




Contrast Enhancement-Based Preprocessing Process to Improve Deep Learning Object Task Performance and Results


Abstract
:1. Introduction
2. Related Works
2.1. Problems Caused by Light
2.2. Contrast Enhancement Method
2.2.1. Color Space Conversion
2.2.2. Intensity Value Mapping
2.2.3. Local Contrast Enhancement
2.2.4. Histogram Equalization (HE)
2.2.5. Adaptive Histogram Equalization (AHE)
2.3. Image Quality Assessment (IQA)
2.4. Feature Point Detection and Matching
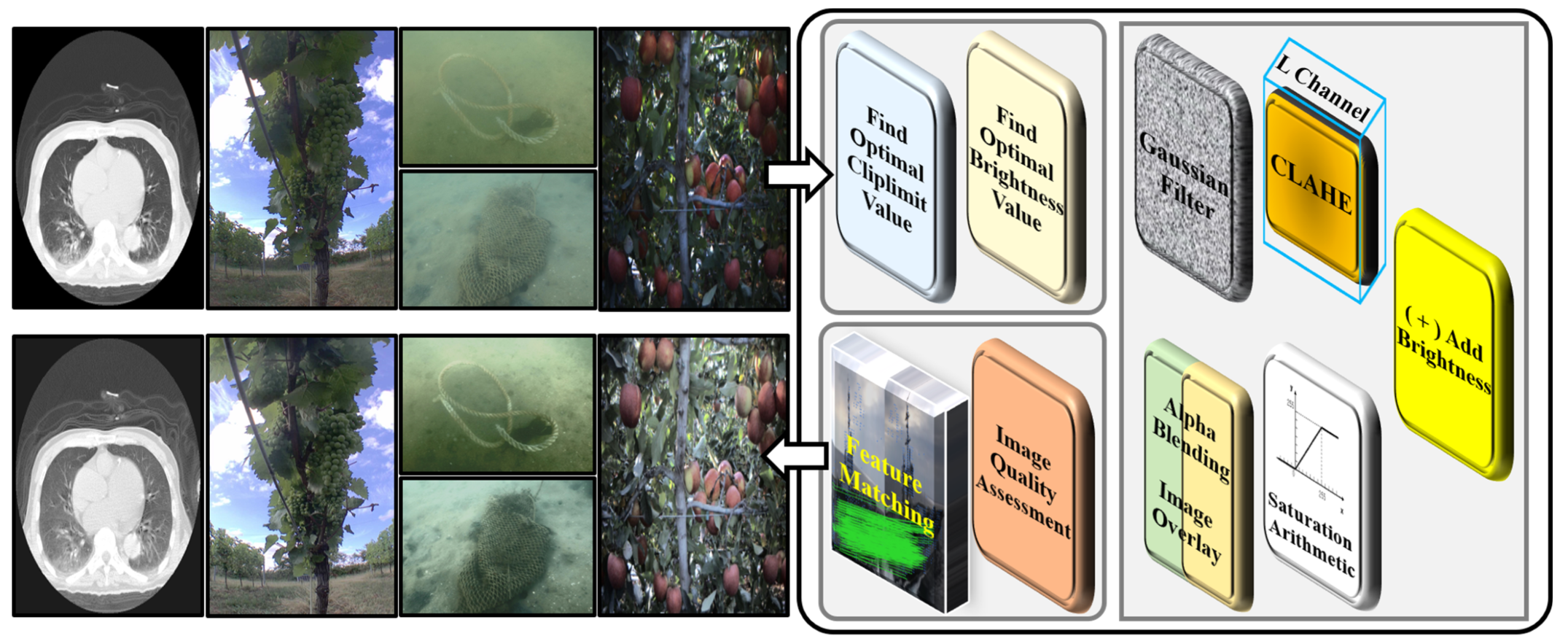
3. Preprocessing Process
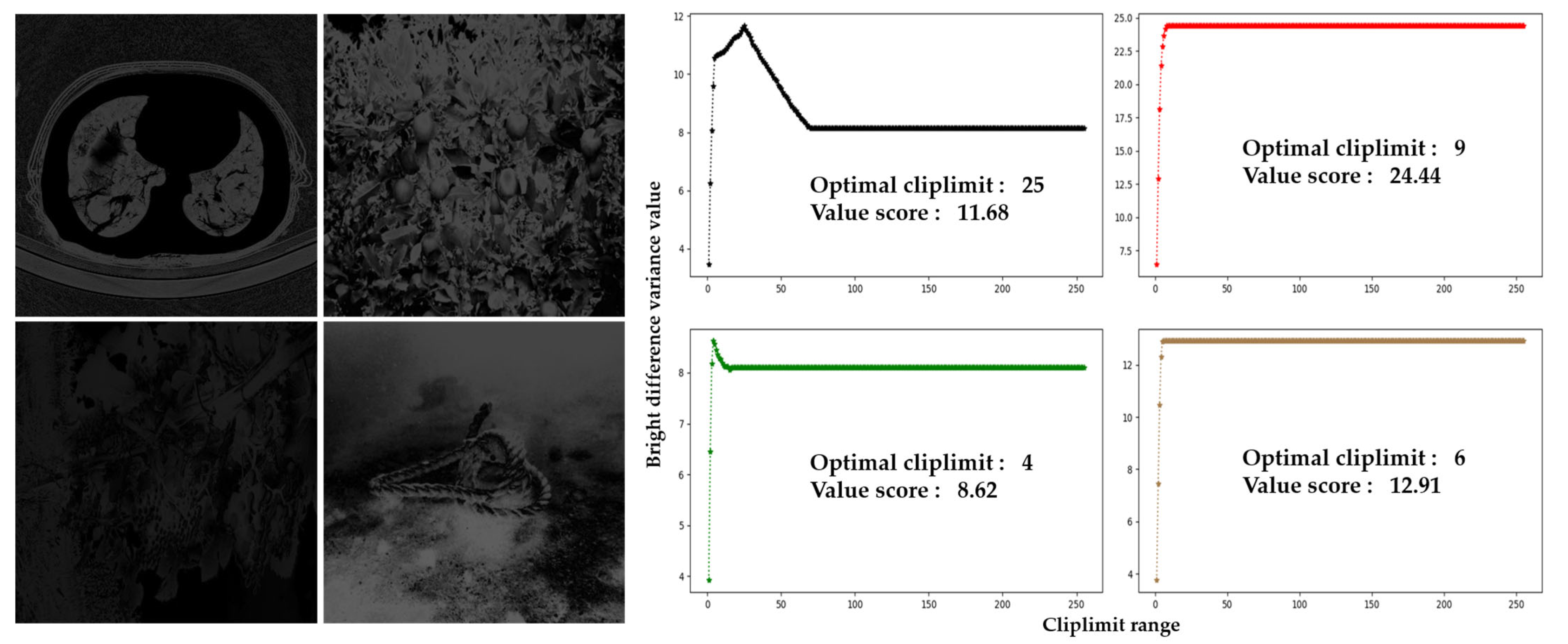
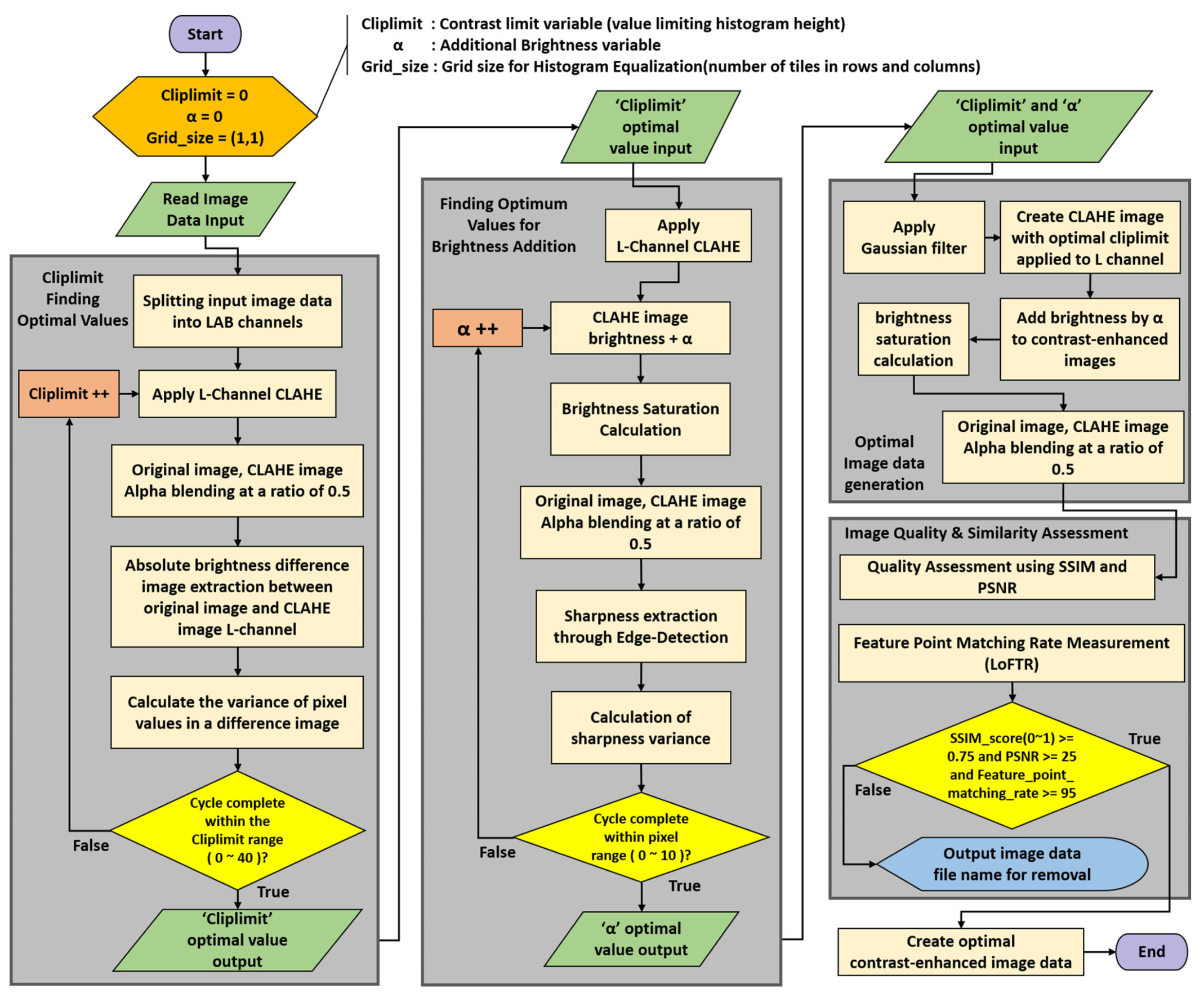
3.1. Finding Optimal Values
3.2. Optimal Image Data Generation
3.3. Quality and Similarity Assessment
4. Training Datasets and Object Recognition Task Performance
4.1. Training Datasets
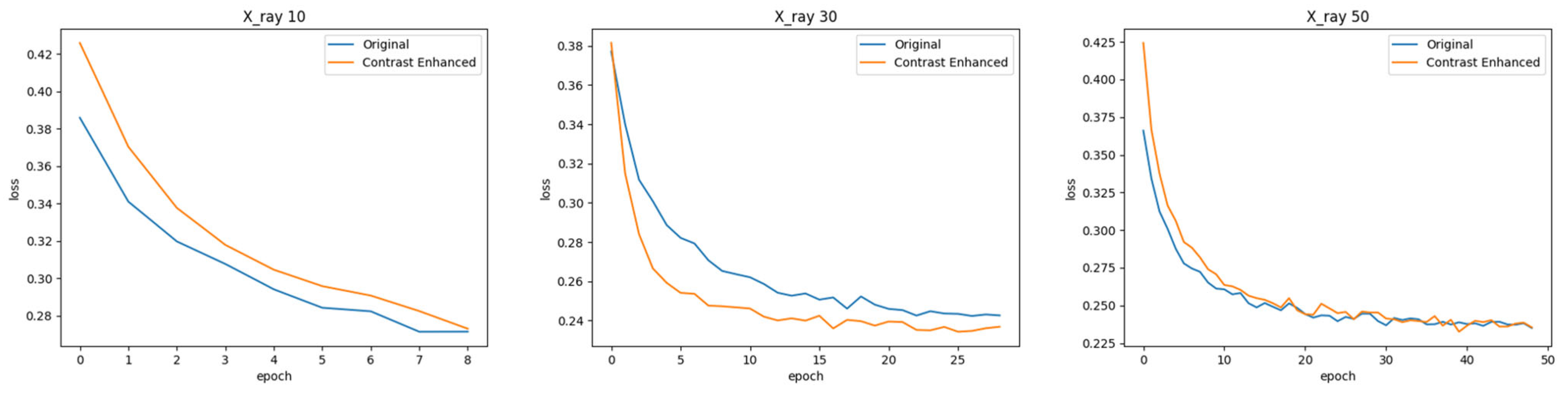
4.1.1. X-ray Dataset
4.1.2. Fruit Tree Dataset
4.1.3. Marine Deposited Waste Dataset
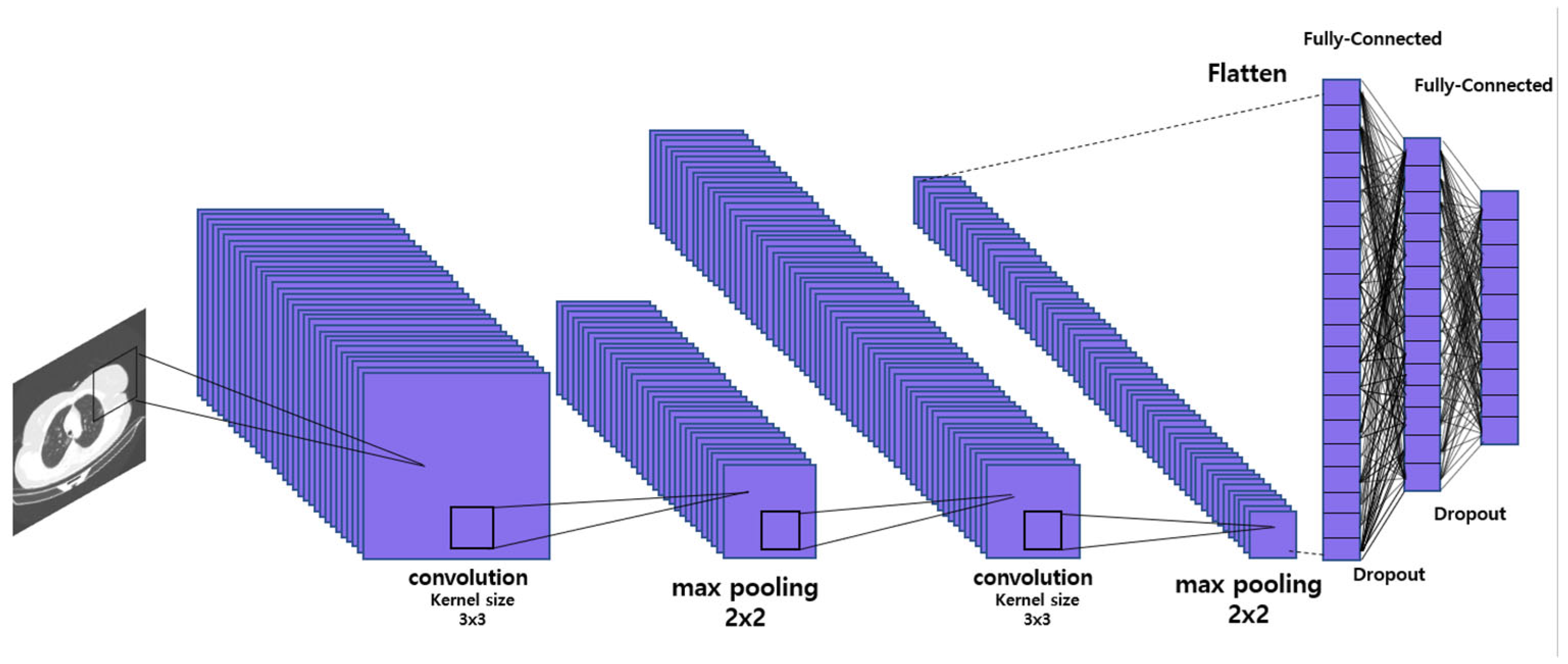
4.2. Classification Task Performance
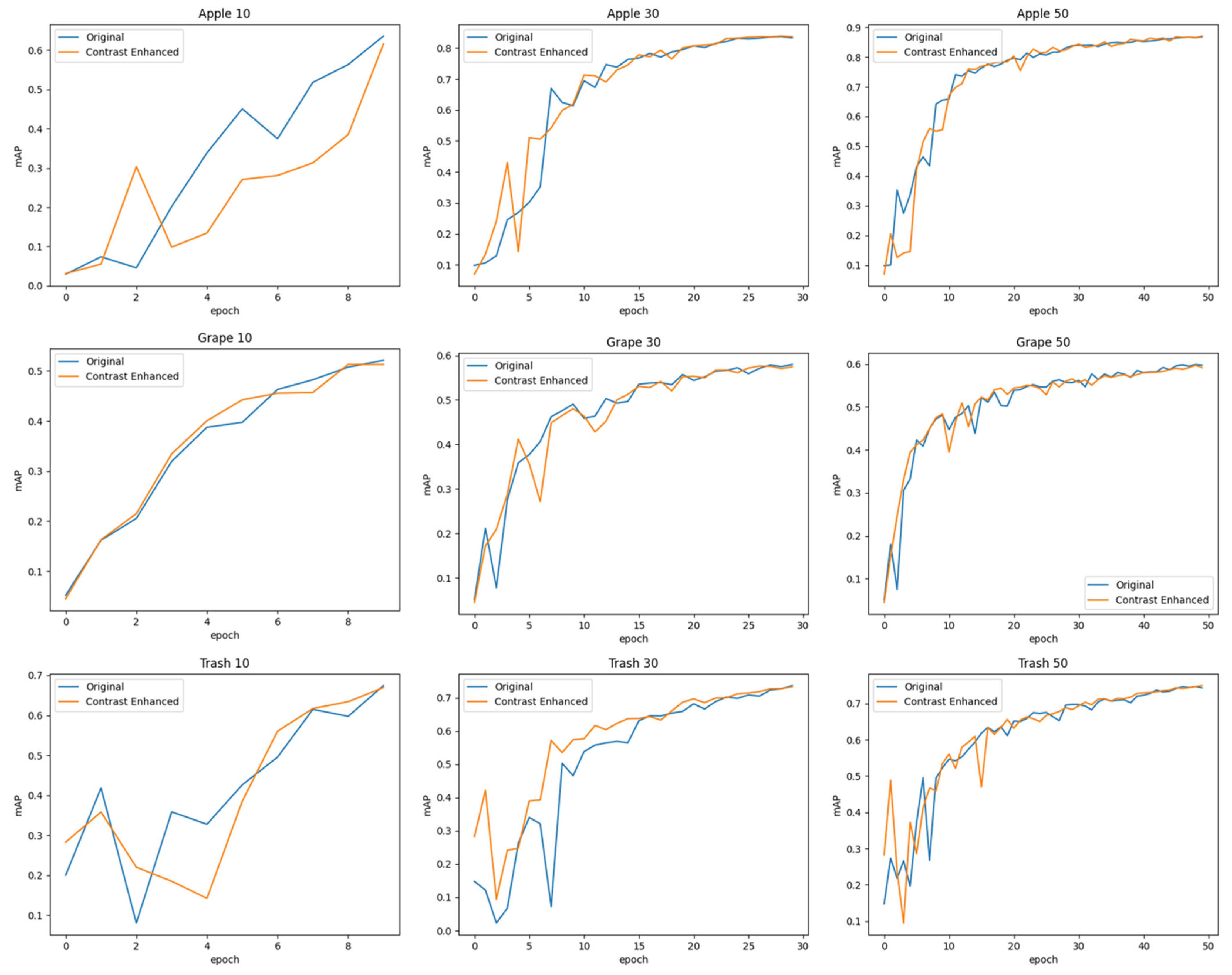
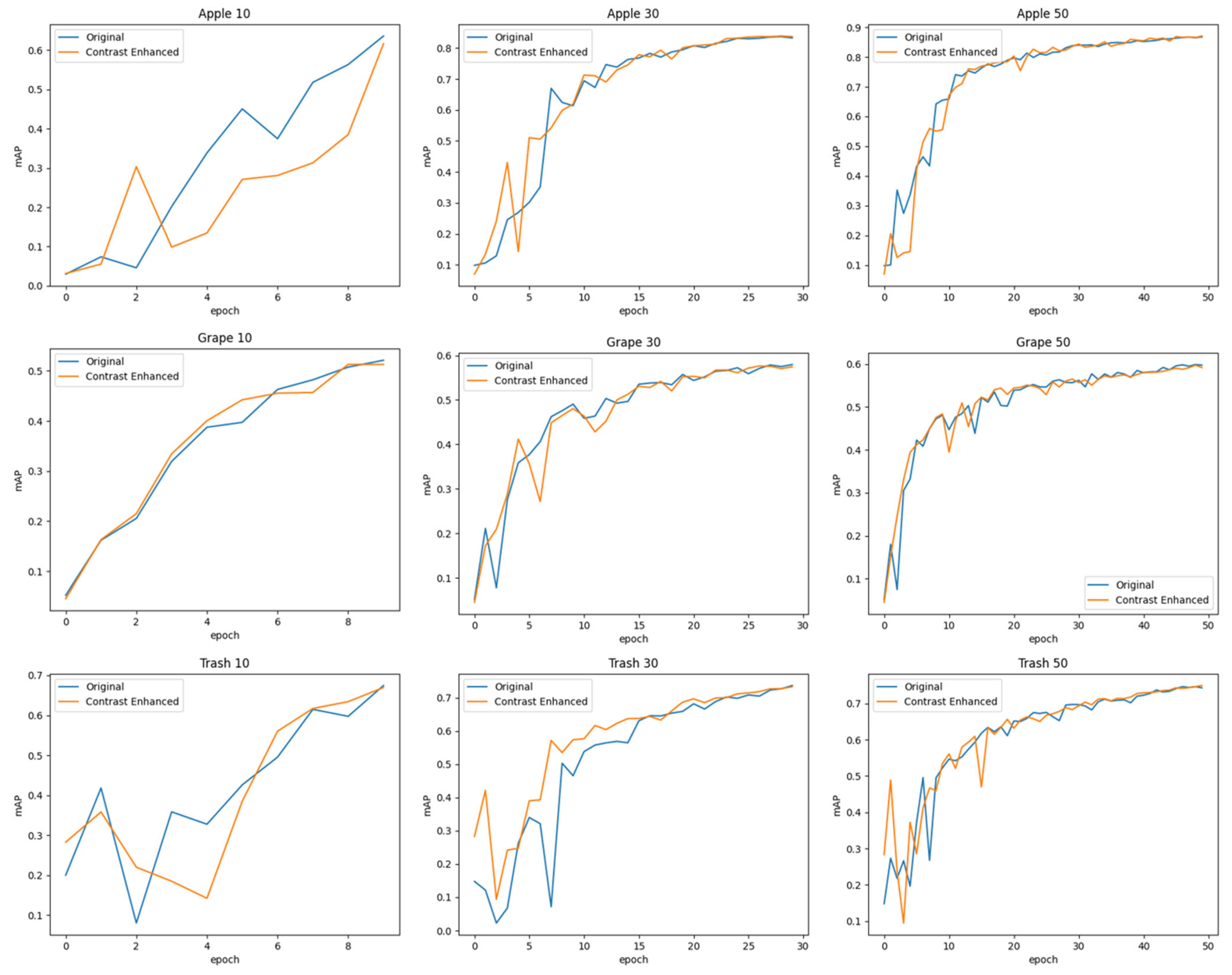
4.3. Object Detection Task Performance
4.4. Instance Segmentation Task Performance
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Paul, N.; Chung, C. Application of HDR algorithms to solve direct sunlight problems when autonomous vehicles using machine vision systems are driving into sun. Comput. Ind. 2018, 98, 192–196. [Google Scholar] [CrossRef]
- Gray, R.; Regan, D. Glare susceptibility test results correlate with temporal safety margin when executing turns across approaching vehicles in simulated low-sun conditions. OPO 2007, 27, 440–450. [Google Scholar] [CrossRef] [PubMed]
- Ning, Y.; Jin, Y.; Peng, Y.D.; Yan, J. Low illumination underwater image enhancement based on nonuniform illumination correction and adaptive artifact elimination. Front. Mar. Sci. 2023, 10, 1–15. [Google Scholar] [CrossRef]
