
WAID: A Large-Scale Dataset for Wildlife Detection with Drones



Abstract
:1. Introduction
- By incorporating the SE modules into the YOLO model, we propose a model called SE-YOLO suitable for wildlife detection in aerial imagery, which improves the accuracy of small wildlife targets in natural environments.
- The SE-YOLO model achieves a mAP of 0.983 on the WAID dataset, and in particular, the recognition performance for minimal targets with 20–50 pixel points reaches 0.926, 0.894, and 0.929 in terms of mAP, recall, and precision, respectively, indicating that SE-YOLO is particularly suitable for the problem of wildlife monitoring in the wild perspective of aerial photography from a UAV.
- To address the scarcity of aerial wildlife datasets in photography, the first valuable open multi-category aerial wildlife image dataset, WAID, has been made available to all researchers for free download from https://github.com/xiaohuicui/WAID (accessed on 12 September 2023). This contributes to the advancement of the academic community of unmanned aerial wildlife monitoring.
2. Related Work
2.1. Diverse Datasets for Wildlife Detection
2.2. Object Detection Methods
2.2.1. Single-Stage Object Detection Method
2.2.2. Two-Stage Object Detection Method
2.3. Gated Channel Attention Mechanism
2.4. Drone-Based Wildlife Detection
3. Methods
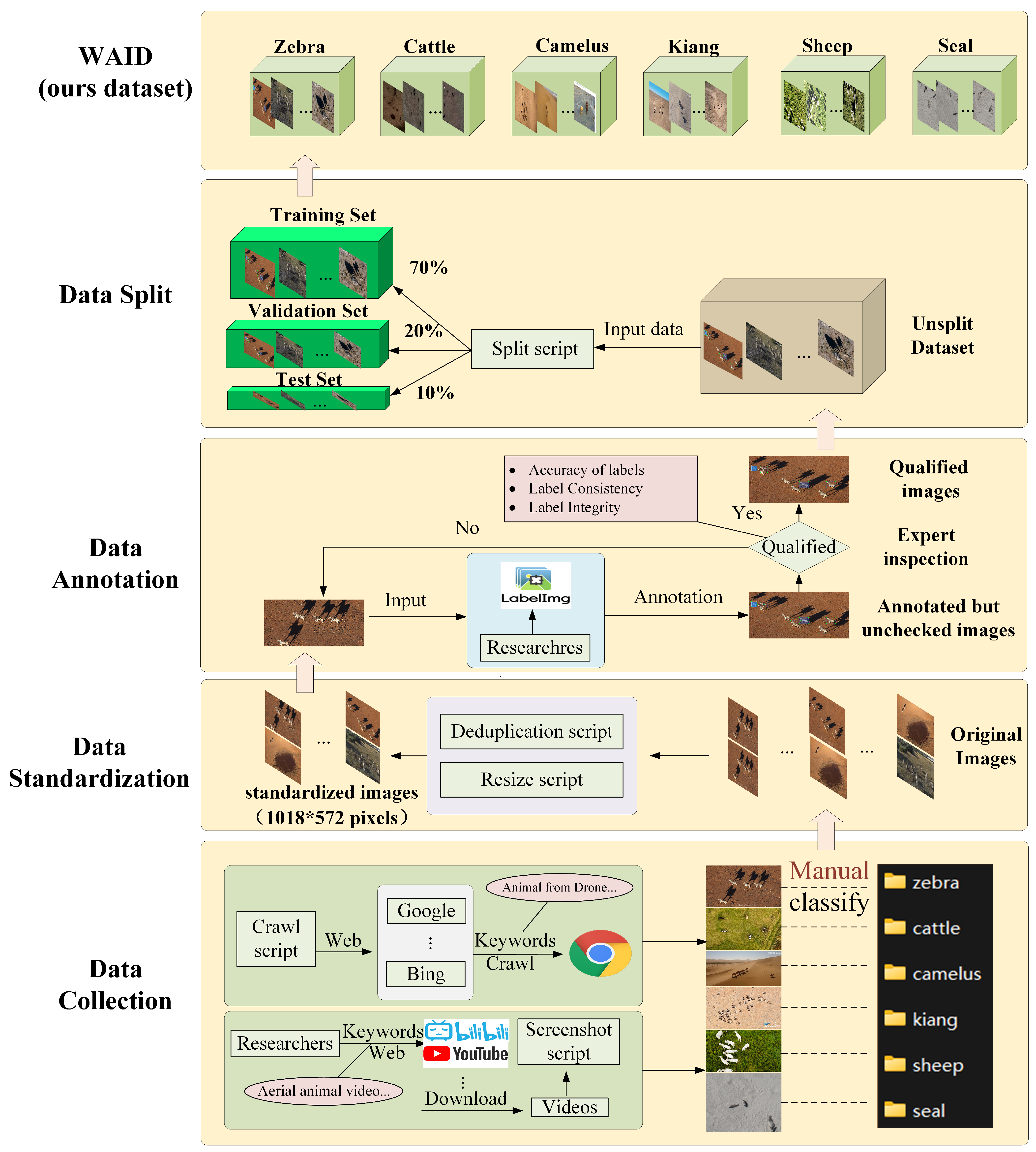
3.1. Dataset Design and Construction
3.1.1. Data Collection and Standardization
3.1.2. Data Annotation
3.1.3. Data Split
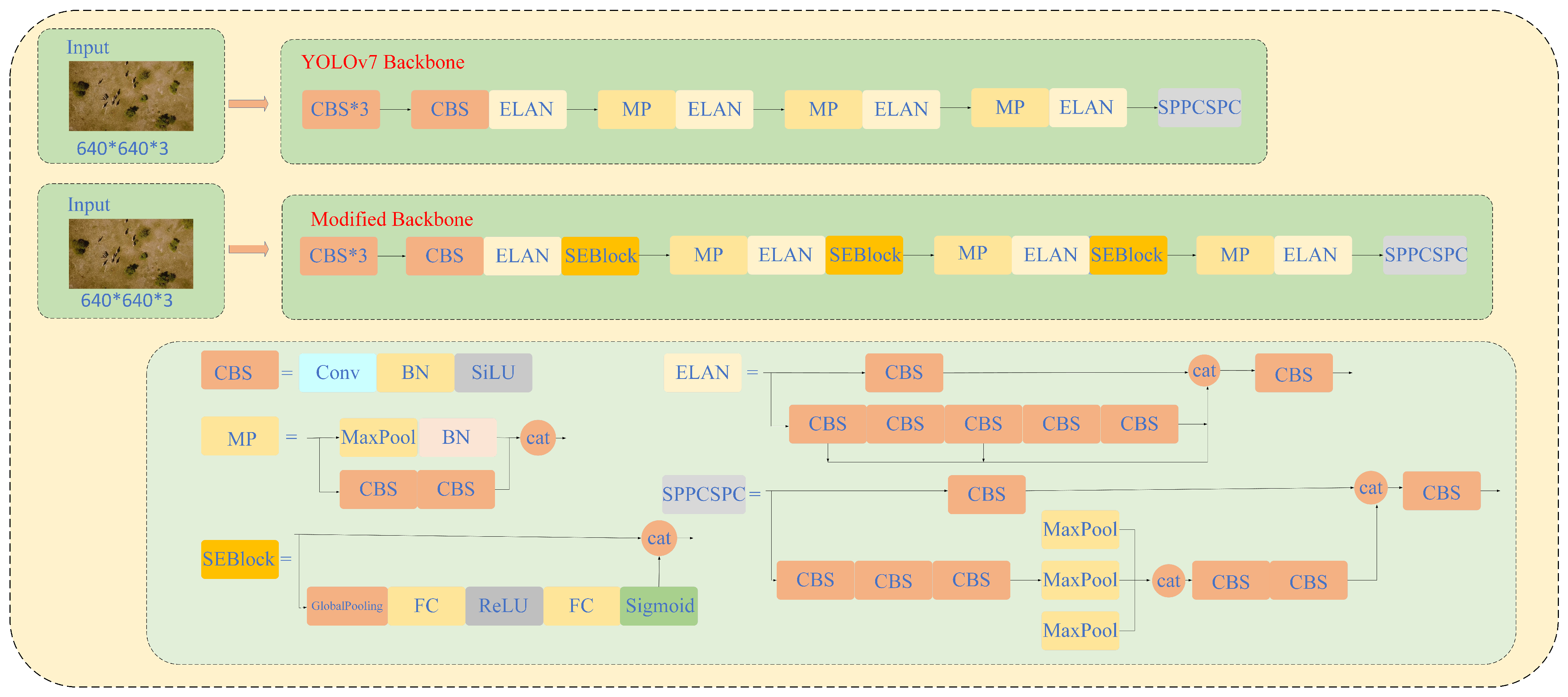
3.2. Improved YOLOv7 Model Based on Attention Mechanism
3.2.1. SEBlock Module
3.2.2. SE-YOLO
4. Experiments and Results
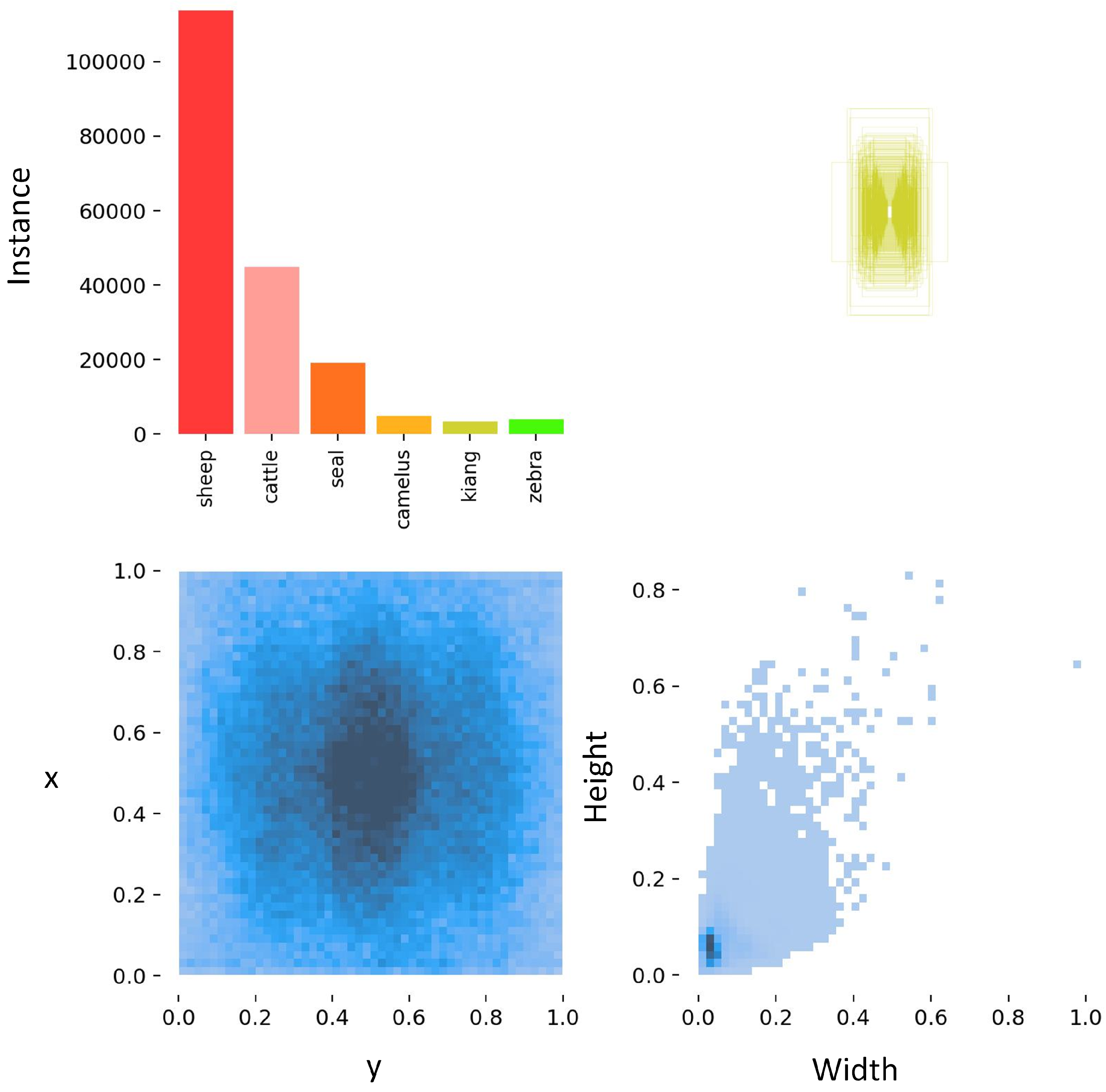
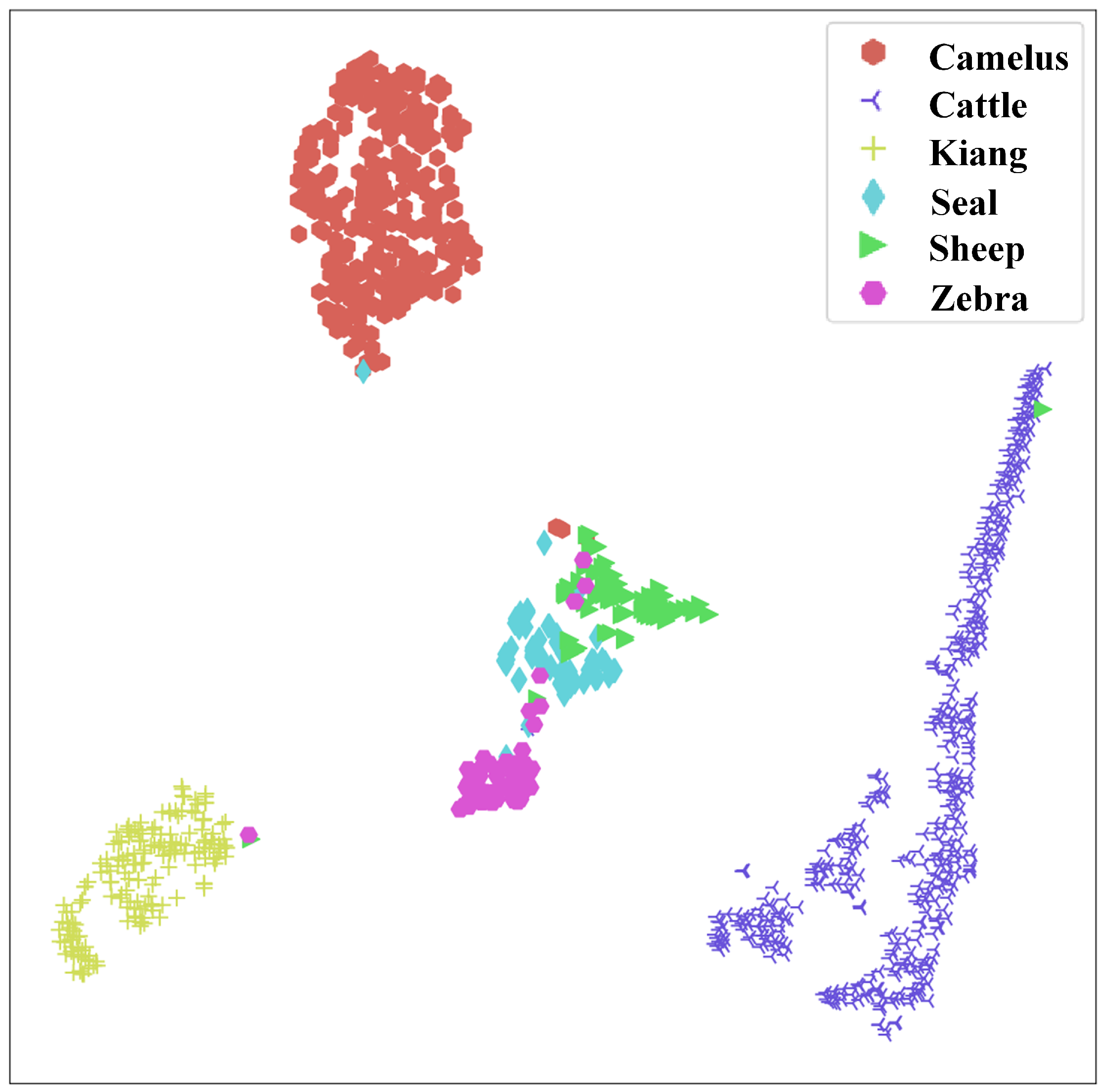
4.1. Statistical Experiments on WAID
4.2. Experiments of State-of-the-Art Algorithms on WAID
4.2.1. Experimental Setups
4.2.2. Evaluation Metrics
4.2.3. Results and Analysis
4.3. Experiments of Cross-Dataset Validation
5. Discussion
5.1. UAV Wildlife Dataset
5.2. Research Contributions
5.3. Future Work
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Valdez, R.; Guzmán-Aranda, J.C.; Abarca, F.J.; Tarango-Arámbula, L.A.; Sánchez, F.C. Wildlife conservation and management in Mexico. Wildl. Soc. Bull. 2006, 34, 270–282. [Google Scholar] [CrossRef]
- Teel, T.L.; Manfredo, M.J. Understanding the diversity of public interests in wildlife conservation. Conserv. Biol. 2010, 24, 128–139. [Google Scholar] [CrossRef]
- Keil, P.; Storch, D.; Jetz, W. On the decline of biodiversity due to area loss. Nat. Commun. 2015, 6, 8837. [Google Scholar] [CrossRef]
- Prokop, P.; Fančovičová, J. Animals in dangerous postures enhance learning, but decrease willingness to protect animals. Eurasia J. Math. Sci. Technol. Educ. 2017, 13, 6069–6077. [Google Scholar] [CrossRef]
