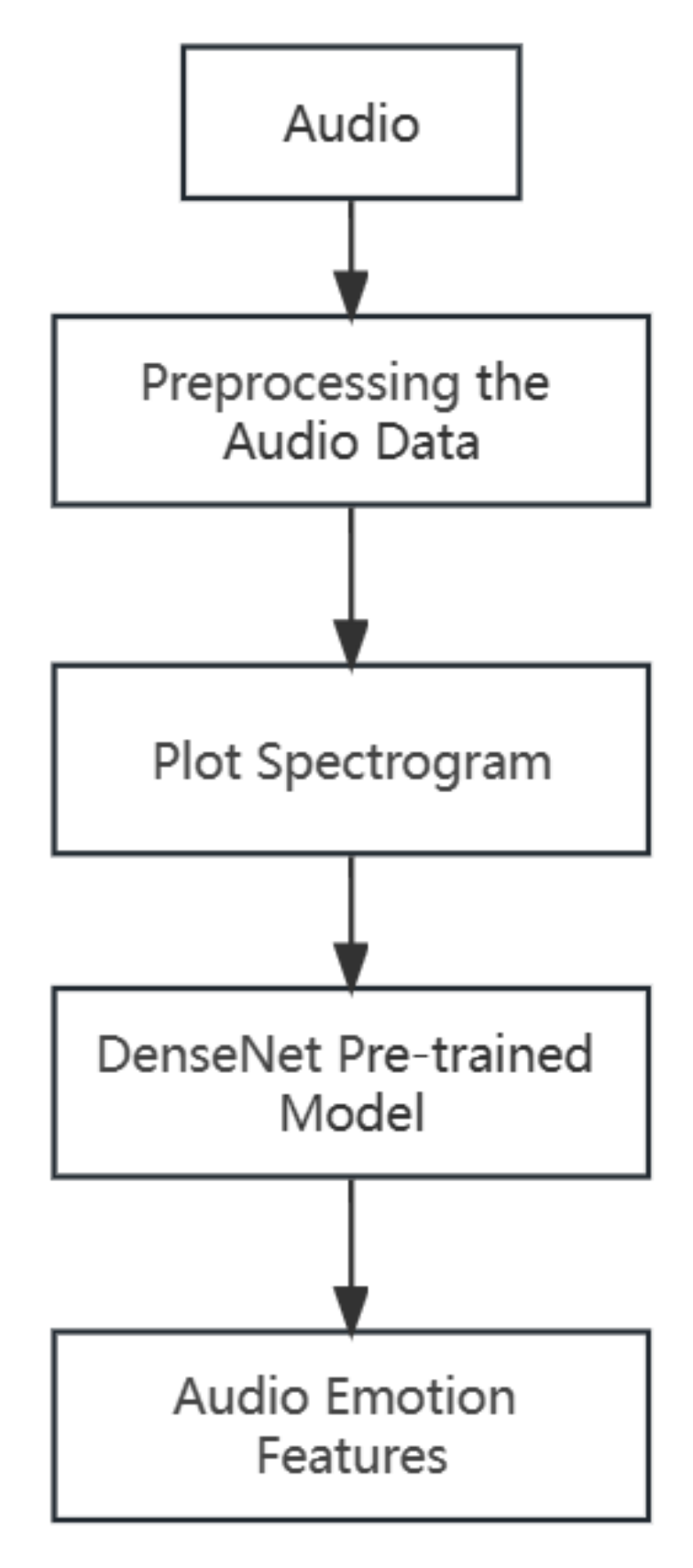
The focus of multimodal emotion recognition lies in how to extract features and perform subsequent fusion. However, most of the current research on multimodal emotion recognition only focuses on the stage of feature fusion, neglecting the initial stage of unimodal emotional feature extraction. For example, in the case of the audio modality, most studies directly extract audio features using open-source toolkits such as Librosa and OpenSmile [
31,
32] and fuse them with features from other modalities. In the context of multi-party dialogues, many researchers have focused on studying the text and audio modalities while neglecting the video modality. Extracting comprehensive features from individual modalities is a prerequisite for multimodal emotion recognition. The more comprehensive the extraction of emotional features from each modality, the better it can reflect the characteristics of emotion.