- An Investigation of Videos for Crowd Analysis. Available online: https://shodhganga.inflibnet.ac.in:8443/jspui/handle/10603/480375 (accessed on 1 March 2023).
- Yu, C.; Li, S.; Feng, W.; Zheng, T.; Liu, S. SACA-fusion: A low-light fusion architecture of infrared and visible images based on self-and cross-attention. Vis. Comput. 2023, 1, 1–10. [Google Scholar] [CrossRef]
- Wu, Y.; Wang, L.; Zhang, L.; Bai, Y.; Cai, Y.; Wang, S.; Li, Y. Improving autonomous detection in dynamic environments with robust monocular thermal SLAM system. ISPRS J. Photogramm. Remote Sens. 2023, 203, 265–284. [Google Scholar] [CrossRef]
- Shareef, A.A.A.; Yannawar1, P.L.; Abdul-Qawy, A.S.H.; Al-Nabhi, H.; Bankar, R.B. Deep Learning Based Model for Fire and Gun Detection. In Proceedings of the First International Conference on Advances in Computer Vision and Artificial Intelligence Technologies (ACVAIT 2022), Aurangabad, India, 1–2 August 2022; Atlantis Press: Amsterdam, The Netherlands, 2023; pp. 422–430. [Google Scholar] [CrossRef]
- Parez, S.; Dilshad, N.; Alghamdi, N.S.; Alanazi, T.M.; Lee, J.W. Visual Intelligence in Precision Agriculture: Exploring Plant Disease Detection via Efficient Vision Transformers. Sensors 2023, 23, 6949. [Google Scholar] [CrossRef]
- Fan, C.; Su, Q.; Xiao, Z.; Su, H.; Hou, A.; Luan, B. ViT-FRD: A Vision Transformer Model for Cardiac MRI Image Segmentation Based on Feature Recombination Distillation. IEEE Access 2023, 1, 1. [Google Scholar] [CrossRef]
- Moreno, H.; Gómez, A.; Altares-López, S.; Ribero, A.; Andujar, D. Analysis of Stable Diffusion-Derived Fake Weeds Performance for Training Convolutional Neural Networks. SSRN 2023, 1, 1–27. [Google Scholar] [CrossRef]
- Bi, L.; Buehner, U.; Fu, X.; Williamson, T.; Choong, P.F.; Kim, J. Hybrid Cnn-Transformer Network for Interactive Learning of Challenging Musculoskeletal Images. SSRN 2023, 1, 1–21. [Google Scholar] [CrossRef]