- Descamps, S.; Béchet, A.; Descombes, X.; Arnaud, A.; Zerubia, J. An automatic counter for aerial images of aggregations of large birds. Bird Study 2011, 58, 302–308. [Google Scholar] [CrossRef]
- Ševo, I.; Avramović, A. Convolutional neural network based automatic object detection on aerial images. IEEE Geosci. Remote Sens. Lett. 2016, 13, 740–744. [Google Scholar] [CrossRef]
- Chabot, D.; Francis, C.M. Computer-automated bird detection and counts in high-resolution aerial images: A review. J. Field Ornithol. 2016, 87, 343–359. [Google Scholar] [CrossRef]
- Li, X.; Xing, L. Use of unmanned aerial vehicles for livestock monitoring based on streaming K-means clustering. IFAC-PapersOnLine 2019, 52, 324–329. [Google Scholar] [CrossRef]
- Sundaram, D.M.; Loganathan, A. FSSCaps-DetCountNet: Fuzzy soft sets and CapsNet-based detection and counting network for monitoring animals from aerial images. J. Appl. Remote Sens. 2020, 14, 026521. [Google Scholar] [CrossRef]
- Ward, S.; Hensler, J.; Alsalam, B.; Gonzalez, L.F. Autonomous UAVs wildlife detection using thermal imaging, predictive navigation and computer vision. In Proceedings of the 2016 IEEE Aerospace Conference, Big Sky, MT, USA, 5–12 March 2016; pp. 1–8. [Google Scholar]
- Barbedo, J.G.A.; Koenigkan, L.V.; Santos, T.T.; Santos, P.M. A study on the detection of cattle in UAV images using deep learning. Sensors 2019, 19, 5436. [Google Scholar] [CrossRef]
- Brown, J.; Qiao, Y.; Clark, C.; Lomax, S.; Rafique, K.; Sukkarieh, S. Automated aerial animal detection when spatial resolution conditions are varied. Comput. Electron. Agric. 2022, 193, 106689. [Google Scholar] [CrossRef]
- Hong, S.J.; Han, Y.; Kim, S.Y.; Lee, A.Y.; Kim, G. Application of deep-learning methods to bird detection using unmanned aerial vehicle imagery. Sensors 2019, 19, 1651. [Google Scholar] [CrossRef]
- Padubidri, C.; Kamilaris, A.; Karatsiolis, S.; Kamminga, J. Counting sea lions and elephants from aerial photography using deep learning with density maps. Anim. Biotelem. 2021, 9, 27. [Google Scholar] [CrossRef]
- Linchant, J.; Lisein, J.; Semeki, J.; Lejeune, P.; Vermeulen, C. Are unmanned aircraft systems (UASs) the future of wildlife monitoring? A review of accomplishments and challenges. Mammal Rev. 2015, 45, 239–252. [Google Scholar] [CrossRef]
- Wang, D.; Shao, Q.; Yue, H. Surveying wild animals from satellites, manned aircraft and unmanned aerial systems (UASs): A review. Remote Sens. 2019, 11, 1308. [Google Scholar] [CrossRef]