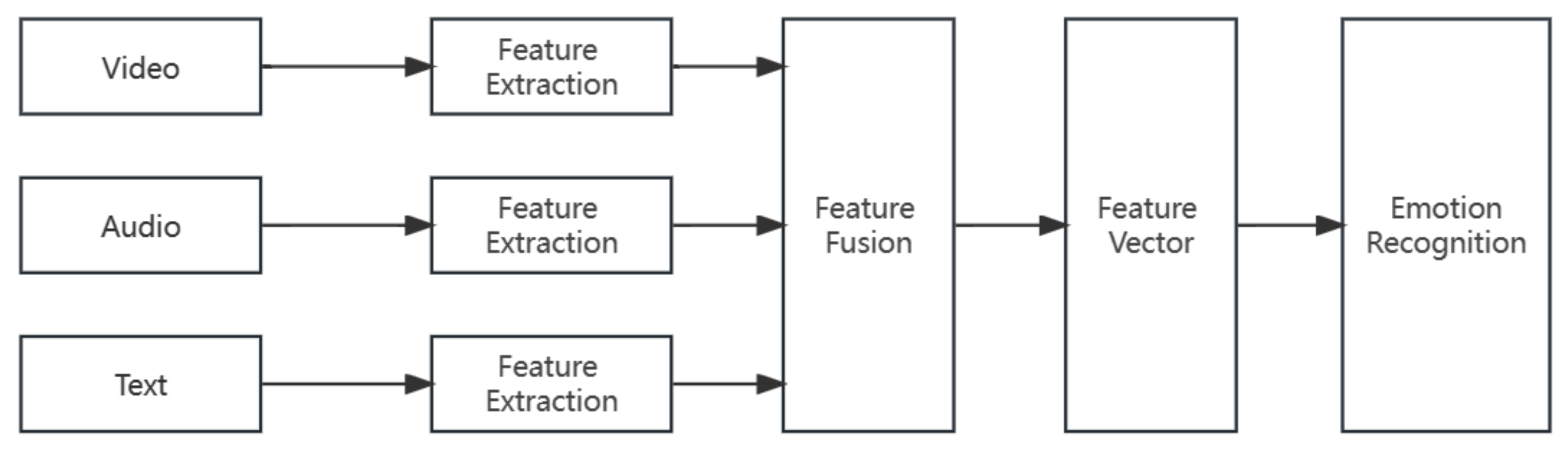
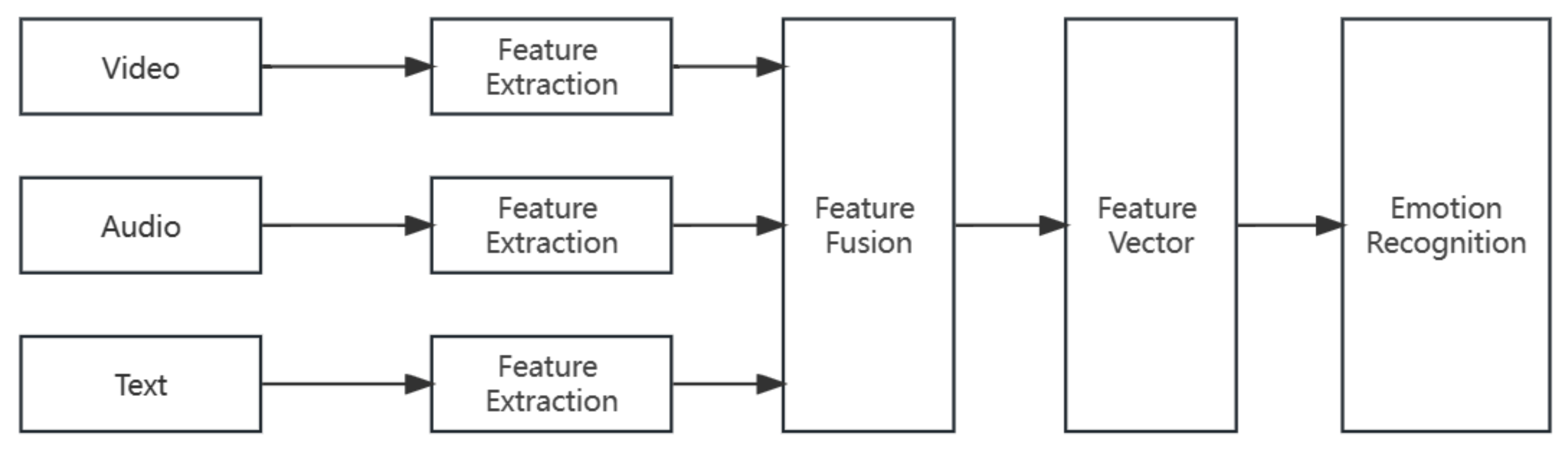
There are three main methods of multimodal fusion: data-level fusion, feature-level fusion, and decision-level fusion. The specific process of feature-level fusion is illustrated in
Figure 1. Feature-level fusion can fully leverage the advantages of each modality, effectively integrate information from different modalities, and consider the correlation between various data in different modalities. However, if the feature-level fusion is achieved by directly concatenating the feature vectors, it will result in high-dimensional vectors, leading to problems such as the curse of dimensionality.
Recently, many research works have focused on attention-based fusion and its variants, such as self-attention, multi-head attention, and transformers [
33]. The attention-based fusion integrates the advantages of early fusion and late fusion and compensates for their shortcomings [
34]. The attention mechanism is a specialized structure that can be embedded in the framework of machine learning models. By employing the attention mechanism, the problem of information overload can be addressed. Furthermore, the attention mechanism can provide an effective resource allocation scheme in neural networks [
