
Novel Paintings from the Latent Diffusion Model through Transfer Learning


Abstract
:1. Introduction
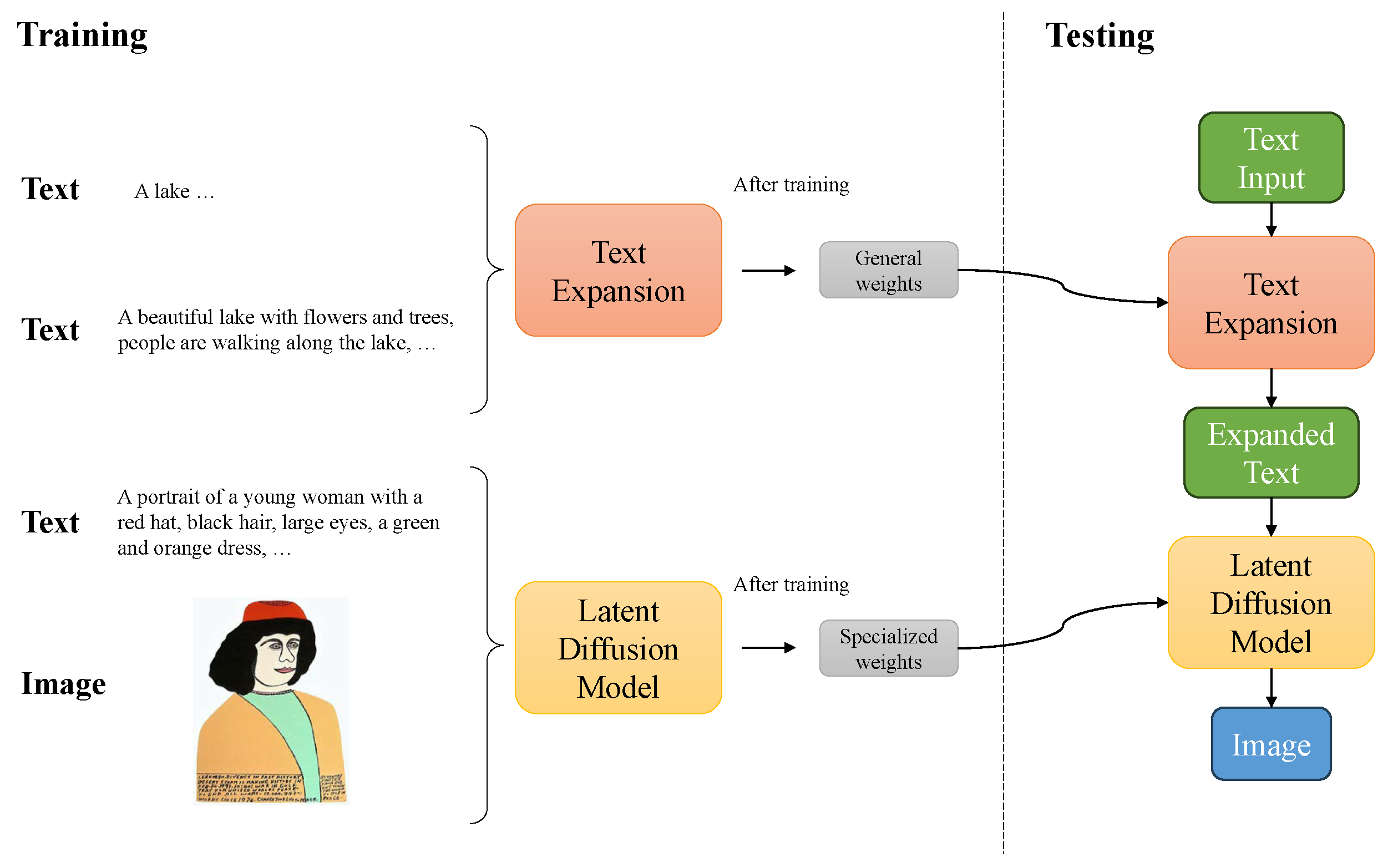
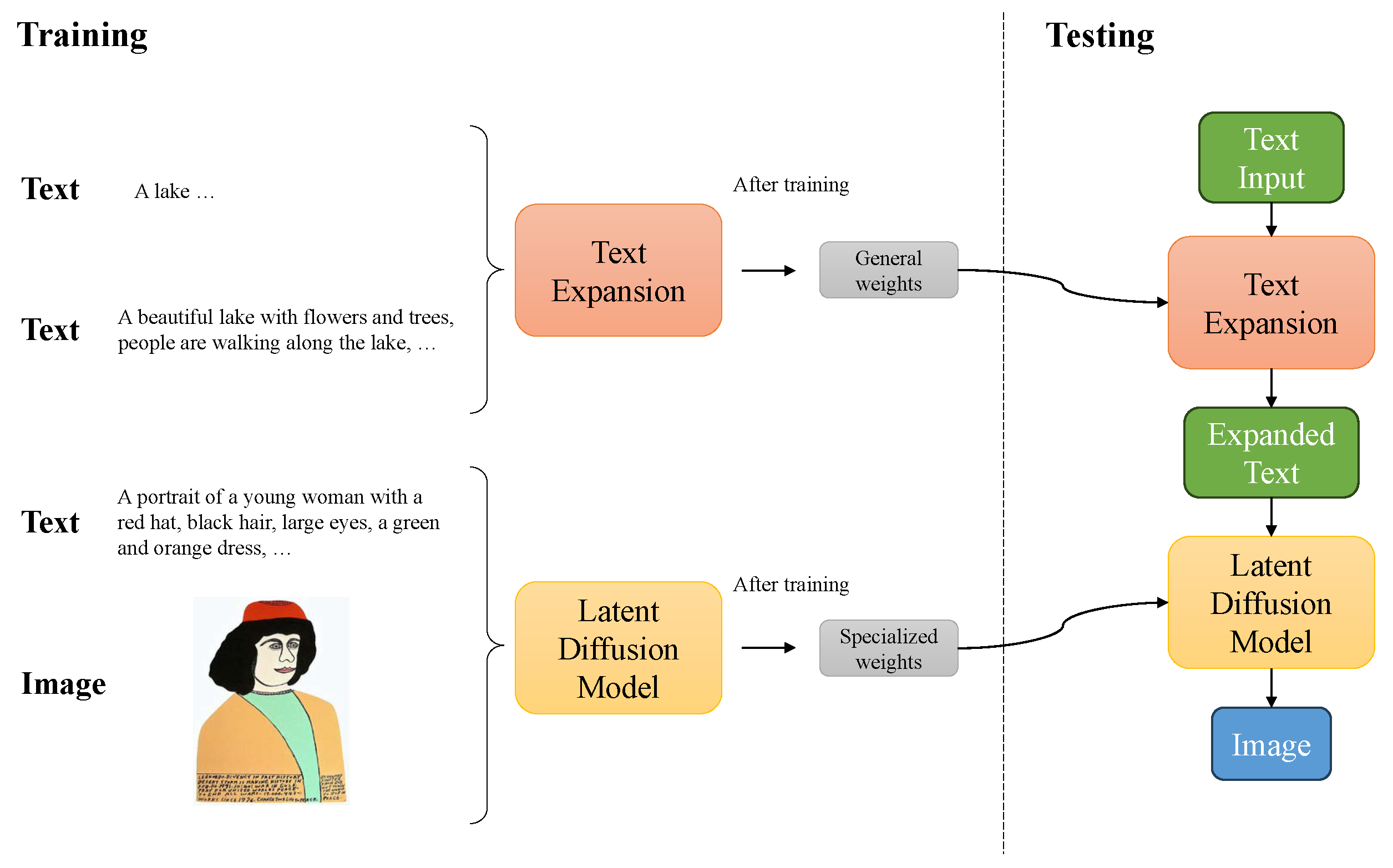
- We propose the painting model to create novel paintings from those late famous artists’ works for the first time, which is based on the latent diffusion model with transfer learning.
- We propose the text prompt expansion, which utilizes positives of large language models for completing the text prompts and generating more detailed images.
- We contribute missing image context descriptions, which are complementary to the original WikiArt dataset, and we will release it to the public.
- We demonstrate photo-realistic painting results by giving different text prompt inputs to the trained model.
2. Related Work
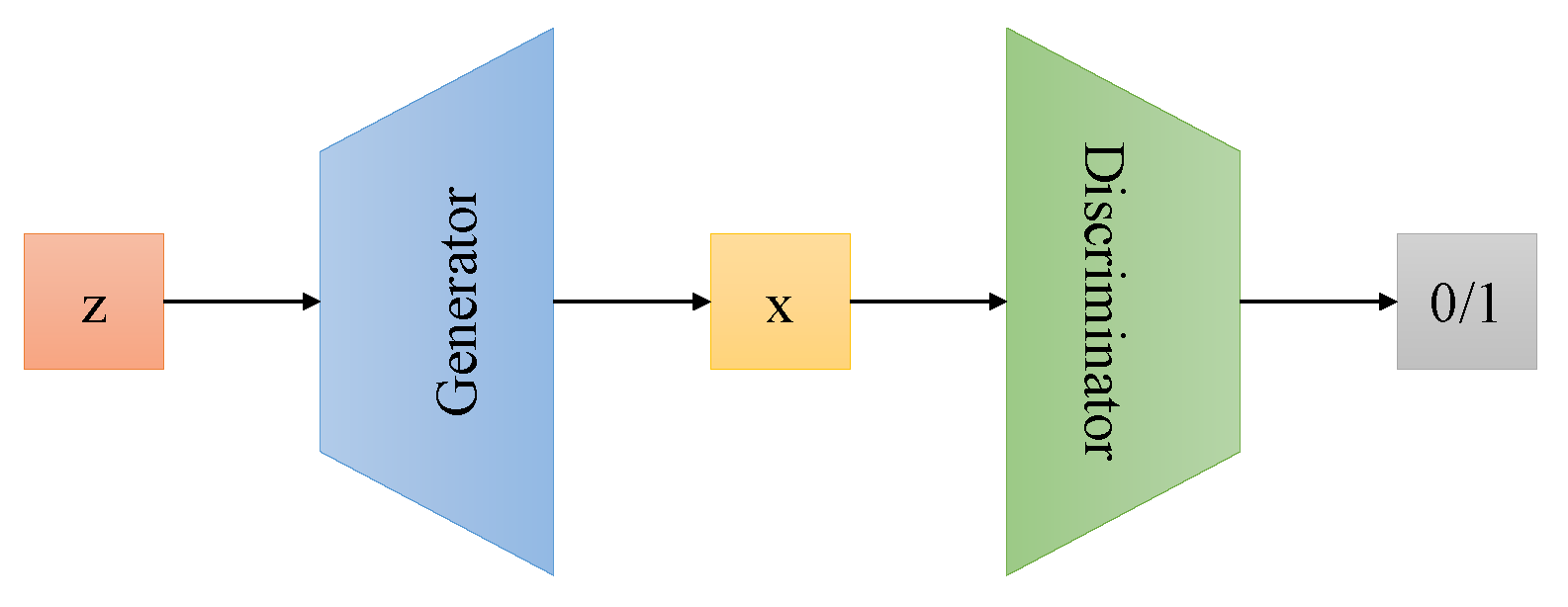
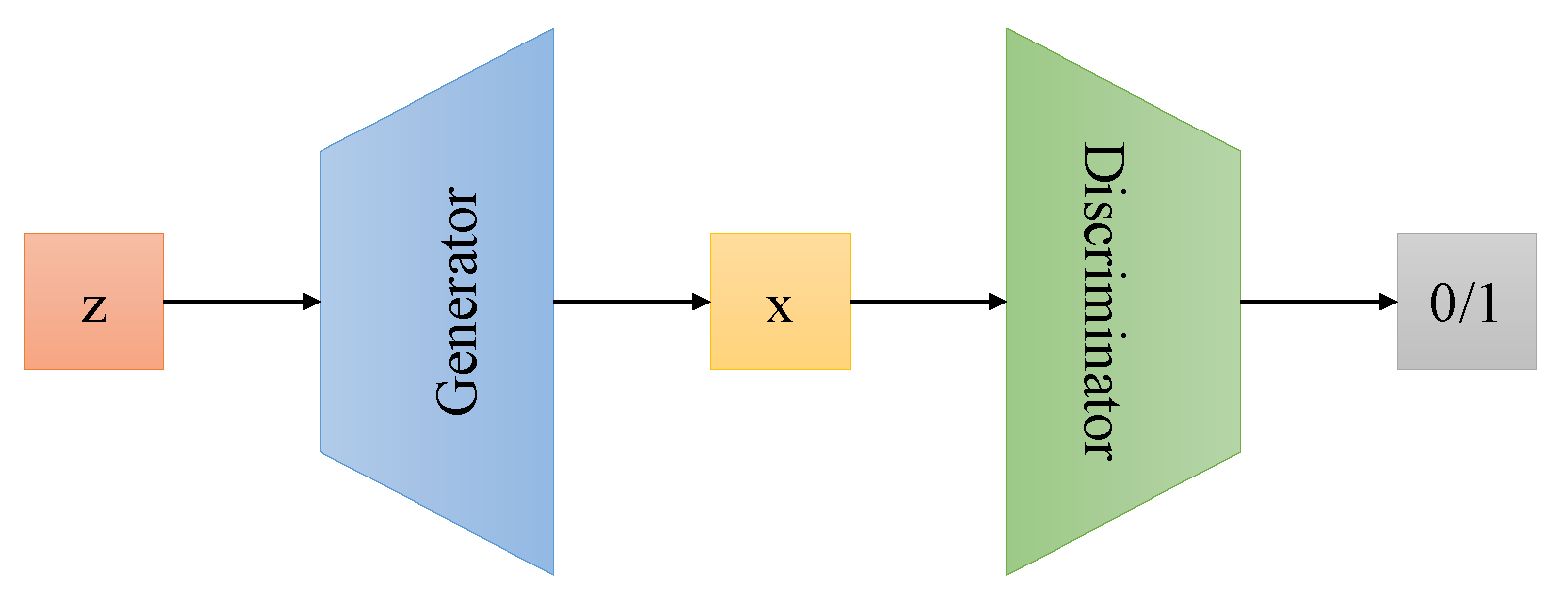
2.1. Generative Adversarial Network
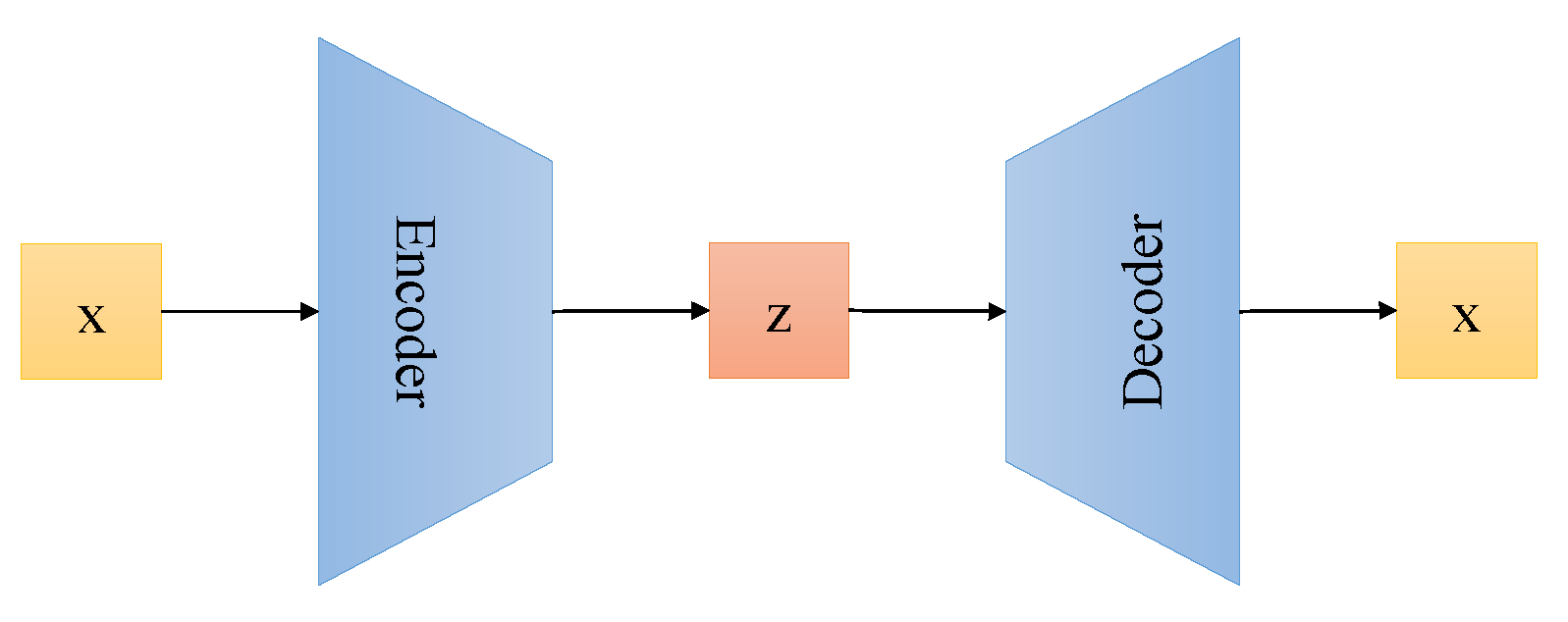