- Weiss, K.; Khoshgoftaar, T.M.; Wang, D. A survey of transfer learning. J. Big Data 2016, 3, 9. [Google Scholar] [CrossRef]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. Imagenet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft Coco: Common objects in context. In Proceedings of the Computer Vision—ECCV 2014, 13th European Conference, Zurich, Switzerland, 6–12 September 2014; Springer: Cham, Switzerland, 2014; pp. 740–755. [Google Scholar]
- Zheng, X.; Kellenberger, B.; Gong, R.; Hajnsek, I.; Tuia, D. Self-supervised pretraining and controlled augmentation improve rare wildlife recognition in UAV images. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 732–741. [Google Scholar]
- Okafor, E.; Smit, R.; Schomaker, L.; Wiering, M. Operational data augmentation in classifying single aerial images of animals. In Proceedings of the 2017 IEEE International Conference on INnovations in Intelligent SysTems and Applications (INISTA), Gdynia, Poland, 3–5 July 2017; pp. 354–360. [Google Scholar]
- Kellenberger, B.; Marcos, D.; Tuia, D. Best practices to train deep models on imbalanced datasets—A case study on animal detection in aerial imagery. In Proceedings of the Joint European Conference on Machine Learning and Knowledge Discovery in Databases, Dublin, Ireland, 10–14 September 2018; Springer: Cham, Switzerland, 2018; pp. 630–634. [Google Scholar]
- Wang, Y.; Han, D.; Wang, L.; Guo, Y.; Du, H. Contextualized Small Target Detection Network for Small Target Goat Face Detection. Animals 2023, 13, 2365. [Google Scholar] [CrossRef]
- Gao, C.; Meng, D.; Yang, Y.; Wang, Y.; Zhou, X.; Hauptmann, A.G. Infrared patch-image model for small target detection in a single image. IEEE Trans. Image Process. 2013, 22, 4996–5009. [Google Scholar] [CrossRef]
- Chen, C.; Liu, M.Y.; Tuzel, O.; Xiao, J. R-CNN for small object detection. In Proceedings of the Computer Vision—ACCV 2016, 13th Asian Conference on Computer Vision, Taipei, Taiwan, 20–24 November 2016; Springer: Cham, Switzerland, 2017; pp. 214–230. [Google Scholar]
- Zhou, P.; Ni, B.; Geng, C.; Hu, J.; Xu, Y. Scale-transferrable object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 528–537. [Google Scholar]
- Pham, M.T.; Courtrai, L.; Friguet, C.; Lefèvre, S.; Baussard, A. YOLO-Fine: One-stage detector of small objects under various backgrounds in remote sensing images. Remote Sens. 2020, 12, 2501. [Google Scholar] [CrossRef]
- Zhong, J.; Li, M.; Qin, J.; Cui, Y.; Yang, K.; Zhang, H. Real-time marine animal detection using YOLO-based deep learning networks in the coral reef ecosystem. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2022, 46, 301–306. [Google Scholar] [CrossRef]
- Roy, A.M.; Bhaduri, J.; Kumar, T.; Raj, K. WilDect-YOLO: An efficient and robust computer vision-based accurate object localization model for automated endangered wildlife detection. Ecol. Inform. 2023, 75, 101919. [Google Scholar] [CrossRef]