35]. As the number of model parameters increases in deep neural networks, the model generally becomes more expressive and capable of storing a greater amount of information. However, the increasing number of parameters also demands significant computational resources during model training, making it challenging. By incorporating the attention mechanism into neural networks, it becomes possible to identify which data in the input sequence contributes more significantly to the task at hand [
36]. Consequently, more limited attention can be allocated to the most valuable portions of information, while reducing attention or disregarding irrelevant information, thus efficiently utilizing computational resources [
37]. Hu [
38] proposed the Multimodal Dynamic Fusion Network (MM-DFN) to recognize emotions by fully understanding multimodal conversational context. Wang et al. [
34] proposed a cross-attention asymmetric fusion module, which utilized information matrices of the acoustic and visual modality as weights to strengthen the text modality.
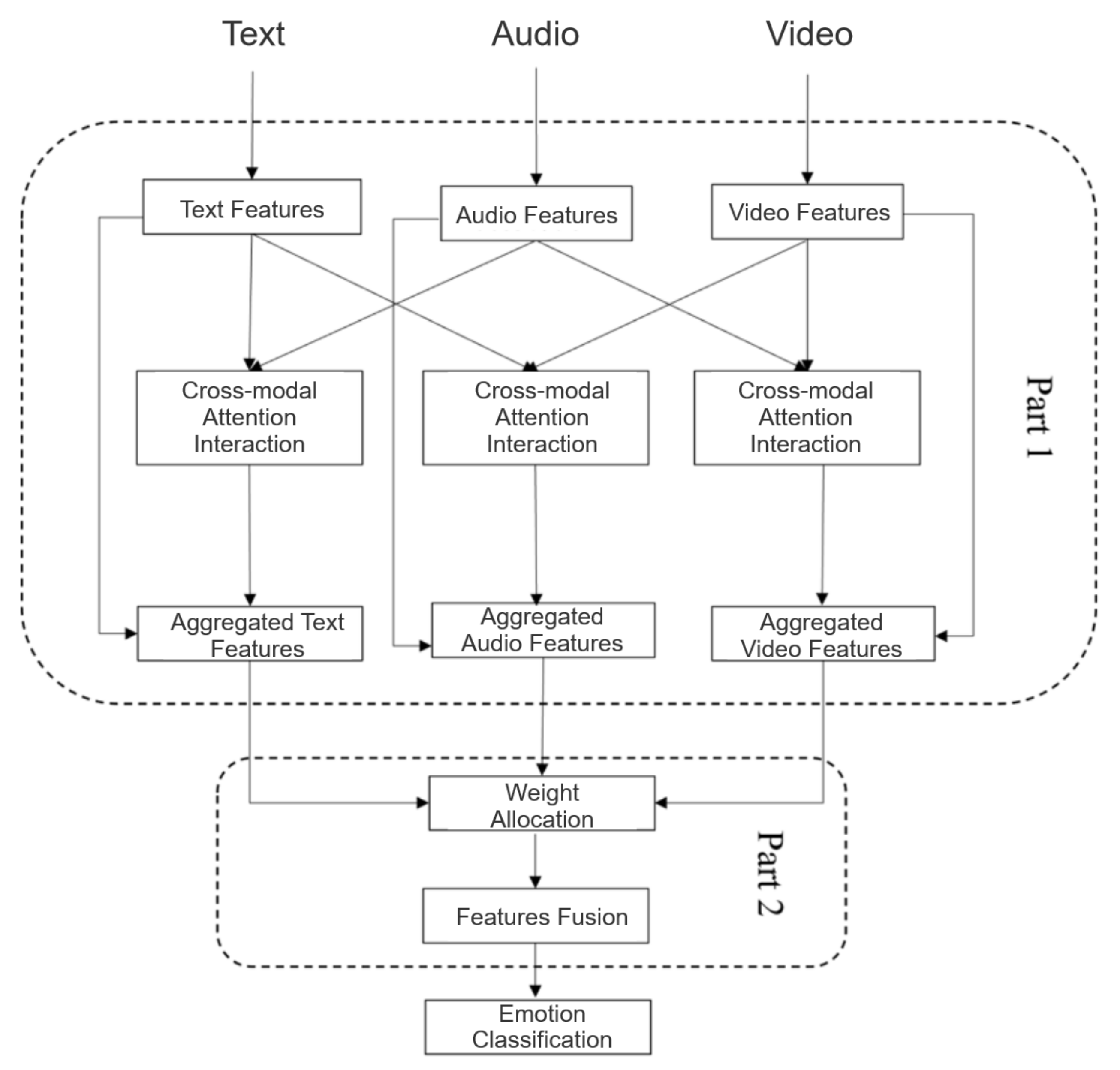
Based on the above situation, we propose M2ER that optimizes the key steps of multimodal emotion recognition in multi-party dialogue scenarios. We mainly focus on how to fully utilize video modalities. The contributions of M2ER are summarized as follows:
We constructed suitable feature extraction models for text, audio, and video modalities. Addressing the challenge of multiple faces appearing in a single frame in the video modality, we propose a method using multi-face localization for speaker recognition, thus extracting features from facial expression sequences of the identified speaker.
For the multimodal fusion model, we adopted the feature-level fusion approach utilizing a multimodal fusion model based on the attention mechanism. The extracted unimodal emotional features are combined using cross-modal attention to capture the intermodal interactions. Furthermore, the attention mechanism employed determines the contribution of each modality to the final emotion classification, enabling the fusion with different weights.