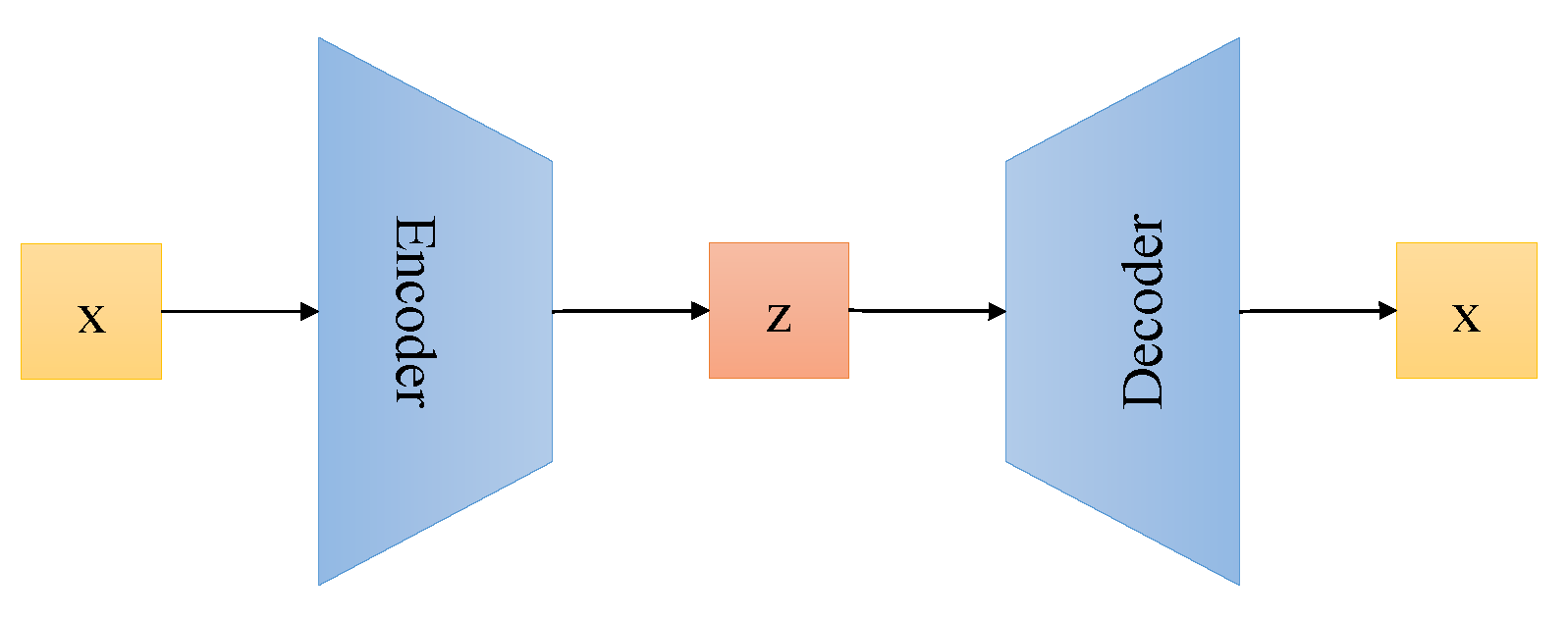
2.2. Variational Autoencoder
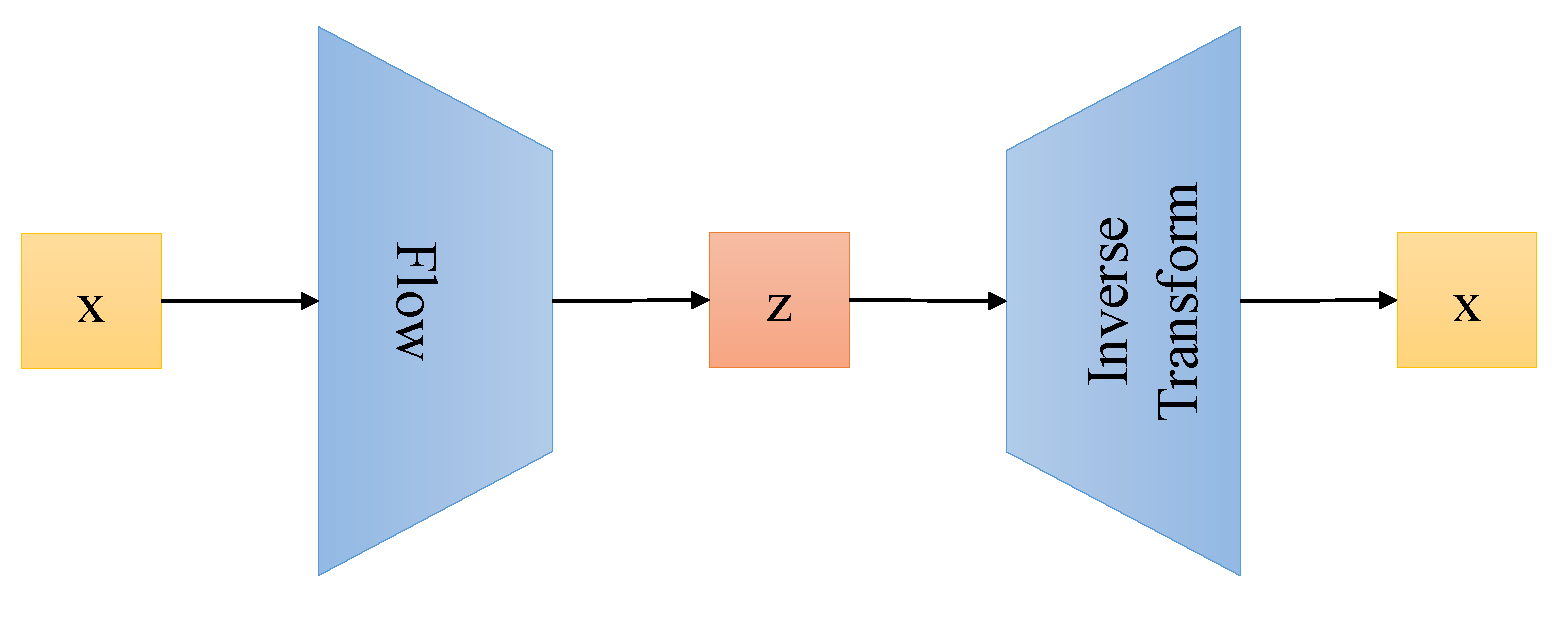
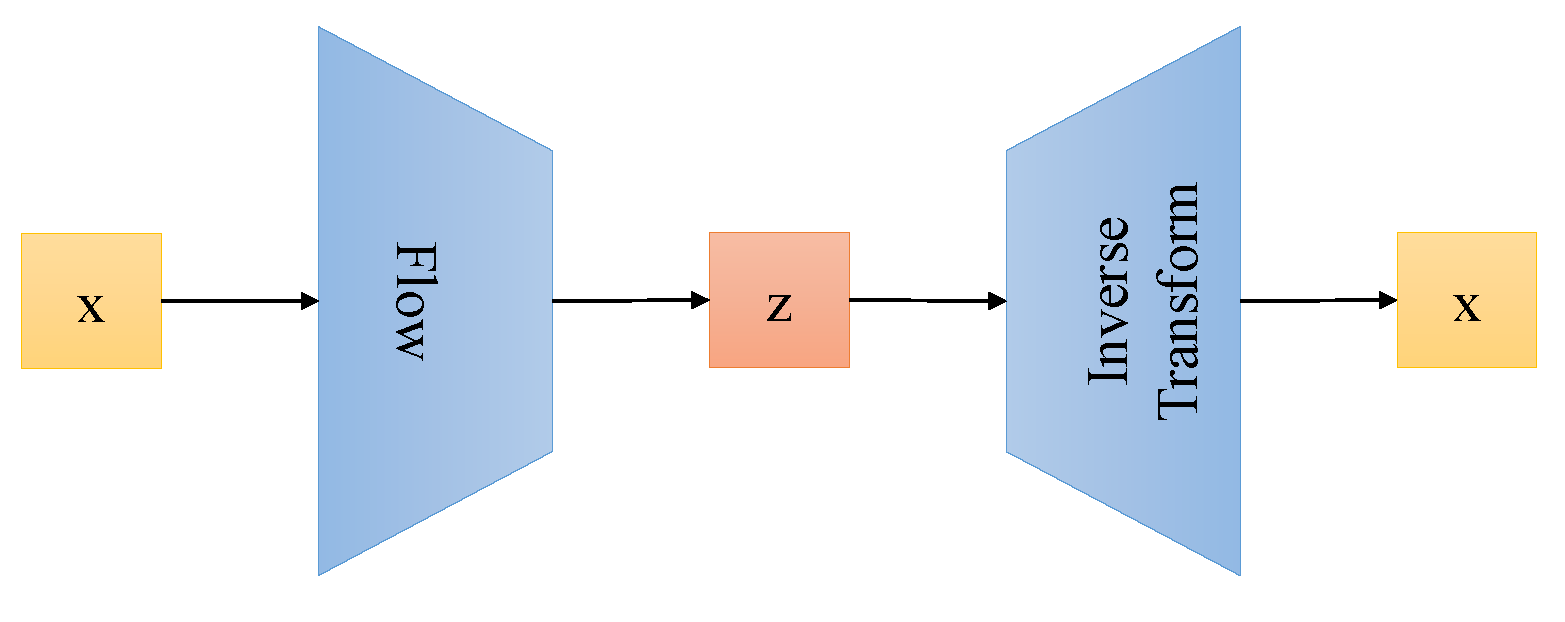
2.3. Flow-Based Generative Models
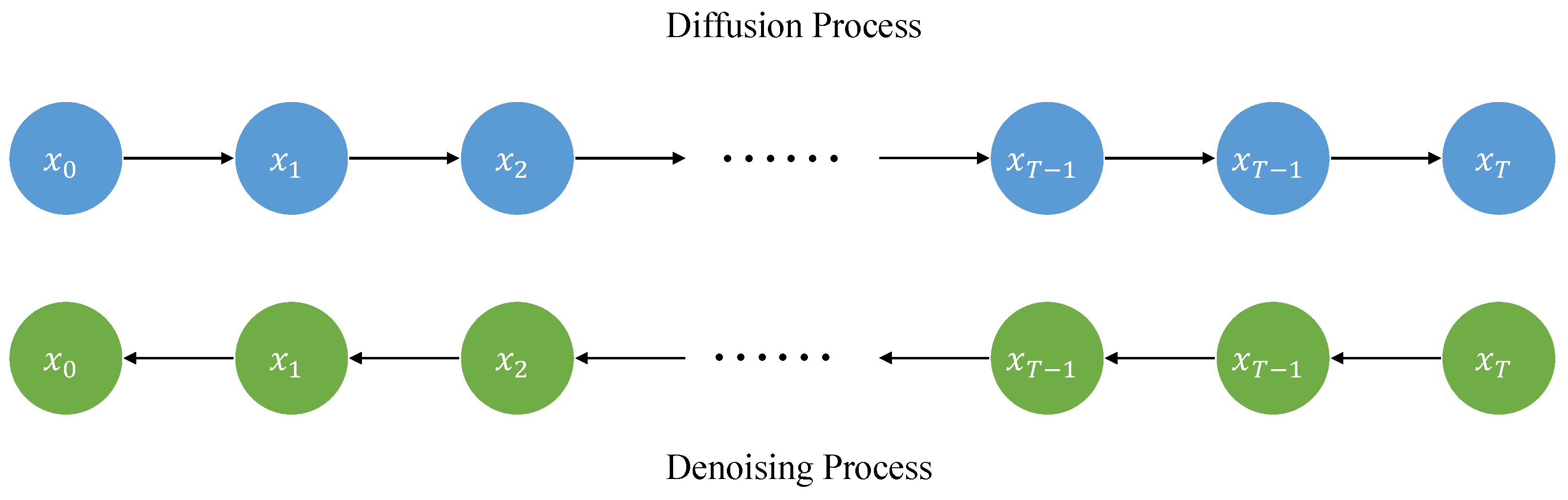
2.4. Diffusion Models
3. Materials and Methods
3.1. Denoising Diffusion Probabilistic Model
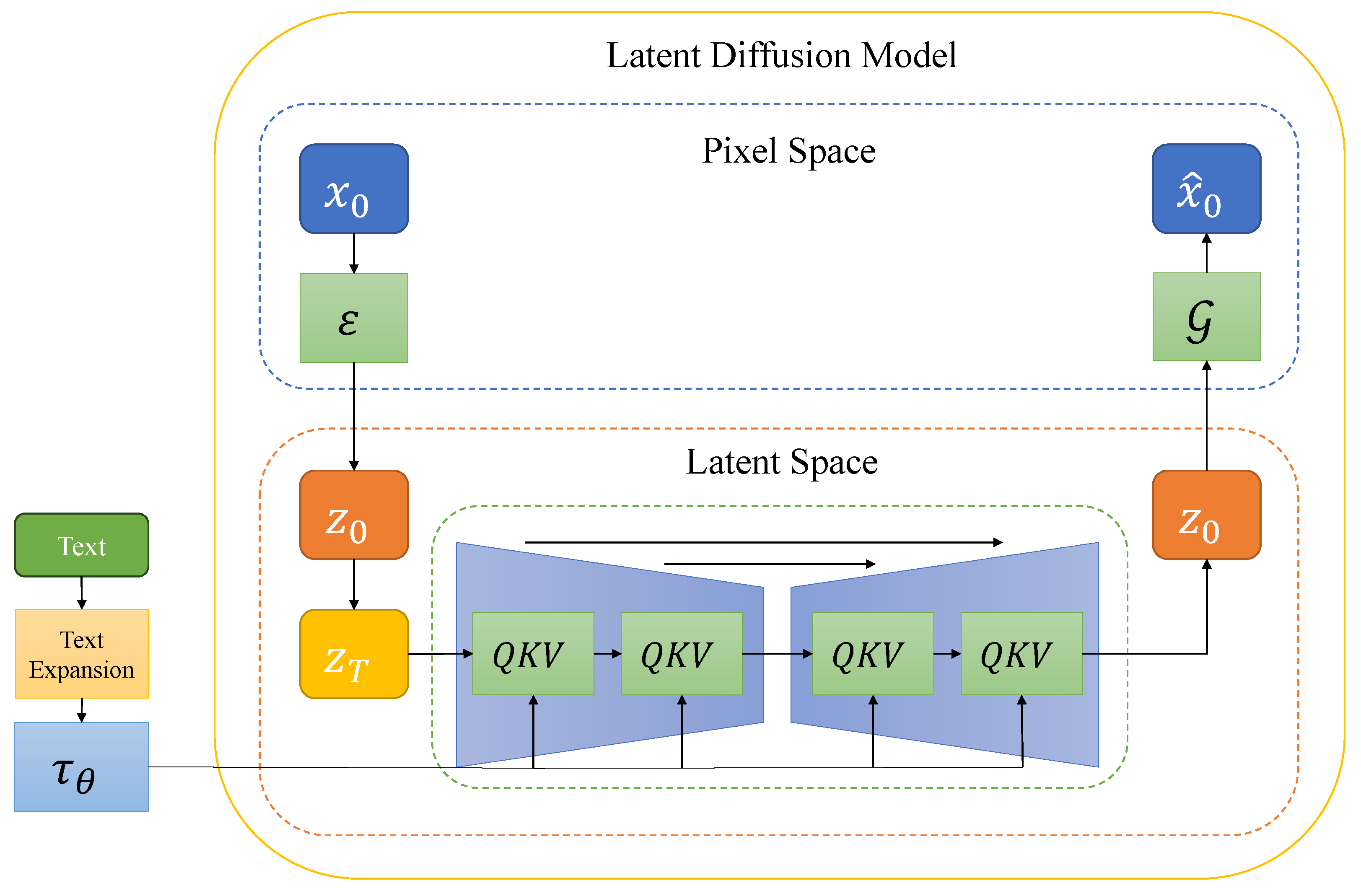
3.2. Latent Diffusion Model
3.2.1. Autoencoder with Regulation
3.2.2. Conditional Denoising Nethwork
3.3. Text Prompt Expansion
4. Experiments
4.1. Dataset
4.2. Implemental Details
4.3. Qualitative Results
4.4. Quantitative Results
5. Discussion and Conclusions
Author Contributions
Funding
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| DOAJ | Directory of open access journals |
| TLA | Three letter acronym |
| LD | Linear dichroism |
References
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative Adversarial Nets. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, USA, 8–13 December 2014; Volume 27. [Google Scholar]