- Wang, C.Y.; Bochkovskiy, A.; Liao, H.Y.M. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023; pp. 7464–7475. [Google Scholar]
- He, Y.; Su, B.; Yan, J.; Tang, J.; Liu, C. Research on underwater object detection of improved YOLOv7 model based on attention mechanism: The underwater detection module YOLOv7-C. In Proceedings of the 2022 4th International Conference on Robotics, Intelligent Control and Artificial Intelligence, Dongguan, China, 16–18 December 2022; pp. 302–307. [Google Scholar]
- Pashler, H.; Johnston, J.C.; Ruthruff, E. Attention and performance. Annu. Rev. Psychol. 2001, 52, 629–651. [Google Scholar] [CrossRef]
- Wang, Y.; Zhang, T.; Wang, G. Small-target predetection with an attention mechanism. Opt. Eng. 2002, 41, 872–885. [Google Scholar] [CrossRef]
- Zuo, Z.; Tong, X.; Wei, J.; Su, S.; Wu, P.; Guo, R.; Sun, B. AFFPN: Attention fusion feature pyramid network for small infrared target detection. Remote Sens. 2022, 14, 3412. [Google Scholar] [CrossRef]
- Zhu, W.; Wang, L.; Jin, Z.; He, D. Lightweight small object detection network with attention mechanism. Opt. Precis. Eng. 2022, 30, 998–1010. [Google Scholar] [CrossRef]
- Kim, M.; Jeong, J.; Kim, S. ECAP-YOLO: Efficient channel attention pyramid YOLO for small object detection in aerial image. Remote Sens. 2021, 13, 4851. [Google Scholar] [CrossRef]
- Dai, Y.; Gieseke, F.; Oehmcke, S.; Wu, Y.; Barnard, K. Attentional feature fusion. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 3–8 January 2021; pp. 3560–3569. [Google Scholar]
- Guo, C.; Fan, B.; Zhang, Q.; Xiang, S.; Pan, C. AugFPN: Improving multi-scale feature learning for object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 12595–12604. [Google Scholar]
- Wang, Z.; Wang, B.; Xu, N. SAR ship detection in complex background based on multi-feature fusion and non-local channel attention mechanism. Int. J. Remote Sens. 2021, 42, 7519–7550. [Google Scholar] [CrossRef]
- Song, H.; Kim, M.; Lee, J.G. Selfie: Refurbishing unclean samples for robust deep learning. In Proceedings of the International Conference on Machine Learning, Long Beach, CA, USA, 9–15 June 2019; pp. 5907–5915. [Google Scholar]
- Ng, X.L.; Ong, K.E.; Zheng, Q.; Ni, Y.; Yeo, S.Y.; Liu, J. Animal Kingdom: A large and diverse dataset for animal behavior understanding. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 19–24 June 2022; pp. 19023–19034. [Google Scholar]
- Cao, J.; Tang, H.; Fang, H.S.; Shen, X.; Lu, C.; Tai, Y.W. Cross-domain adaptation for animal pose estimation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 9498–9507. [Google Scholar]
- Khan, M.H.; McDonagh, J.; Khan, S.; Shahabuddin, M.; Arora, A.; Khan, F.S.; Shao, L.; Tzimiropoulos, G. Animalweb: A large-scale hierarchical dataset of annotated animal faces. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 6939–6948. [Google Scholar]