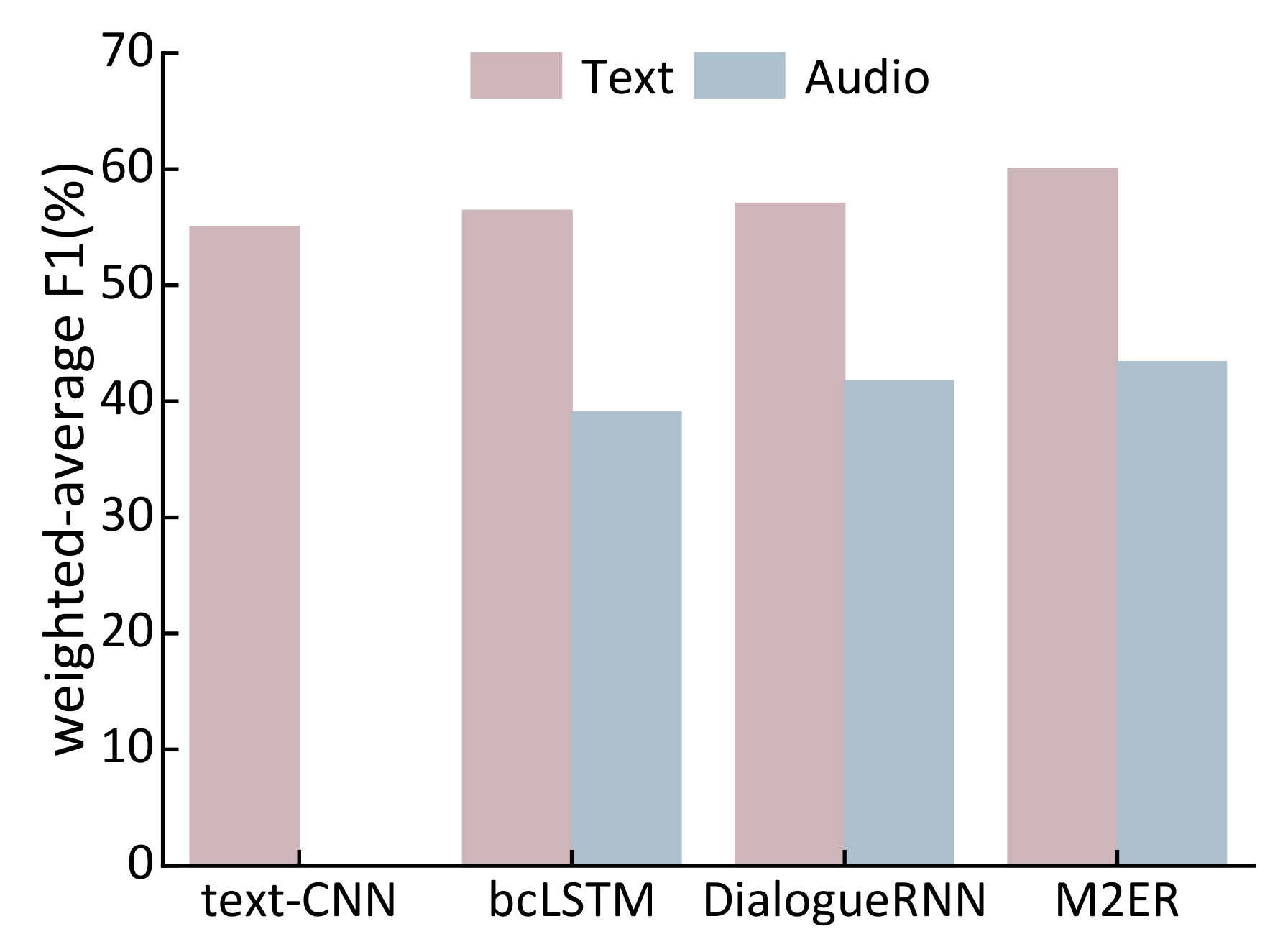
We conducted experiments on the Multimodal Emotion Lines Dataset (MELD) [
39] using both unimodal and multimodal fusion methods and further evaluated the scalability of our models on the MEISD dataset [
40]. The extensive experiments show that our unimodal feature-based emotion recognition model of M2ER outperforms the baseline models. The multimodal fusion model achieves higher recognition accuracy compared to the unimodal emotion recognition systems. Moreover, our fusion model of M2ER exhibits superior performance in multimodal emotion recognition tasks compared to directly concatenated models.
The remaining parts of the paper are structured as follows:
Section 2 presents the detailed design of the proposed M2ER, including the extraction of unimodal features and the multimodal feature fusion model. In
Section 3, we outline the experiments conducted on unimodal and multimodal emotion recognition separately and verify the scalability of the models. Furthermore, we discuss the advantages of our work as well as the limitations and future work in
Section 4; Finally,
Section 5 concludes the work of this paper.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}