- Kingma, D.P.; Welling, M. Auto-encoding variational bayes. arXiv 2013, arXiv:1312.6114. [Google Scholar]
- Sohl-Dickstein, J.; Weiss, E.; Maheswaranathan, N.; Ganguli, S. Deep unsupervised learning using nonequilibrium thermodynamics. In Proceedings of the International Conference on Machine Learning, PMLR, Lille, France, 6–11 July 2015; pp. 2256–2265. [Google Scholar]
- Ho, J.; Jain, A.; Abbeel, P. Denoising diffusion probabilistic models. In Proceedings of the Advances in Neural Information Processing Systems, Virtual, 6–12 December 2020; Volume 33, pp. 6840–6851. [Google Scholar]
- Song, J.; Meng, C.; Ermon, S. Denoising diffusion implicit models. arXiv 2020, arXiv:2010.02502. [Google Scholar]
- Rombach, R.; Blattmann, A.; Lorenz, D.; Esser, P.; Ommer, B. High-resolution image synthesis with latent diffusion models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 10684–10695. [Google Scholar]
- Dhariwal, P.; Nichol, A. Diffusion models beat gans on image synthesis. In Proceedings of the Advances in Neural Information Processing Systems, Virtual, 6–14 December 2021; Volume 34, pp. 8780–8794. [Google Scholar]
- WIKIART. Available online: https://www.wikiart.org/ (accessed on 5 March 2023).
- Radford, A.; Wu, J.; Child, R.; Luan, D.; Amodei, D.; Sutskever, I. Language models are unsupervised multitask learners. OpenAI Blog 2019, 1, 9. [Google Scholar]
- Karras, T.; Laine, S.; Aila, T. A style-based generator architecture for generative adversarial networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 4401–4410. [Google Scholar]
- Karras, T.; Laine, S.; Aittala, M.; Hellsten, J.; Lehtinen, J.; Aila, T. Analyzing and improving the image quality of stylegan. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 8110–8119. [Google Scholar]
