
Know an Emotion by the Company It Keeps: Word Embeddings from Reddit/Coronavirus

 , ,
, ,
Abstract
1. Introduction
2. Related Work
3. Methods
3.1. Data Collection
3.2. Data Cleaning
3.3. Descriptive Initial Analysis
3.4. Model Training: Word2vec
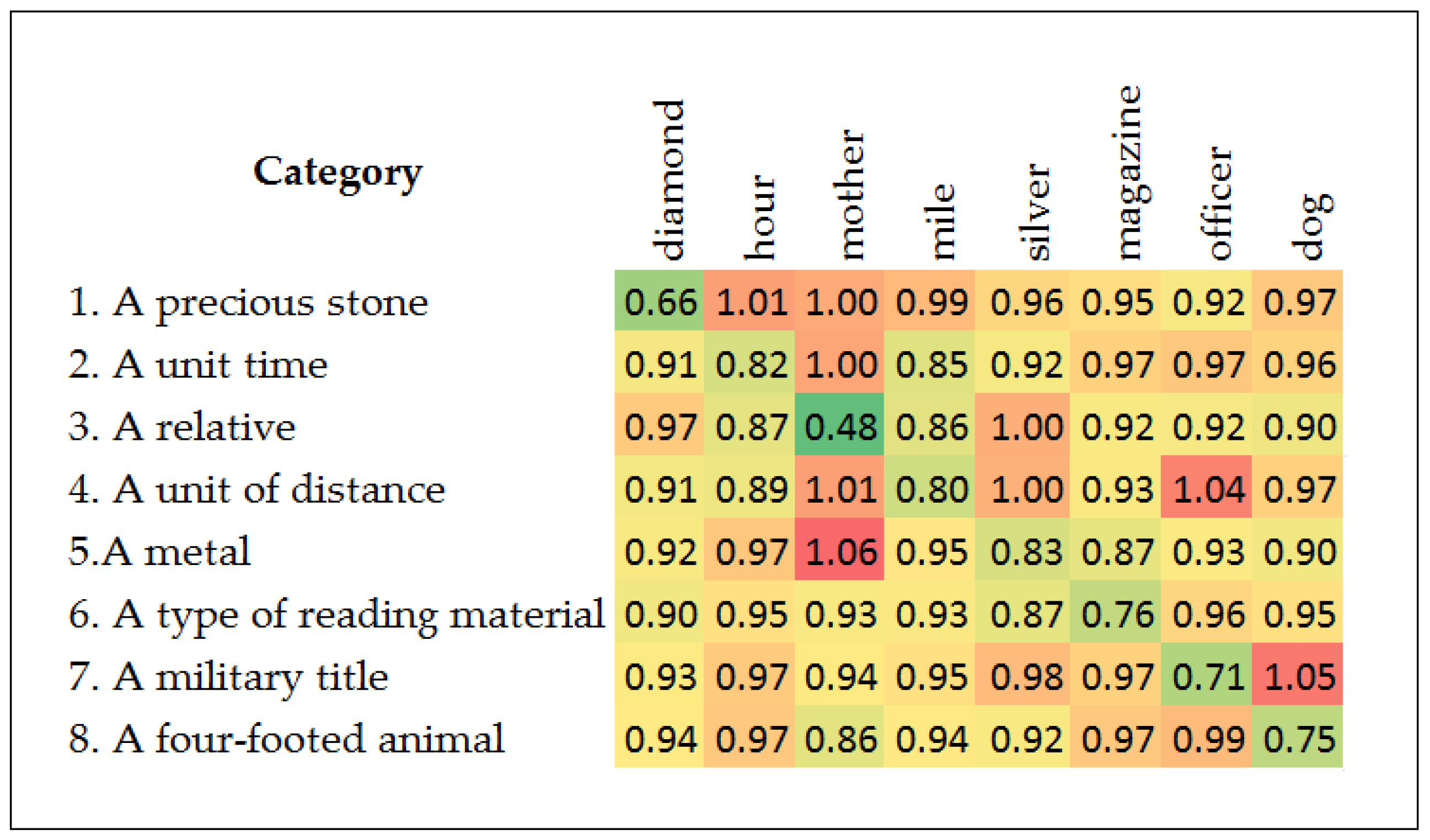
3.5. Model Validation: Semantic Categorization Test
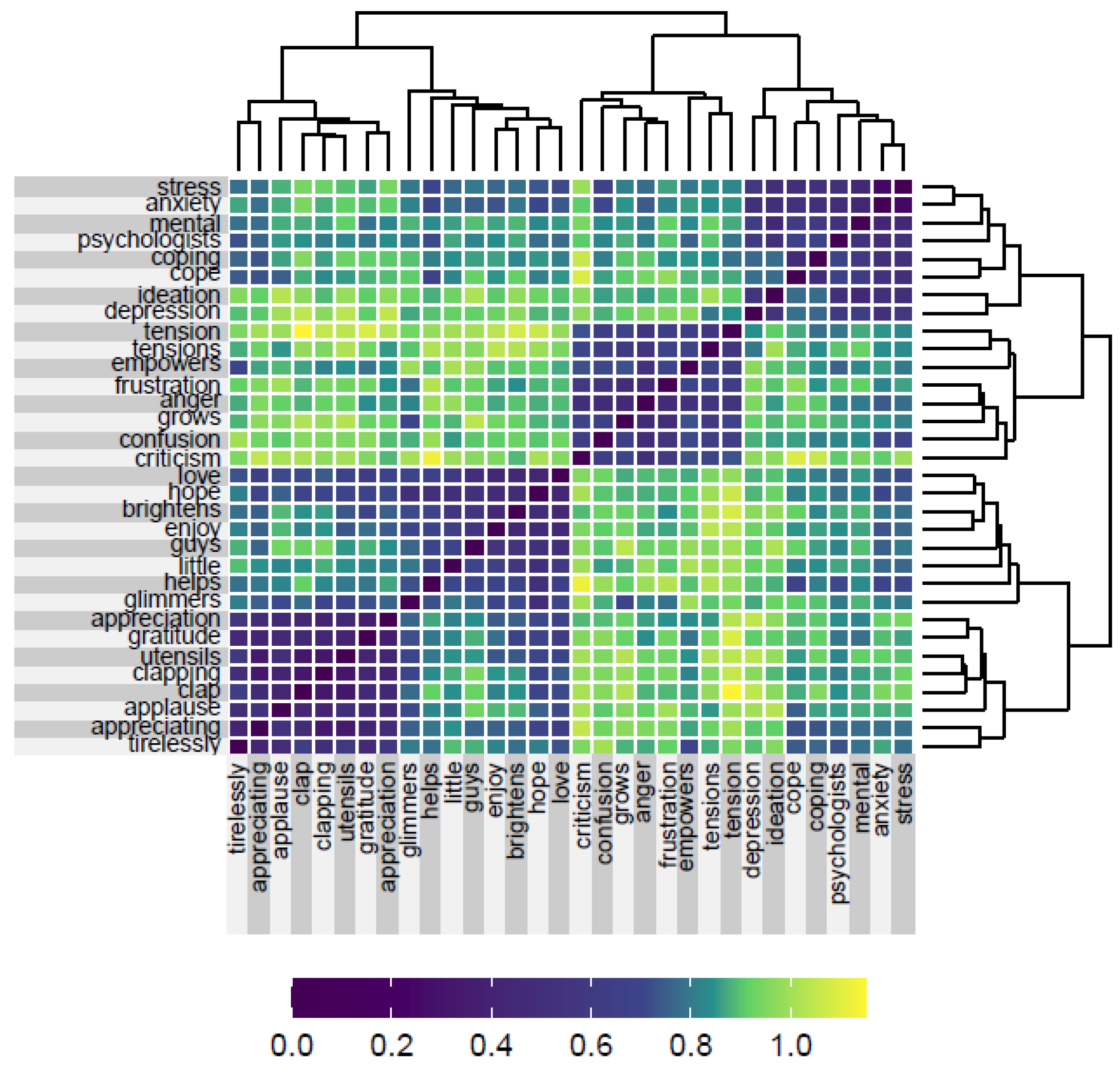
3.6. Model Visualization: Hierarchical Clustering and Heatmaps
4. Results
4.1. Sample Description
4.2. A 3-Steps Validation of the Word2vec Embeddings

{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Category | Closest Terms (Cosine Distance) |
|---|---|
| paris − france + italy = ? | rome (0.584), milan (0.510) |
| brother − sister + husband = ? | wife (0.598) |
| dad − mom + father = ? | mother (0.546), family (0.569) |
| she − he + girl = ? | boy (0.375) |
| his − her + boy = ? | girl (0.570), schoolgirl (0.604) |
| she − he + mother = ? | father (0.373), husband (0.403) |
| boy − girl + man = ? | woman (0.553) |
| doctor − hospital + teacher = ? | school (0.577), teen (0.548) |
| cnn − news + netflix = ? | film (0.640), movies (0.692) |
| iphone − apple + android = ? | ios(0.406), tablet (0.4760), app (0.487) |
| moscow − putin + nyc | Blasio * (0.619), brooklyn (0.581) |
| young − teen + old | 64 (0.633), aged (0.563) |
4.3. Semantic Categorization Test
4.4. Context for Positive and Negative Emotions
5. Discussion
6. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| API | Application Program Interface |
| ARDS | Acute Respiratory Distress Syndrome |
| CVST | Cerebral Venous Sinus System |
| CBOW | Continuous Bag of Words |
| EMA | European Medicines Agency |
| IgM | Immunoglobin M |
| MHRA | Medicines Healthcare products Regulatory Agency |
| NLP | Natural Language Processing |
References
- Melton, C.A.; White, B.M.; Davis, R.L.; Bednarczyk, R.A.; Shaban-Nejad, A. Fine-tuned Sentiment Analysis of COVID-19 Vaccine-Related Social Media Data: Comparative Study. J. Med. Internet Res. 2022, 24, e40408. [Google Scholar] [CrossRef] [PubMed]
- Reddit–Dive into Anything. Founded: June 23, 2005, Medford, Massachusetts, United States. Available online: https://www.reddit.com/ (accessed on 19 March 2023).