- Parsons, M.H.; Stryjek, R.; Fendt, M.; Kiyokawa, Y.; Bebas, P.; Blumstein, D.T. Making a case for the free exploratory paradigm: Animal welfare-friendly assays that enhance heterozygosity and ecological validity. Front. Behav. Neurosci. 2023, 17, 1–8. [Google Scholar] [CrossRef]
- Majid, H.; Ali, K.H. Automatic Diagnosis of Coronavirus Using Conditional Generative Adversarial Network (CGAN). Iraqi J. Sci. 2023, 64, 4542–4556. [Google Scholar] [CrossRef]
- Lee, J.; Seo, K.; Lee, H.; Yoo, J.E.; Noh, J. Deep Learning-Based Lighting Estimation for Indoor and Outdoor. J. Korea Comput. Graph. Soc. 2021, 27, 31–42. [Google Scholar] [CrossRef]
- Hawlader, F.; Robinet, F.; Frank, R. Leveraging the Edge and Cloud for V2X-Based Real-Time Object Detection in Autonomous Driving. arXiv 2023, arXiv:2308.05234. [Google Scholar]
- Lin, T.; Huang, G.; Yuan, X.; Zhong, G.; Huang, X.; Pun, C.M. SCDet: Decoupling discriminative representation for dark object detection via supervised contrastive learning. Vis. Comput 2023. [Google Scholar] [CrossRef]
- Chen, W.; Shah, T. Exploring low-light object detection techniques. arXiv 2021, arXiv:2107.14382. [Google Scholar]
- Jägerbrand, A.K.; Sjöbergh, J. Effects of weather conditions, light conditions, and road lighting on vehicle speed. SpringerPlus 2016, 5, 505. [Google Scholar] [CrossRef]
- Nandal, A.; Bhaskar, V.; Dhaka, A. Contrast-based image enhancement algorithm using grey-scale and colour space. IET Signal Process. 2018, 12, 514–521. [Google Scholar] [CrossRef]
- Pizer, S.M. Intensity mappings to linearize display devices. Comput. Graph. Image Process. 1981, 17, 262–268. [Google Scholar] [CrossRef]
- Mukhopadhyay, S.; Chanda, B. A multiscale morphological approach to local contrast enhancement. Signal Process. 2000, 80, 685–696. [Google Scholar] [CrossRef]