- Karras, T.; Aittala, M.; Laine, S.; Härkönen, E.; Hellsten, J.; Lehtinen, J.; Aila, T. Alias-free generative adversarial networks. In Proceedings of the Advances in Neural Information Processing Systems, Virtual, 6–14 December 2021; Volume 34, pp. 852–863. [Google Scholar]
- Salimans, T.; Goodfellow, I.; Zaremba, W.; Cheung, V.; Radford, A.; Chen, X. Improved techniques for training gans. In Proceedings of the Advances in Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016; Volume 29. [Google Scholar]
- Radford, A.; Metz, L.; Chintala, S. Unsupervised representation learning with deep convolutional generative adversarial networks. arXiv 2015, arXiv:1511.06434. [Google Scholar]
- Arjovsky, M.; Bottou, L. Towards principled methods for training generative adversarial networks. arXiv 2017, arXiv:1701.04862. [Google Scholar]
- Arjovsky, M.; Chintala, S.; Bottou, L. Wasserstein GAN. In Proceedings of the 34th International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017. [Google Scholar]
- Higgins, I.; Matthey, L.; Pal, A.; Burgess, C.; Glorot, X.; Botvinick, M.; Mohamed, S.; Lerchner, A. beta-vae: Learning basic visual concepts with a constrained variational framework. In Proceedings of the International Conference on Learning Representations, Toulon, France, 24–26 April 2017. [Google Scholar]
- Van Den Oord, A.; Vinyals, O. Neural discrete representation learning. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; Volume 30. [Google Scholar]
- Razavi, A.; Van den Oord, A.; Vinyals, O. Generating diverse high-fidelity images with vq-vae-2. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019; Volume 32. [Google Scholar]
- Ramesh, A.; Pavlov, M.; Goh, G.; Gray, S.; Voss, C.; Radford, A.; Chen, M.; Sutskever, I. Zero-shot text-to-image generation. In Proceedings of the International Conference on Machine Learning, PMLR, Virtual, 18–24 July 2021; pp. 8821–8831. [Google Scholar]
- Rombach, R.; Esser, P.; Ommer, B. Network-to-network translation with conditional invertible neural networks. In Proceedings of the Advances in Neural Information Processing Systems, Virtual, 6–12 December 2020; Volume 33, pp. 2784–2797. [Google Scholar]
- Gregor, K.; Papamakarios, G.; Besse, F.; Buesing, L.; Weber, T. Temporal difference variational auto-encoder. arXiv 2018, arXiv:1806.03107. [Google Scholar]
- Rezende, D.; Mohamed, S. Variational inference with normalizing flows. In Proceedings of the International Conference on Machine Learning, PMLR, Lille, France, 6–11 July 2015; pp. 1530–1538. [Google Scholar]
- Su, J.; Wu, G. f-VAEs: Improve VAEs with conditional flows. arXiv 2018, arXiv:1809.05861. [Google Scholar]
- Zhang, L.; Agrawala, M. Adding conditional control to text-to-image diffusion models. arXiv 2023, arXiv:2302.05543. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; Volume 30. [Google Scholar]
- Hugging Face. Available online: https://huggingface.co/datasets/bartman081523/stable-diffusion-discord-prompts (accessed on 5 March 2023).