- Tsao, S.F.; Chen, H.; Tisseverasinghe, T.; Yang, Y.; Li, L.; Butt, Z.A. What social media told us in the time of COVID-19: A scoping review. Lancet Digit. Health 2021, 3, e175–e194. [Google Scholar] [CrossRef] [PubMed]
- White, B.M.; Melton, C.; Zareie, P.; Davis, R.L.; Bednarczyk, R.A.; Shaban-Nejad, A. Exploring celebrity influence on public attitude towards the COVID-19 pandemic: Social media shared sentiment analysis. BMJ Health Care Inform. 2023, 30, e100665. [Google Scholar] [CrossRef] [PubMed]
- Al-Garadi, M.A.; Yang, Y.C.; Sarker, A. The Role of Natural Language Processing during the COVID-19 Pandemic: Health Applications, Opportunities, and Challenges. Healthcare 2022, 10, 2270. [Google Scholar] [CrossRef] [PubMed]
- Didi, Y.; Walha, A.; Wali, A. COVID-19 Tweets Classification Based on a Hybrid Word Embedding Method. Big Data Cogn. Comput. 2022, 6, 58. [Google Scholar] [CrossRef]
- Parikh, S.; Davoudi, A.; Yu, S.; Giraldo, C.; Schriver, E.; Mowery, D. Lexicon Development for COVID-19-related Concepts Using Open-source Word Embedding Sources: An Intrinsic and Extrinsic Evaluation. JMIR Med. Inform. 2021, 9, e21679. [Google Scholar] [CrossRef]
- Sciandra, A. COVID-19 Outbreak through Tweeters’ Words: Monitoring Italian Social Media Communication about COVID-19 with Text Mining and Word Embeddings. In Proceedings of the 2020 IEEE Symposium on Computers and Communications (ISCC), Rennes, France, 7–10 July 2020; pp. 1–6. [Google Scholar] [CrossRef]
- Levy, O.; Goldberg, Y.; Dagan, I. Improving Distributional Similarity with Lessons Learned from Word Embeddings. Trans. Assoc. Comput. Linguist. 2015, 3, 211–225. [Google Scholar] [CrossRef]
- Firth, J.R. A Synopsis of Linguistic Theory 1930–1955. In Studies in Linguistic Analysis. Special Volume of the Philological Society; Blackwell: Oxford, UK, 1957; pp. 1–32. [Google Scholar]
- Harris, Z.S. Distributional Structure; Routledge: New York, NY, USA, 1954. [Google Scholar]
- Mikolov, T.; Corrado, G.; Chen, K.; Dean, J. Efficient Estimation of Word Representations in Vector Space. In Proceedings of the International Conference on Learning Representations, Scottsdale, AZ, USA, 2–4 May 2013; pp. 1–12. [Google Scholar]
- Greenaway, K.H.; Kalokerinos, E.K.; Williams, L.A. Context is Everything (in Emotion Research). Soc. Personal. Psychol. Compass 2018, 12, 12393. [Google Scholar] [CrossRef]
- Barrett, L.F.; Mesquita, B.; Smith, E.R. The context principle. In The Mind in Context; Mesquita, B., Barrett, L.F., Smith, E.R., Eds.; Guilford Press: New York, NY, USA, 2010; pp. 1–22. [Google Scholar]
- Ledgerwood, A. Evaluations in their social context: Distance regulates consistency and context dependence. Soc. Personal. Psychol. Compass 2014, 8, 436–447. [Google Scholar] [CrossRef]
- Moskowitz, J.T.; Cheung, E.O.; Freedman, M.; Fernando, C.; Zhang, M.W.; Huffman, J.C.; Addington, E.L. Measuring positive emotion outcomes in positive psychology interventions: A literature review. Emot. Rev. 2020, 13, 60–73. [Google Scholar] [CrossRef]
- Sun, R.; Balabanova, A.; Bajada, C.J.; Liu, Y.; Kriuchok, M.; Voolma, S.; Pavarini, G. Psychological wellbeing during the global COVID-19 outbreak. PsyArXiv 2020. [Google Scholar] [CrossRef]
- Welles, B.F.; González-Bailón, S. The Oxford Handbook of Networked Communication; Oxford University Press: Oxford, UK, 2020; ISBN 100190460512. [Google Scholar]
- Basile, V.; Cauteruccio, F.; Terracina, G. How Dramatic Events Can Affect Emotionality in Social Posting: The Impact of COVID-19 on Reddit. Future Internet 2021, 13, 29. [Google Scholar] [CrossRef]
- Subreddit Stats. 2023. Available online: https://subredditstats.com/ (accessed on 19 March 2023).
- Subreddit Lists. 2023. Available online: https://redditlist.com/ (accessed on 19 March 2023).
- Coronavirus Subreddit. Available online: https://www.reddit.com/r/Coronavirus/ (accessed on 19 March 2023).
- Reddiquette: An Informal Expression of the Values of Many Redditors, as Written by Redditors Themselves. Available online: https://www.reddithelp.com/hc/en-us/articles/205926439 (accessed on 19 March 2023).
- Mikolov, T.; Sutskever, I.; Chen, K.; Corrado, G.S.; Dean, J. Distributed Representations of Words and Phrases and their Compositionality. In Proceedings of the NIPS’13: 26th International Conference on Neural Information Processing Systems, Lake Tahoe, NV, USA, 5–8 December 2013; Volume 2, pp. 3111–3119. [Google Scholar]
- Wu, G.; Feder, A.; Cohen, H.; Kim, J.J.; Calderon, S.; Charney, D.S.; Mathé, A.A. Understanding resilience. Front. Behav. Neurosci. 2013, 7, 10. [Google Scholar] [CrossRef] [PubMed]
- Rutter, M. Resilience as a dynamic concept. Dev. Psychopathol. 2012, 24, 335–344. [Google Scholar] [CrossRef]
- Newman, R. APA’s resilience initiative. Prof. Psychol. Res. Pract. 2005, 36, 227–229. [Google Scholar] [CrossRef]
- Vella, S.; Pai, N. A theoretical review of psychological resilience: Defining resilience and resilience research over the decades. Arch. Med. Health Sci. 2019, 7, 233–239. [Google Scholar] [CrossRef]
- Tariq, H. Measuring Community Disaster Resilience at local levels: An adaptable Resilience Framework. Int. J. Disaster Risk Reduct. 2021, 62, 102358. [Google Scholar] [CrossRef]
- Israelashvili, J. More Positive Emotions During the COVID-19 Pandemic Are Associated with Better Resilience, Especially for Those Experiencing More Negative Emotions. Front. Psychol. 2021, 12, 648112. [Google Scholar] [CrossRef]
- Zhang, Y.; Wang, X.; Lai, S.; He, S.; Liu, K.; Zhao, J.; Lv, X. Ontology Matching with Word Embeddings. In Chinese Computational Linguistics and Natural Language Processing Based on Naturally Annotated Big Data; NLP-NABD CCL 2014, Lecture Notes in Computer Science; Sun, M., Liu, Y., Zhao, J., Eds.; Springer: Cham, Switzerland, 2014; Volume 8801. [Google Scholar] [CrossRef]
- Battig, W.F.; Montague, W.E. Category norms for verbal items in 56 categories: A replication and extension of the Connecticut norms. J. Exp. Psychol. 1969, 80, 1–46. [Google Scholar] [CrossRef]