- Hum, Y.C.; Lai, K.W.; Mohamad Salim, M.I. Multiobjectives bihistogram equalization for image contrast enhancement. Complexity 2014, 20, 22–36. [Google Scholar] [CrossRef]
- Pizer, S.M.; Amburn, E.P.; Austin, J.D.; Cromartie, R.; Geselowitz, A.; Greer, T.; ter Haar Romeny, B.; Zimmerman, J.B.; Zuiderveld, K. Adaptive histogram equalization and its variations. Comput. Vis. Graph. Image Process. 1987, 39, 355–368. [Google Scholar] [CrossRef]
- Zuiderveld, K. Contrast limited adaptive histogram equalization. In Graphical Gems IV; Academic Press Professional, Inc.: San Diego, CA, USA, 1994; pp. 474–485. [Google Scholar]
- Kim, J.I.; Lee, J.W.; Honga, S.H. A Method of Histogram Compression Equalization for Image Contrast Enhancement. In Proceedings of the 2013 39th Korea Information Processing Society Conference, Busan, Republic of Korea, 10–11 May 2013; Volume 20, pp. 346–349. [Google Scholar]
- Li, G.; Yang, Y.; Qu, X.; Cao, D.; Li, K. A deep learning based image enhancement approach for autonomous driving at night. Knowl. Based Syst. 2021, 213, 106617. [Google Scholar] [CrossRef]
- Chen, Z.; Pawar, K.; Ekanayake, M.; Pain, C.; Zhong, S.; Egan, G.F. Deep learning for image enhancement and correction in magnetic resonance imaging—State-of-the-art and challenges. J. Digit. Imaging 2023, 36, 204–230. [Google Scholar] [CrossRef]
- Wang, Z.; Bovik, A.C.; Lu, L. Why is image quality assessment so difficult? In Proceedings of the 2002 IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP), Orlando, FL, USA, 13–17 May 2002; Volume 4, p. IV–3313. [Google Scholar] [CrossRef]
- Wang, L. A survey on IQA. arXiv 2021, arXiv:2109.00347. [Google Scholar]
- Athar, S.; Wang, Z. Degraded reference image quality assessment. IEEE Trans. Image Process. 2023, 32, 822–837. [Google Scholar] [CrossRef] [PubMed]