- Maggiori, E.; Tarabalka, Y.; Charpiat, G.; Alliez, P. Can semantic labeling methods generalize to any city? The inria aerial image labeling benchmark. In Proceedings of the 2017 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Fort Worth, TX, USA, 23–28 July 2017; pp. 3226–3229. [Google Scholar]
- Chen, Q.; Wang, L.; Wu, Y.; Wu, G.; Guo, Z.; Waslander, S. Aerial imagery for roof segmentation: A large-scale dataset towards automatic mapping of buildings. arXiv 2018, arXiv:1807.09532. [Google Scholar] [CrossRef]
- Van Etten, A.; Lindenbaum, D.; Bacastow, T.M. Spacenet: A remote sensing dataset and challenge series. arXiv 2018, arXiv:1807.01232. [Google Scholar]
- Lee Son, G.; Romain, S.; Rose, C.; Moore, B.; Magrane, K.; Packer, P.; Wallace, F. Development of Electronic Monitoring (EM) Computer Vision Systems and Machine Learning Algorithms for Automated Catch Accounting in Alaska Fisheries; Alaska Fisheries Science Center; NOAA; National Marine Fisheries Service: Seattle, WA, USA, 2023.
- Naude, J.; Joubert, D. The Aerial Elephant Dataset: A New Public Benchmark for Aerial Object Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Long Beach, CA, USA, 16–20 June 2019; pp. 48–55. [Google Scholar]
- Friedrich, N.O.; Meyder, A.; de Bruyn Kops, C.; Sommer, K.; Flachsenberg, F.; Rarey, M.; Kirchmair, J. High-quality dataset of protein-bound ligand conformations and its application to benchmarking conformer ensemble generators. J. Chem. Inf. Model. 2017, 57, 529–539. [Google Scholar] [CrossRef]
- Kazmi, H.; Munné-Collado, Í.; Mehmood, F.; Syed, T.A.; Driesen, J. Towards data-driven energy communities: A review of open-source datasets, models and tools. Renew. Sustain. Energy Rev. 2021, 148, 111290. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single shot multibox detector. In Proceedings of the Computer Vision—ECCV 2016, 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Springer: Cham, Switzerland, 2016; pp. 21–37. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Zhang, S.; Wen, L.; Bian, X.; Lei, Z.; Li, S.Z. Single-shot refinement neural network for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4203–4212. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial pyramid pooling in deep convolutional networks for visual recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef] [PubMed]
- Girshick, R. Fast R-CNN. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. Adv. Neural Inf. Process. Syst. 2015, 28, 91–99. [Google Scholar] [CrossRef] [PubMed]
- Dai, J.; Li, Y.; He, K.; Sun, J. R-FCN: Object detection via region-based fully convolutional networks. Adv. Neural Inf. Process. Syst. 2016, 29, 379–387. [Google Scholar]