- Van Overschelde, J.; Rawson, K.; Dunlosky, J. Category norms: An updated and expanded version of the Battig and Montague (1969) norms. J. Mem. Lang. 2004, 50, 289–335. [Google Scholar] [CrossRef]
- Rajput, N.K.; Grover, B.A.; Rathi, V.K. Word frequency and sentiment analysis of twitter messages during coronavirus pandemic. arXiv 2020, arXiv:2004.03925. [Google Scholar]
- Samuel, J.; Ali, G.; Rahman, M.; Esawi, E.; Samuel, Y. COVID-19 public sentiment insights and machine learning for tweets classi-fication. Information 2020, 11, 314. [Google Scholar] [CrossRef]
- Aljameel, S.S.; Alabbad, D.A.; Alzahrani, N.A.; Alqarni, S.M.; Alamoudi, F.A.; Babili, L.M.; Aljaafary, S.K.; Alshamrani, F.M. A sentiment analysis approach to predict an individual’s awareness of the precautionary procedures to prevent COVID-19 outbreaks in Saudi Arabia. Int. J. Environ. Res. Public Health 2021, 18, 218. [Google Scholar] [CrossRef]
- Muthusami, R.; Bharathi, A.; Saritha, K. COVID-19 outbreak: Tweet based analysis and visualization towards the influence of coronavirus in the world. Gedrag Organ. Rev. 2020, 33, 8–9. [Google Scholar]
- Jalil, Z.; Abbasi, A.; Javed, A.R.; Badruddin Khan, M.; Abul Hasanat, M.H.; Malik, K.M.; Saudagar, A.K.J. COVID-19 Related Sentiment Analysis Using State-of-the-Art Machine Learning and Deep Learning Techniques. Front. Public Health 2022, 9, 812735. [Google Scholar] [CrossRef] [PubMed]
- Rustam, F.; Khalid, M.; Aslam, W.; Rupapara, V.; Mehmood, A.; Choi, G.S. A performance comparison of supervised machine learning models for COVID-19 tweets sentiment analysis. PLoS ONE 2021, 16, e0245909. [Google Scholar] [CrossRef]
- Dangi, D.; Dixit, D.K.; Bhagat, A. Sentiment analysis of COVID-19 social media data through machine learning. Multimed. Tools Appl. 2022, 81, 42261–42283. [Google Scholar] [CrossRef]
- Rahman, M.M.; Islam, M.N. Exploring the Performance of Ensemble Machine Learning Classifiers for Sentiment Analysis of COVID-19 Tweets. In Sentimental Analysis and Deep Learning; Shakya, S., Balas, V.E., Kamolphiwong, S., Du, K.L., Eds.; Advances in Intelligent Systems and Computing; Springer: Singapore, 2022; Volume 1408. [Google Scholar] [CrossRef]
- Es-Sabery, F.; Es-Sabery, K.; Qadir, J.; Sainz-De-Abajo, B.; Hair, A.; Garcia-Zapirain, B.; De la Torre-Diez, I. A MapReduce opinion mining for COVID-19-related tweets classification using enhanced ID3 decision tree classifier. IEEE Access 2021, 9, 58706–58739. [Google Scholar] [CrossRef]
- Basiri, M.E.; Nemati, S.; Abdar, M.; Asadi, S.; Acharrya, U.R. A novel fusion-based deep learning model for sentiment analysis of COVID-19 tweets. Knowl.-Based Syst. 2021, 228, 107242. [Google Scholar] [CrossRef]
- Ibrahim, F.A.; Hassaballah, M.; Ali, A.A.; Nam, Y.; Ibrahim, A.I. COVID19 outbreak: A hierarchical framework for user sentiment analysis. Comput. Mater. Contin. 2022, 70, 2507–2524. [Google Scholar] [CrossRef]
- Bonifazi, G.; Breve, B.; Cirillo, S.; Corradini, E.; Virgili, L. Investigating the COVID-19 vaccine discussions on Twitter through a multilayer network-based approach. Inf. Process Manag. 2022, 59, 103095. [Google Scholar] [CrossRef]
- Naseem, U.; Razzak, I.; Khushi, M.; Eklund, P.W.; Kim, J. Covidsenti: A large-scale benchmark Twitter data set for COVID-19 sentiment analysis. IEEE Trans. Comput. Soc. Syst. 2021, 8, 1003–1015. [Google Scholar] [CrossRef] [PubMed]
- Yan, C.; Law, M.; Nguyen, S.; Cheung, J.; Kong, J. Comparing public sentiment toward COVID-19 vaccines across Canadian cities: Analysis of comments on reddit. J. Med. Internet Res. 2021, 23, e32685. [Google Scholar] [CrossRef] [PubMed]
- Jelodar, H.; Wang, Y.; Orji, R.; Huang, S. Deep Sentiment classification and topic discovery on novel coronavirus or COVID-19 online discussions: NLP using LSTM recurrent neural network approach. IEEE J. Biomed. Health Inform. 2020, 24, 2733–2742. [Google Scholar] [CrossRef]
- Lai, D.; Wang, D.; Calvano, J.; Raja, A.S.; He, S. Addressing immediate public coronavirus (COVID-19) concerns through social media: Utilizing Reddit’s AMA as a framework for public engagement with science. PLoS ONE 2020, 15, e0240326. [Google Scholar] [CrossRef]
- Pal, R.; Chopra, H.; Awasthi, R.; Bandhey, H.; Nagori, A.; Sethi, T. Predicting Emerging Themes in Rapidly Expanding COVID-19 Literature with Unsupervised Word Embeddings and Machine Learning: Evidence-Based Study. J. Med. Internet Res. 2022, 24, e34067. [Google Scholar] [CrossRef] [PubMed]
- Jha, R.A.; Ananthanarayana, V.S. Gaining Actionable Insights in COVID-19 Dataset Using Word Embeddings. In Pattern Recognition and Data Analysis with Applications. Lecture Notes in Electrical Engineering; Gupta, D., Goswami, R.S., Banerjee, S., Tanveer, M., Pachori, R.B., Eds.; Springer: Singapore, 2022; Volume 888. [Google Scholar] [CrossRef]
- Batzdorfer, V.; Steinmetz, H.; Biella, M.; Alizadeh, M. Conspiracy theories on Twitter: Emerging motifs and temporal dynamics during the COVID-19 pandemic. Int. J. Data Sci. Anal. 2022, 13, 315–333. [Google Scholar] [CrossRef]
- Bhandari, A.; Kumar, V.; Thien Huong, P.; Thanh, D. Sentiment Analysis of COVID-19 Tweets: Leveraging Stacked Word Embedding Representation for Identifying Distinct Classes Within a Sentiment. In Artificial Intelligence in Data and Big Data Processing; ICABDE 2021, Lecture Notes on Data Engineering and Communications Technologies; Dang, N.H.T., Zhang, Y.D., Tavares, J.M.R.S., Chen, B.H., Eds.; Springer: Cham, Switzerland, 2022; Volume 124. [Google Scholar] [CrossRef]
- Chan, A.Y.; Ting, C.; Chan, L.G.; Hildon, Z.J.L. “The emotions were like a roller-coaster”: A qualitative analysis of e-diary data on healthcare worker resilience and adaptation during the COVID-19 outbreak in Singapore. Hum. Resour. Health 2022, 20, 60. [Google Scholar] [CrossRef]
- Pushshift Reddit API Documentation. Available online: https://github.com/pushshift/api (accessed on 19 March 2023).