- Sheikh, H.R.; Bovik, A.C. A visual information fidelity approach to video quality assessment. In Proceedings of the First International Workshop on Video Processing and Quality Metrics for Consumer Electronics, Scottsdale, AZ, USA; 2005; Volume 7, pp. 2117–2128. [Google Scholar]
- Larson, E.C.; Chandler, D.M. Most apparent distortion: A dual strategy for full-reference image quality assessment. Image Qual. Syst. Perform. VI 2009, 7242, 270–286. [Google Scholar] [CrossRef]
- Zhang, L.; Zhang, L.; Mou, X.; Zhang, D. FSIM: A feature similarity index for image quality assessment. IEEE Trans. Image Process. 2011, 20, 2378–2386. [Google Scholar] [CrossRef]
- Liu, A.; Lin, W.; Narwaria, M. Image quality assessment based on gradient similarity. IEEE Trans. Image Process. 2011, 21, 1500–1512. [Google Scholar] [CrossRef]
- Xue, W.; Zhang, L.; Mou, X.; Bovik, A.C. Gradient magnitude similarity deviation: A highly efficient perceptual image quality index. IEEE Trans. Image Process. 2013, 23, 684–695. [Google Scholar] [CrossRef]
- Mittal, A.; Moorthy, A.K.; Bovik, A.C. Blind/referenceless image spatial quality evaluator. In Proceedings of the 2011 Conference record of the Forty Fifth Asilomar Conference on Signals, Systems and Computers (ASILOMAR), Pacific Grove, CA, USA, 6–9 November 2011; pp. 723–727. [Google Scholar] [CrossRef]
- Lin, H.; Hosu, V.; Saupe, D. DeepFL-IQA: Weak supervision for deep IQA feature learning. arXiv 2020, arXiv:2001.08113. [Google Scholar]
- Ding, K.; Ma, K.; Wang, S.; Simoncelli, E.P. Image quality assessment: Unifying structure and texture similarity. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 44, 2567–2581. [Google Scholar] [CrossRef] [PubMed]
- Lowe, D.G. Distinctive image features from scale-invariant keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Bay, H.; Ess, A.; Tuytelaars, T.; Van Gool, L. Speeded-up robust features (SURF). Comput. Vis. Image Underst. 2008, 110, 346–359. [Google Scholar] [CrossRef]