- Li, Z.; Peng, C.; Yu, G.; Zhang, X.; Deng, Y.; Sun, J. Light-head R-CNN: In defense of two-stage object detector. arXiv 2017, arXiv:1711.07264. [Google Scholar]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the inception architecture for computer vision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2818–2826. [Google Scholar]
- Yu, C.; Wang, J.; Peng, C.; Gao, C.; Yu, G.; Sang, N. BiSeNet: Bilateral segmentation network for real-time semantic segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 325–341. [Google Scholar]
- Fu, J.; Liu, J.; Jiang, J.; Li, Y.; Bao, Y.; Lu, H. Scene segmentation with dual relation-aware attention network. IEEE Trans. Neural Netw. Learn. Syst. 2020, 32, 2547–2560. [Google Scholar] [CrossRef] [PubMed]
- Wang, Q.; Wu, B.; Zhu, P.; Li, P.; Zuo, W.; Hu, Q. ECA-Net: Efficient channel attention for deep convolutional neural networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 11534–11542. [Google Scholar]
- Tong, W.; Chen, W.; Han, W.; Li, X.; Wang, L. Channel-attention-based DenseNet network for remote sensing image scene classification. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 13, 4121–4132. [Google Scholar] [CrossRef]
- Yang, X.; Shi, J.; Zhang, J. Gated channel attention mechanism YOLOv3 network for small target detection. Adv. Multimed. 2022, 2022, 8703380. [Google Scholar] [CrossRef]
- Hodgson, J.C.; Baylis, S.M.; Mott, R.; Herrod, A.; Clarke, R.H. Precision wildlife monitoring using unmanned aerial vehicles. Sci. Rep. 2016, 6, 22574. [Google Scholar] [CrossRef]
- Sirmacek, B.; Wegmann, M.; Cross, A.; Hopcraft, J.; Reinartz, P.; Dech, S. Automatic population counts for improved wildlife management using aerial photography. In Proceedings of the 6th International Congress on Environmental Modelling and Software, Leipzig, Germany, 1–5 July 2012. [Google Scholar]
- Ruwaimana, M.; Satyanarayana, B.; Otero, V.; Muslim, A.M.; Syafiq, A.M.; Ibrahim, S.; Raymaekers, D.; Koedam, N.; Dahdouh-Guebas, F. The advantages of using drones over space-borne imagery in the mapping of mangrove forests. PLoS ONE 2018, 13, e0200288. [Google Scholar] [CrossRef]
- Raoult, V.; Colefax, A.P.; Allan, B.M.; Cagnazzi, D.; Castelblanco-Martínez, N.; Ierodiaconou, D.; Johnston, D.W.; Landeo-Yauri, S.; Lyons, M.; Pirotta, V.; et al. Operational protocols for the use of drones in marine animal research. Drones 2020, 4, 64. [Google Scholar] [CrossRef]
- Mnih, V.; Hinton, G.E. Learning to detect roads in high-resolution aerial images. In Proceedings of the Computer Vision—ECCV 2010, 11th European Conference on Computer Vision, Heraklion, Crete, Greece, 5–11 September 2010; Springer: Cham, Switzerland, 2010; pp. 210–223. [Google Scholar]