- Lama, Y.; Hu, D.; Jamison, A.; Quinn, S.C.; Broniatowski, D.A. Characterizing Trends in Human Papillomavirus Vaccine Discourse on Reddit (2007–2015): An Observational Study. JMIR Public Health Surveill. 2019, 5, e12480. [Google Scholar] [CrossRef]
- Pushshiftr: An R Package for Connection to the Pushshift.io API. Available online: https://github.com/dashstander/pushshiftr (accessed on 19 March 2023).
- Benoit, K.; Watanabe, K.; Wang, H.; Nulty, P.; Obeng, A.; Müller, S.; Matsuo, A. quanteda: An R package for the quantitative analysis of textual data. J. Open Source Softw. 2018, 3, 774. [Google Scholar] [CrossRef]
- Silge, J.; Robinson, D. tidytext: Text Mining and Analysis Using Tidy Data Principles in R. J. Open Source Softw. 2016, 1, 37. [Google Scholar] [CrossRef]
- dplyr: A Grammar of Data Manipulation. Available online: https://cran.r-project.org/web/packages/dplyr/index.html (accessed on 19 March 2023).
- ggplot2: Create Elegant Data Visualisations Using the Grammar of Graphics. Available online: https://cran.r-project.org/web/packages/ggplot2/ (accessed on 19 March 2023).
- broom: Convert Statistical Objects into Tidy Tibbles. Available online: https://cran.r-project.org/web/packages/broom/index.html (accessed on 19 March 2023).
- wordVectors: An R Package for Building and Exploring Word Embedding Models. Available online: https://github.com/bmschmidt/wordVectors (accessed on 19 March 2023).
- Rousseeuw, P.J. Silhouettes: A graphical aid to the interpretation and validation of cluster analysis. J. Comput. Appl. Math. 1987, 20, 53–65. [Google Scholar] [CrossRef]
- Barter, R.L.; Yu, B. Superheat: An R package for creating beautiful and extendable heatmaps for visualizing complex data. J. Comput. Graph. Stat. 2018, 27, 910–922. [Google Scholar] [CrossRef]
- García-Rudolph, A.; Saurí, J.; Cegarra, B.; Bernabeu Guitart, M. Discovering the Context of People with Disabilities: Semantic Categorization Test and Environmental Factors Mapping of Word Embeddings from Reddit. JMIR Med. Inform. 2020, 8, e17903. [Google Scholar] [CrossRef]
- The Official Website of the Government of Canada. Available online: https://www.btb.termiumplus.gc.ca/publications/covid19-eng.html (accessed on 19 March 2023).
- Mahendiratta, S.; Bansal, S.; Sarma, P.; Kumar, H.; Choudhary, G.; Kumar, S.; Prakash, A.; Sehgal, R.; Medhi, B. Stem cell therapy in COVID-19: Pooled evidence from SARS-CoV-2, SARS-CoV, MERS-CoV and ARDS: A systematic review. Biomed. Pharma-cother. 2021, 137, 111300. [Google Scholar] [CrossRef] [PubMed]
- Lazzeri, C.; Bonizzoli, M.; Batacchi, S.; Di Valvasone, S.; Chiostri, M.; Peris, A. The prognostic role of hyperglycemia and glucose variability in covid-related acute respiratory distress Syndrome. Diabetes Res. Clin. Pract. 2021, 175, 108789. [Google Scholar] [CrossRef] [PubMed]
- Chilosi, M.; Poletti, V.; Ravaglia, C.; Rossi, G.; Dubini, A.; Piciucchi, S.; Pedica, F.; Bronte, V.; Pizzolo, G.; Martignoni, G.; et al. The pathogenic role of epithelial and endothelial cells in early-phase COVID-19 pneumonia: Victims and partners in crime. Mod. Pathol. 2021, 34, 1444–1455. [Google Scholar] [CrossRef]
- Helms, J.; Severac, F.; Merdji, H.; Schenck, M.; Clere-Jehl, R.; Baldacini, M.; Ohana, M.; Grunebaum, L.; Castelain, V.; Anglés-Cano, E.; et al. Higher anticoagulation targets and risk of thrombotic events in severe COVID-19 patients: Bi-center cohort study. Ann. Intensive Care 2021, 11, 14. [Google Scholar] [CrossRef]
- Chang, C.C.; Yang, M.H.; Chang, S.M.; Hsieh, Y.J.; Lee, C.H.; Chen, Y.A.; Yuan, C.H.; Chen, Y.L.; Ho, S.Y.; Tyan, Y.C. Clinical significance of olfactory dysfunction in patients of COVID-19. J Chin. Med. Assoc. 2021, 84, 682–689. [Google Scholar] [CrossRef]
- Rethinavel, H.S.; Ravichandran, S.; Radhakrishnan, R.K.; Kandasamy, M. COVID-19 and Parkinson’s disease: Defects in neurogenesis as the potential cause of olfactory system impairments and anosmia. J. Chem. Neuroanat. 2021, 115, 101965. [Google Scholar] [CrossRef]