- Rublee, E.; Rabaud, V.; Konolige, K.; Bradski, G. ORB: An efficient alternative to SIFT or SURF. In Proceedings of the 2011 International Conference on Computer Vision (ICCV), Barcelona, Spain, 6–13 November 2011; pp. 2564–2571. [Google Scholar] [CrossRef]
- DeTone, D.; Malisiewicz, T.; Rabinovich, A. Superpoint: Self-supervised interest point detection and description. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Salt Lake City, UT, USA, 18–22 June 2018; pp. 224–236. [Google Scholar] [CrossRef]
- Dusmanu, M.; Rocco, I.; Pajdla, T.; Pollefeys, M.; Sivic, J.; Torii, A.; Sattler, T. D2-net: A trainable cnn for joint detection and description of local features. arXiv 2019, arXiv:1905.03561. [Google Scholar] [CrossRef]
- Ono, Y.; Trulls, E.; Fua, P.; Yi, K.M. LF-Net: Learning local features from images. Adv. Neural Inf. Process. Syst. 2018, 31, 1–11. [Google Scholar]
- Revaud, J.; Weinzaepfel, P.; De Souza, C.; Pion, N.; Csurka, G.; Cabon, Y.; Humenberger, M. R2D2: Repeatable and reliable detector and descriptor. arXiv 2019, arXiv:1906.06195. [Google Scholar] [CrossRef]
- Cover, T.; Hart, P. Nearest neighbor pattern classification. IEEE Trans. Inf. Theory 1967, 13, 21–27. [Google Scholar] [CrossRef]
- Bhatia, N. Survey of nearest neighbor techniques. arXiv 2010, arXiv:1007.0085. [Google Scholar] [CrossRef]
- Muja, M.; Lowe, D.G. Fast approximate nearest neighbors with automatic algorithm configuration. In Proceedings of the 4th International Conference on Computer Vision Theory and Applications (VISAPP), Lisboa, Portugal, 5–8 February 2009; Volume 1, pp. 331–340. [Google Scholar]
- Zagoruyko, S.; Komodakis, N. Deep compare: A study on using convolutional neural networks to compare image patches. Comput. Vis. Image Underst. 2017, 164, 38–55. [Google Scholar] [CrossRef]
- Sarlin, P.E.; DeTone, D.; Malisiewicz, T.; Rabinovich, A. Superglue: Learning feature matching with graph neural networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 4938–4947. [Google Scholar]