- Fang, Y.; Du, S.; Abdoola, R.; Djouani, K.; Richards, C. Motion based animal detection in aerial videos. Procedia Comput. Sci. 2016, 92, 13–17. [Google Scholar] [CrossRef]
- Bennitt, E.; Bartlam-Brooks, H.L.; Hubel, T.Y.; Wilson, A.M. Terrestrial mammalian wildlife responses to Unmanned Aerial Systems approaches. Sci. Rep. 2019, 9, 2142. [Google Scholar] [CrossRef] [PubMed]
- Fust, P.; Loos, J. Development perspectives for the application of autonomous, unmanned aerial systems (UASs) in wildlife conservation. Biol. Conserv. 2020, 241, 108380. [Google Scholar] [CrossRef]
- Tan, L.; Lv, X.; Lian, X.; Wang, G. YOLOv4_Drone: UAV image target detection based on an improved YOLOv4 algorithm. Comput. Electr. Eng. 2021, 93, 107261. [Google Scholar] [CrossRef]
- Benjdira, B.; Khursheed, T.; Koubaa, A.; Ammar, A.; Ouni, K. Car detection using unmanned aerial vehicles: Comparison between faster R-CNN and YOLOv3. In Proceedings of the 2019 1st International Conference on Unmanned Vehicle Systems-Oman (UVS), Muscat, Oman, 5–7 February 2019; pp. 1–6. [Google Scholar]
- Hu, J.; Shen, L.; Albanie, S.; Sun, G.; Wu, E. Squeeze-and-excitation networks. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 2011–2023. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30, 5998–6008. [Google Scholar]
- Van der Maaten, L.; Hinton, G. Visualizing data using t-SNE. J. Mach. Learn. Res. 2008, 9, 2579–2605. [Google Scholar]
- Xia, G.S.; Bai, X.; Ding, J.; Zhu, Z.; Belongie, S.; Luo, J.; Datcu, M.; Pelillo, M.; Zhang, L. DOTA: A large-scale dataset for object detection in aerial images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 3974–3983. [Google Scholar]
- Krichen, M.; Adoni, W.Y.H.; Mihoub, A.; Alzahrani, M.Y.; Nahhal, T. Security challenges for drone communications: Possible threats, attacks and countermeasures. In Proceedings of the 2022 2nd International Conference of Smart Systems and Emerging Technologies (SMARTTECH), Riyadh, Saudi Arabia, 9–11 May 2022; pp. 184–189. [Google Scholar]
- Ko, Y.; Kim, J.; Duguma, D.G.; Astillo, P.V.; You, I.; Pau, G. Drone secure communication protocol for future sensitive applications in military zone. Sensors 2021, 21, 2057. [Google Scholar] [CrossRef]
- Vergouw, B.; Nagel, H.; Bondt, G.; Custers, B. Drone technology: Types, payloads, applications, frequency spectrum issues and future developments. In The Future of Drone Use: Opportunities and Threats from Ethical and Legal Perspectives; T.M.C. Asser Press: The Hague, The Netherlands, 2016; pp. 21–45. [Google Scholar]


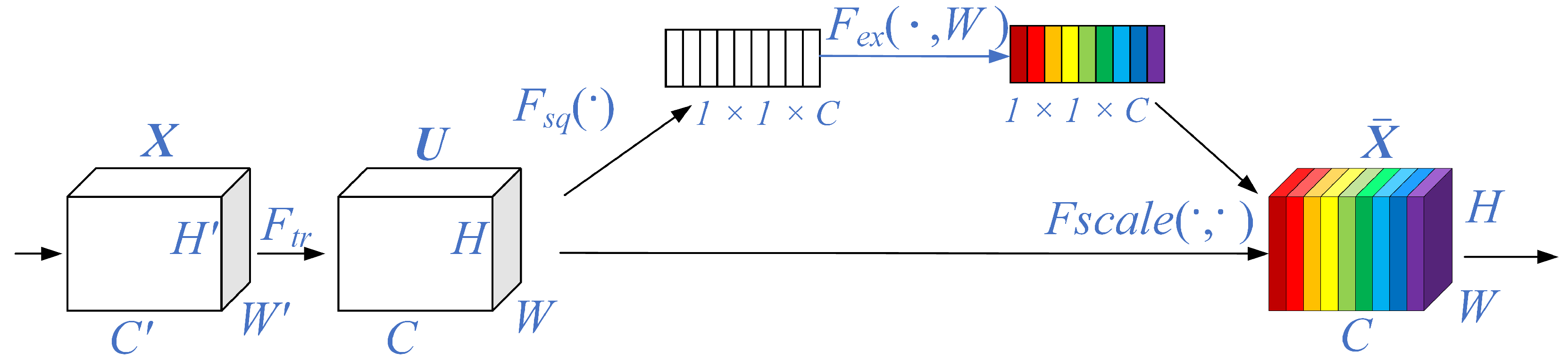



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Animal10 | Animal-Pose | AnimalWeb | Animal Kingdom | WAID (Ours) |
|---|---|---|---|---|---|
| Year | 2019 | 2019 | 2020 | 2022 | 2023 |
| multicategory | √ | √ | √ | √ | √ |
| Wilderness | × | √ | √ | √ | √ |