- Buchheit, K.; Bensko, J.C.; Lewis, E.; Gakpo, D.; Laidlaw, T.M. The importance of timely diagnosis of aspirin-exacerbated respiratory disease for patient health and safety. World J. Otorhinolaryngol. Head Neck Surg. 2020, 6, 203–206. [Google Scholar] [CrossRef] [PubMed]
- Vandergaast, R.; Carey, T.; Reiter, S.; Lathrum, C.; Lech, P.; Gnanadurai, C.; Haselton, M.; Buehler, J.; Narjari, R.; Schnebeck, L.; et al. IMMUNO-COV v2.0: Development and Validation of a High-Throughput Clinical Assay for Measuring SARS-CoV-2-Neutralizing Antibody Titers. mSphere 2021, 6, e0017021. [Google Scholar] [CrossRef] [PubMed]
- Baum, A.; Kyratsous, C.A. SARS-CoV-2 spike therapeutic antibodies in the age of variants. J. Exp. Med. 2021, 218, e20210198. [Google Scholar] [CrossRef]
- Calitri, C.; Fantone, F.; Benetti, S.; Lupica, M.M.; Ignaccolo, M.G.; Banino, E.; Viano, A.; Pace, M.; Castella, A.; Gaido, F.; et al. Long-term clinical and serological follow-up of paediatric patients infected by SARS-CoV-2. Infez Med. 2021, 29, 216–223. [Google Scholar] [PubMed]
- Kutzler, H.L.; Kuzaro, H.A.; Serrano, O.K.; Feingold, A.; Morgan, G.; Cheema, F. Initial Experience of Bamlanivimab Monotherapy Use in Solid Organ Transplant Recipients. Transpl. Infect. Dis. 2021, 23, e13662. [Google Scholar] [CrossRef] [PubMed]
- Wadaa-Allah, A.; Emhamed, M.S.; Sadeq, M.A.; Ben Hadj Dahman, N.; Ullah, I.; Farrag, N.S.; Negida, A. Efficacy of the current investigational drugs for the treatment of COVID-19: A scoping review. Ann. Med. 2021, 53, 318–334. [Google Scholar] [CrossRef]
- Hu, Y.; Meng, X.; Zhang, F.; Xiang, Y.; Wang, J. The in vitro antiviral activity of lactoferrin against common human coronaviruses and SARS-CoV-2 is mediated by targeting the heparan sulfate co-receptor. Emerg. Microbes Infect. 2021, 10, 317–330. [Google Scholar] [CrossRef]
- Vergori, A.; Lorenzini, P.; Cozzi-Lepri, A.; Donno, D.R.; Gualano, G.; Nicastri, E.; Iacomi, F.; Marchioni, L.; Campioni, P.; Schininà, V.; et al. Prophylactic heparin and risk of orotracheal intubation or death in patients with mild or moderate COVID-19 pneumonia. Sci. Rep. 2021, 11, 11334. [Google Scholar] [CrossRef]
- Li, C.; Luo, F.; Liu, C.; Xiong, N.; Xu, Z.; Zhang, W.; Yang, M.; Wang, Y.; Liu, D.; Yu, C.; et al. Effect of a genetically engineered interferon-alpha versus traditional interferon-alpha in the treatment of moderate-to-severe COVID-19: A randomised clinical trial. Ann. Med. 2021, 53, 391–401. [Google Scholar] [CrossRef]
- Daoud, S.; Alabed, S.J.; Dahabiyeh, L.A. Identification of potential COVID-19 main protease inhibitors using structure-based pharmacophore approach, molecular docking and repurposing studies. Acta Pharm. 2021, 71, 163–174. [Google Scholar] [CrossRef]
- Liu, Y.; Cooper, C.L.; Tarba, S.Y. Resilience, wellbeing and HRM: A multidisciplinary perspective. Int. J. Hum. Resour. Manag. 2019, 30, 1227–1238. [Google Scholar] [CrossRef]
- Brog, N.A.; Hegy, J.K.; Berger, T.; Znoj, H. An internet-based self-help intervention for people with psychological distress due to COVID-19: Study protocol for a randomized controlled trial. Trials 2021, 22, 171. [Google Scholar] [CrossRef] [PubMed]
- Park, C.L.; Finkelstein-Fox, L.; Russell, B.S.; Fendrich, M.; Hutchison, M.; Becker, J. Psychological resilience early in the COVID-19 pandemic: Stressors, resources, and coping strategies in a national sample of Americans. Am. Psychol. 2021, 76, 715–728. [Google Scholar] [CrossRef]
- Ameis, S.H.; Lai, M.C.; Mulsant, B.H.; Szatmari, P. Coping, fostering resilience, and driving care innovation for autistic people and their families during the COVID-19 pandemic and beyond. Mol. Autism 2020, 11, 61. [Google Scholar] [CrossRef]
- Tafoya, S.A.; Aldrete-Cortez, V.; Ortiz, S.; Fouilloux, C.; Flores, F.; Monterrosas, A.M. Resilience, sleep quality and morningness as mediators of vulnerability to depression in medical students with sleep pattern alterations. Chronobiol. Int. 2019, 36, 381–391. [Google Scholar] [CrossRef] [PubMed]
- Ungar, M.; Ghazinour, M.; Richter, J. Annual Research Review: What is resilience within the social ecology of human development? J. Child Psychol. Psychiatry 2013, 54, 348–366. [Google Scholar] [CrossRef]