- Hugging Face. Available online: https://huggingface.co/runwayml/stable-diffusion-v1-5 (accessed on 5 March 2023).
- Hugging Face. Available online: https://huggingface.co/gpt2 (accessed on 5 March 2023).
- Zhang, Y.; Huang, X.; Ma, J.; Li, Z.; Luo, Z.; Xie, Y.; Qin, Y.; Luo, T.; Li, Y.; Liu, S.; et al. Recognize Anything: A Strong Image Tagging Model. arXiv 2023, arXiv:2306.03514. [Google Scholar]
- Huang, X.; Zhang, Y.; Ma, J.; Tian, W.; Feng, R.; Zhang, Y.; Li, Y.; Guo, Y.; Zhang, L. Tag2text: Guiding vision-language model via image tagging. arXiv 2023, arXiv:2303.05657. [Google Scholar]
- Radford, A.; Kim, J.W.; Hallacy, C.; Ramesh, A.; Goh, G.; Agarwal, S.; Sastry, G.; Askell, A.; Mishkin, P.; Clark, J.; et al. Learning transferable visual models from natural language supervision. In Proceedings of the International Conference on Machine Learning, PMLR, Virtual, 18–24 July 2021; pp. 8748–8763. [Google Scholar]
- Weiss, K.; Khoshgoftaar, T.M.; Wang, D. A survey of transfer learning. J. Big Data 2016, 3, 1–40. [Google Scholar] [CrossRef]
- LAION. Available online: https://laion.ai/blog/laion-5b/ (accessed on 5 March 2023).








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Artist | Number |
|---|---|
| Vincent van Gogh | 1893 |
| Leonardo da Vinci | 204 |
| Pablo Picasso | 764 |
| Claude Monet | 1343 |
| Theodore Rousseau | 144 |
| Jean-Francois Millet | 122 |
| Nicholas Roerich | 1820 |
| Paul Gauguin | 394 |
| Paul Cezanne | 582 |
| Text Input | An Astronaut Riding a Horse |
|---|---|
| Original | An astronaut in a white suit riding a horse, colorful sky in the background, epic lighting |
| Vincent van Gogh | An astronaut riding a blue horse, the upper part of a spacesuit is white and the lower part is yellow, vibrant high-contrast coloring |
| Leonardo da Vinci | An astronaut riding a horse in space, an astronaut in a triumphant pose, a closeup shot, amazing artwork, comic cover art, high spirits |
| Pablo Picasso | An astronaut riding a horse with a helmet on, horse is dyed in many colors |
| Claude Monet | A painting of a man riding a horse with a space suit on, the horse in a running state |
| Theodore Rousseau | An astronaut riding a horse on the moon, the sky full of stars is behind the astronaut, hard shadows and strong rim light |
| Jean-Francois Millet | An astronaut riding a horse, the horse is charging, the sky is filled with clouds, it seems that a storm is coming, masterpiece |
| Nicholas Roerich | An astronaut riding a horse, planets in the background, an astronaut in colorful clothes, bright light, lunar walk, vibrant colors |
| Paul Gauguin | An astronaut riding a horse over water, an astronaut with a backpack on his back, floating bubbles |
| Paul Cezanne | An astronaut riding a horse in a blue field with orange sky, rainy day, the horse is walking slowly |
| FID ↓ | |
|---|---|
| Original w/o text expansion | 397.0344 |
| Original w/ text expansion | 366.8111 |
| Ours w/o text expansion | 290.1978 |
| Ours w/ text expansion | 284.5017 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, D.; Ma, C.; Sun, S. Novel Paintings from the Latent Diffusion Model through Transfer Learning. Appl. Sci. 2023, 13, 10379. https://doi.org/10.3390/app131810379
Wang D, Ma C, Sun S. Novel Paintings from the Latent Diffusion Model through Transfer Learning. Applied Sciences. 2023; 13(18):10379. https://doi.org/10.3390/app131810379
Chicago/Turabian StyleWang, Dayin, Chong Ma, and Siwen Sun. 2023. "Novel Paintings from the Latent Diffusion Model through Transfer Learning" Applied Sciences 13, no. 18: 10379. https://doi.org/10.3390/app131810379
APA StyleWang, D., Ma, C., & Sun, S. (2023). Novel Paintings from the Latent Diffusion Model through Transfer Learning. Applied Sciences, 13(18), 10379. https://doi.org/10.3390/app131810379