| Multiscale | × | √ | × | √ | √ |
| ValidationSet | × | × | × | √ | √ |
| AerialView | × | × | × | × | √ |
| Class | Sheep | Cattle | Seal | Camelus | Zebra | Kiang |
|---|---|---|---|---|---|---|
| Training | 3602 | 3301 | 2709 | 512 | 443 | 551 |
| Validation | 349 | 943 | 330 | 149 | 126 | 157 |
| Testing | 173 | 471 | 329 | 82 | 65 | 74 |
| Total | 4124 | 4715 | 3368 | 743 | 643 | 782 |
| Method | Backbone | Precision | Recall | mAP |
|---|---|---|---|---|
| YOLOv5 | CSPDarknet53 | 0.949 | 0.916 | 0.956 |
| YOLOv7 | CSPDarknet53 | 0.964 | 0.953 | 0.972 |
| YOLOv8 | CSPDarknet53 | 0.948 | 0.906 | 0.958 |
| Faster-RCNN | ResNet50 | 0.517 | 0.855 | 0.779 |
| Faster-RCNN | VGG16 | 0.279 | 0.756 | 0.610 |
| SSD | MobileNetv2 | 0.757 | 0.446 | 0.591 |
| SSD | VGG16 | 0.930 | 0.430 | 0.739 |
| SE-YOLO | CSPDarknet53 | 0.978 | 0.969 | 0.983 |
| SE-YOLO | YOLOv5 | YOLOv7 | YOLOv8 | SSD (VGG16) | SSD (MobileNetv2) | Faster-RCNN (VGG16) | Faster-RCNN (ResNet50) | |
|---|---|---|---|---|---|---|---|---|
| Sheep | 0.988 | 0.970 | 0.972 | 0.981 | 0.627 | 0.425 | 0.316 | 0.484 |
| Cattle | 0.987 | 0.984 | 0.988 | 0.971 | 0.824 | 0.721 | 0.622 | 0.761 |
| Seal | 0.994 | 0.980 | 0.980 | 0.984 | 0.926 | 0.821 | 0.684 | 0.922 |
| Camelus | 0.983 | 0.943 | 0.978 | 0.921 | 0.763 | 0.654 | 0.746 | 0.910 |
| Kiang | 0.971 | 0.925 | 0.950 | 0.945 | 0.636 | 0.444 | 0.661 | 0.824 |
| Zebra | 0.977 | 0.932 | 0.964 | 0.944 | 0.660 | 0.479 | 0.629 | 0.771 |
| mAP | 0.983 | 0.956 | 0.972 | 0.958 | 0.739 | 0.591 | 0.610 | 0.779 |
| Methods | Precision | Recall | mAP |
|---|---|---|---|
| YOLOv7 | 0.796 | 0.875 | 0.822 |
| SE-YOLO | 0.929 | 0.847 | 0.926 |
| Training Set | Test Set | Precision | Recall | mAP@0.5 | mAP@0.5:0.95 |
|---|---|---|---|---|---|
| WAID | WAID | 0.978 | 0.969 | 0.983 | 0.677 |
| WAID | MSAWID | 0.469 | 0.422 | 0.395 | 0.226 |
| MSAWID | MSAWID | 0.751 | 0.657 | 0.676 | 0.396 |
| MSAWID | WAID | 0.303 | 0.169 | 0.153 | 0.076 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mou, C.; Liu, T.; Zhu, C.; Cui, X. WAID: A Large-Scale Dataset for Wildlife Detection with Drones. Appl. Sci. 2023, 13, 10397. https://doi.org/10.3390/app131810397
Mou C, Liu T, Zhu C, Cui X. WAID: A Large-Scale Dataset for Wildlife Detection with Drones. Applied Sciences. 2023; 13(18):10397. https://doi.org/10.3390/app131810397
Chicago/Turabian StyleMou, Chao, Tengfei Liu, Chengcheng Zhu, and Xiaohui Cui. 2023. "WAID: A Large-Scale Dataset for Wildlife Detection with Drones" Applied Sciences 13, no. 18: 10397. https://doi.org/10.3390/app131810397
APA StyleMou, C., Liu, T., Zhu, C., & Cui, X. (2023). WAID: A Large-Scale Dataset for Wildlife Detection with Drones. Applied Sciences, 13(18), 10397. https://doi.org/10.3390/app131810397