- Yang, C.; Zhou, Y.; Xia, M. How Resilience Promotes Mental Health of Patients with DSM-5 Substance Use Disorder? The Mediation Roles of Positive Affect, Self-Esteem, and Perceived Social Support. Front. Psychiatry 2020, 11, 588968. [Google Scholar] [CrossRef]
- Sterina, E.; Hermida, A.P.; Gerberi, D.J.; Lapid, M.I. Emotional Resilience of Older Adults during COVID-19: A Systematic Review of Studies of Stress and Well-Being. Clin. Gerontol. 2021, 45, 4–19. [Google Scholar] [CrossRef]
- Buchman, A.S.; Yu, L.; Oveisgharan, S.; Petyuk, V.A.; Tasaki, S.; Gaiteri, C.; Wilson, R.S.; Grodstein, F.; Schneider, J.A.; Klein, H.U.; et al. Cortical proteins may provide motor resilience in older adults. Sci. Rep. 2021, 11, 11311. [Google Scholar] [CrossRef]
- Koerner, S.S.; Shirai, Y. Latina/o Family Caregivers’ Reactions to Limited Help from Relatives: From Frustration to Resilience. J. Fam. Nurs. 2019, 25, 590–609. [Google Scholar] [CrossRef]
- Jané-Llopis, E.; Anderson, P.; Segura, L.; Zabaleta, E.; Muñoz, R.; Ruiz, G.; Rehm, J.; Cabezas, C.; Colom, J. Mental ill-health during COVID-19 confinement. BMC Psychiatry 2021, 21, 194. [Google Scholar] [CrossRef] [PubMed]
- Brant-Birioukov, K. COVID-19 and In(di)genuity: Lessons from Indigenous resilience, adaptation, and innovation in times of crisis. Prospects 2021, 51, 247–259. [Google Scholar] [CrossRef] [PubMed]
- Catungal, J.P. Essential workers and the cultural politics of appreciation: Sonic, visual and mediated geographies of public gratitude in the time of COVID-19. Cult. Geogr. 2021, 28, 403–408. [Google Scholar] [CrossRef]
- Elias, A.; Ben, J.; Mansouri, F.; Paradies, Y. Racism and nationalism during and beyond the COVID-19 pandemic. Ethn. Racial Stud. 2021, 44, 783–793. [Google Scholar] [CrossRef]
- Croucher, S.M.; Nguyen, T.; Rahmani, D. Prejudice toward Asian Americans in the Covid-19 Pandemic: The Effects of Social Media use in the United States. Front. Commun. 2020, 5, 39. [Google Scholar] [CrossRef]
- Devakumar, D.; Shannon, G.; Bhopal, S.S.; Abubakar, I. Racism and Discrimination in COVID-19 Responses. Lancet 2020, 395, 1194. [Google Scholar] [CrossRef]
- Selman, L.E.; Chamberlain, C.; Sowden, R.; Chao, D.; Selman, D.; Taubert, M.; Braude, P. Sadness, despair and anger when a patient dies alone from COVID-19: A thematic content analysis of Twitter data from bereaved family members and friends. Palliat. Med. 2021, 35, 1267–1276. [Google Scholar] [CrossRef]
- Gozzi, N.; Tizzani, M.; Starnini, M.; Ciulla, F.; Paolotti, D.; Panisson, A.; Perra, N. Collective response to media coverage of the COVID-19 pandemic on Reddit and Wikipedia: Mixed-methods analysis. J. Med. Internet Res. 2020, 22, e21597. [Google Scholar] [CrossRef]
- Stetten, N.E.; LeBeau, K.; Aguirre, M.A.; Vogt, A.B.; Quintana, J.R.; Jennings, A.R.; Hart, M. Analyzing the Communication Interchange of Individuals with Disabilities Utilizing Facebook, Discussion Forums, and Chat Rooms: Qualitative Content Analysis of Online Disabilities Support Groups. JMIR Rehabil. Assist. Technol. 2019, 6, e12667. [Google Scholar] [CrossRef]
- Li, X.; Zhang, J.; Du, Y.; Zhu, J.; Fan, Y.; Chen, X. A Novel Deep Learning-based Sentiment Analysis Method Enhanced with Emojis in Microblog Social Networks. Enterp. Inf. Syst. 2022, 17, 2037160. [Google Scholar] [CrossRef]
- Corradini, E.; Nocera, A.; Ursino, D.; Virgili, L. Investigating the phenomenon of NSFW posts in Reddit. Inf. Sci. 2021, 566, 140–164. [Google Scholar] [CrossRef]
- Padilla, J.; Kavak, H.; Lynch, C.; Gore, R.; Diallo, S. Temporal and spatiotemporal investigation of tourist attraction visit sentiment on Twitter. PLoS ONE 2018, 13, e0198857. [Google Scholar] [CrossRef] [PubMed]
- Gore, R.; Diallo, S.; Padilla, J. You Are What You Tweet: Connecting the Geographic Variation in America’s Obesity Rate to Twitter Content. PLoS ONE 2015, 10, e0133505. [Google Scholar] [CrossRef] [PubMed]
- Reddit’s 2020 Year in Review. Available online: https://redditblog.com/2020/12/08/reddits-2020-year-in-review/ (accessed on 20 March 2023).