- Luo, Z.; Shen, T.; Zhou, L.; Zhu, S.; Zhang, R.; Yao, Y.; Tian, F.; Quan, L. Geodesc: Learning local descriptors by integrating geometry constraints. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 170–185. [Google Scholar] [CrossRef]
- Woldamanuel, E.M. Grayscale Image Enhancement Using Water Cycle Algorithm. IEEE Access 2023, 11, 86575–86596. [Google Scholar] [CrossRef]
- Johnson, D.H. Signal-to-noise ratio. Scholarpedia 2006, 1, 2088. [Google Scholar] [CrossRef]
- Juneja, S.; Anand, R. Contrast Enhancement of an Image by DWT-SVD and DCT-SVD. In Data Engineering and Intelligent Computing: Proceedings of IC3T 2016, Proceedings of the Third Springer International Conference on Computer & Communication Technologies, Andhra Pradesh, India, 28–29 October 2016; Springer: Singapore, 2018; pp. 595–603. [Google Scholar] [CrossRef]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef] [PubMed]
- Gunraj, H.; Sabri, A.; Koff, D.; Wong, A. COVID-Net CT-2: Enhanced deep neural networks for detection of COVID-19 from chest CT images through bigger, more diverse learning. Front. Med. 2022, 8, 729287. [Google Scholar] [CrossRef] [PubMed]
- Häni, N.; Roy, P.; Isler, V. MinneApple: A benchmark dataset for apple detection and segmentation. IEEE Robot. Autom. Lett. 2020, 5, 852–858. [Google Scholar] [CrossRef]
- Santos, T.; De Souza, L.; Dos Santos, A.; Sandra, A. Embrapa Wine Grape Instance Segmentation Dataset–Embrapa WGISD. Zenodo 2019. [Google Scholar] [CrossRef]
- Chen, X.; Yuan, M.; Fan, C.; Chen, X.; Li, Y.; Wang, H. Research on an Underwater Object Detection Network Based on Dual-Branch Feature Extraction. Electronics 2023, 12, 3413. [Google Scholar] [CrossRef]
- Image of Marine Sediment Trash. Available online: https://www.aihub.or.kr/ (accessed on 18 June 2021).