| Subreddit | Number of Subscribers | Rank | Posts per Day |
|---|---|---|---|
| r/Coronavirus | 2,354,224 | 177 | 101 |
| r/COVID19 | 336,253 | 1357 | 23 |
| r/CoronavirusUS | 140.913 | 3226 | 22 |
| r/COVID-19Positive | 113,778 | 3944 | 29 |
| r/China_Flu | 103,456 | 4261 | 19 |
| r/CovidVaccinated | 27,814 | 11,271 | 62 |
| r/Music | 20,350,355 | 12 | 410 |
| Glossary Term | Glossary Definition | Closest Terms |
|---|---|---|
| ards | Acute respiratory distress syndrome | remestemcel (0.364) [68], glucose (0.461) [69], epithelium (0.461) [70], anticoagulant (0.481) [71] |
| anosmia | The complete or partial loss of the sense of smell. | olfactory, (0.463) [72], parkinson (0.459) [73], aspirin (0.496) [74] |
| antibody | A protein that is produced in response to the introduction of an antigen in an organism | monoclonal (0.436) [75], regeneron (0.478) [76], serological (0.475) [77], bamlanivimab (0.539) [78] |
| antiviral | Medication used for treating viral infections | favipiravir (0.341) [79], remdesivir (0.344) [80], heparin (0.379) [81], interferón (0.385) [82], ritonavir (0.435) [83] |
| Search Term | Closest Terms |
|---|---|
| resilience | wellbeing (0.569) [84], pessimism (0.611) [85], psychological (0.586) [85] |
| resilience + tips | mindfulness (0.580) [86], telehealth (0.588) [87], bedtime (0.577) [88], hobbies (0.546) [89] |
| resilience + older | addiction (0.570) [90], stress (0.588) [91], disability (0.588) [92], resentment (0.598) [93], depressive (0.617) [94] |
| resilience + indigenous | communities (0.520), tribe (0.565), minority (0.618), dignity (0.618), unequal (0.622), unicef (0.632), disparities (0.624) [95] |
| Category | s |
|---|---|
| 29. A sport | 0.495 |
| 3. A relative | 0.329 |
| 54. A city | 0.233 |
| 55. A state | 0.231 |
| 10. A color | 0.169 |
| 58. A type of car | 0.163 |
| 49. A disease | 0.154 |
| 27. An occupation or profession | 0.142 |
| 7. A military title | 0,139 |
| 40. A science | 0.137 |
| Search Term | Closest Terms |
|---|---|
| gratitude | paramedical (0.545), doctors (0.495), appreciation (0.368), selflessly (0.498), tirelessly (0.453), heroes (0.503), honor (0.516), tribute (0.540), hardworking (0.555), flashmovs (0.564) |
| compassion | dalai (0.684), lama (0.685), empathy (0.657), empathetic (0.662), mindfulness (0.633) |
| love | share (0.400), enjoy (0.440), friends (0.489), wish (0.519), god (0.526), smile (0.528), constructive (0.555), entertain(0.525) |
| relief | funds (0.325), aid (0.339), package (0.309), fund (0.341), trillion (0.394), billion (0.414), loan (0.409), liquidity (0.414), payments (0.429), payers (0.397), tax (0.436) |
| hope | Love (0.423), enjoy (0.477), brightens (0.471), help(0.513), inspire (0.517), smile (0.522), laugh (0.536), humor (0.569), fun (0.573), funny (0.573) |
| calm | Listen (0.532), sleep (0.435), meditation (0.544), Roads (0.521), streets (0.546), eerie (0.656), emptiness (0.668), scary (0.575),, panic (0.567), nerves (0.546), keep (0.654) |
| admiration | clapping (0.431), clap (0.455), applause (0.455), balconies (0.484), applauding (0.522), windows (0.472), cheering (0.456), frontline (0.466), healthcare (0.532), |
| Search Term | Closest Terms |
|---|---|
| anger | frustration (0.471), confusion (0.474), tension (0.555), chaos (0.592), dishonesty (0.630), hostility (0.617), bureaucracy (0.625), fear (0.608), drought (0.579), outcry (0.598), outrage (0.618), |
| loneliness | profound (0.607), addiction (0.635), neuropsychiatric (0.630), opioid (0.658) |
| boredom | spotify (0.615), playlists (0.599), song (0.593), halo (0.596), fortnite (0.626), meditation (0.615), illustration (0.631), piano (0.632), |
| fear | conspiracies (0.587), xenophobia (0.612), racism (0.621), burnout (0.623), starving (0.636), sadness(0.532) |
| anxiety | stress (0.251), depression (0.431), meditation (0.578), obsessive (0.532), ideation (0.511), cope (0.529), coping (0.514), tips (0.570) |
| confusion | anger (0.474), frustration (0.546), chaos (0.543), distrust (0.561), tension (0.532), worries (0.522), doubts (0.533) |
| sadness | Disbelief (0.433), downfall (0.544), dislike (0.541), downvotes (0.541), fear (0.532), boredom (0.533), together (0.544), spinning (0.541) |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
García-Rudolph, A.; Sanchez-Pinsach, D.; Frey, D.; Opisso, E.; Cisek, K.; Kelleher, J.D. Know an Emotion by the Company It Keeps: Word Embeddings from Reddit/Coronavirus. Appl. Sci. 2023, 13, 6713. https://doi.org/10.3390/app13116713
García-Rudolph A, Sanchez-Pinsach D, Frey D, Opisso E, Cisek K, Kelleher JD. Know an Emotion by the Company It Keeps: Word Embeddings from Reddit/Coronavirus. Applied Sciences. 2023; 13(11):6713. https://doi.org/10.3390/app13116713
Chicago/Turabian StyleGarcía-Rudolph, Alejandro, David Sanchez-Pinsach, Dietmar Frey, Eloy Opisso, Katryna Cisek, and John D. Kelleher. 2023. "Know an Emotion by the Company It Keeps: Word Embeddings from Reddit/Coronavirus" Applied Sciences 13, no. 11: 6713. https://doi.org/10.3390/app13116713
APA StyleGarcía-Rudolph, A., Sanchez-Pinsach, D., Frey, D., Opisso, E., Cisek, K., & Kelleher, J. D. (2023). Know an Emotion by the Company It Keeps: Word Embeddings from Reddit/Coronavirus. Applied Sciences, 13(11), 6713. https://doi.org/10.3390/app13116713