- Simard, P.Y.; Steinkraus, D.; Platt, J.C. Best practices for convolutional neural networks applied to visual document analysis. In Proceedings of the Seventh International Conference on Document Analysis and Recognition, Edinburgh, UK, 6 August 2003; Volume 3. [Google Scholar]
- Kim, P.; Huang, X.; Fang, Z. SSD PCB Component Detection Using YOLOv5 Model. J. Inf. Commun. Converg. Eng. 2023, 21, 24–31. [Google Scholar] [CrossRef]
- Bolya, D.; Zhou, C.; Xiao, F.; Lee, Y.J. Yolact: Real-time instance segmentation. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 9157–9166. [Google Scholar]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Original Dataset | Contrast-Enhanced | |
|---|---|---|
| Epoch 10 | 99.48% | 99.47% |
| Epoch 30 | 99.9% | 99.92% |
| Epoch 50 | 99.92% | 99.94% |
| Object: Apple | IoU→ Epoch↓ | All | 50 | 55 | 60 | 65 | 70 | 75 | 80 | 85 | 90 | 95 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 10 | 11.49 | 26.1 | 24.42 | 21.63 | 17.32 | 12.85 | 8.29 | 3.3 | 0.93 | 0.02 | 0 | |
| Original | 30 | 11.05 | 25.33 | 23.4 | 20.61 | 16.71 | 12.19 | 8.1 | 3.33 | 0.84 | 0.02 | 0 |
| 50 | 15.2 | 26.53 | 25.54 | 24.38 | 22.75 | 20.5 | 17.53 | 10.89 | 3.75 | 0.17 | 0 | |
| Contrast-Enhanced | 10 | 11.11 | 25.54 | 23.95 | 20.94 | 17.1 | 12.15 | 7.42 | 3.23 | 0.79 | 0.02 | 0 |
| 30 | 16.09 | 27.29 | 26.58 | 25.52 | 24.02 | 21.61 | 17.79 | 12.41 | 5.33 | 0.31 | 0 | |
| 50 | 15.67 | 25.85 | 25.48 | 24.76 | 23.33 | 21.76 | 17.87 | 12.27 | 5.06 | 0.28 | 0 |
| Object: Rope | IoU→ Epoch↓ | All | 50 | 55 | 60 | 65 | 70 | 75 | 80 | 85 | 90 | 95 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 10 | 2.34 | 8.72 | 5.33 | 3.61 | 2.28 | 1.84 | 1 | 0.42 | 0.18 | 0.02 | 0 | |
| Original | 30 | 6.35 | 19.19 | 14.62 | 10.62 | 6.84 | 5.1 | 3.68 | 2.17 | 1.25 | 0.01 | 0 |
| 50 | 6.9 | 23.26 | 17.52 | 12.28 | 7.68 | 4.41 | 2.51 | 1.03 | 0.28 | 0.06 | 0.01 | |
| Contrast-Enhanced | 10 | 2.78 | 9.44 | 6.68 | 5.08 | 3.09 | 1.95 | 1.37 | 0.15 | 0.02 | 0.01 | 0 |
| 30 | 6.58 | 19.46 | 15.81 | 11.08 | 8.09 | 5.04 | 3.75 | 2.07 | 0.45 | 0.09 | 0 | |
| 50 | 6.96 | 21.36 | 16.79 | 11.71 | 7.44 | 4.95 | 3.29 | 1.85 | 1.19 | 0.99 | 0 |
| Object: Fish Net | IoU→ Epoch↓ | All | 50 | 55 | 60 | 65 | 70 | 75 | 80 | 85 | 90 | 95 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 10 | 9.94 | 22.55 | 22.04 | 21.03 | 15.74 | 9.11 | 5.93 | 2.89 | 0.08 | 0.08 | 0 | |
| Original | 30 | 14.33 | 26.55 | 25.8 | 24.6 | 19.03 | 18.06 | 16.63 | 8.84 | 3.05 | 0.64 | 0.07 |
| 50 | 14.25 | 28.69 | 21.89 | 21.89 | 19.74 | 18.94 | 15.25 | 9.03 | 4.57 | 2.18 | 0.27 | |
| Contrast-Enhanced | 10 | 10.55 | 26.44 | 23.22 | 19.83 | 13.76 | 8.05 | 7.88 | 4.56 | 1.66 | 0.07 | 0 |
| 30 | 14.24 | 28.75 | 24.38 | 21.49 | 19.09 | 18.78 | 12.9 | 11.99 | 4.53 | 0.41 | 0.08 | |
| 50 | 16.58 | 30.14 | 28.29 | 27.54 | 25.21 | 19.49 | 18.23 | 11.75 | 4.5 | 0.54 | 0.12 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, T.-s.; Kim, G.T.; Kim, M.; Jang, J. Contrast Enhancement-Based Preprocessing Process to Improve Deep Learning Object Task Performance and Results. Appl. Sci. 2023, 13, 10760. https://doi.org/10.3390/app131910760
Wang T-s, Kim GT, Kim M, Jang J. Contrast Enhancement-Based Preprocessing Process to Improve Deep Learning Object Task Performance and Results. Applied Sciences. 2023; 13(19):10760. https://doi.org/10.3390/app131910760
Chicago/Turabian StyleWang, Tae-su, Gi Tae Kim, Minyoung Kim, and Jongwook Jang. 2023. "Contrast Enhancement-Based Preprocessing Process to Improve Deep Learning Object Task Performance and Results" Applied Sciences 13, no. 19: 10760. https://doi.org/10.3390/app131910760
APA StyleWang, T.-s., Kim, G. T., Kim, M., & Jang, J. (2023). Contrast Enhancement-Based Preprocessing Process to Improve Deep Learning Object Task Performance and Results. Applied Sciences, 13(19), 10760. https://doi.org/10.3390/app131910760